
Контрольные задания > Сколько требуется бит памяти для кодирования кода одного символа в кодировке Windows?

Вопрос:
Ответ:
В кодировке Windows (обычно подразумевается кодировка CP1251) для кодирования одного символа требуется 8 бит (1 байт).
Ответ: в) 8
Смотреть решения всех заданий с фото
Компьютер является универсальным устройством обработки информации и способен работать с различными ее типами. В том числе и с текстовой. Давайте рассмотрим эту возможность подробнее.
Проблема состоит в том, что компьютер в памяти может хранить только числа, причем числа двоичные (о системах счисления). Каким же образом в память можно поместить текст? Очень просто. Ведь символы можно пронумеровать, т. е. дать каждому символу цифровой код и уже его хранить в памяти. Собственно, все именно так устроено. Но тут возникает проблема — Вася пронумеровал буквы так, что прописная буква А имеет код 1, а у Пети прописная буква А имеет код 34. В итоге текст, закодированный на компьютере Васи будет некорректно отображаться на компьютере Пети и наоборот. Как поступить? Очень просто — закодировать символы и принять такое кодирование как стандартное. Таким образом появилась таблица кодировок ASCII (произносится аски).
Разработчики первых компьютеров использовали английский язык, поэтому им необходимо было закодировать 26 прописных букв, 26 строчных букв (строчная буква А и прописная буква а для компьютера совершенно разные символы и имеют разные коды), 10 цифр, знаки препинания, знаки арифметических операций, пробел (да, пробел — тоже символ и имеет свой код), различные спецзнаки. В итоге получается немногим более 100 символов. Сколько памяти необходимо, чтобы сохранить код одного символа? Давайте посчитаем. Воспользуемся формулой
2i=N
где N — количество символов, а i — количество памяти в битах, необходимое для хранения одного символа. Значение N примем равным 100. Чему же равно i? Если i = 6, то 26=64. Этого мало, ведь у нас 100 символов. Если i=7, то 27=128 — то, что нам нужно. Если необходимо закодировать 128 символов, на каждый необходимо 7 бит памяти.
А что же делать тем, кто использует кириллические буквы? Ведь места в получившейся таблице не хватает. А почему бы не расширить ее? Если на каждый символ отвести 8 бит памяти, то можно будет закодировать уже 28=256 символов. Таким образом, появилась расширенная таблица кодировок ASCII, в которой первая часть (символы с десятичными кодами от 0 до 127) содержит латинский алфавит, цифры, знаки препинания, знаки арифметических операций, спецсимволы, а вторая часть (символы с кодами от 128 до 255) — национальные символы разных стран. В России это русские буквы. К сожалению, было несколько вариантов второй части таблицы кодировок ASCII для кириллического алфавита, что часто приводило к некорректному отображению текста. К примеру, прописная буква А в различных таблицах кодировок имеет такие коды:
| Кодировка | Windows (CP1251) | MS-DOS (CP866) | КОИ-8 | Macintosh | ISO-8859 |
| Десятичный код символа | 192 | 128 | 225 | 128 | 176 |
Логотип Unicode
Получается, что русский текст, закодированный в кодировке Windows, будет нечитаем в кодировке КОИ-8. Аналогично и с другими кодировками. Как же решить эту проблему? Может сделать действительно единую международную кодовую таблицу, в которой можно будет поместить гораздо больше, чем 256 символов? Так и поступили в 1991 году, когда консорциум UNICODE представил стандарт кодирования Unicode (читается как юникод), который позволил закодировать символы практически всех языков Мира. Если в ASCII для хранения одного символа требуется 8 бит или 1 байт памяти, то в Unicode — 2 байта или 16 бит. Соответственно, используя 16бит мы можем закодировать 216 = 65536 различных символов! Кроме того, стандарт Unicode развивается и на данный момент позволяет закодировать гораздо больше, чем 65536 символов.
Полученные знания с успехом позволят решить вам задачи А1 части 1 ГИА по информатике
Автор:
Содержание
- 1 Представление символов в вычислительных машинах
- 2 Таблицы кодировок
- 3 Кодировки стандарта ASCII
- 3.1 Структурные свойства таблицы
- 4 Кодировки стандарта UNICODE
- 4.1 Кодовое пространство
- 4.2 Модифицирующие символы
- 4.3 Способы представления
- 4.4 UTF-8
- 4.4.1 Принцип кодирования
- 4.4.1.1 Правила записи кода одного символа в UTF-8
- 4.4.1.2 Определение длины кода в UTF-8
- 4.4.1 Принцип кодирования
- 4.5 UTF-16
- 4.5.1 UTF-16LE и UTF-16BE
- 4.6 UTF-32
- 4.7 Порядок байт
- 4.7.1 Варианты записи
- 4.7.1.1 Порядок от старшего к младшему
- 4.7.1.2 Порядок от младшего к старшему
- 4.7.1.3 Переключаемый порядок
- 4.7.1.4 Смешанный порядок
- 4.7.1.5 Различия
- 4.7.2 Маркер последовательности байт
- 4.7.1 Варианты записи
- 4.8 Проблемы Юникода
- 5 Примеры
- 5.1 Код на python
- 5.2 hex-дамп файла exampleBOM
- 6 См. также
- 7 Источники информации
Представление символов в вычислительных машинах
В вычислительных машинах символы не могут храниться иначе, как в виде последовательностей бит (как и числа). Для передачи символа и его корректного отображения ему должна соответствовать уникальная последовательность нулей и единиц. Для этого были разработаны таблицы кодировок.
Количество символов, которые можно задать последовательностью бит длины , задается простой формулой . Таким образом, от нужного количества символов напрямую зависит количество используемой памяти.
Таблицы кодировок
На заре компьютерной эры на каждый символ было отведено по пять бит. Это было связано с малым количеством оперативной памяти на компьютерах тех лет. В эти символа входили только управляющие символы и строчные буквы английского алфавита.
С ростом производительности компьютеров стали появляться таблицы кодировок с большим количеством символов.
Первой семибитной кодировкой стала ASCII7. В нее уже вошли прописные буквы английского алфавита, арабские цифры, знаки препинания.
Затем на ее базе была разработана ASCII8, в которым уже стало возможным хранение символов: основных и еще столько же расширенных. Первая часть таблицы осталась без изменений, а вторая может иметь различные варианты (каждый имеет свой номер). Эта часть таблицы стала заполняться символами национальных алфавитов.
Но для многих языков (например, арабского, японского, китайского) символов недостаточно, поэтому развитие кодировок продолжалось, что привело к появлению UNICODE.
Кодировки стандарта ASCII
| Определение: |
| ASCII — таблицы кодировок, в которых содержатся основные символы (английский алфавит, цифры, знаки препинания, символы национальных алфавитов(свои для каждого региона), служебные символы) и длина кода каждого символа бит. |
бит:
- ASCII7 — первая кодировка, пригодная для работы с текстом. Помимо маленьких букв английского алфавита и служебных символов, содержит большие буквы английского языка, цифры, знаки препинания и другие символы.
Кодировки стандарта ASCII ( бит):
- ASCII — первая кодировка, в которой стало возможно использовать символы национальных алфавитов.
- КОИ8-R — первая русская кодировка. Символы кириллицы расположены не в алфавитном порядке. Их разместили в верхнюю половину таблицы так, чтобы позиции кириллических символов соответствовали их фонетическим аналогам в английском алфавите. Это значит, что даже при потере старшего бита каждого символа, например, при проходе через устаревший семибитный модем, текст остается «читаемым».
- CP866 — русская кодировка, использовавшаяся на компьютерах IBM в системе DOS.
- Windows-1251 — русская кодировка, использовавшаяся в русскоязычных версиях операционной системы Windows в начале 90-х годов. Кириллические символы идут в алфавитном порядке. Содержит все символы, встречающиеся в типографике обычного текста (кроме знака ударения).
Структурные свойства таблицы
- Цифры 0-9 представляются своими двоичными значениями (например, ), перед которыми стоит . Таким образом, двоично-десятичные числа (BCD) превращаются в ASCII-строку с помощью простого добавления слева к каждому двоично-десятичному полубайту.
- Буквы A-Z верхнего и нижнего регистров различаются в своём представлении только одним битом, что упрощает преобразование регистра и проверку на диапазон. Буквы представляются своими порядковыми номерами в алфавите, записанными в двоичной системе счисления, перед которыми стоит (для букв верхнего регистра) или (для букв нижнего регистра).
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | NUL | SOH | STX | ETX | EOT | ENQ | ACK | BEL | BS | TAB | LF | VT | FF | CR | SO | SI |
| 1 | DLE | DC1 | DC2 | DC3 | DC4 | NAK | SYN | ETB | CAN | EM | SUB | ESC | FS | GS | RS | US |
| 2 | ! | » | # | $ | % | & | ‘ | ( | ) | * | + | , | — | . | / | |
| 3 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | : | ; | < | = | > | ? |
| 4 | @ | A | B | C | D | E | F | G | H | I | J | K | L | M | N | O |
| 5 | P | Q | R | S | T | U | V | W | X | Y | Z | [ | \ | ] | ^ | _ |
| 6 | ` | a | b | c | d | e | f | g | h | i | j | k | l | m | n | o |
| 7 | p | q | r | s | t | u | v | w | x | y | z | { | | | } | ~ | DEL |
Кодировки стандарта UNICODE
Юникод или Уникод (англ. Unicode) — это промышленный стандарт обеспечивающий цифровое представление символов всех письменностей мира, и специальных символов.
Стандарт предложен в 1991 году некоммерческой организацией «Консорциум Юникода» (англ. Unicode Consortium, Unicode Inc.). Применение этого стандарта позволяет закодировать очень большое число символов из разных письменностей.
Стандарт состоит из двух основных разделов: универсальный набор символов (англ. UCS, universal character set) и семейство кодировок (англ. UTF, Unicode transformation format). Универсальный набор символов задаёт однозначное соответствие символов кодам — элементам кодового пространства, представляющим неотрицательные целые числа.Семейство кодировок определяет машинное представление последовательности кодов UCS.
Коды в стандарте Unicode разделены на несколько областей. Область с кодами от U+0000 до U+007F содержит символы набора ASCII с соответствующими кодами. Далее расположены области знаков различных письменностей, знаки пунктуации и технические символы. Под символы кириллицы выделены области знаков с кодами от U+0400 до U+052F, от U+2DE0 до U+2DFF, от U+A640 до U+A69F. Часть кодов зарезервирована для использования в будущем.
