
- Topics
- webarchive, wayback scraper, wayback rebuilder, wayback downloader, wayback machine scraper
- Item Size
- 38.8M
Wayback machine downloader. How to restore website from wayback machine.
- Addeddate
- 2018-04-06 08:35:30
- Color
- color
- Identifier
- wayback-machine-downloader_201804
- Links
-
https://en.archivarix.com/
- Scanner
- Internet Archive HTML5 Uploader 1.6.3
- Sound
- sound
plus-circle Add Review
plus-circle Add Review
comment
Reviews
(1)
There is 1 review for this item. .
17,138
Views
4
Favorites
1
Review
DOWNLOAD OPTIONS
download 1 file
ITEM TILE download
download 1 file
MPEG4 download
download 1 file
OGG VIDEO download
download 1 file
TORRENT download
download 15 Files
download 7 Original
SHOW ALL
IN COLLECTIONS
Community Video
Uploaded by
DavidAr1
on
Как скачать сайт с вебархива
Материал добавлен: 16 Апреля 2024
Материал обновлен: 01 Апреля 2025
- Установка Ruby в Windows
- Запуск программы Ruby в Windows
- Скачивание сайта с web.archive.org на определённую дату
- Скачивание только нужных файлов (изображения, скрипты, стили)
В жизни каждого администратора сайтов бывают ситуации, когда необходимо восстановить сайт, переставший функционировать, а резервная копия оказалась утеряна или вовсе не создавалась.
В этой статье мы расскажем, как восстановить сайт с помощью web.archive.org, используя компьютер с операционной системой Windows 10.
Приступим! Эта инструкция подойдёт тем, кому необходимо восстановить от нескольких десятков до тысяч страниц.
Установка Ruby в Windows
Ruby — популярный язык программирования, на котором создано множество полезных утилит, таких как WPScan, WhatWeb, Wayback Machine Downloader и другие.
Нас интересует именно Wayback Machine Downloader, поэтому начнём с установки Ruby в Windows.
Перейдите на страницу загрузки установщика: https://rubyinstaller.org/downloads
Там вы увидите несколько версий установщиков, отличающихся составом файлов. Все они включают в себя язык Ruby, среду выполнения, документацию и прочее.
Этот установщик обеспечивает совместимость с большинством gem-пакетов и включает MSYS2-Devkit, позволяющий компилировать C-расширения сразу после установки.
- Запустите скачанный файл.
- Согласитесь с лицензионным соглашением.
- Установите все предложенные компоненты (оставьте галочки по умолчанию).
В последнем окне установки оставьте галочку для настройки инструментов MSYS2 и нажмите Finish.
Затем произойдёт установка компонентов Ruby:
1 - MSYS2 base installation 2 - MSYS2 system update (optional) 3 - MSYS2 and MINGW development toolchain Which components shall be installed? If unsure press ENTER [1,3]
Нажмите Enter и установите все компоненты по умолчанию.
После завершения установки нажмите ENTER для выхода.
Готово — Ruby установлен в Windows 10.
Запуск программы Ruby в Windows
Нас интересует утилита Wayback Machine Downloader, предназначенная для восстановления сайтов из веб-архива.
Для её установки выполните следующее:
- Откройте командную строку: нажмите Win + R, введите
cmdи нажмите ENTER.
Введите команду:
gem install wayback_machine_downloader
Проверьте установку с помощью команды:
wayback_machine_downloader --help
Запустите пробное восстановление сайта:
wayback_machine_downloader http://raduga-kanevsk.ucoz.ru
Архив сайта будет сохранён в папке websites, которая находится по пути:
C:\Users\Имя_пользователя\websites
Или: Этот компьютер → Локальный диск (C:) → Пользователи → [Ваш профиль] → websites.
Скачивание сайта с web.archive.org на определённую дату
На сайте web.archive.org введите адрес нужного сайта и нажмите ENTER.
В появившемся календаре выберите диапазон дат — начальную и конечную.
