
From Wikipedia, the free encyclopedia
CUDA
| Developer(s) | Nvidia |
|---|---|
| Initial release | February 16, 2007; 18 years ago[1] |
| Stable release |
12.9 |
| Operating system | Windows, Linux |
| Platform | Supported GPUs |
| Type | GPGPU |
| License | Proprietary |
| Website | developer |
In computing, CUDA (Compute Unified Device Architecture) is a proprietary[2] parallel computing platform and application programming interface (API) that allows software to use certain types of graphics processing units (GPUs) for accelerated general-purpose processing, an approach called general-purpose computing on GPUs. CUDA was created by Nvidia in 2006.[3] When it was first introduced, the name was an acronym for Compute Unified Device Architecture,[4] but Nvidia later dropped the common use of the acronym and now rarely expands it.[5]
CUDA is a software layer that gives direct access to the GPU’s virtual instruction set and parallel computational elements for the execution of compute kernels.[6] In addition to drivers and runtime kernels, the CUDA platform includes compilers, libraries and developer tools to help programmers accelerate their applications.
CUDA is designed to work with programming languages such as C, C++, Fortran, Python and Julia. This accessibility makes it easier for specialists in parallel programming to use GPU resources, in contrast to prior APIs like Direct3D and OpenGL, which require advanced skills in graphics programming.[7] CUDA-powered GPUs also support programming frameworks such as OpenMP, OpenACC and OpenCL.[8][6]
The graphics processing unit (GPU), as a specialized computer processor, addresses the demands of real-time high-resolution 3D graphics compute-intensive tasks. By 2012, GPUs had evolved into highly parallel multi-core systems allowing efficient manipulation of large blocks of data. This design is more effective than general-purpose central processing unit (CPUs) for algorithms in situations where processing large blocks of data is done in parallel, such as:
- cryptographic hash functions
- machine learning
- molecular dynamics simulations
- physics engines
Ian Buck, while at Stanford in 2000, created an 8K gaming rig using 32 GeForce cards, then obtained a DARPA grant to perform general purpose parallel programming on GPUs. He then joined Nvidia, where since 2004 he has been overseeing CUDA development. In pushing for CUDA, Jensen Huang aimed for the Nvidia GPUs to become a general hardware for scientific computing. CUDA was released in 2007. Around 2015, the focus of CUDA changed to neural networks.[9]
The following table offers a non-exact description for the ontology of CUDA framework.
The ontology of CUDA framework
| memory (hardware) |
memory (code, or variable scoping) | computation (hardware) |
computation (code syntax) |
computation (code semantics) |
|---|---|---|---|---|
| RAM | non-CUDA variables | host | program | one routine call |
| VRAM, GPU L2 cache |
global, const, texture | device | grid | simultaneous call of the same subroutine on many processors |
| GPU L1 cache | local, shared | SM («streaming multiprocessor») | block | individual subroutine call |
| warp = 32 threads | SIMD instructions | |||
| GPU L0 cache, register |
thread (aka. «SP», «streaming processor», «cuda core», but these names are now deprecated) | analogous to individual scalar ops within a vector op |
Programming abilities
[edit]
- Copy data from main memory to GPU memory
- CPU initiates the GPU compute kernel
- GPU’s CUDA cores execute the kernel in parallel
- Copy the resulting data from GPU memory to main memory
The CUDA platform is accessible to software developers through CUDA-accelerated libraries, compiler directives such as OpenACC, and extensions to industry-standard programming languages including C, C++, Fortran and Python. C/C++ programmers can use ‘CUDA C/C++’, compiled to PTX with nvcc, Nvidia’s LLVM-based C/C++ compiler, or by clang itself.[10] Fortran programmers can use ‘CUDA Fortran’, compiled with the PGI CUDA Fortran compiler from The Portland Group.[needs update] Python programmers can use the cuNumeric library to accelerate applications on Nvidia GPUs.
In addition to libraries, compiler directives, CUDA C/C++ and CUDA Fortran, the CUDA platform supports other computational interfaces, including the Khronos Group’s OpenCL,[11] Microsoft’s DirectCompute, OpenGL Compute Shader and C++ AMP.[12] Third party wrappers are also available for Python, Perl, Fortran, Java, Ruby, Lua, Common Lisp, Haskell, R, MATLAB, IDL, Julia, and native support in Mathematica.
In the computer game industry, GPUs are used for graphics rendering, and for game physics calculations (physical effects such as debris, smoke, fire, fluids); examples include PhysX and Bullet. CUDA has also been used to accelerate non-graphical applications in computational biology, cryptography and other fields by an order of magnitude or more.[13][14][15][16][17]
CUDA provides both a low level API (CUDA Driver API, non single-source) and a higher level API (CUDA Runtime API, single-source). The initial CUDA SDK was made public on 15 February 2007, for Microsoft Windows and Linux. Mac OS X support was later added in version 2.0,[18] which supersedes the beta released February 14, 2008.[19] CUDA works with all Nvidia GPUs from the G8x series onwards, including GeForce, Quadro and the Tesla line. CUDA is compatible with most standard operating systems.
CUDA 8.0 comes with the following libraries (for compilation & runtime, in alphabetical order):
- cuBLAS – CUDA Basic Linear Algebra Subroutines library
- CUDART – CUDA Runtime library
- cuFFT – CUDA Fast Fourier Transform library
- cuRAND – CUDA Random Number Generation library
- cuSOLVER – CUDA based collection of dense and sparse direct solvers
- cuSPARSE – CUDA Sparse Matrix library
- NPP – NVIDIA Performance Primitives library
- nvGRAPH – NVIDIA Graph Analytics library
- NVML – NVIDIA Management Library
- NVRTC – NVIDIA Runtime Compilation library for CUDA C++
CUDA 8.0 comes with these other software components:
- nView – NVIDIA nView Desktop Management Software
- NVWMI – NVIDIA Enterprise Management Toolkit
- GameWorks PhysX – is a multi-platform game physics engine
CUDA 9.0–9.2 comes with these other components:
- CUTLASS 1.0 – custom linear algebra algorithms,
- NVIDIA Video Decoder was deprecated in CUDA 9.2; it is now available in NVIDIA Video Codec SDK
CUDA 10 comes with these other components:
- nvJPEG – Hybrid (CPU and GPU) JPEG processing
CUDA 11.0–11.8 comes with these other components:[20][21][22][23]
- CUB is new one of more supported C++ libraries
- MIG multi instance GPU support
- nvJPEG2000 – JPEG 2000 encoder and decoder
CUDA has several advantages over traditional general-purpose computation on GPUs (GPGPU) using graphics APIs:
- Scattered reads – code can read from arbitrary addresses in memory.
- Unified virtual memory (CUDA 4.0 and above)
- Unified memory (CUDA 6.0 and above)
- Shared memory – CUDA exposes a fast shared memory region that can be shared among threads. This can be used as a user-managed cache, enabling higher bandwidth than is possible using texture lookups.[24]
- Faster downloads and readbacks to and from the GPU
- Full support for integer and bitwise operations, including integer texture lookups
- Whether for the host computer or the GPU device, all CUDA source code is now processed according to C++ syntax rules.[25] This was not always the case. Earlier versions of CUDA were based on C syntax rules.[26] As with the more general case of compiling C code with a C++ compiler, it is therefore possible that old C-style CUDA source code will either fail to compile or will not behave as originally intended.
- Interoperability with rendering languages such as OpenGL is one-way, with OpenGL having access to registered CUDA memory but CUDA not having access to OpenGL memory.
- Copying between host and device memory may incur a performance hit due to system bus bandwidth and latency (this can be partly alleviated with asynchronous memory transfers, handled by the GPU’s DMA engine).
- Threads should be running in groups of at least 32 for best performance, with total number of threads numbering in the thousands. Branches in the program code do not affect performance significantly, provided that each of 32 threads takes the same execution path; the SIMD execution model becomes a significant limitation for any inherently divergent task (e.g. traversing a space partitioning data structure during ray tracing).
- No emulation or fallback functionality is available for modern revisions.
- Valid C++ may sometimes be flagged and prevent compilation due to the way the compiler approaches optimization for target GPU device limitations.[citation needed]
- C++ run-time type information (RTTI) and C++-style exception handling are only supported in host code, not in device code.
- In single-precision on first generation CUDA compute capability 1.x devices, denormal numbers are unsupported and are instead flushed to zero, and the precision of both the division and square root operations are slightly lower than IEEE 754-compliant single precision math. Devices that support compute capability 2.0 and above support denormal numbers, and the division and square root operations are IEEE 754 compliant by default. However, users can obtain the prior faster gaming-grade math of compute capability 1.x devices if desired by setting compiler flags to disable accurate divisions and accurate square roots, and enable flushing denormal numbers to zero.[27]
- Unlike OpenCL, CUDA-enabled GPUs are only available from Nvidia as it is proprietary.[28][2] Attempts to implement CUDA on other GPUs include:
- Project Coriander: Converts CUDA C++11 source to OpenCL 1.2 C. A fork of CUDA-on-CL intended to run TensorFlow.[29][30][31]
- CU2CL: Convert CUDA 3.2 C++ to OpenCL C.[32]
- GPUOpen HIP: A thin abstraction layer on top of CUDA and ROCm intended for AMD and Nvidia GPUs. Has a conversion tool for importing CUDA C++ source. Supports CUDA 4.0 plus C++11 and float16.
- ZLUDA is a drop-in replacement for CUDA on AMD GPUs and formerly Intel GPUs with near-native performance.[33] The developer, Andrzej Janik, was separately contracted by both Intel and AMD to develop the software in 2021 and 2022, respectively. However, neither company decided to release it officially due to the lack of a business use case. AMD’s contract included a clause that allowed Janik to release his code for AMD independently, allowing him to release the new version that only supports AMD GPUs.[34]
- chipStar can compile and run CUDA/HIP programs on advanced OpenCL 3.0 or Level Zero platforms.[35]
This example code in C++ loads a texture from an image into an array on the GPU:
texture<float, 2, cudaReadModeElementType> tex; void foo() { cudaArray* cu_array; // Allocate array cudaChannelFormatDesc description = cudaCreateChannelDesc<float>(); cudaMallocArray(&cu_array, &description, width, height); // Copy image data to array cudaMemcpyToArray(cu_array, image, width*height*sizeof(float), cudaMemcpyHostToDevice); // Set texture parameters (default) tex.addressMode[0] = cudaAddressModeClamp; tex.addressMode[1] = cudaAddressModeClamp; tex.filterMode = cudaFilterModePoint; tex.normalized = false; // do not normalize coordinates // Bind the array to the texture cudaBindTextureToArray(tex, cu_array); // Run kernel dim3 blockDim(16, 16, 1); dim3 gridDim((width + blockDim.x - 1)/ blockDim.x, (height + blockDim.y - 1) / blockDim.y, 1); kernel<<< gridDim, blockDim, 0 >>>(d_data, height, width); // Unbind the array from the texture cudaUnbindTexture(tex); } //end foo() __global__ void kernel(float* odata, int height, int width) { unsigned int x = blockIdx.x*blockDim.x + threadIdx.x; unsigned int y = blockIdx.y*blockDim.y + threadIdx.y; if (x < width && y < height) { float c = tex2D(tex, x, y); odata[y*width+x] = c; } }
Below is an example given in Python that computes the product of two arrays on the GPU. The unofficial Python language bindings can be obtained from PyCUDA.[36]
import pycuda.compiler as comp import pycuda.driver as drv import numpy import pycuda.autoinit mod = comp.SourceModule( """ __global__ void multiply_them(float *dest, float *a, float *b) { const int i = threadIdx.x; dest[i] = a[i] * b[i]; } """ ) multiply_them = mod.get_function("multiply_them") a = numpy.random.randn(400).astype(numpy.float32) b = numpy.random.randn(400).astype(numpy.float32) dest = numpy.zeros_like(a) multiply_them(drv.Out(dest), drv.In(a), drv.In(b), block=(400, 1, 1)) print(dest - a * b)
Additional Python bindings to simplify matrix multiplication operations can be found in the program pycublas.[37]
import numpy from pycublas import CUBLASMatrix A = CUBLASMatrix(numpy.mat([[1, 2, 3], [4, 5, 6]], numpy.float32)) B = CUBLASMatrix(numpy.mat([[2, 3], [4, 5], [6, 7]], numpy.float32)) C = A * B print(C.np_mat())
while CuPy directly replaces NumPy:[38]
import cupy a = cupy.random.randn(400) b = cupy.random.randn(400) dest = cupy.zeros_like(a) print(dest - a * b)
Supported CUDA compute capability versions for CUDA SDK version and microarchitecture (by code name):
Note: CUDA SDK 10.2 is the last official release for macOS, as support will not be available for macOS in newer releases.
