
17.09.2024 |
17.09.2024 |
Категория Администрирование
Как мониторить службы Windows с помощью Zabbix? Как создать отдельный шаблон с указанием конкретной службы для мониторинга?
Иногда, после перезагрузки сервера, нужная служба может не стартануть, а вы можете это сразу не заметить и получить кучу гневных звонков, что какой-то сервис не работает.
Поэтому правильным решением, будет иметь возможность мониторить службы и автоматически восстанавливать их работоспособность.
Для этого, мы с создадим отдельный шаблон в Zabbix для работы с конкретной Windows службой.
Подробнее в данном видео…
P.S. Все еще идет набор в группы обучения «Комплексное обучение системному администрированию» и «Zabbix — Мониторинг IT»
Подробности тут — https://pages.it-skills.online/gruppa-obucheniya-kosa.html
Zabbix — свободная система мониторинга и отслеживания статусов разнообразных сервисов компьютерной сети, серверов и сетевого оборудования, написанная Алексеем Владышевым. Для хранения данных используется MySQL, PostgreSQL, SQLite или Oracle Database, веб-интерфейс написан на PHP.
Находим наш узел
- Items -> Create new
Задаем имя, в строке Ключ пишем:
service_state[имя службы](имя брать из свойства службы в строке “имя службы”, напримерservice_state[ArcGIS License Manager])- Интервал обновления:
60 сек - Период хранения:
7 дней
Сохраняем.
Создаем триггер: Задаем имя, в строке выражение пишем: {arcgisserver:service_state[ArcGIS License Manager].last(0)}=6
где:
6— остановлен. Т.е. отсылать алерт когда служба остановленаarcgisserver— имя нашего узла- важность —
высокая
Ключи:
- 0 — запущен
- 1 — пауза
- 2 — ожидание старта
- 3 — ожидание паузы
- 4 — ожидание продолжения
- 5 — ожидание остановки
- 6 — остановлен
- 7 — неизвестно
- 255 — такой службы не существует
Сохраняемся.
Так же можно добавить график для наглядности.
Авторский пост защищен лицензией CC BY 4.0 .
И есть ли в этом смысл?

Для тех, кто задумался и сомневается, я решил описать кое-что из своего опыта.
Мониторинг вообще штука полезная, бесспорно. У меня лично в какой-то период возникло сразу несколько задач:
-
Круглосуточно и непрерывно мониторить одну специфическую железку по ряду параметров;
-
Мониторить у рабочих станций информацию о температурах, ЦП в первую очередь;
-
Всякие мелочи в связи с широким внедрением удалёнки: количество подключений по VPN, общее состояние дополнительных виртуальных машин.
Подробнее про локальные задачи:
-
Надо было оценить и наглядно представить данные об интернет-канале. Канал на тот момент представлял собой 4G-роутер Huawei. Это устройство было последним, но далеко не первым в огромном количестве плясок с бубном в попытках избавиться от разного рода нестабильностей. Забегая вперёд: забирать с него данные напрямую о качестве сигнала более-менее стандартными средствами оказалось невозможно, и даже добраться до этих данных — отдельный квест. Пришлось городить дендрофекальную конструкцию, которая, на удивление стабильно, и стала в итоге поставлять данные. Данные в динамике и в графическом представлении оказались настолько неутешительными, что позволили убедить всех причастных таки поменять канал, даже и на более дорогой;
-
Данные о температуре процессора дают сразу несколько линий: можно обнаружить шифровальщик в процессе работы, наглядно сделать вывод о недостаточной мощности рабочей станции, найти повод провести плановую чистку, узнать о нарушении условий эксплуатации. Последний пункт особенно хорош: множество отказов оборудования и BSOD’ов в итоге нашли причину в «я ставлю обогреватель под стол, ну и свой баул, ну да, прям к этой решётке. А что? А я канпуктер развернула, а то неудобно»;
-
Интерфейс того же OpenVPN… ну, он в общем даже и не интерфейс и оставляет желать любого другого. Отдельная история.
Как большой любитель велосипедить всё подряд, сначала я решил свелосипедить и это. Уже валялись под рукой всякие скрипты по сбору статистки, и html проекты с графиками на js, и какие-то тестовые БД… Но тут сработала жадность (и лень, чоужтам). А чего это, подумал я, самому опять корячиться, если в том же Zabbix уже куча всяких шаблонов, и помимо задач из списка можно будет видеть много чего ещё? Да и он бесплатный к тому же. Всего-то делов, виртуалку поднять да клиенты централизованно расставить. Потренируюсь с ним, опять же, он много где используется.
