
Материал из РУВИКИ — свободной энциклопедии
| Windows-1251 | |
|---|---|
| Описывается по ссылке |
iana.org/assignments/cha… msdn.microsoft.com/en-us… microsoft.com/typography… unicode.org/Public/MAPPI… unicode.org/Public/MAPPI… ibm.com/docs/en/db2/11.5… |
Windows-1251 — набор символов и кодировка, являющаяся стандартной 8-битной кодировкой для русских версий Microsoft Windows до 10-й версии. В прошлом пользовалась довольно большой популярностью. Была создана на базе кодировок, использовавшихся в ранних «самопальных» русификаторах Windows в 1990—1991 гг. совместно представителями «Параграфа», «Диалога» и российского отделения Microsoft. Первоначальный вариант кодировки сильно отличался от представленного ниже в таблице (в частности, там было значительное число «белых пятен»). Но, однако был вариативным и представленным в 6 формах применения.
В современных приложениях отдаётся предпочтение Юникоду (UTF-8). На 1 апреля 2019 лишь на 1 % всех веб-страниц используется Windows-1251.[1]
Windows-1251 выгодно отличается от других 8‑битных кириллических кодировок (таких как CP866, KOI8-R и ISO 8859-5) наличием практически всех символов, использующихся в русской типографике для обычного текста (отсутствует только значок ударения); она также содержит все символы для других славянских языков: украинского, белорусского, сербского, македонского и болгарского.
Windows-1251 имеет два недостатка:
- строчная буква «я» имеет код 0xFF (255 в десятичной системе). Она является «виновницей» ряда неожиданных проблем в программах без поддержки чистого 8-го бита, а также (гораздо более частый случай) использующих этот код как служебный (в CP437 он обозначает «неразрывный пробел», в Windows-1252 — ÿ, оба варианта практически не используются; число же
-1, в дополнительном коде длиной 8 бит представляющееся числом255, часто используется в программировании как специальное значение). Тот же недостаток имеет и KOI8-R, но в ней 0xFF есть заглавный твёрдый знак, который применяется редко (только при написании одними лишь заглавными буквами). - отсутствуют символы псевдографики, имеющиеся в CP866 и KOI8 (хотя для самих Windows, для которых она предназначена, в них не было нужды, это делало несовместимость двух использовавшихся в них кодировок заметнее).
Также как недостаток может рассматриваться отдельное расположение буквы «ё», тогда как остальные символы расположены строго в алфавитном порядке. Это усложняет программы лексикографического упорядочения.
Синонимы: CP1251; ANSI (только в русскоязычной ОС Windows).
Первая половина таблицы кодировки (коды от 0x00 до 0x7F) полностью соответствует кодировке ASCII. Числа под буквами обозначают шестнадцатеричный код подходящего символа в Юникоде.
Кодировка Windows-1251[править | править код]
| .0 | .1 | .2 | .3 | .4 | .5 | .6 | .7 | .8 | .9 | .A | .B | .C | .D | .E | .F | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 8. |
Ђ 402 |
Ѓ 403 |
‚ 201A |
ѓ 453 |
„ 201E |
… 2026 |
† 2020 |
‡ 2021 |
€ 20AC |
‰ 2030 |
Љ 409 |
‹ 2039 |
Њ 40A |
Ќ 40C |
Ћ 40B |
Џ 40F |
| 9. |
ђ 452 |
‘ 2018 |
’ 2019 |
“ 201C |
” 201D |
• 2022 |
– 2013 |
— 2014 |
™ 2122 |
љ 459 |
› 203A |
њ 45A |
ќ 45C |
ћ 45B |
џ 45F |
|
| A. |
A0 |
Ў 40E |
ў 45E |
Ј 408 |
¤ A4 |
Ґ 490 |
¦ A6 |
§ A7 |
Ё 401 |
© A9 |
Є 404 |
« AB |
¬ AC |
AD |
® AE |
Ї 407 |
| B. |
° B0 |
± B1 |
І 406 |
і 456 |
ґ 491 |
µ B5 |
¶ B6 |
· B7 |
ё 451 |
№ 2116 |
є 454 |
» BB |
ј 458 |
Ѕ 405 |
ѕ 455 |
ї 457 |
| C. |
А 410 |
Б 411 |
В 412 |
Г 413 |
Д 414 |
Е 415 |
Ж 416 |
З 417 |
И 418 |
Й 419 |
К 41A |
Л 41B |
М 41C |
Н 41D |
О 41E |
П 41F |
| D. |
Р 420 |
С 421 |
Т 422 |
У 423 |
Ф 424 |
Х 425 |
Ц 426 |
Ч 427 |
Ш 428 |
Щ 429 |
Ъ 42A |
Ы 42B |
Ь 42C |
Э 42D |
Ю 42E |
Я 42F |
| E. |
а 430 |
б 431 |
в 432 |
г 433 |
д 434 |
е 435 |
ж 436 |
з 437 |
и 438 |
й 439 |
к 43A |
л 43B |
м 43C |
н 43D |
о 43E |
п 43F |
| F. |
р 440 |
с 441 |
т 442 |
у 443 |
ф 444 |
х 445 |
ц 446 |
ч 447 |
ш 448 |
щ 449 |
ъ 44A |
ы 44B |
ь 44C |
э 44D |
ю 44E |
я 44F |
-
Таблица основного кода ASCII
-
Таблица расширенного кода ASCII
Другие варианты[править | править код]
(Показаны только отличающиеся строки, поскольку всё остальное совпадает)
Официальная кодировка Amiga-1251 (Amiga Inc., 2004 г.)[править | править код]
| .0 | .1 | .2 | .3 | .4 | .5 | .6 | .7 | .8 | .9 | .A | .B | .C | .D | .E | .F | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| A. |
A0 |
¡ A1 |
¢ A2 |
£ A3 |
€ 20AC |
¥ A5 |
¦ A6 |
§ A7 |
Ё 401 |
© A9 |
№ 2116 |
« AB |
¬ AC |
AD |
® AE |
¯ AF |
| B. |
° B0 |
± B1 |
² B2 |
³ B3 |
´ B4 |
µ B5 |
¶ B6 |
· B7 |
ё 451 |
¹ B9 |
º BA |
» BB |
¼ BC |
½ BD |
¾ BE |
¿ BF |
Официальная кодировка KZ-1048 (казахский стандарт)[править | править код]
Данная кодировка утверждена стандартом СТ РК 1048—2002 и зарегистрирована в IANA как KZ-1048 [1].
| .0 | .1 | .2 | .3 | .4 | .5 | .6 | .7 | .8 | .9 | .A | .B | .C | .D | .E | .F | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 8. |
Ђ 402 |
Ѓ 403 |
‚ 201A |
ѓ 453 |
„ 201E |
… 2026 |
† 2020 |
‡ 2021 |
€ 20AC |
‰ 2030 |
Љ 409 |
‹ 2039 |
Њ 40A |
Қ 49A |
Һ 4BA |
Џ 40F |
| 9. |
ђ 452 |
‘ 2018 |
’ 2019 |
“ 201C |
” 201D |
• 2022 |
– 2013 |
— 2014 |
™ 2122 |
љ 459 |
› 203A |
њ 45A |
қ 49B |
һ 4BB |
џ 45F |
|
| A. |
A0 |
Ұ 4B0 |
ұ 4B1 |
Ә 4D8 |
¤ A4 |
Ө 4E8 |
¦ A6 |
§ A7 |
Ё 401 |
© A9 |
Ғ 492 |
« AB |
¬ AC |
AD |
® AE |
Ү 4AE |
| B. |
° B0 |
± B1 |
І 406 |
і 456 |
ө 4E9 |
µ B5 |
¶ B6 |
· B7 |
ё 451 |
№ 2116 |
ғ 493 |
» BB |
ә 4D9 |
Ң 4A2 |
ң 4A3 |
ү 4AF |
Кодировка Windows-1251 (чувашский вариант)[править | править код]
| .0 | .1 | .2 | .3 | .4 | .5 | .6 | .7 | .8 | .9 | .A | .B | .C | .D | .E | .F | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 8. |
Ђ 402 |
Ѓ 403 |
‚ 201A |
ѓ 453 |
„ 201E |
… 2026 |
† 2020 |
‡ 2021 |
€ 20AC |
‰ 2030 |
Љ 409 |
‹ 2039 |
Ӑ 4D0 |
Ӗ 4D6 |
Ҫ 4AA |
Ӳ 4F2 |
| 9. |
ђ 452 |
‘ 2018 |
’ 2019 |
“ 201C |
” 201D |
• 2022 |
– 2013 |
— 2014 |
™ 2122 |
љ 459 |
› 203A |
ӑ 4D1 |
ӗ 4D7 |
ҫ 4AB |
ӳ 4F3 |
Татарский вариант[править | править код]
Эта кодировка была официально принята в Татарстане в 1996 г.
| .0 | .1 | .2 | .3 | .4 | .5 | .6 | .7 | .8 | .9 | .A | .B | .C | .D | .E | .F | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 8. |
Ә 4D8 |
Ѓ 403 |
‚ 201A |
ѓ 453 |
„ 201E |
… 2026 |
† 2020 |
‡ 2021 |
€ 20AC |
‰ 2030 |
Ө 4E8 |
‹ 2039 |
Ү 4AE |
Җ 496 |
Ң 4A2 |
Һ 4BA |
| 9. |
ә 4D9 |
‘ 2018 |
’ 2019 |
“ 201C |
” 201D |
• 2022 |
– 2013 |
— 2014 |
™ 2122 |
ө 4E9 |
› 203A |
ү 4AF |
җ 497 |
ң 4A3 |
һ 4BB |
- ↑ Historical trends in the usage of character encodings, April 2019. Дата обращения: 11 февраля 2016. Архивировано 3 марта 2021 года.