CUDA compute capability by version with associated GPU semiconductors and GPU card models (separated by their various application areas):
* – OEM-only products
Version features and specifications
[edit]
| Feature support (unlisted features are supported for all compute capabilities) | Compute capability (version) | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| 1.0, 1.1 | 1.2, 1.3 | 2.x | 3.0 | 3.2 | 3.5, 3.7, 5.x, 6.x, 7.0, 7.2 | 7.5 | 8.x | 9.0, 10.x, 12.x | |
| Warp vote functions (__all(), __any()) | No | Yes | |||||||
| Warp vote functions (__ballot()) | No | Yes | |||||||
| Memory fence functions (__threadfence_system()) | |||||||||
| Synchronization functions (__syncthreads_count(), __syncthreads_and(), __syncthreads_or()) | |||||||||
| Surface functions | |||||||||
| 3D grid of thread blocks | |||||||||
| Warp shuffle functions | No | Yes | |||||||
| Unified memory programming | |||||||||
| Funnel shift | No | Yes | |||||||
| Dynamic parallelism | No | Yes | |||||||
| Uniform Datapath[57] | No | Yes | |||||||
| Hardware-accelerated async-copy | No | Yes | |||||||
| Hardware-accelerated split arrive/wait barrier | |||||||||
| Warp-level support for reduction ops | |||||||||
| L2 cache residency management | |||||||||
| DPX instructions for accelerated dynamic programming | No | Yes | |||||||
| Distributed shared memory | |||||||||
| Thread block cluster | |||||||||
| Tensor memory accelerator (TMA) unit | |||||||||
| Feature support (unlisted features are supported for all compute capabilities) | 1.0, 1.1 | 1.2, 1.3 | 2.x | 3.0 | 3.2 | 3.5, 3.7, 5.x, 6.x, 7.0, 7.2 | 7.5 | 8.x | 9.0, 10.x, 12.x |
| Compute capability (version) |
[58]
Floating-point types
[edit]
| Data type | Supported vector types | Storage Length Bits (complete vector) |
Used Length Bits (single value) |
Sign Bits | Exponent Bits | Mantissa Bits | Comments |
|---|---|---|---|---|---|---|---|
| E2M1 = FP4 | e2m1x2 / e2m1x4 | 8 / 16 | 4 | 1 | 2 | 1 | |
| E2M3 = FP6 variant | e2m3x2 / e2m3x4 | 16 / 32 | 6 | 1 | 2 | 3 | |
| E3M2 = FP6 variant | e3m2x2 / e3m2x4 | 16 / 32 | 6 | 1 | 3 | 2 | |
| UE4M3 | ue4m3 | 8 | 7 | 0 | 4 | 3 | Used for scaling (E2M1 only) |
| E4M3 = FP8 variant | e4m3 / e4m3x2 / e4m3x4 | 8 / 16 / 32 | 8 | 1 | 4 | 3 | |
| E5M2 = FP8 variant | e5m2 / e5m2x2 / e5m2x4 | 8 / 16 / 32 | 8 | 1 | 5 | 2 | Exponent/range of FP16, fits into 8 bits |
| UE8M0 | ue8m0x2 | 16 | 8 | 0 | 8 | 0 | Used for scaling (any FP4 or FP6 or FP8 format) |
| FP16 | f16 / f16x2 | 16 / 32 | 16 | 1 | 5 | 10 | |
| BF16 | bf16 / bf16x2 | 16 / 32 | 16 | 1 | 8 | 7 | Exponent/range of FP32, fits into 16 bits |
| TF32 | tf32 | 32 | 19 | 1 | 8 | 10 | Exponent/range of FP32, mantissa/precision of FP16 |
| FP32 | f32 / f32x2 | 32 / 64 | 32 | 1 | 8 | 23 | |
| FP64 | f64 | 64 | 64 | 1 | 11 | 52 |
| Data type | Basic Operations | Supported since | Atomic Operations | Supported since for global memory |
Supported since for shared memory |
|---|---|---|---|---|---|
| 8-bit integer signed/unsigned |
loading, storing, conversion | 1.0 | — | — | |
| 16-bit integer signed/unsigned |
general operations | 1.0 | atomicCAS() | 3.5 | |
| 32-bit integer signed/unsigned |
general operations | 1.0 | atomic functions | 1.1 | 1.2 |
| 64-bit integer signed/unsigned |
general operations | 1.0 | atomic functions | 1.2 | 2.0 |
| any 128-bit trivially copyable type | general operations | No | atomicExch, atomicCAS | 9.0 | |
| 16-bit floating point FP16 |
addition, subtraction, multiplication, comparison, warp shuffle functions, conversion |
5.3 | half2 atomic addition | 6.0 | |
| atomic addition | 7.0 | ||||
| 16-bit floating point BF16 |
addition, subtraction, multiplication, comparison, warp shuffle functions, conversion |
8.0 | atomic addition | 8.0 | |
| 32-bit floating point | general operations | 1.0 | atomicExch() | 1.1 | 1.2 |
| atomic addition | 2.0 | ||||
| 32-bit floating point float2 and float4 | general operations | No | atomic addition | 9.0 | |
| 64-bit floating point | general operations | 1.3 | atomic addition | 6.0 |
Note: Any missing lines or empty entries do reflect some lack of information on that exact item.[59]
| FMA per cycle per tensor core[60] | Supported since | 7.0 | 7.2 | 7.5 Workstation | 7.5 Desktop | 8.0 | 8.6 Workstation | 8.7 | 8.6 Desktop | 8.9 Desktop | 8.9 Workstation | 9.0 | 10.0 | 10.1 | 12.0 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Data Type | For dense matrices | For sparse matrices | 1st Gen (8x/SM) | 1st Gen? (8x/SM) | 2nd Gen (8x/SM) | 3rd Gen (4x/SM) | 4th Gen (4x/SM) | 5th Gen (4x/SM) | |||||||
| 1-bit values (AND) | 8.0 as experimental |
No | No | 4096 | 2048 | speed tbd | |||||||||
| 1-bit values (XOR) | 7.5–8.9 as experimental |
No | 1024 | Deprecated or removed? | |||||||||||
| 4-bit integers | 8.0–8.9 as experimental |
256 | 1024 | 512 | |||||||||||
| 4-bit floating point FP4 (E2M1) | 10.0 | No | 4096 | tbd | 512 | ||||||||||
| 6-bit floating point FP6 (E3M2 and E2M3) | 10.0 | No | 2048 | tbd | |||||||||||
| 8-bit integers | 7.2 | 8.0 | No | 128 | 128 | 512 | 256 | 1024 | 2048 | 256 | |||||
| 8-bit floating point FP8 (E4M3 and E5M2) with FP16 accumulate | 8.9 | No | 256 | ||||||||||||
| 8-bit floating point FP8 (E4M3 and E5M2) with FP32 accumulate | 128 | 128 | |||||||||||||
| 16-bit floating point FP16 with FP16 accumulate | 7.0 | 8.0 | 64 | 64 | 64 | 256 | 128 | 512 | 1024 | 128 | |||||
| 16-bit floating point FP16 with FP32 accumulate | 32 | 64 | 128 | 64 | |||||||||||
| 16-bit floating point BF16 with FP32 accumulate | 7.5[61] | 8.0 | No | 64[62] | |||||||||||
| 32-bit (19 bits used) floating point TF32 | speed tbd (32?)[62] | 128 | 32 | 64 | 256 | 512 | 32 | ||||||||
| 64-bit floating point | 8.0 | No | No | 16 | speed tbd | 32 | 16 | tbd |
Note: Any missing lines or empty entries do reflect some lack of information on that exact item.[63][64]
[65]
[66]
[67]
[68]
| Tensor Core Composition | 7.0 | 7.2, 7.5 | 8.0, 8.6 | 8.7 | 8.9 | 9.0 |
|---|---|---|---|---|---|---|
| Dot Product Unit Width in FP16 units (in bytes)[69][70][71][72] | 4 (8) | 8 (16) | 4 (8) | 16 (32) | ||
| Dot Product Units per Tensor Core | 16 | 32 | ||||
| Tensor Cores per SM partition | 2 | 1 | ||||
| Full throughput (Bytes/cycle)[73] per SM partition[74] | 256 | 512 | 256 | 1024 | ||
| FP Tensor Cores: Minimum cycles for warp-wide matrix calculation | 8 | 4 | 8 | |||
| FP Tensor Cores: Minimum Matrix Shape for full throughput (Bytes)[75] | 2048 | |||||
| INT Tensor Cores: Minimum cycles for warp-wide matrix calculation | No | 4 | ||||
| INT Tensor Cores: Minimum Matrix Shape for full throughput (Bytes) | No | 1024 | 2048 | 1024 |
[76][77][78][79]
| FP64 Tensor Core Composition | 8.0 | 8.6 | 8.7 | 8.9 | 9.0 |
|---|---|---|---|---|---|
| Dot Product Unit Width in FP64 units (in bytes) | 4 (32) | tbd | 4 (32) | ||
| Dot Product Units per Tensor Core | 4 | tbd | 8 | ||
| Tensor Cores per SM partition | 1 | ||||
| Full throughput (Bytes/cycle)[73] per SM partition[74] | 128 | tbd | 256 | ||
| Minimum cycles for warp-wide matrix calculation | 16 | tbd | |||
| Minimum Matrix Shape for full throughput (Bytes)[75] | 2048 |
Technical specifications
[edit]
| Technical specifications | Compute capability (version) | ||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1.0 | 1.1 | 1.2 | 1.3 | 2.x | 3.0 | 3.2 | 3.5 | 3.7 | 5.0 | 5.2 | 5.3 | 6.0 | 6.1 | 6.2 | 7.0 | 7.2 | 7.5 | 8.0 | 8.6 | 8.7 | 8.9 | 9.0 | 10.x | 12.x | |
| Maximum number of resident grids per device (concurrent kernel execution, can be lower for specific devices) |
1 | 16 | 4 | 32 | 16 | 128 | 32 | 16 | 128 | 16 | 128 | ||||||||||||||
| Maximum dimensionality of grid of thread blocks | 2 | 3 | |||||||||||||||||||||||
| Maximum x-dimension of a grid of thread blocks | 65535 | 231 − 1 | |||||||||||||||||||||||
| Maximum y-, or z-dimension of a grid of thread blocks | 65535 | ||||||||||||||||||||||||
| Maximum dimensionality of thread block | 3 | ||||||||||||||||||||||||
| Maximum x- or y-dimension of a block | 512 | 1024 | |||||||||||||||||||||||
| Maximum z-dimension of a block | 64 | ||||||||||||||||||||||||
| Maximum number of threads per block | 512 | 1024 | |||||||||||||||||||||||
| Warp size | 32 | ||||||||||||||||||||||||
| Maximum number of resident blocks per multiprocessor | 8 | 16 | 32 | 16 | 32 | 16 | 24 | 32 | |||||||||||||||||
| Maximum number of resident warps per multiprocessor | 24 | 32 | 48 | 64 | 32 | 64 | 48 | 64 | 48 | ||||||||||||||||
| Maximum number of resident threads per multiprocessor | 768 | 1024 | 1536 | 2048 | 1024 | 2048 | 1536 | 2048 | 1536 | ||||||||||||||||
| Number of 32-bit regular registers per multiprocessor | 8 K | 16 K | 32 K | 64 K | 128 K | 64 K | |||||||||||||||||||
| Number of 32-bit uniform registers per multiprocessor | No | 2 K[80]
[81] |
|||||||||||||||||||||||
| Maximum number of 32-bit registers per thread block | 8 K | 16 K | 32 K | 64 K | 32 K | 64 K | 32 K | 64 K | 32 K | 64 K | |||||||||||||||
| Maximum number of 32-bit regular registers per thread | 124 | 63 | 255 | ||||||||||||||||||||||
| Maximum number of 32-bit uniform registers per warp | No | 63[80]
[82] |
|||||||||||||||||||||||
| Amount of shared memory per multiprocessor (out of overall shared memory + L1 cache, where applicable) |
16 KiB | 16 / 48 KiB (of 64 KiB) | 16 / 32 / 48 KiB (of 64 KiB) | 80 / 96 / 112 KiB (of 128 KiB) | 64 KiB | 96 KiB | 64 KiB | 96 KiB | 64 KiB | 0 / 8 / 16 / 32 / 64 / 96 KiB (of 128 KiB) | 32 / 64 KiB (of 96 KiB) | 0 / 8 / 16 / 32 / 64 / 100 / 132 / 164 KiB (of 192 KiB) | 0 / 8 / 16 / 32 / 64 / 100 KiB (of 128 KiB) | 0 / 8 / 16 / 32 / 64 / 100 / 132 / 164 KiB (of 192 KiB) | 0 / 8 / 16 / 32 / 64 / 100 KiB (of 128 KiB) | 0 / 8 / 16 / 32 / 64 / 100 / 132 / 164 / 196 / 228 KiB (of 256 KiB) | 0 / 8 / 16 / 32 / 64 / 100 KiB (of 128 KiB) | ||||||||
| Maximum amount of shared memory per thread block | 16 KiB | 48 KiB | 96 KiB | 48 KiB | 64 KiB | 163 KiB | 99 KiB | 163 KiB | 99 KiB | 227 KiB | 99 KiB | ||||||||||||||
| Number of shared memory banks | 16 | 32 | |||||||||||||||||||||||
| Amount of local memory per thread | 16 KiB | 512 KiB | |||||||||||||||||||||||
| Constant memory size accessible by CUDA C/C++ (1 bank, PTX can access 11 banks, SASS can access 18 banks) |
64 KiB | ||||||||||||||||||||||||
| Cache working set per multiprocessor for constant memory | 8 KiB | 4 KiB | 8 KiB | ||||||||||||||||||||||
| Cache working set per multiprocessor for texture memory | 16 KiB per TPC | 24 KiB per TPC | 12 KiB | 12 – 48 KiB[83] | 24 KiB | 48 KiB | 32 KiB[84] | 24 KiB | 48 KiB | 24 KiB | 32 – 128 KiB | 32 – 64 KiB | 28 – 192 KiB | 28 – 128 KiB | 28 – 192 KiB | 28 – 128 KiB | 28 – 256 KiB | ||||||||
| Maximum width for 1D texture reference bound to a CUDA array |
8192 | 65536 | 131072 | ||||||||||||||||||||||
| Maximum width for 1D texture reference bound to linear memory |
227 | 228 | 227 | 228 | 227 | 228 | |||||||||||||||||||
| Maximum width and number of layers for a 1D layered texture reference |
8192 × 512 | 16384 × 2048 | 32768 x 2048 | ||||||||||||||||||||||
| Maximum width and height for 2D texture reference bound to a CUDA array |
65536 × 32768 | 65536 × 65535 | 131072 x 65536 | ||||||||||||||||||||||
| Maximum width and height for 2D texture reference bound to a linear memory |
65000 x 65000 | 65536 x 65536 | 131072 x 65000 | ||||||||||||||||||||||
| Maximum width and height for 2D texture reference bound to a CUDA array supporting texture gather |
— | 16384 x 16384 | 32768 x 32768 | ||||||||||||||||||||||
| Maximum width, height, and number of layers for a 2D layered texture reference |
8192 × 8192 × 512 | 16384 × 16384 × 2048 | 32768 x 32768 x 2048 | ||||||||||||||||||||||
| Maximum width, height and depth for a 3D texture reference bound to linear memory or a CUDA array |
20483 | 40963 | 163843 | ||||||||||||||||||||||
| Maximum width (and height) for a cubemap texture reference | — | 16384 | 32768 | ||||||||||||||||||||||
| Maximum width (and height) and number of layers for a cubemap layered texture reference |
— | 16384 × 2046 | 32768 × 2046 | ||||||||||||||||||||||
| Maximum number of textures that can be bound to a kernel |
128 | 256 | |||||||||||||||||||||||
| Maximum width for a 1D surface reference bound to a CUDA array |
Not supported |
65536 | 16384 | 32768 | |||||||||||||||||||||
| Maximum width and number of layers for a 1D layered surface reference |
65536 × 2048 | 16384 × 2048 | 32768 × 2048 | ||||||||||||||||||||||
| Maximum width and height for a 2D surface reference bound to a CUDA array |
65536 × 32768 | 16384 × 65536 | 131072 × 65536 | ||||||||||||||||||||||
| Maximum width, height, and number of layers for a 2D layered surface reference |
65536 × 32768 × 2048 | 16384 × 16384 × 2048 | 32768 × 32768 × 2048 | ||||||||||||||||||||||
| Maximum width, height, and depth for a 3D surface reference bound to a CUDA array |
65536 × 32768 × 2048 | 4096 × 4096 × 4096 | 16384 × 16384 × 16384 | ||||||||||||||||||||||
| Maximum width (and height) for a cubemap surface reference bound to a CUDA array | 32768 | 16384 | 32768 | ||||||||||||||||||||||
| Maximum width and number of layers for a cubemap layered surface reference |
32768 × 2046 | 16384 × 2046 | 32768 × 2046 | ||||||||||||||||||||||
| Maximum number of surfaces that can be bound to a kernel |
8 | 16 | 32 | ||||||||||||||||||||||
| Maximum number of instructions per kernel | 2 million | 512 million | |||||||||||||||||||||||
| Maximum number of Thread Blocks per Thread Block Cluster[85] | No | 16 | 8 | ||||||||||||||||||||||
| Technical specifications | 1.0 | 1.1 | 1.2 | 1.3 | 2.x | 3.0 | 3.2 | 3.5 | 3.7 | 5.0 | 5.2 | 5.3 | 6.0 | 6.1 | 6.2 | 7.0 | 7.2 | 7.5 | 8.0 | 8.6 | 8.7 | 8.9 | 9.0 | 10.x | 12.x |
| Compute capability (version) |
[86][87]
Multiprocessor architecture
[edit]
| Architecture specifications | Compute capability (version) | |||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1.0 | 1.1 | 1.2 | 1.3 | 2.0 | 2.1 | 3.0 | 3.2 | 3.5 | 3.7 | 5.0 | 5.2 | 5.3 | 6.0 | 6.1 | 6.2 | 7.0 | 7.2 | 7.5 | 8.0 | 8.6 | 8.7 | 8.9 | 9.0 | 10.x | 12.x | |
| Number of ALU lanes for INT32 arithmetic operations | 8 | 32 | 48 | 192[88] | 128 | 128 | 64 | 128 | 128 | 64 | 64 | 64 | 128 | |||||||||||||
| Number of ALU lanes for any INT32 or FP32 arithmetic operation | — | — | ||||||||||||||||||||||||
| Number of ALU lanes for FP32 arithmetic operations | 64 | 64 | 128 | 128 | ||||||||||||||||||||||
| Number of ALU lanes for FP16x2 arithmetic operations | No | 1 | 128[89] | 128[90] | 64[91] | |||||||||||||||||||||
| Number of ALU lanes for FP64 arithmetic operations | No | 1 | 16 by FP32[92] | 4 by FP32[93] | 8 | 8 / 64[94] | 64 | 4[95] | 32 | 4 | 32 | 2 | 32 | 2 | 64 | 2 | ||||||||||
| Number of Load/Store Units | 4 per 2 SM | 8 per 2 SM | 8 per 2 SM / 3 SM[94] | 8 per 3 SM | 16 | 32 | 16 | 32 | 16 | 32 | ||||||||||||||||
| Number of special function units for single-precision floating-point transcendental functions | 2[96] | 4 | 8 | 32 | 16 | 32 | 16 | |||||||||||||||||||
| Number of texture mapping units (TMU) | 4 per 2 SM | 8 per 2 SM | 8 per 2 / 3SM[94] | 8 per 3 SM | 4 | 4 / 8[94] | 16 | 8 | 16 | 8 | 4 | |||||||||||||||
| Number of ALU lanes for uniform INT32 arithmetic operations | No | 2[97] | ||||||||||||||||||||||||
| Number of tensor cores | No | 8 (1st gen.)[98] | 0 / 8[94] (2nd gen.) | 4 (3rd gen.) | 4 (4th gen.) | |||||||||||||||||||||
| Number of raytracing cores | No | 0 / 1[94] (1st gen.) | No | 1 (2nd gen.) | No | 1 (3rd gen.) | No | |||||||||||||||||||
| Number of SM Partitions = Processing Blocks[99] | 1 | 4 | 2 | 4 | ||||||||||||||||||||||
| Number of warp schedulers per SM partition | 1 | 2 | 4 | 1 | ||||||||||||||||||||||
| Max number of new instructions issued each cycle by a single scheduler[100] | 2[101] | 1 | 2[102] | 2 | 1 | |||||||||||||||||||||
| Size of unified memory for data cache and shared memory | 16 KiB[103] | 16 KiB[103] | 64 KiB | 128 KiB | 64 KiB SM + 24 KiB L1 (separate)[104] | 96 KiB SM + 24 KiB L1 (separate)[104] | 64 KiB SM + 24 KiB L1 (separate)[104] | 64 KiB SM + 24 KiB L1 (separate)[104] | 96 KiB SM + 24 KiB L1 (separate)[104] | 64 KiB SM + 24 KiB L1 (separate)[104] | 128 KiB | 96 KiB[105] | 192 KiB | 128 KiB | 192 KiB | 128 KiB | 256 KiB | |||||||||
| Size of L3 instruction cache per GPU | 32 KiB[106] | use L2 Data Cache | ||||||||||||||||||||||||
| Size of L2 instruction cache per Texture Processor Cluster (TPC) | 8 KiB | |||||||||||||||||||||||||
| Size of L1.5 instruction cache per SM[107] | 4 KiB | 32 KiB | 32 KiB | 48 KiB[84] | 128 KiB | 32 KiB | 128 KiB | ~46 KiB[108] | 128 KiB[109] | |||||||||||||||||
| Size of L1 instruction cache per SM | 8 KiB | 8 KiB | ||||||||||||||||||||||||
| Size of L0 instruction cache per SM partition | only 1 partition per SM | No | 12 KiB | 16 KiB?[110] | 32 KiB | |||||||||||||||||||||
| Instruction Width[107] | 32 bits instructions and 64 bits instructions[111] | 64 bits instructions + 64 bits control logic every 7 instructions | 64 bits instructions + 64 bits control logic every 3 instructions | 128 bits combined instruction and control logic | ||||||||||||||||||||||
| Memory Bus Width per Memory Partition in bits | 64 ((G)DDR) | 32 ((G)DDR) | 512 (HBM) | 32 ((G)DDR) | 512 (HBM) | 32 ((G)DDR) | 512 (HBM) | 32 ((G)DDR) | 512 (HBM) | 32 ((G)DDR) | ||||||||||||||||
| L2 Cache per Memory Partition | 16 KiB[112] | 32 KiB[112] | 128 KiB | 256 KiB | 1 MiB | 512 KiB | 128 KiB | 512 KiB | 256 KiB | 128 KiB | 768 KiB | 64 KiB | 512 KiB | 4 MiB | 512 KiB | 8 MiB[113] | 5 MiB | 6.25 MiB | 8 MiB[114] | |||||||
| Number of Render Output Units (ROP) per memory partition (or per GPC in later models) | 4 | 8 | 4 | 8 | 16 | 8 | 12 | 8 | 4 | 16 | 2 | 8 | 16 | 16 per GPC | 3 per GPC | 16 per GPC | ||||||||||
| Architecture specifications | 1.0 | 1.1 | 1.2 | 1.3 | 2.0 | 2.1 | 3.0 | 3.2 | 3.5 | 3.7 | 5.0 | 5.2 | 5.3 | 6.0 | 6.1 | 6.2 | 7.0 | 7.2 | 7.5 | 8.0 | 8.6 | 8.7 | 8.9 | 9.0 | 10.x | 12.x |
| Compute capability (version) |
For more information read the Nvidia CUDA C++ Programming Guide.[115]
Usages of CUDA architecture
[edit]
- Accelerated rendering of 3D graphics
- Accelerated interconversion of video file formats
- Accelerated encryption, decryption and compression
- Bioinformatics, e.g. NGS DNA sequencing BarraCUDA[116]
- Distributed calculations, such as predicting the native conformation of proteins
- Medical analysis simulations, for example virtual reality based on CT and MRI scan images
- Physical simulations,[117] in particular in fluid dynamics
- Neural network training in machine learning problems
- Large Language Model inference
- Face recognition
- Volunteer computing projects, such as SETI@home and other projects using BOINC software
- Molecular dynamics
- Mining cryptocurrencies
- Structure from motion (SfM) software
Comparison with competitors
[edit]
CUDA competes with other GPU computing stacks: Intel OneAPI and AMD ROCm.
