
Содержание
- ZABBIX: мониторинг кластера Windows Server
- Мониторинг Microsoft Windows на базе Zabbix
- Общая концепция
- Основные возможности
- Triggers
- Инвентаризация
- Графики
- Где скачать
- Zabbix: LLD-мониторинг железа под Windows на PowerShell
- Шаблон
- Скрипты PS
- Подготовка Zabbix-агента
- smartmontools
- OpenHardwareMonitor
- Мониторим всё: расширение агентов Windows и Linux при помощи скриптов
- Немного матчасти
- Мониторинг SMART через UserParameter
- Мониторинг SMART через Flexible UserParameter
- Мониторинг SMART через Flexible UserParameter c Low-level Discovery
- Контроль за установкой новых программ на Windows
- В итоге
- Использование Zabbix для слежения за базой данных MS SQL Server
- Предисловие
- Решение
- Результат
ZABBIX: мониторинг кластера Windows Server
Как известно Zabbix является достаточно мощной системой мониторинга, про нее уже достаточно много написано. Однако недавно у меня встала задача организовать мониторинг кластера Windows Server 2003 силами Zabbix. Поиск в гугле не дал сразу ответа на то как это сделать, и потому пришлось немного подумать…
О том? что из этого получилось под катом…
Исходные данные:
Имя кластера: MS-CLUSTER.DOMAIN.COM
Состоят из 2 узлов.
Узел1: MS-NODE1.DOMAIN.COM
Узел2: MS-NODE2.DOMAIN.COM
IP-адрес узла1: 192.168.0.1
IP-адрес узла2: 192.168.0.2
IP-адрес самого кластера: 192.168.0.3
Задача:
Организовать мониторинг самого кластера и его узлов.
Решение:
На самом деле все очень легко. Но думаю есть люди не знают как это сделать и им очень надо, вот для них эта статья.
Для начала нам понадобится zabbix agent под платформу Windows (можно найти на официальном сайте).
Точнее даже два файла: zabbix_agentd.exe (сам агент) и zabbix_agentd.conf (его конфиг).
Прежде чем ставить давайте поправим конфиг:
# Задаем уровень дебагинга
DebugLevel=3
#Задаем где будет лежать log-файл
LogFile=C:\Zabbix_agent\Zabbix_agentd.log
#Разрешаем выполнение удаленных команд агенту (может пригодиться)
EnableRemoteCommands=1
#Указываем DNS-имя zabbix-сервера
Server=zabbix.domain.com
# Порт, который будет слушать агент
ListenPort=10050
# Порт, который слушает наш сервер (значение по умолчанию)
ServerPort=10051
Это минимум. Его, как вы сами понимаете не достаточно, но это то что должно быть в конфиге обязательно на всех серверах.
Вот теперь начинаем вносить отличия. Сложность в том, что агент, слушая TCP порт не отличает еще и запросы на разные IP адреса (192.168.0.1 и 192.168.0.3 к примеру, когда активным будет первый узел). Дальше я расскажу как это сделать.
На сервере MS-NODE1.DOMAIN.COM создаем папку C:\Zabbix_agent\. Копируем туда два файла (конфиг и сам exe-шник). Переименовываем конфиг в zabbix_agentd_NODE1.conf Добавляем в конфиг следующие строчки.
# Указываем IP-адрес узла1, именно его агент и будет слушать.
ListenIP=192.168.0.1
Теперь у нас есть запущенный zabbix agent, который мониторит Узел1. Чтобы сделать поддержку самого кластера нужно следующее: копируем конфиг в файл zabbix_agentd_CLUSTER.conf
Изменяем там строчку:
Повторяем все вышеописанные действия на машине MS-NODE2.DOMAIN.COM.
Теперь нам необходимо сделать эту службу кластерной. Запускаем оснастку Cluster Administrator нажимаем File->New->Resource. Указываем данные:
Name: Zabbix Agent
Description: Server for monitoring
Resource type: Generic Service
Нажимаем Next.
На следующем окошке выбираем те узлы на которых стоит служба (в нашем случае MS-NODE1.DOMAIN.COM и MS-NODE2.DOMAIN.COM). Next. Затем выбираем в окошке Avalaible resources пункт Cluster IP address. Next. Указываем в поле Service name Zabbix_agent (Cluster), это то имя, которое мы использовали при команде sc.exe. Next. Здесь ничего не указываем. Нажимаем Finish.
P.S. Ну вот и все! Поздравляю вас! теперь можно запустить службу Zabbix_agent (Cluster) на активном узле и начать наслаждаться работающим мониторингом кластера.
Данная статья не подлежит комментированию, поскольку её автор ещё не является полноправным участником сообщества. Вы сможете связаться с автором только после того, как он получит приглашение от кого-либо из участников сообщества. До этого момента его username будет скрыт псевдонимом.
Источник
Мониторинг Microsoft Windows на базе Zabbix
03.09.2019 Update
Кстати новые шаблоны уже доступны
Сегодня мы расскажем о том, как мы ведем мониторинг Windows систем (в скором времени планируем такой же обзор про Linux и как обычно с доступным шаблоном).
Наш путь начался, как часто бывает, со штатного шаблона Zabbix «Template OS Windows Active» для мониторинга Windows-клиентов (рабочие станции и сервера), но ровно через неделю активного использования поняли, в нем много чего не хватает.