- История создании кодировки в сообщении Игоря Семенюка в эхоконференции SU.LAN от 14 января 1996
Кодировка (или кодирование) – это процедура преобразования данных и сигналов из формы представления, удобной для восприятия человеком, в форму, которую распознает электронное устройство. Прием, позволяющий подготовить информацию для обработки, передачи, а также дальнейшего хранения.
Получаемые данные будут обрабатываться в виде логических единиц и нулей – в двоичной системе. Если числовые символы можно перевести в такую форму представления без проблем, то с кириллицей и другими буквами ситуация обстоит иначе. Буквы не поддерживают перевод в двоичный код. Вместо этого записи сначала преобразовываются в числа по специальной таблице символов. Далее компьютер считывает полученные данные и выдает результат.
В истории сложилось так, что были созданы несколько таблиц символов. Связано это с большим количеством национальных алфавитов, а также разными позициями относительно их написания.
Статья расскажет о существующих кодировках, а также поможет понять, как выразить символы кириллицы в UTF-8 и UTF-16.
Виды кодировок
Кодировать символы можно разными способами. Ситуация напрямую зависит от того, какая кодировка используется в системе. Существуют различные ее виды. Основные:
- ASCII;
- CP866;
- KOI8-R;
- Windows 251;
- Unicode.
Чаще всего встречаются первая и последняя кодировки. Не все они распознают буквы русского алфавита. Далее каждый вариант будет рассмотрен более подробно. А еще предстоит выяснить, что делать, если при попытке закодировать кириллицу на экране появляются непонятные записи.
ASCII – базовая кодировка
ASCII – American Standard Code for Information Interchange. В русском языке произносится как «Аски». Базовая кодировка для работы устройств. Первые 128 ее символов являются наиболее используемыми. Они включают в себя:
- латинские буквы;
- цифры (арабские);
- служебные компоненты;
- знаки препинания.
Для кодировки используется один байт. Это привело к тому, что у ASCII появились расширенные версии. Изначально данные таблицы не предоставляли возможность работы с кириллицей и русскими символами. Вместо них на экране появлялись непонятные записи – «кракозябры».


Выше представлены стандартные таблицы ASCII. В них русского алфавита нет – он не предусмотрен действующими правилами.
Расширенные ASCII
ASCII положила начало развития актуальных современных таблиц кодирования информации. Изначально она содержала 128 составляющих, но в расширенной версии их стало 256. Это дало возможность добавления новых алфавитов для корректного распознавания информации и ее дальнейшего отображения на дисплее устройства.
Первая расширенная версия ASCII – это CP866. В ней реализована первая таблица кодировки русских букв. Верхняя часть CP866 полностью совпадает с базовым «Аски», а нижняя позволяет закодировать кириллицу и некоторые символы, которых нет на клавиатуре.

Выше расположена кодовая таблица CP866. Она распространялась компанией IBM и использовалась преимущественно в DOS-системах.
Кириллица с момента образования CP866 стала активно использоваться к компьютерной технике. Это привело к созданию совершенно новых кодировок с русскими символами. Пример – KOI8-R.
Здесь каждый символ тоже кодируется одним байтом. Первая часть соответствует классической ASCII. Во второй располагаются специальные записи, которых нет на клавиатуре, а также русские буквы.
KOI8-R отличается тем, что буквы в русского языка в ней располагаются не в алфавитном порядке. Они располагаются по принципу созвучия с латиницей. Данный прием предпринят для того, чтобы было удобнее переходить с кириллицы на латинские буквы, отбрасывая всего один бит.
Windows 1251
Дальнейшее развитие кодировок связано с появлением графических операционных систем. Для отображения информации на экране псевдографика стала ненужной. Так возникли группы, которые выступали в качестве расширенных версий ASCII, но являлись более совершенными. Псевдографика в них отсутствовала. Они получили название ANSI.
Наглядный и весьма распространенный вариант такой кодировки – это Windows 1251. Он отличается от предшественников следующими особенностями:
- Вместо псевдографики здесь располагаются недостающие символы кириллицы и русской типографики. Знак ударения – единственное исключение. Его там нет.
- На замену псевдографики пришли элементы, приближенные к кириллице – буквы славянских языков.
- Первые 32 элемента отведены под операции, перевод строки и пробел.
- До 127 элемента расположены интернациональные компоненты, латинский алфавит, знаки препинания и математических действий, цифры.
- Оставшееся «пространство» выделено под национальные элементы. Именно они отображают различные мировые алфавиты.

Кодовая таблица, представленная выше – часть Windows 1251, отведенная под кириллицу и иные элементы.
Unicode
Unicode – кодировка, которая пользуется наибольшим спросом в современных компьютерных устройствах. Этот стандарт включает в себя почти все знаки существующих письменных языков. Он преобладает в Интернете. Был создан в 1991 году.
Unicode является многоязычным стандартом, базирующимся на ASCII. Он включает не только кириллицу, но и азиатские иероглифы. Выступает в качестве универсальной кодировки. Включает в себя несколько стандартов.
UTF-32
Первая вариация Unicode. Для кодирования одного элемента здесь используются 32 бита или 4 байта. Данная особенность приводит к тому, что закодированный кириллический символ в UTF-32 будет иметь вес в 4 раза больше, чем в ASCII. Несмотря на соответствующий недостаток, система стала предлагать закодировать знаки в количестве 232.
Все символы в UTF-32 непосредственно индексируемы. Найти тот или иной знак по номеру его позиции в файле удается очень быстро. Это привело к быстрой обработке операций по замене символьных данных.
UTF-16
UTF-16 – новый, более совершенный стандарт Unicode. После появления стала выступать базовым пространством для всех используемых печатных элементов. Кириллическая таблица в ней тоже есть.

Коды символов в UTF-16 содержатся в 16-ричной системе счислений. Увидеть их можно, если перейти в раздел Windows «Таблица символов». Она располагается в меню «Пуск»–«Программы»–«Стандартные»–«Служебные».
При помощи UTF-16 можно закодировать 65 536 элементов. Это число стало базовым для Unicode. Расширенное пространство включает в себя миллион дополнительных символьных записей.
При переходе с ASCII на UTF-16 размер исходного кода документа увеличивается уже не в 4, а в 2 раза. Связано это с использованием 2 байтов для кодирования одного и того же символа или шестнадцать бит.
UTF-8
Со временем был разработан стандарт UTF-8. В нем тоже есть кириллическая кодовая таблица. Носит название переменной длины. Несмотря на то, что в названии стандарта стоит 8, она действительно меняется. Каждый элемент может получить код длиной от 1 до 6 байт включительно. Практически стандартом используются компоненты до 4 байт. Латинские буквы здесь содержатся в одном байте, как и в ASCII.
В UTF-8 русские символы занимают по 2 байта, а грузинские – по 3. Текущий стандарт предусматривает возможность печати не только букв, но и смайликов. С UTF-8 хорошо работают даже системы, которые не ориентированы на Unicode. Связано это с тем, что базовая часть ASCII перешла в новый стандарт Юникода.
Блоки кириллицы
Unicode, начиная с версии 9.0, для кириллицы отвел пять различных блоков:
| Как называется | Диапазон кодов типа hex | Версия Unicode | |
| Cyrillic | Стандартная кириллица | От 0400 до 04FF | 1.1 |
| Cyrillic Supplement | Дополнения | От 0500 до 052F | 3.2 |
| Cyrillic Extended-A | Расширенная кириллица–А | От 2DE0 до 2DFF | 5.1 |
| Extended-B | Кириллица расширенного типа–B | От A640 до A69F | |
| Extended-C | Кириллица расширенная–C | От 1C80 до 1C8F | 9.0 |
Эти 4 раздела содержатся в кодовом пространстве Unicode 448 позиций. Из них 22 не определены.
Все символы кириллицы можно разбить на несколько групп:
- славянские алфавиты;
- исторические буквы и старославянский (церковный славянский) алфавит;
- дополнительные буквы для различных языков, использующих кириллицу;
- церковнославянские буквотипы;
- дополнительные буквы и символы для церковнославянского языка;
- элементы для старой орфографии Абхазии;
- старые формы представления кириллицы.
Несмотря на относительное совершенство Unicode, при использовании кодировок кириллицы в UTF-8 и других возникают некоторые проблемы. Пример – неоднозначность относительно кодирования некоторых букв. Для того, чтобы привести текст к единому стилю и корректному отображению, приходится определять каждым конкретным стандартом форму нормализации информации.