Итак, нам понадобятся:
-
Виртуальная машина или физический хост. Zabbix нетребователен к ресурсам при небольшом количестве хостов на мониторинге: мне хватило одного виртуального процессора на 2ГГц и 4 Гб RAM за глаза;
-
Любой инструмент для автоматического раскидывания zabbix-agent. При некотором скилле это можно делать даже через оригинальный WSUS, или просто батником с psexec, вариантов много. Также желательно запилить предварительно сконфигурированный инсталлятор агента — об этом ниже;
-
Много желания пилить напильником. Скажу честно и сразу: из первоначального списка 3 из 3 реализовывалось руками на местности. Zabbix стандартной комплектации в такое не может.
У Zabbix много вариантов установки. В моём случае (я начинал с 4 LTS) сработала только установка руками в чистую, из собственного образа, OC в виртуальной машине на Hyper-V. Так что, коли не получится с первого раза, — не сдавайтесь, пробуйте. Саму процедуру подробнее описывать не буду, есть куча статей и хороший официальный мануал.

Про формирование инсталлятора агента: один из самых простых способов — использовать утилиты наподобие 7zfx Builder . Нужно будет подготовить:
-
файл zabbix_agentd.conf ;
-
файлы сторонних приложений и скриптов, используемых в userParameters (об этом ниже) ;
-
скрипт инсталлятора с кодом наподобие этого:
SETLOCAL ENABLEDELAYEDEXPANSION
SET INSTDR=C:\Zabbix\Agent
SET IP=192.168.100.10
set ip_address_string="IPv4-адрес"
for /f "usebackq tokens=2 delims=:" %%F in (ipconfig ^| findstr /c:%ip_address_string%) do SET IP=%%F
SET IP=%IP: =%
ECHO SourceIP=%IP%>> "%INSTDR%\conf\zabbix_agentd.conf"
ECHO ListenIP=%IP%>> "%INSTDR%\conf\zabbix_agentd.conf"
ECHO Hostname=%COMPUTERNAME%>> "%INSTDR%\conf\zabbix_agentd.conf"
"%INSTDR%\bin\zabbix_agentd.exe" -c "%INSTDR%\conf\zabbix_agentd.conf" -i
net start "Zabbix Agent"
ENDLOCALКстати, об IP. Адрес в Zabbix является уникальным идентификатором, так что при «свободном» DHCP нужно будет настроить привязки. Впрочем, это и так хорошая практика.
Также могу порекомендовать добавить в инсталлятор следующий код:
sc failure "Zabbix Agent" reset= 30 actions= restart/60000Как и многие сервисы, Zabbix agent под Windows при загрузке ОС стартует раньше, чем некоторые сетевые адаптеры. Из-за этого агент не может увидеть IP, к которому должен быть привязан, и останавливает службу. В оригинальном дистрибутиве при установке настроек перезапуска нет.
После этого добавляем хосты. Не забудьте выбрать Template – OS Windows. Если сервер не видит клиента — проверяем:
-
IP-адрес;
-
файрвол на клиенте;
-
работу службы на клиенте — смотрим zabbix_agentd.log, он вполне информативный.
По моему опыту, сервер и агенты Zabbix очень стабильны. На сервере, возможно, придётся расширить пул памяти по active checks (уведомление о необходимости такого действия появляется в дашборде), на клиентах донастроить упомянутые выше нюансы с запуском службы, а также, при наличии UserParameters, донастроить параметр timeout (пример будет ниже).
Что видно сразу, без настроек?
Сразу видно, что Zabbix заточен под другое  Но и об обычных рабочих станциях в конфигурации «из коробки» можно узнать много: идёт мониторинг оперативной памяти и SWAP, места на жёстких дисках, загрузки ЦП и сетевых адаптеров; будут предупреждения о том, что клиент давно не подключался или недавно перезагружен; агент автоматически создаёт список служб и параметров их работы, и сгенерирует оповещение о «необычном» поведении. Практически из коробки (со скачиванием доп. template’ов с офсайта и небольшой донастройкой) работает всё, что по SNMP: принтеры и МФУ, управляемые свитчи, всякая специфическая мелочь. Иметь алерты по тем же офисным принтерам в едином окне очень удобно.
