
Хорошо, давайте разберемся, как закодировать слово «Видеокарта» в кодировке Windows.
Прежде всего, мы должны знать, как работает кодировка Windows. В Windows используется кодировка ASCII (American Standard Code for Information Interchange). Это значит, что каждой букве или символу соответствует определенный числовой код.
Теперь перейдем к кодированию слова «Видеокарта». Чтобы получить код каждой буквы, мы воспользуемся таблицей ASCII.
Таблица ASCII для русских символов в кодировке Windows:
Буква | Код в десятичной системе
————————-
В | 207
и | 240
д | 232
е | 236
о | 229
к | 240
а | 240
р | 240
т | 232
а | 240
Теперь, когда у нас есть код каждой буквы, мы можем записать закодированное слово «Видеокарта» в виде перечисления кодов в десятичной системе:
207, 240, 232, 236, 229, 240, 240, 240, 232, 240
Надеюсь, что это помогло вам понять, как закодировать слово «Видеокарта» в кодировке Windows. Если у вас есть еще вопросы, пожалуйста, не стесняйтесь задавать.

Вопрос:
Ответ:
Для выполнения задания необходимо взять каждый символ из слова «Видеокарта», найти его код в таблице Windows-1251 (кириллическая кодировка для Windows) и записать в десятичной системе. Распределение кодов:
— В: код 66
— и: код 232
— д: код 228
— е: код 229
— о: код 238
— к: код 234
— а: код 224
— р: код 240
— т: код 242
— а: код 224
Итоговая последовательность: 66 232 228 229 238 234 224 240 242 224
Смотреть решения всех заданий с фото
Похожие
- Закодируй слово «Видеокарта» в кодировке Windows и запиши ответ в виде перечисления кодов в десятичной системе.
Оценка количественных параметров текстовых документов
Установите соответствия между объектами.
Соедините слова и их кодировки в Windows-1251

Варианты ответов
- Ручка
- Карта
- Стена
- Лампа
- Штора
Вопрос 4
Информационный объём текста, подготовленного с помощью компьютера, равен 2 Кбайт. Нужно найти, сколько символов содержит этот текст, если используется шестнадцатиразрядная кодировка.
Вопрос 5
Впишите правильный ответ
Определите слово, которое закодировано в кодировке Windows-1251, а прочитано в КОИ-8.
ХМТНПЛЮЖХЪ


Вопрос 6
В кодировке Unicode на каждый символ отводится два байта. Определите информационный объём слова из 14 символов в этой кодировке.
Варианты ответов
- 14 байт.
- 28 байт.
- 7 байт.
Вопрос 7
Автоматическое устройство осуществило перекодировку информационного сообщения на русском языке, первоначально записанного в 8-битовом коде, в 16-битовую кодировку Unicode. При этом информационное сообщение увеличилось на 1024 байтов. Каков был информационный объём сообщения до перекодировки?
Варианты ответов
- 1 Кбайт
- 2 Кбайт
- 3 Кбайт
Вопрос 8
Считая, что каждый символ кодируется одним байтом, определите, чему равен информационный объём следующего высказывания Славомира Врублевского:
Кто знает все, тому ещё многому нужно учиться.
Варианты ответов
- 368 битов
- 608 битов
- 48 байт
Вопрос 9
Выразите в мегабайтах объём текстовой информации в «Современном словаре иностранных слов» из 740 страниц, если на одной странице размещается в среднем 60 строк по 80 символов (включая пробелы). Считайте, что при записи использовался алфавит мощностью 256 символов.
Варианты ответов
- 3 Мбайт
- 3,39 Мбайт
- 3,5 Мбайт
Вопрос 10
Средняя скорость передачи данных по некоторому каналу связи равна 25 Кбит/с. Сколько секунд потребуется для передачи по этому каналу 100 страниц текста, если считать, что один символ кодируется одним байтом и на каждой странице в среднем 120 символов?
1. oc ( операционная система ) позволяет всем что происходит в компьютере.
2. windows , linux ( возможно ошибка в написании ) , mac os
3.относятся также диалоговые оболочки и сервисные программы.
сервисные программы – это программы обслуживания дисков (копирование, форматирование, «лечение» ), сжатия файлов на дисках (архиваторы), борьбы с компьютерными вирусами и т.д.
Впишите правильный ответ Определите слово, которое закодировано в кодировке Windows-1251, а прочитано в КОИ-8. ХМТНПЛЮЖХ. (Кодовые таблицы возьмите в рабочей тетради или в интернете
в одном часе 3600 секунд. за час произойдёт 3600*10^6 операций.
чтобы выполнить их на арифмометре (не завидую тому, кто решится так делать), потребуется
3600*10^6*10 секунд = 10^7 часов или примерно 1141 год
векторная графика масштабируется без потери качества изображения, но в растровой графике возможно использование более богатой цвтовой палитры.
s-i — высказывание: ученик s (где s — первая буква фамилии) убирал i-й класс.
p: (q-i, r-i), — ученик p высказал q-i и r-i
s-i = f — высказывание s-i — ложно, а s-i = t высказывание s-i — истинно.
тогда, по условию :
где в каждой паре (q-i, r-i) только одно из высказываний является верным (*).
