
В этой статье мы рассмотрим особенности использования встроенных счетчиков производительности Performance Monitor для мониторинга состояния Windows Server. Счетчики PerfMon можно использовать для отслеживания изменений определенных параметров производительности сервера (алертов) и оповещать администратора в случае возникновения высокой загрузки или других нештатных состояниях.
Чаще всего для мониторинга работоспособности, доступности, загруженности серверов используются сторонние продукты. Если вам нужно получать информацию о производительности приложений либо железа только с одного-двух Windows-серверов, либо когда это нужно на непостоянной основе, либо возник более сложный случай, требующий глубокого траблшутинга производительности, то можно воспользоваться встроенным функционалом Windows Performance Monitor.
Performance Monitor имеет огромное количество счётчиков для получения информации о железе, операционной системе, установленном ПО в виде конкретных цифр. Performance Monitor может вести наблюдение за показателями производительности сервера в реальном времени или записывать историю.
Основные возможности Performance Monitor, которые можно использовать отдельно или совместно с другими сторонними системами мониторинга (типа Zabbix, Nagios, Cacti и другие):
- cистема мониторинга при выводе информации о производительности сначала обращается к Performance Monitor;
- главной задачей системы мониторинга является оповещение о наступлении тревожного момента, аварии, а у Performance Monitor – собрать и предоставить диагностические данные.
Текущие значения производительности Windows можно получить из Task Manager, но Performance Monitor умеет несколько больше:
- Task Manager работает только в реальном времени и только на конкретном (локальном) хосте;
- в Performance Monitor можно подключать счётчики с разных серверов, вести наблюдение длительное время и собранную информацию сохранять в файл;
- в Task Manager очень мало показателей производительности.
Мониторинг производительности процессора с Perfomance Monitor
Для снятия данных о производительности процессора воспользуемся несколькими основными счётчиками:
- \Processor\% Processor Time — определяет уровень загрузки ЦП, и отслеживает время, которое ЦП затрачивает на работу процесса. Уровень загрузки ЦП в диапазоне в пределах 80-90 % может указывать на необходимость добавления процессорной мощности.
- \Processor\%Privileged Time — соответствует проценту процессорного времени, затраченного на выполнение команд ядра операционной системы Windows, таких как обработка запросов ввода-вывода SQL Server. Если значение этого счетчика постоянно высокое, и счетчики для объекта Физический диск также имеют высокие значения, то необходимо рассмотреть вопрос об установке более быстрой и более эффективной дисковой подсистемы (см. более подробную статью об анализе производительности дисков с помощью PerfMon).
- \Processor\%User Time — соответствует проценту времени работы CPU, которое он затрачивает на выполнение пользовательских приложений.
Запустите Performance Monitor с помощью команды perfmon. В разделе Performance Monitor отображается загрузкой CPU в реальном времени с помощью графика (параметр Line), с помощью цифр (параметр Report), с помощью столбчатой гистограммы (параметр Histogram bar) (вид выбирается в панели инструментов). Чтобы добавить счетчики, нажмите кнопку “+” (Add Counters).
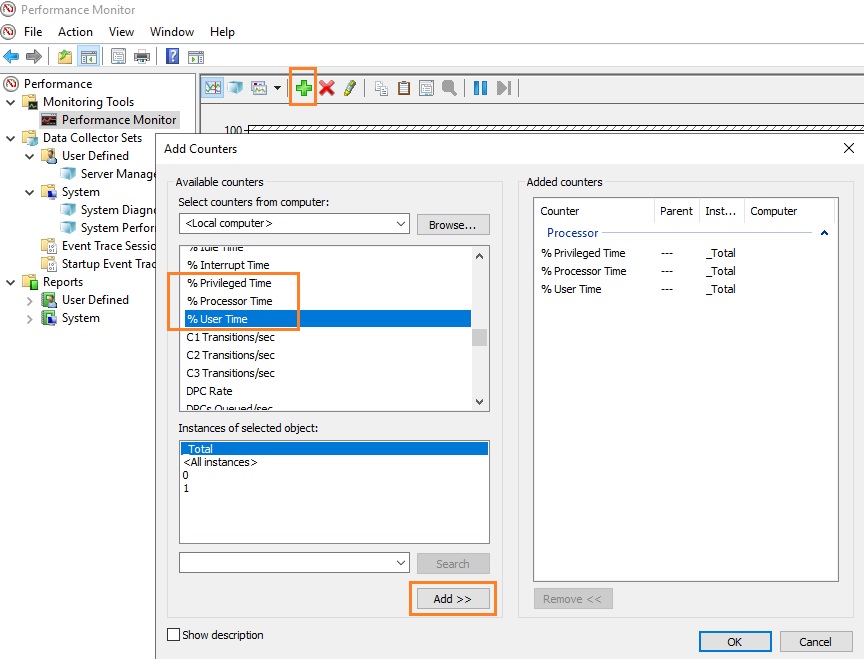
Слева направо двигается линия в реальном времени и отображает график загрузки процессора, на котором можно увидеть, как всплески, так и постоянную нагрузку.
