
Порой бывает нужно скачать какой-нибудь сайт полностью к себе на компьютер. Причины могут быть разные: для сохранения на будущее (сайты часто исчезают и появляются), для возможности просмотра оффлайн и прочего.
Есть много способов скачать сайт. В этой статье рассматривается утилита wget. Она обычно сразу есть в Linux-е, если её нет, то можно легко установить из репозитария. Для Windows придётся сначала установить Cygwin, выбрав при установке wget, так как по умолчанию он не устанавливается.
Скачивается сайт вот такой командой:
|
wget -r -k -l 7 -p -E -nc http://urvanov.ru/ |
или для сайтов с русскими символами в адресах страниц:
|
wget -r -k -l 7 -p -E -nc —restrict-file-names=nocontrol http://urvanov.ru/ |
Здесь ключи обозначают следующее:
-r — рекурсивный обход ссылок на сайте для скачивания всех страниц.
-k — преобразование ссылок для работы на своём компьютере, а не в интернете.
-p — загрузка всех необходимых файлов (css, картинки и прочее)
-l — максимальная глубина вложенности страниц.
-E — добавлять к загруженным файлам расширение «.html».
-nc — не перезаписывать существующие файлы.
—restrict-file-names=nocontrol — отключает экранирование символов (полезно, если имена файлов содержат русские символы). Возможные опции —restrict-file-names=windows (экранирование символов, которых не может быть в имени файла Windows), —restrict-file-names=unix (экранирование символов, которых не может быть в имени файла unix).
WGet — программа для загрузки файлов и
скачивания сайта целиком.
Скачать WGet для Windows можно здесь
Пришедшая из мира Linux, свободно распространяемая утилита Wget позволяет скачивать как отдельные файлы из интернета,
так и сайты целиком, следуя по ссылкам на веб-страницах.
Чтобы получить подсказку по параметрам WGet, наберите команду man wget в Linux или wget.exe —help в Windows.
Допустим, мы хотим создать полную копию сайта www.site.com на своем диске.
Для этого открываем командную строку (Wget — утилита консольная) и пишем такую команду:
wget.exe -r -l10 -k -p -E -nc http://www.site.com
WGET рекурсивно (параметр -r) обойдет каталоги и подкаталоги на удалённом сервере включая css-стили(-k)
с максимальной глубиной рекурсии равной десяти (-l), а затем заменить в загруженных HTML-документах
абсолютные ссылки на относительные (-k) и расширения на html(-E) для последующего локального просмотра скачанного сайта.
При повторном скачивании не будут лица и перезаписываться повторы(-nc).
К сожалению, внутренние стили и картинки указанные в стилях не скачиваются
Если предполагается загрузка с сайта какого-либо одного каталога (со всеми вложенными в него папками),
то логичнее будет включить в командную строку параметр -np. Он не позволит утилите при поиске файлов
подниматься по иерархии каталогов выше указанной директории:
wget.exe -r -l10 -k http://www.site.com -np
Если загрузка данных была случайно прервана, то для возобновления закачки с места останова,
необходимо в команду добавить ключ -с:
wget.exe -r -l10 -k http://www.site.com -c
По умолчанию, всё скаченное сохраняется в рабочей директории утилиты.
Определить другое месторасположение копируемых файлов поможет параметр -P:
wget.exe -r -l10 -k http://www.site.com -P c:\internet\files
Наконец, если сетевые настройки вашей сети предполагают использование прокси-сервера,
то его настройки необходимо сообщить программе. См. Конфигурирование WGET
wget -m -k -nv -np -p --user-agent="Mozilla/5.0 (compatible; Konqueror/3.0.0/10; Linux)" АДРЕС_САЙТА
Загрузка всех URL, указанных в файле FILE:
wget -i FILE
Скачивание файла в указанный каталог (-P):
wget -P /path/for/save ftp://ftp.example.org/some_file.iso
Использование имени пользователя и пароля на FTP/HTTP (вариант 1):
wget ftp://login:password@ftp.example.org/some_file.iso
Использование имени пользователя и пароля на FTP/HTTP (вариант 2):
wget --user=login --password=password ftp://ftp.example.org/some_file.iso
Скачивание в фоновом режиме (-b):
wget -b ftp://ftp.example.org/some_file.iso
Продолжить (-c continue) загрузку ранее не полностью загруженного файла:
wget -c http://example.org/file.iso
Скачать страницу с глубиной следования 10, записывая протокол в файл log:
wget -r -l 10 http://example.org/ -o log
Скачать содержимое каталога http://example.org/~luzer/my-archive/ и всех его подкаталогов,
при этом не поднимаясь по иерархии каталогов выше:
wget -r --no-parent http://example.org/~luzer/my-archive/
Для того, чтобы во всех скачанных страницах ссылки преобразовывались в относительные для локального просмотра,
необходимо использовать ключ -k:
wget -r -l 10 -k http://example.org/
Также поддерживается идентификация на сервере:
wget --save-cookies cookies.txt --post-data 'user=foo&password=bar' http://example.org/auth.php
Скопировать весь сайт целиком:
wget -r -l0 -k http://example.org/
Например, не загружать zip-архивы:
wget -r -R «*.zip» http://freeware.ru
Залогиниться и скачать файлик ключа
@echo off wget --save-cookies cookies.txt --post-data "login=ТВОЙЛОГИН&password=ТВОЙПАРОЛЬ" http://beta.drweb.com/files/ -O- wget --load-cookies cookies.txt "http://beta.drweb.com/files/?p=win%%2Fdrweb32-betatesting.key&t=f" -O drweb32-betatesting.key
Внимание! Регистр параметров WGet различен!
Базовые ключи запуска
-V
—version
Отображает версию Wget.
-h
—help
Выводит помощь с описанием всех ключей командной строки Wget.
-b
—background
Переход в фоновый режим сразу после запуска. Если выходной файл не задан -o, выход перенаправляется в wget-log.
-e command
—execute command
Выполнить command, как если бы она была частью файла .wgetrc.
Команда, запущенная таким образом, будет выполнена после команд в .wgetrc, получая приоритет над ними.
Для задания более чем одной команды wgetrc используйте несколько ключей -e.
Протоколирование и ключи входного файла
-o logfile
—output-file=logfile
Протоколировать все сообщения в logfile. Обычно сообщения выводятся в standard error.
-a logfile
—append-output=logfile
Дописывать в logfile. То же, что -o, только logfile не перезаписывается, а дописывается.
Если logfile не существует, будет создан новый файл.
-d
—debug
Включает вывод отладочной информации, т.е. различной информации, полезной для разработчиков Wget при некорректной работе.
Системный администратор мог выбрать сборку Wget без поддержки отладки, в этом случае -d работать не будет.
Помните, что сборка с поддержкой отладки всегда безопасна — Wget не будет выводить отладочной информации,
пока она явно не затребована через -d.
-q
—quiet
Выключает вывод Wget.
-v
—verbose
Включает подробный вывод со всей возможной информацией. Задано по умолчанию.
-nv
—non-verbose
Неподробный вывод — отключает подробности, но не замолкает совсем (используйте -q для этого),
отображаются сообщения об ошибках и основная информация.
-i file
—input-file=file
Читать URL из входного файла file, в этом случае URL не обязательно указывать в командной строке.
Если адреса URL указаны в командной строке и во входном файле, первыми будут запрошены адреса из командной строки.
Файл не должен (но может) быть документом HTML — достаточно последовательного списка адресов URL.
Однако, при указании —force-html входной файл будет считаться html.
В этом случае могут возникнуть проблемы с относительными ссылками,
которые можно решить указанием <base href=»url»> внутри входного файла или —base=url в командной строке.
-F
—force-html
При чтении списка адресов из файла устанавливает формат файла как HTML.
Это позволяет организовать закачку по относительным ссылкам в локальном HTML-файле при указании <base href=»url»>
внутри входного файла или —base=url в командной строке.
