
Привет, Хабр! Представляю вашему вниманию перевод статьи «Demystifying memory management in modern programming languages» за авторством Deepu K Sasidharan.
В данной серии статей мне бы хотелось развеять завесу мистики над управлением памятью в программном обеспечении (далее по тексту — ПО) и подробно рассмотреть возможности, предоставляемые современными языками программирования. Надеюсь, что мои статьи помогут читателю заглянуть под капот этих языков и узнать для себя нечто новое.
Углублённое изучение концептов управления памятью позволяет писать более эффективное ПО, потому как стиль и практики кодирования оказывают большое влияние на принципы выделения памяти для нужд программы.
Часть 1: Введение в управление памятью
Управление памятью — это целый набор механизмов, которые позволяют контролировать доступ программы к оперативной памяти компьютера. Данная тема является очень важной при разработке ПО и, при этом, вызывает затруднения или же вовсе остаётся черным ящиком для многих программистов.
Для чего используется оперативная память?
Когда программа выполняется в операционный системе компьютера, она нуждается в доступе к оперативной памяти (RAM) для того, чтобы:
- загружать свой собственный байт-код для выполнения;
- хранить значения переменных и структуры данных, которые используются в процессе работы;
- загружать внешние модули, которые необходимы программе для выполнения задач.
Помимо места, используемого для загрузки своего собственного байт-кода, программа использует при работе две области в оперативной памяти — стек (stack) и кучу (heap).
Стек
Стек используется для статичного выделения памяти. Он организован по принципу «последним пришёл — первым вышел» (LIFO). Можно представить стек как стопку книг — разрешено взаимодействовать только с самой верхней книгой: прочитать её или положить на неё новую.
- благодаря упомянутому принципу, стек позволяет очень быстро выполнять операции с данными — все манипуляции производятся с «верхней книгой в стопке». Книга добавляется в самый верх, если нужно сохранить данные, либо берётся сверху, если данные требуется прочитать;
- существует ограничение в том, что данные, которые предполагается хранить в стеке, обязаны быть конечными и статичными — их размер должен быть известен ещё на этапе компиляции;
- в стековой памяти хранится стек вызовов — информация о ходе выполнения цепочек вызовов функций в виде стековых кадров. Каждый стековый кадр это набор блоков данных, в которых хранится информация, необходимая для работы функции на определённом шаге — её локальные переменные и аргументы, с которыми её вызывали. Например, каждый раз, когда функция объявляет новую переменную, она добавляет её в верхний блок стека. Затем, когда функция завершает свою работу, очищаются все блоки памяти в стеке, которые функция использовала — иными словами, очищаются все блоки ее стекового кадра;
- каждый поток многопоточного приложения имеет доступ к своему собственному стеку;
- управление стековой памятью простое и прямолинейное; оно выполняется операционной системой;
- в стеке обычно хранятся данные вроде локальных переменных и указателей;
- при работе со стеком есть вероятность получать ошибки переполнения стека (stack overflow), так как максимальный его размер строго ограничен. Например, ошибка при составлении граничного условия в рекурсивной функции совершенно точно приведёт к переполнению стека;
- в большинстве языков существует ограничение на размер значений, которые можно сохранить в стек;
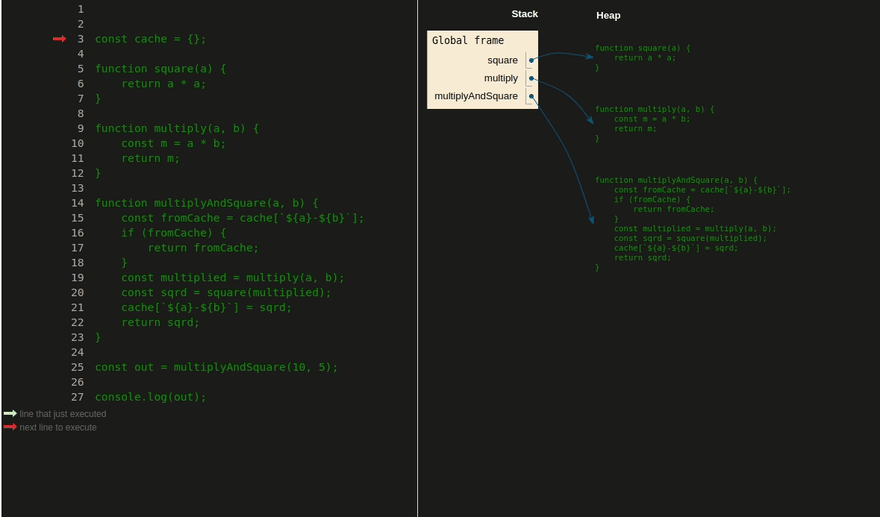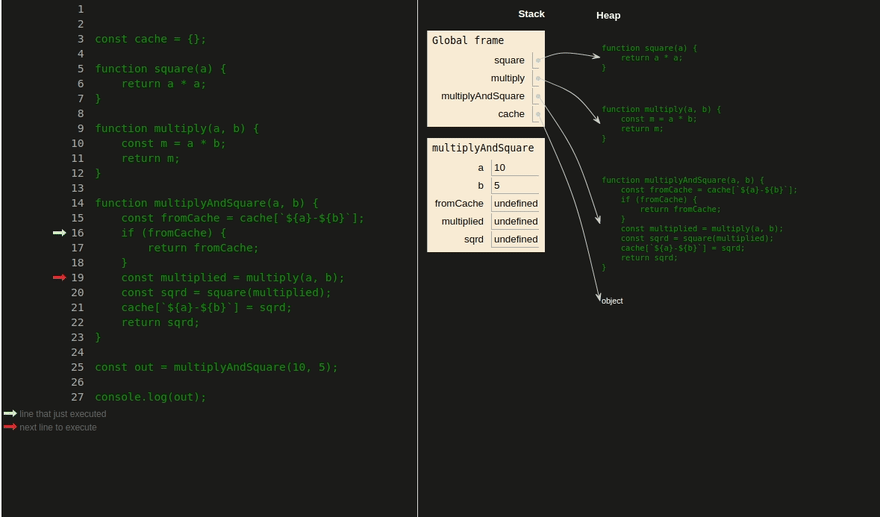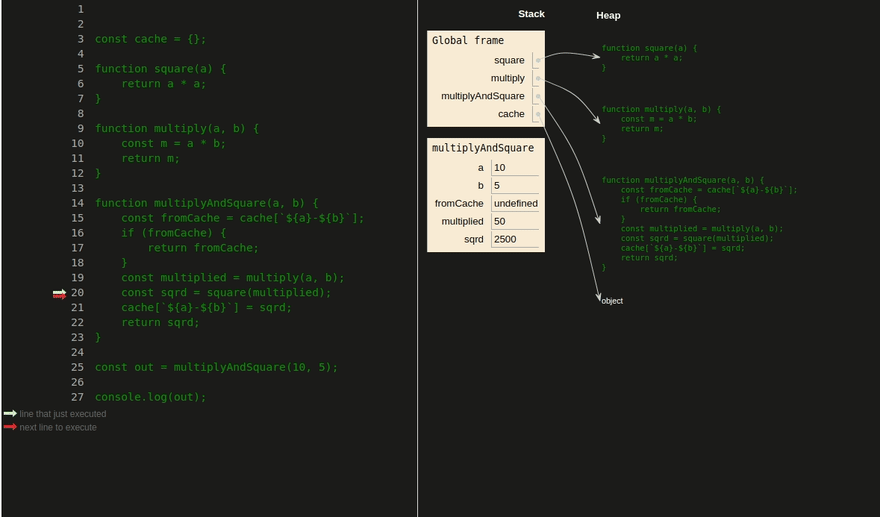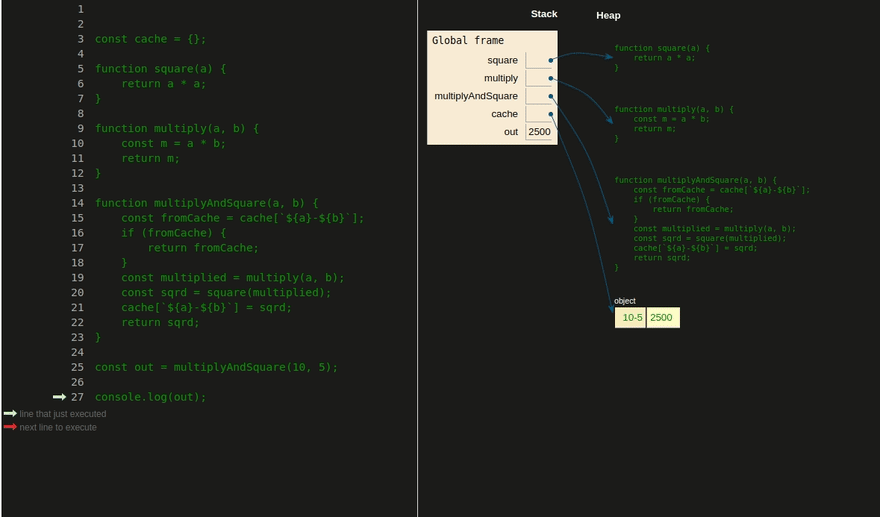
Использование стека в JavaScript. Объекты хранятся в куче и доступны по ссылкам, которые хранятся в стеке. Тут можно посмотреть в видеоформате
Куча
Куча используется для динамического выделения памяти, однако, в отличие от стека, данные в куче первым делом требуется найти с помощью «оглавления». Можно представить, что куча это такая большая многоуровневая библиотека, в которой, следуя определённым инструкциям, можно найти необходимую книгу.
- операции на куче производятся несколько медленнее, чем на стеке, так как требуют дополнительного этапа для поиска данных;
- в куче хранятся данные динамических размеров, например, список, в который можно добавлять произвольное количество элементов;
- куча общая для всех потоков приложения;
- вследствие динамической природы, куча нетривиальна в управлении и с ней возникает большинство всех проблем и ошибок, связанных с памятью. Способы решения этих проблем предоставляются языками программирования;
- типичные структуры данных, которые хранятся в куче — это глобальные переменные (они должны быть доступны для разных потоков приложения, а куча как раз общая для всех потоков), ссылочные типы, такие как строки или ассоциативные массивы, а так же другие сложные структуры данных;
- при работе с кучей можно получить ошибки выхода за пределы памяти (out of memory), если приложение пытается использовать больше памяти, чем ему доступно;
- размер значений, которые могут храниться в куче, ограничен лишь общим объёмом памяти, который был выделен операционной системой для программы.
Почему эффективное управление памятью важно?
В отличие от жёстких дисков, оперативная память весьма ограниченна (хотя и жёсткие диски, безусловно, тоже не безграничны). Если программа потребляет память не высвобождая её, то, в конечном итоге, она поглотит все доступные резервы и попытается выйти за пределы памяти. Тогда она просто упадет сама, или, что ещё драматичнее, обрушит операционную систему. Следовательно, весьма нежелательно относиться легкомысленно к манипуляциям с памятью при разработке ПО.
Различные подходы
Современные языки программирования стараются максимально упростить работу с памятью и снять с разработчиков часть головной боли. И хотя некоторые почтенные языки всё ещё требуют ручного управления, большинство всё же предоставляет более изящные автоматические подходы. Порой в языке используется сразу несколько подходов к управлению памятью, а иногда разработчику даже доступен выбор какой из вариантов будет эффективнее конкретно для его задач (хороший пример — C++). Перейдём к краткому обзору различных подходов.
Ручное управление памятью
Язык не предоставляет механизмов для автоматического управления памятью. Выделение и освобождение памяти для создаваемых объектов остаётся полностью на совести разработчика. Пример такого языка — C. Он предоставляет ряд методов (malloc, realloc, calloc и free) для управления памятью — разработчик должен использовать их для выделения и освобождения памяти в своей программе. Этот подход требует большой аккуратности и внимательности. Так же он является в особенности сложным для новичков.
Сборщик мусора
Сборка мусора — это процесс автоматического управления памятью в куче, который заключается в поиске неиспользующихся участков памяти, которые ранее были заняты под нужды программы. Это один из наиболее популярных вариантов механизма для управления памятью в современных языках программирования. Подпрограмма сборки мусора обычно запускается в заранее определённые интервалы времени и бывает, что её запуск совпадает с ресурсозатратными процессами, в результате чего происходит задержка в работе приложения. JVM (Java/Scala/Groovy/Kotlin), JavaScript, Python, C#, Golang, OCaml и Ruby — вот примеры популярных языков, в которых используется сборщик мусора.
