
Счетчики производительности это встроенные компоненты, которые позволяют собрать статистику использования ресурсов системы, для дальнейшего анализа, с целью выявления узких мест в системе.
Потенциально узкими местами могут являться:
- Процессор
- Память
- Жесткие диски
- Сеть
Ниже приведу основной перечень счетчиков, которые в первую очередь потребуется проанализировать для первичной диагностики производительности системы, их краткую характеристику и возможные Варианты решения, при превышении допустимых показателей. Рассматривать их будем по отдельным логическим блокам.
Процессор
Processor \ %Processor Time — время, которое процессор тратит на выполнение полезной работы, в процентах от общего системного времени. Если среднее значение величины утилизации процессора превышает 70% в течение длительного времени, значит процессор – узкое место в системе.
System \ Processor Queue Length — длина очереди к процессору. Если долгий период времени средняя длина очереди превышает значение 2 * количество ядер процессоров, то это говорит о том, что процессор является узким местом.
Варианты решения:
- Замена процессоров на более быстродействующие;
- Увеличение количества ядер в случае виртуализации;
- Перенос приложений, интенсивно использующих процессор на отдельный компьютер. Например, установка сервера 1С:Предприятия и Microsoft SQL Server на разных компьютерах;
Память
Memory \ Available Mbytes — отражает объем доступной памяти в мегабайтах. Желательное состояние — 25% от общей памяти, если занято больше 90% оперативной памяти, значит нужно однозначно принимать меры для исправления.
Memory \ Pages/sec — характеризует интенсивность обмена между дисковой подсистемой и оперативной памятью. Обращение к дисковой системе происходит из-за того, что запрашиваемые страницы отсутствуют в оперативной памяти. Если значение данного счетчика достигает или превышает 20, следует внимательно изучить активность страничного обмена.
Варианты решения:
- Увеличение объема оперативной памяти, установленной на компьютере;
- Перенос приложений, интенсивно использующих оперативную память, на отдельный компьютер. Например, установка сервера 1С:Предприятия и Microsoft SQL Server на разных компьютерах;
Жесткие диски
Physical Disk \ Avg. Disk sec/Write/Read — показывает среднее время на запись/чтение в секундах.
Данные счетчики показывают, успевает ли накопитель отработать все запросы от выполняющихся процессов. При работе с дисковым кэшем нормальное время на чтение или запись обычно составляет менее 10 мс. Следует учитывать, что если дисков больше одного, то необходимо анализировать каждый по отдельности.
Physical Disk \ Avg. Disk Write/Read Queue Length — средняя длина очереди к диску на запись. В идеале значение этих счетчиков должно равняться 0. Не критично если значение будет не более 2 * количество дисков, работающих параллельно.
Disk bytes/sec — показывает скорость обмена с диском в байт/с при записи или чтении. Данный счетчик может показать, соответствует ли скорость диска заявленным производителем характеристикам.
Рекомендуют от 40 Мб в секунду и выше.
Disk Writes/Reads/sec — это частота выполнения операций чтения и записи. Данный счетчик особо важен для анализа при использовании дисковых массивов. Обычно его рекомендуемое значение указано в документации к конкретному оборудованию.
Варианты решения:
- Установка более быстрых дисков;
- Использование дисков с интерфейсом SCSI;
- Использование аппаратного RAID — контроллера;
- Увеличение количества дисков в RAID — массиве;
Сеть
Основными счетчиками сетевых интерфейсов, требующих внимания являются:
Network Interface \ Bytes Total/sec — этот счетчик показывает скорость, с которой происходит получение или посылка байт через сетевой интерфейс. Его оптимальный показатель — не более 65% от пропускной способности сетевого адаптера.
Output Queue Length — это количество исходящих пакетов в очереди. Всегда должна быть 0, но может достигать 2 на мгновение. Если среднее значение счетчика более двух, это значит что сетевой интерфейс не справляется с передачей данных.
Варианты решения:
- Установка сетевого адаптера с более высокой пропускной способностью (если позволяют параметры сети);
- Установка дополнительного сетевого адаптера;
Для большей наглядности, приведу предельные значения показателей основных счетчиков в виде таблицы:

Разобравшись с тем, какие счетчики нам в первую очередь нужны и за что они отвечают, можем приступить к самой настройке.
Для настройки счетчиков производительности необходимо запустить системный монитор, например, нажатием комбинации клавиш Win + R и написать perfmon.
Здесь правой кнопкой на группу Особые создаем новую группу сборщиков данных:

Далее выбираем, что создавать новую группу будем вручную:

Тип данных выбираем Счетчики производительности:

На следующем шаге должны выбрать, какие конкретно счетчики мы будем анализировать(выбираем счетчики, рассмотренные выше). Интервал выборки можно оставить по умолчанию, однако стоит учитывать, что для более точного анализа, нужно выбрать более короткие интервалы:

Далее необходимо определить каталог для хранения данных. Можно оставить по умолчанию, однако следует учесть, что у пользователя, от именно которого будет запускаться процесс сборки, должно быть право на запись в указанный каталог.

выбираем пользователя и жмем Готово:

После завершения настройки мы можем открыть свойства созданной группы сборщиков и изменить некоторые параметры, например, можем настроить расписание выполнения задания:

задать условие остановки, например, чтобы на каждый день был отдельный файл данных, для более удобного анализа:

Состав счетчиков зависит от версии ОС, от установленных программ, локализации системы и программного обеспечения и др. Следует сказать, что если каких-либо счетчиков не удалось найти, их можно добавить, выполнив команду ниже от имени админимтратора:
- cd %systemroot%\system32
- lodctr /R
Далее проанализируем некоторые графики счетчиков производительности, чтобы понять как выглядят ситуации, которые свидетельствуют о проблемах с производительностью(на анализируемый период просьба не обращать внимания, так как графики приведены чисто в ознакомительных целях).
Процессор
На скриншоте ниже мы видим, что процент загрузки процессора больше 80 на протяжении всего рабочего дня. Однозначно нужно принимать меры:

Тут мы видим, что очередь к процессору также превышает максимально допустимую:

Память
При анализе показателей оперативной памяти, особый интерес представляет минимально доступный объем. Как видим на графике ниже, он у нас равняется 0, что не есть хорошо. Также о проблемах с памятью свидетельствует и среднее значение показателя данного счетчика в 1 ГБ. Это однозначно является узким местом системы:

Диск
На графике ниже можно увидеть, что среднее время на запись составляет 65 мс. Даже с учетом того, что при скорости записи до 50 мс «тормоза» не будут так сильно ощущаться, тут однозначно ситуацию необходимо исправить.

