
Одна из возможных проблем, с которыми можно столкнуться после установки Windows 10 — кракозябры вместо русских букв в интерфейсе программ, а также в документах. Чаще неправильное отображение кириллицы встречается в изначально англоязычных и не совсем лицензионных версиях системы, но бывают и исключения.
В этой инструкции — о том, как исправить «кракозябры» (или иероглифы), а точнее — отображение кириллицы в Windows 10 несколькими способами. Возможно, также будет полезным: Как установить и включить русский язык интерфейса в Windows 10 (для систем на английском и других языках).
Исправление отображения кириллицы с помощью настроек языка и региональных стандартов Windows 10
Самый простой и чаще всего работающий способ убрать кракозябры и вернуть русские буквы в Windows 10 — исправить некоторые неправильные настройки в параметрах системы.
Для этого потребуется выполнить следующие шаги (примечание: привожу также названия нужных пунктов на английском, так как иногда необходимость исправить кириллицу возникает в англоязычных версиях системы без нужды менять язык интерфейса).
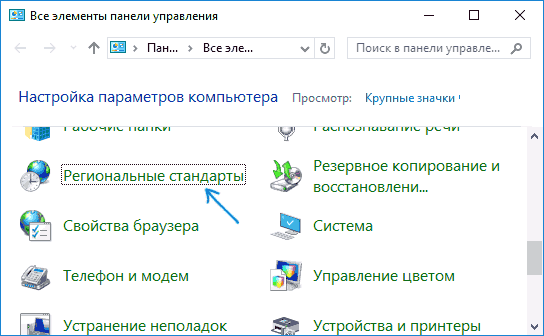
- Откройте панель управления (для этого можно начать набирать «Панель управления» или «Control Panel» в поиске на панели задач.
- Убедитесь, что в поле «Просмотр» (View by) установлено «Значки» (Icons) и выберите пункт «Региональные стандарты» (Region).

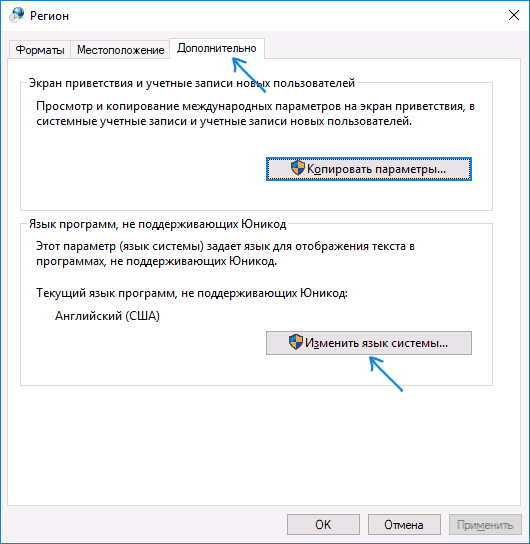
- На вкладке «Дополнительно» (Administrative) в разделе «Язык программ, не поддерживающих Юникод» (Language for non-Unicode programs) нажмите по кнопке «Изменить язык системы» (Change system locale).

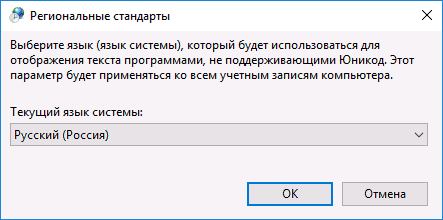
- Выберите русский язык, нажмите «Ок» и подтвердите перезагрузку компьютера.

После перезагрузки проверьте, была ли решена проблема с отображением русских букв в интерфейсе программ и (или) документах — обычно, кракозябры бывают исправлены после этих простых действий.
Как исправить иероглифы Windows 10 путем изменения кодовых страниц
Кодовые страницы представляют собой таблицы, в которых определенным байтам сопоставляются определенные символы, а отображение кириллицы в виде иероглифов в Windows 10 связано обычно с тем, что по умолчанию задана не та кодовая страница и это можно исправить несколькими способами, которые могут быть полезны, когда требуется не изменять язык системы в параметрах.
С помощью редактора реестра
Первый способ — использовать редактор реестра. На мой взгляд, это самый щадящий для системы метод, тем не менее, рекомендую создать точку восстановления прежде чем начинать. Совет про точки восстановления относится и ко всем последующим способам в этом руководстве.
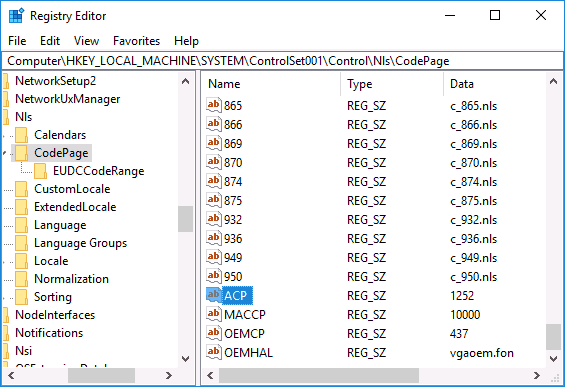
- Нажмите клавиши Win+R на клавиатуре, введите regedit и нажмите Enter, откроется редактор реестра.