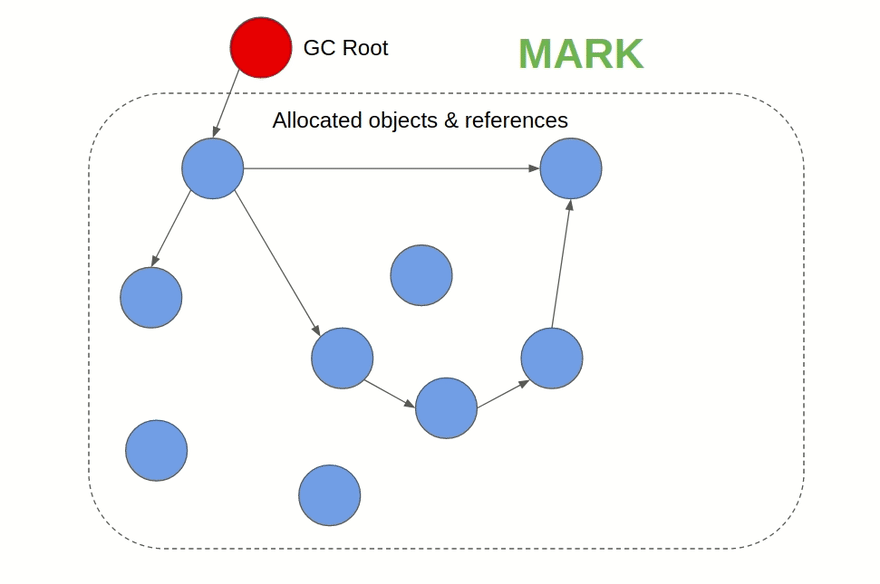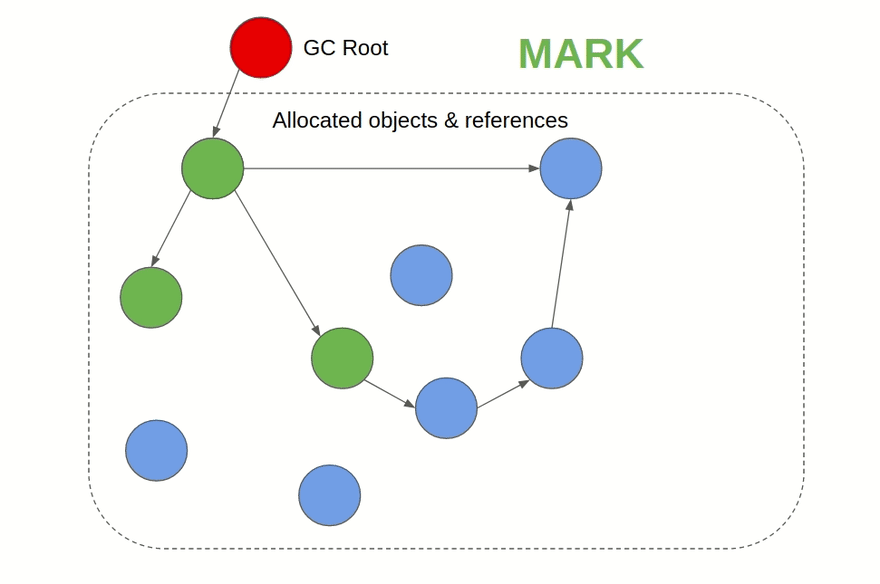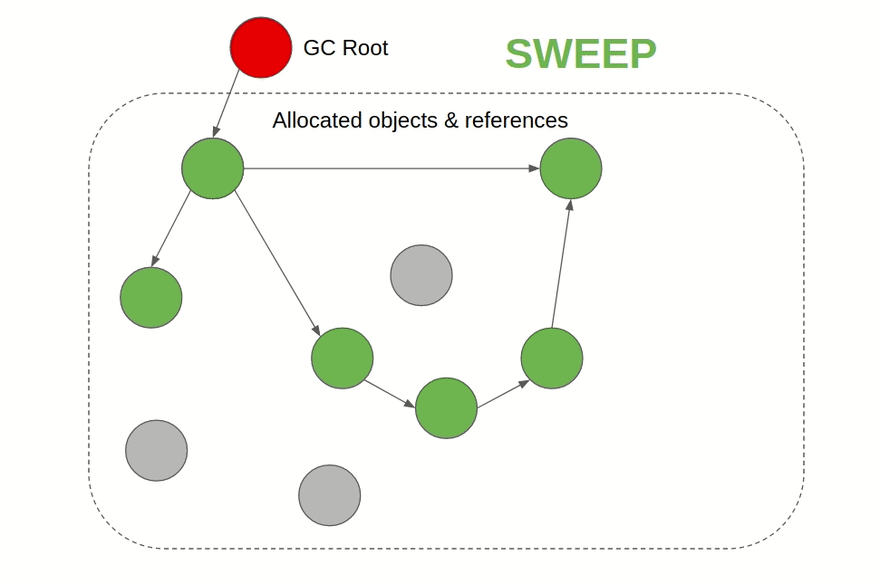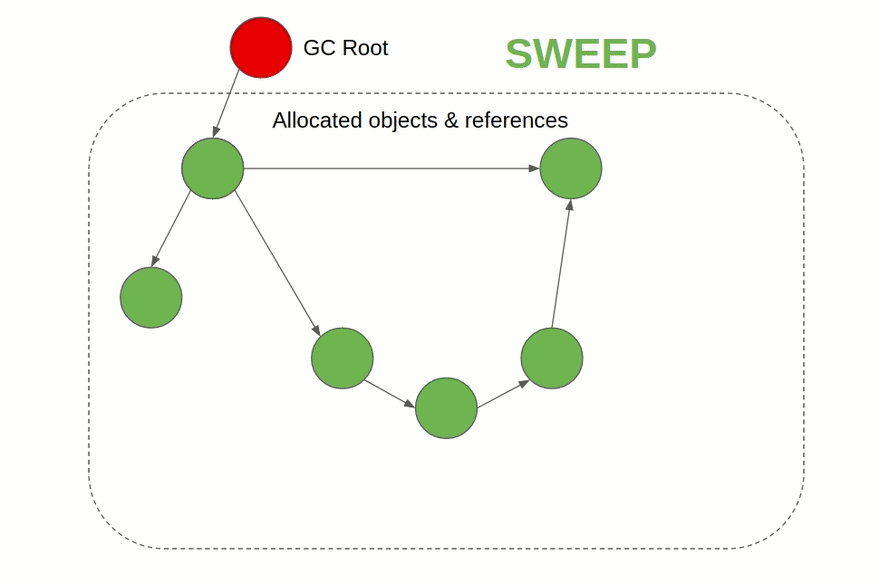
- Сборщик мусора на основе алгоритма пометок (Mark & Sweep): Это алгоритм, работа которого происходит в две фазы: первым делом он помечает объекты в памяти, на которые имеются ссылки, а затем освобождает память от объектов, которые пометки не получили. Этот подход используется, например, в JVM, C#, Ruby, JavaScript и Golang. В JVM существует на выбор несколько разных алгоритмов сборки мусора, а JavaScript-движки, такие как V8, используют алгоритм пометок в дополнение к подсчёту ссылок. Такой сборщик мусора можно подключить в C и C++ в виде внешней библиотеки.

Визуализация алгоритма пометок: помечаются связанные ссылками объекты, а затем удаляются недостижимые
- Сборщик мусора с подсчётом ссылок: для каждого объекта в куче ведётся счётчик ссылок на него — если счётчик достигает нуля, то память высвобождается. Данный алгоритм в чистом виде не способен корректно обрабатывать циклические ссылки объекта на самого себя. Сборщик мусора с подсчётом ссылок, вместе с дополнительными ухищрениями для выявления и обработки циклических ссылок, используется, например, в PHP, Perl и Python. Этот алгоритм сборки мусора так же может быть использован и в C++;
Получение ресурса есть инициализация (RAII)
RAII — это программная идиома в ООП, смысл которой заключается в том, что выделяемая для объекта область памяти строго привязывается к его времени существования. Память выделяется в конструкторе и освобождается в деструкторе. Данный подход был впервые реализован в C++, а так же используется в Ada и Rust.
Автоматический подсчёт ссылок (ARC)
Данный подход весьма похож на сборку мусора с подсчётом ссылок, однако, вместо запуска процесса подсчёта в определённые интервалы времени, инструкции выделения и освобождения памяти вставляются на этапе компиляции прямо в байт-код. Когда же счётчик ссылок достигает нуля, память освобождается как часть нормального потока выполнения программы.
Автоматический подсчёт ссылок всё так же не позволяет обрабатывать циклические ссылки и требует от разработчика использования специальных ключевых слов для дополнительной обработки таких ситуаций. ARC является одной из особенностей транслятора Clang, поэтому присутствует в языках Objective-C и Swift. Так же автоматический подсчет ссылок доступен для использования в Rust и новых стандартах C++ при помощи умных указателей.
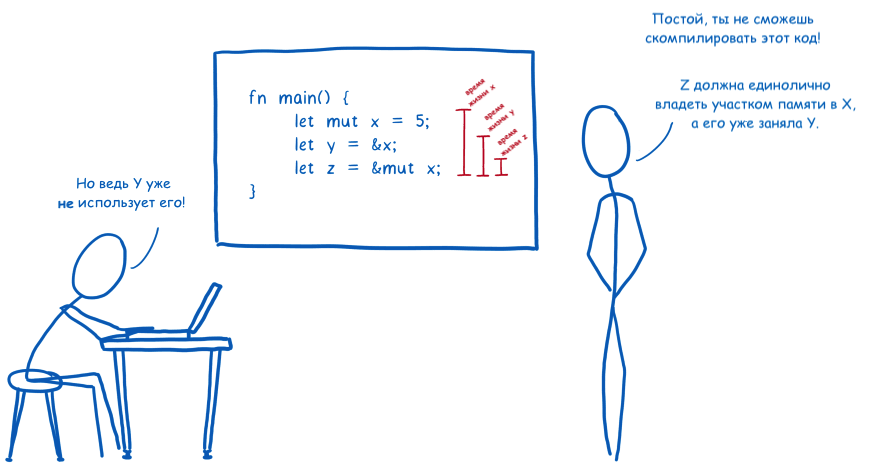
Владение
Это сочетание RAII с концепцией владения, когда каждое значение в памяти должно иметь только одну переменную-владельца. Когда владелец уходит из области выполнения, память сразу же освобождается. Можно сказать, что это примерно как подсчёт ссылок на этапе компиляции. Данный подход используется в Rust и при этом я не смог найти ни одного другого языка, который бы использовал подобный механизм.
В данной статье были рассмотрены основные концепции в сфере управления памятью. Каждый язык программирования использует собственные реализации этих подходов и оптимизированные для различных задач алгоритмы. В следующих частях, мы подробнее рассмотрим решения для управления памятью в популярных языках.
Читайте так же другие части серии:
- > Часть 1: Введение в управление памятью
- Part 2: Memory management in JVM(Java, Kotlin, Scala, Groovy)
- Part 3: Memory management in V8(JavaScript/WebAssembly)
- Part 4: Memory management in Go (in progress)
- Part 5: Memory management in Rust (in progress)
- Part 6: Memory management in Python (in progress)
- Part 7: Memory management in C++ (in progress)
- Part 8: Memory management in C# (in progress)
Ссылки
- http://homepages.inf.ed.ac.uk
- https://javarevisited.blogspot.com
- http://net-informations.com
- https://gribblelab.org
- https://medium.com/computed-comparisons
- https://en.wikipedia.org/wiki/Garbage*collection*(computer_science)
- https://en.wikipedia.org/wiki/Automatic_Reference_Counting
- https://blog.sessionstack.com
Если вам понравилась статья, пожалуйста, поставьте плюс или напишите комментарий.
Вы можете подписаться на автора статьи в Twitter и на LinkedIn.
Иллюстрации:
Визуализация стека сделана с помощью pythontutor.
Иллюстрация концепции владения: Link Clark, The Rust team под Creative Commons Attribution Share-Alike License v3.0.
За вычитку перевода отдельное спасибо Александру Максимовскому и Катерине Шибаковой
Содержание
- ProgrammWS
- Все для начинающего программиста
- Меню сайта
- Информация
- Глава 2. Сложные структуры данных
- Механизм работы с кучами Windows
- Работа с кучей в windows
- Работа с кучей в windows
- Другие функции кучи
- Читайте также
- Управление памятью кучи
- Другие функции взаимоблокировки
- 7.2.1. Поиск повреждений кучи
- Другие функции
- Другие функции
- Другие функции базы данных
- А что же другие?
- 10.1.2.6 Другие функции, имеющие отношение к файловой системе
- 9.4.3 Другие функции UDP
- Другие классы и функции пространств имен WMI
- 4.5.3. Функции, которые создают новые конфигурации из существующих 4.5.3.1. Функции геометрии, которые производят новые конфигурации
- ДРУГИЕ БИБЛИОТЕЧНЫЕ ФУНКЦИИ
- Другие функции
- Другие дополнительные функции XSLT
- Куча больших объектов в системах Windows The large object heap on Windows systems
- Как объект оказывается в куче больших объектов How an object ends up on the LOH
- Когда собираются большие объекты? When is a large object collected?
- Влияние кучи больших объектов на производительность LOH performance implications
- Сбор данных производительности для кучи больших объектов Collect performance data for the LOH
- ETW-события ETW events
- Отладчик A debugger
ProgrammWS
Все для начинающего программиста
Меню сайта
Информация
Программирование — в обычном понимании, это процесс создания компьютерных программ.
В узком смысле (так называемое кодирование) под программированием понимается написание инструкций — программ — на конкретном языке программирования (часто по уже имеющемуся алгоритму — плану, методу решения поставленной задачи). Соответственно, люди, которые этим занимаются, называются программистами (на профессиональном жаргоне — кодерами), а те, кто разрабатывает алгоритмы — алгоритмистами, специалистами предметной области, математиками.