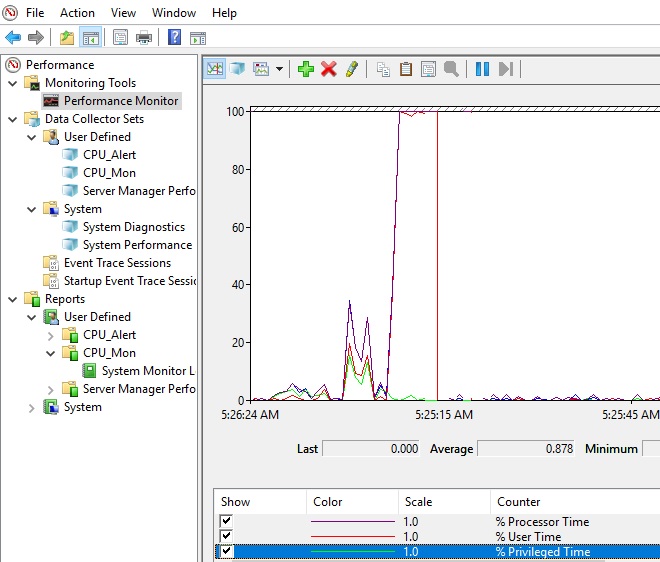
Например, вам нужно посмотреть загрузку процессора виртуальными машинами и самим Hyper-V. Выберите группу счетчиков Hyper-V Hypervisor Logical Processor, выберите счетчик % Total Run Time. Вы можете показывать нагрузку по всем ядрам CPU (Total), либо по конкретным (HV LP №), либо всё сразу (All Instances). Выберем Total и All Instances.
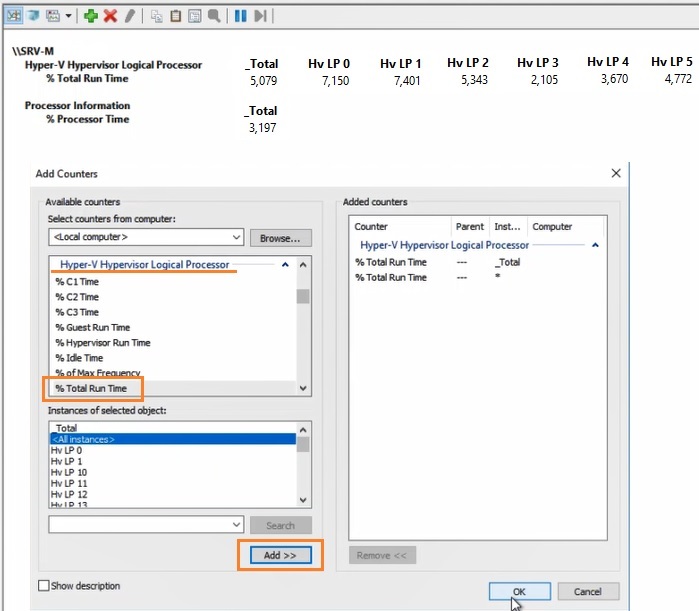
Группы сборщиков данных в PerfMon
Чтобы не сидеть целый за наблюдением движения линии, создаются группы сбор данных (Data Collector Set), задаются для них параметры и периодически просматриваются.