Но и об обычных рабочих станциях в конфигурации «из коробки» можно узнать много: идёт мониторинг оперативной памяти и SWAP, места на жёстких дисках, загрузки ЦП и сетевых адаптеров; будут предупреждения о том, что клиент давно не подключался или недавно перезагружен; агент автоматически создаёт список служб и параметров их работы, и сгенерирует оповещение о «необычном» поведении. Практически из коробки (со скачиванием доп. template’ов с офсайта и небольшой донастройкой) работает всё, что по SNMP: принтеры и МФУ, управляемые свитчи, всякая специфическая мелочь. Иметь алерты по тем же офисным принтерам в едином окне очень удобно.
В общем-то, очень неплохо, но…
Что доделывать?
Оооо. Ну, хотел повелосипедить, так это всегда пожалуйста. Прежде всего, нет алертов на события типа «критические» из системного лога Windows, при том, что механизм доступа к логам Windows встроенный, а не внешний, как Zabbix agent active. Странно, ну штош. Всё придётся добавлять руками.
Например
для записи и оповещения по событию «Система перезагрузилась, завершив работу с ошибками» (Microsoft-Windows-Kernel-Power, коды 41, 1001) нужно создать Item c типом Zabbix agent (active) и кодом в поле Key:
eventlog[System,,,,1001]По этому же принципу создаём оповещения на другие коды. Странно, но готового template я не нашёл.
Cистема автоматизированной генерации по службам генерирует целую тучу спама. Часть служб в Windows предполагает в качестве нормального поведения тип запуска «авто» и остановку впоследствии. Zabbix в такое не может и будет с упорством пьяного сообщать «а BITS-то остановился!». Есть широко рекомендуемый способ избавления от такого поведения — добавление набора служб в фильтр-лист: нужно добавить в Template «Module Windows services by Zabbix agent», в разделе Macros, в фильтре {$SERVICE.NAME.NOT_MATCHES} имя службы в формате RegExp. Получается список наподобие:
^RemoteRegistry|MMCSS|gupdate|SysmonLog|
clr_optimization_v.+|clr_optimization_v.+|
sppsvc|gpsvc|Pml Driver HPZ12|Net Driver HPZ12|
MapsBroker|IntelAudioService|Intel\(R\) TPM Provisioning Service|
dbupdate|DoSvc|BITS.*|ShellHWDetection.*$И он не работает работает с задержкой в 30 дней.

Про службы, автоматически генерируемые в Windows 10, я вообще промолчу.
Нет никаких температур (но это, если подумать, ладно уж), нет SMART и его алертов (тоже отдельная история, конечно). Нет моих любимых UPS.
Некоторые устройства генерируют данные и алерты, работу с которыми надо выстраивать. В частности, например, управляемый свитч Tp-Link генерирует интересный алерт «скорость на порту понизилась». Почти всегда это означает, что рабочая станция просто выключена в штатном режиме (ушла в S3), но сама постановка вопроса заставляет задуматься: сведения, вообще, полезные — м.б. и драйвер глючит, железо дохнет, время странное…
Некоторые встроенные алерты требуют переработки и перенастройки. Часть из них не закрывается в «ручном» режиме по принципу «знаю, не ори, так надо» и создаёт нагромождение информации на дашборде.
Короче говоря, многое требует допиливания напильником под местные реалии и задачи.

О локальных задачах
Всё, что не встроено в Zabbix agent, реализуется через механизм Zabbix agent (active). Суть проста: пишем скрипт, который будет выдавать нужные нам данные. Прописываем наш скрипт в conf:
UserParameter=имя.параметра,путь\к\скрипту Нюансы:
-
если хотите получать в Zabbix строку на кириллице из cmd — не надо. Только powershell;
-
если параметр специфический – для имени нужно будет придумать и сформулировать дерево параметров, наподобие «hardware.huawei.modem.link.speed» ;
-
отладка и стабильность таких параметров — вопрос и скрипта, и самого Zabbix. Об этом дальше.
Хотелка №1: температуры процессоров рабочих станций
В качестве примера реализуем хотелку «темература ЦП рабочей станции». Вам может встретиться вариант наподобие:
wmic /namespace:\root\wmi PATH MSAcpi_ThermalZoneTemperature get CurrentTemperatureно это не работает (вернее, работает не всегда и не везде).
