
Таблица символов относится к служебным программам Windows, то есть, она бесплатная и входит в состав операционной системы Windows. С ее помощью можно найти символы, которых нет на клавиатуре, скопировать их в память компьютера и затем вставить в какое-либо приложение.
Эта таблица есть во всех версиях Windows: 10, 8, 7, Vista, XP. И работает она везде одинаково. Подробно для Windows 7 описано в этой статье.
Как найти Таблицу символов на своем устройстве
Это можно сделать одним из трех вариантов, предложенных ниже:
1) В строке Поиск нужно ввести без кавычек “таблица символов”. В результате поиска должна появиться ссылка на Таблицу символов.
2) Либо в главном меню: Пуск — Программы — Стандартные — Служебные — Таблица символов.
3) Третий вариант для того, чтобы найти таблицу символов. Используем горячие клавиши, то есть:
- нажимаем одновременно две клавиши «Win+R».
- Появится окно “Выполнить”, в котором набираем без кавычек «charmap.exe».
- После чего щелкаем “ОК”, и откроется «Таблица символов».
Таблица символов дает возможность посмотреть все символы, которые входят в какой-либо шрифт. Рассмотрим это на конкретном примере.
Таблица символов Windows для шрифта Times New Roman
Для наглядности эта таблица представлена ниже на рисунке:

Рис. 1. Таблица символов Windows для шрифта Times New Roman. Выделен символ “Параграф”. Указаны клавиши для ввода параграфа: Alt+0167
Порядок расположения символов в Таблице символов такой:
- сначала идут знаки препинания,
- затем цифры,
- английские буквы,
- далее языковые.
- И только после всего этого идут символы, которые отсутствуют на клавиатуре, такие как: ⅜, ∆, ™, ₤ и так далее.
Как скопировать символ из Таблицы символов и поместить его туда, где требуется?
Предлагаю для этого два способа:
- Скопировал (в Таблице символов) — Вставил (там, где требуется).
- С помощью сочетания клавиш (то есть, используя горячие клавиши).
Первый способ: Скопировал в Таблице — Вставил там, где нужно.
Мы копируем (не скачиваем, а именно копируем) символ в Таблице символов для того, чтобы временно поместить его в память компьютера (или аналогичного устройства). Такая временная память называется буфер обмена.
Такой буфер нужен для того, чтобы временно туда поместить символ, а потом вставить его из буфера туда, где мы хотим видеть этот символ. Таким образом, символ не скачивается на диск компьютера, а временно помещается в оперативную память компьютера, то есть, в буфер обмена. А из этого буфера пользователь может вставить символ туда, где потребуется.
Разберем на конкретном примере, как можно символ из Таблицы закинуть в буфер обмена, а потом достать его оттуда и разместить туда, где это необходимо.
Чтобы скопировать символ в память компьютера, нам надо его выделить . Для этого достаточно кликнуть по необходимому символу (цифра 1 на рис. 2).
Затем щелкаем по кнопке «Выбрать» (2 на рис. 2):

Рис. 2. Кликнуть по необходимому символу и нажать на кнопку “Выбрать”
В итоге символ попадет в строку “Для копирования” (1 на рис. 3). Для того, чтобы символ оказался в буфере обмена, надо кликнуть по кнопке «Копировать» (2 на рис. 3):

Рис. 3. Копируем символ из Таблицы в буфер обмена
Есть и быстрый вариант:
По символу кликнуть два раза мышкой и он будет скопирован в буфер обмена.
После этого остается перейти в соответствующее приложение (или в текстовый редактор) и вставить скопированный символ из буфера обмена.
Для этого надо поставить в приложении (в Блокноте, текстовом редакторе и т.п.) курсор в нужное место и нажать на две клавиши Ctrl+V (они выполняют команду “Вставить”).
Если не получается с клавишами Ctrl+V, тогда кликаем правой кнопкой мыши там, где должен быть помещен символ. Откроется меню, в котором щелкаем команду “Вставить”. После этого появится скопированный символ.
Заметим, что можно в Таблице символов в строку “Для копирования” поместить сразу несколько символов и одновременно все их скопировать. Тогда произойдет вставка сразу всех скопированных символов туда, где это требуется (в Блокнот, в какое-то приложение и т.п.)
Второй способ: копируем символ с помощью сочетания клавиш
Для каждого символа в Таблице имеется строго свое сочетание клавиш.
Справа в таблице символов Windows (3 на рис. 3) Вы можете увидеть, какую комбинацию клавиш нужно нажать, чтобы вставить выбранный символ в нужном Вам приложении.
Например, для знака параграфа § следует нажать сочетание клавиш Alt+0167, при этом можно использовать только цифры с малой цифровой клавиатуры.
Более подробно о том, как на практике проверить кодировку символов, используя малую цифровую клавиатуру, можно узнать ЗДЕСЬ. Такой способ ввода символов, которых нет на клавиатуре, требует определенных навыков и, думаю, что редко используется обычными пользователями.