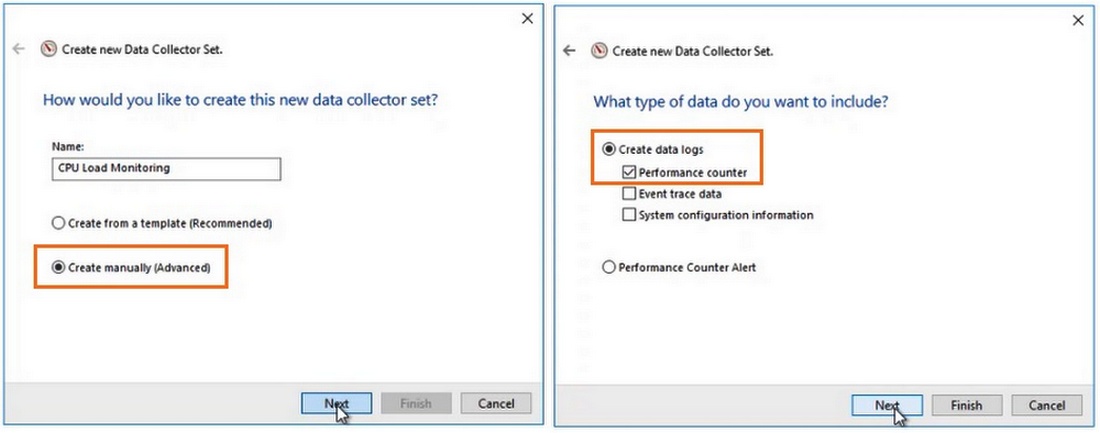
Чтобы создать группу сбора данных, нужно нажать на разделе User Defined правой кнопкой мыши, в меню выбрать New -> Data Collector Set. Выберите Create manually (Advanced) -> Create Data Logs и включите опцию Performance Counter. Нажмите Add и добавите счётчики. В нашем примере % Total Run Time из группы Hyper-V Hypervisor Logical Processor и Available MBytes из Memory. Установите интервал опроса счётчиков в 3 секунды.
Далее вручную запустите созданный Data Collector Set, нажав на нём правой кнопкой мыши и выбрав в меню пункт Start.
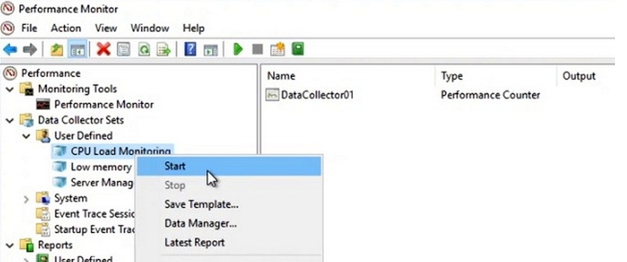
Через некоторое время можно просмотреть отчёт. Для этого в контекстном меню группы сбора данных нужно выбрать пункт Latest Report. Вы можете посмотреть и проанализировать отчёт производительности в виде графика. Отчёт можно скопировать и переслать. Он хранится в C:\PerfLogs\Admin\CPU_Mon и имеет расширение .blg.
Если нужно на другом сервере запустить такой же набор счётчиков, как на первом, то их можно переносить экспортом. Для этого в контекстном меню группы сбора данных выберите пункт Save Template, укажите имя файла (расширение .xml). Скопируйте xml файл на другой сервер, создайте новую группу сбора данных, выберите пункт Create from a template и укажите готовый шаблон.
Создание Alert для мониторинга загрузки CPU
В определённый критический момент в Performance Monitor могут срабатывать алерты, которые помогают ИТ-специалисту прояснить суть проблемы. В первом случае алерт может отправить оповещение, а во втором – запустить другую группу сбора данных.
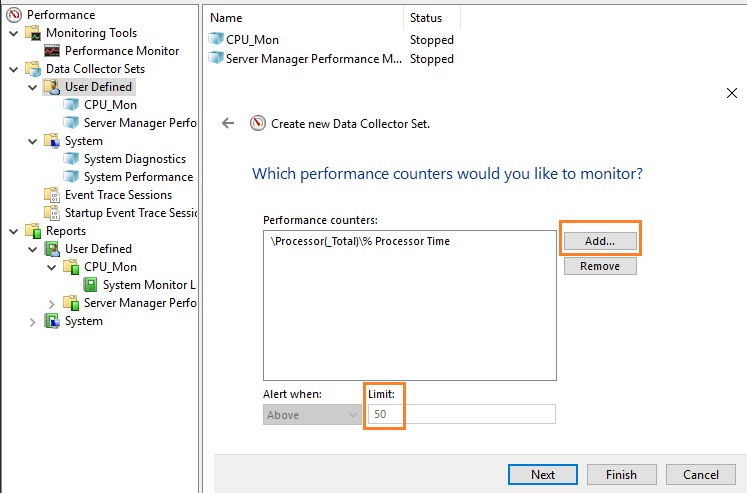
Чтобы создать алерт в PerfMon, нужно создать ещё один Data Collector Set. Укажите его имя CPU_Alert, выберите опцию Create manually (Advanced), а затем — Performance Counter Alert. Добавьте счётчик % Total Run Time из Hyper-V Hypervisor Logical Processor, укажите границу загрузки 50 %, при превышении которой будет срабатывать алерт, установите интервал опроса счётчика в 3 секунды.