На следующем скриншоте можно заметить, что очередь к диску на чтение выше предельно допустимого и его среднее значение достигает 21:

Таким образом, выполнив первоначальный анализ основных счетчиков, можно понять, какие компоненты системы являются наиболее уязвимыми, или хотя бы определить подсистему, которая требует более тщательного анализа, и принять соответствующие меры для устранения проблемы.
Memory: Available Bytes
Порог: Этот счётчик должен быть постоянно выше 5 000 КВ (если не разбираться в нюансах)
Значение: Отслеживает количество доступной памяти в байтах для выполнения различных процессов.. Низкие показатели означают нехватку памяти. Решение — увеличить память.
Есть смысл выставлять порог для \Memory\Available Mbytesвручную из соображений:
•50% свободной памяти доступно = Отлично
•25% доступно памяти = Требует внимания
•10% свободно = Возможны проблемы
•Меньше 5% доступно памяти= Критично для скорости, нужно вмешиваться
Memory: Pages Faults/sec
Порог: Этот счётчик не должен быть, продолжительное время, больше 1000
Значение: Это значение счетчика ошибок страницы. Ошибка страницы возникает, когда процесс ссылается на страницу виртуальной памяти, которая не находится в рабочем множестве оперативной памяти. Данный счетчик учитывает как те ошибки страницы, которые требуют обращения к диску, так и те, которые вызваны нахождением страницы вне рабочего множества в оперативной памяти. Большинство процессоров могут обрабатывать ошибки страницы второго типа без особых задержек. Однако, обработка ошибок страницы первого типа, требующая доступа к диску, может привести к значительным задержкам.
Если значение этого счётчика постоянно больше 0, то это указывает на то что Windows очень интенсивно свопит на диск из-за недостатка памяти.
Process: Page Faults/sec/SQL Server Instance
Порог: Этот счётчик не должен быть, продолжительное время, больше 0
Значение: — отслеживает ошибки страниц памяти из-за того что WIndows обрезает размер working-set для данного процесса. Высокие значения этого счётчика указывают что кто-то усиленно свопит. Решение — найти тот процесс, который это вызывает, потом проанализировать полученную информацию. В любом случае своп указывает на недостаток памяти.
Process: Working Set/SQL Server Instance
— отслеживает память, которую использует процесс SQL для данной instance. Счётчик должен быть больше 5000 КВ, если значение падает ниже, то это означает нехватку памяти для SQL.
SQL Server: Buffer Manager: Buffer Cache Hit Ratio
Порог: Этот счётчик не должен быть, продолжительное время, меньше 90%.
Значение: Счетчик отслеживает, в процентах, долю страниц в буфере кэша. При этом не делает разницы между физической памятью и свопом.
SQL Server: Buffer Manager: Total Pages
— отслеживает общее количество станиц в буфере кэша. Низкие значения счётчика могут означать частые обращения к винту. Решение — увеличить память.
SQL Server: Memory Manager: Total Server Memory
Порог: Этот счётчик не должен быть, продолжительное время, больше физически доступной памяти.
Значние: Счетчик отслеживает общее количество динамической памяти, которую использует SQL. Если значения счётчика, продолжительное время, больше чем физическая память, надо увеличивать физическую память.
Этот счетчик есть смысл рассматривать вместе
SQL Server: Memory Manager: Target Server Memory
Порог: Этот счётчик не должен быть, продолжительное время, больше физически значения счетчика SQL Server: Memory Manager: Total Server Memory
Значение: Счетчик показывает требуемый объем ресурсов.
Для анализа используйте онлайн-сервис. При желании подобрать сервер воспользуйтесь нашими услугами по подбору серверов.
Смотрите также http://www.gilev.ru/ram/
Provide feedback
Saved searches
Use saved searches to filter your results more quickly
Sign up
Appearance settings
Каждый опытный сисадмин знает, что лучший показатель ухудшения быстродействия 1С, это главный бухгалтер, движущийся в сторону ИТ отдела со скоростью, превышающей 1.1 м/с. Но только мудрейшие из них настраивают сбор счетчиков, чтобы эта встреча не застала их врасплох. Об этом и поговорим под катом…

