
Connecting to a Database
psql is a regular PostgreSQL client application. In order to connect to a database you need to know the name of your target database, the host name and port number of the server, and what database user name you want to connect as. psql can be told about those parameters via command line options, namely -d, -h, -p, and -U respectively. If an argument is found that does not belong to any option it will be interpreted as the database name (or the database user name, if the database name is already given). Not all of these options are required; there are useful defaults. If you omit the host name, psql will connect via a Unix-domain socket to a server on the local host, or via TCP/IP to localhost on Windows. The default port number is determined at compile time. Since the database server uses the same default, you will not have to specify the port in most cases. The default database user name is your operating-system user name. Once the database user name is determined, it is used as the default database name. Note that you cannot just connect to any database under any database user name. Your database administrator should have informed you about your access rights.
When the defaults aren’t quite right, you can save yourself some typing by setting the environment variables PGDATABASE, PGHOST, PGPORT and/or PGUSER to appropriate values. (For additional environment variables, see Section 32.15.) It is also convenient to have a ~/.pgpass file to avoid regularly having to type in passwords. See Section 32.16 for more information.
An alternative way to specify connection parameters is in a conninfo string or a URI, which is used instead of a database name. This mechanism give you very wide control over the connection. For example:
$psql "service=myservice sslmode=require"$psql postgresql://dbmaster:5433/mydb?sslmode=require
This way you can also use LDAP for connection parameter lookup as described in Section 32.18. See Section 32.1.2 for more information on all the available connection options.
If the connection could not be made for any reason (e.g., insufficient privileges, server is not running on the targeted host, etc.), psql will return an error and terminate.
If both standard input and standard output are a terminal, then psql sets the client encoding to “auto”, which will detect the appropriate client encoding from the locale settings (LC_CTYPE environment variable on Unix systems). If this doesn’t work out as expected, the client encoding can be overridden using the environment variable PGCLIENTENCODING.
Entering SQL Commands
In normal operation, psql provides a prompt with the name of the database to which psql is currently connected, followed by the string =>. For example:
$ psql testdb
psql (17.5)
Type "help" for help.
testdb=>
At the prompt, the user can type in SQL commands. Ordinarily, input lines are sent to the server when a command-terminating semicolon is reached. An end of line does not terminate a command. Thus commands can be spread over several lines for clarity. If the command was sent and executed without error, the results of the command are displayed on the screen.
If untrusted users have access to a database that has not adopted a secure schema usage pattern, begin your session by removing publicly-writable schemas from search_path. One can add options=-csearch_path= to the connection string or issue SELECT pg_catalog.set_config('search_path', '', false) before other SQL commands. This consideration is not specific to psql; it applies to every interface for executing arbitrary SQL commands.
Whenever a command is executed, psql also polls for asynchronous notification events generated by LISTEN and NOTIFY.
While C-style block comments are passed to the server for processing and removal, SQL-standard comments are removed by psql.
Advanced Features
Variables
psql provides variable substitution features similar to common Unix command shells. Variables are simply name/value pairs, where the value can be any string of any length. The name must consist of letters (including non-Latin letters), digits, and underscores.
To set a variable, use the psql meta-command \set. For example,
testdb=> \set foo bar
sets the variable foo to the value bar. To retrieve the content of the variable, precede the name with a colon, for example:
testdb=> \echo :foo
bar
This works in both regular SQL commands and meta-commands; there is more detail in SQL Interpolation, below.
If you call \set without a second argument, the variable is set to an empty-string value. To unset (i.e., delete) a variable, use the command \unset. To show the values of all variables, call \set without any argument.
Note
The arguments of \set are subject to the same substitution rules as with other commands. Thus you can construct interesting references such as \set :foo 'something' and get “soft links” or “variable variables” of Perl or PHP fame, respectively. Unfortunately (or fortunately?), there is no way to do anything useful with these constructs. On the other hand, \set bar :foo is a perfectly valid way to copy a variable.
A number of these variables are treated specially by psql. They represent certain option settings that can be changed at run time by altering the value of the variable, or in some cases represent changeable state of psql. By convention, all specially treated variables’ names consist of all upper-case ASCII letters (and possibly digits and underscores). To ensure maximum compatibility in the future, avoid using such variable names for your own purposes.
Variables that control psql‘s behavior generally cannot be unset or set to invalid values. An \unset command is allowed but is interpreted as setting the variable to its default value. A \set command without a second argument is interpreted as setting the variable to on, for control variables that accept that value, and is rejected for others. Also, control variables that accept the values on and off will also accept other common spellings of Boolean values, such as true and false.
The specially treated variables are:
AUTOCOMMIT#-
When
on(the default), each SQL command is automatically committed upon successful completion. To postpone commit in this mode, you must enter aBEGINorSTART TRANSACTIONSQL command. Whenoffor unset, SQL commands are not committed until you explicitly issueCOMMITorEND. The autocommit-off mode works by issuing an implicitBEGINfor you, just before any command that is not already in a transaction block and is not itself aBEGINor other transaction-control command, nor a command that cannot be executed inside a transaction block (such asVACUUM).Note
In autocommit-off mode, you must explicitly abandon any failed transaction by entering
ABORTorROLLBACK. Also keep in mind that if you exit the session without committing, your work will be lost.Note
The autocommit-on mode is PostgreSQL‘s traditional behavior, but autocommit-off is closer to the SQL spec. If you prefer autocommit-off, you might wish to set it in the system-wide
psqlrcfile or your~/.psqlrcfile. COMP_KEYWORD_CASE#-
Determines which letter case to use when completing an SQL key word. If set to
lowerorupper, the completed word will be in lower or upper case, respectively. If set topreserve-lowerorpreserve-upper(the default), the completed word will be in the case of the word already entered, but words being completed without anything entered will be in lower or upper case, respectively. DBNAME#-
The name of the database you are currently connected to. This is set every time you connect to a database (including program start-up), but can be changed or unset.
ECHO#-
If set to
all, all nonempty input lines are printed to standard output as they are read. (This does not apply to lines read interactively.) To select this behavior on program start-up, use the switch-a. If set toqueries, psql prints each query to standard output as it is sent to the server. The switch to select this behavior is-e. If set toerrors, then only failed queries are displayed on standard error output. The switch for this behavior is-b. If set tonone(the default), then no queries are displayed. ECHO_HIDDEN#-
When this variable is set to
onand a backslash command queries the database, the query is first shown. This feature helps you to study PostgreSQL internals and provide similar functionality in your own programs. (To select this behavior on program start-up, use the switch-E.) If you set this variable to the valuenoexec, the queries are just shown but are not actually sent to the server and executed. The default value isoff. ENCODING#-
The current client character set encoding. This is set every time you connect to a database (including program start-up), and when you change the encoding with
\encoding, but it can be changed or unset. ERROR#-
trueif the last SQL query failed,falseif it succeeded. See alsoSQLSTATE. FETCH_COUNT#-
If this variable is set to an integer value greater than zero, the results of
SELECTqueries are fetched and displayed in groups of that many rows, rather than the default behavior of collecting the entire result set before display. Therefore only a limited amount of memory is used, regardless of the size of the result set. Settings of 100 to 1000 are commonly used when enabling this feature. Keep in mind that when using this feature, a query might fail after having already displayed some rows.Tip
Although you can use any output format with this feature, the default
alignedformat tends to look bad because each group ofFETCH_COUNTrows will be formatted separately, leading to varying column widths across the row groups. The other output formats work better. HIDE_TABLEAM#-
If this variable is set to
true, a table’s access method details are not displayed. This is mainly useful for regression tests. HIDE_TOAST_COMPRESSION#-
If this variable is set to
true, column compression method details are not displayed. This is mainly useful for regression tests. HISTCONTROL#-
If this variable is set to
ignorespace, lines which begin with a space are not entered into the history list. If set to a value ofignoredups, lines matching the previous history line are not entered. A value ofignorebothcombines the two options. If set tonone(the default), all lines read in interactive mode are saved on the history list.Note
This feature was shamelessly plagiarized from Bash.