Непонятные символы на экране – исправление
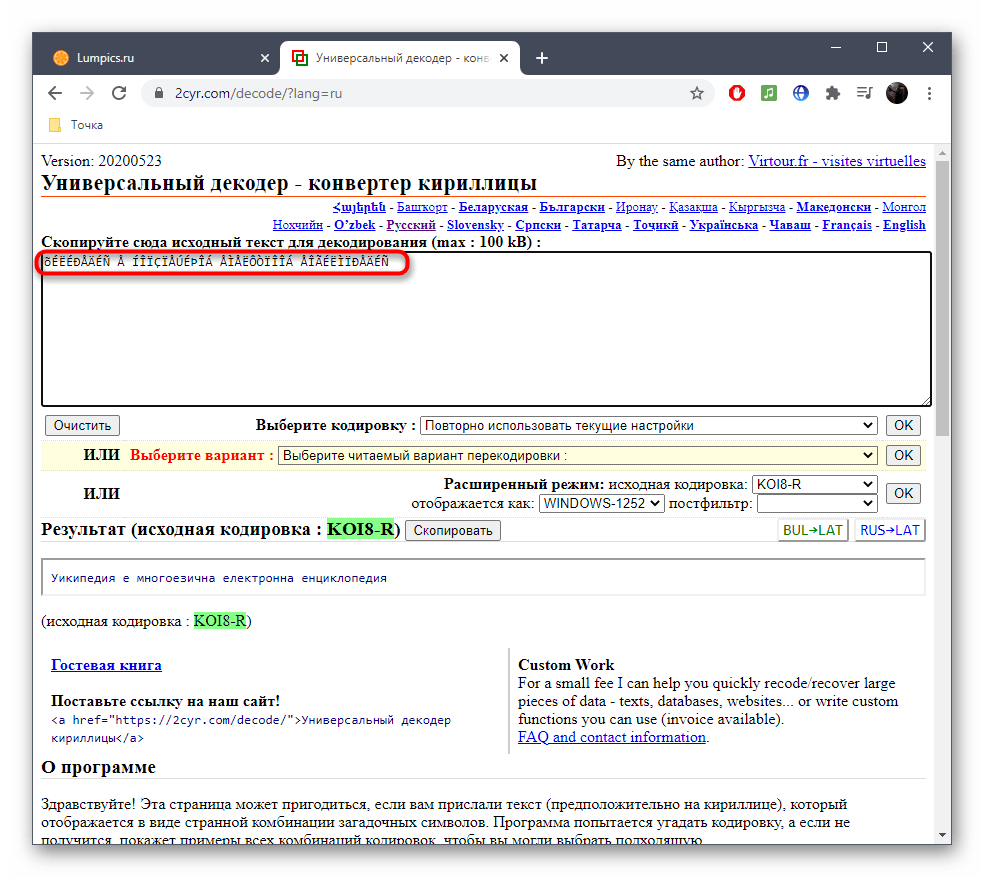
Любая страница данных может быть закодирована не только в ASCII, но и в Unicode. Главное правильно выбрать кодировку для русского текста. Если на экране вместо нормальных текстовых данных отображаются «кракозябры» (или непонятные надписи), значит возникла проблема перекодирования.
Для редактирования и создания новых текстовых документов можно использовать различные приложения, поддерживающие работу не только с Unicode. Тогда вероятность возникновения ошибок отображения информации будет сведена к минимуму. Пример – Notepad++. Он умеет подсвечивать синтаксис сотен языков программирования и разметки, что станет особо полезным при программировании проектов.
Чтобы страница, содержащая текст, была приведена от одного стандарта к другому, потребуется:
- Выделить текст в Notepad++.
- Нажать на кнопку «Кодировка» на верхней панели инструментов.
- Выбрать подходящий вариант. Пример – «Преобразовать в UTF-8».
Желательно выбирать вариант кодировки UTF-8 без BOM для русского языка, отображаемого на странице в документе или на сайте. Этот прием поможет сохранить данные без сигнатуры (добавления лишних трех байтов в самое начало документов).
Десятичная система
При преобразовании информации из одной системы счисления (и кодировки) в другую, могут потребоваться ее десятичные значения. Такой вариант используется в ASCII и UTF-32. При помощи него можно перевести символ в удобную для восприятия компьютером форму. А еще – выполнить дальнейшую перекодировку в те или иные системы счисления.
Десятичная система помогает в Windows вводить различные символы при помощи сочетания с Alt. Для перевода кириллицы в UTF-8 format поможет таблица ниже.



В Unicode transformation символьных записей производится при помощи целых чисел без знаков. Необходимые преобразования помогут выполнить специализированные сайты-конвертеры. Самостоятельно такие операции практически не используются. Таблицы соответствия и конвертеры сильно облегчают эту задачу.
Как освоить кодирование информации
Русская кодировка может некорректно отображаться в некоторых приложениях, а также операционных системах. Связано это с тем, что не все стандарты кодирования данных имеют коды для соответствующих элементов.
Чтобы лучше разобраться в программировании, а также грамотном использовании стандартов кодирования и переводе текста из одной системы в другую, рекомендуется закончить дистанционные онлайн курсы. Они предлагают:
- постоянное кураторство;
- домашние задания и интересные практические задачи;
- возможность освоить инновационные профессии и направления в мире IT в сжатые сроки;
- помощь в формировании портфолио;
- разнообразие направлений – есть предложения как для новичков, так и для взрослых.
По завершении курса обучения ученик получит сертификат в электронной форме, подтверждающий приобретенный спектр знаний и умений.
Хотите стать профессионалом в сфере обработки данных? Добро пожаловать на курсы в Otus:
- Промышленный ML на больших данных
- Data Warehouse Analyst
- Data Engineer
Таблица кодов кириллицы в Unicode, UTF-8 и Windows-1251
Во-первых, напомню, что Юникод — не кодировка, а стандарт кодирования,
кодировки — это UTF-8, UTF-16 и т.д., но, в силу инерции, разработчики и пользователи часто
говорят о «кодировке Юникод», имея в виду распространённую именно в их деревне форму представления символов 
Во-вторых, на самом деле кодирование там довольно замудрённое, возьмём, скажем русскую заглавную «Ж».
Представляемые в Юникоде символы кодируются целыми числами без знака, их можно называть «кодами символов Unicode».
Так, для буквы «Ж» Unicode = 104610 или 041616 или 10000 0101102. Unicode в двоичном виде разбивается на две части: пять левых бит и шесть правых. Левая часть в старших разрядах дополняется до байта признаком 110 двухбайтного кода UTF-8, получаем 11010000. К правой части в старших разрядах приписываются два бита 10 признака продолжения многобайтного кода, получаем 10010110. Окончательно код буквы «Ж» в UTF-8 будет иметь вид
11010000 100101102 или D0 9616.
Именно последний код мы увидим в любом 16-ричном вьюере файла, например, создав в текстовом редакторе файл со словом «Жора» и сохранив его в UTF-8 (только не из Блокнотика Windows, который добавит в начало файла 3-байтовую метку BOM):

просмотр файла в 16-ричном виде из Far Manager
То есть, каждая буква кодируется как бы дважды, сначала в 11-битный Unicode, затем в 16-битный UTF-8.
Ниже приведена таблица кодов кириллицы в Unicode, UTF-8 и однобайтовой кодировке Windows-1251.
