
In today’s interconnected world, the need for efficient and seamless communication is more important than ever. One crucial aspect of this is ensuring that text and characters are correctly encoded, allowing for compatibility across different platforms and languages. In Windows 10, setting the UTF-8 encoding is a vital step to enable smooth communication and eliminate any potential issues with character display and compatibility.
The UTF-8 encoding, which stands for Unicode Transformation Format-8, is a widely used character encoding that supports a vast range of characters from various scripts and languages. By setting the UTF-8 encoding in Windows 10, you guarantee that your system can handle and display text in different languages accurately. This ensures that you can read and share content from around the world without any distortion or loss of information. With the increasing diversity of content and the global nature of communication, setting UTF-8 encoding in Windows 10 is an essential step to enable seamless communication across different languages and platforms.
To set Utf-8 encoding in Windows 10, follow these steps:
- Open the Control Panel.
- Select «Clock and Region» and then click on «Region.»
- In the «Formats» tab, click on «Additional settings.»
- Go to the «General» tab, and under «Language for non-Unicode programs,» select «UTF-8.»
- Click «OK» and restart your computer.

Understanding UTF-8 Encoding in Windows 10
Setting UTF-8 encoding in Windows 10 is crucial for ensuring proper handling and display of characters from different languages and scripts. UTF-8 is a variable-width character encoding that supports almost all characters in the Unicode standard, making it the most widely used encoding worldwide. By setting UTF-8 encoding in Windows 10, you can avoid issues such as garbled text, incorrect character rendering, and missing characters when working with files, websites, or applications that use non-ASCII characters.
1. Setting UTF-8 Encoding for System Locale
The first step to setting UTF-8 encoding in Windows 10 is to configure the system locale settings. The system locale determines the default encoding used by applications and services for non-Unicode programs. Here’s how you can set the UTF-8 system locale:
- Open the Control Panel by searching for it in the Windows 10 Start menu and selecting the corresponding result.
- In the Control Panel, click on «Clock and Region» or «Clock, Language, and Region» depending on your system configuration.
- Under the «Region» or «Region and Language» section, click on «Change date, time, or number formats.»
- In the Formats tab of the Region settings, click on the «Additional settings» button.
- In the «Customize Format» window, navigate to the «Beta: Use Unicode UTF-8 for worldwide language support» section and check the box.
- Click OK to apply the settings and restart your computer for the changes to take effect.
Setting the system locale to UTF-8 ensures that non-Unicode applications and services use this encoding by default, reducing the risk of character-related issues when working with different languages and scripts.
Benefits of Setting UTF-8 Encoding for System Locale
By setting UTF-8 encoding for the system locale, you gain several benefits:
- Compatibility: UTF-8 is widely supported across different platforms, applications, and programming languages, ensuring optimal compatibility and interoperability.
- Character Support: UTF-8 supports nearly all characters and symbols from every major writing system, making it suitable for multilingual applications and content.
- Future-Proofing: UTF-8 is the recommended encoding for future-proofing your systems and applications. It allows seamless incorporation of new characters and scripts as Unicode continues to evolve.
- Global Reach: With UTF-8 encoding, your content can reach a global audience without language or character-based restrictions.
2. Configuring UTF-8 Encoding for Individual Applications
While setting the system locale to UTF-8 is crucial, individual applications can also have their own encoding settings. Configuring UTF-8 encoding for specific applications ensures that they handle non-ASCII characters correctly. Here’s how you can configure UTF-8 encoding for some popular applications:
Microsoft Office Applications
To set UTF-8 encoding for Microsoft Office applications such as Word, Excel, and PowerPoint, follow these steps:
- Open the respective Office application (e.g., Word, Excel).
- Click on «File» at the top left corner and select «Options.»
- In the Options window, navigate to the «Advanced» tab.
- Scroll down to the «International» section.
- Under «Choose the encoding standard to use when saving files,» select «UTF-8.»
- Click OK to save the changes.
Configuring UTF-8 encoding for Microsoft Office applications ensures that you can save and work with documents containing non-ASCII characters without any issues.
Web Browsers
Web browsers are key tools for accessing and viewing websites with different language content. Here’s how you can configure UTF-8 encoding in popular web browsers:
Google Chrome
To set UTF-8 encoding in Google Chrome, follow these steps:
- Open Google Chrome and click on the three-dot menu icon at the top right corner.
- Select «Settings» from the drop-down menu.
- Scroll down and click on «Advanced» to expand the advanced settings.
- Under the «Languages» section, click on «Language and input settings.»
- In the «Languages» settings, click on the «Add» button under the «Customize languages» section.
- Search for «English» in the language list and select «English (United States).»
- Drag «English (United States)» to the top of the list.
- Click «Done» to save the changes.
Configuring UTF-8 encoding in Google Chrome ensures that the browser can handle and display different language content correctly.
3. Troubleshooting UTF-8 Encoding Issues
Despite configuring UTF-8 encoding, you may still encounter issues with character handling in Windows 10. Here are some troubleshooting steps to resolve UTF-8 encoding issues:
Check File Encoding
If you experience character rendering issues with a specific file, check its encoding. Most text editors allow you to view and change the encoding of a file. Ensure that the file’s encoding matches the expected UTF-8 encoding.
Update Applications
If you encounter character handling issues in specific applications, ensure that you have the latest version installed. Application updates often include bug fixes and improvements related to character encoding.
Verify Font Support
In some cases, character rendering issues can occur due to insufficient font support. Ensure that you have appropriate fonts installed for the languages and scripts you are working with. Additionally, check the font settings within applications to ensure they are set to handle UTF-8 encoded characters.
4. Embracing UTF-8 Encoding for Seamless Multilingual Experience
Setting UTF-8 encoding in Windows 10 is a crucial step towards embracing multilingualism and ensuring smooth communication across languages. By configuring the system locale and individual application settings, you can avoid character-related issues and enjoy a seamless experience regardless of the languages and scripts you work with.

