
Время на прочтение8 мин
Количество просмотров180K
Каталог:
Один
Два
Три
Менеджер памяти (и связанные с ним вопросы контроллера кеша, менеджера ввода/вывода и пр) — одна из вещей, в которой (наряду с медициной и политикой) «разбираются все». Но даже люди «изучившие винду досконально» нет-нет, да и начинают писать чепуху вроде (не говоря уже о другой чепухе, написанной там же):
Грамотная работа с памятью!!! За все время использования у меня своп файл не увеличился ни на Килобайт. По этому Фаерфокс с 10-20 окнами сворачивается / разворачивается в/из трея как пуля. Такого эффекта я на винде добивался с отключенным свопом и с переносом tmp файлов на RAM диск.
Или к примеру μTorrent — у меня нет никаких оснований сомневаться в компетентности его авторов, но вот про работу памяти в Windows они со всей очевидностью знают мало. Не забываем и товарищей, производящих софт для слежения за производительностью и не имеющих ни малейшего понятия об управлении памятью в Windows (и поднявших по этому поводу истерику на пол интернета, на Ars-е даже был разбор полетов). Но самое потрясающее, что я видел всвязи с управлением памятью — это совет переместить pagefile на RAM-диск:
Из моих трех гигабайт под RAM disk был выделен один (на тот момент, когда на лаптопе еще была установлена XP), на котором я создал своп на 768МБ …
Цель данной статьи — не полное описание работы менеджера памяти (не хватит ни места ни опыта), а попытка пролить хоть немного света на темное царство мифов и суеверий, окружающих вопросы управления памятью в Windows.
Disclaimer
Сам я не претендую на то, чтобы знать все и никогда не ошибаться, поэтому с радостью приму любые сообщения о неточностях и ошибках.
Введение
С чего начать не знаю, поэтому начну с определений.
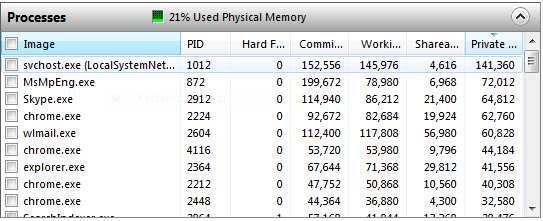
Commit Size — количество памяти, которое приложение запросило под собственные нужды.
Working Set (на картинке выше он так и называется Working Set) — это набор страниц физической памяти, которые в данный момент «впечатаны» в адресное пространство процесса. Рабочий набор процесса System принято выделять в отдельный «Системный рабочий набор», хотя механизмы работы с ним практически не отличаются от механизмов работы с рабочими наборами остальных процессов.
И уже здесь зачастую начинается непонимание. Если присмотреться, можно увидеть, что Commit у многих процессов меньше Working Set-а. То есть если понимать буквально, «запрошено» меньше памяти, чем реально используется. Так что уточню, Commit — это виртуальная память, «подкрепленная» (backed) только физической памятью или pagefile-ом, в то время как Working Set содержит еще и страницы из memory mapped файлов. Зачем это делается? Когда делается NtAllocateVirtualMemory (или любые обертки над heap manager-ом, например malloc или new) — память как бы резервируется (чтоб еще больше запутать, это не имеет никакого отношения к MEM_RESERVE, который резервирует адресное пространство, в данном же случае речь идет о резервировании именно физических страниц, которые система действительно может выделить), но физические страницы впечатываются только при фактическом обращении по выделенному адресу виртуальной памяти. Если позволить приложениям выделить больше памяти, чем система реально может предоставить — рано или поздно может случиться так, что все они попросят реальную страницу, а системе неоткуда будет ее взять (вернее некуда будет сохранить данные). Это не касается memory mapped файлов, так как в любой момент система может перечитать/записать нужную страницу прямо с/на диск(а).
В общем, суммарный Commit Charge в любой момент времени не должен превышать системный Commit Limit (грубо, суммарный объем физической памяти и всех pagefile-ов) и с этим связана одна из неверно понимаемых цифр на Task Manager-ах до Висты включительно.
Commit Limit не является неизменным — он может увеличиваться с ростом pagefile-ов. Вообще говоря, можно считать, что pagefile — это такой очень специальный memory mapped файл: привязка физической страницы в виртуальной памяти к конкретному месту в pagefile-е происходит в самый последний момент перед сбросом, в остальном же механизмы memory mapping-а и swapping-а очень схожи.
Working Set процесса делится на Shareable и Private. Shareable — это memory mapped файлы (в том числе и pagefile backed), вернее те части, которые в данный момент действительно представлены в адресном пространстве процесса физической страницей (это же Working Set в конце концов), а Private — это куча, стеки, внутренние структуры данных типа PEB/TEB и т.д. (опять таки, повторюсь на всякий случай: речь идет только той части кучи и прочих структур, которые физически находятся в адресном пространстве процесса). Это тот минимум информации, с которой уже можно что то делать. Для сильных духом есть Process Explorer, который показывает еще больше подробностей (в частности какая часть вот той Shareable действительно Shared).
И, самое главное, ни один из этих параметров по отдельности не позволяет сделать более менее полноценных выводов о происходящем в программе/системе.
Task Manager
Столбец «Memory» в списке процессов и практически вся вкладка «Performance» настолько часто понимаются неправильно, что у меня есть желание, чтоб Task Manager вообще удалили из системы: те, кому надо смогут воспользоваться Process Explorer-ом или хотя бы Resource Monitor-ом, всем остальным Task Manager только вредит. Для начала, собственно о чем речь
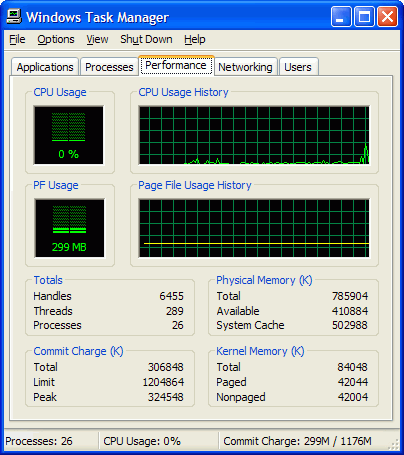

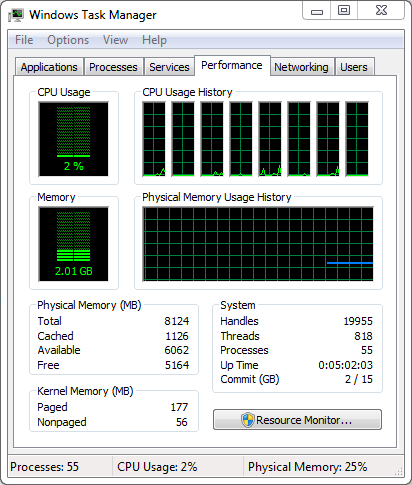
Начну с того, о чем я уже упоминал: Page File usage. XP показывает текущее использование pagefile-а и историю (самое забавное, что в статус баре те же цифры названы правильно), Виста — показывает Page File (в виде дроби Current/Limit), и только Win7 называет его так, чем оно на самом деле является: Commit Charge/Commit Limit.
Эксперимент. Открываем таск менеджер на вкладке с «использованием пейджфайла», открываем PowerShell и копируем в него следующее (для систем, у которых Commit Limit ближе, чем на 3 Гб от Commit Charge можно в последней строчке уменьшить 3Gb, а лучше увеличить pagefile):
add-type -Namespace Win32 -Name Mapping -MemberDefinition @" [DllImport("kernel32.dll", SetLastError = true)] public static extern IntPtr CreateFileMapping( IntPtr hFile, IntPtr lpFileMappingAttributes, uint flProtect, uint dwMaximumSizeHigh, uint dwMaximumSizeLow, [MarshalAs(UnmanagedType.LPTStr)] string lpName); [DllImport("kernel32.dll", SetLastError = true)] public static extern IntPtr MapViewOfFile( IntPtr hFileMappingObject, uint dwDesiredAccess, uint dwFileOffsetHigh, uint dwFileOffsetLow, uint dwNumberOfBytesToMap); "@ $mapping = [Win32.Mapping]::CreateFileMapping(-1, 0, 2, 1, 0, $null) [Win32.Mapping]::MapViewOfFile($mapping, 4, 0, 0, 3Gb)
Это приводит к мгновенному повышению «использования свопфайла» на 3 гигабайта. Повторная вставка «использует» еще 3 Гб. Закрытие процесса мгновенно освобождает весь «занятый свопфайл». Самое интересное, что, как я уже говорил memory mapped файлы (в том числе и pagefile backed) являются shareable и не относятся к какому либо конкретному процессу, поэтому не учитываются в Commit Size никакого из процессов, с другой стороны pagefile backed секции используют (charged against) commit, потому что именно физическая память или пейджфайл, а не какой нибудь посторонний файл, будут использоваться для того, чтобы хранить данные, которые приложение захочет разместить в этой секции. С третьей стороны, после меппинга секции себе в адресное пространство, процесс не трогает ее — следовательно, физические страницы по этим адресам не впечатываются и никаких изменений в Working Set процесса не происходит.