Так мы и начали его кардинальную переделку, часть оставили и добавили много чего нового.
Общая концепция
1. Отдельные настройки шаблона в файле os_windows_active.conf
2. Отдельный скрипт PowerShell — os_windows_active.ps1 для работы шаблона, при этом скрипт должен быть универсальным и работать на большинстве операционных систем с минимумом внешних зависимостей.
3. Шаблон должен быть не зависимым от языка операционной системы, поэтому лучше всего снимать данные со счётчиков используя либо WMI, либо скрипт + zabbix trapper.
4. Шаблон должен давать максимум полезной информации по своему назначению, поэтому он объединяется как мониторинг физических параметров оборудования, так и операционной системы и даже инвентаризации.
Основные возможности
Triggers
Мы включили и оттестировали, только самые критичные триггеры, которые реально показывают проблемы. Но добавили и некоторых других, для более детальной информации.
Physical Memory
Physical disk
Logical disk
Network
Operation system
Инвентаризация
Так как клиенты имеют разные компьютеры, нам требуется получать краткую инвентаризацию по ним, поэтому мы добавили в шаблон сбор данных о компьютере, и этими данными заполняем стандартные поля Zabbix Inventory:
Графики
Мы сделали несколько полезных общих графиков, чтобы наглядно видеть общее состояние клиента и отдельных его подсистем.
OS overview performance
OS detail performance
Где скачать
Данный шаблон и скрипт вы можете бесплатно скачать с GitHub, а также в Zabbix Share.
Наши шаблоны мы продолжим выкладываем в открытый доступ в наш репозитарий Zabbix.
Системное администрирование серверов и DevOps
Источник
Zabbix: LLD-мониторинг железа под Windows на PowerShell
Пришло время и мне собрать свой велосипед для мониторинга физического состояния Windows-железок. Готового решения или хоть более или менее работающего найти не удавалось с момента моего знакомства с Zabbix, а это более 3 лет. А тем более, чтобы оно было… элегантно что ли. Лично мне даже в таких вещах хочется видеть стройность и максимальную функциональность. Именно поэтому далее рассматривается только LLD и PowerShell. Ну и конечно же только бесплатное ПО.
Итак, мониторинг чего будет производиться:
Суммарно понадобятся:
Шаблон
Под спойлером находится актуальный шаблон. Просто сохраните содержимое в формате xml и импортируйте в свой Zabbix.
Шаблон создан в Zabbix версии 3.2, возможно, будет работать и в более ранних версиях. Ключи стандартны и имеют вид ZScript[имя_скрипта, параметр1. параметрN]. Параметры передаются непосредственно в сам скрипт.
Надеюсь, шаблон получился максимально простым и понятным.
Скрипты PS
Ниже приведены необходимые скрипты. Внутри уже находятся и обнаружение, и запрос отдельных элементов. Работа проверена на Windows от XP SP3 до 2016. Само собой, решение с Execution Policy остается за вами.
Обнаруживаются только диски с задействованным СМАРТом. Параметры запрашиваются из столбца «RAW_VALUE». Хотите мониторить другой параметр? Просто укажите его номер. По умолчанию скобки и их содержимое отбрасываются. Если нужный вам параметр диск не отдает, то возвращается пустое поле.
По умолчанию скрипт не обнаруживает названия датчиков, в которых есть #. Для чего это нужно, смотрите ниже.
Также зарезервировано одно имя датчика — Vbat. Это напряжение аккумулятора БИОС. Его значение вынесено в отдельный элемент для триггера (срабатывает если менее 2,9V).
Значения температур и оборотов кулеров на выходе целочисленные, значения напряжений передаются как есть.
Теоретически, можно обнаруживать и другие показатели (нагрузки, частоты. ). Используйте для этого соответствующий второй параметр в ключе. К примеру: ZScript[hard,discovery,load].
Подготовка Zabbix-агента
Для максимальной унификации я использую следующий и единственный параметр для своих скриптов:
Это дает максимальную гибкость и однообразность. Если нужно будет добавить еще параметров для каких-либо скриптов, можно просто добавить переменных в кавычках. На текущие работающие скрипты это никак не повлияет. Префикс windows я использую на всякий случай, мне так удобно хранить шаблоны для гарантированной идентификации.
smartmontools
Для мониторинга состояния дисков используется smartmontools (версия 6.5 на момент написания статьи). При установке ПО по умолчанию ставится утилита smartctl-nc — именно она используется в скрипте для облегчения жизни вашего сервера. Также потребуется прописать пусть к папке bin в переменных средах.
Путь просто добавляем в конец переменной Path через точку с запятой. По умолчанию — C:\Program Files\smartmontools\bin
OpenHardwareMonitor
Для датчиков же используется OHM. Софт бесплатный с открытым кодом. Установка тривиальна, но для полноценной работы необходимо запускать программу в качестве службы. Для подобных вещей есть NSSM, я бы все же советовал качать последнюю сборку. А здесь можно посмотреть синтаксис.
Обещанный выбор датчиков обеспечивается за счет того, что названия датчиков можно изменять! Изменяете имена на удобочитаемые (они будут использованы в именах элементов), а ненужные датчики комментируете #.
Не забывайте перезапустить программу/службу для применения переименования.