предположим в начале, что а-9 = t. тогда из 2) и (*) следует, что (k-9 = f, а-8 = f) — противоречие, т.к. одно из высказываний в паре должно быть верным. следовательно, предположение а-9 = t — не верно, и а-9 = f.
пусть a-9 = f. тогда из 1) и *) следует, что c-7 = t. из 3) и *) следует, что c-8 = f. откуда получим из 3), что к-10 = t. значит, согласно 2) (к-9 = f, а-8 = t)
итак, c-7 = t, к-10 = t и а-8 = t следовательно, савельев убирал 7-й класс, костин — 10-й, андреев — 8-й класс. давыдов, следовательно, убирал оставшийся, 9-й класс (т.е. д-9 = т).
Какие коды в кодировке Windows соответствуют слову «Видеокарта»? Представьте свой ответ в виде перечисления десятичных кодов: 207240232236229240. В примере дано закодированное слово Пример.
Тема: Кодировка Windows
Объяснение: Кодировка – это способ представления символов компьютером, преобразование символов в числовые коды. В кодировке Windows, символы представляются с помощью чисел из диапазона от 0 до 255.
Чтобы узнать коды символов для слова «Видеокарта» в кодировке Windows, мы можем использовать таблицу кодов, которая соответствует этой кодировке. Для каждой буквы слова, мы найдем ее числовой код в таблице.
Теперь представим слово «Видеокарта» в виде десятичных кодов:
В — 207
и — 240
д — 232
е — 236
о — 229
к — 240
а — 240
р — 232
т — 236
а — 240
Таким образом, десятичные коды для слова «Видеокарта» в кодировке Windows будут: 207240232236229240240232236240.
Совет: Чтобы лучше понять кодировку Windows, можно изучить таблицу символов и соответствующие коды. Также полезно практиковаться в нахождении кодов для разных слов и символов.
Упражнение: Какие коды в кодировке Windows соответствуют слову «Программирование»? Представьте свой ответ в виде перечисления десятичных кодов.
Содержание
- Содержание урока
- Практическая работа № 1.4 «Представление текстов. Сжатие текстов»
- Задание 1
- Задание 2
- Задание 3
- Задание 4
- Задание 5
- Задание 6
- Задание 7
- Задание 8
- Задание 9
- Закодируй слово видеокарта в кодировке windows
- Система задач на кодирование текстовой информации.
- Сборник. Решение задач на тему «Кодировнаие текстовой информации»
- Ответ: 320 бит
- Ответ: 544 бит
- Ответ: 38 байт
- Кодировка текста ASCII (Windows 1251, CP866, KOI8-R) и Юникод (UTF 8, 16, 32) — как исправить проблему с кракозябрами
- ASCII — базовая кодировка текста для латиницы
- Расширенные версии Аски — кодировки CP866 и KOI8-R с псевдографикой
- Windows 1251 — современная версия ASCII и почему вылезают кракозябры
- Юникод (Unicode) — универсальные кодировки UTF 8, 16 и 32
- Кракозябры вместо русских букв — как исправить
Содержание урока
Практическая работа № 1.4 «Представление текстов. Сжатие текстов»
Практическая работа № 1.4 «Представление текстов. Сжатие текстов»
Цель работы: практическое закрепление знаний о представлении в компьютере текстовых данных.
Задание 1
Определить, какие символы кодируются таблицей ASCII (DOS) соответствуют всем прописным буквам русского алфавита в кодировочной таблице ANSI (Windows). Для выполнения задания создать текст с русским алфавитом в Блокноте, а затем открыть его в режиме просмотра (клавиша F3) в любом файловом менеджере (Windows Commander, Far, Total Commander, Norton Commander) и преобразовать в другую кодировку. После выполнения задания заполнить таблицу.
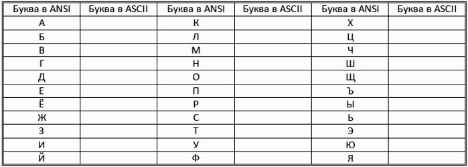
Задание 2
Закодировать текст Happy Birthday to you!! с помощью кодировочной таблицы ASCII
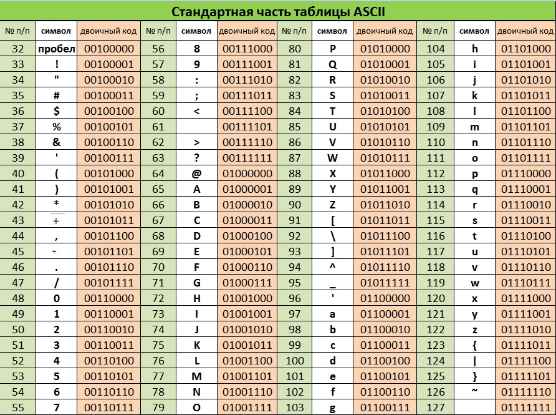
Записать двоичное и шестнадцатеричное представление кода (для записи шестнадцатеричного кода использовать средство для просмотра файлов любого файлового менеджера).
Задание 3
Декодировать текст, записанный в международной кодировочной таблице ASCII (дано десятичное представление).
72 101 108 108 111 44 32 109 121 32 102 114 105 101 110 100 33
Задание 4
Пользуясь таблицей кодировки ASCII, расшифровать текст, представленный в виде двоичных кодов символов.