- Перейдите к разделу реестра
HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\Nls\CodePage
и в правой части пролистайте значения этого раздела до конца.

- Дважды нажмите по параметру ACP, установите значение 1251 (кодовая страница для кириллицы), нажмите Ок и закройте редактор реестра.
- Перезагрузите компьютер (именно перезагрузка, а не завершение работы и включение, в Windows 10 это может иметь значение).
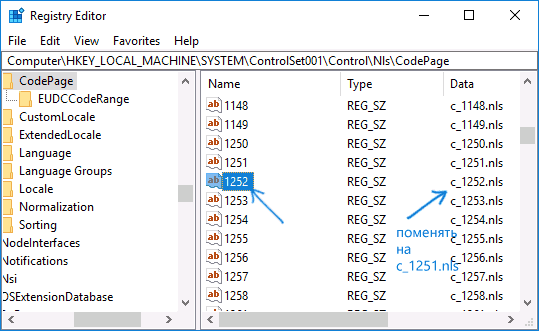
Обычно, это исправляет проблему с отображением русских букв. Вариация способа с помощью редактора реестра (но менее предпочтительная) — посмотреть на текущее значение параметра ACP (обычно — 1252 для изначально англоязычных систем), затем в том же разделе реестра найти параметр с именем 1252 и изменить его значение с c_1252.nls на c_1251.nls.
Путем подмена файла кодовой страницы на c_1251.nls
Второй, не рекомендуемый мной способ, но иногда выбираемый теми, кто считает, что правка реестра — это слишком сложно или опасно: подмена файла кодовой страницы в C:\ Windows\ System32 (предполагается, что у вас установлена западно-европейская кодовая страница — 1252, обычно это так. Посмотреть текущую кодовую страницу можно в параметре ACP в реестре, как было описано в предыдущем способе).
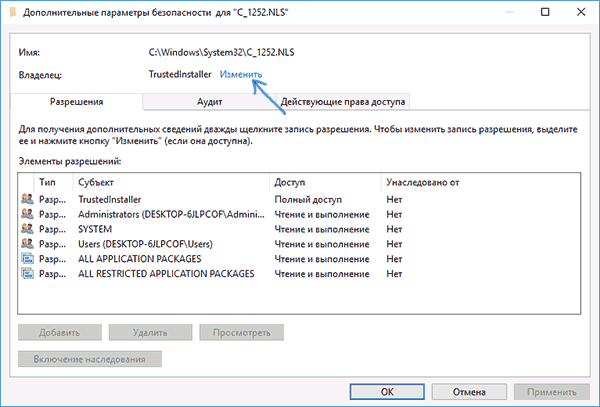
- Зайдите в папку C:\ Windows\ System32 и найдите файл c_1252.NLS, нажмите по нему правой кнопкой мыши, выберите пункт «Свойства» и откройте вкладку «Безопасность». На ней нажмите кнопку «Дополнительно».
- В поле «Владелец» нажмите «Изменить».

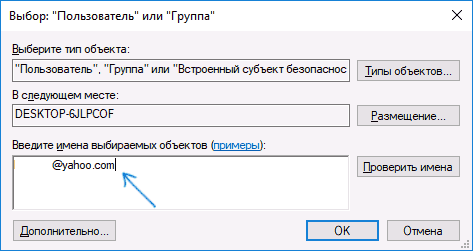
- В поле «Введите имена выбираемых объектов» укажите ваше имя пользователя (с правами администратора). Если в Windows 10 используется учетная запись Майкрософт, вместо имени пользователя укажите адрес электронной почты. Нажмите «Ок» в окне, где указывали пользователя и в следующем (Дополнительные параметры безопасности) окне.

- Вы снова окажетесь на вкладке «Безопасность» в свойствах файла. Нажмите кнопку «Изменить».
- Выберите пункт «Администраторы» (Administrators) и включите полный доступ для них. Нажмите «Ок» и подтвердите изменение разрешений. Нажмите «Ок» в окне свойств файла.
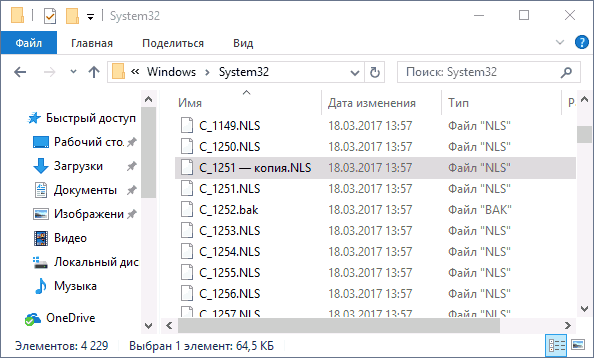
- Переименуйте файл c_1252.NLS (например, измените расширение на .bak, чтобы не потерять этот файл).
