
dbname-
Specifies the name of the database to be dumped. If this is not specified, the environment variable
PGDATABASEis used. If that is not set, the user name specified for the connection is used. -a--data-only-
Dump only the data, not the schema (data definitions). Table data, large objects, and sequence values are dumped.
This option is similar to, but for historical reasons not identical to, specifying
--section=data. -b--large-objects--blobs(deprecated)-
Include large objects in the dump. This is the default behavior except when
--schema,--table, or--schema-onlyis specified. The-bswitch is therefore only useful to add large objects to dumps where a specific schema or table has been requested. Note that large objects are considered data and therefore will be included when--data-onlyis used, but not when--schema-onlyis. -B--no-large-objects--no-blobs(deprecated)-
Exclude large objects in the dump.
When both
-band-Bare given, the behavior is to output large objects, when data is being dumped, see the-bdocumentation. -c--clean-
Output commands to
DROPall the dumped database objects prior to outputting the commands for creating them. This option is useful when the restore is to overwrite an existing database. If any of the objects do not exist in the destination database, ignorable error messages will be reported during restore, unless--if-existsis also specified.This option is ignored when emitting an archive (non-text) output file. For the archive formats, you can specify the option when you call
pg_restore. -C--create-
Begin the output with a command to create the database itself and reconnect to the created database. (With a script of this form, it doesn’t matter which database in the destination installation you connect to before running the script.) If
--cleanis also specified, the script drops and recreates the target database before reconnecting to it.With
--create, the output also includes the database’s comment if any, and any configuration variable settings that are specific to this database, that is, anyALTER DATABASE ... SET ...andALTER ROLE ... IN DATABASE ... SET ...commands that mention this database. Access privileges for the database itself are also dumped, unless--no-aclis specified.This option is ignored when emitting an archive (non-text) output file. For the archive formats, you can specify the option when you call
pg_restore. -epattern--extension=pattern-
Dump only extensions matching
pattern. When this option is not specified, all non-system extensions in the target database will be dumped. Multiple extensions can be selected by writing multiple-eswitches. Thepatternparameter is interpreted as a pattern according to the same rules used by psql‘s\dcommands (see Patterns), so multiple extensions can also be selected by writing wildcard characters in the pattern. When using wildcards, be careful to quote the pattern if needed to prevent the shell from expanding the wildcards.Any configuration relation registered by
pg_extension_config_dumpis included in the dump if its extension is specified by--extension.Note
When
-eis specified, pg_dump makes no attempt to dump any other database objects that the selected extension(s) might depend upon. Therefore, there is no guarantee that the results of a specific-extension dump can be successfully restored by themselves into a clean database. -Eencoding--encoding=encoding-
Create the dump in the specified character set encoding. By default, the dump is created in the database encoding. (Another way to get the same result is to set the
PGCLIENTENCODINGenvironment variable to the desired dump encoding.) The supported encodings are described in Section 23.3.1. -ffile--file=file-
Send output to the specified file. This parameter can be omitted for file based output formats, in which case the standard output is used. It must be given for the directory output format however, where it specifies the target directory instead of a file. In this case the directory is created by
pg_dumpand must not exist before. -Fformat--format=format-
Selects the format of the output.
formatcan be one of the following:pplain-
Output a plain-text SQL script file (the default).
ccustom-
Output a custom-format archive suitable for input into pg_restore. Together with the directory output format, this is the most flexible output format in that it allows manual selection and reordering of archived items during restore. This format is also compressed by default.
ddirectory-
Output a directory-format archive suitable for input into pg_restore. This will create a directory with one file for each table and large object being dumped, plus a so-called Table of Contents file describing the dumped objects in a machine-readable format that pg_restore can read. A directory format archive can be manipulated with standard Unix tools; for example, files in an uncompressed archive can be compressed with the gzip, lz4, or zstd tools. This format is compressed by default using
gzipand also supports parallel dumps. ttar-
Output a
tar-format archive suitable for input into pg_restore. The tar format is compatible with the directory format: extracting a tar-format archive produces a valid directory-format archive. However, the tar format does not support compression. Also, when using tar format the relative order of table data items cannot be changed during restore.
-jnjobs--jobs=njobs-
Run the dump in parallel by dumping
njobstables simultaneously. This option may reduce the time needed to perform the dump but it also increases the load on the database server. You can only use this option with the directory output format because this is the only output format where multiple processes can write their data at the same time.pg_dump will open
njobs+ 1 connections to the database, so make sure your max_connections setting is high enough to accommodate all connections.Requesting exclusive locks on database objects while running a parallel dump could cause the dump to fail. The reason is that the pg_dump leader process requests shared locks (ACCESS SHARE) on the objects that the worker processes are going to dump later in order to make sure that nobody deletes them and makes them go away while the dump is running. If another client then requests an exclusive lock on a table, that lock will not be granted but will be queued waiting for the shared lock of the leader process to be released. Consequently any other access to the table will not be granted either and will queue after the exclusive lock request. This includes the worker process trying to dump the table. Without any precautions this would be a classic deadlock situation. To detect this conflict, the pg_dump worker process requests another shared lock using the
NOWAIToption. If the worker process is not granted this shared lock, somebody else must have requested an exclusive lock in the meantime and there is no way to continue with the dump, so pg_dump has no choice but to abort the dump.To perform a parallel dump, the database server needs to support synchronized snapshots, a feature that was introduced in PostgreSQL 9.2 for primary servers and 10 for standbys. With this feature, database clients can ensure they see the same data set even though they use different connections.
pg_dump -juses multiple database connections; it connects to the database once with the leader process and once again for each worker job. Without the synchronized snapshot feature, the different worker jobs wouldn’t be guaranteed to see the same data in each connection, which could lead to an inconsistent backup. -npattern--schema=pattern-
Dump only schemas matching
pattern; this selects both the schema itself, and all its contained objects. When this option is not specified, all non-system schemas in the target database will be dumped. Multiple schemas can be selected by writing multiple-nswitches. Thepatternparameter is interpreted as a pattern according to the same rules used by psql‘s\dcommands (see Patterns), so multiple schemas can also be selected by writing wildcard characters in the pattern. When using wildcards, be careful to quote the pattern if needed to prevent the shell from expanding the wildcards; see Examples below.Note
When
-nis specified, pg_dump makes no attempt to dump any other database objects that the selected schema(s) might depend upon. Therefore, there is no guarantee that the results of a specific-schema dump can be successfully restored by themselves into a clean database.Note
Non-schema objects such as large objects are not dumped when
-nis specified. You can add large objects back to the dump with the--large-objectsswitch. -Npattern--exclude-schema=pattern-
Do not dump any schemas matching
pattern. The pattern is interpreted according to the same rules as for-n.-Ncan be given more than once to exclude schemas matching any of several patterns.When both
-nand-Nare given, the behavior is to dump just the schemas that match at least one-nswitch but no-Nswitches. If-Nappears without-n, then schemas matching-Nare excluded from what is otherwise a normal dump. -O--no-owner-
Do not output commands to set ownership of objects to match the original database. By default, pg_dump issues
ALTER OWNERorSET SESSION AUTHORIZATIONstatements to set ownership of created database objects. These statements will fail when the script is run unless it is started by a superuser (or the same user that owns all of the objects in the script). To make a script that can be restored by any user, but will give that user ownership of all the objects, specify-O.This option is ignored when emitting an archive (non-text) output file. For the archive formats, you can specify the option when you call
pg_restore. -R--no-reconnect-
This option is obsolete but still accepted for backwards compatibility.
-s--schema-only-
Dump only the object definitions (schema), not data.
This option is the inverse of
--data-only. It is similar to, but for historical reasons not identical to, specifying--section=pre-data --section=post-data.(Do not confuse this with the
--schemaoption, which uses the word “schema” in a different meaning.)To exclude table data for only a subset of tables in the database, see
--exclude-table-data. -Susername--superuser=username-
Specify the superuser user name to use when disabling triggers. This is relevant only if
--disable-triggersis used. (Usually, it’s better to leave this out, and instead start the resulting script as superuser.) -tpattern--table=pattern-
Dump only tables with names matching
pattern. Multiple tables can be selected by writing multiple-tswitches. Thepatternparameter is interpreted as a pattern according to the same rules used by psql‘s\dcommands (see Patterns), so multiple tables can also be selected by writing wildcard characters in the pattern. When using wildcards, be careful to quote the pattern if needed to prevent the shell from expanding the wildcards; see Examples below.As well as tables, this option can be used to dump the definition of matching views, materialized views, foreign tables, and sequences. It will not dump the contents of views or materialized views, and the contents of foreign tables will only be dumped if the corresponding foreign server is specified with
--include-foreign-data.The
-nand-Nswitches have no effect when-tis used, because tables selected by-twill be dumped regardless of those switches, and non-table objects will not be dumped.Note
When
-tis specified, pg_dump makes no attempt to dump any other database objects that the selected table(s) might depend upon. Therefore, there is no guarantee that the results of a specific-table dump can be successfully restored by themselves into a clean database. -Tpattern--exclude-table=pattern-
Do not dump any tables matching
pattern. The pattern is interpreted according to the same rules as for-t.-Tcan be given more than once to exclude tables matching any of several patterns.When both
-tand-Tare given, the behavior is to dump just the tables that match at least one-tswitch but no-Tswitches. If-Tappears without-t, then tables matching-Tare excluded from what is otherwise a normal dump. -v--verbose-
Specifies verbose mode. This will cause pg_dump to output detailed object comments and start/stop times to the dump file, and progress messages to standard error. Repeating the option causes additional debug-level messages to appear on standard error.
-V--version-
Print the pg_dump version and exit.
-x--no-privileges--no-acl-
Prevent dumping of access privileges (grant/revoke commands).
-Zlevel-Z[:methoddetail]--compress=level--compress=[:methoddetail]-
Specify the compression method and/or the compression level to use. The compression method can be set to
gzip,lz4,zstd, ornonefor no compression. A compression detail string can optionally be specified. If the detail string is an integer, it specifies the compression level. Otherwise, it should be a comma-separated list of items, each of the formkeywordorkeyword=value. Currently, the supported keywords arelevelandlong.If no compression level is specified, the default compression level will be used. If only a level is specified without mentioning an algorithm,
gzipcompression will be used if the level is greater than0, and no compression will be used if the level is0.For the custom and directory archive formats, this specifies compression of individual table-data segments, and the default is to compress using
gzipat a moderate level. For plain text output, setting a nonzero compression level causes the entire output file to be compressed, as though it had been fed through gzip, lz4, or zstd; but the default is not to compress. With zstd compression,longmode may improve the compression ratio, at the cost of increased memory use.The tar archive format currently does not support compression at all.
--binary-upgrade-
This option is for use by in-place upgrade utilities. Its use for other purposes is not recommended or supported. The behavior of the option may change in future releases without notice.
--column-inserts--attribute-inserts-
Dump data as
INSERTcommands with explicit column names (INSERT INTO). This will make restoration very slow; it is mainly useful for making dumps that can be loaded into non-PostgreSQL databases. Any error during restoring will cause only rows that are part of the problematictable(column, ...) VALUES ...INSERTto be lost, rather than the entire table contents. --disable-dollar-quoting-
This option disables the use of dollar quoting for function bodies, and forces them to be quoted using SQL standard string syntax.
--disable-triggers-
This option is relevant only when creating a data-only dump. It instructs pg_dump to include commands to temporarily disable triggers on the target tables while the data is restored. Use this if you have referential integrity checks or other triggers on the tables that you do not want to invoke during data restore.
Presently, the commands emitted for
--disable-triggersmust be done as superuser. So, you should also specify a superuser name with-S, or preferably be careful to start the resulting script as a superuser.This option is ignored when emitting an archive (non-text) output file. For the archive formats, you can specify the option when you call
pg_restore. --enable-row-security-
This option is relevant only when dumping the contents of a table which has row security. By default, pg_dump will set row_security to off, to ensure that all data is dumped from the table. If the user does not have sufficient privileges to bypass row security, then an error is thrown. This parameter instructs pg_dump to set row_security to on instead, allowing the user to dump the parts of the contents of the table that they have access to.
Note that if you use this option currently, you probably also want the dump be in
INSERTformat, as theCOPY FROMduring restore does not support row security. --exclude-extension=pattern-
Do not dump any extensions matching
pattern. The pattern is interpreted according to the same rules as for-e.--exclude-extensioncan be given more than once to exclude extensions matching any of several patterns.When both
-eand--exclude-extensionare given, the behavior is to dump just the extensions that match at least one-eswitch but no--exclude-extensionswitches. If--exclude-extensionappears without-e, then extensions matching--exclude-extensionare excluded from what is otherwise a normal dump. --exclude-table-and-children=pattern-
This is the same as the
-T/--exclude-tableoption, except that it also excludes any partitions or inheritance child tables of the table(s) matching thepattern. --exclude-table-data=pattern-
Do not dump data for any tables matching
pattern. The pattern is interpreted according to the same rules as for-t.--exclude-table-datacan be given more than once to exclude tables matching any of several patterns. This option is useful when you need the definition of a particular table even though you do not need the data in it.To exclude data for all tables in the database, see
--schema-only. --exclude-table-data-and-children=pattern-
This is the same as the
--exclude-table-dataoption, except that it also excludes data of any partitions or inheritance child tables of the table(s) matching thepattern. --extra-float-digits=ndigits-
Use the specified value of
extra_float_digitswhen dumping floating-point data, instead of the maximum available precision. Routine dumps made for backup purposes should not use this option. --filter=filename-
Specify a filename from which to read patterns for objects to include or exclude from the dump. The patterns are interpreted according to the same rules as the corresponding options:
-t/--table,--table-and-children,-T/--exclude-table, and--exclude-table-and-childrenfor tables,-n/--schemaand-N/--exclude-schemafor schemas,--include-foreign-datafor data on foreign servers,--exclude-table-dataand--exclude-table-data-and-childrenfor table data, and-e/--extensionand--exclude-extensionfor extensions. To read fromSTDIN, use-as the filename. The--filteroption can be specified in conjunction with the above listed options for including or excluding objects, and can also be specified more than once for multiple filter files.The file lists one object pattern per row, with the following format:
{ include | exclude } { extension | foreign_data | table | table_and_children | table_data | table_data_and_children | schema }PATTERNThe first keyword specifies whether the objects matched by the pattern are to be included or excluded. The second keyword specifies the type of object to be filtered using the pattern:
-
extension: extensions. This works like the-e/--extensionor--exclude-extensionoption. -
foreign_data: data on foreign servers. This works like the--include-foreign-dataoption. This keyword can only be used with theincludekeyword. -
table: tables. This works like the-t/--tableor-T/--exclude-tableoption. -
table_and_children: tables including any partitions or inheritance child tables. This works like the--table-and-childrenor--exclude-table-and-childrenoption. -
table_data: table data of any tables matchingpattern. This works like the--exclude-table-dataoption. This keyword can only be used with theexcludekeyword. -
table_data_and_children: table data of any tables matchingpatternas well as any partitions or inheritance children of the table(s). This works like the--exclude-table-data-and-childrenoption. This keyword can only be used with theexcludekeyword. -
schema: schemas. This works like the-n/--schemaor-N/--exclude-schemaoption.