Строго говоря, пейджфайл действительно «используется» — в нем резервируется место (не конкретное положение, а именно место, как размер), но при этом реальная страница, для которой это место было зарезервировано может находиться в физической памяти, на диске или И ТАМ И ТАМ одновременно. Вот такая вот циферка, признайтесь честно, сколько раз глядя на «Page File usage» в Task Manager-е Вы действительно понимали, что она означает.
Что же до Processes таба — там все еще по дефолту показывается Memory (Private Working Set) и несмотря на то, что он называется совершенно правильно и не должен вызывать недоразумений у знающих людей — проблема в том, что подавляющее большинство людей, которые смотрят на эти цифры совершенно не понимают, что они означают. Простой эксперимент: запускаем утилилиту RamMap (советую скачать весь комплект), запускаете Task Manager со списком процессов. В RamMap выбираете в меню Empty->Empty Working Sets и смотрите на то, что происходит с памятью процессов.
Если кого-то все еще раздражают циферки в Task Manager-е, можете поместить следующий код в профайл павершелла:
add-type -Namespace Win32 -Name Psapi -MemberDefinition @" [DllImport("psapi", SetLastError=true)] public static extern bool EmptyWorkingSet(IntPtr hProcess); "@ filter Reset-WorkingSet { [Win32.Psapi]::EmptyWorkingSet($_.Handle) } sal trim Reset-WorkingSet
После чего станет возможно «оптимизировать» использование памяти одной командой, например для «оптимизации» памяти, занятой хромом: ps chrome | trim
Или вот «оптимизация» памяти всех процессов хрома, использующих больше 100 Мб физической памяти: ps chrome |? {$_.WS -gt 100Mb} | trim
Если хотя бы половина прочитавших отметет саму идею о подобной «оптимизации», как очевиднейший абсурд — можно будет сказать, что я не зря старался.
Кеш
В первую очередь отмечу, что кеш в Windows не блочный, а файловый. Это дает довольно много преимуществ, начиная от более простого поддержания когерентности кеша например при онлайн дефрагментации и простого механизма очистки кеша при удалении файла и заканчивая более консистентными механизмами его реализации (кеш контроллер реализован на основе механизма memory mapping-а), возможностью более интеллектуальных решений на основе более высокоуровневой информации о читаемых данных (к примеру интеллектуальный read-ahead для файлов открытых на последовательный доступ или возможность назначать приоритеты отдельным файловым хендлам).
В принципе из недостатков я могу назвать только значительно более сложную жизнь разработчиков файловых систем: слышали о том, что написание драйверов — это для психов? Так вот, написание драйверов файловых систем — для тех, кого даже психи считают психами.
Если же описывать работу кеша, то все предельно просто: когда файловая система запрашивает у кеш-менеджера какую нибудь часть файла, последний просто меппит часть этого файла в специальный «слот», описываемый структурой VACB (посмотреть все смепленные файлы можно из отладчика ядра с помощью расширения !filecache) после чего просто выполняет операцию копирования памяти (RtlCopyMemory). Происходт Page Fault, так как сразу после отображения файла в память все страницы невалидны и дальше система может либо найти необходимую страницу в одном из «свободных» списков либо выполнить операцию чтения.
Для того, чтобы понять рекурсию нужно понять рекурсию. Каким же образом выполняется операция чтения файла, необходимая для завершения операции чтения этого самого файла? Здесь опять все достаточно просто: пакет запроса на ввод/вывод (IRP) создается с флагом IRP_PAGING_IO и при получении такого пакета файловая система уже не обращается к кешу, а идет непосредственно к нижележащему дисковому устройству за данными. Все эти смепленные слоты идут в System Working Set и составляют ЧАСТЬ кеша.
Страница из лекции какого то токийского университета (эх, мне бы так):
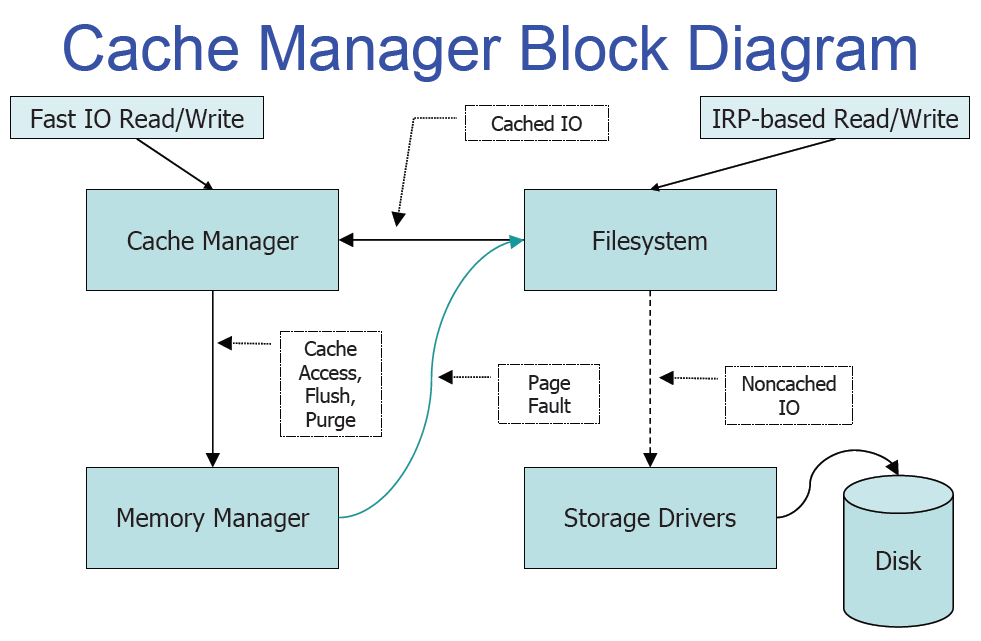
На этом работа собственно кеш-менеджера заканчивается и начинается работа менедера памяти. Когда выше мы делали EmptyWorkingSet это не приводило ни к какой дисковой активности, но тем не менее, физическая память используемая процессом сокращалась (и все физические страницы действительно уходили из адресного пространства процесса делая его почти полностью невалидным). Так куда же она уходит после того, как отбирается у процесса? А уходит она, в зависимости от того, соответствует ли ее содержимое тому, что было прочитано с диска, в один из двух списков: Standby (начиная с Висты это не один список, а 8, о чем позже) или Modified:
Standby список таким образом — это свободная память, содержащая какие то данные с диска (в том числе возможно и pagefile-а).
Если Page Fault происходит по адресу, который спроецирован на часть файла, которая все еще есть в одном из этих списков — она просто возвращается обратно в рабочий набор процесса и впечатывается по искомому адресу (этот процесс называется softfault). Если нет — то, как и в случае со слотами кеш менеджера, выполняется PAGING_IO запрос (называется hardfault).
Modified список может содержать «грязные» страницы достаточно долго, но либо когда размер этого списка чрезмерно вырастает, либо по когда система видит недостаток свободной памяти, либо по таймеру, просыпается modified page writer thread и начинает частями сбрасывать этот список на диск, и перемещая страницы из modified списка в standby (ведь эти страницы опять содержат неизмененную копию данных с диска).
Upd:
Пользователь m17 дал ссылки на выступление Руссиновича на последнем PDC на ту же тему (хм, я честно его до этого не смотрел, хотя пост во много перекликается). Если понимание английского на слух позволяет, то чтение данного топика можно заменить прослушиванием презентаций:
Mysteries of Windows Memory Management Revealed, Part 1 of 2
Mysteries of Windows Memory Management Revealed, Part 2 of 2
Пользователь DmitryKoterov подсказывает, что перенос пейджфайла на RAM диск иногда действительно может иметь смысл (вот уж никогда б наверное и не догадался, если б не написал топик), а именно, если RAM-диск использует физическую память, недоступную остальной системе (PAE + x86 + 4+Gb RAM).
Пользователь Vir2o в свою очередь подсказывает что хотя при некоторых условиях и пожертвовав стабильностью системы ram-диск, использующий физическую память, невидимую остальной системе написать можно, но такое очень маловероятно.
1.
Лекция №3
Управление памятью в ОС Windows
2.
Основные понятия
• Физическая память представляет собой упорядоченное множество
ячеек и все они пронумерованы, то есть с каждой из них можно
обратиться, указав ее порядковый номер (адрес). Количество ячеек
физической памяти ограничено и фиксировано
• Виртуальная память создает иллюзию того, что каждый процесс
имеет доступ к 4Гб непрерывного адресного пространства
• Виртуальное адресное пространство процесса является набором
адресов, доступным всем потокам этого процесса
• ОС распределяет адресное пространство физической и виртуальной
памяти страницами (pages) – блоками по 4Кб
3.
Механизмы управления памятью решают две главные задачи:
• Трансляция, или проецирование, виртуального адресного пространства
процесса на физическую память. Это позволяет ссылаться на
корректные адреса физической памяти, когда нити, выполняемые в
контексте процесса, читают и записывают его в виртуальном адресном
пространстве
• Подкачка части содержимого памяти на диск, когда нити или
системный код пытаются задействовать больший объем физической
памяти, чем тот, который имеется в наличии, и загрузка страниц
обратно в физическую память по мере необходимости
Физическое подмножество виртуального адресного пространства
процесса называется рабочим набором (working set)
4.