Whereas Nvidia’s CUDA is closed-source, Intel’s OneAPI and AMD’s ROCm are open source.
oneAPI is an initiative based in open standards, created to support software development for multiple hardware architectures.[118] The oneAPI libraries must implement open specifications that are discussed publicly by the Special Interest Groups, offering the possibility for any developer or organization to implement their own versions of oneAPI libraries.[119][120]
Originally made by Intel, other hardware adopters include Fujitsu and Huawei.
Unified Acceleration Foundation (UXL)
[edit]
Unified Acceleration Foundation (UXL) is a new technology consortium working on the continuation of the OneAPI initiative, with the goal to create a new open standard accelerator software ecosystem, related open standards and specification projects through Working Groups and Special Interest Groups (SIGs). The goal is to offer open alternatives to Nvidia’s CUDA. The main companies behind it are Intel, Google, ARM, Qualcomm, Samsung, Imagination, and VMware.[121]
Main article: ROCm
ROCm[122] is an open source software stack for graphics processing unit (GPU) programming from Advanced Micro Devices (AMD).
- SYCL – an open standard from Khronos Group for programming a variety of platforms, including GPUs, with single-source modern C++, similar to higher-level CUDA Runtime API (single-source)
- BrookGPU – the Stanford University graphics group’s compiler
- Array programming
- Parallel computing
- Stream processing
- rCUDA – an API for computing on remote computers
- Molecular modeling on GPUs
- Vulkan – low-level, high-performance 3D graphics and computing API
- OptiX – ray tracing API by NVIDIA
- CUDA binary (cubin) – a type of fat binary
- Numerical Library Collection – by NEC for their vector processor
- ^ «NVIDIA® CUDA™ Unleashes Power of GPU Computing — Press Release». nvidia.com. Archived from the original on 29 March 2007. Retrieved 26 January 2025.
- ^ a b Shah, Agam. «Nvidia not totally against third parties making CUDA chips». www.theregister.com. Retrieved 2024-04-25.
- ^ «Nvidia CUDA Home Page». 18 July 2017.
- ^ Shimpi, Anand Lal; Wilson, Derek (November 8, 2006). «Nvidia’s GeForce 8800 (G80): GPUs Re-architected for DirectX 10». AnandTech. Retrieved May 16, 2015.
- ^ «Introduction — nsight-visual-studio-edition 12.6 documentation». docs.nvidia.com. Retrieved 2024-10-10.
- ^ a b Abi-Chahla, Fedy (June 18, 2008). «Nvidia’s CUDA: The End of the CPU?». Tom’s Hardware. Retrieved May 17, 2015.
- ^ Zunitch, Peter (2018-01-24). «CUDA vs. OpenCL vs. OpenGL». Videomaker. Retrieved 2018-09-16.
- ^ «OpenCL». NVIDIA Developer. 2013-04-24. Retrieved 2019-11-04.
- ^ Witt, Stephen (2023-11-27). «How Jensen Huang’s Nvidia Is Powering the A.I. Revolution». The New Yorker. ISSN 0028-792X. Retrieved 2023-12-10.
- ^ «CUDA LLVM Compiler». 7 May 2012.
- ^ First OpenCL demo on a GPU on YouTube
- ^ DirectCompute Ocean Demo Running on Nvidia CUDA-enabled GPU on YouTube
- ^ Vasiliadis, Giorgos; Antonatos, Spiros; Polychronakis, Michalis; Markatos, Evangelos P.; Ioannidis, Sotiris (September 2008). «Gnort: High Performance Network Intrusion Detection Using Graphics Processors» (PDF). Recent Advances in Intrusion Detection. Lecture Notes in Computer Science. Vol. 5230. pp. 116–134. doi:10.1007/978-3-540-87403-4_7. ISBN 978-3-540-87402-7.
- ^ Schatz, Michael C.; Trapnell, Cole; Delcher, Arthur L.; Varshney, Amitabh (2007). «High-throughput sequence alignment using Graphics Processing Units». BMC Bioinformatics. 8: 474. doi:10.1186/1471-2105-8-474. PMC 2222658. PMID 18070356.
- ^ Manavski, Svetlin A.; Giorgio, Valle (2008). «CUDA compatible GPU cards as efficient hardware accelerators for Smith-Waterman sequence alignment». BMC Bioinformatics. 10 (Suppl 2): S10. doi:10.1186/1471-2105-9-S2-S10. PMC 2323659. PMID 18387198.
- ^ «Pyrit – Google Code».
- ^ «Use your Nvidia GPU for scientific computing». BOINC. 2008-12-18. Archived from the original on 2008-12-28. Retrieved 2017-08-08.
- ^ «Nvidia CUDA Software Development Kit (CUDA SDK) – Release Notes Version 2.0 for MAC OS X». Archived from the original on 2009-01-06.
- ^ «CUDA 1.1 – Now on Mac OS X». February 14, 2008. Archived from the original on November 22, 2008.
- ^ «CUDA 11 Features Revealed». 14 May 2020.
- ^ «CUDA Toolkit 11.1 Introduces Support for GeForce RTX 30 Series and Quadro RTX Series GPUs». 23 September 2020.
- ^ «Enhancing Memory Allocation with New NVIDIA CUDA 11.2 Features». 16 December 2020.
- ^ «Exploring the New Features of CUDA 11.3». 16 April 2021.
- ^ Silberstein, Mark; Schuster, Assaf; Geiger, Dan; Patney, Anjul; Owens, John D. (2008). «Efficient computation of sum-products on GPUs through software-managed cache» (PDF). Proceedings of the 22nd annual international conference on Supercomputing – ICS ’08 (PDF). Proceedings of the 22nd annual international conference on Supercomputing – ICS ’08. pp. 309–318. doi:10.1145/1375527.1375572. ISBN 978-1-60558-158-3.
- ^ «CUDA C Programming Guide v8.0» (PDF). nVidia Developer Zone. January 2017. p. 19. Retrieved 22 March 2017.
- ^ «NVCC forces c++ compilation of .cu files». 29 November 2011.
- ^ Whitehead, Nathan; Fit-Florea, Alex. «Precision & Performance: Floating Point and IEEE 754 Compliance for Nvidia GPUs» (PDF). Nvidia. Retrieved November 18, 2014.
- ^ «CUDA-Enabled Products». CUDA Zone. Nvidia Corporation. Retrieved 2008-11-03.
- ^ «Coriander Project: Compile CUDA Codes To OpenCL, Run Everywhere». Phoronix.
- ^ Perkins, Hugh (2017). «cuda-on-cl» (PDF). IWOCL. Retrieved August 8, 2017.
- ^ «hughperkins/coriander: Build NVIDIA® CUDA™ code for OpenCL™ 1.2 devices». GitHub. May 6, 2019.
- ^ «CU2CL Documentation». chrec.cs.vt.edu.
- ^ «GitHub – vosen/ZLUDA». GitHub.
- ^ Larabel, Michael (2024-02-12), «AMD Quietly Funded A Drop-In CUDA Implementation Built On ROCm: It’s Now Open-Source», Phoronix, retrieved 2024-02-12
- ^ «GitHub – chip-spv/chipStar». GitHub.
- ^ «PyCUDA».
- ^ «pycublas». Archived from the original on 2009-04-20. Retrieved 2017-08-08.
- ^ «CuPy». Retrieved 2020-01-08.
- ^ «NVIDIA CUDA Programming Guide. Version 1.0» (PDF). June 23, 2007.
- ^ «NVIDIA CUDA Programming Guide. Version 2.1» (PDF). December 8, 2008.
- ^ «NVIDIA CUDA Programming Guide. Version 2.2» (PDF). April 2, 2009.
- ^ «NVIDIA CUDA Programming Guide. Version 2.2.1» (PDF). May 26, 2009.
- ^ «NVIDIA CUDA Programming Guide. Version 2.3.1» (PDF). August 26, 2009.
- ^ «NVIDIA CUDA Programming Guide. Version 3.0» (PDF). February 20, 2010.
- ^ «NVIDIA CUDA C Programming Guide. Version 3.1.1» (PDF). July 21, 2010.
- ^ «NVIDIA CUDA C Programming Guide. Version 3.2» (PDF). November 9, 2010.
- ^ «CUDA 11.0 Release Notes». NVIDIA Developer.
- ^ «CUDA 11.1 Release Notes». NVIDIA Developer.
- ^ «CUDA 11.5 Release Notes». NVIDIA Developer.
- ^ «CUDA 11.8 Release Notes». NVIDIA Developer.
- ^ «NVIDIA Quadro NVS 420 Specs». TechPowerUp GPU Database. 25 August 2023.
- ^ Larabel, Michael (March 29, 2017). «NVIDIA Rolls Out Tegra X2 GPU Support In Nouveau». Phoronix. Retrieved August 8, 2017.
- ^ Nvidia Xavier Specs on TechPowerUp (preliminary)
- ^ «Welcome — Jetson LinuxDeveloper Guide 34.1 documentation».
- ^ «NVIDIA Bringing up Open-Source Volta GPU Support for Their Xavier SoC».
- ^ «NVIDIA Ada Lovelace Architecture».
- ^ Dissecting the Turing GPU Architecture through Microbenchmarking
- ^ «H.1. Features and Technical Specifications – Table 13. Feature Support per Compute Capability». docs.nvidia.com. Retrieved 2020-09-23.
- ^ «CUDA C++ Programming Guide».
- ^ Fused-Multiply-Add, actually executed, Dense Matrix
- ^ as SASS since 7.5, as PTX since 8.0
- ^ a b unofficial support in SASS
- ^ «Technical brief. NVIDIA Jetson AGX Orin Series» (PDF). nvidia.com. Retrieved 5 September 2023.
- ^ «NVIDIA Ampere GA102 GPU Architecture» (PDF). nvidia.com. Retrieved 5 September 2023.
- ^ Luo, Weile; Fan, Ruibo; Li, Zeyu; Du, Dayou; Wang, Qiang; Chu, Xiaowen (2024). «Benchmarking and Dissecting the Nvidia Hopper GPU Architecture». arXiv:2402.13499v1 [cs.AR].
- ^ «Datasheet NVIDIA A40» (PDF). nvidia.com. Retrieved 27 April 2024.
- ^ «NVIDIA AMPERE GA102 GPU ARCHITECTURE» (PDF). 27 April 2024.
- ^ «Datasheet NVIDIA L40» (PDF). 27 April 2024.
- ^ In the Whitepapers the Tensor Core cube diagrams represent the Dot Product Unit Width into the height (4 FP16 for Volta and Turing, 8 FP16 for A100, 4 FP16 for GA102, 16 FP16 for GH100). The other two dimensions represent the number of Dot Product Units (4×4 = 16 for Volta and Turing, 8×4 = 32 for Ampere and Hopper). The resulting gray blocks are the FP16 FMA operations per cycle. Pascal without Tensor core is only shown for speed comparison as is Volta V100 with non-FP16 datatypes.
- ^ «NVIDIA Turing Architecture Whitepaper» (PDF). nvidia.com. Retrieved 5 September 2023.
- ^ «NVIDIA Tensor Core GPU» (PDF). nvidia.com. Retrieved 5 September 2023.
- ^ «NVIDIA Hopper Architecture In-Depth». 22 March 2022.
- ^ a b shape x converted operand size, e.g. 2 tensor cores x 4x4x4xFP16/cycle = 256 Bytes/cycle
- ^ a b = product first 3 table rows
- ^ a b = product of previous 2 table rows; shape: e.g. 8x8x4xFP16 = 512 Bytes
- ^ Sun, Wei; Li, Ang; Geng, Tong; Stuijk, Sander; Corporaal, Henk (2023). «Dissecting Tensor Cores via Microbenchmarks: Latency, Throughput and Numeric Behaviors». IEEE Transactions on Parallel and Distributed Systems. 34 (1): 246–261. arXiv:2206.02874. doi:10.1109/tpds.2022.3217824. S2CID 249431357.
- ^ «Parallel Thread Execution ISA Version 7.7».
- ^ Raihan, Md Aamir; Goli, Negar; Aamodt, Tor (2018). «Modeling Deep Learning Accelerator Enabled GPUs». arXiv:1811.08309 [cs.MS].
- ^ «NVIDIA Ada Lovelace Architecture».
- ^ a b Jia, Zhe; Maggioni, Marco; Smith, Jeffrey; Daniele Paolo Scarpazza (2019). «Dissecting the NVidia Turing T4 GPU via Microbenchmarking». arXiv:1903.07486 [cs.DC].
- ^ Burgess, John (2019). «RTX ON – The NVIDIA TURING GPU». 2019 IEEE Hot Chips 31 Symposium (HCS). pp. 1–27. doi:10.1109/HOTCHIPS.2019.8875651. ISBN 978-1-7281-2089-8. S2CID 204822166.
- ^ Burgess, John (2019). «RTX ON – The NVIDIA TURING GPU». 2019 IEEE Hot Chips 31 Symposium (HCS). pp. 1–27. doi:10.1109/HOTCHIPS.2019.8875651. ISBN 978-1-7281-2089-8. S2CID 204822166.
- ^ dependent on device
- ^ a b «Tegra X1». 9 January 2015.
- ^ NVIDIA H100 Tensor Core GPU Architecture
- ^ H.1. Features and Technical Specifications – Table 14. Technical Specifications per Compute Capability
- ^ NVIDIA Hopper Architecture In-Depth
- ^ can only execute 160 integer instructions according to programming guide
- ^ 128 according to [1]. 64 from FP32 + 64 separate units?
- ^ 64 by FP32 cores and 64 by flexible FP32/INT cores.
- ^ «CUDA C++ Programming Guide».
- ^ 32 FP32 lanes combine to 16 FP64 lanes. Maybe lower depending on model.
- ^ only supported by 16 FP32 lanes, they combine to 4 FP64 lanes
- ^ a b c d e f depending on model
- ^ Effective speed, probably over FP32 ports. No description of actual FP64 cores.
- ^ Can also be used for integer additions and comparisons
- ^ 2 clock cycles/instruction for each SM partition Burgess, John (2019). «RTX ON – The NVIDIA TURING GPU». 2019 IEEE Hot Chips 31 Symposium (HCS). pp. 1–27. doi:10.1109/HOTCHIPS.2019.8875651. ISBN 978-1-7281-2089-8. S2CID 204822166.
- ^ Durant, Luke; Giroux, Olivier; Harris, Mark; Stam, Nick (May 10, 2017). «Inside Volta: The World’s Most Advanced Data Center GPU». Nvidia developer blog.
- ^ The schedulers and dispatchers have dedicated execution units unlike with Fermi and Kepler.
- ^ Dispatching can overlap concurrently, if it takes more than one cycle (when there are less execution units than 32/SM Partition)
- ^ Can dual issue MAD pipe and SFU pipe
- ^ No more than one scheduler can issue 2 instructions at once. The first scheduler is in charge of warps with odd IDs. The second scheduler is in charge of warps with even IDs.