| Символ | Unicode | UTF-8 | Windows-1251 | ||
|---|---|---|---|---|---|
| 16-ричн. | 10-тичн. | 16-ричн. | 10-тичн. | ||
| А | 0410 | 1040 | D090 | 208 144 | 192 |
| Б | 0411 | 1041 | D091 | 208 145 | 193 |
| В | 0412 | 1042 | D092 | 208 146 | 194 |
| Г | 0413 | 1043 | D093 | 208 147 | 195 |
| Д | 0414 | 1044 | D094 | 208 148 | 196 |
| Е | 0415 | 1045 | D095 | 208 149 | 197 |
| Ж | 0416 | 1046 | D096 | 208 150 | 198 |
| З | 0417 | 1047 | D097 | 208 151 | 199 |
| И | 0418 | 1048 | D098 | 208 152 | 200 |
| Й | 0419 | 1049 | D099 | 208 153 | 201 |
| К | 041A | 1050 | D09A | 208 154 | 202 |
| Л | 041B | 1051 | D09B | 208 155 | 203 |
| М | 041C | 1052 | D09C | 208 156 | 204 |
| Н | 041D | 1053 | D09D | 208 157 | 205 |
| О | 041E | 1054 | D09E | 208 158 | 206 |
| П | 041F | 1055 | D09F | 208 159 | 207 |
| Р | 0420 | 1056 | D0A0 | 208 160 | 208 |
| С | 0421 | 1057 | D0A1 | 208 161 | 209 |
| Т | 0422 | 1058 | D0A2 | 208 162 | 210 |
| У | 0423 | 1059 | D0A3 | 208 163 | 211 |
| Ф | 0424 | 1060 | D0A4 | 208 164 | 212 |
| Х | 0425 | 1061 | D0A5 | 208 165 | 213 |
| Ц | 0426 | 1062 | D0A6 | 208 166 | 214 |
| Ч | 0427 | 1063 | D0A7 | 208 167 | 215 |
| Ш | 0428 | 1064 | D0A8 | 208 168 | 216 |
| Щ | 0429 | 1065 | D0A9 | 208 169 | 217 |
| Ъ | 042A | 1066 | D0AA | 208 170 | 218 |
| Ы | 042B | 1067 | D0AB | 208 171 | 219 |
| Ь | 042C | 1068 | D0AC | 208 172 | 220 |
| Э | 042D | 1069 | D0AD | 208 173 | 221 |
| Ю | 042E | 1070 | D0AE | 208 174 | 222 |
| Я | 042F | 1071 | D0AF | 208 175 | 223 |
| а | 0430 | 1072 | D0B0 | 208 176 | 224 |
| б | 0431 | 1073 | D0B1 | 208 177 | 225 |
| в | 0432 | 1074 | D0B2 | 208 178 | 226 |
| г | 0433 | 1075 | D0B3 | 208 179 | 227 |
| д | 0434 | 1076 | D0B4 | 208 180 | 228 |
| е | 0435 | 1077 | D0B5 | 208 181 | 229 |
| ж | 0436 | 1078 | D0B6 | 208 182 | 230 |
| з | 0437 | 1079 | D0B7 | 208 183 | 231 |
| и | 0438 | 1080 | D0B8 | 208 184 | 232 |
| й | 0439 | 1081 | D0B9 | 208 185 | 233 |
| к | 043A | 1082 | D0BA | 208 186 | 234 |
| л | 043B | 1083 | D0BB | 208 187 | 235 |
| м | 043C | 1084 | D0BC | 208 188 | 236 |
| н | 043D | 1085 | D0BD | 208 189 | 237 |
| о | 043E | 1086 | D0BE | 208 190 | 238 |
| п | 043F | 1087 | D0BF | 208 191 | 239 |
| р | 0440 | 1088 | D180 | 209 128 | 240 |
| с | 0441 | 1089 | D181 | 209 129 | 241 |
| т | 0442 | 1090 | D182 | 209 130 | 242 |
| у | 0443 | 1091 | D183 | 209 131 | 243 |
| ф | 0444 | 1092 | D184 | 209 132 | 244 |
| х | 0445 | 1093 | D185 | 209 133 | 245 |
| ц | 0446 | 1094 | D186 | 209 134 | 246 |
| ч | 0447 | 1095 | D187 | 209 135 | 247 |
| ш | 0448 | 1096 | D188 | 209 136 | 248 |
| щ | 0449 | 1097 | D189 | 209 137 | 249 |
| ъ | 044A | 1098 | D18A | 209 138 | 250 |
| ы | 044B | 1099 | D18B | 209 139 | 251 |
| ь | 044C | 1100 | D18C | 209 140 | 252 |
| э | 044D | 1101 | D18D | 209 141 | 253 |
| ю | 044E | 1102 | D18E | 209 142 | 254 |
| я | 044F | 1103 | D18F | 209 143 | 255 |
| Символы вне общего правила | |||||
| Ё | 0401 | 1025 | D081 | 208 129 | 168 |
| ё | 0451 | 1105 | D191 | 209 145 | 184 |
23.09.2018, 12:37 [143642 просмотра]
Все способы:
- Способ 1: Изменение системного языка
- Способ 2: Изменение параметра использования бета-версии Юникода
- Способ 3: Редактирование реестра
- Способ 4: Замена системного файла
- Способ 5: Проверка целостности системных файлов
- Способ 6: Возвращение Windows к заводским настройкам
- Исправление кодировки в содержании и названиях файлов
- Вопросы и ответы: 7
Способ 1: Изменение системного языка
Чаще всего проблемы с отображением русских букв в Windows 11 связаны с некорректно установленными языковыми параметрами. Подобные дефекты могут появиться как при переименовании файлов, так и в интерфейсах сторонних программ или даже в некоторых частях операционной системы. Соответственно, понадобится проверить вручную языковые настройки и установить нужные, обеспечив тем самым поддержку текстовой кодировки. Универсальную инструкцию по этой теме вы найдете в другой статье на нашем сайте, перейдя по следующей ссылке.
Подробнее: Смена языка интерфейса ОС Windows 11
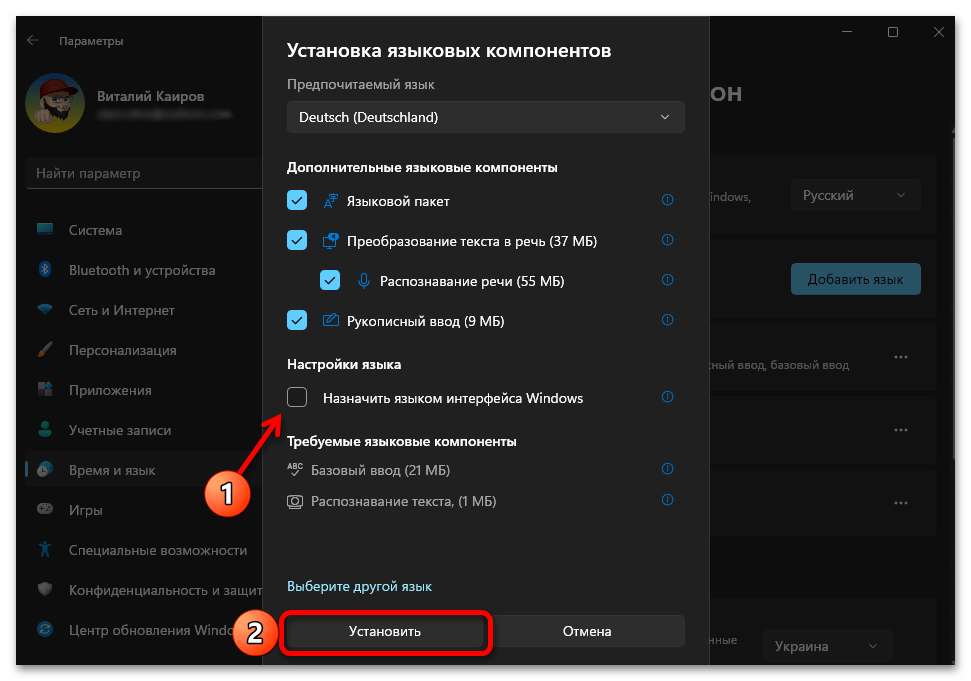
Способ 2: Изменение параметра использования бета-версии Юникода
Юникод (UTF-8) — стандартное кодирование текста для поддержки многих языков. В Windows 11 предлагается использовать его вместо основных языковых кодировок для каждого отдельного региона. Пользователь может столкнуться с отображением «кракозябр» вместо русских букв как при использовании функции, так и когда она отключена. Поэтому понадобится изменить состояние настройки и переключить кодировку. Для этого достаточно следовать предложенной ниже инструкции.
- Откройте «Пуск» и перейдите в «Параметры», кликнув по значку с изображением шестеренки.
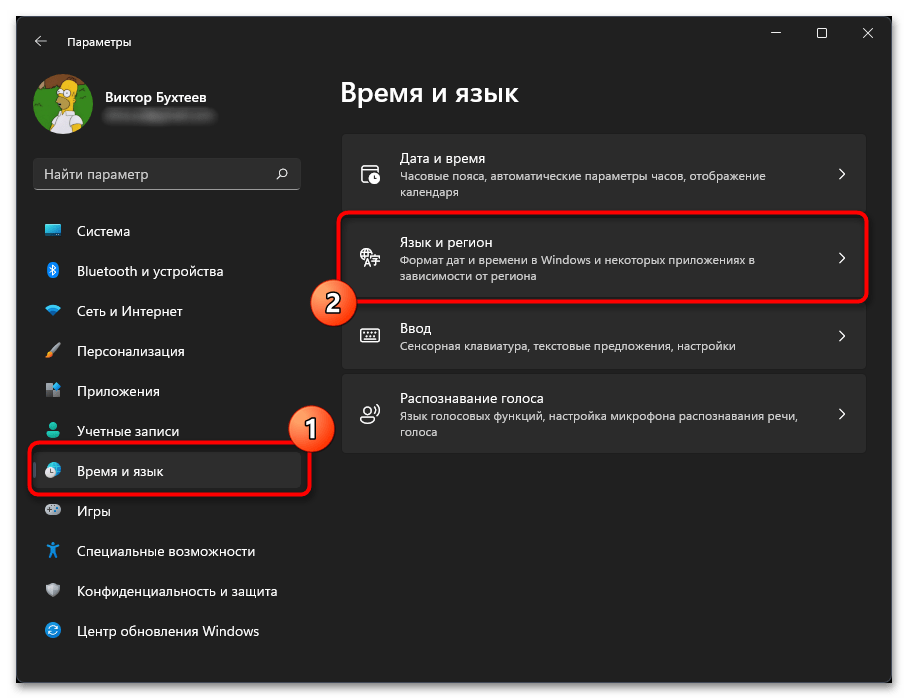
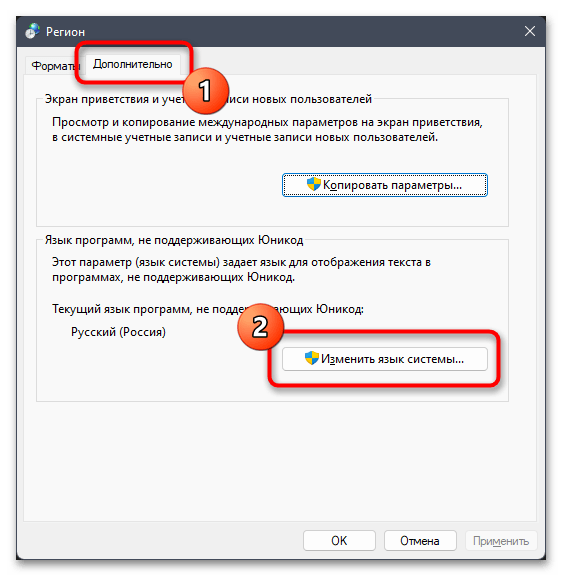
- В новом окне на панели слева выберите раздел «Время и язык», затем щелкните по категории «Язык и регион», чтобы перейти к ней.
