
В этой статье я хотел бы рассказать о такой замечательной штуке, как файлы, отображаемые в память(memory-mapped files, далее — MMF).
Иногда их использование может дать довольно таки существенный прирост производительности по сравнению с обычной буферизированной работой с файлами.
Это механизм, который позволяет отображать файлы на участок памяти. Таким образом, при чтении данных из неё, производится считывание соответствующих байт из файла. С записью аналогично.
«Клёво, конечно, но что это даёт?» — спросите вы. Поясню на примере.
Допустим, перед нами стоит задача обработки большого файла(несколько десятков или даже сотен мегабайт). Казалось бы, задача тривиальна — открываем файл, поблочно копируем из него в память, обрабатываем. Что при этом происходит. Каждый блок копируется во временный кэш, затем из него в нашу память. И так с каждым блоком. Налицо неоптимальное расходование памяти под кэш + куча операций копирования. Что же делать?
Тут-то нам на помощь и приходит механизм MMF. Когда мы обращаемся к памяти, в которую отображен файл, данные загружаются с диска в кэш(если их там ещё нет), затем делается отображение кэша в адресное пространство нашей программы. Если эти данные удаляются — отображение отменяется. Таким образом, мы избавляемся от операции копирования из кэша в буфер. Кроме того, нам не нужно париться по поводу оптимизации работы с диском — всю грязную работу берёт на себя ядро ОС.
В своё время я проводил эксперимент. Замерял с помощью quantify скорость работы программы, которая буферизировано копирует большой файл размером 500 мб в другой файл. И скорость работы программы, которая делает то же, но с помощью MMF. Так вот вторая работает быстрее почти на 30% (в Solaris, в других ОС результат может отличаться). Согласитесь, неплохо.
Чтобы воспользоваться этой возможностью, мы должны сообщить ядру о нашем желании отобразить файл в память. Делается это с помощью функции mmap().
#include<sys/mman.h>
void *mmap(void *addr, size_t len, int prot, int flag, int filedes, off_t off);
Она возвращает адрес начала участка отображаемой памяти или MAP_FAILED в случае неудачи.
Первый аргумент — желаемый адрес начала участка отбраженной памяти. Не знаю, когда это может пригодится. Передаём 0 — тогда ядро само выберет этот адрес.
len — количество байт, которое нужно отобразить в память.
prot — число, определяющее степень защищённости отображенного участка памяти(только чтение, только запись, исполнение, область недоступна). Обычные значения — PROT_READ, PROT_WRITE (можно кобминировать через ИЛИ). Не буду на этом останавливаться — подробнее читайте в манах. Отмечу лишь, что защищённость памяти не установится ниже, чем права, с которыми открыт файл.
flag — описывает атрибуты области. Обычное значение — MAP_SHARED. По поводу остальных — курите маны. Но замечу, что использование MAP_FIXED понижает переносимость приложения, т.к. его подержка является необязательной в POSIX-системах.
filedes — как вы уже догались — дескриптор файла, который нужно отобразить.
off — смещение отображенного участка от начала файла.
Важное замечание. Если вы планируете использовать MMF для записи в файл, перед маппингом необходимо установить конечный размер файла не меньше, чем размер отображенной памяти! Иначе нарвётесь на SIGBUS.
Ниже приведён пример(честно стырен из замечательной книжки «Unix. Профессиональное программирование») программы, которая копирует файл с использованием MMF.
#include <fcntl.h>
#include <sys/mman.h>
int main(int argc, char *argv[])
{
int fdin, fdout;
void *src, *dst;
struct stat statbuf;
if (argc != 3)
err_quit("Использование: %s <fromfile> <tofile>", argv[0]);
if ( (fdin = open(argv[1], O_RDONLY)) < 0 )
err_sys("невозможно открыть %s для чтения", argv[1]);
if ( (fdout = open(argv[2], O_RDWR | O_CREAT | O_TRUNC, FILE_MODE)) < 0 )
err_sys("невозможно создать %s для записи", argv[2]);
if ( fstat(fdin, &statbuf) < 0 ) /* определить размер входного файла */
err_sys("fstat error");
/* установить размер выходного файла */
if ( lseek(fdout, statbuf.st_size - 1, SEEK_SET) == -1 )
err_sys("ошибка вызова функции lseek");
if ( write(fdout, "", 1) != 1 )
err_sys("ошибка вызова функции write");
if ( (src = mmap(0, statbuf.st_size, PROT_READ, MAP_SHARED, fdin, 0)) == MAP_FAILED )
err_sys("ошибка вызова функции mmap для входного файла");
if ( (dst = mmap(0, statbuf.st_size, PROT_READ | PROT_WRITE, MAP_SHARED, fdout, 0)) == MAP_FAILED )
err_sys("ошибка вызова функции mmap для выходного файла");
memcpy(dst, src, statbuf.st_size); /* сделать копию файла */
exit(0);
}
* This source code was highlighted with Source Code Highlighter.