-B URL
—base=URL
Используется совместно c -F для добавления URL к началу относительных ссылок во входном файле, заданном через -i.
Ключи скачивания
—bind-address=ADDRESS
При открытии клиентских TCP/IP соединений bind() на ADDRESS локальной машины. ADDRESS может указываться в виде имени хоста или IP-адреса.
Этот ключ может быть полезен, если машине выделено несколько адресов IP.
-t number
—tries=number
Устанавливает количество попыток в number. Задание 0 или inf соответствует бесконечному числу попыток. По умолчанию равно 20,
за исключением критических ошибок типа «в соединении отказано» или «файл не найден» (404), при которых попытки не возобновляются.
-O file
—output-document=file
Документы сохраняются не в соответствующие файлы, а конкатенируются в файл с именем file.
Если file уже существует, то он будет перезаписан. Если в качестве file задано -, документы будут выведены в стандартный вывод (отменяя -k).
Помните, что комбинация с -k нормально определена только для скачивания одного документа.
-nc
—no-clobber
Если файл скачивается более одного раза в один и тот же каталог, то поведение Wget определяется несколькими ключами, включая -nc.
В некоторых случаях локальный файл будет затёрт или перезаписан при повторном скачивании, в других — сохранён.
При запуске Wget без -N, -nc или -r скачивание того же файла в тот же каталог приводит к тому, что исходная копия файла сохраняется,
а новая копия записывается с именем file.1. Если файл скачивается вновь, то третья копия будет названа file.2 и т.д.
Если указан ключ -nc, такое поведение подавляется, Wget откажется скачивать новые копии файла.
Таким образом, «no-clobber» неверное употребление термина в данном режиме — предотвращается не затирание файлов
(цифровые суффиксы уже предотвращали затирание), а создание множественных копий.
При запуске Wget с ключом -r, но без -N или -nc, перезакачка файла приводит к перезаписыванию на место старого.
Добавление -nc предотвращает такое поведение, сохраняя исходные версии файлов и игнорируя любые новые версии на сервере.
При запуске Wget с ключом -N, с или без -r, решение о скачивании новой версии файла зависит от локальной
и удалённой временных отметок и размера файла. -nc не может быть указан вместе с -N.
При указании -nc файлы с расширениями .html и .htm будут загружаться с локального диска и обрабатываться так,
как если бы они были скачаны из сети.
-c
—continue
Продолжение закачки частично скачанного файла. Это полезно при необходимости завершить закачку,
начатую другим процессом Wget или другой программой. Например:
wget -c ftp://htmlweb.ru/ls-lR.Z
Если в текущем каталоге имеется файл ls-lR.Z, то Wget будет считать его первой частью удалённого файла и запросит сервер
о продолжении закачки с отступом от начала, равному длине локального файла.
Нет необходимости указывать этот ключ, чтобы текущий процесс Wget продолжил закачку при пи потере связи на полпути.
Это изначальное поведение. -c влияет только на закачки, начатые до текущего процесса Wget, если локальные файлы уже существуют.
Без -c предыдущий пример сохранит удалённый файл в ls-lR.Z.1, оставив ls-lR.Z без изменения.
Начиная с версии Wget 1.7, при использовании -c с непустым файлом, Wget откажется начинать закачку сначала,
если сервер не поддерживает закачку, т.к. это привело бы к потере скачанных данных. Удалите файл, если вы хотите начать закачку заново.
Также начиная с версии Wget 1.7, при использовании -c для файла равной длины файлу на сервере Wget откажется
скачивать и выведет поясняющее сообщение. То же происходит, если удалённый файл меньше локального
(возможно, он был изменён на сервере с момента предыдущей попытки) — т.к. «продолжение» в данном случае бессмысленно,
скачивание не производится.
С другой стороны, при использовании -c локальный файл будет считаться недокачанным, если длина удалённого файла больше длины локального.
В этом случае (длина(удалённая) — длина(локальная)) байт будет скачано и приклеено в конец локального файла.
Это ожидаемое поведение в некоторых случаях: например, можно использовать -c для скачивания новой порции собранных данных или лог-файла.
Однако, если файл на сервере был изменён, а не просто дописан, то вы получите испорченный файл. Wget не обладает механизмами проверки,
является ли локальный файл начальной частью удалённого файла. Следует быть особенно внимательным при использовании -c совместно с -r,
т.к. каждый файл будет считаться недокачанным.
Испорченный файл также можно получить при использовании -c с кривым HTTP прокси, который добавляет строку тима «закачка прервана».
В будущих версиях возможно добавление ключа «откат» для исправления таких случаев.
Ключ -c можно использовать только с FTP и HTTP серверами, которые поддерживают заголовок Range.
—progress=type
Выбор типа индикатора хода закачки. Возможные значения: «dot» и «bar».
Индикатор типа «bar» используется по умолчанию. Он отображает ASCII полосу хода загрузки (т.н. «термометр»).
Если вывод не в TTY, то по умолчанию используется индикатор типа «dot».
Для переключения в режим «dot» укажите —progress=dot. Ход закачки отслеживается и выводится на экран в виде точек,
где каждая точка представляет фиксированный размер скачанных данных.
При точечной закачке можно изменить стиль вывода, указав dot:style. Различные стили определяют различное значение для одной точки.
По умолчанию одна точка представляет 1K, 10 точек образуют кластер, 50 точек в строке.
Стиль binary является более «компьютер»-ориентированным — 8K на точку, 16 точек на кластер и 48 точек на строку (384K в строке).
Стиль mega наиболее подходит для скачивания очень больших файлов — каждой точке соответствует 64K, 8 точек на кластер и 48 точек в строке
(строка соответствует 3M).
Стиль по умолчанию можно задать через .wgetrc. Эта установка может быть переопределена в командной строке.
Исключением является приоритет «dot» над «bar», если вывод не в TTY. Для непременного использования bar укажите —progress=bar:force.
-N
—timestamping
Включает использование временных отметок.
-S
—server-response
Вывод заголовков HTTP серверов и ответов FTP серверов.
—spider
При запуске с этим ключом Wget ведёт себя как сетевой паук, он не скачивает страницы, а лишь проверяет их наличие.
Например, с помощью Wget можно проверить закладки:
wget --spider --force-html -i bookmarks.html
Эта функция требует большой доработки, чтобы Wget достиг функциональности реальных сетевых пауков.
-T seconds
—timeout=seconds
Устанавливает сетевое время ожидания в seconds секунд. Эквивалентно одновременному указанию —dns-timeout,
—connect-timeout и —read-timeout.
Когда Wget соединяется или читает с удалённого хоста, он проверяет время ожидания и прерывает операцию при его истечении.
Это предотвращает возникновение аномалий, таких как повисшее чтение или бесконечные попытки соединения.
Единственное время ожидания, установленное по умолчанию, — это время ожидания чтения в 900 секунд.
Установка времени ожидания в 0 отменяет проверки.
Если вы не знаете точно, что вы делаете, лучше не устанавливать никаких значений для ключей времени ожидания.
—dns-timeout=seconds
Устанавливает время ожидания для запросов DNS в seconds секунд. Незавершённые в указанное время запросы DNS будут неуспешны.
По умолчанию никакое время ожидания для запросов DNS не устанавливается, кроме значений, определённых системными библиотеками.
—connect-timeout=seconds
Устанавливает время ожидания соединения в seconds секунд. TCP соединения, требующие большего времени на установку, будут отменены.
По умолчанию никакое время ожидания соединения не устанавливается, кроме значений, определённых системными библиотеками.
—read-timeout=seconds
Устанавливает время ожидания чтения (и записи) в seconds секунд. Чтение, требующее большего времени, будет неуспешным.
Значение по умолчанию равно 900 секунд.