HISTFILE#-
The file name that will be used to store the history list. If unset, the file name is taken from the
PSQL_HISTORYenvironment variable. If that is not set either, the default is~/.psql_history, or%APPDATA%\postgresql\psql_historyon Windows. For example, putting:\set HISTFILE ~/.psql_history-:DBNAME
in
~/.psqlrcwill cause psql to maintain a separate history for each database.Note
This feature was shamelessly plagiarized from Bash.
HISTSIZE#-
The maximum number of commands to store in the command history (default 500). If set to a negative value, no limit is applied.
Note
This feature was shamelessly plagiarized from Bash.
HOST#-
The database server host you are currently connected to. This is set every time you connect to a database (including program start-up), but can be changed or unset.
IGNOREEOF#-
If set to 1 or less, sending an EOF character (usually Control+D) to an interactive session of psql will terminate the application. If set to a larger numeric value, that many consecutive EOF characters must be typed to make an interactive session terminate. If the variable is set to a non-numeric value, it is interpreted as 10. The default is 0.
Note
This feature was shamelessly plagiarized from Bash.
LASTOID#-
The value of the last affected OID, as returned from an
INSERTor\lo_importcommand. This variable is only guaranteed to be valid until after the result of the next SQL command has been displayed. PostgreSQL servers since version 12 do not support OID system columns anymore, thus LASTOID will always be 0 followingINSERTwhen targeting such servers. LAST_ERROR_MESSAGELAST_ERROR_SQLSTATE#-
The primary error message and associated SQLSTATE code for the most recent failed query in the current psql session, or an empty string and
00000if no error has occurred in the current session. ON_ERROR_ROLLBACK#-
When set to
on, if a statement in a transaction block generates an error, the error is ignored and the transaction continues. When set tointeractive, such errors are only ignored in interactive sessions, and not when reading script files. When set tooff(the default), a statement in a transaction block that generates an error aborts the entire transaction. The error rollback mode works by issuing an implicitSAVEPOINTfor you, just before each command that is in a transaction block, and then rolling back to the savepoint if the command fails. ON_ERROR_STOP#-
By default, command processing continues after an error. When this variable is set to
on, processing will instead stop immediately. In interactive mode, psql will return to the command prompt; otherwise, psql will exit, returning error code 3 to distinguish this case from fatal error conditions, which are reported using error code 1. In either case, any currently running scripts (the top-level script, if any, and any other scripts which it may have in invoked) will be terminated immediately. If the top-level command string contained multiple SQL commands, processing will stop with the current command. PORT#-
The database server port to which you are currently connected. This is set every time you connect to a database (including program start-up), but can be changed or unset.
PROMPT1PROMPT2PROMPT3#-
These specify what the prompts psql issues should look like. See Prompting below.
QUIET#-
Setting this variable to
onis equivalent to the command line option-q. It is probably not too useful in interactive mode. ROW_COUNT#-
The number of rows returned or affected by the last SQL query, or 0 if the query failed or did not report a row count.
SERVER_VERSION_NAMESERVER_VERSION_NUM#-
The server’s version number as a string, for example
9.6.2,10.1or11beta1, and in numeric form, for example90602or100001. These are set every time you connect to a database (including program start-up), but can be changed or unset. SHELL_ERROR#-
trueif the last shell command failed,falseif it succeeded. This applies to shell commands invoked via the\!,\g,\o,\w, and\copymeta-commands, as well as backquote (`) expansion. Note that for\o, this variable is updated when the output pipe is closed by the next\ocommand. See alsoSHELL_EXIT_CODE. SHELL_EXIT_CODE#-
The exit status returned by the last shell command. 0–127 represent program exit codes, 128–255 indicate termination by a signal, and -1 indicates failure to launch a program or to collect its exit status. This applies to shell commands invoked via the
\!,\g,\o,\w, and\copymeta-commands, as well as backquote (`) expansion. Note that for\o, this variable is updated when the output pipe is closed by the next\ocommand. See alsoSHELL_ERROR. SHOW_ALL_RESULTS#-
When this variable is set to
off, only the last result of a combined query (\;) is shown instead of all of them. The default ison. The off behavior is for compatibility with older versions of psql. SHOW_CONTEXT#-
This variable can be set to the values
never,errors, oralwaysto control whetherCONTEXTfields are displayed in messages from the server. The default iserrors(meaning that context will be shown in error messages, but not in notice or warning messages). This setting has no effect whenVERBOSITYis set toterseorsqlstate. (See also\errverbose, for use when you want a verbose version of the error you just got.) SINGLELINE#-
Setting this variable to
onis equivalent to the command line option-S. SINGLESTEP#-
Setting this variable to
onis equivalent to the command line option-s. SQLSTATE#-
The error code (see Appendix A) associated with the last SQL query’s failure, or
00000if it succeeded. USER#-
The database user you are currently connected as. This is set every time you connect to a database (including program start-up), but can be changed or unset.
VERBOSITY#-
This variable can be set to the values
default,verbose,terse, orsqlstateto control the verbosity of error reports. (See also\errverbose, for use when you want a verbose version of the error you just got.) VERSIONVERSION_NAMEVERSION_NUM#-
These variables are set at program start-up to reflect psql‘s version, respectively as a verbose string, a short string (e.g.,
9.6.2,10.1, or11beta1), and a number (e.g.,90602or100001). They can be changed or unset.
SQL Interpolation
A key feature of psql variables is that you can substitute (“interpolate”) them into regular SQL statements, as well as the arguments of meta-commands. Furthermore, psql provides facilities for ensuring that variable values used as SQL literals and identifiers are properly quoted. The syntax for interpolating a value without any quoting is to prepend the variable name with a colon (:). For example,
testdb=>\set foo 'my_table'testdb=>SELECT * FROM :foo;
would query the table my_table. Note that this may be unsafe: the value of the variable is copied literally, so it can contain unbalanced quotes, or even backslash commands. You must make sure that it makes sense where you put it.
When a value is to be used as an SQL literal or identifier, it is safest to arrange for it to be quoted. To quote the value of a variable as an SQL literal, write a colon followed by the variable name in single quotes. To quote the value as an SQL identifier, write a colon followed by the variable name in double quotes. These constructs deal correctly with quotes and other special characters embedded within the variable value. The previous example would be more safely written this way:
testdb=>\set foo 'my_table'testdb=>SELECT * FROM :"foo";
Variable interpolation will not be performed within quoted SQL literals and identifiers. Therefore, a construction such as ':foo' doesn’t work to produce a quoted literal from a variable’s value (and it would be unsafe if it did work, since it wouldn’t correctly handle quotes embedded in the value).