Источник
Мониторим всё: расширение агентов Windows и Linux при помощи скриптов
Если нам нужно мониторить состояние серверов и прочих компьютеризированных рабочих мест при помощи Zabbix, то это можно сделать двумя способами.
Первый способ — это при помощи SNMP-запросов, с отправкой которых Zabbix замечательно справляется. Так можно вытащить и загрузку сетевых интерфейсов, и загрузку процессора, памяти. Поверх этого, производители сервера могут выдать нам по SNMP еще много информации о состоянии железа.
Второй заключается в использовании Zabbix агента, который мы будем запускать на наблюдаемой системе. Список наблюдаемых параметров включает в себя как и такие простые вещи, как загрузка процессора, использование памяти, так и более хитрые, такие как чтение текстовых лог-файлов с поддержкой ротации или отслеживание факта изменения любого файла. Можно даже в качестве параметра использовать вывод любой произвольной команды на системе. Возможности Zabbix агента растут от версии к версии.
Что делать, если того, что мы хотим контролировать через Zabbix нет в списке возможностей Zabbix агента? Ждать пока это имплементируют разработчики в следующем релизе? Не обязательно.
Нам оставили несколько стандартных интерфейсов для того, чтобы расширить возможности Заббикса по мониторингу серверов настолько, насколько позволит нам наша фантазия и наличие свободного времени на написание скриптов. Интерфейсы эти UserParameter и zabbix_sender. О первом и пойдет речь, а в качестве примеров будет показано как можно собирать состояние S.M.A.R.T жестких дисков и контролировать, когда кто-то удаляет или устанавливает новые программы на своей Windows-машине.
Немного матчасти
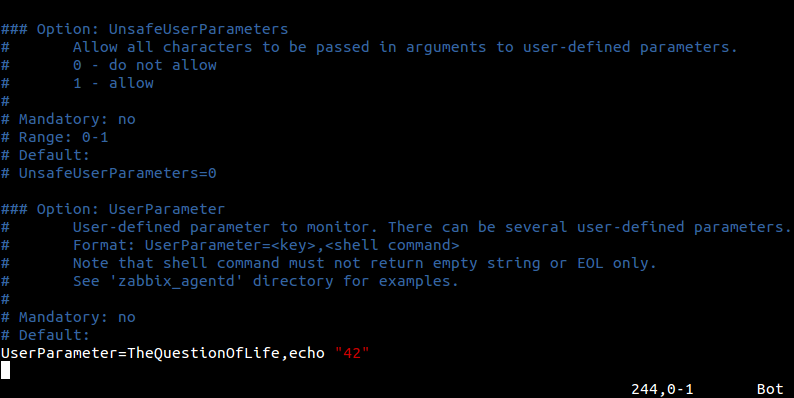
Если вы уже хоть раз настраивали Zabbix агент на сервере, то начать использовать UserParameter не составит труда. Чтобы добавить новый параметр нужно сделать несколько вещей:
— уникальное имя, которое мы придумываем сами. Будем его использовать при настройке элемента данных в Zabbix.
— команда, которую нужно выполнить на наблюдаемом узле сети.
А вот сразу очень простой пример, который лежит в каждом стандартном конфиге для Linux:
и затем выставляем ключ такой же, как указали в конфиг-файле, а тип Zabbix агент:

Мониторинг SMART через UserParameter
Пример выше имеет мало практического применения, учитывая, что уже итак существует стандартный ключ system.users.num, который делает ровно тоже самое.
Так что теперь рассмотрим пример, который уже больше будет походить на реалистичный.
Если нам интересно мониторить момент, когда пора планово менять жесткие диски, то есть два варианта:
и утилита готова к использованию.
Для каждого диска, который есть в системе сначала проверим, что SMART включен:
если вдруг SMART поддерживается диском, но выключен, то активируем его:
Теперь мы можем проверять статус SMART командой:
Именно эту команду мы и запишем в наш zabbix_agentd.conf:
где uHDD.health — ключ.
Мониторинг SMART через Flexible UserParameter
Тут возникает резонный вопрос, как быть если дисков два. Легче всего решить эту проблему поможет способность UserParameter передавать параметры агенту, про которую мы еще не упоминали. Но делается все очень просто, сразу пример:
В веб-интерфейсе Zabbix в ключе мы будем подставлять параметры в квадратные скобки вместо *. Например, для одного элемента данных мы напишем sda, а для другого sdb. В команде этот параметр найдет отражение там, где стоит переменная $1.
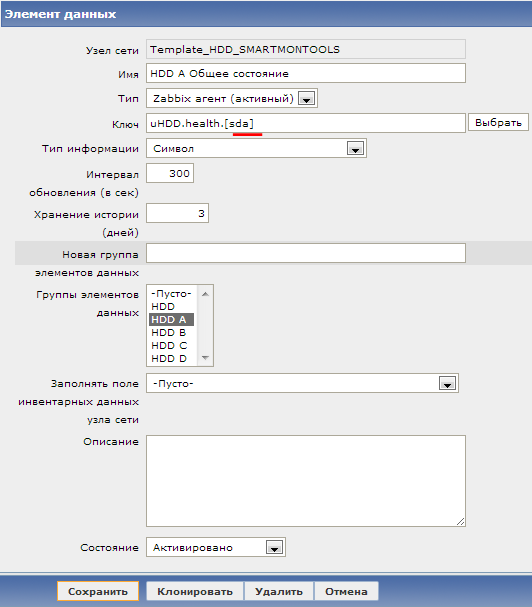
Создадим для второго диска элемент данных:

И через некоторое время сможем наблюдать результат в последних данных:

Мониторинг SMART через Flexible UserParameter c Low-level Discovery
Все получилось. Но тут возникает резонный вопрос, как быть если дисков не два, а двадцать два. И тут нам пригодится замечательная возможность низкоуровнего обнаружения (LLD), про которую мы уже говорили.