Эпиграф:
Существуют две причины, по которым может тормозить компьютер:
1. Вирус.
2. Антивирус.
© советы бывалых сисадминов
Не ошибусь, если скажу, что каждый офисный админ сталкивался с вопросом: Почему тормозит 1С?
И опять же не ошибусь, если первое что он(а) при этом сделает, это откроет диспетчер задач.
Более продвинутые, конечно настроят сбор счетчиков Performance Monitor (Zabbix в данном контексте примерно то же самое).
Тем более, что инструкций, чек-листов по настройке более чем достаточно. Это то и пугает.
Попробую предложить вам обзор основных и свою компиляцию.
Внимание!
Название счетчиков отличается не только в зависимости от языка операционной системы, но и от ее редакции.
Добавим к этому видение и ошибки авторов публикаций и поймем, что простой копипаст может не сработать.
В случае же perfmon это усугубится тем, что никаких ошибок при создании счетчиков в командной строке вам выдано не будет, просто они не будут собираться.
Для того, чтобы увидеть список всех счетчиков производительности, имеющихся на текущем компьютере нужно в командной строке выполнить
- typeperf -q [object] выведет список всех счетчиков
- typeperf -qх [object] выведет список всех счетчиков по экземплярам оборудования, например отдельно для дисков А: и С:
Где необязательный параметр [object] это фильтр по виду счетчиков, например PhysicalDisk
Этот вывод можно переадресовать в файл и далее уже из него выбирать необходимое
typeperf -qx -y -o counters.txt
В дальнейшем, чтобы получить сводную статистику нужно заменить в случае ключа -qx имя конкретного экземпляра на (_Total), а чтобы получить статистику для каждого экземпляра отдельно на (*)
Например:
\PhysicalDisk(_Total)\Current Disk Queue Length
\PhysicalDisk(*)\Current Disk Queue Length
Рекомендуемый мной путь, это создать bat файл из 3 строк.
logman create counter 1C_counter -f bincirc
logman update counter 1C_counter -cf assembled.txt
logman update counter 1C_counter -si 15 -v mmddhhmm
А в файл assembled.txt добавлять названия счетчиков. По одному на строку. Рабочий и рекомендуемый мной пример для Windows Server 2012 R2 ENG будет внизу.
список под спойлером
\Processor(_Total)\% Processor Time
\Processor(_Total)\% User Time
\Processor(_Total)\% Privileged Time
\Memory\Available MBytes
\Memory\Pages/sec
\Memory\% Committed Bytes In Use
\Paging File(*)\% Usage
\System\Context Switches/sec
\System\Processor Queue Length
\System\Processes
\System\Threads
\PhysicalDisk(_Total)\Current Disk Queue Length
\PhysicalDisk(*)\Current Disk Queue Length
\PhysicalDisk(_Total)\Avg. Disk sec/Read
\PhysicalDisk(_Total)\Avg. Disk sec/Write
\Network interface(_Total)\Bytes Total/sec
\Network interface(_Total)\Current Bandwidth
\Process(1cv8)\% Processor Time
\Process(1cv8)\Private Bytes
\Process(1cv8)\Virtual Bytes
\Process(ragent)\% Processor Time
\Process(ragent)\Private Bytes
\Process(ragent)\Virtual Bytes
\Process(rphost)\% Processor Time
\Process(rphost)\Private Bytes
\Process(rphost)\Virtual Bytes
\Process(rmngr)\% Processor Time
\Process(rmngr)\Private Bytes
\Process(rmngr)\Virtual Bytes
\Process(sqlservr)\% Processor Time
\Process(sqlservr)\Private Bytes
\Process(sqlservr)\Virtual Bytes
\SQLServer:General Statistics\User Connections
\SQLServer:General Statistics\Processes blocked
\SQLServer:Buffer Manager\Buffer cache hit ratio
\SQLServer:Buffer Manager\Page life expectancy
\SQLServer:SQL Statistics\Batch Requests/sec
\SQLServer:SQL Statistics\SQL Compilations/sec
\SQLServer:SQL Statistics\SQL Re-Compilations/sec
\SQLServer:Access Methods\Page Splits/sec
\SQLServer:Access Methods\Forwarded Records/sec
\SQLServer:Access Methods\Full Scans/sec
\SQLServer:Memory Manager\Target Server Memory (KB)
\SQLServer:Memory Manager\Total Server Memory (KB)
\SQLServer:Memory Manager\Free Memory (KB)
\SQLServer:Databases(_Total)\Transactions/sec
\SQLServer:Databases(*)\Transactions/sec
Собственно торопыжки могут дальше и не читать. Да они уже и не читают.
С остальными разберемся с рекомендациями
лучших собаководов
Начнем с изучения советов самого вендора: microsoft.com
Публикация Windows VM health
Используя этот вариант вы точно не ошибетесь, но в нем присутствуют счетчики не совсем нужные для мониторинга именно сервера 1С.
Далее, а скорее и выше, в моем топе вариантов идет рекомендация от Евгения Валерьевича Филиппова
Настольная книга 1С: Эксперта по технологическим вопросам. Издание 2
Список небольшой, но все по делу и видно, что автор его использовал в работе.
Список книги Методическое пособие по эксплуатации крупных информационных систем на платформе «1С: Предприятие 8»
А. Асатрян, А. Голиков, А. Морозов, Д. Соломатин, Ю.Федоров
еще лаконичнее, в него добавлен мониторинг 1cv8, ragent, rphost, rmngr его я вынесу в отдельный список, потому что он может и наверное не помешает при любом варианте, кроме разнесенных SQL и 1С серверов.
таблица под спойлером
«\Process(«1cv8*»)\%%Processor Time»
«\Process(«1cv8*»)\Private Bytes»
«\Process(«1cv8*»)\Virtual Bytes»
«\Process(«ragent*»)\%%Processor Time»
«\Process(«ragent*»)\Private Bytes»
«\Process(«ragent*»)\Virtual Bytes»
«\Process(«rphost*»)\%%Processor Time»
«\Process(«rphost*»)\Private Bytes»
«\Process(«rphost*»)\Virtual Bytes»
«\Process(«rmngr*»)\%%Processor Time»
«\Process(«rmngr*»)\Private Bytes»
«\Process(«rmngr*»)\Virtual Bytes»
или как вариант без разбиения
\Process(1cv8)\% Processor Time
\Process(1cv8)\Private Bytes
\Process(1cv8)\Virtual Bytes
\Process(ragent)\% Processor Time
\Process(ragent)\Private Bytes
\Process(ragent)\Virtual Bytes
\Process(rphost)\% Processor Time
\Process(rphost)\Private Bytes
\Process(rphost)\Virtual Bytes
\Process(rmngr)\% Processor Time
\Process(rmngr)\Private Bytes
\Process(rmngr)\Virtual Bytes
\Process(sqlservr)\% Processor Time
\Process(sqlservr)\Private Bytes
\Process(sqlservr)\Virtual Bytes
Список счетчиков оборудования.
Далее идет статья с ИТС Анализ загруженности оборудования для Windows Елена Скворцова и ее полная копия на kb у кого есть туда доступ, в ней подробно и с картинками описан весь процесс настройки. Для первой настройки это очень полезно.
При всей полезности и доступности статьи не покидает ощущение, что ее писали как знаменитое письмо Матроскина: «ваш сын дядя Шарик», разные люди. Например текст не совпадает с картинками, для некоторых счетчиков описаны пороговые значения, но в списке их нет, некоторые счетчики в списке двоятся, из-за этого не получится копипастом в командной строке запустить logman. Это как раз начинающих немного обескураживает.