Упражнение по компьютерной грамотности:
1) Откройте Таблицу символов Windows. Выберите шрифт, которым Вы чаще всего пользуетесь. Найдите два-три символа, которых нет на клавиатуре, выделите и скопируйте их в буфер обмена.
2) Откройте текстовый редактор (например, Блокнот) и вставьте из буфера обмена скопированные туда ранее символы.
Видео “Таблица символов Windows”
Также по теме:
1. Три способа задания параметров шрифта
2. Какие шрифты есть на моем компьютере?
3. Два шрифта без букв
4. Сравнение возможностей Word и Excel для работы с таблицами
Получайте актуальные статьи по компьютерной грамотности прямо на ваш почтовый ящик.
Уже более 3.000 подписчиков
.
Важно: необходимо подтвердить свою подписку! В своей почте откройте письмо для активации и кликните по указанной там ссылке. Если письма нет, проверьте папку Спам.
Вопрос по «Упорядочить значки» в винде и вообще про сортировку по алфавиту…
☑
0
Gray776
29.10.14
✎
11:06
Думаю многие знают что если в начале имени файла поставить символ «_» ну или «~» , а еще можно «!», то при сортировке по имени файла такие файлы/папки поднимутся вверх. А какой символ поставить чтоб наоборот убрать папку/файл в конец списка?
1
Ненавижу 1С
гуру
29.10.14
✎
11:06
букву я
2
Gray776
29.10.14
✎
11:07
(1) можно но это буква можно даже сказать слово(местоимение ))) )
3
Ненавижу 1С
гуру
29.10.14
✎
11:07
(2) буква является символом и что?
4
Gray776
29.10.14
✎
11:09
(1) та да но удобнее мне например было бы не из алфавита символ. И потом ведь может другое название получится…
5
MaXpaT
29.10.14
✎
11:11
открой Таблицу Символов:
Нажмите кнопку Пуск. В поле Найти введите Таблица символов и в списке результатов дважды щелкните Таблица символов.
выбирай чем больше номер, тем дальше будет в сортировке
6
Gray776
29.10.14
✎
11:15
(5) сча я как раз в поисковике кодировку смотрел по таблице тильда по идее предпоследний символ. попробую виндовую таблицу глянуть
7
Gray776
29.10.14
✎
11:16
8
Gray776
29.10.14
✎
11:22
9
Gray776
29.10.14
✎
11:33
(0) Короче тогда перефразируем вопрос какой порядок символов(какой кодировкой) руководствуется сортировщик файлов в виндовс.
Потому как символ «_» имеет код больше чем символ «~», однако при сортировке поднимается выше!
Реализация DI в PHP
Jason-Webb 13.05.2025
Когда я начинал писать свой первый крупный PHP-проект, моя архитектура напоминала запутаный клубок спагетти. Классы создавали другие классы внутри себя, зависимости жостко прописывались в коде, а о. . .
Обработка изображений в реальном времени на C# с OpenCV
stackOverflow 13.05.2025
Объединение библиотеки компьютерного зрения OpenCV с современным языком программирования C# создаёт симбиоз, который открывает доступ к впечатляющему набору возможностей. Ключевое преимущество этого. . .
POCO, ACE, Loki и другие продвинутые C++ библиотеки
NullReferenced 13.05.2025
В C++ разработки существует такое обилие библиотек, что порой кажется, будто ты заблудился в дремучем лесу. И среди этого многообразия POCO (Portable Components) – как маяк для тех, кто ищет. . .
Паттерны проектирования GoF на C#
UnmanagedCoder 13.05.2025
Вы наверняка сталкивались с ситуациями, когда код разрастается до неприличных размеров, а его поддержка становится настоящим испытанием. Именно в такие моменты на помощь приходят паттерны Gang of. . .
Создаем CLI приложение на Python с Prompt Toolkit
py-thonny 13.05.2025
Современные командные интерфейсы давно перестали быть черно-белыми текстовыми программами, которые многие помнят по старым операционным системам. CLI сегодня – это мощные, интуитивные и даже. . .
Конвейеры ETL с Apache Airflow и Python
AI_Generated 13.05.2025
ETL-конвейеры – это набор процессов, отвечающих за извлечение данных из различных источников (Extract), их преобразование в нужный формат (Transform) и загрузку в целевое хранилище (Load). . . .
Выполнение асинхронных задач в Python с asyncio
py-thonny 12.05.2025
Современный мир программирования похож на оживлённый мегаполис – тысячи процессов одновременно требуют внимания, ресурсов и времени. В этих джунглях операций возникают ситуации, когда программа. . .