Низкоуровневое обнаружение позволяет системе мониторинга обнаруживать какое количество однотипных элементов присутствует на узле сети и динамически по шаблону создавать необходимые элементы данных, триггеры и графики для этих элементов. «Из коробки» системе доступна возможность находить файловые системы, сетевые интерфейсы и SNMP OID’ы. Однако, и здесь разработчики оставили возможность дополнить стандартные возможности, нужно просто передать в систему информацию о том, какие элементы обнаружены в формате JSON. Этим и воспользуемся.
Создадим маленький скрипт на perl, smartctl-disks-discovery.pl. Он будет находить все диски в системе и выводить эту информацию в JSON, передавая также информацию, включен ли у диска SMART или нет, а также попытается сам включить SMART, если он выключен:
При запуске скрипт выдает:
Теперь, для того чтобы скрипт автоматически запускался Zabbix’ом, просто добавим еще один UserParameter в zabbix_agentd.conf:
Покончив с настройкой конфига, переходим в веб-интерфейс, где создаем новое правило обнаружения для smartctl:
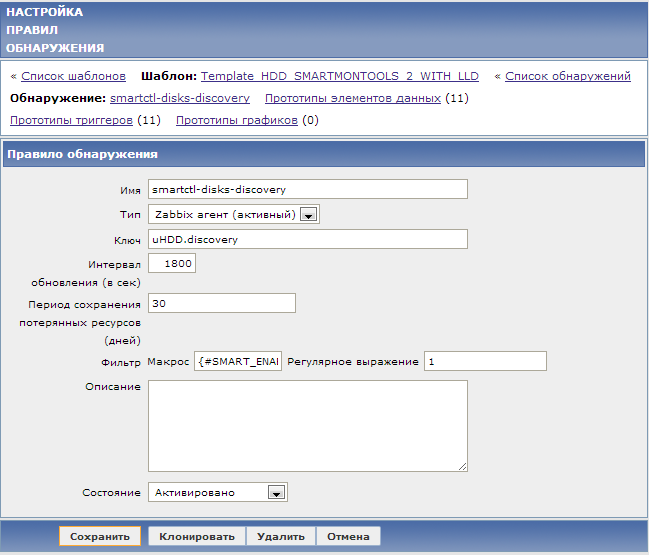
Обратите внимание на ключ и на фильтр, (<#SMART_ENABLED>=1) благодаря последнему будут добавляться только те обнаруженные диски, которые поддерживают SMART. Теперь мы можем переписать два наших элемента данных для дисков sda и sdb в один прототип элементов данных, просто заменив имя диска на макрос <#DISKNAME>:

Последнее, перед тем, как Zabbix сможет запускать команды, которые мы прописали в zabbix_agentd.conf из-под root и мониторить SMART, нужно добавить разрешения для его пользователя запускать эту команду без ввода пароля, для этого добавим в /etc/sudoers строчку:
Готовый шаблон для мониторинга SMART с остальными элементами данных, триггерами прикладываю, так же как и настроенный под него конфиг.
Контроль за установкой новых программ на Windows
Zabbix агент, установленный на Windows, точно также может быть расширен через UserParameter, только команды будут уже другие. Хотя, например, smartctl — кроссплатформенная утилита, и точно также можно ее использовать для контроля за жесткими дисками в Windows.
Кратко рассмотрим еще другой пример. Задача получать уведомление каждый раз, когда пользователь самостоятельно удаляет или устанавливает программы.
Для этого будем использовать наш vbs-скрипт:
Для его интеграции с Zabbix добавим UserParameter в конфиг-файл:
Добавим элемент данных в шаблон для Windows:

Добавим триггер:
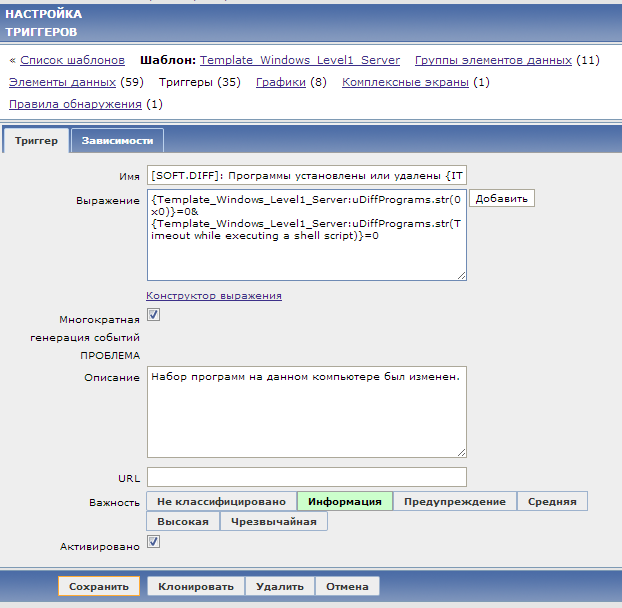
и действие, которое будет отправлять e-mail уведомление:

Весь процесс мониторинга выглядит так: каждый час запускается скрипт Zabbix агентом, который сравнивает два списка программ: текущий и предыдущий. Затем скрипт выписывает все изменения в отдельный файл. Если же изменений нет, то в файл пишется 0x0
Содержимое файла уходит на Zabbix сервер, где поднимается триггер в случае, если значение элемента данных uDiffProgramms отлично от 0x0. Затем отдельное действие отправляет по почте уведомление со списком того, что было установлено или удалено на данном компьютере:

В итоге
UserParameter — отличная и простая возможность расширить функционал системы самостоятельно. Стоит упомянуть и альтернативы: zabbix_sender, который, например, подойдет для тех случаев, когда нужно отправлять данные в Zabbix не по расписанию, (как это делает UserParameter), а по какому-то событию; и system.run[], который похож на UserParameter, но удобнее тем, что не нужно вносить изменения во все конфиги агентов, достаточно просто добавить этот элемент данных в шаблон. Более того, в следующем крупном релизе Zabbix 2.2 нас ожидает еще один новый способ расширить возможности агента- это подключаемые модули. Ждем с нетерпением!