Организация виртуальной памяти
Процесс 1
Процесс 2
Физическая память
Файл подкачки
• В период выполнения диспетчер памяти (в
Ntoskrnl.exe), транслирует, или проецирует
(maps) виртуальные адреса на физические, по
которым хранятся данные
• Подкачка данных на диск освобождает
физическую память для других процессов или
самой ОС
• Диспетчер памяти опирается на аппаратную
поддержку механизма подкачки
• В процессе работы система виртуальной
памяти использует один или несколько файлов
подкачки, расположенных на жестком диске
(pagefile.sys)
5.
Страницы виртуальной памяти имеют три состояния:
Процесс 1
Процесс 2
Физическая память
Файл подкачки
• Большинство страниц пусто, поскольку
процесс их не использует, они никуда не
отображаются
• Используемые страницы отображаются с
помощью невидимого для процесса
указателя в область физической
оперативной памяти (ОЗУ)
• Некоторые страницы, к которым не было
обращений в течение определенного
времени, отображаются с помощью
невидимого для процесса указателя в 4Кб
раздел файла подкачки (pagefile.sys)
6.
Файл подкачки
pagefile.sys может быть создан на каждом логическом диске системы, находится
в корне дерева каталогов и является скрытым и системным файлом
7.
Процесс управления местоположением страниц – в ОЗУ или в
страничном файле называется подкачкой страниц по запросу
Процесс 1
Процесс 2
Физическая память
Файл подкачки
• Приложение делает попытку сохранить данные в памяти
• Диспетчер виртуальной памяти перехватывает запрос и определяет,
сколько страниц необходимо для его выполнения. После этого он
отображает неиспользуемую физическую память на нужные незанятые
области виртуального пространства процесса. При этом диспетчер
виртуальной памяти скрывает от приложения (процесса) способ
организации физической памяти. Когда приложение обратится к
конкретному виртуальному адресу, он будет транслирован в
уникальный физический адрес, не конфликтующий с другими
процессами
• Если в системе не хватает физической памяти, диспетчер виртуальной
памяти выполняет поиск страниц ОЗУ, не использовавшихся в течение
определенного времени, и копирует эти страницы в страничный файл
(pagefile.sys), находящийся на жестком диске. Освободившаяся область
ОЗУ отображается на виртуальное адресное пространство
запросившего память процесса
8.
Структура адресного пространства пользовательского процесса
Системная память
Системный кэш
Пул неподкачиваемой памяти
Пул подкачиваемой памяти
4 Гб
Ядро, HAL, драйверы
2 Гб
• По умолчанию каждый пользовательский процесс в Windows 32-bit
получает закрытое адресное пространство размером до 2 Гб, а
остальные 2 Гб занимает ОС
• Код ОС отображается в верхние 2Гб виртуального адресного
пространства процесса
• При инициализации системы диспетчер памяти создает два типа
динамических пулов памяти, используемых компонентами режима
ядра для выделения системной памяти:
Код приложения
Глобальные переменные
Стеки нитей
Код DLL
• Пул неподкачиваемой памяти (nonpaged pool). Состоит из
диапазонов системных виртуальных адресов, которые всегда
присутствуют в физической памяти и доступны в любой момент.
• Пул подкачиваемой памяти (paged pool). Регион виртуальной памяти
в системном пространстве, содержимое которого система может
выгружать в страничный файл и загружать из него
64 Кб
0
9.
Разделение памяти процессами. Разделяемая память
Процесс 1
Физическая память
Процесс 2
• Разделяемой (shared memory) называется
память, видимая более, чем одному процессу
или присутствующая в виртуальном
пространстве более, чем одного процесса.
• Например, если два процесса используют одну и
ту же DLL, имеет смысл загрузить ее код в
физическую память один раз и сделать ее
доступной всем процессам, в виртуальной
памяти которых присутствует эта DLL.
• Каждый процесс поддерживает закрытые
области памяти для хранения собственных
данных, но программный код и страницы
немодифицируемых данных в принципе можно
использовать совместно с другими процессами.
10.
Режим ядра и пользовательский режим
• Windows и Linux используют два режима доступа к процессору:
пользовательский (user mode – кольцо 3)
ядра (kernel mode — кольцо 0)
• Код приложений работает в пользовательском режиме, тогда как код ОС (например, системные
сервисы и драйверы устройств) – в режиме ядра (режим супервизора)
• В режиме ядра предоставляется доступ ко всей системной памяти и разрешается выполнять
любые машинные команды процессора
• Хотя каждый Win32-процесс имеет свою (закрытую) память, код ОС и драйверы устройств,
работающие в режиме ядра, делят единое виртуальное адресное пространство
• Каждая страница в виртуальной памяти помечается тэгом, определяющим, в каком режиме
Кольца привилегий
архитектуры x86 в
защищённом режиме
должен работать процессор для чтения и/или записи данной страницы
Страницы в системном пространстве доступны лишь в режиме ядра, а все страницы в
пользовательском адресном пространстве – в пользовательском режиме. Страницы только для
чтения (например, содержащие лишь исполняемый код) ни в каком режиме для записи
недоступны
11.
Режим ядра и пользовательский режим
• Windows не предусматривает никакой защиты системной памяти от компонентов, работающих в режиме ядра. Иначе говоря,
код ОС и драйверов устройств в режиме ядра получает полный доступ к системной памяти и может обходить средства
защиты Windows для обращения к любым объектам
• Надо быть осторожным при загрузке драйвера устройства от стороннего поставщика: перейдя в режим ядра, он получит
полный доступ ко всем данным ОС. Такая уязвимость стала одной из причин, по которой в Windows 2000 был введен
механизм проверки цифровых подписей драйверов, предупреждающий пользователя о попытке установки
неавторизированного (неподписанного) драйвера
• Режим гипервизора (Hypervisor mode), который называют Ring -1, реализуется с целью поддержки технологий виртуализации
на уровне аппаратного обеспечения. Это позволяет достигнуть одновременного выполнения нескольких операционных
систем на одном процессоре без существенных потерь производительности. При выполнении привилегированных операций
операционными системами в режиме супервизора управление передается специальной программе — гипервизору.
• Гипервизор осуществляет арбитраж использования имеющихся аппаратных ресурсов несколькими операционными
системами аналогично тому как сами операционные системы осуществляют распределение ресурсов между несколькими
задачами. По сути, гипервизор обычно является небольшим ядром, которое управляет распределением ресурсов между
несколькими операционными системами и работает уровнем ниже, чем сами операционные системы.
Виртуальная память
Виртуальная память — это важная часть операционных систем, включая Windows. Она представляет собой механизм, позволяющий приложениям, работать с большими объемами памяти, чем физически доступно на компьютере, и обеспечивает изоляцию процессов друг от друга. Вот основные аспекты виртуальной памяти в Windows:
Виртуальная адресация
Каждому процессу в Windows предоставляется свое собственное виртуальное адресное пространство. Это означает, что каждый процесс видит свою собственную непрерывную область адресов, начиная с нуля. Этот механизм позволяет изолировать процессы друг от друга, так что один процесс не может напрямую обратиться к памяти другого процесса.
Физическая память и страничный файл
Виртуальная память Windows состоит из физической оперативной памяти (RAM) и страничного файла на диске. Если физическая память заполняется, то часть данных может быть перемещена в страничный файл, освобождая место для новых данных. Этот процесс называется “подкачкой” (paging).
Страницы памяти
Виртуальная память разбивается на небольшие блоки, называемые страницами памяти. Размер страницы обычно составляет 4 КБ. Windows использует систему управления таблицами страниц (Page Table) для отображения виртуальных адресов на физические адреса или на адреса в страничном файле.
Отображение виртуальной памяти
Когда процесс обращается к виртуальной памяти, операционная система Windows преобразует виртуальный адрес в соответствующий физический адрес. Если требуемая страница находится в физической памяти, это происходит незаметно. Если страница находится в страничном файле, она должна быть загружена в физическую память перед доступом к ней.
Защита памяти
Виртуальная память Windows также обеспечивает механизмы защиты. Каждая страница памяти может иметь разрешения на чтение, запись и выполнение. Это позволяет операционной системе и программам контролировать доступ к памяти и предотвращать некорректное или вредоносное поведение.
Управление виртуальной памятью
Операционная система Windows автоматически управляет виртуальной памятью, включая подкачку данных между физической памятью и страничным файлом. Программисты обычно не заботятся о деталях управления виртуальной памятью, но могут использовать API для запроса дополнительной памяти (например, функции VirtualAlloc) и управления защитой памяти (например, функции VirtualProtect).
Управление динамической памятью
Управление памятью в Windows может быть выполнено с использованием различных функций и API операционной системы. Давайте рассмотрим несколько примеров кода на языке C/C++ для выделения и освобождения памяти в Windows.