Самый простой способ, что я нашёл — воспользоваться проектом OpenHardwareMonitor. Он свои результаты выгружает прямо в тот же WMI, так что температуру получим так:
@echo OFF
SETLOCAL ENABLEDELAYEDEXPANSION
SET TMPTMP=0
for /f "tokens=* skip=1 delims=" %%I in ('wmic /namespace:\root\OpenHardwareMonitor PATH Sensor WHERE Identifier^="/intelcpu/0/temperature/1" get Value') DO (
SET TMPTMP=%%I && GOTO :NXT
)
:NXT
ECHO %TMPTMP%
ENDLOCAL
GOTO :EOFКонечно, при условии, что OHM запущен. В текущем релизе OHM не умеет работать в качестве Windows service. Так что придётся либо смущать пользователей очередной иконкой в трее, либо снова городить свой инсталлятор и запихивать OHM в сервисы принудительно. Я выбрал поcледнее, создав инсталляционный cmd для всё того же 7zfx Builder наподобие:
nssm install OHMservice "%programfiles%\OHM\OpenHardwareMonitor.exe"
timeout 3
net start "OHMservice"
del nssm.exe /QДва момента:
-
NSSM — простая и достаточно надёжная утилита с многолетней историей. Применяется как раз в случаях, когда ПО не имеет режима работы «сервис», а надо. Во вредоносности утилита не замечена;
-
Обратите внимание на «intelcpu» в скрипте получения температуры от OHM. Т.к. речь идёт о внедрении в малом офисе, можно рассчитывать на единообразие парка техники. Более того, таким образом лично у меня получилось извлечь и температуру ЦП от AMD. Но тем не менее этот пункт требует особого внимания. Возможно, придётся модифицировать и усложнять инсталлятор для большей универсальности.
Работает более чем надёжно, проблем не замечено.
Хотелка № 2: получаем и мониторим температуру чего угодно
Понадобятся нам две вещи:
-
Штука от братского китайского народа: стандартный цифровой термометр DS18B20, совмещённый с USB-UART контроллером. Стоит не сказать что бюджетно, но приемлемо;
-
powershell cкрипт:
param($cPort='COM3')
$port= new-Object System.IO.Ports.SerialPort $cPort,9600,None,8,one
$port.Open()
$tmp = $port.ReadLine()
$port.Close()
$tmp = $tmp -replace "t1="
if (([int]$tmp -lt 1) -or ([int]$tmp -gt 55)){
#echo ("trigg "+$tmp)
$port.Open()
$tmp = $port.ReadLine()
$port.Close()