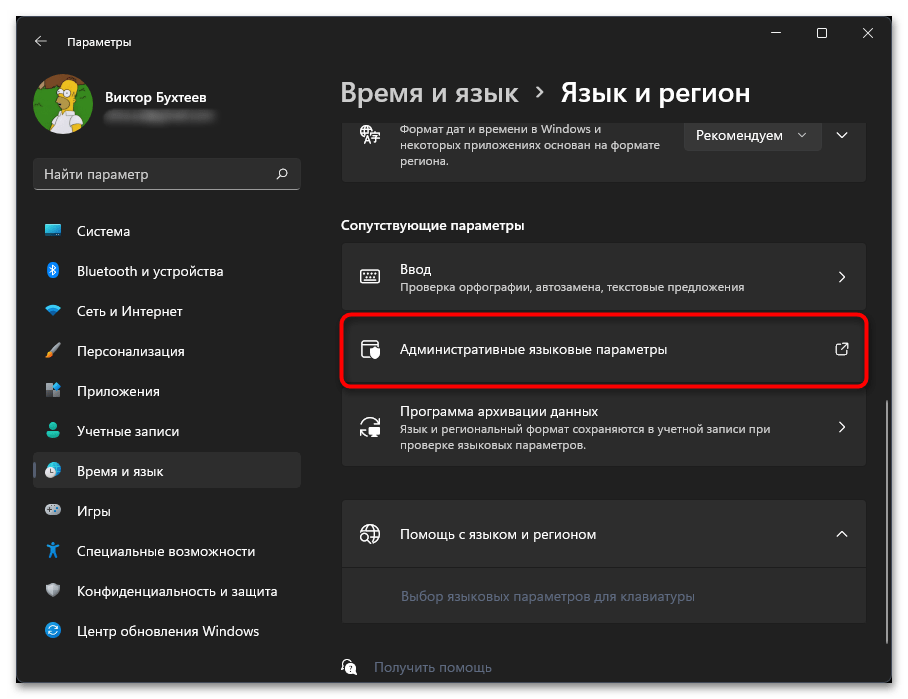
- Нажмите по ссылке «Административные языковые параметры».
- Отобразится дополнительное окно с названием «Регион», в котором следует выбрать вкладку «Дополнительно» и кликнуть по кнопке «Изменить язык системы».
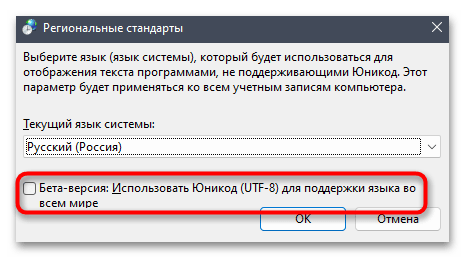
- Поставьте или снимите галочку около пункта «Бета-версия: Использовать Юникод (UTF-8) для поддержки языка во всем мире» в зависимости от того, активна ли она сейчас. Сохраните изменения и отправьте ПК на перезагрузку.
Способ 3: Редактирование реестра
Метод с редактированием реестра несет определенные риски, поскольку будут изменены системные параметры, отвечающие за корректность работы графического интерфейса. Поэтому рекомендуем перед вмешательством обязательно сделать резервную копию и разобраться с тем, как восстановить изначальное состояние реестра, если после применения новых настроек возникнут проблемы с работой ОС.
Подробнее: Восстановление системного реестра Windows 11
После всех подготовительных действий можно переходить непосредственно к настройке реестра. Этот процесс подразумевает проверку текущего языкового параметра с его редактированием или заменой, если это будет необходимо. Внимательно следуйте руководству, чтобы ни на каком из этапов не возникло трудностей.
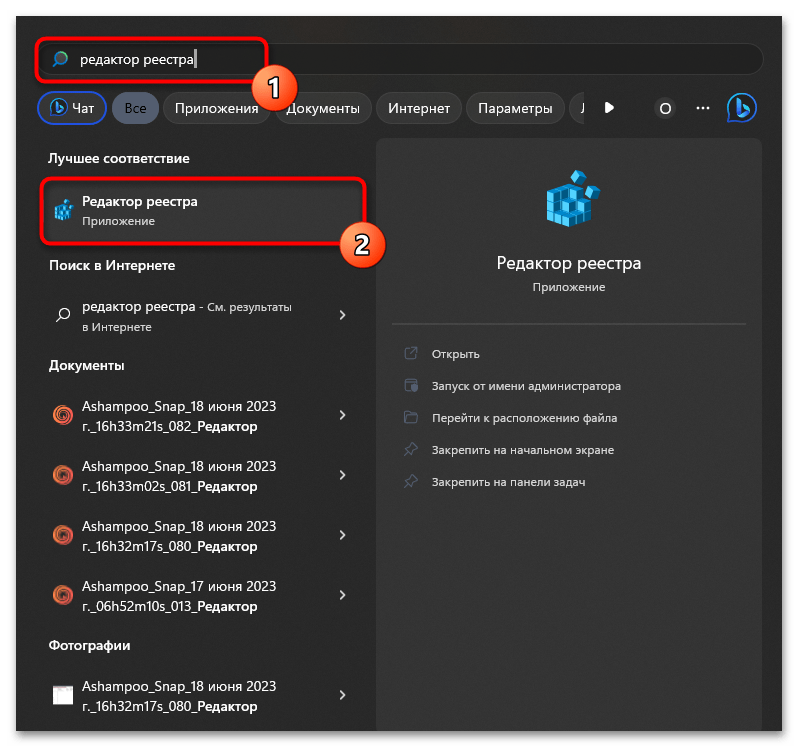
- Откройте «Пуск», через поиск отыщите «Редактор реестра» и запустите данное приложение.
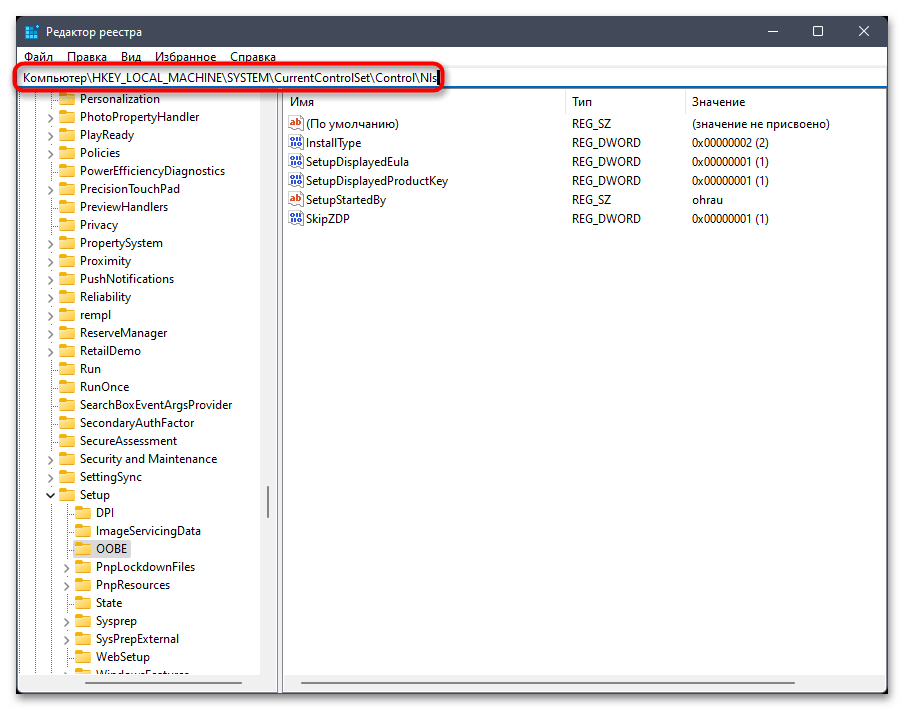
- В его адресную строку вставьте путь
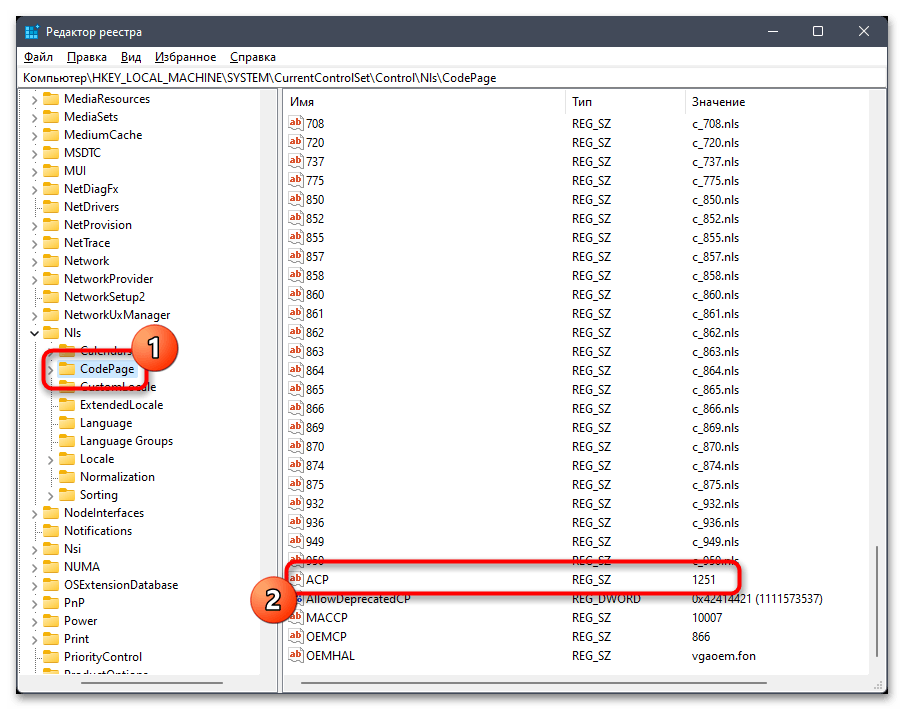
Компьютер\HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\Nlsи перейдите по нему. - На панели слева выберите каталог с названием «CodePage» и внизу списка с параметрами отыщите «ACP». Вам необходимо убедиться в том, что данная настройка имеет значение
1251. - Если это не так, щелкните по параметру дважды и внесите изменение. По завершении обязательно перезагрузите ПК и проверьте, удалось ли такой настройкой исправить «кракозябры».
