
Уровень сложностиПростой
Время на прочтение15 мин
Количество просмотров13K

В этом посте я буду говорить о страничной организации только в контексте PML4 (Page Map Level 4), потому что на данный момент это доминирующая схема страничной организации x86_64 и, вероятно, останется таковой какое-то время.
Окружение
Это необязательно, но я рекомендую подготовить систему для отладки ядра Linux с QEMU + gdb. Если вы никогда этого не делали, то попробуйте такой репозиторий: easylkb (сам я им никогда не пользовался, но слышал о нём много хорошего), а если не хотите настраивать окружение самостоятельно, то подойдёт режим практики в любом из заданий по Kernel Security на pwn.college (вам нужно знать команды vm connect и vm debug).
Я рекомендую вам так поступить, потому что считаю, что самостоятельное выполнение команд вместе со мной и возможность просмотра страниц (page walk) на основании увиденного в gdb — хорошая проверка понимания.
Что такое страница
В x86_64 страница — это срез памяти размером 0x1000 байтов, выровненный по 0x1000 байтам.
Именно поэтому при изучении /proc/<pid>/maps видно, что все диапазоны адресов начинаются и заканчиваются адресами, заканчивающимися на 0x000, ведь минимальный размер распределения памяти в x86_64 равен размеру страницы (0x1000 байтов), а страницы должны быть «выровнены по страницам» (последние 12 битов должны быть равны нулю).
При помощи MMU виртуальную страницу (Virtual Page) можно резолвить в единую физическую страницу (Physical Page) (она же «блок страницы», Page Frame), хотя и многие виртуальные страницы могут ссылаться на одну физическую.
Что такое виртуальный адрес
Как можно догадаться, PML4 имеет четыре уровня структур страничной организации памяти; эти структуры называются таблицами страниц (Page Table). Таблица страниц — это область памяти размером со страницу, содержащая 512 8-байтных элементов таблицы страниц. Каждый элемент таблицы страниц ссылается или на таблицу страниц следующего уровня или на конечный физический адрес, в который резолвится виртуальный адрес.
Элемент таблицы страниц, используемый для трансляции адресов, основан на виртуальном адресе доступа к памяти. Так как на каждый уровень используется 512 элементов, 9 битов виртуального адреса применяются на каждом уровне для индексации в соответствующей таблице страниц.
Допустим, у нас есть такой адрес:
0x7ffe1c9c9000
Последние 12 битов адреса обозначают смещение внутри физической страницы:
0x7ffe1c9c9000 & 0xfff = 0x0
Это значит, что определив физический адрес страницы, в которую резолвится этот виртуальный адрес, мы добавим ноль к результату, чтобы получить конечный физический адрес.
После последних 12 битов, которые являются смещением внутри конечной страницы, виртуальный адрес состоит из индексов таблиц страниц. Как говорилось выше, каждый уровень страничной организации памяти использует 9 битов виртуального адреса, поэтому самый нижний уровень структур страничной организации, то есть таблица страниц, индексируется по следующим 9 битам адреса (благодаря битовому маскированию при помощи & 0x1ff для сдвинутого значения). На следующих уровнях нам просто нужно каждый раз выполнять сдвиг вправо ещё на девять битов и снова маскировать нижние девять битов в качестве нашего индекса. Выполнение этой операции для показанного выше адреса даёт нам следующие индексы:
Level 1, Page Table (PT):
Index = (0x7ffe1c9c9000 >> 12) & 0x1ff = 0x1c9
Level 2, Page Middle Directory (PMD):
Index = (0x7ffe1c9c9000 >> 21) & 0x1ff = 0x0e4
Level 3, Page Upper Directory (PUD):
Index = (0x7ffe1c9c9000 >> 30) & 0x1ff = 0x1f8
Level 4, Page Global Directory (PGD):
Index = (0x7ffe1c9c9000 >> 39) & 0x1ff = 0x0ffБаза
Разобравшись, как выполнять индексацию в таблицах страниц, и поняв, что они приблизительно содержат, нужно узнать, где они находятся конкретно.
У каждого потока CPU есть базовый регистр таблицы страниц под названием cr3.
cr3 содержит физический адрес самого верхнего уровня структуры страничной организации, называемого Page Global Directory (PGD).
При отладке ядра через gdb содержимое cr3 можно считать следующим образом:
gef➤ p/x $cr3
$1 = 0x10d664000В зависимости от используемых функций процессора в регистре cr3 наряду с адресом PGD может храниться и дополнительная информация, поэтому более универсальный способ получения физического адреса PGD из регистра cr3 заключается в маскировании нижних 12 битов его содержимого:
gef➤ p/x $cr3 & ~0xfff
$2 = 0x10d664000Элементы таблиц страниц
Давайте рассмотрим в gdb физический адрес, полученный нами из cr3. Команда monitor xp/... раскрытая gdb благодаря QEMU Monitor, позволяет нам выводить физическую память vm, а команда monitor xp/512gx ... печатает всё содержимое (512 элементов) PGD, на который ссылается cr3:
gef➤ monitor xp/512gx 0x10d664000
...
000000010d664f50: 0x0000000123fca067 0x0000000123fc9067
000000010d664f60: 0x0000000123fc8067 0x0000000123fc7067
000000010d664f70: 0x0000000123fc6067 0x0000000123fc5067
000000010d664f80: 0x0000000123fc4067 0x0000000123fc3067
000000010d664f90: 0x0000000123fc2067 0x000000000b550067
000000010d664fa0: 0x000000000b550067 0x000000000b550067
000000010d664fb0: 0x000000000b550067 0x0000000123fc1067
000000010d664fc0: 0x0000000000000000 0x0000000000000000
000000010d664fd0: 0x0000000000000000 0x0000000000000000
000000010d664fe0: 0x0000000123eab067 0x0000000000000000
000000010d664ff0: 0x000000000b54c067 0x0000000008c33067Вывод получается большим и почти весь он состоит из нулей, поэтому я привожу здесь только самый конец.
Вероятно, этот вывод пока для вас не имеет особого смысла, но мы можем заметить в данных определённые паттерны, например, многие 8-байтные элементы заканчиваются на 0x67.
Расшифровка записей PGD
Возьмём из показанного выше вывода PGD в качестве примера запись PGD по адресу 0x000000010d664f50 со значением 0x0000000123fca067, чтобы понять, как расшифровать запись.
И давайте сделаем это с двоичной формой значения этой записи:
gef➤ p/t 0x0000000123fca067
$6 = 100100011111111001010000001100111Вот небольшая схема с объяснениями, что означает каждый бит записи:
~ PGD Entry ~ Present ──────┐
Read/Write ──────┐|
User/Supervisor ──────┐||
Page Write Through ──────┐|||
Page Cache Disabled ──────┐ ||||
Accessed ──────┐| ||||
Ignored ──────┐|| ||||
Reserved ──────┐||| ||||
┌─ NX ┌─ Reserved Ignored ──┬──┐ |||| ||||
|┌───────────┐ |┌──────────────────────────────────────────────┐ | | |||| ||||
|| Ignored | || PUD Physical Address | | | |||| ||||
|| | || | | | |||| ||||
0000 0000 0000 0000 0000 0000 0000 0001 0010 0011 1111 1100 1010 0000 0110 0111
56 48 40 32 24 16 8 0Вот что означает каждая из этих меток:
-
NX (неисполняемый) — если этот бит установлен, никакое из отображений памяти, являющихся потомком этого PGD, не будет исполняемым.
-
Reserved — эти значения должны быть равны нулю.
-
PUD Physical Address — физический адрес PUD, связанного с этой записью PGD.
-
Accessed — если эта запись или её потомки ссылаются на какую‑то страницу, то этот бит устанавливается MMU и может быть сброшен операционной системой.
-
Page Cache Disabled (PCD) — страницы‑потомки этой записи PGD не должны попадать в иерархию кэшей CPU; иногда этот бит также называют Uncacheable (UC).
-
Page Write Through (WT) — записи в страницы‑потомки этой записи PGD должны сразу же выполнять запись в ОЗУ, а не буферизировать записи в кэш CPU перед обновлением ОЗУ.
-
User/Supervisor — если этот бит сброшен, к страницам‑потомкам этой PGD невозможно выполнить доступ ни из какого режима, за исключением supervisor.
-
Read/Write — если этот бит сброшен, в страницы‑потомки этой PGD нельзя выполнять запись.
-
Present — если этот бит сброшен, то процессор не будет использовать эту запись для трансляции адресов и ни один из остальных битов не будет применяться.
Здесь нас волнует бит Present, биты, определяющие физический адрес следующего уровня структур страничной организации, биты PUD Physical Address и биты разрешений: NX, User/Supervisor, and Read/Write.
-
Бит Present очень важен, потому что без него вся остальная часть записи игнорируется.
-
PUD Physical Address позволяет нам продолжить просмотр страниц (page walk), сообщая, где находится физический адрес следующего уровня структур страничной организации памяти.
-
Биты Permission применяются к страницам, являющимся наследниками записи PGD; они определяют, как можно выполнять доступ к этим страницам.
Остальные биты для наших целей не так важны:
-
Бит Accessed устанавливается, если запись используется при трансляции доступа к памяти, он не важен для просмотра страниц.
-
Page Cache Disabled и Page Write Through не используются для обычного отображения страниц и не влияют на трансляцию страниц и разрешения, так что не будем обращать на них внимания.
Итак, декодировав эту запись, мы получим:
PUD является Present:
gef➤ p/x 0x0000000123fca067 & 0b0001
$18 = 0x1Отображения в PUD и ниже могут быть Writable:
gef➤ p/x 0x0000000123fca067 & 0b0010
$19 = 0x2Отображения в PUD и ниже могут быть доступны для User:
gef➤ p/x 0x0000000123fca067 & 0b0100
$20 = 0x4Физический адрес PUD (биты (51:12] ) — 0x123fca000:
gef➤ p/x 0x0000000123fca067 & ~((1ull<<12)-1) & ((1ull<<51)-1)
$21 = 0x123fca000Отображения в PUD и ниже могут быть Executable:
gef➤ p/x 0x0000000123fca067 & (1ull<<63)
$22 = 0x0Декодирование записей для всех уровней
Разобравшись, как декодировать запись PGD, нам будет легко декодировать остальные уровни, по крайней мере, в общем случае.
На всех этих диаграммах X означает, что бит может быть и нулём, и единицей; в противном случае, если биту присвоено конкретное значение, то оно требуется или для архитектуры или для конкретной кодировки, показанной на диаграмме.
PGD
~ PGD Entry ~ Present ──────┐
Read/Write ──────┐|
User/Supervisor ──────┐||
Page Write Through ──────┐|||
Page Cache Disabled ──────┐ ||||
Accessed ──────┐| ||||
Ignored ──────┐|| ||||
Reserved ──────┐||| ||||
┌─ NX ┌─ Reserved Ignored ──┬──┐ |||| ||||
|┌───────────┐ |┌──────────────────────────────────────────────┐ | | |||| ||||
|| Ignored | || PUD Physical Address | | | |||| ||||
|| | || | | | |||| ||||
XXXX XXXX XXXX 0XXX XXXX XXXX XXXX XXXX XXXX XXXX XXXX XXXX XXXX XXXX 0XXX XXXX
56 48 40 32 24 16 8 0Эту диаграмму мы уже видели, я подробно описал её в предыдущем разделе, но здесь у неё не указана конкретная запись PGD.