Скопируйте ссылку, как показано ниже:
Начало: http://web.archive.org/web/20230327194856/http://raduga-kanevsk.ucoz.ru Конец: http://web.archive.org/web/20231003201927/http://raduga-kanevsk.ucoz.ru
Введите команду в консоли:
wayback_machine_downloader -f20230327194856 -t20231003201927 raduga-kanevsk.ucoz.ru
Сайт будет восстановлен по заданному периоду. Все файлы сохраняются в папке:
C:\Users\Имя_пользователя\websites\raduga-kanevsk.ucoz.ru
Скачивание только нужных файлов (изображения, скрипты, стили)
Если вам не нужен весь сайт, а только определённые типы файлов, используйте фильтр:
wayback_machine_downloader https://site.clan.su --only "/\.(gif|jpg|jpeg|png|js|ttf|woff|woff2|eot|svg)$/i" --directory downloaded-backup/
Просто замените https://site.clan.su на адрес своего сайта.
Файлы будут сохранены в папке:
C:\Users\Имя_пользователя\downloaded-backup
Откройте папку и восстановите необходимые элементы, например, случайно удалённые с FTP-аккаунта.
- Документация по Wayback Machine Downloader
Wayback Machine Downloader
Download an entire website from the Internet Archive Wayback Machine.
Installation
You need to install Ruby on your system (>= 1.9.2) — if you don’t already have it.
Then run:
gem install wayback_machine_downloader
Tip: If you run into permission errors, you might have to add sudo in front of this command.
Basic Usage
Run wayback_machine_downloader with the base url of the website you want to retrieve as a parameter (e.g., http://example.com):
wayback_machine_downloader http://example.com
How it works
It will download the last version of every file present on Wayback Machine to ./websites/example.com/. It will also re-create a directory structure and auto-create index.html pages to work seamlessly with Apache and Nginx. All files downloaded are the original ones and not Wayback Machine rewritten versions. This way, URLs and links structure are the same as before.
Advanced Usage
Usage: wayback_machine_downloader http://example.com
Download an entire website from the Wayback Machine.
Optional options:
-d, --directory PATH Directory to save the downloaded files into
Default is ./websites/ plus the domain name
-s, --all-timestamps Download all snapshots/timestamps for a given website
-f, --from TIMESTAMP Only files on or after timestamp supplied (ie. 20060716231334)
-t, --to TIMESTAMP Only files on or before timestamp supplied (ie. 20100916231334)
-e, --exact-url Download only the url provided and not the full site
-o, --only ONLY_FILTER Restrict downloading to urls that match this filter
(use // notation for the filter to be treated as a regex)
-x, --exclude EXCLUDE_FILTER Skip downloading of urls that match this filter
(use // notation for the filter to be treated as a regex)
-a, --all Expand downloading to error files (40x and 50x) and redirections (30x)
-c, --concurrency NUMBER Number of multiple files to download at a time
Default is one file at a time (ie. 20)
-p, --maximum-snapshot NUMBER Maximum snapshot pages to consider (Default is 100)
Count an average of 150,000 snapshots per page
-l, --list Only list file urls in a JSON format with the archived timestamps, won't download anything
Specify directory to save files to
Optional. By default, Wayback Machine Downloader will download files to ./websites/ followed by the domain name of the website. You may want to save files in a specific directory using this option.
Example:
wayback_machine_downloader http://example.com --directory downloaded-backup/
All Timestamps
Optional. This option will download all timestamps/snapshots for a given website. It will uses the timestamp of each snapshot as directory.
Example:
wayback_machine_downloader http://example.com --all-timestamps
Will download:
websites/example.com/20060715085250/index.html
websites/example.com/20051120005053/index.html
websites/example.com/20060111095815/img/logo.png
...
From Timestamp
Optional. You may want to supply a from timestamp to lock your backup to a specific version of the website. Timestamps can be found inside the urls of the regular Wayback Machine website (e.g., https://web.archive.org/web/20060716231334/http://example.com). You can also use years (2006), years + month (200607), etc. It can be used in combination of To Timestamp.
Wayback Machine Downloader will then fetch only file versions on or after the timestamp specified.
Example:
wayback_machine_downloader http://example.com --from 20060716231334
To Timestamp
Optional. You may want to supply a to timestamp to lock your backup to a specific version of the website. Timestamps can be found inside the urls of the regular Wayback Machine website (e.g., https://web.archive.org/web/20100916231334/http://example.com). You can also use years (2010), years + month (201009), etc. It can be used in combination of From Timestamp.
Wayback Machine Downloader will then fetch only file versions on or before the timestamp specified.