Вот так, считайте, что если вы можете узнать что-то о системе скриптом или командой, значит, вы всегда можете передать это в Zabbix.
Источник
Использование Zabbix для слежения за базой данных MS SQL Server
Предисловие
Часто возникает потребность в режиме реального времени сообщать администратору о проблемах, связанных с БД (базой данных).
В данной статье будет описано, что необходимо настроить в Zabbix для слежения за базой данных MS SQL Server.
Обращаю внимание на то, что подробно как настраивать приводиться не будет, однако формулы и общие рекомендации, а также подробное описание по добавлению пользовательских элементов данных через хранимые процедуры будут приведены в данной статье.
Также здесь будет рассмотрены только основные счетчики производительности.
Решение
Zabbix: perf_counter[\LogicalDisk(_Total)\Avg. Disk sec/Read], а также важно проследить за нужным диском, например так: perf_counter[\LogicalDisk(C:)\Avg. Disk sec/Read]
Zabbix: perf_counter[\LogicalDisk(_Total)\Avg. Disk sec/Write], а также важно проследить за нужным диском, например так: perf_counter[\LogicalDisk(C:)\Avg. Disk sec/Write]
Cредняя длина очереди запросов к диску. Отображает количество запросов к диску, ожидающих обработки в течении определенного интервала времени. Нормальным считается очередь не больше 2 для одиночного диска. Если в очереди больше двух запросов, то возможно диск перегружен и не успевает обрабатывать поступающие запросы. Уточнить, с какими именно операциями не справляется диск, можно с помощью счетчиков Avg. Disk Read Queue Length (очередь запросов на чтение) и Avg. Disk Wright Queue Length (очередь запросов на запись).
Значение Avg. Disk Queue Length не измеряется, а рассчитывается по закону Литтла из математической теории очередей. Согласно этому закону, количество запросов, ожидающих обработки, в среднем равняется частоте поступления запросов, умноженной на время обработки запроса. Т.е. в нашем случае Avg. Disk Queue Length = (Disk Transfers/sec) * (Avg. Disk sec/Transfer).
Avg. Disk Queue Length приводится как один из основных счетчиков для определения загруженности дисковой подсистемы, однако для его адекватной оценки необходимо точно представлять физическую структуру системы хранения. К примеру, для одиночного жесткого диска критическим считается значение больше 2, а если диск располагается на RAID-массиве из 4-х дисков, то волноваться стоит при значении больше 4*2=8.
Это значение счетчика ошибок страницы. Ошибка страницы возникает, когда процесс ссылается на страницу виртуальной памяти, которая не находится в рабочем множестве оперативной памяти. Данный счетчик учитывает как те ошибки страницы, которые требуют обращения к диску, так и те, которые вызваны нахождением страницы вне рабочего множества в оперативной памяти. Большинство процессоров могут обрабатывать ошибки страницы второго типа без особых задержек. Однако, обработка ошибок страницы первого типа, требующая доступа к диску, может привести к значительным задержкам.
Отслеживает количество доступной памяти в байтах для выполнения различных процессов. Низкие показатели означают нехватку памяти. Решение — увеличить память. Этот счётчик в большинстве случаев должен быть постоянно выше 5000 КВ.