Кодовое пространство
Хотя формы записи UTF-8 и UTF-32 позволяют кодировать до кодовых позиций, было принято решение использовать лишь для совместимости с UTF-16. Впрочем, даже и этого на текущий момент более чем достаточно — в версии 6.0 используется чуть менее кодовых позиций ( графических и прочих символов).
Кодовое пространство разбито на плоскостей (англ. planes) по символов. Нулевая плоскость называется базовой, в ней расположены символы наиболее употребительных письменностей. Первая плоскость используется, в основном, для исторических письменностей, вторая — для для редко используемых иероглифов китайского письма, третья зарезервирована для архаичных китайских иероглифов. Плоскости и выделены для частного употребления.
Для обозначения символов Unicode используется запись вида «U+xxxx» (для кодов ) или «U+xxxxx» (для кодов ) или «U+xxxxxx» (для кодов ), где xxx — шестнадцатеричные цифры. Например, символ «я» (U+044F) имеет код .
| Плоскости Юникода | ||
|---|---|---|
| Плоскость | Название | Диапазон символов |
| Plane 0 | Basic multilingual plane (BMP) | U+0000…U+FFFF |
| Plane 1 | Supplementary multilingual plane (SMP) | U+10000…U+1FFFF |
| Plane 2 | Supplementary ideographic plane (SIP) | U+20000…U+2FFFF |
| Planes 3-13 | Unassigned | U+30000…U+DFFFF |
| Plane 14 | Supplementary special-purpose plane (SSP) | U+E0000…U+EFFFF |
| Planes 15-16 | Supplementary private use area (S PUA A/B) | U+F0000…U+10FFFF |
Модифицирующие символы
Графические символы в Юникоде делятся на протяжённые и непротяжённые. Непротяжённые символы при отображении не занимают дополнительного места в строке. К примеру, к ним относятся знак ударения. Протяжённые и непротяжённые символы имеют собственные коды, но последние не могут встречаться самостоятельно. Протяжённые символы называются базовыми (англ. base characters), а непротяженные — модифицирующими (англ. combining characters). Например символ «Й» (U+0419) может быть представлен в виде базового символа «И» (U+0418) и модифицирующего символа « ̆» (U+0306).
Способы представления
Юникод имеет несколько форм представления (англ. Unicode Transformation Format, UTF): UTF-8, UTF-16 (UTF-16BE, UTF-16LE) и UTF-32 (UTF-32BE, UTF-32LE). Была разработана также форма представления UTF-7 для передачи по семибитным каналам, но из-за несовместимости с ASCII она не получила распространения и не включена в стандарт.
UTF-8
UTF-8 — представление Юникода, обеспечивающее наилучшую совместимость со старыми системами, использовавшими -битные символы. Текст, состоящий только из символов с номером меньше , при записи в UTF-8 превращается в обычный текст ASCII. И наоборот, в тексте UTF-8 любой байт со значением меньше изображает символ ASCII с тем же кодом. Остальные символы Юникода изображаются последовательностями длиной от двух до шести байт (на деле, только до четырех байт, поскольку в Юникоде нет символов с кодом больше , и вводить их в будущем не планируется), в которых первый байт всегда имеет вид , а остальные — .
Символы UTF-8 получаются из Unicode cледующим образом:
| Unicode | UTF-8 | Представленные символы |
|---|---|---|
0x00000000 — 0x0000007F |
0xxxxxxx |
ASCII, в том числе английский алфавит, простейшие знаки препинания и арабские цифры |
0x00000080 — 0x000007FF |
110xxxxx 10xxxxxx |
кириллица, расширенная латиница, арабский алфавит, армянский алфавит, греческий алфавит, еврейский алфавит и коптский алфавит; сирийское письмо, тана, нко; Международный фонетический алфавит; некоторые знаки препинания |
0x00000800 — 0x0000FFFF |
1110xxxx 10xxxxxx 10xxxxxx |
все другие современные формы письменности, в том числе грузинский алфавит, индийское, китайское, корейское и японское письмо; сложные знаки препинания; математические и другие специальные символы |
0x00010000 — 0x001FFFFF |
11110xxx 10xxxxxx 10xxxxxx 10xxxxxx |
музыкальные символы, редкие китайские иероглифы, вымершие формы письменности |
111111xx |
служебные символы c, d, e, f |
Несмотря на то, что UTF-8 позволяет указать один и тот же символ несколькими способами, только наиболее короткий из них правильный. Остальные формы, называемые overlong sequence, отвергаются по соображениям безопасности.
Принцип кодирования
Правила записи кода одного символа в UTF-8
1. Если размер символа в кодировке UTF-8 = байт
- Код имеет вид (0aaa aaaa), где «0» — просто ноль, остальные биты «a» — это код символа в кодировке ASCII;
2. Если размер символа в кодировке в UTF-8 байт (то есть от до ):
- 2.1 Первый байт содержит количество байт символа, закодированное в единичной системе счисления;
2 — 11 3 — 111 4 — 1111 5 — 1111 1 6 — 1111 11
- 2.2 «0» — бит терминатор, означающий завершение кода размера
- 2.3 далее идут значащие байты кода, которые имеют вид (10xx xxxx), где «10» — биты признака продолжения, а «x» — значащие биты.
В общем случае варианты представления одного символа в кодировке UTF-8 выглядят так:
(1 байт) 0aaa aaaa (2 байта) 110x xxxx 10xx xxxx (3 байта) 1110 xxxx 10xx xxxx 10xx xxxx (4 байта) 1111 0xxx 10xx xxxx 10xx xxxx 10xx xxxx (5 байт) 1111 10xx 10xx xxxx 10xx xxxx 10xx xxxx 10xx xxxx (6 байт) 1111 110x 10xx xxxx 10xx xxxx 10xx xxxx 10xx xxxx 10xx xxxx
Определение длины кода в UTF-8
| Количество байт UTF-8 | Количество значащих бит |
|---|---|
В общем случае количество значащих бит , кодируемых байтами UTF-8, определяется по формуле:
при
при
UTF-16
UTF-16 — один из способов кодирования символов (англ. code point) из Unicode в виде последовательности -битных слов (англ. code unit). Данная кодировка позволяет записывать символы Юникода в диапазонах U+0000..U+D7FF и U+E000..U+10FFFF (общим количеством ), причем -байтные символы представляются как есть, а более длинные — с помощью суррогатных пар (англ. surrogate pair), для которых и вырезан диапазон .
В UTF-16 символы кодируются двухбайтовыми словами с использованием всех возможных диапазонов значений (от до ). При этом можно кодировать символы Unicode в диапазонах и . Исключенный отсюда диапазон используется как раз для кодирования так называемых суррогатных пар — символов, которые кодируются двумя -битными словами. Символы Unicode до включительно (исключая диапазон для суррогатов) записываются как есть -битным словом. Символы же в диапазоне (больше бит) уже кодируются парой -битных слов. Для этого их код арифметически сдвигается до нуля (из него вычитается минимальное число ). В результате получится значение от нуля до , которое занимает до бит. Старшие бит этого значения идут в лидирующее (первое) слово, а младшие бит — в последующее (второе). При этом в обоих словах старшие бит используются для обозначения суррогата. Биты с по имеют значения , а -й бит содержит у лидирующего слова и — у последующего. В связи с этим можно легко определить к чему относится каждое слово.
UTF-16LE и UTF-16BE
Один символ кодировки UTF-16 представлен последовательностью двух байт или двух пар байт. Который из двух байт в словах идёт впереди, старший или младший, зависит от порядка байт. Подробнее об этом будет сказано ниже.
UTF-32
UTF-32 — один из способов кодирования символов из Юникод, использующий для кодирования любого символа ровно бита. Остальные кодировки, UTF-8 и UTF-16, используют для представления символов переменное число байт. Символ UTF-32 является прямым представлением его кодовой позиции (англ. code point).
Главное преимущество UTF-32 перед кодировками переменной длины заключается в том, что символы Юникод непосредственно индексируемы. Получение -ой кодовой позиции является операцией, занимающей одинаковое время. Напротив, коды с переменной длиной требует последовательного доступа к -ой кодовой позиции. Это делает замену символов в строках UTF-32 простой, для этого используется целое число в качестве индекса, как обычно делается для строк ASCII.
Главный недостаток UTF-32 — это неэффективное использование пространства, так как для хранения символа используется четыре байта. Символы, лежащие за пределами нулевой (базовой) плоскости кодового пространства редко используются в большинстве текстов. Поэтому удвоение, в сравнении с UTF-16, занимаемого строками в UTF-32 пространства не оправдано.
Хотя использование неменяющегося числа байт на символ удобно, но не настолько, как кажется. Операция усечения строк реализуется легче в сравнении с UTF-8 и UTF-16. Но это не делает более быстрым нахождение конкретного смещения в строке, так как смещение может вычисляться и для кодировок фиксированного размера. Это не облегчает вычисление отображаемой ширины строки, за исключением ограниченного числа случаев, так как даже символ «фиксированной ширины» может быть получен комбинированием обычного символа с модифицирующим, который не имеет ширины. Например, буква «й» может быть получена из буквы «и» и диакритического знака «крючок над буквой». Сочетание таких знаков означает, что текстовые редакторы не могут рассматривать -битный код как единицу редактирования. Редакторы, которые ограничиваются работой с языками с письмом слева направо и составными символами (англ. Precomposed character), могут использовать символы фиксированного размера. Но такие редакторы вряд ли поддержат символы, лежащие за пределами нулевой (базовой) плоскости кодового пространства и вряд ли смогут работать одинаково хорошо с символами UTF-16.
Порядок байт
В современной вычислительной технике и цифровых системах связи информация обычно представлена в виде последовательности байт. В том случае, если число не может быть представлено одним байтом, имеет значение в каком порядке байты записываются в памяти компьютера или передаются по линиям связи. Часто выбор порядка записи байт произволен и определяется только соглашениями.
В общем случае, для представления числа , большего (здесь — максимальное целое число, записываемое одним байтом), приходится использовать несколько байт. При этом число записывается в позиционной системе счисления по основанию :
Набор целых чисел , каждое из которых лежит в интервале от до , является последовательностью байт, составляющих . При этом называется младшим байтом, а — старшим байтом числа .