Выделение памяти с использованием malloc и free (C/C++)
#include <stdio.h>
#include <stdlib.h>
int main() {
// Выделение памяти под массив целых чисел
int *arr = (int*)malloc(5 * sizeof(int));
if (arr == NULL) {
printf("Не удалось выделить память\n");
return 1;
}
// Использование выделенной памяти
for (int i = 0; i < 5; i++) {
arr[i] = i * 10;
}
// Освобождение памяти после использования
free(arr);
return 0;
}В этом примере мы используем функции malloc для выделения памяти под массив целых чисел и free для освобождения этой памяти после ее использования.
Выделение памяти с использованием функции VirtualAlloc (WinAPI)
#include <Windows.h>
#include <stdio.h>
int main() {
// Выделение 1 мегабайта (1048576 байт) виртуальной памяти
LPVOID mem = VirtualAlloc(NULL, 1048576, MEM_COMMIT, PAGE_READWRITE);
if (mem == NULL) {
printf("Не удалось выделить виртуальную память\n");
return 1;
}
// Использование выделенной виртуальной памяти
// Освобождение виртуальной памяти
VirtualFree(mem, 0, MEM_RELEASE);
return 0;
}Здесь мы используем функцию VirtualAlloc из библиотеки WinAPI для выделения виртуальной памяти. После использования памяти мы освобождаем ее с помощью функции VirtualFree.
Выделение и освобождение памяти с использованием C++ операторов new и delete
#include <iostream>
#include <windows.h>
int main() {
SetConsoleOutputCP(1251);
// Выделение памяти под одно целое число
int *num = new int;
// Использование выделенной памяти
*num = 42;
std::cout << "Значение: " << *num << std::endl;
// Освобождение памяти
delete num;
return 0;
}Стек и куча
Стек и куча — это две основные области памяти, используемые в программах для хранения данных и управления памятью. Они имеют разные характеристики и предназначены для разных целей. Давайте рассмотрим их более подробно:
Стек (Stack)
- Характеристики:
- Ограниченный по размеру.
- Доступ к данным выполняется в порядке “первым вошел, последним вышел” (LIFO — Last-In, First-Out).
- Часто фиксированный размер стека определяется на этапе компиляции.
- Использование:
- Хранит локальные переменные функций и адреса возврата после вызова функций.
- Используется для управления вызовами функций (стек вызовов).
- Жизненный цикл данных:
- Данные, хранящиеся в стеке, автоматически удаляются при завершении функции, в которой они определены.
- Ограниченное время жизни.
- Примеры языков:
- Стек используется в C, C++, Java (для вызовов методов), Python (для вызовов функций).
Куча (Heap)
- Характеристики:
- Динамически расширяемая область памяти.
- Доступ к данным происходит в произвольном порядке.
- Размер кучи ограничен объемом доступной физической и виртуальной памяти.
- Использование:
- Хранит данные, которые могут иметь долгий или неопределенный срок жизни, такие как объекты, созданные динамически.
- Жизненный цикл данных:
- Данные, хранящиеся в куче, существуют до тех пор, пока на них есть указатели, и могут быть освобождены вручную (например, с помощью
freeв C/C++ или сборщика мусора в других языках).
- Данные, хранящиеся в куче, существуют до тех пор, пока на них есть указатели, и могут быть освобождены вручную (например, с помощью
- Примеры языков:
- Куча используется в C, C++, C#, Java (для объектов, созданных с помощью
new), Python (с использованием модуляgcдля сборки мусора).
- Куча используется в C, C++, C#, Java (для объектов, созданных с помощью
Сравнение стека и кучи
-
Стек обычно быстрее доступен для чтения и записи, чем куча.
-
Куча предоставляет более гибкое управление памятью, но требует явного освобождения ресурсов.
-
Стек обеспечивает управление временем жизни данных автоматически, в то время как в куче это делается вручную.
-
Использование стека ограничено, поэтому он лучше подходит для хранения данных с известным временем жизни, в то время как куча подходит для данных с неопределенным или долгим временем жизни.
-
Оба механизма имеют свои применения и зависят от конкретных требований программы.
Функции для работы со стеком
Windows предоставляет набор функций и API для работы со стеком приложения. Эти функции позволяют программам управлять стеком вызовов функций, а также получать информацию о текущем состоянии стека. Вот некоторые из наиболее часто используемых функций Windows для работы со стеком:
GetCurrentThreadStackLimits (Windows 8.1 и более поздние версии)
Эта функция позволяет получить информацию о границах стека текущего потока. Она возвращает указатель на начало и конец стека текущего потока. Это может быть полезно, например, для отслеживания использования стека и предотвращения переполнения стека.
Пример использования:
void GetStackLimits() {
ULONG_PTR lowLimit, highLimit;
GetCurrentThreadStackLimits(&lowLimit, &highLimit);
printf("Low Limit: 0x%llx\n", lowLimit);
printf("High Limit: 0x%llx\n", highLimit);
}RtlCaptureContext (Windows XP и более поздние версии)
Эта функция захватывает текущий контекст выполнения, включая информацию о регистрах и указателях стека. Это может быть полезно при анализе стека или сохранении контекста выполнения для последующего использования.
Пример использования:
CONTEXT context;
RtlCaptureContext(&context);
// Теперь у вас есть информация о контексте выполнения текущего потокаVirtualQuery (Windows XP и более поздние версии)
Эта функция позволяет получить информацию о виртуальной памяти, включая стек. Вы можете использовать ее для определения границ стеков разных потоков или для анализа виртуальной памяти вашего процесса.
Пример использования:
MEMORY_BASIC_INFORMATION mbi;
VirtualQuery(&someAddress, &mbi, sizeof(mbi));
// Теперь вы можете получить информацию о найденной памяти, включая стекSetThreadStackGuarantee (Windows 8 и более поздние версии)
Эта функция позволяет установить минимальный размер стека для потока. Это может быть полезно, чтобы предотвратить переполнение стека в потоках с большой глубиной вызовов.
Пример использования:
DWORD stackSize = 0x10000; // 64 КБ
SetThreadStackGuarantee(&stackSize);StackWalk64 (DbgHelp API)
Эта функция из библиотеки DbgHelp API позволяет выполнять обход стека вызовов функций для получения информации о вызовах и адресах функций. Она полезна при создании отладочных и профилирующих инструментов.
Пример использования:
STACKFRAME64 stackFrame;
// Настройка параметров и выполнение обхода стекаФункции для работы с кучей
WinAPI предоставляет ряд функций для работы с кучей (памятью, выделяемой в куче). Основные функции включают в себя HeapCreate, HeapAlloc, HeapFree, HeapReAlloc и HeapDestroy. Давайте рассмотрим эти функции более подробно:
HeapCreate
-
Создает новую кучу.
-
Синтаксис:
HANDLE HeapCreate(DWORD flOptions, SIZE_T dwInitialSize, SIZE_T dwMaximumSize); -
Пример:
HANDLE hHeap = HeapCreate(0, 0, 0);
HeapAlloc
-
Выделяет блок памяти из кучи.
-
Синтаксис:
LPVOID HeapAlloc(HANDLE hHeap, DWORD dwFlags, SIZE_T dwBytes); -
Пример:
int* pData = (int*)HeapAlloc(hHeap, 0, sizeof(int) * 10);
HeapFree
-
Освобождает блок памяти, выделенный ранее с помощью
HeapAlloc. -
Синтаксис:
BOOL HeapFree(HANDLE hHeap, DWORD dwFlags, LPVOID lpMem); -
Пример:
HeapFree(hHeap, 0, pData);
HeapReAlloc
-
Изменяет размер выделенного блока памяти в куче.
-
Синтаксис:
LPVOID HeapReAlloc(HANDLE hHeap, DWORD dwFlags, LPVOID lpMem, SIZE_T dwBytes); -
Пример:
pData = (int*)HeapReAlloc(hHeap, 0, pData, sizeof(int) * 20);
HeapDestroy
-
Уничтожает кучу и освобождает все связанные с ней ресурсы.
-
Синтаксис:
BOOL HeapDestroy(HANDLE hHeap); -
Пример:
HeapSize
-
Возвращает размер выделенного блока памяти в куче.
-
Синтаксис:
SIZE_T HeapSize(HANDLE hHeap, DWORD dwFlags, LPCVOID lpMem); -
Пример:
SIZE_T size = HeapSize(hHeap, 0, pData);
HeapValidate
-
Проверяет целостность кучи и выделенных блоков.
-
Синтаксис:
BOOL HeapValidate(HANDLE hHeap, DWORD dwFlags, LPCVOID lpMem); -
Пример:
if (HeapValidate(hHeap, 0, pData)) { printf("Куча валидна.\n"); } else { printf("Куча повреждена.\n"); }
Пример 1: Создание кучи и выделение памяти
#include <Windows.h>
#include <stdio.h>
int main() {
SetConsoleOutputCP(1251);
// Создание кучи
HANDLE hHeap = HeapCreate(0, 0, 0);
if (hHeap == NULL) {
printf("Не удалось создать кучу\n");
return 1;
}
// Выделение памяти из кучи
int *data = (int*)HeapAlloc(hHeap, 0, sizeof(int) * 5);
if (data == NULL) {
printf("Не удалось выделить память из кучи\n");
HeapDestroy(hHeap);
return 1;
}
// Использование выделенной памяти
for (int i = 0; i < 5; i++) {
data[i] = i * 10;
}
// Освобождение памяти
HeapFree(hHeap, 0, data);
// Уничтожение кучи
HeapDestroy(hHeap);
return 0;
}В этом примере мы создаем кучу с помощью HeapCreate, выделяем память из кучи с помощью HeapAlloc, используем эту память и освобождаем ее с помощью HeapFree, а затем уничтожаем кучу с помощью HeapDestroy.