Lines starting with
#are considered comments and ignored. Comments can be placed after an object pattern row as well. Blank lines are also ignored. See Patterns for how to perform quoting in patterns.Example files are listed below in the Examples section.
-
--if-exists-
Use
DROP ... IF EXISTScommands to drop objects in--cleanmode. This suppresses “does not exist” errors that might otherwise be reported. This option is not valid unless--cleanis also specified. --include-foreign-data=foreignserver-
Dump the data for any foreign table with a foreign server matching
foreignserverpattern. Multiple foreign servers can be selected by writing multiple--include-foreign-dataswitches. Also, theforeignserverparameter is interpreted as a pattern according to the same rules used by psql‘s\dcommands (see Patterns), so multiple foreign servers can also be selected by writing wildcard characters in the pattern. When using wildcards, be careful to quote the pattern if needed to prevent the shell from expanding the wildcards; see Examples below. The only exception is that an empty pattern is disallowed.Note
Using wildcards in
--include-foreign-datamay result in access to unexpected foreign servers. Also, to use this option securely, make sure that the named server must have a trusted owner.Note
When
--include-foreign-datais specified, pg_dump does not check that the foreign table is writable. Therefore, there is no guarantee that the results of a foreign table dump can be successfully restored. --inserts-
Dump data as
INSERTcommands (rather thanCOPY). This will make restoration very slow; it is mainly useful for making dumps that can be loaded into non-PostgreSQL databases. Any error during restoring will cause only rows that are part of the problematicINSERTto be lost, rather than the entire table contents. Note that the restore might fail altogether if you have rearranged column order. The--column-insertsoption is safe against column order changes, though even slower. --load-via-partition-root-
When dumping data for a table partition, make the
COPYorINSERTstatements target the root of the partitioning hierarchy that contains it, rather than the partition itself. This causes the appropriate partition to be re-determined for each row when the data is loaded. This may be useful when restoring data on a server where rows do not always fall into the same partitions as they did on the original server. That could happen, for example, if the partitioning column is of type text and the two systems have different definitions of the collation used to sort the partitioning column. --lock-wait-timeout=timeout-
Do not wait forever to acquire shared table locks at the beginning of the dump. Instead fail if unable to lock a table within the specified
timeout. The timeout may be specified in any of the formats accepted bySET statement_timeout. (Allowed formats vary depending on the server version you are dumping from, but an integer number of milliseconds is accepted by all versions.) --no-comments-
Do not dump comments.
--no-publications-
Do not dump publications.
--no-security-labels-
Do not dump security labels.
--no-subscriptions-
Do not dump subscriptions.
--no-sync-
By default,
pg_dumpwill wait for all files to be written safely to disk. This option causespg_dumpto return without waiting, which is faster, but means that a subsequent operating system crash can leave the dump corrupt. Generally, this option is useful for testing but should not be used when dumping data from production installation. --no-table-access-method-
Do not output commands to select table access methods. With this option, all objects will be created with whichever table access method is the default during restore.
This option is ignored when emitting an archive (non-text) output file. For the archive formats, you can specify the option when you call
pg_restore. --no-tablespaces-
Do not output commands to select tablespaces. With this option, all objects will be created in whichever tablespace is the default during restore.
This option is ignored when emitting an archive (non-text) output file. For the archive formats, you can specify the option when you call
pg_restore. --no-toast-compression-
Do not output commands to set TOAST compression methods. With this option, all columns will be restored with the default compression setting.
--no-unlogged-table-data-
Do not dump the contents of unlogged tables and sequences. This option has no effect on whether or not the table and sequence definitions (schema) are dumped; it only suppresses dumping the table and sequence data. Data in unlogged tables and sequences is always excluded when dumping from a standby server.
--on-conflict-do-nothing-
Add
ON CONFLICT DO NOTHINGtoINSERTcommands. This option is not valid unless--inserts,--column-insertsor--rows-per-insertis also specified. --quote-all-identifiers-
Force quoting of all identifiers. This option is recommended when dumping a database from a server whose PostgreSQL major version is different from pg_dump‘s, or when the output is intended to be loaded into a server of a different major version. By default, pg_dump quotes only identifiers that are reserved words in its own major version. This sometimes results in compatibility issues when dealing with servers of other versions that may have slightly different sets of reserved words. Using
--quote-all-identifiersprevents such issues, at the price of a harder-to-read dump script. --rows-per-insert=nrows-
Dump data as
INSERTcommands (rather thanCOPY). Controls the maximum number of rows perINSERTcommand. The value specified must be a number greater than zero. Any error during restoring will cause only rows that are part of the problematicINSERTto be lost, rather than the entire table contents. --section=sectionname-
Only dump the named section. The section name can be
pre-data,data, orpost-data. This option can be specified more than once to select multiple sections. The default is to dump all sections.The data section contains actual table data, large-object contents, and sequence values. Post-data items include definitions of indexes, triggers, rules, and constraints other than validated check constraints. Pre-data items include all other data definition items.
--serializable-deferrable-
Use a
serializabletransaction for the dump, to ensure that the snapshot used is consistent with later database states; but do this by waiting for a point in the transaction stream at which no anomalies can be present, so that there isn’t a risk of the dump failing or causing other transactions to roll back with aserialization_failure. See Chapter 13 for more information about transaction isolation and concurrency control.This option is not beneficial for a dump which is intended only for disaster recovery. It could be useful for a dump used to load a copy of the database for reporting or other read-only load sharing while the original database continues to be updated. Without it the dump may reflect a state which is not consistent with any serial execution of the transactions eventually committed. For example, if batch processing techniques are used, a batch may show as closed in the dump without all of the items which are in the batch appearing.
This option will make no difference if there are no read-write transactions active when pg_dump is started. If read-write transactions are active, the start of the dump may be delayed for an indeterminate length of time. Once running, performance with or without the switch is the same.
--snapshot=snapshotname-
Use the specified synchronized snapshot when making a dump of the database (see Table 9.98 for more details).
This option is useful when needing to synchronize the dump with a logical replication slot (see Chapter 47) or with a concurrent session.
In the case of a parallel dump, the snapshot name defined by this option is used rather than taking a new snapshot.
--strict-names-
Require that each extension (
-e/--extension), schema (-n/--schema) and table (-t/--table) pattern match at least one extension/schema/table in the database to be dumped. This also applies to filters used with--filter. Note that if none of the extension/schema/table patterns find matches, pg_dump will generate an error even without--strict-names.This option has no effect on
--exclude-extension,-N/--exclude-schema,-T/--exclude-table, or--exclude-table-data. An exclude pattern failing to match any objects is not considered an error. --sync-method=method-
When set to
fsync, which is the default,pg_dump --format=directorywill recursively open and synchronize all files in the archive directory.On Linux,
syncfsmay be used instead to ask the operating system to synchronize the whole file system that contains the archive directory. See recovery_init_sync_method for information about the caveats to be aware of when usingsyncfs.This option has no effect when
--no-syncis used or--formatis not set todirectory. --table-and-children=pattern-
This is the same as the
-t/--tableoption, except that it also includes any partitions or inheritance child tables of the table(s) matching thepattern. --use-set-session-authorization-
Output SQL-standard
SET SESSION AUTHORIZATIONcommands instead ofALTER OWNERcommands to determine object ownership. This makes the dump more standards-compatible, but depending on the history of the objects in the dump, might not restore properly. Also, a dump usingSET SESSION AUTHORIZATIONwill certainly require superuser privileges to restore correctly, whereasALTER OWNERrequires lesser privileges. -?--help-
Show help about pg_dump command line arguments, and exit.
The following command-line options control the database connection parameters.
-ddbname--dbname=dbname-
Specifies the name of the database to connect to. This is equivalent to specifying
dbnameas the first non-option argument on the command line. Thedbnamecan be a connection string. If so, connection string parameters will override any conflicting command line options. -hhost--host=host-
Specifies the host name of the machine on which the server is running. If the value begins with a slash, it is used as the directory for the Unix domain socket. The default is taken from the
PGHOSTenvironment variable, if set, else a Unix domain socket connection is attempted. -pport--port=port-
Specifies the TCP port or local Unix domain socket file extension on which the server is listening for connections. Defaults to the
PGPORTenvironment variable, if set, or a compiled-in default. -Uusername--username=username-
User name to connect as.
-w--no-password-
Never issue a password prompt. If the server requires password authentication and a password is not available by other means such as a
.pgpassfile, the connection attempt will fail. This option can be useful in batch jobs and scripts where no user is present to enter a password. -W--password-
Force pg_dump to prompt for a password before connecting to a database.
This option is never essential, since pg_dump will automatically prompt for a password if the server demands password authentication. However, pg_dump will waste a connection attempt finding out that the server wants a password. In some cases it is worth typing
-Wto avoid the extra connection attempt. --role=rolename-
Specifies a role name to be used to create the dump. This option causes pg_dump to issue a
SET ROLErolenamecommand after connecting to the database. It is useful when the authenticated user (specified by-U) lacks privileges needed by pg_dump, but can switch to a role with the required rights. Some installations have a policy against logging in directly as a superuser, and use of this option allows dumps to be made without violating the policy.
Резервное копирование — одна из важнейших задач системного администратора. Хорошо если копии вам никогда не пригодятся, но они должны быть. Сегодня мы рассмотрим некоторые аспекты резервного копирования популярной СУБД PostgreSQL, в частности при ее применении совместно с 1С:Предприятие. Начнем с самого простого и понятного способа — использования утилиты pg_dump, которая, кстати, может использоваться не только для резервного копирования, но и для переноса баз между различными серверами.
Онлайн-курс по устройству компьютерных сетей
На углубленном курсе «Архитектура современных компьютерных сетей» вы с нуля научитесь работать с Wireshark и «под микроскопом» изучите работу сетевых протоколов. На протяжении курса надо будет выполнить более пятидесяти лабораторных работ в Wireshark.
Как и любой иной способ использование pg_dump для копирования имеет свои плюсы и минусы. К основному минусу можно отнести то, что создаваемый дамп является срезом базы данных на некоторый момент времени и позволяет откатиться только на это состояние. Восстановление на произвольный момент времени невозможно.
Иные способы, позволяющие такое восстановление, работают на уровне инстанса и позволяют восстановить сразу весь кластер, т.е. все базы. Поэтому рекомендации по продуктовому применению PostgreSQL предусматривают основную схему: 1 база — 1 инстанс, что для небольших внедрений может быть избыточно как по ресурсам, так и по накладным расходам на администрирование.
В тоже время pg_dump работает на уровне базы данных и позволяет копировать и откатывать именно определенную базу, не затрагивая соседей по кластеру. Это несомненный плюс.
Также pg_dump может использоваться для переноса баз данных, она кроссплатформенна и кроссверсионна, т.е. позволяет переносить базы между разными платформами и разными версиями PostgreSQL. При этом следует помнить, что версии PostgreSQL совместимы снизу вверх, совместимость сверху вниз не поддерживается, либо поддерживается на ограниченное число версий. Т.е. вы всегда сможете загрузить дамп из PostgreSQL 9.6 в PostgreSQL 15, но не наоборот.
Подготовка сервера
Чтобы удобно работать с утилитами PostgreSQL добавим путь к ним в переменную окружения PATH. Для этого перейдем в Свойства системы — Дополнительно — Переменные окружения.