- Удерживая клавишу Ctrl, перетащите находящийся там же в C:\Windows\System32 файл c_1251.NLS (кодовая страница для кириллицы) в другое место этого же окна проводника, чтобы создать копию файла.

- Переименуйте копию файла c_1251.NLS в c_1252.NLS.
- Перезагрузите компьютер.
После перезагрузки Windows 10 кириллица должна будет отображаться не в виде иероглифов, а как обычные русские буквы.
Windows Locale Codes Sorted by Codepage
As defined by Microsoft, a locale is either a language or a language in combination with a country. See Microsoft definitions of locale.
CLICK one of the Column Titles to sort the table by that item.
| Locale | Language code |
LCID string |
Decimal | Hexadecimal | Codepage |
|---|---|---|---|---|---|
| Gujarati | gu | gu | 1095 | 447 | |
| Syriac | 1114 | ||||
| Konkani | 1111 | 457 | |||
| Sanskrit | sa | sa | 1103 | ||
| Marathi | mr | mr | 1102 | ||
| Kannada | kn | kn | 1099 | ||
| Tamil | ta | ta | 1097 | 449 | |
| Divehi; Dhivehi; Maldivian | dv | dv | 1125 | 465 | |
| Punjabi | pa | pa | 1094 | 446 | |
| Hindi | hi | hi | 1081 | 439 | |
| Georgian | ka | 1079 | 437 | ||
| Armenian | hy | hy | 1067 | ||
| Telugu | te | te | 1098 | ||
| Thai | th | th | 1054 | ||
| Japanese | ja | ja | 1041 | 411 | |
| Chinese — Singapore | zh | zh-sg | 4100 | 1004 | |
| Chinese — China | zh | zh-cn | 2052 | 804 | |
| Korean | ko | ko | 1042 | 412 | |
| Chinese — Taiwan | zh | zh-tw | 1028 | 404 | |
| Chinese — Macau SAR | zh | zh-mo | 5124 | 1404 | |
| Chinese — Hong Kong SAR | zh | zh-hk | 3076 | ||
| Romanian — Romania | ro | ro | 1048 | 418 | 1250 |
| Albanian | sq | sq | 1052 | 1250 | |
| Polish | pl | pl | 1045 | 415 | 1250 |
| Hungarian | hu | hu | 1038 | 1250 | |
| Serbian — Latin | sr | sr-sp | 2074 | 1250 | |
| Slovenian | sl | sl | 1060 | 424 | 1250 |
| Czech | cs | cs | 1029 | 405 | 1250 |
| Croatian | hr | hr | 1050 | 1250 | |
| Slovak | sk | sk | 1051 | 1250 | |
| Kyrgyz — Cyrillic | 1088 | 440 | 1251 | ||
| Azeri — Cyrillic | az | az-az | 2092 | 1251 | |
| Russian | ru | ru | 1049 | 419 | 1251 |
| Kazakh | kk | kk | 1087 | 1251 | |
| Ukrainian | uk | uk | 1058 | 422 | 1251 |
| Tatar | tt | tt | 1092 | 444 | 1251 |
| Serbian — Cyrillic | sr | sr-sp | 3098 | 1251 | |
| Belarusian | be | be | 1059 | 423 | 1251 |
| Uzbek — Cyrillic | uz | uz-uz | 2115 | 843 | 1251 |
| Mongolian | mn | mn | 1104 | 450 | 1251 |
| Bulgarian | bg | bg | 1026 | 402 | 1251 |
| FYRO Macedonia | mk | mk | 1071 | 1251 | |
| Afrikaans | af | af | 1078 | 436 | 1252 |
| Faroese | fo | fo | 1080 | 438 | 1252 |
| Swedish — Sweden | sv | sv-se | 1053 | 1252 | |
| Malay — Malaysia | ms | ms-my | 1086 | 1252 | |
| Swahili | sw | sw | 1089 | 441 | 1252 |
| Spanish — Paraguay | es | es-py | 15370 | 1252 | |
| Spanish — Uruguay | es | es-uy | 14346 | 1252 | |
| English — Trinidad | en | en-tt | 11273 | 1252 | |
| English — Phillippines | en | en-ph | 13321 | 3409 | 1252 |
| Spanish — Bolivia | es | es-bo | 16394 | 1252 | |
| Spanish — Nicaragua | es | es-ni | 19466 | 1252 | |
| Catalan | ca | ca | 1027 | 403 | 1252 |
| Danish | da | da | 1030 | 406 | 1252 |
| German — Germany | de | de-de | 1031 | 407 | 1252 |
| English — United States | en | en-us | 1033 | 409 | 1252 |
| Spanish — Spain (Traditional) | es | es-es | 1034 | 1252 | |
| Finnish | fi | fi | 1035 | 1252 | |
| French — France | fr | fr-fr | 1036 | 1252 | |
| Indonesian | id | id | 1057 | 421 | 1252 |
| Italian — Italy | it | it-it | 1040 | 410 | 1252 |
| Basque | eu | eu | 1069 | 1252 | |
| Dutch — Netherlands | nl | nl-nl | 1043 | 413 | 1252 |
| Norwegian — Bokml | nb | no-no | 1044 | 414 | 1252 |
| Portuguese — Brazil | pt | pt-br | 1046 | 416 | 1252 |