Лирическое отступление: Не прошло и месяца с регионального тура конкурса ИТС, где один из вопросов был именно так составлен, в коде вариант ответа один, а в картинке и математически верный совсем другой. Организаторы опирались именно на корректность кода. Хотя понятно, код проверяют слабо, во всех научных книгах об этом предупреждают заранее.
Замыкают список иностранные агенты вендоры.
www.veritas.com Analyzing SQL Performance using Performance Monitor Counters
Понятно, что про 1С они и слыхом не слыхивали, но то, что серверов они видели на порядок более, это факт.
red-gate.com
SQL Server performance and activity monitoring
Что касается, счетчиков для MS SQL, то мой список был в начале публикации.
Вариантов невероятное множество как и экспертов (не факт, что сейчас один из них не съехал тихо под стол при виде его).
Впрочем, настоящий скульный админ никогда не покажет своего отношения, максимум поиграет бровями и пойдет слушать музыку сервера.
Желающие могут провести пару зимних (летних) вечеров разбирая полный список.
таблица под спойлером

— Штурман, приборы!
— Четырнадцать.
— Что четырнадцать?
— А что, приборы!?
©www.anekdot.ru
Бдительный читатель скажет: Мало собрать счетчики оборудования, надо их еще и проанализировать.
А я покажу ему вот эту таблицу.
Техническое отступление: Хотя ней выражено мнение уважаемых экспертов, относиться к нему надо с пониманием.
Например, многие вспомнят времена, когда они умоляли директора докупить планку 32 Мб в сервер упомянутой выше бухгалтерии. То же касается и скорости дисков. Эти значения устаревают.
Внимание!
Что означает словосочетание «Предельные значения». То что их превышение требует вашего внимания и сервер работает не совсем штатно по мнению собравшихся. Не более того. Более того, может быть как раз для вашего варианта работы это нормально.
Возможно у вас есть свое мнение по поводу мониторинга оборудования, приходите в комментарии, пишите свои мысли, желательно со ссылками на источники знаний.
Windows Performance Counter provides an in-depth and consistent interface for collecting different types of system data such as processor, memory, and disk usage statistics. Performance counters can be used to monitor system resources and performance. Windows performance counter data can be viewed in real time with the perfmon utility or alternatively, through the Powershell cmdlet called Get-Counter. The Get-Counter cmdlet gets performance counter data directly from the performance monitoring instrumentation on Windows endpoints. We will focus this blog post on the use of the Get-Counter cmdlet to obtain metrics from a Windows endpoint.
This blog post describes how to use Wazuh to monitor Windows system resources like CPU, RAM, disk, and network traffic. Observing resource usage contributes to the overall security monitoring of endpoints. This is because anomalies in the performance of system resources can be an indicator of ongoing attacks.
List of available counters
Counters are used to inspect the usage of Windows system resources. With the use of the Get-Counter cmdlet in a Powershell console, we can list all available counters:
Get-Counter -ListSet *
This will list a lot of counters, and the information is usually truncated because of its size.
To use this cmdlet, it is recommended to get a list of available counters for a counter set:
(Get-Counter -ListSet * | where {$_.CounterSetName -eq '<CounterSetName>'}).Paths
To list the counter in a counter set, use the CounterSetName variable:
Get-Counter -ListSet * | Select <CounterSetName>
For example, if we need to query the available counters for the Memory counter set, we can run this command:
(Get-Counter -ListSet * | where {$_.CounterSetName -eq 'Memory'}).Paths
We will get a list of counter paths like this:
\Memory\Page Faults/sec \Memory\Available Bytes \Memory\Committed Bytes \Memory\Commit Limit \Memory\Write Copies/sec \Memory\Transition Faults/sec \Memory\Cache Faults/sec \Memory\Demand Zero Faults/sec \Memory\Pages/sec \Memory\Pages Input/sec \Memory\Page Reads/sec \Memory\Pages Output/sec \Memory\Pool Paged Bytes \Memory\Pool Nonpaged Bytes \Memory\Page Writes/sec \Memory\Pool Paged Allocs \Memory\Pool Nonpaged Allocs \Memory\Free System Page Table Entries \Memory\Cache Bytes \Memory\Cache Bytes Peak \Memory\Pool Paged Resident Bytes \Memory\System Code Total Bytes \Memory\System Code Resident Bytes \Memory\System Driver Total Bytes \Memory\System Driver Resident Bytes \Memory\System Cache Resident Bytes \Memory\% Committed Bytes In Use \Memory\Available KBytes \Memory\Available MBytes \Memory\Transition Pages RePurposed/sec \Memory\Free & Zero Page List Bytes \Memory\Modified Page List Bytes \Memory\Standby Cache Reserve Bytes \Memory\Standby Cache Normal Priority Bytes \Memory\Standby Cache Core Bytes \Memory\Long-Term Average Standby Cache Lifetime (s)