Setting utf-8 Encoding in Windows 10
Utf-8 encoding is a character encoding standard used to represent text in various languages, including English. Windows 10, by default, uses a different encoding called ANSI, which may not support all characters from different languages. However, it is possible to set utf-8 encoding in Windows 10 to ensure proper rendering of characters and support for international languages. Here’s how:
Method 1: Changing System Locale
To set utf-8 encoding, you can change the system locale in Windows 10. Follow these steps:
- Open the Control Panel and go to the «Clock and Region» section.
- Select «Region» and click on the «Administrative» tab.
- Click on «Change System Locale» and check the «Beta: Use Unicode UTF-8 for worldwide language support» option.
- Click «OK» and restart your computer for the changes to take effect.
Method 2: Changing File Encoding
If you want to set utf-8 encoding for specific files, you can change their encoding individually. Here’s how:
- Right-click on the file and select «Properties.»
- Go to the «General» tab and click on «Advanced» under «Attributes.»
- In the «Advanced Attributes» window, check the «UTF-8» option under «File Origin
Key Takeaways: How to Set Utf-8 Encoding in Windows 10
- Utf-8 encoding is important for displaying and storing international characters in Windows 10.
- Open Notepad or any text editor to create a new UTF-8 encoded file.
- Choose File > Save As and select UTF-8 encoding from the Encoding dropdown menu.
- Change the file extension to .txt if necessary and click Save.
- You can also set Utf-8 encoding as the default for all new files in Notepad.
Frequently Asked Questions
Here are some common questions related to setting Utf-8 encoding in Windows 10:
1. What is Utf-8 encoding?
Utf-8 encoding is a way of representing characters in a computer system. It allows for the representation of all the characters in the Unicode character set, which includes a vast range of characters used in various languages and symbols. Utf-8 is widely used and recommended for text encoding formats because it can encode any character in a concise and efficient manner.
2. Why should I set Utf-8 encoding in Windows 10?
Setting Utf-8 encoding in Windows 10 is important to ensure that your system can correctly display and handle text in different languages, including characters and symbols that are not present in the default encoding. Utf-8 encoding allows for universal compatibility and ensures that the correct characters are displayed when working with files, websites, or applications that use Utf-8 encoding.
3. How can I set Utf-8 encoding in Windows 10?
To set Utf-8 encoding in Windows 10, you can follow these steps:
- Open the Control Panel by searching for «Control Panel» in the Windows Start menu and selecting it.
- Click on «Clock and Region» and then on «Region».
- In the Region dialog box, click on the «Administrative» tab.
- Under the «Language for non-Unicode programs» section, click on the «Change system locale» button.
- In the «Region Settings» dialog box, select «Beta: Use Unicode UTF-8 for worldwide language support» and click on «OK».
- Restart your computer to apply the changes.
4. Can I change the Utf-8 encoding for specific applications only?
No, the Utf-8 encoding setting in Windows 10 applies system-wide and affects all applications. Changing the encoding setting will ensure that Utf-8 characters are displayed correctly in all programs that use Utf-8 encoding. It is a global setting that affects the entire operating system.
5. Are there any other encoding options available in Windows 10?
Yes, Windows 10 supports various encoding options, including Utf-8, which is the recommended and widely used encoding format. Other options include ANSI, which is mostly used for backward compatibility with older software, and Unicode, which is a more generic term that refers to various character encoding schemes, including Utf-8. However, Utf-8 is the preferred encoding format for its compatibility and efficiency.
Setting UTF-8 encoding in Windows 10 is essential for ensuring compatibility with various languages and characters. By following a few simple steps, you can easily configure your system to use UTF-8 encoding, allowing you to work with multilingual content without any issues.
To set UTF-8 encoding in Windows 10, you need to navigate to the Region settings in the Control Panel. From there, you can access the Administrative tab and change the system locale to use UTF-8 encoding. This will enable your computer to recognize and display characters from different languages accurately.
Once you have set the UTF-8 encoding, you will be able to seamlessly work with files and applications that contain characters from various languages. This is particularly useful for web development, international communication, and working with documents that require special characters.
By ensuring that your Windows 10 system is set to UTF-8 encoding, you can eliminate any potential character display issues and improve overall compatibility. It’s a simple but crucial step that can make a significant difference in your work with multilingual content.
Setting Utf-8 Encoding in Windows 10 allows users to ensure compatibility and proper display of international characters in their applications and documents. With the increasing globalization of communication, it is crucial to have the ability to view and work with text in different languages seamlessly. Utf-8, a widely adopted character encoding standard, offers comprehensive support for a vast range of languages, making it essential for anyone dealing with multilingual content.
To set Utf-8 Encoding in Windows 10, users can follow a straightforward process. First, open the Control Panel by searching for it in the Start menu. Then, navigate to the «Clock and Region» section and select «Region.» In the Region settings, go to the «Administrative» tab, and click on the «Change system locale» button. From there, choose Utf-8 as the default language for non-Unicode programs. By making this adjustment, users can ensure that their Windows 10 system supports Utf-8 encoding, enabling seamless interaction with diverse language content.
To set UTF-8 encoding in Windows 10, follow these steps:
- Open the Control Panel.
- Select «Region» or «Region and Language.»
- Click on the «Administrative» tab.
- Under «Language for non-Unicode programs,» click on «Change system locale.»
- Check the box for «Beta: Use Unicode UTF-8 for worldwide language support.»
- Click «OK» and restart your computer.
By following these steps, you’ll be able to set UTF-8 encoding in Windows 10 and ensure compatibility with international characters and languages.

Understanding Utf-8 Encoding
Utf-8 encoding is a character encoding standard that is commonly used for representing characters in the Unicode character set. It supports almost all characters from all human languages, making it widely used for international communication and data storage. In Windows 10, setting the Utf-8 encoding is crucial to ensure proper display of characters and compatibility with different applications and systems. This article will guide you through the process of setting Utf-8 encoding in Windows 10, empowering you to handle and work with various character sets seamlessly.