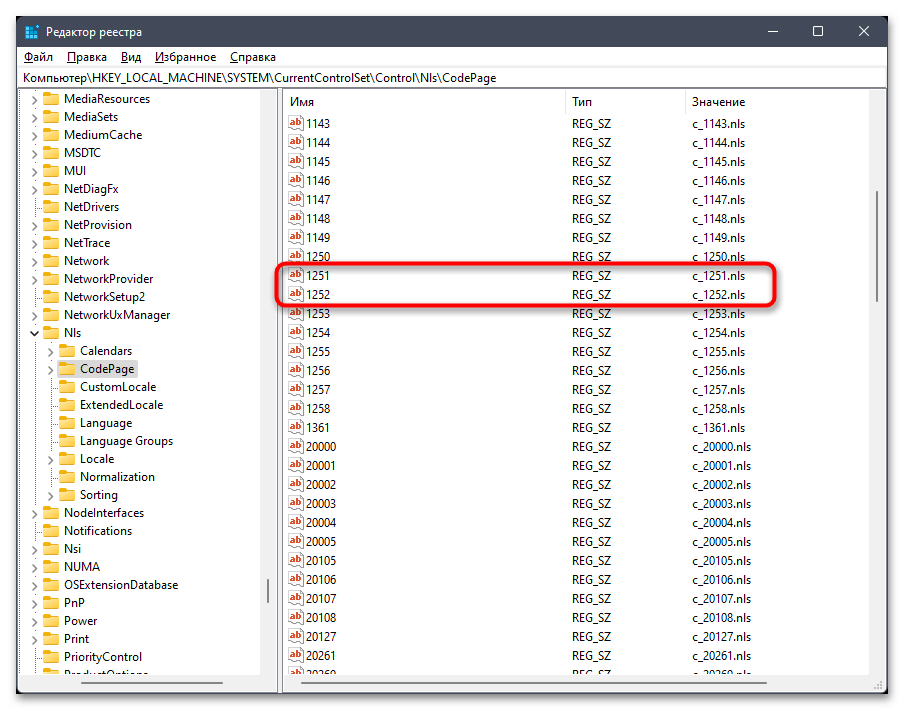
- В случае сохранения ошибки понадобится осуществить подмену файла. Для этого найдите в этой же папке параметры «1251» и «1252». Если каждый из них существует, то «1251» удалите.
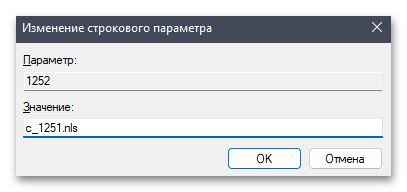
- Для «1252» поменяйте значение на
c_1251.nls, сохраните изменения и снова перезагрузите компьютер.

Если ошибка не исчезла, всегда рекомендуется вернуть настройки по умолчанию, восстановив реестр или самостоятельно воссоздав нужные параметры, изменение которых и производилось ранее.
Способ 4: Замена системного файла
Следующий метод тоже подразумевает изменение системных настроек. При помощи замены файлов можно добиться исправления кодировки, когда язык операционной системы по каким-то причинам распознается некорректно и появляются «кракозябры» вместо нормальных букв. Будьте готовы к тому, что такие изменения тоже могут негативно сказаться на работе ОС, поэтому во время выполнения инструкции соблюдайте все рекомендации по сохранению оригиналов файлов, чтобы в случае чего восстановить все так, как это было ранее.
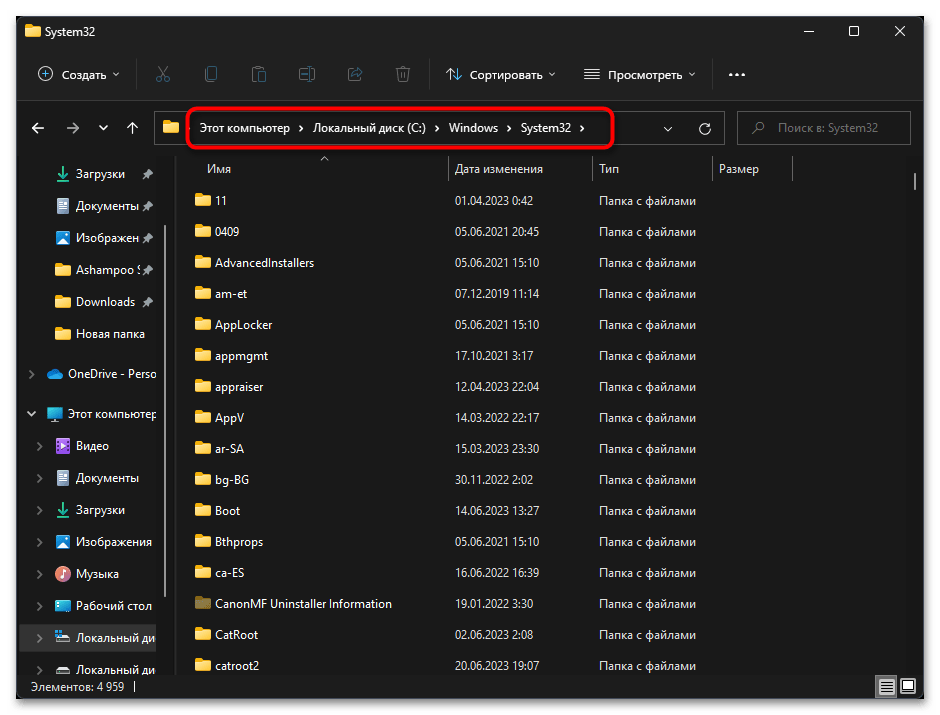
- Откройте «Проводник» и перейдите по пути
C:/Windows/System32. - В данном каталоге отыщите файл с названием «C_1252.NLS».
- Для него нужно изменить владельца, чтобы система разрешила переименование и выполнение других действий. Щелкните по файлу правой кнопкой мыши и из контекстного меню выберите пункт «Свойства».
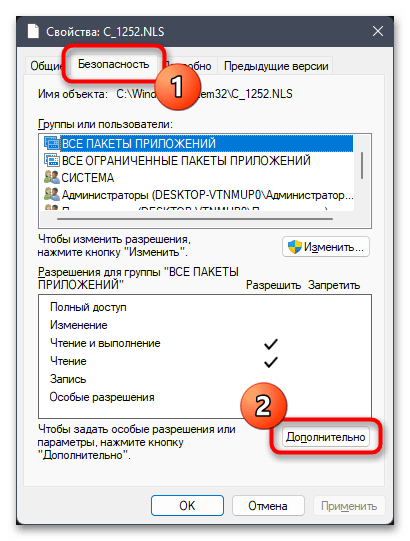
- Перейдите на вкладку «Безопасность» и нажмите по «Дополнительно».
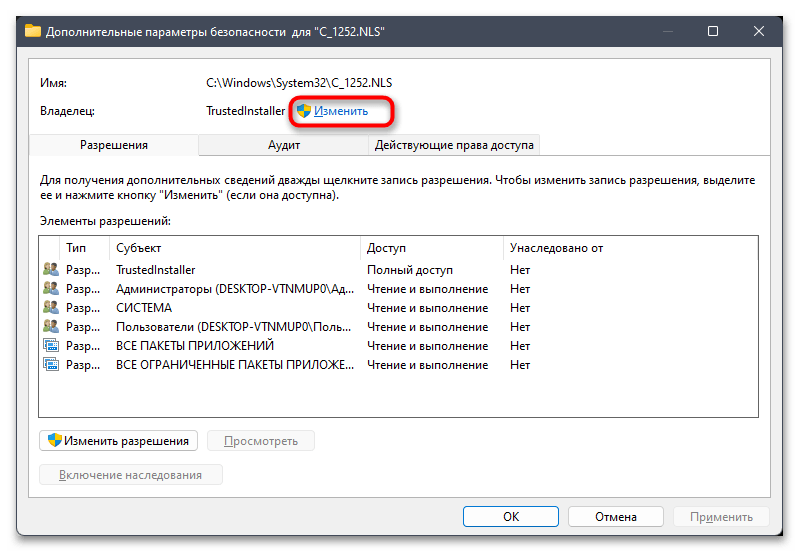
- В новом окне вы увидите текущего владельца файла, коим наверняка будете не вы. Для исправления этой ситуации кликните по «Изменить».
