
Отличие utf-8 и windows 1251. Рассмотрим, чем отличаются две кодировки «utf-8 и windows 1251» в теории и на практике. И как победить некоторые проблемы для кириллицы в utf-8!?
О кодировках utf-8 и windows 1251
Самое главное. что нас интересует, как и меня — в чем же отличие кодировок utf-8 и windows 1251. И отличается только кириллица!
Чем отличаются utf-8 и windows 1251
UTF-8 — это много-байтовая кодировка, а Windows- 1251 однобайтовая. И более того, отличие только в кириллице.
Количество байтов кириллицы в UTF-8 будет в 2 раза больше, чем 1). латиницы в UTF-8 и 2). латиницы + кириллицы в Windows- 1251 → пример
Главное отличие кодировок – это используемый набор символов. В UTF-8 гораздо больше количество символов возможно представить, чем в Windows- 1251. Кодировка Windows- 1251 однобайтовая, т.е. представить в ней можно только 255 символов. Для кириллицы, впрочем, этого вполне достаточно, именно поэтому однобайтовые кодировки до сих пор так массово применяются.
Что такое кодировка windows 1251
Windows-1251 – набор символов и кодировка, являющаяся стандартной 8-битной кодировкой для всех русских версий Microsoft Windows. Пользуется довольно большой популярностью. Windows-1251 выгодно отличается от других 8‑битных кириллических кодировок (таких как CP866, KOI8-R и ISO 8859-5) наличием практически всех символов, использующихся в русской типографике для обычного текста; она также содержит все символы для близких к русскому языку языков: украинского, белорусского, сербского и болгарского.
Что такое кодировка UTF-8
UTF-8 – в настоящее время распространённая кодировка, реализующая представление Юникода, совместимое с 8-битным кодированием текста. Нашла широкое применение в операционных системах и веб-пространстве. Текст, состоящий только из символов Юникода с номерами меньше 128, при записи в UTF-8 превращается в обычный текст ASCII. Остальные символы Юникода изображаются последовательностями длиной от 2 до 6 байт.
Символ в кодировке UTF-8 может кодироваться аж 6 байтами (пока используется только 4 и больше не планируется). Для русского языка, например, символ занимает 2 байта. Все символы, которые есть в таблице символов – поддерживаются этой кодировкой. К примеру, если вам нужен знак копирайта (©), то вам не нужно искать особый шрифт или же изображать символов в графическом формате.
Пример вывода текста в кодировках utf-8 латиницы
Когда и если вы прочитали теорию о разнице кодировок utf-8 и windows 1251 — это уже победа!
А если вы еще и поняли о чем идет речь, то вы вообще Эйнштейн! , то и смысла особого вам читать дальше нет.
А для всех остальных продолжим…
Чем отличается текст в кодировках utf-8 и windows 1251
Теория — это конечно классно и круто, но как обстоит дело на практике!
Как показать отличие двух кодировок!?
У нас на сайте основная кодировка utf-8, и мы не напрягаясь можем посмотреть, что творится с текстом в этой кодировке!
Нам понадобится какой-то текст на латинице:
И… нам нужно такое слово, чтобы имело одинаковое количество букв в слове, ну пусть это будет моё имя…
Пусть это будет слово — «Marat!»
Далее нам потребуется функция var_dump.
И выведем прямо здесь вот такую конструкцию :
var_dump(‘Marat’);
Результат:
string(5) «Marat»
Что мы здесь можем прочитать!?
Что это строка, и что в ней 5 элементов.
Пример вывода текста в кодировках utf-8 кириллицы
Теперь, проделаем тоже самое со строкой на кириллице:
У нас все таже кодировка utf-8.
Но теперь нам понадобится текст на кириллице:
Пусть это будет слово — «Марат!»
Опять var_dump.
И выведем прямо здесь вот такую конструкцию :
var_dump(‘Марат’);
Результат:
string(10) «Марат»
И что мы здесь видим!?
Что количество элементов в строке 10… Если вы читали теорию внимательно, то вот вам показатель того, что одна буква состоит из двух символов, а латиницы это не касается…!
Поэтому, и возникают проблемы с текстом в кодировке utf-8 кириллицы, множество функций тупо не работают.
Как пример…как-то я задолбался со strtolower в utf-8 для кириллицы, что решил написать собственную функцию strtolower, чтобы каждый раз не городить этажерку из нескольких функций…
Пример отличия в кодировках utf-8 и windows 1251
Если вы поленились прочитать два верхних пункта, то ещё раз выведем результаты вывода текста на латинице и на кириллице с одним количеством букв.
Результат вывода var_dump(‘Marat’);:
string(5) «Marat»
Результат var_dump(‘Марат’);:
string(10) «Марат»
Что делать, если функция для кириллицы на utf-8 не работают?
Поскольку я давно занимаюсь сайтами, то могу сказать, что на самом деле таких случаев не так много, когда нужна какая-то специальная функция для обработки кириллицы на utf-8.
Но если уж она возникала, то есть несколько вариантов решения!
Это функции с приставкой «mb_», естественно надо проверять, работает ли она у вас на хостинге.
Второй вариант, это написать собственную функцию, которая будет работать и для латиницы и кириллицы? как это я показал на функции strtolower
И третий вариант перекодировать строку из utf-8 в windows 1251
Рассмотрим, первый попавшийся на ум пример…
Пусть это будет функция str_split и её аналог mb_str_split
print_r (str_split(‘Марат’)); выдаст :
Array
(
[0] => �
[1] => �
[2] => �
[3] => �
[4] => �
[5] => �
[6] => �
[7] => �
[8] => �
[9] => �
)
print_r (mb_str_split(‘Марат’)); выдаст :

Как видим… полный отстой…
Мы далее разбирались с этим здесь.
Как перекодировать строку из utf-8 в windows 1251
Итак… есть третий вариант, борьбы с квадратиками(непонимание кодировки) — перекодировать строку из utf-8 в windows 1251:
iconv(«UTF-8», «windows-1251», $text)
После того, как вы выполнили все намеченные действия с текстом, возвращаем его в исходную кодировку :
iconv(«windows-1251», «UTF-8», $text)
Рассмотрим пример перекодировки текста из UTF-8 в windows-1251 и обратно
Мы использовали var_dump, и он посчитал не правильно, поскольку просто так, на страницу вывести данные с помощью var_dump нельзя, мы использовали вот такой костыль :
ob_start();
var_dump( ‘Марат’ );
echo ob_get_clean();
Теперь попробуем перекодировать строку прямо внутри :
ob_start();
var_dump(iconv(«UTF-8», «windows-1251», ‘Марат’)) ;
echo ob_get_clean() ;
Результат подсчета знаков верный, но видим что слово не было перекодировано обратно :
Исправим:
ob_start();
var_dump(iconv(«UTF-8», «windows-1251», ‘Марат’)) ;
echo iconv(«windows-1251», «UTF-8», ob_get_clean());
Результат :
Итак… вы видели процесс кодировки и перекодировки текста из utf-8 в windows 1251, а потом обратно!
