
Коротко о главном: каждый узел группы доступности должен быть членом отказоустойчивого кластера Windows. Каждый экземпляр SQL Server может иметь несколько групп доступности. В каждой группе доступности может быть до 8 вторичных реплик.
Что это и зачем требуется
Группы доступности AlwaysOn — это решение высокой доступности и аварийного восстановления, является альтернативой зеркальному отображению баз данных на уровне предприятия. Если БД не справляется с потоком запросов или есть опасения, что при сбое на сервере пропадут ценные данные, есть смысл использовать это решение. Группы доступности AlwaysOn могут отвечать за выполнение сразу двух задачи: высокий уровень доступности обеспечивает бесперебойную работу системы, а нагрузка по чтению из БД частично выполняется на репликах.
Создание группы доступности может понадобиться, если вам необходимо:
-
Создать избыточную доступность баз данных (в этом случае рекомендуем располагать ноды в геоудалённых дата-центрах, т.к. избыточная доступность предполагает доступность БД при любых технических неполадках на любой из нод);
-
Увеличить быстродействие ответов баз данных по принципу горизонтального расширения (в этом случае одна нода в кластере является мастером, осуществляющей операции записи и чтения, остальные ноды работают в режиме слушателей и позволяют считывать данные при запросах обращения)
При отказе основой реплики, кластер проголосует за новую основную реплику и Always On переведёт одну из вторичных реплик в статус основной. Так как при работе с Always On пользователи соединяются с прослушивателем кластера (или Listener, то есть специальный IP-адрес кластера и соответствующее ему DNS-имя), то возможность выполнять write-запросы полностью восстановится. Прослушиватель также отвечает за балансировку select-запросов между вторичными репликами.
Подготовка инфраструктуры
Сначала необходимо создать виртуальную машину и пользователей. В VDC создаем 3 ВМ, даём имена согласно ролей, выполняем настройки кастомизации.

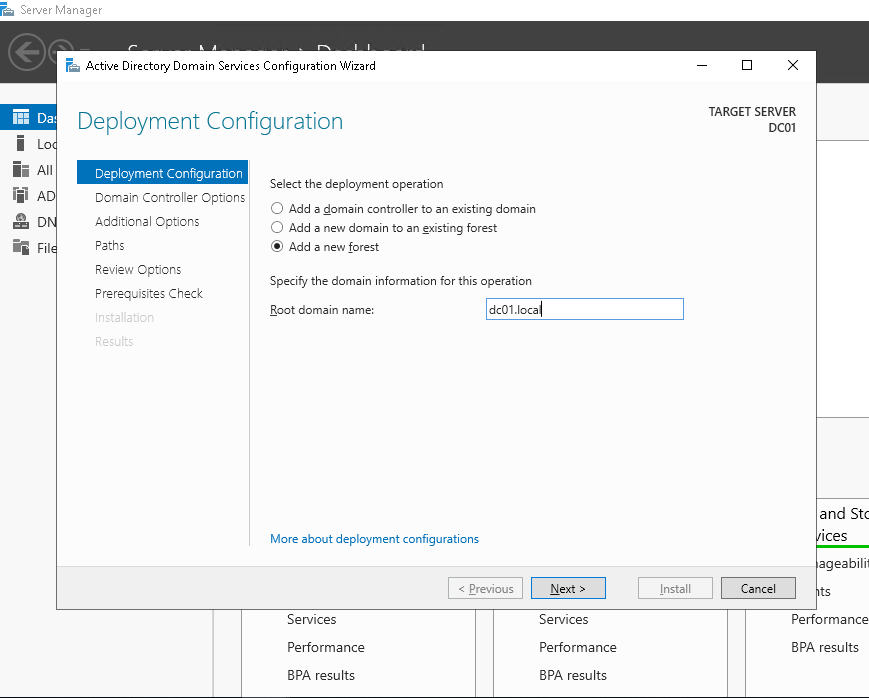
После этого переходим к этапу настройки контроллера домена. Устанавливаем роли AD, DNS, Failover Cluster.

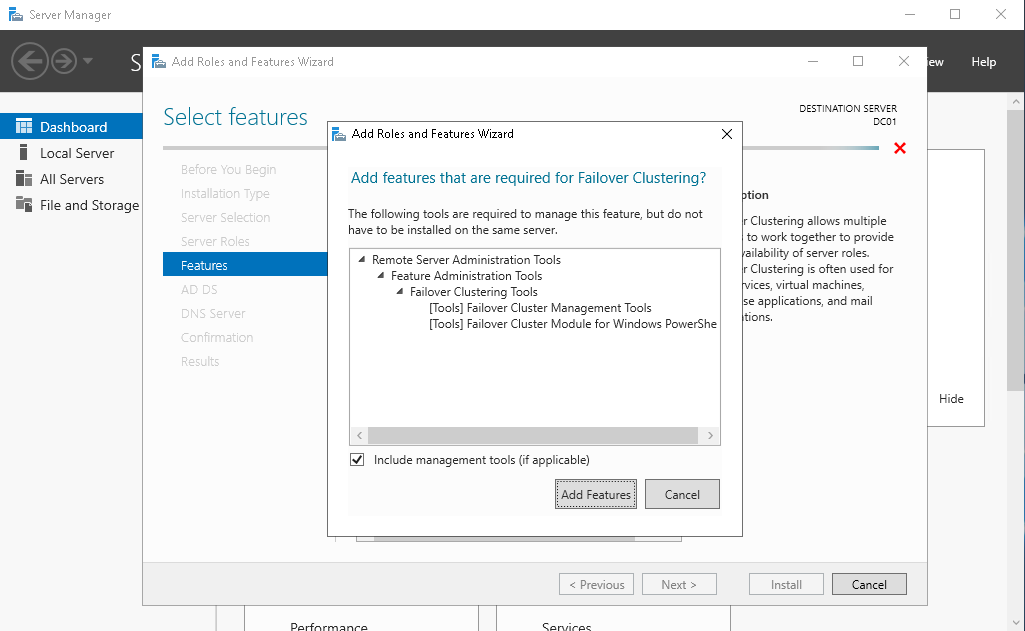
Устанавливаем роль контроллера домена
Создаём в AD компьютеры ND01 и ND02.

На ВМ ND01 и ND02 ставим компонент Failover Cluster

Теперь переходим к созданию кластера отказоустойчивости. На контроллере домена DC01 создаём кластер отказоустойчивости и добавляем в него наши ноды.
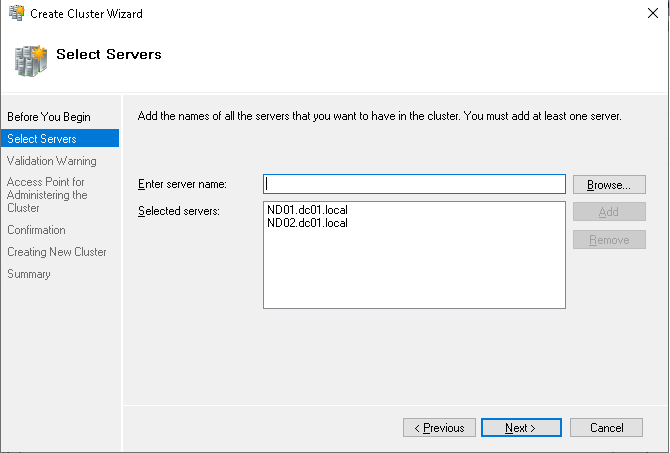
Даём имя кластеру.

При создании кластера снимаем галочку с добавления массивов в каталог. Эту настройку можно сделать позже.

Создание кластера завершено.

Создание свидетеля (Quorum Witness Share)
Переходим к настройке кворума. Для этого выбираем пункты, которые указаны на скриншоте.

В конфигурации свидетеля кворума указываем file share.


После этого необходимо создать директорию на сервере, не участвующем в кластере, но имеющим общую сеть с кластером. После создания такой директории и добавления шары для доступа к ней нод из кластера, в настройке свидетеля нужно указать UNC путь.