PUD
~ PUD Entry, Page Size unset ~ Present ──────┐
Read/Write ──────┐|
User/Supervisor ──────┐||
Page Write Through ──────┐|||
Page Cache Disabled ──────┐ ||||
Accessed ──────┐| ||||
Ignored ──────┐|| ||||
Page Size ──────┐||| ||||
┌─ NX ┌─ Reserved Ignored ──┬──┐ |||| ||||
|┌───────────┐ |┌──────────────────────────────────────────────┐ | | |||| ||||
|| Ignored | || PMD Physical Address | | | |||| ||||
|| | || | | | |||| ||||
XXXX XXXX XXXX 0XXX XXXX XXXX XXXX XXXX XXXX XXXX XXXX XXXX XXXX XXXX 0XXX XXXX
56 48 40 32 24 16 8 0Как видите, показанная выше диаграмма PUD очень похожа на диаграмму PGD, единственное различие заключается в появлении бита Page Size. Установленный бит Page Size сильно меняет интерпретацию записи PUD. В этой диаграмме мы предполагаем, что он сброшен, как и бывает чаще всего.
PMD
~ PMD Entry, Page Size unset ~ Present ──────┐
Read/Write ──────┐|
User/Supervisor ──────┐||
Page Write Through ──────┐|||
Page Cache Disabled ──────┐ ||||
Accessed ──────┐| ||||
Ignored ──────┐|| ||||
Page Size ──────┐||| ||||
┌─ NX ┌─ Reserved Ignored ──┬──┐ |||| ||||
|┌───────────┐ |┌──────────────────────────────────────────────┐ | | |||| ||||
|| Ignored | || PT Physical Address | | | |||| ||||
|| | || | | | |||| ||||
XXXX XXXX XXXX 0XXX XXXX XXXX XXXX XXXX XXXX XXXX XXXX XXXX XXXX XXXX 0XXX XXXX
56 48 40 32 24 16 8 0Диаграмма PMD тоже очень похожа на предыдущую, и, как и в случае с записью PUD, мы игнорируем бит Page Size.
PT
~ PT Entry ~ Present ──────┐
Read/Write ──────┐|
User/Supervisor ──────┐||
Page Write Through ──────┐|||
Page Cache Disabled ──────┐ ||||
Accessed ──────┐| ||||
┌─── NX Dirty ──────┐|| ||||
|┌───┬─ Memory Protection Key Page Attribute Table ──────┐||| ||||
|| |┌──────┬─── Ignored Global ─────┐ |||| ||||
|| || | ┌─── Reserved Ignored ───┬─┐| |||| ||||
|| || | |┌──────────────────────────────────────────────┐ | || |||| ||||
|| || | || 4KB Page Physical Address | | || |||| ||||
|| || | || | | || |||| ||||
XXXX XXXX XXXX 0XXX XXXX XXXX XXXX XXXX XXXX XXXX XXXX XXXX XXXX XXXX XXXX XXXX
56 48 40 32 24 16 8 0В записи Page Table всё становится интереснее: мы видим несколько новых полей/атрибутов, которых не было на предыдущих уровнях.
Вот какие это поля/атрибуты:
-
Memory Protection Key (MPK или PK): это расширение x86_64, позволяющее назначать страницам 4-битные ключи, что можно использовать, чтобы конфигурировать разрешения памяти для всех страниц с этим ключом.
-
Global: этот атрибут связан с тем, как TLB (Translation Lookaside Buffer — кэш MMU для трансляции виртуальных адресов в физические) кэширует трансляцию для страницы; если этот бит установлен, то страница не будет удалена из TLB при переключении контекста; обычно он включён для страниц ядра, чтобы снизить количество промахов TLB.
-
Page Attribute Table (PAT): если значение установлено, то MMU должно обратиться к Page Attribute Table MSR, чтобы определить Memory Type страницы, например, является ли эта страница Uncacheable, Write Through или имеет один из нескольких других типов памяти.
-
Dirty: этот бит похож на бит Accessed, он устанавливается MMU, если в эту страницу выполнена запись, и должен быть сброшен операционной системой.
Ничто из этого не влияет на саму трансляцию адреса, однако конфигурация Memory Protection Key может означать, что ожидаемые разрешения доступа к памяти для страницы, на которую ссылается эта запись, могут быть строже, чем закодированные в самой записи.
В отличие от предыдущих уровней, поскольку это последний, запись хранит последний физический адрес страницы, связанной с виртуальным адресом, который мы транслируем. Применив битовую маску для получения байтов физического адреса и добавив последние 12 байтов исходного виртуального адреса (смещение внутри страницы), мы получим физический адрес!
В общем случае просмотр страниц выполняется всего за несколько этапов:
-
Преобразуем виртуальный адрес в индексы и смещение страницы, сдвинув адрес и применив битовые маски
-
Считываем
cr3, чтобы получить физический адрес PGD -
Чтобы достичь каждого уровня до последнего:
-
Используем индексы, вычисленные из виртуального адреса, чтобы узнать, какую запись из таблицы страниц использовать
-
Применяем битовую маску к записи, чтобы получить физический адрес следующего уровня
-
-
На последнем уровне снова находим запись, соответствующую индексу из виртуального адреса
-
Применяем битовую маску, чтобы получить физический адрес страницы, связанный с виртуальным адресом
-
Добавляем смещение внутри страницы от виртуального адреса до физического адреса страницы
-
Готово!
Увеличиваем масштаб
Как говорилось выше, диаграммы PUD и PMD рассчитаны на общий случай, когда не установлен бит Page Size.
А что происходит, если он установлен?
Если он установлен, то он, по сути, говорит MMU: сворачивайся, мы здесь закончили, не храни просмотр страниц, текущая запись содержит физический адрес страницы, которую мы ищем.
Но это ещё не всё: физический адрес в записях, где установлен бит Page Size, предназначен не для обычной страницы на 4 КБ (0x1000 байтов), это Huge Page, имеющая два варианта: Huge Page на 1 ГБ и Huge Page на 2 МБ.
Когда бит Page Size установлен у записи PUD, то он ссылается на 1-гигабайтную Huge Page, а когда бит Page Size установлен у записи PMD, он ссылается на 2-мегабайтную Huge Page.
Но откуда берутся числа 1 ГБ и 2 МБ?
Каждый уровень таблиц страниц хранит до 512 записей, то есть PT может ссылаться на не более чем 512 страниц и 512 * 4 КБ = 2 МБ. То есть Huge Page на уровне PMD, по сути, означает, что запись ссылается на страницу, имеющую тот же размер, что и полный PT.
Расширяя это на уровень PUD, мы просто снова умножаем на 512 и получаем размер полного PMD, содержащего полные PT: 512 * 512 * 4 КБ = 1 ГБ.
PUD страницы Huge Page
~ PUD Entry, Page Size set ~ Present ─────┐
Read/Write ─────┐|
User/Supervisor ─────┐||
Page Write Through ─────┐|||
Page Cache Disabled ─────┐ ||||
Accessed ─────┐| ||||
Dirty ─────┐|| ||||
┌─── NX Page Size ─────┐||| ||||
|┌───┬─── Memory Protection Key Global ─────┐ |||| ||||
|| |┌──────┬─── Ignored Ignored ───┬─┐| |||| ||||
|| || | ┌─── Reserved Page Attribute Table ───┐ | || |||| ||||
|| || | |┌────────────────────────┐┌───────────────────┐| | || |||| ||||
|| || | || 1GB Page Physical Addr || Reserved || | || |||| ||||
|| || | || || || | || |||| ||||
XXXX XXXX XXXX 0XXX XXXX XXXX XXXX XXXX XX00 0000 0000 0000 000X XXXX 1XXX XXXX
56 48 40 32 24 16 8 0Когда бит Page Size установлен, можно заметить, что запись PUD выглядит больше похожей на запись PT, чем на обычную запись PUD, что логично, ведь она также ссылается на страницу, а не на таблицу страниц.
Однако существуют некоторые отличия от PT:
-
Бит Page Size находится там, где находится в PT бит Page Attribute Table (PAT), поэтому бит PAT перенесён в бит 12.
-
Физический адрес 1-гигабайтной Huge Page должен иметь выравнивание в физической памяти по 1 ГБ; именно поэтому существуют новые биты Reserved и поэтому бит 12 можно задействовать как бит PAT.
В целом здесь нет ничего особо нового, при работе Huge Page с другие различия заключаются в том, что для получения физического адреса страницы к адресу нужно применить другую битовую маску; кроме того, выравнивание по 1 ГБ означает, что при вычислении физического адреса виртуального адреса в странице нам нужно использовать маску, основанную на выравнивании по 1 ГБ, а не по 4 КБ.
PMD страницы Huge Page
~ PMD Entry, Page Size set ~ Present ─────┐
Read/Write ─────┐|
User/Supervisor ─────┐||
Page Write Through ─────┐|||
Page Cache Disabled ─────┐ ||||
Accessed ─────┐| ||||
Dirty ─────┐|| ||||
┌─── NX Page Size ─────┐||| ||||
|┌───┬─── Memory Protection Key Global ─────┐ |||| ||||
|| |┌──────┬─── Ignored Ignored ───┬─┐| |||| ||||
|| || | ┌─── Reserved Page Attribute Table ─────┐ | || |||| ||||
|| || | |┌───────────────────────────────────┐┌────────┐| | || |||| ||||
|| || | || 2MB Page Physical Address ||Reserved|| | || |||| ||||
|| || | || || || | || |||| ||||
XXXX XXXX XXXX 0XXX XXXX XXXX XXXX XXXX XXXX XXXX XXX0 0000 000X XXXX 1XXX XXXX
56 48 40 32 24 16 8 0Здесь ситуация очень похожа на запись PUD с установленным битом Page Size; единственное изменение заключается в том. что поскольку на этом уровне выравнивание для 2-мегабайтных страниц меньше, установлено меньше битов Reserved.
Выравнивание по 2 МБ означает, что смещение внутри huge page должно вычисляться при помощи маски, основанной на выравнивании по 2 МБ.
Просматриваем страницы
В этом разделе давайте посмотрим, как выполнять просмотр страниц вручную в gdb.
Подготовка
Запустив vm и подключив gdb, я сначала выберу адрес для выполнения просмотра страниц; в качестве примера я использую текущий указатель стека при работе ядра:
gef➤ p/x $rsp
$42 = 0xffffffff88c07da8Итак, у нас есть адрес для просмотра, давайте получим физический адрес PGD из cr3:
gef➤ p/x $cr3 & ~0xfff
$43 = 0x10d664000Я воспользуюсь этой небольшой функцией на Python, чтобы извлечь смещения таблиц страниц из виртуального адреса:
def get_virt_indicies(addr):
pageshift = 12
addr = addr >> pageshift
pt, pmd, pud, pgd = (((addr >> (i*9)) & 0x1ff) for i in range(4))
return pgd, pud, pmd, ptНа выходе получаем следующее:
In [2]: get_virt_indicies(0xffffffff88c07da8)
Out[2]: (511, 510, 70, 7)PGD
Полученный нами индекс для PGD на основании виртуального адреса — это 511. Умножив 511 на 8, мы получим байтовое смещение в PGD, с которого начинается запись PGD для нашего виртуального адреса:
gef➤ p/x 5118
$44 = 0xff8Добавив это смещение к физическому адресу PGD, мы получим физический адрес записи PGD:
gef➤ p/x 0x10d664000+0xff8
$45 = 0x10d664ff8А считывание физической памяти по этому адресу даёт нам саму запись PGD:
gef➤ monitor xp/gx 0x10d664ff8
000000010d664ff8: 0x0000000008c33067Похоже, у записи установлены последние три бита (present, user и writeable), а старший бит (NX) сброшен, то есть пока нет никаких ограничений на разрешения страниц, связанных с этим виртуальным адресом.