Вы наверное подумали :
Что за дичь здесь происходит!? Это не дичь! Когда ты внутри, а не снаружи, то все кажется не простым, а очень простым.
И чем больше ты в теме, это просто, как есть, пить, дышать… просто не задумываешься…
Я не говорю, что всегда так, иногда бывает очень трудно какаю-то задачку решить…
Что лучше для кириллицы utf-8 или…
Интересный поисковый запрос — «Что лучше для кириллицы utf-8 или…«…
Дело в том, что я выбрал кодировку «utf-8» уже… 16 лет(число динамичное) назад… и… уже сейчас трудно вспомнить, почему именно её… но точно вам могу заявить, что когда-то пользовался «windows-1251″… и у неё были какие-то заморочки, в виде неадекватного вывода информации, что, я волей неволей перешел на «utf-8»
Какие минусы у utf-8?
Одна из самых главных проблем «utf-8» — это многобайтовость…
Да! Это несколько неудобно в самом начале, но для всякой функции, которая не хочет работать с кириллицей, существуют замены.
В процессе создания сайта у вас может возникнуть несколько проблем, которые вы решите и «тупо» забудете об этом…
Задумывался ли я о переходе с кодировки utf-8 на другую?
Смысл задумываться о переходе с кодировки utf-8 на другую, если всё работает так, как нужно!
|
| Register | Меню vBsupport | Изображения | Files Manager | О рекламе | Today’s Posts | Search |
VBsupport перешел с домена .ORG на родной .RU
Ура!
Пожалуйста, обновите свои закладки — VBsupport.ru
Блок РКН снят, форум доступен на всей территории России, включая новые терртории, без VPN
На форуме введена премодерация ВСЕХ новых пользователей
Почта с временных сервисов, типа mailinator.com, gawab.com и/или прочих, которые предоставляют временный почтовый ящик без регистрации и/или почтовый ящик для рассылки спама, отслеживается и блокируется, а так же заносится в спам-блок форума, аккаунты удаляются
for English speaking users:
You may be surprised with restriction of access to the attachments of the forum. The reason is the recent change in vbsupport.org strategy:
— users with reputation < 10 belong to «simple_users» users’ group
— if your reputation > 10 then administrator (kerk, Luvilla) can decide to move you into an «improved» group, but only manually
Main idea is to increase motivation of community members to share their ideas and willingness to support to each other. You may write an article for the subject where you are good enough, you may answer questions, you may share vbulletin.com/org content with vbsupport.org users, receiving «thanks» equal your reputation points. We should not only consume, we should produce something.
— you may:
* increase your reputation (doing something useful for another members of community) and being improved
* purchase temporary access to the improved category:
10 $ for 3 months. — this group can download attachments, reputation/posts do not matter.
20 $ for 3 months. — this group can download attachments, reputation/posts do not matter + adds eliminated + Inbox capacity increased + files manager increased permissions.
Please contact kerk or Luvilla regarding payments.
Important!:
— if your reputation will become less then 0, you will be moved into «simple_users» users’ group automatically.*
*for temporary groups (pre-paid for 3 months) reputation/posts do not matter.
Уважаемые пользователи!
На форуме открыт новый раздел «Каталог фрилансеров«
и отдельный раздел для платных заказов «Куплю/Закажу«
подробнее….
Если вы хотите приобрести какой то скрипт/продукт/хак из каталогов перечисленных ниже:
Каталог модулей/хаков
Ещё раз обращаем Ваше внимание: всё, что Вы скачиваете и устанавливаете на свой форум, Вы устанавливаете исключительно на свой страх и риск.
Сообщество vBSupport’а физически не в состоянии проверять все стили, хаки и нули, выкладываемые пользователями.
Помните: безопасность Вашего проекта — Ваша забота.
Убедительная просьба: при обнаружении уязвимостей или сомнительных кодов обязательно отписывайтесь в теме хака/стиля
Спасибо за понимание
|
|
|
|
|
artscripts Эксперт
|
Что предпочтительнее Windows-1251 или UTF-8?
