
Случилось мне иметь ноут на OS X, комп на Linux и одного из друзей с Windows. И вот через dropbox обмениваются все эти три компа документами разными. В том числе и текстовыми, в которых хранятся разные заметки, задачи и т.п. И вот незадача: тексты написанные на MacOSx плохо читаются в блокноте Винды, а виндовые в textedit на MacOSx.
И вся причина в том, что на винде блокнот использует кодировку Windows 1251, а на OS X используется по умолчанию MACCYRILLIC. Причем обе программы без проблем работают с UTF-8 кодировкой.
Вот только конвертировать из одной кодировки в другую как-то неудобно, лишнее время тратить на открытие терминала и набор заветных команд iconv…
Пораздумав, написал небольшой скрипт, который сам определяет используемую кодировку и конвертирует в UTF-8 все txt-файлы.
Что использую для всего:
Python 2.7
Mac OS X 10.7.5
PyCharm IDE
Изначально сделал определение кодировки самостоятельно, без дополнительных модулей. Но по совету ad3w решил переписать с использованием готового модуля chardet для определения кодировки.
Кому интересно, предыдущий
ужасный код
Определение происходит простым перебором кодировок и выбором той, в которой не будет лишних символов. А набор символов определяете Вы. Конечно этот способ не подойдет для файлов с DOS-графикой, но в обычных целях использования txt его вполне хватит.
#!/usr/bin/python
# -*- coding: utf-8 -*-
__author__ = 'virtustilus'
import os
import sys
#Автоматический режим при запуске с параметрами
automatic=False
#общие данные
appdata={'enc':'','curfile':''}
#Массив файлов для конвертации
toconvert=[]
#массив на загрузку
r=[]
if len(sys.argv)>1:
r=sys.argv[1:]
automatic=True
else:
i=raw_input(u'INPUT PATH:')
r+=[i]
def print1(s):
"""
Функция печатает данные, если не в автоматическом режиме
"""
if not automatic:
print s
#Строка с возможными символами
utfrustring=u'АБВГДЕЁЖЗИЙКЛМНОПРСТУФХЦЧШЩЪЫЬЭЮЯабвгдеёжзийклмнопрстуфхцчшщъыьэюя'
utfrustring+=u'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz'
utfrustring+=u'1234567890-=—+_}{][\\"|;:\'/?><.,`~§±!@#$%^&*()№ \r\n « » \u0009 \u2013 \u201c \u201d'
def checkline(s,encoding=''):
"""
проверка одной строки на правильность символов
"""
hist=''
b=True
for i in range(0,len(s)):
c=s[i]
try:
if not c in utfrustring:
#Отладка: если в UTF-8 кодировке неверный символ, лучше его показать
if encoding==u'UTF-8':
hist+= c + u' ' + str(hex(ord(c))) + u' at ' + str(i) + u' in: ' + s + '\n'
b=False
break
except:
if encoding==u'UTF-8':
hist+=u'error encoding \n'
b=False
break
return (b,hist)
def check_all_lines(lines, encoding=''):
"""
Проверка массива строк для файла
"""
foundenc=appdata['enc']
if foundenc:
return foundenc
if encoding=='':
foundenc=u'UNICODE'
else:
foundenc=encoding
x=lines[:]
for j in x:
if encoding!='':
try:
j=unicode(j,encoding)
except:
foundenc=''
break
cl=checkline(j,encoding)
if not cl[0]:
if cl[1]!='':
print1(u'Error in:'+appdata['curfile'])
print1(cl[1])
foundenc=''
break
appdata['enc']=foundenc
#Если передана директория, а не файл, собрать все входящие текстовые файлы
