
Брокер сообщений — это программное обеспечение, которое служит промежуточным звеном для пересылки сообщений между различными приложениями. Он действует как определенный сервер, который получает сообщения от одного приложения (называемого продюсером) и маршрутизирует их к одному или нескольким другим приложениям (называемым консьюмером). Основная цель брокера сообщений — обеспечить устойчивую и надежную связь между различными системами, при этом не требуя, чтобы эти системы всегда были доступны и имели прямую связь друг с другом. Это позволяет приложениям работать асинхронно, обеспечивая отказоустойчивость и возможность работы в режиме реального времени. Брокер сообщений может принимать сообщения от множества источников и эффективно маршрутизировать их к нужному приемнику. Сообщения могут быть сгруппированы в топики или очереди в зависимости от требуемой бизнес-логики.
Существует множество различных брокеров сообщений, каждый из которых имеет свои собственные особенности и преимущества. В данной статье мы сфокусируемся на изучении Kafka.
Apache Kafka — это быстрый и масштабируемый брокер сообщений, способный обрабатывать миллионы сообщений в секунду. Брокер особенно ценится за свою отказоустойчивость и возможность длительного хранения данных. Проект изначально разрабатывался компанией LinkedIn, в настоящее время является самым популярным open-source решением в сфере брокеров сообщений и имеет лицензию Apache Software Foundation. Это решение широко используется для построения реальных пайплайнов данных и потоковых приложений. Перемещение и обработка потоков данных между системами или приложениями становится критической задачей. Именно здесь приходит на помощь Kafka, помогая пользователю обрабатывать потоки данных в реальном времени, с минимальной задержкой. В качестве распределенной системы, рассматриваемый брокер делится на множество серверов, которые могут хранить и обрабатывать потоки данных параллельно. Такое распределение позволяет Kafka обеспечивать обработку данных в реальном времени для множества различных источников, обеспечивая надежность и устойчивость к сбоям системы.
В этой статье мы будем изучать процесс установки и настройки Kafka, чтобы вы могли использовать все его преимущества для ваших проектов. Мы рассмотрим процесс для различных операционных систем, включая Windows, Ubuntu и MacOS, чтобы обеспечить максимально возможную гибкость для различных пользователей и потребностей.
cloud
Системные требования
Apache Kafka был разработан таким образом, чтобы максимально эффективно использовать возможности железа, на котором он работает. Однако, существуют некоторые общие рекомендации, которые полезно иметь в виду при настройке системы для работы с этим брокером:
-
Процессор (CPU): Kafka обычно не требует много процессорной мощности, так как большую часть операций он выполняет с помощью прямого доступа к диску (zero-copy). Однако количество ядер CPU может влиять на пропускную способность.
-
Оперативная память (RAM): Рекомендуется иметь как минимум 8GB оперативной памяти, но итоговый объем будет сильно зависеть от массива данных и количества параллельных операций.
-
Дисковое пространство: Kafka эффективно использует файловую систему и прямую запись на диск. Желательно использовать SSD с повышенной скоростью записи/чтения данных. Рекомендуется использовать отдельный диск, чтобы изолировать его работу от других процессов.
-
Сеть: Брокер активно использует сеть для передачи данных. Рекомендуется иметь стабильное подключение с высокой пропускной способностью.
-
Операционная система: Apache Kafka, как правило, работает на Unix-подобных системах, таких как Linux, однако это не ограничивает пользователя в выборе операционной системы.
-
Java: Поскольку инструмент написан на Java, вам потребуется среда выполнения Java (JDK), версии 8 или выше.
Несмотря на то, что Linux дает Kafka ключевое преимущество в виде производительности и масштабируемости, брокер хорошо работает как на Windows, так и на MacOS. Чуть позже мы разберем плюсы и минусы каждого решения, а сейчас приступим к установке.
Процесс установки Kafka достаточно прямолинейный, тем не менее он требует некоторой аккуратности. Вот пошаговая инструкция:
-
Скачивание и установка Java Development Kit (JDK): Apache Kafka работает на Java, поэтому первым делом нужно установить средства разработки, если они у вас были не установлены. Скачать JDK можно с официального сайта Oracle. После установки обязательно проверьте работоспособность, для этого достаточно ввести в командной строке (cmd) следующую команду:
java -version-
Скачивание Apache Kafka: Apache Kafka можно скачать с официального сайта проекта (нам нужны Binary downloads). Рекомендуется выбирать последнюю стабильную версию продукта (на момент написания статьи это 3.7.0, поэтому здесь будет показана установки именно этой версии. Однако, установка от версии к версии не сильно меняется, поэтому эту инструкцию можно применять и к другим версиям продукта)
-
Распаковка: После скачивания архива его следует распаковать и переместить в удобное для вас место. После распаковки дистрибутива, вы увидите различные папки, такие как:
-
bin: Эта папка содержит исполняемые файлы, которые используются для запуска и управления распределенной системой обмена сообщениями. В подпапке/windowsнаходятся специальные версии файлов, предназначенные для использования в OS Windows. -
config: Здесь собраны файлы конфигурации Kafka, в том числеzookeeper.propertiesиserver.properties, которые можно отредактировать для более точной настройки. -
libs: Это папка со всеми библиотеками, которые нужны для запуска и работоспособности. -
logs: Здесь содержатся журналы работы или другими словами логи. Они могут быть полезны при отладке проблем и нахождении зависимостей между компонентами. -
site-docs: Эта папка содержит документацию для версии Kafka, которую вы установили. Может быть полезна для начинающих специалистов. -
LICENSEиNOTICE: Эти файлы содержат лицензионное соглашение и правовые замечания.

-
Базовая настройка каталога данных и логирования: По умолчанию, файлы логов и каталог данных сохраняется в папке
/tmp, что может привести к проблемам производительности, безопасности и управления данными. Рекомендуется поменять стандартные пути на свои -
Перейдите в
config/server.propertiesи откройте файл в любом текстовом редакторе (на скриншоте VSCode). -
Найдите поле
log.dirs(можно воспользоваться поиском, для этого нажмите сочетание клавиш Ctrl+F)
-
Поменяйте стандартный путь
/tmp/kafka-logsна постоянный путь. Напримерc:/kafka/kafka-logs. После чего сохраните файл и закройте его. -
Аналогичные действия нужно сделать и для каталога данных. Для этого перейдите в
config/zookeeper.propertiesи откройте файл в любом текстовом редакторе. -
В параметре
dataDirтакже нужно поменять стандартный путь на свой. Пример постоянного пути есть ниже на скриншоте.
На этом базовая настройка закончена. Этого хватит чтобы запустить сервер Zookeeper и Kafka и проверить работоспособность системы.
-
Запуск сервера Zookeeper и Kafka: Для запуска нужно перейти в папку с распакованным архивом и открыть командную строку. Для запуска Zookeeper используйте следующую команду:
.\bin\windows\zookeeper-server-start.bat .\config\zookeeper.properties. Обратите внимание, наш Zookeeper запущен на 2181 порту. Это стандартный порт для этой службы.
Если у вас появляется ошибка «The input line is too long. The syntax of the command is incorrect», переместите папку с Kafka в каталог, ближе к корню диска. Во время запуска zookeeper-server-start.bat вызывает CLASSPATH несколько раз, что приводит к переполнению переменной. Среда cmd.exe поддерживает не более 8191 символов.
Откройте новое окно терминала для запуска Kafka-server и используйте следующую команду:
.\bin\windows\kafka-server-start.bat .\config\server.properties-
Проверка работоспособности: Для проверки работоспособности попробуем создать тему с помощью следующей команды:
.\bin\windows\kafka-topics.bat --create --bootstrap-server localhost:9092 --partitions 1 --replication-factor 1 --topic TestTopicОбратите внимание, что порт 2181 совпадает с открытым портом для Zookeeper.
Для наглядности создадим еще одну тему под названием NewTopic. Теперь проверим, какие темы у нас существуют, следующей командой:
.\bin\windows\kafka-topics.bat --list --bootstrap-server localhost:9092В новой командной строке мы можем повзаимодействовать с темой, а именно создать несколько сообщений и прочитать их после. Для этого в новом окне введите следующую команду:
.\bin\windows\kafka-console-producer.bat --broker-list localhost:9092 --topic TestTopicПосле старта команды можно передавать любые сообщения:
Для того чтобы начать получать сообщения, в новом окне консоли введите следующую команду:
.\bin\windows\kafka-console-consumer.bat --bootstrap-server localhost:9092 --topic TestTopic --from-beginningКак видно на скриншоте, мы получили сообщения по теме TestTopic.
Это простой функционал, который помогает понять и разобраться в инструментах Kafka. Однако у вас может что-то пойти не так, походу установки и тестов. Вот некоторые типовые ошибки, которые могут возникнуть:
-
Проблемы с JDK: Убедитесь что у вас установлен JDK, а не JRE. Также обратите внимание на версию, она должна быть 8 или выше.
-
Проверка переменных окружения: После установки Java убедитесь, что переменная
JAVA_HOMEправильно установлена и что путь к каталогуbinприсутствует в системном пути. -
Проблемы с firewall и антивирусом: Иногда сторонние антивирусные программы или firewall могут блокировать Kafka. Если вы столкнулись с проблемами подключения, попробуйте на время отключить их.
-
Порты: По умолчанию Zookeeper слушает на порту 2181, а Kafka на 9092. Убедитесь, что эти порты свободны или переназначьте стандартные порты для этих служб.
-
Запуск Zookeeper перед Kafka: Перед тем как запускать Kafka, убедитесь, что Zookeeper уже работает. Если нет, то запустите Zookeeper.
-
Неправильное завершение Kafka: Если Kafka завершается неправильно, то возможно некоторые данные еще остались во временной папке. Если вы начинаете сталкиваться с трудностями при запуске, попробуйте очистить временные файлы.
Установка и настройка Kafka на Ubuntu
На самом деле, шаги не будут сильно отличаться, в зависимости от дистрибутива Linux, который вы выбрали (в нашем случае это Ubuntu). Отличия будут касаться установочных менеджеров и незначительных особенностей каждой операционной системы. Шаги будут похожи на установку для Windows, поэтому вы можете обращаться к этому разделу тоже, даже если у вас операционная система Linux.
vds
-
Скачивание и установка Java Development Kit (JDK): Как уже упоминалось, Apache Kafka работает на Java, поэтому первым делом нужно установить JDK. Однако перед этим, рекомендуем обновить список пакетов и версии этих пакетов командой:
sudo apt update
sudo apt upgradeВ Linux-системах установку можно сделать довольно просто через терминал, для этого достаточно ввести следующие команды:
sudo apt install default-jre
sudo apt install default-jdk-
Скачивание и разархивирование: Apache Kafka можно скачать с официального сайта проекта. Рекомендуется выбирать последнюю стабильную версию продукта. Для скачивания можно воспользоваться утилитой
wgetиз консоли:
wget https://downloads.apache.org/kafka/3.7.0/kafka_2.13-3.7.0.tgzДля распаковки воспользуйтесь следующей командой:
tar xzf kafka_2.13-3.7.0.tgzОбратите внимание, что на момент прочтения статьи, версия продукта может быть другой, соответственно команды, а конкретно цифры в ссылке, будут выглядеть по-другому. По итогу вышеописанных действий у вас должна появиться папка с продуктом рядом с архивом. Перейдите в появившуюся папку командой:
cd kafka_2.13-3.7.0-
Проверка работоспособности: Остальные пункты похожи на то, что мы делали для Windows, поэтому рекомендуем прочитать инструкцию начиная с 3 пункта. Для запуска Zookeeper нужно написать следующую команду:
bin/zookeeper-server-start.sh config/zookeeper.propertiesЗатем в новом окне терминала запустите Kafka:
bin/kafka-server-start.sh config/server.propertiesЭто основная установка и настройка. Для продакшн-среды есть возможность настройки различных параметров, таких как многочисленные бэкапы, конфигурация сети, разделение данных и так далее, но это более трудоемкий и сложный процесс.
Также стоит упомянуть про некоторые возможные трудности, с которыми можно столкнуться в процессе установки Kafka на Linux:
-
Разрешение прав доступа: При работе с Linux иногда возникают проблемы с правами доступа к определенным файлам или каталогам. Чтобы обойти это, можно использовать sudo перед командами, которые будут вызывать проблемы. Однако будьте осторожны с этим, потому что sudo дает полный админский доступ, что может повлечь за собой последствия с нарушением безопасности.
-
Ошибки памяти Java: Если у вас возникают проблемы с памятью Java при работе с Kafka, вы можете попробовать увеличить максимальное количество памяти, выделенной для JVM с помощью флага -Xmx. Для этого нужно будет добавить флаг в файл конфигурации, который находится в
bin/kafka-server-start.sh. Однако учтите, что важно оставить достаточно памяти для работы других процессов в системе. Увеличение максимального объема памяти JVM может привести к замедлению работы системы, если JVM начнет использовать все доступные ресурсы. -
Управление версиями: При работе с Linux иногда возникают проблемы с версиями. Всегда проверяйте версию Kafka и все связанные инструменты, такие как Zookeeper, для обеспечения совместимости.