Очень много иногда вижу вопросов, и не только на этом форуме, что все таки лучше Windows-1251 или UTF-8? Пришел к выводу, что надо бы для пользователей опубликовать одну статейку, которую читал уже давненько. Лично для меня, так все проекты давно на utf-8, но как говориться объясни разницу. для этого приведу в пример статейку: Источник: http://exclusiveblog.ru/markup/windows1251-or-utf8 Quote: На днях пришлось решать небольшую проблему с плохой восприимчивостью комплекта Denwer к кодировки UTF-8. Проблема, честно говоря, оказалась пустяковая, и была решена минут за 15, 10 из которых заняло использование Гугла. В этом время, исследуя различные форумы, я заметил, что для многие не могут разобраться с этой проблемой достаточно долго. Кроме того, понял, что многих интересует зачем вообще использовать UTF-8, если есть прекрасная такая “русская” кодировка Windows-1251. Вот и решил написать пару постов на эту тему. Начну я с общего описания данных кодировок, а продолжу, непосредственно, описанием решения проблемы использования UTF-8 на пакете Denwer. Не так давно, в связи со сложившимися обстоятельствами, решил отказаться от кодировки Windows-1251, с которой работал очень давно, и целиком и полностью перейти на UTF-8. Все причины перехода раскрывать не буду, но основные из них: большинство современных веб-платформ по-умолчанию работают именно на ней; набор используемых в кодировки символов около 100000; Немного теории UTF-8 – в настоящее время распространённая кодировка, реализующая представление Юникода, совместимое с 8-битным кодированием текста. Нашла широкое применение в операционных системах и веб-пространстве. Текст, состоящий только из символов Юникода с номерами меньше 128, при записи в UTF-8 превращается в обычный текст ASCII. Остальные символы Юникода изображаются последовательностями длиной от 2 до 6 байт. Основные отличия кодировок Символ в кодировке UTF-8 может кодироваться аж 6 байтами (пока используется только 4 и больше не планируется). Для русского языка, например, символ занимает 2 байта. Все символы, которые есть в таблице символов – поддерживаются этой кодировкой. К примеру, если вам нужен знак копирайта (©), то вам не нужно искать особый шрифт или же изображать символов в графическом формате. Плюсы UTF-8: UTF-8 позволяет работать одновременно с несколькими языками, т.е. выдавать тексты, в которых используются символы разных алфавитов и даже иероглифы. С использованием кодировки 1251 это невозможно; Минусы UTF-8… А есть ли они у этой кодировки вообще? Я знаю только разных мифах и легендах на эту тему, вот некоторые из них: “У UTF-8 есть проблемы со старыми браузерами” – маловероятно… Во всяком случае, если под старыми не подразумевают Lynx и Mosaic _); Я не призываю всех поголовно переходить на utf-8. я просто хотел рассказать, что намного удобнее использовать именно эту кодировку. Расписать можно на эту тему еще кучу постов. но очевидно что utf-8 это международный стандарт, используемый всем миром)) Дополнения на эту тему: Источник: http://makart.ucoz.ru/publ/1-1-0-6 UTF?8 — вовсе не «новомодная» или «молодая» кодировка, она успешно применяется более десяти лет. Если некий разработчик узнал о ней недавно или не знает до сих пор — это недостаток его квалификации, а не кодировки. С UTF?8 возникают проблемы на веб?сервере? «Я поместил на сервер страницу в UTF?8, а она отображается кракозябрами»,— так иногда жалуются начинающие разработчики. На самом деле, такая проблема случается с самыми разными кодировками и не связана ни с какими специфическими особенностями UTF?8. Здесь неприятность в том, что страница сделана в одной кодировке, а сервер в заголовках HTTP сообщает другую. Надо привести настройки сервера в соответствие с действительной кодировкой веб?страниц. Повторю, что это надо сделать при любой кодировке. Файлы в UTF?8 занимают много места? Говорят, что документы в UTF?8 становятся в два раза больше, чем в старых кодировках. Это миф из разряда «слышал звон, да не знаю, где он». На самом деле — раз на раз не приходится. Например, если документ состоит только из символов ASCII (латинские буквы, цифры, знаки препинания и т. д.) — то в кодировке UTF?8 он будет занимать ровно столько же байтов, сколько в любой другой. Если документ содержит только буквы русского алфавита и никаких других символов (что, согласитесь, бывает достаточно редко) — то в UTF?8 он действительно станет в два раза больше. А если в нём, например, поровну русских и арабских букв — в UTF?8 он будет в два раза меньше, чем, например, в Windows?1251 или Asmo?708. Та самая страница, которую вы сейчас читаете, в кодировке UTF?8 занимает 35 килобайтов. А если перевести её, например, в Windows?1251, она будет занимать 26 килобайтов (убедитесь сами). Кстати, сравнивая страницы, посмотрите, насколько легче читается код в UTF?8. Рассуждая о «весе» веб?страниц, следует отметить, что основную часть этого веса обычно составляет не код HTML, а изображения. (А также, возможно, другие объекты: ролики Flash, файлы JavaScript и т. д.) В результате даже в тех случаях, когда документ в UTF?8 увеличивается — это практически незаметно в общем объёме данных. По?моему, «разбухание» кода на несколько процентов — недорогая цена за главное преимущество UTF?8, с которого мы начали. Тем, кто заботится о «весе», следовало бы в первую очередь выкинуть из кода устаревшие атрибуты HTML (вроде cellpadding или valign) и подстановки для тех символов, которым они не нужны (например, — для длинного тире или для неразрывного пробела). Действительно, иногда доходит до маразма — некто упирается: «Не буду делать страницы в UTF?8, потому что они от этого увеличиваются» — а сам при этом ваяет код с жуткими атрибутами и подстановками, который без них мог бы быть в пять раз короче. Серверные языки программирования и базы данных плохо поддерживают UTF?8? Кто?то скажет: «Всё это хорошо, пока мы имеем дело со статичными веб?страницами. Но если мы пользуемся PHP и MySQL, про UTF?8 лучше забыть». Это тоже неправда. В древности, действительно, некоторые языки программирования и системы управления базами данных не умели работать с UTF?8. Но сейчас все современные языки программирования и базы данных находятся в прекрасных отношениях с этой кодировкой. А несовременными языками и базами пользоваться не ст?ит: чем древнее ваши системы, тем проще их взломать. Единственная трудность с серверными программами — в том, что многие из них по умолчанию настроены не на UTF?8, а на другие кодировки. Ну так перенастройте; мы же с вами не дети малые, чтобы везде и всюду использовать только настройки по умолчанию. Поисковые системы плохо работают с UTF?8? Ещё приходится слышать, будто поисковые системы «спотыкаются» об UTF?8. Эти сведения, опять же, устарели лет на восемь. Вот вам, например, поисковая система «Яндекс»: Убедитесь, что она прекрасно находит всё, что угодно, на моём персональном сайте, где, между прочим, её работу «осложняет» не только UTF?8, но и переносы в словах. Таким образом, не существует никаких противопоказаний к широкому применению UTF?8. Те, кто считает по?другому, просто отстали от жизни. Когда UTF?8 не надо использовать Конечно, бывают случаи, когда самую лучшую кодировку UTF?8 использовать всё?таки нежелательно. Хотя это вовсе не те ситуации, которыми пугают адепты вышеразвенчанных мифов. Во?первых, иногда нам требуется не создавать новый документ, а внести изменения в уже существующий. Обычно в таких случаях нет смысла преобразовывать имеющийся документ в кодировку UTF?8, поэтому приходится редактировать его в той кодировке, в которой он представлен. Во?