One example use of this mechanism is to copy the contents of a file into a table column. First load the file into a variable and then interpolate the variable’s value as a quoted string:
testdb=>\set content `cat my_file.txt`testdb=>INSERT INTO my_table VALUES (:'content');
(Note that this still won’t work if my_file.txt contains NUL bytes. psql does not support embedded NUL bytes in variable values.)
Since colons can legally appear in SQL commands, an apparent attempt at interpolation (that is, :name, :'name', or :"name") is not replaced unless the named variable is currently set. In any case, you can escape a colon with a backslash to protect it from substitution.
The :{? special syntax returns TRUE or FALSE depending on whether the variable exists or not, and is thus always substituted, unless the colon is backslash-escaped.name}
The colon syntax for variables is standard SQL for embedded query languages, such as ECPG. The colon syntaxes for array slices and type casts are PostgreSQL extensions, which can sometimes conflict with the standard usage. The colon-quote syntax for escaping a variable’s value as an SQL literal or identifier is a psql extension.
Prompting
The prompts psql issues can be customized to your preference. The three variables PROMPT1, PROMPT2, and PROMPT3 contain strings and special escape sequences that describe the appearance of the prompt. Prompt 1 is the normal prompt that is issued when psql requests a new command. Prompt 2 is issued when more input is expected during command entry, for example because the command was not terminated with a semicolon or a quote was not closed. Prompt 3 is issued when you are running an SQL COPY FROM STDIN command and you need to type in a row value on the terminal.
The value of the selected prompt variable is printed literally, except where a percent sign (%) is encountered. Depending on the next character, certain other text is substituted instead. Defined substitutions are:
%M#-
The full host name (with domain name) of the database server, or
[local]if the connection is over a Unix domain socket, or[local:, if the Unix domain socket is not at the compiled in default location./dir/name] %m#-
The host name of the database server, truncated at the first dot, or
[local]if the connection is over a Unix domain socket. %>#-
The port number at which the database server is listening.
%n#-
The database session user name. (The expansion of this value might change during a database session as the result of the command
SET SESSION AUTHORIZATION.) %/#-
The name of the current database.
%~#-
Like
%/, but the output is~(tilde) if the database is your default database. %##-
If the session user is a database superuser, then a
#, otherwise a>. (The expansion of this value might change during a database session as the result of the commandSET SESSION AUTHORIZATION.) %p#-
The process ID of the backend currently connected to.
%R#-
In prompt 1 normally
=, but@if the session is in an inactive branch of a conditional block, or^if in single-line mode, or!if the session is disconnected from the database (which can happen if\connectfails). In prompt 2%Ris replaced by a character that depends on why psql expects more input:-if the command simply wasn’t terminated yet, but*if there is an unfinished/* ... */comment, a single quote if there is an unfinished quoted string, a double quote if there is an unfinished quoted identifier, a dollar sign if there is an unfinished dollar-quoted string, or(if there is an unmatched left parenthesis. In prompt 3%Rdoesn’t produce anything. %x#-
Transaction status: an empty string when not in a transaction block, or
*when in a transaction block, or!when in a failed transaction block, or?when the transaction state is indeterminate (for example, because there is no connection). %l#-
The line number inside the current statement, starting from
1. %digits#-
The character with the indicated octal code is substituted.
%:name:#-
The value of the psql variable
name. See Variables, above, for details. %`command`#-
The output of
command, similar to ordinary “back-tick” substitution. %[…%]#-
Prompts can contain terminal control characters which, for example, change the color, background, or style of the prompt text, or change the title of the terminal window. In order for the line editing features of Readline to work properly, these non-printing control characters must be designated as invisible by surrounding them with
%[and%]. Multiple pairs of these can occur within the prompt. For example:testdb=> \set PROMPT1 '%[%033[1;33;40m%]%n@%/%R%[%033[0m%]%# '
results in a boldfaced (
1;) yellow-on-black (33;40) prompt on VT100-compatible, color-capable terminals. %w#-
Whitespace of the same width as the most recent output of
PROMPT1. This can be used as aPROMPT2setting, so that multi-line statements are aligned with the first line, but there is no visible secondary prompt.
To insert a percent sign into your prompt, write %%. The default prompts are '%/%R%x%# ' for prompts 1 and 2, and '>> ' for prompt 3.
Note
This feature was shamelessly plagiarized from tcsh.
Command-Line Editing
psql uses the Readline or libedit library, if available, for convenient line editing and retrieval. The command history is automatically saved when psql exits and is reloaded when psql starts up. Type up-arrow or control-P to retrieve previous lines.
You can also use tab completion to fill in partially-typed keywords and SQL object names in many (by no means all) contexts. For example, at the start of a command, typing ins and pressing TAB will fill in insert into . Then, typing a few characters of a table or schema name and pressing TAB will fill in the unfinished name, or offer a menu of possible completions when there’s more than one. (Depending on the library in use, you may need to press TAB more than once to get a menu.)
Tab completion for SQL object names requires sending queries to the server to find possible matches. In some contexts this can interfere with other operations. For example, after BEGIN it will be too late to issue SET TRANSACTION ISOLATION LEVEL if a tab-completion query is issued in between. If you do not want tab completion at all, you can turn it off permanently by putting this in a file named .inputrc in your home directory:
$if psql set disable-completion on $endif
(This is not a psql but a Readline feature. Read its documentation for further details.)
The -n (--no-readline) command line option can also be useful to disable use of Readline for a single run of psql. This prevents tab completion, use or recording of command line history, and editing of multi-line commands. It is particularly useful when you need to copy-and-paste text that contains TAB characters.
October 5, 2020 PostgreSQL
Sometimes you may need to connect to postgresql from command line in windows. In this article, I will show you how to do this.
First, psql must be installed on your server. If you installed pgadmin, postgresql on the server you want to connect to, psql was installed with it. In this article, I will assume that you have installed pgadmin.
We open the command line to connect to postgres and run the following command and go to the path where psql.exe is.
|
c:\Program Files (x86)\pgAdmin 4\v4\runtime> |
After going to the path above, we list the files in it with the dir command.
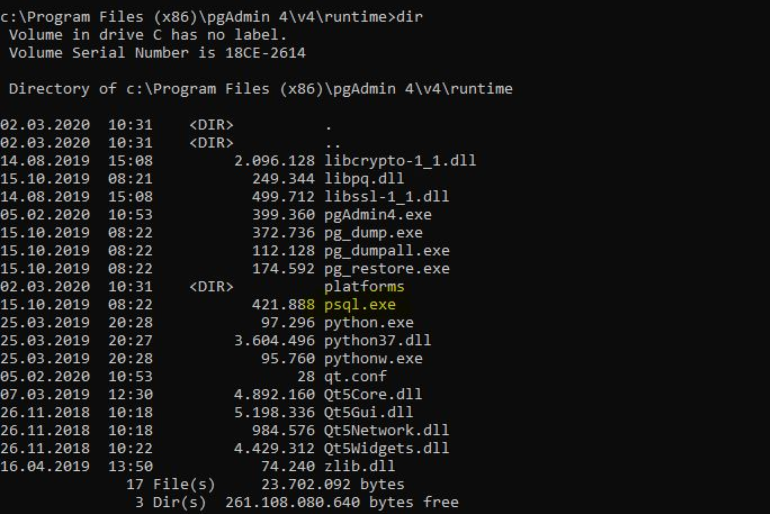
Connect To Postgres Database from command line in Windows
Now we see that we have a psql client, we can connect to postgres db from command line in windows as follows.
|
psql —h localhost —U postgres |
You may also want to read below articles;
How To Connect To Database On PostgreSQL,
How To Create a Linked Server To Connect To PostgreSQL From SQL Server,
How To Find PostgreSQL lib and bin Directories,
How To Stop, Start, Restart and Reload PostgreSQL Service
Also you can find many article about Postgresql from below link.
https://dbtut.com/index.php/category/postgres/
If you want to read more about psql, open the below link.
https://www.postgresql.org/docs/current/app-psql.html
postgres
You’ve installed PostgreSQL. Now what? I assume you’ve been given a task that
uses psql and you want to learn the absolute minimum to
get the job done.