—limit-rate=amount
Устанавливает ограничение скорости скачивания в amount байт в секунду. Значение может быть выражено в байтах,
килобайтах с суффиксом k или мегабайтах с суффиксом m. Например, —limit-rate=20k установит ограничение скорости скачивания в 20KB/s.
Такое ограничение полезно, если по какой-либо причине вы не хотите, чтобы Wget не утилизировал всю доступную полосу пропускания.
Wget реализует ограничение через sleep на необходимое время после сетевого чтения, которое заняло меньше времени,
чем указанное в ограничении. В итоге такая стратегия приводит к замедлению скорости TCP передачи приблизительно до указанного ограничения.
Однако, для установления баланса требуется определённое время, поэтому не удивляйтесь, если ограничение будет плохо работать
для небольших файлов.
-w seconds
—wait=seconds
Ждать указанное количество seconds секунд между закачками. Использование этой функции рекомендуется для снижения нагрузки на сервер
уменьшением частоты запросов. Вместо секунд время может быть указано в минутах с суффиксом m, в часах с суффиксом h или днях с суффиксом d.
Указание большого значения полезно, если сеть или хост назначения недоступны, так чтобы Wget ждал достаточное время для исправления
неполадок сети до следующей попытки.
—waitretry=seconds
Если вы не хотите, чтобы Wget ждал между различными закачками, а только между попытками для сорванных закачек,
можно использовать этот ключ. Wget будет линейно наращивать паузу, ожидая 1 секунду после первого сбоя для данного файла,
2 секунды после второго сбоя и так далее до максимального значения seconds.
Таким образом, значение 10 заставит Wget ждать до (1 + 2 + … + 10) = 55 секунд на файл.
Этот ключ включён по умолчанию в глобальном файле wgetrc.
—random-wait
Некоторые веб-сайты могут анализировать логи для идентификации качалок, таких как Wget,
изучая статистические похожести в паузах между запросами. Данный ключ устанавливает случайные паузы в диапазоне от 0 до 2 * wait секунд,
где значение wait указывается ключом —wait. Это позволяет исключить Wget из такого анализа.
В недавней статье на тему разработки популярных пользовательских платформ был представлен код,
позволяющий проводить такой анализ на лету. Автор предлагал блокирование подсетей класса C для
блокирования программ автоматического скачивания, несмотря на возможную смену адреса, назначенного DHCP.
На создание ключа —random-wait подвигла эта больная рекомендация блокировать множество невиновных пользователей по вине одного.
-Y on/off
—proxy=on/off
Включает или выключает поддержку прокси. Если соответствующая переменная окружения установлена, то поддержка прокси включена по умолчанию.
-Q quota
—quota=quota
Устанавливает квоту для автоматических скачиваний. Значение указывается в байтах (по умолчанию),
килобайтах (с суффиксом k) или мегабайтах (с суффиксом m).
Квота не влияет на скачивание одного файла. Так если указать wget -Q10k ftp://htmlweb.ru/ls-lR.gz,
файл ls-lR.gz будет скачан целиком. То же происходит при указании нескольких URL в командной строке.
Квота имеет значение при рекурсивном скачивании или при указании адресов во входном файле.
Т.о. можно спокойно указать wget -Q2m -i sites — закачка будет прервана при достижении квоты.
Установка значений 0 или inf отменяет ограничения.
—dns-cache=off
Отключает кеширование запросов DNS. Обычно Wget запоминает адреса, запрошенные в DNS,
так что не приходится постоянно запрашивать DNS сервер об одном и том же (обычно небольшом) наборе адресов.
Этот кэш существует только в памяти. Новый процесс Wget будет запрашивать DNS снова.
Однако, в некоторых случаях кеширование адресов не желательно даже на короткий период запуска такого приложения как Wget.
Например, секоторые серверы HTTP имеют динамически выделяемые адреса IP, которые изменяются время от времени.
Их записи DNS обновляются при каждом изменении. Если закачка Wget с такого хоста прерывается из-за смены адреса IP,
Wget повторяет попытку скачивания, но (из-за кеширования DNS) пытается соединиться по старому адресу.
При отключенном кешировании DNS Wget будет производить DNS-запросы при каждом соединении и, таким образом,
получать всякий раз правильный динамический адрес.
Если вам не понятно приведённое выше описание, данный ключ вам, скорее всего, не понадобится.
—restrict-file-names=mode
Устанавливает, какие наборы символов могут использоваться при создании локального имени файла из адреса удалённого URL.
Символы, запрещённые с помощью этого ключа, экранируются, т.е. заменяются на %HH, где HH — шестнадцатиричный код соответствующего символа.
По умолчанию Wget экранирует символы, которые не богут быть частью имени файла в вашей операционной системе,
а также управляющие символы, как правило непечатные. Этот ключ полезен для смены умолчания,
если вы сохраняете файл на неродном разделе или хотите отменить экранирование управляющих символов.
Когда mode установлен в «unix», Wget экранирует символ / и управляющие символы в диапазонах 0-31 и 128-159. Это умолчание для Ос типа Unix.
Когда mode установлен в «windows», Wget экранирует символы \, |, /, :, ?, «, *, <, > и управляющие символы в диапазонах 0-31 и 128-159.
Дополнительно Wget в Windows режиме использует + вместо : для разделения хоста и порта в локальных именах файлов и @ вместо ?
для отделения запросной части имени файла от остального. Таким образом, адрес URL, сохраняемый в Unix режиме как
www.htmlweb.ru:4300/search.pl?input=blah, в режиме Windows будет сохранён как www.htmlweb.ru+4300/search.pl@input=blah.
Этот режим используется по умолчанию в Windows.
Если к mode добавить, nocontrol, например, unix,nocontrol, экранирование управляющих символов отключается.
Можно использовать —restrict-file-names=nocontrol для отключения экранирования управляющих символов без влияния
на выбор ОС-зависимого режима экранирования служебных символов.
Ключи каталогов
-nd
—no-directories
Не создавать структуру каталогов при рекурсивном скачивании. С этим ключом все файлы сохраняются в текущий каталог
без затирания (если имя встречается больше одного раза, имена получат суффикс .n).
-x
—force-directories
Обратное -nd — создаёт структуру каталогов, даже если она не создавалась бы в противном случае.
Например, wget -x http://htmlweb.ru/robots.txt сохранит файл в htmlweb.ru/robots.txt.
-nH
—no-host-directories
Отключает создание хост-каталога. По умолчания запуск Wget -r http://htmlweb.ru/ создаст структуру каталогов,
начиная с htmlweb.ru/. Данный ключ отменяет такое поведение.
—protocol-directories
Использовать название протокола как компонент каталога для локальный файлов.
Например, с этим ключом wget -r http://host сохранит в http/host/… вместо host/….
—cut-dirs=number
Игнорировать number уровней вложенности каталогов. Это полезный ключ для чёткого управления каталогом для
сохранения рекурсивно скачанного содержимого.
Например, требуется скачать каталог ftp://htmlweb.ru/pub/xxx/. При скачивании с -r локальная копия будет сохранена
в ftp.htmlweb.ru/pub/xxx/. Если ключ -nH может убрать ftp.htmlweb.ru/ часть, остаётся ненужная pub/xemacs.
Здесь на помощь приходит —cut-dirs; он заставляет Wget закрывать глаза на number удалённых подкаталогов.
Ниже приведены несколько рабочих примеров —cut-dirs.
No options -> ftp.htmlweb.ru/pub/xxx/ -nH -> pub/xxx/ -nH --cut-dirs=1 -> xxx/ -nH --cut-dirs=2 -> . --cut-dirs=1 -> ftp.htmlweb.ru/xxx/
Если вам нужно лишь избавиться от структуры каталогов, то этот ключ может быть заменён комбинацией -nd и -P.
Однако, в отличии от -nd, —cut-dirs не теряет подкаталоги — например, с -nH —cut-dirs=1,
подкаталог beta/ будет сохранён как xxx/beta, как и ожидается.