| Spanish — Chile | es | es-cl | 13322 | 1252 | |
| Spanish — Honduras | es | es-hn | 18442 | 1252 | |
| Galician | gl | 1110 | 456 | 1252 | |
| Spanish — El Salvador | es | es-sv | 17418 | 1252 | |
| Icelandic | is | is | 1039 | 1252 | |
| English — Australia | en | en-au | 3081 | 1252 | |
| Spanish — Dominican Republic | es | es-do | 7178 | 1252 | |
| English — Southern Africa | en | en-za | 7177 | 1252 | |
| German — Austria | de | de-at | 3079 | 1252 | |
| French — Monaco | fr | 6156 | 1252 | ||
| Spanish — Panama | es | es-pa | 6154 | 1252 | |
| English — Ireland | en | en-ie | 6153 | 1809 | 1252 |
| Spanish — Guatemala | es | es-gt | 4106 | 1252 | |
| Spanish — Costa Rica | es | es-cr | 5130 | 1252 | |
| Portuguese — Portugal | pt | pt-pt | 2070 | 816 | 1252 |
| French — Canada | fr | fr-ca | 3084 | 1252 | |
| English — New Zealand | en | en-nz | 5129 | 1409 | 1252 |
| Spanish — Ecuador | es | es-ec | 12298 | 1252 | |
| German — Liechtenstein | de | de-li | 5127 | 1407 | 1252 |
| French — Switzerland | fr | fr-ch | 4108 | 1252 | |
| German — Luxembourg | de | de-lu | 4103 | 1007 | 1252 |
| English — Canada | en | en-ca | 4105 | 1009 | 1252 |
| French — Luxembourg | fr | fr-lu | 5132 | 1252 | |
| Spanish — Venezuela | es | es-ve | 8202 | 1252 | |
| English — Zimbabwe | en | 12297 | 3009 | 1252 | |
| Spanish — Peru | es | es-pe | 10250 | 1252 | |
| English — Belize | en | en-bz | 10249 | 2809 | 1252 |
| Spanish — Colombia | es | es-co | 9226 | 1252 | |
| Spanish — Puerto Rico | es | es-pr | 20490 | 1252 | |
| English — Caribbean | en | en-cb | 9225 | 2409 | 1252 |
| Malay — Brunei | ms | ms-bn | 2110 | 1252 | |
| English — Great Britain | en | en-gb | 2057 | 809 | 1252 |
| Swedish — Finland | sv | sv-fi | 2077 | 1252 | |
| Spanish — Mexico | es | es-mx | 2058 | 1252 | |
| French — Belgium | fr | fr-be | 2060 | 1252 | |
| Italian — Switzerland | it | it-ch | 2064 | 810 | 1252 |
| Dutch — Belgium | nl | nl-be | 2067 | 813 | 1252 |
| English — Jamaica | en | en-jm | 8201 | 2009 | 1252 |
| Norwegian — Nynorsk | nn | no-no | 2068 | 814 | 1252 |
| Spanish — Argentina | es | es-ar | 11274 | 1252 | |
| German — Switzerland | de | de-ch | 2055 | 807 | 1252 |
| Greek | el | el | 1032 | 408 | 1253 |
| Turkish | tr | tr | 1055 | 1254 | |
| Uzbek — Latin | uz | uz-uz | 1091 | 443 | 1254 |
| Azeri — Latin | az | az-az | 1068 | 1254 | |
| Hebrew | he | he | 1037 | 1255 | |
| Arabic — Saudi Arabia | ar | ar-sa | 1025 | 401 | 1256 |
| Arabic — Jordan | ar | ar-jo | 11265 | 1256 | |
| Arabic — Kuwait | ar | ar-kw | 13313 | 3401 | 1256 |
| Arabic — Syria | ar | ar-sy | 10241 | 2801 | 1256 |
| Arabic — Lebanon | ar | ar-lb | 12289 | 3001 | 1256 |
| Arabic — Iraq | ar | ar-iq | 2049 | 801 | 1256 |
| Arabic — Bahrain | ar | ar-bh | 15361 | 1256 | |
| Arabic — Yemen | ar | ar-ye | 9217 | 2401 | 1256 |
| Arabic — Qatar | ar | ar-qa | 16385 | 4001 | 1256 |
| Urdu | ur | ur | 1056 | 420 | 1256 |
| Arabic — Egypt | ar | ar-eg | 3073 | 1256 | |
| Arabic — United Arab Emirates | ar | ar-ae | 14337 | 3801 | 1256 |
| Arabic — Tunisia | ar | ar-tn | 7169 | 1256 | |
| Farsi — Persian | fa | fa | 1065 | 429 | 1256 |
| Arabic — Morocco | ar | ar-ma | 6145 | 1801 | 1256 |
| Arabic — Libya | ar | ar-ly | 4097 | 1001 | 1256 |
| Arabic — Algeria | ar | ar-dz | 5121 | 1401 | 1256 |
| Arabic — Oman | ar | ar-om | 8193 | 2001 | 1256 |
| Lithuanian | lt | lt | 1063 | 427 | 1257 |
| Latvian | lv | lv | 1062 | 426 | 1257 |
| Estonian | et | et | 1061 | 425 | 1257 |
| Vietnamese | vi | vi | 1066 | 1258 | |
| Unicode | UTF-8 | 0 | 65001 |
This table was generated from information at Microsoft Windows Encodings and Code Pages and additional resources listed below.