Пример 2: Выделение строки в куче
#include <Windows.h>
#include <stdio.h>
int main() {
SetConsoleOutputCP(1251);
// Создание кучи
HANDLE hHeap = HeapCreate(0, 0, 0);
if (hHeap == NULL) {
printf("Не удалось создать кучу\n");
return 1;
}
// Выделение строки в куче
char *str = (char*)HeapAlloc(hHeap, 0, 256);
if (str == NULL) {
printf("Не удалось выделить память для строки\n");
HeapDestroy(hHeap);
return 1;
}
// Копирование строки в выделенную память
strcpy_s(str, 256, "Пример строки в куче");
// Использование строки
// Освобождение памяти
HeapFree(hHeap, 0, str);
// Уничтожение кучи
HeapDestroy(hHeap);
return 0;
}В этом примере мы выделяем память для строки в куче, копируем строку в эту память, используем ее и освобождаем память.
Отображение файлов на адресное пространство
File mapping (сопоставление файла) в WinAPI — это механизм, который позволяет отображать содержимое файла в виртуальную память процесса. Это может быть полезно для обмена данными между процессами, создания разделяемой памяти или для улучшения производительности при доступе к большим файлам. Давайте рассмотрим основы использования file mapping в WinAPI:
Создание файла для сопоставления
Сначала необходимо создать или открыть файл, который вы хотите сопоставить. Это можно сделать с помощью функций, таких как CreateFile или OpenFile. Например:
HANDLE hFile = CreateFile(
L"C:\\example.txt", // Имя файла
GENERIC_READ | GENERIC_WRITE, // Режим доступа
0, // Атрибуты файла
NULL, // Дескриптор безопасности
OPEN_ALWAYS, // Действие при открытии (создать, если не существует)
FILE_ATTRIBUTE_NORMAL, // Атрибуты файла
NULL // Шаблон для атрибутов
);Создание отображения файла в памяти
Затем создайте отображение файла в виртуальную память с помощью функции CreateFileMapping. Это создает объект отображения файла, который может быть использован для доступа к содержимому файла:
HANDLE hMapFile = CreateFileMapping(
hFile, // Дескриптор файла
NULL, // Атрибуты безопасности (можно использовать NULL)
PAGE_READWRITE, // Режим доступа к файлу в отображении
0, // Размер отображения файла (0 - весь файл)
0, // Высший значащий байт размера файла
NULL // Имя отображения файла (можно использовать NULL)
);Отображение файла в виртуальную память
Завершите процесс сопоставления файла, отображая его в виртуальную память с помощью функции MapViewOfFile:
LPVOID pData = MapViewOfFile(
hMapFile, // Дескриптор отображения файла
FILE_MAP_ALL_ACCESS, // Режим доступа к отображению
0, // Смещение в файле
0, // Начальный байт отображения
0 // Размер отображения (0 - весь файл)
);Использование данных
Теперь pData указывает на начало отображения файла в виртуальной памяти. Вы можете работать с данными, как с обычной памятью.
Освобождение ресурсов
После завершения работы с данными не забудьте освободить ресурсы:
UnmapViewOfFile(pData); // Освобождение отображения файла
CloseHandle(hFile); // Закрытие дескриптора файла
CloseHandle(hMapFile); // Закрытие дескриптора отображения файлаНаверх
6.2. Функции ОС по управлению памятью
Под памятью (memory) в данном случае подразумевается оперативная (основная) память компьютера. В однопрограммных операционных системах основная память разделяется на две части. Одна часть для операционной системы (резидентный монитор, ядро), а вторая – для выполняющейся в текущий момент времени программы. В многопрограммных ОС «пользовательская» часть памяти – важнейший ресурс вычислительной системы – должна быть распределена для размещения нескольких процессов, в том числе процессов ОС. Эта задача распределения выполняется операционной системой динамически специальной подсистемой управления памятью (memory management). Эффективное управление памятью жизненно важно для многозадачных систем. Если в памяти будет находиться небольшое число процессов, то значительную часть времени процессы будут находиться в состоянии ожидания ввода-вывода и загрузка процессора будет низкой.
В ранних ОС управление памятью сводилось просто к загрузке программы и ее данных из некоторого внешнего накопителя (перфоленты, магнитной ленты или магнитного диска) в ОЗУ. При этом память разделялась между программой и ОС. На рис. 6.3 показаны три варианта такой схемы. Первая модель раньше применялась на мэйнфреймах и мини-компьютерах. Вторая схема сейчас используется на некоторых карманных компьютерах и встроенных системах, третья модель была характерна для ранних персональных компьютеров с MS-DOS.
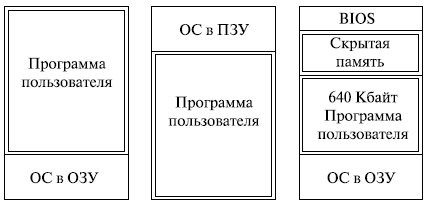
Рис.
6.3.
Варианты распределения памяти
С появлением мультипрограммирования задачи ОС, связанные с распределением имеющейся памяти между несколькими одновременно выполняющимися программами, существенно усложнились.
Функциями ОС по управлению памятью в мультипрограммных системах являются:
- отслеживание (учет) свободной и занятой памяти;
- первоначальное и динамическое выделение памяти процессам приложений и самой операционной системе и освобождение памяти по завершении процессов;
- настройка адресов программы на конкретную область физической памяти;
- полное или частичное вытеснение кодов и данных процессов из ОП на диск, когда размеры ОП недостаточны для размещения всех процессов, и возвращение их в ОП;
- защита памяти, выделенной процессу, от возможных вмешательств со стороны других процессов;
- дефрагментация памяти.
Перечисленные функции особого пояснения не требуют, остановимся только на задаче преобразования адресов программы при ее загрузке в ОП.
Для идентификации переменных и команд на разных этапах жизненного цикла программы используются символьные имена, виртуальные (математические, условные, логические – все это синонимы) и физические адреса (рис. 6.4).
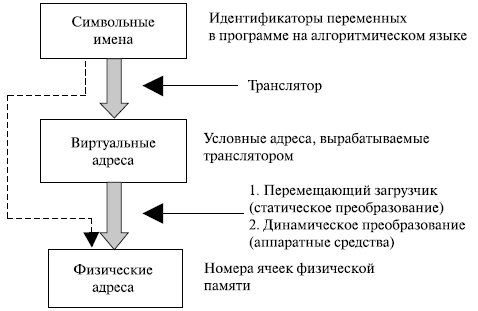
Рис.
6.4.
Типы адресов
Символьные имена присваивает пользователь при написании программ на алгоритмическом языке или ассемблере. Виртуальные адреса вырабатывает транслятор, переводящий программу на машинный язык. Поскольку во время трансляции неизвестно, в какое место оперативной памяти будет загружена программа, транслятор присваивает переменным и командам виртуальные (условные) адреса, считая по умолчанию, что начальным адресом программы будет нулевой адрес.
Физические адреса соответствуют номерам ячеек оперативной памяти, где в действительности будут расположены переменные и команды.
Совокупность виртуальных адресов процесса называется виртуальным адресным пространством. Диапазон адресов виртуального пространства у всех процессов один и тот же и определяется разрядностью адреса процессора (для Pentium адресное пространство составляет объем, равный 232 байт, с диапазоном адресов от 0000.000016 до FFFF.FFFF16).
Существует два принципиально отличающихся подхода к преобразованию виртуальных адресов в физические. В первом случае такое преобразование выполняется один раз для каждого процесса во время начальной загрузки программы в память. Преобразование осуществляет перемещающий загрузчик на основании имеющихся у него данных о начальном адресе физической памяти, в которую предстоит загружать программу, а также информации, предоставляемой транслятором об адресно-зависимых элементах программы.
Второй способ заключается в том, что программа загружается в память в виртуальных адресах. Во время выполнения программы при каждом обращении к памяти операционная система преобразует виртуальные адреса в физические.
6.3. Распределение памяти
Существует ряд базовых вопросов управления памятью, которые в различных ОС решаются по-разному. Например, следует ли назначать каждому процессу одну непрерывную область физической памяти или можно выделять память участками? Должны ли сегменты программы, загруженные в память, находиться на одном месте в течение всего периода выполнения процесса или их можно время от времени сдвигать? Что делать, если сегменты программы не помещаются в имеющуюся память? Как сократить затраты ресурсов системы на управление памятью? Имеется и ряд других не менее интересных проблем управления памятью [5, 10, 13, 17].
Ниже приводится классификация методов распределения памяти, в которой выделено два класса методов – с перемещением сегментов процессов между ОП и ВП (диском) и без перемещения, т.е. без привлечения внешней памяти (рис. 6.5). Данная классификация учитывает только основные признаки методов. Для каждого метода может быть использовано несколько различных алгоритмов его реализации.