-
Правильная остановка Kafka и Zookeeper: Для остановки Kafka и Zookeeper в Linux вы можете использовать команды
kafka-server-stop.sh
zookeeper-server-stop.shРекомендуется всегда останавливать эти службы правильно, чтобы избежать потери данных.
-
Проблемы с логированием: Инструмент генерирует огромное количество логов, удостоверьтесь, что у вас есть достаточно свободного места на диске и активирована ротация логов.
-
Порты и пределы файлов: Убедитесь, что у вас есть разрешение на открытие необходимого количества файлов или сокетов. Linux имеет системные ограничения, которые можно изменить при необходимости.
Установка и настройка Kafka на MacOS
Вот пошаговый процесс установки и настройки Kafka на системе MacOS:
-
Установка Homebrew: Homebrew — менеджер пакетов, который упрощает установку программного обеспечения на операционной системе MacOS. Homebrew не требует прав администратора для установки ПО, что делает его удобным для использования и уменьшает риски связанные с безопасностью. Если у вас еще нет Homebrew, вы можете установить его, используя следующую команду в терминале:
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"В нашем случае, Homebrew понадобится для установки Kafka и его зависимостей.
-
Обновление Homebrew: В случае если у вас уже был установлен Homebrew, его не помешало бы обновить до новейшей версии командой.
brew update-
Установка Java Development Kit (JDK): Для установки JDK можно воспользоваться Homebrew, который мы только что установили. Для этого в консоли введите следующую команду:
brew install openjdk-
Установка Kafka: Установите Kafka следующей командой:
brew install kafka-
Запуск Kafka и Zookeeper: Сначала запустите Zookeeper, а затем Kafka. Замените
usr/local/binна путь к исполняемым файлам Kafka и Zookeeper, если они у вас в другом месте:
zookeeper-server-start /usr/local/etc/kafka/zookeeper.properties
kafka-server-start /usr/local/etc/kafka/server.propertiesТакже стоит отметить, что для простоты демонстрации мы запустили Zookeeper и Kafka в режиме standalone на локальной машине. Для создания полноценной распределенной сети на нескольких машинах, вам потребуется изменить файлы конфигурации соответствующим образом. Среди ключевых параметров для изменения:
-
Разделы — сущности, которые позволяют распараллелить обработку данных. Количество разделов определяет, сколько потоков одновременно сможет обрабатывать данные в рамках топика.
-
Реплики — копии существующих разделов, для обеспечения отказоустойчивости. Количество реплик определяет, сколько копий каждого раздела будет храниться в кластере.
-
Информация о брокере — полный список всех серверов, которые будут участвовать в кластере.
Как и для других операционных систем, мы отметим типичные проблемы при установке Kafka на MacOS:
-
JDK нужной версии: Проверьте, установлен ли JDK версии 8 или выше. Если JDK не установлен, то вы можете столкнуться с ошибкой при попытке запуска.
-
Переменные среды: Kafka может не работать, если переменные среды установлены неправильно или не установлены вовсе. Например, вы должны установить переменную среды
KAFKA_HOMEна путь к директории. Иногда для корректной работы могут потребоваться и другие переменные среды, напримерJAVA_HOME. -
Путь к файлам и разрешения: Kafka может не найти нужные файлы или не сможет запуститься, если у него нет разрешения на чтение и запись в определенные директории. Вам может потребоваться изменить разрешения или переместить некоторые файлы.
-
Проблемы с Homebrew: Убедитесь, что Homebrew установлен корректно и обновлен до последней версии. Иногда установка через Homebrew может привести к конфликту версия или проблемам с зависимостями.
-
Проблемы с зависимостями: Система требует наличия Zookeeper чтобы функционировать. Первым делом запускайте Zookeeper, а потом уже Kafka.
-
Порты: Kafka и Zookeeper используют определенные порты (9092 и 2181 соответственно) по умолчанию. Если эти порты используются другими приложениями, инструмент не сможет запуститься.
-
Конфигурация: Ошибки в файлах конфигурации Kafka или неправильно заданные параметры могут привести к проблемам при попытке запуска.
Зачастую установка Kafka идет довольно гладко, если использовать Homebrew. Вероятность столкнуться с проблемой в MacOS мала.
Установка и настройка Kafka в Docker
Docker — это платформа, предназначенная для разработки, доставки и запуска приложений в контейнерах. Контейнеры позволяют упаковать приложение со всем его окружением и зависимостями в один пакет, который можно легко распространять и устанавливать на любой системе. Установка Kafka в Docker — это хороший способ быстро и без особых трудностей начать работать с системой. Вот несколько простых шагов, для установки:
-
Первым делом, нужен сам Docker. Скачайте Kafka с официального сайта проекта способом, соответствующим вашей ОС.
-
Запустите экземпляр, с помощью этой команды:
docker run -p 9092:9092 apache/kafka:3.7.0Обратите внимание, что ваша версия Kafka может отличаться от той, что в примере.
Вы можете проверить работоспособность инструмента аналогично разделу установки на Linux.
Общие рекомендации по выбору ОС
Как мы выяснили, возможность установить Kafka есть во всех основных операционных системах, а также в Docker. В зависимости от конкретной ситуации и потребностей, каждая из них имеет свои преимущества и недостатки. Если у вас стоит выбор, на какой ОС развернуть Kafka, ниже будут рассмотрены плюсы и минусы каждой системы.
Windows
-
Плюсы:
-
Простота использования: Windows по-прежнему остается одной из самых популярных операционных систем с большим количеством документации и комьюнити.
-
Интеграция: Очень хорошо интегрируется с другими продуктами и сервисами Microsoft.
-
Минусы:
-
Windows не всегда является наилучшим выбором для развертывания серверных приложений, скорее всего вам придется столкнуться с некоторыми проблемами совместимости и производительности.
-
Наличие Powershell и WSL (Windows Subsystem for Linux) может упростить работу, однако эти системы не всегда могут быть оптимальными для работы с Linux-приложениями.
-
Kafka и Zookeeper обычно тестируются и используются на Unix-подобных системах, что может привести к большему количеству багов и проблем.
macOS
-
Плюсы:
-
Простая установка с минимальными трудностями.
-
Удобные инструменты для установки и управления продуктами.
-
Система на базе Unix, что облегчает работу с большинством инструментов.
-
Минусы:
-
Ресурсоемкая система: Если ваш Mac не обладает достаточными ресурсами, это может замедлить работу.
-
Возможные проблемы совместимости между версиями macOS и Kafka, что может привести к фатальным ошибкам.
Linux
-
Плюсы:
-
Из-за того, что Linux — это система с открытым исходным кодом и поддерживается большим сообществом, почти всегда есть способы решения той или иной проблемы.
-
Linux занимает меньше системных ресурсов, что делает его более эффективным в работе с Kafka.
-
Операционные системы на базе Linux часто являются предпочтительными для серверных приложений.
-
Минусы:
-
Требует больше технических навыков для настройки и управления, по сравнению с Windows и macOS.
-
Возможные сложности при установке и настройке GUI.
Docker
-
Плюсы:
-
Портативность: Docker-контейнеры можно запускать на любой операционной системе. Это может облегчить развертывание брокера в различных окружениях.
-
Изоляция: Docker обеспечивает изоляцию между приложениями, что означает, что работа Kafka не будет влиять на другие приложения.
-
Воспроизводимость: Используя Docker, можно создать конфигурацию, которую легко воспроизвести. Это облегчает процесс обновления и развертывания.
-
Интеграция с другими инструментами: Docker хорошо взаимодействует с популярными решениями, что упрощает управление и масштабирование контейнеров Kafka.
-
-
Минусы:
-
Сложность: Docker добавляет дополнительный слой сложности в установку брокера.
-
Управление данными: Брокер хранит все сообщения на диске. Его конфигурация и управление могут быть сложными, учитывая контейеризованную среду.
-
Производительность: Как и любая другая система, работающая в контейнере, производительность брокера может быть ограничена ресурсами контейнера. Это может потребовать более тонкой настройки Docker.
-
Управление: Управление и мониторинг брокера в контейнере может быть сложным, особенно в больших системах. Возможно потребуются инструменты автоматизации, такие как Kubernetes и Prometheus.
-
В целом, Linux является наиболее распространенным выбором для работы с Apache Kafka, особенно для серверов и рабочих станций. Однако, выбор операционной системы будет напрямую зависеть от ваших предпочтений и требований.
Запуск Kafka в облаке
Мы рассмотрели процесс установки Kafka на разные операционные системы, однако этот процесс может затянуться в связи с некоторыми ошибками. Если вы хотите избежать заморочек с установкой и настройкой, обратите внимание на наше решение.
Timeweb Cloud предлагает гибкое и масштабируемое облачное решение для запуска экземпляра Kafka за пару минут. Вам не нужно устанавливать и настраивать ПО, достаточно выбрать регион и конфигурацию.
Решение Timeweb Cloud обеспечит стабильность и быстродействие вашему проекту на Kafka, благодаря профессиональной поддержке и высокопроизводительной инфраструктуре. Все это позволяет полностью сосредоточиться на разработке и масштабировании вашего проекта, не беспокоясь о технической стороне процесса.
Попробуйте Timeweb Cloud уже сегодня и откройте для себя преимущества работы с надежным и высокопроизводительным облачных хостингом.
Заключение
Apache Kafka — это серьезный, надежный и масштабируемый брокер сообщений, который обеспечивает высокую пропускную способность, устойчивость к отказам и низкую временную задержку. Вот несколько причин, почему стоит выбирать Kafka в качестве среды обмена сообщениями:
-
Высокая пропускная способность: Apache Kafka способен обрабатывать миллионы сообщений в секунду, что делает его отличным выбором для приложений, которые обрабатывают огромные объемы данных в реальном времени.
-
Устойчивость к отказам: Kafka обеспечивает восстановление от сбоев и обеспечивает высокую доступность данных благодаря своим механизмам репликации.
-
Масштабируемость: Kafka легко масштабируется, добавляя больше узлов в кластер без прерывания сервиса.
-
Долгосрочное хранение данных: В отличие от большинства других брокеров сообщений, Kafka поддерживает долгосрочное хранение данных. Можно настроить период удержания данных в Kafka, и они будут сохраняться до истечении этого времени.
-
Распределенная система: Kafka по сути является распределенной системой, это означает, что сообщения могут быть потребляемы в любом порядке и по многим каналам.
-
Интеграция с большим количеством систем: Kafka может быть легко интегрирована с различными системами, такими как Hadoop, Spark, Storm, Flink и многими другими.
-
Быстрая обработка: Apache Kafka обеспечивает низкую задержку, что делает его отличным выбором для приложений, которым требуется быстрая обработка данных в реальном времени.
-
Топология «публикация-подписка»: Kafka позволяет источникам данных отправлять сообщения в топики, а приложениям-получателя — подписывать на интересующие их топики.
Все эти преимущества делают Kafka одним из наиболее популярных и надежных брокеров сообщений на рынке. Однако, как всегда, выбор инструмента должен основываться на требованиях проекта и предпочтениям команды.
Время на прочтение11 мин
Количество просмотров280K
Данная статья будет полезной тем, кто только начал знакомиться с микросервисной архитектурой и с сервисом Apache Kafka. Материал не претендует на подробный туториал, но поможет быстро начать работу с данной технологией. Я расскажу о том, как установить и настроить Kafka на Windows 10. Также мы создадим проект, используя Intellij IDEA и Spring Boot.
Зачем?
Трудности в понимании тех или иных инструментов часто связаны с тем, что разработчик никогда не сталкивался с ситуациями, в которых эти инструменты могут понадобиться. С Kafka всё обстоит точно также. Опишем ситуацию, в которой данная технология будет полезной. Если у вас монолитная архитектура приложения, то разумеется, никакая Kafka вам не нужна. Всё меняется с переходом на микросервисы. По сути, каждый микросервис – это отдельная программа, выполняющая ту или иную функцию, и которая может быть запущена независимо от других микросервисов. Микросервисы можно сравнить с сотрудниками в офисе, которые сидят за отдельными столами и независимо от коллег решают свою задачу. Работа такого распределённого коллектива немыслима без централизованной координации. Сотрудники должны иметь возможность обмениваться сообщениями и результатами своей работы между собой. Именно эту проблему и призвана решить Apache Kafka для микросервисов.
Apache Kafka является брокером сообщений. С его помощью микросервисы могут взаимодействовать друг с другом, посылая и получая важную информацию. Возникает вопрос, почему не использовать для этих целей обычный POST – reqest, в теле которого можно передать нужные данные и таким же образом получить ответ? У такого подхода есть ряд очевидных минусов. Например, продюсер (сервис, отправляющий сообщение) может отправить данные только в виде response’а в ответ на запрос консьюмера (сервиса, получающего данные). Допустим, консьюмер отправляет POST – запрос, и продюсер отвечает на него. В это время консьюмер по каким-то причинам не может принять полученный ответ. Что будет с данными? Они будут потеряны. Консьюмеру снова придётся отправлять запрос и надеяться, что данные, которые он хотел получить, за это время не изменились, и продюсер всё ещё готов принять request.
Apache Kafka решает эту и многие другие проблемы, возникающие при обмене сообщениями между микросервисами. Не лишним будет напомнить, что бесперебойный и удобный обмен данными – одна из ключевых проблем, которую необходимо решить для обеспечения устойчивой работы микросервисной архитектуры.