Есть смысл выставлять порог для Available Mbytes вручную из соображений:
Если кол-во ожидающих запросов резко возрастает, то следующим запросом можно вывести все выполняющиеся и ожидающие запросы в данный момент времени с детализацией от куда и под каким логином выполняется запрос, текст и план запроса, а также прочие детали:
Результат
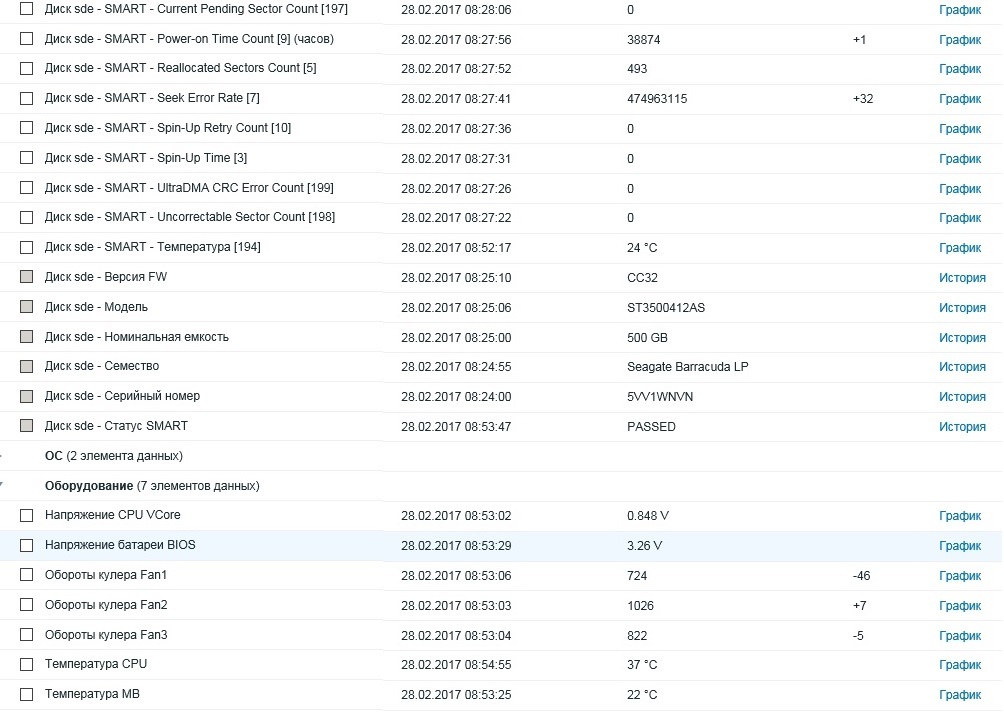
В данной статье был рассмотрен пример счетчиков производительности (элементы данных) в Zabbix. Данный подход позволяет уведомлять администраторов о разных проблемах в реальном времени или через какое-то определенное время. Таким образом, данный подход позволяет минимизировать в будущем наступления критической проблемы и остановки работы СУБД и сервера, что в свою очередь защищает производство от остановки рабочих процессов.
Предыдущая статья: Регламентные работы с базой данных информационной системы 24×7 в MS SQL Server
Источник
Для того, чтобы при помощи активного агента Zabbix следить за дисковым пространством компьютера, как оказалось, не нужно писать скриптов. Совсем. 🙂 Все уже умеет делать активный Zabbix-агент «из коробки». Достаточно создать шаблон и назначить его компьютеру. Всё.
А теперь по порядку.
Дано.
Сферический компьютер в вакууме. Нужно следить за заполненностью системного диска Windows. Предположим, что у нас всё стандартно, поэтому в качестве буквы системного диска используется «C:».
Решение.
При помощи активного агента Zabbix будем собирать 4 параметра диска «C:»:
- общий размер диска
- размер занятого места
- размер свободного места
- процент свободного места.
На основании этих параметров создадим 4 триггера:
- Предупреждение. Свободно менее 20%
- Средняя важность. Свободно менее 10%
- Высокая важность. Свободно менее 1 Гб.
- Чрезвычайная важность. Свободно менее 100 Мб.
И создадим 2 графика:
- Размер свободного места
- Размер свободного места в процентах.
Создаём шаблон.
Имя шаблона: Active Computer — SystemDrive
Группа данных: Filesystems
Элементы данных:
- SystemDriveSizeFree — vfs.fs.size[«c:»,free]
- SystemDriveSizePFree — vfs.fs.size[«c:»,pfree]
- SystemDriveSizeTotal — vfs.fs.size[«c:»,total]
- SystemDriveSizeUsed — vfs.fs.size[«c:»,used]
Триггеры:
- Предупреждение. Меньше 20% свободно на системном диске компьютера {HOST.NAME} {Active Computer — SystemDrive:vfs.fs.size[«c:»,pfree].last()}<20
- Средняя .Меньше 10% свободно на системном диске компьютера {HOST.NAME} {Active Computer — SystemDrive:vfs.fs.size[«c:»,pfree].last()}<10
- Высокая. Меньше 1ГБ свободно на системном диске компьютера {HOST.NAME} {Active Computer — SystemDrive:vfs.fs.size[«c:»,free].last()}<1073741824
- Чрезвычайная. Меньше 100 Мб свободно на системном диске компьютера {HOST.NAME} {Active Computer — SystemDrive:vfs.fs.size[«c:»,free].last()}<104857600
Теперь то же самое, но в картинках.














Файл с экспортированным шаблоном можно скачать тут: zbx_export_templates_Active_Computer_SystemDrive.xml
Назначаем шаблон компьютеру
И начинаем получать данные… 🙂

Ура!!!
Всё работает.
A few years ago we moved from Nagios to Zabbix for our server monitoring needs. I wasn’t a big fan of Nagios, finding it a pain to manage with its myriad configuration files. It’s probably gotten better since I last toyed with it but since we moved to Zabbix I haven’t had much reason to look at Nagios again.