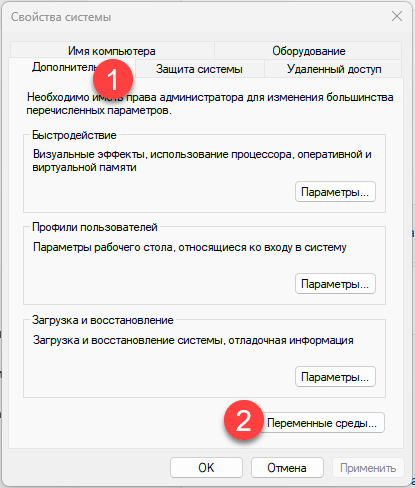
Затем найдем в списке переменную PATH и изменим ее, добавив новой строкой путь к папке bin вашего экземпляра PostgreSQL, в нашем случае это C:\Program Files\PostgreSQL\15.5-10.1C\bin:
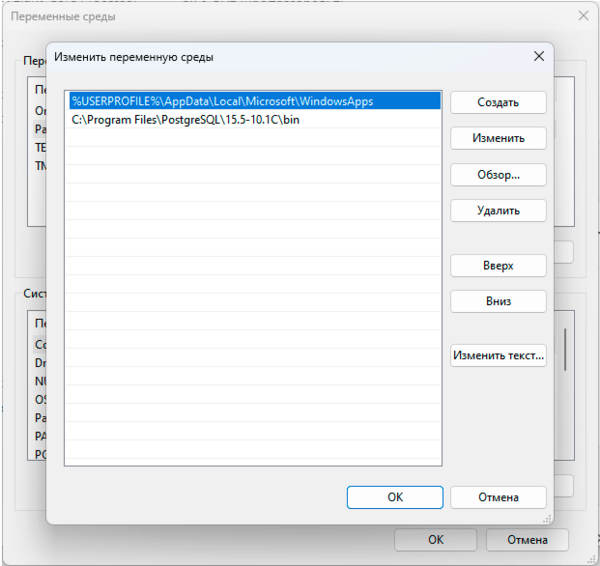
Теперь вы можете обращаться к утилитам PostgreSQL просто по имени. Однако при написании скриптов всегда указывайте полный путь, что позволит избежать ошибок, если у запустившего пользователя скрипт в переменной PATH не окажется указанного выше пути.
Следующий вопрос — пароль суперпользователя СУБД, либо другого пользователя, имеющего нужные права для выгрузки и загрузки базы. В подавляющем большинстве случаев с пользователями никто не заморачивается и все работают от суперпользователя postgres. Для этого можно пойти несколькими путями, один из них создание специального файла паролей, для этого создайте в указанные ниже директорию и файл:
%APPDATA%\postgresql\pgpass.confПосле чего внесите в него следующие строки:
#имя_узла:порт:база_данных:имя_пользователя:парольlocalhost:*:*:postgres:MyPa$$Word_1
Первая строка — это подсказка-комментарий, чтобы вам потом не приходилось вспоминать синтаксис. А ниже мы указали, что при подключении к инстансу расположенному на локальном узле localhost, использующему любой порт, для любой базы данных, при подключении пользователем postgres использовать указанный пароль. Первые четыре поля могут использовать подстановочный знак * указывающий на любое значение. Например, если у вас множество серверов с одинаковым паролем, то можете указать так:
*:*:*:postgres:MyPa$$Word_1Данный способ является рекомендуемым, но у него есть недостаток в виде хранения пароля в открытом виде. Поэтому можно использовать альтернативу, разрешить локальные подключения без пароля. Для этого найдите файл pg_hba.conf который находится в директории кластера data, в нашем случае он расположен по умолчанию в C:\Program Files\PostgreSQL\15.5-10.1C\data. В данный файл добавьте строку:
host all all localhost trustСохраните файл и перезапустите службу PostgreSQL. После чего вы можете без пароля подключаться к базе через localhost, обратите внимание, что в данном случае localhost не равнозначен 127.0.0.1 и если вы укажете адрес, то подключиться не получится.
Создание резервной копии базы данных
Утилита pg_dump умеет создавать копии в разных форматах, каждый из которых имеет свои достоинства и недостатки.
- plain — выгрузка в текстовом SQL формате. Наиболее универсальна, а при необходимости позволяет вручную откорректировать дамп или выполнить частичную загрузку или восстановление, например отдельной таблицы. Не сжимается, имеет большой размер.
- custom — собственный формат pg_dump, предусматривает сжатие данных и возможность многопоточной загрузки, выгружается всегда однопоточно
- directory — выгрузка в виде директории, на каждую таблицу выгружается отдельный сжатый файл, позволяет многопоточную выгрузку и загрузку.
- tar — представляет, по сути, выгрузку в виде директории, но упакованной в tar-архив, сжатие не предусмотрено, поэтому размер выгрузки будет больше, чем у директории, однопоточен.
Таким образом, наиболее удобными с практической точки зрения является формат custom, либо directory — если вам требуется многопоточная выгрузка. При переносе между разными системами предпочтительно использовать plain, так как он представляет набор SQL команд и может быть легко отредактирован вручную.
Итак приступим. Прежде всего следует узнать какие базы данных есть на нашем сервере и как они называются, для этого выполним:
psql -h localhost -U postgres -lВ выводе мы увидим список баз и их параметры:
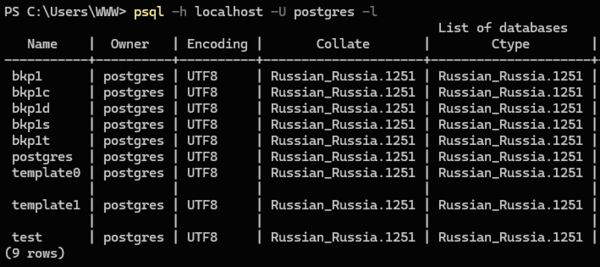
В нашем случае мы будем бекапить базу данных bkp1 и местом хранения резервных копий определим D:\Backup. Начнем с текстового формата, он используется по умолчанию и отдельно указывать его не нужно:
pg_dump -h localhost -U postgres -f D:\Backup\bkp1.sql bkp1Общий синтаксис команды такой: сначала указываем все используемые ключи, первый аргумент без ключа считается именем базы данных, и оно должно быть последним в команде. Указывать ключи после имени базы не следует. В команде мы использовали ключи:
- -h сервер — указывает имя или адрес компьютера, на котором работает сервер СУБД
- -U имя_пользователя — имя пользователя, под которым производится подключение
- -f файл — файл, в который производится выгрузка
Также ниже мы будем использовать ключи:
- -F формат — формат выгрузки
- -j число_заданий — количество потоков
С полным перечнем ключей можно ознакомиться в официальной документации.
В некоторых источниках можно встретить команду в виде:
pg_dump -h localhost -U postgres bkp1 > D:\Backup\bkp1.sqlВажно! В среде Windows не используйте перенаправление для выгрузки и загрузки резервных копий!
Мы неоднократно сталкивались с тем, что выгруженные через перенаправление копии внешне выглядели вполне нормально, в том числе и копии в текстовом формате, но при восстановлении отказывались загружаться. Это происходит не всегда и не везде, но для исключения подобных ситуаций перенаправление в Windows использовать не следует.
Теперь создадим выгрузку в формате custom:
pg_dump -h localhost -U postgres -Fc -f D:\Backup\bkp1.dump bkp1Здесь у нас добавился еще один ключ, указывающий на формат выгрузки, если вы хотите выгрузить в формате tar, просто замените -Fc на -Ft.
И, наконец, в формате директории:
pg_dump -h localhost -U postgres -Fd -f D:\Backup\bkp1_dir -j 4 bkp1Для данного формата у нас появился еще один ключ, указывающий число потоков выгрузки. Число потоков не должно превышать количество ядер процессора, но не все так просто: pg_dump спокойно нагрузит каждый поток, создав 100% загрузку ядер процессора, но сможет ли его принять устройство хранения? Может получиться так, что скорость записи на накопитель окажется бутылочным горлышком и вместо ускорения вы получите замедление как выгрузки дампа, так и всей системы вообще.
Поэтому начните с небольшого количества, двух или четырех потоков, оцените нагрузку на систему и остановитесь на некотором оптимальном значении, это особенно важно, если на сервере в момент выгрузки будут работать пользователи. Нам ведь совершенно ни к чему чтобы они каждый час жаловались на тормоза.
Еще одна тонкость, что будет если указанный файл выгрузки существует? Форматы, custom и tar молча перезапишут его. При выгрузке в формате directory вы получите сообщение, что целевая директория не пуста и выгрузка выполнена не будет. Это следует учитывать при написании скриптов, потому как при ошибке вы либо останетесь без старых копий, либо не будут создаваться новые. Хотя визуально все будет нормально.
Особенно легко ошибиться в случае с directory, если вы используете для выгрузки одну и ту же директорию, потом дополнительно архивируете ее и отправляете на устройство хранения. В этом случае вы будете архивировать одну и ту же старую копию. Поэтому директорию выгрузки надо всегда очищать или удалять.
Восстановление базы данных из резервной копии
Начнем с того, что восстановить базу данных PostgreSQL можно только в новую, пустую базу. Если мы хотим восстановить ее в существующую, то ее придется сначала удалить, а потом создать новую с таким же именем. Исключение — формат plain, это просто набор SQL-команд, которые мы можем выполнить на рабочей базе, выборочно туда что-то подгрузив. Но это требует определенных знаний и квалификации, что выходит за рамки нашей статьи.
Итак, прежде всего удалим старую базу:
dropdb -h localhost -U postgres -i bkp1В приведенной команде мы использовали ключ -i который запросит интерактивное подтверждение действия:
База данных "bkp1" будет удалена навсегда.
Продолжить? (y/n)Почему мы это сделали и советуем вам поступать также? Как показывает практика, данные команды часто вводятся методом копирования, неважно откуда, из статьи, документации, собственных записей, истории команд. В этом случае интерактивный запрос послужит предохранителем, который позволит остановиться и задуматься что вы делаете.
А теперь создадим новую:
createdb -h localhost -U postgres -T template0 bkp1Ключ -T указывает использовать при создании базы полностью пустой шаблон template0. Если вы хотите выполнить восстановление в отдельную новую базу, то просто создайте ее приведенной выше командой.
Начнем восстановление с формата plain, так как это не дамп, а набор SQL команд, то для их исполнения мы будем использовать утилиту psql:
psql -h localhost -U postgres -d bkp1 D:\Backup\bkp1.sqlФормат команды здесь такой же, сначала ключи, потом файл или директория, из которой идет восстановление. Ключ -d указывает имя базы данных, в которую мы загружаем выгрузку.
Для остальных форматов следует использовать утилиту pg_restore, например восстановим дамп формата custom, в два потока:
pg_restore -h localhost -U postgres -d bkp1 -j 2 D:\Backup\bkp1.dumpСинтаксис тот же самый, просто указываем базу и файл, с форматом утилита разберется самостоятельно. Если же вы попытаетесь подсунуть ей формат plain, то утилита откажется делать загрузку и любезно посоветует вам использовать для этого psql.
Что касается выбора количества потоков, то исходим из тех же соображений: один поток — одно ядро и обязательно тестируем, чтобы производительность диска не стала узким горлышком. Если вы выполняете восстановление в рабочее время, то учтите также влияние на работу пользователей, чтобы не вышло что вы запустили восстановление, а у всех остальных все стало.
При восстановлении из формата directory вместо файла укажите путь к папке:
pg_restore -h localhost -U postgres -d bkp1 -j 2 D:\Backup\bkp1_dirНапоминаем, что формат tar многопоточную загрузку не поддерживает, но вы можете его распаковать и загрузить многопоточно в формате directory.
Также есть способ несколько упростить себе жизнь, чтобы не удалять и не создавать заново базу данных мы можем выполнить:
pg_restore -h localhost -U postgres -d postgres -C -c D:\Backup\bkp1.dumpКлючи -C -c предписывают перед загрузкой удалить и создать заново базу имя которой записано в дампе, в ключе -d при этом потребуется указать любую существующую базу, обычно указывается стандартная postgres. В результате выполнения данной команды вы можете получать некоторые безвредные сообщения об ошибках.
Однако использовать эту команду следует очень осторожно и только на том сервере, откуда был сделан дамп. Также убедитесь, что вы взяли именно тот дамп, что надо. Но мы не рекомендуем так делать, особенно на продуктовых серверах, лучше осознанно удалите базу руками.
Онлайн-курс по устройству компьютерных сетей
На углубленном курсе «Архитектура современных компьютерных сетей» вы с нуля научитесь работать с Wireshark и «под микроскопом» изучите работу сетевых протоколов. На протяжении курса надо будет выполнить более пятидесяти лабораторных работ в Wireshark.
Обновлено:
Опубликовано:
Тематические термины: PostgreSQL, SQL
В данной инструкции рассмотрены варианты и примеры создания резервных копий и восстановления баз СУБД PostgreSQL.
Создание копий
Базовая команда
Пользователь и пароль
Сжатие данных
Скрипт
На удаленном сервере
Дамп определенной таблицы
Каждая таблица в свой файл
Для определенной схемы
Только схемы
Только данные
pgAdmin
Не текстовые форматы
pg_basebackup
pg_dumpall (все базы данных)
Восстановление
Базовая команда
С авторизацией
Из файла gz
Определенную базу
Определенную таблицу
С помощью pgAdmin
pg_restore (бинарные бэкапы)
Работа с CSV
Возможные проблемы
Input file appears to be a text format dump. please use psql
No matching tables were found
Too many command-line arguments
Aborting because of server version mismatch
No password supplied
Неверная команда \
Все команды, которые приводятся ниже, должны выполняться из командной строки. В Linux — это окно терминала, в Windows — командная строка (cmd.exe) с переходом в папку установки PostgreSQL.
Создание резервных копий
Базовая команда
Синтаксис:
pg_dump <параметры> <имя базы> > <файл, куда сохранить дамп>
Пример:
pg_dump users > /tmp/users.dump
Также путь к файлу можно указать с помощью опции -f:
pg_dump users -f /tmp/users.dump
Пользователь и пароль
Если резервная копия выполняется не от учетной записи postgres, необходимо добавить опцию -U с указанием пользователя:
pg_dump -U dmosk -W users > /tmp/users.dump
* где dmosk — имя учетной записи; опция W потребует ввода пароля.
Сжатие данных
Для экономии дискового пространства или более быстрой передачи по сети можно сжать наш архив. Можно для этого использовать разные подходы — использовать опцию -Z с указанием уровня компрессии от 0 до 9 или передать результат архиватору gzip. Рассмотрим оба примера.