This is both a brief tutorial and a
quick reference for the absolute least you need to know about psql.
I assume you’re familiar with the command line and have a rough idea about
what database administration tasks, but aren’t familiar with how to
use psql to do the basics.
View on GitHub Pages or directly on GitHub
The PostgreSQL documentation is incredibly
well written and thorough, but frankly, I didn’t know where to start reading. This
is my answer to that problem.
If you have any complaints or suggestions please let me know by
sending your feedback to tomcampbell@gmail.com.
It shows how to do the following at the psql prompt:
- Start and quit
psql - Get help
- Get information about databases
- Create databases
- CREATE TABLEs
- INSERT, or add records to a table
- SELECT, to do simple queries
- Reference pointing to the official PostgreSQL documentation
If you don’t have access to a live PostgreSQL installation at the moment we still have your back.
You can follow through the examples and the output is shown as if you
did type everything out.
The psql command line utility
Many administrative tasks can or should be done on your local machine,
even though if database lives on the cloud.
You can do some of them through a visual user interface, but that’s not covered here.
Knowing how to perform these operations on the command line means you can script them,
and scripting means you can automate tests, check errors, and do data entry on the command line.
This section isn’t a full cheat sheet for psql.
It covers the most common operations and shows them roughly in sequence,
as you’d use them in a typical work session.
| Starting and quitting the psql interactive terminal |
|---|
| Command-line prompts for psql |
| Quitting psql |
| Opening a connection locally |
| Opening a connection remotely |
| Using the psql prompt |
| Getting information about databases |
| \h Help |
| \l List databases |
| \c Connect to a database |
| \dt Display tables |
| \d and \d+ Display columns (field names) of a table |
| \du Display user roles |
| Creating and using tables and records |
| Creating a database |
| Creating a table (CREATE TABLE) |
| Adding a record (INSERT INTO) |
| Inserting several records at once (INSERT INTO) |
| Adding only specific fields from a record |
| Doing a simple query–get a list of records (SELECT) |
| Maintenance and operations |
| Timing |
| Watch |
| Maintenance |
What you need to know
Before using this section, you’ll need:
- The user name and password for your PostgreSQL database
- The IP address of your remote instance
Command-line prompts on the operating system
The $ starting a command line in the examples below represents your operating system prompt.
Prompts are configurable so it may well not look like this.
On Windows it might look like C:\Program Files\PostgreSQL> but Windows prompts are also configurable.
$ psql -U sampleuser -h localhost
A line starting with # represents a comment. Same for everything to the right of a #.
If you accidentally type it or copy and paste it in, don’t worry. Nothing will happen.
This worked to connect to Postgres on DigitalOcean
# -U is the username (it will appear in the \l command)
# -h is the name of the machine where the server is running.
# -p is the port where the database listens to connections. Default is 5432.
# -d is the name of the database to connect to. I think DO generated this for me, or maybe PostgreSQL.
# Password when asked is csizllepewdypieiib
$ psql -U doadmin -h production-sfo-test1-do-user-4866002-0.db.ondigitalocean.com -p 25060 -d mydb
# Open a database in a remote location.
$ psql -U sampleuser -h production-sfo-test1-do-user-4866002-0.db.ondigitalocean.com -p 21334
Using psql
You’ll use psql (aka the PostgreSQL interactive terminal) most of all because it’s used to create databases and tables, show information about tables, and even to enter information (records) into the database.
Quitting pqsql
Before we learn anything else, here’s how to quit psql and return to the operating system prompt.
You type backslash, the letter q, and then you press the Enter or return key.
# Press enter after typing \q
# Remember this is backslash, not forward slash
postgres=# \q
This takes you back out to the operating system prompt.
Opening a connection locally
A common case during development is opening a connection to a local database (one on your own machine).
Run psql with -U (for user name) followed by the name of the database, postgres in this example:
# Log into Postgres as the user named postgres
$ psql -U postgres
Opening a connection remotely
To connect your remote PostgreSQL instance from your local machine, use psql at your operating system command line.
Here’s a typical connection.
# -U is the username (it will appear in the \l command)
# -h is the name of the machine where the server is running.
# -p is the port where the database listens to connections. Default is 5432.
# -d is the name of the database to connect to. I think DO generated this for me, or maybe PostgreSQL.
$ psql -U doadmin -h production-sfo-test1-do-user-4866002-0.db.ondigitalocean.com -p 25060 -d defaultdb
Here you’d enter the password. In case someone is peering over your shoulder, the characters are hidden. After you’ve entered your information properly you’ll get this message (truncated for clarity):
Looking at the psql prompt
A few things appear, then the psql prompt is displayed.
The name of the current database appears before the prompt.
psql (11.1, server 11.0)
Type "help" for help.
postgres=#
At this point you’re expected to type commands and parameters into the command line.
psql vs SQL commands
psql has two different kinds of commands. Those starting with a backslash
are for psql itself, as illustrated by the use of \q to quit.
Those starting with valid SQL are of course interactive SQL used to
create and modify PostgreSQL databases.
Warning: SQL commands end with a semicolon!
One gotcha is that almost all SQL commands you enter into psql must end in a semicolon.
- For example,suppose you want to remove a table named
sample_property_5. You’d enter this command:
postgres=# DROP TABLE "sample_property_5";
It’s easy to forget. If you do forget the semicolon, you’ll see this perplexing prompt.
Note that a [ has been inserted before the username portion of the prompt, and another
prompt appears below it:
[postgres=# DROP TABLE "sample_property_5"
postgres=#
When you do, just remember to finish it off with that semicolon:
[postgres=# DROP TABLE "sample_property_5"
postgres=# ;
Scrolling through the command history
- Use the up and down arrow keys to move backwards and forwards through the command history.
Getting information about databases
These aren’t SQL commands so just press Enter after them. Remember that:
- When there’s more output than fits the screen, it pauses. Press space to continue
- If you want to halt the output, press
q.
\h Help
# Get help. Note it's a backslash, not a forward slash.
postgres=# \h
You’ll get a long list of commands, then output is paused:
Available help:
ABORT CREATE USER
...
ALTER AGGREGATE CREATE USER MAPPING
ALTER PROCEDURE DROP INDEX
:
- Press space to continue, or
qto stop the output.
You can get help on a particular item by listing it after the \h command.