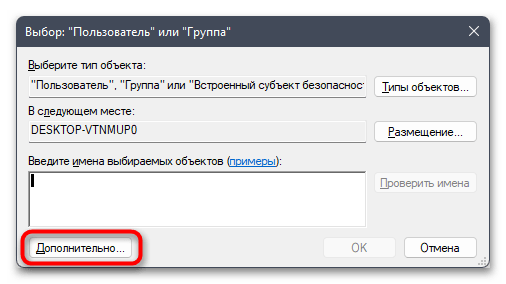
- Можете ввести имя объекта вручную, но в большинстве случаев у пользователя нет информации о том, как точно называется его учетная запись. Поэтому лучше пойти простым путем автоматического поиска, сначала нажав по «Дополнительно».
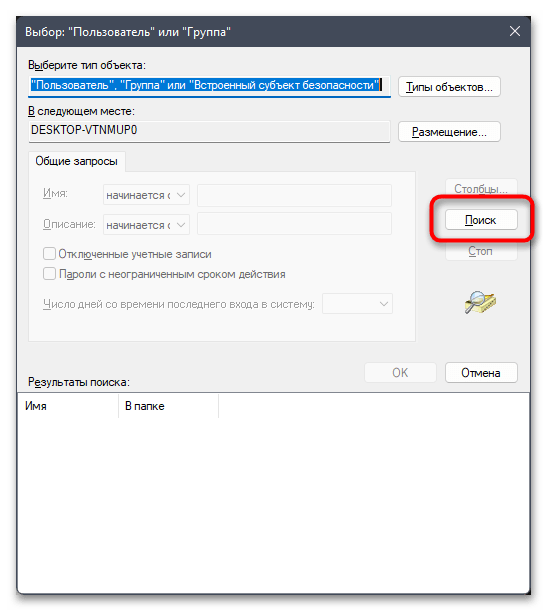
- В следующем окне нажмите кнопку «Поиск».
- Дождитесь загрузки учетных записей и выберите среди них свою. Подтвердите внесение изменений и закройте данное окно.
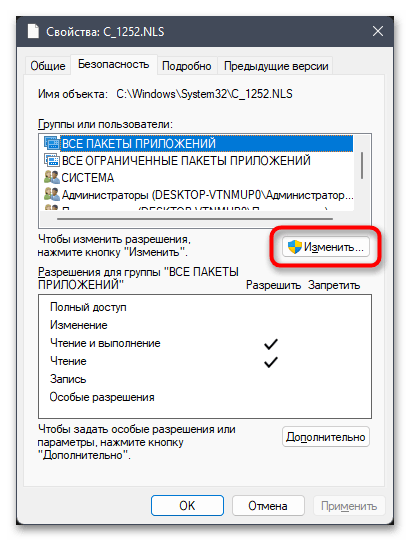
- Остается только добавить полные права доступа к файлу для нового владельца. В окне «Свойств» на вкладке «Безопасность» нажмите по «Изменить».
- В списке «Группы или пользователи» выберите свою учетную запись, предоставьте полные права и сохраните изменения.
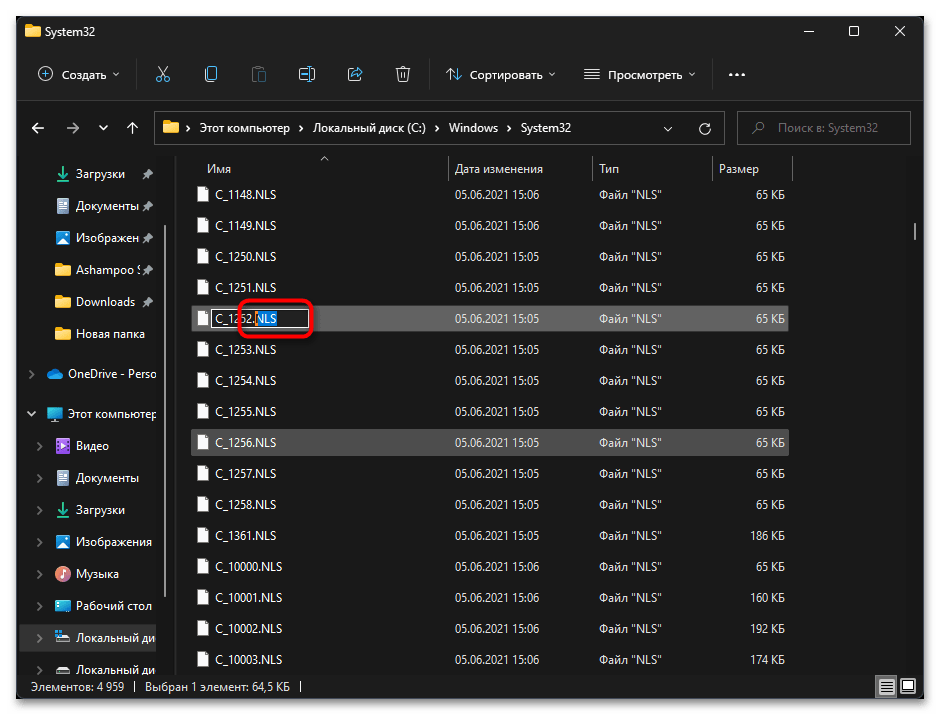
- Теперь вам нужно переименовать файл «C_1252.NLS». Лучшим вариантом будет изменить его формат, допустим, на текстовый. Если что-то пойдет не так, его всегда можно вернуть к NLS.
- Далее в этой же папке отыщите файл «C_1251.NLS» и создайте его копию на рабочем столе.
- Для данного файла с названием «C_1251.NLS» установите новое, переименовав его на «C_1252.NLS». Если действие недоступно, измените владельца и для этого файла точно так же, как это было показано выше.

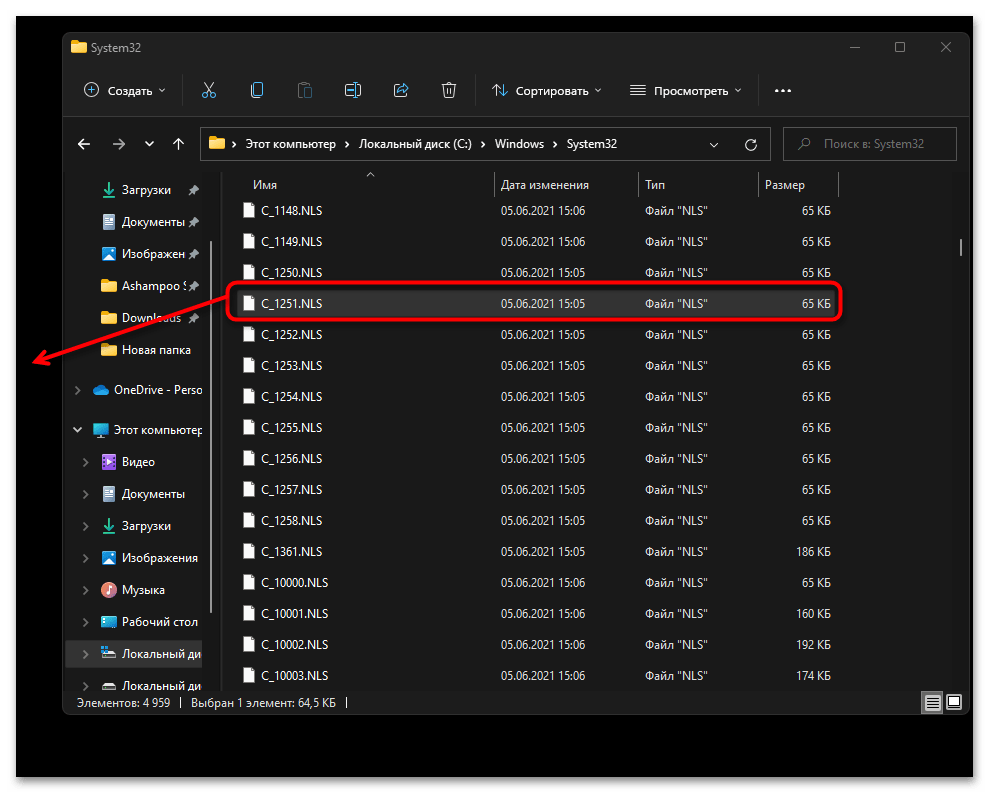
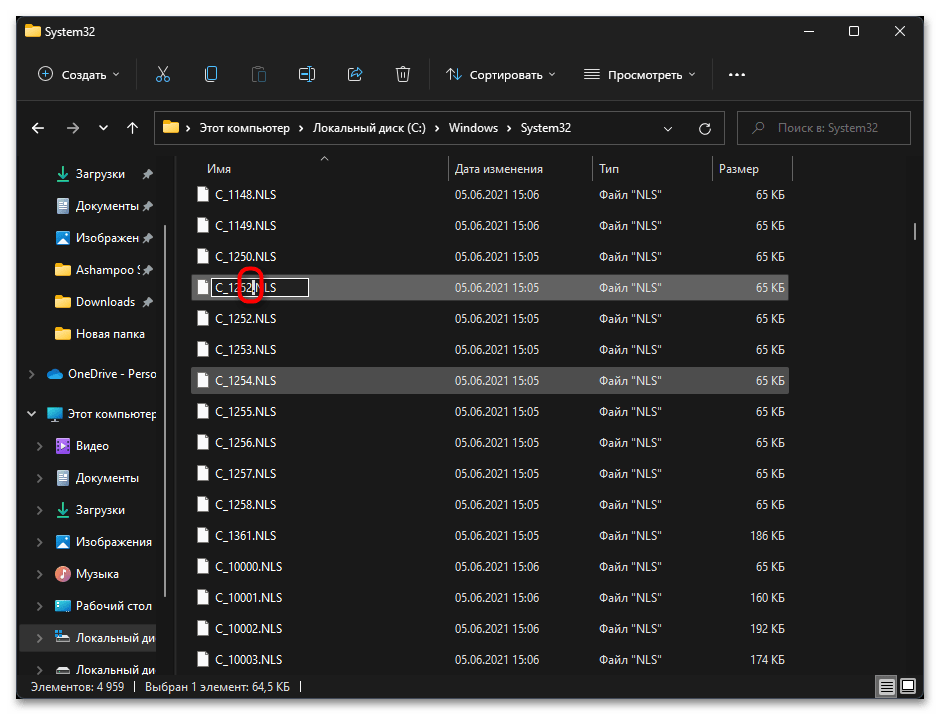
При помощи нехитрых манипуляций вы произвели замену файлов, отвечающих за локализацию в Windows 11. «C_1252.NLS» нужен для нормального отображения английского языка системы, который является основным. При помощи замены мы сделали так, чтобы основным теперь считался русский и кодировка была исправлена в тех местах, где наблюдаются проблемы с отображением букв. Если после перезагрузки компьютера выяснилось, что система функционирует хуже, появились ошибки и сама проблема не была исправлена, верните оригинальные файлы в ту же папку и снова перезагрузите ПК.
