
Аннотация: Алгоритмы планирования. Состояния потоков. Кванты. Приоритеты.
Алгоритм планирования в Windows. Динамическое повышение приоритета.
Если операционная система поддерживает многопоточность, она может распределять процессорное время либо между процессами, либо между потоками. В операционной системе Windows процессор предоставляется потокам, иначе говоря, осуществляется планирование на уровне потоков.
Таким образом, если один процесс имеет пять потоков, а второй – десять, то первый процесс будет занимать процессор в два раза больше времени, чем второй (при условии, конечно, что все потоки имеют равный приоритет и выполняют примерно одинаковую работу).
Алгоритмы планирования
Существуют разные алгоритмы планирования. Рассмотрим основные виды.
1. Вытесняющие/невытесняющие алгоритмы.
В случае вытесняющего алгоритма операционная система в любой момент времени может прервать выполнение текущего потока и переключить процессор на другой поток. В невытесняющих алгоритмах поток, которому предоставлен процессор, только сам решает, когда передать управление операционной системе.
2. Алгоритмы с квантованием.
Каждому потоку предоставляется квант времени, в течение которого поток может выполняться на процессоре. По истечении кванта операционная система переключает процессор на следующий поток в очереди. Квант обычно равен целому числу интервалов системного таймера1Системный таймер – электронное устройство на материнской плате или в процессоре, которое вырабатывает сигнал прерывания через строго определенные промежутки времени (интервал системного таймера)..
3. Алгоритмы с приоритетами.
Каждому потоку назначается приоритет (priority) – целое число, обозначающее степень привилегированности потока. Операционная система при наличии нескольких готовых к выполнению потоков выбирает из них поток с наибольшим приоритетом.
В Windows реализован смешанный алгоритм планирования – вытесняющий, на основе квантования и приоритетов.
Состояния потоков
За время своего существования поток может находиться в нескольких состояниях. Перечислим основные состояния:
- Готовность (Ready) – поток готов к выполнению и ждет своей очереди занять процессор.
- Выполнение (Running) – поток выполняется на процессоре.
- Ожидание (Waiting) – поток не может выполняться, поскольку ждет наступление некоторого события (например, завершения операции ввода-вывода или сообщения от другого потока)
Кроме основных существует ещё несколько состояний – Инициализация (Init), Завершение (Terminate), Состояние простоя (Standby), Переходное состояние (Transition), Состояние отложенной готовности (Deferred ready). Подробнее о них можно узнать в [5; 2].
На рис.9.1 показаны основные состояния потока, возможные переходы между состояниями и условия переходов.
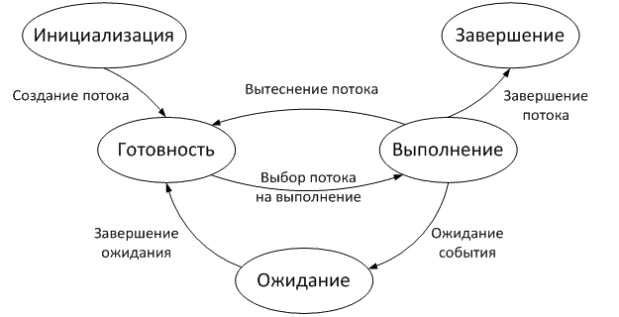
Рис.
9.1.
Состояния потока
Кванты
В Windows имеется два базовых размера кванта – 2 интервала системного таймера и 12 интервалов. Если квант времени короткий, то потоки будут переключаться быстрее и «отзывчивость» (responsiveness) системы улучшится – это важное свойство для пользователя, поэтому в клиентских системах Windows по умолчанию используются короткие кванты. При этом производительность системы в целом снижается, поскольку потоки не будут успевать выполнять свои задачи в течение выделенного кванта, а частые переключения создадут высокие накладные расходы (служебные операции системы при смене потоков). Вследствие этого в серверных версиях Windows по умолчанию применяются длинные кванты.
Длительность интервала системного таймера (в сотнях наносекунд) хранится в переменной KeMaximumIncrement (для x86 – файл base\ntos\ex\i386\splocks.asm, строка 140; для x64 – файл base\ntos\ex\amd64\hifreqlk.asm, строка 147) и устанавливается функцией KeSetTimeIncrement (файл base\ntos\ke\miscc.c, строка 711 на основе значения, предоставляемого HAL.
Каждый процесс хранит величину кванта в поле QuantumReset структуры KPROCESS (файл base\ntos\inc\ke.h, строка 1029). Значение в этом поле равно количеству интервалов таймера, умноженному на 3. Например, для длинных квантов (12 интервалов) значение QuantumReset будет равно 36. Таким образом, при каждом срабатывании таймера (возникает прерывание) система уменьшает квант выполняющегося потока на 3 единицы.
Умножение на три введено для того чтобы можно было в разной степени уменьшать квант в двух различных ситуациях – срабатывании таймера (квант уменьшается на 3 единицы) и выходе из состояния ожидания (квант уменьшается на единицу). Уменьшение кванта при выходе потока из состояния ожидания применяется чтобы избежать ситуации бесконечно выполняющегося потока: если при каждом срабатывании таймера поток находится в состоянии ожидания, а при выходе из ожидания значение кванта не изменяется, то теоретически поток может выполняться бесконечно. Поэтому при выходе из состояния ожидания текущее значение его кванта уменьшается на единицу.
Значение кванта может быть изменено пользователем. Например, на Windows 7 нужно проделать следующее: Компьютер – Свойства – Дополнительные параметры системы – вкладка «Дополнительно» – раздел «Быстродействие» – Параметры – вкладка «Дополнительно» – раздел «Распределение времени процессора». Можно выбрать короткие кванты («Оптимизировать работу программ») или длинные («Оптимизировать работу служб, работающих в фоновом режиме») (рис.9.2).
Рис.
9.2.
Изменение величины кванта в Windows 7number
За изменение величины кванта отвечает функция KeSetQuantumProcess (файл base\ntos\ke\procobj.c, строка 1393).
Кроме длинных и коротких квантов в Windows реализовано динамическое увеличение размера кванта для потоков активного процесса (т.е. того процесса, окно которого в настоящий момент активно). За повышение кванта (и приоритета) отвечает функция PspComputeQuantumAndPriority (файл base\ntos\ps\psquery.c, строка 4415). Более подробную информацию о динамическом увеличении кванта см. [5, стр. 361].
Приоритеты
В операционной системе Windows имеется 32 уровня приоритета – от 0 до 31 (рис.9.3).
Рис.
9.3.
Приоритеты в Windows
Приоритеты назначаются процессам и потокам. У процесса имеется единственный приоритет, который называется базовым. Значение этого приоритета хранится в поле BasePriority структуры KPROCESS (файл base\ntos\inc\ke.h, строка 1028). В WinAPI для работы с базовым приоритетом процесса используются классы приоритета (например, REALTIME, NORMAL и т. д.); соответствие классов приоритета числовым значениям показано на рис.9.3. Например, при создании процесса можно указать класс приоритета в качестве параметра WinAPI-функции CreateProcess, иначе будет установлен приоритет по умолчанию (см. лекцию 6 «Процессы и потоки», раздел «Создание процесса»). В дальнейшем класс приоритета процесса можно изменить при помощи WinAPI-функции SetPriorityClass.
В WRK структура PROCESS_PRIORITY_CLASS и значения соответствующих констант (заметьте, что эти значения не совпадают с числовыми значениями приоритетов) определены в файле public\sdk\inc\ntpsapi.h (строка 399). Класс приоритета процесса хранится в поле PriorityClass структуры EPROCESS (см. лекцию 7 «Процессы и потоки», раздел «Структуры данных для процессов и потоков»). Таким образом, если, например, процессу назначен класс приоритета High, то в поле PriorityClass запишется число 3 (значение константы PROCESS_PRIORITY_CLASS_HIGH), в поле BasePriority – значение 13 (соответствующее числовое значение приоритета).