- ^ a b shared memory only, no data cache
- ^ a b c d e f shared memory separate, but L1 includes texture cache
- ^ «H.6.1. Architecture». docs.nvidia.com. Retrieved 2019-05-13.
- ^ «Demystifying GPU Microarchitecture through Microbenchmarking» (PDF).
- ^ a b Jia, Zhe; Maggioni, Marco; Staiger, Benjamin; Scarpazza, Daniele P. (2018). «Dissecting the NVIDIA Volta GPU Architecture via Microbenchmarking». arXiv:1804.06826 [cs.DC].
- ^ Jia, Zhe; Maggioni, Marco; Smith, Jeffrey; Daniele Paolo Scarpazza (2019). «Dissecting the NVidia Turing T4 GPU via Microbenchmarking». arXiv:1903.07486 [cs.DC].
- ^ «Dissecting the Ampere GPU Architecture through Microbenchmarking».
- ^ Note that Jia, Zhe; Maggioni, Marco; Smith, Jeffrey; Daniele Paolo Scarpazza (2019). «Dissecting the NVidia Turing T4 GPU via Microbenchmarking». arXiv:1903.07486 [cs.DC]. disagrees and states 2 KiB L0 instruction cache per SM partition and 16 KiB L1 instruction cache per SM
- ^ «asfermi Opcode». GitHub.
- ^ a b for access with texture engine only
- ^ 25% disabled on RTX 4060, RTX 4070, RTX 4070 Ti and RTX 4090
- ^ 25% disabled on RTX 5070 Ti and RTX 5090
- ^ «CUDA C++ Programming Guide, Compute Capabilities». docs.nvidia.com. Retrieved 2025-02-06.
- ^ «nVidia CUDA Bioinformatics: BarraCUDA». BioCentric. 2019-07-19. Retrieved 2019-10-15.
- ^ «Part V: Physics Simulation». NVIDIA Developer. Retrieved 2020-09-11.
- ^ «oneAPI Programming Model». oneAPI.io. Retrieved 2024-07-27.
- ^ «Specifications | oneAPI». oneAPI.io. Retrieved 2024-07-27.
- ^ «oneAPI Specification — oneAPI Specification 1.3-rev-1 documentation». oneapi-spec.uxlfoundation.org. Retrieved 2024-07-27.
- ^ «Exclusive: Behind the plot to break Nvidia’s grip on AI by targeting software». Reuters. Retrieved 2024-04-05.
- ^ «Question: What does ROCm stand for? · Issue #1628 · RadeonOpenCompute/ROCm». Github.com. Retrieved January 18, 2022.
- Buck, Ian; Foley, Tim; Horn, Daniel; Sugerman, Jeremy; Fatahalian, Kayvon; Houston, Mike; Hanrahan, Pat (2004-08-01). «Brook for GPUs: stream computing on graphics hardware». ACM Transactions on Graphics. 23 (3): 777–786. doi:10.1145/1015706.1015800. ISSN 0730-0301.
- Nickolls, John; Buck, Ian; Garland, Michael; Skadron, Kevin (2008-03-01). «Scalable Parallel Programming with CUDA: Is CUDA the parallel programming model that application developers have been waiting for?». Queue. 6 (2): 40–53. doi:10.1145/1365490.1365500. ISSN 1542-7730.
- Official website
What is CUDA?
The need for enhanced computation power is increasing day by day. Manufacturers across the globe are now facing challenges to further improve CPUs due to limitations i.e. size, temperature, etc. In such a situation, solution providers have started to look for performance enhancement elsewhere. One of the solutions that allow a drastic increase in performance is the use of GPUs for parallel computing. The number of cores in a GPU is far more than that of a CPU. A CPU is designed to perform tasks sequentially, a set of tasks can be offloaded on the GPU which allows parallelization.
Compute Unified Architecture (CUDA) is a platform for general-purpose processing on Nvidia’s GPUs. Tasks that don’t require sequential execution can be run in parallel with other tasks on GPU using CUDA. With language support of C, C++, and Fortran, it is extremely easy to offload computation-intensive tasks to Nvidia’s GPU using CUDA. CUDA is being used in domains that require a lot of computation power Or in scenarios where parallelization is possible and high performance is required and allow parallelization. Domains such as machine learning, research, and analysis of medical sciences, physics, supercomputing, crypto mining, scientific modeling, and simulations, etc. are using CUDA.
History of CUDA
The use of GPU for parallel computing started almost two decades ago. A group of researchers at Stanford unveiled Brook; a platform for general-purpose programming models. The research was funded by Nvidia and the lead researcher Ian Buck later joined Nvidia to develop a commercial product for GPU-based parallel computing called CUDA. A total of 32 releases have been made so far by Nvidia with the current version titled CUDA toolkit 11.1 Update 1. Initially, the supported language for CUDA was C however, CUDA now supports C++ as well.
How does it work?
Within the supported CUDA compiler, any piece of code can be run on GPU by using the __global__ keyword. Programmers must change their malloc/new and free/delete calls as per the CUDA guidelines so that appropriate space could be allocated on GPU. Once the computation on GPU is finished, the results are synchronized and ported to the CPU.
Try it nowGet Free License
How to download CUDA?
The latest version of CUDA can be downloaded from https://developer.nvidia.com/CUDA-downloads. Different versions of CUDA for different operating systems i.e. Windows and Linux are available. In case you are looking to download an older version of CUDA, check out this URL: https://developer.nvidia.com/cuda-toolkit-archive.
CUDA for Windows
To install CUDA for Windows, you must have a CUDA-supported GPU, a supported version of Windows, and Visual Studio installed. Before you download CUDA, verify that your system has a GPU supported by CUDA. Once verified, download the desired version of CUDA and install it on your system. A detailed installation guide is present here: https://docs.nvidia.com/cuda/cuda-installation-guide-microsoft-windows/index.html
CUDA for Linux
Before you download CUDA for Linux, you must have a CUDA-supported GPU, a supported version of Linux with a GCC compiler and toolchain. CUDA’s installer for various distributions of Linux is present at https://developer.nvidia.com/CUDA-downloads. You can also install CUDA using the package manager of your Linux distribution. A detailed installation guide for numerous Linux distributions is present at https://docs.nvidia.com/cuda/cuda-installation-guide-linux/index.html.
CUDA Advantages
- It’s free
- The installation process is very easy
- Requires no new knowledge and can be easily used with existing C, C++, and Fortran Code
- Third-party wrappers for other programming languages i.e. Java, Python, etc. are also available.
- Widespread and vibrant community
- A wide range of libraries is available for various parallel computing tasks
- Much faster than competitors i.e. OpenCL
CUDA and Incredibuild
Incredibuild turbocharges compilations, as well as CUDA compilations and the NVIdia NSight development environment, tests, and tons of other compute-intensive workloads by seamlessly and concurrently distributing processes across idle CPUs across remote hosts in your local network or the cloud, seamlessly transforming each host into a supercomputer with hundreds of cores – radically shortening compilation times and other huge scope of applications.
Nvidia Nsight Systems and CUDA
Nvidia Nsight Systems collects data from CPU, GPU, driver, and Kernal and presents it against a consistent timeline. This information allows developers to understand the behavior of a program over time. Nsight System has a couple of modules: Nsight Compute and Nsight Graphics, and numerous APIs. With Nsight Compute, programs are first executed so that parts of programs that don’t perform well could be identified. Programmers can then change the execution process of these identified processes to improve performance. Nsight Graphics is a standalone developer tool that enables debugging, profiling, and exporting frames, built with supported graphic SDKs.
CUDA Alternatives
The biggest alternative to CUDA is OpenCL. OpenCL was created by Apple (OpenCL along with OpenGL is deprecated for Apple hardware, in favor of Metal 2) and Khronos Group and launched in 2009. The biggest difference between OpenCL and CUDA is the supported hardware. CUDA is specifically designed for Nvidia’s GPUs however, OpenCL works on Nvidia and AMD’s GPUs. OpenCL’s code can be run on both GPU and CPU whilst CUDA’s code is only executed on GPU. CUDA is much faster on Nvidia GPUs and is the priority of machine learning researchers. Read more for an in-depth comparison of CUDA vs OpenCL.
In this blog, we will learn about the essential role of CUDA, NVIDIA’s parallel computing platform, for data scientists and software engineers engaged in projects demanding accelerated applications through offloading intensive computations to NVIDIA GPUs. After installing CUDA on your computer, the question of its installation location may arise. To address this query, our article will delve into the diverse locations where CUDA may be installed on your system.

Where did CUDA get installed in my computer?
As a data scientist or software engineer, you may be working on projects that require the use of CUDA, the parallel computing platform and programming model developed by NVIDIA. CUDA enables developers to accelerate their applications by offloading the intensive computations to NVIDIA GPUs. However, once you install CUDA on your computer, you may be left wondering where it got installed. In this article, we will explore the various locations where CUDA may be installed on your computer.
Table of Contents
- What is CUDA?
- Where is CUDA installed on my computer?
- How to verify the CUDA installation
- Common Errors
- Conclusion
What is CUDA?
Before we dive into the locations where CUDA may be installed, let’s briefly review what CUDA is and how it works. CUDA is a parallel computing platform and programming model developed by NVIDIA. It enables developers to harness the power of NVIDIA GPUs to accelerate their applications. CUDA provides a set of programming tools and libraries that allow developers to write high-performance applications that can leverage the parallel processing capabilities of GPUs.
Where is CUDA installed on my computer?
When you install CUDA on your computer, it gets installed in several locations. The locations may vary depending on your operating system and the version of CUDA you installed. Here are the most common locations where CUDA may be installed:
1. CUDA Toolkit installation directory
The CUDA Toolkit is the main package that contains all the necessary tools and libraries to develop and run CUDA applications. When you install the CUDA Toolkit, it gets installed in a directory that you specify during the installation process. The default installation directory on Windows is C:\Program Files\NVIDIA [GPU](https://saturncloud.io/glossary/gpu) Computing Toolkit\CUDA\, while on Linux, it is /usr/local/cuda/. The CUDA Toolkit contains several subdirectories, including bin, lib, and include, which contain the binaries, libraries, and header files, respectively.
2. NVIDIA GPU driver installation directory
The NVIDIA GPU driver is the software that enables communication between the CPU and the GPU. When you install the CUDA Toolkit, it may also install or update the NVIDIA GPU driver. The NVIDIA GPU driver gets installed in a directory that varies depending on your operating system and the version of the driver. On Windows, the driver is usually installed in C:\Windows\System32\drivers\nvlddmkm.sys, while on Linux, it is installed in /usr/lib/x86_64-linux-gnu/libnvidia-gl-<version>.so.
3. Environment variables
When you install the CUDA Toolkit, it also sets several environment variables that are necessary for CUDA to work correctly. The environment variables include CUDA_HOME, which points to the installation directory of the CUDA Toolkit, and PATH, which includes the CUDA binaries directory. On Windows, the environment variables are usually set in the System Properties > Advanced > Environment Variables window, while on Linux, they are set in the .bashrc file.
How to verify the CUDA installation
Now that we know where CUDA may be installed on our computer, let’s learn how to verify the installation. Here are the steps to verify the CUDA installation:
- Open a command prompt (on Windows) or a terminal (on Linux).
- Type
nvcc --versionand press Enter. - If CUDA is installed correctly, you should see the version of the CUDA Toolkit that is installed, along with the version of the NVIDIA GPU driver.
If you encounter any errors while verifying the CUDA installation, make sure that the environment variables are set correctly and that the CUDA Toolkit and NVIDIA GPU driver are installed correctly.
Common Errors
CUDA Not Found
-
Possible Causes
- CUDA Not Installed: Ensure that CUDA is installed on your system.
- Incorrect Environment Variable: Verify that the CUDA_PATH environment variable is set. If not, set it manually or reinstall CUDA.
-
Solutions:
If CUDA is not found, check if it’s installed and set the CUDA_PATH environment variable:
export CUDA_PATH=/path/to/cuda
Incorrect CUDA Version
Possible Causes:
- Outdated Environment Variable: Update the CUDA_PATH environment variable to point to the correct CUDA version.
- Multiple CUDA Installations: If you have multiple CUDA installations, ensure that the correct one is set in the environment variable.
Solutions:
If the detected CUDA version is incorrect, update the CUDA_PATH variable:
export CUDA_PATH=/path/to/correct/cuda
Conclusion
In this article, we explored the various locations where CUDA may be installed on your computer. We learned that CUDA is installed in the CUDA Toolkit installation directory, the NVIDIA GPU driver installation directory, and environment variables. We also learned how to verify the CUDA installation using the nvcc --version command. As a data scientist or software engineer, knowing where CUDA is installed on your computer is essential for developing and running CUDA applications.
About Saturn Cloud
Saturn Cloud is your all-in-one solution for data science & ML development, deployment, and data pipelines in the cloud. Spin up a notebook with 4TB of RAM, add a GPU, connect to a distributed cluster of workers, and more. Request a demo today to learn more.
Saturn Cloud provides customizable, ready-to-use cloud environments for collaborative data teams.
Try Saturn Cloud and join thousands of users moving to the cloud without
having to switch tools.
Введение
Устройства для превращения персональных компьютеров в маленькие суперкомпьютеры известны довольно давно. Ещё в 80-х годах прошлого века на рынке предлагались так называемые транспьютеры, которые вставлялись в распространенные тогда слоты расширения ISA. Первое время их производительность в соответствующих задачах впечатляла, но затем рост быстродействия универсальных процессоров ускорился, они усилили свои позиции в параллельных вычислениях, и смысла в транспьютерах не осталось. Хотя подобные устройства существуют и сейчас — это разнообразные специализированные ускорители. Но зачастую сфера их применения узка и особого распространения такие ускорители не получили.
Но в последнее время эстафета параллельных вычислений перешла к массовому рынку, так или иначе связанному с трёхмерными играми. Универсальные устройства с многоядерными процессорами для параллельных векторных вычислений, используемых в 3D-графике, достигают высокой пиковой производительности, которая универсальным процессорам не под силу. Конечно, максимальная скорость достигается лишь в ряде удобных задач и имеет некоторые ограничения, но такие устройства уже начали довольно широко применять в сферах, для которых они изначально и не предназначались. Отличным примером такого параллельного процессора является процессор Cell, разработанный альянсом Sony-Toshiba-IBM и применяемый в игровой приставке Sony PlayStation 3, а также и все современные видеокарты от лидеров рынка — компаний Nvidia и AMD.
Cell мы сегодня трогать не будем, хоть он и появился раньше и является универсальным процессором с дополнительными векторными возможностями, речь сегодня не о нём. Для 3D видеоускорителей ещё несколько лет назад появились первые технологии неграфических расчётов общего назначения GPGPU (General-Purpose computation on GPUs). Ведь современные видеочипы содержат сотни математических исполнительных блоков, и эта мощь может использоваться для значительного ускорения множества вычислительно интенсивных приложений. И нынешние поколения GPU обладают достаточно гибкой архитектурой, что вместе с высокоуровневыми языками программирования и программно-аппаратными архитектурами, подобными рассматриваемой в этой статье, раскрывает эти возможности и делает их значительно более доступными.
На создание GPCPU разработчиков побудило появление достаточно быстрых и гибких шейдерных программ, которые способны исполнять современные видеочипы. Разработчики задумали сделать так, чтобы GPU рассчитывали не только изображение в 3D приложениях, но и применялись в других параллельных расчётах. В GPGPU для этого использовались графические API: OpenGL и Direct3D, когда данные к видеочипу передавались в виде текстур, а расчётные программы загружались в виде шейдеров. Недостатками такого метода является сравнительно высокая сложность программирования, низкая скорость обмена данными между CPU и GPU и другие ограничения, о которых мы поговорим далее.
Вычисления на GPU развивались и развиваются очень быстро. И в дальнейшем, два основных производителя видеочипов, Nvidia и AMD, разработали и анонсировали соответствующие платформы под названием CUDA (Compute Unified Device Architecture) и CTM (Close To Metal или AMD Stream Computing), соответственно. В отличие от предыдущих моделей программирования GPU, эти были выполнены с учётом прямого доступа к аппаратным возможностям видеокарт. Платформы не совместимы между собой, CUDA — это расширение языка программирования C, а CTM — виртуальная машина, исполняющая ассемблерный код. Зато обе платформы ликвидировали некоторые из важных ограничений предыдущих моделей GPGPU, использующих традиционный графический конвейер и соответствующие интерфейсы Direct3D или OpenGL.
Конечно же, открытые стандарты, использующие OpenGL, кажутся наиболее портируемыми и универсальными, они позволяют использовать один и тот же код для видеочипов разных производителей. Но у таких методов есть масса недостатков, они значительно менее гибкие и не такие удобные в использовании. Кроме того, они не дают использовать специфические возможности определённых видеокарт, такие, как быстрая разделяемая (общая) память, присутствующая в современных вычислительных процессорах.
Именно поэтому компания Nvidia выпустила платформу CUDA — C-подобный язык программирования со своим компилятором и библиотеками для вычислений на GPU. Конечно же, написание оптимального кода для видеочипов совсем не такое простое и эта задача нуждается в длительной ручной работе, но CUDA как раз и раскрывает все возможности и даёт программисту больший контроль над аппаратными возможностями GPU. Важно, что поддержка Nvidia CUDA есть у чипов G8x, G9x и GT2xx, применяемых в видеокартах Geforce серий 8, 9 и 200, которые очень широко распространены. В настоящее время выпущена финальная версия CUDA 2.0, в которой появились некоторые новые возможности, например, поддержка расчётов с двойной точностью. CUDA доступна на 32-битных и 64-битных операционных системах Linux, Windows и MacOS X.