а) С помощью опции -Z:
pg_dump -Z9 users > users.sql.gz
б) С использованием gzip:
pg_dump users | gzip > users.sql.gz
В обоих случаях будет использоваться gzip и перед восстановлением данных необходимо будет извлечь архив с помощью gunzip. Подробнее об этом ниже.
Скрипт для автоматического резервного копирования
Рассмотрим 2 варианта написания скрипта для резервирования баз PostgreSQL в системах Linux, а также приведем пример скрипта для Powershell (Windows).
Linux (bash)
Первый вариант — запуск скрипта от пользователя root для резервирования одной базы. Второй — запуск от пользователя postgres для резервирования всех баз, созданных в СУБД.
Для начала, создадим каталог, в котором разместим скрипт, например:
mkdir /scripts
И сам скрипт:
vi /scripts/postgresql_dump.sh
Вариант 1. Запуск от пользователя root; одна база.
#!/bin/sh
PATH=/etc:/bin:/sbin:/usr/bin:/usr/sbin:/usr/local/bin:/usr/local/sbin
PGPASSWORD=password
export PGPASSWORD
pathB=/backup
dbUser=dbuser
database=db
find $pathB \( -name «*-1[^5].*» -o -name «*-[023]?.*» \) -ctime +61 -delete
pg_dump -U $dbUser $database | gzip > $pathB/pgsql_$(date «+%Y-%m-%d»).sql.gz
unset PGPASSWORD
* где password — пароль для подключения к postgresql; /backup — каталог, в котором будут храниться резервные копии; dbuser — имя учетной записи для подключения к БУБД; pathB — путь до каталога, где будут храниться резервные копии.
* данный скрипт сначала удалит все резервные копии, старше 61 дня, но оставит от 15-о числа как длительный архив. После при помощи утилиты pg_dump будет выполнено подключение и резервирование базы db. Пароль экспортируется в системную переменную на момент выполнения задачи.
Для запуска резервного копирования по расписанию, сохраняем скрипт в файл, например, /scripts/postgresql_dump.sh и создаем задание в планировщике:
crontab -e
3 0 * * * /scripts/postgresql_dump.sh
* наш скрипт будет запускаться каждый день в 03:00.
Вариант 2. Запуск от пользователя postgres; все базы.
#!/bin/bash
PATH=/etc:/bin:/sbin:/usr/bin:/usr/sbin:/usr/local/bin:/usr/local/sbin
pathB=/backup/postgres
find $pathB \( -name «*-1[^5].*» -o -name «*-[023]?.*» \) -ctime +61 -delete
for dbname in `echo «SELECT datname FROM pg_database;» | psql | tail -n +3 | head -n -2 | egrep -v ‘template0|template1|postgres’`; do
pg_dump $dbname | gzip > $pathB/$dbname-$(date «+%Y-%m-%d»).sql.gz
done;
* где /backup — каталог, в котором будут храниться резервные копии; pathB — путь до каталога, где будут храниться резервные копии.
* данный скрипт сначала удалит все резервные копии, старше 61 дня, но оставит от 15-о числа как длительный архив. После найдет все созданные в СУБД базы, кроме служебных и при помощи утилиты pg_dump будет выполнено резервирование каждой найденной базы. Пароль нам не нужен, так как по умолчанию, пользователь postgres имеет возможность подключаться к базе без пароля.
Необходимо убедиться, что у пользователя postgre будет разрешение на запись в каталог назначения, в нашем примере, /backup/postgres.
Зададим в качестве владельца файла, пользователя postgres:
chown postgres:postgres /scripts/postgresql_dump.sh
Для запуска резервного копирования по расписанию, сохраняем скрипт в файл, например, /scripts/postgresql_dump.sh и создаем задание в планировщике:
crontab -e -u postgres
* мы откроем на редактирование cron для пользователя postgres.
3 0 * * * /scripts/postgresql_dump.sh
* наш скрипт будет запускаться каждый день в 03:00.
Права и запуск
Разрешаем запуск скрипта, как исполняемого файла:
chmod +x /scripts/postgresql_dump.sh
Единоразово можно запустить задание на выполнение резервной копии:
/scripts/postgresql_dump.sh
… или от пользователя postgres:
su — postgres -c «/scripts/postgresql_dump.sh»
Windows (Powershell)
Данный скрипт создаст бэкапы для всех баз, кроме служебных:
$Env:PGPASSWORD = ‘password’;
$DateStr = (Get-Date).ToString(«yyyy-MM-dd»)
$BackupPath = ‘C:\TmpBackup’
psql -Atc «SELECT datname FROM pg_database;» | foreach {
if ($_ -notmatch ‘postgres|template1|template0’) {
pg_dump $_ > $BackupPath\$_.$DateStr.sql
}
}
* все резервные копии будут размещены в каталоге C:\TmpBackup.
На удаленном сервере
Если сервер баз данных находится на другом сервере, просто добавляем опцию -h:
pg_dump -h 192.168.0.15 users > /tmp/users.dump
* необходимо убедиться, что сама СУБД разрешает удаленное подключение. Подробнее читайте инструкцию Как настроить удаленное подключение к PostgreSQL.
Дамп определенной таблицы
Запускается с опцией -t <table> или —table=<table>:
pg_dump -t students users > /tmp/students.dump
* где students — таблица; users — база данных.
Если наша таблица находится в определенной схеме, то она указывается вместе с ней, например:
pg_dump -t public.students users > /tmp/students.dump
* где public — схема; students — таблица; users — база данных.
Размещение каждой таблицы в отдельный файл
Также называется резервированием в каталог. Данный способ удобен при больших размерах базы или необходимости восстанавливать отдельные таблицы. Выполняется с ипользованием ключа -d:
pg_dump -d customers > /tmp/folder
* где /tmp/folder — путь до каталога, в котором разместяться файлы дампа для каждой таблицы.
Для определенной схемы
В нашей базе может быть несколько схем. Если мы хотим сделать дамп только для определенной схемы, то используем опцию -n, например:
pg_dump -n public peoples > /tmp/peoples.public.sql
* в данном примере мы заархивируем схему public базы данных peoples.
Только схемы (структуры)
Для резервного копирования без данных (только таблицы и их структуры):
pg_dump —schema-only users > /tmp/users.schema.dump
Также, внутри каждой базы могут быть свои схемы с данными. Если нам нужно сделать дамп именно той схемы, которая внутри базы, используем ключ -n:
pg_dump —schema-only users -n production > /tmp/users.schema_production.dump
* в данном примере мы создадим дамп структуры базы данных users только для схемы production.
Или полный дамп с данными для схемы внутри базы данных:
pg_dump users -n production > /tmp/users.production.dump
Только данные
pg_dump —data-only users > /tmp/users.data.dump
Использование pgAdmin
Данный метод хорошо подойдет для компьютеров с Windows и для быстрого создания резервных копий из графического интерфейса.
Запускаем pgAdmin — подключаемся к серверу — кликаем правой кнопкой мыши по базе, для которой хотим сделать дамп — выбираем Резервная копия:
В открывшемся окне выбираем путь для сохранения данных и настраиваемый формат:

При желании, можно изучить дополнительные параметры для резервного копирования:

После нажимаем Резервная копия — ждем окончания процесса и кликаем по Завершено.
Не текстовые форматы дампа
Другие форматы позволяют делать частичное восстановление, работать в несколько потоков и сжимать данные.
Бинарный с компрессией:
pg_dump -Fc users > users.bak
Тарбол:
pg_dump -Ft users > users.tar
Directory-формат:
pg_dump -Fd users > users.dir
Использование pg_basebackup
Утилита pg_basebackup идет в комплекте с СУБД и позволяет создать резервную копию кластера PostgreSQL. При этом, с ее помощью нельзя снять дамп определенной базы — только целиком все данные и конфигурационные файлы. Для восстановления информации нужно будет разместить полученные файлы в рабочий каталог СУБД.
Пример команды:
pg_basebackup -D /backup
* в данном примере создается резервная копия локального сервера с сохранением данных в каталог /backup.
Если мы хотим забрать данные, подключившись к удаленному серверу, нам нужно обеспечить доступ с правами replication. Для этого в файл pg_hba.conf добавляем строку:
…
host replication all 192.168.0.15/32 trust
…
* где 192.168.0.15 — компьютер, на котором мы будем запускать pg_basebackup.
Не забываем перезапустить службу postgresql, например:
systemctl restart postgresql-14
Теперь можно снимать бэкап кластера:
pg_basebackup -d postgresql://postgres@node1 -D /backup
* в данном примере создается резервная копия для сервера node1 с сохранением ее в каталог /backup.
** обратите внимание, что у нас должен быть возможность подключения к серверу node1 под пользователем postgres с компьютера, где мы запускаем pg_basebackup (для этого мы и меняли настройку в файле pg_hba.conf).
pg_dumpall
Данная утилита делает выгрузку всех баз данных, в том числе системных. На выходе получаем файл для восстановления в формате скрипта.
pg_dumpall > cluster.bak
Утилиту удобно использовать с ключом -g (—globals-only) — выгрузка только глобальных объектов (ролей и табличных пространств).
Для создание резервного копирования со сжатием:
pg_dumpall | gzip > cluster.tar.gz
Восстановление
Нам может понадобиться удалить старую базу. Это можно сделать с помощью SQL-запроса:
=# DROP DATABASE users;
* в данном примере будет удалена база с именем users.
Убедитесь, что удаляете базу с нужным названием на правильном сервере.
Если получаем ошибку на подобие:
ERROR: database «users» is being accessed by other users
… значит база используется приложением. Либо останавливаем его, либо выполняем:
=# SELECT pg_terminate_backend(pid) FROM pg_stat_activity WHERE datname = ‘users’; DROP DATABASE users;
Также может понадобиться создать базу данных (не потребуется, если делали дамп с опцией -C). Для этого используем SQL-запрос:
=# CREATE DATABASE users WITH ENCODING=’UTF-8′;
* где users — имя базы; UTF-8 — используемая кодировка.
Если мы получим ошибку:
ERROR: encoding «UTF8» does not match locale «en_US»
DETAIL: The chosen LC_CTYPE setting requires encoding «LATIN1».Указываем больше параметров при создании базы:
CREATE DATABASE users WITH OWNER ‘postgres’ ENCODING ‘UTF8’ LC_COLLATE = ‘ru_RU.UTF-8’ LC_CTYPE = ‘ru_RU.UTF-8’ TEMPLATE = template0;
Базовая команда
Синтаксис:
psql <имя базы> < <файл с дампом>
Пример:
psql users < /tmp/users.dump
С авторизацией
При необходимости авторизоваться при подключении к базе вводим:
psql -U dmosk -W users < /tmp/users.dump
* где dmosk — имя учетной записи; опция W потребует ввода пароля.
Из файла gz
Сначала распаковываем файл, затем запускаем восстановление:
gunzip users.sql.gz
psql users < users.sql
Или одной командой:
zcat users.sql.gz | psql users
Определенную базу
Если резервная копия делалась для определенной базы, запускаем восстановление:
psql users < /tmp/database.dump
Если делался полный дамп (всех баз), восстановить определенную можно при помощи утилиты pg_restore с параметром -d:
pg_restore -d users cluster.bak
Определенную таблицу
Если резервная копия делалась для определенной таблицы, можно просто запустить восстановление:
psql users < /tmp/students.dump
Если делался полный дамп, восстановить определенную таблицу можно при помощи утилиты pg_restore с параметром -t:
pg_restore -a -t students users.dump
С помощью pgAdmin
Запускаем pgAdmin — подключаемся к серверу — кликаем правой кнопкой мыши по базе, для которой хотим восстановить данные — выбираем Восстановить:
Выбираем наш файл с дампом:

И кликаем по Восстановить:

Использование pg_restore
Данная утилита предназначена для восстановления данных не текстового формата (в одном из примеров создания копий мы тоже делали резервную копию не текстового формата).
Из бинарника:
pg_restore -Fc users.bak
Из тарбола:
pg_restore -Ft users.tar
С созданием новой базы:
pg_restore -Ft -C users.tar
Мы можем использовать опцию d для указания подключения к конкретному серверу и базе, например:
pg_restore -d «postgresql://dmosk_user:dmosk_pass@localhost/dmosk_base» -Fc users.bak
* в данном примере мы подключимся к локальной базе (localhost) с названием dmosk_base от пользователя dmosk_user с паролем dmosk_pass.
Работа с CSV
Мы можем переносить данные с использованием файлов csv. Это нельзя назвать напрямую резервным копированием, но в рамках данной инструкции материал будет интересен.
Создание файла CSV (экспорт)
Пример запроса (выполняется в командной оболочке SQL):
> COPY (SELECT * FROM public.users WHERE name LIKE ‘А%’) TO ‘/tmp/users.csv’ WITH CSV DELIMITER ‘;’ HEADER;
* в данном примере мы выгрузим все данные для таблицы users в схеме public, где значение поля name начинается с буквы А. Результат будет сохранен в файл /tmp/users.csv. Также мы указываем, что в качестве разделителя данных нужно использовать точку с запятой и первой строкой сделать заголовок.
Также мы можем сделать выгрузку, но сделать вывод в оболочку и перенаправить его в файл:
psql -d «postgresql://pg_user:pg_pass@localhost:5432/pg_databasename» -c «COPY (SELECT * FROM public.users WHERE name LIKE ‘А%’) TO STDIN WITH CSV DELIMITER ‘;’ HEADER;» > /tmp/users.csv
Импорт данных из файла CSV
Также можно выполнить запрос в оболочке SQL:
> COPY public.users FROM ‘/tmp/test.csv’ DELIMITER ‘;’ CSV HEADER;
Или перенаправить запрос через STDOUT из файла:
psql -d «postgresql://pg_user:pg_pass@localhost:5432/pg_databasename» -c «COPY public.users FROM STDOUT DELIMITER ‘;’ CSV HEADER;» < /tmp/users.csv
* в нашем примере мы выполним импорт данных из ранее созданного файла /tmp/users.csv в таблицу users.