-P prefix
—directory-prefix=prefix
Устанавливает корневой каталог в prefix. Корневой каталог — это каталог, куда будут сохранены все файлы и подкаталоги,
т.е. вершина скачиваемого дерева. По умолчанию . (текущий каталог).
Ключи HTTP
-E
—html-extension
Данный ключ добавляет к имени локального файла расширение .html, если скачиваемый URL имеет тип application/xhtml+xml или text/html,
а его окончание не соответствует регулярному выражению \.[Hh][Tt][Mm][Ll]?. Это полезно, например, при зеркалировании сайтов,
использующих .asp страницы, когда вы хотите, чтобы зеркало работало на обычном сервере Apache.
Также полезно при скачивании динамически-генерируемого содержимого. URL типа http://site.com/article.cgi?25
будет сохранён как article.cgi?25.html.
Сохраняемые таким образом страницы будут скачиваться и перезаписываться при каждом последующем зеркалировании,
т.к. Wget не может сопоставить локальный файл X.html удалённому адресу URL X
(он ещё не знает, что URL возвращает ответ типа text/html или application/xhtml+xml).
Для предотвращения перезакачивания используйте ключи -k и -K, так чтобы оригинальная версия сохранялась как X.orig.
—http-user=user
—http-passwd=password
Указывает имя пользователя user и пароль password для доступа к HTTP серверу. В зависимости от типа запроса Wget закодирует их,
используя обычную (незащищённую) или дайджест схему авторизации.
Другой способ указания имени пользователя и пароля — в самом URL. Любой из способов раскрывает ваш пароль каждому,
кто запустит ps. Во избежание раскрытия паролей, храните их в файлах .wgetrc или .netrc и убедитесь в недоступности
этих файлов для чтения другими пользователями с помощью chmod. Особо важные пароли не рекомендуется хранить даже в этих файлах.
Вписывайте пароли в файлы, а затем удаляйте сразу после запуска Wget.
—no-cache
Отключает кеширование на стороне сервера. В этой ситуации Wget посылает удалённому серверу соответствующую директиву
(Pragma: no-cache) для получения обновлённой, а не кешированной версии файла. Это особенно полезно для стирания устаревших
документов на прокси серверах.
Кеширование разрешено по умолчанию.
—no-cookies
Отключает использование cookies. Cookies являются механизмом поддержки состояния сервера.
Сервер посылает клиенту cookie с помощью заголовка Set-Cookie, клиент включает эту cookie во все последующие запросы.
Т.к. cookies позволяют владельцам серверов отслеживать посетителей и обмениваться этой информацией между сайтами,
некоторые считают их нарушением конфиденциальности. По умолчанию cookies используются;
однако сохранение cookies по умолчанию не производится.
—load-cookies file
Загрузка cookies из файла file до первого запроса HTTP. file — текстовый файл в формате,
изначально использовавшемся для файла cookies.txt Netscape.
Обычно эта опция требуется для зеркалирования сайтов, требующих авторизации для части или всего содержания.
Авторизация обычно производится с выдачей сервером HTTP cookie после получения и проверки регистрационной информации.
В дальнейшем cookie посылается обозревателем при просмотре этой части сайта и обеспечивает идентификацию.
Зеркалирование такого сайта требует от Wget подачи таких же cookies, что и обозреватель.
Это достигается через —load-cookies — просто укажите Wget расположение вашего cookies.txt, и он отправит идентичные обозревателю cookies.
Разные обозреватели хранят файлы cookie в разных местах:
Netscape 4.x. ~/.netscape/cookies.txt.
Mozilla and Netscape 6.x. Файл cookie в Mozilla тоже называется cookies.txt, располагается где-то внутри ~/.mozilla в директории вашего профиля.
Полный путь обычно выглядит как ~/.mozilla/default/some-weird-string/cookies.txt.
Internet Explorer. Файл cookie для Wget может быть получен через меню File, Import and Export, Export Cookies.
Протестировано на Internet Explorer 5; работа с более ранними версиями не гарантируется.
Other browsers. Если вы используете другой обозреватель, —load-cookies будет работать только в том случае,
если формат файла будет соответствовать формату Netscape, т.е. то, что ожидает Wget.
Если вы не можете использовать —load-cookies, может быть другая альтернатива.
Если обозреватель имеет «cookie manager», то вы можете просмотреть cookies, необходимые для зеркалирования.
Запишите имя и значение cookie, и вручную укажите их Wget в обход «официальной» поддержки:
wget --cookies=off --header "Cookie: name=value"
—save-cookies file
Сохранение cookies в file перед выходом. Эта опция не сохраняет истекшие cookies и cookies
без определённого времени истечения (так называемые «сессионные cookies»).
См. также —keep-session-cookies.
—keep-session-cookies
При указании —save-cookies сохраняет сессионные cookies. Обычно сессионные cookies не сохраняются,
т.к подразумевается, что они будут забыты после закрытия обозревателя. Их сохранение полезно для сайтов,
требующих авторизации для доступа к страницам. При использовании этой опции разные процессы Wget для сайта будут выглядеть
как один обозреватель.
Т.к. обычно формат файла cookie file не содержит сессионных cookies, Wget отмечает их временной отметкой истечения 0.
—load-cookies воспринимает их как сессионные cookies, но это может вызвать проблемы у других обозревателей
Загруженные таким образом cookies интерпретируются как сессионные cookies, то есть для их сохранения с
—save-cookies необходимо снова указывать —keep-session-cookies.
—ignore-length
К сожалению, некоторые серверы HTTP (CGI программы, если точнее) посылают некорректный заголовок Content-Length,
что сводит Wget с ума, т.к. он думает, что документ был скачан не полностью.
Этот синдром можно заметить, если Wget снова и снова пытается скачать один и тот же документ,
каждый раз указывая обрыв связи на том же байте.
С этим ключом Wget игнорирует заголовок Content-Length, как будто его никогда не было.
—header=additional-header
Укажите дополнительный заголовок additional-header для передачи HTTP серверу. Заголовки должны содержать «:»
после одного или более непустых символов и недолжны содержать перевода строки.
Вы можете указать несколько дополнительных заголовков, используя ключ —header многократно.
wget --header='Accept-Charset: iso-8859-2' --header='Accept-Language: hr' http://aaa.hr/
Указание в качестве заголовка пустой строки очищает все ранее указанные пользовательские заголовки.
—proxy-user=user
—proxy-passwd=password
Указывает имя пользователя user и пароль password для авторизации на прокси сервере. Wget кодирует их, использую базовую схему авторизации.
Здесь действуют те же соображения безопасности, что и для ключа —http-passwd.
—referer=url
Включает в запрос заголовок `Referer: url’. Полезен, если при выдаче документа сервер считает, что общается с интерактивным обозревателем,
и проверяет, чтобы поле Referer содержало страницу, указывающую на запрашиваемый документ.
—save-headers
Сохраняет заголовки ответа HTTP в файл непосредственно перед содержанием, в качестве разделителя используется пустая строка.
-U agent-string
—user-agent=agent-string
Идентифицируется как обозреватель agent-string для сервера HTTP.
HTTP протокол допускает идентификацию клиентов, используя поле заголовка User-Agent. Это позволяет различать программное обеспечение,
обычно для статистики или отслеживания нарушений протокола. Wget обычно идентифицируется как Wget/version, где version — текущая версия Wget.
Однако, некоторые сайты проводят политику адаптации вывода для обозревателя на основании поля User-Agent.
В принципе это не плохая идея, но некоторые серверы отказывают в доступе клиентам кроме Mozilla и Microsoft Internet Explorer.
Этот ключ позволяет изменить значение User-Agent, выдаваемое Wget. Использование этого ключа не рекомендуется,
если вы не уверены в том, что вы делаете.