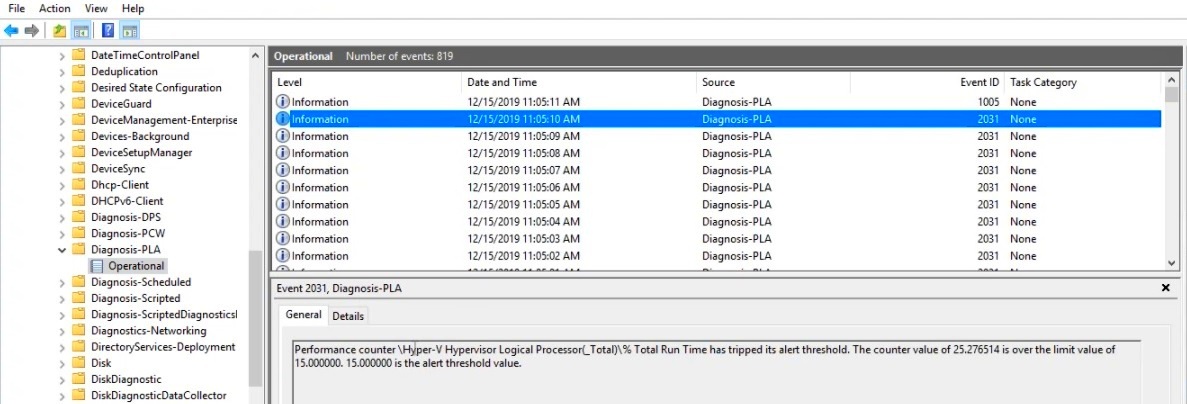
Далее нужно зайти в свойства данной группы сбора информации, перейти на вкладку Alert Action, включить опцию Log an entry in the application event log и запустить группу сбора данных. Когда сработает алерт, в журнале (в консоли Event Viewer в разделе Applications and Services Logs\Microsoft\Windows\Diagnosis-PLA\Operational) появится запись:
“Performance counter \Processor(_Total)\% Processor Time has tripped its alert threshold. The counter value of 100.000000 is over the limit value of 50.000000. 50.000000 is the alert threshold value”.
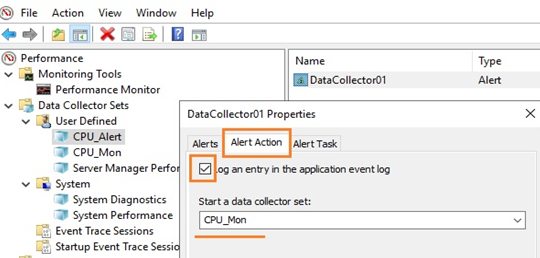
Здесь же рассмотрим и второй случай, когда нужно запустить другую группу сбора данных. Например, алерт срабатывает при достижении высокой загрузки CPU, делает запись в лог, но вы хотите включить сбор данных с других счётчиков для получения дополнительной информации. Для этого необходимо в свойствах алерта в меню Alert Action в выпадающем списке Start a data collector set выбрать ранее созданную группу сбора, например, CPU_Mon. Рядом находится вкладка Alert Task, в которой можно указать разные аргументы либо подключить готовую задачу из консоли Task Scheduler, указав её имя в поле Run this task when an alert is triggered. Будем использовать второй вариант.