Установка и настройка ZooKeeper и Apache Kafka на Windows 10
Первое, что надо знать для начала работы — это то, что Apache Kafka работает поверх сервиса ZooKeeper. ZooKeeper — это распределенный сервис конфигурирования и синхронизации, и это всё, что нам нужно знать о нём в данном контексте. Мы должны скачать, настроить и запустить его перед тем, как начать работу с Kafka. Прежде чем начать работу с ZooKeeper, убедитесь, что у вас установлен и настроен JRE.
Скачать свежею версию ZooKeeper можно с официального сайта.
Извлекаем из скаченного архива ZooKeeper`а файлы в какую-нибудь папку на диске.
В папке zookeeper с номером версии, находим папку conf и в ней файл “zoo_sample.cfg”.

Копируем его и меняем название копии на “zoo.cfg”. Открываем файл-копию и находим в нём строчку dataDir=/tmp/zookeeper. Прописываем в данной строчке полный путь к нашей папке zookeeper-х.х.х. У меня это выглядит так: dataDir=C:\\ZooKeeper\\zookeeper-3.6.0
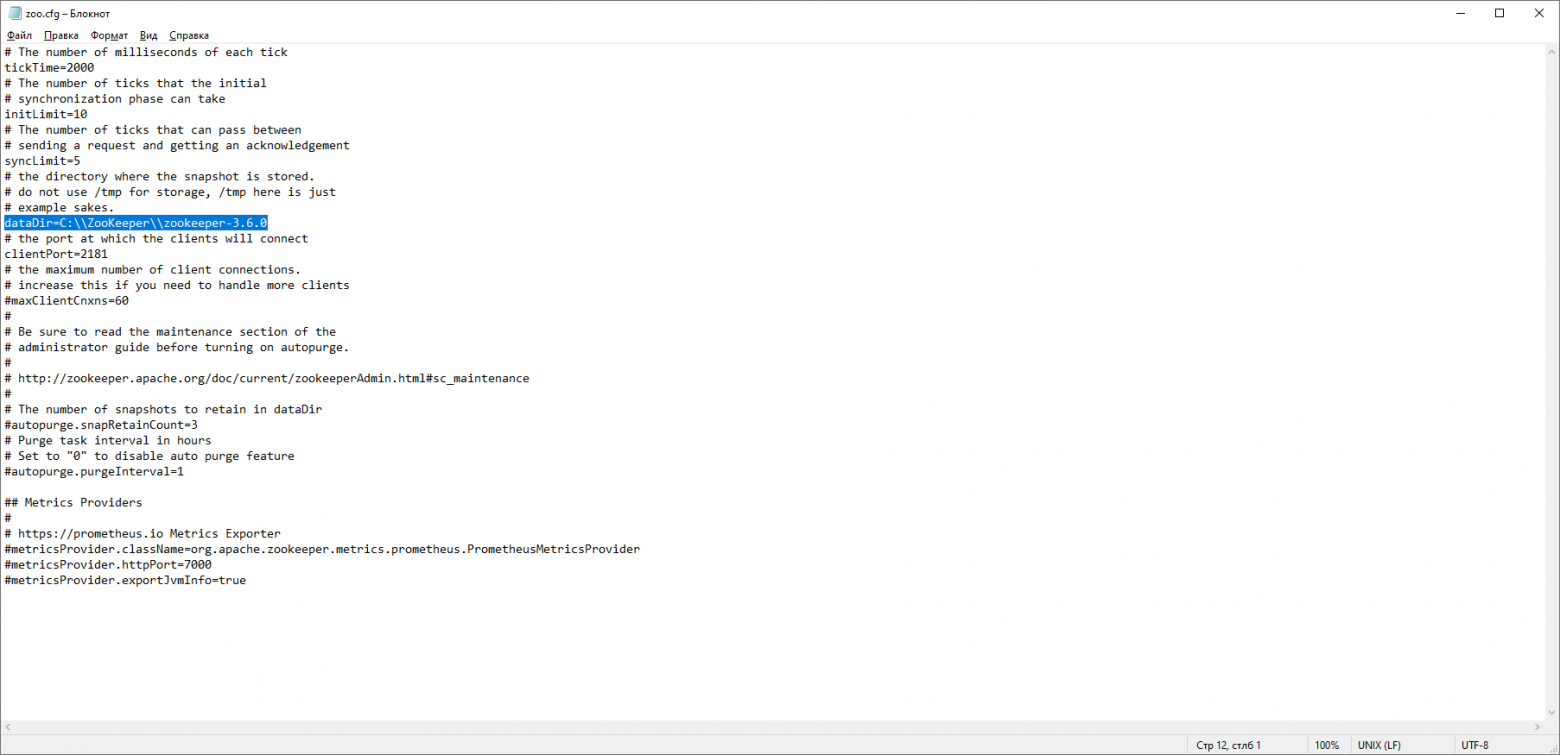
Теперь добавим системную переменную среды: ZOOKEEPER_HOME = C:\ ZooKeeper \zookeeper-3.4.9 и в конце системной переменной Path добавим запись: ;%ZOOKEEPER_HOME%\bin;
Запускаем командную строку и пишем команду:
zkserverЕсли всё сделано правильно, вы увидите примерно следующее.

Это означает, что ZooKeeper стартанул нормально. Переходим непосредственно к установке и настройке сервера Apache Kafka. Скачиваем свежую версию с официального сайта и извлекаем содержимое архива: kafka.apache.org/downloads
В папке с Kafka находим папку config, в ней находим файл server.properties и открываем его.
Находим строку log.dirs= /tmp/kafka-logs и указываем в ней путь, куда Kafka будет сохранять логи: log.dirs=c:/kafka/kafka-logs.
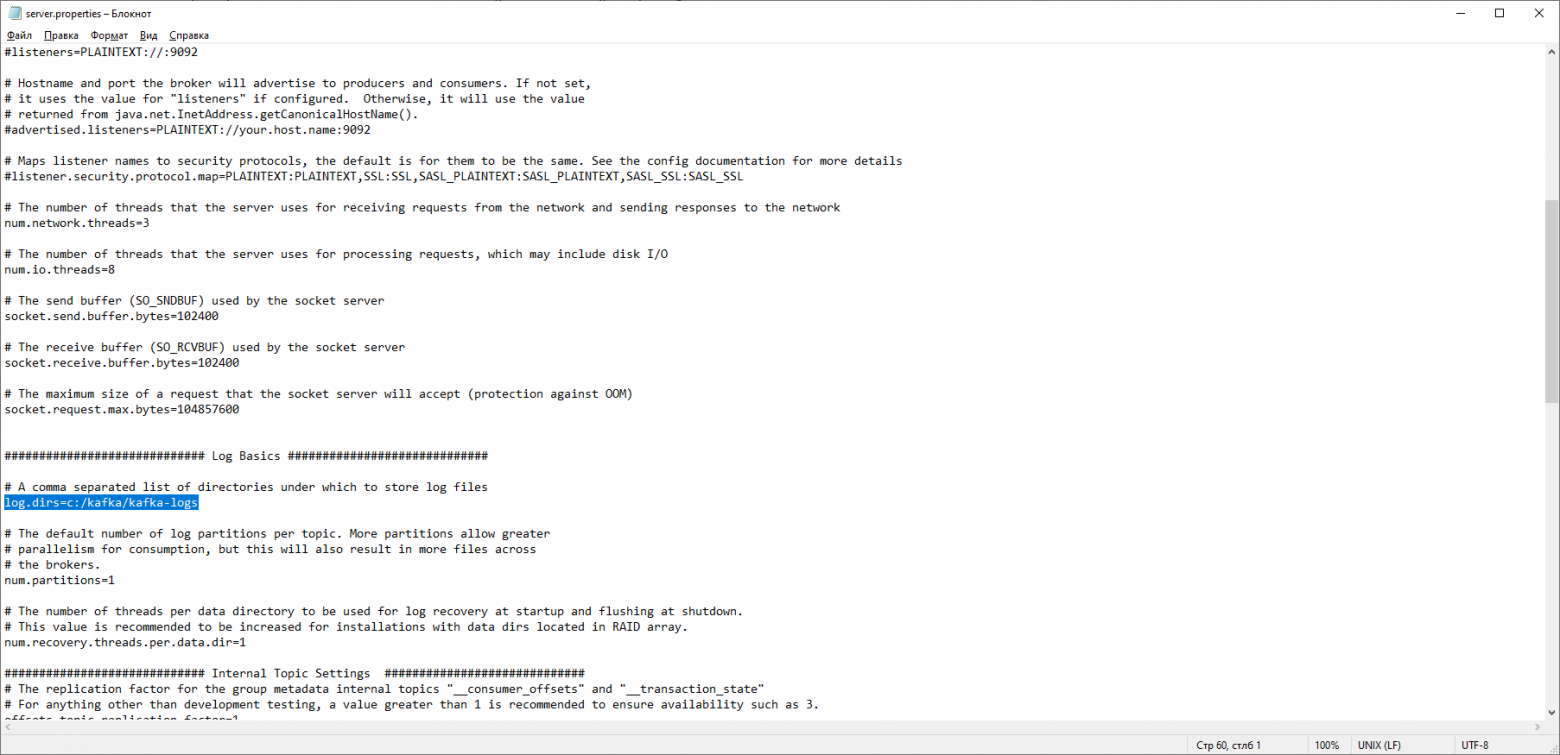
В этой же папке редактируем файл zookeeper.properties. Строчку dataDir=/tmp/zookeeper меняем на dataDir=c:/kafka/zookeeper-data, не забывая при этом, после имени диска указывать путь к своей папке с Kafka. Если вы всё сделали правильно, можно запускать ZooKeeper и Kafka.

Для кого-то может оказаться неприятной неожиданностью, что никакого GUI для управления Kafka нет. Возможно, это потому, что сервис рассчитан на суровых нёрдов, работающих исключительно с консолью. Так или иначе, для запуска кафки нам потребуется командная строка.
Сначала надо запустить ZooKeeper. В папке с кафкой находим папку bin/windows, в ней находим файл для запуска сервиса zookeeper-server-start.bat, кликаем по нему. Ничего не происходит? Так и должно быть. Открываем в этой папке консоль и пишем:
start zookeeper-server-start.batОпять не работает? Это норма. Всё потому что zookeeper-server-start.bat для своей работы требует параметры, прописанные в файле zookeeper.properties, который, как мы помним, лежит в папке config. Пишем в консоль:
start zookeeper-server-start.bat c:\kafka\config\zookeeper.properties Теперь всё должно стартануть нормально.

Ещё раз открываем консоль в этой папке (ZooKeeper не закрывать!) и запускаем kafka:
start kafka-server-start.bat c:\kafka\config\server.propertiesДля того, чтобы не писать каждый раз команды в командной строке, можно воспользоваться старым проверенным способом и создать батник со следующим содержимым:
start C:\kafka\bin\windows\zookeeper-server-start.bat C:\kafka\config\zookeeper.properties
timeout 10
start C:\kafka\bin\windows\kafka-server-start.bat C:\kafka\config\server.propertiesСтрока timeout 10 нужна для того, чтобы задать паузу между запуском zookeeper и kafka. Если вы всё сделали правильно, при клике на батник должны открыться две консоли с запущенным zookeeper и kafka.Теперь мы можем прямо из командной строки создать продюсера сообщений и консьюмера с нужными параметрами. Но, на практике это может понадобиться разве что для тестирования сервиса. Гораздо больше нас будет интересовать, как работать с kafka из IDEA.
Работа с kafka из IDEA
Мы напишем максимально простое приложение, которое одновременно будет и продюсером и консьюмером сообщения, а затем добавим в него полезные фичи. Создадим новый спринг-проект. Удобнее всего делать это с помощью спринг-инициалайзера. Добавляем зависимости org.springframework.kafka и spring-boot-starter-web


В итоге файл pom.xml должен выглядеть так:

Для того, чтобы отправлять сообщения, нам потребуется объект KafkaTemplate<K, V>. Как мы видим объект является типизированным. Первый параметр – это тип ключа, второй – самого сообщения. Пока оба параметра мы укажем как String. Объект будем создавать в классе-рестконтроллере. Объявим KafkaTemplate и попросим Spring инициализировать его, поставив аннотацию Autowired.
@Autowired
private KafkaTemplate<String, String> kafkaTemplate;В принципе, наш продюсер готов. Всё что осталось сделать – это вызвать у него метод send(). Имеется несколько перегруженных вариантов данного метода. Мы используем в нашем проекте вариант с 3 параметрами — send(String topic, K key, V data). Так как KafkaTemplate типизирован String-ом, то ключ и данные в методе send будут являться строкой. Первым параметром указывается топик, то есть тема, в которую будут отправляться сообщения, и на которую могут подписываться консьюмеры, чтобы их получать. Если топик, указанный в методе send не существует, он будет создан автоматически. Полный текст класса выглядит так.
@RestController
@RequestMapping("msg")
public class MsgController {
@Autowired
private KafkaTemplate<String, String> kafkaTemplate;
@PostMapping
public void sendOrder(String msgId, String msg){
kafkaTemplate.send("msg", msgId, msg);
}
}
Контроллер мапится на localhost:8080/msg, в теле запроса передаётся ключ и само сообщений.