В более широком смысле под программированием понимают весь спектр деятельности, связанный с созданием и поддержанием в рабочем состоянии программ — программного обеспечения ЭВМ. Более точен современный термин — «программная инженерия» (также иначе «инженерия ПО»). Сюда входят анализ и постановка задачи, проектирование программы, построение алгоритмов, разработка структур данных, написание текстов программ, отладка и тестирование программы (испытания программы), документирование, настройка (конфигурирование), доработка и сопровождение.
Глава 2. Сложные структуры данных
Механизм работы с кучами Windows
Этот механизм наиболее эффективен для поддержки работы с такими структурами данных, как связные списки, деревья и т. п. Как правило, отдельные элементы этих структур имеют небольшой размер, в то время как общее количество памяти, занимаемое этими структурами в разные моменты времени работы приложения, может быть разным. Главное преимущество использования кучи — свобода в определении размера выделяемой памяти. В то же время это самый медленный механизм динамического выделения памяти.
Windows поддерживает работу с двумя видами куч: стандартной и дополнительной.
Во время создания система выделяет процессу стандартную кучу (или кучу по умолчанию), размер которой составляет 1 Мбайт. При желании можно указать компоновщику ключ /HEAP с новой величиной размера стандартной кучи. Создание и уничтожение стандартной кучи производится системой, поэтому в API не существует функций, управляющих этим процессом. Только одна функция должна вызываться перед началом работы со стандартной кучей — GetProcessHeap:
GetProcessHeap возвращает описатель, используемый далее другими функциями работы с кучей.
Для более эффективного управления памятью и локализации структур хранения в адресном пространстве процесса можно создавать дополнительные кучи. Сделать это можно с использованием функции HeapCreate:
HANDLE HeapCreate(DWORD flOptions. SIZE_T dwInitialSize, SIZE_T dwMaximutnSize)
Размер создаваемой этой функцией кучи определяется параметрами dwInitialSize (начальный размер) и dwMaximumSize (максимальный размер). Возвращаемое функцией HeapCreate значение — описатель кучи, который используется затем другими функциями, работающими с данной кучей. Уничтожение дополнительной кучи осуществляется вызовом функции HeapDestroy, которой в качестве параметра передается описатель уничтожаемой кучи:
BOOL HeapDestroytHANDLE hHeap)
Важно отметить, что на этапе создания как стандартной, так и дополнительных куч реального выделения памяти для них не производится. Главное — получить указатель и сообщить системе характеристики и размер создаваемой кучи.
После получения описателя работа со стандартной и дополнительной кучами осуществляется с помощью функций НеарАПос, HeapReAlloc, HeapSize, HeapFree. Рассмотрим их подробнее.
Выделение физической памяти из кучи производится по запросу НеарАПос:
LPVOID HeapAlloc(HANDLE hHeap. DWORD dwFlags. SIZEJ dwBytes)
Здесь параметр hHeap сообщает НеарАПос, в пространстве какой кучи требуется выделение памяти размером dwBytes байт. Параметр dwFlags представляет собой флаги, с помощью которых можно влиять на особенности выделяемой памяти. В случае успеха функция НеарАПос возвращает адрес, который используется далее для доступа к физической памяти в выделенном блоке.
В ходе работы с выделенным блоком может сложиться ситуация, когда необходимо изменить его размер в большую или меньшую сторону. Для этого предназначена функция HeapReAHoc:
LPVOID HeapReA11oc(HANDLE hHeap. DWORD dwFlags, LPVOID ipMem, SIZE_T dwByt
Параметр hHeap идентифицирует кучу, в которой изменяется размер блока, а параметр lpMem является адресом блока (полученным ранее с помощью НеарАПос), размер которого изменяется. Новый размер блока указывается параметром dwBytes.
Играя размерами блоков, вы можете совсем запутаться. Функция HeapSize поможет вам определить текущий размер блока по адресу 1 рМет в куче hHeap.
DWORD HeapSize(HANDLE hHeap. DWORD dwFlags, LPCVOIO lpMem)
И наконец, когда блок по адресу lpMem в куче hHeap становится ненужным, его можно освободить вызовом функции HeapFree:
BOOL HeapFreeCHANDLE hHeap. DWORD dwFlags. LPVOID lpMem)
Это минимальный набор функций Windows для работы с кучами. Он столь подробно был обсужден нами с целью дальнейшего использования этих функций для разработки приложений этого раздела.
Источник
Работа с кучей в windows
Объясните немного про кучи
я так понимаю что их используют когда жалко памяти и известно что программа больше чем нужно не закушает
а поскольку скажем new char вместо 1 байта займет сразу 4096, то делается так:
1. выделяется столько памяти, сколько будет нужно программе (например 1МБ)
2. переопределяются операторы new и delete
2.1: при new просто возвращается указатель на начало незанятой памяти в куче, а указатель на начало передвигается на sizeof()
2.2: при delete просто происходит уменьшение значения указателей на на sizeof()(если они больше удаляемого), а содержимое кучи сдвигается (опять же справа от старого указателя) на те же sizeof()байт влево
я так себе представляю работу с кучей?
Fireman, в операторе new/ delete можно перегрузить operator new/delete, т.е только функции непосредственно выделяющие память. Глобальную перегрузку обычно не делают, реализуют только для классов/структур.
В принципе можно создать статический контейнер, который хранит указатели на выделенные участки памяти, соответственно в new вносить запись в контейнер, а в delete удалять. Этот контейнер можно юзать и для «контроля» памяти.
ну а если используется очень много, но маленьких, то наоборот(в смысле очень сильно страдает призводительность)
Не столько производительность, сколько оптимальность использования памяти (из-за фрагментации).
1. выделяется столько памяти, сколько будет нужно программе (например 1МБ)
2. переопределяются операторы new и delete
2.1: при new просто возвращается указатель на начало незанятой памяти в куче, а указатель на начало передвигается на sizeof()
2.2: при delete просто происходит уменьшение значения указателей на на sizeof()(если они больше удаляемого), а содержимое кучи сдвигается (опять же справа от старого указателя) на те же sizeof()байт влево
я так себе представляю работу с кучей?
Flex Ferrum, но вот взять скажем Windows
там каждой программе выделяется 4ГБ памяти (2 нижних для системных нужд)
и динамически работая с памятью (new delete) все манипуляции с памятью берет на себя система
но ведь часто такое состояние дел не удовлетворяет, раве не так?
Как я понимаю ситуация, когда использование системных средств для работы с динамической памятью не удовлетворяет это ситуация нехватки производительности, когда необходимо избежать затрат на динамическое распределение памяти, у вас такая ситуация?
Источник
Работа с кучей в windows
Windows поддерживает пулы памяти, называемые кучами (heaps). Процесс может иметь несколько куч, которые используются для распределения памяти.
Рис. 5.1. Архитектура системы управления памятью Windows
Во многих случаях одной кучи вполне достаточно, но в силу ряда причин, о которых будет сказано ниже, иногда целесообразно иметь в своем распоряжении несколько куч. Если одной кучи вам хватает, можно обойтись использованием функций управления памятью, предоставляемых библиотекой С (malloc, free, calloc, realloc).
Кучи являются объектами Windows и, следовательно, имеют дескрипторы. Дескриптор кучи используется при распределении памяти. У каждого процесса имеется куча, заданная по умолчанию, которую использует функция malloc и для получения дескриптора которой используется следующая функция:
Возвращаемое значение: дескриптор кучи процесса; в случае неуспешного завершения — NULL.
Заметьте, что для индикации неудачного завершения функции используется возвращаемое значение NULL, а не INVALID_HANDLE_VALUE, как в случае функции CreateFile.
Программа также может создать несколько различных куч. Иногда для размещения в памяти отдельных структур данных оказывается удобным, чтобы для каждой из них была предусмотрена своя куча. Использование независимых куч обеспечивает ряд преимуществ.
• Отсутствие взаимной дискриминации между потоками. Ни один из потоков не сможет получить больше памяти, чем распределено для ее кучи. В частности, так называемая утечка памяти (memory leak), возникающая в тех случаях, когда программа «забывает» своевременно освободить память, занятую элементами данных, необходимости в которых больше нет, будет влиять лишь на один поток процесса.[22]
• Повышение производительности. Предоставление собственной кучи каждого потока уменьшает состязательность между ними, в результате чего общая производительность программы может значительно повыситься. См. главу 9.
• Эффективность размещения данных. Размещение элементов данных фиксированного размера в небольшой куче может оказаться гораздо более эффективным, чем размещение множества элементов самых различных размеров в одной большой куче. При этом также уменьшается фрагментация памяти. Кроме того, предоставление каждого потока собственной кучи существенно упрощает синхронизацию потоков, что приводит к дополнительному повышению производительности.
• Эффективность освобождения памяти. Области памяти, распределенные для кучи в целом и всех структур данных, которые она содержит, могут быть освобождены с помощью единственного вызова функции. Этот вызов также устранит отрицательные последствия утечки памяти, связанной с данной кучей.
• Эффективность локализации обращений к памяти. Сохранение структуры данных в небольшой куче гарантирует, что для всех элементов данных потребуется сравнительно небольшое количество страниц, а это может уменьшить вероятность возникновения ошибок страниц в процессе обработки элементов структур данных.
Ценность указанных преимуществ может варьироваться в зависимости от приложения, и многие программисты ограничиваются использованием только кучи процесса, для управления которой используют функции библиотеки С. Однако такой выбор лишает программу возможности воспользоваться способностью функций управления памятью Windows генерировать исключения (обсуждается при рассмотрении функций). В любом случае для создания и уничтожения куч применяются две функции, описания которых приводятся ниже.[23]
Начальный размер кучи, устанавливаемый параметром dwInitialSize (который может быть нулевым), всегда округляется до величины, кратной размеру страницы, и определяет объем физической памяти (в файле подкачки), который передается (commit) в распоряжение кучи (для последующего распределения памяти по запросам) первоначально, а не в ответ на запросы распределения (allocation) памяти из кучи. Когда программа исчерпывает первоначальный размер кучи, куче автоматически передаются дополнительные страницы памяти вплоть до пор, пока она не достигнет установленного для нее максимального размера. Поскольку файл подкачки является ограниченным ресурсом, рекомендуется откладывать передачу памяти куче на более поздний срок, если только заранее не известно, какой размер кучи потребуется. Максимально допустимый размер кучи при ее увеличении в результате динамического расширения определяется значением параметра dwMaximumSize (если оно ненулевое). Рост куч процессов, заданных по умолчанию, также осуществляется динамическим путем.
HANDLE HeapCreate(DWORD flOptions, SIZE_T dwInitialSize, SIZE_T dwMaximumSize)
Возвращаемое значение: дескриптор кучи; в случае неудачного завершения — NULL.
Типом данных обоих упомянутых полей, связанных с размерами кучи, является не DWORD, a SIZE_T. Тип данных SIZE_T определяется как 32– или 64-битовое целое число без знака, в зависимости от флагов компилятора (_WIN32 или _WIN64). Этот тип данных был введен специально для того, чтобы обеспечить возможность миграции приложений Win64 (см. главу 16), и охватывает весь диапазон 32– и 64-битовых указателей. Вариантом этого типа данных для чисел со знаком является тип SSIZE_T).
flOptions — этот параметр может объединять следующие два флага:
• HEAP_GENERATE_EXCEPTIONS: в случае ошибки при распределении памяти вместо возврата значения NULL генерируется исключение, которое должно быть обработано средствами SEH (см. главу 4). Если установлен этот флаг, то такие исключения при сбоях будет возбуждаться не самой функцией HeapCreate, а такими функциями, как HeapAlloc, к рассмотрению которых мы вскоре перейдем.
• HEAP_NO SERIALIZE: при определенных обстоятельствах, о которых сказано ниже, установка этого флага может привести к незначительному повышению производительности.
Существуют другие важные моменты, связанные с параметром dwMaximumSize.
• Если параметр dwMaximumSize имеет ненулевое значение, то виртуальное адресное пространство резервируется в соответствии с этим значением, даже если первоначально не все оно передается в распоряжение кучи. Это значение определяет максимальный размер кучи, о котором в этом случае говорят как о нерастущем (nongrowable). Данный параметр ограничивает размер кучи, чтобы, например, обеспечить отсутствие дискриминации между потоками, о чем говорилось выше.
• Если же значение dwMaximumSize равно 0, то куча может расти (grow), превышая предел, установленный начальным размером, и в этом случае максимальный размер кучи ограничивается лишь объемом доступного виртуального адресного пространства, не распределенного в данный момент для других куч и файла подкачки.
Заметьте, что кучи не имеют атрибутов защиты, поскольку доступ к ним извне процесса невозможен. В то же время, для объектов отображения файлов, описанных далее в этой главе, защита предусмотрена (глава 15), так как они могут совместно использоваться несколькими процессами.
Для уничтожения объекта кучи используется функция HeapDestroy. Она также может служить примером исключения из общих правил, в данном случае — правила, согласно которому для удаления ненужных дескрипторов любого типа используется функция CloseHandle.