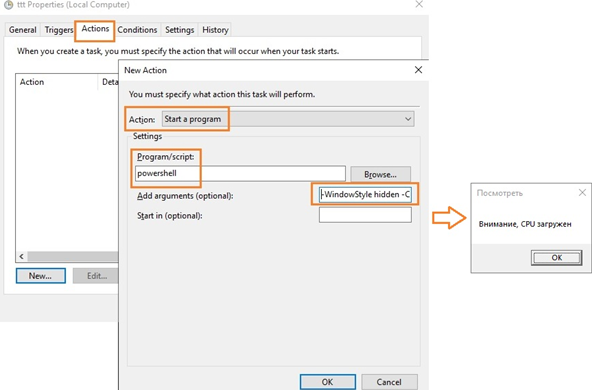
С помощью Task Scheduler можно выполнить какие-то действия: выполнить команду, отправить письмо или вывести сообщение на экран (сейчас последниед ве функции не поддерживаются, считаются устаревшими (deprecated)). Для вывода на уведомления на экран можно использовать скриптом PowerShell. Для этого в консоли Task Scheduler создайте новую задачу, на вкладке Triggers выберите One time, на вкладке Actions в выпадающем поле Action выбирите параметр Start a program, в поле Program/Script укажите powershell.exe, а в поле Add arguments (optional) следующий код:
-WindowStyle hidden -Command "& {[System.Reflection.Assembly]::LoadWithPartialName('System.Windows.Forms'); [System.Windows.Forms.MessageBox]::Show('Внимание, CPU загружен', 'Посмотреть')}"
Для отправки письма вы можете воспользоваться командлетом PowerShell Send-MailMessage или стороннюю утилиту mailsend.exe.. Для этого создайте аналогичное задание в Task Scheduler, в поле Program/Script укажите полный путь к утилите (у нас C:\Scripts\Mail\mailsend.exe), а в поле Add arguments (optional) через параметры нужно передать значения: электронный адрес, адрес и номер порта SMTP-сервера, текст письма и заголовка, пароль:
-to [email protected] -from [email protected] -ssl -port 465 -auth -smtp smtp.ddd.com -sub Alarm -v -user [email protected] +cc +bc -M "Alarm, CPU, Alarm" -pass "it12345"
где +cc означает не запрашивать копию письма, +bc — не запрашивать скрытую копию письма.
Каждый опытный сисадмин знает, что лучший показатель ухудшения быстродействия 1С, это главный бухгалтер, движущийся в сторону ИТ отдела со скоростью, превышающей 1.1 м/с. Но только мудрейшие из них настраивают сбор счетчиков, чтобы эта встреча не застала их врасплох. Об этом и поговорим под катом…

Эпиграф:
Существуют две причины, по которым может тормозить компьютер:
1. Вирус.
2. Антивирус.
© советы бывалых сисадминов
Не ошибусь, если скажу, что каждый офисный админ сталкивался с вопросом: Почему тормозит 1С?
И опять же не ошибусь, если первое что он(а) при этом сделает, это откроет диспетчер задач.
Более продвинутые, конечно настроят сбор счетчиков Performance Monitor (Zabbix в данном контексте примерно то же самое).
Тем более, что инструкций, чек-листов по настройке более чем достаточно. Это то и пугает.
Попробую предложить вам обзор основных и свою компиляцию.
Внимание!
Название счетчиков отличается не только в зависимости от языка операционной системы, но и от ее редакции.
Добавим к этому видение и ошибки авторов публикаций и поймем, что простой копипаст может не сработать.
В случае же perfmon это усугубится тем, что никаких ошибок при создании счетчиков в командной строке вам выдано не будет, просто они не будут собираться.
Для того, чтобы увидеть список всех счетчиков производительности, имеющихся на текущем компьютере нужно в командной строке выполнить
- typeperf -q [object] выведет список всех счетчиков
- typeperf -qх [object] выведет список всех счетчиков по экземплярам оборудования, например отдельно для дисков А: и С:
Где необязательный параметр [object] это фильтр по виду счетчиков, например PhysicalDisk
Этот вывод можно переадресовать в файл и далее уже из него выбирать необходимое
typeperf -qx -y -o counters.txt
В дальнейшем, чтобы получить сводную статистику нужно заменить в случае ключа -qx имя конкретного экземпляра на (_Total), а чтобы получить статистику для каждого экземпляра отдельно на (*)
Например:
\PhysicalDisk(_Total)\Current Disk Queue Length
\PhysicalDisk(*)\Current Disk Queue Length
Рекомендуемый мной путь, это создать bat файл из 3 строк.
logman create counter 1C_counter -f bincirc
logman update counter 1C_counter -cf assembled.txt
logman update counter 1C_counter -si 15 -v mmddhhmm
А в файл assembled.txt добавлять названия счетчиков. По одному на строку. Рабочий и рекомендуемый мной пример для Windows Server 2012 R2 ENG будет внизу.