- For example, to get help on
DROP TABLE:
postgres=# \h drop table
You’ll get help on just that item:
Command: DROP TABLE
Description: remove a table
Syntax:
DROP TABLE [ IF EXISTS ] name [, ...] [ CASCADE | RESTRICT ]
\l List databases
What most people think of as a database (say, a list of customers) is actually a table. A database is a set of tables, information about those tables, information about users and their permissions, and much more. Some of these databases (and the tables within) are updated automatically by PostgreSQL as you use them.
To get a list of all databases:
postgres=# \l
List of databases
Name | Owner | Encoding | Collate | Ctype | Access privileges
-----------+----------+----------+-------------+-------------+-----------------------
visitor | tom | UTF8 | en_US.UTF-8 | en_US.UTF-8 |
markets | tom | UTF8 | en_US.UTF-8 | en_US.UTF-8 |
postgres | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 |
template0 | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | =c/postgres +
| | | | | postgres=CTc/postgres
template1 | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | =c/postgres +
| | | | | postgres=CTc/postgres
tom | tom | UTF8 | en_US.UTF-8 | en_US.UTF-8 |
You can get info on a single database by following the \l prompt with its name.
- For example, to view information about the
template0database:
postgres=# \l template0
The output would be:
postgres=# \l
List of databases
Name | Owner | Encoding | Collate | Ctype | Access privileges
-----------+----------+----------+-------------+-------------+-----------------------
template0 | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | =c/postgres +
| | | | | postgres=CTc/postgres
\l+ List databases with size, tablespace, and description
To get additional information on the space consumed by database tables
and comments describing those tables, use \l+:
postgres=# \l+
\x Expand/narrow table lists
Use \x (X for eXpanded listing) to control
whether table listings use a wide or narrow format.
| Command | Effect |
|---|---|
\x off |
Show table listings in wide format |
\x on |
Show table listings in narrow format |
\x |
Reverse the previous state |
\x auto |
Use terminal to determine format |
Example: Here’s an expanded listing:
/* List all databases. */
postgres=# \l
List of databases
Name | Owner | Encoding | Collate | Ctype | Access privileges
-----------+----------+----------+-------------+-------------+-----------------------
foo | tom | UTF8 | en_US.UTF-8 | en_US.UTF-8 |
foobarino | tom | UTF8 | en_US.UTF-8 | en_US.UTF-8 |
postgres | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 |
template0 | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | =c/postgres +
| | | | | postgres=CTc/postgres
template1 | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | =c/postgres +
| | | | | postgres=CTc/postgres
tom | tom | UTF8 | en_US.UTF-8 | en_US.UTF-8 |
(6 rows)
Use \x on for narrower listings:
/* Turn on narrow listings. */
postgres=# \x on
postgres=# \l
-[ RECORD 1 ]-----+----------------------
Name | foo
Owner | tom
Encoding | UTF8
Collate | en_US.UTF-8
Ctype | en_US.UTF-8
Access privileges |
-[ RECORD 2 ]-----+----------------------
Name | foobarino
Owner | tom
Encoding | UTF8
Collate | en_US.UTF-8
Ctype | en_US.UTF-8
Access privileges |
-[ RECORD 3 ]-----+----------------------
Name | postgres
Owner | postgres
Encoding | UTF8
Collate | en_US.UTF-8
Ctype | en_US.UTF-8
Access privileges |
\c Connect to a database
To see what’s inside a database, connect to it using \c followed by the database name.
The prompt changes to match the name of the database you’re connecting to.
(The one named postgres is always interesting.) Here we’re connecting to the one named
markets:
postgres=# \c markets
psql (11.1, server 11.0)
You are now connected to database "markets" as user "tom".
markets=#
\dt Display tables
- Use
\dtto list all the tables (technically, relations) in the database:
markets=# \dt
List of relations
Schema | Name | Type | Owner
--------+------------------------------+-------+----------
public | addresspool | table | tom
public | adlookup | table | tom
public | bidactivitysummary | table | tom
public | bidactivitydetail | table | tom
public | customerpaymentsummary | table | tom
...
- If you choose a database such as
postgresthere could be many tables.
Remember you can pause output by pressing space or halt it by pressingq.
\d and \d+ Display columns (field names) of a table
To view the schema of a table, use \d followed by the name of the table.
- To view the schema of a table named
customerpaymentsummary, enter
markets=# \d customerpaymentsummary
Table "public.customerpaymentsummary"
Column | Type | Collation | Nullable | Default
------------------------------+-----------------------------+-----------+----------+--------
usersysid | integer | | not null |
paymentattemptsall | integer | | |
paymentattemptsmailin | integer | | |
paymentattemptspaypal | integer | | |
paymentattemptscreditcard | integer | | |
paymentacceptedoutagecredit | integer | | |
totalmoneyin | numeric(12,2) | | |
updatewhen1 | timestamp without time zone | | |
updatewhen2 | timestamp without time zone | | |
To view more detailed information on a table, use \d+:
markets=# \d customerpaymentsummary
Table "public.customerpaymentsummary"
Column | Type | Collation | Nullable | Default | Storage | Stats target |
------------------------------+-----------------------------+-----------+----------+---------+---------+---------------
usersysid | integer | | not null | | plain | |
paymentattemptsall | integer | | | | plain | |
paymentattemptsmailin | integer | | | | plain | |
paymentattemptspaypal | integer | | | | plain | |
paymentattemptscreditcard | integer | | | | plain | |
paymentacceptedoutagecredit | integer | | | | plain | |
totalmoneyin | numeric(12,2) | | | | main | |
updatewhen1 | timestamp without time zone | | | | plain | |
updatewhen2 | timestamp without time zone | | | | plain | |
Indexes:
\du Display user roles
- To view all users and their roles, use
\du:
postgres=# \du
List of roles
Role name | Attributes | Member of
------------+------------------------------------------------------------+-----------
smanager | Superuser | {}
postgres | Superuser, Create role, Create DB, Replication, Bypass RLS | {}
tom | Superuser, Create role, Create DB | {}
- To view the role of a specific user, pass it after the
\ducommand.
For example, to see the onlytomrole:
postgres=# \du tom
List of roles
Role name | Attributes | Member of
------------+------------------------------------------------------------+-----------
tom | Superuser, Create role, Create DB | {}
Creating a database
Before you add tables, you need to create a database to contain those tables.
That’s not done with psql, but instead it’s done with createdb
(a separate external command; see the PostgreSQL createdb documentation) at the operating system command line:
# Replace markets with your database name
$ createdb markets
On success, there is no visual feedback. Thanks, PostgreSQL.
Adding tables and records
Creating a table (CREATE TABLE)
To add a table schema to the database:
postgres=# create table if not exists product (
id SERIAL,
name VARCHAR(100) NOT NULL,
sku CHAR(8)
);
And psql responds with:
For more see CREATE TABLE in the PostgreSQL official docs.
Adding a record (INSERT INTO)
- Here’s how to add a record, populating every field:
# The id field is an automatically assigned
# when you use DEFAULT. The serial primary key means
# that number will be increased by at least
# 1 and assigned to that same field when
# a new record is created.
# Using DEFAULT is a placeholder.
# In its place PostgreSQL automatically generates a unique integer for it.
postgres=# INSERT INTO product VALUES(DEFAULT, 'Apple, Fuji', '4131');
PostgreSQL responds with:
- Try it again and you get a simliar response.
postgres=# INSERT INTO product VALUES(DEFAULT, 'Banana', '4011');
INSERT 0 1
Adding (inserting) several records at once
- You can enter a list of records using this syntax:
postgres=# INSERT INTO product VALUES
(DEFAULT, 'Carrots', 4562),
(DEFAULT, 'Durian', 5228)
;
Adding only specific (columns) fields from a record
You can add records but specify only selected fields (also known as columns). MySQL will use common sense default values for the rest.