Варианты записи
Порядок от старшего к младшему
Порядок от старшего к младшему (англ. big-endian): , запись начинается со старшего и заканчивается младшим. Этот порядок является стандартным для протоколов TCP/IP, он используется в заголовках пакетов данных и во многих протоколах более высокого уровня, разработанных для использования поверх TCP/IP. Поэтому, порядок байт от старшего к младшему часто называют сетевым порядком байт (англ. network byte order). Этот порядок байт используется процессорами IBM 360/370/390, Motorola 68000, SPARC (отсюда третье название — порядок байт Motorola, Motorola byte order).
В этом же виде (используя представление в десятичной системе счисления) записываются числа индийско-арабскими цифрами в письменностях с порядком знаков слева направо (латиница, кириллица). Для письменностей с обратным порядком (арабская) та же запись числа воспринимается как «от младшего к старшему».
Порядок байт от старшего к младшему применяется во многих форматах файлов — например, PNG, FLV, EBML.
Порядок от младшего к старшему
Порядок от младшего к старшему (англ. little-endian): , запись начинается с младшего и заканчивается старшим. Этот порядок записи принят в памяти персональных компьютеров с x86-процессорами, в связи с чем иногда его называют интеловский порядок байт (по названию фирмы-создателя архитектуры x86).
В противоположность порядку big-endian, соглашение little-endian поддерживают меньше кросс-платформенных протоколов и форматов данных; существенные исключения: USB, конфигурация PCI, таблица разделов GUID, рекомендации FidoNet.
Переключаемый порядок
Многие процессоры могут работать и в порядке от младшего к старшему, и в обратном, например, ARM, PowerPC (но не PowerPC 970), DEC Alpha, MIPS, PA-RISC и IA-64. Обычно порядок байт выбирается программно во время инициализации операционной системы, но может быть выбран и аппаратно перемычками на материнской плате. В этом случае правильнее говорить о порядке байт операционной системы. Переключаемый порядок байт иногда называют англ. bi-endian.
Смешанный порядок
Смешанный порядок байт (англ. middle-endian) иногда используется при работе с числами, длина которых превышает машинное слово. Число представляется последовательностью машинных слов, которые записываются в формате, естественном для данной архитектуры, но сами слова следуют в обратном порядке.
Классический пример middle-endian — представление -байтных целых чисел на -битных процессорах семейства PDP-11 (известен как PDP-endian). Для представления двухбайтных значений (слов) использовался порядок little-endian, но -хбайтное двойное слово записывалось от старшего слова к младшему.
В процессорах VAX и ARM используется смешанное представление для длинных вещественных чисел.
Различия
Существенным достоинством little-endian по сравнению с big-endian порядком записи считается возможность «неявной типизации» целых чисел при чтении меньшего объёма байт (при условии, что читаемое число помещается в диапазон). Так, если в ячейке памяти содержится число , то прочитав его как int16 (два байта) мы получим число , прочитав один байт — число . Однако, это же может считаться и недостатком, потому что провоцирует ошибки потери данных.
Обратно, считается что у little-endian, по сравнению с big-endian есть «неочевидность» значения байт памяти при отладке (последовательность байт (A1, B2, C3, D4) на самом деле значит , для big-endian эта последовательность (A1, B2, C3, D4) читалась бы «естественным» для арабской записи чисел образом: ). Наименее удобным в работе считается middle-endian формат записи; он сохранился только на старых платформах.
Для записи длинных чисел (чисел, длина которых существенно превышает разрядность машины) обычно предпочтительнее порядок слов в числе little-endian (поскольку арифметические операции над длинными числами производятся от младших разрядов к старшим). Порядок байт в слове — обычный для данной архитектуры.
Маркер последовательности байт
Для определения формата представления Юникода в начало текстового файла записывается сигнатура — символ U+FEFF (неразрывный пробел с нулевой шириной), также именуемый маркером последовательности байт (англ. byte order mark (BOM)). Это позволяет различать UTF-16LE и UTF-16BE, поскольку символа U+FFFE не существует.
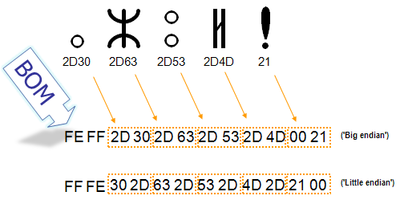
Представление BOM в кодировках
| Кодирование | Представление (Шестнадцатеричное) |
|---|---|
| UTF-8 | EF BB BF
|
| UTF-16 (BE) | FE FF
|
| UTF-16 (LE) | FF FE
|
| UTF-32 (BE) | 00 00 FE FF
|
| UTF-32 (LE) | FF FE 00 00
|
В кодировке UTF-8, наличие BOM не является существенным, поскольку, нет альтернативной последовательности байт. Когда BOM используется на страницах или редакторах для контента закодированного в UTF-8, иногда он может представить пробелы или короткие последовательности символов, имеющие странный вид (такие как ). Именно поэтому, при наличии выбора, для совместимости, как правило, лучше упустить BOM в UTF-8 контенте.Однако BOM могут еще встречаться в тексте закодированном в UTF-8, как побочный продукт перекодирования или потому, что он был добавлен редактором. В этом случае BOM часто называют подписью UTF-8.
Когда символ закодирован в UTF-16, его или байта можно упорядочить двумя разными способами (little-endian или big-endian). Изображение справа показывает это. Byte order mark указывает, какой порядок используется, так что приложения могут немедленно расшифровать контент. UTF-16 контент должен всегда начинатся с BOM.
BOM также используется для текста обозначенного как UTF-32. Аналогично UTF-16 существует два варианта четырёхбайтной кодировки — UTF-32BE и UTF-32LE. К сожалению, этот способ не позволяет надёжно различать UTF-16LE и UTF-32LE, поскольку символ U+0000 допускается Юникодом
Проблемы Юникода
В Юникоде английское «a» и польское «a» — один и тот же символ. Точно так же одним символом (но отличающимся от «a» латинского) считаются русское «а» и сербское «а». Такой принцип кодирования не универсален; по-видимому, решения «на все случаи жизни» вообще не может существовать.
Примеры
Если записать строку ‘hello мир’ в файл exampleBOM, а затем сделать его hex-дамп, то можно убедиться в том, что разные символы кодируются разным количеством байт. Например, английские буквы,пробел, знаки препинания и пр. кодируются одним байтом, а русские буквы — двумя
Код на python
#!/usr/bin/env python
#coding:utf-8
import codecs
f = open('exampleBOM','w')
b = u'hello мир'
f.write(codecs.BOM_UTF8)
f.write(b.encode('utf-8'))
f.close()
hex-дамп файла exampleBOM
| Символ | BOM | h | e | l | l | o | Пробел | м | и | р | |||||
| Код в UNICODE | EF | BB | BF | 68 | 65 | 6C | 6C | 6F | 20 | D0 | BC | D0 | B8 | D1 | 80 |
| Код в UTF-8 | 11101111 | 10111011 | 10111111 | 01101000 | 01100101 | 01101100 | 01101100 | 01101111 | 00100000 | 11010000 | 10111100 | 11010000 | 10111000 | 11010001 | 10000000 |
См. также
- Представление целых чисел: прямой код, код со сдвигом, дополнительный код
- Представление вещественных чисел
Источники информации
- Wikipedia — таблица ASCII
- Wikipedia — стандарт UNICODE
- Wikipedia — Byte order mark
- Wikipedia — Порядок байтов
- Wikipedia — Юникод
- Wikipedia — Windows-1251
- Wikipedia — UTF-8
- Wikipedia — UTF-16
- Wikipedia — UTF-32
Содержание
- 1 символ это сколько бит
- Содержание
- Алгоритм кодирования [ править | править код ]
- Примеры кодирования [ править | править код ]
- Маркер UTF-8 [ править | править код ]
- Пятый и шестой байты [ править | править код ]
- Сколько требуется бит памяти для кодирования кода одного символа в кодировке windows
- Сколькими битами кодируется 1 символ в unicode. Кодирование текста
- Единицы измерения объема данных и ёмкости памяти: килобайты, мегабайты, гигабайты…
- Компьютерная грамотность с Надеждой
- Заполняем пробелы — расширяем горизонты!
- Двоичное кодирование текстовой информации и таблица кодов ASCII
- Сколько значений можно закодировать с помощью нуля и единицы
- Как происходит кодирование текстовой информации
- Таблица ASCII
- Коды из международной таблицы ASCII
- Кодировка слова МИР
- Неужели нужно знать все коды?
1 символ это сколько бит
Я просто смущен. сколько символов в одном бите?
Это зависит от характера и того, в каком кодировании он находится:
Символ ASCII в 8-разрядной кодировке ASCII составляет 8 бит (1 байт), хотя он может поместиться в 7 бит.
Символ ISO-8895-1 в кодировке ISO-8859-1 составляет 8 бит (1 байт).
Символ Unicode в кодировке UTF-8 находится между 8 битами (1 байт) и 32 битами (4 байта).
Символ Юникода в кодировке UTF-16 находится между 16 (2 байтами) и 32 битами (4 байта), хотя большинство общих символов принимают 16 бит. Это кодировка, используемая Windows внутренне.
Символ Unicode в кодировке UTF-32 всегда 32 бита (4 байта).
Символ ASCII в UTF-8 — 8 бит (1 байт), а в UTF-16 — 16 бит.
Дополнительные символы (не ASCII) в ISO-8895-1 (0xA0-0xFF) будут принимать 16 бит в UTF-8 и UTF-16.
Это означало бы, что между 0.03125 и 0.125 символами.
Один бит это 1/8 (одна восьмая или 0.125 символа). Из учебника информатики мы знаем что для того чтобы записать один символ нам нужен 1 байт, который состоит из 8 бит, отсюда 1 бит это 1/8 символа или 0.125 символа. Почему 1 символ это байт? Все дело в том что машина (компьютер) не понимает наши буквы и символы, она понимает только значения «верно» и «ложь» которые записаны в двоичном коде (то есть при помощи двух символов 1 и 0). Соответственно для того чтобы закодировать один из 256 символов при помощи нолей и единиц нам потребуется восемь мест в каждом из которых может быть только один из двух вариантов: единица или ноль. Таким местом как раз и является один бит который может содержать только ноль или единицу, а вот последовательность из восьми нолей или единиц можно описать один из 256 символов. Таким образом и получается что для записи одного символа нам нужно 8 бит или один байт.