список под спойлером
\Processor(_Total)\% Processor Time
\Processor(_Total)\% User Time
\Processor(_Total)\% Privileged Time
\Memory\Available MBytes
\Memory\Pages/sec
\Memory\% Committed Bytes In Use
\Paging File(*)\% Usage
\System\Context Switches/sec
\System\Processor Queue Length
\System\Processes
\System\Threads
\PhysicalDisk(_Total)\Current Disk Queue Length
\PhysicalDisk(*)\Current Disk Queue Length
\PhysicalDisk(_Total)\Avg. Disk sec/Read
\PhysicalDisk(_Total)\Avg. Disk sec/Write
\Network interface(_Total)\Bytes Total/sec
\Network interface(_Total)\Current Bandwidth
\Process(1cv8)\% Processor Time
\Process(1cv8)\Private Bytes
\Process(1cv8)\Virtual Bytes
\Process(ragent)\% Processor Time
\Process(ragent)\Private Bytes
\Process(ragent)\Virtual Bytes
\Process(rphost)\% Processor Time
\Process(rphost)\Private Bytes
\Process(rphost)\Virtual Bytes
\Process(rmngr)\% Processor Time
\Process(rmngr)\Private Bytes
\Process(rmngr)\Virtual Bytes
\Process(sqlservr)\% Processor Time
\Process(sqlservr)\Private Bytes
\Process(sqlservr)\Virtual Bytes
\SQLServer:General Statistics\User Connections
\SQLServer:General Statistics\Processes blocked
\SQLServer:Buffer Manager\Buffer cache hit ratio
\SQLServer:Buffer Manager\Page life expectancy
\SQLServer:SQL Statistics\Batch Requests/sec
\SQLServer:SQL Statistics\SQL Compilations/sec
\SQLServer:SQL Statistics\SQL Re-Compilations/sec
\SQLServer:Access Methods\Page Splits/sec
\SQLServer:Access Methods\Forwarded Records/sec
\SQLServer:Access Methods\Full Scans/sec
\SQLServer:Memory Manager\Target Server Memory (KB)
\SQLServer:Memory Manager\Total Server Memory (KB)
\SQLServer:Memory Manager\Free Memory (KB)
\SQLServer:Databases(_Total)\Transactions/sec
\SQLServer:Databases(*)\Transactions/sec
Собственно торопыжки могут дальше и не читать. Да они уже и не читают.
С остальными разберемся с рекомендациями
лучших собаководов
Начнем с изучения советов самого вендора: microsoft.com
Публикация Windows VM health
Используя этот вариант вы точно не ошибетесь, но в нем присутствуют счетчики не совсем нужные для мониторинга именно сервера 1С.
Далее, а скорее и выше, в моем топе вариантов идет рекомендация от Евгения Валерьевича Филиппова
Настольная книга 1С: Эксперта по технологическим вопросам. Издание 2
Список небольшой, но все по делу и видно, что автор его использовал в работе.
Список книги Методическое пособие по эксплуатации крупных информационных систем на платформе «1С: Предприятие 8»
А. Асатрян, А. Голиков, А. Морозов, Д. Соломатин, Ю.Федоров
еще лаконичнее, в него добавлен мониторинг 1cv8, ragent, rphost, rmngr его я вынесу в отдельный список, потому что он может и наверное не помешает при любом варианте, кроме разнесенных SQL и 1С серверов.
таблица под спойлером
«\Process(«1cv8*»)\%%Processor Time»
«\Process(«1cv8*»)\Private Bytes»
«\Process(«1cv8*»)\Virtual Bytes»
«\Process(«ragent*»)\%%Processor Time»
«\Process(«ragent*»)\Private Bytes»
«\Process(«ragent*»)\Virtual Bytes»
«\Process(«rphost*»)\%%Processor Time»
«\Process(«rphost*»)\Private Bytes»
«\Process(«rphost*»)\Virtual Bytes»
«\Process(«rmngr*»)\%%Processor Time»
«\Process(«rmngr*»)\Private Bytes»
«\Process(«rmngr*»)\Virtual Bytes»
или как вариант без разбиения
\Process(1cv8)\% Processor Time
\Process(1cv8)\Private Bytes
\Process(1cv8)\Virtual Bytes
\Process(ragent)\% Processor Time
\Process(ragent)\Private Bytes
\Process(ragent)\Virtual Bytes
\Process(rphost)\% Processor Time
\Process(rphost)\Private Bytes
\Process(rphost)\Virtual Bytes
\Process(rmngr)\% Processor Time
\Process(rmngr)\Private Bytes
\Process(rmngr)\Virtual Bytes
\Process(sqlservr)\% Processor Time
\Process(sqlservr)\Private Bytes
\Process(sqlservr)\Virtual Bytes
Список счетчиков оборудования.
Далее идет статья с ИТС Анализ загруженности оборудования для Windows Елена Скворцова и ее полная копия на kb у кого есть туда доступ, в ней подробно и с картинками описан весь процесс настройки. Для первой настройки это очень полезно.