Поток имеет два значения приоритета – базовый и текущий. При создании потока базовый приоритет потока принимается равным базовому приоритету процесса-владельца. Можно изменить базовый приоритет потока при помощи WinAPI-функции SetThreadPriority. Параметрами этой функции являются дескриптор потока и относительный приоритет, который определяет смещение базового приоритета (таблица 7.1).
Таблица
9.1.
Влияние относительных приоритетов
| Относительный приоритет | Смещение для динамических приоритетов | Смещение для приоритетов реального времени |
|---|---|---|
| Time Critical | Базовый приоритет = 15 | Базовый приоритет = 31 |
| Highest | +2 | +2 |
| Above Normal | +1 | +1 |
| Normal | 0 | 0 |
| Below Normal | –1 | –1 |
| Lowest | –2 | –2 |
| Idle | Базовый приоритет = 1 | Базовый приоритет = 16 |
Пример. Имеется процесс с базовым приоритетом Below Normal (6). Поток, принадлежащий этому процессу, имеет такой же базовый приоритет. Вызов функции SetThreadPriority с параметром Highest сделает базовый приоритет потока равным 8, а с параметром Time Critical – равным 15.
Текущий приоритет потока при создании потока равен базовому, но в дальнейшем может динамически повышаться и понижаться операционной системой (эта процедура будет рассмотрена далее). Заметим, что для потоков с базовым приоритетом Real Time текущий приоритет не изменяется и всегда равен базовому.
Базовый приоритет потока хранится в поле BasePriority, а текущий – в поле Priority структуры KTHREAD (файл base\ntos\inc\ke.h, строки 1123 и 1237).
Оцениваем алгоритмы планирования процессов в операционных системах
Уровень сложностиСредний
Время на прочтение17 мин
Количество просмотров12K

Планирование процессов в операционных системах — это как умение акробата балансировать на тонкой нити. Этот незаметный сложный механизм определяет, как ваш компьютер управляет своими ресурсами. На первый взгляд все кажется просто: переключайте задачи на процессоре как можно быстрее, чтобы минимизировать время простоя и максимизировать общую производительность. Но в реальности это глубокий исследовательский вопрос, который требует учета множества факторов: приоритетов задач, доступности ресурсов и оптимизации. Давайте разбираться вместе!
Используйте навигацию, если не хотите читать текст полностью:
→ Потоки и процессы
→ Описание алгоритмов планирования
→ FIFO
→ RR
→ SJF
→ Метрики оценки производительности
→ Описание прикладной задачи
→ Реализация и симуляция алгоритмов
→ Результаты симуляций и их анализ
→ Заключение
Потоки и процессы
Главная задача операционной системы — отдавать программам необходимые ресурсы: дисковое пространство, оперативную память, ядра процессора, устройства ввода-вывода и т. д. Крутится все вокруг центрального процессора (он же ЦП, или CPU). В подробности мы уйдем чуть позже, а пока сведем все к простому тезису: если ЦП успевает оперативно переключаться между потоками, производительность компьютера в целом повышается. Современные операционные системы фактически планируют именно потоки уровня ядра, а не сами процессы.
Однако термины «планирование процессов» и «планирование потоков» часто используются как синонимы. Для простоты я буду использовать термин «планирование процессов» при упоминании общих концепций планирования, а «планирование потоков» — для обозначения идей, специфичных для потоков.

Описание алгоритмов планирования
Итак, ядро — базовая вычислительная единица ЦП, на которой выполняется процесс. То есть под «запуском на ЦП» обычно подразумевается выполнение процесса именно на ядре ЦП.
Источник.
В системе с одним ядром одновременно может выполняться только один процесс. Остальные в это время ждут, когда оно освободится. Если процессов в данный момент нет, ЦП простаивает.
Это противоречит идее мультипрограммирования, в котором мы стараемся использовать все время работы ЦП продуктивно. Идея проста: процесс выполняется по кругу до завершения запроса ввода-вывода. То есть, если есть несколько процессов, они встают в очередь и выполняются друг за другом. Если процесс один, он крутится до тех пор, пока не появится новый. Когда это происходит, операционная система дожидается завершения процесса, забирает у него ЦП и передает новому.
В многоядерной системе концепция загрузки ЦП распространяется на все процессорные ядра системы. Такое планирование — фундаментальная функция операционной системы, которой уделяется наибольшее внимание.
Выполнение процесса начинается с загрузки процессора. За этим следует цепочка пакетов ввода-вывода и, наконец, последний всплеск частоты ЦП заканчивается системным запросом на прекращение выполнения. Речь не о повышении тактовой частоты процессора, а о периодах его активности при выполнении процессов. Длительность этого всплеска заметно различается от процесса к процессу и от компьютера к компьютеру. Но, как правило, график изменения частоты ЦП имеет вид, как на рисунке ниже.
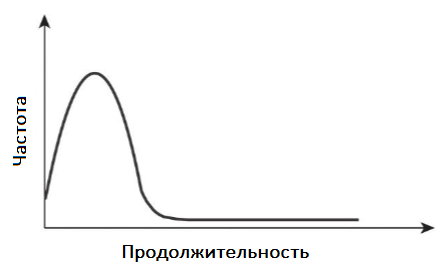
Кривая обычно характеризуется как экспоненциальная или гиперэкспоненциальная, с большим количеством коротких и небольшим — длинных всплесков частоты ЦП.
Важно, что графики будут разными для программ, связанных с вводом-выводом, и программ, привязанным к ЦП. Первые обычно имеют много коротких всплесков частоты процессора. Вторые — несколько длительных. Такое распределение может быть важным при реализации алгоритма планирования.
Каждый раз, когда ЦП простаивает, операционная система должна выбрать один из процессов в очереди готовности для выполнения. За это отвечает планировщик: он выбирает из памяти процесс, готовый к выполнению, и выделяет ему ЦП. Концептуально можно сказать, что все процессы выстраиваются в очередь, чтобы запуститься на процессоре. Записи в очередях обычно представляют собой блоки управления процессами — PCB, или process control block.
Решения по планированию ЦП могут приниматься при следующих обстоятельствах.
- Процесс переключается из состояния выполнения в состояние ожидания (например, в результате запроса ввода-вывода или вызова wait() для завершения дочернего процесса).
- Процесс переходит из состояния выполнения в состояние готовности (например, при возникновении прерывания).
- Процесс переходит из состояния ожидания в состояние готовности (например, при завершении ввода-вывода).
- Процесс завершается.
Для первой и последней ситуаций выбора планирования нет. Новый процесс, если он существует в очереди готовности, должен быть выбран для выполнения. В этих ситуациях говорим, что схема планирования является невытесняющей, или кооперативной. В противном случае это упреждающее действие. При невытесняющем планировании процесс сохраняет ЦП до тех пор, пока либо не завершится, либо не переключится в состояние ожидания. При упреждающем планировании ОС может временно приостановить выполнение текущего процесса, чтобы переключить ЦП на выполнение другого, более приоритетного.
Практически все современные операционные системы, включая Windows, macOS, Linux и UNIX, используют алгоритмы упреждающего планирования. К сожалению, оно может привести к состояниям гонки, когда данные распределяются между несколькими процессами.
Предлагаю рассмотреть случай двух процессов, которые совместно используют данные. Пока один обновляет их, он вытесняется, чтобы второй мог работать. Затем второй процесс пытается прочитать данные, которые находятся в противоречивом состоянии.
Вытеснение также влияет на структуру ядра операционной системы. Во время обработки системного вызова ядро может быть занято какой-либо деятельностью от имени процесса. Такие действия могут включать изменение важных данных ядра (например, очередей ввода-вывода).
Что произойдет, если процесс будет вытеснен в середине этих изменений и ядру (или драйверу устройства) потребуется прочитать или изменить ту же структуру? Наступит хаос. Ядра операционной системы могут быть спроектированы как с вытесняющим, так и с невытесняющим режимом. Невытесняющее ядро будет ждать завершения системного вызова или блокировки процесса, ожидая завершения ввода-вывода, прежде чем выполнять переключение контекста.