Вот вобщем-то и всё. Надеюсь, эта статья была полезной. С удовольствием приму конструктивную критику.
Материал из РУВИКИ — свободной энциклопедии
Отображение файла в память (на память) — это способ работы с файлами в некоторых операционных системах, при котором всему файлу или некоторой непрерывной его части ставится в соответствие определённый участок памяти (диапазон адресов оперативной памяти). При этом чтение данных из этих адресов фактически приводит к чтению данных из отображенного файла, а запись данных по этим адресам приводит к записи этих данных в файл. Отображать на память часто можно не только обычные файлы, но и файлы устройств.
Альтернативой отображению может служить прямое чтение файла или запись в файл. Такой способ работы менее удобен по следующим причинам:
- Необходимо постоянно помнить текущую позицию файла и вовремя её передвигать на позицию, откуда будет производиться чтение или куда будет идти запись.
- Каждый вызов смены/чтения текущей позиции, записи/чтения — это системный вызов, который приводит к потере времени.
- Для работы через чтение/запись всё равно приходится выделять буфера определённого размера, таким образом, в общем виде работа состоит из трёх этапов: чтение в буфер -> модификация данных в буфере -> запись в файл. При отображении же работа состоит только из одного этапа: модификации данных в определённой области памяти.
Дополнительным преимуществом использования отображения является меньшая, по сравнению с чтением/записью, нагрузка на операционную систему — дело в том, что при использовании отображений операционная система не загружает в память сразу весь файл, а делает это по мере необходимости, блоками размером со страницу памяти (как правило, 4 килобайта). Таким образом, даже имея небольшое количество физической памяти (например, 32 мегабайта), можно легко отобразить файл размером 100 мегабайт или больше, и при этом для системы это не приведет к большим накладным расходам.
Также выигрыш происходит и при записи из памяти на диск: если вы обновили большое количество данных в памяти, они могут быть одновременно (за один проход головки над диском) записаны на диск.
Файл, отображенный на память, удобен также тем, что можно достаточно легко менять его размер и при этом (после переотображения) получать в своё распоряжение непрерывный кусок памяти нужного размера. С динамической памятью такой трюк не всегда возможен из-за явления фрагментации. Когда же мы работаем с отображенным на память файлом — менеджер памяти автоматически настраивает процессор так, что странички ОЗУ, хранящие соседние фрагменты файла, образуют непрерывный диапазон адресов.
Основная причина, по которой следует пользоваться отображением, — выигрыш в производительности. Однако необходимо помнить о компромиссах, на которые придется пойти. Обычный ввод-вывод чреват накладными расходами на дополнительные системные вызовы и лишнее копирование данных, использование отображений чревато замедлениями из-за страничных ошибок доступа. Допустим, страница, относящаяся к нужному файлу, уже лежит в кэше, но не ассоциирована с данным отображением. Если она была изменена другим процессом, то попытка ассоциировать её с отображением может закончиться неудачей и привести к необходимости повторно зачитывать данные с диска либо сохранять данные на диск. Таким образом, хотя программа и делает меньше операций для доступа через отображение, в реальности операция записи данных в какое-то место файла может занять больше времени, чем с использованием операций файлового ввода-вывода (при том, что в среднем использование отображений даёт выигрыш).
Другой недостаток в том, что размер отображения зависит от используемой архитектуры. Теоретически, 32-битные архитектуры (Intel 386, ARM 9) не могут создавать отображения длиной более 4 Гб.
Пожалуй, наиболее общий случай, когда применяется отображение файлов на память, — загрузка процесса в память (это справедливо и для Microsoft Windows, и для Unix-подобных систем).
После запуска процесса операционная система отображает его файл на память, для которой разрешено выполнение (атрибут executable). Большинство систем, использующих отображение файлов, использует методику загрузка страницы по первому требованию, при которой файл загружается в память не целиком, а небольшими частями, размером со страницу памяти, при этом страница загружается только тогда, когда она действительно нужна[1]. В случае с исполняемыми файлами такая методика позволяет операционной системе держать в памяти только те части машинного кода, которые реально нужны для выполнения программы.