вторых, иногда работу сайта обеспечивает программное ядро (так называемый «движок»), которое не умеет работать с UTF?8. В такой ситуации, конечно, следует задуматься, нет ли возможности подправить «движок» или заменить его на другой. Но это не всегда удаётся. Некоторые программные ядра обеспечивают функциональные достоинства, ради которых можно смириться с устаревшей кодировкой. Как работать с UTF?8 В качестве «недостатков» UTF?8 упоминают и тот факт, что с ней сложно работать — мол, не все текстовые редакторы её поддерживают. Ну так пользуйтесь хорошим редактором, у которого нет проблем с современными кодировками. Кодировку UTF?8 понимают все нынешние редакторы — от стандартного «Блокнота» в Windows до Dreamweaver’а. (Сам я, кстати, пользуюсь EmEditor’ом, и этот сайт сделан именно его средствами.) Надеюсь, что дальнейшие рекомендации будут вам полезны при работе с UTF?8. Отключайте BOM При сохранении файла многие текстовые редакторы предлагают флажок «Include Unicode Signature (BOM)», «Add Byte Order Mark» или нечто подобное. Прежде всего убедитесь, что в вашем редакторе это есть. Если похожей настройки не обнаружено (как, например, в «Блокноте») — пользоваться таким редактором для серьёзных задач не ст?ит. Найдя этот флажок — отключите его. Byte Order Mark (BOM) — это три служебных байта, которые автоматически записываются в начало документа и обозначают, что он сохранён в кодировке UTF. Подробности можно прочитать в справочнике, а практическая сторона заключается в том, что эти служебные байты в UTF?8 не являются необходимыми, зато, наоборот, могут ввести в заблуждение некоторые старые браузеры и другие программы. Настройте простые сочетания клавиш для специальных символов Если за каждой кавычкой, тире или неразрывным пробелом лезть в «Таблицу символов» — можно до старости провозиться с одним?единственным документом. Для наиболее распространённых специальных символов рекомендуется настроить сочетания клавиш, что обеспечит любой хороший редактор. Например, я наладил EmEditor так, что по нажатию Ctrl? -? ?? в документе появляется длинное тире, а по нажатию Ctrl? пробел? ?? — неразрывный пробел. Таких сочетаний клавиш у меня около 20, и они позволяют вводить наиболее полезные специальные символы так же просто, как обычные буквы и знаки препинания. Конечно, когда мне требуется редко используемый символ — буква «юс», рожица или иероглиф,— я обращаюсь к «Таблице символов». Указывайте кодировку везде, где требуется Убедитесь, что веб?сервер сообщает правильную кодировку страниц. Если это не так — обратитесь к администратору сервера или прочтите справочные материалы о том, как настроить кодировку. Встречаются службы размещения сайтов (хостинги), которые «намертво привязаны» к какой?либо одной кодировке и не позволяют хозяевам сайтов пользоваться другими кодировками. С такими хостингами связываться не ст?ит. В какой кодировке делать страницы — должен решать разработчик сайта, а не служба его размещения. В коде HTML часто имеет смысл использовать элемент meta: Существуют разные мнения про использование meta для указания кодировки. Когда?то я считал, что этот элемент скорее вреден, чем полезен. Однако ряд исследований и собственный опыт заставили меня пересмотреть свою точку зрения. Применять или не применять meta — следует решать отдельно для каждого конкретного сайта. Не забывайте о шрифтах Какой бы кодировкой вы ни пользовались, надо помнить, что браузеры отображают только те символы, которые есть в установленных на компьютере шрифтах. «Таблица символов» показывает именно их. Перечень стандартных шрифтов Windows размещён в разделе «Справочники». В Unicode можно найти немало других символов — например, руны (, и пр.), буквы глаголицы (, и пр.), разнообразные значки и пиктограммы (, , и пр.). Но вставить их в документ не получится: у подавляющего большинства пользователей нет шрифтов, в которых присутствовали бы эти знаки. Тут даже UTF?8, при всех её достоинствах, помочь не в силах. Приходится размещать такие символы в виде растровых изображений (как сделано здесь) или искать другие обходные пути. Многие другие «экзотические» символы обычно доступны на компьютерах пользователей, но браузеру приходится помогать найти нужный шрифт. Например, чтобы отобразить старославянские буквы (?, ? и пр.) или математические знаки (?, ? и пр.) — я указываю в CSS шрифт «Lucida Sans Unicode». Один из редких мифов в пользу UTF?8 говорит, что эта кодировка заставляет компьютер отображать такие символы, которые недостижимы ни в одной старой кодировке. Однако чудес не бывает: если у вас на компьютере нет шрифта, в котором присутствует скрипичный ключ,— то вы не увидите этого символа в UTF?8 с таким же успехом, как в любой другой кодировке. Главное преимущество UTF?8 — не в волшебном расширении набора символов, а в простом способе их включения в документ.
Смотрите в будущее Если вы знакомы с Unicode, то, возможно, поинтересуетесь, почему я советую именно UTF?8, а не другие современные кодировки — скажем, UTF?16 или UTF?32. Отвечаю: они обеспечивают то же главное преимущество, что и UTF?8, но обладают и рядом недостатков. Во?первых, они, в отличие от UTF?8, действительно заметно увеличивают «вес» файлов. Во?вторых, с ними в некоторых используемых ныне браузерах ещё возникают проблемы. Кстати, Консорциум W3C рекомендует использовать для веб-страниц именно UTF?8.
Last edited by artscripts : 06-30-2011 at 04:45 PM.
|
|
||||
|
Реклама на форуме А что у нас тут интересного? =) |
|
|
|
|
Centurion Эксперт
|
а плюсы и минусы Windows-1251?) |
|
|
|
|
artscripts Эксперт
|
Centurio, для меня плюсов не))) одни минусы) |
|
|
|
|
AleX Гость |
Если форум не мультиязычный, то предпочтительнее использовать Windows-1251. Да и, с ним геморроя меньше. |
|
|
|
|
artscripts Эксперт
|
AleX, ну тут я спорить не буду, но каждому свою, но к примеру начинаешь парсить инфу на свой форум с других ресурсов и опа кракозяблы пошли, ужас, приходиться дописывать в парсеры свои кодировки типа iconv(«UTF-8″,»CP1251», $file);, а если парсешь ява скрипт? ИМхо. намного проще поставить utf-8 и вообще не парится не над мультиязычностью, не над интеграцией сторонних серверов и парсингом. |
|
|
|
|
AleX Гость |
Quote: Originally Posted by artscripts но к примеру начинаешь парсить инфу на свой форум с других ресурсов и опа кракозяблы пошли, ужас Парсинг и работа форума — разные вещи. Большинство администраторов таким не занимаются. Quote: Originally Posted by artscripts А есть ли они у этой кодировки вообще? Есть. cp1251 — 1 байт на символ, в utf8 — 2 байта на символ. В итоге, БД будет занимать значительно больше места, чем cp1251. |
|
|
|
|
J. Corvin Глумливый Специалист
|
Quote: Originally Posted by artscripts начинаешь парсить инфу на свой форум с других ресурсов и опа кракозяблы пошли, ужас, приходиться дописывать в парсеры свои кодировки типа iconv(«UTF-8″,»CP1251», $file);, а если парсешь ява скрипт? ИМхо. намного проще поставить utf-8 и вообще не парится не над мультиязычностью, не над интеграцией сторонних серверов и парсингом. Согласен, тоже давно отказался от cp1251 из-за подобных заморочек. |
|
|
|
|
artscripts Эксперт
|
Quote: Originally Posted by AleX Есть. cp1251 — 1 байт на символ, в utf8 — 2 байта на символ. В итоге, БД будет занимать значительно больше места, чем cp1251. Немного не так в этой кодировке латиница по 1 байту, кириллица по 2 байта, редко используемые иероглифы еще больше, там каждый символ по разному весит. И не забывайте что Юникод 8 битный. что равняется 1 байту.) На эту тему можно спорить бесконечно, но мое мнение windows-1251 устаревшая кодировка, и лучше начинать сразу с utf-8 делать проект, прежде чем через пару лет проекта ты начнешь понимать, что тебе надо на сайт мулльтиязычность и внедрить иностранные серверы, или любые работающие с бникодом. вот тут и начнуться проблемы ) |
|
|
|
|
AleX Гость |
artscripts, уже есть проекты с utf8. Больше проблем, чем пользы — вылазят косяки, при «кристальной» БД. |
|
|
|
|
artscripts Эксперт
|
AleX, тьфу тьфу тьфу, я пока на своих проектах косяков вообще не обнаруживаю) Но я еще раз повторюсь, все на любителя. И да спасибо, всегда интересно что-либо пообсуждать спокойно с адекватными людьми)) |
|
Show more comments
«
Previous Thread |
Next Thread
»
|
All times are GMT +4. The time now is 02:40 PM.