Разница между CPU и GPU в параллельных расчётах
Рост частот универсальных процессоров упёрся в физические ограничения и высокое энергопотребление, и увеличение их производительности всё чаще происходит за счёт размещения нескольких ядер в одном чипе. Продаваемые сейчас процессоры содержат лишь до четырёх ядер (дальнейший рост не будет быстрым) и они предназначены для обычных приложений, используют MIMD — множественный поток команд и данных. Каждое ядро работает отдельно от остальных, исполняя разные инструкции для разных процессов.
Специализированные векторные возможности (SSE2 и SSE3) для четырехкомпонентных (одинарная точность вычислений с плавающей точкой) и двухкомпонентных (двойная точность) векторов появились в универсальных процессорах из-за возросших требований графических приложений, в первую очередь. Именно поэтому для определённых задач применение GPU выгоднее, ведь они изначально сделаны для них.
Например, в видеочипах Nvidia основной блок — это мультипроцессор с восемью-десятью ядрами и сотнями ALU в целом, несколькими тысячами регистров и небольшим количеством разделяемой общей памяти. Кроме того, видеокарта содержит быструю глобальную память с доступом к ней всех мультипроцессоров, локальную память в каждом мультипроцессоре, а также специальную память для констант.
Самое главное — эти несколько ядер мультипроцессора в GPU являются SIMD (одиночный поток команд, множество потоков данных) ядрами. И эти ядра исполняют одни и те же инструкции одновременно, такой стиль программирования является обычным для графических алгоритмов и многих научных задач, но требует специфического программирования. Зато такой подход позволяет увеличить количество исполнительных блоков за счёт их упрощения.
Итак, перечислим основные различия между архитектурами CPU и GPU. Ядра CPU созданы для исполнения одного потока последовательных инструкций с максимальной производительностью, а GPU проектируются для быстрого исполнения большого числа параллельно выполняемых потоков инструкций. Универсальные процессоры оптимизированы для достижения высокой производительности единственного потока команд, обрабатывающего и целые числа и числа с плавающей точкой. При этом доступ к памяти случайный.
Разработчики CPU стараются добиться выполнения как можно большего числа инструкций параллельно, для увеличения производительности. Для этого, начиная с процессоров Intel Pentium, появилось суперскалярное выполнение, обеспечивающее выполнение двух инструкций за такт, а Pentium Pro отличился внеочередным выполнением инструкций. Но у параллельного выполнения последовательного потока инструкций есть определённые базовые ограничения и увеличением количества исполнительных блоков кратного увеличения скорости не добиться.
У видеочипов работа простая и распараллеленная изначально. Видеочип принимает на входе группу полигонов, проводит все необходимые операции, и на выходе выдаёт пиксели. Обработка полигонов и пикселей независима, их можно обрабатывать параллельно, отдельно друг от друга. Поэтому, из-за изначально параллельной организации работы в GPU используется большое количество исполнительных блоков, которые легко загрузить, в отличие от последовательного потока инструкций для CPU. Кроме того, современные GPU также могут исполнять больше одной инструкции за такт (dual issue). Так, архитектура Tesla в некоторых условиях запускает на исполнение операции MAD+MUL или MAD+SFU одновременно.
GPU отличается от CPU ещё и по принципам доступа к памяти. В GPU он связанный и легко предсказуемый — если из памяти читается тексель текстуры, то через некоторое время придёт время и для соседних текселей. Да и при записи то же — пиксель записывается во фреймбуфер, и через несколько тактов будет записываться расположенный рядом с ним. Поэтому организация памяти отличается от той, что используется в CPU. И видеочипу, в отличие от универсальных процессоров, просто не нужна кэш-память большого размера, а для текстур требуются лишь несколько (до 128-256 в нынешних GPU) килобайт.
Да и сама по себе работа с памятью у GPU и CPU несколько отличается. Так, не все центральные процессоры имеют встроенные контроллеры памяти, а у всех GPU обычно есть по несколько контроллеров, вплоть до восьми 64-битных каналов в чипе Nvidia GT200. Кроме того, на видеокартах применяется более быстрая память, и в результате видеочипам доступна в разы большая пропускная способность памяти, что также весьма важно для параллельных расчётов, оперирующих с огромными потоками данных.
В универсальных процессорах большие количества транзисторов и площадь чипа идут на буферы команд, аппаратное предсказание ветвления и огромные объёмы начиповой кэш-памяти. Все эти аппаратные блоки нужны для ускорения исполнения немногочисленных потоков команд. Видеочипы тратят транзисторы на массивы исполнительных блоков, управляющие потоками блоки, разделяемую память небольшого объёма и контроллеры памяти на несколько каналов. Вышеперечисленное не ускоряет выполнение отдельных потоков, оно позволяет чипу обрабатывать нескольких тысяч потоков, одновременно исполняющихся чипом и требующих высокой пропускной способности памяти.
Про отличия в кэшировании. Универсальные центральные процессоры используют кэш-память для увеличения производительности за счёт снижения задержек доступа к памяти, а GPU используют кэш или общую память для увеличения полосы пропускания. CPU снижают задержки доступа к памяти при помощи кэш-памяти большого размера, а также предсказания ветвлений кода. Эти аппаратные части занимают большую часть площади чипа и потребляют много энергии. Видеочипы обходят проблему задержек доступа к памяти при помощи одновременного исполнения тысяч потоков — в то время, когда один из потоков ожидает данных из памяти, видеочип может выполнять вычисления другого потока без ожидания и задержек.
Есть множество различий и в поддержке многопоточности. CPU исполняет 1-2 потока вычислений на одно процессорное ядро, а видеочипы могут поддерживать до 1024 потоков на каждый мультипроцессор, которых в чипе несколько штук. И если переключение с одного потока на другой для CPU стоит сотни тактов, то GPU переключает несколько потоков за один такт.
Кроме того, центральные процессоры используют SIMD (одна инструкция выполняется над многочисленными данными) блоки для векторных вычислений, а видеочипы применяют SIMT (одна инструкция и несколько потоков) для скалярной обработки потоков. SIMT не требует, чтобы разработчик преобразовывал данные в векторы, и допускает произвольные ветвления в потоках.
Вкратце можно сказать, что в отличие от современных универсальных CPU, видеочипы предназначены для параллельных вычислений с большим количеством арифметических операций. И значительно большее число транзисторов GPU работает по прямому назначению — обработке массивов данных, а не управляет исполнением (flow control) немногочисленных последовательных вычислительных потоков. Это схема того, сколько места в CPU и GPU занимает разнообразная логика:
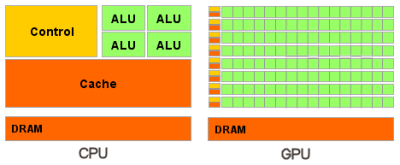
В итоге, основой для эффективного использования мощи GPU в научных и иных неграфических расчётах является распараллеливание алгоритмов на сотни исполнительных блоков, имеющихся в видеочипах. К примеру, множество приложений по молекулярному моделированию отлично приспособлено для расчётов на видеочипах, они требуют больших вычислительных мощностей и поэтому удобны для параллельных вычислений. А использование нескольких GPU даёт ещё больше вычислительных мощностей для решения подобных задач.
Выполнение расчётов на GPU показывает отличные результаты в алгоритмах, использующих параллельную обработку данных. То есть, когда одну и ту же последовательность математических операций применяют к большому объёму данных. При этом лучшие результаты достигаются, если отношение числа арифметических инструкций к числу обращений к памяти достаточно велико. Это предъявляет меньшие требования к управлению исполнением (flow control), а высокая плотность математики и большой объём данных отменяет необходимость в больших кэшах, как на CPU.
В результате всех описанных выше отличий, теоретическая производительность видеочипов значительно превосходит производительность CPU. Компания Nvidia приводит такой график роста производительности CPU и GPU за последние несколько лет:
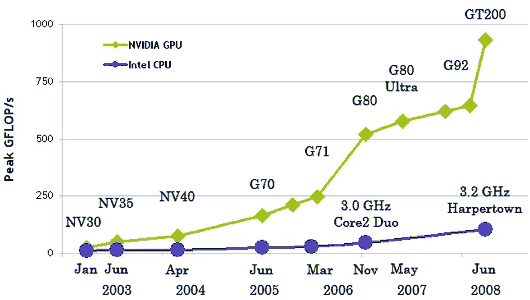
Естественно, эти данные не без доли лукавства. Ведь на CPU гораздо проще на практике достичь теоретических цифр, да и цифры приведены для одинарной точности в случае GPU, и для двойной — в случае CPU. В любом случае, для части параллельных задач одинарной точности хватает, а разница в скорости между универсальными и графическими процессорами весьма велика, и поэтому овчинка стоит выделки.
Первые попытки применения расчётов на GPU
Видеочипы в параллельных математических расчётах пытались использовать довольно давно. Самые первые попытки такого применения были крайне примитивными и ограничивались использованием некоторых аппаратных функций, таких, как растеризация и Z-буферизация. Но в нынешнем веке, с появлением шейдеров, начали ускорять вычисления матриц. В 2003 году на SIGGRAPH отдельная секция была выделена под вычисления на GPU, и она получила название GPGPU (General-Purpose computation on GPU) — универсальные вычисления на GPU).
Наиболее известен BrookGPU — компилятор потокового языка программирования Brook, созданный для выполнения неграфических вычислений на GPU. До его появления разработчики, использующие возможности видеочипов для вычислений, выбирали один из двух распространённых API: Direct3D или OpenGL. Это серьёзно ограничивало применение GPU, ведь в 3D графике используются шейдеры и текстуры, о которых специалисты по параллельному программированию знать не обязаны, они используют потоки и ядра. Brook смог помочь в облегчении их задачи. Эти потоковые расширения к языку C, разработанные в Стэндфордском университете, скрывали от программистов трёхмерный API, и представляли видеочип в виде параллельного сопроцессора. Компилятор обрабатывал файл .br с кодом C++ и расширениями, производя код, привязанный к библиотеке с поддержкой DirectX, OpenGL или x86.
Естественно, у Brook было множество недостатков, на которых мы останавливались, и о которых ещё подробнее поговорим далее. Но даже просто его появление вызвало значительный прилив внимания тех же Nvidia и ATI к инициативе вычислений на GPU, так как развитие этих возможностей серьёзно изменило рынок в дальнейшем, открыв целый новый его сектор — параллельные вычислители на основе видеочипов.
В дальнейшем, некоторые исследователи из проекта Brook влились в команду разработчиков Nvidia, чтобы представить программно-аппаратную стратегию параллельных вычислений, открыв новую долю рынка. И главным преимуществом этой инициативы Nvidia стало то, что разработчики отлично знают все возможности своих GPU до мелочей, и в использовании графического API нет необходимости, а работать с аппаратным обеспечением можно напрямую при помощи драйвера. Результатом усилий этой команды стала Nvidia CUDA (Compute Unified Device Architecture) — новая программно-аппаратная архитектура для параллельных вычислений на Nvidia GPU, которой посвящена эта статья.
Области применения параллельных расчётов на GPU
Чтобы понять, какие преимущества приносит перенос расчётов на видеочипы, приведём усреднённые цифры, полученные исследователями по всему миру. В среднем, при переносе вычислений на GPU, во многих задачах достигается ускорение в 5-30 раз, по сравнению с быстрыми универсальными процессорами. Самые большие цифры (порядка 100-кратного ускорения и даже более!) достигаются на коде, который не очень хорошо подходит для расчётов при помощи блоков SSE, но вполне удобен для GPU.
Это лишь некоторые примеры ускорений синтетического кода на GPU против SSE-векторизованного кода на CPU (по данным Nvidia):
- Флуоресцентная микроскопия: 12x;
- Молекулярная динамика (non-bonded force calc): 8-16x;
- Электростатика (прямое и многоуровневое суммирование Кулона): 40-120x и 7x.
А это табличка, которую очень любит Nvidia, показывая её на всех презентациях, на которой мы подробнее остановимся во второй части статьи, посвящённой конкретным примерам практических применений CUDA вычислений:
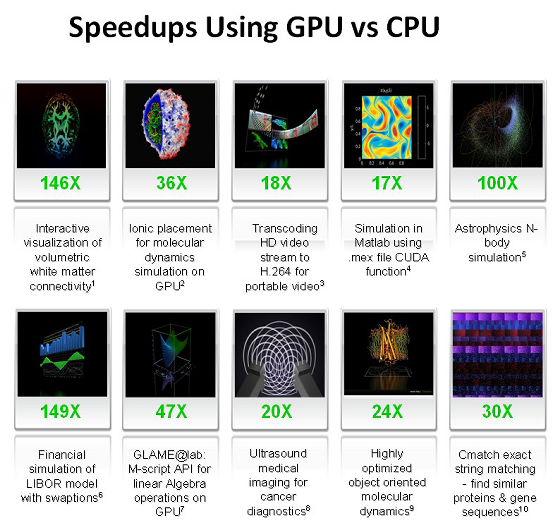
Как видите, цифры весьма привлекательные, особенно впечатляют 100-150-кратные приросты. В следующей статье, посвящённой CUDA, мы подробно разберём некоторые из этих цифр. А сейчас перечислим основные приложения, в которых сейчас применяются вычисления на GPU: анализ и обработка изображений и сигналов, симуляция физики, вычислительная математика, вычислительная биология, финансовые расчёты, базы данных, динамика газов и жидкостей, криптография, адаптивная лучевая терапия, астрономия, обработка звука, биоинформатика, биологические симуляции, компьютерное зрение, анализ данных (data mining), цифровое кино и телевидение, электромагнитные симуляции, геоинформационные системы, военные применения, горное планирование, молекулярная динамика, магнитно-резонансная томография (MRI), нейросети, океанографические исследования, физика частиц, симуляция свёртывания молекул белка, квантовая химия, трассировка лучей, визуализация, радары, гидродинамическое моделирование (reservoir simulation), искусственный интеллект, анализ спутниковых данных, сейсмическая разведка, хирургия, ультразвук, видеоконференции.
Подробности о многих применениях можно найти на сайте компании Nvidia в разделе по технологии CUDA. Как видите, список довольно большой, но и это ещё не всё! Его можно продолжать, и наверняка можно предположить, что в будущем будут найдены и другие области применения параллельных расчётов на видеочипах, о которых мы пока не догадываемся.
Возможности Nvidia CUDA
Технология CUDA — это программно-аппаратная вычислительная архитектура Nvidia, основанная на расширении языка Си, которая даёт возможность организации доступа к набору инструкций графического ускорителя и управления его памятью при организации параллельных вычислений. CUDA помогает реализовывать алгоритмы, выполнимые на графических процессорах видеоускорителей Geforce восьмого поколения и старше (серии Geforce 8, Geforce 9, Geforce 200), а также Quadro и Tesla.
Хотя трудоёмкость программирования GPU при помощи CUDA довольно велика, она ниже, чем с ранними GPGPU решениями. Такие программы требуют разбиения приложения между несколькими мультипроцессорами подобно MPI программированию, но без разделения данных, которые хранятся в общей видеопамяти. И так как CUDA программирование для каждого мультипроцессора подобно OpenMP программированию, оно требует хорошего понимания организации памяти. Но, конечно же, сложность разработки и переноса на CUDA сильно зависит от приложения.
Набор для разработчиков содержит множество примеров кода и хорошо документирован. Процесс обучения потребует около двух-четырёх недель для тех, кто уже знаком с OpenMP и MPI. В основе API лежит расширенный язык Си, а для трансляции кода с этого языка в состав CUDA SDK входит компилятор командной строки nvcc, созданный на основе открытого компилятора Open64.
Перечислим основные характеристики CUDA:
- унифицированное программно-аппаратное решение для параллельных вычислений на видеочипах Nvidia;
- большой набор поддерживаемых решений, от мобильных до мультичиповых
- стандартный язык программирования Си;
- стандартные библиотеки численного анализа FFT (быстрое преобразование Фурье) и BLAS (линейная алгебра);
- оптимизированный обмен данными между CPU и GPU;
- взаимодействие с графическими API OpenGL и DirectX;
- поддержка 32- и 64-битных операционных систем: Windows XP, Windows Vista, Linux и MacOS X;
- возможность разработки на низком уровне.
Касательно поддержки операционных систем нужно добавить, что официально поддерживаются все основные дистрибутивы Linux (Red Hat Enterprise Linux 3.x/4.x/5.x, SUSE Linux 10.x), но, судя по данным энтузиастов, CUDA прекрасно работает и на других сборках: Fedora Core, Ubuntu, Gentoo и др.
Среда разработки CUDA (CUDA Toolkit) включает:
- компилятор nvcc;
- библиотеки FFT и BLAS;
- профилировщик;
- отладчик gdb для GPU;
- CUDA runtime драйвер в комплекте стандартных драйверов Nvidia
- руководство по программированию;
- CUDA Developer SDK (исходный код, утилиты и документация).
В примерах исходного кода: параллельная битонная сортировка (bitonic sort), транспонирование матриц, параллельное префиксное суммирование больших массивов, свёртка изображений, дискретное вейвлет-преобразование, пример взаимодействия с OpenGL и Direct3D, использование библиотек CUBLAS и CUFFT, вычисление цены опциона (формула Блэка-Шоулза, биномиальная модель, метод Монте-Карло), параллельный генератор случайных чисел Mersenne Twister, вычисление гистограммы большого массива, шумоподавление, фильтр Собеля (нахождение границ).