$tmp = $tmp -replace "t1="
}
echo ($tmp)Связка работает достаточно надёжно, но есть интересный момент: иногда, бессистемно, появляются провалы или пики на графиках:
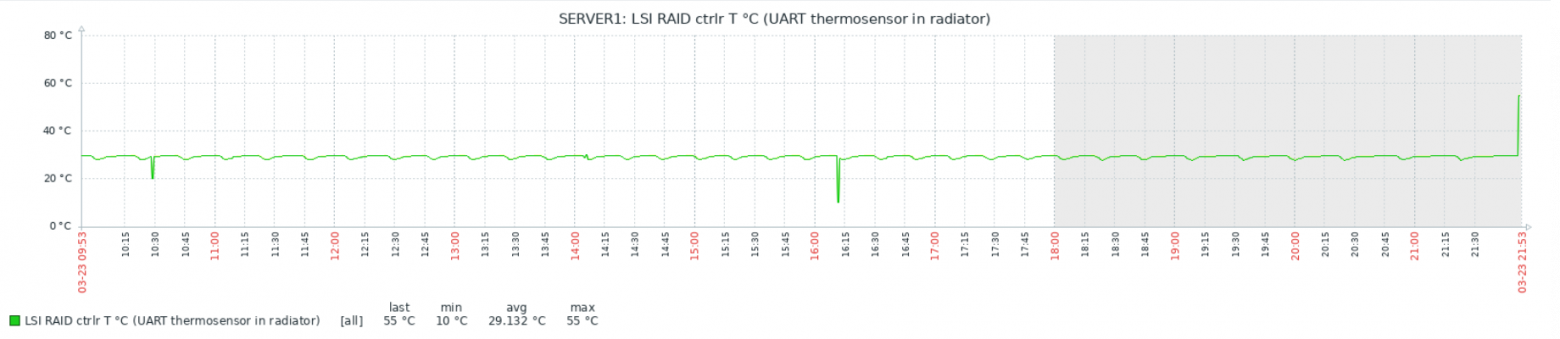
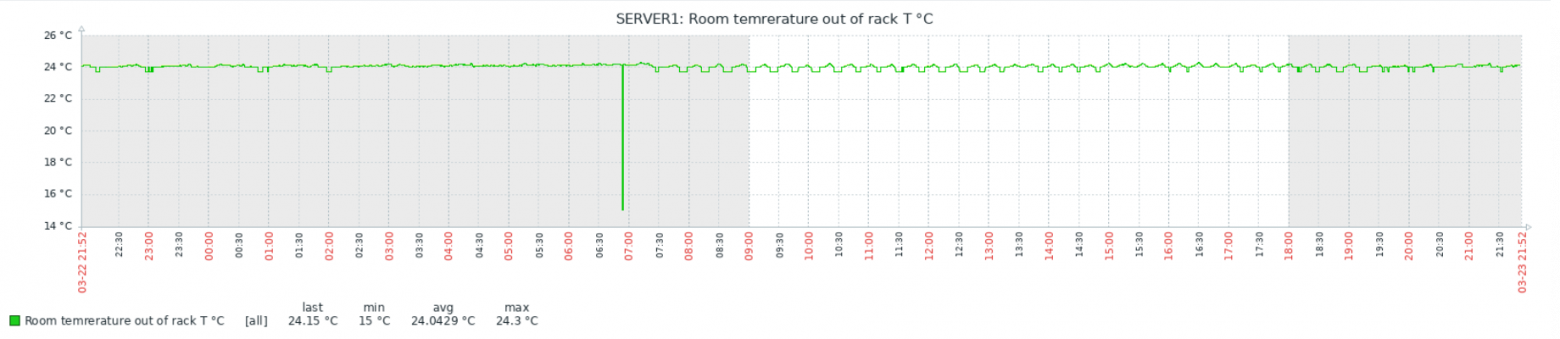
Тесты показали, что проблема в самом Zabbix, а данные с китайских датчиков приходят верные. Детальное рассмотрение пиков и провалов выявило неожиданный факт: похоже Zabbix иногда получает и/или записывает в БД не полное значение, а «хвост». Т.е., например, 1.50 от значения 21.50. При этом положение точки не важно — может получить и 1.50, и 50, и даже 0. Как так происходит, мне выяснить пока не удалось. Изменение timeout на поведение не влияет никак, ни в большую, ни в меньшую сторону.
Наверное, стоило бы написать багрепорт. Но уже вышел 6.0 LTS (у меня 5) и обновляться в текущей ситуации, пожалуй, не буду.
Хотелка № 3: OpenVPN подключения
Template’ов для OpenVPN и Zabbix существует довольно много, но все они реализованы на том или ином sh под *nix’ы . В свою очередь, «dashboard» OpenVPN-сервера представляет из себя, по сути, вывод утилиты в консоль, который пишется в файл по событиям. Мне лень было считать трафик по отдельным пользователям и вообще делать их discover, т.к. подключений и пользователей немного. Ограничился текущим количеством подключений:
$openvpnLogPath = "C:\OpenVPN\config\"
$openvpnLogName = "openvpn-status.log"
try {
$logData = Get-Content $openvpnLogPath$openvpnLogName -ErrorAction Stop
}
catch{
Write-Host("Missing log file")
exit 1
}
$logHeader = "OpenVPN CLIENT LIST"
$logHeader2 = "Common Name,Real Address,Bytes Received,Bytes Sent,Connected Since"
$logMark1 = "ROUTING TABLE"
if ($logData[0] -ne $logHeader -or $logData[2] -ne $logHeader2 ){
Write-Host("Bad log file")
exit 1
}
$i = 0
foreach ($tmpStr in ($logData | select -skip 3)) {
if ($tmpStr -eq $logMark1) {break}
$i++
}
Write-Host($i)
exit 0Хотелка № 4: спецжелезка 1
Для большого количества специфического оборудования существуют написанные энтузиастами Template’ы. Обычно они используют и реализуют функционал, уже имеющийся в утилитах к этим железкам.