Возможные ошибки
Рассмотрим некоторые проблемы, с которыми можно столкнуться при работе с дампами PostgreSQL.
Input file appears to be a text format dump. please use psql.
Причина: дамп сделан в текстовом формате, поэтому нельзя использовать утилиту pg_restore.
Решение: восстановить данные можно командой psql <имя базы> < <файл с дампом> или выполнив SQL, открыв файл, скопировав его содержимое и вставив в SQL-редактор.
No matching tables were found
Причина: Таблица, для которой создается дамп не существует. Утилита pg_dump чувствительна к лишним пробелам, порядку ключей и регистру.
Решение: проверьте, что правильно написано название таблицы и нет лишних пробелов.
Too many command-line arguments
Причина: Утилита pg_dump чувствительна к лишним пробелам.
Решение: проверьте, что нет лишних пробелов.
Aborting because of server version mismatch
Причина: несовместимая версия сервера и утилиты pg_dump. Может возникнуть после обновления или при выполнении резервного копирования с удаленной консоли.
Решение: нужная версия утилиты хранится в каталоге /usr/lib/postgresql/<version>/bin/. Необходимо найти нужный каталог, если их несколько и запускать нужную версию. При отсутствии последней, установить.
No password supplied
Причина: нет системной переменной PGPASSWORD или она пустая.
Решение: либо настройте сервер для предоставление доступа без пароля в файле pg_hba.conf либо экспортируйте переменную PGPASSWORD (export PGPASSWORD или set PGPASSWORD).
Неверная команда \
Причина: при выполнении восстановления возникла ошибка, которую СУБД не показывает при стандартных параметрах восстановления.
Решение: запускаем восстановление с опцией -v ON_ERROR_STOP=1, например:
psql -v ON_ERROR_STOP=1 users < /tmp/users.dump
Теперь, когда возникнет ошибка, система прекратит выполнять операцию и выведет сообщение на экран.
PostgreSQL remains among the most efficient and widely applied open-source relational database management systems. It provides the superior function of saving, configuring, and extracting information most effectively. In the process of migrating data, creating backups, or transferring databases between environments, knowing how to dump and restore PostgreSQL is essential.
In this article, we will go through the individual steps to dump and restore PostgreSQL databases using both the command-line interface (CLI) and pgAdmin, a popular graphical user interface for PostgreSQL management.
How to Dump a PostgreSQL Database?
A PostgreSQL dump file is a text file consisting of SQL statements that can recreate a database’s structure and content. This «backup» file can be used later to restore the database. Here, we will discuss two methods for dumping a PostgreSQL database: using the pg_dump command-line tool and pgAdmin.
Method 1: Using the pg_dump Command-Line Tool
The pg_dump command-line utility is the most commonly used method to dump a PostgreSQL database. It creates a logical backup, saving the database as a plain-text file or in a custom format.
Step 1: Open Terminal or Command Prompt
Start by opening the Terminal on Linux/Mac or Command Prompt on Windows.
Step 2. Navigate to PostgreSQL Bin Directory (Optional)
If the path to PostgreSQL’s bin directory is not added to your system’s PATH, a command ‘cd’ will be used to navigate to the directory. This directory is usually located within your PostgreSQL installation directory.
Step 3. Execute the pg_dump Command
The command for the pg_dump will be «pg_dump database_name«. Optional parameters including username, hostname, and port settings can be specified here.
pg_dump -U username -h hostname -p port dbname > dump.sql
- Replace username with your PostgreSQL username.
- Replace hostname with the server where the database is located (use «localhost» if local).
- Replace port with the port number (default is 5432).
- Replace dbname with the name of the database we want to dump.
- Replace dump.sql with the name of your dump file.
Step 4. Enter Password (If Required)
Enter the password associated with the corresponding username when prompted.
Step 5. Verify Dump
After all the commands finish running, check that a file named ‘dump.sql’ (or any other name we want) has been created inside this directory. It will be in the current directory. The data file saves the SQL statements in order to set up the database structure and to insert the data.
Example:
pg_dump -U postgres -h localhost -p 5432 -d northwind > C:\Users\Sanket\Desktop\northwind_backup.sql
Output
Explanation:
Once we have completed these steps, we dump the Northwind database via the use of ‘pg_dump’ command line tool. Now the dump file is ready for restoring the database later or moving the database to another PostgreSQL instance.
Database administrators as well as developers perform dumping databases as a regular one-off operation to preserve the database data integrity and uptime in different scenarios.
Method 2: Using pgAdmin
For users who prefer a graphical interface, pgAdmin provides an easy way to create database backups.
Step 1: Open pgAdmin
Launch pgAdmin connect to your PostgreSQL server.
Step 2: Navigate to the Databases Section
In the object browser, click the + button to widen the server node, the Databases section under it.
Step 3: Right-click on the Database
Right-click on the database you want to dump and select «Backup.»
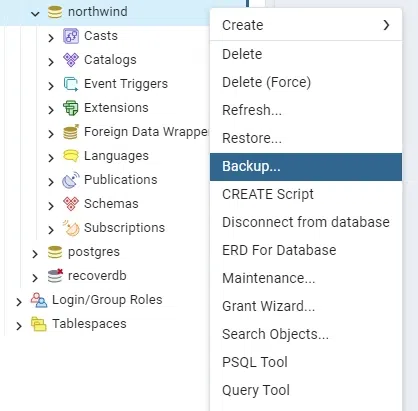
Step 4: Specify Backup Options
A dialog box will appear, allowing you to select the backup type (plain, custom, tar) and specify the filename.
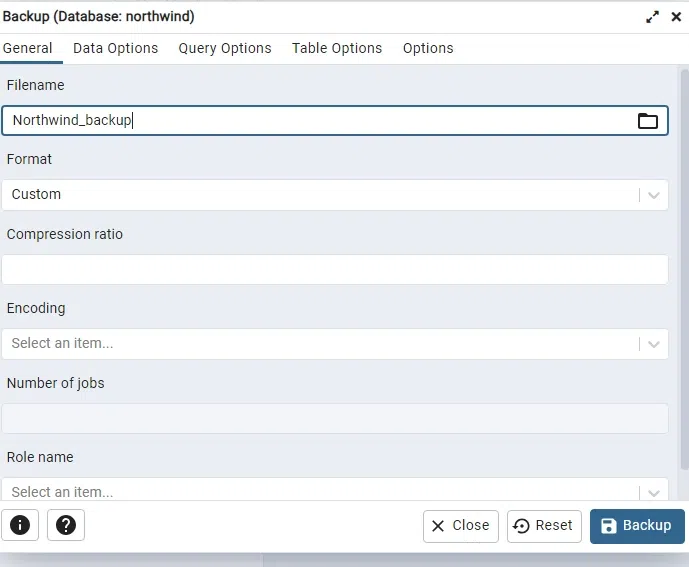
Step 5: Initiate Backup
Clicking on «Backup» to initiate the backup process. At the finishing point, you are left dump file that holds the database schema and data in it.
How to Restore a PostgreSQL Database?
PostgreSQL database recovery is one of the most important tasks in database administration. It can be used to recover from a backup, migrate data, or create a new environment. In this section, we will go over how to restore a PostgreSQL database. We will use the PostgreSQL command-line tool (psql) as well as the popular graphical interface (pgAdmin) to do this.
Method 1: Restoring Backup Using psql Command-Line Tool
The psql tool is commonly used to restore PostgreSQL backups from a SQL dump file.
Step 1: Open Terminal or Command Prompt
Open your terminal or command prompt window.
Step 2: Connect to PostgreSQL Server
Execute the following command to connect to the PostgreSQL server using the psql command-line tool:
psql -U postgres
Enter the password for the Postgres user if prompted.
Step 3: Create a New Database
Inside the psql environment, create a new database named ‘recoverdb‘:
Step 4: Exit psql Environment
Type ‘\q' to exit the psql environment.
Step 5: Restore Backup
Outside the psql environment, use the following command to restore the backup file to the ‘recoverdb‘ database:
psql -U postgres -d recoverdb -f "C:\Users\Sanket\Desktop\northwind_backup.sql"
Example:
Type the command to recover the dump file in recoverdb database which we created before.
Enter password and the database will be recovered from northwind_backup.sql dump file
Method 2: Restoring Backup Using pgAdmin
Restoring a database through pgAdmin is easy and user-friendly.
Step 1: Launch pgAdmin
Open pgAdmin and connect to your PostgreSQL server.
Step 2: Create a New Database
Navigate to the Databases section, right-click on the server, and select «Create» > «Database…«. Enter recoverdb as the database name and click «Save«.
Step 3: Restore Backup
Right-click on the ‘recoverdb' database you just created and select «Restore.» In the dialog box that appears, navigate to the location of your backup file (‘northwind_backup.sql') and select it.
Click «Restore» to initiate the restoration process.
Conclusion
Backup/Restore and database dumping are common tasks for database administrators and developers. Whether you are migrating data, making backups, or transferring databases between environments, understanding how to dump and restore PostgreSQL databases is crucial.
By following the steps outlined in this article, we can reliably and efficiently dump and restore our PostgreSQL databases without risking data integrity or availability. Both pg_dump and pgAdmin offer powerful options for ensuring our database backups are properly created and restored.
Задача резервного копирования — одна из основных при сопровождении и поддержке PostgreSQL. Для резервного копирования логической схемы и данных можно использовать как встроенные инструменты СУБД, так и внешние. В этой статье мы разберем оба варианта.
Для начала подготовим сервер. Для демо-стенда закажем виртуальный сервер в Облачной платформе. Для этого откроем панель управления my.selectel.ru, перейдем в меню Облачная платформа и нажмем на кнопку Создать сервер.
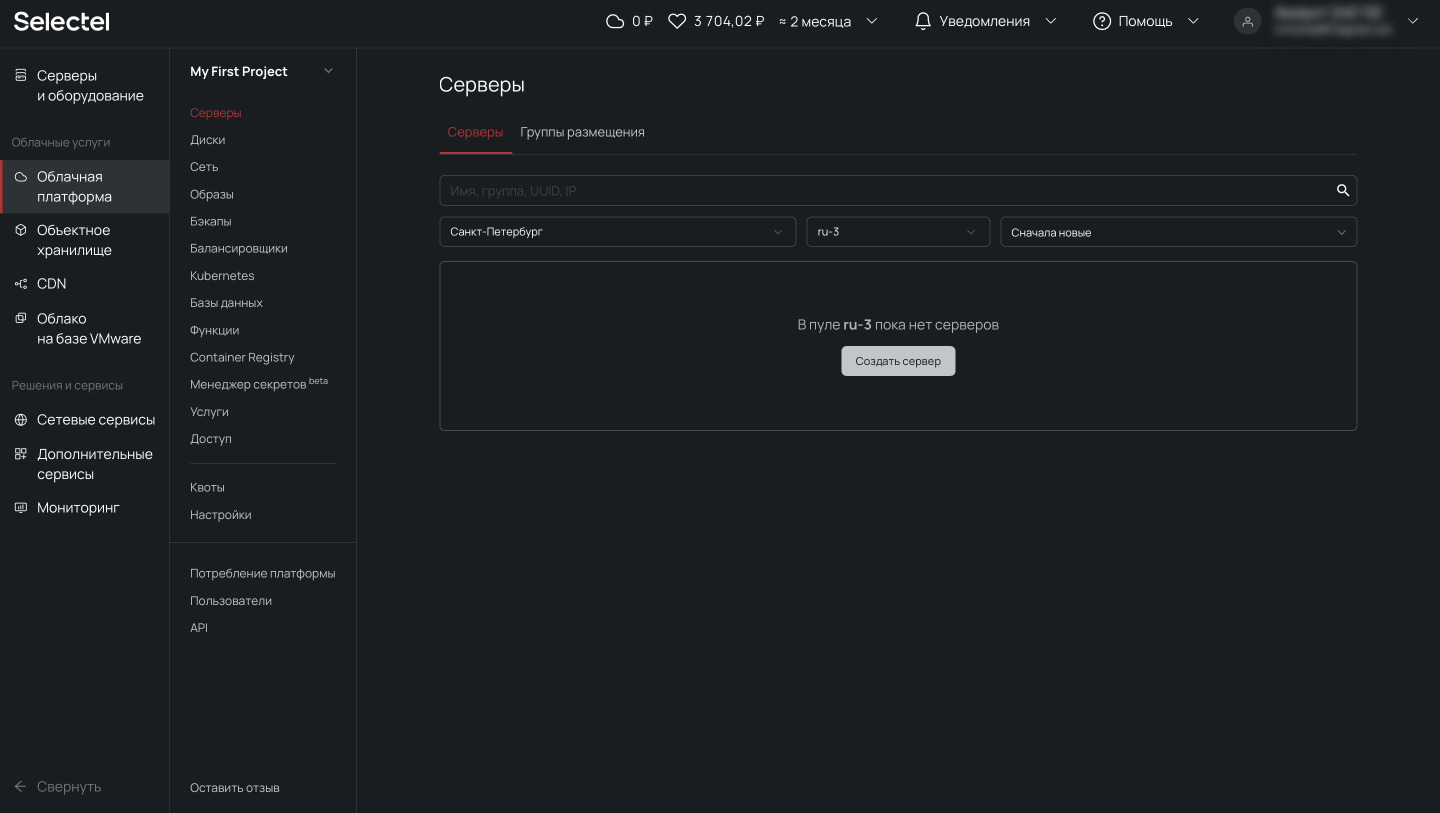
В статье будем использовать виртуальный сервер с конфигурацией 2 vCPU, 4 ГБ RAM и 10 ГБ HDD с операционной системой CentOS 8 Stream 64-bit.