Преимущества и ограничения CUDA
С точки зрения программиста, графический конвейер является набором стадий обработки. Блок геометрии генерирует треугольники, а блок растеризации — пиксели, отображаемые на мониторе. Традиционная модель программирования GPGPU выглядит следующим образом:
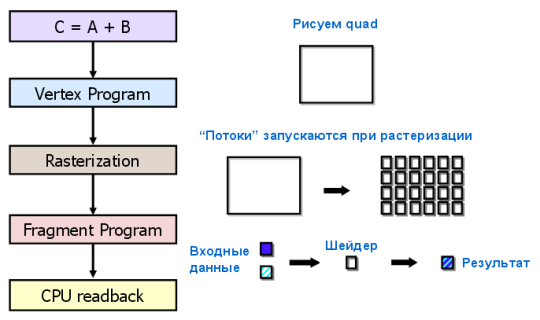
Чтобы перенести вычисления на GPU в рамках такой модели, нужен специальный подход. Даже поэлементное сложение двух векторов потребует отрисовки фигуры на экране или во внеэкранный буфер. Фигура растеризуется, цвет каждого пикселя вычисляется по заданной программе (пиксельному шейдеру). Программа считывает входные данные из текстур для каждого пикселя, складывает их и записывает в выходной буфер. И все эти многочисленные операции нужны для того, что в обычном языке программирования записывается одним оператором!
Поэтому, применение GPGPU для вычислений общего назначения имеет ограничение в виде слишком большой сложности обучения разработчиков. Да и других ограничений достаточно, ведь пиксельный шейдер — это всего лишь формула зависимости итогового цвета пикселя от его координаты, а язык пиксельных шейдеров — язык записи этих формул с Си-подобным синтаксисом. Ранние методы GPGPU являются хитрым трюком, позволяющим использовать мощность GPU, но без всякого удобства. Данные там представлены изображениями (текстурами), а алгоритм — процессом растеризации. Нужно особо отметить и весьма специфичную модель памяти и исполнения.
Программно-аппаратная архитектура для вычислений на GPU компании Nvidia отличается от предыдущих моделей GPGPU тем, что позволяет писать программы для GPU на настоящем языке Си со стандартным синтаксисом, указателями и необходимостью в минимуме расширений для доступа к вычислительным ресурсам видеочипов. CUDA не зависит от графических API, и обладает некоторыми особенностями, предназначенными специально для вычислений общего назначения.
Преимущества CUDA перед традиционным подходом к GPGPU вычислениям:
- интерфейс программирования приложений CUDA основан на стандартном языке программирования Си с расширениями, что упрощает процесс изучения и внедрения архитектуры CUDA;
- CUDA обеспечивает доступ к разделяемой между потоками памяти размером в 16 Кб на мультипроцессор, которая может быть использована для организации кэша с широкой полосой пропускания, по сравнению с текстурными выборками;
- более эффективная передача данных между системной и видеопамятью
- отсутствие необходимости в графических API с избыточностью и накладными расходами;
- линейная адресация памяти, и gather и scatter, возможность записи по произвольным адресам;
- аппаратная поддержка целочисленных и битовых операций.
Основные ограничения CUDA:
- отсутствие поддержки рекурсии для выполняемых функций;
- минимальная ширина блока в 32 потока;
- закрытая архитектура CUDA, принадлежащая Nvidia.
Слабыми местами программирования при помощи предыдущих методов GPGPU является то, что эти методы не используют блоки исполнения вершинных шейдеров в предыдущих неунифицированных архитектурах, данные хранятся в текстурах, а выводятся во внеэкранный буфер, а многопроходные алгоритмы используют пиксельные шейдерные блоки. В ограничения GPGPU можно включить: недостаточно эффективное использование аппаратных возможностей, ограничения полосой пропускания памяти, отсутствие операции scatter (только gather), обязательное использование графического API.
Основные преимущества CUDA по сравнению с предыдущими методами GPGPU вытекают из того, что эта архитектура спроектирована для эффективного использования неграфических вычислений на GPU и использует язык программирования C, не требуя переноса алгоритмов в удобный для концепции графического конвейера вид. CUDA предлагает новый путь вычислений на GPU, не использующий графические API, предлагающий произвольный доступ к памяти (scatter или gather). Такая архитектура лишена недостатков GPGPU и использует все исполнительные блоки, а также расширяет возможности за счёт целочисленной математики и операций битового сдвига.
Кроме того, CUDA открывает некоторые аппаратные возможности, недоступные из графических API, такие как разделяемая память. Это память небольшого объёма (16 килобайт на мультипроцессор), к которой имеют доступ блоки потоков. Она позволяет кэшировать наиболее часто используемые данные и может обеспечить более высокую скорость, по сравнению с использованием текстурных выборок для этой задачи. Что, в свою очередь, снижает чувствительность к пропускной способности параллельных алгоритмов во многих приложениях. Например, это полезно для линейной алгебры, быстрого преобразования Фурье и фильтров обработки изображений.
Удобнее в CUDA и доступ к памяти. Программный код в графических API выводит данные в виде 32-х значений с плавающей точкой одинарной точности (RGBA значения одновременно в восемь render target) в заранее предопределённые области, а CUDA поддерживает scatter запись — неограниченное число записей по любому адресу. Такие преимущества делают возможным выполнение на GPU некоторых алгоритмов, которые невозможно эффективно реализовать при помощи методов GPGPU, основанных на графических API.
Также, графические API в обязательном порядке хранят данные в текстурах, что требует предварительной упаковки больших массивов в текстуры, что усложняет алгоритм и заставляет использовать специальную адресацию. А CUDA позволяет читать данные по любому адресу. Ещё одним преимуществом CUDA является оптимизированный обмен данными между CPU и GPU. А для разработчиков, желающих получить доступ к низкому уровню (например, при написании другого языка программирования), CUDA предлагает возможность низкоуровневого программирования на ассемблере.
История развития CUDA
Разработка CUDA была анонсирована вместе с чипом G80 в ноябре 2006, а релиз публичной бета-версии CUDA SDK состоялся в феврале 2007 года. Версия 1.0 вышла в июне 2007 года под запуск в продажу решений Tesla, основанных на чипе G80, и предназначенных для рынка высокопроизводительных вычислений. Затем, в конце года вышла бета-версия CUDA 1.1, которая, несмотря на малозначительное увеличение номера версии, ввела довольно много нового.
Из появившегося в CUDA 1.1 можно отметить включение CUDA-функциональности в обычные видеодрайверы Nvidia. Это означало, что в требованиях к любой CUDA программе достаточно было указать видеокарту серии Geforce 8 и выше, а также минимальную версию драйверов 169.xx. Это очень важно для разработчиков, при соблюдении этих условий CUDA программы будут работать у любого пользователя. Также было добавлено асинхронное выполнение вместе с копированием данных (только для чипов G84, G86, G92 и выше), асинхронная пересылка данных в видеопамять, атомарные операции доступа к памяти, поддержка 64-битных версий Windows и возможность мультичиповой работы CUDA в режиме SLI.
На данный момент актуальной является версия для решений на основе GT200 — CUDA 2.0, вышедшая вместе с линейкой Geforce GTX 200. Бета-версия была выпущена ещё весной 2008 года. Во второй версии появились: поддержка вычислений двойной точности (аппаратная поддержка только у GT200), наконец-то поддерживается Windows Vista (32 и 64-битные версии) и Mac OS X, добавлены средства отладки и профилирования, поддерживаются 3D текстуры, оптимизированная пересылка данных.
Что касается вычислений с двойной точностью, то их скорость на текущем аппаратном поколении ниже одинарной точности в несколько раз. Причины рассмотрены в нашей базовой статье по Geforce GTX 280. Реализация в GT200 этой поддержки заключается в том, блоки FP32 не используются для получения результата в четыре раза меньшем темпе, для поддержки FP64 вычислений в Nvidia решили сделать выделенные вычислительные блоки. И в GT200 их в десять раз меньше, чем блоков FP32 (по одному блоку двойной точности на каждый мультипроцессор).
Реально производительность может быть даже ещё меньше, так как архитектура оптимизирована для 32-битного чтения из памяти и регистров, кроме того, двойная точность не нужна в графических приложениях, и в GT200 она сделана скорее, чтобы просто была. Да и современные четырехъядерные процессоры показывают не намного меньшую реальную производительность. Но будучи даже в 10 раз медленнее, чем одинарная точность, такая поддержка полезна для схем со смешанной точностью. Одна из распространенных техник — получить изначально приближенные результаты в одинарной точности, и затем их уточнить в двойной. Теперь это можно сделать прямо на видеокарте, без пересылки промежуточных данных к CPU.
Ещё одна полезная особенность CUDA 2.0 не имеет отношения к GPU, как ни странно. Просто теперь можно компилировать код CUDA в высокоэффективный многопоточный SSE код для быстрого исполнения на центральном процессоре. То есть, теперь эта возможность годится не только для отладки, но и реального использования на системах без видеокарты Nvidia. Ведь использование CUDA в обычном коде сдерживается тем, что видеокарты Nvidia хоть и самые популярные среди выделенных видеорешений, но имеются не во всех системах. И до версии 2.0 в таких случаях пришлось бы делать два разных кода: для CUDA и отдельно для CPU. А теперь можно выполнять любую CUDA программу на CPU с высокой эффективностью, пусть и с меньшей скоростью, чем на видеочипах.
Решения с поддержкой Nvidia CUDA
Все видеокарты, обладающие поддержкой CUDA, могут помочь в ускорении большинства требовательных задач, начиная от аудио- и видеообработки, и заканчивая медициной и научными исследованиями. Единственное реальное ограничение состоит в том, что многие CUDA программы требуют минимум 256 мегабайт видеопамяти, и это — одна из важнейших технических характеристик для CUDA-приложений.
Актуальный список поддерживающих CUDA продуктов можно получить на вебсайте Nvidia. На момент написания статьи расчёты CUDA поддерживали все продукты серий Geforce 200, Geforce 9 и Geforce 8, в том числе и мобильные продукты, начиная с Geforce 8400M, а также и чипсеты Geforce 8100, 8200 и 8300. Также поддержкой CUDA обладают современные продукты Quadro и все Tesla: S1070, C1060, C870, D870 и S870.


Особо отметим, что вместе с новыми видеокартами Geforce GTX 260 и 280, были анонсированы и соответствующие решения для высокопроизводительных вычислений: Tesla C1060 и S1070 (представленные на фото выше), которые будут доступны для приобретения осенью этого года. GPU в них применён тот же — GT200, в C1060 он один, в S1070 — четыре. Зато, в отличие от игровых решений, в них используется по четыре гигабайта памяти на каждый чип. Из минусов разве что меньшая частота памяти и ПСП, чем у игровых карт, обеспечивающая по 102 гигабайт/с на чип.
Состав Nvidia CUDA
CUDA включает два API: высокого уровня (CUDA Runtime API) и низкого (CUDA Driver API), хотя в одной программе одновременное использование обоих невозможно, нужно использовать или один или другой. Высокоуровневый работает «сверху» низкоуровневого, все вызовы runtime транслируются в простые инструкции, обрабатываемые низкоуровневым Driver API. Но даже «высокоуровневый» API предполагает знания об устройстве и работе видеочипов Nvidia, слишком высокого уровня абстракции там нет.
Есть и ещё один уровень, даже более высокий — две библиотеки:
CUBLAS — CUDA вариант BLAS (Basic Linear Algebra Subprograms), предназначенный для вычислений задач линейной алгебры и использующий прямой доступ к ресурсам GPU;
CUFFT — CUDA вариант библиотеки Fast Fourier Transform для расчёта быстрого преобразования Фурье, широко используемого при обработке сигналов. Поддерживаются следующие типы преобразований: complex-complex (C2C), real-complex (R2C) и complex-real (C2R).
Рассмотрим эти библиотеки подробнее. CUBLAS — это переведённые на язык CUDA стандартные алгоритмы линейной алгебры, на данный момент поддерживается только определённый набор основных функций CUBLAS. Библиотеку очень легко использовать: нужно создать матрицу и векторные объекты в памяти видеокарты, заполнить их данными, вызвать требуемые функции CUBLAS, и загрузить результаты из видеопамяти обратно в системную. CUBLAS содержит специальные функции для создания и уничтожения объектов в памяти GPU, а также для чтения и записи данных в эту память. Поддерживаемые функции BLAS: уровни 1, 2 и 3 для действительных чисел, уровень 1 CGEMM для комплексных. Уровень 1 — это векторно-векторные операции, уровень 2 — векторно-матричные операции, уровень 3 — матрично-матричные операции.
CUFFT — CUDA вариант функции быстрого преобразования Фурье — широко используемой и очень важной при анализе сигналов, фильтрации и т.п. CUFFT предоставляет простой интерфейс для эффективного вычисления FFT на видеочипах производства Nvidia без необходимости в разработке собственного варианта FFT для GPU. CUDA вариант FFT поддерживает 1D, 2D, и 3D преобразования комплексных и действительных данных, пакетное исполнение для нескольких 1D трансформаций в параллели, размеры 2D и 3D трансформаций могут быть в пределах [2, 16384], для 1D поддерживается размер до 8 миллионов элементов.
Основы создания программ на CUDA
Для понимания дальнейшего текста следует разбираться в базовых архитектурных особенностях видеочипов Nvidia. GPU состоит из нескольких кластеров текстурных блоков (Texture Processing Cluster). Каждый кластер состоит из укрупнённого блока текстурных выборок и двух-трех потоковых мультипроцессоров, каждый из которых состоит из восьми вычислительных устройств и двух суперфункциональных блоков. Все инструкции выполняются по принципу SIMD, когда одна инструкция применяется ко всем потокам в warp (термин из текстильной промышленности, в CUDA это группа из 32 потоков — минимальный объём данных, обрабатываемых мультипроцессорами). Этот способ выполнения назвали SIMT (single instruction multiple threads — одна инструкция и много потоков).
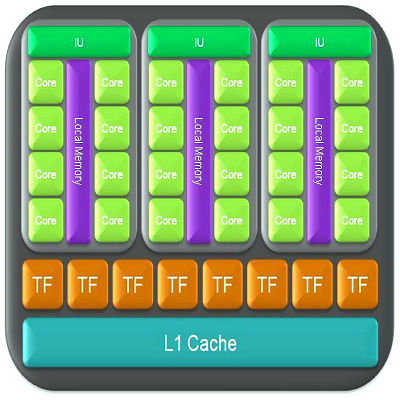
Каждый из мультипроцессоров имеет определённые ресурсы. Так, есть специальная разделяемая память объемом 16 килобайт на мультипроцессор. Но это не кэш, так как программист может использовать её для любых нужд, подобно Local Store в SPU процессоров Cell. Эта разделяемая память позволяет обмениваться информацией между потоками одного блока. Важно, что все потоки одного блока всегда выполняются одним и тем же мультипроцессором. А потоки из разных блоков обмениваться данными не могут, и нужно помнить это ограничение. Разделяемая память часто бывает полезной, кроме тех случаев, когда несколько потоков обращаются к одному банку памяти. Мультипроцессоры могут обращаться и к видеопамяти, но с большими задержками и худшей пропускной способностью. Для ускорения доступа и снижения частоты обращения к видеопамяти, у мультипроцессоров есть по 8 килобайт кэша на константы и текстурные данные.
Мультипроцессор использует 8192-16384 (для G8x/G9x и GT2xx, соответственно) регистра, общие для всех потоков всех блоков, выполняемых на нём. Максимальное число блоков на один мультипроцессор для G8x/G9x равно восьми, а число warp — 24 (768 потоков на один мультипроцессор). Всего топовые видеокарты серий Geforce 8 и 9 могут обрабатывать до 12288 потоков единовременно. Geforce GTX 280 на основе GT200 предлагает до 1024 потоков на мультипроцессор, в нём есть 10 кластеров по три мультипроцессора, обрабатывающих до 30720 потоков. Знание этих ограничений позволяет оптимизировать алгоритмы под доступные ресурсы.
Первым шагом при переносе существующего приложения на CUDA является его профилирование и определение участков кода, являющихся «бутылочным горлышком», тормозящим работу. Если среди таких участков есть подходящие для быстрого параллельного исполнения, эти функции переносятся на Cи расширения CUDA для выполнения на GPU. Программа компилируется при помощи поставляемого Nvidia компилятора, который генерирует код и для CPU, и для GPU. При исполнении программы, центральный процессор выполняет свои порции кода, а GPU выполняет CUDA код с наиболее тяжелыми параллельными вычислениями. Эта часть, предназначенная для GPU, называется ядром (kernel). В ядре определяются операции, которые будут исполнены над данными.
Видеочип получает ядро и создает копии для каждого элемента данных. Эти копии называются потоками (thread). Поток содержит счётчик, регистры и состояние. Для больших объёмов данных, таких как обработка изображений, запускаются миллионы потоков. Потоки выполняются группами по 32 штуки, называемыми warp’ы. Warp’ам назначается исполнение на определенных потоковых мультипроцессорах. Каждый мультипроцессор состоит из восьми ядер — потоковых процессоров, которые выполняют одну инструкцию MAD за один такт. Для исполнения одного 32-поточного warp’а требуется четыре такта работы мультипроцессора (речь о частоте shader domain, которая равна 1.5 ГГц и выше).