BOOL HeapDestroy(HANDLE hHeap)
Параметр hHeap должен указывать на кучу, созданную посредством вызова функции HeapCreate. Будьте внимательны и следите за тем, чтобы случайно не уничтожить кучу процесса, заданную по умолчанию (дескриптор которой получают с помощью функции GetProcessHeap). В результате уничтожения кучи освобождается область виртуального адресного пространства и физическая область сохранения файла подкачки. Разумеется, правильно спроектированная программа должна уничтожать кучи, необходимости в которых больше нет.
Помимо всего прочего, уничтожение кучи позволяет быстро освободить память, занимаемую структурами данных, избавляя вас от необходимости отдельного уничтожения каждой из структур, однако экземпляры объектов C++ уничтожены не будут, поскольку их деструкторы при этом не вызываются. Применение операции уничтожения кучи имеет следующие положительные стороны:
1. Отпадает необходимость в написании программного кода, обеспечивающего обход структур данных.
2. Отпадает необходимость в освобождении памяти, занимаемой каждым из элементов, по отдельности.
3. Система не затрачивает время на обслуживание кучи, поскольку отмена распределения памяти для всех элементов структуры данных осуществляется посредством единственного вызова функции.
Функции библиотеки С используют только одну кучу. В силу этого иметь дело с чем-либо, напоминающим дескрипторы куч Windows, в данном случае не приходится.
В UNIX адресное пространство процесса может быть увеличено с помощью функции sbrk, однако эта функция не является диспетчером памяти общего назначения.
При неудачных попытках распределения памяти в UNIX сигналы не генерируются, поэтому в программах должна быть предусмотрена явная проверка значений возвращаемых указателей.
Источник
Другие функции кучи
Другие функции кучи
Функция HeapCompact пытается уплотнить, или дефрагментировать, смежные блоки в куче. Функция HeapValidate пытается обнаруживать повреждения кучи. Функция HeapWalk перечисляет блоки в куче, а функция GetProcessHeaps получает все действительные дескрипторы куч.
Функции HeapLock и HeapUnlock позволяют потоки сериализовать доступ к куче, о чем говорится в главе 8.
Имейте в виду, что эти функции не работают под управлением Windows 9x или Windows СЕ. Кроме того, имеются некоторые вышедшие из употребления функции, которые использовались ранее для совместимости с 16-битовыми системами. Мы упомянули об этих функциях лишь для того, чтобы лишний раз подчеркнуть тот факт, что многие функции продолжают поддерживаться, хотя никакой необходимости в них больше нет.
Читайте также
Управление памятью кучи
Управление памятью кучи Для получения блока памяти из кучи следует указать дескриптор области памяти кучи, размер блока и некоторые флаги. LPVOID НеарАllос(HANDLE hHeap, DWORD dwFlags, SIZE_T dwBytes) Возвращаемое значение: в случае успешного выполнения — указатель на распределенный блок
Другие функции взаимоблокировки
Другие функции взаимоблокировки Ранее уже было продемонстрировано, что функции InterlockedIncrement и InterlockedDecrement могут пригодиться в тех случаях, когда все, что требуется — это выполнение простейших операций над переменными, доступ к которым разделяется несколькими потоками.
7.2.1. Поиск повреждений кучи
7.2.1. Поиск повреждений кучи Когда память распределяется в куче, функциям управления памятью необходимо место для хранения информации о распределениях. Таким местом является сама куча; это значит, что куча состоит из чередующихся областей памяти, которые используются
Другие функции
Другие функции
Другие функции базы данных
Другие функции базы данных DB2/400 поддерживает и несколько дополнительных функций. Некоторые из них расширяют возможности применения AS/400 в клиент/серверных системах и средах распределенных баз данных, другие призваны повысить производительность базы данных. В этом
А что же другие?
А что же другие? Этот фрагмент истории десктопов был начат кратким рассказом о Xfce и ею же уместно его и завершить. Мы оставили её на уровне 3-й версии, которая, будучи переписана на основе библиотек Gtk, обрела статус свободной среды. Но на этом её история не закончилась.При
10.1.2.6 Другие функции, имеющие отношение к файловой системе
10.1.2.6 Другие функции, имеющие отношение к файловой системе Такие функции работы с файловой системой, как stat и chmod, выполняются одинаково, как для обычных файлов, так и для устройств; они манипулируют с индексом, не обращаясь к драйверу. Даже системная функция lseek работает
9.4.3 Другие функции UDP
9.4.3 Другие функции UDP Кроме отправки и получения датаграмм, UDP должен руководствоваться здравым смыслом при пересылке данных вниз, от приложения к IP, и обеспечивать указание на ошибки от IP к
Другие классы и функции пространств имен WMI
Другие классы и функции пространств имен WMI WMI является неисчерпаемой темой для обсуждения, так как содержит просто огромное количество классов, не говоря уже о количестве функций, реализованных в этих классах. Для рассмотрения всех функций WMI (не говоря уже об объектах
4.5.3. Функции, которые создают новые конфигурации из существующих 4.5.3.1. Функции геометрии, которые производят новые конфигурации
4.5.3. Функции, которые создают новые конфигурации из существующих 4.5.3.1. Функции геометрии, которые производят новые конфигурации Раздел «4.5.2. Функции Geometry» обсуждает несколько функций, которые создают новые конфигурации из
ДРУГИЕ БИБЛИОТЕЧНЫЕ ФУНКЦИИ
ДРУГИЕ БИБЛИОТЕЧНЫЕ ФУНКЦИИ Большинство библиотек будут выполнять и ряд дополнительных функций в тех случаях, которые мы рассмотрели. Кроме функций, распределяющих память, есть функции, освобождающие память после работы с нею. Могут быть другие функции, работающие
Другие функции
Другие функции Функция Краткое описание assert проверка утверждения о состоянии переменных getenv получить значение переменной среды (окружения) perror напечатать сообщение об ошибке putenv изменить значение переменной среды swab поменять местами два смежных
Другие дополнительные функции XSLT
Другие дополнительные функции XSLT Функция current Выражение для этой функции имеет вид:node-set current()Функция current возвращает множество, состоящее из текущего узла преобразования.Мы часто использовали термины текущий узел и узел контекста как синонимы: действительно, в
Источник
Куча больших объектов в системах Windows The large object heap on Windows systems
Как объект оказывается в куче больших объектов How an object ends up on the LOH
Большим считается объект не менее 85 000 байт. If an object is greater than or equal to 85,000 bytes in size, it’s considered a large object. Это число рассчитано путем настройки производительности. This number was determined by performance tuning. Если запрашивается выделение 85 000 или более байтов, среда выполнения отправляет объект в кучу больших объектов. When an object allocation request is for 85,000 or more bytes, the runtime allocates it on the large object heap.
Чтобы понять, что это значит, давайте рассмотрим основные принципы работы сборщика мусора. To understand what this means, it’s useful to examine some fundamentals about the garbage collector.
Сборщик мусора работает по поколениям. The garbage collector is a generational collector. Он имеет три поколения: поколение 0, поколение 1 и поколение 2. It has three generations: generation 0, generation 1, and generation 2. Причина использования трех поколений в том, что в правильно настроенных приложениях большинство объектов отмирают на стадии gen0. The reason for having 3 generations is that, in a well-tuned app, most objects die in gen0. Например, в серверном приложении выделения памяти, связанные с каждым запросом, должны исчезнуть после завершения запроса. For example, in a server app, the allocations associated with each request should die after the request is finished. Находящиеся в пути запросы на выделение памяти достигнут поколения 1 и умрут там. The in-flight allocation requests will make it into gen1 and die there. По сути, поколение 1 служит буфером между областями молодых объектов и областями долгоживущих объектов. Essentially, gen1 acts as a buffer between young object areas and long-lived object areas.
Маленькие объекты всегда размещаются в поколении 0 и, в зависимости от времени их существования, могут перейти в поколение 1 или поколение 2. Small objects are always allocated in generation 0 and, depending on their lifetime, may be promoted to generation 1 or generation2. Большие объекты всегда размещаются в поколении 2. Large objects are always allocated in generation 2.
Большие объекты принадлежат к поколению 2, поскольку они собираются только при сборке поколения 2. Large objects belong to generation 2 because they are collected only during a generation 2 collection. При сборке поколения собираются и все предыдущие поколения. When a generation is collected, all its younger generation(s) are also collected. Например, когда происходит сборка мусора поколения 1, собираются поколения 1 и 0. For example, when a generation 1 GC happens, both generation 1 and 0 are collected. А когда происходит сборка мусора поколения 2, собирается вся куча. And when a generation 2 GC happens, the whole heap is collected. Поэтому сборка мусора поколения 2 также называется полной сборкой мусора. For this reason, a generation 2 GC is also called a full GC. В этой статье используется термин «сборка мусора поколения 2», а не «полная сборка мусора», но эти термины равнозначны. This article refers to generation 2 GC instead of full GC, but the terms are interchangeable.
Поколения обеспечивают логическое представление кучи сборки мусора. Generations provide a logical view of the GC heap. На физическом уровне объекты существуют в управляемых сегментах кучи. Physically, objects live in managed heap segments. Управляемый сегмент кучи — это блок памяти, который сборщик мусора резервирует в ОС через вызов функции VirtualAlloc от имени управляемого кода. A managed heap segment is a chunk of memory that the GC reserves from the OS by calling the VirtualAlloc function on behalf of managed code. При загрузке CLR сборка мусора выделяет два первоначальных сегмента кучи: один для маленьких объектов (куча маленьких объектов, или SOH) и один для больших объектов (куча больших объектов, или LOH). When the CLR is loaded, the GC allocates two initial heap segments: one for small objects (the small object heap, or SOH), and one for large objects (the large object heap).
После этого запросы на выделение памяти удовлетворяются путем размещения управляемых объектов в одном из этих сегментов управляемой кучи. The allocation requests are then satisfied by putting managed objects on these managed heap segments. Если объект меньше 85 000 байтов, он будет помещен в сегмент SOH. В противном случае он помещается в сегмент LOH. If the object is less than 85,000 bytes, it is put on the segment for the SOH; otherwise, it is put on an LOH segment. Память из сегментов выделяется (блоками) по мере того, как в них помещается все больше объектов. Segments are committed (in smaller chunks) as more and more objects are allocated onto them. В куче маленьких объектов объекты, пережившие сборку мусора, переходят в следующее поколение. For the SOH, objects that survive a GC are promoted to the next generation. Объекты, пережившие сборку мусора поколения 0, считаются объектами поколения 1 и так далее. Objects that survive a generation 0 collection are now considered generation 1 objects, and so on. Однако объекты, пережившие сборку мусора последнего поколения, по-прежнему будут относиться к этому поколению. However, objects that survive the oldest generation are still considered to be in the oldest generation. Другими словами, выжившие из поколения 2 — это объекты поколения 2; а выжившие из кучи больших объектов — это объекты кучи больших объектов (которые собираются с поколением 2). In other words, survivors from generation 2 are generation 2 objects; and survivors from the LOH are LOH objects (which are collected with gen2).
Пользовательский код может размещать объекты только в поколении 0 (маленькие объекты) или в куче больших объектов (большие объекты). User code can only allocate in generation 0 (small objects) or the LOH (large objects). Только сборщик мусора может помещать объекты в поколение 1 (повышая уровень выживших из поколения 0) и поколение 2 (повышая уровень выживших из поколений 1 и 2). Only the GC can “allocate” objects in generation 1 (by promoting survivors from generation 0) and generation 2 (by promoting survivors from generations 1 and 2).
При запуске сборки мусора сборщик мусора отслеживает живые объекты и сжимает их. When a garbage collection is triggered, the GC traces through the live objects and compacts them. Но поскольку сжатие требует большого количества ресурсов, сборщик мусора сметает кучу больших объектов, составляя свободный список из мертвых объектов, которые можно повторно использовать позднее для удовлетворения запросов на выделение памяти для больших объектов. But because compaction is expensive, the GC sweeps the LOH; it makes a free list out of dead objects that can be reused later to satisfy large object allocation requests. Смежные мертвые объекты превращаются в один свободный объект. Adjacent dead objects are made into one free object.
На рис. 1 проиллюстрирована ситуация, где сборщик мусора формирует поколение 1 после первого поколения 0, где объекты Obj1 и Obj3 мертвы; и он формирует поколение 2 после первого поколения 1, где объекты Obj2 и Obj5 мертвы. Figure 1 illustrates a scenario where the GC forms generation 1 after the first generation 0 GC where Obj1 and Obj3 are dead, and it forms generation 2 after the first generation 1 GC where Obj2 and Obj5 are dead. Это и следующие изображения приводятся только для иллюстрации; они содержат мало объектов, чтобы продемонстрировать происходящее в куче. Note that this and the following figures are only for illustration purposes; they contain very few objects to better show what happens on the heap. На самом деле сборщик мусора обрабатывает гораздо больше объектов. In reality, many more objects are typically involved in a GC.