Другой общеупотребимый случай использования отображений — создание разделяемых несколькими процессами фрагментов памяти. В современных ОС (использующих защищенный режим) процесс, вообще говоря, не позволяет другим процессам обращаться к «своей» памяти. Программы, которые пытаются обратиться не к своей памяти, генерируют исключительные ситуации invalid page faults или segmentation violation.
Использование файлов, отображенных на память, — это один из наиболее популярных и безопасных (без возникновения исключительных ситуаций) способов сделать память доступной нескольким процессам. Два или более приложений могут одновременно отобразить один и тот же физический файл на свою память и обратиться к этой памяти.
Большинство современных операционных систем или оболочек поддерживает те или иные формы работы с файлами, отображенными на память. Например, функция mmap()[2] , создающая отображение для файла с данным дескриптором, начиная с некоторого места в файле и с некоторой длиной, является частью спецификации POSIX. Таким образом, огромное количество POSIX-совместимых систем, таких как UNIX, Linux, FreeBSD, Mac OS X [3] или OpenVMS, поддерживает общий механизм отображения файлов. ОС Microsoft Windows также поддерживает определённый API для этих целей, например, CreateFileMapping() [4].
Python[править | править код]
import mmap import os filename = "/tmp/1.txt" File = open(filename, "r+b") size = os.path.getsize(filename) data = mmap.mmap(File.fileno(), size) print data[0:5] # выведет первые 5 символов файла print data.read(size) # выведет содержимое файла целиком string = "Hello from Python!!!" data.resize( size+len(string)) # увеличивам "отображённый размер" на размер строки, которую хотим вписать data.seek(size) # Устанавливаем курсор в конец файла data.write( string ) # и дописываем строку в конец файла data.close() File.close() ## Закрываем файл
- ↑ Demand Paging (недоступная ссылка)
- ↑ Memory Mapped Files Архивировано 9 февраля 2007 года.
- ↑ Apple — Mac OS X Leopard — Technology — UNIX Архивировано 23 апреля 2009 года.
- ↑ CreateFileMapping Function (Windows). Дата обращения: 29 апреля 2010. Архивировано 10 октября 2008 года.
Управление памятью в Windows
Прежде чем перейти к рассмотрению формата PE, необходимо поговорить об особенностях управления памятью в Windows, так как без знания этих особенностей невозможно понять некоторые существенные детали формата.
Управление памятью в Windows NT/2k/XP/2k3 осуществляет менеджер виртуальной памяти (virtual-memory manager). Он использует страничную схему управления памятью, при которой вся физическая память делится на одинаковые отрезки размером в 4096 байт, называемые физическими страницами. Если физических страниц не хватает для работы системы, редко используемые страницы могут вытесняться на жесткий диск, в один или несколько файлов подкачки (pagefiles). Вытесненные страницы затем могут быть загружены обратно в память, если возникнет необходимость. Таким образом, программы могут использовать значительно большее количество памяти, чем реально присутствует в системе.
Виртуальное адресное пространство процесса
Каждый процесс в Windows запускается в своем виртуальном адресном пространстве размером в 4 Гб. При этом первые 2 Гб адресного пространства могут непосредственно использоваться процессом, а остальные 2 Гб резервируются операционной системой для своих нужд (рис. 2.1).
Рис.
2.1.
Виртуальное адресное пространство процесса
Виртуальное адресное пространство также делится на виртуальные страницы размером в 4096 байт. При этом процессу выделяется только то количество виртуальных страниц, которое ему реально нужно. Поэтому тот факт, что процесс может адресовать 4 Гб виртуального адресного пространства, еще не означает, что каждому процессу выделяется по 4 Гб оперативной памяти. Как правило, процесс использует только малую часть своего адресного пространства, хотя стремительное удешевление модулей памяти способно в самое ближайшее время существенно изменить картину и вызвать повсеместно переход к 64-разрядным архитектурам.
Виртуальные страницы могут отображаться операционной системой в страницы физической памяти, могут храниться в файле подкачки, а также могут быть вообще недоступны процессу. Обращение к недоступной виртуальной странице вызывает аварийное завершение процесса с сообщением «Access violation«.
Адресное пространство процесса называется виртуальным, потому что процесс для работы с памятью использует не реальные адреса физической памяти, а так называемые виртуальные адреса. При обращении по некоторому виртуальному адресу происходит перевод этого виртуального адреса в физический адрес. Перевод виртуальных адресов в физические адреса реализован на аппаратном уровне в процессоре и поэтому осуществляется достаточно быстро.