—post-data=string
—post-file=file
Использует метод POST для всех запросов HTTP и отправляет указанные данные в запросе. —post-data отправляет в качестве данных строку string,
а —post-file — содержимое файла file. В остальном они работают одинаково.
Пожалуйста, имейте в виду, что Wget должен изначально знать длину запроса POST. Аргументом ключа —post-file должен быть обычный файл;
указание FIFO в виде /dev/stdin работать не будет. Не совсем понятно, как можно обойти это ограничение в HTTP/1.0.
Хотя HTTP/1.1 вводит порционную передачу, для которой не требуется изначальное знание длины, клиент не может её использовать,
если не уверен, что общается с HTTP/1.1 сервером. А он не может этого знать, пока не получит ответ, который, в свою очередь,
приходит на полноценный запрос. Проблема яйца и курицы.
Note: если Wget получает перенаправление в ответ на запрос POST, он не отправит данные POST на URL перенаправления.
Часто URL адреса, обрабатывающие POST, выдают перенаправление на обычную страницу (хотя технически это запрещено),
которая не хочет принимать POST. Пока не ясно, является ли такое поведение оптимальным; если это не будет работать, то будет изменено.
Пример ниже демонстрирует, как авторизоваться на сервере, используя POST, и затем скачать желаемые страницы,
доступные только для авторизованных пользователей:
wget --save-cookies cookies.txt --post-data 'user=foo&password=bar' http://htmlweb.ru/auth.php
wget --load-cookies cookies.txt -p http://server.com/interesting/article.php
Конфигурирование WGET
Основные настроки, которые необходимо писать каждый раз, можно указать в конфигурационном файле программы.
Для этого зайдите в рабочую директорию Wget, найдите там файл sample.wgetrc,
переименуйте его в .wgetrc и редакторе пропишите необходимые конфигурационные параметры.
user-agent = "Mozilla/5.0" tries = 5 количество попыток скачать wait = 0 не делать паузы continue = on нужно докачивать dir_prefix = ~/Downloads/ куда складывать скачаное use_proxy=on - использовать прокси http_proxy - характеристики вашего прокси-сервера.
Как под Windows заставить WGET читать настройки из wgetrc файла:
- Задать переменную окружения WGETRC, указав в ней полный путь к файлу.
- Задать переменную HOME, в которой указать путь к домашней папке пользователя (c:\Documents and settings\jonh).
Тогда wget будет искать файл «wgetrc» в этой папке. - Кроме этого можно создать файл wget.ini в той же папке, где находится wget.exe,
и задать там дополнительные параметры командной строки wget.
Полезную информацию по WGET можно почерпнуть здесь:
- http://mydebianblog.blogspot.com/2007/09/wget.html
- http://forum.ru-board.com/topic.cgi?forum=5&topic=10066
- PhantomJS — Используйте, если вам нужно скачать сайт, часть данных на котором загружается с помощью JavaScript
GNU Wget — консольная программа для загрузки файлов по сети. Поддерживает протоколы HTTP, FTP и HTTPS, а также работу через HTTP прокси-сервер. Программа включена почти во все дистрибутивы Linux. Утилита разрабатывалась для медленных соединений, поэтому она поддерживает докачку файлов при обрыве соединения.
Для работы с Wget под Windows, переходим по ссылке и скачиваем файл wget.exe. Создаем директорию C:\Program Files\Wget-Win64 и размещаем в ней скачанный файл. Для удобства работы добавляем в переменную окружения PATH путь до исполняемого файла.
Давайте попробуем что-нибудь скачать, скажем дистрибутив Apache под Windows:
> wget https://home.apache.org/~steffenal/VC15/binaries/httpd-2.4.35-win64-VC15.zip --2018-09-14 10:34:09-- https://home.apache.org/~steffenal/VC15/binaries/httpd-2.4.35-win64-VC15.zip Resolving home.apache.org (home.apache.org)... 163.172.16.173 Connecting to home.apache.org (home.apache.org)|163.172.16.173|:443... connected. HTTP request sent, awaiting response... 200 OK Length: 17856960 (17M) [application/zip] Saving to: 'httpd-2.4.35-win64-VC15.zip' httpd-2.4.35-win64-VC15.zip 100%[=================================================>] 17,03M 8,50MB/s in 2,0s 2018-09-14 10:34:12 (8,50 MB/s) - 'httpd-2.4.35-win64-VC15.zip' saved [17856960/17856960]
Если утилита ругается на сертификаты при скачивании по HTTPS, нужно использовать дополнительную опцию --no-check-certificate.
Примеры
Загрузка всех URL, указанных в файле (каждая ссылка с новой строки):
> wget -i download.txt
Скачивание файлов в указанный каталог:
> wget -P /path/for/save ftp://ftp.example.org/image.iso
Скачивание файла file.zip и сохранение под именем archive.zip:
> wget -O archive.zip http://example.com/file.zip
Продолжить загрузку ранее не полностью загруженного файла:
> wget -c http://example.org/image.iso
Вывод заголовков HTTP серверов и ответов FTP серверов:
> wget -S http://example.org/
Скачать содержимое каталога archive и всех его подкаталогов, при этом не поднимаясь по иерархии каталогов выше:
> wget -r --no-parent http://example.org/some/archive/
Использование имени пользователя и пароля на FTP/HTTP:
> wget --user=login --password=password ftp://ftp.example.org/image.iso
> wget ftp://login:password@ftp.example.org/image.iso
Отправить POST-запрос в формате application/x-www-form-urlencoded:
> wget --post-data="user=evgeniy&password=qwerty" http://example.org/auth/
Сохранение cookie в файл cookie.txt для дальнейшей отправки серверу:
> wget --save-cookie cookie.txt http://example.org/
Сохраненный файл cookie.txt:
# HTTP cookie file. # Generated by Wget on 2018-09-14 11:40:37. # Edit at your own risk. example.org FALSE / FALSE 1570196437 visitor 71f61d2a01de1394f60120c691a52c56
Отправка cookie, сохраненных ранее в файле cookie.txt:
> wget --load-cookie cookie.txt http://example.org/
Отправка заголовков:
> wget --header="Accept-Language: ru-RU,ru;q=0.9" --header="Cookie: PHPSESSID=....." http://example.org/
Справка по утилите:
> wget -h GNU Wget 1.11.4, программа для загрузки файлов из сети в автономном режиме. Использование: wget [ОПЦИЯ]... [URL]...