Если после создания свидетеля у вас возникнет ошибка как на примере ниже,

…то в этом случае необходимо проверить настройки прав доступа к сетевой директории, указанной в настройках свидетеля.
Переходим к установке MS SQL 2015 Enterprise на ноды в кластере. Перед установкой модуля необходимо отключить брандмауэр на работу в доменной сети на всех ВМ, участвующих в кластере.

Устанавливаем MS SQL в standalone режиме, без дополнительных модулей. При выборе пользователя для примера берём Администратора доменной сети. Для боевых серверов рекомендуем сделать отдельного пользователя. Наверное, не нужно объяснять, почему это важно.


Затем необходимо установить SQL Management Studio на обе ноды в кластере.
Добавление тестовой базы данных в MSSQL
На ноде ND01 устанавливаем тестовый образец базы данных. Имя тестовой БД будет Bike-Store. Тестовая БД взята отсюда.

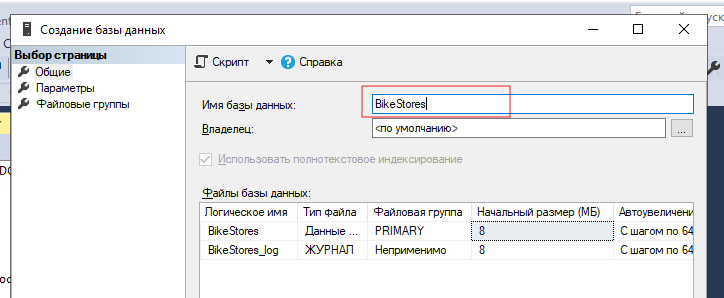
После установки БД выделяем созданную базу данных, после чего выбираем файл БД при помощи комбинации Ctrl+O.

После открытия файла нажимаем «Выполнить»
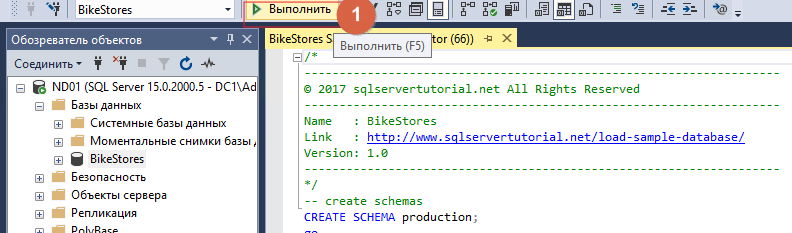
Когда добавили новую базу, необходимо наполнить её. Для этого открываем файл BikeStores Sample Database — load data.sql и добавляем его таким же методом. В конце операции должно появиться сообщение, что «Запрос успешно выполнен».

Важно! Перед развертыванием группы доступности обязательно делаем резервную копию БД, в противном случае не получится создать группу доступности

Настройка Always On в MS SQL Server
Для каждой ноды необходимо включить поддержку схемы AlwaysON в SQL Server Configuration Manager в свойствах экземпляра.

На ноде ND01 В SQL Server Management Studio выберите узел «Always On High Availability» и запустите мастер настройки группы доступности (New Availability Group Wizard).
Присваиваем имя нашей группе доступности: BikeStores-AG
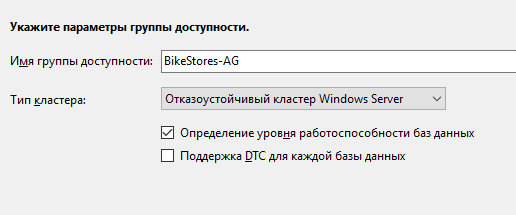
Нажмите «Добавить реплику» и подключитесь к второму серверу SQL. Таким образом можно добавить до 8 серверов.
Ключевые параметры
-
Исходная роль – роль реплики на момент создания группы. Может быть Primary и Secondary;
-
Автоматический переход – если база данных станет недоступна, Always On переведёт primary роль на другую реплику. Отмечаем чекбокс;
-
Режим доступности – возможно выбрать Synchronous Commit или Asynchronous Commit. При выборе синхронного режима транзакции, поступающие на primary реплику, будут отправлены на все остальные вторичные реплики с синхронным режимом. Primary реплика завершит транзакцию только после того, как реплики запишут транзакцию на диск. Таким образом исключается возможность потери данных при сбое primary реплики. При асинхронном режиме основная реплика сразу записывает изменения, не дожидаясь ответа от вторичных реплик;
-
Вторичная реплика для чтения – параметр, задающий возможность делать select-запросы к вторичным репликам. При значении yes, клиенты даже при соединении без ApplicationIntent=readonly смогут получить read-only доступ;
-
Для фиксации требуются синхронизированные получатели – число синхронизированных вторичных реплик для завершения транзакции. Нужно выставлять в зависимости от количества реплик. Имейте в виду, что, если вторичных синхронизированных реплик станет меньше указанного числа (например, при аварии), базы данных группы доступности станут недоступны даже для чтения.
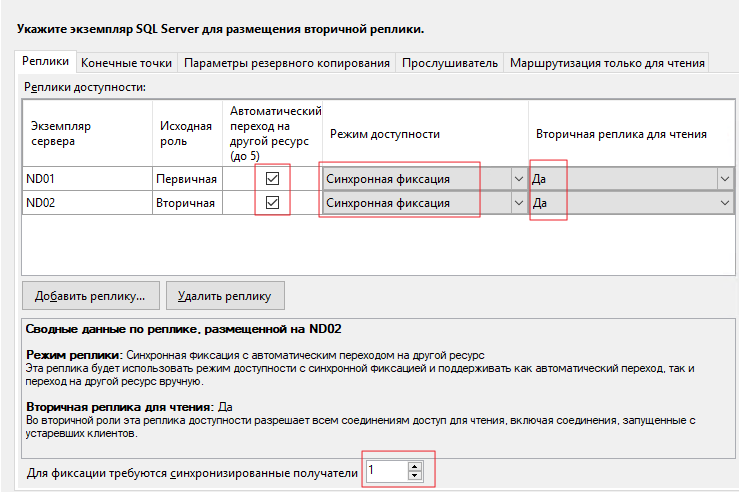
На вкладке Параметры резервного копирования можно выбрать откуда будут делаться бекапы. Оставляем всё по умолчанию – Предпочитать вторичную.
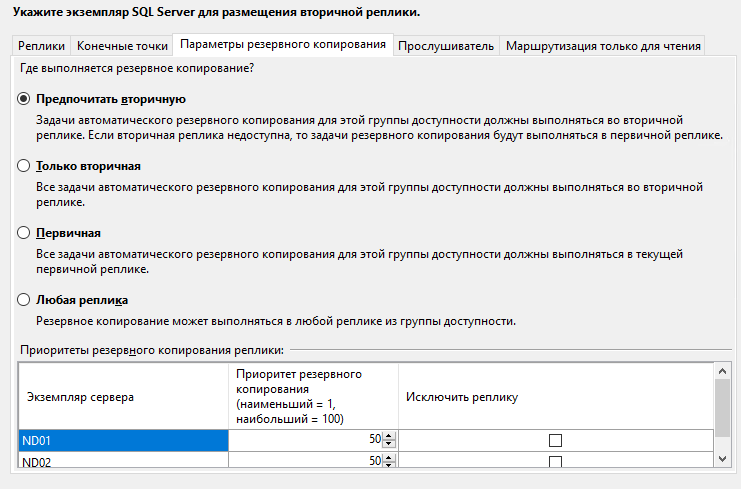
Указываем имя слушателя группы доступности, порт и IP-адрес.