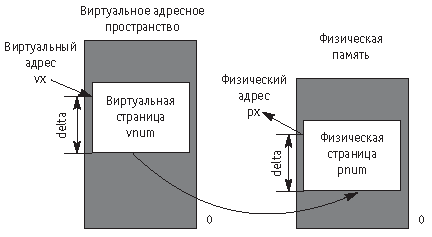
Рис.
2.2.
Перевод виртуального адреса в физический адрес
Рассмотрим на примере, как осуществляется перевод некоторого виртуального адреса vx в физический адрес px (рис 2.2). Сначала вычисляется номер vnum виртуальной страницы, соответствующий виртуальному адресу vx, а также смещение delta виртуального адреса относительно начала этой виртуальной страницы:
vnum := vx div 4096; delta := vx mod 4096;
Далее возможны три варианта развития событий:
- Виртуальная страница vnum недоступна. В этом случае перевод виртуального адреса vx в физический адрес невозможен, и процесс завершается с сообщением «Access Violation«;
- Виртуальная страница находится в файле страничной подкачки, и ее надо сначала загрузить в память. Тогда пусть pnum будет номером физической страницы, в которую мы загружаем нашу виртуальную страницу;
- Виртуальная страница уже находится в памяти, и ей соответствует некоторая физическая страница. В этом случае pnum — номер этой физической страницы.
После чего адрес px вычисляется следующим образом:
Такая организация памяти процесса обладает следующими свойствами:
- Процессы изолированы друг от друга. Один процесс не может обратиться к памяти другого процесса.
- Передача виртуальных адресов между процессами совершенно бессмысленна. Один и тот же виртуальный адрес в адресных пространствах разных процессов соответствует разным физическим адресам.
- Процессы используют преимущества плоской адресации памяти. Виртуальный адрес представляет собой 32-разрядное целое значение, что делает возможной легкую реализацию адресной арифметики.
Отображаемые в память файлы
Отображаемые в память файлы (memory-mapped files) — это мощная возможность операционной системы. Она позволяет приложениям осуществлять доступ к файлам на диске тем же самым способом, каким осуществляется доступ к динамической памяти, то есть через указатели. Смысл отображения файла в память заключается в том, что содержимое файла (или часть содержимого) отображается в некоторый диапазон виртуального адресного пространства процесса, после чего обращение по какому-либо адресу из этого диапазона означает обращение к файлу на диске. Естественно, не каждое обращение к отображенному в память файлу вызывает операцию чтения/записи. Менеджер виртуальной памяти кэширует обращения к диску и тем самым обеспечивает высокую эффективность работы с отображенными файлами.
Виртуальная память
Виртуальная память — это важная часть операционных систем, включая Windows. Она представляет собой механизм, позволяющий приложениям, работать с большими объемами памяти, чем физически доступно на компьютере, и обеспечивает изоляцию процессов друг от друга. Вот основные аспекты виртуальной памяти в Windows:
Виртуальная адресация
Каждому процессу в Windows предоставляется свое собственное виртуальное адресное пространство. Это означает, что каждый процесс видит свою собственную непрерывную область адресов, начиная с нуля. Этот механизм позволяет изолировать процессы друг от друга, так что один процесс не может напрямую обратиться к памяти другого процесса.
Физическая память и страничный файл
Виртуальная память Windows состоит из физической оперативной памяти (RAM) и страничного файла на диске. Если физическая память заполняется, то часть данных может быть перемещена в страничный файл, освобождая место для новых данных. Этот процесс называется “подкачкой” (paging).
Страницы памяти
Виртуальная память разбивается на небольшие блоки, называемые страницами памяти. Размер страницы обычно составляет 4 КБ. Windows использует систему управления таблицами страниц (Page Table) для отображения виртуальных адресов на физические адреса или на адреса в страничном файле.
Отображение виртуальной памяти
Когда процесс обращается к виртуальной памяти, операционная система Windows преобразует виртуальный адрес в соответствующий физический адрес. Если требуемая страница находится в физической памяти, это происходит незаметно. Если страница находится в страничном файле, она должна быть загружена в физическую память перед доступом к ней.
Защита памяти
Виртуальная память Windows также обеспечивает механизмы защиты. Каждая страница памяти может иметь разрешения на чтение, запись и выполнение. Это позволяет операционной системе и программам контролировать доступ к памяти и предотвращать некорректное или вредоносное поведение.
Управление виртуальной памятью
Операционная система Windows автоматически управляет виртуальной памятью, включая подкачку данных между физической памятью и страничным файлом. Программисты обычно не заботятся о деталях управления виртуальной памятью, но могут использовать API для запроса дополнительной памяти (например, функции VirtualAlloc) и управления защитой памяти (например, функции VirtualProtect).