Мультипроцессор не является традиционным многоядерным процессором, он отлично приспособлен для многопоточности, поддерживая до 32 warp’ов единовременно. Каждый такт аппаратное обеспечение выбирает, какой из warp’ов исполнять, и переключается от одного к другому без потерь в тактах. Если проводить аналогию с центральным процессором, это похоже на одновременное исполнение 32 программ и переключение между ними каждый такт без потерь на переключение контекста. Реально ядра CPU поддерживают единовременное выполнение одной программы и переключаются на другие с задержкой в сотни тактов.
Модель программирования CUDA
Повторимся, что CUDA использует параллельную модель вычислений, когда каждый из SIMD процессоров выполняет ту же инструкцию над разными элементами данных параллельно. GPU является вычислительным устройством, сопроцессором (device) для центрального процессора (host), обладающим собственной памятью и обрабатывающим параллельно большое количество потоков. Ядром (kernel) называется функция для GPU, исполняемая потоками (аналогия из 3D графики — шейдер).
Мы говорили выше, что видеочип отличается от CPU тем, что может обрабатывать одновременно десятки тысяч потоков, что обычно для графики, которая хорошо распараллеливается. Каждый поток скалярен, не требует упаковки данных в 4-компонентные векторы, что удобнее для большинства задач. Количество логических потоков и блоков потоков превосходит количество физических исполнительных устройств, что даёт хорошую масштабируемость для всего модельного ряда решений компании.
Модель программирования в CUDA предполагает группирование потоков. Потоки объединяются в блоки потоков (thread block) — одномерные или двумерные сетки потоков, взаимодействующих между собой при помощи разделяемой памяти и точек синхронизации. Программа (ядро, kernel) исполняется над сеткой (grid) блоков потоков (thread blocks), см. рисунок ниже. Одновременно исполняется одна сетка. Каждый блок может быть одно-, двух- или трехмерным по форме, и может состоять из 512 потоков на текущем аппаратном обеспечении.
Блоки потоков выполняются в виде небольших групп, называемых варп (warp), размер которых — 32 потока. Это минимальный объём данных, которые могут обрабатываться в мультипроцессорах. И так как это не всегда удобно, CUDA позволяет работать и с блоками, содержащими от 64 до 512 потоков.
Группировка блоков в сетки позволяет уйти от ограничений и применить ядро к большему числу потоков за один вызов. Это помогает и при масштабировании. Если у GPU недостаточно ресурсов, он будет выполнять блоки последовательно. В обратном случае, блоки могут выполняться параллельно, что важно для оптимального распределения работы на видеочипах разного уровня, начиная от мобильных и интегрированных.
Модель памяти CUDA
Модель памяти в CUDA отличается возможностью побайтной адресации, поддержкой как gather, так и scatter. Доступно довольно большое количество регистров на каждый потоковый процессор, до 1024 штук. Доступ к ним очень быстрый, хранить в них можно 32-битные целые или числа с плавающей точкой.
Каждый поток имеет доступ к следующим типам памяти:
Глобальная память — самый большой объём памяти, доступный для всех мультипроцессоров на видеочипе, размер составляет от 256 мегабайт до 1.5 гигабайт на текущих решениях (и до 4 Гбайт на Tesla). Обладает высокой пропускной способностью, более 100 гигабайт/с для топовых решений Nvidia, но очень большими задержками в несколько сот тактов. Не кэшируется, поддерживает обобщённые инструкции load и store, и обычные указатели на память.
Локальная память — это небольшой объём памяти, к которому имеет доступ только один потоковый процессор. Она относительно медленная — такая же, как и глобальная.
Разделяемая память — это 16-килобайтный (в видеочипах нынешней архитектуры) блок памяти с общим доступом для всех потоковых процессоров в мультипроцессоре. Эта память весьма быстрая, такая же, как регистры. Она обеспечивает взаимодействие потоков, управляется разработчиком напрямую и имеет низкие задержки. Преимущества разделяемой памяти: использование в виде управляемого программистом кэша первого уровня, снижение задержек при доступе исполнительных блоков (ALU) к данным, сокращение количества обращений к глобальной памяти.
Память констант — область памяти объемом 64 килобайта (то же — для нынешних GPU), доступная только для чтения всеми мультипроцессорами. Она кэшируется по 8 килобайт на каждый мультипроцессор. Довольно медленная — задержка в несколько сот тактов при отсутствии нужных данных в кэше.
Текстурная память — блок памяти, доступный для чтения всеми мультипроцессорами. Выборка данных осуществляется при помощи текстурных блоков видеочипа, поэтому предоставляются возможности линейной интерполяции данных без дополнительных затрат. Кэшируется по 8 килобайт на каждый мультипроцессор. Медленная, как глобальная — сотни тактов задержки при отсутствии данных в кэше.
Естественно, что глобальная, локальная, текстурная и память констант — это физически одна и та же память, известная как локальная видеопамять видеокарты. Их отличия в различных алгоритмах кэширования и моделях доступа. Центральный процессор может обновлять и запрашивать только внешнюю память: глобальную, константную и текстурную.
Из написанного выше понятно, что CUDA предполагает специальный подход к разработке, не совсем такой, как принят в программах для CPU. Нужно помнить о разных типах памяти, о том, что локальная и глобальная память не кэшируется и задержки при доступе к ней гораздо выше, чем у регистровой памяти, так как она физически находится в отдельных микросхемах.
Типичный, но не обязательный шаблон решения задач:
- задача разбивается на подзадачи;
- входные данные делятся на блоки, которые вмещаются в разделяемую память;
- каждый блок обрабатывается блоком потоков;
- подблок подгружается в разделяемую память из глобальной;
- над данными в разделяемой памяти проводятся соответствующие вычисления;
- результаты копируются из разделяемой памяти обратно в глобальную.
Среда программирования
В состав CUDA входят runtime библиотеки:
- общая часть, предоставляющая встроенные векторные типы и подмножества вызовов RTL, поддерживаемые на CPU и GPU;
- CPU-компонента, для управления одним или несколькими GPU;
- GPU-компонента, предоставляющая специфические функции для GPU.
Основной процесс приложения CUDA работает на универсальном процессоре (host), он запускает несколько копий процессов kernel на видеокарте. Код для CPU делает следующее: инициализирует GPU, распределяет память на видеокарте и системе, копирует константы в память видеокарты, запускает несколько копий процессов kernel на видеокарте, копирует полученный результат из видеопамяти, освобождает память и завершает работу.
В качестве примера для понимания приведем CPU код для сложения векторов, представленный в CUDA:

Функции, исполняемые видеочипом, имеют следующие ограничения: отсутствует рекурсия, нет статических переменных внутри функций и переменного числа аргументов. Поддерживается два вида управления памятью: линейная память с доступом по 32-битным указателям, и CUDA-массивы с доступом только через функции текстурной выборки.
Программы на CUDA могут взаимодействовать с графическими API: для рендеринга данных, сгенерированных в программе, для считывания результатов рендеринга и их обработки средствами CUDA (например, при реализации фильтров постобработки). Для этого ресурсы графических API могут быть отображены (с получением адреса ресурса) в пространство глобальной памяти CUDA. Поддерживаются следующие типы ресурсов графических API: Buffer Objects (PBO / VBO) в OpenGL, вершинные буферы и текстуры (2D, 3D и кубические карты) Direct3D9.
Стадии компиляции CUDA-приложения:
Файлы исходного кода на CUDA C компилируются при помощи программы NVCC, которая является оболочкой над другими инструментами, и вызывает их: cudacc, g++, cl и др. NVCC генерирует: код для центрального процессора, который компилируется вместе с остальными частями приложения, написанными на чистом Си, и объектный код PTX для видеочипа. Исполнимые файлы с кодом на CUDA в обязательном порядке требуют наличия библиотек CUDA runtime library (cudart) и CUDA core library (cuda).
Оптимизация программ на CUDA
Естественно, в рамках обзорной статьи невозможно рассмотреть серьёзные вопросы оптимизации в CUDA программировании. Поэтому просто вкратце расскажем о базовых вещах. Для эффективного использования возможностей CUDA нужно забыть про обычные методы написания программ для CPU, и использовать те алгоритмы, которые хорошо распараллеливаются на тысячи потоков. Также важно найти оптимальное место для хранения данных (регистры, разделяемая память и т.п.), минимизировать передачу данных между CPU и GPU, использовать буферизацию.
В общих чертах, при оптимизации программы CUDA нужно постараться добиться оптимального баланса между размером и количеством блоков. Большее количество потоков в блоке снизит влияние задержек памяти, но снизит и доступное число регистров. Кроме того, блок из 512 потоков неэффективен, сама Nvidia рекомендует использовать блоки по 128 или 256 потоков, как компромиссное значение для достижения оптимальных задержек и количества регистров.
Среди основных моментов оптимизации программ CUDA: как можно более активное использование разделяемой памяти, так как она значительно быстрее глобальной видеопамяти видеокарты; операции чтения и записи из глобальной памяти должны быть объединены (coalesced) по возможности. Для этого нужно использовать специальные типы данных для чтения и записи сразу по 32/64/128 бита данных одной операцией. Если операции чтения трудно объединить, можно попробовать использовать текстурные выборки.
Выводы
Представленная компанией Nvidia программно-аппаратная архитектура для расчётов на видеочипах CUDA хорошо подходит для решения широкого круга задач с высоким параллелизмом. CUDA работает на большом количестве видеочипов Nvidia, и улучшает модель программирования GPU, значительно упрощая её и добавляя большое количество возможностей, таких как разделяемая память, возможность синхронизации потоков, вычисления с двойной точностью и целочисленные операции.
CUDA — это доступная каждому разработчику ПО технология, её может использовать любой программист, знающий язык Си. Придётся только привыкнуть к иной парадигме программирования, присущей параллельным вычислениям. Но если алгоритм в принципе хорошо распараллеливается, то изучение и затраты времени на программирование на CUDA вернутся в многократном размере.
Вполне вероятно, что в силу широкого распространения видеокарт в мире, развитие параллельных вычислений на GPU сильно повлияет на индустрию высокопроизводительных вычислений. Эти возможности уже вызвали большой интерес в научных кругах, да и не только в них. Ведь потенциальные возможности ускорения хорошо поддающихся распараллеливанию алгоритмов (на доступном аппаратном обеспечении, что не менее важно) сразу в десятки раз бывают не так часто.
Универсальные процессоры развиваются довольно медленно, у них нет таких скачков производительности. По сути, пусть это и звучит слишком громко, все нуждающиеся в быстрых вычислителях теперь могут получить недорогой персональный суперкомпьютер на своём столе, иногда даже не вкладывая дополнительных средств, так как видеокарты Nvidia широко распространены. Не говоря уже об увеличении эффективности в терминах GFLOPS/$ и GFLOPS/Вт, которые так нравятся производителям GPU.
Будущее множества вычислений явно за параллельными алгоритмами, почти все новые решения и инициативы направлены в эту сторону. Пока что, впрочем, развитие новых парадигм находится на начальном этапе, приходится вручную создавать потоки и планировать доступ к памяти, что усложняет задачи по сравнению с привычным программированием. Но технология CUDA сделала шаг в правильном направлении и в ней явно проглядывается успешное решение, особенно если Nvidia удастся убедить как можно разработчиков в его пользе и перспективах.
Но, конечно, GPU не заменят CPU. В их нынешнем виде они и не предназначены для этого. Сейчас что видеочипы движутся постепенно в сторону CPU, становясь всё более универсальными (расчёты с плавающей точкой одинарной и двойной точности, целочисленные вычисления), так и CPU становятся всё более «параллельными», обзаводясь большим количеством ядер, технологиями многопоточности, не говоря про появление блоков SIMD и проектов гетерогенных процессоров. Скорее всего, GPU и CPU в будущем просто сольются. Известно, что многие компании, в том числе Intel и AMD работают над подобными проектами. И неважно, будут ли GPU поглощены CPU, или наоборот.
В статье мы в основном говорили о преимуществах CUDA. Но есть и ложечка дёгтя. Один из немногочисленных недостатков CUDA — слабая переносимость. Эта архитектура работает только на видеочипах этой компании, да ещё и не на всех, а начиная с серии Geforce 8 и 9 и соответствующих Quadro и Tesla. Да, таких решений в мире очень много, Nvidia приводит цифру в 90 миллионов CUDA-совместимых видеочипов. Это просто отлично, но ведь конкуренты предлагают свои решения, отличные от CUDA. Так, у AMD есть Stream Computing, у Intel в будущем будет Ct.
Которая из технологий победит, станет распространённой и проживёт дольше остальных — покажет только время. Но у CUDA есть неплохие шансы, так как по сравнению с Stream Computing, например, она представляет более развитую и удобную для использования среду программирования на обычном языке Си. Возможно, в определении поможет третья сторона, выпустив некое общее решение. К примеру, в следующем обновлении DirectX под версией 11, компанией Microsoft обещаны вычислительные шейдеры, которые и могут стать неким усреднённым решением, устраивающим всех, или почти всех.
Судя по предварительным данным, этот новый тип шейдеров заимствует многое из модели CUDA. И программируя в этой среде уже сейчас, можно получить преимущества сразу и необходимые навыки для будущего. С точки зрения высокопроизводительных вычислений, у DirectX также есть явный недостаток в виде плохой переносимости, так как этот API ограничен платформой Windows. Впрочем, разрабатывается и ещё один стандарт — открытая мультиплатформенная инициатива OpenCL, которая поддерживается большинством компаний, среди которых Nvidia, AMD, Intel, IBM и многие другие.
Не забывайте, что в следующей статье по CUDA вас ждёт исследование конкретных практических применений научных и других неграфических вычислений, выполненных разработчиками из разных уголков нашей планеты при помощи Nvidia CUDA.
CUDA is a parallel computing platform and programming model developed by Nvidia for general computing on its own GPUs (graphics processing units). CUDA enables developers to speed up compute-intensive applications by harnessing the power of GPUs for the parallelizable part of the computation.
While there have been other proposed APIs for GPUs, such as OpenCL, and there are competitive GPUs from other companies, such as AMD, the combination of CUDA and Nvidia GPUs dominates several application areas, including deep learning, and is a foundation for some of the fastest computers in the world.
Overview of CUDA
GPUs are hundreds/thousands of cores which are specialized for data parallel processing. This makes extremely fast and highly parallel workloads such as Deep learning, Image processing and linear algebra.
Data Parallelism : It means data is spread across many cores with each core doing a same operation on a small piece of data. In CUDA this model is called SIMT : Single Instruction, Multiple Thread. It works well for larger array or matrix operations where each result element can be computed separately .
And This is where CUDA comes in…
Programming GPUs used to be a pretty difficult task, even though the hardware is flexible.
So to solve this problem NVIDIA created CUDA, which is a framework for programming NVIDIA GPUs.
-
It gives us a general purpose programming model, that is suitable for all kinds of parallel processing not just for graphics.
-
CUDA programming can be easily scaled to use the resources of any GPU that you run them on.
-
The CUDA language is an extension of C/C++ so it’s fairly easy for an C++ programmers to learn (we can also use CUDA with C or FORTRAN)
CUDA : Compute Unified Device Architecture
-
It is an extension of the C programming language.
-
An API Model for parallel computing created by NVIDIA.
-
Programs written using CUDA harness the power of GPU, thus increasing the computing power.
CUDA is a parallel computing and an API model using CUDA, one can utilize the power of NVIDIA GPUs to perform general tasks, such as multiplying matrices and performing other linear algebra operations, instead of just doing graphical calculations.
CUDA programming model is a heterogeneous model in which both the CPU and GPU are used.
In CUDA,
Host : The CPU and its memory. Device : The GPU and its memory.
Code run on the host can manage memory on both the host and device and also launches kernels which are functions executed on the device.
These kernels are executed by many GPU threads in parallel.
A typical sequence of operations for a CUDA C program is,
-
Declare and allocate host and device memory.
-
Initialize host data.
-
Transfer data from the host to device.
-
Execute one or more kernels.
-
Transfer results from the device to the host.
Difference between CUDA and openCL:
-
CUDA is a proprietary framework created by NVIDIA.
And openCL (Open Compute Language) is an open standard that runs on hardware by multiple vendors including desktops or laptops GPUs by AMD/ATI and NVIDIA (not much efficient as CUDA).
-
CUDA accelerates more features and provides better acceleration.
-
Using openCL, migrating to other platforms is easy.
Using CUDA, it’s harder to migrate because it has explicit optimization options to harness more GFLOPs percentage per architecture.
-
CUDA is better for solving large and sparse linear systems furthermore, it is possible to note that openCL, despite being an open standard may be considered more complex than CUDA in relation to programming.
CUDA has been developed specially for NVIDIA’s GPU, hence CUDA can’t be programmed on AMD GPUs.AMD GPUs won’t be able to run the CUDA binary (.cubin) files as these files are specially created for the NVIDIA GPU architecture.But openCL is not as much as efficient as CUDA in NVIDIA.
To use CUDA we have to install the CUDA toolkit, which gives us a bunch of different tools.
NVCC Compiler : (NVIDIA CUDA Compiler) which processes a single source file and translates it into both code that runs on a CPU known as Host in CUDA, and code for GPU which is known as a device.
Debugger : The toolkit includes the debugging tool. CUDA GDB — The NVIDIA tool for debugging CUDA applications running on Linux and Mac, providing developers with a mechanism for debugging CUDA applications running on actual hardware. CUDA-GDB is an extension to the x86-64 port of GDB, the GNU Project debugger.