Если все тесты во время окончания прошли успешно, то нажимаем кнопку «Далее».
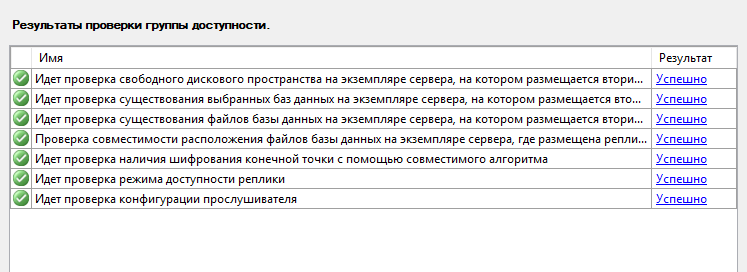

На этом первичная настройка группы доступности AlwaysON завершена. Вы можете провести тесты отказоустойчивости, попеременно отключая каждую ноду в кластере, а также давая простые запросы select, insert.
Надеемся, наша инструкция по создании групп доступности поможет вам обеспечить надлежащий уровень работоспособности вашей ИТ-инфраструктуры. В дальнейшем мы планируем выпустить и другие варианты сценариев. Если вам интересны какие-то нюансы – напишите о них в комментариях. Спасибо за внимание!
Киберпонедельник-2021
В России стартовала распродажа «Киберпонедельник-2021». Мы тоже решили принять участие в этой акции, и на три дня открыли бесплатный доступ к видеокурсу «Управление виртуальным дата центром и сетями в vCloud Director (VMware)» специально для тех, кто хочет разобраться в этой теме и научиться управлять облачной инфраструктурой.
В результате вы и ваши сотрудники сможете эффективнее использовать облачные платформы и больше не будете не путаться при работе с виртуальными машинами.
Курс уже получил 91 оценок от 366 студентов, средняя оценка — 4,5. Сейчас он снова бесплатно доступен на Udemy! Регистрируйтесь и учитесь!
Что ещё интересного есть в блоге Cloud4Y
→ В тюрьму за приложение
→ 2020 – год всемирной мобильности (как бы иронично это ни звучало)
→ Виртуальные машины и тест Гилева
→ Китайские регуляторы хотят получать от ИТ-гигантов данные о потребительских кредитах
→ Как настроить SSH-Jump Server
Подписывайтесь на наш Telegram-канал, чтобы не пропустить очередную статью. Пишем не чаще двух раз в неделю и только по делу.
This topic aims to explain the Quorum configuration in a Failover Clustering. As part of my job, I work with Hyper-V Clusters where the Quorum is not well configured and so my customers have not the expected behavior when an outage occurs. I work especially on Hyper-V clusters but the following topic applies to most of Failover Cluster configuration.
What’s a Failover Cluster Quorum
A Failover Cluster Quorum configuration specifies the number of failures that a cluster can support in order to keep working. Once the threshold limit is reached, the cluster stops working. The most common failures in a cluster are nodes that stop working or nodes that can’t communicate anymore.
Imagine that quorum doesn’t exist, and you have two-nodes cluster. Now there is a network problem, and the two nodes can’t communicate. If there is no Quorum, what prevents both nodes to operate independently and take disks ownership on each side? This situation is called Split-Brain. Quorum exists to avoid Split-Brain and prevents corruption on disks.
The Quorum is based on a voting algorithm. Each node in the cluster has a vote. The cluster keeps working while more than half of the voters are online. This is the quorum (or the majority of votes). When there are too many of failures and not enough online voters to constitute a quorum, the cluster stop working.
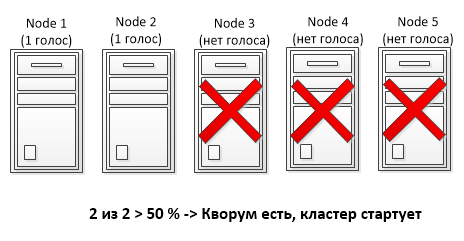
Below is a two nodes cluster configuration:

The majority of vote is 2 votes. So a two nodes cluster as above is not really resilient because if you lose a node, the cluster is down.
Below a three-node cluster configuration:

Now you add a node in your cluster. So, you are in a three-node cluster. The majority of vote is still 2 votes. But because there are three nodes, you can lose a node and the cluster keep working.
Below a four-node cluster configuration:

Despite its four nodes, this cluster can support one node failure before losing the quorum. The majority of vote is 3 votes so you can lose only one node.
On a five-node cluster the majority of votes is still 3 votes so you can lose two nodes before the cluster stop working and so on. As you can see, the majority of nodes must remain online in order to the cluster keeps working and this is why it is recommended to have an odd majority of votes. But sometimes we want only a two-node cluster for some applications that don’t require more nodes (as Virtual Machine Manager, SQL AlwaysOn and so on). In this case we add a disk witness, a file witness or in Windows Server 2016, a cloud Witness.
As said before, it is recommended to have an odd majority of votes. But sometimes we don’t want an odd number of nodes. In this case, a disk witness, a file witness or a cloud witness can be added to the cluster. This witness too has a vote. So when there are an even number of nodes, the witness enables to have an odd majority of vote. Below, the requirements and recommendations of each Witness type (except Cloud Witness):
So below you can find again a two-nodes Cluster with a witness:
Now there is a witness, you can lose a node and keep the quorum. Even if a node is down, the cluster still working. So when you have an even number of nodes, the quorum witness is required. But to keep an odd majority of votes, when you have an odd number of nodes, you should not implement a quorum witness.
Quorum configuration
Below you can find the four possible cluster configuration (taken from this link):
- Node Majority (recommended for clusters with an odd number of nodes)
Can sustain failures of half the nodes (rounding up) minus one. For example, a seven node cluster can sustain three node failures.
- Node and Disk Majority (recommended for clusters with an even number of nodes).
Can sustain failures of half the nodes (rounding up) if the disk witness remains online. For example, a six node cluster in which the disk witness is online could sustain three node failures.
Can sustain failures of half the nodes (rounding up) minus one if the disk witness goes offline or fails. For example, a six node cluster with a failed disk witness could sustain two (3-1=2) node failures.
- Node and File Share Majority (for clusters with special configurations)
Works in a similar way to Node and Disk Majority, but instead of a disk witness, this cluster uses a file share witness.
Note that if you use Node and File Share Majority, at least one of the available cluster nodes must contain a current copy of the cluster configuration before you can start the cluster. Otherwise, you must force the starting of the cluster through a particular node. For more information, see “Additional considerations” in Start or Stop the Cluster Service on a Cluster Node.
- No Majority: Disk Only (not recommended)
Can sustain failures of all nodes except one (if the disk is online). However, this configuration is not recommended because the disk might be a single point of failure.
Stretch Cluster Scenario
Unfortunately (I don’t like stretch cluster in Hyper-V scenario), some customers have stretch cluster between two datacenters. And the most common mistake I see to save money is the below scenario:

So the customer tells me: Ok I’ve followed the recommendation because I have four nodes in my cluster but I have added a witness to obtain an odd majority of votes. So let’s start the production. The cluster is running for a while and then one day the room 1 is underwater. So you lose Room 1:

In this scenario you should have also stretch storage and so if you have implemented a disk witness it should move to room 2. But in the above case you have lost the majority of votes and so the cluster stop working (sometimes with some luck, the cluster is still working because the disk witness has time to failover but it is lucky). So when you implement a stretch cluster, I recommend the below scenario:

In this scenario, even if you lose a room, the cluster still works. Yes I know, three rooms are expensive but I have not recommended you to make a stretch cluster (Hyper-V case). Fortunately, in Windows Server 2016, the quorum witness can be hosted in Microsoft Azure (Cloud Witness).
Dynamic Quorum (from Windows Server 2012 feature)
Dynamic Quorum enables to assign vote to node dynamically to avoid losing the majority of votes and so the cluster can run with one node (known as last-man standing). Let’s take the above example with four-node cluster without quorum witness. I said that the Quorum is 3 votes so without dynamic quorum, if you lose two nodes, the cluster is down.
Now I enable the Dynamic Quorum. The majority of votes is computed automatically related to running nodes. Let’s take again the Four-Node example:

So, why implementing a witness, especially for stretched cluster? Because Dynamic Quorum works great when the failure is sequential and not simultaneous. So for the stretched cluster scenario, if you lose a room, the failure is simultaneous and the dynamic quorum has not the time to recalculate the majority of votes. Moreover I have seen strange behavior with dynamic quorum especially with two-node cluster. This is why in Windows Server 2012, I always disabled the dynamic quorum when I didn’t use a quorum witness.
The dynamic quorum has been enhanced in Windows Server 2012 R2. Now there is Dynamic Witness implemented. This feature calculates if the Quorum Witness has a vote. There are two cases:
- If there is an even number of nodes in the cluster with the dynamic quorum enabled, the Dynamic Witness is enabled on the Quorum Witness and so the witness has vote.
- If there is an odd number of nodes in the cluster with the dynamic quorum enabled, the Dynamic Witness is enabled on the Quorum Witness and so the witness has not vote.
So since Windows Server 2012 R2, Microsoft recommends to always implement a witness in a cluster and let the dynamic quorum to decide for you.
The Dynamic Quorum is enabled by default since Windows Server 2012. In the below example, there is a four-node cluster on Windows Server 2016. But it is the same behavior.