Checking Current Encoding Settings
Before diving into the process of setting Utf-8 encoding, it’s important to check the current encoding settings on your Windows 10 system. This will help you understand the current state and determine if any changes are required. Follow the steps below to check the current encoding settings:
1. Open the Control Panel by searching for it in the Windows search bar.
2. In the Control Panel, click on «Clock and Region» and then select «Region.»
3. In the Region window, go to the «Administrative» tab.
4. Under the «Language for non-Unicode programs» section, you will see the current system locale. Note down this information for reference.
Setting Utf-8 as the System Locale
If your current system locale is not Utf-8, you can change it to Utf-8 to enable proper Utf-8 encoding. Follow the steps below to set Utf-8 as the system locale:
1. Open the Control Panel by searching for it in the Windows search bar.
2. In the Control Panel, click on «Clock and Region» and then select «Region.»
3. In the Region window, go to the «Administrative» tab.
4. Under the «Language for non-Unicode programs» section, click on the «Change system locale» button.
5. In the Region Settings window, select «Beta: Use Unicode UTF-8 for worldwide language support» checkbox.
6. Click on «OK» to save the changes and restart your computer for the settings to take effect.
Testing Utf-8 Encoding
After setting Utf-8 as the system locale, it’s important to test whether the changes have been applied successfully. Follow the steps below to test Utf-8 encoding:
- Open a text editor or any application that allows you to input text.
- Type and save some text that includes characters from different languages, such as accents, diacritics, or non-Latin characters.
- Open the saved file and check if all the characters are displayed correctly without any gibberish or question marks.
- If all characters are displayed correctly, it means that Utf-8 encoding is working properly.
Modifying Utf-8 Encoding in Specific Applications
In some cases, you may encounter issues with Utf-8 encoding in specific applications, even after setting it as the system locale. This can happen if the application has its own character encoding settings that override the system settings. Here’s how you can modify Utf-8 encoding in specific applications:
1. Open the application in which you are facing Utf-8 encoding issues.
2. Look for the application’s language or encoding settings, usually found in the preferences or settings menu.
3. Select Utf-8 as the preferred encoding option.
4. Save the changes and restart the application if required.
Common Applications with Utf-8 Encoding Settings
Many popular applications have Utf-8 encoding settings that can be modified to ensure proper character display. Here are a few examples:
| Application | Location of Utf-8 Encoding Settings |
| Notepad++ | Settings > Preferences > New Document > Encoding |
| Sublime Text | View > Encoding |
| Visual Studio Code | File > Save with Encoding |
| Microsoft Office | Options > Advanced > General > File Locations > File Encoding |
| Browsers (Chrome, Firefox, etc.) | Settings > Advanced > Fonts and Encoding |
Using Utf-8 Encoding for Web Development
Utf-8 encoding plays a crucial role in web development, ensuring that websites can display and handle multilingual content properly. When working with web development tools and frameworks, it’s important to set Utf-8 encoding to ensure seamless language support. Here are some key points to remember when using Utf-8 encoding for web development:
- Set the « tag in the « section of your HTML files.
- Ensure that your server-side scripts and databases are also set to Utf-8 encoding.
- If using a content management system (CMS) like WordPress, check the encoding settings in the CMS admin panel.
- Validate and sanitize user input to prevent potential encoding-related security vulnerabilities.
Setting Utf-8 Encoding for File Opening
Besides setting Utf-8 as the system locale, you may also need to specify the encoding when opening specific files to ensure they are interpreted correctly. The steps below will guide you through the process of setting Utf-8 encoding when opening files:
1. Open the application used to open the file, such as a text editor.
2. In the application, locate the file opening or file import feature.
3. Look for an option related to encoding or character set. The terminology may vary depending on the application.
4. Choose Utf-8 or the appropriate encoding option from the available list.
5. Open the desired file with the specified Utf-8 encoding to ensure proper interpretation of the characters.
Conclusion
Setting Utf-8 encoding in Windows 10 is crucial for proper handling and display of multilingual content. By following the steps outlined in this article, you can ensure seamless support for characters from various languages and encoding standards. Whether it’s setting Utf-8 as the system locale, modifying encoding settings in specific applications, or using Utf-8 for web development, understanding and implementing Utf-8 encoding will enhance your experience in working with diverse character sets.

Setting Utf-8 Encoding in Windows 10
Utf-8 encoding is widely used to support international characters and symbols in various software applications, including Windows 10. To set Utf-8 encoding in Windows 10, follow these steps:
Using Registry Editor
1. Press Windows key + R to open the Run dialog box.
2. Type «regedit» and press Enter to open the Registry Editor.
3. Navigate to the following registry key: HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Internet Explorer\Main\FeatureControl\FEATURE_BROWSER_EMULATION
4. Right-click on the empty space in the right pane and select «New» -> «DWORD (32-bit) Value».
5. Name the new value «iexplore.exe».
6. Double-click on the «iexplore.exe» value and set the «Value data» to 8888 (Hexadecimal).
Using Notepad
1. Open Notepad.
2. Click on «File» -> «Save As».
3. In the «Encoding» dropdown, select «Utf-8».
4. Choose the desired location and filename for your file, and click «Save».
With these simple
Key Takeaways: How to Set Utf-8 Encoding in Windows 10
- Open the Control Panel by searching for it in the Windows search bar.
- Click on «Clock and Region» and then select «Region» from the options.
- In the Region window, click on the «Administrative» tab.
- Under the «Language for non-Unicode programs» section, click on «Change system locale».
- Check the box next to «Beta: Use Unicode UTF-8 for worldwide language support».