При всей полезности и доступности статьи не покидает ощущение, что ее писали как знаменитое письмо Матроскина: «ваш сын дядя Шарик», разные люди. Например текст не совпадает с картинками, для некоторых счетчиков описаны пороговые значения, но в списке их нет, некоторые счетчики в списке двоятся, из-за этого не получится копипастом в командной строке запустить logman. Это как раз начинающих немного обескураживает.

Лирическое отступление: Не прошло и месяца с регионального тура конкурса ИТС, где один из вопросов был именно так составлен, в коде вариант ответа один, а в картинке и математически верный совсем другой. Организаторы опирались именно на корректность кода. Хотя понятно, код проверяют слабо, во всех научных книгах об этом предупреждают заранее.
Замыкают список иностранные агенты вендоры.
www.veritas.com Analyzing SQL Performance using Performance Monitor Counters
Понятно, что про 1С они и слыхом не слыхивали, но то, что серверов они видели на порядок более, это факт.
red-gate.com
SQL Server performance and activity monitoring
Что касается, счетчиков для MS SQL, то мой список был в начале публикации.
Вариантов невероятное множество как и экспертов (не факт, что сейчас один из них не съехал тихо под стол при виде его).
Впрочем, настоящий скульный админ никогда не покажет своего отношения, максимум поиграет бровями и пойдет слушать музыку сервера.
Желающие могут провести пару зимних (летних) вечеров разбирая полный список.
таблица под спойлером

— Штурман, приборы!
— Четырнадцать.
— Что четырнадцать?
— А что, приборы!?
©www.anekdot.ru
Бдительный читатель скажет: Мало собрать счетчики оборудования, надо их еще и проанализировать.
А я покажу ему вот эту таблицу.
Техническое отступление: Хотя ней выражено мнение уважаемых экспертов, относиться к нему надо с пониманием.
Например, многие вспомнят времена, когда они умоляли директора докупить планку 32 Мб в сервер упомянутой выше бухгалтерии. То же касается и скорости дисков. Эти значения устаревают.
Внимание!
Что означает словосочетание «Предельные значения». То что их превышение требует вашего внимания и сервер работает не совсем штатно по мнению собравшихся. Не более того. Более того, может быть как раз для вашего варианта работы это нормально.
Возможно у вас есть свое мнение по поводу мониторинга оборудования, приходите в комментарии, пишите свои мысли, желательно со ссылками на источники знаний.
Performance is a basis for measuring
how fast application and system tasks are completed on a computer, and
reliability is a basis for measuring system operation. How reliable a
system is will be based on whether it regularly operates at the level
at which it was designed to perform. Based on these descriptions, it
should be easy to recognize that performance and reliability monitoring
are crucial aspects in the overall availability and health of a Windows
Server 2012 infrastructure. To ensure maximum uptime, a
well-thought-through process needs to be put in place to monitor,
identify, diagnose, and analyze system performance. This process should
invariably provide a means for quickly comparing system performances at
varying instances in time and detecting and potentially preventing a
catastrophic incident before it causes system downtime.
Performance Monitor, which is an MMC snap-in,
provides a number of tools for administrators that enable them to
conduct real-time system monitoring, examine system resources, collect
performance data, and create performance reports from a single console.
This tool is literally a combination of three legacy Windows Server
monitoring tools: System Monitor, Performance Monitor, and Server
Performance Advisor. However, new features and functionalities have
been introduced to shake things up, including data collector sets,
Resource view, scheduling, diagnostic reporting, and wizards and
templates for creating logs. To launch the Performance Monitor MMC
snap-in tool, select Server Manager or type perfmon.msc at a command prompt.
The Performance Monitor MMC snap-in consists the following elements:
• Overview screen
• Performance Monitor
• Data collector sets
• Report generation
The upcoming sections further explore these major elements of the Performance Monitoring tool.
1. Performance Monitor Overview
The first area of interest in the Performance
Monitor snap-in is the Overview of Performance Monitor screen, also
known as the Performance icon. It is displayed as the home page in the
central details pane when the Performance Monitor tool is invoked.
The Overview of Performance Monitor screen
presents holistic, real-time graphical illustrations of a Windows
Server 2012 system’s CPU usage, disk usage, network usage, and memory
usage, as displayed in Figure 1.