I verify if the dynamic quorum is enabled and also the dynamic witness:

The Dynamic Quorum and the Dynamic Witness are well enabled. Because I have four nodes, the Witness has a vote and this is why the Dynamic Witness is enabled. If you want to disable the Dynamic Quorum you can run this command:
(Get-Cluster).DynamicQuorum = 0
Cloud Quorum Witness (from Windows Server 2016 feature)
By implementing a Cloud Quorum Witness, you avoid to spending money on the third room in case of stretch cluster. Below is the scenario:

The Cloud Witness, hosted in Microsoft Azure, has also one vote. In this way you have also an odd majority of votes. For that you need an existing storage account in Microsoft Azure. You also need an access key. Now you have just to configure the quorum as a standard witness. Select Configure a Cloud Witness when it is asked.

Then specify the Azure Storage Account and a storage key.

At the end of the configuration, the Cloud Witness should be online.

Conclusion
In conclusion, I recommend this when you are configuring a Quorum in a failover cluster:
- Prior to Windows Server 2012 R2, always keep an odd majority of vote
– In case of an even number of nodes, implement a witness
– In case of an odd number of nodes, do not implement a witness
- Since Windows Server 2012 R2, Always implement a quorum witness
– Dynamic Quorum manage the assigned vote to the nodes
– Dynamic Witness manage the assigned vote to the Quorum Witness
- In case of stretch cluster, implement the witness in a third room or use Microsoft Azure.
Кворум (Quorum) в переводе с латыни означает большинство, а кворумные модели используется в отказоустойчивых кластерах Windows для определения работоспособности кластера. При выходе из строя одного или нескольких узлов кластера среди оставшихся проводится голосование, и если они набирают большинство голосов (кворум), то кластер продолжает работу, если же не набирают — кластер останавливается.
Служба кластера (Failover Clustering) появилась еще в Windows NT 4.0. Тогда под кластером подразумевалось два узла (Node), объединенные вместе и имеющие доступ к общему хранилищу, на котором располагался кворумный диск, или диск-свидетель (Disk Witness). Голосования как такового не было, а работоспособность кластера определялась доступностью кворумного диска. При выходе из строя одного из узлов второй захватывал диск и продолжал работу.
Такая модель кворума сохранилась и до сих пор под названием Disk Only. При использовании этой модели кластер может пережить потерю всех узлов кластера кроме одного, который владеет кворумным диском. Как вы понимаете, здесь диск является единой точкой отказа и при его отказе весь кластер становится неработоспособным.
В Windows Server 2003 появились две новые модели кворума, основанные на голосовании:
Node Majority (большинство узлов) — каждому узлу кластера назначается голос, диск-свидетель голоса не имеет.
Node and Disk Majority (большинство узлов и диск) — каждый узел кластера и диск-свидетель имеет голос и участвует в голосовании.
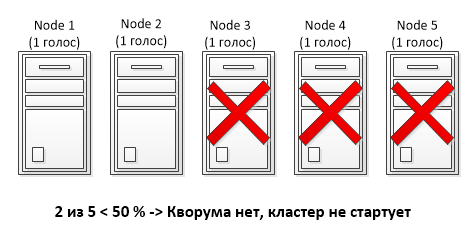
Выбор модели напрямую зависел от количества узлов в кластере, так Node Majority удобнее использовать при нечетном количестве узлов, а Node and Disk Majority при четном. В любом случае для продолжения работы кластера необходимо набрать большинство голосов (>50%).
Для примера возьмем 5-ти узловой кластер с кворумной моделью Node Majority. У каждого узла 1 голос, соответственно все 5 голосов составляют 100%. Для того, чтобы набрать кворум, необходимо более 50% голосов, что в данном случае составляет 3 голоса из 5. Путем несложных подсчетов 🙂 получаем, что данный кластер может перенести выход из строя не более 2 узлов. При выходе из строя третьего узла оставшиеся узлы не смогут собрать большинство и кластер будет остановлен.
Node Weight
В Windows Server 2003 R2 появилась еще одна модель кворума под названием Node and File Share Majority (большинство узлов и файловая шара) и стало возможным использовать в качестве свидетеля вместо диска файловую шару (Share Witness).
Затем все затихло, и следующие изменения появились только в Windows Server 2008 R2 SP1. Там после установки обновления KB 2494036 появилось понятие веса кластерного узла (Node Weight) и стало возможным его изменение.
Смысл изменения веса заключался в том, в том, чтобы исключить один или несколько узлов из процесса голосования, чтобы их падение не приводило к остановке кластера. При этом узел продолжает участвовать в работе кластера и обрабатывать клиентские подключения, но не участвует в голосовании. Исключение из голосования достигалось путем установки значения параметра NodeWeight равным 0. Изменение веса узла производилось вручную, с помощью PowerShell или через правку реестра.
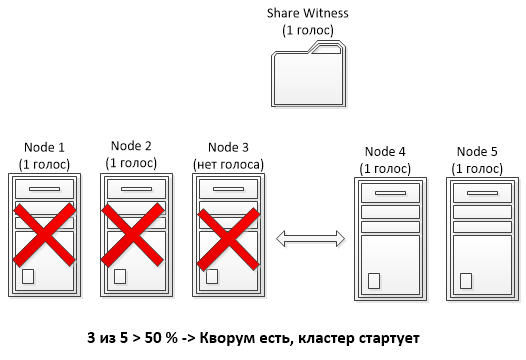
Для примера возьмем мультисайтовый кластер, состоящий из 5 узлов и использующий кворумную модель с файловой шарой (Node and File Share Majority). Три узла кластера находятся в основном сайте, два в резервном, и где-то в третьем размещена файловая шара-свидетель. При обычном подходе выход трех узлов в основном сайте из строя (напр. отключение электричества) приведет к падению всего кластера, так как оставшиеся в резервном сайте 2 узла + файловая шара не наберут больше половины голосов (3 голоса из 6).
А вот если отобрать у одного из узлов в основном сайте голос, то мы получим 2 голоса в основном сайте и 2 в резервном. Соответственно при падении основного сайта оставшиеся узлы в резервном с помощью шары смогут набрать большинство (3 из 5) и стартовать кластер.
Dynamic Quorum
Все эти изменения потихоньку подвели нас к понятию динамического кворума (Dynamic Quorum), который появился в Windows Server 2012. Суть динамического кворума в том, что при выходе из строя узла служба кластера автоматически исключает этот узел из голосования, устанавливая его вес в 0, и пересчитывает общее количество голосов в кворуме. Проверка и пересчет голосов производится каждые 5 минут, либо при наступлении определенных событий (напр. добавление или удаление узла). Пересчет производится в зависимости от ситуации:
• При выходе из строя узла — узел с наименьшим номером (Node ID) из оставшихся приводит вес узла в 0;
• При штатном выключении узла — узел сам удаляет свой голос в процессе выключения сервера;
• При добавлении узла в кластер — узел добавляет свой голос в процессе добавления.
При использовании динамического кворума каждый узел имеет два параметра — динамический вес (DynamicWeight) и целевой вес (NodeWeight) узла. Динамический кворум работает только с динамическим весом, не изменяя целевой вес. Принцип такой: при отключении узла его динамический вес устанавливается в 0, а когда узел стартовал и работает, то его динамический вес повышается до целевого. Таким образом, динамический кворум позволяет кластеру выжить даже в том случае, если у него остался всего один узел. Единственное ограничение — узлы должны выходить из строя по очереди, чтобы было время на пересчет кворума. При одновременном выходе из строя более 50% узлов динамический кворум не сработает и кластер будет остановлен.
В качестве примера возьмем 5-ти узловой кластер с моделью Node Majority. Как вы помните из предыдущего примера, при использовании стандартной кворумной модели такой кластер переживает потерю максимум двух узлов. Но поскольку динамический кворум автоматически пересчитывает общее количество голосов, то теперь при выходе из строя 3 узлов мы получим не 2 голоса из 5, а 2 голоса из 2, что даст возможность кластеру продолжить работу при последовательной потере более половины узлов (3 из 5).
Примечание. Если в кластере остаются только 2 узла и нет диска-свидетеля, то возможна ситуация Split-Brain, когда при потере связи между узлами каждый из них посчитает себя самостоятельным. Для избежания этого кластерная служба снижает вес одного из оставшихся узлов до 0. Соответственно при потере связи служба кластера на одном узле будет остановлена, а на втором продолжит работать.
Dynamic Witness
И еще одно нововведение, появившееся в Windows Server 2012 R2 — динамический свидетель (Dynamic Witness). Как вы понимаете, для получения большинства голосов нужно нечетное их количество, именно поэтому при четном числе узлов используется модель с диском-свидетелем (Node and Disk Majority). Однако при использовании динамического кворума такой подход не очень хорошо работает, ведь при пересчете вместо нечетного мы получим четное число.
При использовании динамического свидетеля вес диска является величиной переменной и зависит от количества работающих узлов в кластере. Так например, в 5-ти узловом кластере с моделью Node and Disk Majority диск-свидетель имеет нулевой вес и не участвует в голосовании. При потере одного узла и пересчете кворума количество голосов становится четным, и чтобы этого избежать диск свидетель получает голос. И так вплоть до последнего узла, при нечетном количестве узлов в кластере вес диска равен 0, а при четном 1.
Примечание. При наличии диска-свидетеля служба кластера никогда не понижает количество голосов ниже 2.
LowerQuorumPriorityNodeID
При использовании геораспределенных кластеров актуальна проблема одновременной потери 50% узлов, что может привести к различным неприятным ситуациям.
Для примера возьмем мультисайтовый 4-х узловой кластер с общим диском (Node and Disk Majority). Кластер разделен ровно пополам, два узла кластера находятся в основном сайте, два в резервном, всего 5 голосов (4 узла + диск). Вроде все красиво, при выходе из строя одного сайта сайта узлы в другом вместе со свидетелем смогут набрать кворум и продолжить работу.
А теперь предположим, что диск-свидетель выходит из строя и становится недоступен. Динамический кворум автоматически поддерживает нечетное количество голосов, поэтому у одного из узлов, выбранного произвольно, динамический вес понижается до 0. В результате мы имеем 3 голоса — 2 в одном сайте и 1 в другом. Если теперь связь между сайтами прервется, то кворум будет собран в том сайте, где осталось 2 голоса, и не факт что это будет основной сайт.
Для того, чтобы избежать подобной ситуации, в Window Server 2012 R2 можно использовать свойство кластера LowerQuorumPriorityNodeID. С помощью этого свойства можно указать номер конкретного узла, динамический вес которого должен быть понижен. И в случае разрыва связи кворум будет собран в основном сайте, как и планировалось.