Работа с gRPC сервисами на C#
UnmanagedCoder 12.05.2025
gRPC (Google Remote Procedure Call) — открытый высокопроизводительный RPC-фреймворк, изначально разработанный компанией Google. Он отличается от традиционых REST-сервисов как минимум тем, что. . .
CQRS (Command Query Responsibility Segregation) на Java
Javaican 12.05.2025
CQRS — Command Query Responsibility Segregation, или разделение ответственности команд и запросов. Суть этого архитектурного паттерна проста: операции чтения данных (запросы) отделяются от операций. . .
Шаблоны и приёмы реализации DDD на C#
stackOverflow 12.05.2025
Когда я впервые погрузился в мир Domain-Driven Design, мне показалось, что это очередная модная методология, которая скоро канет в лету. Однако годы практики убедили меня в обратном. DDD — не просто. . .
Содержание
- 1 Представление символов в вычислительных машинах
- 2 Таблицы кодировок
- 3 Кодировки стандарта ASCII
- 3.1 Структурные свойства таблицы
- 4 Кодировки стандарта UNICODE
- 4.1 Кодовое пространство
- 4.2 Модифицирующие символы
- 4.3 Способы представления
- 4.4 UTF-8
- 4.4.1 Принцип кодирования
- 4.4.1.1 Правила записи кода одного символа в UTF-8
- 4.4.1.2 Определение длины кода в UTF-8
- 4.4.1 Принцип кодирования
- 4.5 UTF-16
- 4.5.1 UTF-16LE и UTF-16BE
- 4.6 UTF-32
- 4.7 Порядок байт
- 4.7.1 Варианты записи
- 4.7.1.1 Порядок от старшего к младшему
- 4.7.1.2 Порядок от младшего к старшему
- 4.7.1.3 Переключаемый порядок
- 4.7.1.4 Смешанный порядок
- 4.7.1.5 Различия
- 4.7.2 Маркер последовательности байт
- 4.7.1 Варианты записи
- 4.8 Проблемы Юникода
- 5 Примеры
- 5.1 Код на python
- 5.2 hex-дамп файла exampleBOM
- 6 См. также
- 7 Источники информации
Представление символов в вычислительных машинах
В вычислительных машинах символы не могут храниться иначе, как в виде последовательностей бит (как и числа). Для передачи символа и его корректного отображения ему должна соответствовать уникальная последовательность нулей и единиц. Для этого были разработаны таблицы кодировок.
Количество символов, которые можно задать последовательностью бит длины , задается простой формулой . Таким образом, от нужного количества символов напрямую зависит количество используемой памяти.
Таблицы кодировок
На заре компьютерной эры на каждый символ было отведено по пять бит. Это было связано с малым количеством оперативной памяти на компьютерах тех лет. В эти символа входили только управляющие символы и строчные буквы английского алфавита.
С ростом производительности компьютеров стали появляться таблицы кодировок с большим количеством символов.
Первой семибитной кодировкой стала ASCII7. В нее уже вошли прописные буквы английского алфавита, арабские цифры, знаки препинания.
Затем на ее базе была разработана ASCII8, в которым уже стало возможным хранение символов: основных и еще столько же расширенных. Первая часть таблицы осталась без изменений, а вторая может иметь различные варианты (каждый имеет свой номер). Эта часть таблицы стала заполняться символами национальных алфавитов.
Но для многих языков (например, арабского, японского, китайского) символов недостаточно, поэтому развитие кодировок продолжалось, что привело к появлению UNICODE.
Кодировки стандарта ASCII
| Определение: |
| ASCII — таблицы кодировок, в которых содержатся основные символы (английский алфавит, цифры, знаки препинания, символы национальных алфавитов(свои для каждого региона), служебные символы) и длина кода каждого символа бит. |
бит:
- ASCII7 — первая кодировка, пригодная для работы с текстом. Помимо маленьких букв английского алфавита и служебных символов, содержит большие буквы английского языка, цифры, знаки препинания и другие символы.
Кодировки стандарта ASCII ( бит):
- ASCII — первая кодировка, в которой стало возможно использовать символы национальных алфавитов.
- КОИ8-R — первая русская кодировка. Символы кириллицы расположены не в алфавитном порядке. Их разместили в верхнюю половину таблицы так, чтобы позиции кириллических символов соответствовали их фонетическим аналогам в английском алфавите. Это значит, что даже при потере старшего бита каждого символа, например, при проходе через устаревший семибитный модем, текст остается «читаемым».
- CP866 — русская кодировка, использовавшаяся на компьютерах IBM в системе DOS.
- Windows-1251 — русская кодировка, использовавшаяся в русскоязычных версиях операционной системы Windows в начале 90-х годов. Кириллические символы идут в алфавитном порядке. Содержит все символы, встречающиеся в типографике обычного текста (кроме знака ударения).
Структурные свойства таблицы
- Цифры 0-9 представляются своими двоичными значениями (например, ), перед которыми стоит . Таким образом, двоично-десятичные числа (BCD) превращаются в ASCII-строку с помощью простого добавления слева к каждому двоично-десятичному полубайту.