Сравнивая UTF-8 и UTF-16, можно отметить, что наибольший выигрыш в компактности UTF-8 даёт для текстов на латинице, поскольку латинские буквы без диакритических знаков, цифры и наиболее распространённые знаки препинания кодируются в UTF-8 лишь одним байтом, и коды этих символов соответствуют их кодам в ASCII. [4] [5]
Содержание
Алгоритм кодирования [ править | править код ]
Алгоритм кодирования в UTF-8 стандартизирован в RFC 3629 и состоит из 3 этапов:
1. Определить количество октетов (байтов), требуемых для кодирования символа. Номер символа берётся из стандарта Юникод.
| Диапазон номеров символов | Требуемое количество октетов |
|---|---|
| 00000000-0000007F | 1 |
| 00000080-000007FF | 2 |
| 00000800-0000FFFF | 3 |
| 00010000-0010FFFF | 4 |
Для символов Юникода с номерами от U+0000 до U+007F (занимающими один байт c нулём в старшем бите) кодировка UTF-8 полностью соответствует 7-битной кодировке US-ASCII.
2. Установить старшие биты первого октета в соответствии с необходимым количеством октетов, определённом на первом этапе:
Если для кодирования требуется больше одного октета, то в октетах 2-4 два старших бита всегда устанавливаются равными 102 (10xxxxxx). Это позволяет легко отличать первый октет в потоке, потому что его старшие биты никогда не равны 102.
| Количество октетов | Значащих бит | Шаблон |
|---|---|---|
| 1 | 7 | 0xxxxxxx |
| 2 | 11 | 110xxxxx 10xxxxxx |
| 3 | 16 | 1110xxxx 10xxxxxx 10xxxxxx |
| 4 | 21 | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx |
3. Установить значащие биты октетов в соответствии с номером символа Юникода, выраженном в двоичном виде. Начать заполнение с младших битов номера символа, поставив их в младшие биты последнего октета, продолжить справа налево до первого октета. Свободные биты первого октета, оставшиеся незадействованными, заполнить нулями.
Примеры кодирования [ править | править код ]
| Символ | Двоичный код символа | UTF-8 в двоичном виде | UTF-8 в шестнадцатеричном виде | |
|---|---|---|---|---|
| $ | U+0024 | 100100 | 0 0100100 | 24 |
| ¢ | U+00A2 | 10 100010 | 110 00010 10 100010 | C2 A2 |
| € | U+20AC | 10 0000 10 101100 | 1110 0010 10 000010 10 101100 | E2 82 AC |
| �� | U+10348 | 1 0000 0011 01 001000 | 11110 000 10 010000 10 001101 10 001000 | F0 90 8D 88 |
Маркер UTF-8 [ править | править код ]
| 1-й байт | 2-й байт | 3-й байт | |
|---|---|---|---|
| Двоичный код | 1110 1111 | 1011 1011 | 1011 1111 |
| Шестнадцатеричный код | EF | BB | BF |
Пятый и шестой байты [ править | править код ]
Источник
Кодирование текстовой информации
Двоичное кодирование – один из распространенных способов представления информации. В вычислительных машинах, в роботах и станках с числовым программным управлением, как правило, вся информация, с которой имеет дело устройство, кодируется в виде слов двоичного алфавита.
Начиная с конца 60-х годов, компьютеры все больше стали использоваться для обработки текстовой информации, и в настоящее время основная доля персональных компьютеров в мире (и большая часть времени) занята обработкой именно текстовой информации. Все эти виды информации в компьютере представлены в двоичном коде, т. е. используется алфавит мощностью два (всего два символа 0 и 1). Связано это с тем, что удобно представлять информацию в виде последовательности электрических импульсов: импульс отсутствует (0), импульс есть (1).
С точки зрения ЭВМ текст состоит из отдельных символов. К числу символов принадлежат не только буквы (заглавные или строчные, латинские или русские), но и цифры, знаки препинания, спецсимволы типа «=», «(«, «&» и т.п. и даже (обратите особое внимание!) пробелы между словами.
Тексты вводятся в память компьютера с помощью клавиатуры. На клавишах написаны привычные нам буквы, цифры, знаки препинания и другие символы. В оперативную память они попадают в двоичном коде. Это значит, что каждый символ представляется 8-разрядным двоичным кодом.
В процессе вывода символа на экран компьютера производится обратный процесс — декодирование, то есть преобразование кода символа в его изображение. Важно, что присвоение символу конкретного кода — это вопрос соглашения, которое фиксируется в кодовой таблице.
Теперь возникает вопрос, какой именно восьмиразрядный двоичный код поставить в соответствие каждому символу. Понятно, что это дело условное, можно придумать множество способов кодировки.
Все символы компьютерного алфавита пронумерованы от 0 до 255. Каждому номеру соответствует восьмиразрядный двоичный код от 00000000 до 11111111. Этот код просто порядковый номер символа в двоичной системе счисления.
Виды таблиц кодировок
Таблица, в которой всем символам компьютерного алфавита поставлены в соответствие порядковые номера, называется таблицей кодировки.
Для разных типов ЭВМ используются различные таблицы кодировки.
Таблица кодов ASCII делится на две части.
Международным стандартом является лишь первая половина таблицы, т.е. символы с номерами от 0 (00000000), до 127 (01111111).
Структура таблицы кодировки ASCII
Символы с номерами от 0 до 31 принято называть управляющими.
Их функция – управление процессом вывода текста на экран или печать, подача звукового сигнала, разметка текста и т.п.
Стандартная часть таблицы (английский). Сюда входят строчные и прописные буквы латинского алфавита, десятичные цифры, знаки препинания, всевозможные скобки, коммерческие и другие символы.
Все остальные отражаются определенными знаками.
Альтернативная часть таблицы (русская).
Вторая половина кодовой таблицы ASCII, называемая кодовой страницей (128 кодов, начиная с 10000000 и кончая 11111111), может иметь различные варианты, каждый вариант имеет свой номер.
Кодовая страница в первую очередь используется для размещения национальных алфавитов, отличных от латинского. В русских национальных кодировках в этой части таблицы размещаются символы русского алфавита.
Обращается внимание на то, что в таблице кодировки буквы (прописные и строчные) располагаются в алфавитном порядке, а цифры упорядочены по возрастанию значений. Такое соблюдение лексикографического порядка в расположении символов называется принципом последовательного кодирования алфавита.
Для букв русского алфавита также соблюдается принцип последовательного кодирования.
К сожалению, в настоящее время существуют пять различных кодировок кириллицы (КОИ8-Р, Windows. MS-DOS, Macintosh и ISO). Из-за этого часто возникают проблемы с переносом русского текста с одного компьютера на другой, из одной программной системы в другую.
Хронологически одним из первых стандартов кодирования русских букв на компьютерах был КОИ8 («Код обмена информацией, 8-битный»). Эта кодировка применялась еще в 70-е годы на компьютерах серии ЕС ЭВМ, а с середины 80-х стала использоваться в первых русифицированных версиях операционной системы UNIX.
От начала 90-х годов, времени господства операционной системы MS DOS, остается кодировка CP866 («CP» означает «Code Page», «кодовая страница»).
Компьютеры фирмы Apple, работающие под управлением операционной системы Mac OS, используют свою собственную кодировку Mac.
Кроме того, Международная организация по стандартизации (International Standards Organization, ISO) утвердила в качестве стандарта для русского языка еще одну кодировку под названием ISO 8859-5.
Наиболее распространенной в настоящее время является кодировка Microsoft Windows, обозначаемая сокращением CP1251. Введена компанией Microsoft; с учетом широкого распространения операционных систем (ОС) и других программных продуктов этой компании в Российской Федерации она нашла широкое распространение.
С конца 90-х годов проблема стандартизации символьного кодирования решается введением нового международного стандарта, который называется Unicode.
Это 16-разрядная кодировка, т.е. в ней на каждый символ отводится 2 байта памяти. Конечно, при этом объем занимаемой памяти увеличивается в 2 раза. Но зато такая кодовая таблица допускает включение до 65536 символов. Полная спецификация стандарта Unicode включает в себя все существующие, вымершие и искусственно созданные алфавиты мира, а также множество математических, музыкальных, химических и прочих символов.
Внутреннее представление слов в памяти компьютера
с помощью таблицы ASCII
Таким образом, каждая кодировка задается своей собственной кодовой таблицей. Как видно из таблицы, одному и тому же двоичному коду в различных кодировках поставлены в соответствие различные символы.
Н апример, последовательность числовых кодов 221, 194, 204 в кодировке СР1251 образует слово «ЭВМ» (Рис. 10), тогда как в других кодировках это будет бессмысленный набор символов.
К счастью, в большинстве случаев пользователь не должен заботиться о перекодировках текстовых документов, так как это делают специальные программы-конверторы, встроенные в приложения.
Источник
Сколькими битами кодируется 1 символ в unicode. Кодирование текста
Начиная с конца 60-х годов, компьютеры все больше стали использоваться для обработки текстовой информации и в настоящее время большая часть персональных компьютеров в мире (и наибольшее время) занято обработкой именно текстовой информации.
Для кодирования одного символа требуется 1 байт информации. Если рассматривать символы как возможные события, то можно вычислить, какое количество различных символов можно закодировать: N = 2I = 28 = 256.
Такое количество символов вполне достаточно для представления текстовой информации, включая прописные и строчные буквы русского и латинского алфавита, цифры, знаки, графические символы и пр. Кодирование заключается в том, что каждому символу ставится в соответствие уникальный десятичный код от 0 до 255 или соответствующий ему двоичный код от 00000000 до 11111111.
К сожалению, в настоящее время существуют пять различных кодовых таблиц для русских букв (КОИ8, СР1251, СР866, Mac, ISO), поэтому тексты, созданные в одной кодировке, не будут правильно отображаться в другой.