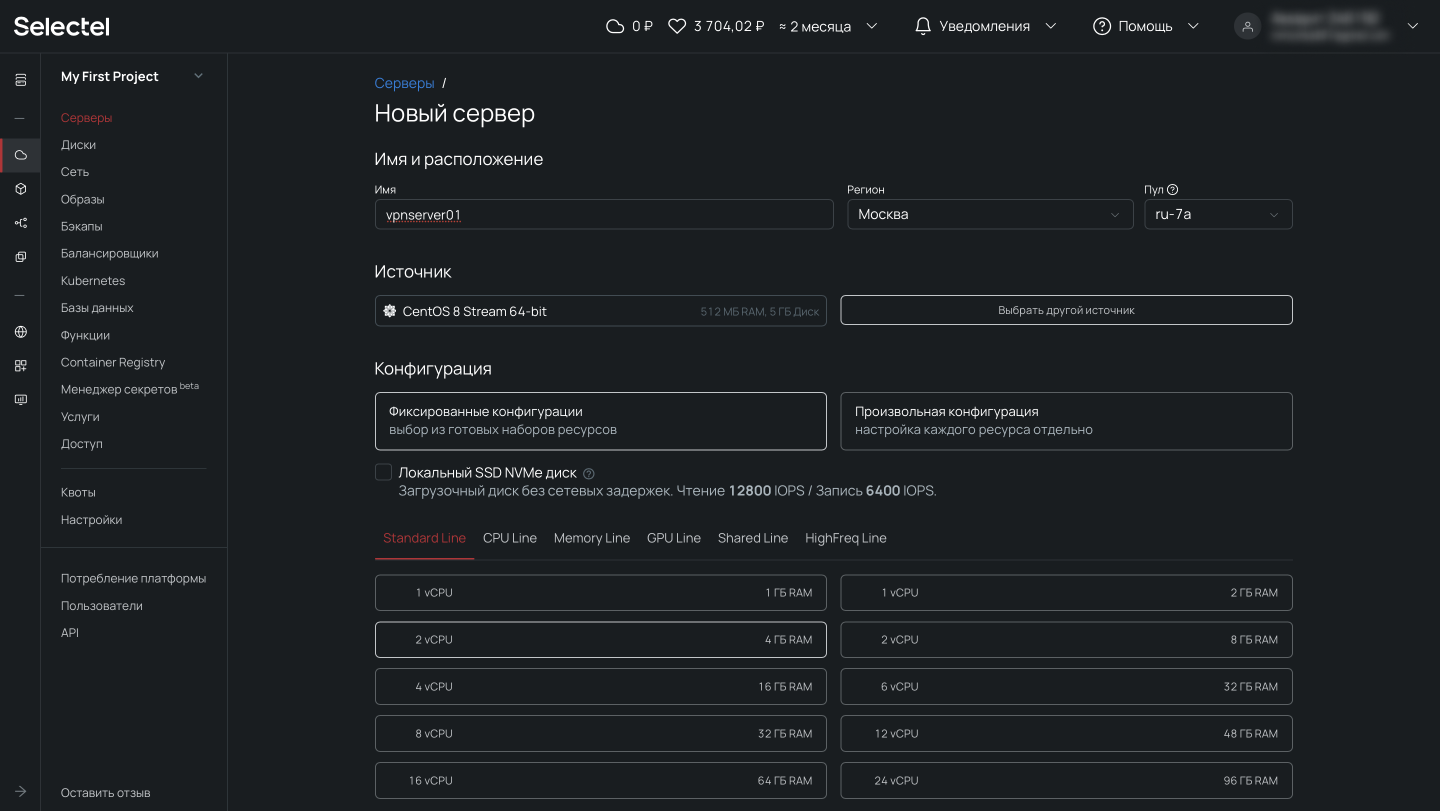
Теперь прокрутим представление ниже, где находятся настройки сети. Важно, чтобы у сервера был внешний плавающий IP-адрес для доступа извне.
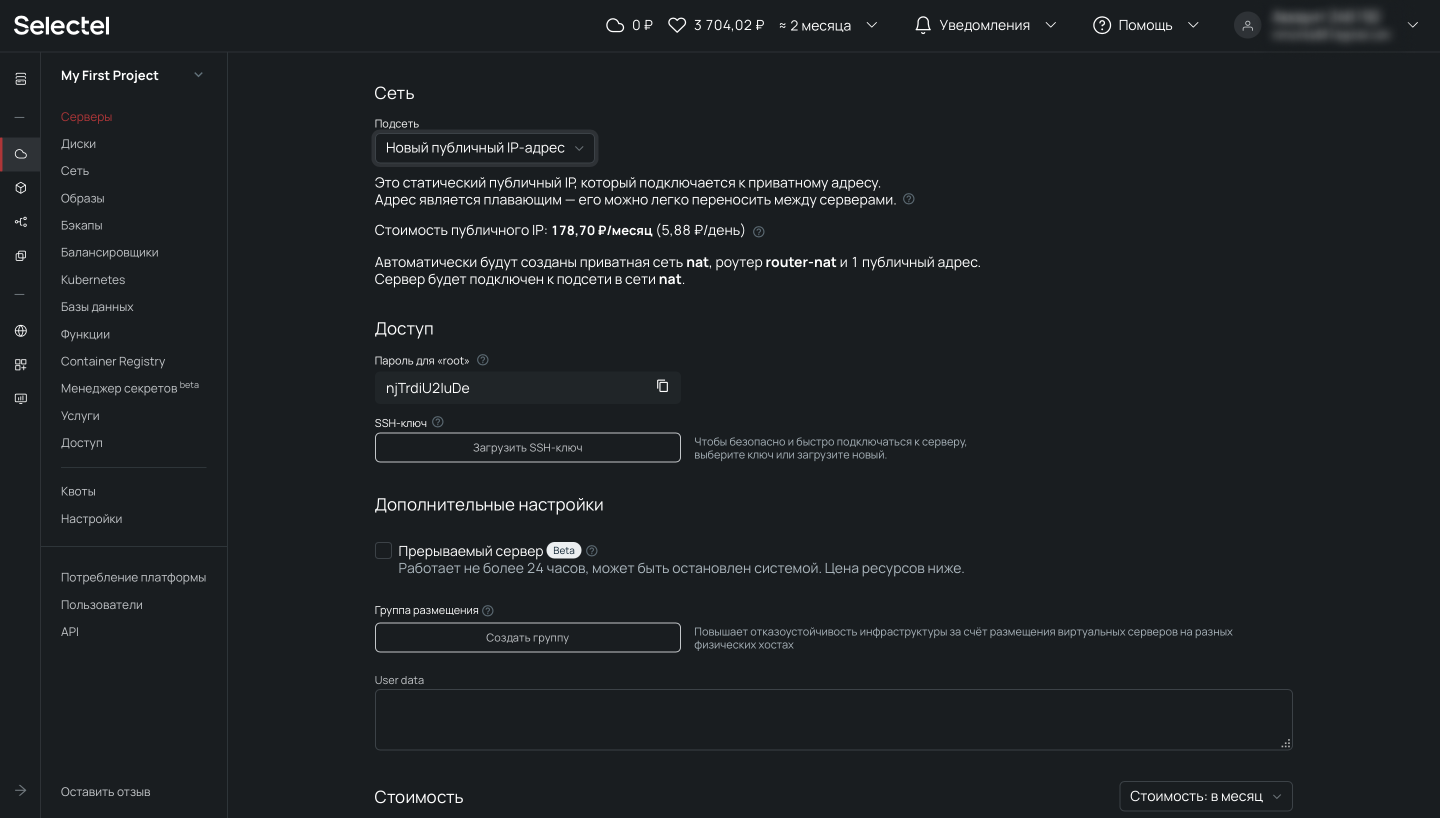
После выбора операционной системы, конфигурации сервера и выполнения сетевых настроек переходим к завершению заказа и нажимаем на кнопку Создать. Через несколько минут сервер будет готов.
Перед началом демонстрации возможностей резервного копирования, мы подготовили PostgreSQL. Для целей наполнения базы данных и создания непрерывного потока записи, развернули там Zabbix (некоторое время назад публиковали о нем статью).
Доверьте нам развертывание и администрирование баз данных в облаке.
Создание резервных копий и восстановление из командной строки
В этом разделе мы расскажем как сделать дамп базы данных PostgreSQL в консоли при подключении по SSH, разберем синтаксис и покажем примеры использования утилит pg_dump, pg_dumpall, pg_restore, pg_basebackup и wal-g.
Утилита pg_dump
В PostgreSQL есть встроенный инструмент для создания резервных копий — утилита pg_dump. Утилита имеет простой синтаксис:
# pg_dump <параметры> <имя базы> > <файл для сохранения копии> В простейшем случае достаточно указать имя базы данных, которую в дальнейшем нужно будет восстановить. Резервная копия создается следующей командой:
# pg_dump zabbix > /tmp/zabbix.dumpЕсли требуется авторизация под определенным пользователем, можно воспользоваться ключом -U:
# pg_dump -U zabbix -W zabbix > /tmp/zabbix.dump # pg dump u postgresКлюч -U определяет пользователя, а -W обязывает ввести пароль.
Чтобы сэкономить место на диске, можно сразу же сжимать дамп:
# pg_dump -U zabbix -W zabbix | gzip > /tmp/zabbix.gzРезервное копирование обычно выполняется по расписанию, например, ежедневно в 3 часа ночи. Нижеприведенный пример скрипта не только выполняет бэкап, но и удаляет все файлы старше 61 дня (за исключением 15-го числа месяца).
#!/bin/sh
PATH=/etc:/bin:/sbin:/usr/bin:/usr/sbin:/usr/local/bin:/usr/local/sbin
PGPASSWORD=some_password
export PGPASSWORD
pathB=/mnt/backup
dbUser=dbadmin
database=zabbix
find $pathB \( -name "*-1[^5].*" -o -name "*-[023]?.*" \) -ctime +61 -delete
pg_dump -U $dbUser $database | gzip > $pathB/pgsql_$(date "+%Y-%m-%d").sql.gz
unset PGPASSWORDЧтобы настроить регулярное выполнение, выполним следующую команду в планировщике crontab:
# crontab -e
3 0 * * * /etc/scripts/pgsql_dump.sh # postgres pg dumpЧтобы выполнить аналогичную команду на удаленном сервере, достаточно добавить ключ -h:
# pg_dump -h 192.168.56.101 zabbix > /tmp/zabbix.dumpКлюч -t задает таблицу, для которой нужно создать резервную копию:
# pg_dump -t history zabbix > /tmp/zabbix.dump # postgres dump tableПри помощи специальных ключей можно создавать резервные копии структуры данных или непосредственно данных:
# pg_dump --schema-only zabbix > /tmp/zabbix.dump
# pg_dump --data-only zabbix > /tmp/zabbix.dumpУ утилиты pg_dump также есть ключи для сохранения дампа в другие форматы. Чтобы сохранить копию в виде бинарного файла используются ключи -Fc:
# pg_dump -Fc zabbix > /tmp/zabbix.bakЧтобы создать архив — -Ft:
# pg_dump -Ft zabbix > /tmp/zabbix.tarЧтобы сохранить в directory-формате — -Fd:
# pg_dump -Fd zabbix > /tmp/zabbix.dirРезервное копирование в виде каталогов позволяет выполнять процесс в многопоточном режиме.
Ниже мы перечислим возможные параметры утилиты pg_dump.
-d <имя_бд>, —dbname=имя_бд — база данных, к которой выполняется подключение.
-h <сервер>, —host=сервер — имя сервера.
-p <порт>, —port=порт — порт для подключения.
-U <пользователь>, —username=пользователь) — учетная запись, используемое для подключения.
-w, —no-password — деактивация требования ввода пароля.
-W, —password — активация требования ввода пароля.
—role=имя роли — роль, от имени которой генерируется резервная копия.
-a, —data-only — вывод только данных, вместо схемы объектов (DDL).
-b, —blobs — параметр добавляет в выгрузку большие объекты.
-c, —clean — добавление команд DROP перед командами CREATE в файл резервной копии.
-C, —create — генерация реквизитов для подключения к базе данных в файле резервной копии.
-E <кодировка>, —encoding=кодировка — определение кодировки резервной копии.
-f <файл>, —file=файл — задает имя файла, в который будет сохраняться вывод утилиты.
-F <формат>, —format=формат — параметр определяет формат резервной копии. Доступные форматы:
- p, plain) — формирует текстовый SQL-скрипт;
- c, custom) — формирует резервную копию в архивном формате;
- d, directory) — формирует копию в directory-формате;
- t, tar) — формирует копию в формате tar.
-j <число_заданий>, —jobs=число_заданий — параметр активирует параллельную выгрузку для одновременной обработки нескольких таблиц (равной числу заданий). Работает только при выгрузке копии в формате directory.
-n <схема>, —schema=схема — выгрузка в файл копии только определенной схемы.
-N <схема>, —exclude-schema=схема — исключение из выгрузки определенных схем.
-o, —oids — добавляет в выгрузку идентификаторы объектов (OIDs) вместе с данными таблиц.
-O, —no-owner — деактивация создания команд, определяющих владельцев объектов в базе данных.
-s, —schema-only —добавление в выгрузку только схемы данных, без самих данных.
-S <пользователь>, —superuser=пользователь — учетная запись привилегированного пользователя, которая должна использоваться для отключения триггеров.
-t <таблица>, —table=таблица — активация выгрузки определенной таблицы.