In this example, only the name field will be populated. The sku column is left blank, and the id column is incremented and inserted.
Two records are added:
postgres=# INSERT INTO product (name) VALUES
('Endive'),
('Figs')
;
PostgreSQL responds with the number of records inserted:
INSERT 0 2
For more on INSERT, see INSERT in the PostgreSQL official docs
Doing a simple query–get a list of records (SELECT)
Probably the most common thing you’ll do with a table is to obtain information about it
with the SELECT statement. It’s a huge topic
- Let’s list all the records in the
producttable:
postgres=# SELECT * FROM product;
The response:
postgres=# select * from product;
id | name | sku
----+-------------+----------
1 | Apple, Fuji | 4131
2 | Banana | 4011
(2 rows)
Note
If your table has mixed case objects such as column names or indexes, you’ll need to enclose them in double quotes.
For example, If a column name were Product instead of product your query would need to look like this:
For more on SELECT, see the SELECT in the PostgreSQL official docs.
Maintenance and operations issues
Timing
\t Timing SQL operations
Use \t to show timing for all SQL operations performed.
| Command | Effect |
|---|---|
\timing off |
Disable timing of SQL operations |
\timing on |
Show timing after all SQL operations |
\timing |
Toggle (reverse) the setting |
Example of \t Timing command
tom=# insert into todo values ('Retry on Android before app submission,'8.x and earlier');
INSERT 0 1
tom=# \timing on
Timing is on.
tom=# insert into todo values ('Correct footer bug','Mobile version only');
INSERT 0 1
Time: 1.067 ms
tom=# insert into todo values ('Retry on Android before app submission', '8.x and earlier');
INSERT 0 1
Time: 23.312 ms
tom=# \timing
Timing is off.
Watch
The \watch command repeats the previous command at the specified interval.
To use it, enter the SQL command you want repeated, then
use \watch followed by the number of seconds you want for
the interval between repeats, for rexample, \watch 1
to repeat it every second.
Example of the \Watch command
Here’s an example of using \watch to see if any records have been
inserted within the last 5 seconds.
tom=# select count(*);
count
--------
726
(726 rows)
tom=# \watch 5
Mon Nov 16 13:50:36 2020 (every 2s)
count
--------
726
(726 rows)
Mon Nov 16 13:50:38 2020 (every 2s)
count
--------
726
(726 rows)
Mon Nov 16 13:50:40 2020 (every 2s)
count
--------
726
(726 rows)
Locate the pg_hba.conf file
Postgres configuration is stored in a file named pg_hba.conf somewhere in the file system, but
that location varies widely. The way to find it is to use show hba_file like this:
See below for hot reloading this file while Postgres is running.
Reload the configuration file while Postgres is running
If you make changes to the pg_hba.conf Postgres configuration sometimes you need to restart.
But you may just choose to reload the pg_hba.conf configuration file like this:
Reference
- PostgreSQL offical docs: Server Administration
psql, a.k.a the PostgreSQL interactive terminalcreatedbin the PostgreSQL offical docsCREATE TABLEin the PostgreSQL official docsINSERTin the PostgreSQL official docs
Краткая история psql
Чтобы понять, почему PostgreSQL имеет собственную утилиту командной строки, и почему она так тесно интегрирована в работу с PostgreSQL, нам необходимо быстро напомнить себе о том, как PostgreSQL стал PostgreSQL.

Почему вам следует использовать psql
Если вы новичок в мире PostgreSQL, использование утилиты командной строки для подключения и выполнения запросов к базе данных может показаться вам архаичным. Как бывший многолетний разработчик SQL Server я знаю, что отсутствие последовательного, стандартизированного инструмента с графическим интерфейсом временами очень огорчало.
Однако спустя некоторое время я понял, что зачастую много проще запрыгнуть в базу данных с помощью psql, когда мне просто необходимо подключиться, взглянуть на схему и выполнить простые запросы. Использование мета-команд становится второй натурой при получении подробной информации об объектах базы данных. Это подобно инструменту с сотнями эффективных примочек для быстрой работы с базой данных.
Более привлекательно то, что вы можете так сконфигурировать psql, что наряду с результатами будет возвращаться SQL, который она выполняет для каждой команды. Это может стать окном в изучение многих лежащих в основе каталога PostgreSQL таблиц, которые управляют тем, как используется база данных.
И последнее, важно, что во многих (многих!) статьях, руководствах, книгах и видео, которые показывают, как использовать функции PostgreSQL, демонстрация понятий будет происходить с помощью psql. Знание того, как подключиться с помощью этого инструмента и выполнить основные мета-команды, быстро помогут вам двигаться вперед.
Короче говоря, psql — это мощный инструмент в вашем арсенале для PostgreSQL. Знание того, как подключиться к базе данных и выполнить основные команды, быстро окупится в вашей работе с PostgreSQL. В общем, я думаю, что изучение даже основ стоит потраченного времени.
Установка psql
Инструмент командной строки (CLI) psql имеется для Linux, MacOS и Windows. Он идет вместе с установочным пакетом сервера PostgreSQL или может быть установлен отдельно как автономное приложение CLI.
Кроме того, версия psql совместима с версией PostgreSQL, поскольку запросы, которые она выполняет при использовании мета-команд, должна работать с более новыми схемами каталога. Было предпринято много усилий для поддержания обратной совместимости psql с поддерживаемыми версиями PostgreSQL, поэтому самая новая версия psql должна работать, по крайней мере, с пятью последними главными релизами.
Проверка наличия Psql
Поскольку psql поступает вместе с сервером PostgreSQL, возможно, эта утилита уже имеется на вашем компьютере, если вы устанавливали PostgreSQL. Из терминала или командной строки Windows наберите следующее:
$> psql --version
psql (PostgreSQL) 15.0 (Ubuntu 15.0-1.pgdg20.04+1)
Если в ответ вы увидите версию psql, то psql у вас уже установлена. Если версия устарела, рассмотрите возможность ее обновления.
Хорошим правилом является постараться иметь такую версию psql, которая соответствует самой новой версии PostgreSQL в вашем рабочем окружении. Для основных команд, которые мы рассмотрим ниже, весьма вероятно, что будет работать любая ваша версия, но хорошей практикой является обновление psql.
Установка на Linux
Все основные дистрибутивы Linux должны иметь пакет для postgresql-client. Он может использоваться только для установки инструментов PostgreSQL, а не самого сервера, включая psql, pg_dump, pg_restore и других.
В качестве примера будет использовать Ubuntu, но менеджер пакетов вашего дистрибутива должен иметь пакет с идентичным (или очень похожим) именем для выполнения тех же функций. Команды ниже установят самую последнюю версию этих инструментов.
Из строки терминала выполните следующие команды:
$> sudo apt-get update
$> sudo apt-get install postgresql-client
По завершению проверьте установку с помощью получения версии psql, как было показано ранее.
Установка на Windows
Для Windows у вас имеется два варианта.