Отправитель сообщений готов, теперь создадим слушателя. Spring так же позволяет cделать это без особых усилий. Достаточно создать метод и пометить его аннотацией @KafkaListener, в параметрах которой можно указать только топик, который будет слушаться. В нашем случае это выглядит так.
@KafkaListener(topics="msg")У самого метода, помеченного аннотацией, можно указать один принимаемый параметр, имеющий тип сообщения, передаваемого продюсером.
Класс, в котором будет создаваться консьюмер необходимо пометить аннотацией @EnableKafka.
@EnableKafka
@SpringBootApplication
public class SimpleKafkaExampleApplication {
@KafkaListener(topics="msg")
public void msgListener(String msg){
System.out.println(msg);
}
public static void main(String[] args) {
SpringApplication.run(SimpleKafkaExampleApplication.class, args);
}
}Так же в файле настроек application.property необходимо указать параметр консьюмера groupe-id. Если этого не сделать, приложение не запустится. Параметр имеет тип String и может быть любым.
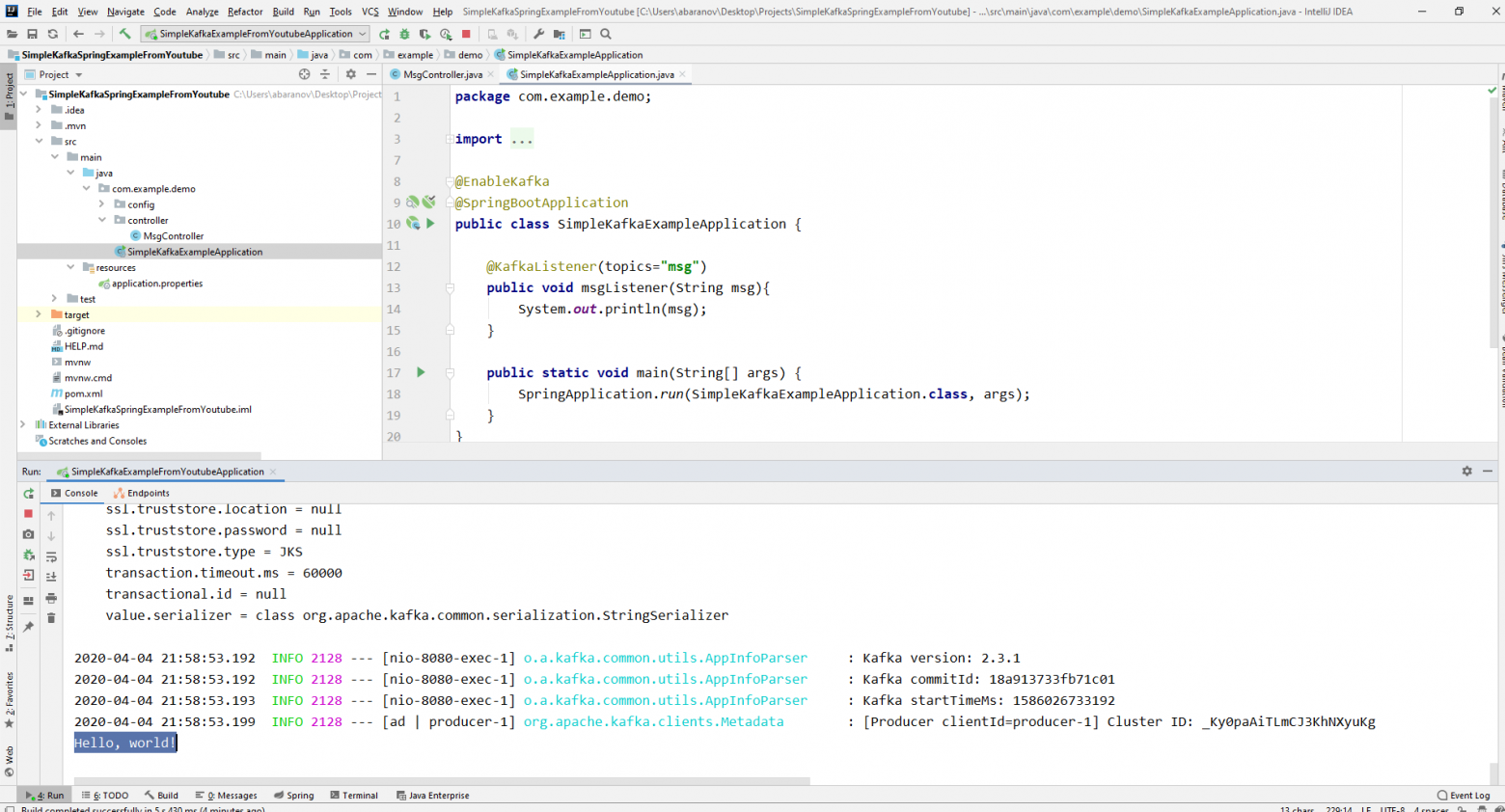
spring.kafka.consumer.group-id=app.1Наш простейший кафка-проект готов. У нас есть отправитель и получатель сообщений. Осталось только запустить. Для начала запускаем ZooKeeper и Kafka с помощью батника, который мы написали ранее, затем запускаем наше приложение. Отправлять запрос удобнее всего с помощью Postman. В теле запроса не забываем указывать параметры msgId и msg.
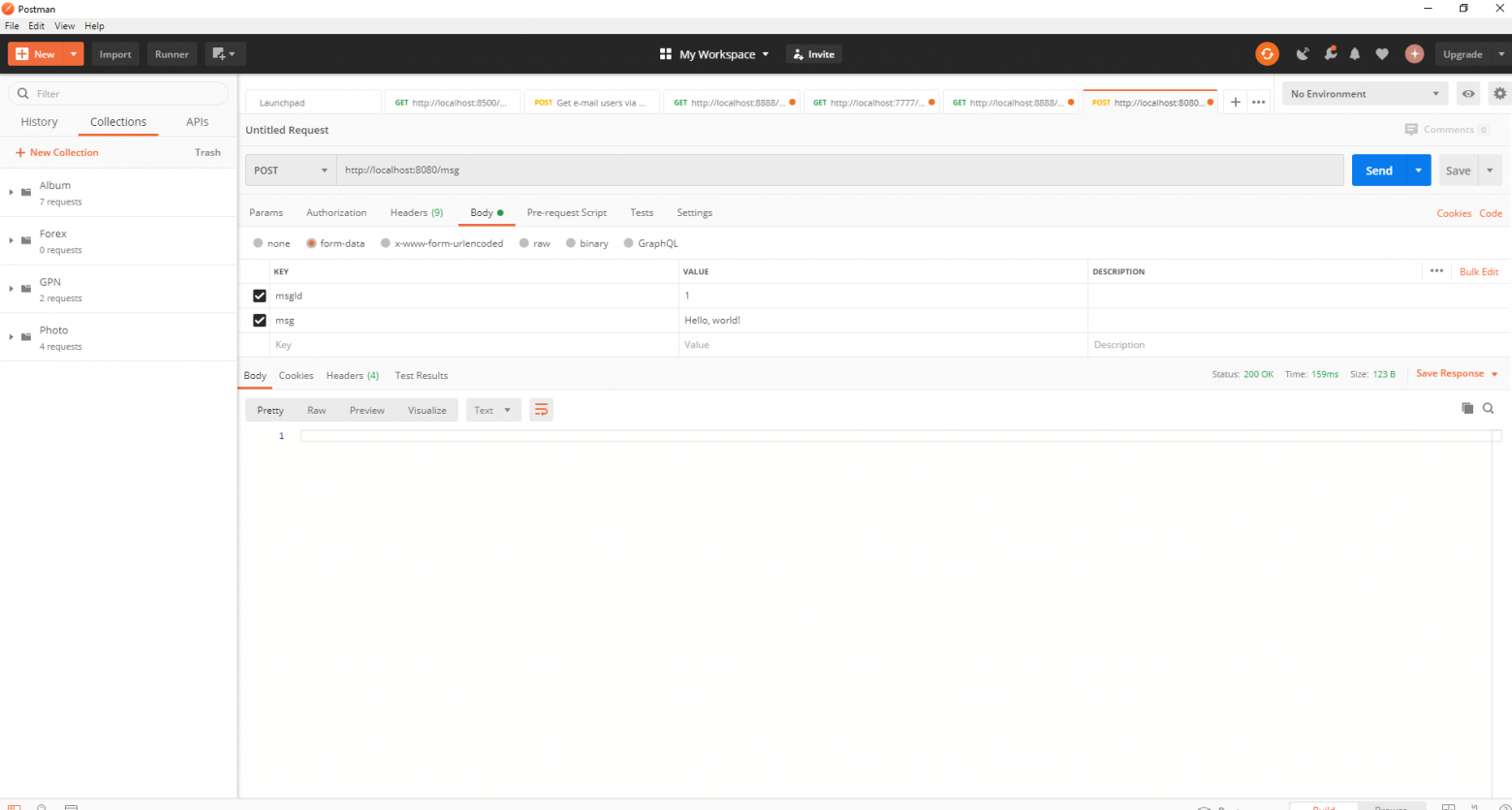
Если мы видим в IDEA такую картину, значит всё работает: продюсер отправил сообщение, консьюмер получил его и вывел в консоль.
Усложняем проект
Реальные проекты с использованием Kafka конечно же сложнее, чем тот, который мы создали. Теперь, когда мы разобрались с базовыми функциями сервиса, рассмотрим, какие дополнительные возможности он предоставляет. Для начала усовершенствуем продюсера.
Если вы открывали метод send(), то могли заметить, что у всех его вариантов есть возвращаемое значение ListenableFuture<SendResult<K, V>>. Сейчас мы не будем подробно рассматривать возможности данного интерфейса. Здесь будет достаточно сказать, что он нужен для просмотра результата отправки сообщения.
@PostMapping
public void sendMsg(String msgId, String msg){
ListenableFuture<SendResult<String, String>> future = kafkaTemplate.send("msg", msgId, msg);
future.addCallback(System.out::println, System.err::println);
kafkaTemplate.flush();
}Метод addCallback() принимает два параметра – SuccessCallback и FailureCallback. Оба они являются функциональными интерфейсами. Из названия можно понять, что метод первого будет вызван в результате успешной отправки сообщения, второго – в результате ошибки.Теперь, если мы запустим проект, то увидим на консоли примерно следующее:
SendResult [producerRecord=ProducerRecord(topic=msg, partition=null, headers=RecordHeaders(headers = [], isReadOnly = true), key=1, value=Hello, world!, timestamp=null), recordMetadata=msg-0@6]Посмотрим ещё раз внимательно на нашего продюсера. Интересно, что будет если в качестве ключа будет не String, а, допустим, Long, а в качестве передаваемого сообщения и того хуже – какая-нибудь сложная DTO? Попробуем для начала изменить ключ на числовое значение…

Если мы укажем в продюсере в качестве ключа Long, то приложение нормально запуститься, но при попытке отправить сообщение будет выброшен ClassCastException и будет сообщено, что класс Long не может быть приведён к классу String.

Если мы попробуем вручную создать объект KafkaTemplate, то увидим, что в конструктор в качестве параметра передаётся объект интерфейса ProducerFactory<K, V>, например DefaultKafkaProducerFactory<>. Для того, чтобы создать DefaultKafkaProducerFactory, нам нужно в его конструктор передать Map, содержащий настройки продюсера. Весь код по конфигурации и созданию продюсера вынесем в отдельный класс. Для этого создадим пакет config и в нём класс KafkaProducerConfig.
@Configuration
public class KafkaProducerConfig {
private String kafkaServer="localhost:9092";
@Bean
public Map<String, Object> producerConfigs() {
Map<String, Object> props = new HashMap<>();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,
kafkaServer);
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
LongSerializer.class);
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
StringSerializer.class);
return props;
}
@Bean
public ProducerFactory<Long, String> producerFactory() {
return new DefaultKafkaProducerFactory<>(producerConfigs());
}
@Bean
public KafkaTemplate<Long, String> kafkaTemplate() {
return new KafkaTemplate<>(producerFactory());
}
}
В методе producerConfigs() создаём мапу с конфигурациями и в качестве сериализатора для ключа указываем LongSerializer.class. Запускаем, отправляем запрос из Postman и видим, что теперь всё работает, как надо: продюсер отправляет сообщение, а консьюмер принимает его.
Теперь изменим тип передаваемого значения. Что если у нас не стандартный класс из библиотеки Java, а какой-нибудь кастомный DTO. Допустим такой.
@Data
public class UserDto {
private Long age;
private String name;
private Address address;
}
@Data
@AllArgsConstructor
public class Address {
private String country;
private String city;
private String street;
private Long homeNumber;
private Long flatNumber;
}Для отправки DTO в качестве сообщения, нужно внести некоторые изменения в конфигурацию продюсера. В качестве сериализатора значения сообщения укажем JsonSerializer.class и не забудем везде изменить тип String на UserDto.