Definitions
Locale: A collection of language-related, user-preference information represented as a list of values. (Reference)
Locale ID (LCID): A 32-bit value defined by Microsoft Windows that consists of a language ID, sort ID, and reserved bits that identify a particular language.
Codepage: «An ordered set of characters in which a numeric index (code point values) is associated with each character. The first 128 characters of each codepage are functionally the same and include all characters needed to type English text. The upper 128 characters of OEM and ANSI codepages contain characters used in a language or group of languages (Taken from Related resources below)».
Related resources
- FAQs about Locales and Languages
- ISO 8859 character sets
- Character sets recognized by Internet Explorer
- National Language Support (NLS) Information for Microsoft Windows XP
- Code pages supported by Windows
- Locales and Language Groups
- Windows XP — List of Locale IDs, Input Locale, and Language Collection
Кодовая страница (англ. code page) — таблица, сопоставляющая каждому значению байта некоторый символ (или его отсутствие). Обычно код символа имеет размер 8 бит, так что кодовая страница может содержать максимум 256 символов, из чего вытекает резкая недостаточность всякой 8-битной кодовой страницы для представления многоязычных текстов. К тому же часть символов используется как управляющие, из-за чего число печатных символов редко превышает 223[1].
Исторически термин code page был введён корпорацией IBM; сменные кодовые страницы использовались для поддержки различных языков (имеющих алфавитные системы письма). В последнее время имеется путаница между термином «кодовая страница» и более общим понятием набора символов (кодировки).
[править] Кодовые страницы сегодня
В настоящее время в основном используются кодировки двух типов: совместимые с ASCII и совместимые с EBCDIC[2], с подавляющим преобладанием первых. В ASCII-совместимых кодировках фиксированы коды 95 печатных символов и 33 управляющих, а остальные 128 кодовых позиций используются для различных символов, не входящих в ASCII.
Для кодирования текстов на русском языке (то есть букв кириллицы) наиболее широко применяются следующие кодовые страницы:
- Windows-1251, она же Microsoft code page 1251 (CP1251) — в системах Windows;
- Семейство кодовых страниц KOI8;
- Альтернативная кодировка, она же IBM code page 866 — в системах DOS, а также в текстовых окнах Microsoft Windows (см. ниже);
- MacCyrillic — на компьютерах Macintosh.
Использование различных кодовых страниц создаёт много неудобств как для пользователей, так и для программистов. При попытке прочесть текстовый файл при помощи кодовой страницы, несовместимой с той в которой он был создан, возникают кракозябры. В последние годы получил широкое распространение Unicode как альтернатива традиционным кодовым страницам.
[править] В системе Microsoft Windows
В системах Microsoft Windows кодовые страницы являются важным компонентом локализации, задаваемым в ключах реестра HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\Nls\CodePage\[3].
Исторически (в системах Windows 3.x и Windows 9x) имелось два типа кодовых страниц. Кодовые страницы «ANSI»[4] (англ. ANSI code page, в реестре: ACP), также называемые Windows[5] — родные кодовые страницы Windows. Содержат много символов типографики, но почти не содержат псевдографику по причине того, что предназначены для использования в графическом окружении. Впоследствии корпорация Microsoft признала, что использование имени ANSI было вызвано недоразумением.[6] К кодировкам «ANSI»/Windows относят, в частности, Windows-1252 и вышеупомянутую Windows-1251. Microsoft также относит к кодовым страницам кодовые таблицы, некоторые позиции которых требуют второго (завершающего) байта для формирования символа, то есть допускающие двухбайтовое представление некоторых символов[7], хотя они, строго говоря, являются уже кодировками с переменной длиной символа.
Кодировки OEM (англ. OEM code page, в реестре: OEMCP) основаны на CP437 и содержат VGA-совместимую псевдографику. Вышеупомянутая альтернативная кодировка известна в Windows как CP866.
Начиная с Windows NT появился третий класс кодовых страниц: кодировки Macintosh (англ. Macintosh code page, в реестре: MACCP), совместимых с MacOS.