Эта схема гарантирует простоту структуры ядра, поскольку оно не будет вытеснять процесс, пока структуры его данных находятся в несогласованном состоянии. К сожалению, эта модель плохо подходит для поддержки вычислений в реальном времени. Большинство современных операционных систем теперь полностью вытесняют работу в режиме ядра.
Хотя большинство современных архитектур ЦП имеют несколько процессорных ядер, я рассказываю о планировании в контексте только одного. То есть ниже я опишу ситуации, когда нам доступен один процессор с одним ядром. Следовательно, воображаемая система способна одновременно запускать только один процесс.
FIFO
FIFO (First In, First Out), также известный как FCFS (First Come, First Serve), является простейшим алгоритмом составления расписания. Он просто ставит процессы в очередь выполнения в том порядке, в котором они поступают.
Принцип работы
Когда процесс попадает в очередь готовности, его блок управления процессом привязывается к хвосту. Когда процессор освобождается, он выделяется процессу, а после завершения удаляет его из очереди.
Стоит сказать, что код планирования FIFO прост в написании и понимании. Вместе с тем, среднее время ожидания в соответствии с политикой этого алгоритма часто бывает довольно продолжительным. Сейчас разберем это подробнее.
Рассмотрим следующий набор процессов, пребывающих в момент времени 0, с продолжительностью загрузки ЦП, заданной в миллисекундах:
Если процессы поступают в последовательности P1, P2, P3 и обслуживаются в порядке FIFO, получаем результат, показанный на диаграмме Ганта. Это гистограмма, которая иллюстрирует конкретный график, включая время начала и окончания каждого из участвующих процессов:

Источник.
Мы видим, что время ожидания составляет 0 мс для процесса P1, 24 миллисекунды для P2 и 27 мс для P3. Таким образом, среднее время ожидания составляет (0 + 24 + 27)/3 = 17 мс. Однако если процессы поступают в порядке P2, P3, P1, результаты будут другими:

Источник.
Среднее время ожидания теперь составляет (6 + 0 + 3)/3 = 3 мс. Это существенное сокращение. Пример наглядно показывает, что среднее время ожидания в соответствии с политикой FIFO обычно не минимально и может существенно меняться, если время загрузки процессов на ЦП сильно различается.
Теперь рассмотрим производительность планирования FIFO в динамической ситуации. Предположим, у нас есть процесс, привязанный к процессору (назовем его P1), и множество процессов, связанных с вводом-выводом. Поскольку они протекают вокруг системы, может возникнуть следующий сценарий.
P1 получит и удержит ЦП. За это время все остальные процессы завершат ввод-вывод и перейдут в очередь готовности. Пока они ждут, операции ввода-вывода устройства простаивают. В конце концов, P1 завершит нагрузку на ЦП и перейдет к устройству ввода-вывода.
Все процессы, связанные с вводом-выводом, которые имеют короткие нагрузки на ЦП, выполняются быстро и возвращаются в очереди ввода-вывода. В этот момент процессор простаивает. P1 затем вернется в очередь готовности, и ему будет выделен ЦП. Опять же, все процессы ввода-вывода в конечном итоге ждут в очереди готовности, пока не завершится P1. Возникает эффект конвоя, поскольку все остальные процессы ждут, пока один большой процесс выйдет из ЦП. Этот эффект приводит к более низкой загрузке ЦП и устройств, чем это было бы возможно, если бы более коротким процессам разрешалось запускаться первыми.
Алгоритм FIFO не является вытесняющим. Забрав ЦП, процесс сохраняет его либо до своего завершения, либо до появления запроса ввода-вывода. То есть FIFO особенно неприятен для интерактивных систем, где важно, чтобы каждый процесс получал долю ресурсов ЦП через определенные промежутки времени. Было бы катастрофой позволить одному процессу удерживать процессор в течение длительного периода времени.
Преимущества и недостатки
Преимущества FIFO
- Простота реализации и понимания.
- Минимальные накладные расходы на планирование, так как переключение контекста происходит только при завершении процесса.
- Отсутствие стагнации (starvation) процессов, так как каждый процесс гарантированно получит возможность выполнения.
- Справедливость по отношению ко всем процессам, независимо от их длительности или приоритета.
Недостатки FIFO
- Низкая пропускная способность системы, особенно если длительные процессы блокируют короткие (эффект конвоя).
- Высокое среднее время ожидания и время отклика, особенно для коротких процессов, если они находятся в конце очереди.
- Отсутствие приоритизации процессов, что может привести к проблемам с выполнением срочных задач.
- Неэффективное использование ресурсов процессора, особенно в системах с процессами различной длительности.
- Сложности с соблюдением дедлайнов процессов из-за отсутствия механизма приоритетов.
RR
RR (Round Robin Scheduling) — это алгоритм циклического планирования с вытеснением, при котором процессор выдает процессы по очереди на фиксированный квант времени. Если процесс не успевает завершиться за отведенное ему время, он прерывается и помещается в конец очереди готовности.
Принцип работы
Начинается все, как в FIFO: процессы встают в очередь в том порядке, в котором приходят. Затем определяется небольшая единица времени, называемая квантом или интервалом. Обычно до 100 мс. Планировщик ЦП обходит очередь готовности и выделяет каждому процессу ЦП на интервал до одного кванта времени.
Планировщик ЦП выбирает первый процесс из очереди готовности, устанавливает таймер на прерывание через один квант времени и направляет процесс. Затем происходит одно из двух.
- Если процесс успевает выполниться за один квант времени, он добровольно освобождает процессор. Затем планировщик переходит к следующему процессу в очереди готовности.
- Если не успевает, срабатывает таймер, который вызывает прерывание для операционной системы. Оно не является критическим или аварийным, а лишь сигнализирует операционной системе, что нужно переключить процесс, чтобы поддерживать работу алгоритма. Соответственно, будет выполнено переключение контекста, а процесс будет помещен в конец очереди готовности.
В любом сценарии планировщик ЦП выберет следующий процесс в очереди готовности. Среднее время ожидания в соответствии с политикой RR часто бывает большим. Рассмотрим следующий набор процессов, которые прибывают в момент времени 0, с продолжительностью загрузки ЦП, заданной в миллисекундах:
Мы используем временной квант в 4 мс, и процесс P1 получит его полностью. Однако по условию для выполнения ему нужно еще 20 мс. Следовательно, он вытесняется по истечении первого кванта времени, а ЦП передается следующему процессу в очереди, P2. Ему нужно всего 3 мс, поэтому он завершается до истечения своего кванта времени. Затем процессор передается следующему процессу, P3. С ним повторяется предыдущий сценарий. Затем ЦП возвращается процессу P1, который будет удерживать его циклами по 4 мс, пока не завершится. В результате график RR выглядит следующим образом:

Источник.
Давайте посчитаем среднее время ожидания для этого расписания. P1 ждет 6 мс (суммарное время выполнения процессов P2 и P3). P2 ждет 4 мс, пока выполняется P1. P3 ждет 7 мс, пока выполняются P1 и P2. Таким образом, среднее время ожидания составляет 17/3 = 5,66 мс. В алгоритме планирования RR ЦП не выделяется ни одному процессу более чем на один квант времени подряд (если только это не единственный работающий процесс).
Если загрузка ЦП процесса превышает один квант времени, этот процесс вытесняется и помещается обратно в очередь готовности. Таким образом, алгоритм планирования RR является упреждающим. Если в очереди готовности находится n процессов и квант времени равен q, то каждый процесс получает 1/n процессорного времени порциями максимум по q единиц времени.
Каждый процесс должен ждать не более (n — 1) * q единиц времени до своего следующего кванта. Например, есть пять процессов и временной квант 20 мс. Значит, каждый процесс будет получать ЦП в свое распоряжение через каждые 100 мс.
Производительность алгоритма RR сильно зависит от размера временного кванта. С одной стороны, если он чрезвычайно велик, политика RR будет схожа с политикой FIFO. С другой, если он чрезвычайно мал (скажем, одна миллисекунда), подход RR может привести к большому количеству переключений контекста.