Маскирование битов [12, 51) даёт нам физический адрес PUD:
gef➤ p/x 0x0000000008c33067 & ~((1<<12)-1) & ((1ull<<51) - 1)
$46 = 0x8c33000PUD
Индекс, полученный для PUD на основании виртуального адреса — это 510. Умножив 510 на 8, мы получим байтовое смещение в PUD, с которого начинается запись PUD для нашего виртуального адреса:
gef➤ p/x 5108
$47 = 0xff0Добавив это смещение к физическому адресу PUD, мы получим физический адрес записи PUD:
gef➤ p/x 0x8c33000+0xff0
$48 = 0x8c33ff0А считывание физической памяти по этому адресу даёт нам саму запись PUD:
gef➤ monitor xp/gx 0x8c33ff0
0000000008c33ff0: 0x0000000008c34063На этом этапе нам нужно начать обращать внимание на Size Bit (бит 7), потому что если это 1-гигабайтная страница, мы остановим на этом просмотр страниц.
gef➤ p/x 0x0000000008c34063 & (1<<7)
$49 = 0x0
Похоже, в этой записи от сброшен, так что мы продолжим просмотр страниц.
Также обратим внимание, что запись PUD заканчивается на 0x3, а не на 0x7, как на предыдущем уровне, младшие два бита (present, writeable) по-прежнему установлены, а бит user теперь сброшен. Это значит, что доступ в пользовательском режиме к страницам, принадлежащим к этой записи PUD, приведёт к page fault из-за безуспешной проверки разрешения на доступ.
Бит NX по-прежнему сброшен, поэтому страницы, принадлежащие к этому PUD, по-прежнему могут быть исполняемыми.
Маскирование битов [12, 51) даёт нам физический адрес PMD:
gef➤ p/x 0x0000000008c34063 & ~((1ull<<12)-1) & ((1ull<<51)-1)
$50 = 0x8c34000PMD
Индекс, полученный нами для PMD на основании виртуального адреса — это 70, поэтому умножение 70 на 8 позволит нам получить байтовое смещение в PMD с которого начинается запись PMD для нашего виртуального адреса:
gef➤ p/x 708
$51 = 0x230Добавив это смещение к физическому адресу PMD, получим физический адрес записи PMD:
gef➤ p/x 0x8c34000+0x230
$52 = 0x8c34230А считывание физической памяти по этому адресу даёт нам саму запись PMD:
gef➤ monitor xp/gx 0x8c34230
0000000008c34230: 0x8000000008c001e3На этом уровне нам тоже нужно обращать внимание на Size Bit, потому что если это страница на 2 МБ, мы остановим на этом просмотр страниц.
gef➤ p/x 0x8000000008c001e3 & (1<<7)
$53 = 0x80Похоже, наш виртуальный адрес ссылается на 2-мегабайтную Huge Page! Поэтому физический адрес в записи PMD — это физический адрес Huge Page.
Кроме того, судя по битам разрешений, страница по-прежнему Present и Writeable, а бит User по-прежнему сброшен, так что доступ к этой странице есть только из режима supervisor (ring-0).
В отличие от предыдущих уровней, здесь старший бит NX установлен:
gef➤ p/x 0x8000000008c001e3 & (1ull<<63)
$54 = 0x8000000000000000То есть Huge Page — это не исполняемая память.
Применив битовую маску к битам [21:51), мы получим физический адрес huge page:
gef➤ p/x 0x8000000008c001e3 & ~((1ull<<21)-1) & ((1ull<<51)-1)
$56 = 0x8c00000Теперь нам нужно применить маску к виртуальному адресу, основанному на 2-мегабайтному выравниванию страниц, чтобы получить смещение в Huge Page.
2 МБ эквивалентно 1<<21, поэтому применив битовую маску (1ull<<21)-1, мы получим смещение:
gef➤ p/x 0xffffffff88c07da8 & ((1ull<<21)-1)
$57 = 0x7da8Добавив это смещение к базовому адресу 2-мегабайтной Huge Page, мы получим физический адрес, связанный с виртуальным адресом, с которого мы начинали:
gef➤ p/x 0x8c00000 + 0x7da8
$58 = 0x8c07da8Похоже, виртуальный адрес 0xffffffff88c07da8 имеет физический адрес 0x8c07da8!
Проверка
Есть несколько способов проверки правильного просмотра страниц, легче всего будет просто сдампить память по виртуальному и физическому адресу, а затем сравнить их. Если они похожи, то, вероятно, мы всё сделали правильно:
Физический:
gef➤ monitor xp/10gx 0x8c07da8
0000000008c07da8: 0xffffffff810effb6 0xffffffff88c07dc0
0000000008c07db8: 0xffffffff810f3685 0xffffffff88c07de0
0000000008c07dc8: 0xffffffff8737dce3 0xffffffff88c3ea80
0000000008c07dd8: 0xdffffc0000000000 0xffffffff88c07e98
0000000008c07de8: 0xffffffff8138ab1e 0x0000000000000000Виртуальный:
gef➤ x/10gx 0xffffffff88c07da8
0xffffffff88c07da8: 0xffffffff810effb6 0xffffffff88c07dc0
0xffffffff88c07db8: 0xffffffff810f3685 0xffffffff88c07de0
0xffffffff88c07dc8: 0xffffffff8737dce3 0xffffffff88c3ea80
0xffffffff88c07dd8: 0xdffffc0000000000 0xffffffff88c07e98
0xffffffff88c07de8: 0xffffffff8138ab1e 0x0000000000000000На мой взгляд, выглядит неплохо!
Ещё один способ проверки — использовать команду monitor gva2gpa (гостевой виртуальный адрес в гостевой физический адрес), раскрытую gdb благодаря QEMU Monitor:
gef➤ monitor gva2gpa 0xffffffff88c07da8
gpa: 0x8c07da8Если предположить, что QEMU выполняет трансляцию адресов правильно (вероятно, это справедливое предположение), то у нас есть ещё одно подтверждение успешности просмотра страниц!
Подведём итог
Надеюсь, теперь у вас есть достаточно чёткое понимание того, как работает страничная организация памяти в системах x86_64. Я хотел уместить в пост много информации, поэтому пришлось подумать, как всё это упорядочить, и я всё ещё не уверен, что это идеальный способ.
Как бы то ни было, я считаю страничную организацию памяти довольно удобной; мне кажется, это одна из тех вещей, разобравшись в которых, можно их понять. Но чтобы разобраться, нужно время и изучение gdb.
Если эта публикация вас вдохновила и вы хотите поддержать автора — не стесняйтесь нажать на кнопку
Сказки про «полезные» оптимизаторы памяти
Организация памяти в Windows XP
Страничная организация памяти
Сегментная организация памяти
Сегментно-страничная организация памяти
Принцип работы менеджера памяти
Фокусы оптимизаторов памяти
Практические примеры
dRAMatic v 8.1
Clean RAM 1.21
FAST Defrag 2.3
FreeRAM XP Pro 1.52
Memory Optimizer 2002a
MemTurbo 2
RAM Idle Professional 3.4
Выводы
Нас так часто обманывают, что мы к этому уже привыкли и не доверяем никому и ничему. Ложь рекой льется с экранов телевизоров, из уст высокопоставленных чиновников, в центральной прессе то и дело появляются проплаченные заказные статьи с явной неправдой, а уж про ненадлежащую рекламу и говорить не приходится. Вспомним хотя бы страшилки про птичий грипп, которые внезапно возникли и так же неожиданно, подчиняясь чьей-то искусной дирижерской палочке, исчезли. Или про отравленное грузинское и молдавское вино. В результате эти вина исчезли с прилавков магазинов, а вместо них нам предложили довольствоваться дешевым вином из других стран, которое как нельзя лучше соответствует слову «бормотуха». Примеры такого «гуманизма» встречаются на каждом шагу. «Но при чем здесь программное обеспечение и компьютеры?» — спросите вы. Все очень просто: принцип «обмани и получи выгоду» нередко применяется и в области программного обеспечения. Наряду с полезными программами пользователям нередко (причем за деньги) предлагают и откровенные пустышки, которые, по заявлениям производителей, способны в разы увеличить производительность системы. В лучшем случае они не навредят, а в худшем — вместо обещанного увеличения производительности приведут к обратному эффекту. Классическим примером такого рода программ являются оптимизаторы оперативной памяти, которые и будут рассмотрены в настоящей статье.
Принцип, которым руководствуются компании, предлагающие оптимизаторы памяти, достаточно прост и неоригинален. Надо заставить пользователя поверить в чудодейственные возможности утилиты и убедить его, что использование оптимизатора памяти позволит и решить проблему нехватки памяти, и повысить производительность ПК. Сделать это не так уж сложно, особенно если речь идет о неискушенном пользователе. Алгоритм убеждения примерно таков. Прежде всего необходимо убедить пользователя, что операционная система Windows XP далека от идеала. Учитывая постоянную критику в адрес Microsoft, сделать это легко (тем более что в этом есть доля истины), ну а для пущей убедительности можно напомнить о регулярном появлении так называемых заплаток и обновлений к операционной системе. Далее нужно убедить пользователя, что исправить недочеты операционной системы можно с помощью сторонних утилит (факт достаточно спорный, хотя отчасти он соответствует действительности). В качестве примера можно привести множество сторонних утилит (те же дефрагментаторы), которые по некоторым характеристикам лучше встроенных в операционную систему. Ну а если все это «приправить» научными терминами об утечке оперативной памяти, о необходимости ее дефрагментации и о неоптимизированных алгоритмах выделения оперативной памяти процессам (главное при этом — окончательно запудрить мозги специфическими терминами), то необходимость использования сторонних оптимизаторов памяти (наделенных интеллектуальными, продвинутыми алгоритмами слежения за состоянием памяти, позволяющих оптимизировать ее распределение и проводящих в случае необходимости автоматическую дефрагментацию) становится просто очевидным фактом.
На сфабрикованную таким образом утку кто-нибудь да клюнет. Причем, как показывает практика, клюют многие.
Чтобы доказать пользователю необоснованность приведенных выше рассуждений, необходимо сначала рассказать, каким образом операционная система Windows XP распределяет оперативную память.
Организация памяти в Windows XP
В любой момент компьютер выполняет сразу несколько процессов (или задач), каждый из которых располагает своим адресным пространством. Было бы слишком накладно отдавать всю физическую память какой-то одной задаче, тем более что многие из них реально используют только небольшую часть своего адресного пространства. Поэтому необходим механизм разделения небольшой физической памяти между различными задачами. Кроме того, уже давно существует проблема размещения в памяти программ, размер которых превышает размер доступной физической памяти.
Одним из способов разделения физической памяти между различными процессами и размещения в памяти программ, размер которых превышает размер доступной физической памяти, является использование технологии виртуальной памяти (virtual memory), которая впервые была реализована в 1959 году на компьютере «Атлас», разработанном в Манчестерском университете. Однако популярной технология виртуальной памяти стала лишь спустя десятилетия.
Виртуальная память делит физическую память на отдельные блоки и распределяет их между различными задачами. При этом она предусматривает некоторую схему защиты, которая ограничивает задачу теми блоками, которые ей принадлежат. Кроме того, виртуальная память позволяет объединить (с точки зрения программ) физическую оперативную память компьютера и внешнюю память (например, память жесткого диска).
Системы виртуальной памяти можно разделить на три класса:
- системы с фиксированным размером блоков, называемых страницами, — страничная организация памяти;
- системы с переменным размером блоков, называемых сегментами, — сегментная организация памяти;
- комбинированные системы с сегментно-страничной организацией памяти.
В настоящее время актуально говорить только о сегментно-страничной организации памяти, однако для лучшего понимания этого способа мы рассмотрим также страничную и сегментную организацию памяти.
Страничная организация памяти
В случае страничной организации памяти и виртуальная и физическая память представляются в виде набора неперекрывающихся блоков одинакового размера, называемых страницами. Передача информации (считывание, запись) всегда осуществляется целыми страницами.
При страничной организации виртуальный адрес памяти требуемого элемента задается в виде номера страницы и смещения относительно начала страницы. Любой выполняемый процесс (программа) имеет дело только с виртуальными адресами и не знает физических адресов данных, с которыми работает. Для преобразования виртуальных адресов в физические используются таблицы страниц (page table), размещаемые в оперативной памяти. Важно, что каждому процессу соответствует собственная таблица страниц.