Powered by vBulletin® Version 3.5.7
Copyright ©2000 — 2025, Jelsoft Enterprises Ltd.
Взял с сайта
Немного теории
Windows-1251 – набор символов и кодировка, являющаяся стандартной 8-битной кодировкой для всех русских версий Microsoft Windows. Пользуется довольно большой популярностью. Windows-1251 выгодно отличается от других 8‑битных кириллических кодировок (таких как CP866, KOI8-R и ISO 8859-5) наличием практически всех символов, использующихся в русской типографике для обычного текста; она также содержит все символы для близких к русскому языку языков: украинского, белорусского, сербского и болгарского.
UTF-8 – в настоящее время распространённая кодировка, реализующая представление Юникода, совместимое с 8-битным кодированием текста. Нашла широкое применение в операционных системах и веб-пространстве. Текст, состоящий только из символов Юникода с номерами меньше 128, при записи в UTF-8 превращается в обычный текст ASCII. Остальные символы Юникода изображаются последовательностями длиной от 2 до 6 байт.
Основные отличия кодировок
Главное отличие кодировок – это используемый набор символов. В UTF-8 гораздо больше количество символов возможно представить, чем в Windows- 1251. Кодировка Windows- 1251 однобайтовая, т.е. представить в ней можно только 255 символов. Для кириллицы, впрочем, этого вполне достаточно, именно поэтому однобайтовые кодировки до сих пор так массово применяются.
Символ в кодировке UTF-8 может кодироваться аж 6 байтами (пока используется только 4 и больше не планируется). Для русского языка, например, символ занимает 2 байта. Все символы, которые есть в таблице символов – поддерживаются этой кодировкой. К примеру, если вам нужен знак копирайта (©), то вам не нужно искать особый шрифт или же изображать символов в графическом формате.
Плюсы UTF-8:
UTF-8 позволяет работать одновременно с несколькими языками, т.е. выдавать тексты, в которых используются символы разных алфавитов и даже иероглифы. С использованием кодировки 1251 это невозможно;
использование UTF-8 позволяет отказаться от кодовых таблиц, трансляций символов и всех прочих извращений, что были ранее с однобайтовыми кодировками;
Нет кучи кодировок для одного и того же языка, как это было ранее для русского: cp1251, cp866, koi8r, iso8859-5.
Минусы UTF-8… А есть ли они у этой кодировки вообще? Я знаю только разных мифах и легендах на эту тему, вот некоторые из них:
“У UTF-8 есть проблемы со старыми браузерами” – маловероятно… Во всяком случае, если под старыми не подразумевают Lynx и Mosaic _);
“С UTF-8 возникают проблемы на сервере” – ну да, если сервер по-умолчанию пытается определить другую кодировку. Но это не минус кодировки, уж точно…
- IT
- Cancel
Windows-1251 – набор символов и кодировка, являющаяся стандартной 8-битной кодировкой для всех русских версий Microsoft Windows. Пользуется довольно большой популярностью. Windows-1251 выгодно отличается от других 8‑битных кириллических кодировок (таких как CP866, KOI8-R и ISO 8859-5) наличием практически всех символов, использующихся в русской типографике для обычного текста; она также содержит все символы для близких к русскому языку языков: украинского, белорусского, сербского и болгарского.
UTF-8 – в настоящее время распространённая кодировка, реализующая представление Юникода, совместимое с 8-битным кодированием текста. Нашла широкое применение в операционных системах и веб-пространстве. Текст, состоящий только из символов Юникода с номерами меньше 128, при записи в UTF-8 превращается в обычный текст ASCII. Остальные символы Юникода изображаются последовательностями длиной от 2 до 6 байт.
Основные отличия кодировок
Главное отличие кодировок – это используемый набор символов. В UTF-8 гораздо больше количество символов возможно представить, чем в Windows- 1251. Кодировка Windows- 1251 однобайтовая, т.е. представить в ней можно только 255 символов. Для кириллицы, впрочем, этого вполне достаточно, именно поэтому однобайтовые кодировки до сих пор так массово применяются.
Символ в кодировке UTF-8 может кодироваться аж 6 байтами (пока используется только 4 и больше не планируется). Для русского языка, например, символ занимает 2 байта. Все символы, которые есть в таблице символов – поддерживаются этой кодировкой. К примеру, если вам нужен знак копирайта (©), то вам не нужно искать особый шрифт или же изображать символов в графическом формате.
Плюсы UTF-8:
- UTF-8 позволяет работать одновременно с несколькими языками, т.е. выдавать тексты, в которых используются символы разных алфавитов и даже иероглифы. С использованием кодировки 1251 это невозможно;
- использование UTF-8 позволяет отказаться от кодовых таблиц, трансляций символов и всех прочих извращений, что были ранее с однобайтовыми кодировками;
- Нет кучи кодировок для одного и того же языка, как это было ранее для русского: cp1251, cp866, koi8r, iso8859-5.