01010000 01100101 01110010 01101101 00100000 01010101
01101110 01101001 01110110 01100101 01110010 01110011
01101001 01110100 01111001
Задание 5
Пользуясь кодовой страницей Windows-1251 таблицы кодировки ASCII, получить шестнадцатеричный код слова ИНФОРМАТИЗАЦИЯ.
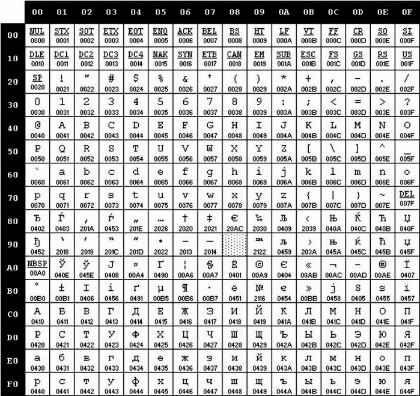
Задание 6
Во сколько раз увеличится объём памяти, необходимый для хранения текста, если его преобразовать из кодировки KOI8-R в кодировку Unicode?
Задание 7
С помощью табличного процессора Excel построить кодировочную таблицу ASCII, в которой символы буду автоматически отображаться на экране в соответствии с их заданным десятичным номером (использовать соответствующую текстовую функцию).
Справочная информация
Закодируем с помощью данного дерева слово «hello»:
0101 100 01111 01111 1110
При размещении этого кода в памяти побитово он примет вид:
010110001111011111110
Таким образом, текст, занимающий в кодировки ASCII 5 байтов, в кодировке Хаффмена займет 3 байта.
Задание 8
Используя метод сжатия Хаффмена, закодируйте следующие слова:
а) administrator
б) revolution
в) economy
г) department
Задание 9
Используя дерево Хаффмена, декодируйте следующие слова:
а) 01110011 11001001 10010110 10010111 100000
б) 00010110 01010110 10011001 01101101 01000100 000
Следующая страница Практическая работа № 1.5 «Представление изображения и звука»
Источник
Закодируй слово видеокарта в кодировке windows
Система задач на кодирование текстовой информации.
В задачах данного типа используются следующие понятия: кодирование, код, кодовая таблица (таблица кодировки). В задачах могут быть использованы следующие таблицы кодировки ASCII, Unicode, ISO, DOS, MAC, КОИ-8.
Решение задач на кодирование текстовой информации.
Задача 1. Текст, состоящий из 142 символов, закодирован с помощью таблицы кодировок Unicode. Определите количество информации (в битах) содержащейся в тексте.
Решение. Воспользуемся формулой: I= K×i, где I- количество информации, K- количество символов в тексте, i – информационный вес одного символа.
В таблице кодировок Unicode, для хранения каждого символа используется 2 байта. В тесте 142 символа, следовательно, I= 142×2=284байта.
Переводим из одной единицы измерения в другую, так как 1байт=8бит, то 284байт×8бит= 2272 бит.
Ответ. Информационный объем текста 2272бит.
Задача2. Сообщение из 118 символов было записано в 8-битной кодировке Windows-1251, после вставки в текстовый редактор сообщение было перекодировано в 16-битный код Unicode. На какое количество информации увеличилось количество памяти, занимаемое сообщением?
Решение. В кодировке Windows-1251, для хранения одного символа используется 8 бит, вычислим количество информации в сообщение. I= K×i, следовательно I=118×1=118байт.
В кодировке Unicode, для хранения одного символа используется 16 бит, тогда количество информации в сообщение будет равно: I=118×2=236байт.
В задачи стоит вопрос, на какое количество информации увеличилось количество памяти, для этого необходимо найти разность полученных объемов. 236-118=118байт.
Ответ: на 118 байт увеличилось количество памяти занятое сообщением.
Задача3. Автоматическое устройство осуществило перекодировку информационного сообщения на русском языке, первоначально записанного в 16-битном коде Unicode, в 8-битную кодировку КОИ-8. При этом количество информации уменьшилось на 480бит. Какова длина сообщения в символах?
Решение. Обозначим количество символов в сообщении через х.
Составим уравнение: количество бит, которое было первоначально, минус количество бит после перекодировки равно 480 бит.
Ответ: сообщение содержит 60 символов.
Задача4. С помощью последовательности десятичных кодов 99 111 109 112 117 116 101 114 закодировано слово computer. Какая последовательность десятичных кодов будет соответствовать этому же слову, записанному прописными буквами?
Решение. Таблица кодировок сначала содержит прописные буквы в алфавитном порядке, а затем строчные. Так как разница между десятичным кодом строчной буквы латинского алфавита и десятичным кодом соответствующей прописной буквы равна 32, то десятичный код прописной буквы С равен 99-32=67.
Аналогичным образом находятся остальные десятичные коды. 111-32=79, 109-32=77, 112-32=80, 117-32=85, 116-32=84, 101-32=69, 114-32=82.
Последовательность десятичных кодов слова COMPUTER составляет 67 79 77 80 85 84 69 82.
Ответ. 67 79 77 80 85 84 69 82.