Frequently Asked Questions
Here are some common questions about setting Utf-8 Encoding in Windows 10:
1. How do I change the encoding to Utf-8 in Windows 10?
To change the encoding to Utf-8 in Windows 10, follow these steps:
1. Open the Control Panel by searching for it in the Windows Start Menu.
2. Click on «Clock and Region» and then «Region».
3. In the «Formats» tab, click on «Additional settings».
4. In the «Code page conversion tables» section, select «Utf-8» from the drop-down menu.
5. Click «Apply» and then «OK» to save the changes.
2. Why is Utf-8 encoding important?
Utf-8 encoding is important because it supports a wide range of characters and symbols from different languages. It is a universal encoding standard that allows for seamless communication and compatibility between different systems and devices.
By using Utf-8 encoding, you ensure that your text is correctly displayed and interpreted across platforms, making it essential for international communication, website development, and data storage.
3. Can I change the encoding for specific files or folders?
Yes, you can change the encoding for specific files or folders in Windows 10. Follow these steps:
1. Right-click on the file or folder you want to change the encoding for.
2. Select «Properties» from the context menu.
3. In the «Properties» window, go to the «General» tab.
4. Click on the «Advanced…» button.
5. In the «Advanced Attributes» window, check the box next to «Utf-8» under «File Encoding».
6. Click «OK» to save the changes.
4. How can I check the current encoding of a file in Windows 10?
To check the current encoding of a file in Windows 10, follow these steps:
1. Right-click on the file and select «Properties».
2. In the «Properties» window, go to the «General» tab.
3. Under «Attributes», you will see the «Encoding» information.
5. Can I set Utf-8 as the default encoding in Windows 10?
Yes, you can set Utf-8 as the default encoding in Windows 10. Here’s how:
1. Open the Control Panel and click on «Clock and Region» and then «Region».
2. In the «Formats» tab, click on «Additional settings».
3. In the «Code page conversion tables» section, select «Utf-8» from the drop-down menu.
4. Click «Apply» and then «OK» to save the changes.
To summarize, setting UTF-8 encoding in Windows 10 is an important step to ensure compatibility and proper display of characters in various applications. By following the steps outlined in this article, you can easily change the default encoding settings and avoid any issues with text encoding in your system.
Remember, UTF-8 is a widely accepted and flexible encoding format that supports a wide range of characters from different languages. It is crucial for international communication, web development, and file sharing. Keeping your system’s default encoding as UTF-8 will ensure seamless interactions with texts from around the world.
-
Доступные статьи
-
PHP
-
Локали и кодировки
Локали и кодировки
- Введение
-
Работа с локалями в PHP
- Windows
- UNIX (FreeBSD)
- Кодировки в MySQL
- Кодировка HTML-страниц
- Заключение
Введение
При разработке веб-приложений есть три важных момента, связанных с кодировками: информация в файлах-сценариях, информация в базе данных и браузер пользователя. Если выставить хотя бы одну кодировку неверно, то, в лучшем случае, данные отобразятся неверно, в худшем, безвозвратно потеряются. Чтобы этого не произошло, а приложение работало корректно при любых настройках сервера, нужно правильно выставить кодировки.
Работа с локалями в PHP
Работа с локалями в PHP выглядит одинаково и в UNIX, и в Windows, и в любой другой платформе. Для установки значений локали служит всего одна функция setlocale(). Чтобы выставить локаль, нужно передать функции первым аргументом категорию, на которую эта локаль распространяется, последующими список возможных локалей. Результатом будет название первой подходящей локали, которая и была установлена.
Пример - установка и использование локали
|
<?php // Установка локали echo setlocale(LC_ALL, 'ru_RU.CP1251', 'rus_RUS.CP1251', 'Russian_Russia.1251'); // Выведет ru_RU.CP1251 для FreeBSD // Выведет rus_RUS.CP1251 для линукса // Выведет Russian_Russia.1251 для Windows // ... // Вывод локализованных сообщений, например, даты echo '<br />', strftime('Число: %d, месяц: %B, день недели: %A'); ?> ru_RU.CP1251 Число: 10, месяц: октября, день недели: пятница или Russian_Russia.1251 Число: 10, месяц: Октябрь, день недели: пятница |
Локали в Windows
Для того, чтобы узнать, какие локали доступны в Windows, нужно зайти в панель управления, «Язык и региональные стандарты».
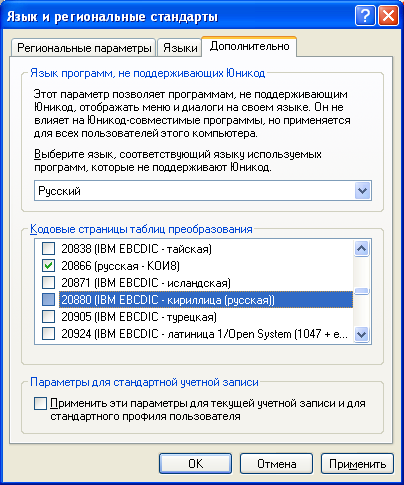
На вкладке «Дополнительно», в разделе «Кодовые страницы таблиц преобразования» показан список всех возможных локалей для Windows, которые можно использовать в PHP.
Кодовые страницы, которые отмечены в списке, из PHP могут быть использованы по их номеру.
В общем случае, использование выглядит по следующей схеме: Язык_Регион.Номер_кодовой_страницы
Для России это может выглядеть как Russian_Russia.1251 (cp1251) или Russian_Russia.20866 (KOI8-R).
Для Украины — Ukrainian_Ukraine.1251 (cp1251).
Вместо длинных названий можно использовать сокращённые russian, american, ukrainian и так далее. При этом кодовая страница выставится с учётом региональных настроек, для России и Украины — 1251, для Америки — 1252.
Единственная кодировка, с которой у меня возникли проблемы, как ни странно, оказалась UTF-8. При попытке выставить эту кодировку, выставляются все категории локалей, кроме основной. Вывод локализованных сообщений при этом идёт в cp1251.