Минусы UTF-8… А есть ли они у этой кодировки вообще? Я знаю только разных мифах и легендах на эту тему, вот некоторые из них:
- “У UTF-8 есть проблемы со старыми браузерами” – маловероятно… Во всяком случае, если под старыми не подразумевают Lynx и Mosaic _);
- “С UTF-8 возникают проблемы на сервере” – ну да, если сервер по-умолчанию пытается определить другую кодировку. Но это не минус кодировки, уж точно…
http://exclusiveblog.ru/notes/windows1251-or-utf8
Немного теории оказывается полезно, чтобы разложить все в голове у себя по полочкам.
Как работают кодировки текста. Откуда появляются «кракозябры». Принципы кодирования. Обобщение и детальный разбор
Время на прочтение10 мин
Количество просмотров143K
Данная статья имеет цель собрать воедино и разобрать принципы и механизм работы кодировок текста, подробно этот механизм разобрать и объяснить. Полезна она будет тем, кто только примерно представляет, что такое кодировки текста и как они работают, чем отличаются друг от друга, почему иногда появляются не читаемые символы, какой принцип кодирования имеют разные кодировки.
Чтобы получить детальное понимание этого вопроса придется прочитать и свести воедино не одну статью и потратить довольно значительное время на это. В данном материале же это все собрано воедино и по идее должно сэкономить время и разбор на мой взгляд получился довольно подробный.
О чем будет под катом: принцип работы одно байтовых кодировок (ASCII, Windows-1251 и т.д.), предпосылки появления Unicode, что такое Unicode, Unicode-кодировки UTF-8, UTF-16, их отличия, принципиальные особенности, совместимость и несовместимость разных кодировок, принципы кодирования символов, практический разбор кодирования и декодирования.
Вопрос с кодировками сейчас конечно уже потерял актуальность, но все же знать как они работают сейчас и как работали раньше и при этом не потратить много времени на это думаю лишним не будет.
Предпосылки Unicode
Начать думаю стоит с того времени когда компьютеризация еще не была так сильно развита и только набирала обороты. Тогда разработчики и стандартизаторы еще не думали, что компьютеры и интернет наберут такую огромную популярность и распространенность. Собственно тогда то и возникла потребность в кодировке текста. В каком то же виде нужно было хранить буквы в компьютере, а он (компьютер) только единицы и нули понимает. Так была разработана одно-байтовая кодировка ASCII (скорее всего она не первая кодировка, но она наиболее распространенная и показательная, по этому ее будем считать за эталонную). Что она из себя представляет? Каждый символ в этой кодировке закодирован 8-ю битами. Несложно посчитать что исходя из этого кодировка может содержать 256 символов (восемь бит, нулей или единиц 28=256).
Первые 7 бит (128 символов 27=128) в этой кодировке были отданы под символы латинского алфавита, управляющие символы (такие как переносы строк, табуляция и т.д.) и грамматические символы. Остальные отводились под национальные языки. То есть получилось что первые 128 символов всегда одинаковые, а если хочешь закодировать свой родной язык пожалуйста, используй оставшуюся емкость. Собственно так и появился огромный зоопарк национальных кодировок. И теперь сами можете представить, вот например я находясь в России беру и создаю текстовый документ, у меня по умолчанию он создается в кодировке Windows-1251 (русская кодировка использующаяся в ОС Windows) и отсылаю его кому то, например в США. Даже то что мой собеседник знает русский язык, ему не поможет, потому что открыв мой документ на своем компьютере (в редакторе с дефолтной кодировкой той же самой ASCII) он увидит не русские буквы, а кракозябры. Если быть точнее, то те места в документе которые я напишу на английском отобразятся без проблем, потому что первые 128 символов кодировок Windows-1251 и ASCII одинаковые, но вот там где я написал русский текст, если он в своем редакторе не укажет правильную кодировку будут в виде кракозябр.
Думаю проблема с национальными кодировками понятна. Собственно этих национальных кодировок стало очень много, а интернет стал очень широким, и в нем каждый хотел писать на своем языке и не хотел чтобы его язык выглядел как кракозябры. Было два выхода, указывать для каждой страницы кодировки, либо создать одну общую для всех символов в мире таблицу символов. Победил второй вариант, так создали Unicode таблицу символов.
Небольшой практикум ASCII
Возможно покажется элементарщиной, но раз уж решил объяснять все и подробно, то это надо.
Вот таблица символов ASCII:
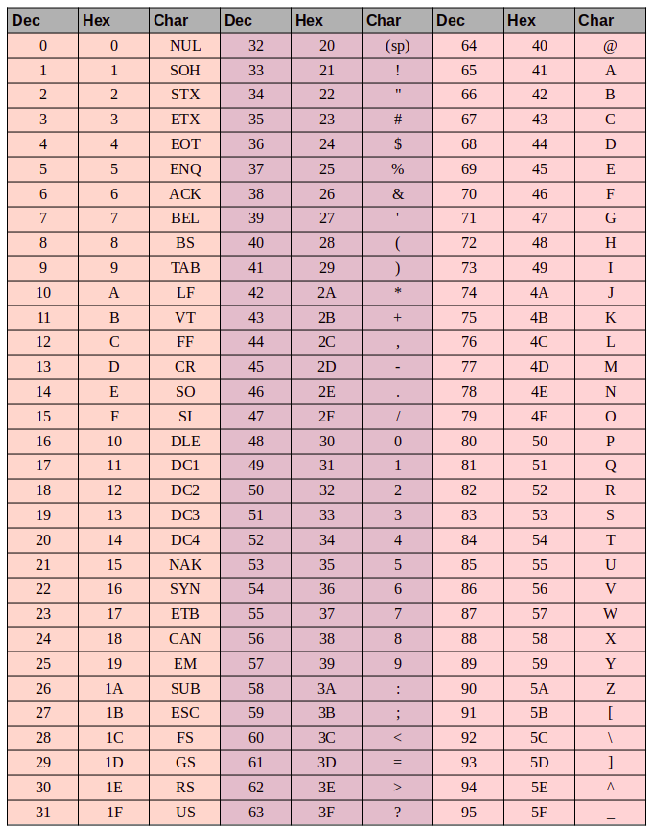
Тут имеем 3 колонки:
- номер символа в десятичном формате
- номер символа в шестнадцатиричном формате
- представление самого символа.