@Configuration
public class KafkaProducerConfig {
private String kafkaServer="localhost:9092";
@Bean
public Map<String, Object> producerConfigs() {
Map<String, Object> props = new HashMap<>();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,
kafkaServer);
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
LongSerializer.class);
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
JsonSerializer.class);
return props;
}
@Bean
public ProducerFactory<Long, UserDto> producerFactory() {
return new DefaultKafkaProducerFactory<>(producerConfigs());
}
@Bean
public KafkaTemplate<Long, UserDto> kafkaTemplate() {
return new KafkaTemplate<>(producerFactory());
}
}Отправим сообщение. В консоль будет выведена следующая строка:

Теперь займёмся усложнением консьюмера. До этого наш метод public void msgListener(String msg), помеченный аннотацией @KafkaListener(topics=«msg») в качестве параметра принимал String и выводил его на консоль. Как быть, если мы хотим получить другие параметры передаваемого сообщения, например, ключ или партицию? В этом случае тип передаваемого значения необходимо изменить.
@KafkaListener(topics="msg")
public void orderListener(ConsumerRecord<Long, UserDto> record){
System.out.println(record.partition());
System.out.println(record.key());
System.out.println(record.value());
}Из объекта ConsumerRecord мы можем получить все интересующие нас параметры.
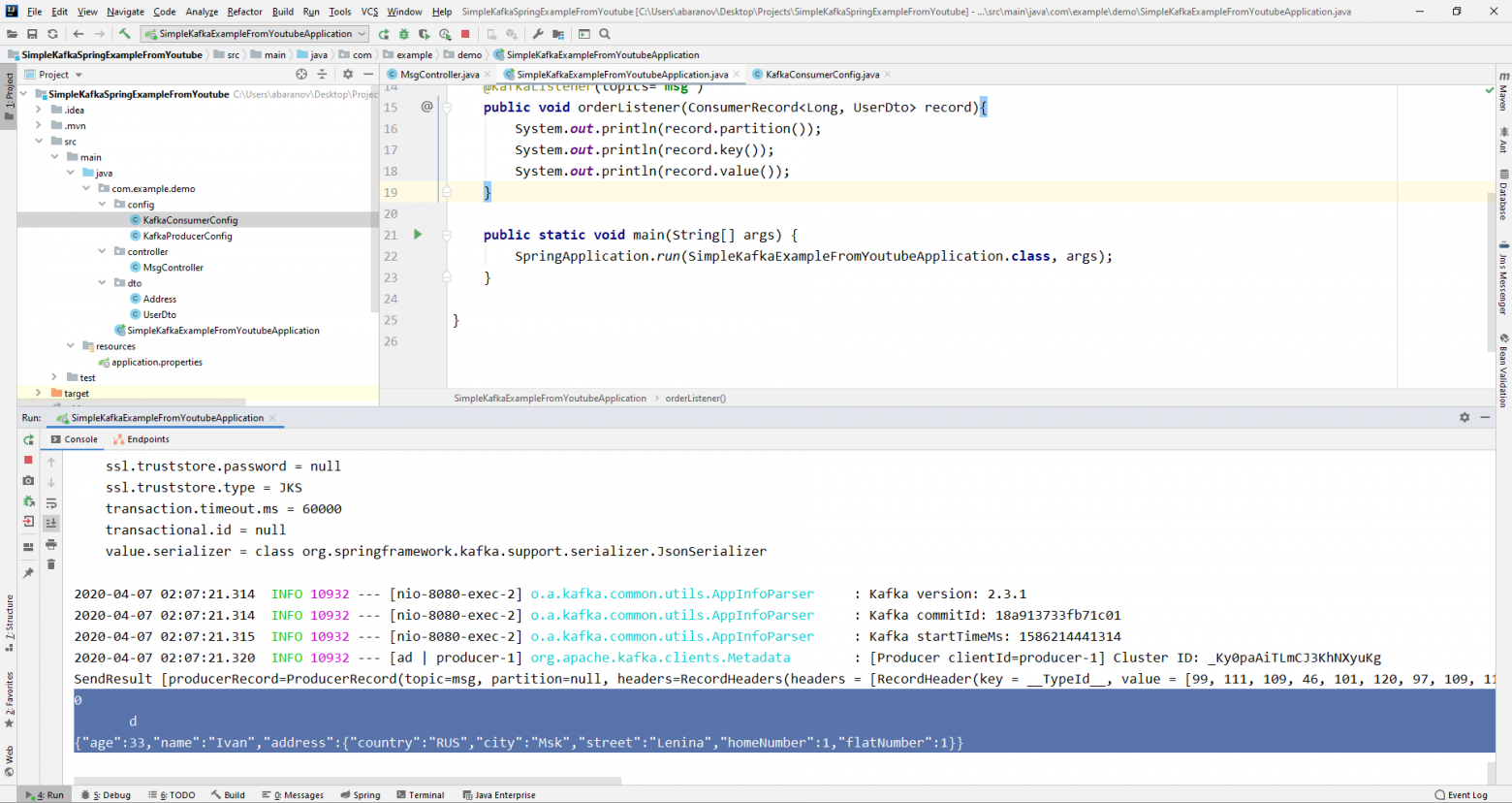
Мы видим, что вместо ключа на консоль выводятся какие-то кракозябры. Это потому, что для десериализации ключа по умолчанию используется StringDeserializer, и если мы хотим, чтобы ключ в целочисленном формате корректно отображался, мы должны изменить его на LongDeserializer. Для настройки консьюмера в пакете config создадим класс KafkaConsumerConfig.
@Configuration
public class KafkaConsumerConfig {
@Value("${spring.kafka.bootstrap-servers}")
private String kafkaServer;
@Value("${spring.kafka.consumer.group-id}")
private String kafkaGroupId;
@Bean
public Map<String, Object> consumerConfigs() {
Map<String, Object> props = new HashMap<>();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, kafkaServer);
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, LongDeserializer.class);
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
props.put(ConsumerConfig.GROUP_ID_CONFIG, kafkaGroupId);
return props;
}
@Bean
public KafkaListenerContainerFactory<?> kafkaListenerContainerFactory() {
ConcurrentKafkaListenerContainerFactory<Long, UserDto> factory =
new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(consumerFactory());
return factory;
}
@Bean
public ConsumerFactory<Long, UserDto> consumerFactory() {
return new DefaultKafkaConsumerFactory<>(consumerConfigs());
}
}Класс KafkaConsumerConfig очень похож на KafkaProducerConfig, который мы создавали ранее. Здесь так же присутствует Map, содержащий необходимые конфигурации, например, такие как десериализатор для ключа и значения. Созданная мапа используется при создании ConsumerFactory<>, которая в свою очередь, нужна для создания KafkaListenerContainerFactory<?>. Важная деталь: метод возвращающий KafkaListenerContainerFactory<?> должен называться kafkaListenerContainerFactory(), иначе Spring не сможет найти нужного бина и проект не скомпилируется. Запускаем.
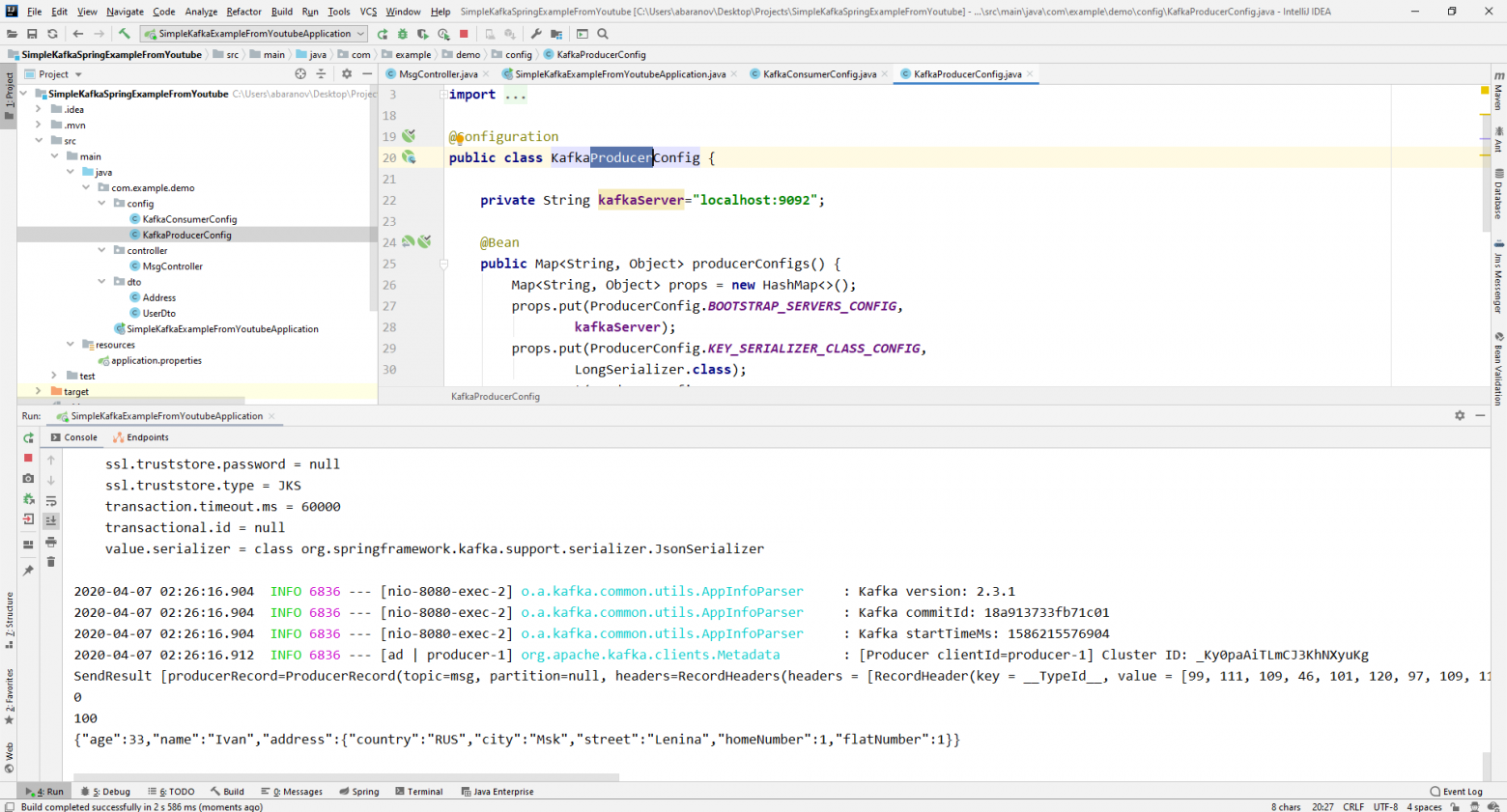
Видим, что теперь ключ отображается как надо, а это значит, что всё работает. Конечно, возможности Apache Kafka далеко выходят за пределы тех, что описаны в данной статье, однако, надеюсь, прочитав её, вы составите представление о данном сервисе и, самое главное, сможете начать работу с ним.
Мойте руки чаще, носите маски, не выходите без необходимости на улицу, и будьте здоровы.
Last Updated :
28 Jun, 2022
Apache Kafka is an open-source application used for real-time streams for data in huge amount. Apache Kafka is a publish-subscribe messaging system. A messaging system lets you send messages between processes, applications, and servers. Broadly Speaking, Apache Kafka is software where topics can be defined and further processed.
Downloading and Installation
Apache Kafka can be downloaded from its official site kafka.apache.org
For the installation process, follow the steps given below:
Step 1: Go to the Downloads folder and select the downloaded Binary file.
Step 2: Extract the file and move the extracted folder to the directory where you wish to keep the files.
Step 3: Copy the path of the Kafka folder. Now go to config inside kafka folder and open zookeeper.properties file. Copy the path against the field dataDir and add /zookeeper-data to the path.
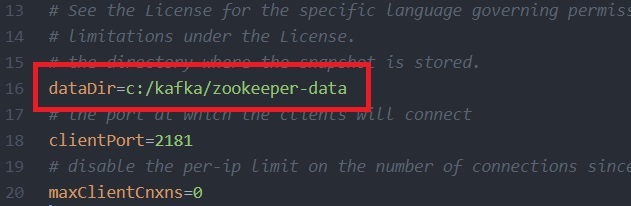
For example if the path is c:/kafka
Step 4: Now in the same folder config open server.properties and scroll down to log.dirs and paste the path. To the path add /kafka-logs
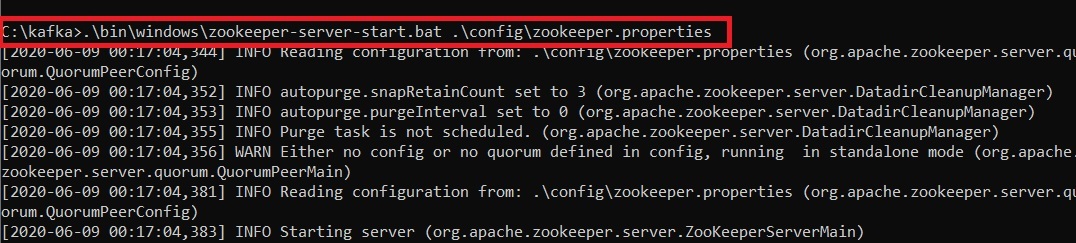
Step 5: This completes the configuration of zookeeper and kafka server. Now open command prompt and change the directory to the kafka folder. First start zookeeper using the command given below:
.\bin\windows\zookeeper-server-start.bat .\config\zookeeper.properties
Step 6: Now open another command prompt and change the directory to the kafka folder. Run kafka server using the command:
.\bin\windows\kafka-server-start.bat .\config\server.properties

Now kafka is running and ready to stream data.