[править] Примечания
- ↑ Одним из немногих исключений является кодировка VISCII для вьетнамской латиницы, совместимая с ASCII за вычетом шести кодов в зоне управляющих символов, заменённых на буквы, см. RFC 1456. Таким образом, она содержит 229 печатных символов.
- ↑ Кодировки на базе EBCDIC (например, ДКОИ-8) используются только на некоторых мэйнфреймах.
- ↑ REG: CurrentControlSet, PART 1, Microsoft (англ.)
- ↑ Кодовые страницы в Visual C++, MSDN
- ↑ Code Pages, MSDN
- ↑ MSDN: Glossary of Terms
- ↑ Windows code pages, MSDN
[править] См. также
- Консоль Linux
| Кодировки символов | |||
|---|---|---|---|
| Основы → | алфавит • текст ( файл • данные ) • набор символов • конверсия | ||
| Исторические кодировки → | Докомп.: семафорная (Макарова) • Морзе • Бодо • МТК-2 | Комп.: 6 бит • УПП • RADIX-50 • EBCDIC ( ДКОИ-8 ) • КОИ-7 • ISO 646 | |
| совре- менное 8-битное представ- ление |
символы → | ASCII ( управляющие • печатные ) | не-ASCII ( псевдографика ) |
| 8бит. код.стр. | Разные → Кириллица: КОИ-8 • ГОСТ 19768-87 • MacCyrillic | ||
| ISO 8859 → | 1(лат.) 2 3 4 5(кир.) 6 7 8 9 10 11 12 13 14 15(€) 16 | ||
| Windows → | 1250 1251(кир.) 1252 1253 1254 1255 1256 1257 1258 | WGL4 | ||
| IBM&DOS → | 437 • 850 • 852 • 855 • 866 «альт.» • ( МИК ) • ( НИИ ЭВМ ) | ||
| Много- байтные |
Традиционные → | DBCS ( GB2312 ) • HTML | |
| Unicode → | UTF-16 • UTF-8 • список символов ( кириллица ) | ||
| Связанные темы → |
интерфейс пользователя • раскладка клавиатуры • локаль • перевод строки • шрифт • кракозябры • транслит • нестандартные шрифты • текст как изображение | Утилиты: iconv • recode |
Для обычного виндоадмина PostgreSQL — как взрыв мозга и разрыв GUI шаблонов ))
И так задача — нужно создать пользователя БД. Средство администрирования pgAdmin не позволяет создать пользователя для определенной БД. Можно создать роль, но как привязать её к БД средствами GUI интерфейса совсем непонятно. Ладно, берем утилиту psql.exe, запускаем и получаем грозное сообщение:
C:\Programs\PostgreSQL\9.0\bin>psql -U postgres
psql (9.0.10)
ПРЕДУПРЕЖДЕНИЕ: Кодовая страница консоли (866) отличается от основной
страницы Windows (1251).
8-битовые (русские) символы могут отображаться некорректно.
Подробнее об этом смотрите документацию psql, раздел
«Notes for Windows users».
Введите «help», чтобы получить справку.
Можно впасть в депрессию, представив что нужно будет читать иероглифы, полученные отображением cp1251 под dos866. Но не всё потеряно. Рецепт из доки:
- \q или Ctrl+Z — выходим обратно в шелл
- chcp 1251 — меняем кодировку шелла на win1251
- в свойствах окна шелла меняем шрифт на Lucida Console
Ок. Кодировку починили, делаем пользователя. В сеансе psql:
- Подключаемся к БД — CONNECT our_database_name
- Создаем роль CREATE USER djangoweb;
(обазательно точку с запятой в конце, иначе не SQL не выполнится)
Вряд ли это сейчас сильно актуально, но может кому-то покажется интересным (или просто вспомнит былые годы).