Задача5. Для кодирования букв А, Б, В, Г решили использовать двухразрядные последовательные числа (от 00 до 11 соответственно). Какая получиться последовательность, если таким способом закодировать последовательность символов ВАБВГАБГ и записать результат шестнадцатеричным кодом?
Решение. Для записи текстовой информации необязательно использовать стандартные 8-битные и 16-битные кодовые таблицы. Если количество различных символов в сообщении мало, можно использовать особые, короткие, коды для записи каждого символа. Последовательность нулей и единиц, которыми кодируются символы сообщения, называются кодовыми словами. Если вероятность появления каждого символа сообщения одинакова, то символы кодируют кодовыми словами одинаковой длины. Составим таблицу кодовых слов. Для этого выпишем кодовое слово для каждой буквы.
Закодируем данную последовательность ВАБВГАБГ символов, для этого выпишем коды букв в том же порядке, что и буквы исходного сообщения, согласно этой таблицы.
Используя правила перевода из двоичной системы счисления в шестнадцатеричную, сгруппируем получившиеся двоичные цифры по 4 и вместо каждой группы напишем соответствующую шестнадцатеричную цифру.
Ответ: 86С7.
Задача 6. Для 5 букв латинского алфавита заданы их двоичные коды для некоторых букв из двух бит, для некоторых из трех. Эти коды представлены в таблице:
Определите, какой набор букв закодирован двоичной строкой 0110100011000.
Решение. Так как код записывается начиная с младшего разряда, то необходимо разбить двоичную строку, начиная справа: 0110|100|011|000. При этом видно, что последние три буквы будут C, E, A. Кода 0110 нет, тогда его можно разбить код из двух бит: 01|10, следовательно, 01-В, 10-D. Итак, двоичной строкой 0110100011000 закодирован следующий набор букв BDCEA.
Ответ: двоичной строкой закодирован набор букв BDCEA.
Источник
Сборник. Решение задач на тему «Кодировнаие текстовой информации»
Решение задач на тему «Кодирование текстовой информации»
Объем памяти, занимаемый текстом.
В задачах такого типа используются понятия:
единицы измерения информации (бит, байт и др.)
Для представления текстовой (символьной) информации в компьютере используется алфавит мощностью 256 символов. Один символ из такого алфавита несет 8 бит информации (2 8 =256). 8 бит =1 байту, следовательно, двоичный код каждого символа в компьютерном тексте занимает 1 байт памяти.
1. Сколько бит памяти займет слово «Микропроцессор»?([1], c .131, пример 1)
Слово состоит из 14 букв. Каждая буква – символ компьютерного алфавита, занимает 1 байт памяти. Слово занимает 14 байт =14*8=112 бит памяти.
2. Текст занимает 0, 25 Кбайт памяти компьютера. Сколько символов содержит этот текст? ([1], c .133, №31)
Переведем Кб в байты: 0, 25 Кб * 1024 =256 байт. Так как текст занимает объем 256 байт, а каждый символ – 1 байт, то в тексте 256 символов.
Ответ: 256 символов
3. Текст занимает полных 5 страниц. На каждой странице размещается 30 строк по 70 символов в строке. Какой объем оперативной памяти (в байтах) займет этот текст? ([1], c .133, №32)
30*70*5 = 10500 символов в тексте на 5 страницах. Текст займет 10500 байт оперативной памяти.
4. Считая, что каждый символ кодируется одним байтом, оцените информационный объем следующего предложения из пушкинского четверостишия:
Певец-Давид был ростом мал, Но повалил же Голиафа! (ЕГЭ_2005. демо, уровень А)
В тексте 50 символов, включая пробелы и знаки препинания. При кодировании каждого символа одним байтом на символ будет приходиться по 8 бит, Следовательно, переведем в биты 50*8= 400 бит.
5 . Считая, что каждый символ кодируется одним байтом, оцените информационный объем следующего предложения в кодировке КОИ-8: Сегодня метеорологи предсказывали дождь. (ЕГЭ_2005, уровень А)
В таблице КОИ-8 каждый символ закодирован с помощью 8 бит. См. решение задачи №4.
Ответ: 320 бит
6. Считая, что каждый символ кодируется 16 битами, оцените информационный объем следующего предложения в кодировке Unicode :
Каждый символ кодируется 8 битами.
34 символа в предложении. Переведем в биты: 34*16=544 бита.
Ответ: 544 бит
7. Каждый символ закодирован двухбайтным словом. Оцените информационный объем следующего предложения в этой кодировке:
В одном килограмме 100 грамм.
19 символов в предложении. 19*2 =38 байт
Ответ: 38 байт
8. Текст занимает полных 10 секторов на односторонней дискете объемом 180 Кбайт. Дискета разбита на 40 дорожек по 9 секторов. Сколько символов содержит текст? ([1], c .133, №34)
180 Кбайт : 360 * 10 =5 Кбайт – поместится на одном секторе.
5*1024= 5120 символов содержит текст.
Ответ: 5120 символов
9. Сообщение передано в семибитном коде. Каков его информационный объем в байтах, если известно, что передано 2000 символов.
Если код символа содержит 7 бит, а всего 2000 символов, узнаем сколько бит займет все сообщение. 2000 х 7=14000 бит.