Боли лирическое отступление
установив один из таких темплейтов, я узнал, что «нормальная рабочая» температура чипа RAID-контроллера в серваке — 65+ градусов. Это, в свою очередь, побудило внимательнее посмотреть и на контроллер, и на сервер в целом. Были найдены косяки и выражены «фи»:
-
Apaptec’у – за игольчатый радиатор из неизвестного крашеного силумина высотой чуть более чем нихрена, поток воздуха к которому закрыт резервной батарейкой с высотой больше, чем радиатор. Особенно мне понравилось потом читать у Adaptec того же «ну, это его нормальная рабочая температура. Не волнуйтесь». Ответственно заявляю: при такой «нормальной рабочей температуре» контроллер безбожно и непредсказуемо-предсказуемо глючил;
-
Одному отечественному сборщику серверов. «Берём толстый жгут проводов. Скрепляем его, чтобы он был толстым, плотным, надёжным. Вешаем это прямо перед забором воздуха вентиляторами продува серверного корпуса. Идеально!». На «полу» сервера было дофига места, длины кабелей тоже хватало, но сделали почему-то так.
Также был замечен интересный нюанс поведения, связанный с Zabbix. Со старым RAID контроллером при наличии в системном логе специфичных репортов, отваливался мониторинг температуры контроллера в Zabbix, но! при запуске руками в консоли скрипта или спец. утилиты температура выводилась корректно и без задержек.
Но полный функционал реализован далеко не всегда. В частности, мне понадобились температуры жёстких дисков с нового RAID-контроллера (ну люблю я температуры, что поделать ), которых в оригинальном темплейте не было. Пришлось самому реализовывать температуры и заодно autodiscover физических дисков: https://github.com/automatize-it/zabbix-lsi-raid/commit/1d3a8b3a0e289b8c2df637028475177a2b940689

Оригинальный репозиторий, вероятно, заброшен, как это довольно часто бывает.
Хотелка № 5, на десерт: спецжелезка 2
Как и обещал, делюсь опытом вырывания данных из беспроводной железки Huawei. Речь о 4G роутере серии B*. Внутри себя железка имеет ПО на ASP, а данные о качестве сигнала — RSSI, SINR и прочее — в пользовательском пространстве показывать не хочет совсем. Смотри, мол, картинку с уровнем сигнала и всё, остальное не твоего юзерского ума дело. К счастью, в ПО остались какие-то хвосты, выводящие нужное в plain JSON. К сожалению, взять да скачать это wget-ом не получается никак: мало того, что авторизация, так ещё и перед генерацией plain json требуется исполнение JS на клиенте. К счастью, существует проект phantomjs. Кроме того, нам понадобится перенесённая руками кука из браузера, где мы единожды авторизовались в веб-интерфейсе, вручную. Кука живёт около полугода, можно было и скрипт написать, но я поленился.
Алгоритм действий и примеры кода:
вызываем phantomjs с кукой и сценарием:
phantomjs.exe --cookies-file=cookie.txt C:\cmd\yota_signal\scenery.jsПримеры сценариев:
//получаем общий уровень сигнала
var url = "http://192.168.2.1/html/home.html";
var page = require('webpage').create();
page.open(url, function(status) {
//console.log("Status: " + status);
if(status === "success") {
var sgnl = page.evaluate(function() {
return document.getElementById("status_img").innerHTML; //
});
var stt = page.evaluate(function() {
return document.getElementById("index_connection_status").innerText; //
});
var sttlclzd = "dis";
var sgnlfnd = "NA";
if (stt.indexOf("Подключено") != -1) {sttlclzd = "conn";}
if (sgnl.indexOf("icon_signal_01") != -1) {sgnlfnd = "1";}
else {
var tmpndx = sgnl.indexOf("icon_signal_0");
sgnlfnd = sgnl.substring(tmpndx+13,tmpndx+14);
}
console.log(sttlclzd+","+sgnlfnd);
var fs = require('fs');
try {
fs.write("C:\\cmd\\siglvl.txt", sgnlfnd, 'w');
} catch(e) {
console.log(e);
}
}
phantom.exit();
});
//получаем технические параметры сигнала через какбэ предназначенный для этого "API"
var url = "http://192.168.2.1/api/device/signal";
var page = require('webpage').create();
page.onLoadFinished = function() {
//console.log("page load finished");
//page.render('export.png');
console.log(page.content);
parser = new DOMParser();
xmlDoc = parser.parseFromString(page.content,"text/xml");
var rsrq = xmlDoc.getElementsByTagName("rsrq")[0].childNodes[0].nodeValue.replace("dB","");
var rsrp = xmlDoc.getElementsByTagName("rsrp")[0].childNodes[0].nodeValue.replace("dBm","");
var rssi = xmlDoc.getElementsByTagName("rssi")[0].childNodes[0].nodeValue.replace("dBm","").replace(">=","");
var sinr = xmlDoc.getElementsByTagName("sinr")[0].childNodes[0].nodeValue.replace("dB","");
var fs = require('fs');
try {
fs.write("C:\\cmd\\rsrq.txt", rsrq, 'w');
fs.write("C:\\cmd\\rsrp.txt", rsrp, 'w');
fs.write("C:\\cmd\\rssi.txt", rssi, 'w');
fs.write("C:\\cmd\\sinr.txt", sinr, 'w');
} catch(e) {
console.log(e);
}
phantom.exit();
};
page.open(url, function() {
page.evaluate(function() {
});
});
Конструкция запускается из планировщика задач. В Zabbix-агенте производится лишь чтение соответствующих файлов:
UserParameter=internet.devices.huawei1.signal.level,type C:\cmd\siglvl.txt 
Требует постоянного присмотра, ручных прибиваний и перезапусков процессов, обновления кук. Но для такого шаткого нагромождения фекалий и палок работает достаточно стабильно.