Запуск: -V, --version вывод версии Wget и выход. -h, --help вывод этой справки. -b, --background после запуска перейти в фоновый режим. -e, --execute=КОМАНДА выполнить команду в стиле .wgetrc. Журналирование и входной файл: -o, --output-file=ФАЙЛ записывать сообщения в ФАЙЛ. -a, --append-output=ФАЙЛ дописывать сообщения в конец ФАЙЛА. -d, --debug вывод большого количества отладочной информации. -q, --quiet молча (без выходных данных). -v, --verbose подробный вывод (по умолчанию). -nv, --no-verbose отключение подробного режима, но не полностью. -i, --input-file=ФАЙЛ загрузка URL-ов, найденных в ФАЙЛЕ. -F, --force-html считать, что входной файл - HTML. -B, --base=URL добавление URL в начало относительных ссылок в файле -F -i. Загрузка: -t, --tries=ЧИСЛО установить ЧИСЛО повторных попыток (0 без ограничения). --retry-connrefused повторять, даже если в подключении отказано. -O, --output-document=ФАЙЛ записывать документы в ФАЙЛ. -nc, --no-clobber пропускать загрузки, которые приведут к загрузке уже существующих файлов. -c, --continue возобновить загрузку частично загруженного файла. --progress=ТИП выбрать тип индикатора выполнения. -N, --timestamping не загружать повторно файлы, только если они не новее, чем локальные. -S, --server-response вывод ответа сервера. --spider ничего не загружать. -T, --timeout=СЕКУНДЫ установка значений всех тайм-аутов в СЕКУНДЫ. --dns-timeout=СЕК установка тайм-аута поиска в DNS в СЕК. --connect-timeout=СЕК установка тайм-аута подключения в СЕК. --read-timeout=СЕК установка тайм-аута чтения в СЕК. -w, --wait=СЕКУНДЫ пауза в СЕКУНДАХ между загрузками. --waitretry=СЕКУНДЫ пауза в 1..СЕКУНДЫ между повторными попытками загрузки. --random-wait пауза в 0...2*WAIT секунд между загрузками. --no-proxy явно выключить прокси. -Q, --quota=ЧИСЛО установить величину квоты загрузки в ЧИСЛО. --bind-address=АДРЕС привязка к АДРЕСУ (имя хоста или IP) локального хоста. --limit-rate=СКОРОСТЬ ограничение СКОРОСТИ загрузки. --no-dns-cache отключение кэширования поисковых DNS-запросов. --restrict-file-names=ОС ограничение на символы в именах файлов, использование которых допускает ОС. --ignore-case игнорировать регистр при сопоставлении файлов и/или каталогов. -4, --inet4-only подключаться только к адресам IPv4. -6, --inet6-only подключаться только к адресам IPv6. --prefer-family=СЕМЕЙСТВО подключаться сначала к адресам указанного семейства, может быть IPv6, IPv4 или ничего. --user=ПОЛЬЗОВАТЕЛЬ установить и ftp- и http-пользователя в ПОЛЬЗОВАТЕЛЬ. --password=ПАРОЛЬ установить и ftp- и http-пароль в ПАРОЛЬ. Каталоги: -nd, --no-directories не создавать каталоги. -x, --force-directories принудительно создавать каталоги. -nH, --no-host-directories не создавать каталоги как на хосте. --protocol-directories использовать имя протокола в каталогах. -P, --directory-prefix=ПРЕФИКС сохранять файлы в ПРЕФИКС/... --cut-dirs=ЧИСЛО игнорировать ЧИСЛО компонентов удалённого каталога. Опции HTTP: --http-user=ПОЛЬЗОВАТЕЛЬ установить http-пользователя в ПОЛЬЗОВАТЕЛЬ. --http-password=ПАРОЛЬ установить http-пароль в ПАРОЛЬ. --no-cache отвергать кэшированные сервером данные. -E, --html-extension сохранять HTML-документы с расширением .html. --ignore-length игнорировать поле заголовка Content-Length. --header=СТРОКА вставить СТРОКУ между заголовками. --max-redirect максимально допустимое число перенаправлений на страницу. --proxy-user=ПОЛЬЗОВАТЕЛЬ установить ПОЛЬЗОВАТЕЛЯ в качестве имени пользователя для прокси. --proxy-password=ПАРОЛЬ установить ПАРОЛЬ в качестве пароля для прокси. --referer=URL включить в HTTP-запрос заголовок Referer: URL. --save-headers сохранять HTTP-заголовки в файл. -U, --user-agent=АГЕНТ идентифицировать себя как АГЕНТ вместо Wget/ВЕРСИЯ. --no-http-keep-alive отключить поддержание активности HTTP (постоянные подключения). --no-cookies не использовать кукисы. --load-cookies=ФАЙЛ загрузить кукисы из ФАЙЛА перед сеансом. --save-cookies=ФАЙЛ сохранить кукисы в ФАЙЛ после сеанса. --keep-session-cookies загрузить и сохранить кукисы сеанса (непостоянные). --post-data=СТРОКА использовать метод POST; отправка СТРОКИ в качестве данных. --post-file=ФАЙЛ использовать метод POST; отправка содержимого ФАЙЛА. --content-disposition Учитывать заголовок Content-Disposition при выборе имён для локальных файлов (ЭКСПЕРИМЕНТАЛЬНЫЙ). --auth-no-challenge Отправить базовые данные аутентификации HTTP не дожидаясь ответа от сервера. Опции HTTPS (SSL/TLS): --secure-protocol=ПР выбор безопасного протокола: auto, SSLv2, SSLv3 или TLSv1. --no-check-certificate не проверять сертификат сервера. --certificate=FILE файл сертификата пользователя. --certificate-type=ТИП тип сертификата пользователя: PEM или DER. --private-key=ФАЙЛ файл секретного ключа. --private-key-type=ТИП тип секретного ключа: PEM или DER. --ca-certificate=ФАЙЛ файл с набором CA. --ca-directory=КАТ каталог, в котором хранится список CA. --random-file=ФАЙЛ файл со случайными данными для SSL PRNG. --egd-file=ФАЙЛ файл, определяющий сокет EGD со случайными данными. Опции FTP: --ftp-user=ПОЛЬЗОВАТЕЛЬ установить ftp-пользователя в ПОЛЬЗОВАТЕЛЬ. --ftp-password=ПАРОЛЬ установить ftp-пароль в ПАРОЛЬ. --no-remove-listing не удалять файлы файлы .listing. --no-glob выключить маски для имён файлов FTP. --no-passive-ftp отключить "пассивный" режим передачи. --retr-symlinks при рекурсии загружать файлы по ссылкам (не каталоги). --preserve-permissions сохранять права доступа удалённых файлов. Рекурсивная загрузка: -r, --recursive включение рекурсивной загрузки. -l, --level=ЧИСЛО глубина рекурсии (inf и 0 - бесконечность). --delete-after удалять локальные файлы после загрузки. -k, --convert-links делать ссылки локальными в загруженном HTML. -K, --backup-converted перед преобразованием файла X делать резервную копию X.orig. -m, --mirror короткая опция, эквивалентная -N -r -l inf --no-remove-listing. -p, --page-requisites загрузить все изображения и проч., необходимые для отображения HTML-страницы. --strict-comments включить строгую (SGML) обработку комментариев HTML. Разрешения/запреты при рекурсии: -A, --accept=СПИСОК список разрешённых расширений, разделённых запятыми. -R, --reject=СПИСОК список запрещённых расширений, разделённых запятыми. -D, --domains=СПИСОК список разрешённых доменов, разделённых запятыми. --exclude-domains=СПИСОК список запрещённых доменов, разделённых запятыми. --follow-ftp следовать по ссылкам FTP в HTML-документах. --follow-tags=СПИСОК список используемых тегов HTML, разделённых запятыми. --ignore-tags=СПИСОК список игнорируемых тегов HTML, разделённых запятыми. -H, --span-hosts заходить на чужие хосты при рекурсии. -L, --relative следовать только по относительным ссылкам. -I, --include-directories=СПИСОК список разрешённых каталогов. -X, --exclude-directories=СПИСОК список исключаемых каталогов. -np, --no-parent не подниматься в родительский каталог.
Дополнительно
- WGet — программа для загрузки файлов
Поиск:
CLI • Cookie • FTP • HTTP • HTTPS • Linux • POST • Web-разработка • Windows • wget • Форма
Каталог оборудования
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua.
Производители
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua.
Функциональные группы
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua.
In some rare cases you might run into the need to download a complete website onto your local machine for offline usage. There are many GUI tools to do this with loads of options. But did you know that you can do this with a shell command using a utility that you most likely already have installed?
Depending on your needs, downloading the html content of the website is just half of the job. You will need all the images, style-sheets and other linked media files. Linux provides already a command line tool that can do this and on many distributions this little tool might already be installed. The tool is called wget(1).
In case wget is not installed yet, install the package “wget” from whatever package repository is used by your distribution.
$ wget --mirror --convert-links --backup-converted --page-requisites --continue --adjust-extension --restrict-file-names=windows https://www.tinned-software.net 2>&1 | tee wget_download.log | grep "\-\-" --2020-07-08 16:01:56-- https://www.tinned-software.net/ Last-modified header missing -- time-stamps turned off. --2020-07-08 16:01:57-- https://www.tinned-software.net/robots.txt --2020-07-08 16:01:57-- https://www.tinned-software.net/favicon.ico --2020-07-08 16:01:57-- https://www.tinned-software.net/css/style_screen.css?v=3 ...