Управление динамической памятью
Управление памятью в Windows может быть выполнено с использованием различных функций и API операционной системы. Давайте рассмотрим несколько примеров кода на языке C/C++ для выделения и освобождения памяти в Windows.
Выделение памяти с использованием malloc и free (C/C++)
#include <stdio.h>
#include <stdlib.h>
int main() {
// Выделение памяти под массив целых чисел
int *arr = (int*)malloc(5 * sizeof(int));
if (arr == NULL) {
printf("Не удалось выделить память\n");
return 1;
}
// Использование выделенной памяти
for (int i = 0; i < 5; i++) {
arr[i] = i * 10;
}
// Освобождение памяти после использования
free(arr);
return 0;
}В этом примере мы используем функции malloc для выделения памяти под массив целых чисел и free для освобождения этой памяти после ее использования.
Выделение памяти с использованием функции VirtualAlloc (WinAPI)
#include <Windows.h>
#include <stdio.h>
int main() {
// Выделение 1 мегабайта (1048576 байт) виртуальной памяти
LPVOID mem = VirtualAlloc(NULL, 1048576, MEM_COMMIT, PAGE_READWRITE);
if (mem == NULL) {
printf("Не удалось выделить виртуальную память\n");
return 1;
}
// Использование выделенной виртуальной памяти
// Освобождение виртуальной памяти
VirtualFree(mem, 0, MEM_RELEASE);
return 0;
}Здесь мы используем функцию VirtualAlloc из библиотеки WinAPI для выделения виртуальной памяти. После использования памяти мы освобождаем ее с помощью функции VirtualFree.
Выделение и освобождение памяти с использованием C++ операторов new и delete
#include <iostream>
#include <windows.h>
int main() {
SetConsoleOutputCP(1251);
// Выделение памяти под одно целое число
int *num = new int;
// Использование выделенной памяти
*num = 42;
std::cout << "Значение: " << *num << std::endl;
// Освобождение памяти
delete num;
return 0;
}Стек и куча
Стек и куча — это две основные области памяти, используемые в программах для хранения данных и управления памятью. Они имеют разные характеристики и предназначены для разных целей. Давайте рассмотрим их более подробно:
Стек (Stack)
- Характеристики:
- Ограниченный по размеру.
- Доступ к данным выполняется в порядке “первым вошел, последним вышел” (LIFO — Last-In, First-Out).
- Часто фиксированный размер стека определяется на этапе компиляции.
- Использование:
- Хранит локальные переменные функций и адреса возврата после вызова функций.
- Используется для управления вызовами функций (стек вызовов).
- Жизненный цикл данных:
- Данные, хранящиеся в стеке, автоматически удаляются при завершении функции, в которой они определены.
- Ограниченное время жизни.
- Примеры языков:
- Стек используется в C, C++, Java (для вызовов методов), Python (для вызовов функций).
Куча (Heap)
- Характеристики:
- Динамически расширяемая область памяти.
- Доступ к данным происходит в произвольном порядке.
- Размер кучи ограничен объемом доступной физической и виртуальной памяти.
- Использование:
- Хранит данные, которые могут иметь долгий или неопределенный срок жизни, такие как объекты, созданные динамически.
- Жизненный цикл данных:
- Данные, хранящиеся в куче, существуют до тех пор, пока на них есть указатели, и могут быть освобождены вручную (например, с помощью
freeв C/C++ или сборщика мусора в других языках).
- Данные, хранящиеся в куче, существуют до тех пор, пока на них есть указатели, и могут быть освобождены вручную (например, с помощью
- Примеры языков:
- Куча используется в C, C++, C#, Java (для объектов, созданных с помощью
new), Python (с использованием модуляgcдля сборки мусора).
- Куча используется в C, C++, C#, Java (для объектов, созданных с помощью
Сравнение стека и кучи
-
Стек обычно быстрее доступен для чтения и записи, чем куча.
-
Куча предоставляет более гибкое управление памятью, но требует явного освобождения ресурсов.
-
Стек обеспечивает управление временем жизни данных автоматически, в то время как в куче это делается вручную.
-
Использование стека ограничено, поэтому он лучше подходит для хранения данных с известным временем жизни, в то время как куча подходит для данных с неопределенным или долгим временем жизни.
-
Оба механизма имеют свои применения и зависят от конкретных требований программы.