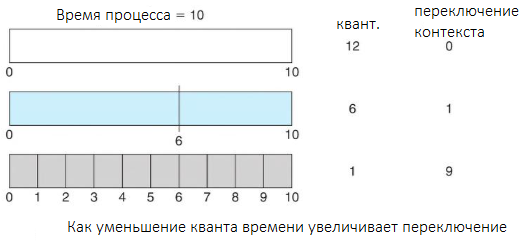
Источник.
Предположим, у нас есть только один процесс продолжительностью 10 мс и квант времени, равный 12 мс. В этом случае процесс завершится менее чем за один квант без каких-либо дополнительных затрат. Однако если квант равен шести миллисекундам, то процессу потребуется два кванта, что приведет к переключению контекста. Если квант времени равен одной миллисекунде, произойдет девять переключений контекста, что замедлит выполнение процесса (рис. выше).
Таким образом, мы хотим, чтобы квант времени был большим по сравнению со временем переключения контекста. Если последнее составляет примерно 10% кванта времени, то на переключение контекста будет потрачено около 10% времени процессора. На практике большинство современных ОС имеют кванты от 10 до 100 миллисекунд. Время, необходимое для переключения контекста, обычно составляет менее 10 микросекунд (0,01 мс). Таким образом, время переключения контекста составляет небольшую часть кванта времени.
Выбор кванта времени
Время выполнения также зависит от размера кванта времени.
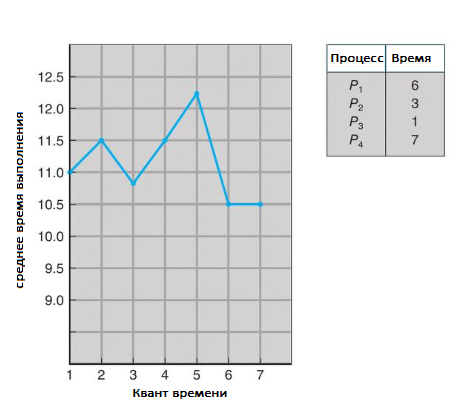
Источник.
Как мы можем видеть на рисунке выше, среднее время выполнения набора процессов не обязательно улучшается по мере увеличения размера кванта времени. В общем, среднее время обработки можно улучшить, если большинство процессов завершат следующий цикл загрузки ЦП за один квант времени. Например, для трех процессов по 10 мс каждый и при кванте времени в 1 мс среднее время выполнения равно 29 мс. Однако если квант времени равен 10, то среднее время выполнения падает до 20. Если добавить время переключения контекста, в среднем время выполнения увеличивается еще больше. И это при меньшем временном интервале, поскольку нужно больше переключений контекста.
Временной интервал должен быть большим по сравнению со временем переключения контекста, но в то же время не превышать его слишком сильно. Как указано выше, если квант времени слишком велик, планирование RR перерождается в политику FIFO. Эмпирическое правило заключается в том, что 80% пакетов процессорного времени должны быть короче кванта времени.
Преимущества и недостатки
Преимущества RR
- Справедливое распределение процессорного времени.
- Отсутствие блокировки системы одним процессом.
- Низкое время отклика для интерактивных процессов.
Недостатки
- Необходимость выбора оптимального кванта времени.
- Накладные расходы на переключение контекста.
- Неэффективность для процессов с очень короткими или очень длинными временами выполнения.
SJF
SJF (Shortest Job First) — это алгоритм, который выбирает в первую очередь процесс с минимальным ожидаемым временем выполнения. Он может работать как с вытеснением (тогда это будет SRTF — Shortest Remaining Time First), так и без него.
Принцип работы
Алгоритм сортирует процессы в очереди по ожидаемому времени выполнения от меньшего к большему. После назначает ЦП сначала процессам с коротким временем выполнения, а затем все более и более длинным.
Если следующие пакеты ЦП двух процессов одинаковы, для разрыва связи используется планирование FIFO. Обратите внимание, что более подходящим термином для этого метода планирования был бы алгоритм «самый короткий следующий пакет ЦП».Это потому, что планирование зависит от длины следующего пакета ЦП процесса, а не от его общей длины.
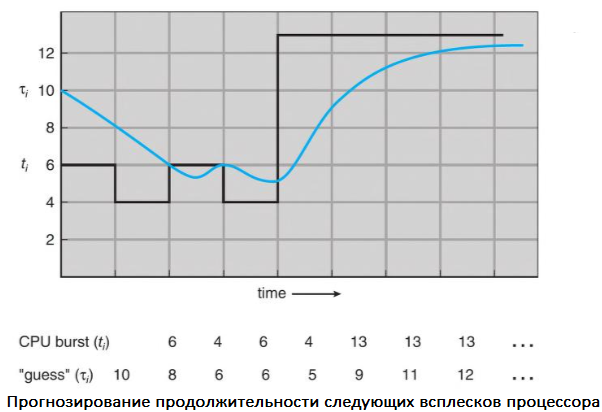
Я использую термин термин SJF, потому что большинство людей применяют его, и он часто встречается в учебниках для обозначения этого типа планирования. В качестве примера планирования SJF рассмотрим следующий набор процессов с продолжительностью загрузки ЦП, заданной в миллисекундах:
Используя планирование SJF, запланировали бы эти процессы в соответствии со следующей диаграммой Ганта:

Время ожидания — 3 миллисекунды для процесса P1,16 — для P2, 9 — для P3 и 0 — для P4. Таким образом, среднее время ожидания будет (3 + 16 + 9 + 0)/4 = 7 миллисекунд. Для сравнения: если бы использовали схему планирования FIFO, среднее время ожидания составило бы 10,25 миллисекунды.
SJF является доказуемо оптимальным, поскольку обеспечивает минимальное среднее время ожидания для данного набора процессов. Постановка короткого процесса перед длинным уменьшает среднее время ожидания.
Несмотря на это, SJF нельзя реализовать на уровне планирования ЦП, поскольку нет способа узнать длину следующего пакета. Один из подходов к этой проблеме — попытаться аппроксимировать планирование SJF. Мы можем не знать продолжительность следующего пакета процессора, но можем предсказать его значение. Ожидаемо, что следующий пакет будет аналогичен по длине предыдущим. Вычислив приблизительную длину следующего пакета ЦП, можем выбрать процесс с самым коротким прогнозируемым пакетом ЦП.
Следующий пакет ЦП обычно прогнозируется как экспоненциальное среднее измеренных длин предыдущих пакетов. Можем определить это значение с помощью следующей формулы:
Здесь tn — длина n-го пакета ЦП, а 𝛕n + 1 — наше прогнозируемое значение для следующего пакета ЦП. Переменная α находится в диапазоне от 0 до 1.
Значение tn содержит нашу самую свежую информацию, а 𝛕n хранит прошлую историю. Параметр α контролирует относительный вес недавней и прошлой истории в нашем прогнозе. Если α = 0, то 𝛕n+1 = 𝛕n и недавняя история не оказывает влияния (текущие условия считаются переходными).
Если α = 1, то 𝛕n+1 = tn и имеет значение только самый последний пакет процессора (предполагается, что история устарела и не имеет значения). Чаще всего α = 1/2, поэтому недавняя и прошлая история имеют одинаковый вес. Начальное значение 𝛕0 может быть определено как константа или среднее значение всей системы. На рисунке показано экспоненциальное среднее при α = 1/2 и 𝛕0 = 10.
Источник.
Чтобы понять поведение экспоненциального среднего, мы можем расширить формулу для 𝛕n + 1, заменив 𝛕n и найдя:
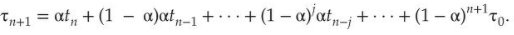
Обычно α < 1. В результате (1 — α) также меньше 1, и каждый последующий термин имеет меньший вес, чем его предшественник.