Once wget is installed, the command above will download a whole website. This is what the arguments used above mean:
- –mirror Turn on options suitable for mirroring. This option turns on recursion and time-stamping and sets infinite recursion depth.
- –convert-links This option will rewrite any links so the downloaded content can be browsed locally.
- –backup-converted This option created a backup of the downloaded content before converting it.
- –page-requisites This option causes wget to download all the files that are necessary to properly display a given HTML page.
- –continue Continue the download of already partially downloaded files.
- –adjust-extension Ensures a file-extension matching the content type delivered by the server is used to store the file.
- –restrict-file-names=windows Ensures the filenames do not contain any characters not allowed in filenames. Windows is used here as it is a bit more restrictive than “unix”.
The last two arguments are getting more and more important as many modern URLs don’t include a file extension (and some even use non-ASCII characters).
The output is piped into the command tee(1) to redirect the output to a file and as well as to the console. The grep(1) is only used to show the files downloaded.
The result is a local copy of the website with all links rewritten so they are not pointing to the website but to the local files on disk.
Tip
Checkout the manpage of wget(1) as there are many more settings that might be useful. You can define the depth of links to follow, the number of retries if a page could not be downloaded and more.
Observations
While testing the above command, I noticed that there are a few rare cases where the rewriting of the links does not catch all the possible ways the resource URLs are constructed, but in most cases, this produces a full copy of the website which can be opened and navigated through offline.
Read more of my posts on my blog at https://blog.tinned-software.net/.
This entry was posted in Linux Administration, Web technologies and tagged mirror, wget. Bookmark the permalink.
WGET is a free tool to crawl websites and download files via the command line.
In this wget tutorial, we will learn how to install and how to use wget commands with examples.

What is Wget?
Wget is free command-line tool created by the GNU Project that is used todownload files from the internet.
- It lets you download files from the internet via FTP, HTTP or HTTPS (web pages, pdf, xml sitemaps, etc.).
- It provides recursive downloads, which means that Wget downloads the requested document, then the documents linked from that document, and then the next, etc.
- It follows the links and directory structure.
- It lets you overwrite the links with the correct domain, helping you create mirrors of websites.
What Is the Wget Command?
The wget command is a tool developed by the GNU Project to download files from the web. Wget allows you to retrieve content and files from web servers using a command-line interface. The name “wget” comes from “World Wide Web” and “get”. Wget supports downloads via FTP, SFTP, HTTP, and HTTPS protocols.
Wget is used by developers to automate file downloads.
Install Wget
To install wget on Windows, install the executable file from eternallybored.org. To install wget on Mac, use the brew install wget command on Mac. Make sure that it is not already installed first by running the wget -V command in the command line interface. For more details on how to install Wget, read one of the following tutorials.
- Install Wget on Mac
- Install Wget on Windows
- Install Wget on Linux
Downloading Files From the Command Line (Wget Basics)
Let’s look at the wget syntax, view the basic commands structure and understand the most important options.
Wget Syntax
Wget has two arguments: [OPTION] and [URL] .
wget [OPTION]... [URL]...
- [OPTION] tells what to do with the [URL] argument provided after. It has a short and a long-form (ex:
-Vand--versionare doing the same thing). - [URL] is the file or the directory you wish to download.
- You can call many OPTIONS or URLs at once.
View WGET Arguments
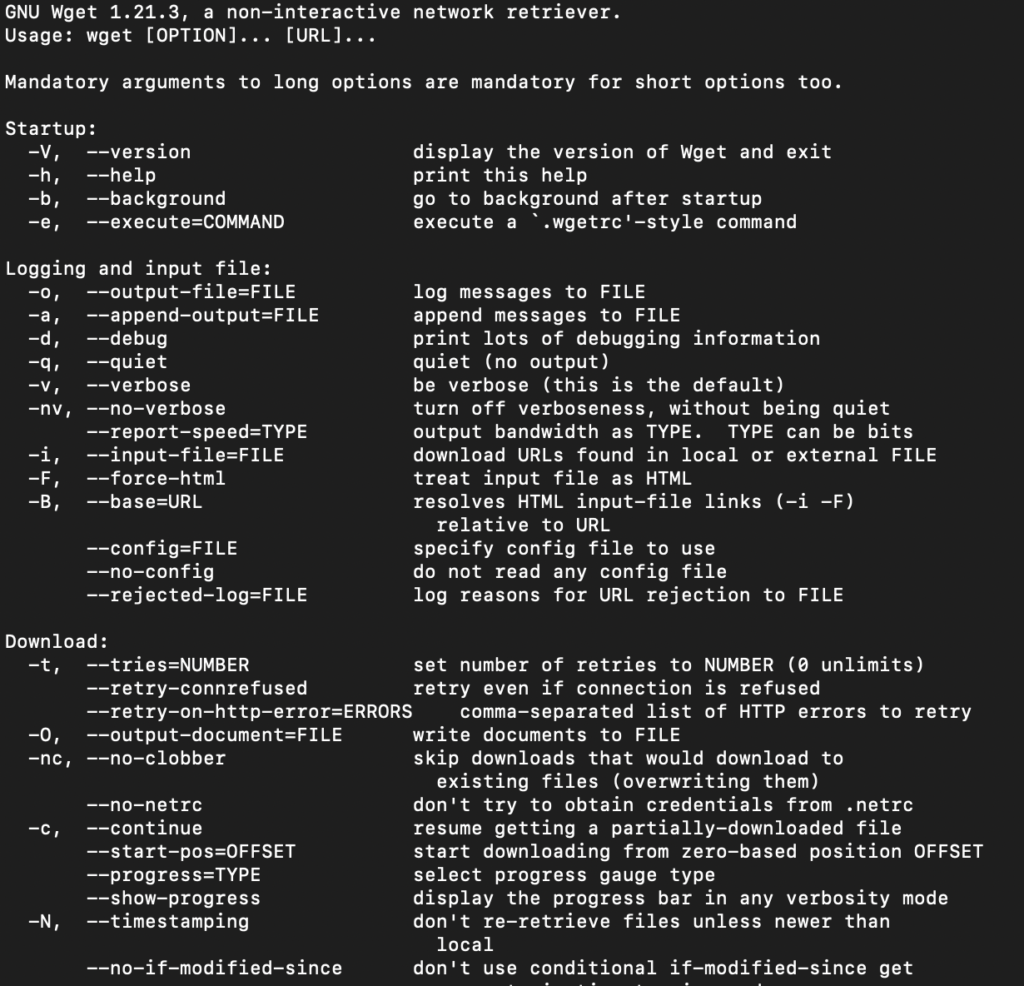
To view available wget Arguments, use the wget help command:
The output will show you an exhaustive list of all the wget command parameters.
Here are the 11 best things that you can do with Wget:
- Download a single file
- Download a files to a specific directory
- Rename a downloaded files
- Define User Agent
- Extract as Googlebot
- Extract Robots.txt when it changes
- Convert links on a page
- Mirror a single page
- Extract Multiple URLs from a list
- Limit Speed
- Number of attempts
- Use Proxies
- Continue Interrupted Downloads
- Extract Entire Website
Download a single file with Wget
$ wget https://example.com/robots.txt
Download a File to a Specific Output Directory
Here replace <YOUR-PATH> by the output directory location where you want to save the file.
$ wget ‐P <YOUR-PATH> https://example.com/sitemap.xml
Rename Downloaded File when Retrieving with Wget
To output the file with a different name:
$ wget -O <YOUR-FILENAME.html> https://example.com/file.html
Define User Agent in WGET
Identify yourself. Define your user-agent.
$ wget --user-agent=Chrome https://example.com/file.html
Extract as Googlebot with Wget Command
$ wget --user-agent="Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Mobile Safari/537.36 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)" https://example.com/path
Let’s extract robots.txt only if the latest version in the server is more recent than the local copy.