I also try to use SNMP monitoring for everything. SNMP is widely supported – all sorts of hardware has SNMP support, and with the net-snmp package you can pretty easily create your own SNMP-monitorable stuff on Linux. Since almost all of our stuff runs on Linux this has worked out pretty well, but our Exchange server is probably going to be running on Windows for the foreseeable future. Windows has SNMP support, it’s just not on by default. However, even when it’s enabled it doesn’t have the simple “dskPercent” monitoring I’ve come to know and love with net-snmp on Linux, which simply tells you how full a given disk is as a percent. This makes it easy to set alerts when a disk reaches 80% full.
On Windows I found these objects that can be used to get something similar:
[evan@monitoring02 14:41:24 ~]$ snmpwalk -v 2c -c community 192.168.1.20 | grep -i storage HOST-RESOURCES-MIB::hrStorageIndex.1 = INTEGER: 1 HOST-RESOURCES-MIB::hrStorageIndex.2 = INTEGER: 2 HOST-RESOURCES-MIB::hrStorageIndex.3 = INTEGER: 3 HOST-RESOURCES-MIB::hrStorageIndex.4 = INTEGER: 4 HOST-RESOURCES-MIB::hrStorageIndex.5 = INTEGER: 5 HOST-RESOURCES-MIB::hrStorageIndex.6 = INTEGER: 6 HOST-RESOURCES-MIB::hrStorageType.1 = OID: HOST-RESOURCES-TYPES::hrStorageRemovableDisk HOST-RESOURCES-MIB::hrStorageType.2 = OID: HOST-RESOURCES-TYPES::hrStorageFixedDisk HOST-RESOURCES-MIB::hrStorageType.3 = OID: HOST-RESOURCES-TYPES::hrStorageCompactDisc HOST-RESOURCES-MIB::hrStorageType.4 = OID: HOST-RESOURCES-TYPES::hrStorageFixedDisk HOST-RESOURCES-MIB::hrStorageType.5 = OID: HOST-RESOURCES-TYPES::hrStorageVirtualMemory HOST-RESOURCES-MIB::hrStorageType.6 = OID: HOST-RESOURCES-TYPES::hrStorageRam HOST-RESOURCES-MIB::hrStorageDescr.1 = STRING: A:\ HOST-RESOURCES-MIB::hrStorageDescr.2 = STRING: C:\ Label: Serial Number b78d19 HOST-RESOURCES-MIB::hrStorageDescr.3 = STRING: D:\ Label:EXCH201064 Serial Number xxxxxxxx HOST-RESOURCES-MIB::hrStorageDescr.4 = STRING: E:\ Label:Exchange2010 Serial Number xxxxxxxx HOST-RESOURCES-MIB::hrStorageDescr.5 = STRING: Virtual Memory HOST-RESOURCES-MIB::hrStorageDescr.6 = STRING: Physical Memory HOST-RESOURCES-MIB::hrStorageAllocationUnits.1 = INTEGER: 0 Bytes HOST-RESOURCES-MIB::hrStorageAllocationUnits.2 = INTEGER: 4096 Bytes HOST-RESOURCES-MIB::hrStorageAllocationUnits.3 = INTEGER: 2048 Bytes HOST-RESOURCES-MIB::hrStorageAllocationUnits.4 = INTEGER: 4096 Bytes HOST-RESOURCES-MIB::hrStorageAllocationUnits.5 = INTEGER: 65536 Bytes HOST-RESOURCES-MIB::hrStorageAllocationUnits.6 = INTEGER: 65536 Bytes HOST-RESOURCES-MIB::hrStorageSize.1 = INTEGER: 0 HOST-RESOURCES-MIB::hrStorageSize.2 = INTEGER: 10459647 HOST-RESOURCES-MIB::hrStorageSize.3 = INTEGER: 546570 HOST-RESOURCES-MIB::hrStorageSize.4 = INTEGER: 104824319 HOST-RESOURCES-MIB::hrStorageSize.5 = INTEGER: 393172 HOST-RESOURCES-MIB::hrStorageSize.6 = INTEGER: 196600 HOST-RESOURCES-MIB::hrStorageUsed.1 = INTEGER: 0 HOST-RESOURCES-MIB::hrStorageUsed.2 = INTEGER: 5885720 HOST-RESOURCES-MIB::hrStorageUsed.3 = INTEGER: 546570 HOST-RESOURCES-MIB::hrStorageUsed.4 = INTEGER: 44650892 HOST-RESOURCES-MIB::hrStorageUsed.5 = INTEGER: 166057 HOST-RESOURCES-MIB::hrStorageUsed.6 = INTEGER: 152902
I thought initially that the hrStorageUsed and hrStorageSize values were being reported in bytes, but according to this MSDN article, the units are reported in “allocation units,” which I assume are being reported under hrStorageAllocationUnits, so you just need to multiply the values by the allocation units.