Начну с небольшого экскурса в историю компьютера. Поскольку компьютер использовался для обработки информации, то он просто обязан представлять эту информацию в «человеческом» виде. Компьютер хранит информацию в виде чисел (байтов), а человек воспринимает символы (буквы, цифры, различные знаки). Значит, надо сделать сопоставление число <-> символ и задача будет решена. Сначала посчитаем, сколько символов нам надо (не забудем, что «мы» — американцы, использующие латинский алфавит). Нам надо 10 цифр + 26 заглавных букв английского алфавита + 26 строчных букв + математические знаки (хотя бы +-/*=><%) + знаки препинания (.,!?:;’” ) + различные скобки + служебные символы (_^%$@|) + 32 непечатных управляющих символов для работы с устройствами (в первую очередь, с телетайпом). В общем, 128 символов хватает «впритык» и этот стандартный набор символов «мы» назвали ASCII, т.е. «American Standard Code for Information Interchange»
Отлично, для 128 символов достаточно 7 бит. С другой стороны, в байте 8 бит и каналы связи 8-битные (забудем про «доисторические» времена, когда в байте и каналах бит было меньше). По 8-ми битному каналу будем передавать 7 бит кода символа и 1 бит контрольный (для повышения надежности и распознавания ошибок). И все было замечательно, пока компьютеры не стали использоваться в других странах (где латиница содержит больше 26 символов или вообще используется не латинский алфавит). Вместо того, чтобы всем поголовно освоить английский, жители СССР, Франции, Германии, Грузии и десятков других стран захотели, чтобы компьютер общался с ними на их родном языке. Пути были разные (в зависимости от остроты проблемы): одно дело, если к 26 символам латиницы надо добавить 2-3 национальных символа (можно пожертвовать какими-то специальными) и другое дело, когда надо «вклинить» кириллицу. Теперь «мы» — русские, стремящиеся «русифицировать» технику. Первыми были решения на основе замены строчных английских букв прописными русскими. Однако проблема в том, что русских букв (33) и они не влезают на 26 мест. Надо «уплотнить» и первой жертвой этого уплотнения пала буква Ё (еe просто повсеместно заменили на Е). Другой прием – вместо «русских» A,E,K,M,H,O,P,C,T стали использовать похожие английские (таких букв даже больше чем надо, но в некоторых парах прописные похожие, а строчные — не очень: Hh Tt Bb Kk Mm). Но все же «вклинили » и в результате весь вывод шел ПРОПИСНЫМИ БУКВАМИ, что неудобно и некрасиво, однако со временем привыкли. Второй прием – «переключение языка». Код русского символа совпадал с кодом английского символа, но устройство помнило, что сейчас оно в русском режиме и выводило символ кириллицы (а в английском режиме – латиницы). Режим переключался двумя служебными символами: Shift Out (SO, код 14) на русский и Shift IN (SI, код 15) на английский (интересно, что когда-то в печатных машинках использовалась двухцветная лента и SO приводил к физическому подъему ленты и в результате печать шла красным, а SI ставил ленту на место и печать снова шла черным). Текст с большими и маленькими буквами стал выглядеть вполне прилично. Все эти варианты более-менее работали на больших компьютерах, но после выпуска IBM PC началось массовое распространение персональных компьютеров по всему миру и надо было что-то решать централизовано.
Решением стала разработанная фирмой IBM технология кодовых страниц. К этому времени «контрольный символ» при передаче потерял свою актуальность и все 8-бит можно было использовать для кода символа. Вместо диапазона кодов 0-127 стал доступен диапазон 0-255. Кодовая страница (или кодировка)– это сопоставление кода из диапазона 0-255 некоему графическому образу (например, букве «Я» кириллицы или букве «омега» греческого). Нельзя сказать «символ с кодом 211 выглядит так», но можно сказать «символ с кодом 211 в кодовой странице CP1251 выглядит так: У, а в CP1253(греческая) выглядит так: Σ ». Во всех (или почти всех) кодовых таблица первые 128 кодов соответствуют таблице ASCII, только для первых 32 непечатных кодов IBM «назначила» свои картинки (которые показывается при выводе на экран монитора). В верхней части IBM разместила символы псевдографики (для рисования различных рамок), дополнительные символы латиницы, используемые в странах Западной Европы, некоторые математические символы и отдельные символы греческого алфавита. Эта кодовая страница получила название CP437 (IBM разработала и множество других кодовых страниц) и по умолчанию использовалась в видеоадаптерах. Кроме того, различные центры стандартизации (мировые и национальные) создали кодовые страницы для отображения национальных символов. Наши компьютерные «умы» предложили 2 варианта: основная кодировка ДОС и альтернативная кодировка ДОС. Основная предназначалась для работы везде, а альтернативная — в особых случаях, когда использование основной неудобно. Оказалось, что таких особых случаев большинство и основной (не по названию, а по использованию) стала именно «альтернативная» кодировка. Думаю, такой исход был ясен с самого начала для большинства специалистов (кроме «ученых мужей», оторванных от жизни). Дело в том, что в большинстве случаев использовались английские программы, которые «для красоты» активно использовали псевдографику для рисования различных рамок и тп. Типичные пример — суперпопулярный Нортон коммандер, стоящий тогда на большинстве компьютеров. Основная кодировка на местах псевдографики разместила русские символы и панели нортона выглядели просто ужасно (равно как и любой другой псевдографический вывод). А альтернативная кодировка бережно сохранила символы пседографики, использую для русских букв другие места. В результате и с Нортон коммандером и с другими программами вполне можно было работать. Андрей Чернов (широко известная личность в то время) разработал кодировку KOI8-R (КОИ8), пришедшую с «больших» компьютеров, где господствовал UNIX. Ее особенностью было то, что если у русского символа пропадал 8-й бит, то получившийся в результате «обрезания» английский символ будет созвучен исходному русскому. И вместо «Привет» получался «pRIVET», что не совсем то, но хотя бы читаемо. В результате в СССР на компьютерах использовали 3 различных кодовых страницы (основную, альтернативную и KOI8). И это не считая различных «вариаций», когда в альтернативной кодировке, скажем, отдельные символы (а то и строки) изменялись. От KOI8 тоже «отпочковывались» варианты — украинский, белорусский, таджикский, кавказский и др. Оборудование (принтеры, видеодаптеры) тоже надо было настраивать (или «прошивать») для работы со своими кодировками. Коммерсанты могли привезти дешевую партию принтеров (из эмиратов, например, по бартеру) а они не работали с русскими кодировками.