Алгоритм SJF может быть вытесняющим и невытесняющим. Выбор возникает, когда новый процесс поступает в очередь готовности, в то время как предыдущий все еще выполняется. Следующий пакет ЦП вновь прибывшего процесса может быть короче, чем то, что осталось от текущего. SJF с вытеснением, соответственно, вытесняет выполняющийся в данный момент процесс, тогда как SJF без вытеснения позволяет ему завершить пакетную нагрузку ЦП. Вытесняющее планирование SJF иногда называют планированием с наименьшим оставшимся временем. В качестве примера рассмотрим следующие четыре процесса с продолжительностью загрузки ЦП, заданной в миллисекундах:

Вот как в таких условиях будет выглядеть результирующий график упреждающего SJF:

Источник.
P1 запускается в момент времени 0, поскольку это единственный процесс в очереди. P2 прибывает в момент 1. Оставшееся время для процесса P1 (7 миллисекунд) больше, чем время, необходимое для P2 (4 миллисекунды), поэтому P1 вытесняется, а P2 планируется. Среднее время ожидания для этого примера составляет [(10 – 1) + (1 – 1) + (17 – 2) + (5 – 3)]/4 = 26/4 = 6,5 миллисекунд. Невытесняющее планирование SJF приведет к тому, что среднее время ожидания составит 7,75 миллисекунды.
Преимущества и недостатки
Преимущества SJF
- Минимизация среднего времени ожидания процессов.
- Эффективное использование процессора.
Недостатки
- Необходимость знать или прогнозировать время выполнения процессов.
- Возможность голодания длинных процессов.
- Сложность реализации алгоритма прогнозирования времен выполнения.
Метрики оценки производительности
Среднее время ожидания
Среднее время ожидания (Average Waiting Time, AWT) определяется как среднее время, которое процессы проводят в очереди готовности перед их выполнением на процессоре. Оно рассчитывается как сумма всех времен ожидания процессов, поделенная на количество процессов:
Здесь Wi — время ожидания i-го процесса, n — общее количество процессов.
Среднее время выполнения
Среднее время выполнения (Average Turnaround Time, ATT) определяется как время от момента поступления процесса в систему до его завершения. Оно включает время ожидания и время выполнения на процессоре:
Здесь Ti — время выполнения i-го процесса, n — общее количество процессов.
Среднее время отклика
Среднее время отклика (Average Response Time, ART) — это время от поступления запроса до начала его обработки процессором. Время отклика не включает время, необходимое для выполнения процесса, только время ожидания до первого выполнения:
Здесь Ri — время отклика i-го процесса, n — общее количество процессов.
Описание прикладной задачи
Определение наборов процессов для тестирования
Для тестирования производительности алгоритмов планирования я выбрал несколько наборов процессов, которые характеризуются различным временем выполнения и поступления.
- Набор 1. Процессы с равномерным распределением времени выполнения.
- Набор 2. Процессы с переменным временем выполнения, имитирующие рабочую нагрузку на сервере.
- Набор 3. Процессы с коротким временем выполнения, чередующиеся с длительными процессами, чтобы проверить алгоритмы на предмет устойчивости к эффекту конвоя.
Каждый набор был разработан таким образом, чтобы обеспечить разнообразие сценариев для тщательного тестирования алгоритмов FIFO, Round Robin и SJF.
Реализация и симуляция алгоритмов
Краткое описание реализации алгоритмов
Подходы, которые я использовал для реализации алгоритмов планирования процессов:
- FIFO (First-In First-Out) — процессы обрабатываются в порядке их поступления;
- Round Robin — процессы получают процессорное время по очереди с фиксированным квантом времени;
- SJF (Shortest Job First) — процессы обрабатываются в порядке возрастания их ожидаемого времени выполнения.
Проведение симуляции для каждого алгоритма
Для проведения симуляций написан скрипт на Python, который моделирует выполнение процессов в операционной системе Linux:
# Определение процессов для симуляции
processes = [
{'id': 1, 'burst_time': 10},
{'id': 2, 'burst_time': 5},
{'id': 3, 'burst_time': 8}
]
time_quantum = 4
Симуляция FIFO:
# FIFO Scheduling
def fifo_scheduling(processes):
waiting_time = 0
total_waiting_time = 0
total_turnaround_time = 0
response_time = 0
total_response_time = 0
for i, process in enumerate(processes):
if i == 0:
response_time = 0
else:
response_time = waiting_time
total_response_time += response_time
total_waiting_time += waiting_time
waiting_time += process['burst_time']
total_turnaround_time += waiting_time
avg_waiting_time = total_waiting_time / len(processes)
avg_turnaround_time = total_turnaround_time / len(processes)
avg_response_time = total_response_time / len(processes)
return avg_waiting_time, avg_turnaround_time, avg_response_time
Симуляция Round Robin:
# Round Robin Scheduling
def round_robin_scheduling(processes, time_quantum):
from collections import deque
q = deque(processes)
current_time = 0
waiting_time = {process['id']: 0 for process in processes}
remaining_time = {process['id']: process['burst_time'] for process in processes}
response_time = {process['id']: -1 for process in processes}
completed_processes = 0
total_waiting_time = 0
total_turnaround_time = 0
total_response_time = 0
while completed_processes < len(processes):
process = q.popleft()
if response_time[process['id']] == -1:
response_time[process['id']] = current_time
if remaining_time[process['id']] > time_quantum:
current_time += time_quantum
remaining_time[process['id']] -= time_quantum
q.append(process)
else:
current_time += remaining_time[process['id']]
waiting_time[process['id']] = current_time - process['burst_time']
total_turnaround_time += current_time
total_waiting_time += waiting_time[process['id']]
total_response_time += response_time[process['id']]
remaining_time[process['id']] = 0
completed_processes += 1
avg_waiting_time = total_waiting_time / len(processes)
avg_turnaround_time = total_turnaround_time / len(processes)
avg_response_time = total_response_time / len(processes)
return avg_waiting_time, avg_turnaround_time, avg_response_time
Симуляция SJF:
# SJF Scheduling
def sjf_scheduling(processes):
sorted_processes = sorted(processes, key=lambda x: x['burst_time'])
waiting_time = 0
total_waiting_time = 0
total_turnaround_time = 0
response_time = 0
total_response_time = 0
for i, process in enumerate(sorted_processes):
if i == 0:
response_time = 0
else:
response_time = waiting_time
total_response_time += response_time
total_waiting_time += waiting_time
waiting_time += process['burst_time']
total_turnaround_time += waiting_time
avg_waiting_time = total_waiting_time / len(processes)
avg_turnaround_time = total_turnaround_time / len(processes)
avg_response_time = total_response_time / len(processes)
return avg_waiting_time, avg_turnaround_time, avg_response_time
Выполнение симуляций:
# Выполнение симуляций
fifo_results = fifo_scheduling(processes)
rr_results = round_robin_scheduling(processes, time_quantum)
sjf_results = sjf_scheduling(processes)
print("FIFO Results: ", fifo_results)
print("Round Robin Results: ", rr_results)
print("SJF Results: ", sjf_results)
Результаты симуляций и их анализ
Выводы
Для систем с равномерной нагрузкой лучше использовать алгоритм FIFO, так как он проще в реализации и предполагает минимальные управленческие расходы. Это затраты системы на выполнение задач, связанных с управлением процессами. В контексте планирования процессов в операционных системах, такие расходы включают время процессора, память, код и данные ОС.
Для интерактивных систем и систем реального времени, где важна справедливость и быстрота отклика, лучше всего подходит алгоритм Round Robin. Он гарантирует равномерное распределение процессорного времени и быструю реакцию системы на запросы пользователей.
Для вычислительных задач, требующих минимизации общего времени выполнения, наиболее эффективным является алгоритм SJF. Однако следует учитывать риск голодания для длительных процессов, поэтому можно рассмотреть использование модифицированных версий алгоритма.
Заключение
Анализ и симуляции показали, что у каждого алгоритма планирования есть сильные и слабые стороны. FIFO подходит для простых систем с однородной нагрузкой. Round Robin справедливо распределяет процессорное время, но требует точной настройки. SJF обеспечивает наименьшее среднее время ожидания и выполнения, однако может вызвать голодание долгих процессов и требует точной оценки времени выполнения.
Выбор подходящего алгоритма зависит от специфики задач и требований системы и оптимальный выбор может варьироваться в зависимости от контекста использования.