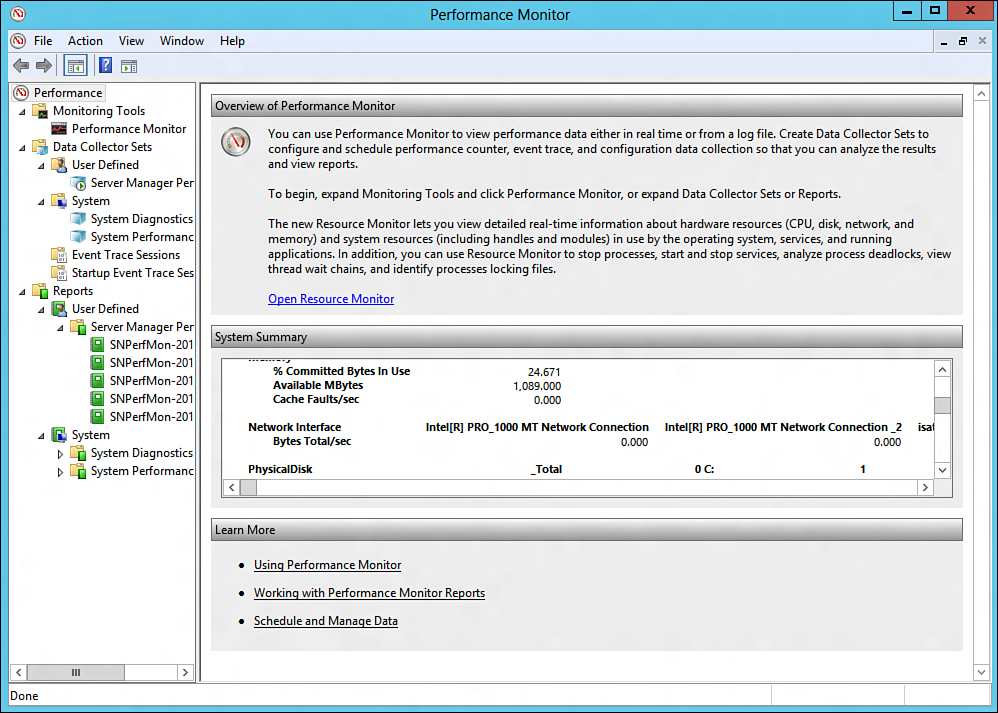
Figure 1. Viewing the Overview of Performance Monitor screen.
Additional process-level details can be
viewed to better understand your system’s current resource usage by
reviewing subsections beneath each metric being displayed. For example,
the Memory section includes % Committed Bytes in Use, Available Mbytes,
and Cache Faults/sec.
The Overview of Performance Monitor
screen is the first level of defense when there is a need to get a
quick overview of a system’s resources. If quick diagnosis of an issue
cannot be achieved, an administrator should leverage the additional
tools within Performance Monitor. These are covered in the upcoming
sections.
Reading Time: 2 minutes
Monitoring CPU and memory performance is essential for maintaining the health and stability of your Windows Server 2012. In this post, we’ll show you how to use the Server Manager tool to keep an eye on these vital system resources.
Step 1: Open Server Manager
First, open the Server Manager tool by clicking on the Server Manager icon in the taskbar, or by pressing the Windows key + X and selecting Server Manager from the menu.
Step 2: Navigate to Performance Monitor
In the Server Manager window, click on the “Performance Monitor” option in the left-hand navigation pane.
Step 3: Select Performance Counters
In the Performance Monitor window, click on the green plus sign icon to add a new performance counter. Here, you can choose from a wide variety of performance counters, including CPU usage, memory usage, disk usage, and network usage.
After a couple of minutes, you will see the graphs filling up with data.
** Additionally you can turn on Performance Alerts and alter the Performance Graph Display Period ( starting from 1 to 7 Days ). To do so, at the Performance Section click Tasks and set the Graph display period and Alerting Thresholds according to your needs.
Step 4: Customize the Display
Once you’ve selected your desired performance counter(s), you can customize the display to make it more visually appealing. For example, you can change the color of the graph, add a title or description, or adjust the scale of the graph.
Step 5: Save Your Custom Display
Finally, you can save your custom display for future use by clicking on the “Save” button in the top right-hand corner of the window.
By following these simple steps, you can easily monitor CPU and memory performance on your Windows Server 2012 using the Server Manager tool. With this information at your fingertips, you can quickly identify and resolve any performance issues before they become a problem.
Thanks for reading my blog!
Provide feedback
Saved searches
Use saved searches to filter your results more quickly
Sign up
Appearance settings