Force quorum resiliency
В ситуации, когда кворум невозможно собрать автоматически, есть возможность принудительно запустить службу кластера на оставшихся узлах, использовав форсирование кворума (ForceQuorum). Для этого администратор должен выбрать один из доступных узлов и вручную запустить на нем службу кластера в форсированном режиме. Сделать это можно из командной строки, командой net start clussvc /fq либо с помощью PowerShell, командлетом Start-ClusterNode с ключом ForceQuorum.
После этого на всех остальных узлах служба кластера также должна быть запущена вручную, командой net start clussvc /pq или командлетом Start-ClusterNode с ключом PreventQuorum. Это не даст им собрать свой собственный кластер, а заставит искать существующий и присоединяться к нему.
Подобный подход не всегда возможен. Например возьмем ситуацию, когда у нас имеется мультисайтовый 5-ти узловой кластер, узлы которого разнесены на два сайта (основной и резервный). В основном сайте находятся 3 узла, в резервном соответствено 2. Связь с основным сайтом теряется, что означает одновременную потерю более 50% узлов. В этой ситуации динамический кворум не поможет, и для возобновления работы кластера в резервном сайте администратор должен будет вручную запустить службу кластера с ключом ForceQuorum.
А теперь предположим, что имели место проблемы с сетью, и в самом ЦОДе все продолжает работать. Соответственно, имея большинство, узлы в основном сайте соберут кворум и будут продолжать работу. А как только подключение будет восстановлено, мы получим Split-Brain, т.к. узлы кластера в основном и резервном сайтах, потеряв связь друг с другом, будут считать себя себя самостоятельным кластером.
Так было раньше, а в Windows Server 2012 R2 ситуация изменилась. Ключ PreventQuorum более не нужен, поскольку узлы кластера, запущенные с ключом ForceQuorum, считаются приоритетными. При восстановлении работы кластера остальные узлы проверяют состояние кластера, и если видят, что он был запущен с ключом ForceQuorum, то рестартуют службу кластера и присоединяются к нему.
А теперь для наглядности давайте рассмотрим несколько живых примеров.
Пример1. Настройка веса узла
Для примера возьмем 4-х узловой кластер с ″оригинальным″ именем Cluster1. Откроем оснастку Failover Cluster Manager, зайдем в раздел «Nodes» и посмотрим список его узлов. Здесь нас интересуют две колонки:
• Assigned Vote — голос, который назначен узлу в общем случае. Определяется целевым весом узла (NodeWeight);
• Current Vote — голос, который имеет узел в данный момент. Зависит от текущего значения динамического веса узла (DynamicWeight).
По умолчанию для работающих узлов эти параметры идентичны и ровны 1.

Как вы помните, целевой вес узла может быть изменен вручную. Для этого кликаем правой клавишей на имени кластера и в контекстном меню переходим в раздел More Actions -> Configure Cluster Quorum Settings.

И перейдя в расширенные настройки кворума (Advanced quorum configuration) выбираем те узлы кластера, которые будут иметь право голоса.
Примечание. Выбрав пункт No Nodes мы получим кворумную модель Disk Only, в которой право голоса есть только у кворумного ресурса.

Также понизить целевой вес выбранных узлов можно с помощью PowerShell, вот такой командой:
(Get-ClusterNode -Name SRV5).NodeWeight = 0
(Get-ClusterNode -Name SRV6).NodeWeight = 0
В результате узлы лишаются голоса и не участвуют в голосовании, хотя и продолжают работать в кластере. Обратите внимание, что теперь для выбранных узлов оба параметра имеют нулевое значение. Это связано с тем, динамический вес узла никогда не устанавливается в 1 при целевом весе равном 0.

Пример 2. Dynamic Quorum
В отличие от ручного понижения веса, динамический кворум не трогает целевой вес узла, а работает только с динамическим весом. Для наглядности остановим 2 узла кластера и посмотрим, что стало с их весами. Поскольку после остановки динамический вес их стал равен о, то они больше не имеют голоса. Однако их целевой вес остался прежним, и как только узлы будут включены, механизм динамического кворума тут же повысит их динамический вес до целевого, они получат обратно свои голоса и смогут участвовать в голосовании.