Переведем результат в байты. 14000 : 8 =1750 байт
10. Сколько секунд потребуется модему, передающему сообщение со скоростью 28800 бит/с, чтобы передать 100 страниц текста в 30 строк по 60 символов каждая, при условии, что каждый символ кодируется одним байтом? (ЕГЭ_2005, уровень В)
Найдем объем сообщения. 30*60*8*100 =1440000 бит.
Найдем время передачи сообщения модемом. 1440000 : 28800 =50 секунд
11. Сколько секунд потребуется модему, передающему сообщения со скоростью 14400 бит/с, чтобы передать сообщение длиной 225 Кбайт? (ЕГЭ_2005, уровень В)
Переведем 225 Кб в биты.225 Кб *1024*8 = 1843200 бит.
Найдем время передачи сообщения модемом. 1843200: 14400 =128 секунд.
Кодирование (декодирование) текстовой информации.
В задачах такого типа используются понятия:
Кодирование – отображение дискретного (прерывного, импульсного) сообщения в виде определенных сочетаний символов.
Код (от французского слова code – кодекс, свод законов) – правило по которому выполняется кодирование.
Кодовая таблица (или кодовая страница) – таблица, устанавливающая соответствие между символами алфавита и двоичными числами.
Примеры кодовых таблиц (имеются на CD диске к учебнику Н. Угринович):

Рис.1 Кодировка КОИ8-Р
ASCII – American Standard Code for Information Interchange (американский стандарт кодов для обмена информацией) – это восьмиразрядная кодовая таблица, в ней закодировано 256 символов (127- стандартные коды символов английского языка, спецсимволы, цифры, а коды от 128 до 255 – национальный стандарт, алфавит языка, символы псевдографики, научные символы, коды от 0 до 32 отведены не символам, а функциональным клавишам).

Рис. 2 Международная кодировка ASCII
Unicode – стандарт, согласно которому для представления каждого символа используется 2 байта. (можно кодировать математические символы, русские, английские, греческие, и даже китайские). C его помощью можно закодировать не 256, а 65536 различных символов. Полная спецификация стандарта Unicode включает в себя все существующие, вымершие и искусственно созданные алфавиты мира, а также множество математических, музыкальных, химических и прочих символов

1) #160 неразрывный пробел,
2) #173 мягкий перенос.
Рис. 3 Кодировка CP 1251

1) #255 неразрывный пробел.
Рис. 4 Кодировка СР866

#202 неразрывный пробел.
Рис. 5 Кодировка Mac

1) Коды 128-159 не используются;
2) #160 неразрывный пробел,
3) #173 мягкий перенос.
Рис. 6 Кодировка ISO 8859-5
Используем кодировочные таблицы
12. Как будет выглядеть слово «диск», записанное в кодировке СР1251, в других кодировках. ([2], стр. 68 №2.63)
Последовательность десятичных кодов слова «диск» составляем на основе кодировочных таблиц
13. Перейдите от двоичного кода к десятичному и декодируйте следующие тексты:
а) 01010101 01110000 0100000 00100110 00100000 01000100 1101111 01110111 01101110;
б) 01001001 01000010 01001101;
в) 01000101 01101110 01110100 01100101 01110010
Решение:
1. Переведите коды из двоичной системы счисления в десятичную.
а) 01010101 01110000 00100000 00100110 00100000 01000100 1101111 01110111 01101110 → 85 112 32 38 32 68 111 119 110
б) 01001001 01000010 01001101 → 73 66 77
в) 01000101 01101110 01110100 01100101 01110010 → 69 110 116 101 114
2. Запустите текстовый редактор Hieroglyph
3. Включить клавишу Num Lock. Удерживая клавишу Alt, набрать код символа на цифровой клавиатуре. Отпустить клавишу Alt, на экране появится соответствующая буква.
а ) 85 112 32 26 32 68 111 119 110 → Up & Down;
б ) 73 66 77 → IBM;
в ) 69 110 116 101 114 → Enter
1 4. Декодируйте следующие тексты, заданные десятичным кодом:
а) 087 111 114 100;
б) 068 079 083;
в) 080 097 105 110 116 098 114 117 115 104.
Решение:
Запустите текстовый редактор Hieroglyph. Включить клавишу Num Lock. Удерживая клавишу Alt, набрать код символа на цифровой клавиатуре. Отпустить клавишу Alt, на экране появится соответствующая буква.
а) 087 111 114 100 → Word;
б) 068 079 083 → DOS;
в) 080 097 105 110 116 098 114 117 115 104 → Paintbrush.
Не используем кодировочные таблицы
15. Буква « I »в таблице кодировки символов имеет десятичный код 105. что зашифровано последовательностью десятичных кодов: 108 105 110 107? ([1],пример 2, стр.132)
Учитываем принцип последовательности кодирования и порядок букв в латинском алфавите и, можно, не обращаться к таблице кодировки символов.