В настоящее время широкое распространение получил новый международный стандарт Unicode, который отводит на каждый символ не один байт, а два, поэтому с его помощью можно закодировать не 256 символов, а N = 216 = 65536 различных
В результате чего один и то же файл с текстом, закодированный в расширенной кодировке ASCII и в кодировке UTF 32, в последнем случае будет иметь размер (весить) в четыре раза больше. Это плохо, но зато теперь у нас появилась возможность закодировать с помощью UTF 32 число символов равное двум в тридцать второй степени (миллиарды символов, которые покроют любое реально необходимое значение с колоссальным запасом).
Но многим странам с языками европейской группы такое огромное количество символов использовать в кодировке вовсе и не было необходимости, однако при использовании UTF 32 они ни за что ни про что получали четырехкратное увеличение веса текстовых документов, а в результате и увеличение объема интернет трафика и объема хранимых данных. Это много и такое расточительство себе никто не мог позволить.
В результате откроется таблица с векторными формами всех установленных у вас в системе шрифтов. Если вы выберите в Дополнительных параметрах набор символов Юникод, то сможете увидеть для каждого шрифта в отдельности весь ассортимент входящих в него символов. Кстати, щелкнув по любому из этих символов вы сможете увидеть его двухбайтовый код в кодировке UTF 16, состоящий из четырех шестнадцатеричных цифр:
Сколько символов можно закодировать в UTF 16 с помощью 16 бит? 65 536 символов (два в степени шестнадцать) было принято за базовое пространство в Юникод. Помимо этого существуют способы закодировать с помощью UTF 16 около двух миллионов символов, но ограничились расширенным пространством в миллион символов текста.
В UTF 8 все латинские символы кодируются в один байт, так же как и в старой кодировке ASCII. Что примечательно, в случае кодирования только латиницы, даже те программы, которые не понимают Юникод, все равно прочитают то, что закодировано в UTF 8. Т.е. базовая часть кодировки ASCII перешла в UTF 8.
Теоретически давно существует решение этих проблем. Оно называетсяUnicode (Юникод). Unicode – это кодировочная таблица, в которой для кодирования каждого символа используется 2 байта, т.е. 16 бит. На основании такой таблицы может быть закодированоN=2 16 =65 536 символов.
Юникод включает практически все современные письменности, в том числе: арабскую, армянскую, бенгальскую, бирманскую, греческую, грузинскую, деванагари, иврит, кириллицу, коптскую, кхмерскую, латинскую, тамильскую, хангыль, хань (Китай, Япония, Корея), чероки, эфиопскую, японскую (катакана, хирагана, кандзи) и другие.
С академической целью добавлены многие исторические письменности, в том числе: древнегреческая, египетские иероглифы, клинопись, письменность майя, этрусский алфавит.
В Юникоде представлен широкий набор математических и музыкальных символов, а также пиктограмм.
Для символов кириллицы в Юникоде выделено два диапазона кодов:
Но внедрение таблицы Unicode в чистом виде сдерживается по той причине, что если код одного символа будет занимать не один байт, а два байта, что для хранения текста понадобится вдвое больше дискового пространства, а для его передачи по каналам связи – вдвое больше времени.
В кодируемом английском тексте используется только 26 букв латинского алфавита и еще 6 знаков пунктуации. В этом случае текст, содержащий 1000 символов можно гарантированно сжать без потерь информации до размера:
Словарь Эллочки – «людоедки» (персонаж романа «Двенадцать стульев») составляет 30 слов. Сколько бит достаточно, чтобы закодировать весь словарный запас Эллочки? Варианты: 8, 5, 3, 1.
Единицы измерения объема данных и ёмкости памяти: килобайты, мегабайты, гигабайты…
Итак, в мы выяснили, что в большинстве современных кодировок под хранение на электронных носителях информации одного символа текста отводится 1 байт. Т.е. в байтах измеряется объем (V), занимаемый данными при их хранении и передаче (файлы, сообщения).
Объем данных (V) – количество байт, которое требуется для их хранения в памяти электронного носителя информации.
Однако байт – мелкая единица измерения объема данных, более крупными являются килобайт, мегабайт, гигабайт, терабайт…
Следует запомнить, что приставки “кило”, “мега”, “гига”… не являются в данном случае десятичными. Так “кило” в слове “килобайт” не означает “тысяча”, т.е. не означает “10 3 ”. Бит – двоичная единица, и по этой причине в информатике удобно пользоваться единицами измерения кратными числу “2”, а не числу “10”.
1 байт = 2 3 =8 бит, 1 килобайт = 2 10 = 1024 байта. В двоичном виде 1 килобайт = &10000000000 байт.
Т.е. “кило” здесь обозначает ближайшее к тысяче число, являющееся при этом степенью числа 2, т.е. являющееся “круглым” числом в двоичной системе счисления.
Источник
Компьютерная грамотность с Надеждой
Заполняем пробелы — расширяем горизонты!
Двоичное кодирование текстовой информации и таблица кодов ASCII
Минимальные единицы измерения информации – это бит и байт.
Один бит позволяет закодировать 2 значения (0 или 1).
Используя два бита, можно закодировать 4 значения: 00, 01, 10, 11.
Тремя битами кодируются 8 разных значений: 000, 001, 010, 011, 100, 101, 110, 111.
Сколько значений можно закодировать с помощью нуля и единицы
Из приведенных примеров видно, что добавление одного бита увеличивает в 2 раза то количество значений, которое можно закодировать:
1 бит кодирует —> 2 разных значения (2 1 = 2),
2 бита кодируют —> 4 разных значения (2 2 = 4),
3 бита кодируют —> 8 разных значений (2 3 = 8),
4 бита кодируют —> 16 разных значений (2 4 = 16),
5 бит кодируют —> 32 разных значения (2 5 = 32),
6 бит кодируют —> 64 разных значения (2 6 = 64),
7 бит кодируют —> 128 разных значения (2 7 = 128),
8 бит кодируют —> 256 разных значений (2 8 = 256),
9 бит кодируют —> 512 разных значений (2 9 = 512),
10 бит кодируют —> 1024 разных значений (2 10 = 1024).
Мы помним, что в одном байте не 9 и не 10 бит, а всего 8. Следовательно, с помощью одного байта можно закодировать 256 разных символов. Как Вы думаете, много это или мало? Давайте посмотрим на примере кодирования текстовой информации.
Как происходит кодирование текстовой информации
В русском языке 33 буквы и, значит, для их кодирования надо 33 байта. Компьютер различает большие (заглавные) и маленькие (строчные) буквы, только если они кодируются различными кодами. Значит, чтобы закодировать большие и маленькие буквы русского алфавита, потребуется 66 байт.
А дальше дело осталось за малым. Надо сделать так, чтобы все люди на Земле договорились между собой о том, какие именно коды (с 0 до 255, т.е. всего 256) присвоить символам. Допустим, все люди договорились, что код 33 означает восклицательный знак (!), а код 63 – вопросительный знак (?). И так же – для всех применяемых символов. Тогда это будет означать, что текст, набранный одним человеком на своем компьютере, всегда можно будет прочитать и распечатать другому человеку на другом компьютере.
Таблица ASCII
Такая всеобщая договоренность об одинаковом использовании чего-либо называется стандартом. В нашем случае стандарт должен представлять из себя таблицу, в которой зафиксировано соответствие кодов (с 0 до 255) и символов. Подобная таблица называется таблицей кодировки.
Но не всё так просто. Ведь символы, которые хороши, например, для Греции, не подойдут для Турции потому, что там используются другие буквы. Аналогично то, что хорошо для США, не подойдет для России, а то, что подойдет для России, не годится для Германии.
Поэтому приняли решение разделить таблицу кодов пополам.
Первые 128 кодов (с 0 до 127) должны быть стандартными и обязательными для всех стран и для всех компьютеров, это – международный стандарт.
А со второй половиной таблицы кодов (с 128 до 255) каждая страна может делать все, что угодно, и создавать в этой половине свой стандарт – национальный.
Первую (международную) половину таблицы кодов называют таблицей ASCII, которую создали в США и приняли во всем мире.
За вторую половину кодовой таблицы (с 128 до 255) стандарт ASCII не отвечает. Разные страны создают здесь свои национальные таблицы кодов.
Может быть и так, что в пределах одной страны действуют разные стандарты, предназначенные для различных компьютерных систем, но только в пределах второй половины таблицы кодов.
Коды из международной таблицы ASCII
0-31 – Особые символы, которые не распечатываются на экране или на принтере. Они служат для выполнения специальных действий, например, для «перевода каретки» – перехода текста на новую строку, или для «табуляции» – установки курсора на специальные позиции в строке текста и т.п.
32 – Пробел, который является разделителем между словами. Это тоже символ, подлежащий кодировке, хоть он и отображается в виде «пустого места» между словами и символами.
33-47 – Специальные символы (круглые скобки и пр.) и знаки препинания (точка, запятая и пр.).
48-57 – Цифры от 0 до 9.
58-64 – Математические символы: плюс (+), минус (-), умножить (*), разделить (/) и пр., а также знаки препинания: двоеточие, точка с запятой и пр.
65-90 – Заглавные (прописные) английские буквы.
91-96 – Специальные символы (квадратные скобки и пр.).
97-122 – Маленькие (строчные) английские буквы.
123-127 – Специальные символы (фигурные скобки и пр.).
За пределами таблицы ASCII, начиная с цифры 128 по 159, идут заглавные (прописные) русские буквы. А с цифры 160 по 170 и с 224 по 239 – маленькие (строчные) русские буквы.
Кодировка слова МИР
Пользуясь показанной кодировкой, мы можем представить себе, как компьютер кодирует и затем воспроизводит. Например, рассмотрим слово МИР (заглавными буквами). Это слово представляется тремя кодами:
букве М соответствует код 140 (по национальной российской системе кодировки),
для буквы И – это код 136 и
буква Р – это 144.
Но как уже говорилось ранее, компьютер воспринимает информацию только в двоичном виде, т.е. в виде последовательности нулей и единиц. Каждый байт, соответствующий каждой букве слова МИР, содержит последовательность из восьми нулей и единиц. Используя правила перевода десятичной информации в двоичную, можно заменить десятичные значения кодов букв на их двоичные аналоги.
Десятичной цифре 140 соответствует двоичное число 10001100. Это можно проверить, если сделать следующие вычисления: 2 7 + 2 3 +2 2 = 140. Степень, в которую возводится каждая «двойка» – это номер позиции двоичного числа 10001100, в которой стоит «1». Причем позиции нумеруются справа налево, начиная с нулевого номера позиции: 0, 1, 2 и т.д.