- Буквы A-Z верхнего и нижнего регистров различаются в своём представлении только одним битом, что упрощает преобразование регистра и проверку на диапазон. Буквы представляются своими порядковыми номерами в алфавите, записанными в двоичной системе счисления, перед которыми стоит (для букв верхнего регистра) или (для букв нижнего регистра).
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | NUL | SOH | STX | ETX | EOT | ENQ | ACK | BEL | BS | TAB | LF | VT | FF | CR | SO | SI |
| 1 | DLE | DC1 | DC2 | DC3 | DC4 | NAK | SYN | ETB | CAN | EM | SUB | ESC | FS | GS | RS | US |
| 2 | ! | » | # | $ | % | & | ‘ | ( | ) | * | + | , | — | . | / | |
| 3 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | : | ; | < | = | > | ? |
| 4 | @ | A | B | C | D | E | F | G | H | I | J | K | L | M | N | O |
| 5 | P | Q | R | S | T | U | V | W | X | Y | Z | [ | \ | ] | ^ | _ |
| 6 | ` | a | b | c | d | e | f | g | h | i | j | k | l | m | n | o |
| 7 | p | q | r | s | t | u | v | w | x | y | z | { | | | } | ~ | DEL |
Кодировки стандарта UNICODE
Юникод или Уникод (англ. Unicode) — это промышленный стандарт обеспечивающий цифровое представление символов всех письменностей мира, и специальных символов.
Стандарт предложен в 1991 году некоммерческой организацией «Консорциум Юникода» (англ. Unicode Consortium, Unicode Inc.). Применение этого стандарта позволяет закодировать очень большое число символов из разных письменностей.
Стандарт состоит из двух основных разделов: универсальный набор символов (англ. UCS, universal character set) и семейство кодировок (англ. UTF, Unicode transformation format). Универсальный набор символов задаёт однозначное соответствие символов кодам — элементам кодового пространства, представляющим неотрицательные целые числа.Семейство кодировок определяет машинное представление последовательности кодов UCS.
Коды в стандарте Unicode разделены на несколько областей. Область с кодами от U+0000 до U+007F содержит символы набора ASCII с соответствующими кодами. Далее расположены области знаков различных письменностей, знаки пунктуации и технические символы. Под символы кириллицы выделены области знаков с кодами от U+0400 до U+052F, от U+2DE0 до U+2DFF, от U+A640 до U+A69F. Часть кодов зарезервирована для использования в будущем.
Кодовое пространство
Хотя формы записи UTF-8 и UTF-32 позволяют кодировать до кодовых позиций, было принято решение использовать лишь для совместимости с UTF-16. Впрочем, даже и этого на текущий момент более чем достаточно — в версии 6.0 используется чуть менее кодовых позиций ( графических и прочих символов).
Кодовое пространство разбито на плоскостей (англ. planes) по символов. Нулевая плоскость называется базовой, в ней расположены символы наиболее употребительных письменностей. Первая плоскость используется, в основном, для исторических письменностей, вторая — для для редко используемых иероглифов китайского письма, третья зарезервирована для архаичных китайских иероглифов. Плоскости и выделены для частного употребления.
Для обозначения символов Unicode используется запись вида «U+xxxx» (для кодов ) или «U+xxxxx» (для кодов ) или «U+xxxxxx» (для кодов ), где xxx — шестнадцатеричные цифры. Например, символ «я» (U+044F) имеет код .
| Плоскости Юникода | ||
|---|---|---|
| Плоскость | Название | Диапазон символов |
| Plane 0 | Basic multilingual plane (BMP) | U+0000…U+FFFF |
| Plane 1 | Supplementary multilingual plane (SMP) | U+10000…U+1FFFF |
| Plane 2 | Supplementary ideographic plane (SIP) | U+20000…U+2FFFF |
| Planes 3-13 | Unassigned | U+30000…U+DFFFF |
| Plane 14 | Supplementary special-purpose plane (SSP) | U+E0000…U+EFFFF |
| Planes 15-16 | Supplementary private use area (S PUA A/B) | U+F0000…U+10FFFF |
Модифицирующие символы
Графические символы в Юникоде делятся на протяжённые и непротяжённые. Непротяжённые символы при отображении не занимают дополнительного места в строке. К примеру, к ним относятся знак ударения. Протяжённые и непротяжённые символы имеют собственные коды, но последние не могут встречаться самостоятельно. Протяжённые символы называются базовыми (англ. base characters), а непротяженные — модифицирующими (англ. combining characters). Например символ «Й» (U+0419) может быть представлен в виде базового символа «И» (U+0418) и модифицирующего символа « ̆» (U+0306).