Введение
Для обмена данными между Comindware Platform и внешними системами (а также для работы обсуждений) необходимо настроить подключение к брокеру сообщений Kafka.
Здесь представлена инструкция по установке Kafka в ОС Windows с использованием KRaft (без использования Zookeeper) и подключению Kafka к Comindware Platform.
Предварительные условия
Должно быть установлено ПО Java и заданы следующие системные переменные:
JAVA_HOME— путь к исполняемым файлам Open JDK, напримерC:\Program Files\jdk\jdk-<version>\binJAVA_HOME_DLL— путь к DLL-файлу Open JDK, напримерC:\Program Files\jdk\jdk-<version>\bin\server\jvm.dllPath— короткий путь к файлам Java:%JAVA_HOME%\bin
Процесс установки
-
Скачайте последнюю версию Kafka с официального сайта.
Внимание!
Для корректной работы Kafka рекомендуется скачивать архив с бинарными файлами.
-
Распакуйте файлы архива, например в папку
C:\kafkaВнимание!
Рекомендуется использовать путь минимальной длины и названия папок без пробелов, иначе некоторые команды могут не сработать.
-
Создайте папку для журналов, например
X:\kafka\logs.Внимание!
Рекомендуется создавать папку для журналов на отдельном диске, а не на диске где установлено ПО Kafka.
-
Откройте файл конфигурации Kafka
C:\kafka\config\kraft\server.properties. -
Отредактируйте файл конфигурации, указав IP-адрес сервера Kafka, папку для журналов и размеры сообщений.
Внимание!
При указании пути к папке журналов используйте косую черту
/вместо\:# Роли, в которых должен выступать сервер Kafkaprocess.roles=broker,controller# Идентификатор узлаnode.id=1# IP-адрес сервера Kafkacontroller.quorum.voters=1@<KafkaIP>:9093# IP-адрес сервера Kafkalisteners=PLAINTEXT://<KafkaIP>:9092,CONTROLLER://<KafkaIP>:9093# Имя слушателя для связи между брокерамиinter.broker.listener.name=PLAINTEXT# Имена слушателей контроллераcontroller.listener.names=CONTROLLER# Карта протоколов безопасности для слушателейlistener.security.protocol.map=CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT,SSL:SSL,SASL_PLAINTEXT:SASL_PLAINTEXT,SASL_SSL:SASL_SSL# Количество сетевых потоковnum.network.threads=3# Количество потоков ввода-выводаnum.io.threads=8# Размер буфера отправки сокетаsocket.send.buffer.bytes=102400# Размер буфера приёма сокетаsocket.receive.buffer.bytes=102400# Максимальный размер запросаsocket.request.max.bytes=104857600# Путь к файлам журналовlog.dirs=X:/kafka/logs# Количество разделов (партиций) по умолчаниюnum.partitions=4# Количество потоков восстановления на каталог данныхnum.recovery.threads.per.data.dir=1# Фактор репликации темы смещенийoffsets.topic.replication.factor=1# Фактор репликации журнала состояния транзакцийtransaction.state.log.replication.factor=1# Минимальное количество ISR для журнала состояния транзакцийtransaction.state.log.min.isr=1# Время хранения журналов (в часах)log.retention.hours=168# Размер сегмента журналаlog.segment.bytes=1073741824# Интервал проверки хранения журналов (в миллисекундах)log.retention.check.interval.ms=300000# Максимальный размер запросаmax.request.size=104857600# Максимальный размер сообщенияmax.message.bytes=104857600# Максимальный размер сообщенияmessage.max.bytes=104857600# Максимальный размер сообщения для выборкиfetch.message.max.bytes=104857600# Максимальный размер сообщения для выборки репликиreplica.fetch.max.bytes=104857600 -
Откройте PowerShell от имени администратора и выполните команды:
cd "C:\kafka\bin\windows\".\kafka-storage.bat random-uuid -
Kafka выдаст UID, например,
kNZtrWDsRvW0udJeaEahsg -
Используйте полученный UID в следующей команде:
.\kafka-storage.bat format -t kNZtrWDsRvW0udJeaEahsg -c C:\kafka\config\kraft\server.properties -
Загрузите с официального сайта архив NSSM и распакуйте его.
- В папке
\win64найдите файлnssm.exeи скопируйте его в папкуC:\kafka\bin\windows\. -
В PowerShell от имени администратора выполните следующую команду:
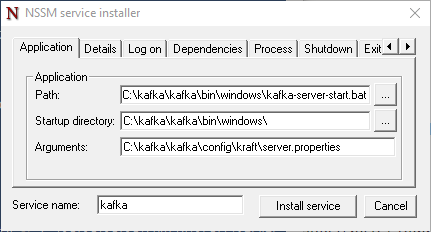
.\nssm install kafka -
Запустится программа
NSSM service installer.
Диалоговое окно NSSM service installer -
Укажите следующие пути к файлам службы Kafka:
- Path
C:\kafka\bin\windows\kafka-server-start.bat- Startup directory
C:\kafka\bin\windows\- Arguments
C:\kafka\config\kraft\server.properties -
Нажмите кнопку «Install service».
- Произойдёт установка сервиса.
-
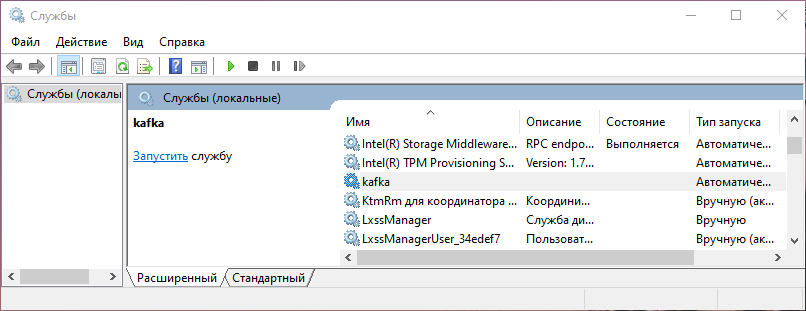
По завершении установки откройте программу «Службы» (Services) и найдите в списке
kafka.
Kafka в списке служб -
С помощью свойств службы включите и настройте автоматический перезапуск Kafka.
Окно настройки службы Kafka -
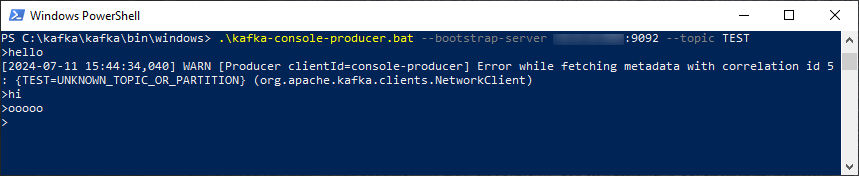
Протестируйте работу Kafka, выполнив в PowerShell следующие команды:
cd "C:\kafka\bin\windows\".\kafka-console-producer.bat --bootstrap-server <KafkaIP>:9092 --topic TEST# Отправьте любое сообщение, например:hello -
При правильной работе Kafka выдаст предупреждение, что раннее такой ветки сообщений не было, и создаст её.
Создание ветки сообщений Kafka в powershell.exe
Подключение экземпляра Comindware Platform к Kafka
-
Откройте папку
C:\ProgramData\comindware\configs\instance -
Задайте параметры подключения к Kafka в файле
<instanceName>.yml(<instanceName>— имя экземпляра ПО):# IP-адрес сервера Kafkamq.server: <KafkaIP>:9092# Имя экземпляра ПОmq.group: <instanceName># Идентификатор узла очереди сообщенийmq.node: <instanceName> -
Удалите следующую строку из файла
<instanceName>.yml:kafkaBootstrapServer:Внимание!
Для корректной работы экземпляра ПО необходимо соблюсти следующие условия:
- IP-адрес и порт Kafka должны быть обязательно прописаны цифрами в формате
XX.XX.XX.XX:XXXX. То есть недопустимо указывать имя хоста вместо IP-адреса и опускать номер порта. -
Значения параметров
mq.server(адрес и порт сервера очереди сообщений),mq.group(идентификатор группы очереди сообщений),mq.node(идентификатор узла очереди сообщений) должны совпадать во всех файлах конфигурации:C:\ProgramData\comindware\configs\instance\<instanceName>.ymlC:\ProgramData\comindware\configs\instance\apigateway.ymlC:\ProgramData\comindware\configs\instance\adapterhost.yml
- IP-адрес и порт Kafka должны быть обязательно прописаны цифрами в формате
-
Задайте параметры подключения к Kafka в файле
apigateway.yml:# Укажите IP-адрес сервера Kafkamq.server: <KafkaIP>:9092# Укажите имя экземпляра ПОmq.group: <instanceName># Идентификатор узла очереди сообщенийmq.node: <instanceName> -
Задайте параметры подключения к Kafka в файле
adapterhost.yml:# Укажите IP-адрес сервера Kafkamq.server: <KafkaIP>:9092 -
Перезапустите экземпляр ПО.
-
Проверьте соединение с Kafka в браузере по ссылке (
<instanceAddress>— URL экземпляра ПО):<instanceAddress>/async
Дополнительные рекомендации
Настройка безопасности
Для повышения безопасности рекомендуется настроить SSL/TLS для шифрования данных и аутентификацию с использованием SASL. Подробные инструкции см. в официальной документации Apache Kafka (на английском языке): https://kafka.apache.org/documentation/#security.
Мониторинг и управление
Для мониторинга и управления сервером Kafka рекомендуется использовать инструменты, такие как Prometheus и Grafana. Подробные инструкции по настройке мониторинга см. в официальной документации Apache Kafka (на английском языке): https://kafka.apache.org/documentation/#monitoring.
- /
- /
Kafka • 9 апреля 2025 • 10 мин чтения

Apache Kafka — это распределённая платформа обмена сообщениями, созданная для работы с огромными потоками данных в реальном времени. С её помощью компании обмениваются информацией между системами, собирают события, логируют действия пользователей, отслеживают транзакции и строят аналитику в реальном времени. Платформа работает быстро, стабильно и горизонтально масштабируется, что делает её незаменимым инструментом для архитектур типа event-driven.
Что такое Kafka и зачем она нужна?
Представьте крупный интернет-магазин. Клиенты делают заказы, служба доставки отслеживает статусы, аналитика считает конверсии, отдел маркетинга реагирует на поведение пользователей. Все эти действия генерируют события. Kafka превращает их в поток сообщений, который можно обрабатывать, сохранять, фильтровать и передавать между системами в режиме реального времени. При этом данные не теряются, даже если один из компонентов временно «упал».
Kafka — это не просто «очередь сообщений». Это полноценный брокер событий, способный обрабатывать миллионы сообщений в секунду.
Она хорошо подходит для:
- потоковой аналитики (stream processing),
- построения ETL-конвейеров,
- микросервисных архитектур,
- журналирования (логгирования),
- передачи сообщений между приложениями и модулями.
В современных системах Kafka занимает центральное место как посредник между источниками данных (приложениями, сенсорами, логами) и потребителями (базами, аналитическими платформами, алертингом).
Как работает Apache Kafka
Архитектура строится вокруг понятий:
- Брокер Kafka — сервер, принимающий и раздающий сообщения;
- Продюсер (producer) — источник данных, который отправляет сообщения;
- Консьюмер (consumer) — получатель сообщений;
- Топик (topic) — логическая категория сообщений, по сути, «канал»;
- Партиция (partition) — часть топика, физически разделённая для масштабируемости;
- ZooKeeper — сервис координации, необходимый для управления кворумом и брокерами (в версиях до Kafka 3.x).
Kafka сохраняет сообщения в партициях на диск, и каждый консьюмер может читать их с любой позиции. Это значит, что один поток можно обрабатывать параллельно несколькими сервисами без риска потерь или дублирования.
С момента выпуска в 2011 году платформа стала стандартом для real-time потоковой обработки. Её используют LinkedIn, Netflix, Uber, Яндекс и тысячи других компаний.
Почему стоит изучать Kafka сейчас
Микросервисы, big data, IoT, машинное обучение — все эти направления требуют обмена данными без задержек. Платформа идеально ложится в этот стек. Она способна выдерживать колоссальную нагрузку и при этом сохраняет данные надёжно и предсказуемо.
Новичку может показаться, что настроить и запустить это решение сложно. Но это не так — нужно лишь понять базовую логику и правильно развернуть компоненты. Эта статья расскажет, как установить Apache Kafka, как её настроить и с чего начать запуск.
Вы научитесь:
- Устанавливать Kafka на Windows, Ubuntu, macOS;
- Разворачивать Kafka в Docker;
- Настраивать окружение: JAVA_HOME, KAFKA_HOME;
- Работать с ZooKeeper и systemd;
- Поднимать Kafka-сервер и отправлять первые сообщения;
- Разбираться, как работает kafka-server-start.sh и другие команды.