Итак, закодируем строку «ok» (англ.) в кодировке ASCII. Символ «o» (англ.) имеет позицию 111 в десятичном виде и 6F в шестнадцатиричном. Переведем это в двоичную систему — 01101111. Символ «k» (англ.) — позиция 107 в десятеричной и 6B в шестнадцатиричной, переводим в двоичную — 01101011. Итого строка «ok» закодированная в ASCII будет выглядеть так — 01101111 01101011. Процесс декодирования будет обратный. Берем по 8 бит, переводим их в 10-ичную кодировку, получаем номер символа, смотрим по таблице что это за символ.
Unicode
С предпосылками создания общей таблицы для всех в мире символов, разобрались. Теперь собственно, к самой таблице. Unicode — именно эта таблица и есть (это не кодировка, а именно таблица символов). Она состоит из 1 114 112 позиций. Большинство этих позиций пока не заполнены символами, так что вряд ли понадобится это пространство расширять.
Разделено это общее пространство на 17 блоков, по 65 536 символов в каждом. Каждый блок содержит свою группу символов. Нулевой блок — базовый, там собраны наиболее употребляемые символы всех современных алфавитов. Во втором блоке находятся символы вымерших языков. Есть два блока отведенные под частное использование. Большинство блоков пока не заполнены.
Итого емкость символов юникода составляет от 0 до 10FFFF (в шестнадцатиричном виде).
Записываются символы в шестнадцатиричном виде с приставкой «U+». Например первый базовый блок включает в себя символы от U+0000 до U+FFFF (от 0 до 65 535), а последний семнадцатый блок от U+100000 до U+10FFFF (от 1 048 576 до 1 114 111).
Отлично теперь вместо зоопарка национальных кодировок, у нас есть всеобъемлющая таблица, в которой зашифрованы все символы которые нам могут пригодиться. Но тут тоже есть свои недостатки. Если раньше каждый символ был закодирован одним байтом, то теперь он может быть закодирован разным количеством байтов. Например для кодирования всех символов английского алфавита по прежнему достаточно одного байта например тот же символ «o» (англ.) имеет в юникоде номер U+006F, то есть тот же самый номер как и в ASCII — 6F в шестнадцатиричной и 111 в десятеричной. А вот для кодирования символа «U+103D5» (это древнеперсидская цифра сто) — 103D5 в шестнадцатиричной и 66 517 в десятеричной, тут нам потребуется уже три байта.
Решить эту проблему уже должны юникод-кодировки, такие как UTF-8 и UTF-16. Далее речь пойдет про них.
UTF-8
UTF-8 является юникод-кодировкой переменной длинны, с помощью которой можно представить любой символ юникода.
Давайте поподробнее про переменную длину, что это значит? Первым делом надо сказать, что структурной (атомарной) единицей этой кодировки является байт. То что кодировка переменной длинны, значит, что один символ может быть закодирован разным количеством структурных единиц кодировки, то есть разным количеством байтов. Так например латиница кодируется одним байтом, а кириллица двумя байтами.
Немного отступлю от темы, надо написать про совместимость ASCII и UTF
То что латинские символы и основные управляющие конструкции, такие как переносы строк, табуляции и т.д. закодированы одним байтом делает utf-кодировки совместимыми с кодировками ASCII. То есть фактически латиница и управляющие конструкции находятся на тех же самых местах как в ASCII, так и в UTF, и то что закодированы они и там и там одним байтом и обеспечивает эту совместимость.
Давайте возьмем символ «o»(англ.) из примера про ASCII выше. Помним что в таблице ASCII символов он находится на 111 позиции, в битовом виде это будет 01101111. В таблице юникода этот символ — U+006F что в битовом виде тоже будет 01101111. И теперь так, как UTF — это кодировка переменной длины, то в ней этот символ будет закодирован одним байтом. То есть представление данного символа в обеих кодировках будет одинаково. И так для всего диапазона символов от 0 до 128. То есть если ваш документ состоит из английского текста то вы не заметите разницы если откроете его и в кодировке UTF-8 и UTF-16 и ASCII (прим. в UTF-16 такие символы все равно будут закодированы двумя байтами, по этому вы не увидите разницы, если ваш редактор будет игнорировать нулевые байты), и так до момента пока вы не начнете работать с национальным алфавитом.
Сравним на практике как будет выглядеть фраза «Hello мир» в трех разных кодировках: Windows-1251 (русская кодировка), ISO-8859-1 (кодировка западно-европейских языков), UTF-8 (юникод-кодировка). Суть данного примера состоит в том что фраза написана на двух языках. Посмотрим как она будет выглядеть в разных кодировках.

В кодировке ISO-8859-1 нет таких символов «м», «и» и «р».
Теперь давайте поработаем с кодировками и разберемся как преобразовать строку из одной кодировки в другую и что будет если преобразование неправильное, или его нельзя осуществить из за разницы в кодировках.
Будем считать что изначально фраза была записана в кодировке Windows-1251. Исходя из таблицы выше запишем эту фразу в двоичном виде, в кодировке Windows-1251. Для этого нам потребуется всего только перевести из десятеричной или шестнадцатиричной системы (из таблицы выше) символы в двоичную.
01001000 01100101 01101100 01101100 01101111 00100000 11101100 11101000 11110000
Отлично, вот это и есть фраза «Hello мир» в кодировке Windows-1251.
Теперь представим что вы имеете файл с текстом, но не знаете в какой кодировке этот текст. Вы предполагаете что он в кодировке ISO-8859-1 и открываете его в своем редакторе в этой кодировке. Как сказано выше с частью символов все в порядке, они есть в этой кодировке, и даже находятся на тех же местах, но вот с символами из слова «мир» все сложнее. Этих символов в этой кодировке нет, а на их местах в кодировке ISO-8859-1 находятся совершенно другие символы. А конкретно «м» — позиция 236, «и» — 232. «р» — 240. И на этих позициях в кодировке ISO-8859-1 находятся следующие символы позиция 236 — символ «ì», 232 — «è», 240 — «ð»
Значит фраза «Hello мир» закодированная в Windows-1251 и открытая в кодировке ISO-8859-1 будет выглядеть так: «Hello ìèð». Вот и получается что эти две кодировки совместимы лишь частично, и корректно перекодировать строку из одной кодировке в другую не получится, потому что там просто напросто нет таких символов.