if len(r)==1 and os.path.isdir(r[0]):
a=r[0]
r[:]=[]
for i in os.walk(a):
p=i[2]
for j in p:
if j.endswith('.txt'):
r+=[i[0]+'/'+j]
if len(r)>0:
for i in r:
i=unicode(i,u'UTF-8')
#обратите внимание, тут конвертация имени файла в UNICODE и проверка txt также в UNICODE: u'.txt'
if i.endswith(u'.txt'):
f=file(i,'r')
lines=f.readlines()
f.close()
appdata['curfile']=i
#Проверяем некоторые кириллические кодировки
check_all_lines(lines,'')
check_all_lines(lines,u'MACCYRILLIC')
check_all_lines(lines,u'CP866')
check_all_lines(lines,u'CP1251')
check_all_lines(lines,u'KOI8R')
check_all_lines(lines,u'CP10007')
check_all_lines(lines,u'UTF-8-MAC')
check_all_lines(lines,u'UTF-8')
check_all_lines(lines,u'UTF-8-MAC')
check_all_lines(lines,u'UTF-16')
check_all_lines(lines,u'UTF-16BE')
check_all_lines(lines,u'UTF-7')
check_all_lines(lines,u'CP1252')
check_all_lines(lines,u'KOI8-U')
check_all_lines(lines,u'KOI8-RU')
check_all_lines(lines,u'ISO-8859-5')
if not appdata['enc']:
toconvert.append((i,u'NOT FOUND ENCODING'))
if appdata['enc'] and appdata['enc']!=u'UTF-8':
toconvert.append((i,appdata['enc']))
else:
print1(u'\nFile '+i+u' is not text file. \n\n')
if toconvert:
c=0
for i in toconvert:
if i[1]!=u'NOT FOUND ENCODING':
c+=1
if c>0:
print1(u'\n\n FOUND FILES TO CONVERT: ')
for i in toconvert:
print1(i[0] + u' in encoding ' + i[1])
bt=True
if not automatic:
w=raw_input(u'Convert '+str(c)+u' files? (N)')
bt= (w=='Y' or w=='y' or w=='Д' or w=='д' or w=='да' or w=='Да')
if bt:
for i in toconvert:
if i[1]!=u'NOT FOUND ENCODING':
f=file(i[0],'r')
x=f.readlines()
f.close()
x=[ unicode(k,i[1]) for k in x ]
x=[ k.encode(u'UTF-8') for k in x]
f=file(i[0],'w')
f.writelines(x)
f.close()
print1(u'FILE '+i[0]+u' CONVERTED SUCCESSFULLY :) ')
else:
print1(u'Bye!')
else:
print1(u'NO FILES TO CONVERT')
for i in toconvert:
print1(i[0] + u' in encoding ' + i[1])
else:
print1(u' ALL ENCODING IS OK (UTF-8)!!! :)')
else:
print1(u'NO ONE TXT FILE')
Скачиваем модуль chardet 1.1,
Распаковываем и устанавливаем:
python setup.py install
Создаем свой скрипт для перекодировки файлов:
Предыдущая редакция
#!/usr/bin/python
# -*- coding: utf-8 -*-
__author__ = 'virtustilus'
import os
import sys
import chardet
files=sys.argv[1:]
#если запуск без параметров, запрашиваем путь
if len(files)==0: files=[raw_input(u'INPUT PATH:')]
#собираем текстовые файлы и проходим по папкам
files_to_convert=[]
for i in files:
if os.path.exists(i):
if os.path.isdir(i):
for w in os.walk(i):
for wfile in w[2]:
if wfile.lower().endswith('.txt'):
files_to_convert+=[w[0]+'/'+wfile]
elif os.path.isfile(i):
#если был выбран файл специально, не важно какое расширение
files_to_convert+=[i]
if len(files_to_convert)>0:
for i in files_to_convert:
f=file(i,'r')
text=''.join(f.readlines())
f.close()
enc=chardet.detect(text).get('encoding')
#Чтобы лишний раз не перезаписывать файл (dropbox), проверяем его кодировку
if enc!='UTF-8':
#Обходим ошибку перекодировки файла при пустом файле или другом случае
try:
text=text.decode(enc).encode('UTF-8')
f=file(i,'w')
f.write(text)
f.close()
except:
pass
#!/usr/bin/python
# -*- coding: utf-8 -*-
__author__ = 'virtustilus'
import os
import sys
import chardet
def may_be_1251(text_not_changed, encoding):
"""
Функция проверяет возможность Win1251, если chardet написал, что это MacCyrillic
И возвращает кодировку
Например в данном тексте chardet считает, что это MacCyrillic:
1. ”становить пробную Advanced-версию
2. ”бедитьс€, что программа закрыта (в т.ч. и агент в области уведомлений)
3. —копировать библиотеку mfc100u.dll в папку с программой и согласитьс€ на замену
"""
simbols = u'АБВГДЕЁЖЗИЙКЛМНОПРСТУФХЦЧШЩЪЫЬЭЮЯабвгдеёжзийклмнопрстуфхцчшщъыьэюя'
simbols += u'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz'
simbols += u'1234567890-=—+_}{][\\"|;:\'/?><.,`~§±!@#$%^&*()№ \r\n'
if encoding.lower() == 'maccyrillic':
err_mac = err_win = 0
try:
t_win = text_not_changed.decode('cp1251')
except:
err_win += 1000000
try:
t_mac = text_not_changed.decode('MacCyrillic')
except:
err_mac += 1000000
for i in t_win:
if i not in simbols and i != u'\n':
err_win += 1
for i in t_mac:
if i not in simbols:
err_mac += 1
if err_mac > err_win:
encoding = 'cp1251'
return encoding
paths = sys.argv[1:]
#если запуск без параметров, запрашиваем путь
if len(paths) == 0: paths = [raw_input(u'INPUT PATH:')]
#выбираем директории и файлы (файлы любые, т.к. они были выбраны пользователем "не зря")
dirs = [i for i in paths if os.path.exists(i) and os.path.isdir(i)]
files = [i for i in paths if os.path.exists(i) and os.path.isfile(i)]
#рекурсивно проходим по поддиректориям
for i_dir in dirs:
for wpath, wdirs, wfiles in os.walk(i_dir):
files += [wpath + '/' + i for i in wfiles if i.lower().endswith('.txt')]
for i in files:
with open(i, 'r') as f:
text = ''.join(f.readlines())
enc = may_be_1251(text, chardet.detect(text).get('encoding'))
#Чтобы лишний раз не перезаписывать файл (dropbox), проверяем его кодировку
if enc and enc.lower() != 'utf-8':
#Обходим ошибку перекодировки файла при пустом файле или другом случае
try:
text = text.decode(enc)
#На новой версии OS X 10.8 текстедиту не нравятся символы \r
text = text.replace(u'\r', '').encode('utf-8')
#Обнаружил проблему: если питон увидит кодировку, то он в ней и будет работать. Нам это не нужно, поэтому удаляем файл
os.unlink(i)
with open(i, 'w') as f:
f.write(text)
except:
pass
Далее необходимо сделать удобным запуск данного скрипта прямо из папки в OS X.
Открываем Automator и создаем Службу.
Вверху выбираем пункты, чтобы получилось «Служба получает файлы и папки в Finder.app».
Далее ставим действие «получить выбранные объекты Finder».
Далее «Запустить Shell-скрипт» в настройках его «Передать ввод: как аргументы» и в нем содержание:
for f in "$@"
do
python /ПУТЬ_К_ВАШЕМУ_СКРИПТУ/convert_encoding.py "$f" 2>/dev/null
done
Дописал 2>/dev/null, чтобы автоматор не останавливал выполнение при выводе ошибки модуля chardet.
И последний пункт «Show Growl Notification» (в нем можно написать, что конвертация произведена).