Преобразование логических (виртуальных) адресов в физические происходит следующим образом. Когда какой-либо выполняемый процесс обращается по виртуальному адресу, в котором содержится информация о номере требуемой страницы и смещении в пределах страницы, происходит обращение к таблице страниц этого процесса, в которой каждому номеру страницы поставлен в соответствие физический адрес страницы в памяти.
Таким образом, по номеру страницы определяется физический адрес этой страницы в памяти. Далее с учетом известного смещения в пределах требуемой страницы определяется физический адрес искомого элемента памяти (рис. 1).
Рис. 1. Связь логического и физического адресов при страничной организации памяти
Любой процесс может выполняться только в том случае, если используемые им страницы памяти размещаются в оперативной памяти. При отсутствии запрашиваемой страницы в оперативной памяти возникает исключительная ситуация — страничное нарушение (page fault). Тогда затребованная страница подкачивается из внешней памяти (своп-файла) в свободный страничный кадр физической памяти, а при отсутствии свободных страничных кадров в оперативной памяти первоначально в своп-файл выгружается мало используемая страница памяти.
При страничной организации памяти может возникать проблема ее внутренней фрагментации (внешней фрагментации в данном случае принципиально не существует). Внутренняя фрагментация памяти происходит по причине того, что адресное пространство процесса может занимать только целое число страниц, при этом некоторые страницы заняты не полностью.
Важно отметить, что при страничной организации памяти любому процессу доступна лишь та физическая память, которая ему соответствует, и не доступна память другого процесса, поскольку процесс не имеет возможности адресовать память за пределами своей таблицы страниц, включающей только его собственные страницы.
Сегментная организация памяти
Понятие сегментированной памяти связано с необходимостью разделения хранимых в памяти данных между различными процессами. Именно в этом заключается главное отличие сегментированной организации памяти от страничной.
Участки памяти, хранящие однородные данные, которые доступны нескольким процессам, называются сегментами. Каждый сегмент представляет собой отдельную логическую единицу информации, содержащую совокупность данных или программ и расположенную в адресном пространстве пользователя. Сегменты создаются пользователями, которые могут обращаться к ним по символическому имени. В каждом сегменте устанавливается собственная нумерация слов начиная с нуля.
При сегментной организации памяти каждый сегмент определяется двумя величинами: именем сегмента и смещением. В отличие от страниц, разные сегменты могут иметь различные размеры, причем размер сегмента может меняться динамически.
Точно так же, как и при страничной организации, при сегментной организации памяти для преобразования виртуального адреса требуемого элемента в физический адрес используются таблицы сегментов. В таблице сегментов, помимо физического адреса начала сегмента, содержится также длина сегмента. Преобразование логических адресов в физические происходит следующим образом. Когда выполняемый процесс обращается по виртуальному адресу, происходит обращение к таблице сегментов, что позволяет определить физический адрес требуемого сегмента. Используя информацию о смещении в пределах сегмента, можно определить физический адрес искомого элемента (рис. 2).
Рис. 2. Преобразование логического адреса при сегментной
организации памяти
Сегментно-страничная организация памяти
Сегментная организация памяти в чистом виде не встречается и в этом смысле интересна лишь в теоретическом аспекте. Как уже отмечалось, в операционных системах семейства Windows используется комбинированная сегментно-страничная организация памяти.
При сегментно-страничной организации памяти происходит двухуровневая трансляция виртуального адреса в физический. В этом случае виртуальный адрес состоит из трех полей: номера сегмента виртуальной памяти, номера страницы внутри сегмента и смещения внутри страницы. Соответственно для преобразования виртуальных адресов в физические применяются две таблицы: таблица сегментов, которая связывает номер сегмента с таблицей страниц и называется также таблицей каталогов страниц, и отдельная таблица страниц для каждого сегмента (рис. 3). При преобразовании виртуального адреса элемента в физический адрес первоначально по номеру каталога страниц устанавливается требуемая таблица страниц. Далее с использованием таблицы страниц и номера страницы определяется физический адрес страницы, а зная смещение внутри страницы, можно определить физический адрес искомого элемента.
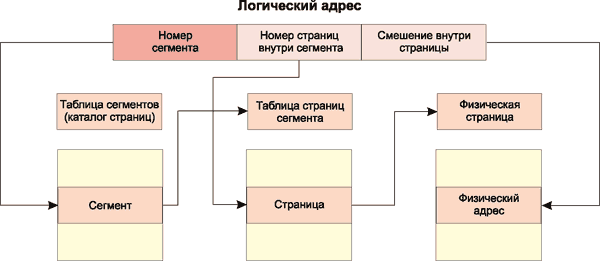
Рис. 3. Формирование физического адреса при сегментно-страничной организации памяти
Главная особенность сегментно-страничной организации виртуальной памяти заключается в том, что при этом имеется возможность совместно применять одни и те же сегменты данных и программного кода в виртуальной памяти разных процессов, поскольку для совместно используемых сегментов поддерживаются общие таблицы страниц.
Далее мы рассмотрим 32-разрядные операционные системы (к коим относится и Windows XP) в совокупности с процессорами, поддерживающими 32-разрядную адресацию памяти (современные 64-разрядные процессоры при применении 32-разрядной ОС работают как 32-разрядные процессоры).
При 32-разрядной адресации памяти объем виртуальной адресуемой памяти составляет 232 = 4 Гбайт. При сегментно-страничной организации памяти адрес, как уже отмечалось, состоит из трех полей, которые определяют номер каталога страниц, номер страницы и смещение в пределах страницы. Для задания номера каталога и номера страницы используется по 10 бит, а для задания смещения — оставшиеся 12 бит. В этом случае поддерживается 210 =1 024 каталога страниц и 1024 страницы внутри каждого каталога, а общее количество страниц может составлять 220 = 1 048 576. Учитывая, что для задания смещения внутри страницы применяется 12 разрядов адреса, нетрудно посчитать, что размер одной страницы составляет 212 = 4096 байт = 4 Кбайт.
Рассмотрим более подробно отдельный элемент (запись) таблицы страниц (Page Table Element, PTE). Каждая запись таблицы страниц является 32-разрядной. Старшие пять разрядов определяют тип доступа к странице (нет доступа, только чтение, чтение и запись). Следующие 20 бит задают физический адрес страницы в памяти. Если учесть, что для задания смещения в пределах страниц используется 12 бит, то в совокупности с 20 битами, применяемыми для описания физического адреса страницы, получаем как раз 32-разрядную адресацию памяти. Следующие 4 бита в PTE определяют применяемый файл подкачки (один из 16 возможных), а последние 3 бита задают состояние страницы памяти. Первый из этих битов (T-бит, Transition) определяет, является ли страница переходной (T = 1) или нет (T = 0), второй бит (D-бит, Dirty) — была ли произведена в страницу запись (D = 1) или запись не проводилась (D = 0), последний бит (P-бит, Present) — находится ли страница в оперативной памяти (P = 1) или же в файле подкачки (P = 0). Информация о состоянии страницы необходима для того, чтобы принять решение о сохранении страницы в файле подкачки при ее вытеснении (принудительном освобождении занятой памяти). Действительно, если страница не изменялась в памяти после загрузки, то ее можно просто стереть, ведь в файле подкачки сохранилась ее копия.
Принцип работы менеджера памяти
Для управления виртуальной памятью в операционной системе Windows предусмотрен специальный менеджер Virtual Memory Manager (VMM). Он является составной частью ядра операционной системы и представляет собой отдельный процесс, постоянно находящийся в оперативной памяти. Основная задача VMM заключается в управлении страницами виртуальной памяти.
Каждому процессу (запущенному приложению) VMM выделяет часть физической памяти, которая называется рабочим набором (Working Set). Кроме того, VMM создает базу состояния страниц (page-frame database), которая организована как шесть списков страниц одного типа. Выделяют следующие типы страниц:
- Valid — рабочая страница используется процессом. Такие страницы памяти реально существуют в физической памяти. Если процесс освобождает страницу памяти, то VMM убирает ее из списка Valid. Если процесс пытается обратиться к странице, которой нет в списке Valid, то генерируется ошибка (Page Fault) и VMM может отвести процессу новую страницу. Страницы типа Valid в таблице страниц описываются как присутствующие (P = 1);
- Modified — модифицированная страница, то есть страница, содержимое которой было изменено. В таблице страниц данные страницы отмечаются как отсутствующие (P = 0) и переходные (T = 1);
- Standby — резервная страница, содержимое которой не изменялось. В таблице страниц такие страницы отмечаются как отсутствующие (P = 0) и переходные (T = 1);
- Free — свободная страница, на которую не ссылается ни один рабочий набор и которой нет ни в одной таблице страниц. В список Free помещаются страницы, которые освободились после окончания процесса. Свободные страницы могут применяться, однако прежде они подлежат процедуре обнуления (заполнения нулями). Процедурой обнуления страниц занимается специальная подпрограмма менеджера памяти Zero Page Thread;
- Zeroed — пустая страница, которая является свободной и обнуленной. Такие страницы готовы к использованию любым процессом;
- Bad — страница, которая вызывает аппаратные ошибки и не может применяться ни одним процессом.
Как уже отмечалось, если какой-нибудь процесс обращается к странице, которой нет в рабочем наборе (в списке Valid), то возникает ошибка обращения к странице. В этом случае задача VMM заключается в том, чтобы разрешить данную конфликтную ситуацию и выделить страницу свободной физической памяти для хранения данных, к которым обратился процесс. Существует несколько способов решения данной конфликтной ситуации. Во-первых, VMM может расширить рабочий набор процесса, добавив к нему необходимую страницу. Однако если в памяти нет места для выделения дополнительных страниц, то VMM замещает страницу, находящуюся в рабочем наборе, новой страницей. Понятно, что в идеале замещению должна подлежать та страница, к которой в будущем не будет обращений, или страница, которая не будет использоваться дольше других. Однако достоверного способа определить, какая именно страница отвечает перечисленным критериям, нет. Поэтому менеджер памяти применяет следующий хитроумный алгоритм. Он периодически просматривает список рабочих страниц (Valid) и помечает их как отсутствующие (P = 0). Однако данные страницы не удаляются из рабочего процесса — они остаются на месте и просто переводятся из категории Valid в категорию модифицированных (Modified) или резервных (Standby) страниц (естественно, никаких изменений в содержимом этих страниц не производится). Если измененная таким образом страница требуется какому-нибудь процессу, то происходит обращение к ней и возникает ошибка обращения к странице. Но поскольку в действительности страница находится в физической памяти и ее содержимое не подвергалось изменению, то менеджеру памяти достаточно просто перевести данную страницу обратно в категорию Valid, сделав ее доступной для процесса. Если же страница не используется в течение длительного времени процессами, то обращений к ней не происходит и она со временем переводится в категорию свободных (Free) страниц, а затем обнуляется и переводится в категорию пустых (Zeroed) страниц.
Таким образом, менеджер памяти автоматически забирает страницы из рабочих наборов неактивных процессов, то есть процессы, не проявляющие активности в течение длительного времени, автоматически освобождают всю физическую память.
На рис. 4 показаны переходы между различными категориями (списками) страниц.
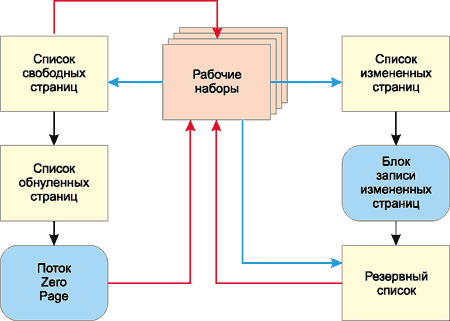
Рис. 4. Переходы между различными категориями страниц памяти
Фокусы оптимизаторов памяти
После того как мы разобрались с основами организации памяти и принципами функционирования менеджера памяти в операционных системах семейства Windows, самое время рассмотреть, каким образом с помощью оптимизаторов памяти можно увеличить объем доступной (Available) физической памяти. Для операционной системы доступной памятью является сумма пустых (Zeroed), свободных (Free) и резервных (Standby) страниц.