Тут и будут необходимы юникод-кодировки, а конкретно в данном случае рассмотрим UTF-8. То что символы в ней могут быть закодированы разным количеством байтов от 1 до 4 мы уже выяснили. Теперь стоит сказать что с помощью UTF могут быть закодированы не только 256 символов, как в двух предыдущих, а вобще все символы юникода
Работает она следующим образом. Первый бит каждого байта кодирующего символ отвечает не за сам символ, а за определение байта. То есть например если ведущий (первый) бит нулевой, то это значит что для кодирования символа используется всего один байт. Что и обеспечивает совместимость с ASCII. Если внимательно посмотрите на таблицу символов ASCII то увидите что первые 128 символов (английский алфавит, управляющие символы и знаки препинания) если их привести к двоичному виду, все начинаются с нулевого бита (будьте внимательны, если будете переводить символы в двоичную систему с помощью например онлайн конвертера, то первый нулевой ведущий бит может быть отброшен, что может сбить с толку).
01001000 — первый бит ноль, значит 1 байт кодирует 1 символ -> «H»
01100101 — первый бит ноль, значит 1 байт кодирует 1 символ -> «e»
Если первый бит не нулевой то символ кодируется несколькими байтами.
Для двухбайтовых символов первые три бита должны быть такие — 110
11010000 10111100 — в начале 110, значит 2 байта кодируют 1 символ. Второй байт в таком случае всегда начинается с 10. Итого отбрасываем управляющие биты (начальные, которые выделены красным и зеленым) и берем все оставшиеся (10000111100), переводим их в шестнадцатиричный вид (043С) -> U+043C в юникоде равно символ «м».
для трех-байтовых символов в первом байте ведущие биты — 1110
11101000 10000111 101010101 — суммируем все кроме управляющих битов и получаем что в 16-ричной равно 103В5, U+103D5 — древнеперситдская цифра сто (10000001111010101)
для четырех-байтовых символов в первом байте ведущие биты — 11110
11110100 10001111 10111111 10111111 — U+10FFFF это последний допустимый символ в таблице юникода (100001111111111111111)
Теперь, при желании, можем записать нашу фразу в кодировке UTF-8.
UTF-16
UTF-16 также является кодировкой переменной длинны. Главное ее отличие от UTF-8 состоит в том что структурной единицей в ней является не один а два байта. То есть в кодировке UTF-16 любой символ юникода может быть закодирован либо двумя, либо четырьмя байтами. Давайте для понятности в дальнейшем пару таких байтов я буду называть кодовой парой. Исходя из этого любой символ юникода в кодировке UTF-16 может быть закодирован либо одной кодовой парой, либо двумя.
Начнем с символов которые кодируются одной кодовой парой. Легко посчитать что таких символов может быть 65 535 (2в16), что полностью совпадает с базовым блоком юникода. Все символы находящиеся в этом блоке юникода в кодировке UTF-16 будут закодированы одной кодовой парой (двумя байтами), тут все просто.
символ «o» (латиница) — 00000000 01101111
символ «M» (кириллица) — 00000100 00011100
Теперь рассмотрим символы за пределами базового юникод диапазона. Для их кодирования потребуется уже две кодовые пары (4 байта). И механизм их кодирования немного сложнее, давайте по порядку.
Для начала введем понятия суррогатной пары. Суррогатная пара — это две кодовые пары используемые для кодирования одного символа (итого 4 байта). Для таких суррогатных пар в таблице юникода отведен специальный диапазон от D800 до DFFF. Это значит, что при преобразовании кодовой пары из байтового вида в шестнадцатиричный вы получаете число из этого диапазона, то перед вами не самостоятельный символ, а суррогатная пара.
Чтобы закодировать символ из диапазона 10000 — 10FFFF (то есть символ для которого нужно использовать более одной кодовой пары) нужно:
- из кода символа вычесть 10000(шестнадцатиричное) (это наименьшее число из диапазона 10000 — 10FFFF)
- в результате первого пункта будет получено число не больше FFFFF, занимающее до 20 бит
- ведущие 10 бит из полученного числа суммируются с D800 (начало диапазона суррогатных пар в юникоде)
- следующие 10 бит суммируются с DC00 (тоже число из диапазона суррогатных пар)
- после этого получатся 2 суррогатные пары по 16 бит, первые 6 бит в каждой такой паре отвечают за определение того что это суррогат,
- десятый бит в каждом суррогате отвечает за его порядок если это 1 то это первый суррогат, если 0, то второй
Разберем это на практике, думаю станет понятнее.
Для примера зашифруем символ, а потом расшифруем. Возьмем древнеперсидскую цифру сто (U+103D5):
- 103D5 — 10000 = 3D5
- 3D5 =
0000000000 1111010101(ведущие 10 бит получились нулевые приведем это к шестнадцатиричному числу, получим 0 (первые десять), 3D5 (вторые десять)) - 0 + D800 = D800 (
1101100000000000) первые 6 бит определяют что число из диапазона суррогатных пар десятый бит (справа) нулевой, значит это первый суррогат - 3D5 + DC00 = DFD5 (
1101111111010101) первые 6 бит определяют что число из диапазона суррогатных пар десятый бит (справа) единица, значит это второй суррогат - итого данный символ в UTF-16 —
1101100000000000 1101111111010101
Теперь наоборот раскодируем. Допустим что у нас есть вот такой код — 1101100000100010 1101111010001000:
- переведем в шестнадцатиричный вид = D822 DE88 (оба значения из диапазона суррогатных пар, значит перед нами суррогатная пара)
1101100000100010— десятый бит (справа) нулевой, значит первый суррогат1101111010001000— десятый бит (справа) единица, значит второй суррогат- отбрасываем по 6 бит отвечающих за определение суррогата, получим
0000100010 1010001000(8A88) - прибавляем 10000 (меньшее число суррогатного диапазона) 8A88 + 10000 = 18A88
- смотрим в таблице юникода символ U+18A88 = Tangut Component-649. Компоненты тангутского письма.
Спасибо тем кто смог дочитать до конца, надеюсь было полезно и не очень занудно.
Вот некоторые интересные ссылки по данной теме:
habr.com/ru/post/158895 — полезные общие сведения по кодировкам
habr.com/ru/post/312642 — про юникод
unicode-table.com/ru — сама таблица юникод символов
Ну и собственно куда же без нее
ru.wikipedia.org/wiki/%D0%AE%D0%BD%D0%B8%D0%BA%D0%BE%D0%B4 — юникод
ru.wikipedia.org/wiki/ASCII — ASCII
ru.wikipedia.org/wiki/UTF-8 — UTF-8
ru.wikipedia.org/wiki/UTF-16 — UTF-16