Способы представления
Юникод имеет несколько форм представления (англ. Unicode Transformation Format, UTF): UTF-8, UTF-16 (UTF-16BE, UTF-16LE) и UTF-32 (UTF-32BE, UTF-32LE). Была разработана также форма представления UTF-7 для передачи по семибитным каналам, но из-за несовместимости с ASCII она не получила распространения и не включена в стандарт.
UTF-8
UTF-8 — представление Юникода, обеспечивающее наилучшую совместимость со старыми системами, использовавшими -битные символы. Текст, состоящий только из символов с номером меньше , при записи в UTF-8 превращается в обычный текст ASCII. И наоборот, в тексте UTF-8 любой байт со значением меньше изображает символ ASCII с тем же кодом. Остальные символы Юникода изображаются последовательностями длиной от двух до шести байт (на деле, только до четырех байт, поскольку в Юникоде нет символов с кодом больше , и вводить их в будущем не планируется), в которых первый байт всегда имеет вид , а остальные — .
Символы UTF-8 получаются из Unicode cледующим образом:
| Unicode | UTF-8 | Представленные символы |
|---|---|---|
0x00000000 — 0x0000007F |
0xxxxxxx |
ASCII, в том числе английский алфавит, простейшие знаки препинания и арабские цифры |
0x00000080 — 0x000007FF |
110xxxxx 10xxxxxx |
кириллица, расширенная латиница, арабский алфавит, армянский алфавит, греческий алфавит, еврейский алфавит и коптский алфавит; сирийское письмо, тана, нко; Международный фонетический алфавит; некоторые знаки препинания |
0x00000800 — 0x0000FFFF |
1110xxxx 10xxxxxx 10xxxxxx |
все другие современные формы письменности, в том числе грузинский алфавит, индийское, китайское, корейское и японское письмо; сложные знаки препинания; математические и другие специальные символы |
0x00010000 — 0x001FFFFF |
11110xxx 10xxxxxx 10xxxxxx 10xxxxxx |
музыкальные символы, редкие китайские иероглифы, вымершие формы письменности |
111111xx |
служебные символы c, d, e, f |
Несмотря на то, что UTF-8 позволяет указать один и тот же символ несколькими способами, только наиболее короткий из них правильный. Остальные формы, называемые overlong sequence, отвергаются по соображениям безопасности.
Принцип кодирования
Правила записи кода одного символа в UTF-8
1. Если размер символа в кодировке UTF-8 = байт
- Код имеет вид (0aaa aaaa), где «0» — просто ноль, остальные биты «a» — это код символа в кодировке ASCII;
2. Если размер символа в кодировке в UTF-8 байт (то есть от до ):
- 2.1 Первый байт содержит количество байт символа, закодированное в единичной системе счисления;
2 — 11 3 — 111 4 — 1111 5 — 1111 1 6 — 1111 11
- 2.2 «0» — бит терминатор, означающий завершение кода размера
- 2.3 далее идут значащие байты кода, которые имеют вид (10xx xxxx), где «10» — биты признака продолжения, а «x» — значащие биты.
В общем случае варианты представления одного символа в кодировке UTF-8 выглядят так:
(1 байт) 0aaa aaaa (2 байта) 110x xxxx 10xx xxxx (3 байта) 1110 xxxx 10xx xxxx 10xx xxxx (4 байта) 1111 0xxx 10xx xxxx 10xx xxxx 10xx xxxx (5 байт) 1111 10xx 10xx xxxx 10xx xxxx 10xx xxxx 10xx xxxx (6 байт) 1111 110x 10xx xxxx 10xx xxxx 10xx xxxx 10xx xxxx 10xx xxxx
Определение длины кода в UTF-8
| Количество байт UTF-8 | Количество значащих бит |
|---|---|
В общем случае количество значащих бит , кодируемых байтами UTF-8, определяется по формуле:
при
при
UTF-16
UTF-16 — один из способов кодирования символов (англ. code point) из Unicode в виде последовательности -битных слов (англ. code unit). Данная кодировка позволяет записывать символы Юникода в диапазонах U+0000..U+D7FF и U+E000..U+10FFFF (общим количеством ), причем -байтные символы представляются как есть, а более длинные — с помощью суррогатных пар (англ. surrogate pair), для которых и вырезан диапазон .
В UTF-16 символы кодируются двухбайтовыми словами с использованием всех возможных диапазонов значений (от до ). При этом можно кодировать символы Unicode в диапазонах и . Исключенный отсюда диапазон используется как раз для кодирования так называемых суррогатных пар — символов, которые кодируются двумя -битными словами. Символы Unicode до включительно (исключая диапазон для суррогатов) записываются как есть -битным словом. Символы же в диапазоне (больше бит) уже кодируются парой -битных слов. Для этого их код арифметически сдвигается до нуля (из него вычитается минимальное число ). В результате получится значение от нуля до , которое занимает до бит. Старшие бит этого значения идут в лидирующее (первое) слово, а младшие бит — в последующее (второе). При этом в обоих словах старшие бит используются для обозначения суррогата. Биты с по имеют значения , а -й бит содержит у лидирующего слова и — у последующего. В связи с этим можно легко определить к чему относится каждое слово.