These counter paths can be used to get the desired metrics.
Getting metrics with Powershell
Once we know which counter to query, we can run the Powershell cmdlet to obtain the information we want to measure. Each counter is uniquely identified through its name and its path (counter path), or location:
(Get-Counter '<CounterPath>').CounterSamples[0]
The result will be a Powershell object with some properties. For example:
Path InstanceName CookedValue ---- ------------ ----------- \\win10-tools\processor(_total)\% processor time _total 3.14235688964537
We can configure the Wazuh command module to analyze performance metrics with this information.
Infrastructure
To demonstrate the monitoring of Windows resources using Wazuh, we set up the following infrastructure:
1. A pre-built ready-to-use Wazuh OVA 4.12.0. Follow this guide to download the virtual machine. This endpoint hosts the Wazuh central components (Wazuh server, Wazuh indexer, and Wazuh dashboard).
2. Windows 11 endpoint with Wazuh agent 4.12.0 installed and enrolled to the Wazuh server. To install the Wazuh agent, refer to the installation guide.
Configuration
Perform the following configuration steps on the Wazuh server, Wazuh dashboard, and the Windows endpoint.
Wazuh server
To generate an alert on the Wazuh dashboard, we need to create rules to match the generated logs.
1. Create rules to detect metrics in the logs from the command monitoring module. Add the rules to the custom rules file /var/ossec/etc/rules/windows_performance_monitor.xml on the Wazuh server:
<group name="WinCounter,">
<rule id="301000" level="0">
<decoded_as>json</decoded_as>
<match>^{"winCounter":</match>
<description>Windows Performance Counter: $(winCounter.Path)</description>
</rule>
<rule id="302000" level="3">
<if_sid>301000</if_sid>
<field name="winCounter.Path">memory\\available mbytes</field>
<description>Windows Counter: Available Memory</description>
<group>MEMUsage,</group>
</rule>
<rule id="302001" level="5">
<if_sid>302000</if_sid>
<field name="winCounter.CookedValue" type="pcre2">^[5-9]\d\d$</field>
<description>Windows Counter: Available Memory less than 1GB</description>
<group>MEMUsage,</group>
</rule>
<rule id="302002" level="7">
<if_sid>302000</if_sid>
<field name="winCounter.CookedValue" type="pcre2">^[1-4]\d\d$</field>
<description>Windows Counter: Available Memory less than 500GB</description>
<group>MEMUsage,</group>
</rule>
<rule id="302003" level="3">
<if_sid>301000</if_sid>
<field name="winCounter.Path">free megabytes</field>
<description>Windows Counter: Disk Space Free</description>
<group>DiskFree,</group>
</rule>
<rule id="302004" level="3">
<if_sid>301000</if_sid>
<field name="winCounter.Path">bytes received/sec</field>
<description>Windows Counter: Network Traffic In</description>
<group>NetworkTrafficIn,</group>
</rule>
<rule id="302005" level="3">
<if_sid>301000</if_sid>
<field name="winCounter.Path">bytes sent/sec</field>
<description>Windows Counter: Network Traffic Out</description>
<group>NetworkTrafficOut,</group>
</rule>
<rule id="303000" level="3">
<if_sid>301000</if_sid>
<field name="winCounter.Path">processor\S+ processor time</field>
<description>Windows Counter: CPU Usage</description>
<group>CPUUsage,</group>
</rule>
<rule id="303001" level="5">
<if_sid>303000</if_sid>
<field name="winCounter.CookedValue">^8\d.\d+$</field>
<description>Windows Counter: CPU Usage above 80%</description>
<group>CPUUsage,</group>
</rule>
<rule id="303002" level="7">
<if_sid>303000</if_sid>
<field name="winCounter.CookedValue">^9\d.\d+$</field>
<description>Windows Counter CPU Usage above 90%</description>
<group>CPUUsage,</group>
</rule>
</group>
Where:
- Rule ID
301000is the base rule for detecting all the logs from the winCounter commands. - Rule ID
302000is triggered when a memory metric check is done. - Rule ID
302001is triggered when the memory utilized is less than 1GB. - Rule ID
302002is triggered when the memory available is less than 500GB. - Rule ID
302003is triggered when a disk metric check is done. - Rule ID
302004is triggered when the incoming network traffic is checked. - Rule ID
302005is triggered when the outgoing network traffic is checked. - Rule ID
303000is triggered when a CPU metric check is done. - Rule ID
303001is triggered when the CPU usage exceeds 80%. - Rule ID
303002is triggered when the CPU usage exceeds 90%.
3. Restart the Wazuh manager to apply these changes:
$ sudo systemctl restart wazuh-manager
You will see relevant alerts on the Wazuh dashboard after restarting the Wazuh manager service:

Modifying the Wazuh template
To use the alerts to create visualizations and dashboards later on, we need to set the data type of all custom fields to long. By default, the Wazuh indexer analyzes values from existing alerts as string data types. To change the default data type from string to long, do the following:
Wazuh server
1. Add the custom fields in the Wazuh template. Find the data section in the /etc/filebeat/wazuh-template.json file, and add the highlighted custom fields to the data properties section:
{
"order": 0,
"index_patterns": [
"wazuh-alerts-4.x-*",
"wazuh-archives-4.x-*"
],
"settings": {
...
},
"mappings": {
"dynamic_templates": [
{
...
"data": {
"properties": {
"winCounter": {
"properties": {
"CookedValue": {
"type": "long"
},
"RawValue": {
"type": "long"
}
}
},
"audit": {
"properties": {
"acct": {
"type": "keyword"
...
2. To apply the changes to the Wazuh template, run the command below:
$ sudo filebeat setup -index-management
An expected output is shown below:
ILM policy and write alias loading not enabled. Index setup finished.
Wazuh dashboard
Perform the following steps on the Wazuh dashboard to initialize the data fields in the Wazuh alerts index using queries sent to the Wazuh indexer:
1. Navigate to Indexer management > Dev Tools on the Wazuh dashboard. Execute the commands from steps 2 and 3 in the console on this page.
2. Run the following command to view all wazuh-alerts-* indices and identify the most recent:
GET _cat/indices/wazuh-alerts-*
In the sample output below, we provide a summary of the Wazuh alert indices:
green open wazuh-alerts-4.x-2025.04.30 rzOQQaiUSLqB6QlC7UAh2A 3 0 428 0 1.1mb 1.1mb green open wazuh-alerts-4.x-2025.05.09 K7aTNJZ_TVWtsXGcEVuhPw 3 0 76 0 563.8kb 563.8kb green open wazuh-alerts-4.x-2025.05.06 J4kxPaGfTlWQMGJO0ijB-w 3 0 367953 0 146.3mb 146.3mb green open wazuh-alerts-4.x-2025.04.16 KbnV-7h9TlyHxwiYLd5TEA 3 0 17 0 129.8kb 129.8kb green open wazuh-alerts-4.x-2025.05.05 QcyOTFaeRaSZSaKSg88iyQ 3 0 163576 0 66.4mb 66.4mb green open wazuh-alerts-4.x-2025.05.08 pCyBCy-CQ92T_oKJHmBgKg 3 0 107217 0 44.7mb 44.7mb green open wazuh-alerts-4.x-2025.04.17 L5LG6JFGR1ihAftFO6jCqQ 3 0 159 0 630.4kb 630.4kb green open wazuh-alerts-4.x-2025.05.02 qj_971hcSL2A6b3IqfnTug 3 0 142433 0 60.3mb 60.3mb green open wazuh-alerts-4.x-2025.05.03 PLIivUjNRTaATVwZcqmg_A 3 0 20489 0 12.1mb 12.1mb
The Wazuh alert index pattern uses the format wazuh-alerts-4.x-YYYY.MM.DD. Identify the most recent alerts index in your output and write down the name. The most recent index is typically the current date. For example, the most recent alerts index in the example output above is wazuh-alerts-4.x-2025.05.09
3. Run the following command to initialize the fields with the expected data types. Replace <RECENT_ALERTS_INDEX> with your most recent Wazuh alerts index:
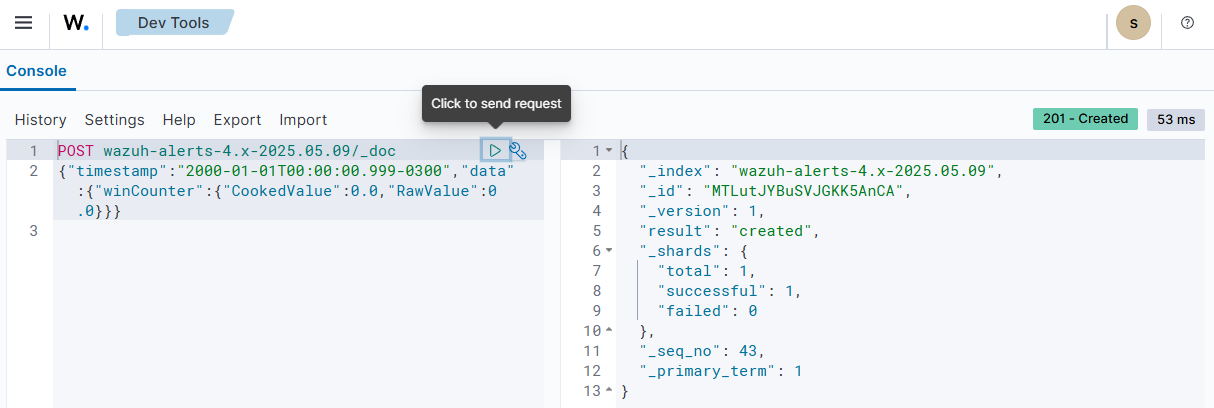
POST <RECENT_ALERTS_INDEX>/_doc
{"timestamp":"2000-01-01T00:00:00.999-0300","data":{"winCounter":{"CookedValue":0.0,"RawValue":0.0}}}
If successful, the Wazuh indexer returns a 201 – Created status code along with a JSON response that provides details about the operation. We show a successful execution in the image below.
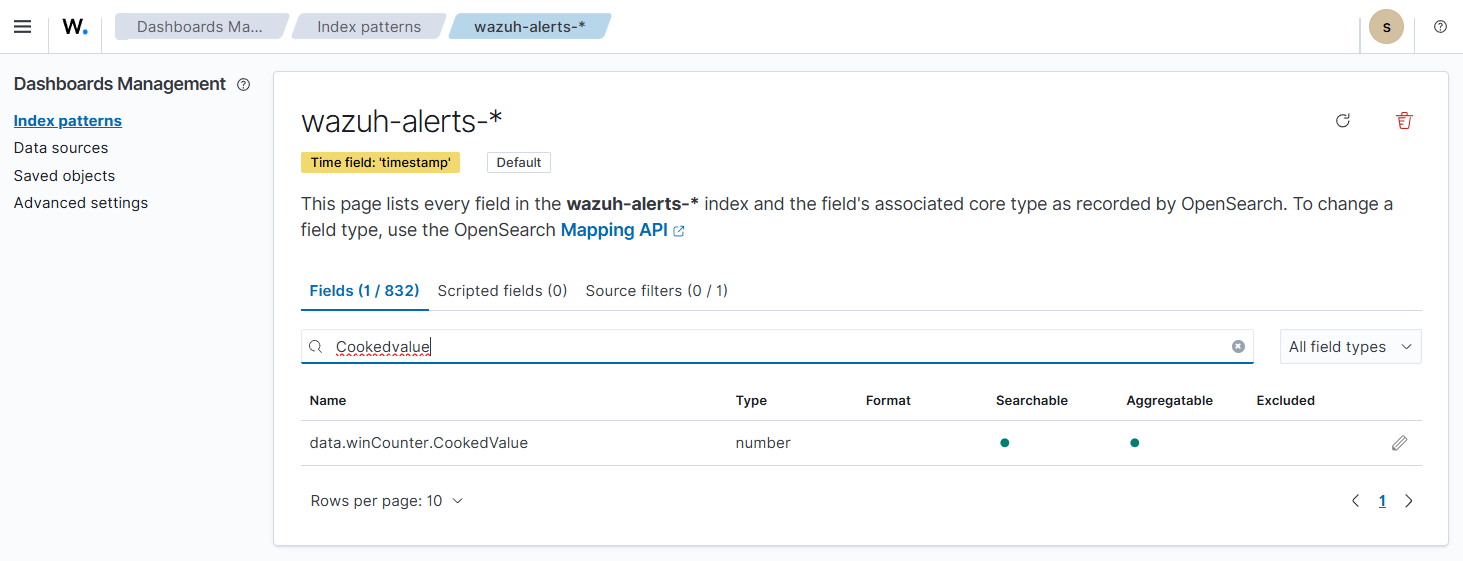
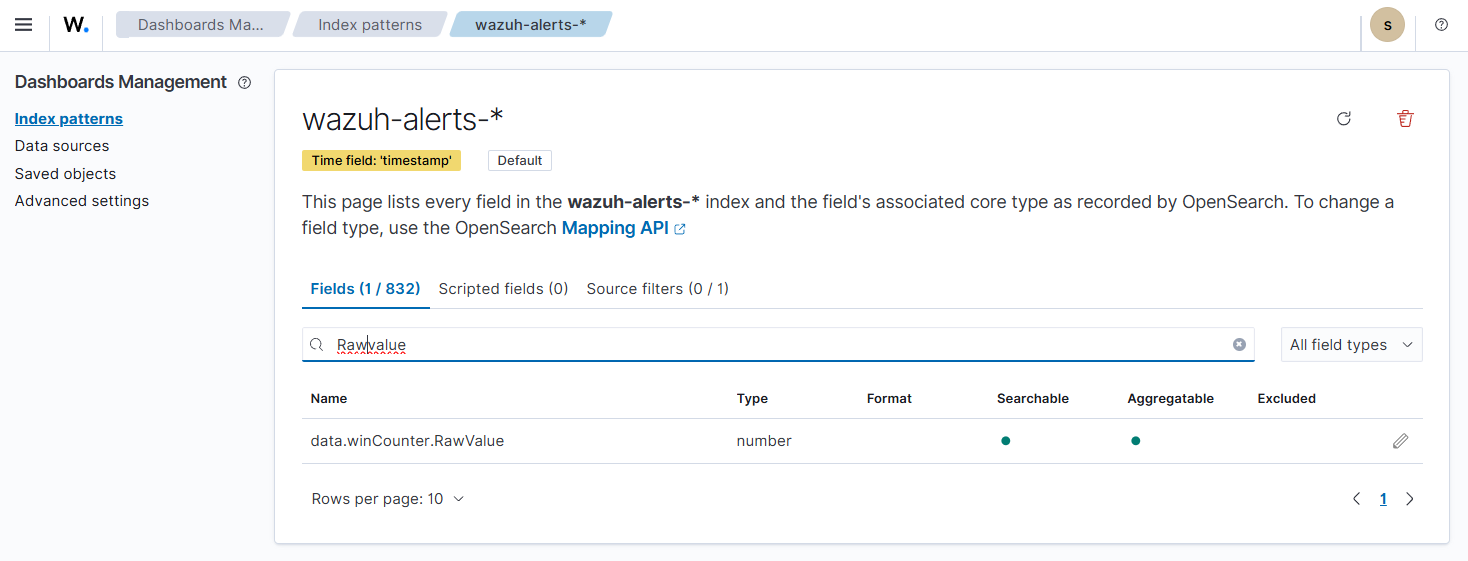
4. Navigate to Dashboard management > Dashboards Management > Index patterns, select the wazuh-alerts-* index. Click the refresh button in the top-right hand corner of the page to refresh the index pattern.