Пример - установка локали UTF-8 на Windows
|
<? // Кодировка страницы windows-1251 header('Content-Type: text/html; charset=windows-1251'); echo '<pre>'; // Локаль устанавливаем UTF-8 echo setlocale(LC_ALL, 'Russian_Russia.65001'), PHP_EOL; // Но данные будут выводиться всё равно в cp1251 :((( echo strftime('%A'), PHP_EOL; ?> LC_COLLATE=Russian_Russia.65001;LC_CTYPE=Russian_Russia.1251; LC_MONETARY=Russian_Russia.65001;LC_NUMERIC=Russian_Russia.65001; LC_TIME=Russian_Russia.65001 пятница |
Пока это можно списать на внутренний механизм PHP работы со строками. С шестой версии PHP вся обработка строк должна будет вестись в UTF-8, но до тех пор надо просто знать об этом и делать поправку.
Ещё одной странностью при работе с локалями в PHP на Windows является неправильная работа с категориями локалей. Так, например, я выставляю локаль на функции времени KOI8-R, setlocale(LC_TIME, 'Russian_Russia.20866'), но почему-то выставляется cp1251 на все категории. Суть проблемы я так и не понял, возможно, это просто баг (проверялось на PHP 5.2.3), а возможно, что внутренний механизм Windows просто не позволяет этого делать. Хотя по мне, так это чистой воды баг.
В общем-то, на этом можно и закончить разговор о локалях на Windows. Главное, запомнить, что локали, которые портированы из UNIX, под WIndows работают только для «галочки». Шаг влево, шаг вправо и результат будет непредсказуемым. Безопасно можно использовать только cp1251 (windows-1251) и KOI8-R, и только для LC_ALL.
Код - установка локали на Windows
|
<?php // Устновка локалей для Windows // Кодировка Windows-1251 setlocale(LC_ALL, 'Russian_Russia.1251'); // Кодировка KOI8-R setlocale(LC_ALL, 'Russian_Russia.20866'); // Кодировка UTF-8 (использовать осторожно) setlocale(LC_ALL, 'Russian_Russia.65001'); ?> |
Локали в UNIX
Выше я описал работу с локалями в Windows, теперь можно заострить внимание на UNIX-like системах. Для простоты, я буду их называть UNIX, а подразумевать FreeBSD :). В контексте данной статьи это не особо важно.
Итак, дистрибутивы UNIX поставляются в одном виде для всех, и работа рассчитана на многопользовательский режим, поэтому о правильной настройке локали должен заботиться сам пользователь, например:
zg# locale LANG= LC_CTYPE="ru_RU.KOI8-R" LC_COLLATE="ru_RU.KOI8-R" LC_TIME="ru_RU.KOI8-R" LC_NUMERIC="ru_RU.KOI8-R" LC_MONETARY="ru_RU.KOI8-R" LC_MESSAGES="ru_RU.KOI8-R" LC_ALL=ru_RU.KOI8-R zg#
Так может выглядеть работа системной команды locale, которая выводит текущие настройки локали для пользователя. А так, обычно, выглядят настройки локали для пользователя, под которым работает PHP:
passthru('locale'); ================ LANG= LC_CTYPE="C" LC_COLLATE="C" LC_TIME="C" LC_NUMERIC="C" LC_MONETARY="C" LC_MESSAGES="C" LC_ALL=
Функция ucwords() должна была сделать заглавными первые буквы всех слов. А перед этим strtolower() должна была предварительно все заглавные буквы сделать строчными. Но ничего не произошло. Так же не будет работать следующий код:
echo ucwords(strtolower('привет, МИР!')); ================ привет, МИР!
Хотя \w является множеством знаков, из которых может состоять слово (алфавит, цифры и _), регулярное выражение не срабатывает. Причина как раз в том, что, работая с cp1251, мы не сказали об этом php. Чтобы исправить положение, достаточно воспользоваться функцией setlocale() и указать правильную локаль, например, так:
setlocale(LC_ALL, 'ru_RU.CP1251');
Здесь первый аргумент — это категория, на которую будет распространяться локаль (константа LC_*), второй — название локали. Начиная с версии 4.3.0 можно указывать несколько имён локалей в виде массива или в качестве дополнительных аргументов. После вызова функция установит первую подходящую локаль и вернёт её имя:
echo setlocale(LC_ALL, 'cp1251', 'koi8-r', 'ru_RU.KOI8-R'); ================ ru_RU.KOI8-R
С помощью команды grep я отобрал локали, которые поддерживают русский язык. Любую из них можно использовать, однако следует понимать, что данные должны быть в кодировке, на которую рассчитана локаль. Если же это правило не будет соблюдено, то результат может оказаться весьма неожиданным:
echo setlocale(LC_ALL, 'ru_RU.KOI8-R'), PHP_EOL; echo ucwords(strtolower('привет, МИР!')); =============== ru_RU.KOI8-R пРИВЕТ, мИР!
Если учесть, что koi8-r достаточно популярная кодировка для UNIX-севреров, а windows-1251 для русскоязычных сайтов, то подобное «необычное» поведение не такая уж и редкость. Когда-то я и сам столкнулся с этой проблемой при портировании проекта на реальный хостинг.
После установки правильной локали все примеры, которые не работали выше, будут работать как нужно!
echo setlocale(LC_ALL, 'ru_RU.CP1251', 'rus_RUS.CP1251', 'Russian_Russia.1251'), PHP_EOL; echo ucwords(strtolower('привет, МИР!')), PHP_EOL; echo preg_match('/^\w+$/', 'привет') ? 'нашёл' : 'не работает', PHP_EOL; echo strftime('Сегодня: %A, %d %B, %Y года'); =============== ru_RU.CP1251 Привет, Мир! нашёл Сегодня: суббота, 12 июля, 2008 года
По-русски заговорит и функция strftime(), которая корректно работает с локалями, а также и всё остальное, что зависит от локали.
Кодировки в MySQL
Напомню, что возможность задавать кодировки появилась только в MySQL 4.1.11 и выше.