Прежде всего отметим, что ни один оптимизатор памяти не может подменить собой менеджера памяти, который, как уже говорилось, является частью ядра операционной системы. Поэтому единственное, что может сделать оптимизатор памяти, — это вмешаться в работу менеджера памяти.
Итак, рассмотрим первую возможность, предоставляемую всеми оптимизаторами памяти, — увеличение доступной памяти. Достигается это следующим образом. Оптимизатор памяти, как и любая программа, является процессом, которому менеджер памяти выделяет свой рабочий набор. Оптимизаторы памяти ведут себя весьма агрессивно и требуют под свои нужды выделения все новых и новых страниц, то есть постоянно расширяют свой рабочий набор. Сделать это нетрудно — нужно лишь за короткое время реализовать многочисленные обращения к несуществующим страницам памяти, что вызывает ошибки обращения. В ответ на возникающие ошибки обращения менеджер памяти увеличивает рабочий набор оптимизатора сначала за счет доступной памяти, а когда лимит доступной памяти исчерпывается, расширение рабочего набора оптимизатора достигается за счет механизма замещения страниц, осуществляемого менеджером памяти. То есть рабочие наборы всех остальных процессов уменьшаются, а рабочий набор оптимизатора памяти увеличивается.
После того как рабочий набор, выделяемый оптимизатору памяти, достигает требуемого значения (это значение можно задавать в оптимизаторах памяти), оптимизатор памяти заканчивает свой процесс, высвобождая рабочий набор. В результате образуется большое количество (заданное в настройках оптимизатора) доступной памяти.
Описанный алгоритм увеличения доступной памяти, который используют все оптимизаторы памяти, имеет одно существенное негативное последствие. Дело в том, что, во-первых, такая «оптимизация» памяти приостанавливает работу всех остальных программ (особенно если оптимизация происходит в автоматическом режиме), а во-вторых, в процессе замещения страниц происходит вытеснение страниц, принадлежащих различным процессам, на жесткий диск ПК. После того как оптимизатор заканчивает свою работу, активным процессам, чьи рабочие наборы были вытеснены на диск, приходится повторно считывать данные с диска, что, конечно же, негативно сказывается на производительности ПК. Поэтому оптимизаторы памяти создают лишь иллюзию того, что они освобождают память, делая ее доступной. На самом деле, как только оптимизатор заканчивает свою деятельность, менеджер памяти возвращает все к исходному состоянию, но достигается это за счет снижения производительности системы.
Другой распространенный миф, связанный с оптимизаторами памяти, заключается в том, что эти утилиты якобы способны высвобождать память, занимаемую неактивными процессами, и предотвращать утечку памяти. Однако если вспомнить алгоритм работы менеджера памяти, то становится понятно, что эту задачу решает именно менеджер памяти, который автоматически высвобождает память неактивных процессов. Проблема утечки памяти, которая возникает по причине того, что некоторые процессы не могут корректно освободить память, также решается менеджером памяти, поскольку, как уже отмечалось, память всех неактивных процессов постоянно высвобождается. И даже если какой-то процесс остается незавершенным (хотя и неактивным), используемый им рабочий набор вытесняется в файл подкачки на жесткий диск.
Последний фокус оптимизаторов памяти связан с ее дефрагментацией. Дефрагментация памяти действительно присутствует, поскольку является побочным эффектом высвобождения большого (причем сплошного) объема памяти. Однако есть одно маленькое «но»! Все дело в том, что сплошной объем памяти является виртуальным, а информация о том, как именно расположены в физической памяти соответствующие страницы, остается недоступной оптимизатору памяти, поскольку соответствие между логическими и физическими адресами страниц определяется уже на аппаратном, а не на программном уровне. В итоге, несмотря на то, что виртуальная память дефрагментируется, физическая память остается нетронутой, а значит, и толку от такого рода дефрагментации нет никакого.
Практические примеры
После теоретического разоблачения оптимизаторов памяти перейдем к рассмотрению практических примеров. Мы выбрали несколько популярных оптимизаторов памяти, которые легко можно найти в Интернете. Думается, их будет вполне достаточно, чтобы убедиться в никчемности подобных устройств.
Для тестирования оптимизаторов памяти использовался ноутбук на базе мобильной технологии Intel Centrino, оснащенный процессором Intel Pentium M (Dothan) с тактовой частотой 1,6 ГГц и 512 Мбайт оперативной памяти DDR400.
Прежде чем приступать к рассмотрению того, как различные оптимизаторы влияют на производительность системы, проведем простой эксперимент, демонстрирующий действие менеджера памяти, входящего в состав операционной системы Windows XP Professional SP2.
Загрузим ноутбук и запустим Windows Task Manager, который позволяет контролировать объем доступной памяти (Avaliable). В нашем случае после загрузки операционной системы объем доступной памяти составляет 334 000 Кбайт (рис. 5).
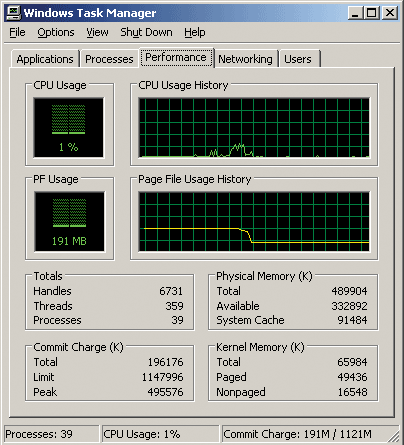
Рис. 5. Объем доступной памяти после загрузки операционной системы
Далее последовательно загрузим несколько приложений: документ Word, Adobe Photoshop CS2 c фотографией размером 3 Мбайт, утилиту Paint и приложение Solid Works 2005 c загруженным проектом. После открытия всех указанных приложений, которые в первый момент воспринимаются операционной системой как активные, размер доступной памяти уменьшается до 47 300 Кбайт (рис. 6).
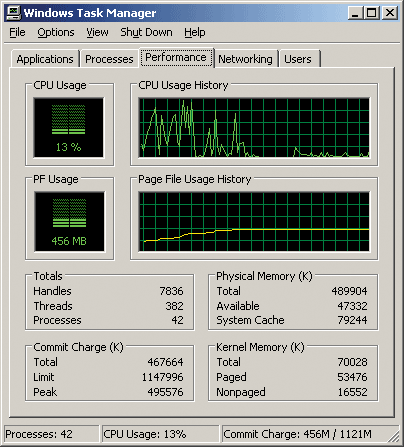
Рис. 6. Объем доступной памяти после загрузки приложений
Теперь сделаем приложения неактивными (для этого просто не будем производить каких-либо действий с компьютером) и понаблюдаем за изменением доступной памяти с помощью утилиты Windows Task Manager. Уже через 10 минут «бездействия» объем доступной памяти достигнет 311 500 Кбайт, то есть станет почти таким же, как и в случае загрузки операционной системы без указанных приложений. Данный пример доказывает, что менеджер памяти автоматически регулирует объем доступной памяти, изымая ее у неактивных процессов.
Для того чтобы продемонстрировать пагубное влияние оптимизаторов памяти, воспользуемся бенчмарком PCMark05. Все подтесты, входящие в этот тест, нам не потребуются, поскольку в данном случае нас не интересует производительность жесткого диска, графической подсистемы или латентность памяти. Мы выберем лишь подтесты, нуждающиеся в большом объеме оперативной памяти. Понятно, что эти подтесты должны быть многозадачными, поскольку в данном случае мы имеем несколько активных процессов, для каждого из которых в оперативной памяти создается свой рабочий набор. В бенчмарке PCMark05 многозадачными являются три подтеста: Multithreaded Test 1, Multithreaded Test 2 и Multithreaded Test 3.
Поскольку практически все оптимизаторы памяти позволяют задавать размер доступной памяти, по достижении которого автоматически начинается процедура высвобождения доступной памяти, мы установим данный барьер на уровне 220 000 Кбайт и попробуем запустить при этом тест PCmark05. Изменение размера доступной памяти контролируется с помощью утилиты Windows Task Manager.
В первом подтесте объем доступной памяти не ниже 210 000 Кбайт, во втором подтесте — не ниже 260 000 Кбайт, а в третьем — не ниже 214 000 Кбайт. Понятно, что для того, чтобы в ходе теста автоматически активировался оптимизатор памяти, необходимо выбрать барьер доступной памяти на уровне примерно 250 000 Кбайт. В этом случае в ходе выполнения первого и третьего подтестов будет активизироваться оптимизатор памяти.
dRAMatic v 8.1
Утилиту dRAMatic v 8.1 можно смело отнести к разряду классических оптимизаторов памяти. Она позволяет производить дефрагментацию оперативной памяти, хотя на самом деле под этим понимается просто высвобождение доступной памяти как в ручном, так и в автоматическом режиме. В последнем случае имеется возможность указать размер доступной памяти, по достижении которого оптимизатор автоматически начинает процесс ее высвобождения. Как выяснилось в ходе тестирования, утилита не слишком агрессивна и не представляет угрозы для активных процессов, которые активно утилизируют процессор. Так, отобрать страницы памяти у активных процессов в первом и втором подтестах утилита оказалась не в состоянии и ее автоматический запуск не реализовывался при достижении установленного барьера доступной памяти. В этом смысле данную утилиту можно было бы классифицировать как безвредную и бесполезную.
Clean RAM 1.21
Данная утилита отличается крайне простым интерфейсом и практически не имеет настроек. Автоматический режим работы утилиты не предусмотрен. Единственное, что можно сделать с ее помощью, — это в ручном режиме высвободить заданное количество доступной оперативной памяти. Кроме того, данная утилита показывает объем доступной памяти. Поэтому, если не нажимать на кнопку Clean RAM now (приступить к высвобождению памяти), утилиту Clean RAM 1.2 можно считать вполне безобидной.
FAST Defrag 2.3
Утилита FAST Defrag 2.3 поддерживает множество языков, в том числе и русский. Она работает как в ручном, так и в автоматическом режиме. В ручном режиме можно указать объем высвобождаемой памяти. Автоматический режим работы утилиты предусматривает несколько возможных настроек. Так, можно задать автоматическую очистку памяти при достижении заданного значения загрузки процессора (от 1 до 99%), при достижении заданного значения загрузки памяти (от 1 до 100%) и при достижении заданного значение оставшейся свободной памяти (от 1 до 25%). Кроме того, имеется возможность задать автоматическую очистку памяти при старте утилиты.
При тестировании утилиты FAST Defrag 2.3 с помощью бенчмарка PCMark05 выяснилось, что достичь объема оставшейся свободной памяти в 25% не удается, поэтому для автоматического запуска утилиты мы применяли критерий загрузки процессора, установив порог, равный 99%. Данный уровень загрузки процессора достигается во всех трех подтестах бенчмарка PCMark05, поэтому формально автоматическая очистка памяти должна была бы запускаться в каждом из подтестов. Но выяснилось, что утилита не такая уж и агрессивная и что при загрузке процессора в 100% она не может начать оптимизацию памяти. Поэтому действие этой утилиты никак не отражалось на результатах теста.
В целом же можно констатировать, что FAST Defrag 2.3 — это еще один совершенно бесполезный (правда, и безвредный) оптимизатор памяти.
FreeRAM XP Pro 1.52
Данную утилиту можно отнести к разряду продвинутых и весьма вредоносных оптимизаторов памяти.
Как и большинство оптимизаторов памяти, FreeRAM XP Pro 1.52 может запускаться как в ручном, так и в автоматическом режиме. Отличительной его особенностью является большое количество всевозможных настроек, создающих иллюзию полезности решения.