В
разных ОС процессы реализуются
по-разному. Эти различия заключаются
в том, какими структурами данных
представлены процессы, как они именуются,
какими способами защищены друг от друга
и какие отношения существуют между
ними. Процессы Windows NT имеют следующие
характерные свойства:
Процессы
Windows NT реализованы в форме объектов, и
доступ к ним осуществляется посредством
службы объектов.
Процесс
Windows NT имеет многонитевую организацию.
Как
объекты-процессы, так и объекты-нити
имеют встроенные средства синхронизации.
Менеджер
процессов Windows NT не поддерживает между
процессами отношений типа «родитель-потомок».
В
любой системе понятие «процесс»
включает следующее:
исполняемый
код,
собственное
адресное пространство, которое
представляет собой совокупность
виртуальных адресов, которые может
использовать процесс,
ресурсы
системы, такие как файлы, семафоры и
т.п., которые назначены процессу
операционной системой.
хотя
бы одну выполняемую нить.
Адресное
пространство каждого процесса защищено
от вмешательства в него любого другого
процесса. Это обеспечивается механизмами
виртуальной памяти. Операционная
система, конечно, тоже защищена от
прикладных процессов. Чтобы выполнить
какую-либо процедуру ОС или прочитать
что-либо из ее области памяти, нить
должна выполняться в режиме ядра.
Пользовательские процессы получают
доступ к функциям ядра посредством
системных вызовов. В пользовательском
режиме выполняются не только прикладные
программы, но и защищенные подсистемы
Windows NT.
В
Windows NT процесс — это просто объект,
создаваемый и уничтожаемый менеджером
объектов. Объект-процесс, как и другие
объекты, содержит заголовок, который
создает и инициализирует менеджер
объектов. Менеджер процессов определяет
атрибуты, хранимые в теле объекта-процесса,
а также обеспечивает системный сервис,
который восстанавливает и изменяет
эти атрибуты.
В
число атрибутов тела объекта-процесса
входят:
Идентификатор
процесса — уникальное значение, которое
идентифицирует процесс в рамках
операционной системы.
Токен
доступа — исполняемый объект, содержащий
информацию о безопасности.
Базовый
приоритет — основа для исполнительного
приоритета нитей процесса.
Процессорная
совместимость — набор процессоров, на
которых могут выполняться нити процесса.
Предельные
значения квот — максимальное количество
страничной и нестраничной системной
памяти, дискового пространства,
предназначенного для выгрузки страниц,
процессорного времени — которые могут
быть использованы процессами пользователя.
Время
исполнения — общее количество времени,
в течение которого выполняются все
нити процесса.
Объект-нить
имеет следующие атрибуты тела:
Идентификатор
клиента — уникальное значение, которое
идентифицирует нить при ее обращении
к серверу.
Контекст
нити — информация, которая необходима
ОС для того, чтобы продолжить выполнение
прерванной нити. Контекст нити содержит
текущее состояние регистров, стеков и
индивидуальной области памяти, которая
используется подсистемами и библиотеками.
Динамический
приоритет — значение приоритета нити
в данный момент.
Базовый
приоритет — нижний предел динамического
приоритета нити.
Процессорная
совместимость нитей — перечень типов
процессоров, на которых может выполняться
нить.
Время
выполнения нити — суммарное время
выполнения нити в пользовательском
режиме и в режиме ядра, накопленное за
период существования нити.
Состояние
предупреждения — флаг, который показывает,
что нить должна выполнять вызов
асинхронной процедуры.
Счетчик
приостановок — текущее количество
приостановок выполнения нити.
Как
видно из перечня, многие атрибуты
объекта-нити аналогичны атрибутам
объекта-процесса. Весьма сходны и
сервисные функции, которые могут быть
выполнены над объектами-процессами и
объектами-нитями: создание, открытие,
завершение, приостановка, запрос и
установка информации, запрос и установка
контекста и другие функции.
В
Windows NT реализована вытесняющая
многозадачность, при которой операционная
система не ждет, когда нить сама захочет
освободить процессор, а принудительно
снимает ее с выполнения после того, как
та израсходовала отведенное ей время
(квант), или если в очереди готовых
появилась нить с более высоким
приоритетом. При такой организации
разделения процессора ни одна нить не
займет процессор на очень долгое время.
В
ОС Windows NT нить в ходе своего существования
может иметь одно из шести состояний
(рисунок 1.3). Жизненный цикл нити
начинается в тот момент, когда программа
создает новую нить. Запрос передается
NT executive, менеджер процессов выделяет
память для объекта-нити и обращается
к ядру, чтобы инициализировать объект-нить
ядра. После инициализации нить проходит
через следующие состояния:
3.
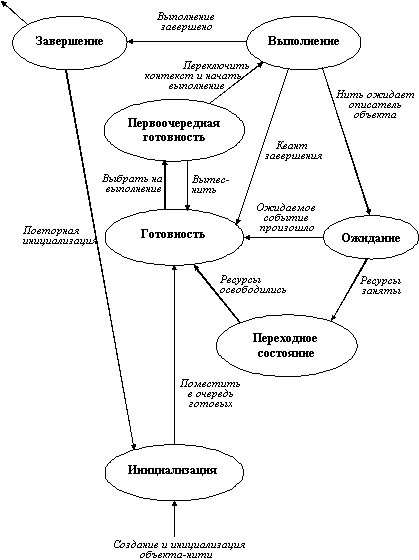
Рис.
1.3. Граф состояний нити
Готовность.
При поиске нити на выполнение диспетчер
просматривает только нити, находящиеся
в состоянии готовности, у которых есть
все для выполнения, но не хватает только
процессора.
Первоочередная
готовность (standby).
Для каждого процессора системы выбирается
одна нить, которая будет выполняться
следующей (самая первая нить в очереди).
Когда условия позволяют, происходит
переключение на контекст этой нити.
Выполнение.
Как только происходит переключение
контекстов, нить переходит в состояние
выполнения и находится в нем до тех
пор, пока либо ядро не вытеснит ее из-за
того, что появилась более приоритетная
нить или закончился квант времени,
выделенный этой нити, либо нить завершится
вообще, либо она по собственной инициативе
перейдет в состояние ожидания.
Ожидание.
Нить может входить в состояние ожидания
несколькими способами: нить по своей
инициативе ожидает некоторый объект
для того, чтобы синхронизировать свое
выполнение; операционная система
(например, подсистема ввода-вывода)
может ожидать в интересах нити; подсистема
окружения может непосредственно
заставить нить приостановить себя.
Когда ожидание нити подойдет к концу,
она возвращается в состояние готовности.
Переходное
состояние.
Нить входит в переходное состояние,
если она готова к выполнению, но ресурсы,
которые ей нужны, заняты. Например,
страница, содержащая стек нити, может
быть выгружена из оперативной памяти
на диск. При освобождении ресурсов нить
переходит в состояние готовности.
Завершение.
Когда выполнение нити закончилось, она
входит в состояние завершения. Находясь
в этом состоянии, нить может быть либо
удалена, либо не удалена. Это зависит
от алгоритма работы менеджера объектов,
в соответствии с которым он и решает,
когда удалять объект. Если executive имеет
указатель на объект-нить, то она может
быть инициализирована и использована
снова.
Диспетчер
ядра использует для определения порядка
выполнения нитей алгоритм, основанный
на приоритетах, в соответствии с которым
каждой нити присваивается число —
приоритет, и нити с более высоким
приоритетом выполняются раньше нитей
с меньшим приоритетом. В самом начале
нить получает приоритет от процесса,
который создает ее. В свою очередь,
процесс получает приоритет в тот момент,
когда его создает подсистема той или
иной прикладной среды. Значение базового
приоритета присваивается процессу
системой по умолчанию или системным
администратором. Нить наследует этот
базовый приоритет и может изменить
его, немного увеличив или уменьшив. На
основании получившегося в результате
приоритета, называемого приоритетом
планирования, начинается выполнение
нити. В ходе выполнения приоритет
планирования может меняться.