Более подробно о переводе чисел из одной системы счисления в другую можно узнать, например, из учебников по информатике или через Интернет.
Аналогичным образом можно убедиться, что цифре 136 соответствует двоичное число 10001000 (проверка: 2 7 + 2 3 = 136). А цифре 144 соответствует двоичное число 10010000 (проверка: 2 7 + 2 4 = 144).
Таким образом, в компьютере слово МИР будет храниться в виде следующей последовательности нулей и единиц (бит): 10001100 10001000 10010000.
Разумеется, что все показанные выше преобразования данных производятся с помощью компьютерных программ, и они не видны пользователям. Они лишь наблюдают результаты работы этих программ, как при вводе информации с помощью клавиатуры, так и при ее выводе на экран монитора или на принтер.
Неужели нужно знать все коды?
Следует отметить, что на уровне изучения компьютерной грамотности пользователям компьютеров не обязательно знать двоичную систему счисления. Достаточно иметь представление о десятичных кодах символов.
Только системные программисты на практике используют двоичную, шестнадцатеричную, восьмеричную и иные системы счисления. Особенно это важно для них, когда компьютеры выводят сообщения об ошибках в программном обеспечении, в которых указываются ошибочные значения без преобразования в десятичную систему.
Упражнения по компьютерной грамотности, позволяющие самостоятельно увидеть и почувствовать описанные системы кодировок, приведены в статье «Проверяем, кодирует ли компьютер текст?»
Источник
Решение задач на тему «Кодирование текстовой информации»
Типы
задач:
-
Объем
памяти, занимаемый текстом. -
Кодирование
(декодирование) текстовой информации. -
Внутреннее
представление текста в компьютере.
-
Объем памяти,
занимаемый текстом.
Методические рекомендации:
В задачах такого
типа используются понятия:
-
алфавит,
-
мощность алфавита
-
символ,
-
единицы измерения
информации (бит, байт и др.)
Для представления текстовой (символьной)
информации в компьютере используется
алфавит мощностью 256 символов. Один
символ из такого алфавита несет 8 бит
информации (28 =256). 8 бит =1 байту,
следовательно, двоичный код каждого
символа в компьютерном тексте занимает
1 байт памяти.
Уровень
«3»
1. Сколько бит памяти займет слово
«Микропроцессор»?([1], c.131,
пример 1)
Решение:
Слово состоит из 14 букв. Каждая буква –
символ компьютерного алфавита, занимает
1 байт памяти. Слово занимает 14 байт
=14*8=112 бит памяти.
Ответ: 112 бит
2. Текст занимает 0, 25 Кбайт памяти
компьютера. Сколько символов содержит
этот текст? ([1], c.133,
№31)
Решение:
Переведем Кб в байты: 0, 25 Кб * 1024 =256 байт.
Так как текст занимает объем 256 байт, а
каждый символ – 1 байт, то в тексте 256
символов.
Ответ: 256 символов
3. Текст занимает полных 5 страниц.
На каждой странице размещается 30 строк
по 70 символов в строке. Какой объем
оперативной памяти (в байтах) займет
этот текст? ([1], c.133,
№32)
Решение:
30*70*5 = 10500 символов в тексте на 5 страницах.
Текст займет 10500 байт оперативной памяти.
Ответ: 10500 байт
4.
Считая, что каждый символ
кодируется одним байтом, оцените
информационный объем следующего
предложения из пушкинского четверостишия:
Певец-Давид был ростом мал, Но повалил
же Голиафа! (ЕГЭ_2005. демо, уровень
А)
|
1) |
400 бит |
2) |
50 бит |
3) |
400 байт |
4) |
5 байт |
Решение:
В тексте 50 символов, включая пробелы и
знаки препинания. При кодировании
каждого символа одним байтом на символ
будет приходиться по 8 бит, Следовательно,
переведем в биты 50*8= 400 бит.
Ответ: 400 бит
5.
Считая, что каждый символ кодируется
одним байтом, оцените информационный
объем следующего предложения в кодировке
КОИ-8: Сегодня метеорологи предсказывали
дождь. (ЕГЭ_2005, уровень А)
Решение:
В таблице КОИ-8 каждый символ закодирован
с помощью 8 бит. См. решение задачи №4.
Ответ: 320 бит
6. Считая, что каждый символ кодируется
16 битами, оцените информационный объем
следующего предложения в кодировке
Unicode:
Каждый
символ кодируется 8 битами.
(ЕГЭ_2005,
уровень А)
Решение:
34 символа в предложении. Переведем в
биты: 34*16=544 бита.
Ответ: 544 бит
7. Каждый символ
закодирован двухбайтным словом. Оцените
информационный объем следующего
предложения в этой кодировке:
В одном килограмме
100 грамм.
(ЕГЭ_2005,
уровень А)
Решение:
19 символов
в предложении. 19*2 =38 байт
Ответ: 38 байт
Уровень
«4»
8. Текст занимает полных 10 секторов
на односторонней дискете объемом 180
Кбайт. Дискета разбита на 40 дорожек по
9 секторов. Сколько символов содержит
текст? ([1], c.133,
№34)
Решение:
-
40*9 = 360 -секторов на дискете.
-
180 Кбайт : 360 * 10 =5 Кбайт – поместится на
одном секторе. -
5*1024= 5120 символов содержит текст.
Ответ:
5120 символов
9. Сообщение
передано в семибитном коде. Каков его
информационный объем в байтах, если
известно, что передано 2000 символов.
Решение:
Если код символа
содержит 7 бит, а всего 2000 символов,
узнаем сколько бит займет все сообщение.
2000 х 7=14000 бит.
Переведем результат
в байты. 14000 : 8 =1750 байт
Ответ:
1750 байт.
Уровень
«5»
10. Сколько секунд
потребуется модему, передающему сообщение
со скоростью 28800 бит/с, чтобы передать
100 страниц текста в 30 строк по 60 символов
каждая, при условии, что каждый символ
кодируется одним байтом? (ЕГЭ_2005, уровень
В)
Решение:
-
Найдем объем сообщения. 30*60*8*100 =1440000
бит. -
Найдем время передачи сообщения модемом.
1440000 : 28800 =50 секунд
Ответ:
50 секунд
11. Сколько секунд
потребуется модему, передающему сообщения
со скоростью 14400 бит/с, чтобы передать
сообщение длиной 225 Кбайт? (ЕГЭ_2005, уровень
В)
Решение:
-
Переведем 225 Кб в биты.225 Кб
*1024*8 =1843200 бит. -
Найдем время передачи сообщения модемом.
1843200: 14400 =128 секунд.
Ответ:
128 секунд
-
Кодирование
(декодирование) текстовой информации.
Методические рекомендации:
В задачах такого
типа используются понятия:
Кодирование –отображение дискретного
(прерывного, импульсного) сообщения в
виде определенных сочетаний символов.
Код (от французского слова code
– кодекс, свод законов) – правило по
которому выполняется кодирование.
Кодовая таблица (или кодовая страница)
– таблица, устанавливающая соответствие
между символами алфавита и двоичными
числами.
Примеры кодовых таблиц (имеются на CD
диске к учебнику Н. Угринович):
-
КОИ-7, КОИ-8 – кодирование русских
букв и символов (семи-, восьми -битное
кодирование)

1) #154 неразрывный пробел.
Рис.1 Кодировка КОИ8-Р
-
ASCII –AmericanStandardCodeforInformationInterchange(американский
стандарт кодов для обмена информацией)
– это восьмиразрядная кодовая таблица,
в ней закодировано 256 символов (127-
стандартные коды символов английского
языка, спецсимволы, цифры, а коды от 128
до 255 – национальный стандарт, алфавит
языка, символы псевдографики, научные
символы, коды от 0 до 32 отведены не
символам, а функциональным клавишам).

1) #32 — пробел.
Рис. 2 Международная кодировка ASCII
-
Unicode – стандарт,
согласно которому для представления
каждого символа используется 2 байта.
(можно кодировать математические
символы, русские, английские, греческие,
и даже китайские).Cего
помощью можно закодировать не 256, а
65536 различных символов. Полная спецификация
стандарта Unicode включает в себя все
существующие, вымершие и искусственно
созданные алфавиты мира, а также
множество математических, музыкальных,
химических и прочих символов -
СР1251 — наиболее
распространенной в настоящее время
является кодировка Microsoft Windows, («CP»
означает «Code Page», «кодовая
страница»).

1)
#160 неразрывный пробел,
2)
#173 мягкий перенос.
Рис. 3 Кодировка CP1251
-
СР866 —
кодировка под MS DOS

1) #255 неразрывный пробел.
Рис. 4 Кодировка СР866
-
Мас –кодировка
в ПК фирмы Apple, работающих под управлением
операционной системыMac
OS.

-
#202 неразрывный пробел.
Рис. 5 Кодировка Mac
-
ISO 8859-5 -Международная
организация по стандартизации
(International Standards Organization, ISO) утвердила в
качестве стандарта для русского языка
еще одну кодировку.

1) Коды 128-159 не используются;
2) #160 неразрывный пробел,
3) #173 мягкий перенос.
Рис. 6 Кодировка ISO 8859-5
Соседние файлы в папке Информ
- #
- #
- #
- #
- #
- #
- #
- #
- #
Цель урока. Познакомить
учащихся со способами представления и организации текстов в компьютерной
памяти.
Изучаемые вопросы:
- Преимущества файлового хранения текстов.
- Кодирование текстов.
- Кодировочная таблица, международный стандарт ASCII.
Ход
урока
I.
Организационный момент
II. Объяснение
нового материала
Компьютер может работать с четырьмя
видами информации: текстовой, графической, числовой и звуковой. Одним из самых
массовых приложений ЭВМ является работа с текстами: создание текстовых
документов и хранение их на магнитных носителях в виде файлов.
Почему же работа с тестовой
информацией на компьютерах нашла такое большое распространение?
Почему за очень короткий срок
(10-15 лет) практически на всех предприятиях и во всех организациях, в том
числе и в нашей школе, пишущие машинки заменили на компьютеры?
Чтобы ответить на эти вопросы
рассмотрим отличия обработки и хранения текстов при ручной записи и при
создании текстов на компьютере.