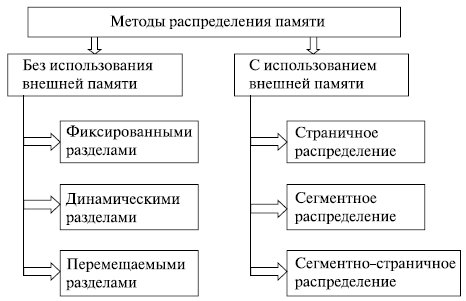
Рис.
6.5.
Классификация методов распределения памяти
На рис. 6.6 показаны два примера фиксированного распределения. Одна возможность состоит в использовании разделов одинакового размера. В этом случае любой процесс, размер которого не превышает размера раздела, может быть загружен в любой доступный раздел. Если все разделы заняты и нет ни одного процесса в состоянии готовности или работы, ОС может выгрузить процесс из любого раздела и загрузить другой процесс, обеспечивая тем самым процессор работой.

Рис.
6.6.
Варианты фиксированного распределения памяти
При использовании разделов с одинаковым размером имеются две проблемы.
- Программа может быть слишком велика для размещения в разделе. В этом случае программист должен разрабатывать программу, использующую оверлеи, чтобы в любой момент времени требовался только один раздел памяти. Когда требуется модуль, отсутствующий в данный момент в ОП, пользовательская программа должна сама его загрузить в раздел памяти программы. Таким образом, в данном случае управление памятью во многом возлагается на программиста.
- Использование ОП крайне неэффективно. Любая программа, независимо от ее размера, занимает раздел целиком. При этом могут оставаться неиспользованные участки памяти большого размера. Этот феномен появления неиспользованной памяти называется внутренней фрагментацией (internal fragmentation).
Бороться с этими трудностями (хотя и не устранить полностью) можно посредством использования разделов разных размеров. В этом случае программа размером до 8 Мбайт может обойтись без оверлеев, а разделы малого размера позволяют уменьшить внутреннюю фрагментацию при загрузке небольших программ.
В том случае, когда разделы имеют одинаковый раздел, размещение процессов тривиально – в любой свободный раздел. Если все разделы заняты процессами, которые не готовы к немедленной работе, любой из них может быть выгружен для освобождения памяти для нового процесса.
Когда разделы имеют разные размеры, есть два возможных подхода к назначению процессов разделам памяти. Простейший путь состоит в том, чтобы каждый процесс размещался в наименьшем разделе, способном вместить данный процесс (в этом случае в задании пользователя указывался размер требуемой памяти). При таком подходе для каждого раздела требуется очередь планировщика, в которой хранятся выгруженные из памяти процессы, предназначенные для данного раздела памяти. Достоинство такого способа в возможности распределения процессов между разделами ОП так, чтобы минимизировать внутреннюю фрагментацию.
Недостаток заключается в том, что отдельные очереди для разделов могут привести к неоптимальному распределению памяти системы в целом. Например, если в некоторый момент времени нет ни одного процесса размером от 7 до 12 Мбайт, то раздел размером 12 Мбайт будет пустовать, в то время как он мог бы использоваться меньшими процессами. Поэтому более предпочтительным является использование одной очереди для всех процессов. В момент, когда требуется загрузить процесс в ОП, выбирается наименьший доступный раздел, способный вместить данный процесс.
В целом можно отметить, что схемы с фиксированными разделами относительно просты, предъявляют минимальные требования к операционной системе; накладные расходы работы процессора на распределение памяти невелики. Однако у этих схем имеются серьезные недостатки.
- Количество разделов, определенное в момент генерации системы, ограничивает количество активных процессов (т.е. уровень мультипрограммирования).
- Поскольку размеры разделов устанавливаются заранее во время генерации системы, небольшие задания приводят к неэффективному использованию памяти. В средах, где заранее известны потребности в памяти всех задач, применение рассмотренной схемы может быть оправдано, но в большинстве случаев эффективность этой технологии крайне низка.
Для преодоления сложностей, связанных с фиксированным распределением, был разработан альтернативный подход, известный как динамическое распределение. В свое время этот подход был применен фирмой IBM в операционной системе для мэйнфреймов в OS/MVT (мультипрограммирование с переменным числом задач – Multiprogramming With a Variable number of Tasks). Позже этот же подход к распределению памяти использован в ОС ЕС ЭВМ [12] .
При динамическом распределении образуется перемененное количество разделов переменной длины. При размещении процесса в основной памяти для него выделяется строго необходимое количество памяти. В качестве примера рассмотрим использование 64 Мбайт (рис. 6.7) основной памяти. Изначально вся память пуста, за исключением области, задействованной ОС. Первые три процесса загружаются в память, начиная с адреса, где заканчивается ОС, и используют столько памяти, сколько требуется данному процессу. После этого в конце ОП остается свободный участок памяти, слишком малый для размещения четвертого процесса. В некоторый момент времени все процессы в памяти оказываются неактивными, и операционная система выгружает второй процесс, после чего остается достаточно памяти для загрузки нового, четвертого процесса.

Рис.
6.7.
Вариант использования памяти
Поскольку процесс 4 меньше процесса 2, появляется еще свободный участок памяти. После того как в некоторый момент времени все процессы оказались неактивными, но стал готовым к работе процесс 2, свободного места в памяти для него не находится, а ОС вынуждена выгрузить процесс 1, чтобы освободить необходимое место и разместить процесс 2 в ОП. Как показывает данный пример, этот метод хорошо начинает работу, но плохо продолжает. В конечном счете, он приводит к наличию множества мелких свободных участков памяти, в которых нет возможности разместить какой-либо новый процесс. Это явление называется внешней фрагментацией (external fragmentation), что отражает тот факт, что сильно фрагментированной становится память, внешняя по отношению ко всем разделам.
Один из методов преодоления внешней фрагментации – уплотнение (compaction) процессов в ОП. Осуществляется это перемещением всех занятых участков так, чтобы вся свободная память образовала единую свободную область. В дополнение к функциям, которые ОС выполняет при распределении памяти динамическими разделами, в данном случае она должна еще время от времени копировать содержимое разделов из одного места в другое, корректируя таблицы свободных и занятых областей. Эта процедура называется уплотнением или сжатием.
Перечислим функции операционной системы по управлению памятью в этом случае.
- Перемещение всех занятых участков в сторону старших или младших адресов при каждом завершении процесса или для вновь создаваемого процесса в случае отсутствия раздела достаточного размера.
- Коррекция таблиц свободных и занятых областей.
- Изменение адресов команд и данных, к которым обращаются процессы при их перемещении в памяти, за счет использования относительной адресации.
- Аппаратная поддержка процесса динамического преобразования относительных адресов в абсолютные адреса основной памяти.
- Защита памяти, выделяемой процессу, от взаимного влияния других процессов.
Уплотнение может выполняться либо при каждом завершении процесса, либо только тогда, когда для вновь создаваемого процесса нет свободного раздела достаточного размера. В первом случае требуется меньше вычислительной работы при корректировке таблиц свободных и занятых областей, а во втором – реже выполняется процедура сжатия.
Так как программа перемещается по оперативной памяти в ходе своего выполнения, в данном случае невозможно выполнить настройку адресов с помощью перемещающего загрузчика. Здесь более подходящим оказывается динамическое преобразование адресов. Достоинствами распределения памяти перемещаемыми разделами являются эффективное использование оперативной памяти, исключение внутренней и внешней фрагментации, недостатком – дополнительные накладные расходы ОС.
При использовании фиксированной схемы распределения процесс всегда будет назначаться одному и тому же разделу памяти после его выгрузки и последующей загрузке в память. Это позволяет применять простейший загрузчик, который замещает при загрузке процесса все относительные ссылки абсолютными адресами памяти, определенными на основе базового адреса загруженного процесса.
Ситуация усложняется, если размеры разделов равны (или неравны) и существует единая очередь процессов, – процесс по ходу работы может занимать разные разделы. Такая же ситуация возможна и при динамическом распределении. В этих случаях расположение команд и данных, к которым обращается процесс, не является фиксированным и изменяется всякий раз при выгрузке, загрузке или перемещении процесса. Для решения этой проблемы в программах используются относительные адреса. Это означает, что все ссылки на память в загружаемом процессе даются относительно начала этой программы. Таким образом, для корректной работы программы требуется аппаратный механизм, который бы транслировал относительные адреса в физические в процессе выполнения команды, обращающейся к памяти.
Применяемый обычно способ трансляции показан на рис. 6.8. Когда процесс переходит в состояние выполнения, в специальный регистр процесса, называемый базовым, загружается начальный адрес процесса в основной памяти. Кроме того, используется «граничный» (bounds) регистр, в котором содержится адрес последней ячейки программы. Эти значения заносятся в регистры при загрузке программы в основную память. При выполнении процесса относительные адреса в командах обрабатываются процессором в два этапа. Сначала к относительному адресу прибавляется значение базового регистра для получения абсолютного адреса. Затем полученный абсолютный адрес сравнивается со значением в граничном регистре. Если полученный абсолютный адрес принадлежит данному процессу, команда может быть выполнена. В противном случае генерируется соответствующее данной ошибке прерывание.