Ответ: Закодировано слово « link »
16. Десятичный код (номер) буквы «е» в таблице кодировки символов ASCII равен 101. Какая последовательность десятичных кодов будет соответствовать слову:
Учитываем принцип последовательности кодирования и порядок букв в латинском алфавите:
Источник
Кодировка текста ASCII (Windows 1251, CP866, KOI8-R) и Юникод (UTF 8, 16, 32) — как исправить проблему с кракозябрами
Здравствуйте, уважаемые читатели блога KtoNaNovenkogo.ru. Сегодня мы поговорим с вами про то, откуда берутся кракозябры на сайте и в программах, какие кодировки текста существуют и какие из них следует использовать. Подробно рассмотрим историю их развития, начиная от базовой ASCII, а также ее расширенных версий CP866, KOI8-R, Windows 1251 и заканчивая современными кодировками консорциума Юникод UTF 16 и 8.
Кому-то эти сведения могут показаться излишними, но знали бы вы, сколько мне приходит вопросов именно касаемо вылезших кракозябров (не читаемого набора символов). Теперь у меня будет возможность отсылать всех к тексту этой статьи и самостоятельно отыскивать свои косяки. Ну что же, приготовьтесь впитывать информацию и постарайтесь следить за ходом повествования.
ASCII — базовая кодировка текста для латиницы
Развитие кодировок текстов происходило одновременно с формированием отрасли IT, и они за это время успели претерпеть достаточно много изменений. Исторически все начиналось с довольно-таки не благозвучной в русском произношении EBCDIC, которая позволяла кодировать буквы латинского алфавита, арабские цифры и знаки пунктуации с управляющими символами.
Но все же отправной точкой для развития современных кодировок текстов стоит считать знаменитую ASCII (American Standard Code for Information Interchange, которая по-русски обычно произносится как «аски»). Она описывает первые 128 символов из наиболее часто используемых англоязычными пользователями — латинские буквы, арабские цифры и знаки препинания.
Еще в эти 128 знаков, описанных в ASCII, попадали некоторые служебные символы навроде скобок, решеток, звездочек и т.п. Собственно, вы сами можете увидеть их:
Именно эти 128 символов из первоначального вариант ASCII стали стандартом, и в любой другой кодировке вы их обязательно встретите и стоять они будут именно в таком порядке.
Тут, наверное, стоит еще немного сказать про системы счисления, которые используются при описании. Во-первых, как вы все знаете, компьютер работает только с числами в двоичной системе, а именно с нулями и единицами («булева алгебра», если кто проходил в институте или в школе). Один байт состоит из восьми бит, каждый из которых представляет из себя двойку в степени, начиная с нулевой, и до двойки в седьмой:
Не трудно понять, что всех возможных комбинаций нулей и единиц в такой конструкции может быть только 256. Переводить число из двоичной системы в десятичную довольно просто. Нужно просто сложить все степени двойки, над которыми стоят единички.
В нашем примере это получается 1 (2 в степени ноль) плюс 8 (два в степени 3), плюс 32 (двойка в пятой степени), плюс 64 (в шестой), плюс 128 (в седьмой). Итого получает 233 в десятичной системе счисления. Как видите, все очень просто.
Но если вы присмотритесь к таблице с символами ASCII, то увидите, что они представлены в шестнадцатеричной кодировке. Например, «звездочка» соответствует в Аски шестнадцатеричному числу 2A. Наверное, вам известно, что в шестнадцатеричной системе счисления используются кроме арабских цифр еще и латинские буквы от A (означает десять) до F (означает пятнадцать).
Ну так вот, для перевода двоичного числа в шестнадцатеричное прибегают к следующему простому и наглядному способу. Каждый байт информации разбивают на две части по четыре бита, как показано на приведенном выше скриншоте. Т.о. в каждой половинке байта двоичным кодом можно закодировать только шестнадцать значений (два в четвертой степени), что можно легко представить шестнадцатеричным числом.
Причем, в левой половине байта считать степени нужно будет опять начиная с нулевой, а не так, как показано на скриншоте. В результате, путем нехитрых вычислений, мы получим, что на скриншоте закодировано число E9. Надеюсь, что ход моих рассуждений и разгадка данного ребуса вам оказались понятны. Ну, а теперь продолжим, собственно, говорить про кодировки текста.
Расширенные версии Аски — кодировки CP866 и KOI8-R с псевдографикой
Итак, мы с вами начали говорить про ASCII, которая являлась как бы отправной точкой для развития всех современных кодировок (Windows 1251, юникод, UTF 8).
Изначально в нее было заложено только 128 знаков латинского алфавита, арабских цифр и еще чего-то там, но в расширенной версии появилась возможность использовать все 256 значений, которые можно закодировать в одном байте информации. Т.е. появилась возможность добавить в Аски символы букв своего языка.
Тут нужно будет еще раз отвлечься, чтобы пояснить — зачем вообще нужны кодировки текстов и почему это так важно. Символы на экране вашего компьютера формируются на основе двух вещей — наборов векторных форм (представлений) всевозможных знаков (они находятся в файлах со шрифтами, которые установлены на вашем компьютере) и кода, который позволяет выдернуть из этого набора векторных форм (файла шрифта) именно тот символ, который нужно будет вставить в нужное место.
Понятно, что за сами векторные формы отвечают шрифты, а вот за кодирование отвечает операционная система и используемые в ней программы. Т.е. любой текст на вашем компьютере будет представлять собой набор байтов, в каждом из которых закодирован один единственный символ этого самого текста.