Преимущества файлового хранения
текстов:
- экономия бумаги;
- компактное размещение;
- возможность многократного использования магнитного носителя для хранения
разных документов; - возможность быстрого копирования на другие магнитные носители;
- возможность передачи текста по линиям компьютерной связи.
Самое поразительное отличие
компьютерного текста от бумажного, если информация в нем организована по
принципу гипертекста. Гипертекст – это способ организации текстовой информации,
внутри которой установлены смысловые связи (гиперсвязи) между ее различными фрагментами.
С гипертекстом вы уже встречались при работе со справочной системой ОС Windows.
Иногда бывает так, что текст,
состоящий из букв русского алфавита, полученный с другого компьютера,
невозможно прочитать — на экране монитора видна какая-то «абракадабра».
Ребята, как вы думаете, почему это
происходит?
Пока у вас еще нет точного ответа.
В конце урока попробуем еще раз ответить на этот вопрос.
С точки зрения компьютера текст —
это любая последовательность символов из компьютерного алфавита. Совсем не обязательно,
чтобы это был текст на одном из естественных языков (русском, английском и
др.). Это могут быть математические или химические формулы, номера телефонов,
числовые таблицы. Самое главное, чтобы все используемые символы входили бы в
компьютерный алфавит.
Включить слайд Компьютерный алфавит
презентации Кодирование текстов
Для представления информации в
компьютере используется алфавит мощностью 256 символов.
Чему равен информационный вес
одного символа такого алфавита?
Вспомним формулу, связывающую информационный
вес символа алфавита и мощность алфавита: 2i = N
Если мощность алфавита равна 256,
то i = 8, и, следовательно, один символ несет 8 бит информации.
Всякая информация представляется в
памяти ЭВМ в двоичном виде, а это значит, что каждый символ представляется
8-разрядным двоичным кодом.
8 бит = 1 байту, поэтому двоичный
код каждого символа в компьютерном тексте занимает 1 байт памяти.
Удобство побайтового кодирования
символов очевидно, поскольку байт — наименьшая адресуемая часть памяти и, следовательно,
процессор может обратиться к каждому символу отдельно, выполняя обработку
текста. С другой стороны, 256 символов – это вполне достаточное количество для
представления самой разнообразной символьной информации.
Теперь возникает вопрос, какой именно
восьмиразрядный двоичный код поставить в соответствие каждому символу. Понятно,
что это дело условное, можно придумать множество способов кодировки.
Все символы компьютерного алфавита
пронумерованы от 0 до 255. Каждому номеру соответствует восьмиразрядный
двоичный код от 00000000 до 11111111. Этот код просто порядковый номер символа
в двоичной системе счисления.
Таблица, в которой всем символам
компьютерного алфавита поставлены в соответствие порядковые номера, называется
таблицей кодировки.
Международным стандартом для ПК
стала таблица ASCII (читается аски) (Американский стандартный код для
информационного обмена). На практике можно встретиться и с другой таблицей –
КОИ-8 (Код обмена информацией), которая используется в глобальных компьютерных
сетях.
Рассмотрим таблицу кодов ASCII
(учебник, стр.75).
Включить слайд Кодирование символов
презентации Кодирование текстов
Таблица кодов ASCII делится на две
части.
Международным стандартом является
лишь первая половина таблицы, т.е. символы с номерами от 0 (00000000), до 127
(01111111). Сюда входят строчные и прописные буквы латинского алфавита,
десятичные цифры, знаки препинания, всевозможные скобки, коммерческие и другие
символы.
Символы с номерами от 0 до 31
принято называть управляющими. Их функция – управление процессом вывода текста
на экран или печать, подача звукового сигнала, разметка текста и т.п.
Символ 32 — пробел, т.е. пустая
позиция в тексте. Все остальные отражаются определенными знаками.
Обращаю ваше внимание на то, что в
таблице кодировки буквы (прописные и строчные) располагаются в алфавитном
порядке, а цифры упорядочены по возрастанию значений. Такое соблюдение
лексикографического порядка в расположении символов называется принципом
последовательного кодирования алфавита.
Вторая половина кодовой таблицы
ASCII, называемая кодовой страницей (128 кодов, начиная с 10000000 и кончая
11111111), может иметь различные варианты, каждый вариант имеет свой номер.
Кодовая страница в первую очередь
используется для размещения национальных алфавитов, отличных от латинского. В
русских национальных кодировках в этой части таблицы размещаются символы
русского алфавита. Для букв русского алфавита также соблюдается принцип
последовательного кодирования.
К сожалению, в настоящее время
существуют пять различных кодировок кириллицы (КОИ8-Р, Windows. MS-DOS,
Macintosh и ISO). Из-за этого часто возникают проблемы с переносом русского
текста с одного компьютера на другой, из одной программной системы в другую.
Хронологически одним из первых
стандартов кодирования русских букв на компьютерах был КОИ8 («Код обмена
информацией, 8-битный»). Эта кодировка применялась еще в 70-ые годы на
компьютерах серии ЕС ЭВМ, а с середины 80-х стала использоваться в первых
русифицированных версиях операционной системы UNIX.
От начала 90-х годов, времени
господства операционной системы MS DOS, остается кодировка CP866
(«CP» означает «Code Page», «кодовая страница»).
Компьютеры фирмы Apple, работающие
под управлением операционной системы Mac OS, используют свою собственную
кодировку Mac.
Кроме того, Международная
организация по стандартизации (International Standards Organization, ISO)
утвердила в качестве стандарта для русского языка еще одну кодировку под
названием ISO 8859-5.
Наиболее распространенной в
настоящее время является кодировка Microsoft Windows, обозначаемая сокращением
CP1251.
С конца 90-х годов проблема
стандартизации символьного кодирования решается введением нового международного
стандарта, который называется Unicode. Это 16-разрядная кодировка, т.е. в ней
на каждый символ отводится 2 байта памяти. Конечно, при этом объем занимаемой
памяти увеличивается в 2 раза. Но зато такая кодовая таблица допускает
включение до 65536 символов. Полная спецификация стандарта Unicode включает в
себя все существующие, вымершие и искусственно созданные алфавиты мира, а также
множество математических, музыкальных, химических и прочих символов.
Ребята, какие будут вопросы по теме
урока?
А теперь давайте еще раз попробуем
ответить на вопрос, который был задан в начале урока:
Почему иногда текст, состоящий из
букв русского алфавита, полученный с другого компьютера, мы видим на своем
компьютере в виде «абракадабры»?
Ожидаемый ответ. На компьютерах
применяется разная кодировка символов русского языка.
Сейчас мы решим несколько примеров.
Пример 1. Сколько бит
памяти компьютера занимает слово МИКРОПРОЦЕССОР?
Прежде, чем приступить к решению
примера, вспомним, какой объем памяти занимает один
символ компьютерного текста.
Ожидаемый ответ. 1
байт
Решение. Слово
состоит из 14 букв. Каждая буква является символом компьютерного алфавита и
поэтому занимает 1 байт памяти. Слово займет 14 байт = 112 бит памяти, т.к. 1
байт = 8 бит.
В чем заключается принципа
последовательного кодирования алфавита?
Ожидаемый ответ. В
таблице кодировки буквы (прописные и строчные) располагаются в алфавитном
порядке, а цифры упорядочены по возрастанию значений
Знание принципа последовательного
кодирования позволяет нам решать некоторые задачи без обращения к таблице
кодировки символов.
Пример 2. Что
зашифровано последовательностью десятичных кодов: 108 105 110 107, если буква i
в таблице кодировки символов имеет десятичный код 105?
Решение. Вспомним
порядок букв в латинском алфавите — … i, j, k, l, m, n, o … . Буква j будет
иметь код 106, k — код 107 и и.д. Следовательно, закодировано слово link.
Что обозначает понятие
«кодовая страница»?
Ожидаемый ответ. Так
называется вторая половина кодовой таблицы ASCII, предназначенная для
размещения национальных алфавитов, отличных от латинского.
Соблюдается ли принцип
последовательного кодирования в кодовых страницах?
Ожидаемый ответ.
Соблюдается
Выясним это, решив следующий
пример.
Пример 3. С помощью
последовательности десятичных кодов: 225 232 242 зашифровано слово бит. Найти
последовательность десятичных кодов этого же слова, записанного заглавными
буквами.
Решение. При решении
учтем, что разница между десятичным кодом строчной буквы кириллицы и десятичным
кодом соответствующей заглавной буквы равна 32. Если букве б соответствует код
225, заглавная буква Б имеет десятичный код 225-32=193. Следовательно, слову
БИТ соответствует последовательность кодов: 193 200 210.
III. Самостоятельная
практическая работа
(параллельно вызываются ученики для
решения примеров у доски)
Пример 4. Свободный
объем оперативной памяти компьютера 640 Кбайт. Сколько страниц книги поместится
в ней, если на странице 16 строк по 64 символа в строке?
Ответ:(640?1024)/(16?64)=640
стр.
Пример 5. Текст
занимает полных 10 секторов на односторонней дискете объемом 180 Кбайт. Дискета
разбита на 40 дорожек по 9 секторов. Сколько символов содержит текст?
Ответ:((180?1024)/(40?9))?10=5120
симв.
IV. Подведение
итогов урока
V. Домашнее
задание
Читать: § 13; выполнить ДЗ №10
Тестирование по разделу
«Текстовые редакторы»
A01:
Таблица кодировки символов
устанавливает соответствие между
1) символами, их десятичными
номерами и двоичными кодами
2) символами разных алфавитов
3) символами и количеством байтов,
которые они занимают
4) символами и номерами ячеек
памяти, которые они занимают
5) символами и клавишами
A02:
Что будет меняться при представлении
символа на экране монитора в различных кодировках (Windows, MS-DOS, КОИ8-Р
и т.д.)?
1) гарнитура шрифта
2) размер символа
3) символ
4) начертание символа
5) изменений не будет
A03:
Код (номер) буквы «j» в
таблице кодировки символов равен 106. Какая последовательность букв будет
соответствовать слову «file»?
Алфавит латинских букв:
abcdefghijklmn …
1) 110 107 104 111
2) 74 98 120 66
3) 132 112 90 140
4) 102 105 108 101
5) 90 102 114 86
A04:
Последовательность кодов 105 162
109 таблицы кодировки шифрует некоторые символы. Вставить вместо многоточия верное
утверждение.