В отличие от php, проблемы с кодировками базы данных проявляют себя гораздо быстрее, чем проблемы с локалью. И связано это прежде всего с хранением и выборкой данных, поскольку от этого зависит информация на сайте. Я не буду подробно расписывать все тонкости, поскольку есть отдельная статья, остановлюсь на самых важных моментах.
Первое, чему необходимо научиться, смотреть текущие настройки соединения с mysql:
mysql> show variables like 'char%'; +--------------------------+----------------------------------+ | Variable_name | Value | +--------------------------+----------------------------------+ | character_set_client | cp1251 | | character_set_connection | cp1251 | | character_set_database | cp1251 | | character_set_filesystem | binary | | character_set_results | cp1251 | | character_set_server | cp1251 | | character_set_system | utf8 | | character_sets_dir | /usr/local/share/mysql/charsets/ | +--------------------------+----------------------------------+ 8 rows in set (0.00 sec)
Критичными для пользователя являются character_set_client и character_set_results, которые отвечают за кодировку, в которой данные поступают в базу, и кодировку, в которой данные поступают из базы к пользователю. Если эти две кодировки отличаются от той, в которой работает клиент, в нашем случае php-скрипты, то неминуемо будут «странности», например, при сортировке выборки или внесении данных в базу.
Второе, что необходимо знать, как правильно сообщить mysql о кодировках. Самый простой и правильный способ, это использовать запрос set names:
mysql> set names 'cp1251'; Query OK, 0 rows affected (0.00 sec)
После этого три переменные character_set_client, character_set_connection и character_set_results примут значение cp1251. Это будет означать — клиент работает в кодировке windows-1251 (cp1251).
Помимо этого можно устанавливать непосредственно серверные переменные:
mysql> set character_set_client='UTF8'; Query OK, 0 rows affected (0.00 sec) mysql> show variables like 'char%'; +--------------------------+----------------------------------+ | Variable_name | Value | +--------------------------+----------------------------------+ | character_set_client | utf8 | | character_set_connection | cp1251 | .....
Теперь данные поступают и извлекаются в разных кодировках.
Список доступных кодировок можно просмотреть так:
mysql> show charset; +----------+-----------------------------+---------------------+--------+ | Charset | Description | Default collation | Maxlen | +----------+-----------------------------+---------------------+--------+ | dec8 | DEC West European | dec8_swedish_ci | 1 | | cp850 | DOS West European | cp850_general_ci | 1 | | hp8 | HP West European | hp8_english_ci | 1 | | koi8r | KOI8-R Relcom Russian | koi8r_general_ci | 1 | | latin1 | cp1252 West European | latin1_swedish_ci | 1 | | latin2 | ISO 8859-2 Central European | latin2_general_ci | 1 | | swe7 | 7bit Swedish | swe7_swedish_ci | 1 | | ascii | US ASCII | ascii_general_ci | 1 | | hebrew | ISO 8859-8 Hebrew | hebrew_general_ci | 1 | | koi8u | KOI8-U Ukrainian | koi8u_general_ci | 1 | | greek | ISO 8859-7 Greek | greek_general_ci | 1 | | cp1250 | Windows Central European | cp1250_general_ci | 1 | | latin5 | ISO 8859-9 Turkish | latin5_turkish_ci | 1 | | armscii8 | ARMSCII-8 Armenian | armscii8_general_ci | 1 | | utf8 | UTF-8 Unicode | utf8_general_ci | 3 | | cp866 | DOS Russian | cp866_general_ci | 1 | | keybcs2 | DOS Kamenicky Czech-Slovak | keybcs2_general_ci | 1 | | macce | Mac Central European | macce_general_ci | 1 | | macroman | Mac West European | macroman_general_ci | 1 | | cp852 | DOS Central European | cp852_general_ci | 1 | | latin7 | ISO 8859-13 Baltic | latin7_general_ci | 1 | | cp1251 | Windows Cyrillic | cp1251_general_ci | 1 | | cp1256 | Windows Arabic | cp1256_general_ci | 1 | | cp1257 | Windows Baltic | cp1257_general_ci | 1 | | binary | Binary pseudo charset | binary | 1 | | geostd8 | GEOSTD8 Georgian | geostd8_general_ci | 1 | +----------+-----------------------------+---------------------+--------+ 26 rows in set (0.00 sec)
И третье, что необходимо знать, — правила создания таблиц для хранения данных в нужной кодировке. К слову, данные можно хранить в любой кодировке, а работать с ними в кодировке клиента. Однако, важно понимать, что кодировки носят национальный характер и должны соответствовать вносимым данным. Иначе будут потери. Для русского языка есть три национальных кодировки koi8r, cp866, cp1251, которые могут конвертироваться друг в друга без потерь. Также можно использовать интернациональную кодировку UTF8.
Кодировку можно выставить на базу данных, таблицу и поле таблицы. Так, например, можно создать базу данных в кодировке koi8r:
CREATE DATABASE `test` DEFAULT CHARACTER SET koi8r;
Следует отметить, что кодировка базы данных влияет только на дефолтные значения кодировок при создании таблиц. Это значит, что неважно в какой кодировке была создана база, если кодировка таблицы была задана явно. Это же правило относится и к полям таблицы.
Следующим шагом я создам таблицу в cp1251 и одним полем в utf8:
CREATE TABLE `t` ( `id` VARCHAR( 60 ) NOT NULL , `data` TEXT CHARACTER SET utf8 NOT NULL , PRIMARY KEY ( `id` ) ) TYPE = MYISAM CHARACTER SET cp1251;
После того, как таблица создана с нужными параметрами кодировки, mysql автоматически начинает переводить данные при внесении и выборке.
mysql> select * from t; +--------+-------------+ | id | data | +--------+-------------+ | привет | привет мир! | +--------+-------------+ 1 row in set (0.00 sec)
Данные хранятся в разном виде, но поступают к пользователю именно так, как надо!