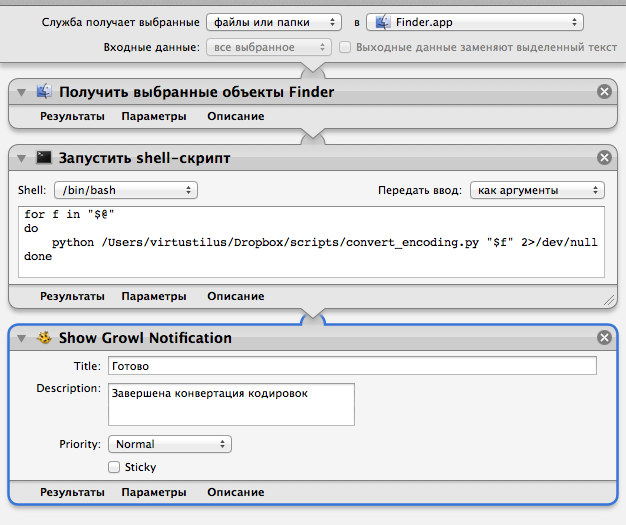
Сохраняем с именем латинскими буквами (с русскими у меня почему-то пункт в меню не появлялся, пока не переименовал) и проверяем.
Новый пункт меню появится в Finder в меню файлов и папок в подменю Сервисы.
P.S. Это уже 5-ая редакция скрипта после комментариев и опыта его использования.
P.S. Обнаружил проблему: если питон увидит кодировку файла, в который пишет, то он в ней и будет работать. Нам это не нужно, поэтому удаляем файл перед сохранением.
While opening .txt files in Mac OS (the text in russian and usually I don’t know whether it was encoded with ANSI or Windows-1251 etc) the text displays incorrectly.
Same happens with some programs (for instance, Guitar Pro 5 — the name of the composition (inside the program) is in russian — so in Mac OS I can see only unreadable symbols).
So the question is: can I add the support of Windows standart encodings for that situations not to happen?
Thank you in advance.
MacBook Pro 13″,
Mac OS X (10.6.5)
Posted on Nov 24, 2010 1:10 PM
Posted on Nov 24, 2010 1:22 PM
twofacedv wrote:
So the question is: can I add the support of Windows standart encodings for that situations not to happen?
It is already there. MacOS X fully supports Russian and most other languages too. You just happened to pick two worst case scenarios.
For Guitar Pro 5, there is nothing you can do but contact them and report the bug. That is a 3rd party product and obviously has trouble with Russian. It seems to be a cross-platform program and that is likely the reason.
Text files are always difficult. There is nothing about a text file that indicates what encoding it is. You would have to open it in something like TextWrangler that might be able to detect the encoding. If all else fails, you could try various, likely encodings until it was readable. Once you get there, save the file as UTF-8 and you won’t have any more problems with it.
Russian character encoding
Массовое перекодирование на Маке
* Запустите Terminal
* Перейдите в каталог с файлами, которые Вы хотите преобразовать из кодировки Windows (windows-1251) в кодировку MacOSX (utf-8)
* Выполните следующую команду:
for i in *; do iconv -f windows-1251 -t utf-8 «$i» >tmp; mv tmp «$i»; done
Что можно изменить:
* вместо wildcard «*» можно указать более точное значение, скажем, «*.txt»
* если Вы хотите обратную перекодировку — поменяйте местами входную и выходную кодировки (-f utf-8 -t windows-1251)
* если вы хотите перекодировать между другими кодировками, то вот список поддерживаемых командой iconv кодировок можно получить командой iconv -l
Возможная проблема: если слишком много файлов, может не поместиться в environment (там ограничение на размер). Или куча подкаталогов, которые тоже надо обработать.
Решение:
find . -name «*.txt» | while read i; do iconv -f windows-1251 -t utf-8 «$i» >tmp; mv tmp «$i»; done
Нюансы: ищет во всех подкаталогах от текущего. Не обязательно переходить в обрабатываемый каталог — для этого достаточно будет заменить «.» в параметрах find на имя каталога в который переходить (не забывайте, что имя с пробелами и некоторыми другими символами лучше всего заключать в двойные или даже одинарные кавычки)
- Home
- /
-
Windows-1251
- /
- Windows-1251 vs Mac OS Roman
Welcome to our comprehensive guide on Windows-1251 and Mac OS Roman, two essential character encoding systems used to represent text in different operating environments. In this article, we will explore the key differences between these encodings, their historical significance, and their applications in modern computing. Whether you’re a developer, a digital content creator, or simply curious about how text is displayed across various platforms, you’ll gain valuable insights into how Windows-1251 supports Cyrillic scripts while Mac OS Roman caters to Western European languages. Join us as we delve into the intricacies of text encoding and help you choose the right system for your needs!