Примечание. Динамический кворум включен по умолчанию, но при желании его можно отключить, установив значение DynamicQuorum равным 0. В Windows Server 2012 R2 сделать это возможно только с помощью PowerShell, командой:
(Get-Cluster -Name Cluster1).DynamicQuorum = 0
Пример 3. Dynamic Witness
Перейдем к демонстрации работы динамического свидетеля. В качестве подопытного используем все тот же 4-х узловой кластер с диском-свидетелем. Откроем консоль PowerShell и проверим состояние и веса кластерных узлов командой:
Get-ClusterNode -Cluster Cluster1 | ft -a Name, State, NodeWeight, DynamicWeight
А для вывода веса диска-свидетеля выполним команду:
Get-Cluster -Name Cluster1 | fl WitnessDynamicWeight
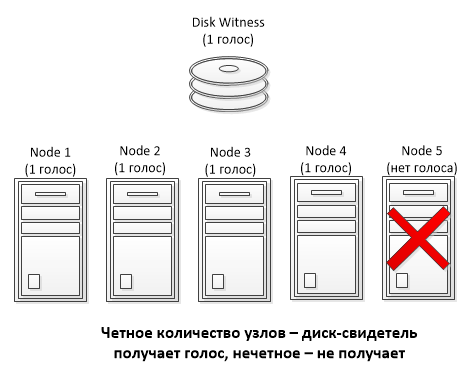
Как видите, поскольку у нас четное число узлов (4 узла ), свидетель имеет вес равный 1.

Остановим один из узлов и еще раз проверим их состояние. Поскольку теперь количество активных узлов нечетное (3 узла), то вес свидетеля становится лишним и его значение автоматически устанавливается равным 0.

Таким образом Dynamic Quorum и Dynamic Witness позволяют не заморачиваться количеством узлов в кластере и выбором кворумной модели. По сути в Windows Server 2012 R2 остается всего одна основная модель Node and Disk Majority. Эта модель рекомендуется к использованию в большинстве случаев и выбирается по умолчанию при создании кластера.
Пример 4. LowerQuorumPriorityNodeID
Берем 4-х узловой кластер и диск-свидетель. Проверяем его параметры — тип кворума Node and Disk Majority, веса всех узлов и диска ровны 1, всего в наличии 5 голосов.

Отключаем диск-свидетель, делая его вес равным 0. Еще раз проверяем параметры узлов, и видим, что динамический кворум пересчитал голоса и для сохранения нечетного их количества понизил динамический вес первого узла.

Предположим нас не устраивает такое положение вещей, и мы хотим, чтобы в подобной ситуации всегда понижался вес четвертого узла. Для этого установим значение LowerQuorumPriorityNodeID равным 4, выполнив команду:
(Get-Cluster -Name Cluster1).LowerQuorumPriorityNodeID = 4
Примечание. Значение LowerQuorumPriorityNodeID это номер узла (ID), которому надо понизить вес. Одновременно можно указать только один узел.
Еще раз смоделируем ситуацию с отключением диска и посмотрим параметры узлов. Как видите, теперь вес понижен у узла с ID=4, который указан в свойстве LowerQuorumPriorityNodeID.