В ручном режиме можно задать размер доступной памяти, которая должна быть высвобождена. Естественно, это не означает, что при оптимизации указанный размер будет достигнут.
Для запуска утилиты в автоматическом режиме предусмотрена масса настроек, которые определяют критерии запуска. Так, можно настроить запуск оптимизатора через определенные временные интервалы или при достижении определенного значения доступной памяти. Кроме того, можно настраивать условия запуска в зависимости от загрузки процессора, временной интервал ожидания перед запуском оптимизатора и многое другое.
Как выяснилось в ходе тестирования, утилита ведет себя довольно агрессивно и способна начать оптимизацию памяти даже при 100% загрузке процессора. Естественно, что в этом случае производительность в тесте падает. Во-первых, оптимизатор памяти постоянно запускается, утилизируя процессор, а во-вторых, из-за высвобождения доступной памяти происходит постоянное вытеснение рабочих наборов активных процессов на жесткий диск и их последующая подкачка. Собственно, именно это и можно наблюдать по результатам теста, которые значительно ухудшаются.
Memory Optimizer 2002a
Оптимизатор Memory Optimizer 2002a имеет простой интерфейс и как и большинство оптимизаторов памяти, допускает как ручную, так и автоматическую оптимизацию памяти. Возможности настройки оптимизатора вполне типичны. При настройке автоматического режима необходимо указать критерии запуска утилиты.
В ходе тестирования выяснилось, что утилита ведет себя весьма агрессивно и способна высвобождать память даже при 100% загрузке процессора. Естественно, такая агрессия в отношении активных процессов отрицательно сказывается на результатах теста.
MemTurbo 2
MemTurbo 2 — еще один оптимизатор памяти, который можно отнести к разряду безвредных. Оптимизатор обладает красивым графическим интерфейсом, а объем доступной памяти отображает в графическом виде. Данная утилита допускает работу оптимизатора в ручном и автоматическом режимах и предлагает большое количество настроек. В частности, предусмотрено множество настроек для автоматического запуска оптимизатора.
Как выяснилось в ходе тестирования, настройка утилиты на автоматический запуск по критерию достижения заданного размера оставшейся доступной памяти не сказывается на результатах теста. Дело в том, что, несмотря на выполнение критерия автозапуска, при 100% загрузке процессора оптимизация памяти не начинается. Поэтому данная утилита не оказывала влияния на действие активных процессов в ходе тестирования.
В целом можно отметить, что данная утилита не является агрессивной и в этом смысле безобидна, но и бесполезна (впрочем, как и все оптимизаторы памяти).
RAM Idle Professional 3.4
Утилиту RAM Idle Professional 3.4 можно отнести к разряду твикеров операционной системы, но, поскольку одно из центральных мест в ней занимает оптимизатор памяти, мы решили рассмотреть ее в нашем обзоре.
По возможностям настройки оптимизатор RAM Idle Professional 3.4 отличается от других тем, что в нем не предусмотрено ручного режима оптимизации. При настройке автоматического режима допускается указание критического размера доступной памяти. Кроме того, можно настроить автоматическую оптимизацию после старта программы через заданный интервал времени, а также автоматический запуск оптимизации через заданные временные промежутки. В последнем случае можно указать, какой объем памяти требуется освободить в процессе оптимизации.
Тестирование оптимизатора RAM Idle Professional 3.4 показало, что данная программа ведет себя довольно агрессивно. Оптимизация памяти происходит даже при 100% нагрузке на процессор, что, естественно, отрицательно сказывается на результатах теста.
Выводы
Рассмотрение оптимизаторов памяти можно было бы продолжать и далее. Однако, думается, в этом нет необходимости. Все оптимизаторы построены по одному и тому же принципу и отличаются лишь интерфейсом, настройками и своей агрессивностью. Менее агрессивные оптимизаторы не приносят особого вреда (как, впрочем, и пользы), а использование агрессивных оптимизаторов может привести к падению производительности системы. Нужны ли утилиты, создающие иллюзию того, что за счет их применения увеличивается производительность ПК, — решать вам.
КомпьютерПресс 6’2006
Литература
- Современные операционные системы, Э. Таненбаум, 2002, СПб, Питер, 1040 стр., (в djvu 10.1Мбайт) подробнее>>
- Сетевые операционные системы Н. А. Олифер, В. Г. Олифер (в zip архиве 1.1Мбайт)
- Сетевые операционные системы Н. А. Олифер, В. Г. Олифер, 2001, СПб, Питер, 544 стр., (в djvu 6.3Мбайт) подробнее>>
6.1 Основные понятия
Менеджер памяти — часть операционной системы, отвечающая за управление памятью.
Основные методы распределения памяти:
-
Без использования внешней памяти (например: HDD)
-
С использованием внешней памяти
6.2 Методы без использования внешней памяти
6.2.1 Однозадачная система без подкачки на диск
Память разделяется только между программой и операционной системой.
Схемы разделения памяти:
Схемы разделения памяти
Третий вариант используется в MS-DOS. Та часть, которая находится в ПЗУ, часто называется BIOS.
6.2.2 Распределение памяти с фиксированными разделами.
Память просто разделяется на несколько разделов (возможно, не равных). Процессы могут быть разными, поэтому каждому разделу необходим разный размер памяти.
Системы могут иметь:
-
общую очередь ко всем разделам
-
к каждому разделу отдельную очередь

Распределение памяти с фиксированными разделами
Недостаток системы многих очередей очевиден, когда большой раздел может быть свободным, а к маленькому выстроилась очередь.
Алгоритмы планирования в случае одной очереди:
-
поочередный
-
выбирается задача, которая максимально займет раздел
Также может быть смешанная система.
6.2.3 Распределение памяти динамическими разделами
В такой системе сначала память свободна, потом идет динамическое распределение памяти.
Распределение памяти динамическими разделами.
Недостатки:
-
Сложность
-
Память фрагментируется
Перемещаемые разделы
Это один из методов борьбы с фрагментацией. Но на него уходит много времени.

Перемещаемые разделы
Рост разделов
Иногда процессу может понадобиться больше памяти, чем предполагалось изначально.

Рост разделов
Настройка адресов и защита памяти
В предыдущих примерах мы можем увидеть две основные проблемы.
-
Настройка адресов или перемещение программ в памяти
-
Защита адресного пространства каждой программы
Решение обоих проблем заключается в оснащении машины специальными аппаратными регистрами.
-
Базовый (указывает начало адресного пространства программы)
-
Предельный (указывает конец адресного пространства программы)
6.3 Методы с использованием внешней памяти (свопинг и виртуальная память)
Так как памяти, как правило, не хватает. Для выполнения процессов часто приходится использовать диск.
Основные способы использования диска:
-
Свопинг (подкачка) — процесс целиком загружается в память для работы
-
Виртуальная память — процесс может быть частично загружен в память для работы
6.3.1 Свопинг (подкачка)
При нехватке памяти процессы могут быть выгружены на диск.

т.к. процесс С очень большой, процесс А был выгружен временно на диск,
после завершения процесса С он снова был загружен в память.
Как мы видим процесс А второй раз загрузился в другое адресное пространство, должны создаваться такие условия, которые не повлияют на работу процесса.
Свопер — планировщик, управляющий перемещением данных между памятью и диском.
Этот метод был основным для UNIX до версии 3BSD.
Управление памятью с помощью битовых массивов
Вся память разбивается на блоки (например, по 32бита), массив содержит 1 или 0 (занят или незанят).
Чтобы процессу в 32Кбита занять память, нужно набрать последовательность из 1000 свободных блоков.
Такой алгоритм займет много времени.

битовые массивы и списки
Управление памятью с помощью связных списков
Этот способ отслеживает списки занятых (между процессами) и свободных (процессы) фрагментов памяти.
Запись в списке указывает на:
-
занят (P) или незанят (H) фрагмент
-
адрес начала фрагмента
-
длину фрагмента

Четыре комбинации соседей для завершения процесса X
Алгоритмы выделения блока памяти:
-
первый подходящий участок.
-
следующий подходящий участок, стартует не сначала списка, а с того места на котором остановился в последний раз.
-
самый подходящий участок (медленнее, но лучше использует память).
-
самый неподходящий участок, расчет делается на то, что программа займет самый большой участок, а лишнее будет отделено в новый участок, и он будет достаточно большой для другой программы.
6.3.2 Виртуальная память
Основная идея заключается в разбиении программы на части, и в память эти части загружаются по очереди.
Программа при этом общается с виртуальной памятью, а не с физической.

Диспетчер памяти преобразует виртуальные адреса в физические.
Страничная организация памяти
Страницы — это части, на которые разбивается пространство виртуальных адресов.
Страничные блоки — единицы физической памяти.
Страницы всегда имеют фиксированный размер. Передача данных между ОЗУ и диском всегда происходит в страницах.
Х — обозначает не отображаемую страницу в физической памяти.
Страничное прерывание — происходит, если процесс обратился к странице, которая не загружена в ОЗУ (т.е. Х). Процессор передается другому процессу, и параллельно страница загружается в память.
Таблица страниц — используется для хранения соответствия адресов виртуальной страницы и страничного блока.
Таблица может быть размещена:
-
в аппаратных регистрах (преимущество: более высокое быстродействие, недостаток — стоимость)
-
в ОЗУ

Типичная запись в таблице страниц
Присутствие/отсутствие — загружена или незагружена в память
Защита — виды доступа, например, чтение/запись.
Изменение — изменилась ли страница, если да то при выгрузке записывается на диск, если нет, просто уничтожается.
Обращение — было ли обращение к странице, если нет, то это лучший кандидат на освобождение памяти.
Информация о адресе страницы когда она хранится на диске, в таблице не размещается.
Для ускорения доступа к страницам в диспетчере памяти создают буфер быстрого преобразования адреса, в котором хранится информация о наиболее часто используемых страниц.
Страничная организация памяти используется, и в UNIX, и в Windows.
Хранение страничной памяти на диске
Статическая область свопинга
После запуска процесса он занимает определенную память, на диске сразу ему выделяется такое же пространство. Поэтому файл подкачки должен быть не меньше памяти. А в случае нехватки памяти даже больше. Как только процесс завершится, он освободит память и место на диске.
На диске всегда есть дубликат страницы, которая находится в памяти.
Этот механизм наиболее простой.

Статический и динамический методы организации свопинга.
Динамическая область свопинга
Предполагается не выделять страницам место на диске, а выделять только при выгрузке страницы, и как только страница вернется в память освобождать место на диске.
Этот механизм сложнее, так как процессы не привязаны к какому-то пространству на диске, и нужно хранить информацию (карту диска) о местоположении на диске каждой страницы.
Аннотация: В лекции рассматриваются: откачка и подкачка (swapping); стратегии динамического распределения памяти; фрагментация; принципы страничной организации; таблица страниц; использование ассоциативной памяти; двухуровневые, иерархические, хешированные и инвертированные таблицы страниц; разделяемые страницы.
Презентацию к данной лекции Вы можете скачать здесь.
Введение
Страничная организация памяти (paging) – наиболее распространенная стратегия управления памятью, используемая практически во всех операционных системах. В данной лекции рассматриваются общие проблемы управления памятью, принципы страничной организации и ее различные формы.
Откачка и подкачка
Пользовательский процесс может находиться в различных состояниях во время обработки системой. В частности, процесс может быть некоторое время неактивным, если, например, он исполняется в режиме разделения времени, и пользователь за терминалом обдумывает следующую команду или редактирует исходный код своей программы. В подобных случаях процесс может быть откачан операционной системой на диск, в связи с тем, что занимаемая им память оказывается необходимой в данный момент для другого, активного, процесса.
Откачка и подкачка (swapping) – это действия операционной системы по откачке (записи) образа неактивного процесса на диск или подкачке (считыванию) активного процесса в основную память. Необходимость выполнения подобных действий вызвана нехваткой основной памяти.