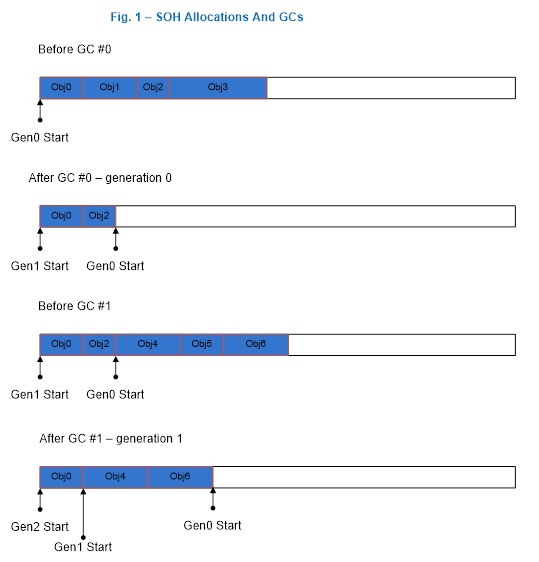
Рис. 1. Сборка мусора поколения 0 и поколения 1. Figure 1: A generation 0 and a generation 1 GC.

Рис. 2. После сборки мусора поколения 2 Figure 2: After a generation 2 GC
Если свободного пространства недостаточно для выполнения запросов на выделение памяти для больших объектов, сборщик мусора пытается получить дополнительные сегменты от ОС. If there isn’t enough free space to accommodate the large object allocation requests, the GC first attempts to acquire more segments from the OS. Если это не удается, он инициирует сборку мусора поколения 2 в надежде освободить место. If that fails, it triggers a generation 2 GC in the hope of freeing up some space.
В ходе сборки мусора поколения 1 или 2 сборщик мусора отдает ОС сегменты, в которых нет живых объектов (вызывая функцию VirtualFree). During a generation 1 or generation 2 GC, the garbage collector releases segments that have no live objects on them back to the OS by calling the VirtualFree function. Свободное место после последнего живого объекта до конца сегмента освобождается (за исключением временных сегментов с объектами поколения 0 и 1, в которых сборщик мусора сохраняет свободное пространство, поскольку вскоре приложение будет размещать в него объекты). Space after the last live object to the end of the segment is decommitted (except on the ephemeral segment where gen0/gen1 live, where the garbage collector does keep some committed because your application will be allocating in it right away). А свободные пространства остаются выделенными, хотя и сбрасываются, освобождая ОС от необходимости записывать данные с них обратно на диск. And the free spaces remain committed though they are reset, meaning that the OS doesn’t need to write data in them back to disk.
Поскольку куча больших объектов собирается только во время сборки мусора поколения 2, сегмент этой кучи можно освободить только во время этой сборки мусора. Since the LOH is only collected during generation 2 GCs, the LOH segment can only be freed during such a GC. На рисунке 3 показан сценарий, где сборщик мусора возвращает ОС один сегмент (сегмент 2) и освобождает дополнительное место в оставшихся сегментах. Figure 3 illustrates a scenario where the garbage collector releases one segment (segment 2) back to the OS and decommits more space on the remaining segments. Если освободившееся пространство в конце сегмента необходимо использовать для удовлетворения запросов на выделение памяти для большого объекта, он фиксирует память снова. If it needs to use the decommitted space at the end of the segment to satisfy large object allocation requests, it commits the memory again. (Дополнительные сведения о фиксации и освобождении см. в документации по VirtualAlloc. (For an explanation of commit/decommit, see the documentation for VirtualAlloc.
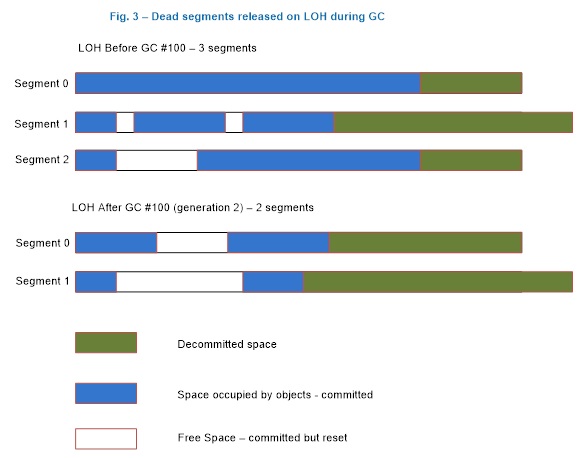
Рис. 3. Куча больших объектов после сборки мусора поколения 2 Figure 3: The LOH after a generation 2 GC
Когда собираются большие объекты? When is a large object collected?
Как правило, сборка мусора происходит при выполнении одного из следующих трех условий: In general, a GC occurs under one of the following three conditions:
Выделение памяти превышает пороговое значение для поколения 0 или больших объектов. Allocation exceeds the generation 0 or large object threshold.
Пороговое значение является свойством поколения. The threshold is a property of a generation. Пороговое значение для поколения задается, когда сборщик мусора распределяет в него объекты. A threshold for a generation is set when the garbage collector allocates objects into it. При превышении порогового значения для этого поколения происходит сборка мусора. When the threshold is exceeded, a GC is triggered on that generation. При распределении маленьких или больших объектов учитываются пороговые значения для поколения 0 или кучи больших объектов соответственно. When you allocate small or large objects, you consume generation 0 and the LOH’s thresholds, respectively. Когда сборщик мусора распределяет объекты в поколения 1 и 2, учитываются соответствующие пороговые значения. When the garbage collector allocates into generation 1 and 2, it consumes their thresholds. Эти пороговые значения динамически настраиваются в ходе работы программы. These thresholds are dynamically tuned as the program runs.
Это типичный случай. Как правило, сборка мусора происходит в связи с распределениями в управляемой куче. This is the typical case; most GCs happen because of allocations on the managed heap.
Если вызывается метод GC.Collect() без параметров или другая перегрузка передается GC.MaxGeneration как аргумент, сборка мусора в куче больших объектов происходит одновременно со сборкой мусора в управляемой куче. If the parameterless GC.Collect() method is called or another overload is passed GC.MaxGeneration as an argument, the LOH is collected along with the rest of the managed heap.
В системе недостаточно памяти. The system is in low memory situation.
Это происходит, когда сборщик мусора получает от ОС уведомление верхней памяти. This occurs when the garbage collector receives a high memory notification from the OS. Если сборщик мусора считает, что сборка мусора поколения 2 будет продуктивной, он запускает ее. If the garbage collector thinks that doing a generation 2 GC will be productive, it triggers one.
Влияние кучи больших объектов на производительность LOH performance implications
Распределение в куче больших объектов влияет на производительность следующим образом. Allocations on the large object heap impact performance in the following ways.
Затраты на распределение. Allocation cost.
CLR гарантирует очистку памяти для каждого выдаваемого им нового объекта. The CLR makes the guarantee that the memory for every new object it gives out is cleared. Это значит, что при распределении большого объекта ресурсы, в основном, расходуются на очистку памяти (если не запускается сборка мусора). This means the allocation cost of a large object is completely dominated by memory clearing (unless it triggers a GC). Если очистка одного байта занимает два цикла, то на очистку самого маленького большого объекта уйдет 170 000 циклов. If it takes 2 cycles to clear one byte, it takes 170,000 cycles to clear the smallest large object. Очистка памяти для объекта размером 16 МБ на компьютере с частотой 2 ГГц занимает приблизительно 16 мс. Clearing the memory of a 16MB object on a 2GHz machine takes approximately 16ms. Это довольно большие затраты. That’s a rather large cost.
Затраты на сбор. Collection cost.
Поскольку куча больших объектов и поколение 2 собираются вместе, при превышении порогового значения для любого из них запускается сборка мусора поколения 2. Because the LOH and generation 2 are collected together, if either one’s threshold is exceeded, a generation 2 collection is triggered. Если сборка поколения 2 была запущена из-за кучи больших объектов, то само поколение 2 необязательно значительно уменьшится после сборки мусора. If a generation 2 collection is triggered because of the LOH, generation 2 won’t necessarily be much smaller after the GC. Если в поколении 2 не так много данных, влияние минимально. If there’s not much data on generation 2, this has minimal impact. Но если поколение 2 большое, запуск многочисленных сборок мусора поколения 2 может вызвать проблемы с производительностью. But if generation 2 is large, it can cause performance problems if many generation 2 GCs are triggered. Если у вас много больших объектов с временным размещением и большая куча маленьких объектов, на сборку мусора может уходить слишком много времени. If many large objects are allocated on a very temporary basis and you have a large SOH, you could be spending too much time doing GCs. Кроме того, затраты на распределение могут нарастать, если вы и дальше будете распределять и освобождать очень большие объекты. In addition, the allocation cost can really add up if you keep allocating and letting go of really large objects.
Элементы массива со ссылочными типами. Array elements with reference types.
Очень большие объекты в куче обычно являются массивами (очень большие объекты-экземпляры весьма редки). Very large objects on the LOH are usually arrays (it’s very rare to have an instance object that’s really large). Если элементы массива имеют много ссылок, затраты выше, чем для элементов с небольшим количеством ссылок. If the elements of an array are reference-rich, it incurs a cost that is not present if the elements are not reference-rich. Если элемент не содержит ссылок, сборщику мусора совсем не придется перебирать массив. If the element doesn’t contain any references, the garbage collector doesn’t need to go through the array at all. Например, в случае использования массива для хранения узлов в двоичном дереве одной из возможных реализаций является обозначение узлов справа и слева от узла реальными узлами: For example, if you use an array to store nodes in a binary tree, one way to implement it is to refer to a node’s right and left node by the actual nodes:
Если num_nodes является большим, сборщик мусора должен обработать как минимум две ссылки на элемент. If num_nodes is large, the garbage collector needs to go through at least two references per element. Другой подход состоит в сохранении индекса правого и левого узла: An alternative approach is to store the index of the right and the left nodes:
Из трех факторов первые два обычно важнее, чем третий. Out of the three factors, the first two are usually more significant than the third. По этой причине рекомендуется распределять пул больших объектов, которые можно использовать повторно, вместо распределения временных. Because of this, we recommend that you allocate a pool of large objects that you reuse instead of allocating temporary ones.
Сбор данных производительности для кучи больших объектов Collect performance data for the LOH
Прежде чем собирать данные производительности для определенной области, вы должны выполнить следующие действия: Before you collect performance data for a specific area, you should already have done the following:
Найти свидетельство, которое нужно учитывать в этой области. Found evidence that you should be looking at this area.
Исследовать другие известные области и не найти в них причину проблемы с производительностью. Exhausted other areas that you know of without finding anything that could explain the performance problem you saw.
Дополнительные сведения об основах памяти и ЦП см. в блоге Понять проблемы, прежде чем пытаться найти решение. See the blog Understand the problem before you try to find a solution for more information on the fundamentals of memory and the CPU.
Для сбора данных о производительности кучи больших объектов можно использовать следующие средства: You can use the following tools to collect data on LOH performance:
Использование счетчиков памяти обычно является хорошим первым этапом поиска проблем с производительностью (хотя мы рекомендуем использовать События трассировки Windows). These performance counters are usually a good first step in investigating performance issues (although we recommend that you use ETW events). Чтобы настроить монитор производительности, добавьте нужные счетчики, как показано на рисунке 4. You configure Performance Monitor by adding the counters that you want, as Figure 4 shows. К куче больших объектов относятся следующие счетчики: The ones that are relevant for the LOH are:
Число сборок мусора поколения 2 Gen 2 Collections
Показывает количество сборок мусора поколения 2 с момента запуска процесса. Displays the number of times generation 2 GCs have occurred since the process started. Этот счетчик увеличивает число в конце сборки мусора поколения 2 (иначе называемой полной сборкой мусора). The counter is incremented at the end of a generation 2 collection (also called a full garbage collection). Этот счетчик отображает последнее значение. This counter displays the last observed value.
Размер кучи для массивных объектов Large Object Heap size
Отображает текущий размер кучи больших объектов в байтах, включая свободное пространство. Displays the current size, in bytes, including free space, of the LOH. Этот счетчик обновляется в конце сборки мусора, не при каждом выделении памяти. This counter is updated at the end of a garbage collection, not at each allocation.