First time that you extract use -S to keep a timestamps of the file.
$ wget -S https://example.com/robots.txt
Later, to check if the robots.txt file has changed, and download it if it has.
$ wget -N https://example.com/robots.txt
Wget command to Convert Links on a Page
Convert the links in the HTML so they still work in your local version. (ex: example.com/path to localhost:8000/path)
$ wget --convert-links https://example.com/path
Mirror a Single Webpage in Wget
To mirror a single web page so that it can work on your local.
$ wget -E -H -k -K -p --convert-links https://example.com/path
Add all urls in a urls.txt file.
https://example.com/1 https://example.com/2 https://example.com/3
To be a good citizen of the web, it is important not to crawl too fast by using --wait and --limit-rate.
--wait=1: Wait 1 second between extractions.--limit-rate=10K: Limit the download speed (bytes per second)
Define Number of Retry Attempts in Wget
Sometimes the internet connection fails, sometimes the attempts it blocked, sometimes the server does not respond. Define a number of attempts with the -tries function.
$ wget -tries=10 https://example.com
How to Use Proxies With Wget?
To set a proxy with Wget, we need to update the ~/.wgetrc file located at /etc/wgetrc.
You can modify the ~/.wgetrc in your favourite text editor.
$ vi ~/.wgetrc # VI $ code ~/.wgetrc # VSCode
And add these lines to the wget parameters:
use_proxy = on http_proxy = http://username:password@proxy.server.address:port/ https_proxy = http://username:password@proxy.server.address:port/
Then, by running any wget command, you’ll be using proxies.
Alternatively, you can use the -e command to run wget with proxies without changing the environment variables.
wget -e use_proxy=yes -e http_proxy=http://proxy.server.address:port/ https://example.com
How to remove the Wget proxies?
When you don’t want to use the proxies anymore, update the ~/.wgetrc to remove the lines that you added or simply use the command below to override them:
Continue Interrupted Downloads with Wget
When your retrieval process is interrupted, continue the download with restarting the whole extraction using the -c command.
$ wget -c https://example.com
Recursive mode extract a page, and follows the links on the pages to extract them as well.
This is extracting your entire site and can put extra load on your server. Be sure that you know what you do or that you involve the devs.
$ wget --recursive --page-requisites --adjust-extension --span-hosts --wait=1 --limit-rate=10K --convert-links --restrict-file-names=windows --no-clobber --domains example.com --no-parent example.com
| Command | What it does |
|---|---|
| –recursive | Follow links in the document. The maximum depth is 5. |
| –page-requisites | Get all assets (CSS/JS/images) |
| –adjust-extension | Save files with .html at the end. |
| –span-hosts | Include necessary assets from offsite as well. |
| –wait=1 | Wait 1 second between extractions. |
| –limit-rate=10K | Limit the download speed (bytes per second) |
| –convert-links | Convert the links in the HTML so they still work in your local version. |
| –restrict-file-names=windows | Modify filenames to work in Windows. |
| –no-clobber | Overwrite existing files. |
| –domains example.com | Do not follow links outside this domain. |
| –no-parent | Do not ever ascend to the parent directory when retrieving recursively |
| –level | Specify the depth of crawling. |
$ wget --spider -r https://example.com -o wget.log
Wget VS Curl
Wget’s strength compared to curl is its ability to download recursively. This means that it will download a document, then follow the links and then download those documents as well.
Use Wget With Python
Wget is strictly command line, but there is a package that you can import the wget package that mimics wget.
import wget url = 'http://www.jcchouinard.com/robots.txt' filename = wget.download(url) filename
Debugging: What to Do When Wget is Not Working
Wget Command Not Found
If you get the -bash: wget: command not found error on Mac, Linux or Windows, it means that the wget GNU is either not installed or does not work properly.
Go back and make sure that you installed wget properly.
Wget is not recognized as an internal or external command
If you get the following error
'wget' is not recognized as an internal or external command, operable program or batch file
It is more than likely that the wget package was not installed on Windows. Fix the error by installing wget first and then start over using the command.
Otherwise, it may also mean that the wget command is not not found in your system’s PATH.
Adding Wget to the System’s Path (Windows)
Adding the wget command to the system’s path will allow you to run wget from anywhere.
To add wget to the Windows System ‘s Path you need to copy the wget.exe file to the right directory.
- Download the wget file for Windows
- Press
Windows + Eto open File Explorer. - Find where you downloaded
wget.exe(e.g. Downloads folder) - Copy the
wget.exefile - Paste into the System Directory (System32 is already in your system’s path)
- Go to
C:\Windows\System32. - Paste your
wget.exefile into your System32 folder
- Go to
wget: missing URL
The “wget: missing URL” error message occurs when you run the wget command without providing a URL to download.
One of the use cases that I have seen this is when users used flags without the proper casing.
$ wget -v # wget: missing URL
Above the casing of the v flag should not be lowercase, but uppercase.
Or use the verbose way of calling it with the double-dash and full name.
$ wget --version # No error
Alternatives to Wget on Mac and Windows
You can use cURL as an alternative of Wget command line tool. It also has to be installed on Mac, Linux and Windows.
Wget for Web Scraping
By allowing you to download files from the Internet, the wget command-line tool is incredibly useful in web scraping. It has a set of useful features that make web scraping easy:
- Batch Downloading:
wgetallows you to download multiple files or web pages in a single command. - Recursive Downloading: the
--recursiveflag inwgetallows you to follow links and download an entire website - Retries:
wgetis designed to handle unstable network connections and interruptions and retry failed extractions - Command-line options: Options are available to improve scraping capabilities (download speed, User-Agent headers, cookies for authentication, etc.).
- Header and User-Agent Spoofing: To avoid being blocked by websites when web scraping,
wgetallows you to change the User-Agent header to make your requests appear more regular users. - Limiting Server Load: By using the
--waitand--limit-rateoptions, you can control the speed at whichwgetfetches data.
About Wget
| Wget was developed by | Hrvoje Nikšić |
| Wget is Maintained by | Tim Rühsen and al. |
| Wget Supported Protocols | HTTP(S), FTP(S) |
| Wget was Created In | January 1996 |
| Installing Wget | brew install wget |
| Wget Command | wget [option]…[URL]… |
Wget FAQs
What is Wget Used For?
Wget is used to download files from the Internet without the use of a browser. It supports HTTP, HTTPS, and FTP protocols, as well as retrieval through HTTP proxies.
How Does Wget Work?
Wget is non-interactive and allows to download files from the internet in the background without the need of a browser or user interface. It works by following links to create local versions of remote web sites, while respecting robots.txt.
What is the Difference Between Wget and cURL?
Both Wget and cURL are command-line utilities that allow file transfer from the internet. Although, Curl generally offers more features than Wget, wget provide features such as recursive downloads.
Can you Use Wget With Python?
Yes, you can run wget get in Python by installing the wget library with $pip install wget
Does Wget Respect Robots.txt?
Yes, Wget respects the Robot Exclusion Standard (/robots.txt)
Is Wget Free?
Yes, GNU Wget is free software that everyone can use, redistribute and/or modify under the terms of the GNU General Public License
What is recursive download?
Recursive download, or recursive retrieval, is the capacity of downloading documents, follow the links within them and finally downloading those documents until all linked documents are downloaded, or the maximum depth specified is reached.
How to specify download location in Wget?
Use the -P or –directory-prefix=PREFIX. Example: $ wget -P /path <url>
Conclusion
This is it.
You now know how to install and use Wget in your command-line.
SEO Strategist at Tripadvisor, ex- Seek (Melbourne, Australia). Specialized in technical SEO. Writer in Python, Information Retrieval, SEO and machine learning. Guest author at SearchEngineJournal, SearchEngineLand and OnCrawl.