Example:
wayback_machine_downloader http://example.com --to 20100916231334
Exact Url
Optional. If you want to retrieve only the file matching exactly the url provided, you can use this flag. It will avoid downloading anything else.
For example, if you only want to download only the html homepage file of example.com:
wayback_machine_downloader http://example.com --exact-url
Only URL Filter
Optional. You may want to retrieve files which are of a certain type (e.g., .pdf, .jpg, .wrd…) or are in a specific directory. To do so, you can supply the --only flag with a string or a regex (using the ‘/regex/’ notation) to limit which files Wayback Machine Downloader will download.
For example, if you only want to download files inside a specific my_directory:
wayback_machine_downloader http://example.com --only my_directory
Or if you want to download every images without anything else:
wayback_machine_downloader http://example.com --only "/\.(gif|jpg|jpeg)$/i"
Exclude URL Filter
-x, --exclude EXCLUDE_FILTER
Optional. You may want to retrieve files which aren’t of a certain type (e.g., .pdf, .jpg, .wrd…) or aren’t in a specific directory. To do so, you can supply the --exclude flag with a string or a regex (using the ‘/regex/’ notation) to limit which files Wayback Machine Downloader will download.
For example, if you want to avoid downloading files inside my_directory:
wayback_machine_downloader http://example.com --exclude my_directory
Or if you want to download everything except images:
wayback_machine_downloader http://example.com --exclude "/\.(gif|jpg|jpeg)$/i"
Expand downloading to all file types
Optional. By default, Wayback Machine Downloader limits itself to files that responded with 200 OK code. If you also need errors files (40x and 50x codes) or redirections files (30x codes), you can use the --all or -a flag and Wayback Machine Downloader will download them in addition of the 200 OK files. It will also keep empty files that are removed by default.
Example:
wayback_machine_downloader http://example.com --all
Only list files without downloading
It will just display the files to be downloaded with their snapshot timestamps and urls. The output format is JSON. It won’t download anything. It’s useful for debugging or to connect to another application.
Example:
wayback_machine_downloader http://example.com --list
Maximum number of snapshot pages to consider
-p, --snapshot-pages NUMBER
Optional. Specify the maximum number of snapshot pages to consider. Count an average of 150,000 snapshots per page. 100 is the default maximum number of snapshot pages and should be sufficient for most websites. Use a bigger number if you want to download a very large website.
Example:
wayback_machine_downloader http://example.com --snapshot-pages 300
Download multiple files at a time
Optional. Specify the number of multiple files you want to download at the same time. Allows one to speed up the download of a website significantly. Default is to download one file at a time.
Example:
wayback_machine_downloader http://example.com --concurrency 20
Using the Docker image
As an alternative installation way, we have a Docker image! Retrieve the wayback-machine-downloader Docker image this way:
docker pull hartator/wayback-machine-downloader
Then, you should be able to use the Docker image to download websites. For example:
docker run --rm -it -v $PWD/websites:/websites hartator/wayback-machine-downloader http://example.com
Contributing
Contributions are welcome! Just submit a pull request via GitHub.
To run the tests:
bundle install
bundle exec rake test
Оглавление:
- 1 Установка Ruby
- 2 Установка Wayback Machine Downloader
- 3 Качаем сайт с веб-архива бесплатно
- 4 Результат
Статья последний раз была обновлена 02.07.2024
Рано или поздно любому вебмастеру потребуется скачать какой-то сайт с вебархива. Цели бывают разные, от получения забытого поисковиками и типо уникального контента, до полного копирования сайта с сохранением всей страктуры, для восстановления на приобретенном дроп-домене. Лучше всего для этого подойдет бесплатный сервис web.archive.org. У сервиса нет никаких квот на объемы данных и время скачивания. Нам потребуется только терминал и 5 минут на настройку. Все манипуляции будут производиться в операционной системе Windows пусть 10.
Установка Ruby
Поддержка Ruby в системе необходима для работы нашей утилиты для скачивания сайтов с вебархива. Установить проще всего дистрибутивно, то есть зайти на сайт этого языка программирования и скачать инсталлятор. Все должно установиться автоматически, включая переменные окружения, и по итогу Ruby вот так мило встанет на диск C:
Установка Wayback Machine Downloader
Это и есть наша бесплатная консольная утилита для скачивания архивной версии сайта. Устанавливать мы ее будем через встроенный в Ruby пакетный менеджер RubyGems, вот такой командой:
gem install wayback_machine_downloader
У меня эта программа уже установлена:
И теперь переходим к самому главному!