Таким образом, с помощью LowerQuorumPriorityNodeID мы можем более гибко управлять кластером и выбирать, какая из его частей в случае разрыва связи продолжит работу, а какая будет остановлена.
This article will teach you how to Configuring Cluster Quorum Witness in Windows Failover Cluster Quorum modes that are needed for the availability groups. The cluster database configuration, also named the quorum, provides details as to which cluster node must be active at any specified time in the cluster setup. I have set up a basic 2-node Windows server cluster, where I have two servers (SRV2022-01 and SRV2022-02) running Windows Server 2022 and one running Windows Server 2022 Domain Controller (DC2022). It also assumes that Node01 and Node02 will communicate with each other over two network connections; I have labeled them Primary and Cluster.
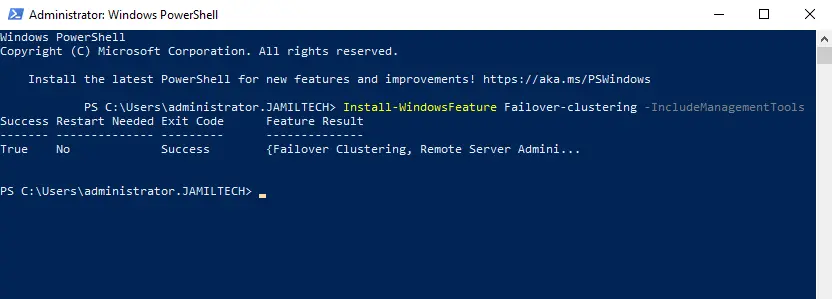
Now enable the failover clustering feature on both the servers we need to add to the cluster. Visit Microsoft to learn about how to set the cluster quorum.
Enable Failover Clustering Feature PowerShell
To enable failover clustering features and management tools via the PowerShell command,. Type the following PowerShell command and then hit enter.
Install-WindowsFeature -Name Failover-Clustering –IncludeManagementTools
We do not have any shared storage, and I am not using a node and disk quorum as suggested. Alternatively, I will use the File Share Witness quorum.
Follow this article on how to configure file share witness in Server 2022.
Configuring Cluster Quorum Witness
Open Failover cluster manager, right-click on your cluster (Cluster.jamiltech.local), choose More Actions, and then select Configure cluster quorum settings.
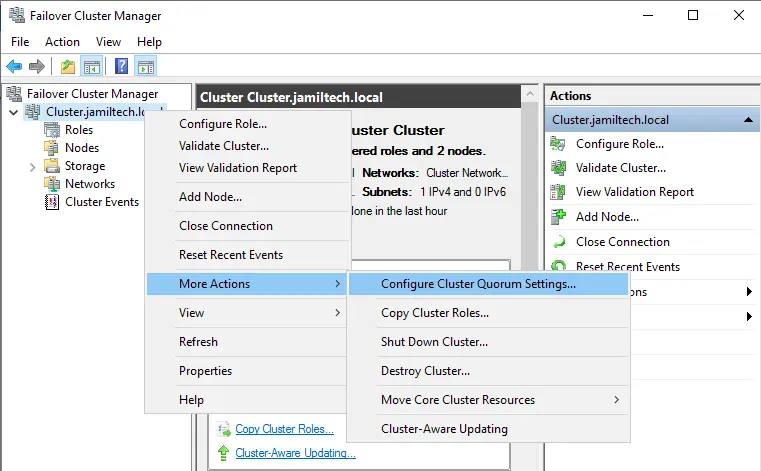
Configure the Cluster Quorum Wizard and click on the next button.
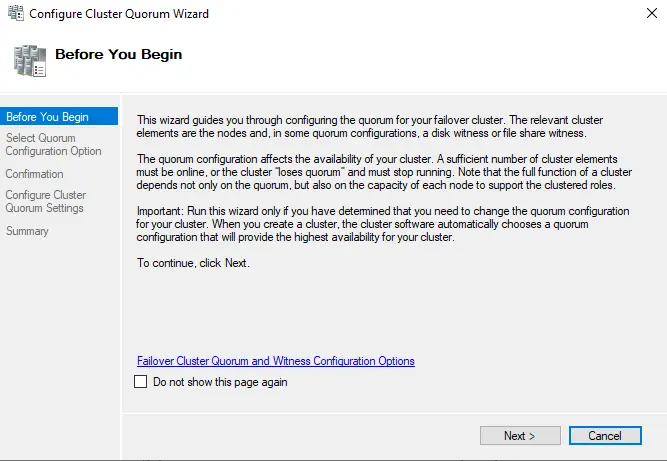
In the Select the Quorum Witness page, select the box “Advanced Quorum Configuration” and then choose Next.
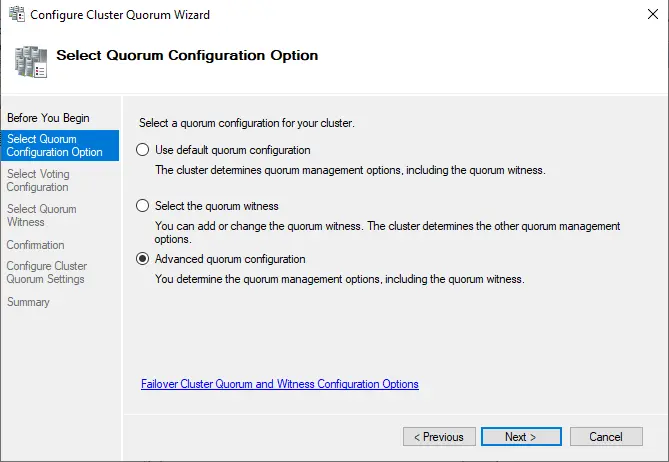
Select all nodes from the “select voting configuration” page, and then choose next.
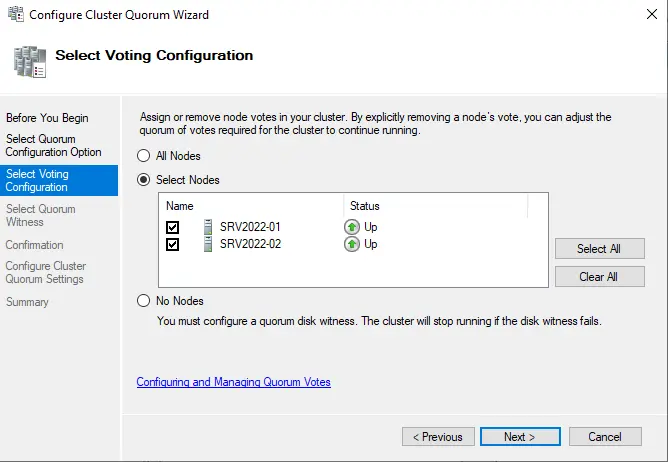
Select the box “configure a file share witness” and then click next.
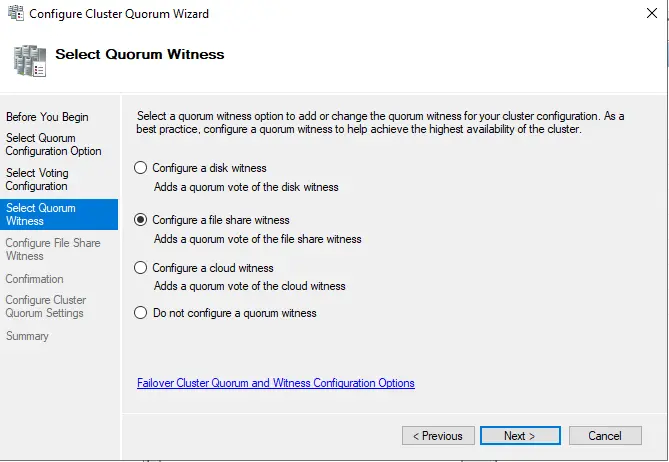
Enter the share path in the “file share path” box or choose the browse button to select, to configure a file share witness screen.
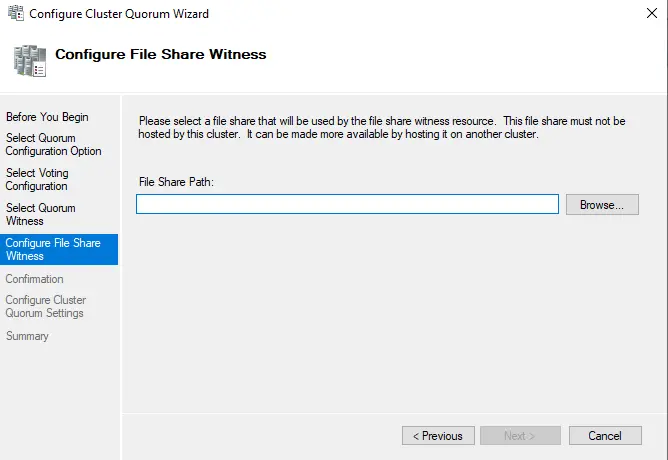
Click on the Browse button.
Type quorum shared server name, choose check names and then choose ok.
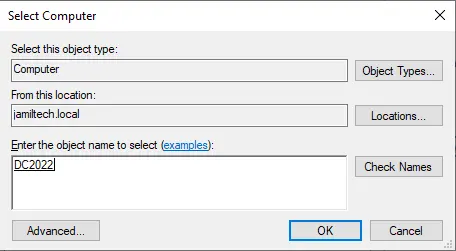
Click ok
Click next
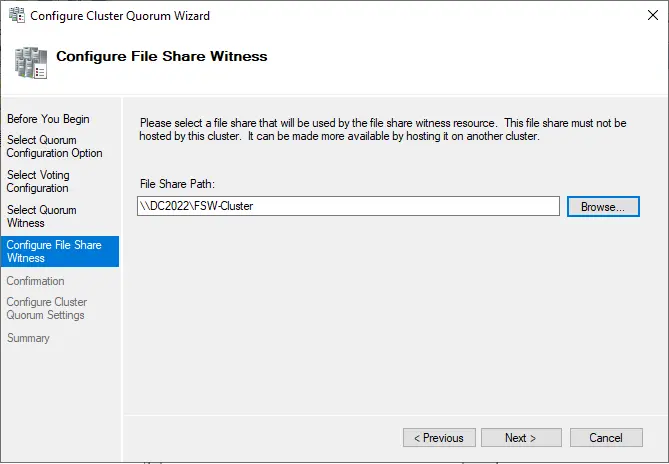
Review the confirmation screen with the configured quorum settings and then choose next.
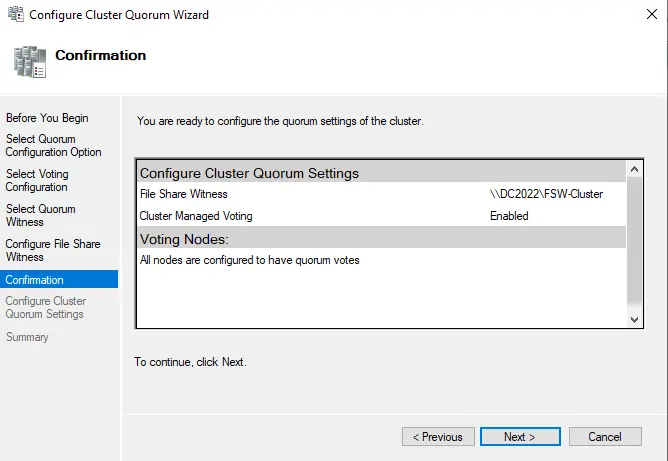
Choose the finish button to complete the quorum settings.
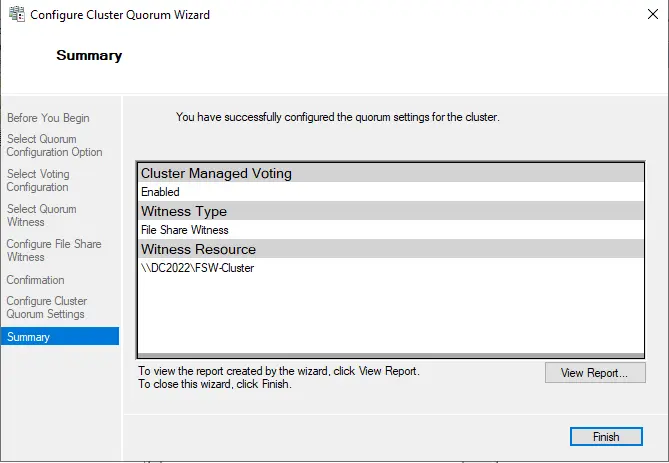
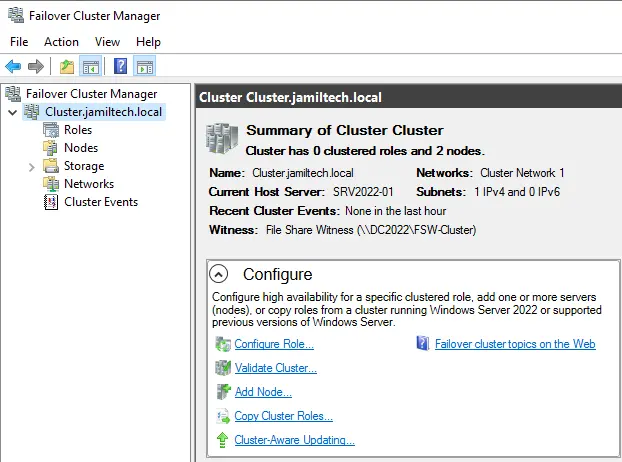
Now current host server Node01 is SRV2022-01.
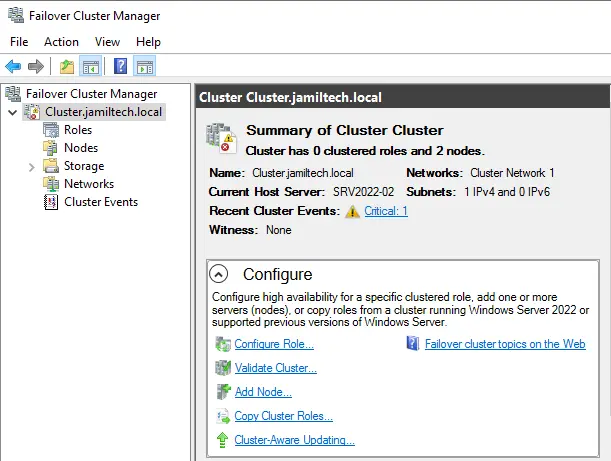
After testing Current Host Server Node02 is SRV2022-02.
Jamilhttp://jamiltech.com
A Professional Technology Blog Writer | An energetic professional with more than 20+ years of rich experience in Technology, Planning, Designing, Installation, and Networking.
Skip to content
Menu
Close
Starting with Windows Server 2016, Microsoft introduced a new type of quorum witness for a Windows Server Failover Cluster (WSFC). This quorum witness leverages Microsoft Azure and is called a Cloud Witness. This type of quorum witness is applicable to multi-site stretched WSFCs.
Cloud Witness Requirements
- An Azure Storage account : Storage Account Name and Access Key.
- Internet or ExpressRoute connectivity from all the database servers to https://<storageaccount>.blob.core.windows.net
Azure Storage Account Recommendations