Файл откачки (backing store) — область дисковой памяти, используемая операционной системой для хранения образов откачанных процессов. Файл откачки организуется максимально эффективно: обеспечивается прямой доступ ко всем образам процессов в памяти (например, через таблицу по номеру процесса).
Популярная разновидность стратегии откачки и подкачки – roll out / roll in: откачка и подкачка на базе приоритетов; более приоритетные процессы исполняются, менее приоритетные – откачиваются на диск.
Наибольшие временные затраты на откачку – это затраты на передачу данных: полный образ процесса может занимать большую область памяти. Общее время откачки пропорционально размеру откачиваемых данных.
В распространенных ОС – UNIX, Linux, Windows и др. – реализованы различные стратегии откачки и подкачки.
Схема откачки и подкачки изображена на
рис.
16.1.
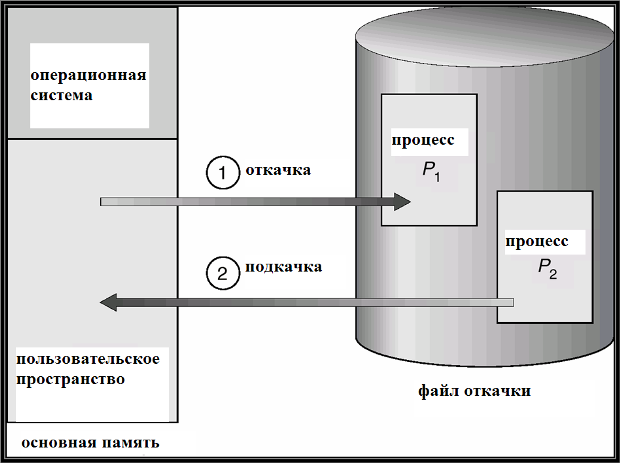
Рис.
16.1.
Схема откачки и подкачки.
Смежное распределение памяти
Наиболее простая и распространенная стратегия распределения памяти – смежное распределение памяти –
распределение памяти для пользовательских процессов в одной смежной области памяти. Основная память разбивается на
две смежных части (partitions), которые «растут» навстречу друг другу: резидентная часть ОС и вектор прерываний –
по меньшим адресам. Для пользовательских процессов память распределяется в
одном и том же смежном участке памяти. Для каждого процесса регистр перемещения указывает на начало выделенной ему
области памяти, регистр границы содержит длину диапазона логических адресов. Каждый логический адрес должен быть меньше
содержимого регистра границы. Физический адрес вычисляется аппаратно как сумма логического адреса и значения регистра
перемещения. Схема адресации с аппаратной поддержкой регистров перемещения и границы изображена на
рис.
16.2.
Общая задача распределения памяти и стратегии ее решения
В общем случае, в операционных системах может использоваться смежное распределение памяти в нескольких смежных областях. Свободная область – это смежный блок свободной памяти. Свободные области могут быть произвольно разбросаны по памяти. При загрузке процесса ему предоставляется память из любой свободной смежной области, которая достаточно велика для его размещения. При этом операционная система хранит список свободных областей памяти и список занятых областей памяти. Все эти области могут быть произвольно расположены в памяти и иметь различную длину.
Возникает общая задача распределения памяти: Имеется список свободных областей памяти и список занятых областей разного размера. Разработать и реализовать оптимальный (по некоторому критерию) алгоритм выделения свободного смежного участка памяти длины n (слов или байтов).
Для решения данной задачи применяются следующие стратегии: метод первого подходящего (first-fit), метод наиболее подходящего (best-fit) и метод наименее подходящего (worst-fit).Рассмотрим каждую из них подробнее.
Метод первого подходящего:Выбирается первый по списку свободный участок подходящего размера (не меньшего, чем n ). На первый взгляд, данная стратегия оптимальна, но далее мы увидим, что это не всегда так.
Метод наиболее подходящего:Выбирается из списка наиболее подходящий свободный участок (минимального размера, не меньшего, чем n ). В отличие от предыдущего метода, требует просмотра всего списка, если список не упорядочен по размеру областей. Применение метода приводит к образованию оставшейся части самого маленького размера.
Метод наименее подходящего: Выбирается из списка подходящая область наибольшего размера. Почему наибольшего? Чтобы избежать фрагментации (проблема фрагментации подробно рассмотрена далее в данной лекции).
Применение первой и второй стратегий лучше со следующих точек зрения: скорость выполнения и минимальность объема использованной памяти. Однако их применение может создать фрагментацию.
Фрагментация
Фрагментация – это дробление памяти на мелкие не смежные свободные области маленького размера. Фрагментация возникает после выполнения системой большого числа запросов на память, таких, что размеры подходящих свободных участков памяти оказываются немного больше, чем требуемые. Например, если имеется 100 смежных свободных областей памяти по 1000 слов, то после выполнения 100 запросов на память по 999 слов каждый в списке свободной памяти останутся 1000 областей по одному слову.
Фрагментация бывает внутренняя и внешняя. При внешней фрагментации имеется достаточно большая область свободной памяти, но она не является непрерывной. Внутренняя фрагментация может возникнуть вследствие применения системой специфической стратегии выделения памяти, при которой фактически в ответ на запрос память выделяется несколько большего размера, чем требуется, — например, с точностью до страницы (листа ), размер которого – степень двойки. Страничная организация памяти подробно рассматривается далее в данной лекции.
Внешняя фрагментация может быть уменьшена или ликвидирована путем применения компактировки (compaction) – сдвига или перемешивания памяти с целью объединения всех не смежных свободных областей в один непрерывный блок. Компактировка может выполняться либо простым сдвигом всех свободных областей памяти, либо путем перестановки занятых областей, с выбором на каждом шаге подходящей свободной области методом наиболее подходящего. Компактировка возможна, только если связывание адресов и перемещение (см. лекцию 15) происходит динамически. Компактировка выполняется во время исполнения программы.
При компактировке памяти и анализе свободных областей может быть выявлена проблема зависшей задачи: какая-либо задача может «застрять» в памяти, так как выполняет ввод-вывод в свою область памяти (по этой причине откачать ее невозможно). Решение данной проблемы: ввод-вывод должен выполняться только в специальные буфера, выделяемой для этой цели операционной системой.
Организация виртуальной памяти
Страничное преобразование
Отложенное копирование
Свопинг
Адресное пространство процесса
Восьмидесятые годы благодаря появлению персональных компьютеров породили иллюзию простоты системного программирования. Нет вины инженеров компании Intel в том, что им удалось разместить на кристалле только то, что удалось разместить.
- Страничное преобразование
- Отложенное копирование
- Свопинг
- Адресное пространство процесса
Восьмидесятые годы благодаря появлению персональных компьютеров породили иллюзию простоты системного программирования. Нет вины инженеров компании Intel в том, что им удалось разместить на кристалле только то, что удалось разместить. Наоборот, их продукт следует считать величайшим техническим достижением, изменившим наш мир. Но факт остается фактом — процессор 8086 не предоставлял операционным системам тот сервис, который требовался согласно разработанным теориям создания операционных систем. В первую очередь это касалось систем управления памятью, планировщиков и систем защиты. Достаточно обратиться к классическим книгам того времени [1, 2], чтобы убедиться в том, что теория организации вычислительного процесса была хорошо разработана и реализована.
Но время диктует свои законы. Изменились микропроцессоры, и появились новые операционные системы. Однако у многих профессионалов осталась иллюзия того, что ОС от Microsoft — это лишь красивые картинки на экране и простейшее ядро внутри, а для серьезных задач требуются «серьезные» системы. На примере системы управления памятью покажем, что Windows NT — серьезная операционная система, построенная в соответствии с классическими принципами.
Организация виртуальной памяти
Страничное преобразование
Виртуальная память в Windows NT имеет страничную организацию, принятую во многих современных операционных системах. В общем виде схема страничной организации описывается следующим образом: линейный адрес разбивается на несколько частей. Старшая часть адреса содержит в себе номер элемента в корневой таблице. Этот элемент содержит адрес таблицы следующего уровня. Следующая часть линейного адреса содержит номер элемента уже в этой таблице и так далее, до последней таблицы, которая содержит номер физической страницы. А самая младшая часть адреса уже является номером байта в этой физической странице.
Процессоры Intel начиная с Pentium Pro позволяют операционным системам применять одно-, двух- и трехступенчатые схемы. И даже разрешается одновременное использование страниц различного размера. Эта возможность, конечно, повысила бы эффективность страничного преобразования, будь она внедрена в Windows NT. Увы, эта ОС возникла раньше и поддерживает только двухступенчатую схему преобразования с фиксированным размером страниц. Размер страниц для платформы Intel составляет 4 Кбайт, а для DEC Alpha — 8 Кбайт. Схема страничного преобразования (рис. 1) выглядит так:
Рисунок 1.
Схема страничного преобразования адреса для платформы Intel
32-разрядный линейный адрес разбивается на три части. Старшие 10 разрядов адреса определяют номер одного из 1024 элементов в каталоге страниц, адрес которого находится в регистре процессора CR3. Этот элемент содержит физический адрес таблицы страниц. Следующие 10 разрядов линейного адреса определяют номер элемента таблицы. Элемент, в свою очередь, содержит физический адрес страницы виртуальной памяти. Размер страницы — 4 Кбайт, и младших 12 разрядов линейного адреса как раз хватает (212 = 4096), чтобы определить точный физический номер адресуемой ячейки памяти внутри этой страницы.
Рассмотрим отдельный элемент таблицы страниц (PTE — Page Table Element) более подробно, так как он содержит массу полезной информации (рис 2).
Рисунок 2.
Элемент таблицы страниц в Windows NT
Старшие пять бит определяют тип страницы с точки зрения допустимых операций. Win32 API поддерживает три допустимых значения этого поля: PAGE_NOACCESS, PAGE_READONLY и PAGE_READWRITE. Следующие 20 бит определяют базовый физический адрес страницы в памяти. Если дополнить их 12 младшими разрядами линейного адреса, они образуют физический адрес ячейки памяти, к которой производится обращение. Следующие четыре бита PTE описывают используемый файл подкачки. Комбинацией этих битов ссылаются на один из 16 возможных в системе файлов. Последние три бита определяют состояние страницы в системе. Старший из них (T-Transition) отмечает страницу как переходную, следующий (D-Dirty) — как страницу, в которую была произведена запись. Информация об изменениях в странице необходима системе для того, чтобы принять решение о сохранении страницы в файле подкачки при ее вытеснении (принудительном освобождении занятой памяти). Действительно, если страница не изменялась в памяти после загрузки, то ее можно просто стереть, ведь в файле подкачки сохранилась ее копия. И наконец, младший бит (P-Present) определяет, присутствует ли страница в оперативной памяти или же она находится в файле подкачки. Конечно, 16 файлов подкачки явно недостаточно. В дальнейшем мы увидим, что в качестве файлов подкачки могут выступать исполняемые файлы, а также файлы, отображаемые в память. Официальная документация Microsoft весьма скупа на комментарии по этой ситуации. Отмечается лишь, что при отсутствии страницы в памяти 28 бит рассмотренного элемента таблицы страниц не несут никакой полезной информации и используются для определения местонахождения выгруженной страницы.
Для ускорения страничного преобразования в процессоре имеется специальная кэш-память, называемая TLB (Translation Lookaside Buffer). В ней хранятся наиболее часто используемые элементы каталога и таблиц страниц. Конечно, переключение процессов и даже потоков приводит к тому, что данные внутри этого буфера становятся неактуальными, т. е. недействительными. Это влечет за собой дополнительные потери производительности при переключении. К счастью, временной промежуток, выделяемый системой процессу, составляет 17 мс. Даже на машине с производительностью всего 20 MIPS за это время успеет выполниться непрерывный участок программы длиной (17 мс Ё 20 MIPS) 340 тыс. команд. Этого более чем достаточно, чтобы пренебречь потерями производительности при выполнении начального участка процесса.