Функции для работы со стеком
Windows предоставляет набор функций и API для работы со стеком приложения. Эти функции позволяют программам управлять стеком вызовов функций, а также получать информацию о текущем состоянии стека. Вот некоторые из наиболее часто используемых функций Windows для работы со стеком:
GetCurrentThreadStackLimits (Windows 8.1 и более поздние версии)
Эта функция позволяет получить информацию о границах стека текущего потока. Она возвращает указатель на начало и конец стека текущего потока. Это может быть полезно, например, для отслеживания использования стека и предотвращения переполнения стека.
Пример использования:
void GetStackLimits() {
ULONG_PTR lowLimit, highLimit;
GetCurrentThreadStackLimits(&lowLimit, &highLimit);
printf("Low Limit: 0x%llx\n", lowLimit);
printf("High Limit: 0x%llx\n", highLimit);
}RtlCaptureContext (Windows XP и более поздние версии)
Эта функция захватывает текущий контекст выполнения, включая информацию о регистрах и указателях стека. Это может быть полезно при анализе стека или сохранении контекста выполнения для последующего использования.
Пример использования:
CONTEXT context;
RtlCaptureContext(&context);
// Теперь у вас есть информация о контексте выполнения текущего потокаVirtualQuery (Windows XP и более поздние версии)
Эта функция позволяет получить информацию о виртуальной памяти, включая стек. Вы можете использовать ее для определения границ стеков разных потоков или для анализа виртуальной памяти вашего процесса.
Пример использования:
MEMORY_BASIC_INFORMATION mbi;
VirtualQuery(&someAddress, &mbi, sizeof(mbi));
// Теперь вы можете получить информацию о найденной памяти, включая стекSetThreadStackGuarantee (Windows 8 и более поздние версии)
Эта функция позволяет установить минимальный размер стека для потока. Это может быть полезно, чтобы предотвратить переполнение стека в потоках с большой глубиной вызовов.
Пример использования:
DWORD stackSize = 0x10000; // 64 КБ
SetThreadStackGuarantee(&stackSize);StackWalk64 (DbgHelp API)
Эта функция из библиотеки DbgHelp API позволяет выполнять обход стека вызовов функций для получения информации о вызовах и адресах функций. Она полезна при создании отладочных и профилирующих инструментов.
Пример использования:
STACKFRAME64 stackFrame;
// Настройка параметров и выполнение обхода стекаФункции для работы с кучей
WinAPI предоставляет ряд функций для работы с кучей (памятью, выделяемой в куче). Основные функции включают в себя HeapCreate, HeapAlloc, HeapFree, HeapReAlloc и HeapDestroy. Давайте рассмотрим эти функции более подробно:
HeapCreate
-
Создает новую кучу.
-
Синтаксис:
HANDLE HeapCreate(DWORD flOptions, SIZE_T dwInitialSize, SIZE_T dwMaximumSize); -
Пример:
HANDLE hHeap = HeapCreate(0, 0, 0);
HeapAlloc
-
Выделяет блок памяти из кучи.
-
Синтаксис:
LPVOID HeapAlloc(HANDLE hHeap, DWORD dwFlags, SIZE_T dwBytes); -
Пример:
int* pData = (int*)HeapAlloc(hHeap, 0, sizeof(int) * 10);
HeapFree
-
Освобождает блок памяти, выделенный ранее с помощью
HeapAlloc. -
Синтаксис:
BOOL HeapFree(HANDLE hHeap, DWORD dwFlags, LPVOID lpMem); -
Пример:
HeapFree(hHeap, 0, pData);
HeapReAlloc
-
Изменяет размер выделенного блока памяти в куче.
-
Синтаксис:
LPVOID HeapReAlloc(HANDLE hHeap, DWORD dwFlags, LPVOID lpMem, SIZE_T dwBytes); -
Пример:
pData = (int*)HeapReAlloc(hHeap, 0, pData, sizeof(int) * 20);
HeapDestroy
-
Уничтожает кучу и освобождает все связанные с ней ресурсы.
-
Синтаксис:
BOOL HeapDestroy(HANDLE hHeap); -
Пример:
HeapSize
-
Возвращает размер выделенного блока памяти в куче.
-
Синтаксис:
SIZE_T HeapSize(HANDLE hHeap, DWORD dwFlags, LPCVOID lpMem); -
Пример:
SIZE_T size = HeapSize(hHeap, 0, pData);
HeapValidate
-
Проверяет целостность кучи и выделенных блоков.