-T <таблица>, —exclude-table=таблица —исключение из выгрузки определенной таблицы.
-v, —verbose — режим подробного логирования.
-V, —version — вывод версии pg_dump.
-Z 0..9, —compress=0..9 — установка уровня сжатия данных. 0 — сжатие выключено.
Утилита pg_dumpall
Утилита pg_dumpall реализует резервное копирование всего экземпляра (кластера или инстанса) базы данных без указания конкретной базы данных на инстансе. По принципу схожа с pg_dump. Добавим, что только утилиты pg_dump и pg_dumpall предоставляют возможность создания логической копии данных, остальные утилиты, рассматриваемые в этой статье, позволяют создавать только бинарные копии.
# pg_dumpall > /tmp/instance.bakЧтобы сразу сжать резервную копию экземпляра базы данных, нужно передать вывод на архиватор gzip:
# pg_dumpall | gzip > /tmp/instance.tar.gzНиже приведены параметры, с которыми может вызываться утилита pg_dumpall.
-d <имя_бд>, —dbname=имя_бд — имя базы данных.
-h <сервер>, —host=сервер — имя сервера.
-p <порт>, —port=порт — TCP-порт, на который принимаются подключения.
-U <пользователь>, —username=пользователь — имя пользователя для подключения.
-w, —no-password — деактивация требования ввода пароля.
-W, —password — активация требования ввода пароля.
—role=<имя роли> — роль, от имени которой генерируется резервная копия.
-a, —data-only — создание резервной копии без схемы данных.
-c, —clean — добавление операторов DROP перед операторами CREATE.
-f <имя_файла>, —file=имя_файла — активация направления вывода в указанный файл.
-g, —globals-only — выгрузка глобальных объектов без баз данных.
-o, —oids — выгрузка идентификаторов объектов (OIDs) вместе с данными таблиц.
-O, —no-owner — деактивация генерации команд, устанавливающих принадлежность объектов, как в исходной базе данных.
-r, —roles-only — выгрузка только ролей без баз данных и табличных пространств.
-s, —schema-only — выгрузка только схемы без самих данных.
-S <имя_пользователя>, —superuser=имя_пользователя — привилегированный пользователь, используемый для отключения триггеров.
-t, —tablespaces-only — выгрузка табличных пространства без баз данных и ролей.
-v, —verbose — режим подробного логирования.
-V (—version — вывод версии утилиты pg_dumpall.
Утилита pg_restore
Утилита позволяет восстанавливать данные из резервных копий. Например, чтобы восстановить только определенную БД (в нашем примере zabbix), нужно запустить эту утилиту с параметром -d:
# pg_restore -d zabbix /tmp/zabbix.bakЧтобы этой же утилитой восстановить определенную таблицу, нужно использовать ее с параметром -t:
# pg_restore -a -t history /tmp/zabbix.bakТакже утилитой pg_restore можно восстановить данные из бинарного или архивного файла. Соответственно:
# pg_restore -Fc zabbix.bak
# pg_restore -Ft zabbix.tarПри восстановлении можно одновременно создать новую базу:
# pg_restore -Ft -С zabbix.tarВосстановить данные из дампа также возможно при помощи psql:
# psql zabbix < /tmp/zabbix.dumpЕсли для подключения нужно авторизоваться, вводим следующую команду:
# psql -U zabbix -W zabbix < /tmp/zabbix.dumpНиже приведен синтаксис утилиты pg_restore.
-h <сервер>, —host=сервер — имя сервера, на котором работает база данных.
-p <порт>, —port=порт — TCP-порт, через база данных принимает подключения.
-U <пользователь>, —username=пользователь — имя пользователя для подключения..
-w, —no-password — деактивация требования ввода пароля.
-W, —password — активация требования ввода пароля.
—role=имя роли — роль, от имени которой выполняется восстановление резервная копия.
<имя_файла> — расположение восстанавливаемых данных.
-a, —data-only — восстановление данных без схемы.
-c, —clean — добавление операторов DROP перед операторами CREATE.
-C, —create — создание базы данных перед запуском процесса восстановления.
-d <имя_бд>, —dbname=имя_бд — имя целевой базы данных.
-e, —exit-on-error — завершение работы в случае возникновения ошибки при выполнении SQL-команд.
-f <имя_файла>, —file=имя_файла — файл для вывода сгенерированного скрипта.
-F <формат>, —format=формат — формат резервной копии. Допустимые форматы:
- p, plain — формирует текстовый SQL-скрипт;
- c, custom — формирует резервную копию в архивном формате;
- d, directory — формирует копию в directory-формате;
- t, tar — формирует копию в формате tar.
-I <индекс>, —index=индекс — восстановление только заданного индекса.
-j <число-заданий>, —jobs=число-заданий — запуск самых длительных операций в нескольких параллельных потоках.
-l, —list) — активация вывода содержимого архива.
-L <файл-список>, —use-list=файл-список — восстановление из архива элементов, перечисленных в файле-списке в соответствующем порядке.
-n <пространство_имен>, —schema=схема — восстановление объектов в указанной схеме.
-O, —no-owner — деактивация генерации команд, устанавливающих владение объектами по образцу исходной базы данных.
-P <имя-функции(тип-аргумента[, …])>, —function=имя-функции(тип-аргумента[, …]) — восстановление только указанной функции.
-s, —schema-only — восстановление только схемы без самих данных.
-S <пользователь>, —superuser=пользователь — учетная запись привилегированного пользователя, используемая для отключения триггеров.
-t <таблица>, —table=таблица — восстановление определенной таблицы.
-T <триггер>, —trigger=триггер — восстановление конкретного триггера.
-v, —verbose — режим подробного логирования.
-V, —version — вывод версии утилиты pg_restore.
Утилита pg_basebackup
Утилитой pg_basebackup можно выполнять резервное копирования работающего кластера баз данных PostgreSQL. Результирующий бинарный файл можно использовать для репликации или восстановления на определенный момент в прошлом. Утилита создает резервную копию всего экземпляра базы данных и не дает возможности создавать слепки данных отдельных сущностей. Подключение pg_basebackup к PostgreSQL выполняется при помощи протокола репликации с полномочиями суперпользователя или с правом REPLICATION.
Для выполнения резервного копирования локальной базы данных достаточно передать утилите pg_basebackup параметр -D, обозначающий директорию, в которой будет сохранена резервная копия:
# pg_basebackup -D /tmpЧтобы создать сжатые файлы из табличных пространств, добавим параметры -Ft и -z:
# pg_basebackup -D /tmp -Ft -z То же самое, но со сжатием bzip2 и для экземпляра базы с общим табличным пространством:
# pg_basebackup -D /tmp -Ft | bzip2 > backup.tar.bz2Ниже приведен синтаксис утилиты pg_basebackup.
-d <строка_подключения>, —dbname=строка_подключения — определение базы данных в виде строки для подключения.
-h <сервер>, —host=сервер — имя сервера с базой данных.
-p <порт>, —port=порт — TCP-порт, через база данных принимает подключения.
-s <интервал>, —status-interval=интервал — количество секунд между отправками статусных пакетов.
-U <пользователь>, —username=пользователь — установка имени пользователя для подключения.
-w, —no-password — отключение запроса на ввод пароля.
-W, —password — принудительный запрос пароля.
-V, —version — вывод версии утилиты pg_basebackup.
-?, —help — вывод справки по утилите pg_basebackup.
-D каталог, —pgdata=каталог — директория записи данных.
-F <формат>, —format=формат — формат вывода. Допустимые варианты:
- p, plain — значение для записи выводимых данных в текстовые файлы;
- t, tar — значение, указывающее на необходимость записи в целевую директорию в формате tar.
-r <скорость_передачи>, —max-rate=скорость_передачи — предельная скорость передачи данных в Кб/с.
-R, —write-recovery-conf — записать минимальный файл recovery.conf в директорию вывода.
-S <имя_слота>, —slot=имя_слота — задание слота репликации при использовании WAL в режиме потоковой передачи.
-T <каталог_1=каталог_2>, —tablespace-mapping=каталог_1=каталог_2 — активация миграции табличного пространства из одного каталога в другой каталог при копировании.
—xlogdir=каталог_xlog — директория хранения журналов транзакций.
-X <метод>, —xlog-method=метод — активация вывода файлов журналов транзакций WAL в резервную копию на основе следующих методов:
- f, fetch — включение режима сбора файлов журналов транзакций при окончании процесса копирования;
- s, stream — включение передачи журнала транзакций в процессе создания резервной копии.
-z, —gzip — активация gzip-сжатия результирующего tar-файла.
-Z <уровень>, —compress=уровень — определение уровня сжатия механизмом gzip.
-c , —checkpoint=fast|spread — активация режима реперных точек.
-l <метка>, —label=метка — установка метки резервной копии.
-P, —progress — активация в вывод отчета о прогрессе.
-v, —verbose — режим подробного логирования.
Утилита wal-g
Wal-g — утилита для резервного копирования и восстановления базы данных PostgreSQL. При помощи wal-g можно выполнять сохранение резервных копий на хранилищах S3 или просто на файловой системе. Ниже мы разберем установку, настройку и работу с утилитой. Покажем как выполнить резервное копирование в Объектное хранилище S3 от Selectel.
Создадим пользователя для облачного хранилища, учетные данные которого будем потом использовать для сохранения резервной копии. Перейдем в меню Пользователи и нажмем кнопку Создать пользователя:
Дополнительную информацию можно получить в нашей Базе знаний. Первую часть логина изменить нельзя — это идентификатор пользователя в панели управления. Вторая часть логина задается произвольно. Например, 123456_wal-g:
Теперь перейдем к установке wal-g. Скачаем готовый установочный пакет из репозитория на github.com, распакуем и скопируем папку содержающую исполняемые файлы:
# cd /tmp
# curl -L "https://github.com/wal-g/wal-g/releases/download/v0.2.19/wal-g.linux-amd64.tar.gz" -o "wal-g.linux-amd64.tar.gz
# tar -xzf wal-g.linux-amd64.tar.gz
# mv wal-g /usr/local/bin/Заполним конфигурационный файл wal-g и изменим его владельца на учетную запись postgres:
# cat > //6ef4e6a1-9d49-47ac-bfed-170f67a815cf.selcdn.net/var/lib/pgsql/.walg.json << EOF
{
"WALG_S3_PREFIX": "s3://container",
"AWS_ENDPOINT": "https://s3.selcdn.ru"
"AWS_ACCESS_KEY_ID": "123456_wal-g",
"AWS_SECRET_ACCESS_KEY": "password",
"WALG_COMPRESSION_METHOD": "brotli",
"WALG_DELTA_MAX_STEPS": "5",
"PGDATA": "/var/lib/pgsql/data",
"PGHOST": "/var/run/postgresql/.s.PGSQL.5432"
}
EOF
# chown postgres: /var/lib/pgsql/.walg.jsonДалее настроим автоматизированное создание резервных копий в PostgreSQL и перезагрузим процессы базы данных:
# echo "wal_level=replica" >> /var/lib/pgsql/data/postgresql.conf
# echo "archive_mode=on" >> /var/lib/pgsql/data/postgresql.conf
# echo "archive_command='/usr/local/bin/wal-g wal-push \"%p\" >> /var/log/postgresql/archive_command.log 2>&1' " >> /var/lib/pgsql/data/postgresql.conf
# echo “archive_timeout=60” >> /var/lib/pgsql/data/postgresql.conf
# echo "restore_command='/usr/local/bin/wal-g wal-fetch \"%f\" \"%p\" >> /var/log/postgresql/restore_command.log 2>&1' " >> /var/lib/pgsql/data/postgresql.conf
# killall -s HUP postgresТеперь проверим корректность проведения настроек и загрузим резервную копию в хранилище:
# su - postgres -c '/usr/local/bin/wal-g backup-push /var/lib/pgsql/data'После выполнения процесса резервного копирования, в созданном контейнере появится директория с резервными копиями баз данных:
Такой процесс в продакшене может выполняться при помощи планировщика заданий на регулярной основе.
Утилита pgAdmin
Управлять созданием резервных копий возможно также и в графическом интерфейсе. Для этого мы будем использовать утилиту pgAdmin (в примере — работа с утилитой на локальном устройстве, но то же самое можно сделать на сервере). Актуальную версию для Windows или другой поддерживаемой ОС можно свободно скачать с официального сайта.
После скачивания утилиту нужно установить и запустить. Она работает в виде веб-приложения через браузер.
После добавления сервера с базой данных, в интерфейсе появляется возможность создания резервной копии. Аналогичным образом здесь же можно выполнить восстановление из резервной копии.