Windows
NT поддерживает 32 уровня приоритетов,
разделенных на два класса — класс
реального времени и класс переменных
приоритетов. Нити реального времени,
приоритеты которых находятся в диапазоне
от 16 до 31, являются более приоритетными
процессами и используются для выполнения
задач, критичных ко времени.
Каждый
раз, когда необходимо выбрать нить для
выполнения, диспетчер прежде всего
просматривает очередь готовых нитей
реального времени и обращается к другим
нитям, только когда очередь нитей
реального времени пуста. Большинство
нитей в системе попадают в класс нитей
с переменными приоритетами, диапазон
приоритетов которых от 0 до 15. Этот класс
имеет название «переменные приоритеты»
потому, что диспетчер настраивает
систему, выбирая (понижая или повышая)
приоритеты нитей этого класса.
Алгоритм
планирования нитей в Windows NT объединяет
в себе обе базовых концепции — квантование
и приоритеты. Как и во всех других
алгоритмах, основанных наквантовании,
каждой нити назначается квант, в течение
которого она может выполняться. Нить
освобождает процессор, если:
блокируется, уходя в состояние ожидания;
завершается; исчерпан квант; в очереди
готовых появляется более приоритетная
нить.
Использование динамических
приоритетов,
изменяющихся во времени, позволяет
реализовать адаптивное планирование,
при котором не дискриминируются
интерактивные задачи, часто выполняющие
операции ввода-вывода и недоиспользующие
выделенные им кванты. Если нить полностью
исчерпала свой квант, то ее приоритет
понижается на некоторую величину. В то
же время приоритет нитей, которые
перешли в состояние ожидания, не
использовав полностью выделенный им
квант, повышается. Приоритет не
изменяется, если нить вытеснена более
приоритетной нитью.
Для
того, чтобы обеспечить хорошее время
реакции системы, алгоритм планирования
использует наряду с квантованием
концепцию абсолютных
приоритетов.
В соответствии с этой концепцией при
появлении в очереди готовых нитей
такой, у которой приоритет выше, чем у
выполняющейся в данный момент, происходит
смена активной нити на нить с самым
высоким приоритетом.
В
многопроцессорных системах при
диспетчеризации и планировании нитей
играет роль их процессорная совместимость:
после того, как ядро выбрало нить с
наивысшим приоритетом, оно проверяет,
какой процессор может выполнить данную
нить и, если атрибут нити «процессорная
совместимость» не позволяет нити
выполняться ни на одном из свободных
процессоров, то выбирается следующая
в порядке приоритетов нить.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Рассмотрим, как в системе Windows осуществляется планирование потоков для их выполнения на центральном процессоре. Также посмотрим на приоритеты процессов и потоков.
Планирование потоков в системе
В Windows всегда выполняется хотя бы один поток с самым высоким приоритетом. Если в системе много ядер, то Windows делит все ядра на группы по 64 ядра. Каждому процессу даётся доступ к определённой группе ядер. Следовательно потоки этих процессов могут видеть только свою группу ядер.
Поток выполняется на процессоре определённое время, затем уступает место другому потоку. Кстати, максимальное время на которое поток может занять процессор называется квантом. Причем время кванта можно настроить, выбрав короткие или длинные кванты. Как это сделать, я покажу ниже в этой статье, так что читайте дальше.
Поток может не отработать весь свой квант, так как если другой поток готов к выполнению и имеет более высокий приоритет, то он вытеснит первый поток.
В системе существует планировщик, который и занимается управлением потоками. Именно он решает какой поток будет выполняться на процессоре следующим. Причем планировщик работает в режиме ядра.
Так как процессор постоянно обрабатывает разные, несвязанные между собой потоки, то он должен запоминать на каком результате он остановился выполняя определённый поток. Такое запоминание предыдущего потока и переключение на новый называют — переключением контекста.
Планирование осуществляется на уровне потоков, а не процессов. Например, Процесс_А имеет 10 потоков, а Процесс_Б — 2 потока. Тогда процессорное время распределился между этими 12 потоками равномерно.
Приоритеты потоков
Планирование потоков полагается на их приоритеты. Windows использует 32 уровня приоритета для потоков от 0 до 31:
- 16 — 31 — уровни реального времени;
- 1 — 15 — обычные динамические приоритеты;
- 0 — зарезервирован для потока обнуления страниц.
Вначале поток получает свой Базовый приоритет, который наследуется от приоритета процесса:
- реального времени (24),
- высокий (13),
- выше среднего (10),
- обычный (8),
- ниже среднего (6),
- низкий (4).
Дальше назначается относительный приоритет который увеличивает или уменьшает приоритет потока:
- критический по времени (+15),
- наивысший (+2),
- выше среднего(+1),
- обычный (0),
- ниже среднего (-1),
- самый низкий (-2),
- уровень простоя (-15).
После получения базового приоритета и корректировки относительным приоритетом получается динамический приоритет:
| Базовый приоритет ⇨
Относительный приоритет ⇩ |
Реального времени (24) |
Высокий (13) |
Выше среднего (10) |
Обычный (8) |
Ниже среднего (6) |
Низкий (4) |
| Критический по времени (+15 но не выше 15 если это не поток реального времени и не выше 31 если поток реального времени) |
31 | 15 | 15 | 15 | 15 | 15 |
| Наивысший (+2) | 26 | 15 | 12 | 10 | 8 | 6 |
| Выше среднего (+1) | 25 | 14 | 11 | 9 | 7 | 5 |
| Обычный (0) | 24 | 13 | 10 | 8 | 6 | 4 |
| Ниже среднего (-1) | 23 | 12 | 9 | 7 | 5 | 3 |
| Самый низкий (-2) | 22 | 11 | 8 | 6 | 4 | 2 |
| Уровень простоя (-15 но не ниже 1 если это не поток реального времени и не ниже 16 если это поток реального времени) |
16 | 1 | 1 | 1 | 1 | 1 |
Изменить базовый приоритет процесса можно из «Диспетчера задач» на вкладке «Подробности«, или в «Process Explorer«. Однако, это не поменяет относительный приоритет потока.

Приоритеты отдельных потоков можно посмотреть в программе «Process Explorer«. Но изменять их нет смысла, так как только разработчик данной программы понимает как лучше расставить приоритеты потокам.
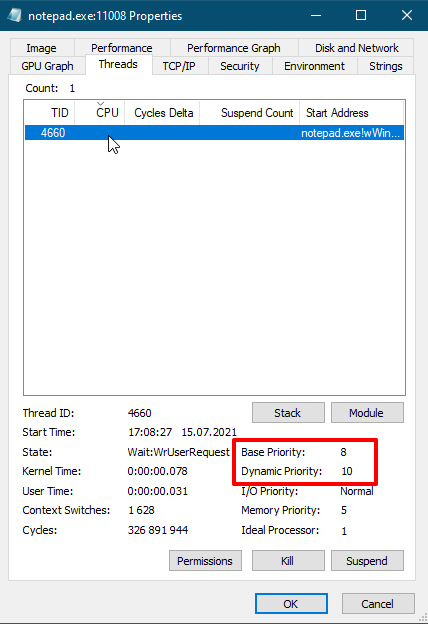
Получается что относительный приоритет у потока Notepad.exe равен 2, так как динамический приоритет больше базового на 2.
Состояния потоков
Поток может находиться в следующих состояниях:
- Готов (Ready) — поток готов к выполнению и ожидает процессор.
- Готов с отложенным выполнением (Deferred ready) — поток выбран для выполнения на конкретном ядре и ожидает именно это ядро.
- В повышенной готовности (Standby) — поток выбран следующим для выполнения на конкретном ядре. Как только сможет процессор выполнит переключение контекста на этот поток.
- Выполнение (Running) — выполняется на процессоре пока не истечет его квант времени, или пока его не вытеснит поток с большем приоритетом.
- Ожидание (Waiting) — поток ждет каких-то ресурсов.
- Переходное состояние (Transition) — готов к выполнению, но стек ядра выгружен из памяти, как только стек загрузится в память поток перейдет в состояние Готов.