Here are some recommendations for Azure Storage accounts for use by Cloud Witnesses:
- Enforce access control via IAM and Azure Storage Firewall to restrict access to users and networks.
- Enforce TLS v1.2 (or the latest TLS protocol) for access to the Storage Account.
- Add a ‘delete’ resource lock for the storage account, given that it’s used by a core component (Cloud Witness) of your WSFCs.
- Store Azure Storage Account Access keys in a secure system on-premises or in Azure Key Vault for use by teams building WSFCs.
Cloud Witness Deployment
Refer the Microsoft documentation for an overview of the Cloud Witness and its deployment. The salient features are given below:
- When a cloud witness is configured for a cluster using an Azure storage account for the first time, a container called msft-cloud-witness is created within the storage account. The cluster then creates a unique file named with the clusterid.
- Multiple WSFCs may share the same Azure Storage Account with each WSFC operating on a unique file within the msft-cloud-witness container.
WSFC+Cloud Witness: Resilience Tests
I performed resilience tests with an on-premises WSFC (Windows Server 2019) and Cloud Witness and the details are provided below:
WSFC PARAMETERS
- With Powershell as Administrator, execute the following commands on one of the cluster nodes:
# Enable Site Fault Tolerance (Get-Cluster).AutoAssignNodeSite=1 # Set Heartbeat frequency for nodes in the same subnet (Get-Cluster).SameSubnetDelay=1000 # Set minimum number of missed heartbeats between nodes in the same subnet before recovery action (Get-Cluster).SameSubnetThreshold=10 # Set Heartbeat frequency for nodes in the different sites (Get-Cluster).CrossSiteDelay=1000 # Set minimum number of missed heartbeats between nodes in different sites before recovery action (Get-Cluster).CrossSiteThreshold=10
NOTE:
- The heartbeat parameters above were suitable for my network infrastructure spanning 2 sites and availability requirements, but may be considered too aggressive for some environments.
- All other timeout parameters (Lease Time, HealthCheck Time, etc.) were kept with default values.
TEST METHOD:
- The clustered role on the WSFC being accessed by the test client during resilience tests is a SQL AG (AG + AG Listener).
- The test client (shell scripts) use sqlcmd with the latest MSSQL ODBC driver that supports AGs (e.g. MultiSubnetFailover, ApplicationIntent).
- Node failures were simulated by powering off the Virtual Machines (not graceful – similar to pressing the power button on your laptop to power it down).
- Network failures were simulated with firewall rules denying relevant traffic.
- The Cloud Witness failure was simulated by deleting the relevant Azure storage account.
NOTE: The client (simple scripts) does not simulate real-world applications, but offers some insight into the impact on clients.
The images below describe the different types of resilience tests performed in the IA LAB.
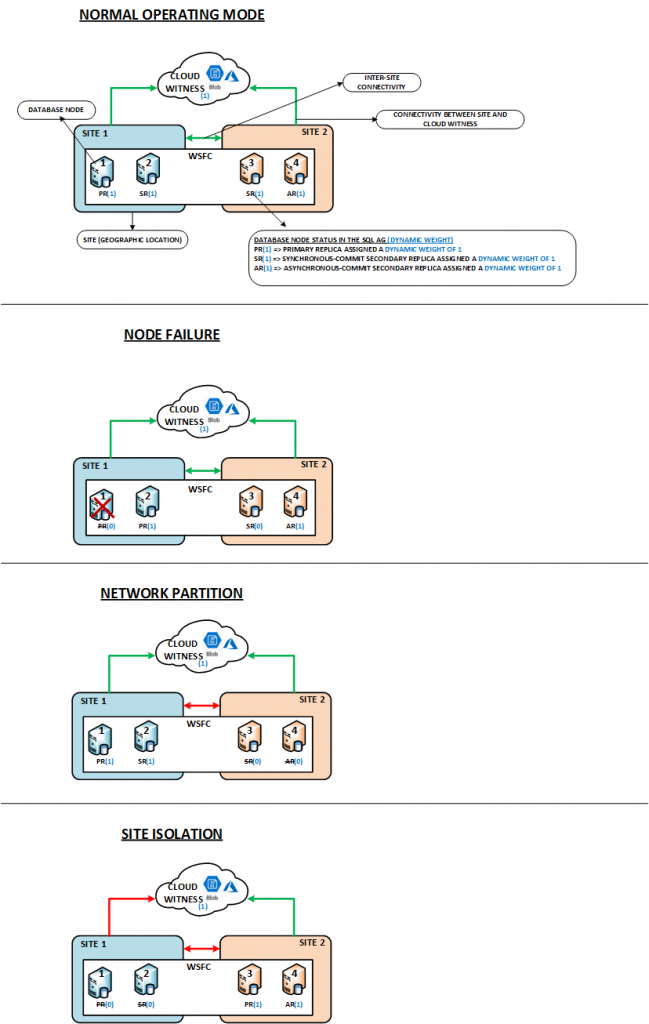
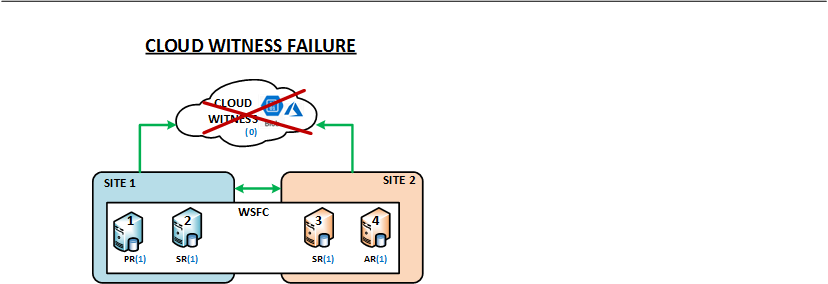
The following table summarizes the observations based on several resilience tests pertaining to the types of tests described above.

WSFC GUIDELINES
- Enable Site Fault tolerance either by using (Get-Cluster).AutoAssignNodeSite=1 or manually configuring sites and node-site affinity with the New-ClusterFaultDomain and Set-ClusterFaultDomain powershell cmdlets.
- Do not set “Preferred owners”, unless absolutely required and you know what you’re doing.
- Do not allow the cluster group and SQL AG clustered resource to remain in different sites. There wouldn’t be an issue with this under normal operations. However, a network partition could cause the SQL AG clustered resource to failover to the site hosting the cluster group.
(Visited 1,793 times, 2 visits today)