NVIDIA Visual Profiler : The NVIDIA Visual Profiler is a cross-platform performance profiling tool that delivers developers vital feedback for optimizing CUDA C/C++ applications.First introduced in 2008, Visual Profiler supports all 350 million+ CUDA capable NVIDIA GPUs shipped since 2006 on Linux, Mac OS X, and Windows. The NVIDIA Visual Profiler is available as part of the CUDA Toolkit.
Documentation : There are a bunch of sample programs and user guides.
Libraries : There are libraries for various domains such as Math Libraries (cuBLAS, cuFFT, cuRAND, cuSOLVER, cuTENSOR etc.) , Parallel Algorithm Libraries (nvGRAPH, Thrust), Deep Learning Libraries (cuDNN, TensorRT, deepStream SDK), Image and Video Processing Libraries (nvJPEG, NVIDIA Codec SDK), Communication Libraries (NCCL) etc.
Programming with CUDA
Programming model and how that model maps to hardware?
How to Launch kernels, debugging device code and handling errors?
The CUDA Programming Model
You will learn the software and hardware architecture of CUDA and they are connected to each other to allow us to write scalable programs.
-
Software : Drivers and Runtime API.
-
Execution Model : Kernels, Threads and Blocks.
-
Hardware Architecture : Which provides faster and scalable execution of CUDA programs.
Software
-
Driver API : The CUDA display driver includes a low level interface called the driver API. This is available in any systems with NVIDIA Driver.
-
Runtime API : The CUDA toolkit includes the higher level interface called the Runtime API. We can access it by using the CUDA syntax extensions and compiling your program with NVCC.
#include<cuda_runtime_api.h>
This provides all the basic functions we use like cudaMalloc(), cudaMemcpy() etc.
We can find the API version with deviceQuery sample.
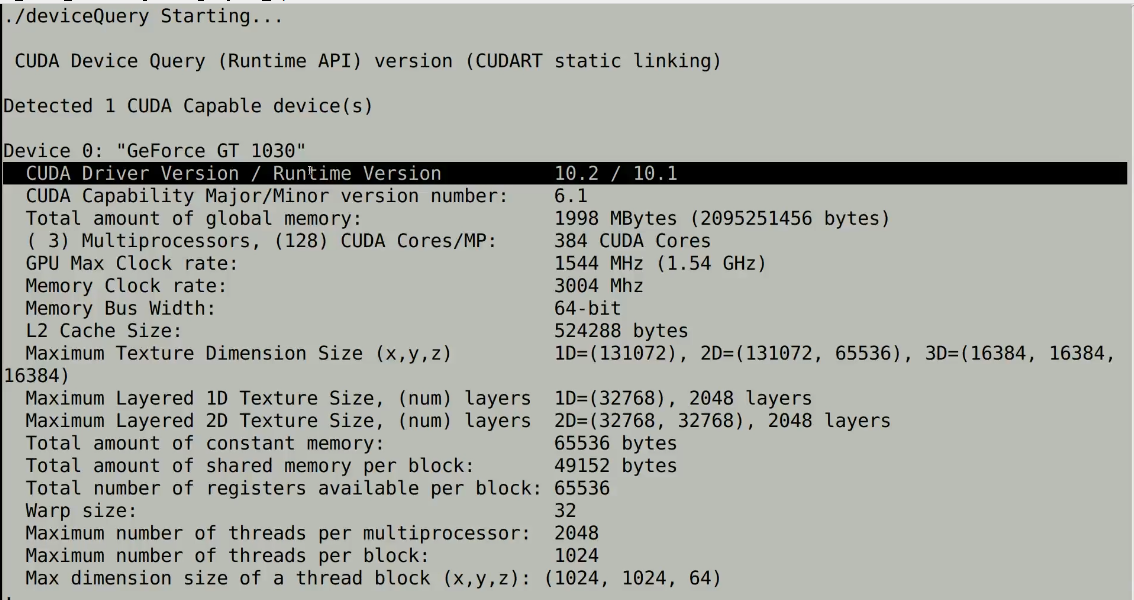
Execution Model
- Kernel : A kernel is a special function to be run on a GPU (device) instead of a CPU (host). We use the keyword __global__ to define a kernel.
Kernels are launched in the host and then executed in parallel by multiple threads on the device.
Kernels are the parallel programs to be run on the device (the NVIDIA graphics card inside the host system).
Typically one thread for each data element you want to process.
-
Threads and Blocks :
-
Threads are grouped into the blocks and the blocks are arranged into a grid.
-
Blocks and Grid can have 1, 2 & 3 dimensions.
-
Threads within the same block share certain resources and can communicate or synchronize with each other.
-
This is very important when we start implementing some more complicated parallel algorithms.
-
The arrangement of the grid can also impact the performance.

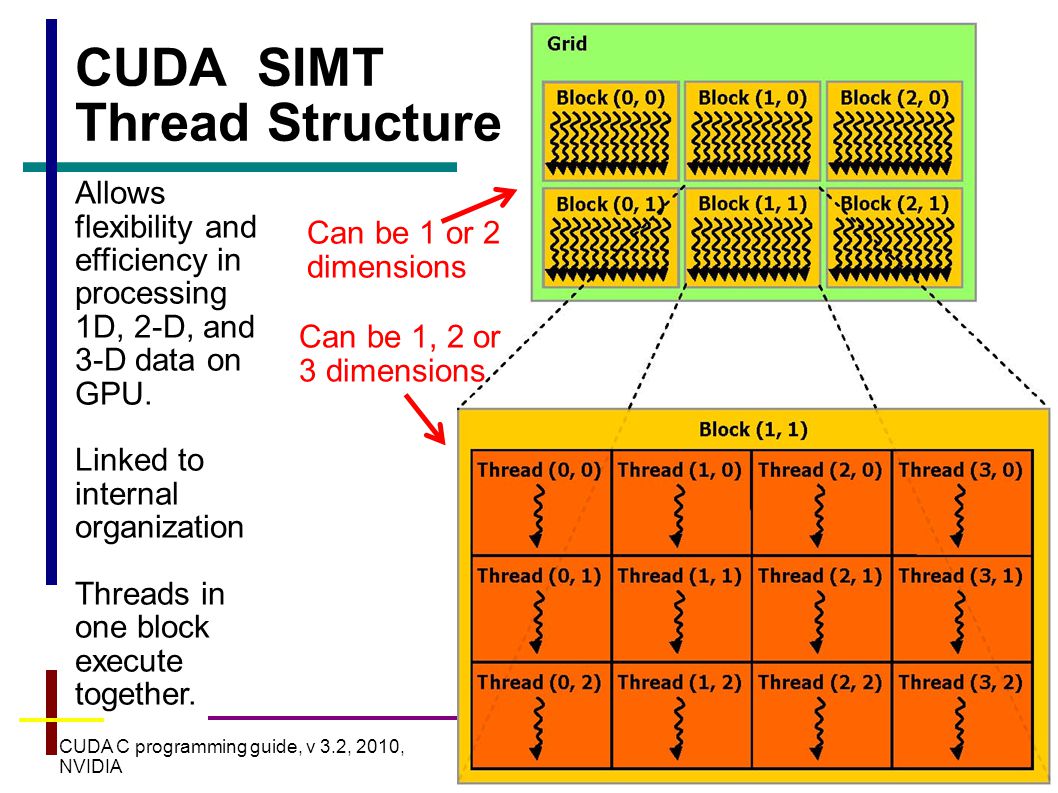
Hardware Architecture
CUDA devices contain multiple streaming multiprocessors (SMs). This uses Single Instructions Multiple Thread (SIMT) architecture with hardware multithreading support.
-
Streaming Multiprocessors (SMs)
-
SIMT Architecture
-
Hardware Multithreading
Streaming Multiprocessors (SMs)
A CUDA device is made up with several streaming multiprocessors or SMs.
Each SMs contains a number of CUDA cores as well as some shared cache, Registers and memory which all are shared between the cores.
The device also has a larger pool of global memory which is shared between the SMs.
The exact no. depends on your hardware.
./deviceQuery Starting...
CUDA Device Query (Runtime API) version (CUDART static linking)
Detected 1 CUDA Capable device(s)
Device 0: "GeForce GTX 1080" CUDA
Driver Version / Runtime Version 10.0 / 10.0 CUDA
Capability Major/Minor version number: 6.1
Total amount of global memory: 8119 MBytes (8513585152 bytes)
Compute Capability
(Version No. which identifies general specifications of a CUDA device.)
Every CUDA device is identified by a compute capability, which indicates its general Hardware features and specifications.
Appendix H — Compute Capabilities
SIMT Architecture
NVIDIA called their hardware architecture SIMT for Single Instruction Multiple Thread.
This basically means that you have many light weight threads running the same instructions across different data.
In SIMT architecture you can adjust the no. of threads. In each thread actually it has some independent states.
Individual threads can even run different instructions although are typically less efficient.
This architecture allows CUDA programs to scale across different hardware. You don’t need to worry about the exact number of SMs or cores available, because CUDA will take care of creating and scheduling all your threads.
Warps
CUDA hardware executes threads in groups of 32 which are called warps. All the thread in the warps run at the same time on the same SM and typically will execute the same instructions.
Hardware Multithreading
This hardware multithreading model allows CUDA to manage thousands of threads very efficiently.
So putting this all together,
This is basically what happens when you run a kernel.
Running a Kernel :
- The blocks are assigned to available SMs.
You are often having more blocks that run one time in which case some of them are in wait.
-
Each block is split into warps of 32 threads, which are scheduled and run on the SMs.
-
You can have multiple warps/blocks running on each SM and the hardware will switch between then whenever a warp needs to wait.
-
As blocks finish executing, the SMs are freed up and CUDA will schedule new blocks until the entire grid is done.
A Basic CUDA (compute unified device architecture) Program Outline
Host The CPU and its memory (host memory)
Device The GPU and its memory (device memory)
int main(){
// Allocate memory for array on host (CPU)
// Allocate memory for array on device
// Fill array on host
// Copy data from host array to device array
// Do something on device (e.g. vector addition)
// Copy data from device array to host array
// Check data for correctness
// Free Host Memory
// Free Device Memory
}
Let’s Come to the code::
The vector addition sample adds two vectors A and B to produce C, where Ci = Ai + Bi.
Basically this is the CUDA kernel.
//Each thread takes care of one element of c
__global__ void vecAdd(double *a, double *b, double *c, int n)
{
// Get our global thread ID
int id = blockIdx.x*blockDim.x+threadIdx.x;
// Make sure we do not go out of bounds
if (id < n)
c[id] = a[id] + b[id];
}
__global__ : Indicates the function is a CUDA kernel function – called by the host and executed on the device.
__void__ : Kernel does not return anything.
int *a, int *b, int *c : Kernel function arguments ( a, b, c are pointers to device memory)
**int i = blockDim.x * blockIdx.x + threadIdx.x; ** This defines a unique thread id among all threads in a grid.
blockDim : Gives the number of threads within each block
blockIdx : Specifies which block the thread belongs to (within the grid of blocks)
threadIdx : Specifies a local thread id within a thread block
int main( int argc, char* argv[] )
{
// Size of vectors
int n = 100000;
Allocate memory for array on host
// Host input vectors
double *h_a;
double *h_b;
//Host output vector
double *h_c;
Allocate memory for array on device(GPU)
// Device input vectors
double *d_a;
double *d_b;
//Device output vector
double *d_c;
// Size, in bytes, of each vector
size_t bytes = n*sizeof(double);
Simple CUDA API for handling device memory cudaMalloc(), cudaFree(), cudaMemcpy()
// Allocate memory for each vector on host
h_a = (double*)malloc(bytes);
h_b = (double*)malloc(bytes);
h_c = (double*)malloc(bytes);
// Allocate memory for each vector on GPU
cudaMalloc(&d_a, bytes);
cudaMalloc(&d_b, bytes);
cudaMalloc(&d_c, bytes);
int i;
// Initialize vectors on host
for( i = 0; i < n; i++ ) {
h_a[i] = sin(i)*sin(i);
h_b[i] = cos(i)*cos(i);
}
cudaMemcpy() copies elements b/w host and device
// Copy host vectors to device
cudaMemcpy( d_a, h_a, bytes, cudaMemcpyHostToDevice);
cudaMemcpy( d_b, h_b, bytes, cudaMemcpyHostToDevice);
Thread Block organization
int blockSize, gridSize;
// Number of threads in each thread block
blockSize = 1024;
// Number of thread blocks in grid
gridSize = (int)ceil((float)n/blockSize);
Execute the kernel
vecAdd<<<gridSize, blockSize>>>(d_a, d_b, d_c, n);
Copy array back to host
cudaMemcpy( h_c, d_c, bytes, cudaMemcpyDeviceToHost );
Sum up vector c and print result
double sum = 0;
for(i=0; i<n; i++)
sum += h_c[i];
printf("final result: %f\n", sum/n);
Release device memory
cudaFree(d_a);
cudaFree(d_b);
cudaFree(d_c);
Release host memory
free(h_a);
free(h_b);
free(h_c);
return 0;
}
This was basic vector addition program in CUDA.
Kernel Execution Configuration
Kernel execution configuration is to control the layout of threads and blocks when running a kernel.
Launching kernel:
my_kernel«< GRID_DIMENSION, BLOCK DIMENSION »>(…)
Triple bracket syntax used for launching the kernels.
The first argument is the grid dimension, which defines the number and layout of the blocks and the second argument is block dimension. These values can be integer for dimensional grid.
Code:
// Demonstration of kernel execution configuration for a 1D-Grid
#include <cuda_runtime_api.h>
#include <stdio.h>
// Error checking macro
#definecudaCheckError(code){
if ((code) != cudaSuccess) {
fprintf(stderr, "Cuda failure %s:%d: '%s' \n", __FILE__, __LINE__,
cudaGetErrorString(code));
}}
__global__ void kernel_1d(){
int index = blockIdx.x * blockDim.x + threadIdx.x;
printf("block %d, thread %d, index %d\n", blockIdx.x, threadIdx.x, index);
}
int main(){
kernel_1d<<<4, 8>>>();
cudaCheckError(cudaDeviceSynchronize());
}
Result :
block 3, thread 0, index 24
block 3, thread 1, index 25
block 3, thread 2, index 26
block 3, thread 3, index 27
block 3, thread 4, index 28
block 3, thread 5, index 29
block 3, thread 6, index 30
block 3, thread 7, index 31
block 0, thread 0, index 0
block 0, thread 1, index 1
block 0, thread 2, index 2
block 0, thread 3, index 3
block 0, thread 4, index 4
block 0, thread 5, index 5
block 0, thread 6, index 6
block 0, thread 7, index 7
block 1, thread 0, index 8
block 1, thread 1, index 9
block 1, thread 2, index 10
block 1, thread 3, index 11
block 1, thread 4, index 12
block 1, thread 5, index 13
block 1, thread 6, index 14
block 1, thread 7, index 15
block 2, thread 0, index 16
block 2, thread 1, index 17
block 2, thread 2, index 18
block 2, thread 3, index 19
block 2, thread 4, index 20
block 2, thread 5, index 21
block 2, thread 6, index 22
block 2, thread 7, index 23
We are calling printf function in device code. The cuda runtime does a magic behind the scenes here, so the messages we print here, were actually copied back to the host and displayed just like a regular printf.
It’s pretty useful for testing and debugging.
Now we’ll launch this kernel with 4 blocks, each containing 8 threads for a total of 32.
One thing you will notice here is that the result of this code is out of order. The print statements from each block are grouped together because the block fits into a single warp so it all runs at once.
But the blocks run in parallel across multiple SM so they can run in any order.
Here is the code which calculates that-
int index = blockIdx.x *blockDim.x + threadIdx.x;
It uses the block no., the block size and the thread index within the block to determine overall index into our data.
For 2D data : Image or Matrix or 3D dim3 is there. We’ll look into that later blogs.
Choosing Block Size :
-
Performance is depending on Block size. Block size will have a big impact.
-
Occupancy — Keeping all SMs busy.
-
Synchronization and Communication (between threads and blocks)
Occupancy :
This comes up alot when talking about CUDA performance.
Occupancy means the ratio between the no. of active warps and the maximum number of devices can support.
In general “Higher is better” as it allows the scheduler to see memory access.
Code:
// Demonstration of the CUDA occupancy API.
#include <cuda_runtime_api.h>
#include <stdio.h>
__global__ void kernel_1d() {}
int main()
{
// The launch configurator returned block size
int block_size;
// The minimum grid size needed to achieve max occupancy
int min_grid_size;
cudaOccupancyMaxPotentialBlockSize(&min_grid_size, &block_size, kernel_1d, 0, 0);
printf("Block size %d\nMin grid size %d\n", block_size, min_grid_size);
}
Result :
Block size 1024
Min grid size 26
Occupancy API telles us Best block size is 1024 and to maximize occupancy we need 26 blocks. We can use this info to calculate the grid layer for my kernel.
Basics of debugging with CUDA — GDB on linux and handling errors
CUDA — GDB is the extension of GDB debugger, which supports CUDA debugging.
It supports breakpoints, single stepping and everything else you expect from a debugger.
Debug the Host and Device code-
nvcc -g -G -o test_bug test_bug.cu
-G enables debugging for device code.
-g enabling debug symbols as in GCC.
References :
What is CUDA? Parallel programming for GPUs
CUDA-Zone
Easier Introduction to CUDA