Подробнее с кодировками и проблемами их использования можно ознакомиться на http://dev.mysql.com/doc/refman/5.1/en/charset.html.
Кодировка HTML-страниц
Объявить кодировку html-страницы можно двумя способами: через заголовки и мета-тег в самой странице. Мета-тег используется только в статичных страницах.
<meta http-equiv="Content-Type" content="text/html; charset=windows-1251">
Я не буду его разбирать, это проблемы html. Во всех остальных случаях предпочтительней использовать HTTP-заголовок Content-Type.
PHP позволяет работать с HTTP-заголовками посредством функции header():
// Объявление типа содержимого и его кодировки header('Content-Type: text/html; charset=windows-1251');
Но браузер отобразит страницу корректно только в том случае, когда php-файлы сами были созданы в кодировке cp1251. Также нужно понимать, что заголовки должны быть отправлены до любого вывода на экран.
При необходимости перекодировать страницы «на лету», достаточно воспользоваться буферизацией и iconv:
Код - динамическая перекодировка
|
|
1 |
<?php iconv_set_encoding('internal_encoding', 'WINDOWS-1251'); // Исходная кодировка файлов iconv_set_encoding('output_encoding' , 'UTF-8'); // Конечная кодировка ob_start('ob_iconv_handler'); // буферизация header('Content-Type: text/html; charset=UTF8'); ?> Привет, мир! |
Надпись «Привет, мир!» будет выведена в юникоде, при этом браузер получит информацию о кодировке через заголовки и правильно отобразит страницу. Но важно понимать, что внутри скрипта и при соединении с базой данных надо использовать windows-1251 (cp1251), поскольку страница должна быть сформирована в одной кодировке.
Важно помнить, что функции iconv доступны не всегда, и проверка на доступность этих функций не будет лишней.
Заключение
Для безопасной разработки русскоязычных веб-проектов необходимо включать в файл с общими настройками следующие команды:
Код - файл общих настроек
|
|
1 |
<?php // Файл общих настроек ... // Вывод заголовка с данными о кодировке страницы header('Content-Type: text/html; charset=windows-1251'); // Настройка локали setlocale(LC_ALL, 'ru_RU.CP1251', 'rus_RUS.CP1251', 'Russian_Russia.1251', 'russian'); // Настройка подключения к базе данных mysql_query('SET names "cp1251"'); ?> |
Как ни странно, но эти три строчки кода значительно повышают портируемость веб-проектов.
Introduction
When it comes to developing and running applications on Windows, one of the most critical aspects to consider is the locale and code page settings. These settings determine how text is displayed and processed within an application, and they can have a significant impact on the overall user experience. In this article, we will explore the possibility of setting the locale of a Windows application to UTF-8, a widely used encoding standard that supports a vast range of characters from different languages.
Understanding Locale and Code Page
Before we dive into the specifics of setting the locale to UTF-8, let’s take a moment to understand the concepts of locale and code page. A locale is a set of parameters that defines the language, country, and cultural settings for an application. It includes settings such as date and time formats, currency symbols, and text encoding. A code page, on the other hand, is a specific character encoding scheme used to represent text in a particular locale.
The Challenge of UTF-8 in Windows
UTF-8 is a variable-width encoding standard that can represent any Unicode character using a single byte or up to four bytes. It is widely used in web development, programming, and other areas where text encoding is critical. However, Windows has traditionally used a different encoding scheme, known as the Windows-1252 code page, which is a superset of the ISO-8859-1 standard.
AppLocale: A Solution for Non-Unicode Applications
As mentioned earlier, there is an application called AppLocale that can change the code page of non-Unicode applications to solve text display problems. AppLocale is a free tool developed by Microsoft that allows users to run non-Unicode applications in a specific locale, including UTF-8. However, AppLocale has some limitations, and it may not work with all applications.
Setting Locale to UTF-8: Is it Possible?
So, is it possible to set the locale of a Windows application to UTF-8? The answer is not a simple yes or no. While it is technically possible to set the locale to UTF-8, it may not work with all applications, especially those that are not designed to handle Unicode characters.
Using the SetThreadLocale Function
One way to set the locale to UTF-8 is by using the SetThreadLocale function, which is a part of the Windows API. This function allows developers to set the locale for a specific thread, which can be useful for applications that need to handle multiple languages.
Example Code
#include <Windows.h>
int main() {
// Set the locale to UTF-8
SetThreadLocale(0x0409); // 0x0409 is the code page for UTF-8
// Your application code here...
return 0;
}
Using the SetThreadLocaleEx Function
Another way to set the locale to UTF-8 is by using the SetThreadLocaleEx function, which is an extended version of the SetThreadLocale function. This function allows developers to set the locale for a specific thread and also specify the code page.
Example Code
#include <Windows.h>
int main() {
// Set the locale to UTF-8
SetThreadLocaleEx(0x0409, 0x0809); // 0x0409 is the code page for UTF-8, 0x0809 is the code page for UTF-8 with a specific language
// Your application code here...
return 0;
}
Limitations and Considerations
While it is possible to set the locale to UTF-8 using the SetThreadLocale or SetThreadLocaleEx functions, there are some limitations and considerations to keep in mind. For example:
- Not all applications are designed to handle Unicode characters, and setting the locale to UTF-8 may cause display problems or other issues.
- Some applications may require specific code pages or locales to function correctly.
- Setting the locale to UTF-8 may affect the behavior of certain system functions or APIs.
Conclusion
In conclusion, while it is possible to set the locale of a Windows application to UTF-8, it may not work with all applications, especially those that are not designed to handle Unicode characters. Developers should carefully consider the limitations and considerations mentioned above before setting the locale to UTF-8. Additionally, using tools like AppLocale or the SetThreadLocale or SetThreadLocaleEx functions can help solve text display problems in non-Unicode applications.
Recommendations
Based on our research and analysis, we recommend the following:
- Use AppLocale or the
SetThreadLocaleorSetThreadLocaleExfunctions to set the locale to UTF-8, especially for applications that require Unicode support. - Carefully consider the limitations and considerations mentioned above before setting the locale to UTF-8.