Итого
Стоит ли заморачиваться на Zabbix, если у вас 20 машин и 1-2 сервера, да ещё и инфраструктура Windows?
Как можно понять из вышеизложенного, работы будет много. Я даже рискну предположить, что объёмы работ и уровень квалификации для них сравнимы с решением «свелосипедить своё с нуля по-быстрому на коленке».
Не стоит рассматривать Zabbix как панацею или серебряную пулю.
Тем не менее, использование уже готового и популярного продукта имеет свои преимущества — в первую очередь, это релевантный опыт для интересных работодателей.
А красивые графики дают усладу глазам и часто — новое видение процессов в динамике.
Если захочется внедрить, то могу пообещать, как минимум — скучно не будет! 
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
Мониторите малые офисы?
61.22% Мониторю, Заббиксом60
3.06% Мониторю, не Заббиксом3
2.04% Мониторю, самописной системой2
25.51% Не мониторю, но вообще надо бы25
8.16% Не мониторю и не надо8
Проголосовали 98 пользователей. Воздержались 30 пользователей.
This time we’re going to look at how to monitor any Windows Service with the Zabbix agent. Zabbix website guide is quite clear, but none the less here’s a short step-by-step guide on how to do it.
1. The Template
When you work with Zabbix, it’s always a good idea to start with a fresh new template, unless the changes you are making will effect ALL the hosts which the template is linked to. Rarely this is the case, and as such a separate template is a good idea. This gives you more control over what you’r doing and how it’s being implemented. To create a new template, navigate to Configuration -> Templates. Click on “New Template” and name it as you please, tutorial if you like. Any new template that you create will automatically be placed in the Templates group, which is good. Give the template a description if you want but other than this, there are no additional requirements for a template. To finish things off, click Add at the bottom of the Template tab to save it.
2. Applications and Items
Open up the template you just created and lets start off by creating a application in the “Applications” view. Click on Create Application on the top right corner of the Zabbix webpage and give the Application a name. If you look at any other template, that is created while Zabbix is installed, an Application contains one or more items. The application you create could be named “Services” or if you want to monitor more than one service that is required for the application to run, you could name it like the Application is. None of this matters, as long as it makes sense to you! Click Add once you’ve named the application and lets move on to the Items, where the magic happens.
This brand new template has no items, like it had no applications. We need to define what will be a part of this template and in this case, an Item equals to one service. Click “Create Item” on the top right corner and let’s create our first Windows Service. Give the Item a name, preferably something that describes what you are monitoring. The type should be “Zabbix agent” and the key is what’s important. The key should be service_state[service_name], and the service name you can find from services.msc (win+r to run services.msc). If we were to monitor that Windows Time service is running, open up the properties of “Windows Time“. What would be entered in service_state, is the service name from the properties; W32Time. This tells Zabbix what key to look for within the services. Zabbix gets back a numeric value if the service is running, stopped or something else, so type of information and data type is numeric (unsigned) and Decimal. Specify the update interval according to how critical the application is, 30 seconds should be more than enough for any service. Lastly select the Application you created from the Applications list and give the item a suiting description.