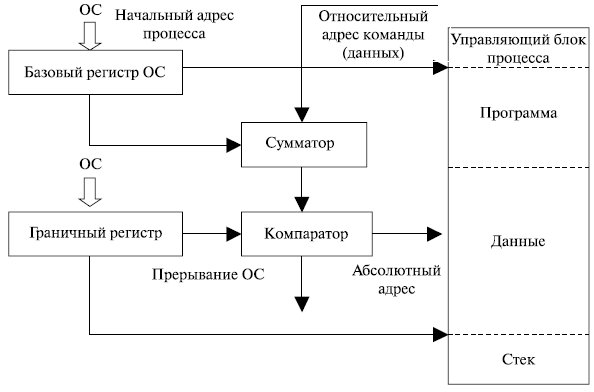
Рис.
6.8.
Преобразование адресов
Введение
Управление памятью – это критически важная и при этом довольно сложная задача для операционной системы. Это дает возможность запускать несколько процессов одновременно без сбоев.
Понимание того, как работает управление памятью в операционных системах, имеет ключевое значение для стабильности и высокой производительности системы.
В этой статье мы рассмотрим ключевые концепции управления памятью в операционных системах.
Что такое управление памятью?
Основные компоненты управления памятью – это процессор и блок памяти. Эффективность системы зависит от того, как эти два компонента взаимодействуют друг с другом.
Эффективность управления памятью зависит от двух факторов:
1. Организация блока памяти. Блок памяти состоит из нескольких типов памяти. Иерархия и организация памяти компьютера влияют на скорость доступа к данным и размер хранилища. Более быстрые и меньшие кэши хранятся ближе к процессору, а более крупная и медленная память – дальше.
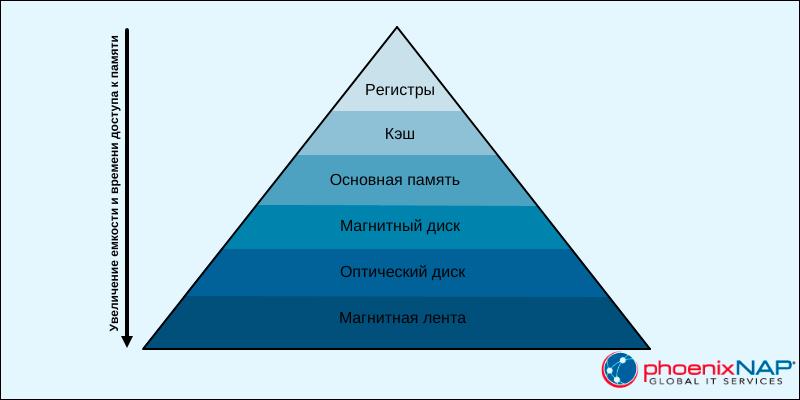
2. Доступ к памяти. Процессор постоянно обращается к данным, которые хранятся в памяти. Эффективный доступ к памяти влияет на то, насколько быстро процессор выполняет задачи и становится доступным для новых. Доступ к памяти предусматривает работу с адресами и определение правил доступа на разных уровнях памяти.
Управление памятью позволяет найти компромисс между скоростью, вместимостью и энергопотреблением компьютера. Основная память обеспечивает быстрый доступ, но не постоянное хранение. А вот вспомогательная память обеспечивает постоянное хранение, но медленный доступ.
Для чего нужно управление памятью?
Основная память – это неотъемлемая часть операционной системы. С ее помощью процессор может получать доступ к данным, которые необходимы для запуска процессов. Однако многочисленные операции чтения-записи замедляют работу системы.
В связи с этим, чтобы оптимизировать использование процессора и повысить скорость компьютера, в памяти размещаются несколько процессов сразу. Управление памятью необходимо для того, чтобы наиболее эффективно разделить память между процессами.
Таким образом, управление памятью влияет на следующие факторы:
- Использование ресурсов. Управление памятью – это ключевой аспект распределения ресурсов компьютера. Центральный компонент – оперативная память, и процессы используют ее для работы. Операционная система сама решает, как разделить память между процессами. Правильное распределение гарантирует, что каждый процесс получит необходимое количество памяти для одновременного выполнения.
- Оптимизация производительности. Те или иные механизмы управления памятью оказывают значительное влияние на скорость и стабильность системы. Все эти механизмы направлены на то, чтобы сократить количество операций получения доступа к памяти, которые дают большую нагрузку на процессор.
- Безопасность. Управление памятью обеспечивает безопасность данных и процессов. Изоляция памяти позволяет сделать так, чтобы процессы использовали только ту память, которую им предоставили. Кроме того, управление памятью позволяет реализовать механизм прав доступа, который поможет предотвратить вход в закрытые области памяти.
Для отслеживания выделенной процессам памяти операционные системы используют адреса памяти.
Адреса памяти
Адреса памяти крайне важны для управления памятью в операционных системах. Адрес памяти – это уникальный идентификатор конкретной области или ячейки памяти. С помощью адресов можно легко находить и получать доступ к информации, которая хранится в памяти.
Механизмы управления памятью позволяют отслеживать каждую ячейку памяти, сопоставлять адреса и управлять адресным пространством памяти. В различных ситуациях могут потребоваться разные способы обращения к ячейкам памяти.
Ниже описаны два типа адресов основной памяти. Каждый из них играет свою роль в управлении памятью и служит определенной цели.
Физические адреса
Физический адрес – это числовой идентификатор, который указывает на ячейку физической памяти. Этот адрес представляет собой фактическое расположение данных в аппаратном обеспечении и играет важнейшую роль в низкоуровневом управлении памятью.
Аппаратные компоненты, такие как процессор и контроллер памяти, используют именно физические адреса. Эти адреса уникальны и указывают на конкретную ячейку, за счет чего аппаратное обеспечение может быстро находить любые данные. Для пользовательских программ физические адреса непригодны.
Виртуальные адреса
Виртуальный адрес – это адрес, сгенерированный программой. Он представляет собой абстракцию физической памяти. Все процессы используют адресное пространство виртуальной памяти в качестве выделенной памяти.
Виртуальные адреса не соответствуют никаким ячейкам физической памяти. Программы читают и создают виртуальные адреса, не подозревая о существовании физического адресного пространства. Блок оперативной памяти (MMU — Main Memory Unit) отвечает за сопоставление виртуальных адресов с физическими, чтобы обеспечить правильный доступ к памяти.
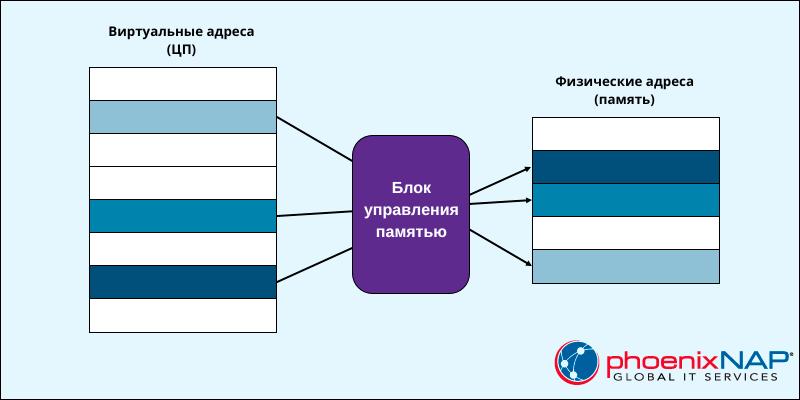
Для более эффективного использования памяти виртуальное адресное пространство разделено на сегменты и страницы.
Статическая и динамическая загрузка
Статическая и динамическая загрузка – это два способа выделения памяти под исполняемые программы. Они различаются количеством используемой памяти и ресурсов. Выбор зависит от количества доступной памяти и ресурсов, а также необходимой производительности.
- Статическая загрузка распределяет память и адреса при запуске программы. Однако, когда программа заранее загружается в память вместе со всеми необходимыми ресурсами, мы получаем предсказуемое, но крайне неэффективное использование ресурсов. Системные утилиты и приложения используют статическую загрузку с целью упростить распространение программ. Исполняемые файлы требуют компиляции и, как правило, представляют собой довольно большие файлы. Как правило, статическую загрузку используют операционные системы реального времени, загрузчики и устаревшие системы.
- Динамическая загрузка распределяет память и адреса непосредственно во время выполнения программы, и сама программа запрашивает ресурсы по мере необходимости. Динамическая загрузка позволяет снизить объем потребляемой памяти и обеспечивает многозадачную среду. Исполняемые файлы меньше по размеру, но добавляют дополнительную сложность за счет утечек памяти, потребления ресурсов и ошибок в процессе выполнения. Современные операционные системы (Linux, macOS, Windows), мобильные операционные системы (Android, iOS) и веб-браузеры используют именно динамическую загрузку.