✅ Кстати, если вы давно хотели разобраться в брокерах сообщений — сейчас самое время. Kafka уже вошла в стандартную IT-сборку крупных проектов, и умение с ней работать добавит веса в любом резюме.
Дальше мы разберёмся с системными требованиями, а затем по шагам пройдём через установку на всех популярных платформах, включая Docker. В конце статьи вы получите работающую Kafka-систему, готовую к тестированию и развитию.
Основные компоненты и файлы
Перед тем как перейти к практике, важно понять структуру и ключевые файлы дистрибутива Apache Kafka. После загрузки вы получите архив, содержащий директории:
- /bin — здесь лежат исполняемые скрипты, например kafka-server-start.sh, kafka-topics.sh, zookeeper-server-start.sh.
- /config — конфигурационные файлы Kafka и ZooKeeper (server.properties, zookeeper.properties и др.).
- /libs — библиотеки Java, необходимые для работы сервера.
- /logs — каталог логов.
- /data — в некоторых сборках может быть создана директория хранения сообщений.
Это важно: Kafka — это Java-приложение. Значит, перед запуском вам потребуется установленная Java версии 8 и выше (JDK, не JRE). Также желательно настроить переменные среды: JAVA_HOME и KAFKA_HOME.
Kafka без ZooKeeper?
В последних версиях системы появился режим KRaft (Kafka Raft), который позволяет запускать Kafka без ZooKeeper. Он упрощает архитектуру, снижает количество компонентов и точек отказа. Однако:
- Поддержка KRaft по-прежнему развивается.
- Большинство документации и статей (включая референсы) ориентированы на классическую схему с ZooKeeper.
В рамках этой статьи мы рассмотрим оба подхода: с ZooKeeper и в Docker-сценарии — без него.
Что понадобится для установки
Чтобы установить Apache Kafka, нужно:
- Скачать дистрибутив с официального сайта или через менеджер пакетов;
- Убедиться в наличии Java (JDK);
- Подготовить переменные окружения;
- Настроить конфигурационные файлы;
- Запустить ZooKeeper (если используется);
- Запустить Kafka-брокер;
- Создать топик;
- Проверить отправку и получение сообщений.
В нашем боте-помощнике вы найдете полезную информацию по установке и работе с кластером из одного брокера
Дарим туториал по основам Apache Kafka
В зависимости от операционной системы эти шаги могут немного отличаться. Далее мы подробно рассмотрим установку на:
- Windows;
- Ubuntu;
- macOS;
- через Docker — самый простой путь, если нужен локальный стенд без лишней мороки.
Что вы получите в итоге
После выполнения инструкции вы:
- Развернёте локальный Kafka-брокер;
- Настроите его под свою ОС;
- Научитесь создавать топики и передавать сообщения;
- Поймёте, как запустить Kafka, как она обрабатывает потоки и как ей управлять через CLI.
Если вы новичок — не переживайте: шаги даны последовательно, объяснены термины и приведены примеры.
💡 Совет: сохраняйте скрипты и команды, которые будете использовать. Это поможет быстрее разворачивать систему в будущем и автоматизировать установку.
Немного об опыте: Kafka в реальных проектах
Решение применяется не только в highload-сервисах. Его используют для:
- систем мониторинга (например, метрики Prometheus через Kafka в ClickHouse),
- обработки логов (Logstash → Kafka → Elasticsearch),
- распределённых очередей (например, в микросервисах с Java и Spring Boot),
- потоковой агрегации данных в финансовых системах.
Пример: один из банков использует Kafka для отслеживания транзакций в реальном времени, реагируя на события быстрее, чем это позволяла старая очередь на RabbitMQ.
Такие примеры показывают, что знание этой платформы — не просто теория, а навык, который нужен в боевых условиях.
Хотите стать гуру равномерного распределения нагрузки? На курсе «Apache Kafka База» расскажем, как работать с платформой, как настраивать распределенный отказоустойчивый кластер и отслеживать метрики.
Готовы приступить к установке? Начнём с самого базового: что нужно, чтобы система «потянула» эту систему.
Системные требования
Перед тем как перейти к установке Apache Kafka, важно понять, какие ресурсы необходимы для её стабильной работы. Платформа не требует сверхмощного оборудования, но некоторые требования желательно учитывать — особенно если вы планируете развернуть полноценный кластер или подключать Kafka к продакшн-сервисам.
Минимальные системные требования
Для тестовой установки или локального стенда достаточно следующей конфигурации:
- Процессор: 2 ядра (x86_64 или ARM64)
- Оперативная память: от 4 ГБ (рекомендуется 8 ГБ для одновременного запуска ZooKeeper и Kafka)
- Диск: минимум 5 ГБ свободного пространства
- Java: JDK 8, 11 или 17 (Kafka поддерживает Java 8+, но лучше использовать актуальную LTS-версию)
Для продакшн-сценариев рекомендуются более высокие параметры, особенно по оперативной памяти и скорости дисков (желательно SSD). Система интенсивно использует дисковую подсистему, так как сохраняет все сообщения на диск.
Программные зависимости
Apache Kafka работает на Java и не требует специфической ОС. Вы можете развернуть её на:
- Windows (от Windows 10 и выше),
- Linux (Ubuntu, CentOS, Debian),
- macOS (от Catalina 10.15).
Платформа не зависит от конкретной ОС, но в Linux-среде работать с ней проще и стабильнее, особенно при автоматизации запуска и настройки.
Для запуска потребуется:
- Java JDK — убедитесь, что установлена полная Java-разработка, а не только JRE.
- ZooKeeper (если используете классическую архитектуру Kafka до версии 3.x);
- Переменные окружения: JAVA_HOME, KAFKA_HOME;
- Bash-совместимый терминал (особенно актуально для macOS и Linux).
Программные зависимости
Apache Kafka работает на Java и не требует специфической ОС. Вы можете развернуть её на:
- Windows (от Windows 10 и выше),
- Linux (Ubuntu, CentOS, Debian),
- macOS (от Catalina 10.15).
Платформа не зависит от конкретной ОС, но в Linux-среде работать с ней проще и стабильнее, особенно при автоматизации запуска и настройки.
Для запуска потребуется:
- Java JDK — убедитесь, что установлена полная Java-разработка, а не только JRE.
- ZooKeeper (если используете классическую архитектуру Kafka до версии 3.x);
- Переменные окружения: JAVA_HOME, KAFKA_HOME;
- Bash-совместимый терминал (особенно актуально для macOS и Linux).
Требования к сети
Решение активно взаимодействует с внешними сервисами и клиентами. Поэтому убедитесь, что:
- Открыты нужные порты:
- 2181 — для ZooKeeper;
- 9092 — для Kafka по умолчанию;
- Не конфликтуют службы с аналогичными портами;
- Локальный hostname или IP указан корректно в конфигурации (advertised.listeners), иначе консьюмеры не смогут подключаться.
Поддержка Docker
Если вы не хотите устанавливать Kafka и ZooKeeper вручную, используйте Docker. Он упрощает запуск, особенно при работе с микросервисами и временными стендами.
Плюсы запуска через Docker:
- Быстрый старт;
- Не требует настройки окружения;
- Легко разворачивать несколько брокеров;
- Можно интегрировать с Docker Compose.
Мы подробно разберём этот способ в одном из следующих разделов.
Kafka в облаке
Платформу можно разворачивать не только локально. Все крупные облачные провайдеры предлагают готовые managed-решения:
- Confluent Cloud — официальный сервис от разработчиков Kafka;
- AWS MSK (Managed Streaming for Apache Kafka);
- Azure Event Hubs (с поддержкой протокола Kafka);
- Google Cloud Pub/Sub (совместимость с Kafka-экосистемой).
Для обучения и отладки рекомендуется сначала выполнить локальную установку, а уже потом пробовать кластерные и облачные варианты.
Теперь, когда мы определились с требованиями, можно переходить к практике. Начнём с самой распространённой ОС — Windows.
Установка и настройка на Windows
Хотя Apache Kafka изначально создавалась для Linux, развернуть её на Windows тоже возможно. Особенно если вы хотите попробовать брокер сообщений локально, без виртуальных машин и Docker-контейнеров.
Шаг 1: Установка Java (JDK)
Kafka работает на Java, поэтому первым делом нужно установить JDK.
- Скачайте последнюю LTS-версию JDK с сайта https://adoptium.net или https://jdk.java.net.
- Установите JDK и пропишите переменную окружения JAVA_HOME:
- Откройте Свойства системы → Переменные среды.
- Добавьте JAVA_HOME со значением пути к установленному JDK (например, C:\Program Files\Java\jdk-17).
- В переменную Path добавьте %JAVA_HOME%\bin.
Проверьте в терминале:
Если выводится версия JDK — всё готово.
Шаг 2: Скачивание и распаковка
- Перейдите на «официальный сайт Kafka».
- Скачайте архив Binary downloads с поддержкой Scala (обычно kafka_2.13-x.x.x.tgz).
- Распакуйте архив в любую директорию, например: C:\kafka.
⚠️ Название папки не должно содержать пробелов или русских букв.
Шаг 3: Настройка переменных окружения (по желанию)
Чтобы удобно запускать систему из любого места, пропишите переменную KAFKA_HOME:
- Добавьте KAFKA_HOME = C:\kafka
- В Path добавьте:
Шаг 4: Запуск ZooKeeper и Kafka
В классической схеме Kafka зависит от ZooKeeper, поэтому сначала запускается он. Перейдите в папку bin/windows и запустите ZooKeeper:
zookeeper-server-start.bat ..\..\config\zookeeper.properties
Откройте новое окно терминала и запустите Kafka:
kafka-server-start.bat ..\..\config\server.properties
Если всё прошло успешно, в терминале появится сообщение Kafka started.
Шаг 5: Создание топика
После запуска можно создать топик — логическую категорию сообщений:
kafka-topics.bat —create —topic test —bootstrap-server localhost:9092 —partitions 1 —replication-factor 1
Проверьте, что топик создан:
kafka-topics.bat —list —bootstrap-server localhost:9092
Шаг 6: Отправка и получение сообщений
kafka-console-producer.bat —broker-list localhost:9092 —topic test
Введите сообщение и нажмите Enter.
Запуск консьюмера:
kafka-console-consumer.bat —bootstrap-server localhost:9092 —topic test —from-beginning
Вы увидите отправленные сообщения.
Возможные ошибки и решения
- Missing JAVA_HOME — убедитесь, что переменная окружения прописана.
- Порты 2181 или 9092 заняты — остановите другие процессы.
- Kafka не запускается — проверьте версию Java и корректность путей.
🛠️ Совет: создайте .bat-файлы с командами запуска, чтобы не вводить их вручную.
Теперь вы знаете, как установить Apache Kafka на Windows и выполнить базовую настройку. Переходим к Ubuntu.
Установка и настройка на Ubuntu
Установка Kafka на Ubuntu — один из самых стабильных и удобных способов для локальной разработки. Здесь меньше ограничений, чем в Windows, а управление сервисами можно полностью автоматизировать через systemd.
Шаг 1: Обновление системы и установка Java
Платформа требует установленной Java (JDK). Установим OpenJDK 11, подходящую для Kafka 2.x и 3.x.
sudo apt update && sudo apt upgrade -y
sudo apt install openjdk-11-jdk -y
Проверьте установку:
java -version
Шаг 2: Загрузка
Перейдите на официальный сайт «kafka.apache.org/downloads» и скопируйте ссылку на нужную версию. Затем скачайте архив через wget:
wget https://downloads.apache.org/kafka/3.6.0/kafka_2.13-3.6.0.tgz
Распакуйте архив:
tar -xvzf kafka_2.13-3.6.0.tgz
mv kafka_2.13-3.6.0 /opt/kafka
Шаг 3: Проверка переменной окружения JAVA_HOME
Убедитесь, что JAVA_HOME прописана. Добавьте её в .bashrc:
echo «export JAVA_HOME=$(dirname $(dirname $(readlink -f $(which javac))))» >> ~/.bashrc
echo «export PATH=\$PATH:\$JAVA_HOME/bin» >> ~/.bashrc
source ~/.bashrc
Шаг 4: Запуск ZooKeeper и Kafka вручную
Помним, что ZooKeeper запускается первым:
/opt/kafka/bin/zookeeper-server-start.sh /opt/kafka/config/zookeeper.properties
Откройте новый терминал и запустите Kafka-брокер:
/opt/kafka/bin/kafka-server-start.sh /opt/kafka/config/server.properties
Шаг 5: Создание топика
/opt/kafka/bin/kafka-topics.sh —create —topic test —bootstrap-server localhost:9092 —replication-factor 1 —partitions 1
Проверьте:
/opt/kafka/bin/kafka-topics.sh —list —bootstrap-server localhost:9092
Шаг 6: Отправка и получение сообщений
Продюсер:
/opt/kafka/bin/kafka-console-producer.sh —broker-list localhost:9092 —topic test
Консьюмер:
/opt/kafka/bin/kafka-console-consumer.sh —bootstrap-server localhost:9092 —topic test —from-beginning
Шаг 7 (опционально): Автозапуск через systemd
Создайте юнит-файлы:
sudo nano /etc/systemd/system/zookeeper.service
Вставьте:
[Unit]
Description=Apache ZooKeeper
After=network.target
[Service]
Type=simple
ExecStart=/opt/kafka/bin/zookeeper-server-start.sh /opt/kafka/config/zookeeper.properties
ExecStop=/opt/kafka/bin/zookeeper-server-stop.sh
Restart=on-abnormal
[Install]
WantedBy=multi-user.target
Аналогично создайте kafka.service:
sudo nano /etc/systemd/system/kafka.service
[Unit]
Description=Apache Kafka
After=zookeeper.service
[Service]
Type=simple
ExecStart=/opt/kafka/bin/kafka-server-start.sh /opt/kafka/config/server.properties
ExecStop=/opt/kafka/bin/kafka-server-stop.sh
Restart=on-abnormal
[Install]
WantedBy=multi-user.target
Активируйте сервисы:
sudo systemctl daemon-reexec
sudo systemctl enable zookeeper kafka
sudo systemctl start zookeeper
sudo systemctl start kafka
Всё готово к работе. Теперь вы знаете, как поднять Kafka на Ubuntu вручную или через systemd. Далее — установка на macOS.