Каждый процесс Windows NT имеет свой отдельный каталог страниц и свое собственное независимое адресное пространство, что очень хорошо с точки зрения защиты процессов друг от друга. Но за это удовольствие приходится платить ресурсами. Независимым процессам почти всегда приходится обмениваться информацией друг с другом. Windows NT предоставляет большое количество способов обмена, в том числе и при OLE. Но все они имеют в основе одно и то же действие: один процесс пишет нечто в некоторую ячейку памяти, а другой из нее читает. Это означает, что должны быть участки памяти, доступные разным процессам. На первый взгляд, это не проблема — могут же различные PTE ссылаться на одну и ту же страницу. Однако в каждом PTE хранятся атрибуты страницы, а ссылка на страницу со стороны PTE делается только в одну сторону. Это означает, что при изменении какого-либо атрибута в одном из PTE невозможно сделать то же самое для всех других PTE, ссылающихся на ту же страницу. Именно поэтому для совместно используемых страниц применяется механизм прототипов элементов таблицы страниц (Prototype Page Table Entry). Для совместно используемых страниц создается прототип PTE, который и содержит актуальные атрибуты страницы. Все PTE, принадлежащие различным процессам, ссылаются не на саму страницу, а на этот прототип, атрибуты которого и являются актуальными (рис. 3).
Рисунок 3.
Совместное использование страниц процессами
Сам прототип хранится в старших адресах каждого процесса. Общий размер памяти, отводимый для хранения прототипов, не превышает 8 Мбайт.
Отложенное копирование
Все гениальное — просто. Многие программисты получили истинное наслаждение, впервые ознакомившись с тем, как изящно в Unix реализовано порождение процессов. В результате исполнения системного вызова fork(), призванного создавать новые процессы, два независимых процесса начинают совместно использовать одну и ту же область кода. Прошло немало времени, прежде чем пытливая инженерная мысль нашла возможность совместно использовать одну и ту же область данных. Действительно, нет необходимости каждому процессу иметь отдельный экземпляр данных, если эти данные только читаются. Проблема состоит в том, как определить, будут ли данные читаться в будущем или нет. Неважно, области кода или данных принадлежит совместно используемая память. Существенно лишь то, производится или нет изменение данных процессами. Если процесс производит запись, он должен иметь свою отдельную копию изменяемых данных. Если же в записи нет необходимости, то он может совместно использовать данные с остальными процессами. Подобный подход называется отложенным копированием (lazy evaluation): решение о необходимости копирования страницы откладывается до того момента, когда процесс попытается что-либо записать в нее. Все страницы порожденного процесса защищаются от записи. При попытке изменения защищенной страницы возникает процессорное исключение, страница копируется системой, и только после этого в нее разрешается запись.
Данный механизм, едва появившись, сразу же стал классическим и сегодня является составной частью многих систем Unix. Нет ничего удивительного, что он изначально присутствует в архитектуре и более молодой системы Microsoft Windows NT. Наиболее активно он используется при работе различных процессов с совместно используемыми динамически загружаемыми библиотеками (DLL), а также при запуске программ.
Свопинг
Конечно, компьютер может и не иметь 4 Гбайт оперативной памяти, адресуемых процессорами Intel для того, чтобы обеспечить все линейное адресное пространство процесса физическими ячейками памяти. Windows NT, как и все другие операционные системы, применяет свопинг (swapping). Не используемые в конкретный момент страницы памяти могут быть вытеснены на диск в так называемый файл подкачки. В соответствующем элементе таблицы страниц эта страница помечается как отсутствующая, и при попытке обращения к ней возникает исключительная ситуация — «сбой» страницы. Обрабатывая ее, операционная система находит страницу на диске и переписывает ее в память, соответствующим образом подстраивая элемент таблицы страниц. После этого попытка выполнить команду, вызвавшую исключение, повторяется.
С понятием свопинга неразрывно связаны три стратегии: выборка (fetch), размещение (placement) и замещение (replacement).
- Выборка определяет, в какой момент необходимо переписать страницу с диска в память. В Windows NT используется классическая схема выборки с упреждением: система переписывает в память не только выбранную страницу, но и несколько следующих по принципу пространственной локальности, гласящему: наиболее вероятным является обращение к тем ячейкам памяти, которые находятся в непосредственной близости от ячейки, к которой производится обращение в настоящий момент. Поэтому вероятность того, что будут востребованы последовательные страницы, достаточна высока. Их упреждающая подкачка позволяет снизить накладные расходы, связанные с обработкой прерываний.
- Размещение определяет, в какое место оперативной памяти необходимо поместить подгружаемую страницу. Для систем со страничной организацией данная стратегия практически не имеет никакого значения, и поэтому Windows NT выбирает первую попавшуюся свободную страницу.
- Замещение начинает действовать с того момента, когда в оперативной памяти компьютера не остается свободного места для размещения подгружаемой страницы. В этом случае необходимо решить, какую страницу вытеснить из физической памяти в файл подкачки. Можно было бы отделаться общими словами [6], сказав, что в данном случае Windows NT использует алгоритм FIFO: вытесняется страница, загруженная раньше всех, т. е. самая «старая». Однако механизм замещения настолько интересен, что заслуживает более пристального внимания, и мы еще расскажем о нем.
Несомненный теоретический интерес представляет тот факт, что Windows NT — это система, в которую включены средства динамического анализа рабочего множества процесса, которые используются при организации свопинга. Но обо всем по порядку.
Часть ядра Windows NT, которая занимается управлением виртуальной памятью, называется VMM — Virtual Memory Manager. Это независимый привилегированный процесс, постоянно находящийся в оперативной памяти компьютера. VMM поддерживает специальную структуру, называемую базой данных страниц (page-frame database). В ней содержатся элементы для каждой страницы. Состояние каждой страницы описывается с помощью следующих категорий:
Valid — страница используется процессом. Она реально существует в памяти и помечена в PTE как присутствующая.
Modified — содержимое страницы было изменено. В PTE страница помечена как отсутствующая (P=0) и переходная (T=1).
Standby — содержимое страницы не изменялось. В PTE страница помечена как отсутствующая (P=0) и переходная (T=1).
Free — страница, на которую не ссылается ни один PTE. Страница свободна, но подлежит обнулению, прежде чем будет использована.
Zeroed — свободная и обнуленная страница, пригодная к непосредственному использованию любым процессом.
Bad — страница, которая вызывает аппаратные ошибки и не может быть использована ни одним процессом.
Все состояния, за исключением Modified и Standby, можно обнаружить в большинстве операционных систем. Страница, находящаяся в одном из этих состояний, реально располагается в памяти, в PTE содержится ее реальный адрес, но сама страница помечена как отсутствующая. При обращении к этой странице возникает аппаратное исключение, однако его обработка не вызывает больших временных затрат. Необходимо просто пометить страницу как присутствующую (Valid, P=1) и еще раз запустить последнюю команду.
Сама база данных страниц организована как шесть независимых связных списков, каждый из которых объединяет элементы, соответствующие страницам одного типа.
Каждый элемент базы связан двунаправленной ссылкой с соответствующим элементом таблицы страниц для организации двустороннего доступа. Прототип не имеет доступа к PTE. Это и не нужно, поскольку именно он уполномочен представлять атрибуты страницы, а не PTE.
Важнейшее понятие при организации свопинга — рабочее множество процесса (working set). В соответствии с принципом локальности процесс не использует всю память одновременно. Состав и количество страниц, с которыми процесс работает, меняется на протяжении его жизни. Страницы, с которыми процесс работает в течение фиксированного интервала времени, есть его рабочее множество на этом интервале. Переход от одного рабочего множества к другому осуществляется не равномерно, а скачками. Это вызвано семантикой процесса: переходами от обработки одного массива к обработке другого, от подпрограммы к подпрограмме, от цикла к циклу и т. д. Не нужно, чтобы в оперативной памяти размещались все страницы процесса, однако необходимо, чтобы в ней помещалось его рабочее множество. В противном случае возникает режим интенсивной подкачки, называемый трешингом (trashing), с которым сталкивается любой пользователь PC, запустивший одновременно слишком много приложений. В таком режиме затраты системы на переписывание страниц с диска в память и обратно значительно превышают время, выделяемое на полезную деятельность. Фактически система перестает заниматься чем-либо, кроме перемещения головок жесткого диска.
Теперь настало время разрешить интригу, которая возникла несколько абзацев назад, и подробно рассмотреть стратегию замещения страниц Windows NT. В классической теории операционных систем идеальной считается следующая стратегия: замещению подлежит страница, которая не будет использоваться в будущем дольше других. В той же классической теории эта стратегия признается неосуществимой, поскольку нет никакого разумного способа определить, какая из страниц подпадает под этот критерий. К счастью, в мире еще есть инженеры, готовые ломать голову над неосуществимыми идеями. Программистам Microsoft удалось приблизиться к этой стратегии на основе анализа рабочего множества процесса. В Windows NT используется весьма близкая стратегия: из памяти вытесняются страницы, вышедшие из рабочего множества процесса. Как же VMM узнает, какие страницы больше не принадлежат рабочему множеству? А очень просто! Периодически VMM просматривает список страниц с атрибутом Valid и пытается похитить их у процесса. Он помечает их как отсутствующие (P=0), но на самом деле оставляет их на месте, только переводит в разряд Modified или Standby в зависимости от значения бита D из PTE. Если похищенная страница принадлежит рабочему множеству, то к ней в ближайшее время произойдет обращение. Это, конечно, вызовет исключение — ведь страница-то помечена как отсутствующая. Но VMM очень быстро сделает эту страницу вновь доступной процессу, поскольку она реально находится в памяти. Если страница находится вне рабочего множества, то обращений к ней не будет и она со временем перейдет в разряд Free, а затем Zeroed и станет доступна другим процессам системы.
Адресное пространство процесса
В Windows NT используется плоская (flat) модель памяти. Каждому процессу выделяется «личное» изолированное адресное пространство. На 32-разрядных компьютерах размер этого пространства составляет 4 Гбайт и может быть расширен до 32 Гбайт при работе Windows NT 5.0 на процессоре Alpha. Это пространство разбивается на регионы, различные для разных версий системы (рис. 5).
В Windows NT 4.0 младшие 2 Гбайт памяти выделяются процессу для произвольного использования, а старшие 2 Гбайт резервируются и используются операционной системой. В младшую часть адресного пространства помещаются и некоторые системные динамически связываемые библиотеки (DLL). Желание расширить доступное процессу адресное пространство привело к тому, что Windows NT 4.0 Enterprise процессу выделяется дополнительный 1 Гбайт за счет сокращения системной области (рис. 5).
Разработчики Windows NT 5.0 для платформы Alpha пошли дальше. Alpha — 64-разрядный процессор, но под управлением Windows NT версии до 4.0 включительно в его адресном пространстве используются только 2 Гбайт старших и 2 Гбайт младших адресов (рис. 5).
Дело в том, что в Win32 API для хранения адреса используются 32-разрядные переменные. Windows NT расширяет их до 64-разрядных с учетом знака. Спецификация VLM (Very Large Memory), которая будет реализована в Windows NT 5.0 для процессора Alpha, подразумевает использование 64-разрядных переменных для хранения адресов (рис. 5).
Если системе, которую вы разрабатываете, недостаточно для работы 32 Гбайт физической памяти, то, вероятно, вам стоит выбрать другую операционную систему. Если же вы готовы потесниться и произвести некоторую оптимизацию своего кода, то, возможно, вам подойдет и Windows NT.
|
Windows NT 4.0 / Windows NT 4.0 Enterprise |
||
|
Windows NT на процессоре Alpha |
Windows NT 5.0 при использовании спецификации VLM |
|
| Рисунок 5. Адресное пространство процесса Windows NT |