5. Verify that the updated CookedValue and RawValue fields are now changed to the number data type by searching the wazuh-alerts-* Fields.
Windows endpoint
Using the Wazuh command module, we write wodle commands to run Get-Counter cmdlet on the Windows endpoint. The output of the Powershell commands are converted to JSON format using the ConvertTo-Json -compress flag. For example:
Powershell -c @{ winCounter = (Get-Counter ‘\Processor(*)\% Processor Time’).CounterSamples[0] } | ConvertTo-Json -compress
Take the following steps to configure the Wazuh command monitoring module on the Windows endpoint.
1. Edit the Wazuh agent C:\Program Files (x86)\ossec-agent\ossec.conf file and add the following command monitoring configuration within the <ossec_config> block:
<!-- CPU Usage -->
<wodle name="command">
<disabled>no</disabled>
<tag>CPUUsage</tag>
<command>Powershell -c "@{ winCounter = (Get-Counter '\Processor(_Total)\% Processor Time').CounterSamples[0] } | ConvertTo-Json -compress"</command>
<interval>1m</interval>
<ignore_output>no</ignore_output>
<run_on_start>yes</run_on_start>
<timeout>0</timeout>
</wodle>
<!-- Memory Usage -->
<wodle name="command">
<disabled>no</disabled>
<tag>MEMUsage</tag>
<command>Powershell -c "@{ winCounter = (Get-Counter '\Memory\Available MBytes').CounterSamples[0] } | ConvertTo-Json -compress"</command>
<interval>1m</interval>
<ignore_output>no</ignore_output>
<run_on_start>yes</run_on_start>
<timeout>0</timeout>
</wodle>
<!-- Network Received -->
<wodle name="command">
<disabled>no</disabled>
<tag>NetworkTrafficIn</tag>
<command>Powershell -c "@{ winCounter = (Get-Counter '\Network Interface(*)\Bytes Received/sec').CounterSamples[0] } | ConvertTo-Json -compress"</command>
<interval>1m</interval>
<ignore_output>no</ignore_output>
<run_on_start>yes</run_on_start>
<timeout>0</timeout>
</wodle>
<!-- Network Sent -->
<wodle name="command">
<disabled>no</disabled>
<tag>NetworkTrafficOut</tag>
<command>Powershell -c "@{ winCounter = (Get-Counter '\Network Interface(*)\Bytes Sent/sec').CounterSamples[0] } | ConvertTo-Json -compress"</command>
<interval>1m</interval>
<ignore_output>no</ignore_output>
<run_on_start>yes</run_on_start>
<timeout>0</timeout>
</wodle>
<!-- Disk Free -->
<wodle name="command">
<disabled>no</disabled>
<tag>DiskFree</tag>
<command>Powershell -c "@{ winCounter = (Get-Counter '\LogicalDisk(*)\Free Megabytes').CounterSamples[0] } | ConvertTo-Json -compress"</command>
<interval>1m</interval>
<ignore_output>no</ignore_output>
<run_on_start>yes</run_on_start>
<timeout>0</timeout>
</wodle>
Note
You can use the centralized configuration to distribute this setting across multiple monitored endpoints. However, remote commands are disabled by default for security reasons and have to be explicitly enabled on each agent.
2. Restart the Wazuh agent to apply this change:
> NET START Wazuh
Building custom visualizations and dashboards
We can further improve the viewing of existing metrics using custom dashboards, visualizations, and graphs. This presents a dynamic representation for monitoring system performance.
Creating custom visualizations
Wazuh dashboard
Click the upper-left menu icon and navigate to ☰ > Explore > Visualize > Create new visualization.
We use the line visualization format and wazuh-alerts-* as the index pattern name. This will create a data tab where the required filters are specified. The Wazuh dashboard visualization builder contains two aggregation objects; metric and bucket aggregation as shown above:
- The metric aggregation contains the actual values of the metric to be calculated. It is typically represented on the Y-axis.
- The bucket aggregation determines how the data is segmented or grouped such as by date. It is typically represented on the X-axis.
Both the Y-axis and the X-axis are used to plot the data points on a visualization chart. Follow the instructions below to create individual visualizations for this blog post.
CPU usage visualization
a. Select the line visualization format on the Visualize tab, and use wazuh-alerts-* as the index pattern name.
b. Set the following values on Y-axis, in Metrics:
Aggregation=MaxField=data.winCounter.CookedValueCustom label=CPU usage
c. Add an X-axis in Buckets and set the following values:
Aggregation=Date HistogramField=timestampMinimum interval=Minute
d. Click on Add filter by the top left of the dashboard, and set the following values:
Field=rule.idOperator=isValue=303000
e. Click the Update button.
f. Click the upper-right Save button and assign a title to save the visualization.
Memory usage visualization
a. Select the line visualization format on the Visualize tab, and use wazuh-alerts-* as the index pattern name.
b. Set the following values on the Y-axis, in Metrics:
Aggregation=MaxField=data.winCounter.CookedValueCustom label=Memory Available
c. Add an X-axis in Buckets and set the following values:
Aggregation=Date HistogramField=timestampMinimum interval=Minute
d. On the top left of the dashboard, click on Add filter and set the following values:
Field=rule.idOperator=isValue=302000
e. Click the Update button.
f. Click the upper-right Save button and assign a title to save the visualization.
Disk usage visualization
a. Select the metric visualization format on the Visualize tab, and use wazuh-alerts-* as the index pattern name.
b. Set the following values on the Y-axis, in Metrics:
Aggregation=MaxField=data.winCounter.CookedValueCustom label=Disk Free
c. On the top left of the dashboard, click on Add filter and set the following values:
Field=rule.idOperator=isValue=302003
d. Click the Update button.
e. Click the upper-right Save button and assign a title to save the visualization.
Network inbound visualization
a. Select the line visualization format on the Visualize tab, and use wazuh-alerts-* as the index pattern name.
b. Set the following values on the Y-axis, in Metrics:
Aggregation=MaxField=data.winCounter.CookedValueCustom label=Network Inbound
c. Add an X-axis in Buckets and set the following values:
Aggregation=Date HistogramField=timestampMinimum interval=Minute
d. Click on Add filter by the top left of the dashboard, and set the following values:
Field=rule.idOperator=isValue=302004
e. Click the Update button.
f. Click the upper-right Save button and assign a title to save the visualization.
Network outbound visualization
a. Select the line visualization format on the Visualize tab, and use wazuh-alerts-* as the index pattern name.
b. Set the following values on the Y-axis, in Metrics:
Aggregation=MaxField=data.winCounter.CookedValueCustom label=Network Outbound
c. Add an X-axis in Buckets and set the following values:
Aggregation=Date HistogramField=timestampMinimum interval=Minute
d. Click on Add filter by the top left of the dashboard, and set the following values:
Field=rule.idOperator=isValue=302005
e. Click the Update button.
f. Click the upper-right Save button and assign a title to save the visualization.
Once this is applied, we can build custom visualizations and dashboards with those values.
Creating custom dashboards
1. Click on the upper-left menu icon and navigate to ☰ > Explore > Dashboards > Create new dashboard.
2. Click Add an existing and select the earlier created visualizations to populate the dashboard.
3. Save the dashboard by selecting the save option on the top-right navigation bar.
The GIF below shows a sample dashboard containing the newly created visualizations.

Conclusion
This guide details how Wazuh can be used to monitor Windows system resources like CPU, RAM, etc. Observing resource usage contributes to the overall security monitoring of endpoints.
If you have any questions or require assistance regarding this setup, refer to our community channels.
References
- About microsoft performance counters
- Microsoft Get-Counter
- Scheduling remote commands for Wazuh agents
- Wazuh rules syntax
- Configuration options of the Wazuh command wodle