Статическое и динамическое связывание
Статическое и динамическое связывание — это два способа работы с библиотеками и зависимостями программ, аналогичные статической и динамической загрузке:
- Статическое связывание выделяет память для библиотек и зависимостей при запуске программы и до компиляции. Программы являются полностью готовыми и не требуют внешних библиотек в процессе компиляции.
- Динамическое связывание выделяет память для библиотек и зависимостей после запуска программы и по мере необходимости. После компиляции программы находятся в поиске необходимых внешних библиотек.
Как правило, статическая загрузка и связывание объединяются в единый подход управления памятью, при котором все ресурсы программы определяются заранее. Аналогичным образом динамическая загрузка и связывание создают свою стратегию, в которой программы распределяют и ищут ресурсы по мере необходимости.
Комбинирование различных стратегий загрузки и связывания в некотором смысле возможно. Такой смешанный подход будет довольно сложен с точки зрения управления, но при этом даст преимущества обоих методов.
Подкачка
Подкачка (англ. swapping) – это механизм управления памятью, который операционные системы используют для того, чтобы освобождать место в оперативной памяти. Механизм позволяет перемещать неактивные процессы или данные между оперативной памятью и вспомогательным хранилищем, например, жестким или SSD-диском.
Для разрешения вопроса, связанного с ограниченным размером оперативной памяти, процесс подкачки прибегает к использованию виртуальной памяти. За счет этого, подкачка считается крайне важным методом управления памятью в операционных системах. Этот метод использует область вспомогательной памяти и создает там swap-память, то есть дополнительный раздел или файл.
Swap-пространство позволяет превысить объем оперативной памяти за счет разделения данных на блоки фиксированного размера (страницы). Механизм подкачки отслеживает, какие страницы находятся в оперативной памяти, а какие откачиваются из-за ошибок страниц.
Чрезмерная подкачка приводит к снижению производительности, так как вспомогательная память начинает работать медленнее. Различные стратегии подкачки и значения коэффициента подкачки позволяют минимизировать ошибки страниц, гарантируя, что в оперативной памяти находятся только необходимые данные.
Фрагментация
Фрагментация – это то, что мы получаем при попытке разделить память на разделы. Операционная система занимает только часть основной памяти. Оставшаяся основная память предназначена для процессов и делится на более мелкие разделы. Такое разделение не подразумевает использование виртуальной памяти.
Существует два способа, как можно разбить оставшуюся память: на разделы фиксированного или динамически меняющегося размера. В результате вы получите два разных типа фрагментации:
- Внутренняя. Если оставшаяся память разделена на одинаковые по размеру разделы, то программы, размер которых превышает размер раздела, требуют перекрытия, а программы меньшего размера занимают больше места, чем им положено. И все это нераспределенное пространство создает внутреннюю фрагментацию.
- Внешняя. Динамическое разделение оставшейся памяти позволяет создавать разделы с изменяемым размером. Процесс получает ровно столько памяти, сколько ему необходимо. Когда процесс завершается, пространство освобождается. Через какое-то время начинают появляться неиспользуемые интервалы памяти, что приводит к внешней фрагментации.
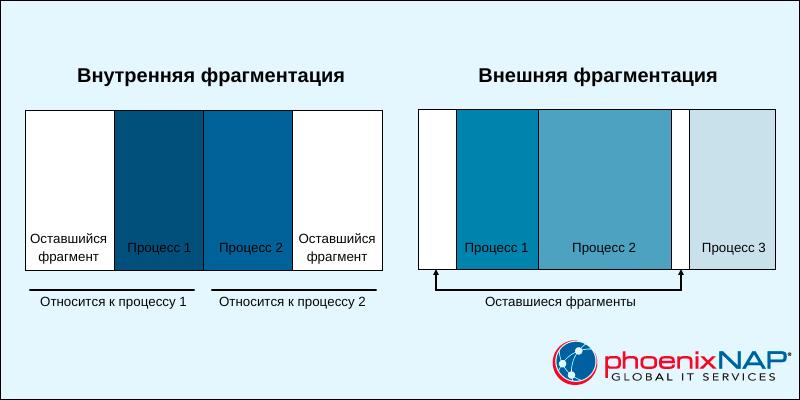
Внутренняя фрагментация требует конструктивных изменений. Как правило, это разрешается с помощью механизма подкачки и сегментации.
Внешняя фрагментация требует, чтобы операционная система выполняла периодическую дефрагментацию и освобождала неиспользуемое пространство.
Методы управления памятью
Разные методы управления памяти решают разные проблемы, возникающие вследствие неправильной организации памяти. Одна из основных целей этих методов – оптимизировать потребление ресурсов в системе.
Существует два основных подхода к распределению и управлению памятью: управление непрерывной памятью и управление несмежной памятью. Каждый из этих подходов имеет свои преимущества, и выбор зависит от требований системы и аппаратной архитектуры.
Схемы управления непрерывной памятью
Схемы управления непрерывной памятью выделяют процессам блоки непрерывной памяти. Адреса памяти и процессы имеют линейную зависимость, что упрощает реализацию этой системы.
Существуют различные способы реализации схем управления непрерывной памятью. Ниже мы представили краткое описание известных схем.
Выделение общей непрерывной памяти
Персональное выделение непрерывной памяти – это один из первых методов управления памятью. При такой схеме оперативная память делится на два раздела:
- Раздел операционной системы. Раздел закреплен за операционной системой, которая загружается в него при запуске.
- Раздел пользовательского процесса. Второй раздел предназначен для загрузки одного пользовательского процесса и всех связанных с ним данных.
Такая схема была реализована в более старых операционных системах, таких как MS-DOS. Система довольно простая, и отслеживать необходимо всего два раздела. Но такой простой подход не обеспечивает изоляцию процессов и приводит к тому, что память тратиться впустую.
Современные операционные системы не используют такой метод управления памятью. Но эта схема заложила фундамент для развития других методов управления памятью.
Распределение с фиксированными разделами
Распределение с фиксированными разделами – это схема управления памятью, которая подразумевает деление оперативной памяти на разделы одинакового размера. Размер раздела определяется заранее, поэтому необходимо заранее знать, сколько памяти требуется процессам.
Операционная система отслеживает и выделяет процессам разделы. Каждый процесс получает выделенный ему раздел, который обеспечивает изоляцию памяти и безопасность процесса.
Однако использование разделов фиксированного размера приводит к фрагментации. Если процессы оказываются меньше раздела, то возникает внутренняя фрагментация. А внешняя фрагментация возникает со временем, в результате чего становится сложнее выделять память под более крупные процессы.
Алгоритм двойников
Алгоритм двойников – это схема динамического управления памятью. Здесь оперативная память делится на блоки переменного размера. Зачастую размеры представляются степенями двойки (2 Кб, 4 Кб, 8 Кб, 16 Кб и т.д.).
Когда процесс запрашивает память, ОС начинает искать наиболее подходящий блок наименьшего размера, чтобы выделить его под этот процесс. Если блоков поменьше нет, тогда большие блоки делятся пополам. Когда память освобождается, ОС проверяет, свободны ли соседние блоки (блоки-двойники), и объединяет их в более крупные.
Для отслеживания состояния блоков памяти и поиска свободных алгоритм двойников использует двоичное дерево. Такая схема поддерживает баланс между фрагментацией и эффективным распределением памяти. Самые примечательные области применения – это память ядра Linux и встроенные системы.
Схемы управления несмежной памятью
Схемы управления несмежной памятью позволяют распределять процессы по всей памяти. Адреса памяти и процессы имеют нелинейную зависимость, и процессы могут получить память где угодно.
Эти схемы направлены на решение проблем фрагментации, но они довольно сложны с точки зрения реализации. Большая часть современных операционных систем используют именно управление несмежной памятью.
Ниже мы привели описание самых важных механизмов управления несмежной памятью.
Страничная организация памяти
Страничная организация памяти – это подход к управлению оперативной и виртуальной памятью. При таком подходе память делится на блоки одинакового размера:
- Страницы. Блоки виртуальной памяти с логическими адресами.
- Страничные кадры. Блоки оперативной памяти с физическими адресами.
Этот механизм к каждому процессу применяет таблицу страниц, где отслеживает процесс сопоставления адресов страниц и кадров. А вот операционная система по мере необходимости перемещает данные между оперативной и вспомогательной памятью, используя подкачку.
Страничная организация памяти позволяет сократить внешнюю фрагментацию. Это гибкий, переносимый и эффективный механизм управления памятью. Его используют многие современные операционные системы (Linux, Windows и macOS).
Сегментация
Сегментация — это схема управления памятью, при которой память делится на логические сегменты. Каждый сегмент соответствует определенной области, где в рамках процесса выполняются различные функции и задачи.
В отличие от страниц, сегменты имеют разные размеры. Каждый сегмент имеет уникальный идентификатор, который называется дескриптором сегмента. Операционная система хранит таблицу сегментов, содержащую дескриптор, смещение и базовый адрес. И чтобы вычислить физический адрес, процессор объединяет смещение и базовый адрес.
Сегментация — это динамический, безопасный и логический подход к управлению памятью. Однако этот механизм довольно сложен и подходит не для всех случаев.
Заключение
Прочитав данное руководство, вы ознакомились со всеми подробностями управления памятью в операционных системах.