What is Windows-1251
Windows-1251, also known as CP1251, is a character encoding system designed by Microsoft for languages that use the Cyrillic script. It is a single-byte encoding scheme, which means it can represent up to 256 characters. Windows-1251 includes characters used in various Slavic languages, like Russian, Bulgarian, Serbian, and Ukrainian, making it essential for text representation in these languages on Windows operating systems.
The encoding supports uppercase and lowercase Cyrillic letters, punctuation marks, and some special symbols. It is widely used in legacy systems and applications that require compatibility with older software that may not support Unicode.
Popular Use Cases of Windows-1251
Windows-1251 is predominantly used in applications that require Cyrillic text input and output. Some common use cases include:
- Legacy Software: Many older Windows applications still utilize Windows-1251 for displaying Cyrillic characters, especially in Eastern European countries.
- Text Files: Files encoded in Windows-1251 are prevalent among documents, emails, and chat software that need to maintain compatibility with older systems.
- Web Content: Although Unicode has become the standard for web content, some websites and online platforms still use Windows-1251 to serve pages in specific Cyrillic languages or to cater to audiences using legacy systems.
What is Mac OS Roman
Mac OS Roman, also known as MacRoman, is a character encoding system used primarily by Apple’s Macintosh operating systems. It is a single-byte encoding that supports a wide range of characters used in Western European languages, including English, French, German, Italian, and Spanish. Mac OS Roman was developed to ensure that text displayed correctly on Macintosh computers, allowing for the representation of various character sets without the need for multiple encodings.
This encoding includes standard Latin script characters, diacritics, and some special symbols, making it suitable for applications that focus on Western languages.
Popular Use Cases of Mac OS Roman
Mac OS Roman is often employed in contexts where compatibility with older Mac applications is crucial. Here are some common use cases:
- Classic Mac Applications: Many legacy Mac applications utilize Mac OS Roman for text processing, particularly in older software not updated to support Unicode.
- Document Formats: Files created in older versions of Mac software, such as TextEdit or Microsoft Word for Mac, may still be encoded in Mac OS Roman.
- Cross-Platform Compatibility: When transferring documents between different systems, especially from Mac to Windows or vice-versa, Mac OS Roman may be used to ensure that text appears correctly on older Macintosh systems.
Windows-1251 vs Mac OS Roman: Understanding the Differences
While both Windows-1251 and Mac OS Roman are single-byte character encodings designed for different language sets, they serve distinct purposes and user bases.
-
Character Set: Windows-1251 is tailored specifically for Cyrillic scripts, making it suitable for Slavic languages. In contrast, Mac OS Roman focuses on Latin characters, primarily for Western European languages.
-
Application Environment: Windows-1251 is predominantly used in Windows environments, while Mac OS Roman is specific to Macintosh systems. This results in different use cases and compatibility issues when exchanging text files between these platforms.
- Legacy Support: Both encodings are considered legacy formats, with Unicode being the preferred choice for modern applications. However, understanding these encodings is essential for maintaining compatibility with older software and systems.
Conclusion
In summary, Windows-1251 and Mac OS Roman serve specific niches in the world of character encoding. Windows-1251 is vital for representing Cyrillic characters in Windows environments, while Mac OS Roman caters to Latin scripts in Mac environments. As the tech landscape continues to evolve towards Unicode, these encodings remain relevant for legacy applications and systems. Understanding the differences between these two encodings is crucial for developers, linguists, and anyone working with multilingual text data.