UTF-16LE и UTF-16BE
Один символ кодировки UTF-16 представлен последовательностью двух байт или двух пар байт. Который из двух байт в словах идёт впереди, старший или младший, зависит от порядка байт. Подробнее об этом будет сказано ниже.
UTF-32
UTF-32 — один из способов кодирования символов из Юникод, использующий для кодирования любого символа ровно бита. Остальные кодировки, UTF-8 и UTF-16, используют для представления символов переменное число байт. Символ UTF-32 является прямым представлением его кодовой позиции (англ. code point).
Главное преимущество UTF-32 перед кодировками переменной длины заключается в том, что символы Юникод непосредственно индексируемы. Получение -ой кодовой позиции является операцией, занимающей одинаковое время. Напротив, коды с переменной длиной требует последовательного доступа к -ой кодовой позиции. Это делает замену символов в строках UTF-32 простой, для этого используется целое число в качестве индекса, как обычно делается для строк ASCII.
Главный недостаток UTF-32 — это неэффективное использование пространства, так как для хранения символа используется четыре байта. Символы, лежащие за пределами нулевой (базовой) плоскости кодового пространства редко используются в большинстве текстов. Поэтому удвоение, в сравнении с UTF-16, занимаемого строками в UTF-32 пространства не оправдано.
Хотя использование неменяющегося числа байт на символ удобно, но не настолько, как кажется. Операция усечения строк реализуется легче в сравнении с UTF-8 и UTF-16. Но это не делает более быстрым нахождение конкретного смещения в строке, так как смещение может вычисляться и для кодировок фиксированного размера. Это не облегчает вычисление отображаемой ширины строки, за исключением ограниченного числа случаев, так как даже символ «фиксированной ширины» может быть получен комбинированием обычного символа с модифицирующим, который не имеет ширины. Например, буква «й» может быть получена из буквы «и» и диакритического знака «крючок над буквой». Сочетание таких знаков означает, что текстовые редакторы не могут рассматривать -битный код как единицу редактирования. Редакторы, которые ограничиваются работой с языками с письмом слева направо и составными символами (англ. Precomposed character), могут использовать символы фиксированного размера. Но такие редакторы вряд ли поддержат символы, лежащие за пределами нулевой (базовой) плоскости кодового пространства и вряд ли смогут работать одинаково хорошо с символами UTF-16.
Порядок байт
В современной вычислительной технике и цифровых системах связи информация обычно представлена в виде последовательности байт. В том случае, если число не может быть представлено одним байтом, имеет значение в каком порядке байты записываются в памяти компьютера или передаются по линиям связи. Часто выбор порядка записи байт произволен и определяется только соглашениями.
В общем случае, для представления числа , большего (здесь — максимальное целое число, записываемое одним байтом), приходится использовать несколько байт. При этом число записывается в позиционной системе счисления по основанию :
Набор целых чисел , каждое из которых лежит в интервале от до , является последовательностью байт, составляющих . При этом называется младшим байтом, а — старшим байтом числа .
Варианты записи
Порядок от старшего к младшему
Порядок от старшего к младшему (англ. big-endian): , запись начинается со старшего и заканчивается младшим. Этот порядок является стандартным для протоколов TCP/IP, он используется в заголовках пакетов данных и во многих протоколах более высокого уровня, разработанных для использования поверх TCP/IP. Поэтому, порядок байт от старшего к младшему часто называют сетевым порядком байт (англ. network byte order). Этот порядок байт используется процессорами IBM 360/370/390, Motorola 68000, SPARC (отсюда третье название — порядок байт Motorola, Motorola byte order).
В этом же виде (используя представление в десятичной системе счисления) записываются числа индийско-арабскими цифрами в письменностях с порядком знаков слева направо (латиница, кириллица). Для письменностей с обратным порядком (арабская) та же запись числа воспринимается как «от младшего к старшему».
Порядок байт от старшего к младшему применяется во многих форматах файлов — например, PNG, FLV, EBML.
Порядок от младшего к старшему
Порядок от младшего к старшему (англ. little-endian): , запись начинается с младшего и заканчивается старшим. Этот порядок записи принят в памяти персональных компьютеров с x86-процессорами, в связи с чем иногда его называют интеловский порядок байт (по названию фирмы-создателя архитектуры x86).
В противоположность порядку big-endian, соглашение little-endian поддерживают меньше кросс-платформенных протоколов и форматов данных; существенные исключения: USB, конфигурация PCI, таблица разделов GUID, рекомендации FidoNet.