3. The trigger
To get any kind of alarm from the service, we need to create a trigger. Triggers define how to interact with the values that are returned tot he Zabbix Server by the agent. In this case, we receive a numeric decimal value that was defined in the item before. You can use the expression builder if you want, or write the expression yourself. If you use the expression builder, make sure you select the template when you choose what item to interact with.
The trigger is written inside { } brackets, and starts off with the template name. In my example, I’ve named the template “Template Windows Time Service“. Continued from that, the Item key is written with : in between, the key being in this example service_state[W32Time]. We want to trigger if the value changes, meaning we want to interact with the last value provided using .last(). We want an alert to trigger, if the service state is anything else than running, meaning we use the expression <>0. The value zero comes from how Zabbix agent presents the service state to us. You can find the list of service states here (search for service_state).
Give the trigger a severity that you think is appropriate and your done.
4. Testing
Apply this template to a Windows Host you are monitoring, and stop the service if possible. Within a short while, you should see a trigger on your dashboard regarding the service in question. That’s it, you can add multiple applications to this template, and multiple services. But in it’s simplest form, one template may contain one application with one item and it’s trigger.
You can download an example template here:
Прочитано: 10 065
На предыдущей работе я довольно напользовался тем, что в моей системе мониторинга Zabbix использовал разобранную возможность мониторить статусы установленных служб в системах. К примеру есть важный процесс и его нужно мониторить, как он только выключится, то нужно сразу же смотреть почему такое произошло, а не ждать когда тебе начнут звонить. Караул — почему сервисы не работают как и должны работать. А потому данная заметка будет своеобразной пошаговой напоминалкой самому себе, как в кратчайшие сроки поставить те или иные сервисы Windows на мониторинг в универсальный конструктор мониторинга Zabbix.
У меня Zabbix развернут на Ubuntu 12.04.5 Server amd64 версии 2.2.11
ekzorchik@srv-mon:~$ apt-cache show zabbix-server-mysql | grep Version
Version: 1:2.2.11-1+precise
Первое условие на станции Windows которую нужно мониторить на предмет статуса запущенного сервиса должен стоят Zabbix–агент и заведен на Zabbix-сервер.
Задача: мониторить буду службу: FusionInventory-Agent
это агент GLPI посредством которого происходит инвентаризация рабочей станции: Какая ось, какой софт, какое железо, кто сейчас работает, IP-адрес станции и т. д.
Теперь создаю новый элемент данных в дефолтном шаблоне Template OS Windows:
http://IP&DNS — Configuration — Templates — Template OS Windows — Items — Create Item
Name: GLPI Agent
Type: Zabbix agent
Key: service_state[FusionInventory-Agent]
Update interval (in sec): 60
History storage period (in days): 7
Trend storage period (in days): 365
New Application: Services
Description: Мониторим статус работы службы установленного агента GLPI
Enabled: Отмечаю галочкой
Сохраняю внесенные изменения: Save
На заметку: ключ service_state принимает ответные значения:
State of service. 0 – running, 1 – paused, 2 – start pending, 3 – pause pending, 4 – continue pending, 5 – stop pending, 6 – stopped, 7 – unknown, 255 – no such service
Теперь создаю Trigger (описание тревоги на этот элемент данных), в этом же Template OS Windows — Triggers — Create Trigger
Name: Service State — GLPI Agent on {HOSTNAME}
Expression: – Add находим нужно правило, в моем случаем правило следующее:
{Template OS Windows:service_state[FusionInventory-Agent].last()}=6
Severity: High
Enabled: Отмечаю галочкой
Сохраняю внесенные изменения: Save
Теперь проверяю, сейчас на хосте (W7X86) выключаю/останавливаю службу и в Zabbix’е – Monitoring у меня в где Windows Stations обозначена среагированная проблема:
Перехожу в группу и вижу на каких хоста сработало уведомление о неполадках:
Тип уведомление: Высокий
Время последнего изменения статуса
Продолжительность недоступности сервиса в связи с выключенным состояние службы FusionInventory-Agent

вернув сервис в режим “Старт” , уведомление в Zabbix о сработанных триггерах вернулось в норму:

Если ведем какие-либо работы, то можно на сработанных триггер по этому хосту поставить комментарий (Acknowledge) или же когда сервис в строю:
Message: Работа сервиса восстановлена
После нажимаю: Acknowledge and return
По такому принципу можно настроить свой шаблон и свои элементы данных которые нужно отслеживать.
На этом собственно пока все, до новых встреч на моем блога, с уважением автор блога – ekzorchik.