Распространенным средством просмотра счетчиков производительности является монитор производительности (perfmon.exe). A common way to look at performance counters is with Performance Monitor (perfmon.exe). Нажмите «Добавить счетчики», чтобы добавить нужный счетчик для интересующих вас процессов. Use “Add Counters” to add the interesting counter for processes that you care about. Данные счетчика производительности можно сохранить в файле журнала, как показано на рисунке 4. You can save the performance counter data to a log file, as Figure 4 shows:
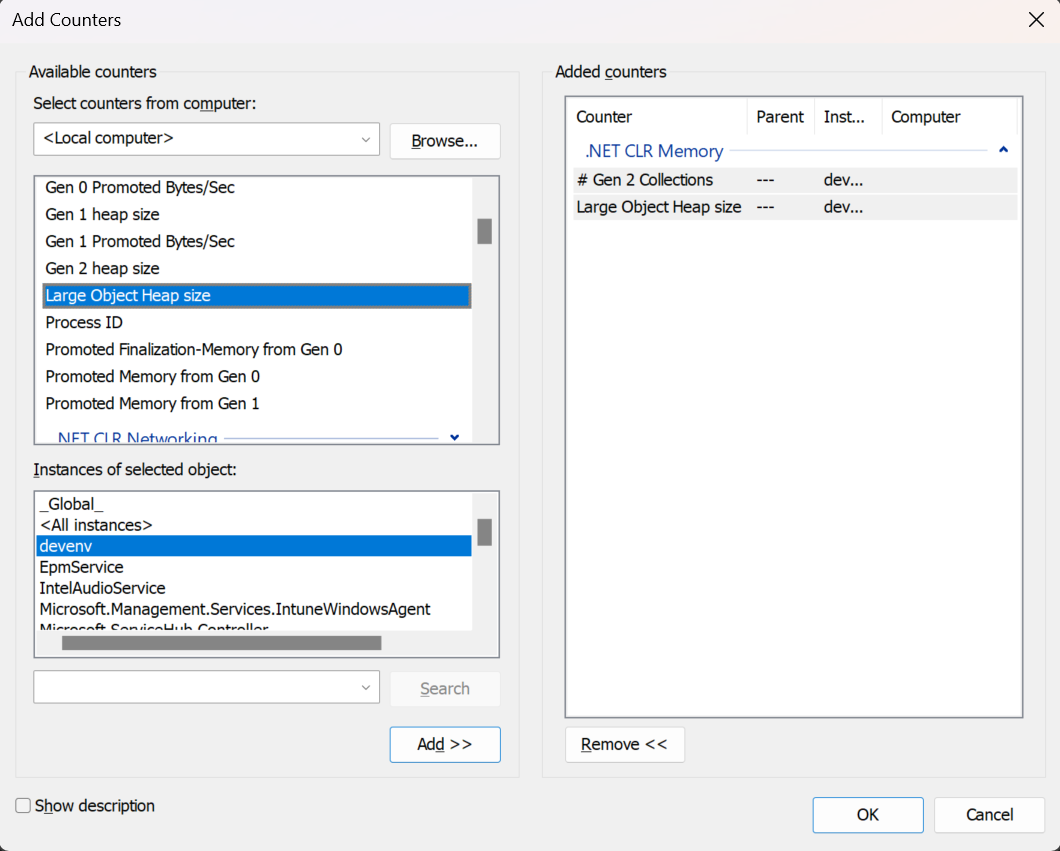
Рис. 4. Куча больших объектов после сборки мусора поколения 2 Figure 4: The LOH after a generation 2 GC
Счетчики производительности также можно запросить программно. Performance counters can also be queried programmatically. Многие собирают эти данные таким способом в рамках рутинного процесса тестирования. Many people collect them this way as part of their routine testing process. При обнаружении счетчиков с необычными значениями можно использовать другие способы получения подробностей, чтобы помочь расследованию. When they spot counters with values that are out of the ordinary, they use other means to get more detailed data to help with the investigation.
Рекомендуется использовать события трассировки событий Windows вместо счетчиков производительности, так как трассировка событий Windows предоставляет гораздо больше сведений. We recommend that you to use ETW events instead of performance counters, because ETW provides much richer information.
ETW-события ETW events
Сборщик мусора предоставляет широкий набор событий трассировки событий Windows, помогая разобраться в функциях кучи. The garbage collector provides a rich set of ETW events to help you understand what the heap is doing and why. В следующих записях блога описывается, как собирать и интерпретировать события сборки мусора с помощью трассировки событий Windows: The following blog posts show how to collect and understand GC events with ETW:
Чтобы выявить чрезмерную сборку мусора поколения 2, вызванную временными распределениями кучи больших объектов, ищите сборку мусора в столбце «Причина активации». To identify excessive generation 2 GCs caused by temporary LOH allocations, look at the Trigger Reason column for GCs. Чтобы провести простой тест и распределить только временные большие объекты, соберите информацию о событиях трассировки событий Windows с помощью следующей командной строки PerfView: For a simple test that only allocates temporary large objects, you can collect information on ETW events with the following PerfView command line:
Результат будет выглядеть примерно следующим образом: The result is something like this:

.
Рис. 5. События трассировки событий Windows, отображаемые с помощью PerfView Figure 5: ETW events shown using PerfView
Как видите, все сборки мусора относятся к поколению 2 и активируются функцией AllocLarge. Это означает, что эта сборка мусора вызвана распределением большого объекта. As you can see, all GCs are generation 2 GCs, and they are all triggered by AllocLarge, which means that allocating a large object triggered this GC. Мы знаем, что эти распределения являются временными, так как в столбце % выживания LOH значится 1 %. We know that these allocations are temporary because the LOH Survival Rate % column says 1%.
Можно собирать дополнительные события трассировки событий Windows, которые показывают, кто распределил эти большие объекты. You can collect additional ETW events that tell you who allocated these large objects. Следующая командная строка: The following command line:
собирает событие AllocationTick, которое возникает примерно каждые 100 000 распределений. collects an AllocationTick event which is fired approximately every 100k worth of allocations. Другими словами, событие возникает при каждом выделении памяти для большого объекта. In other words, an event is fired each time a large object is allocated. Затем вы можете изучить одно из представлений GC Heap Alloc, где отображаются стеки вызовов, распределившие большие объекты: You can then look at one of the GC Heap Alloc views which show you the callstacks that allocated large objects:

.
Рис. 6. Представление GC Heap Alloc Figure 6: A GC Heap Alloc view
Отладчик A debugger
Команды отладки, описанные в этом разделе, применимы к отладчикам Windows. The debugging commands mentioned in this section are applicable to the Windows Debuggers.
Ниже приведен пример выходных данных анализа кучи больших объектов: The following shows sample output from analyzing the LOH:
Размер кучи больших объектов равен (16 754 224 + 16 699 288 + 16 284 504) = 49 738 016 байт. The LOH heap size is (16,754,224 + 16,699,288 + 16,284,504) = 49,738,016 bytes. Между адресами 023e1000 и 033db630 8 008 736 байт занимает массив объектов System.Object, 6 663 696 байт занимает массив объектов System.Byte и 2 081 792 байт свободно. Between addresses 023e1000 and 033db630, 8,008,736 bytes are occupied by an array of System.Object objects, 6,663,696 bytes are occupied by an array of System.Byte objects, and 2,081,792 bytes are occupied by free space.
Иногда в отладчике общий размер кучи больших объектов менее 85 000 байт. Sometimes, the debugger shows that the total size of the LOH is less than 85,000 bytes. Дело в том, что сама среда выполнения использует кучу больших объектов для размещения некоторых объектов, которые меньше большого объекта. This happens because the runtime itself uses the LOH to allocate some objects that are smaller than a large object.
Поскольку куча больших объектов не сжимается, иногда она считается источником фрагментации. Because the LOH is not compacted, sometimes the LOH is thought to be the source of fragmentation. Фрагментация означает: Fragmentation means:
Ниже приведен пример фрагментации в пространстве виртуальной памяти: The following example shows fragmentation in the VM space:
Фрагментация виртуальной памяти чаще вызывается временными большими объектами, которые требуют частых сборок мусора для получения новых сегментов управляемой кучи от ОС и возвращения ОС пустых сегментов. It’s more common to see VM fragmentation caused by temporary large objects that require the garbage collector to frequently acquire new managed heap segments from the OS and to release empty ones back to the OS.
Чтобы проверить, вызывается ли фрагментация виртуальной памяти кучей больших объектов, можно установить точку останова на функциях VirtualAlloc и VirtualFree, чтобы увидеть, кто ее вызывает. To verify whether the LOH is causing VM fragmentation, you can set a breakpoint on VirtualAlloc and VirtualFree to see who call them. Например, чтобы узнать, кто пытался выделить блоки виртуальной памяти ОС размером более 8 МБ, можно установить точку останова следующим образом: For example, to see who tried to allocate virtual memory chunks larger than 8MBB from the OS, you can set a breakpoint like this:
Эта команда останавливает отладчик и показывает стек вызовов только в том случае, если VirtualAlloc вызывается с объемом выделенной памяти более 8 МБ (0x800000). This command breaks into the debugger and shows the call stack only if VirtualAlloc is called with an allocation size greater than 8MB (0x800000).
В CLR 2.0 добавлена функция накопления виртуальной памяти, которую можно использовать в случае, когда сегменты (включая кучи больших и маленьких объектов) часто фиксируются и освобождаются. CLR 2.0 added a feature called VM Hoarding that can be useful for scenarios where segments (including on the large and small object heaps) are frequently acquired and released. Для настройки накопления виртуальной памяти установите флаг запуска STARTUP_HOARD_GC_VM через API размещения. To specify VM Hoarding, you specify a startup flag called STARTUP_HOARD_GC_VM via the hosting API. Вместо возвращения пустых сегментов операционной системе CRL освобождает память в этих сегментах и помещает их в список ожидания. Instead of releasing empty segments back to the OS, the CLR decommits the memory on these segments and puts them on a standby list. (Обратите внимание, что среда CLR не выполняет эти действия со слишком большими сегментами.) Позже среда CLR использует эти сегменты для удовлетворения запросов на новый сегмент. (Note that the CLR doesn’t do this for segments that are too large.) The CLR later uses those segments to satisfy new segment requests. В следующий раз, когда приложению потребуется новый сегмент, среда CLR возьмет его из списка ожидания, если найдет сегмент подходящего размера. The next time that your app needs a new segment, the CLR uses one from this standby list if it can find one that’s big enough.
Накопление виртуальной памяти удобно использовать для приложений, в которых необходимо закрепить уже полученные сегменты, например некоторых серверных приложений, имеющих приоритет в системе, чтобы избежать исключений нехватки памяти. VM hoarding is also useful for applications that want to hold onto the segments that they already acquired, such as some server apps that are the dominant apps running on the system, to avoid out-of-memory exceptions.
Мы настоятельно рекомендуем тщательно тестировать приложение при использовании этой функции и убедиться, что использование памяти достаточно стабильно. We strongly recommend that you carefully test your application when you use this feature to ensure your application has fairly stable memory usage.
Источник
В программировании есть два разных понятия, которые обозначаются одним и тем же словом «куча». Одно про выделение памяти, второе — про организацию данных. Разберём оба и закроем этот вопрос.
Это про данные
Эта статья из цикла про типы данных. Уже было:
- Про деревья
- Про стеки
Ещё бывают связанные списки, очереди, множества, хеш-таблицы, карты и кучи. Вот сегодня про кучи.
Куча и работа с памятью
Каждая запущенная программа использует собственную область оперативной памяти. Эта область делится на несколько частей: в одной хранятся данные, в другой — сам код программы, в третьей — константы. Ещё в эту область входят стек вызовов и куча. Про стек вызовов мы уже рассказывали в отдельной статье, теперь поговорим про кучу.
В отличие от стека, который строго упорядочен и все элементы там идут друг за другом, данные в куче могут храниться как угодно. Технически куча — это область памяти, которую компьютер выделяет программе и говорит: вот тебе свободная память для переменных, делай с ней что хочешь.
То, как программист распорядится этой памятью и каким образом будет с ней работать, влияет на быстродействие и работоспособность всей программы.
Аналогия со стройплощадкой
Представьте, что мы строим дом, а куча — это огромная площадка для хранения стройматериалов. Площадка может быть большой, но она не безграничная, поэтому важно как-то по-умному ей пользоваться. Например:
На стройке: мы выгрузили кирпич на один участок, использовали этот кирпич. Теперь нужно сказать, что этот участок можно снова использовать под стройматериалы. Новый кирпич можно разгрузить сюда же, а не искать новое место на площадке.
В программе: мы выделили память для переменной, использовали переменную, она больше не нужна. Можно сказать «Эта память свободна» и использовать её снова.
На стройке: мы храним определённый вид труб на палете №53. Мы говорим крановщику: «Поднимайте на этаж то, что лежит на палете 53». Если мы ошибёмся с номером, то крановщик поднимет на этаж не те трубы.
В программе: в некоторых языках мы можем обратиться к куче напрямую через специальный указатель. Если мы ошиблись и сказали обратиться не к тому участку памяти, программа заберёт не те данные, а дальше будет ошибка.
👉 Прямой доступ к памяти есть не во всех языках программирования. Многие компиляторы и интерпретаторы ставят между программистом и памятью своеобразного администратора — диспетчера памяти. Он сам решает, какие переменные нужны, а какие нет; когда чистить память; сколько памяти на что выделить.
С одной стороны, это удобно: программист просто говорит «храни данные». А где они будут храниться и как их получить — это вопрос другой системы.
С другой стороны, автоматические диспетчеры памяти бывают менее эффективными, чем если управлять памятью вручную. Поэтому драйвера или софт для высоконагруженных систем чаще пишут в «ручном режиме».
Вам может быть интересно:
Куча и организация данных
Второй вид кучи в программировании — это организация данных.
Куча — это такой вид дерева, у которого есть одно важное свойство:
если узел A — это родитель узла B, то ключ узла A больше ключа узла B (или равен ему).
Если мы представим какой-то набор данных в виде кучи, он может выглядеть, например, так:

У кучи нет ограничений на число потомков у каждого родителя, но на практике чаще всего используются бинарные кучи. Бинарные — значит, у каждого родителя может быть не больше двух потомков.
Для чего нужны кучи данных
Так как данные в куче упорядочены заранее понятным образом, то их можно использовать для быстрого нахождения нужного элемента или оптимальной последовательности действий, например:
- для пирамидальной сортировки большого количества данных, когда объём требуемой памяти не зависит от размера массива, который мы сортируем;
- для нахождения самого быстрого пути из точки A в точку B, когда мы знаем промежуточные расстояния между ними и точками по пути;
- для поиска нужного элемента по каким-то критериям за минимальное время;
- для вычисления оптимальной последовательности действий, если мы знаем параметры и условия для каждого действия.