Качаем сайт с веб-архива бесплатно
В терминале вводим команду:
wayback_machine_downloader https://site.com
Где https://site.com — любой сайт, который нужно скачать (сайт можно указать и без протокола). Оговорка, почти любой. Некоторые сайты закрывают доступ боту вебархива в robots.txt и не сканируются сервисом, также владельцы сайта могут попросить удалить все снимки своего сайта, и это будет выполнено безоговорочно администрацией Wayback Machine.
Дополнительные параметры утилиты можно посмотреть на ее старнице в GitHub (см. ссылку выше по тексту).
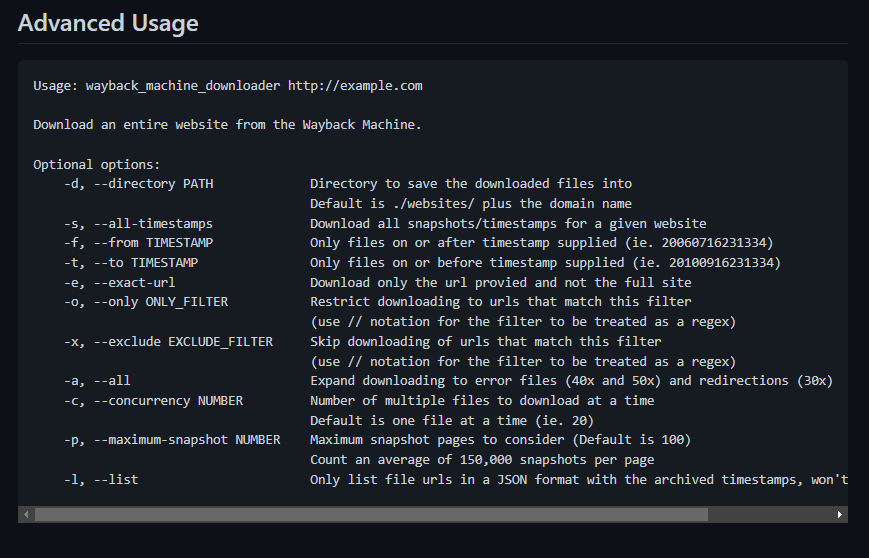
Для понимания, как пользоваться дополнительными параметрами, приведу пример. Ситуация такая, что сайт обновлялся только до определенной даты, а потом домен был припаркован. Значит нам нужно скачать сайт только до определенной даты, чтобы не скачивать мусорные страницы из снимков архива. Для наглядности проще всего посмотреть эти моменты на сайте веб-архива:

Это значение в URL — 20150214182119 называется TIMESTAMP, теперь мы можем использовать его в параметрах утилиты для скачивания старого сайта. Вот так:
wayback_machine_downloader https://site.com --to 20150214182119
Еще одна важная опция. Если скачиваемый сайт огромен, то нужно скачивать его не постранично, а, например, по 20 страниц за один подход:
wayback_machine_downloader https://site.com --to 20150214182119 --concurrency 20
Результат
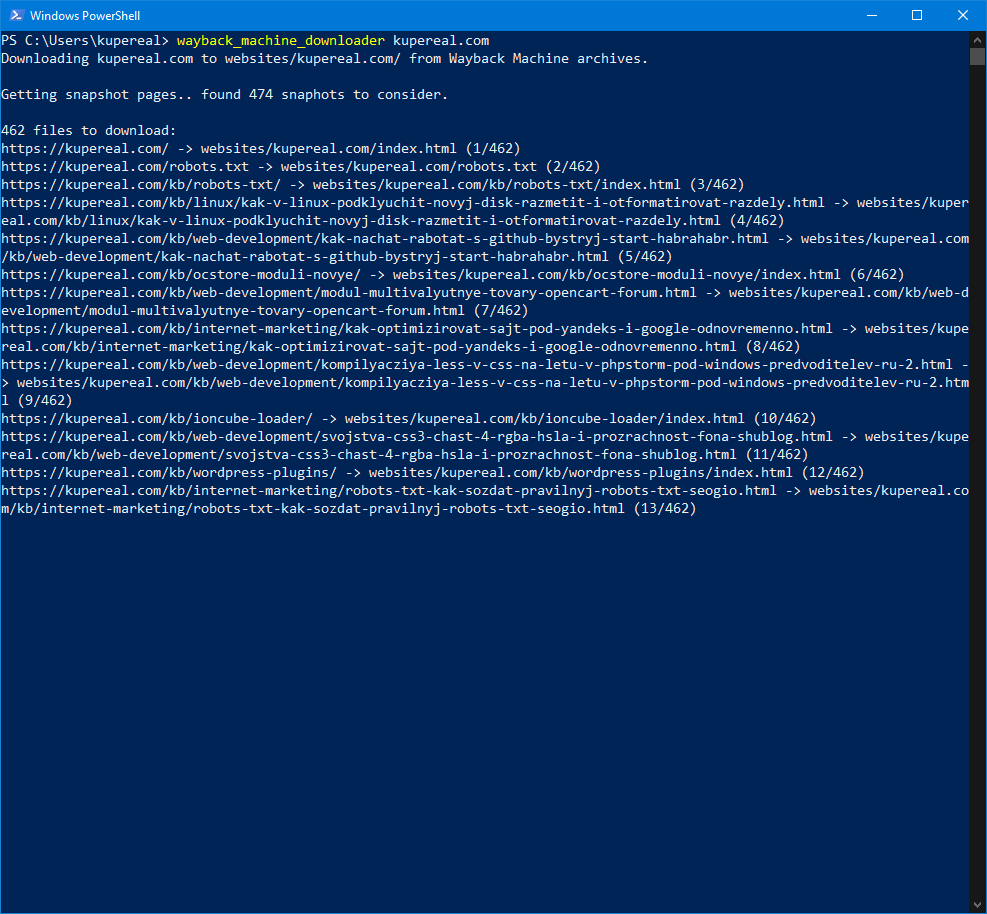
Отменить процесс можно нажав Ctrl+C. Все сайты по умолчанию будут скачиваться в папку websites в профиле пользователя.
Скачиваться сайт будет в HTML формате, с сохранением структуры катологов, все внутренние ссылки тоже будут работать. По сути, это не просто скачивание архива сайта, а создание готового статического сайта на файлах, который потом можно выгружать на любой хостинг. Если вы планируете размещать статические сайты массово, то