-
Синтаксис:
BOOL HeapValidate(HANDLE hHeap, DWORD dwFlags, LPCVOID lpMem); -
Пример:
if (HeapValidate(hHeap, 0, pData)) { printf("Куча валидна.\n"); } else { printf("Куча повреждена.\n"); }
Пример 1: Создание кучи и выделение памяти
#include <Windows.h>
#include <stdio.h>
int main() {
SetConsoleOutputCP(1251);
// Создание кучи
HANDLE hHeap = HeapCreate(0, 0, 0);
if (hHeap == NULL) {
printf("Не удалось создать кучу\n");
return 1;
}
// Выделение памяти из кучи
int *data = (int*)HeapAlloc(hHeap, 0, sizeof(int) * 5);
if (data == NULL) {
printf("Не удалось выделить память из кучи\n");
HeapDestroy(hHeap);
return 1;
}
// Использование выделенной памяти
for (int i = 0; i < 5; i++) {
data[i] = i * 10;
}
// Освобождение памяти
HeapFree(hHeap, 0, data);
// Уничтожение кучи
HeapDestroy(hHeap);
return 0;
}В этом примере мы создаем кучу с помощью HeapCreate, выделяем память из кучи с помощью HeapAlloc, используем эту память и освобождаем ее с помощью HeapFree, а затем уничтожаем кучу с помощью HeapDestroy.
Пример 2: Выделение строки в куче
#include <Windows.h>
#include <stdio.h>
int main() {
SetConsoleOutputCP(1251);
// Создание кучи
HANDLE hHeap = HeapCreate(0, 0, 0);
if (hHeap == NULL) {
printf("Не удалось создать кучу\n");
return 1;
}
// Выделение строки в куче
char *str = (char*)HeapAlloc(hHeap, 0, 256);
if (str == NULL) {
printf("Не удалось выделить память для строки\n");
HeapDestroy(hHeap);
return 1;
}
// Копирование строки в выделенную память
strcpy_s(str, 256, "Пример строки в куче");
// Использование строки
// Освобождение памяти
HeapFree(hHeap, 0, str);
// Уничтожение кучи
HeapDestroy(hHeap);
return 0;
}В этом примере мы выделяем память для строки в куче, копируем строку в эту память, используем ее и освобождаем память.
Отображение файлов на адресное пространство
File mapping (сопоставление файла) в WinAPI — это механизм, который позволяет отображать содержимое файла в виртуальную память процесса. Это может быть полезно для обмена данными между процессами, создания разделяемой памяти или для улучшения производительности при доступе к большим файлам. Давайте рассмотрим основы использования file mapping в WinAPI:
Создание файла для сопоставления
Сначала необходимо создать или открыть файл, который вы хотите сопоставить. Это можно сделать с помощью функций, таких как CreateFile или OpenFile. Например:
HANDLE hFile = CreateFile(
L"C:\\example.txt", // Имя файла
GENERIC_READ | GENERIC_WRITE, // Режим доступа
0, // Атрибуты файла
NULL, // Дескриптор безопасности
OPEN_ALWAYS, // Действие при открытии (создать, если не существует)
FILE_ATTRIBUTE_NORMAL, // Атрибуты файла
NULL // Шаблон для атрибутов
);Создание отображения файла в памяти
Затем создайте отображение файла в виртуальную память с помощью функции CreateFileMapping. Это создает объект отображения файла, который может быть использован для доступа к содержимому файла:
HANDLE hMapFile = CreateFileMapping(
hFile, // Дескриптор файла
NULL, // Атрибуты безопасности (можно использовать NULL)
PAGE_READWRITE, // Режим доступа к файлу в отображении
0, // Размер отображения файла (0 - весь файл)
0, // Высший значащий байт размера файла
NULL // Имя отображения файла (можно использовать NULL)
);Отображение файла в виртуальную память
Завершите процесс сопоставления файла, отображая его в виртуальную память с помощью функции MapViewOfFile:
LPVOID pData = MapViewOfFile(
hMapFile, // Дескриптор отображения файла
FILE_MAP_ALL_ACCESS, // Режим доступа к отображению
0, // Смещение в файле
0, // Начальный байт отображения
0 // Размер отображения (0 - весь файл)
);Использование данных
Теперь pData указывает на начало отображения файла в виртуальной памяти. Вы можете работать с данными, как с обычной памятью.
Освобождение ресурсов
После завершения работы с данными не забудьте освободить ресурсы:
UnmapViewOfFile(pData); // Освобождение отображения файла
CloseHandle(hFile); // Закрытие дескриптора файла
CloseHandle(hMapFile); // Закрытие дескриптора отображения файлаНаверх
Отображением файла в память мы с вами пользовались в заметках об OpenGL, посвященных работе с моделями и текстурами, но не рассматривали подробно, как именно это работает. И хотя я почти уверен, что многие читатели этого блога уже знакомы с отображением файлов в память, я все же посчитал необходимом написать соответствующие заметки для тех читателей, кому данный механизм не знаком. Сегодня мы рассмотрим, как все это работает под Windows.