Зачем это знать
Если вы просто пишете веб-приложения на JS — в принципе, это знать не нужно. Вы не можете из JS напрямую управлять памятью, а для простых задач вам вряд ли придётся часто обходить деревья и делать сложные сортировки.
Понимание структур данных нужно для глубокой экспертной работы с софтом. Это как понимание принципов работы механизма внутреннего сгорания. Вам необязательно в этом разбираться, если вы просто хотите водить автомобиль, но обязательно — если хотите собирать гоночные болиды.
Иллюстратор
Даня Берковский
Виртуальная память
Виртуальная память — это важная часть операционных систем, включая Windows. Она представляет собой механизм, позволяющий приложениям, работать с большими объемами памяти, чем физически доступно на компьютере, и обеспечивает изоляцию процессов друг от друга. Вот основные аспекты виртуальной памяти в Windows:
Виртуальная адресация
Каждому процессу в Windows предоставляется свое собственное виртуальное адресное пространство. Это означает, что каждый процесс видит свою собственную непрерывную область адресов, начиная с нуля. Этот механизм позволяет изолировать процессы друг от друга, так что один процесс не может напрямую обратиться к памяти другого процесса.
Физическая память и страничный файл
Виртуальная память Windows состоит из физической оперативной памяти (RAM) и страничного файла на диске. Если физическая память заполняется, то часть данных может быть перемещена в страничный файл, освобождая место для новых данных. Этот процесс называется “подкачкой” (paging).
Страницы памяти
Виртуальная память разбивается на небольшие блоки, называемые страницами памяти. Размер страницы обычно составляет 4 КБ. Windows использует систему управления таблицами страниц (Page Table) для отображения виртуальных адресов на физические адреса или на адреса в страничном файле.
Отображение виртуальной памяти
Когда процесс обращается к виртуальной памяти, операционная система Windows преобразует виртуальный адрес в соответствующий физический адрес. Если требуемая страница находится в физической памяти, это происходит незаметно. Если страница находится в страничном файле, она должна быть загружена в физическую память перед доступом к ней.
Защита памяти
Виртуальная память Windows также обеспечивает механизмы защиты. Каждая страница памяти может иметь разрешения на чтение, запись и выполнение. Это позволяет операционной системе и программам контролировать доступ к памяти и предотвращать некорректное или вредоносное поведение.
Управление виртуальной памятью
Операционная система Windows автоматически управляет виртуальной памятью, включая подкачку данных между физической памятью и страничным файлом. Программисты обычно не заботятся о деталях управления виртуальной памятью, но могут использовать API для запроса дополнительной памяти (например, функции VirtualAlloc) и управления защитой памяти (например, функции VirtualProtect).
Управление динамической памятью
Управление памятью в Windows может быть выполнено с использованием различных функций и API операционной системы. Давайте рассмотрим несколько примеров кода на языке C/C++ для выделения и освобождения памяти в Windows.
Выделение памяти с использованием malloc и free (C/C++)
#include <stdio.h>
#include <stdlib.h>
int main() {
// Выделение памяти под массив целых чисел
int *arr = (int*)malloc(5 * sizeof(int));
if (arr == NULL) {
printf("Не удалось выделить память\n");
return 1;
}
// Использование выделенной памяти
for (int i = 0; i < 5; i++) {
arr[i] = i * 10;
}
// Освобождение памяти после использования
free(arr);
return 0;
}В этом примере мы используем функции malloc для выделения памяти под массив целых чисел и free для освобождения этой памяти после ее использования.
Выделение памяти с использованием функции VirtualAlloc (WinAPI)
#include <Windows.h>
#include <stdio.h>
int main() {
// Выделение 1 мегабайта (1048576 байт) виртуальной памяти
LPVOID mem = VirtualAlloc(NULL, 1048576, MEM_COMMIT, PAGE_READWRITE);
if (mem == NULL) {
printf("Не удалось выделить виртуальную память\n");
return 1;
}
// Использование выделенной виртуальной памяти
// Освобождение виртуальной памяти
VirtualFree(mem, 0, MEM_RELEASE);
return 0;
}Здесь мы используем функцию VirtualAlloc из библиотеки WinAPI для выделения виртуальной памяти. После использования памяти мы освобождаем ее с помощью функции VirtualFree.
Выделение и освобождение памяти с использованием C++ операторов new и delete
#include <iostream>
#include <windows.h>
int main() {
SetConsoleOutputCP(1251);
// Выделение памяти под одно целое число
int *num = new int;
// Использование выделенной памяти
*num = 42;
std::cout << "Значение: " << *num << std::endl;
// Освобождение памяти
delete num;
return 0;
}Стек и куча
Стек и куча — это две основные области памяти, используемые в программах для хранения данных и управления памятью. Они имеют разные характеристики и предназначены для разных целей. Давайте рассмотрим их более подробно:
Стек (Stack)
- Характеристики:
- Ограниченный по размеру.
- Доступ к данным выполняется в порядке “первым вошел, последним вышел” (LIFO — Last-In, First-Out).
- Часто фиксированный размер стека определяется на этапе компиляции.
- Использование:
- Хранит локальные переменные функций и адреса возврата после вызова функций.
- Используется для управления вызовами функций (стек вызовов).
- Жизненный цикл данных:
- Данные, хранящиеся в стеке, автоматически удаляются при завершении функции, в которой они определены.
- Ограниченное время жизни.
- Примеры языков:
- Стек используется в C, C++, Java (для вызовов методов), Python (для вызовов функций).
Куча (Heap)
- Характеристики:
- Динамически расширяемая область памяти.
- Доступ к данным происходит в произвольном порядке.
- Размер кучи ограничен объемом доступной физической и виртуальной памяти.
- Использование:
- Хранит данные, которые могут иметь долгий или неопределенный срок жизни, такие как объекты, созданные динамически.
- Жизненный цикл данных:
- Данные, хранящиеся в куче, существуют до тех пор, пока на них есть указатели, и могут быть освобождены вручную (например, с помощью
freeв C/C++ или сборщика мусора в других языках).
- Данные, хранящиеся в куче, существуют до тех пор, пока на них есть указатели, и могут быть освобождены вручную (например, с помощью
- Примеры языков:
- Куча используется в C, C++, C#, Java (для объектов, созданных с помощью
new), Python (с использованием модуляgcдля сборки мусора).
- Куча используется в C, C++, C#, Java (для объектов, созданных с помощью
Сравнение стека и кучи
-
Стек обычно быстрее доступен для чтения и записи, чем куча.
-
Куча предоставляет более гибкое управление памятью, но требует явного освобождения ресурсов.
-
Стек обеспечивает управление временем жизни данных автоматически, в то время как в куче это делается вручную.
-
Использование стека ограничено, поэтому он лучше подходит для хранения данных с известным временем жизни, в то время как куча подходит для данных с неопределенным или долгим временем жизни.
-
Оба механизма имеют свои применения и зависят от конкретных требований программы.
Функции для работы со стеком
Windows предоставляет набор функций и API для работы со стеком приложения. Эти функции позволяют программам управлять стеком вызовов функций, а также получать информацию о текущем состоянии стека. Вот некоторые из наиболее часто используемых функций Windows для работы со стеком:
GetCurrentThreadStackLimits (Windows 8.1 и более поздние версии)
Эта функция позволяет получить информацию о границах стека текущего потока. Она возвращает указатель на начало и конец стека текущего потока. Это может быть полезно, например, для отслеживания использования стека и предотвращения переполнения стека.
Пример использования:
void GetStackLimits() {
ULONG_PTR lowLimit, highLimit;
GetCurrentThreadStackLimits(&lowLimit, &highLimit);
printf("Low Limit: 0x%llx\n", lowLimit);
printf("High Limit: 0x%llx\n", highLimit);
}RtlCaptureContext (Windows XP и более поздние версии)
Эта функция захватывает текущий контекст выполнения, включая информацию о регистрах и указателях стека. Это может быть полезно при анализе стека или сохранении контекста выполнения для последующего использования.
Пример использования:
CONTEXT context;
RtlCaptureContext(&context);
// Теперь у вас есть информация о контексте выполнения текущего потокаVirtualQuery (Windows XP и более поздние версии)
Эта функция позволяет получить информацию о виртуальной памяти, включая стек. Вы можете использовать ее для определения границ стеков разных потоков или для анализа виртуальной памяти вашего процесса.
Пример использования:
MEMORY_BASIC_INFORMATION mbi;
VirtualQuery(&someAddress, &mbi, sizeof(mbi));
// Теперь вы можете получить информацию о найденной памяти, включая стекSetThreadStackGuarantee (Windows 8 и более поздние версии)
Эта функция позволяет установить минимальный размер стека для потока. Это может быть полезно, чтобы предотвратить переполнение стека в потоках с большой глубиной вызовов.
Пример использования:
DWORD stackSize = 0x10000; // 64 КБ
SetThreadStackGuarantee(&stackSize);StackWalk64 (DbgHelp API)
Эта функция из библиотеки DbgHelp API позволяет выполнять обход стека вызовов функций для получения информации о вызовах и адресах функций. Она полезна при создании отладочных и профилирующих инструментов.
Пример использования:
STACKFRAME64 stackFrame;
// Настройка параметров и выполнение обхода стекаФункции для работы с кучей
WinAPI предоставляет ряд функций для работы с кучей (памятью, выделяемой в куче). Основные функции включают в себя HeapCreate, HeapAlloc, HeapFree, HeapReAlloc и HeapDestroy. Давайте рассмотрим эти функции более подробно:
HeapCreate
-
Создает новую кучу.
-
Синтаксис:
HANDLE HeapCreate(DWORD flOptions, SIZE_T dwInitialSize, SIZE_T dwMaximumSize); -
Пример:
HANDLE hHeap = HeapCreate(0, 0, 0);
HeapAlloc
-
Выделяет блок памяти из кучи.
-
Синтаксис:
LPVOID HeapAlloc(HANDLE hHeap, DWORD dwFlags, SIZE_T dwBytes); -
Пример:
int* pData = (int*)HeapAlloc(hHeap, 0, sizeof(int) * 10);
HeapFree
-
Освобождает блок памяти, выделенный ранее с помощью
HeapAlloc. -
Синтаксис:
BOOL HeapFree(HANDLE hHeap, DWORD dwFlags, LPVOID lpMem); -
Пример:
HeapFree(hHeap, 0, pData);
HeapReAlloc
-
Изменяет размер выделенного блока памяти в куче.
-
Синтаксис:
LPVOID HeapReAlloc(HANDLE hHeap, DWORD dwFlags, LPVOID lpMem, SIZE_T dwBytes); -
Пример:
pData = (int*)HeapReAlloc(hHeap, 0, pData, sizeof(int) * 20);
HeapDestroy
-
Уничтожает кучу и освобождает все связанные с ней ресурсы.
-
Синтаксис:
BOOL HeapDestroy(HANDLE hHeap); -
Пример:
HeapSize
-
Возвращает размер выделенного блока памяти в куче.
-
Синтаксис:
SIZE_T HeapSize(HANDLE hHeap, DWORD dwFlags, LPCVOID lpMem); -
Пример:
SIZE_T size = HeapSize(hHeap, 0, pData);
HeapValidate
-
Проверяет целостность кучи и выделенных блоков.
-
Синтаксис:
BOOL HeapValidate(HANDLE hHeap, DWORD dwFlags, LPCVOID lpMem); -
Пример:
if (HeapValidate(hHeap, 0, pData)) { printf("Куча валидна.\n"); } else { printf("Куча повреждена.\n"); }
Пример 1: Создание кучи и выделение памяти
#include <Windows.h>
#include <stdio.h>
int main() {
SetConsoleOutputCP(1251);
// Создание кучи
HANDLE hHeap = HeapCreate(0, 0, 0);
if (hHeap == NULL) {
printf("Не удалось создать кучу\n");
return 1;
}
// Выделение памяти из кучи
int *data = (int*)HeapAlloc(hHeap, 0, sizeof(int) * 5);
if (data == NULL) {
printf("Не удалось выделить память из кучи\n");
HeapDestroy(hHeap);
return 1;
}
// Использование выделенной памяти
for (int i = 0; i < 5; i++) {
data[i] = i * 10;
}
// Освобождение памяти
HeapFree(hHeap, 0, data);
// Уничтожение кучи
HeapDestroy(hHeap);
return 0;
}В этом примере мы создаем кучу с помощью HeapCreate, выделяем память из кучи с помощью HeapAlloc, используем эту память и освобождаем ее с помощью HeapFree, а затем уничтожаем кучу с помощью HeapDestroy.