лучше выбрать хостинг с раздельной оплатой за сервисы, когда например можно оплачивать только наличие веб-сервера Apache и не платить за интерпретатор PHP или поддержку СУБД MySQL. Как вариант, можно использовать бесплатные площадки для подобных сайтов типа GitHub Pages или Cloudflare Pages. Но это уже отдельная история…
- Об авторе
- Недавние публикации
IT-специалист широкого профиля, в настоящее время занимаюсь разработкой и преимущественно продвижением веб-сайтов (SEO, SEM, SMO, SMM).
Что входит в наш Wayback Downloader?
Наш сайт-зеркало создает набор файлов, который называется загрузчик wayback machine. Этот zip-файл включает в себя всё, что нужно для восстановления и возможного возобновления веб-сайта из веб-архива.
- Он содержит все файлы HTML, CSS, JS и изображения.
- Он содержит всю информацию, удаленную из archive.org, так что он выглядит точно так же, как оригинал.
- Все URL восстанавливаются как оригинальные посредством создания файла .htaccess, который отвечает за любые переадресации или перезаписи.
Фактически: мы заботимся обо всех технических деталях и даже предоставляем помощь в установке, если Вы в ней нуждаетесь.
Что такое веб-архив?
Веб-архив безоговорочно является самым известным инструментом резервного копирования всемирной паутины. Он показывает веб-сайты в том виде, в котором они отображались в разные моменты времени.
Целью интернет-архива является резервное копирование интернета в целом в разные моменты времени в течении последних 20-ти лет. Вы можете путешествовать в прошлое до самого существования определенного сайта или страницы.
Мы предлагаем программный инструмент, который делает скачивание сайта с Wayback Machine простым. Мы назвали её Wayback Machine Downloads (Wayback Machine загрузчик).
Наш Wayback-загрузчик – замечательный инструмент. Он переходит на web.archive.org и вытягивает данные полезным, простым и умным способом.