Переключаемый порядок
Многие процессоры могут работать и в порядке от младшего к старшему, и в обратном, например, ARM, PowerPC (но не PowerPC 970), DEC Alpha, MIPS, PA-RISC и IA-64. Обычно порядок байт выбирается программно во время инициализации операционной системы, но может быть выбран и аппаратно перемычками на материнской плате. В этом случае правильнее говорить о порядке байт операционной системы. Переключаемый порядок байт иногда называют англ. bi-endian.
Смешанный порядок
Смешанный порядок байт (англ. middle-endian) иногда используется при работе с числами, длина которых превышает машинное слово. Число представляется последовательностью машинных слов, которые записываются в формате, естественном для данной архитектуры, но сами слова следуют в обратном порядке.
Классический пример middle-endian — представление -байтных целых чисел на -битных процессорах семейства PDP-11 (известен как PDP-endian). Для представления двухбайтных значений (слов) использовался порядок little-endian, но -хбайтное двойное слово записывалось от старшего слова к младшему.
В процессорах VAX и ARM используется смешанное представление для длинных вещественных чисел.
Различия
Существенным достоинством little-endian по сравнению с big-endian порядком записи считается возможность «неявной типизации» целых чисел при чтении меньшего объёма байт (при условии, что читаемое число помещается в диапазон). Так, если в ячейке памяти содержится число , то прочитав его как int16 (два байта) мы получим число , прочитав один байт — число . Однако, это же может считаться и недостатком, потому что провоцирует ошибки потери данных.
Обратно, считается что у little-endian, по сравнению с big-endian есть «неочевидность» значения байт памяти при отладке (последовательность байт (A1, B2, C3, D4) на самом деле значит , для big-endian эта последовательность (A1, B2, C3, D4) читалась бы «естественным» для арабской записи чисел образом: ). Наименее удобным в работе считается middle-endian формат записи; он сохранился только на старых платформах.
Для записи длинных чисел (чисел, длина которых существенно превышает разрядность машины) обычно предпочтительнее порядок слов в числе little-endian (поскольку арифметические операции над длинными числами производятся от младших разрядов к старшим). Порядок байт в слове — обычный для данной архитектуры.
Маркер последовательности байт
Для определения формата представления Юникода в начало текстового файла записывается сигнатура — символ U+FEFF (неразрывный пробел с нулевой шириной), также именуемый маркером последовательности байт (англ. byte order mark (BOM)). Это позволяет различать UTF-16LE и UTF-16BE, поскольку символа U+FFFE не существует.
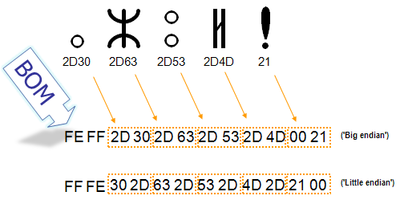
Представление BOM в кодировках
| Кодирование | Представление (Шестнадцатеричное) |
|---|---|
| UTF-8 | EF BB BF
|
| UTF-16 (BE) | FE FF
|
| UTF-16 (LE) | FF FE
|
| UTF-32 (BE) | 00 00 FE FF
|
| UTF-32 (LE) | FF FE 00 00
|
В кодировке UTF-8, наличие BOM не является существенным, поскольку, нет альтернативной последовательности байт. Когда BOM используется на страницах или редакторах для контента закодированного в UTF-8, иногда он может представить пробелы или короткие последовательности символов, имеющие странный вид (такие как ). Именно поэтому, при наличии выбора, для совместимости, как правило, лучше упустить BOM в UTF-8 контенте.Однако BOM могут еще встречаться в тексте закодированном в UTF-8, как побочный продукт перекодирования или потому, что он был добавлен редактором. В этом случае BOM часто называют подписью UTF-8.
Когда символ закодирован в UTF-16, его или байта можно упорядочить двумя разными способами (little-endian или big-endian). Изображение справа показывает это. Byte order mark указывает, какой порядок используется, так что приложения могут немедленно расшифровать контент. UTF-16 контент должен всегда начинатся с BOM.
BOM также используется для текста обозначенного как UTF-32. Аналогично UTF-16 существует два варианта четырёхбайтной кодировки — UTF-32BE и UTF-32LE. К сожалению, этот способ не позволяет надёжно различать UTF-16LE и UTF-32LE, поскольку символ U+0000 допускается Юникодом
Проблемы Юникода
В Юникоде английское «a» и польское «a» — один и тот же символ. Точно так же одним символом (но отличающимся от «a» латинского) считаются русское «а» и сербское «а». Такой принцип кодирования не универсален; по-видимому, решения «на все случаи жизни» вообще не может существовать.