Пример 2: Выделение строки в куче
#include <Windows.h>
#include <stdio.h>
int main() {
SetConsoleOutputCP(1251);
// Создание кучи
HANDLE hHeap = HeapCreate(0, 0, 0);
if (hHeap == NULL) {
printf("Не удалось создать кучу\n");
return 1;
}
// Выделение строки в куче
char *str = (char*)HeapAlloc(hHeap, 0, 256);
if (str == NULL) {
printf("Не удалось выделить память для строки\n");
HeapDestroy(hHeap);
return 1;
}
// Копирование строки в выделенную память
strcpy_s(str, 256, "Пример строки в куче");
// Использование строки
// Освобождение памяти
HeapFree(hHeap, 0, str);
// Уничтожение кучи
HeapDestroy(hHeap);
return 0;
}В этом примере мы выделяем память для строки в куче, копируем строку в эту память, используем ее и освобождаем память.
Отображение файлов на адресное пространство
File mapping (сопоставление файла) в WinAPI — это механизм, который позволяет отображать содержимое файла в виртуальную память процесса. Это может быть полезно для обмена данными между процессами, создания разделяемой памяти или для улучшения производительности при доступе к большим файлам. Давайте рассмотрим основы использования file mapping в WinAPI:
Создание файла для сопоставления
Сначала необходимо создать или открыть файл, который вы хотите сопоставить. Это можно сделать с помощью функций, таких как CreateFile или OpenFile. Например:
HANDLE hFile = CreateFile(
L"C:\\example.txt", // Имя файла
GENERIC_READ | GENERIC_WRITE, // Режим доступа
0, // Атрибуты файла
NULL, // Дескриптор безопасности
OPEN_ALWAYS, // Действие при открытии (создать, если не существует)
FILE_ATTRIBUTE_NORMAL, // Атрибуты файла
NULL // Шаблон для атрибутов
);Создание отображения файла в памяти
Затем создайте отображение файла в виртуальную память с помощью функции CreateFileMapping. Это создает объект отображения файла, который может быть использован для доступа к содержимому файла:
HANDLE hMapFile = CreateFileMapping(
hFile, // Дескриптор файла
NULL, // Атрибуты безопасности (можно использовать NULL)
PAGE_READWRITE, // Режим доступа к файлу в отображении
0, // Размер отображения файла (0 - весь файл)
0, // Высший значащий байт размера файла
NULL // Имя отображения файла (можно использовать NULL)
);Отображение файла в виртуальную память
Завершите процесс сопоставления файла, отображая его в виртуальную память с помощью функции MapViewOfFile:
LPVOID pData = MapViewOfFile(
hMapFile, // Дескриптор отображения файла
FILE_MAP_ALL_ACCESS, // Режим доступа к отображению
0, // Смещение в файле
0, // Начальный байт отображения
0 // Размер отображения (0 - весь файл)
);Использование данных
Теперь pData указывает на начало отображения файла в виртуальной памяти. Вы можете работать с данными, как с обычной памятью.
Освобождение ресурсов
После завершения работы с данными не забудьте освободить ресурсы:
UnmapViewOfFile(pData); // Освобождение отображения файла
CloseHandle(hFile); // Закрытие дескриптора файла
CloseHandle(hMapFile); // Закрытие дескриптора отображения файлаНаверх
Регион куча
Как уже говорилось, в ряде случаев система сама резервирует регионы в адресном пространстве процесса.
Примерами таких регионов могут служить регион куча и регион стека потока.
Куча (heap) — зарезервированный регион размером в одну и более страниц, который рекомендуется использовать для хранения множества небольших порций данных. В отличие от функции VirtualAlloc правила гранулярности выделения памяти при этом соблюдать не обязательно.
Передачей памяти кучам, а также учетом свободной и занятой памяти в куче занимается специальный диспетчер куч (heap manager). Эта деятельность не документирована.
Стандартная куча процесса размером 1 Мб (эту величину можно изменить) резервируется в момент создания процесса. Обычно куча динамически меняет свой размер (флаг growable ). Стандартную кучу процесса используют не только приложения, но и некоторые Win32-функции. Для использования стандартной кучи необходимо получить ее описатель при помощи функции GetProcessHeap.
При желании процесс может создать дополнительные кучи при помощи функции HeapCreate (обратная операция HeapDestroy ). Прикладная программа выделяет память в куче с помощью функции HeapAlloc, а освобождает при помощи HeapFree.
Поскольку кучами могут пользоваться все потоки процесса, по умолчанию организуется синхронизация (флаг SERIALIZE ), которую, хотя это и не рекомендуется, для повышения быстродействия можно отменить. Задачу синхронизации доступа потоков к куче можно также решить, создавая каждому потоку свою собственную кучу.
Прогон программы выделения памяти в стандартной куче
#include <windows.h>
#include <stdio.h>
void main(void)
{
HANDLE hHeap;
long Size = 1024;
long Shift = 1017;
char * pHeap;
char * String;
hHeap = GetProcessHeap();
pHeap = (char *) HeapAlloc(hHeap, HEAP_ZERO_MEMORY, Size);
if(pHeap == NULL) { printf("HeapAlloc error\n"); return; }
String = pHeap + Shift;
sprintf(String, "Hello, world");
printf("Heap contents string: %s\n", String);
HeapFree(hHeap,0,pHeap);
}
В приведенной программе происходит выделение массива памяти в стандартной куче процесса.
Далее туда записывается текстовая строка, которая затем выводится на экран. Если возникает ситуация выхода за пределы выделенной памяти, которую легко смоделировать, увеличивая значение параметра Shift, — возникает ошибка исполнения.
В качестве самостоятельного упражнения можно рекомендовать наблюдение за наращиванием объема переданной в куче памяти при помощи счетчиков производительности. Объем виртуальной памяти процесса должен начать расти в случае выхода за пределы начального размера кучи (1 Мб) и при образовании дополнительных куч.
Регион стека потока. Сторожевые страницы
Для поддержки функционирования стека потока также резервируется соответствующий регион. Стек — динамическая структура. Принято, чтобы стек увеличивал свой размер в сторону уменьшения адресов. Сколько страниц памяти потребуется стеку потока, заранее не известно. Поэтому в ОС Windows организована поэтапная, по мере необходимости, передача физической памяти стеку при помощи механизма так называемых «сторожевых» страниц (guard page). Обращение к сторожевой странице имеет следствием уведомление системы об этом (исключительная ситуация 0x80000001 ), после чего флаг PAGE GUARD сбрасывается и со страницей можно работать как с обычной страницей преданной памяти. Сторожевая страница служит ловушкой для перехвата ссылок за ее пределы.
При создании потока для его стека резервируется регион размером 1 Мб (по умолчанию), и ему передается 2 страницы памяти (эти параметры могут быть изменены). Нижняя страница является сторожевой. Как только верхняя страница оказалась заполненной и произошло обращение к нижней странице, это замечается системой и региону передается еще одна страница, теперь уже она становится сторожевой. Вследствие такой тактики самая нижняя переданная региону стека страница всегда остается сторожевой и ее задача — просигнализировать системе о том, что объем переданной стеку памяти нужно увеличить.
Прогон программы, моделирующей обращение к сторожевым страницам
#include <windows.h>
#include <stdio.h>
void main(void)
{
PVOID pMem = NULL;
char * String;
char * pMemCommited;
int nPageSize = 4096;
int Shift = 4000;
pMem = VirtualAlloc(0, nPageSize*16,
MEM_RESERVE |MEM_COMMIT, PAGE_READWRITE| PAGE_GUARD );
pMemCommited = (char *)pMem + 3 * nPageSize;
String = pMemCommited + Shift;
__try {
sprintf(String,"Hello, world");
printf("Before exception number 0x80000001 string: %s \n", String);
}
__except(EXCEPTION_EXECUTE_HANDLER)
{
sprintf(String,"Hello, world");
printf("After exception number 0x80000001 string: %s \n", String);
}
VirtualFree(String, 0, MEM_RELEASE);
}
В приведенной программе происходит передача памяти региону и установка флага PAGE_GUARD для его страниц. Кроме того, используется структурная обработка исключений. В случае попытки записи текстовой строки на сторожевую страницу (в блоке try ) возникает исключительная ситуация exception 0x80000001. При повторной попытке записи на эту страницу (блок except ) подобная ситуация уже не возникает.
Написание, компиляция и прогон программы, моделирующей рост стека при помощи механизма сторожевых страниц
В качестве самостоятельного упражнения рекомендуется написать программу, в которой сторожевая страница все время находится на границе фрагмента переданной памяти. В случае обращения к сторожевой странице объем переданной процессу памяти нужно увеличить, а сторожевую страницу переместить.
Регион файла, отображаемого в память
Техника файлов, проецируемых в память (см.
рис.
9.4), активно используется новейшими ОС. Она позволяет пользователю решать такие задачи, как работа с данными файла при помощи операций копирования и перемещения байтов в памяти или организация совместного доступа к областям памяти. Этот механизм также активно используется самой операционной системой, например, для загрузки в память исполняемых модулей, динамических библиотек и отображения файла в буфер кэша для осуществления операций стандартного ввода-вывода.
Отображение файла в память означает резервирование региона нужного размера и передача ему соответствующего объема физической памяти (передавать память здесь тоже можно поэтапно). Однако, в отличие от обычных регионов, выгрузка фрагментов оперативной памяти во внешнюю память будет при этом осуществляться не в системную область внешней памяти ( pagefile.sys ), а непосредственно в отображаемый файл. Отображение может быть выполнено на конкретный диапазон виртуальных адресов, если это не противоречит местоположению уже существующих регионов виртуальной памяти.
Для отображения файла в память используется функция CreateFileMapping, а для получения указателя на отображенную область — функция MapViewOfFile. Успешное выполнение обеих операций позволяет прикладной программе работать с этой областью как с любым другим фрагментом выделенной памяти, в частности, изменять ее содержимое. В связи с этим возникает проблема соответствия (когерентности) содержимого региона и файла на диске. Операционная система старается обеспечить когерентность, однако в распоряжении пользователя есть возможность в любой момент сбросить содержимое памяти на диск при помощи функции FlushViewOfFile.
Другой интересный момент связан с тем, что система рассматривает проецируемый в память файл как объект многоцелевого назначения. Поэтому отображение файла в память сопровождается созданием
сопутствующего объекта ядра (в данном случае это объект-секция) с именем в пространстве объектов, по которому он может быть доступен другим процессам, счетчикам ссылок с атрибутами защиты. Как обычно ссылка на объект хранится в таблице описателей каждого процесса, имеющего к объекту доступ.
Прогон программы, демонстрирующей отображение файла в память
#include <windows.h>
#include <stdio.h>
void main(void){
HANDLE hMapFile;
LPVOID lpMapAddress;
HANDLE hFile;
char * String;
hFile = CreateFile( "MyFile.txt", // имя файла
GENERIC_READ | GENERIC_WRITE, // режим доступа
FILE_SHARE_READ| FILE_SHARE_WRITE, // совместный доступ
NULL, // защита по умолчанию
CREATE_ALWAYS, // способ создания
FILE_ATTRIBUTE_NORMAL, // атрибуты файла
NULL); // файл атрибутов
if (hFile == INVALID_HANDLE_VALUE) printf("Could not open file\n");
hMapFile = CreateFileMapping(hFile, // описатель отображаемого файла
NULL, // атрибуты защиты по умолчанию
PAGE_READWRITE, // режим доступа
0, // старшее двойное слово размера буфера
20, // младшее двойное слово размера буфера
"MyFileObject"); // имя объекта
if (hMapFile == NULL) {
printf("Could not create file-mapping object.\n"); return;
}
lpMapAddress = MapViewOfFile(hMapFile, // описатель отображаемого файла
FILE_MAP_ALL_ACCESS, // режимы доступа
0, 0, // отображение файла с начала
0); // отображение целого файла
if (lpMapAddress == NULL) {
printf("Could not map view of file.\n"); return;
}
String = (char *)lpMapAddress;
sprintf(String, "Hello, world");
printf("%s\n", String);
if (!UnmapViewOfFile(lpMapAddress)) printf("Could not unmap view of file.\n");
}
Приведенная программа демонстрирует этапы создания файла, проецирования его в память, изменения его содержимого и отображения на диск.
Написание, компиляция и прогон программы, демонстрирующей различные аспекты проецирования файла в память
На основе предыдущей программы рекомендуется написать программу отображения файла в память с промежуточной выгрузкой файла на диск при помощи функции FlushViewOfFile. Рассмотрите различные варианты существования файла и его размеров до и после отображения.
Решение задачи совместного доступа к памяти будет приведено ниже.
Здесь мы временно прекратим изучение виртуальной памяти процесса. Основным итогом изложенного можно считать знакомство с возможностями ОС создавать в ней разнообразные регионы. В качестве самостоятельного упражнения можно рекомендовать анализ состояния виртуального адресного пространства при помощи функций VirtualQuery и VirtualQueryEx (см., например,
[
Рихтер
]
). Теперь перейдем к рассмотрению других аспектов функционирования менеджера памяти: структуре физической памяти и особенностям трансляции адреса.
Заключение
Система управления памятью является одной из наиболее важных в составе ОС. Традиционная схема предполагает связывание виртуального и физического адреса на стадии исполнения программы. Для управления виртуальным адресным пространством в нем принято организовывать сегменты (регионы), для описания которых используются структуры данных VAD (virtual address descriptors). Для создания региона и передачи ему физической памяти можно использовать функцию VirtualAlloc. Описана техника использования таких регионов, как куча процесса, стек потока и регион файла, отображаемого в память.