Программа, отображающая этот текст на экране (текстовый редактор, браузер и т.п.), при разборе кода считывает кодировку очередного знака и ищет соответствующую ему векторную форму в нужном файле шрифта, который подключен для отображения данного текстового документа. Все просто и банально.
Значит, чтобы закодировать любой нужный нам символ (например, из национального алфавита), должно быть выполнено два условия — векторная форма этого знака должна быть в используемом шрифте и этот символ можно было бы закодировать в расширенных кодировках ASCII в один байт. Поэтому таких вариантов существует целая куча. Только лишь для кодирования символов русского языка существует несколько разновидностей расширенной Аски.
Т.е. ее верхняя часть полностью совпадала с базовой версией Аски (128 символов латиницы, цифр и еще всякой лабуды), которая представлена на приведенном чуть выше скриншоте, а вот уже нижняя часть таблицы с кодировкой CP866 имела указанный на скриншоте чуть ниже вид и позволяла закодировать еще 128 знаков (русские буквы и всякая там псевдографика):
Видите, в правом столбце цифры начинаются с 8, т.к. числа с 0 до 7 относятся к базовой части ASCII (см. первый скриншот). Т.о. русская буква «М» в CP866 будет иметь код 9С (она находится на пересечении соответствующих строки с 9 и столбца с цифрой С в шестнадцатеричной системе счисления), который можно записать в одном байте информации, и при наличии подходящего шрифта с русскими символами эта буква без проблем отобразится в тексте.
CP866 распространяла компания IBM, но кроме этого для символов русского языка были разработаны еще ряд кодировок, например, к этому же типу (расширенных ASCII) можно отнести KOI8-R :
Принцип ее работы остался тот же самый, что и у описанной чуть ранее CP866 — каждый символ текста кодируется одним единственным байтом. На скриншоте показана вторая половина таблицы KOI8-R, т.к. первая половина полностью соответствует базовой Аски, которая показана на первом скриншоте в этой статье.
Среди особенностей кодировки KOI8-R можно отметить то, что русские буквы в ее таблице идут не в алфавитном порядке, как это, например, сделали в CP866.
Если посмотрите на самый первый скриншот (базовой части, которая входит во все расширенные кодировки), то заметите, что в KOI8-R русские буквы расположены в тех же ячейках таблицы, что и созвучные им буквы латинского алфавита из первой части таблицы. Это было сделано для удобства перехода с русских символов на латинские путем отбрасывания всего одного бита (два в седьмой степени или 128).
Windows 1251 — современная версия ASCII и почему вылезают кракозябры
Дальнейшее развитие кодировок текста было связано с тем, что набирали популярность графические операционные системы и необходимость использования псевдографики в них со временем пропала. В результате возникла целая группа, которая по своей сути по-прежнему являлись расширенными версиями Аски (один символ текста кодируется всего одним байтом информации), но уже без использования символов псевдографики.
Она выгодно отличалась от используемых ранее CP866 и KOI8-R тем, что место символов псевдографики в ней заняли недостающие символы русской типографики (окромя знака ударения), а также символы, используемые в близких к русскому славянских языках (украинскому, белорусскому и т.д.):
Очень часто они вылезали при отправке и получении сообщений по электронной почте, что повлекло за собой создание очень сложных перекодировочных таблиц, которые, собственно, решить эту проблему в корне не смогли, и зачастую пользователи для переписки использовали транслит латинских букв, чтобы избежать пресловутых кракозябров при использовании русских кодировок подобных CP866, KOI8-R или Windows 1251.
По сути, кракозябры, вылазящие вместо русского текста, были результатом некорректного использования кодировки данного языка, которая не соответствовала той, в которой было закодировано текстовое сообщение изначально.
Допустим, если символы, закодированные с помощью CP866, попробовать отобразить, используя кодовую таблицу Windows 1251, то эти самые кракозябры (бессмысленный набор знаков) и вылезут, полностью заменив собой текст сообщения.
Аналогичная ситуация очень часто возникает при создании сайтов на WordPress и Joomla, форумов или блогов, когда текст с русскими символами по ошибке сохраняется не в той кодировке, которая используется на сайте по умолчанию, или же не в том текстовом редакторе, который добавляет в код отсебятину не видимую невооруженным глазом.
В конце концов такая ситуация с множеством кодировок и постоянно вылезающими кракозябрами многим надоела, появились предпосылки к созданию новой универсальной вариации, которая бы заменила собой все существующие и решила бы, наконец, на корню проблему с появлением не читаемых текстов. Кроме этого существовала проблема языков подобных китайскому, где символов языка было гораздо больше, чем 256.
Юникод (Unicode) — универсальные кодировки UTF 8, 16 и 32
Эти тысячи знаков языковой группы юго-восточной Азии никак невозможно было описать в одном байте информации, который выделялся для кодирования символов в расширенных версиях ASCII. В результате был создан консорциум под названием Юникод (Unicode — Unicode Consortium) при сотрудничестве многих лидеров IT индустрии (те, кто производит софт, кто кодирует железо, кто создает шрифты), которые были заинтересованы в появлении универсальной кодировки текста.
Но многим странам с языками европейской группы такое огромное количество знаков использовать в кодировке вовсе и не было необходимости, однако при задействовании UTF-32 они ни за что ни про что получали четырехкратное увеличение веса текстовых документов, а в результате и увеличение объема интернет трафика и объема хранимых данных. Это много, и такое расточительство себе никто не мог позволить.