Тем не менее в целом кодовые страницы позволили решить проблему вывода национальных символов (устройство просто должно уметь работать с соответствующей кодовой страницей), но породили проблему множественности кодировок, когда почтовая программа отправляет данные в одной кодировке, а принимающая программа показывает их в другой. В результате пользователь видит так называемые «кракозябры» (вместо «привет» написано «ЏаЁўҐв» или «оПХБЕР»). Потребовались программы-перекодировщики, переводящие данные из одной кодировки в другую. Увы, порой письма при прохождении через почтовые серверы неоднократно автоматически перекодировались (или даже «обрезался» 8-й бит) и нужно было найти и выполнить всю цепочку обратных преобразований.
После массового перехода на Windows к трем кодовым страницам добавилась четвертая (Windows-1251 она же CP1251 она же ANSI ) и пятая (CP866 она же OEM или DOS). Не удивляйтесь — Windows для работы с кириллицей в консоли по-умолчанию использует кодировку CP866 (русские символы такие же как в «альтернативной кодировке», только некоторые спецсимволы отличаются), для других целей — кодировку CP1251. Почему Windows понадобилось две кодировки, неужели нельзя было обойтись одной? Увы, не получается: DOS-кодировка используется в именах файлов (тяжелое наследие DOS) и консольные команды типа dir, copy должны правильно показывать и правильно обрабатывать досовские имена файлов. С другой стороны, в этой кодировке много кодов отведено символам псевдографики (различным рамкам и т.п.), а Windows работает в графическом режиме и ей (а точнее, windows-приложениям) не нужны символы псевдографики (но нужны занятые ими коды, которые в CP1251 использованы для других полезных символов). Пять кириллических кодировок поначалу еще больше усугубили ситуацию, но со временем наиболее популярными стали Windows-1251 и KOI8, а досовскими просто стали меньше пользоваться. Еще при использовании Windows стало неважно, какая кодировка в видеоадаптере (только изредка, до загрузки Windows в диагностических сообщениях можно видеть «кракозябры»).
Решение проблемы кодировок пришло, когда повсеместно стала внедряться система Unicode (и для персональных ОС и для серверов). Unicode каждому национальному символу ставит в соответствие раз и навсегда закрепленное за ним 20-ти битовое число («точку» в кодовом пространстве Unicode, причем чаще всего хватает 16 бит, поскольку 20-битные коды используются для редких символов и иероглифов), поэтому нет необходимости перекодировать (подробнее об Unicode см следующую запись в журнале). Теперь для любой пары <код байта>+<кодовая страница> можно определить соответствующий ей код в Unicode (сейчас в кодовых страницах для каждого 8-битного кода показывается 16-битный код Unicode) и потом при необходимости вывести этот символ для любой кодовой страницы, где он присутствует. В настоящее время проблема кодировок и перекодировок для пользователей практически исчезла, но все же изредка приходят письма, где либо тема письма либо содержание «не в той» кодировке.
Интересно, что примерно год назад проблема кодировок ненадолго всплыла при «наезде» ФАС на сотовых операторов, мол те дискриминируют русскоязычных пользователей, поскольку за передачу кириллицы берут больше. Это объясняется техническим решением, выбранным разработчиком протокола SMS связи. Если бы его россияне разработали, они бы, возможно, отдали приоритет кириллице. В указанной статье «начальник управления контроля транспорта и связи Дмитрий Рутенберг отметил, что существуют и восьмибитные кодировки для кириллицы, которые могли бы использовать операторы.» Во как — на улице 21-й век, Unicode шагает по миру, а господин Рутенберг тянет нас в начало 90-х, когда шла «война кодировок» и проблема перекодировок стояла во весь рост. Интересно, в какой кодировке должен получить СМС Вася Пупкин, пользующийся финским телефоном, находящийся в Турции на отдыхе, от жены с корейским телефоном, отправляющей СМС из Казахстана? А от своего французского компаньона (с японским телефоном), находящегося в Испании? Думаю, никакой начальник ответа на этот вопрос дать не сможет. К счастью, это «экономное» предложение не воплотилось в жизнь.
Юный читатель может спросить — а что помешало сразу использовать Unicode, зачем были придуманы эти заморочки с кодовыми страницами? Думаю, дело в финансовой стороне проблемы. Unicode требует в 2 раза больше памяти, а память стоит денег (и дисковая и ОЗУ). Стал бы американец покупать компьютер на 1-2 тыс дороже из-за того, что «теперь новая ОС требует больше памяти, но позволяет без проблем работать с русским, европейскими, арабскими языками»? Боюсь, простой англоязычный покупатель воспринял бы такой аргумент «неадекватно» (и обратился бы к другим производителям).