Если вы хотите использовать psql в командной строке Windows, вам необходмо установить PostgreSQL и все инструменты, используя пакет установки на PostreSQL.org. В процессе установки вы сможете решить, какие компоненты сервера и инструментов устанавливать.
На Windows 10 и выше есть возможность установки инструментов в среде Windows Subsystem для Linux 2 (WSL2) и использовать обычное управление пакетами Linux для установки компонентов, как показано выше. Опять, в зависимости от используемого дистрибутива для хоста WSL, команды пакета могут несколько отличаться.
Установка на MacOS
Есть множество способов установки PostgreSQL на MacOS, многие из которых включают полный сервер и связанные с ним инструменты.
Самый быстрый способ установки PostgreSQL на MacOS — использование Postgres.app. Он обеспечивает полную установку сервера PostgreSQL, которая может быть запущена и остановлена по желанию, а простые инструкции на их домашней странице покажут вам, как убедиться, что инструменты командной строки PostgreSQL готовы к использованию из терминала.
Как альтернативу, вы можете просто установить PostgreSQL, используя Homebrew. Пакет libpq устанавливает только инструментарий (не сервер).
ryan@mba-laptop % brew doctor
ryan@mba-laptop % brew update
ryan@mba-laptop % brew install libpq
Поскольку это не полный сервер PostgreSQL, вам также потребуется корректно установить пути, чтобы вы могли использовать psql из терминала. Наиболее простой способ это сделать — позволить Homebrew обновить связи следующим образом.
ryan@mba-laptop % brew link --force libpq
Docker
Наконец, это будет упущением, если я не упомяну альтернативный вариант — Docker. Может быть использован любой из официальных контейнеров PostgreSQL через интерактивную оболочку Docker для подключения и использования psql. Пытаетесь ли вы подключиться к PostgreSQL на самом экземпляре Docker или удаленно, может использоваться установленное приложение psql (при корректно установленной сети).
Как пример, следующие команды могут использоваться для загрузки и запуска контейнера PostgreSQL Docker, подключения к выполняющейся оболочке и использования psql внутри контейнера.
ryan@redgate-laptop:~$ docker run --name pg15 -p 5432:5432 -e POSTGRES_PASSWORD=password -d postgres
ryan@redgate-laptop:~$ docker exec -it pg15 bash
root@80049acea1c0:/# psql -h localhost -U postgres
Подключение к PostgreSQL
После установки psql имеется два способа указать основные параметры подключения для целевой базы данных. Вам потребуется следующая информация для подключения к PostgreSQL.
- Имя хоста
- Порт (по умолчанию 5432)
- Имя пользователя
- Пароль
- Имя базы данных
Задание отдельных параметров
Подключитесь к базе данных, используя описанные выше параметры. Если сервер PostgreSQL запущен на порте по умолчанию 5432, вы можете опустить переключатель -p и psql попытается подключиться к этому порту автоматически.
psql -h [hostname] -p [port] -U [username] -d [database name]
Если вся информация корректна, вам будет предложено ввести пароль. При использовании отдельных параметров для подключения к PostgreSQL не существует метода предоставления пароля в командной строке. Вы всегда будете получать приглашение ввода, или же вы можете указать пароль в файле .pgpass.
Использование URI для подключения к PostgreSQL
Как альтернатива, вы можете использовать параметры подключения для создания URI подключения к базе данных PostgreSQL.
psql postgresql://[имя пользователя]:[пароль]@[имя хоста]:[порт]/[имя базы данных]
При использовании этой формы вы можете указать пароль в строке подключения, если он не содержит точки с запятой (;) или амперсанда (&), т.к. они помешают парсингу URI-подключения. Если опустить пароль, то PostgreSQL запросит его.
Заключение
Приложение командной строки psql является полезным инструментом для каждого, кто работает с PostgreSQL. За десятилетия разработки появились сотни встроенных мета-команд, помогающих разработчикам и администраторам работать с PostgreSQL быстро и эффективно. Знания о том, как установить и использовать его для подключения к базам данных, является важным навыком для пользователей PostgreSQL.Дополнительным преимуществом является то, что последние версии psql могут использоваться, по крайней мере, с пятью последними основными релизами PostgreSQL из-за неустанной работы сообщества по поддержанию обратной совместимости.
Конечно, эти знания являются только частью пазла. В следующей статье мы проведем экскурс по основным мета-командам, которые вам следует знать, чтобы ускорить разработку баз данных PostgreSQL.
PostgreSQL — это бесплатная объектно-реляционная СУБД с мощным функционалом, который позволяет конкурировать с платными базами данных, такими как Microsoft SQL, Oracle. PostgreSQL поддерживает пользовательские данные, функции, операции, домены и индексы. В данной статье мы рассмотрим установку и краткий обзор по управлению базой данных PostgreSQL. Мы установим СУБД PostgreSQL в Windows 10, создадим новую базу, добавим в неё таблицы и настроим доступа для пользователей. Также мы рассмотрим основы управления PostgreSQL с помощью SQL shell и визуальной системы управления PgAdmin. Надеюсь эта статья станет хорошей отправной точкой для обучения работы с PostgreSQL и использованию ее в разработке и тестовых проектах.
Содержание:
- Установка PostgreSQL 11 в Windows 10
- Доступ к PostgreSQL по сети, правила файерволла
- Утилиты управления PostgreSQL через командную строку
- PgAdmin: Визуальный редактор для PostgresSQL
- Query Tool: использование SQL запросов в PostgreSQL
Установка PostgreSQL 11 в Windows 10
Для установки PostgreSQL перейдите на сайт https://www.postgresql.org и скачайте последнюю версию дистрибутива для Windows, на сегодняшний день это версия PostgreSQL 11 (в 11 версии PostgreSQL поддерживаются только 64-х битные редакции Windows). После загрузки запустите инсталлятор.
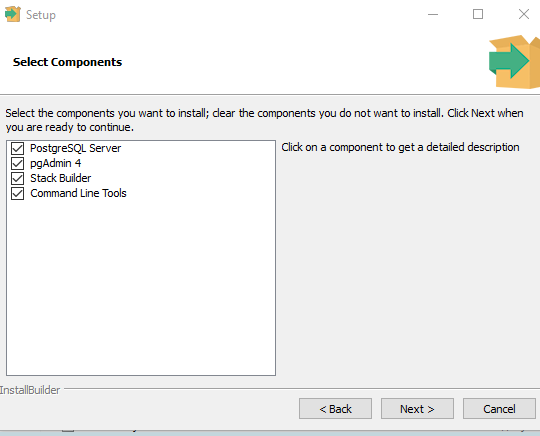
В процессе установки установите галочки на пунктах:
- PostgreSQL Server – сам сервер СУБД
- PgAdmin 4 – визуальный редактор SQL
- Stack Builder – дополнительные инструменты для разработки (возможно вам они понадобятся в будущем)
- Command Line Tools – инструменты командной строки
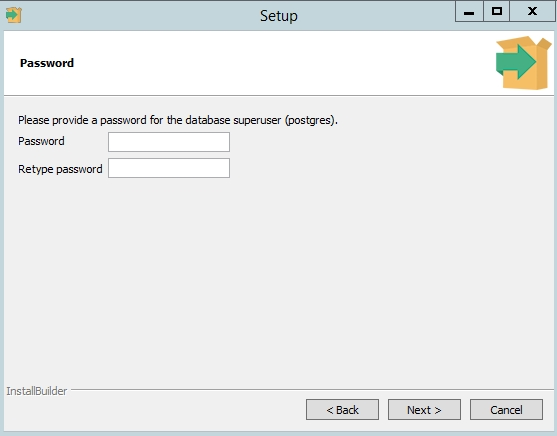
Установите пароль для пользователя postgres (он создается по умолчанию и имеет права суперпользователя).