Заведем такую структуру, хранящую хэндл файла, хэндл отображения, размер файла, а также указатель на участок памяти с отображением:
#include <windows.h>
struct FileMapping {
HANDLE hFile;
HANDLE hMapping;
size_t fsize;
unsigned char* dataPtr;
};
Рассмотрим чтение из файла с использованием отображения.
Открываем файл:
HANDLE hFile = CreateFile(fname, GENERIC_READ, 0, nullptr,
OPEN_EXISTING,
FILE_ATTRIBUTE_NORMAL, nullptr);
if(hFile == INVALID_HANDLE_VALUE) {
std::cerr << «fileMappingCreate — CreateFile failed, fname = «
<< fname << std::endl;
return nullptr;
}
С процедурой CreateFile мы уже знакомы по заметке Учимся работать с файлами через Windows API, поэтому двигаемся дальше.
Получаем размер файла:
DWORD dwFileSize = GetFileSize(hFile, nullptr);
if(dwFileSize == INVALID_FILE_SIZE) {
std::cerr << «fileMappingCreate — GetFileSize failed, fname = «
<< fname << std::endl;
CloseHandle(hFile);
return nullptr;
}
Вторым аргументом процедура GetFileSize получает указатель на DWORD для записи старшей части размера файла. Передав в качестве этого аргумента nullptr, мы ограничили размер файла, который может вернутся. Если размер файла будет 4 Гб или больше, процедура вернет ошибку.
Создаем отображение:
HANDLE hMapping = CreateFileMapping(hFile, nullptr, PAGE_READONLY,
0, 0, nullptr);
if(hMapping == nullptr) {
std::cerr << «fileMappingCreate — CreateFileMapping failed, fname = «
<< fname << std::endl;
CloseHandle(hFile);
return nullptr;
}
Заметьте, что hMapping проверяется на равенство nullptr. Это не баг — согласно MSDN, в случае ошибки CreateFileMapping действительно возвращает пустой указатель, а не INVALID_HANDLE_VALUE, как можно было бы ожидать. Такая неконсистентность, к сожалению, встречается время от времени в WinAPI. Мы уже встречались с этой проблемой, изучая работу с реестром.
Наконец, получаем указатель на участок памяти с отображением, используя процедуру MapViewOfFile:
unsigned char* dataPtr = (unsigned char*)MapViewOfFile(hMapping,
FILE_MAP_READ,
0,
0,
dwFileSize);
if(dataPtr == nullptr) {
std::cerr << «fileMappingCreate — MapViewOfFile failed, fname = «
<< fname << std::endl;
CloseHandle(hMapping);
CloseHandle(hFile);
return nullptr;
}
Затем заполняем структуру FileMapping и возвращаем указатель на нее в качестве результата:
FileMapping* mapping = (FileMapping*)malloc(sizeof(FileMapping));
if(mapping == nullptr) {
std::cerr << «fileMappingCreate — malloc failed, fname = «
<< fname << std::endl;
UnmapViewOfFile(dataPtr);
CloseHandle(hMapping);
CloseHandle(hFile);
return nullptr;
}
mapping—>hFile = hFile;
mapping—>hMapping = hMapping;
mapping—>dataPtr = dataPtr;
mapping—>fsize = (size_t)dwFileSize;
return mapping;
Теперь читая mapping->fsize байт памяти по адресу mapping->dataPtr можно получить содержимое файла.
Когда отображение становится ненужным, не забываем его закрыть:
UnmapViewOfFile(mapping—>dataPtr);
CloseHandle(mapping—>hMapping);
CloseHandle(mapping—>hFile);
free(mapping);
Как видите, все предельно просто. Исходники к этой заметке вы найдете здесь.
В качестве домашнего задания можете попробовать модифицировать код так, чтобы через отображение файл можно было не только читать, но и писать в него.
Задание со звездочкой для желающих — ответьте на следующий вопрос. Можно ли, работая с отображением файла в память, менять его размер, например, делать append или обрезать файл посередине, и если можно, то как? Если честно, я сам так с лету не готов ответить на этот вопрос, потому что такой задачи передо мной не вставало. Так что, с нетерпением жду ваших вариантов ответа в комментариях!
Дополнение: Пример отображения файла в память под Linux и MacOS
Метки: C/C++, WinAPI.