- Завершение (Terminated) — поток выполнил свою работу и завершился сам, или его завершили принудительно.
- Инициализация (Initializated) — состояние при создании потока.
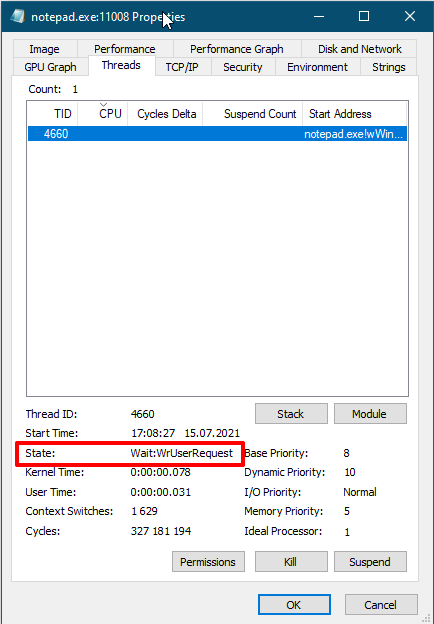
Кванты времени
Как я уже говорил квант времени выполнения потока может быть длинным или коротким. В настольных системах по умолчанию квант времени короткий, чтобы различные приложения быстро уступали друг другу место. В серверных системах по умолчанию длинный квант времени, чтобы серверные службы реже переключали контекст процессора.
Итак, теперь я вам покажу как переключить систему на работу с длинным или коротким квантом. Длительность кванта времени настраивается тут: «Свойства системы» / «Дополнительные параметры системы» / «Дополнительно» / «Быстродействие» / «Параметры» / «Дополнительно»:

- Программ — короткий квант времени;
- Служб — длинный квант времени.
На серверной системе можно выбрать «программ» если это сервер терминалов или просто настольный компьютер с установленной серверной системой.
На десктопной системе можно выбрать «служб» если вы запускаете какую-то длительную компиляцию или рендерите видео, а потом вернуть обратно в состояние «программ«.
Изменение приоритета планировщиком
Планировщик Windows периодически меняет текущий приоритет потоков. Делается это например для:
- повышения приоритета, если поток слишком долго ожидает выполнение (предотвращает зависание программы);
- повышения приоритета, если происходит ввод из пользовательского интерфейса (сокращение времени отклика);
- повышения приоритета, после завершения операции ввода/вывода (чтобы потоки ждущие ввод/вывод быстрее выполнялись). При ждать могут:
- диск, cd-rom, параллельный порт, видео — повышение на 1 пункт;
- сеть, почтовый слот, именованный канал, последовательный порт — повышение на 2 пункта;
- клавиатура или мышь — повышение на 6 пунктов;
- звуковая карта — повышение на 8 пунктов.
- когда поток ожидает ресурс, который занят другим потоком, то система может повысить приоритет потока который занял нужный ресурс, чтобы он быстрее выполнил свою работу и освободил этот ресурс;
- повышается приоритет у потоков которые на первом плане, а свёрнутые приложения работают с низким приоритетом.
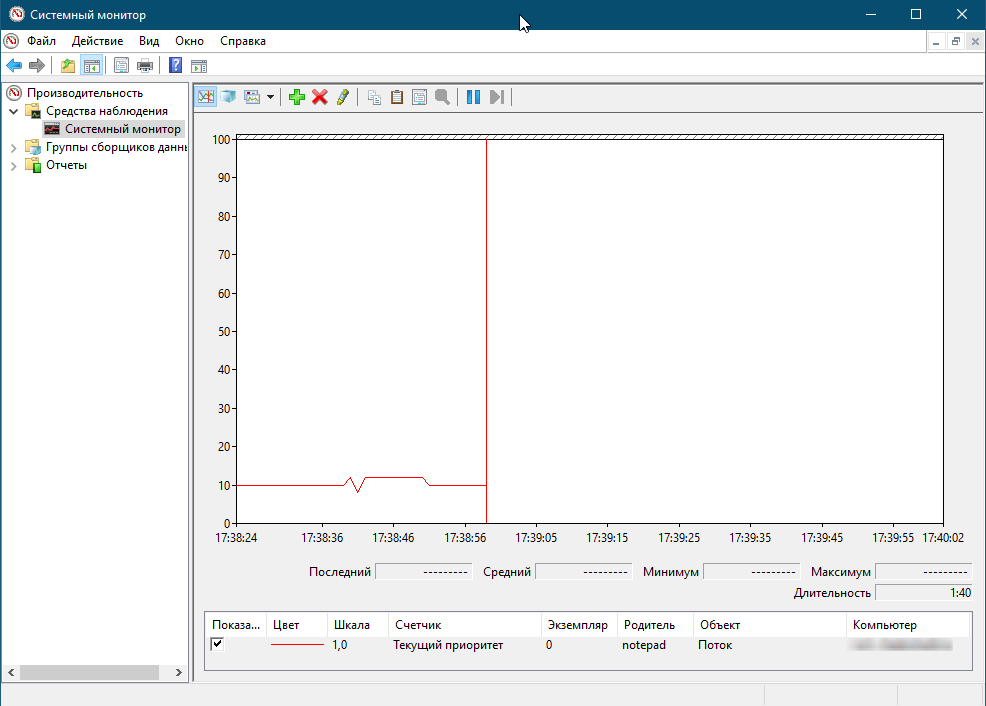
Эксперимент
Позвольте продемонстрировать следующий эксперимент, который покажет как посмотреть за повышением и понижением динамического приоритета:
- Запустите программу «Блокнот».
- Запустите «Системный монитор».
- Щелкните на кнопке панели инструментов «Добавить» (Add Counter).
- Выберите объект «Поток» (Thread), а затем выберите счетчик «Текущий приоритет» (Priority Current).
- В поле со списком введите «Notepad», а затем щелкните на кнопке «Поиск» (Search).
- Найдите строку «Notepad/0». Выберите ее, щелкните на кнопке «Добавить» (Add), а затем щелкните на кнопке «ОК».
- Как только вы щелкните мышкой по блокноту, то заметите в Системном мониторе, что приоритет у потока «Блокнот» поднялся до 12, если свернуть блокнот то приоритет вновь упадет до 10.
Поток простоя — idle
К вашему сведению процессор всегда обрабатывает какой-нибудь поток. Когда кажется что процессор ничем не занят, на самом деле запускается специальный поток idle (поток простоя). Притом, на каждое ядро процессора существует свой собственный поток простоя. В общем-то все потоки простоя принадлежат процессу простоя. Поток простоя имеет самый низкий приоритет (1), поэтому выполняется только тогда — когда полезных потоков нет.
Групповое планирование
Планирование потоков на базе потоков отлично работает, но не способно решить задачу равномерного распределения процессорного времени между несколькими пользователями на терминальном сервере. Потому в Windows Server 2012 появился механизм группового планирования.
Термины группового планирования:
- поколение — период времени, в течении которого отслеживается использование процессора;
- квота — процессорное время, разрешенное группе на поколение (исчерпание квоты означает, что группа израсходовала весь свой бюджет);
- вес — относительная важность группы от 1 до 9 (по умолчанию 5);
- справедливое долевое планирование — вид планирования, при котором потокам исчерпавшим квоту могут выделяться циклы простоя;
- ранг — приоритет групповой политики, 0 — наивысший, чем больше процессорного времени истратила группа, тем больше будет ранг, и с меньшей вероятностью получит процессорное время (ранг всегда превосходит приоритет) (0 ранг у потоков которые: не входят ни в одну группу, не израсходовали квоту, потоки с приоритетами реального времени).
Где же применяется групповое планирование? Например его использует механизм DFSS для справедливого распределения процессорного времени между сеансами на машине. Этот механизм включается по умолчанию при установке роли служб терминалов.
Помимо DFSS групповое планирование применяется в объектах Jobs (Задания), так мы можем ограничить Задание по % потребления CPU, например задание будет потреблять не больше 20% процессорного времени.
Вернуться к оглавлению
Если понравилась статья, подпишись на мой канал в VK или Telegram.