В операционной системе Windows вы можете пройти по пути «Пуск» — «Программы» — «Стандартные» — «Служебные» — «Таблица символов». В результате откроется таблица с векторными формами всех установленных у вас в системе шрифтов. Если вы выберете в «Дополнительных параметрах» набор знаков Юникод, то сможете увидеть для каждого шрифта в отдельности весь ассортимент входящих в него символов.
Сколько символов можно закодировать в UTF-16 с помощью 16 бит? 65 536 (два в степени шестнадцать), и именно это число было принято за базовое пространство в Юникоде. Помимо этого существуют способы закодировать с помощью нее и около двух миллионов знаков, но ограничились расширенным пространством в миллион символов текста.
Но даже эта удачная версия кодировки Юникода не принесла особого удовлетворения тем, кто писал, допустим, программы только на английском языке, ибо у них, после перехода от расширенной версии ASCII к UTF-16, вес документов увеличивался в два раза (один байт на один символ в Аски и два байта на тот же самый символ в ЮТФ-16).
На практике же в UTF-8 используется только диапазон от одного до четырех байт, потому что за четырьмя байтами кода ничего уже даже теоретически не возможно представить. Все латинские знаки в ней кодируются в один байт, так же как и в старой доброй ASCII.
Что примечательно, в случае кодирования только латиницы, даже те программы, которые не понимают Юникод, все равно прочитают то, что закодировано в ЮТФ-8. Т.е. базовая часть Аски просто перешла в это детище консорциума Unicode.
В приведенной чуть выше «Таблице символов» видно, что разные шрифты поддерживают разное количество знаков. Некоторые насыщенные символами Юникода шрифты могут весить очень прилично. Но зато теперь они отличаются не тем, что они созданы для разных кодировок, а тем, что производитель шрифта заполнил или не заполнил единое кодовое пространство теми или иными векторными формами до конца.
Кракозябры вместо русских букв — как исправить
Давайте теперь посмотрим, как появляются вместо текста кракозябры или, другими словами, как выбирается правильная кодировка для русского текста. Собственно, она задается в той программе, в которой вы создаете или редактируете этот самый текст, или же код с использованием текстовых фрагментов.
В верхнем меню Notepad++ есть пункт «Кодировки», где у вас будет возможность преобразовать уже имеющийся вариант в тот, который используется на вашем сайте по умолчанию:
Дело в том, что когда разрабатывали кодировку ЮТФ-16, зачем-то решили прикрутить к ней такую вещь, как возможность записывать код символа, как в прямой последовательности (например, 0A15), так и в обратной (150A). А для того, чтобы программы понимали, в какой именно последовательности читать коды, и был придуман BOM (Byte Order Mark или, другими словами, сигнатура), которая выражалась в добавлении трех дополнительных байтов в самое начало документов.
Что примечательно, некоторые программы в Windows не умеют этого делать (не умеют сохранять текст в ЮТФ-8 без BOM), например, все тот же пресловутый Блокнот Windows. Он сохраняет документ в UTF-8, но все равно добавляет в его начало сигнатуру (три дополнительных байта). Причем эти байты будут всегда одни и те же — читать код в прямой последовательности. Но на серверах из-за этой мелочи может возникнуть проблема — вылезут кракозябры.
Поэтому ни в коем случае не пользуйтесь обычным блокнотом Windows для редактирования документов вашего сайта, если не хотите появления кракозябров. Лучшим и наиболее простым вариантом я считаю уже упомянутый редактор Notepad++, который практически не имеет недостатков и состоит из одних лишь достоинств.
В Notepad ++ при выборе кодировки у вас будет возможность преобразовать текст в кодировку UCS-2, которая по своей сути очень близка к стандарту Юникод. Также в Нотепаде можно будет закодировать текст в ANSI, т.е. применительно к русскому языку это будет уже описанная нами чуть выше Windows 1251. Откуда берется эта информация?
Она прописана в реестре вашей операционной системы Windows — какую кодировку выбирать в случае ANSI, какую выбирать в случае OEM (для русского языка это будет CP866). Если вы установите на своем компьютере другой язык по умолчанию, то и эти кодировки будут заменены на аналогичные из разряда ANSI или OEM для того самого языка.
После того, как вы в Notepad++ сохраните документ в нужной вам кодировке или же откроете документ с сайта для редактирования, то в правом нижнем углу редактора сможете увидеть ее название:
Вообще, во всех языках гипертекстовой разметки кроме Html используется специальное объявление xml, в котором указывается кодировка текста.
Прежде, чем начать разбирать код, браузер узнает, какая версия используется и как именно нужно интерпретировать коды символов этого языка. Но что примечательно, в случае, если вы сохраняете документ в принятом по умолчанию юникоде, то это объявление xml можно будет опустить (кодировка будет считаться UTF-8, если нет BOM или ЮТФ-16, если BOM есть).
Эта запись довольно сильно отличается от принятой в стандарте в Html 4.01, но полностью соответствует новому внедряемому потихоньку стандарту Html 5, и она будет стопроцентно правильно понята любыми используемыми на текущий момент браузерами.
Источник