Примеры
Если записать строку ‘hello мир’ в файл exampleBOM, а затем сделать его hex-дамп, то можно убедиться в том, что разные символы кодируются разным количеством байт. Например, английские буквы,пробел, знаки препинания и пр. кодируются одним байтом, а русские буквы — двумя
Код на python
#!/usr/bin/env python
#coding:utf-8
import codecs
f = open('exampleBOM','w')
b = u'hello мир'
f.write(codecs.BOM_UTF8)
f.write(b.encode('utf-8'))
f.close()
hex-дамп файла exampleBOM
| Символ | BOM | h | e | l | l | o | Пробел | м | и | р | |||||
| Код в UNICODE | EF | BB | BF | 68 | 65 | 6C | 6C | 6F | 20 | D0 | BC | D0 | B8 | D1 | 80 |
| Код в UTF-8 | 11101111 | 10111011 | 10111111 | 01101000 | 01100101 | 01101100 | 01101100 | 01101111 | 00100000 | 11010000 | 10111100 | 11010000 | 10111000 | 11010001 | 10000000 |
См. также
- Представление целых чисел: прямой код, код со сдвигом, дополнительный код
- Представление вещественных чисел
Источники информации
- Wikipedia — таблица ASCII
- Wikipedia — стандарт UNICODE
- Wikipedia — Byte order mark
- Wikipedia — Порядок байтов
- Wikipedia — Юникод
- Wikipedia — Windows-1251
- Wikipedia — UTF-8
- Wikipedia — UTF-16
- Wikipedia — UTF-32
При работе с текстами в Windows обычных символов, ввод которых возможен напрямую с клавиатуры может быть недостаточно и в этой ситуации приходится прибегать к тому или иному методу вставки специальных символов.
В этой инструкции подробно о способах вставить специальные символы в Windows 11 и Windows 10 — часть из них присутствовали и в предыдущих версиях системы, а один появился сравнительно недавно.
Панель вставки специальных символов
В Windows 11 и Windows 10 присутствует новая панель для вставки эмодзи, просмотра истории буфера обмена и, в том числе, вставки специальных символов. Эта панель незначительно отличается в этих версиях ОС, но принцип использования один и тот же:
- При вводе текста в какой-либо программе нажмите клавиши Windows + «.» (точка) или Windows + V, чтобы открыть панель с открытой вкладкой вставки эмодзи или истории буфера обмена соответственно. Windows — это клавиша с эмблемой ОС.
- Переключитесь на вкладку «Символы», её значок выглядит по-разному в 10-й и 11-й версиях Windows:

- Выберите символы, которые нужно вставить и вставьте их в месте текущего ввода, нажимая по ним кнопкой мыши — вы можете вставить единственный символ, а можете — несколько по порядку.



Способ кажется не слишком удобным, так как нужные символы нужно искать, но по мере использования те из них, которые требуются чаще всего, будут отображаться вверху списка.
Приведенный выше способ — новый для последних версий Windows и ранее отсутствовал. Но есть и другие методы ввода специальных символов, которые одинаково работают во всех версиях ОС за последние два десятка лет.
Таблица символов
Встроенное приложение Windows «Таблица символов» — классический способ вставки специальных символов. Порядок использования будет следующим:
- Используйте поиск в панели задач по словосочетанию «Таблица символов», либо нажмите клавиши Win+R на клавиатуре, введите charmap и нажмите Enter.
- Откроется приложение «Таблица символов», в котором вы можете выбрать шрифт и конкретный символ, после чего двойным кликом по символу добавить его в список «Для копирования». В список можно добавить несколько символов.
- Нажмите кнопку «Копировать», чтобы скопировать выбранные символы в буфер обмена.

- Вставьте символы из буфера обмена в вашем документе с помощью клавиш Ctrl+V, Shift+Insert, контекстного или главного меню программы.
- Если включить опцию «Дополнительные параметры» в таблице символов, вы можете изменить кодировку набора символов, а самой полезное — искать нужный символ по названию, при условии, что вы его знаете: например, dash для тире и длинных тире.



Обратите внимание, что в правой нижней части окна утилиты для некоторых выбранных символов отображается информация о клавише для его ввода, она может пригодиться для следующего способа ввода.
Ввод специальных символов с клавиатуры
Если на вашей клавиатуре есть цифровой блок, вы можете использовать его для быстрого ввода нужного символа с помощью его Alt-кода. Сам код можно посмотреть в «Таблице символов» в пункте «Клавиша», как это было описано выше.
Для ввода символа с клавиатуры в любом приложении, где вводится текст, выполните следующие действия:
- Нажмите и удерживайте левую клавишу Alt и вводите цифры кода по порядку на цифровом блоке клавиатуры, после окончания ввода, отпустите клавишу Alt.
- Например, для длинного тире «—» (em dash), удерживая клавишу Alt, потребуется ввести 0-1-5-1.
- Нужный символ будет введён в текущей позиции курсора.
Надеюсь, инструкция была полезной. Если же остаются вопросы — задавайте их в комментариях ниже, буду рад ответить.