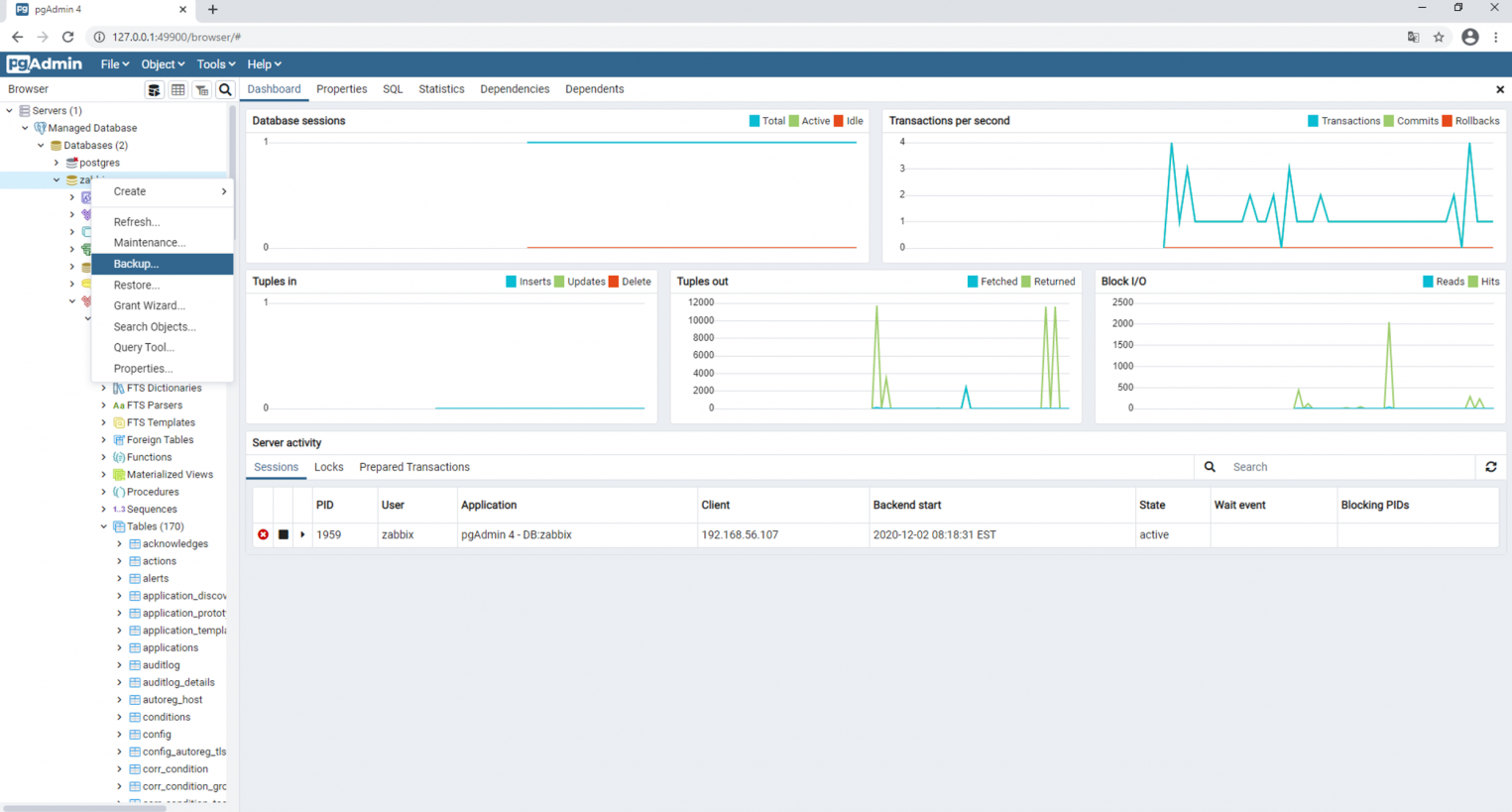
После выполнения команды Backup резервная копия сохраняется в заранее определенную директорию.
Работа с облачной базой данных в панели управления Selectel
В облачной платформе Selectel есть возможность создавать управляемые базы данных (Managed Databases). Такие БД разворачиваются в несколько кликов мыши, однако, их основные преимущества — автоматическое резервное копирование, отказоустойчивость, быстрое масштабирование и управление различными характеристиками из графического интерфейса. Ниже мы создадим экземпляр управляемой базы данных, создадим резервную копию базы данных на виртуальном сервере и восстановим ее в управляемую базу данных.
Чтобы создать управляемую базу данных, перейдем в меню Базы данных и нажмем кнопку Создать кластер:
Появится форма создания кластера. Здесь можно выбрать версию PostgreSQL, конфигурацию кластера, настройки сети, режим пулинга и размер пула.
Обращаем внимание на блок Резервные копии, в котором указаны частота резервного копирования, время и срок хранения выгрузок. Под капотом используется механизм wal-g, о котором мы писали выше.
Автоматическое создание резервных копий отключить нельзя.
Следующий шаг — создание пользователя, от имени которого мы позже будем обращаться к базе данных. Для этого перейдем на вкладку Пользователи и нажмем на кнопку Создать пользователя.
После этого появится приглашение ввести имя пользователя и пароль. После ввода этих данных нажимаем Сохранить.
Пользователь создан и отображается в списке пользователей.
Теперь создадим базу данных. Для этого перейдем на вкладку Базы данных и нажмем на кнопку Создать базу данных.
Заполняем необходимые поля и нажимаем кнопку Сохранить.
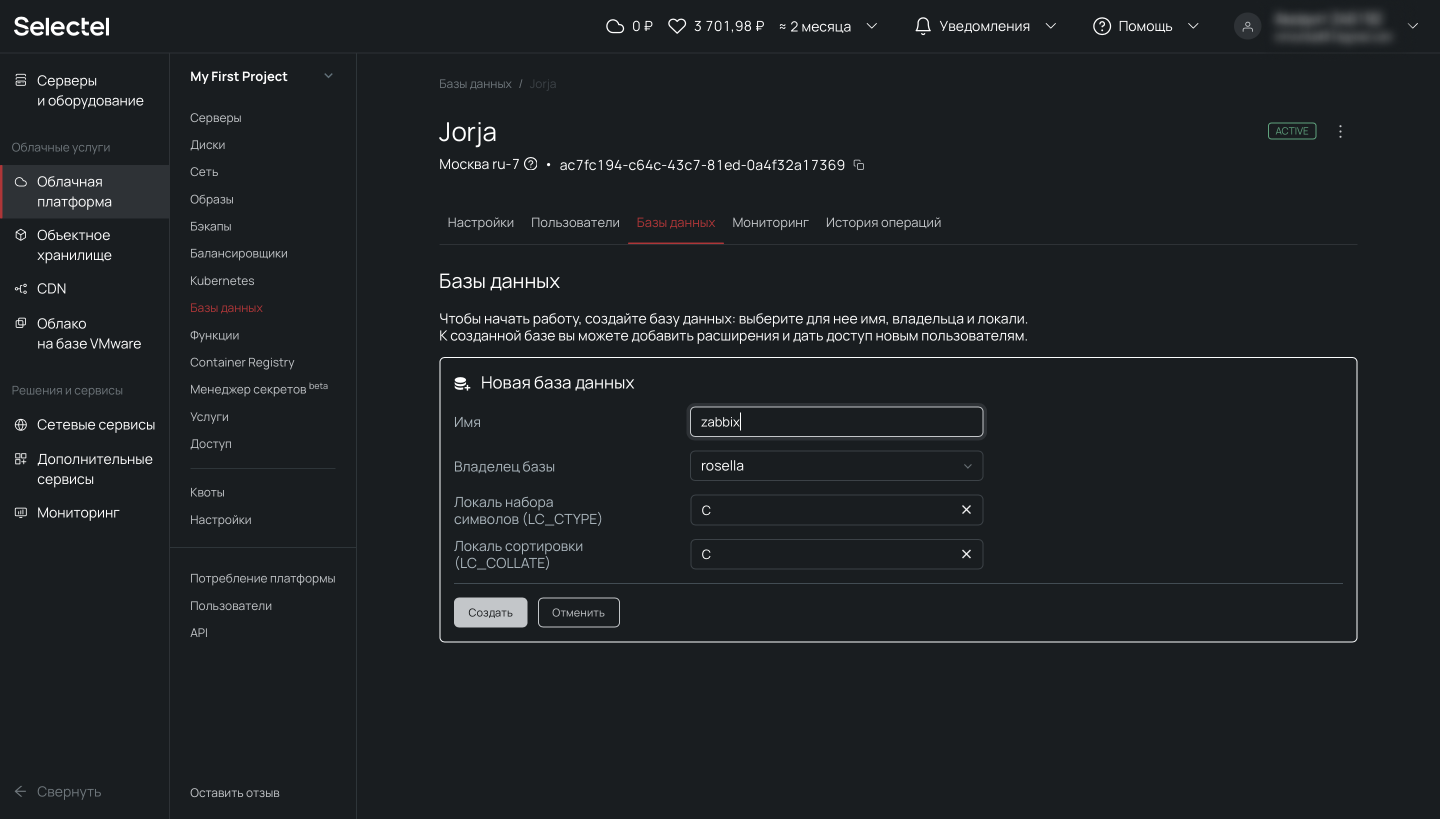
База данных создана и отображается в списке баз данных.
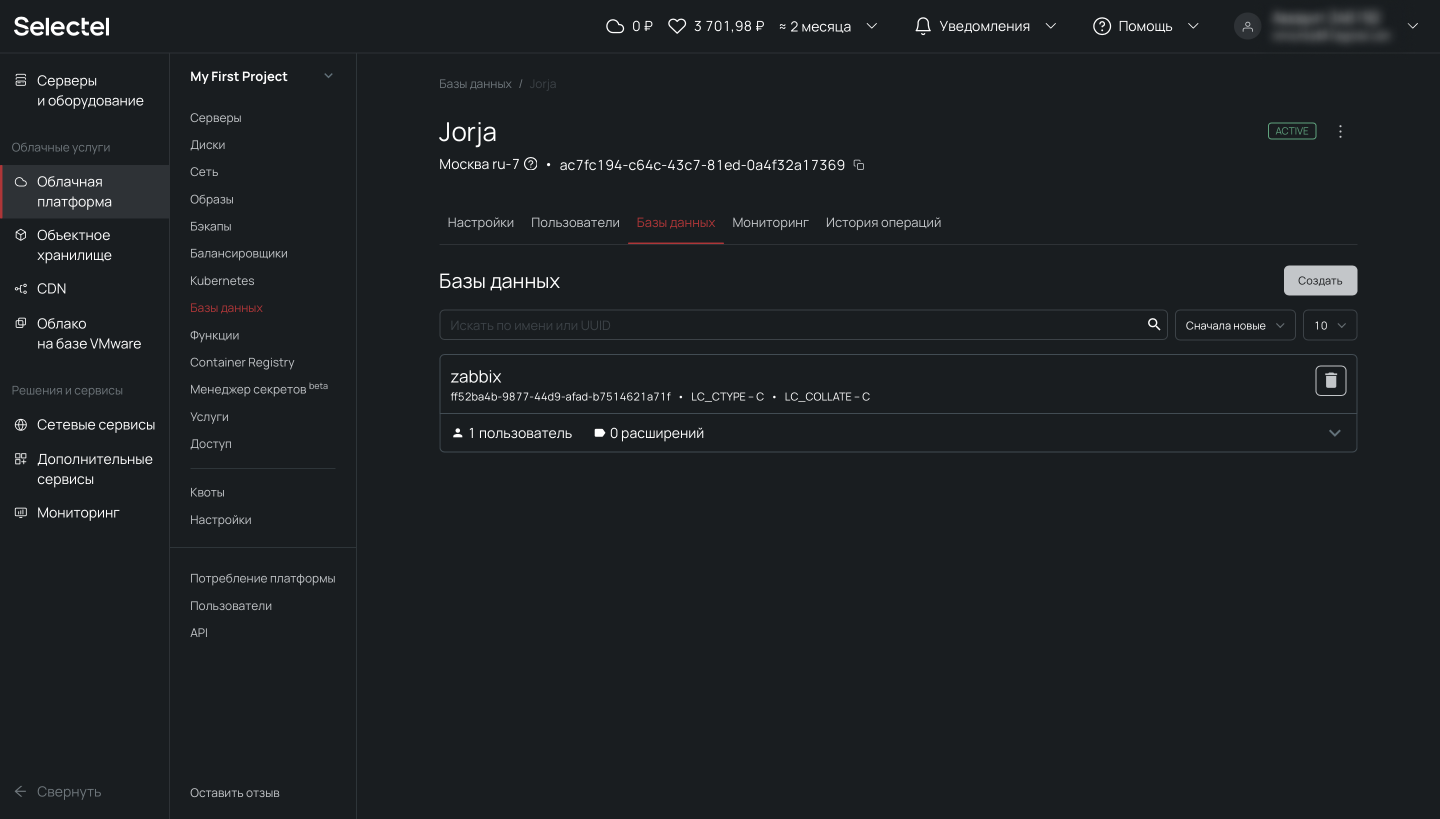
Теперь проверим возможность подключения. Для этого откроем консоль и вводим реквизиты:
# psql "host=192.168.0.3 \
port=6432 \
user=rosella \
dbname=zabbix \
sslmode=disable"В консоли должно появиться приглашение к вводу SQL-запроса или других управляющих команд.

Выполним резервное копирование при помощи команды pg_dump:
# pg_dump zabbix > /tmp/zabbix.dumpИ следом резервное восстановление в созданную управляемую базу данных:
# psql -h 192.168.0.3 -U rosella -d zabbix < /tmp/zabbix.dumpВ результате выполнения команды выше мы восстановили резервную копию в управляемую базу данных.
Чтобы воспользоваться восстановлением из резервной копии, которая автоматически создается на платформе Selectel, необходимо нажать на символ с тремя точками. В открывшемся меню нужно нажать на опцию Восстановить. После этого появится модальное окно, в котором можно выбрать резервную копию, а также дату и время, на которое нужно восстановить базу данных. Это так называемый Point-in-Time Recovery из WAL-файлов.
Услуга «Управляемые базы данных в облаке» позволяет перенести существующий кластер PostgreSQL на сервис управляемых баз данных бесшовно и без простоя, обратившись в техническую поддержку. Инженеры Selectel готовы помочь с переносом, а также проконсультировать по всем связанным с этим процессом вопросам.
Заключение
Мы рассмотрели возможности выполнения резервного копирования и показали отличия утилит pg_dump, pg_dumpall, pg_restore, pg_basebackup и wal-g. Вы увидели как можно создать управляемую базу данных, чтобы переложить часть административных задач на облачного провайдера.
Узнать подробнее об управляемых базах данных можно в документации Selectel.