- Test your application thoroughly to ensure that it works correctly with the set locale.
- Consider using Unicode-aware libraries or frameworks to handle text encoding and display.
Final Thoughts
Frequently Asked Questions
In our previous article, we explored the possibility of setting the locale of a Windows application to UTF-8. In this article, we will answer some of the most frequently asked questions related to this topic.
Q: What is the difference between a locale and a code page?
A: A locale is a set of parameters that defines the language, country, and cultural settings for an application. It includes settings such as date and time formats, currency symbols, and text encoding. A code page, on the other hand, is a specific character encoding scheme used to represent text in a particular locale.
Q: Why is it difficult to set the locale to UTF-8 in Windows?
A: Windows has traditionally used a different encoding scheme, known as the Windows-1252 code page, which is a superset of the ISO-8859-1 standard. This means that many Windows applications are not designed to handle Unicode characters, and setting the locale to UTF-8 may cause display problems or other issues.
Q: Can I use AppLocale to set the locale to UTF-8?
A: Yes, AppLocale is a free tool developed by Microsoft that allows users to run non-Unicode applications in a specific locale, including UTF-8. However, AppLocale has some limitations, and it may not work with all applications.
Q: How do I set the locale to UTF-8 using the SetThreadLocale function?
A: To set the locale to UTF-8 using the SetThreadLocale function, you need to call the function with the code page for UTF-8, which is 0x0409. Here is an example code snippet:
#include <Windows.h>
int main() {
// Set the locale to UTF-8
SetThreadLocale(0x0409); // 0x0409 is the code page for UTF-8
// Your application code here...
return 0;
}
Q: How do I set the locale to UTF-8 using the SetThreadLocaleEx function?
A: To set the locale to UTF-8 using the SetThreadLocaleEx function, you need to call the function with the code page for UTF-8 and the language ID for the specific language you want to use. Here is an example code snippet:
#include <Windows.h>
int main() {
// Set the locale to UTF-8
SetThreadLocaleEx(0x0409, 0x0809); // 0x0409 is the code page for UTF-8, 0x0809 is the code page for UTF-8 with a specific language
// Your application code here...
return 0;
}
Q: What are the limitations and considerations when setting the locale to UTF-8?
A: When setting the locale to UTF-8, you should be aware of the following limitations and considerations:
- Not all applications are designed to handle Unicode characters, and setting the locale to UTF-8 may cause display problems or other issues.
- Some applications may require specific code pages or locales to function correctly.
- Setting the locale to UTF-8 may affect the behavior of certain system functions or APIs.
Q: Can I use Unicode-aware libraries or frameworks to handle text encoding and display?
A: Yes, you can use Unicode-aware libraries or frameworks to handle text encoding and display. These libraries and frameworks can help you to handle Unicode characters and display them correctly, even if the application is not designed to handle Unicode.
Q: What are some best practices for setting the locale to UTF-8?
A: Here are some best practices for setting the locale to UTF-8:
- Test your application thoroughly to ensure that it works correctly with the set locale.
- Use Unicode-aware libraries or frameworks to handle text encoding and display.
- Consider using AppLocale or the
SetThreadLocaleorSetThreadLocaleExfunctions to set the locale to UTF-8. - Be aware of the limitations and considerations mentioned above when setting the locale to UTF-8.
Conclusion
In conclusion, setting the locale of a Windows application to UTF-8 is possible, but it requires careful consideration of the limitations and considerations mentioned above. By using tools like AppLocale or the SetThreadLocale or SetThreadLocaleEx functions, developers can solve text display problems in non-Unicode applications and ensure that their applications work correctly with Unicode characters.
The other day I was experimenting with PostgreSQL under Windows and I was very confused setting a locale in the command line when initializing the database cluster. If I didn’t specify a locale in the --locale option of initdb, then the locale that was used was: Greek_Greece.1253. Well, I needed to initialize the cluster with en_US.UTF-8, but it would not be accepted. After some experimentation, I realized that no matter what name I tried, for example en_US.UTF-8, el_GR.UTF-8 etc, it did not work out! This led me to the conclusion that Windows uses different names than those I used in Linux for the same task.
At this point, I should note that I didn’t use the PostgreSQL Windows Installer package, which would have probably taken care of the locale setting automatically or provide me with an option to customize it, but, as the advanced computer guru that I am, I preferred the bare Windows binaries package instead.
After several unsuccessful attempts, I thought of using the locale Python module and see if it could help me get a list of locale names that Windows supports. I managed to get a list of locales, but it turned out that those would not be accepted by initdb either.
As a last resort, I decided to dig into MSDN for an answer. My experience with that place is minimal, so it took me a while before familiarizing myself and making progress with my research. But finally, I managed to locate the needed information. So, Windows uses the same pattern for locale names:
language_territory.codeset
But the names for the language and territory parts are different. To get a proper name it is required to combine information from the following three pages:
- language: Language Strings
- territory: Country/Region Strings
- codeset: Code Pages Supported by Windows
So, for instance, if you want to set the “en_US.UTF-8” locale in Windows, you have to use “american_usa“. It is a bit frustrating that locale names are not common among the various operating systems. I needed to do a very simple thing and this has added a lot of overhead. I am very disappointed.
As an example, I post the command line options I finally used with initdb in order to initialize the PostgreSQL database cluster:
initdb.exe --auth=md5 --locale=american_usa --encoding=UTF8 --pgdata=G:\PostgreSQL\data --xlogdir=G:\PostgreSQL\xlogs -U postgres -W
As a general conclusion, I would say it would be a lot better if we spent our time doing more creative things than trying to match the locale names between various operating systems. I am quite sure that both Linux and Windows use names based on some kind of standard, but why can’t they be based on a single standard?
Locale in Windows by George Notaras is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.
Copyright © 2011 — Some Rights Reserved