Установка и настройка на macOS
Установка Apache Kafka на macOS проще всего через Homebrew. Это быстро, удобно и хорошо подходит для локальной разработки. Ниже — пошаговая инструкция для запуска Kafka с ZooKeeper на macOS.
Шаг 1: Установка Homebrew (если не установлен)
Откройте терминал и выполните:
/bin/bash -c «$(curl -fsSL
https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)»
Проверьте установку:
brew —version
Шаг 2: Установка Kafka и ZooKeeper
Установим Kafka вместе с зависимостями:
brew install kafka
Homebrew установит Kafka и ZooKeeper в стандартные директории и автоматически добавит бинарные файлы в PATH.
Шаг 3: Запуск ZooKeeper
Вам всё ещё требуется ZooKeeper, если вы не используете режим KRaft. Запустите его через brew:
brew services start zookeeper
Проверьте статус:
brew services list
Шаг 4: Запуск Kafka
После запуска ZooKeeper включаем нашу платформу:
brew services start kafka
Вы также можете выполнить ручной запуск:
kafka-server-start /opt/homebrew/etc/kafka/server.properties
Шаг 5: Создание топика
kafka-topics —create —topic test —bootstrap-server localhost:9092 —partitions 1 —replication-factor 1
Проверим наличие:
kafka-topics —list —bootstrap-server localhost:9092
Шаг 6: Тестовый обмен сообщениями
Продюсер:
kafka-console-producer —broker-list localhost:9092 —topic test
Консьюмер:
kafka-console-consumer —bootstrap-server localhost:9092 —topic test —from-beginning
Шаг 7: Управление сервисами
Остановить Kafka и ZooKeeper можно командой:
brew services stop kafka
brew services stop zookeeper
Если вы хотите отключить автозапуск:
brew services remove kafka
brew services remove zookeeper
Примечания
- Решение работает на Java, убедитесь, что у вас установлен JDK 11 или выше. Если нет — установите через brew:
brew install openjdk@11
- Убедитесь, что в PATH добавлены Kafka-утилиты. Обычно Homebrew делает это автоматически, но можно добавить вручную:
export PATH=»/opt/homebrew/bin:$PATH»
Kafka успешно развернута на macOS. Это одна из самых простых платформ для локального тестирования брокеров сообщений. Далее — установка через Docker.
Установка и настройка в Docker
Если не хочется возиться с установкой Java, конфигурацией ZooKeeper и путями, проще всего развернуть Kafka в Docker. Этот способ подойдёт как для локального тестирования, так и для развёртывания на сервере без сложной подготовки среды.
Шаг 1: Установка Docker
Если Docker ещё не установлен, скачайте его с «официального сайта» и установите в системе.
Проверьте установку:
docker —version
Шаг 2: Запуск Kafka и ZooKeeper в Docker через команду
Требуется ZooKeeper. Самый быстрый способ — поднять оба сервиса через одну команду:
docker run -d —name zookeeper \
-e ALLOW_ANONYMOUS_LOGIN=yes \
-p 2181:2181 \
bitnami/zookeeper:latest
Затем запустим Kafka, привязав её к ZooKeeper:
docker run -d —name kafka \
-e KAFKA_BROKER_ID=1 \
-e KAFKA_ZOOKEEPER_CONNECT=host.docker.internal:2181 \
-e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://localhost:9092 \
-e KAFKA_LISTENERS=PLAINTEXT://0.0.0.0:9092 \
-p 9092:9092 \
bitnami/kafka:latest
Если вы на Linux, замените host.docker.internal на IP вашей машины (172.17.0.1 или localhost).
Шаг 3: Проверка работы
Убедитесь, что оба контейнера работают:
docker ps
Вы увидите bitnami/zookeeper и bitnami/kafka в списке запущенных контейнеров.
Шаг 4: Взаимодействие внутри контейнера
Подключимся к Kafka-контейнеру:
docker exec -it kafka bash
Создание топика:
kafka-topics.sh —create —topic test —bootstrap-server localhost:9092 —partitions 1 —replication-factor 1
Проверка:
kafka-topics.sh —list —bootstrap-server localhost:9092
Запуск продюсера:
kafka-console-producer.sh —broker-list localhost:9092 —topic test
Запуск консьюмера:
kafka-console-consumer.sh —bootstrap-server localhost:9092 —topic test —from-beginning
Шаг 5: Docker Compose (альтернатива)
Можно использовать docker-compose.yml, чтобы управлять системой проще. Создайте файл:
version: ‘3’
services:
zookeeper:
image: bitnami/zookeeper:latest
ports:
— «2181:2181»
environment:
— ALLOW_ANONYMOUS_LOGIN=yes
kafka:
image: bitnami/kafka:latest
ports:
— «9092:9092»
environment:
— KAFKA_BROKER_ID=1
— KAFKA_ZOOKEEPER_CONNECT=zookeeper:2181
— KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://localhost:9092
— KAFKA_LISTENERS=PLAINTEXT://0.0.0.0:9092
depends_on:
— zookeeper
Запустите:
docker-compose up -d
Kafka и ZooKeeper будут запущены в изолированной сети, и вы сможете легко ими управлять.
💡 Docker — лучший способ для быстрого развёртывания на локальной машине, особенно если вы не хотите вручную ставить Java и настраивать конфиги. Работает одинаково хорошо на Windows, macOS и Linux.
Теперь, когда Kafka работает в контейнере, переходим к настройке пользователей.
Начните бесплатно изучать работу с Apache Kafka!
Дарим демодоступ к обучению на 3 дня, чтобы вы познакомились с материалами и спикерами курса.
Создание пользователя
Apache Kafka может работать в режиме с ограниченным доступом, где каждый клиент — будь то продюсер или консьюмер — аутентифицируется и авторизуется. Это важно, если вы планируете использовать систему в команде или продакшене. На локальных стендах этот шаг можно пропустить, но для практики и понимания процесса он полезен.
Зачем вообще создавать пользователей?
Kafka поддерживает механизмы:
- SASL/PLAIN — простая аутентификация по логину и паролю;
- SASL/SCRAM — хешированная схема хранения паролей;
- SSL — обмен ключами и сертификатами;
- ACL (Access Control Lists) — контроль прав доступа на уровне топиков и ресурсов.
В этом разделе покажем, как добавить пользователя и включить базовую защиту через SASL/PLAIN
Шаг 1: Включение SASL в конфиге Kafka
Откройте файл:
/opt/kafka/config/server.properties
Добавьте или раскомментируйте:
listeners=SASL_PLAINTEXT://:9092
advertised.listeners=SASL_PLAINTEXT://localhost:9092
security.inter.broker.protocol=SASL_PLAINTEXT
sasl.mechanism.inter.broker.protocol=PLAIN
sasl.enabled.mechanisms=PLAIN
authorizer.class.name=kafka.security.auth.SimpleAclAuthorizer
super.users=User:admin
Шаг 2: Добавление паролей пользователей
Создайте файл kafka_server_jaas.conf:
KafkaServer {
org.apache.kafka.common.security.plain.PlainLoginModule required
username=»admin»
password=»admin-secret»
user_admin=»admin-secret»
user_user1=»user1-secret»;
};
Здесь user_user1 — наш пользователь.
Шаг 3: Подключение JAAS-файла
Добавьте путь к kafka_server_jaas.conf в переменную окружения:
export KAFKA_OPTS=»-Djava.security.auth.login.config=/opt/kafka/config/kafka_server_jaas.conf»
Это можно прописать в systemd-юните или запускном скрипте Kafka.
Шаг 4: Перезапуск
Остановите и запустите Kafka с учётом настроек:
systemctl restart kafka
Или вручную:
/opt/kafka/bin/kafka-server-stop.sh
/opt/kafka/bin/kafka-server-start.sh /opt/kafka/config/server.properties
Шаг 5: Проверка авторизации клиента
Создайте аналогичный файл для клиента:
KafkaClient {
org.apache.kafka.common.security.plain.PlainLoginModule required
username=»user1″
password=»user1-secret»;
};
И при запуске консольных утилит укажите его:
KAFKA_OPTS=»-Djava.security.auth.login.config=/opt/kafka/config/kafka_client_jaas.conf» \
kafka-console-consumer.sh —bootstrap-server localhost:9092 —topic test —from-beginning \
—consumer.config /opt/kafka/config/client.properties
Файл client.properties должен содержать:
security.protocol=SASL_PLAINTEXT
sasl.mechanism=PLAIN
Теперь вы знаете, как создать пользователя, защитить соединение и управлять доступом. Это особенно важно при масштабировании и работе в командах.
Следующий шаг — подготовка файлов и папок. Переходим к загрузке дистрибутива.
Загрузка файлов
Перед тем как запустить Kafka, нужно загрузить дистрибутив и разложить файлы по нужным директориям. В большинстве случаев это делается вручную: вы скачиваете архив, распаковываете его и указываете путь в переменных окружения.
Где скачать
Официальный источник — «сайт Apache Kafka»:
Выбирайте версию, совместимую с вашей версией Scala и Java. Рекомендуется скачивать binary builds with Scala 2.13, так как они чаще всего используются.
Пример команды для Linux или macOS
wget https://downloads.apache.org/kafka/3.6.0/kafka_2.13-3.6.0.tgz
tar -xvzf kafka_2.13-3.6.0.tgz
sudo mv kafka_2.13-3.6.0 /opt/kafka
Пример для Windows
- Перейдите «по ссылке»
- Скачайте архив .tgz
- Распакуйте его с помощью 7-Zip или встроенного архиватора
- Поместите папку в C:\kafka или другую директорию без пробелов в названии
Структура папки Kafka
После распаковки вы получите примерно такую структуру:
kafka_2.13-3.6.0/
├── bin/
├── config/
├── libs/
├── logs/
└── site-docs/
- bin/ — исполняемые скрипты для запуска Kafka, ZooKeeper, создания топиков и др.
- config/ — конфигурационные файлы: server.properties, zookeeper.properties
- logs/ — логи работы брокера
- libs/ — зависимости Java
Рекомендации
- Убедитесь, что у вас достаточно свободного места (минимум 2–3 ГБ).
- Не размещайте Kafka в папках с кириллическими символами или пробелами.
- При использовании Docker загрузка архива не требуется — всё работает через образы.
⚡ На этом этапе система уже скачана, распакована и готова к запуску. Осталось лишь немного настроить — и можно переходить к тестированию.
Заключение
Apache Kafka — мощный инструмент для передачи данных в реальном времени. Несмотря на репутацию сложной системы, на практике она устанавливается и настраивается за полчаса — особенно если вы работаете локально или через Docker.
Мы разобрали:
- как установить на Windows, Ubuntu, macOS;
- как поднять Kafka через Docker без лишних зависимостей;
- базовую архитектуру и назначение компонентов;
- как настроить Kafka для передачи сообщений;
- как запустить систему, создать топик, передать данные;
- основы авторизации с помощью SASL/PLAIN;
- требования к системе и особенности запуска с systemd.
Теперь у вас на руках все инструменты, чтобы самостоятельно развернуть Kafka, экспериментировать с её возможностями и начать строить потоковую архитектуру.
⚙️ Kafka открывает двери в мир больших данных, микросервисов и real-time аналитики. Даже если вы не планируете становиться DevOps-инженером — умение работать с Kafka даст вам серьёзное преимущество.
Если вы дочитали до этого момента — значит, готовы двигаться дальше. Следующий шаг — попробовать на практике. Разверните Kafka, создайте пару топиков, подключите простенький микросервис или Python-скрипт и понаблюдайте, как всё работает в реальном времени.
📌 Читайте блог Слёрма
Если тема оказалась вам полезной — обязательно загляните в другие статьи блога slurm.io. Мы регулярно публикуем гайды по DevOps, микросервисам, Kubernetes и облачным технологиям.
✅ Хотите научиться работать с Kafka в продакшене? Следите за нашими курсами и воркшопами — в них вы научитесь не только настраивать эту платформу, но и строить отказоустойчивые кластеры, подключать мониторинг и интегрировать её в CI/CD-пайплайны.
Статью подготовили

Понравилась статья? Будем рады вашему лайку и репосту — вдруг кому-то тоже пригодится:)