In Zabbix, I check hrStorageUsed every 15 minutes as “disk_1_used”. I check hrStorageSize every 2 hours (since the actual size of the disk/partition isn’t likely to change that often) as “disk_1_size”. To calculate the percentage, I created a “Calculated” item with this formula:
100*(last("disk_1_used") / last("disk_1_size"))

The values for disk_1_used and disk_1_size are in Storage Allocation Units, but since this is a percentage that doesn’t matter. However, I do also like to get an idea of the actual disk space being consumed; luckily this is also relatively easy to obtain in Zabbix using Calculated items. I monitor hrStorageAllocationUnits as “disk_1_allocunit” (every 7200 seconds since this too is unlikely to change much) and then the formula for the calculated used disk space is simply:
last("disk_1_used") * last("disk_1_allocunit")
")
Once all the work is done, here’s what the result looks like:
When I log in to the actual machine (my vCenter VM in this case) and check disk usage, the numbers match what Zabbix’s calculated values show, though Zabbix seems to be reporting values in “mebibytes” rather than “megabytes”:
I created a template in Zabbix which monitors these data for disks 1-5 and then applied it to all Windows servers; now I just need to apply some alert triggers and mission accomplished.
Как в Zabbix 2.0 сделать мониторинг свободного места на дисках?
По сути ничего сложного нет, но поиск по интернету ничего хорошего не нашел (может быть я плохо искал), и так, как это сделал я?!
Как добавлять триггеры и шаблоны можно посмотреть в постах ранее, по этому сразу к делу.
Мне нужно было мониторить 5 дисков (кол-во не важно, но для наглядности).
1. Создаем шаблон (к примеру Windows Disk)
2. Создаем группу данных (к примеру DiskSize)
3. Далее создаем элемент данных, вот тут то самая и суть (вот так должен выглядеть «элемент данных»)
— первое это ключ (vfs.fs.size[C:,free]) по которую забикс будет проверять место на диске.
C: — это имя диска, free — это свободное место (по умолчанию забикс это будет отдавать в килобайтах), это не удобно, по этому делаем пользовательский множитель 0.000000000931322574615478515625 — почему именно такой? (на сколько я понял, раз множитель, значит надо умножить и кроме как число в строчку вставить нельзя, а чтобы из КБ перевести в ГБ, надо несколько раз разделить на 1024 или умножить на вот это самое число).
В итоге получаем элемент данных в ГБ (что намного удобнее).
Далее делаем триггер который будет срабатывать когда на диске остается меньше 20 ГБ.
Сам триггер выглядит вот так (см.ниже).
В нем добавляем выражение «{Windows Disk:vfs.fs.size[C:,free].last(0)}<20» — тут все предельно ясно, смотрим последнее значение и если оно меньше 20 (ГБ), то начинаем кричать. Удачи.
Загрузка…
Доброго времени суток, в этой статье мы научимся исключать из правил обнаружения службы Windows, которые не хотим мониторить используя штатный шаблон Template OS Windows by Zabbix Agent.
В примере использую Zabbix v.6.4.4, в других версиях всё выглядит +/- точно так же.
Открываем раздел Data Collection и переходим на вкладку «Templates», в графе поиска «Name» вбиваем имя нашего шаблона: «Os windows» и нажимаем кнопочку «Apply». В результатах поиска должен найтись нужный нам шаблон: «Template OS Windows by Zabbix Agent», кликаем по нему:

Перейдя в настройки шаблона кликаем по привязанному к нему шаблону «Template Module Windows services by Zabbix agent»:

Далее переходим на вкладку «Macros» и тут нас с вами интересует макрос под названием —
«{$SERVICE.NAME.NOT_MATCHES}»:

Именно в этот макрос нам необходимо добавить названия служб, которые мы хотим исключить из обнаружения Zabbix Server-ом.
Оригинальное значение макроса следующее:
^RemoteRegistry|MMCSS|gupdate|SysmonLog|clr_optimization_v.+|clr_optimization_v.+|sppsvc|gpsvc|Pml Driver HPZ12|Net Driver HPZ12|MapsBroker|IntelAudioService|Intel(R) TPM Provisioning Service|dbupdate|DoSvc$
В моём случае значение макроса имеет следующее значение:
^RemoteRegistry|MMCSS|gupdate|SysmonLog|clr_optimization_v.+|clr_optimization_v.+|sppsvc|gpsvc|Pml Driver HPZ12|Net Driver HPZ12|MapsBroker|IntelAudioService|Intel\(R\) TPM Provisioning Service|dbupdate|DoSvc|CDPUserSvc.|WpnUser.|WpnService|CDPSvc|OneSyncSvc.|SCardSvr|TrustedInstaller|BITS
|RasMan|WbioSrvc|VeeamVssSupport|edgeupdate$
Таким образом из низкоуровнего обнаружения я исключил мониторинг служб: CDPUserSvc, WpnUser, WpnService, CDPSvc, OneSyncSvc., SCardSvr, TrustedInstaller, BITS, RasMan, WbioSrvc, VeeamVssSupport, edgeupdate.
Сделано это было в связи с возникновением бесконечных триггеров плана:
Service “OneSyncSvc” (Синхронизация узла) is not running (startup type automatic delayed)
После внесения изменений в макрос шаблона нам нужно отвязать шаблон, привязанный к хосту и снова привязать его, LLD обнаружение пройдёт заново и на основе служб исключённых из мониторинга не будут созданы items и triggers.
Точно таким же образом вы можете исключить службы из LLD для конкретного хоста, к которому привязан шаблон OS Windows by Zabbix agent, для этого перейдите в настройки хоста, откройте вкладку «Macros», перейдите в «Inherited and host macros», среди макросов найдите {$SERVICE.NAME.NOT_MATCHES} и можете внести изменения для LLD служб конкретного хоста.
Надеюсь статья была для вас полезной, всего доброго!