По умолчание СУБД слушает на порту 5432, который нужно будет добавить в исключения в правилах фаерволла.
Нажимаете Далее, Далее, на этом установка PostgreSQL завершена.
Доступ к PostgreSQL по сети, правила файерволла
Чтобы разрешить сетевой доступ к вашему экземпляру PostgreSQL с других компьютеров, вам нужно создать правила в файерволе. Вы можете создать правило через командную строку или PowerShell.
Запустите командную строку от имени администратора. Введите команду:
netsh advfirewall firewall add rule name="Postgre Port" dir=in action=allow protocol=TCP localport=5432
- Где rule name – имя правила
- Localport – разрешенный порт
Либо вы можете создать правило, разрешающее TCP/IP доступ к экземпляру PostgreSQL на порту 5432 с помощью PowerShell:
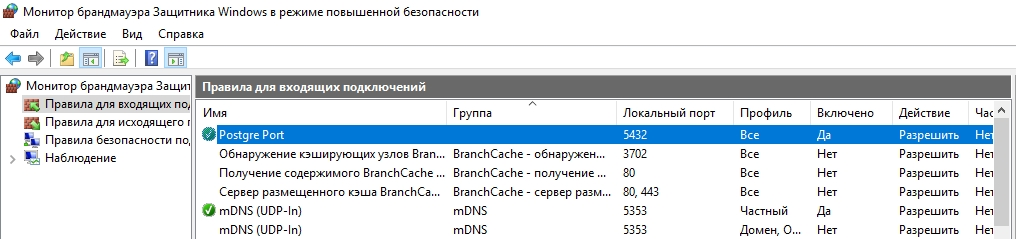
New-NetFirewallRule -Name 'POSTGRESQL-In-TCP' -DisplayName 'PostgreSQL (TCP-In)' -Direction Inbound -Enabled True -Protocol TCP -LocalPort 5432
После применения команды в брандмауэре Windows появится новое разрешающее правило для порта Postgres.
Совет. Для изменения порта в установленной PostgreSQL отредактируйте файл postgresql.conf по пути C:\Program Files\PostgreSQL\11\data.
Измените значение в пункте
port = 5432
. Перезапустите службу сервера postgresql-x64-11 после изменений. Можно перезапустить службу с помощью PowerShell:
Restart-Service -Name postgresql-x64-11

Более подробно о настройке параметров в конфигурационном файле postgresql.conf с помощью тюнеров смотрите в статье.
Утилиты управления PostgreSQL через командную строку
Рассмотрим управление и основные операции, которые можно выполнять с PostgreSQL через командную строку с помощью нескольких утилит. Основные инструменты управления PostgreSQL находятся в папке bin, потому все команды будем выполнять из данного каталога.
- Запустите командную строку.
Совет. Перед запуском СУБД, смените кодировку для нормального отображения в русской Windows 10. В командной строке выполните:
chcp 1251 - Перейдите в каталог bin выполнив команду:
CD C:\Program Files\PostgreSQL\11\bin

Основные команды PostgreSQL:

PgAdmin: Визуальный редактор для PostgresSQL
Редактор PgAdmin служит для упрощения управления базой данных PostgresSQL в понятном визуальном режиме.
По умолчанию все созданные базы хранятся в каталоге base по пути C:\Program Files\PostgreSQL\11\data\base.
Для каждой БД существует подкаталог внутри PGDATA/base, названный по OID базы данных в pg_database. Этот подкаталог по умолчанию является местом хранения файлов базы данных; в частности, там хранятся её системные каталоги. Каждая таблица и индекс хранятся в отдельном файле.
Для резервного копирования и восстановления лучше использовать инструмент Backup в панели инструментов Tools. Для автоматизации бэкапа PostgreSQL из командной строки используйте утилиту pg_dump.exe.
Query Tool: использование SQL запросов в PostgreSQL
Для написания SQL запросов в удобном графическом редакторе используется встроенный в pgAdmin инструмент Query Tool. Например, вы хотите создать новую таблицу в базе данных через инструмент Query Tool.
- Выберите базу данных, в панели Tools откройте Query Tool
- Создадим таблицу сотрудников:
CREATE TABLE employee
(
Id SERIAL PRIMARY KEY,
FirstName CHARACTER VARYING(30),
LastName CHARACTER VARYING(30),
Email CHARACTER VARYING(30),
Age INTEGER
);
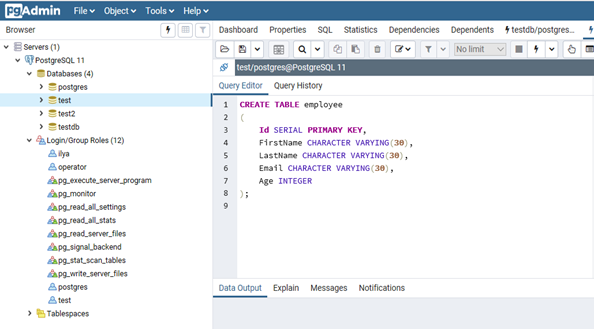
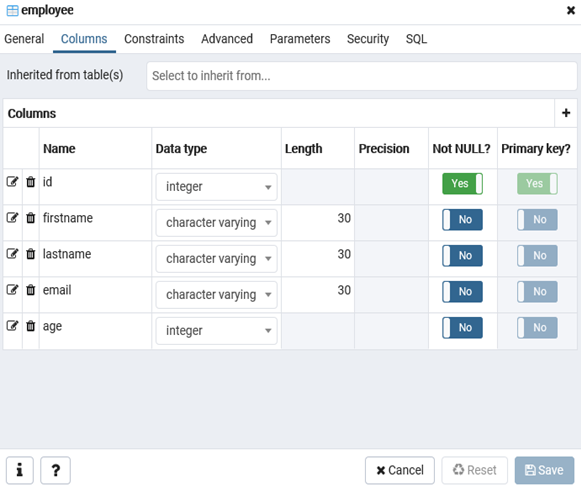
Id — номер сотрудника, которому присвоен ключ SERIAL. Данная строка будет хранить числовое значение 1, 2, 3 и т.д., которое для каждой новой строки будет автоматически увеличиваться на единицу. В следующих строках записаны имя, фамилия сотрудника и его электронный адрес, которые имеют тип CHARACTER VARYING(30), то есть представляют строку длиной не более 30 символов. В строке — Age записан возраст, имеет тип INTEGER, т.к. хранит числа.
После того, как написали код SQL запроса в Query Tool, нажмите клавишу F5 и в базе будет создана новая таблица employee.
Для заполнения полей в свойствах таблицы выберите таблицу employee в разделе Schemas -> Tables. Откройте меню Object инструмент View/Edit Data.
Здесь вы можете заполнить данные в таблице.
После заполнения данных выполним инструментом Query простой запрос на выборку:
select Age from employee;