«Среди этих символов …»
1) не может быть букв русского
алфавита
2) не может быть букв латинского
алфавита
3) могут быть буквы русского и
латинского алфавитов
4) не может быть букв русского и
латинского алфавитов
5) может быть только одна буква
латинского алфавита
A05:
Для хранения текста требуется 10
Кбайт. Сколько страниц займет этот текст, если на странице размещается 40
строк по 64 символа в строке?
1) 4
2) 40
3) 160
4) 256
5) 320
A06:
Координаты курсора текстового
редактора фиксируются
1) в меню текстового редактора
2) в словаре текстового редактора
3) в строке состояния текстового
редактора
4) в окне текстового редактора
5) в буфере для копирования
A07:
Выберите фразу, написание которой
соответствует правилам набора текста на компьютере:
1) Во всех трамваях окна изо льда .
Белы деревья, крыши, провода
2) Я светлый образ в сердце
берегу:у зимней Волги Ярославль в снегу.
3) Во всех трамваях окна изо льда.
Белы деревья , крыши , провода.
4) Я светлый образ в сердце берегу:
у зимней Волги Ярославль в снегу.
5) Во всех трамваях окна изо
льда.Белы деревья, крыши , провода.
A08:
Выбрать действие, относящееся к
форматированию текста:
1) копирование фрагментов текста
2) исправление опечаток
3) проверка орфографии
4) изменение размера полей
5) перемещение фрагментов текста
A09:
При печати документа на странице
умещается 60 строк по 80 символов в каждой. Какие параметры необходимо
изменить, чтобы на странице умещалось меньшее количество символов?
1) изменить кодировку
2) изменить начертание шрифта
3) уменьшить размер полей страницы
4) уменьшить гарнитуру шрифта
5) увеличить интервал между
строками
A10:
Какие символы могут быть
зашифрованы кодами таблицы ASCII: 119 и 251?
1) «д» и «ш»
2) «j» и «s»
3) «d» и «D»
4) «я» и «t»
5) «w» и «ы»
A11:
В текстовом редакторе можно
использовать только один шрифт и две кнопки для установки таких эффектов как
полужирное начертание и курсив. Сколько различных начертаний символов можно
получить?
1) 1
2) 2
3) 3
4) 4
5) 6
A12:
Размер окна текстового редактора –
20 строк по 64 символа в строке. Курсор находится в левом верхнем углу экрана и
указывает на символ, стоящий в 25-й строке и 5 позиции текста. Какой из
указанных символов будет виден в окне?
1) стоящий в 25-й строке и 70
позиции текста
2) стоящий в 35-й строке и 50
позиции текста
3) стоящий в 1-й строке и 1 позиции
текста
4) стоящий в 46-й строке и 57
позиции текста
5) стоящий в 20-й строке и 5
позиции текста
A13:
В минимальный набор функций,
которые должен выполнять текстовый редактор, не входит:
1) сохранение файлов
2) загрузка файлов
3) форматирование текста
4) работа с графикой
5) редактирование текста
A14:
Для редактирования неверно
набранных символов используются клавиши:
1) Backspace,
Delete, Insert
2) Home, End,
Insert
3) Home, End
4) Backspace,
Delete
5) Shift, Enter
A15:
Буфер обмена — это:
1) раздел оперативной памяти
2) раздел жесткого магнитного диска
3) часть устройства ввода
4) раздел ПЗУ
5) часть устройства вывода
A16:
Текст занимает 0,25 Кбайт памяти
компьютера. Сколько символов содержит текст?
1) 32
2) 64
3) 128
4) 256
5) 512
A17:
Во время работы текстового
редактора орфографический словарь
1) по мере необходимости
загружается в оперативную память
2) по мере необходимости
загружается во внешнюю память
3) постоянно находится в устройстве
ввода
4) постоянно находится в ПЗУ
5) постоянно находится в устройстве
вывода
A18:
Для перемещении фрагмента текста из
одного места документа в другое необходимо выполнить команду(ы):
1) Копировать, Вставить
2) Вырезать
3) Вырезать, Вставить
4) Сохранить, Вставить
5) Вставить
A19:
Текст состоит из 50 строк по 60
символов в каждой. Размер окна текстового редактора 20 ´ 50 символов.
Курсор стоит в левом верхнем углу рабочего поля и в строке состояния
отображается его позиция: (11,11). Сколько символов будет видно на экране?
1) 20
2) 200
3) 100
4) 500
5) 1000
A20:
Сколько слов (с точки зрения
текстового редактора)содержится в следующем тексте, содержащем ряд ошибок: «Раз,два, три, четыре, пять. Вышел
зайчик по гулять. В друг охотник вы бегает.»
1) 9
2) 10
3) 11
4) 12
5) 13
Литература
И. Семакин и др. Информатика.
Базовый курс 7 – 9.
- N=2 i , I=log2 1/p какие это формулы и когда они применяются?
- Для знакового представления информации используется………
- Какие единицы информации вы знаете?
- Вы подошли к светофору, когда горел желтый цвет. После этого загорелся зеленый. Какое количество информации вы при этом получили?
- Объем информационного сообщения составляет 1 6 384 бита. Выразить его в килобайтах.
- Сколько бит информации содержит сообщение объемом 4 Мб? Ответ дать в степенях 2.
- В корзине лежат 8 шаров. Все шары разного цвета. Сколько информации несет сообщение о том, что из корзины достали красный шар?
- Сообщение, записанное буквами из 16-символьного алфавита, содержит 512 символов. Какой объем информации оно несет в килобайтах?
- Сколько символов содержит сообщение, записанное с помощью 16-символьного алфавита, если объем ею составил 1/16 часть килобайта?
3. Кодирование информации в компьютере — Подготовка к ГИА
Количество различных цветов K и количество битов для их кодирования глубина цвета L связаны формулой K 2 L.
Формула объема памяти в информатике
В традиционной кодировке (Windows, ASCII) для кодирования одного символа используется 1 байт (8 бит). Эта величина и является информационным весом одного символа. Такой 8-ми разрядный код позволяет закодировать 256 различных символов, т.к. 2 8 =256.
В настоящее время широкое распространение получил новый международный стандарт Unicode, который отводит на каждый символ два байта (16 бит). С его помощью можно закодировать 2 16 = 65536 различных символов.
Информация в кодировке Unicode передается со скоростью 128 знаков в секунду в течение 32 минут. Какую часть дискеты ёмкостью 1,44Мб займёт переданная информация?
nсимв = v*t = 245760 символов V=nсимв*i = 245760*16 = 3932160 бит = 491520 байт = 480 Кб = 0,469Мб, что составляет 0,469Мб*100%/1,44Мб = 33% объёма дискеты
Мнение эксперта
Знайка, главный эксперт в Цветочном городе
Если у вас возникли сложности, обращайтесь ко мне, и я помогу разобраться 🦉
Задать вопрос эксперту
Решение задач по теме «Количество информации» Сообщение о том, что он вчера получил четверку, несет 2 бита информации. А если у Вас остались вопросы, задайте их мне!
Представление символов, таблицы кодировок — Викиконспекты
Коды с 33 по 127 являются интернациональными и соответствуют символам латинского алфавита, цифрам, знакам арифметических операций и знакам препинания.
Кодировки стандарта ASCII [ править ]
- ASCII — первая кодировка, в которой стало возможно использовать символы национальных алфавитов.
- КОИ8-R — первая русская кодировка. Символы кириллицы расположены не в алфавитном порядке. Их разместили в верхнюю половину таблицы так, чтобы позиции кириллических символов соответствовали их фонетическим аналогам в английском алфавите. Это значит, что даже при потере старшего бита каждого символа, например, при проходе через устаревший семибитный модем, текст остается «читаемым».
- CP866 — русская кодировка, использовавшаяся на компьютерах IBM в системе DOS.
- Windows-1251 — русская кодировка, использовавшаяся в русскоязычных версиях операционной системы Windows в начале 90-х годов. Кириллические символы идут в алфавитном порядке. Содержит все символы, встречающиеся в типографике обычного текста (кроме знака ударения).
Структурные свойства таблицы [ править ]
Различия [ править ]
Сколько символов содержит сообщение, записанное с помощью 16-символьного алфавита, если его объем составил 1 16 часть мегабайта.
Содержание
Водитель передает сигнал с помощью гудка или миганием фар. Вы встречаетесь с кодированием информации при переходе дороги в виде сигналов светофора.
Та же проблема универсального средства кодирования достаточно успешно реализуется в отдельных отраслях техники, науки и культуры.
В качестве примеров можно привести систему записи математических выражений, телеграфную азбуку, морскую флажковую азбуку, систему Брайля для слепых и многое другое.
Мнение эксперта
Знайка, главный эксперт в Цветочном городе
Если у вас возникли сложности, обращайтесь ко мне, и я помогу разобраться 🦉
Задать вопрос эксперту
Как кодируется звуковая информация Который из двух байт в словах идёт впереди, старший или младший, зависит от порядка байт. А если у Вас остались вопросы, задайте их мне!
Содержание
Та же проблема универсального средства кодирования достаточно успешно реализуется в отдельных отраслях техники, науки и культуры.
Примеры решенных задач
Решение.
Слово состоит из 14 букв. Каждая буква является символом компьютерного алфавита и поэтому занимает 1 байт памяти. Слово займет 14 байт = 112 бит памяти, т.к. 1 байт = 8 бит.
Пример №2.
Буква «i» в таблице кодировки символов имеет десятичный код 105. Что зашифровано последовательностью десятичных кодов: 108 105 110 107?
Пример №3.
С помощью последовательности десятичных кодов: 99 111 109 112 117 116 101 114 зашифровано слово «computer». Какая последовательность десятичных кодов будет соответствовать этому же слову, записанному заглавными буквами?
01110011 01110100 01101111 01110000 соответствует слову «stop». Построить внутреннее шестнадцатеричное представление этого слова.
Содержание:
- 0.1 3. Кодирование информации в компьютере — Подготовка к ГИА
- 1 Формула объема памяти в информатике
- 1.1 Представление символов, таблицы кодировок — Викиконспекты
- 1.2 Кодировки стандарта ASCII [ править ]
- 1.3 Различия [ править ]
- 1.4 Содержание
- 1.5 Содержание