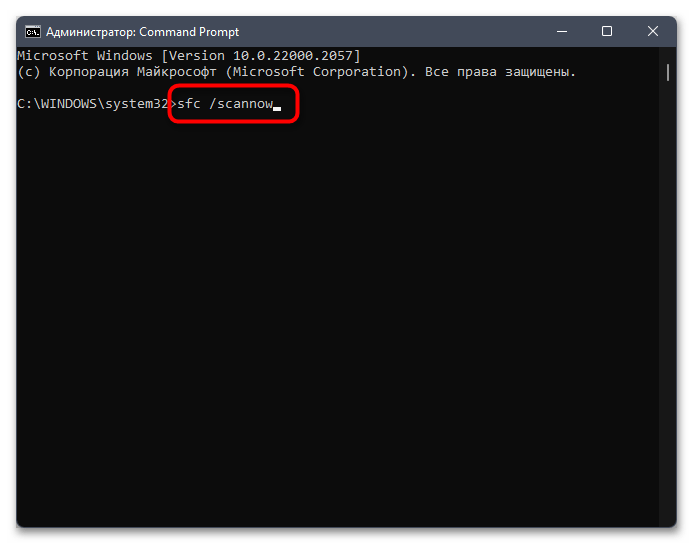
Способ 5: Проверка целостности системных файлов
Не стоит исключать тот факт, что появление «кракозябр» вместо нормального отображения букв иногда свидетельствует о том, что в системе нарушена целостность файлов, отвечающих за локализацию или работу с определенными текстовыми кодировками. Самостоятельно проверить вы это не сможете, поэтому доверьте операцию автоматизированным средствам, а именно специальным консольным утилитам. Информацию об их применении вы найдете в материале от другого нашего автора по ссылке ниже.
Подробнее: Использование и восстановление проверки целостности системных файлов в Windows
Способ 6: Возвращение Windows к заводским настройкам
Единственный метод исправления ситуации, который еще не был рассмотрен в рамках данной статьи, подразумевает восстановление стандартного состояния Windows 11, что в большинстве случаев решает самые распространенные системные проблемы. Сделать это можно и полной переустановкой, но куда проще восстановить заводские настройки. Для этого подходит стандартное средство операционной системы, об использовании которого читайте в материале по следующей ссылке.
Подробнее: Сброс Windows 11 к заводским настройкам
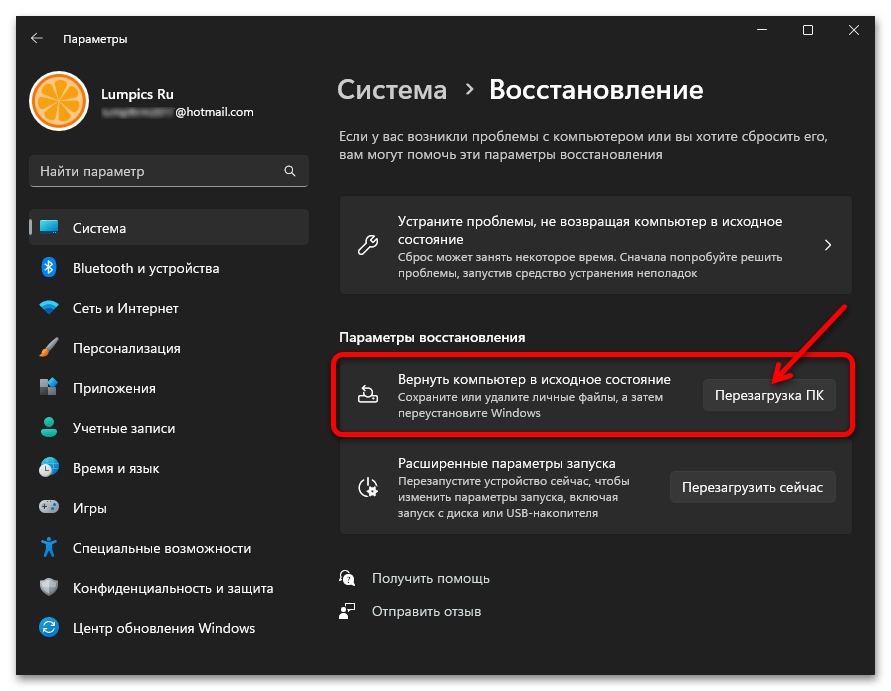
Исправление кодировки в содержании и названиях файлов
В некоторых случаях пользователь сталкивается с тем, что «кракозябры» отображаются только в названиях конкретных текстовых файлов или после их открытия через текстовые редакторы, когда речь идет о просмотре содержимого. В первую очередь можем порекомендовать сменить текстовый редактор, поскольку не все поддерживают разные кодировки, особенно если речь идет о стандартном «Блокноте». Если это не принесло должного результата, можно попробовать восстановить кодировку через разные онлайн-сервисы. Они поддерживают как загрузку файлов целиком, так и вставку содержимого из буфера обмена.
Подробнее: Исправление кодировки при помощи онлайн-сервисов
Наша группа в TelegramПолезные советы и помощь
Reference of Extended ASCII Table for Windows-1251
The ASCII table, when defined according to the Windows-1251 character encoding (also known as Code page 1251), includes ASCII control characters and ASCII printable characters. Moreover, it also includes the extended ASCII character set unique to Windows-1251. This character set is particularly designed to support Cyrillic languages.
ASCII control characters (character code 0-31)
The first 32 characters in the ASCII-table are unprintable control codes and are used to control peripherals such as printers.
| DEC | OCT | HEX | BIN | Symbol | HTML Number | HTML Name | Description | |
|---|---|---|---|---|---|---|---|---|
| 0 | 000 | 00 | 00000000 | ␀ | � | Null character | ||
| 1 | 001 | 01 | 00000001 | ␁ |  | Start of Heading | ||
| 2 | 002 | 02 | 00000010 | ␂ |  | Start of Text | ||
| 3 | 003 | 03 | 00000011 | ␃ |  | End of Text | ||
| 4 | 004 | 04 | 00000100 | ␄ |  | End of Transmission | ||
| 5 | 005 | 05 | 00000101 | ␅ |  | Enquiry | ||
| 6 | 006 | 06 | 00000110 | ␆ |  | Acknowledge | ||
| 7 | 007 | 07 | 00000111 | ␇ |  | Bell, Alert | ||
| 8 | 010 | 08 | 00001000 | ␈ |  | Backspace | ||
| 9 | 011 | 09 | 00001001 | ␉ | 	 | Horizontal Tab | ||
| 10 | 012 | 0A | 00001010 | ␊ | | Line Feed | ||
| 11 | 013 | 0B | 00001011 | ␋ |  | Vertical Tabulation | ||
| 12 | 014 | 0C | 00001100 | ␌ |  | Form Feed | ||
| 13 | 015 | 0D | 00001101 | ␍ | | Carriage Return | ||
| 14 | 016 | 0E | 00001110 | ␎ |  | Shift Out | ||
| 15 | 017 | 0F | 00001111 | ␏ |  | Shift In | ||
| 16 | 020 | 10 | 00010000 | ␐ |  | Data Link Escape | ||
| 17 | 021 | 11 | 00010001 | ␑ |  | Device Control One (XON) | ||
| 18 | 022 | 12 | 00010010 | ␒ |  | Device Control Two | ||
| 19 | 023 | 13 | 00010011 | ␓ |  | Device Control Three (XOFF) | ||
| 20 | 024 | 14 | 00010100 | ␔ |  | Device Control Four | ||
| 21 | 025 | 15 | 00010101 | ␕ |  | Negative Acknowledge | ||
| 22 | 026 | 16 | 00010110 | ␖ |  | Synchronous Idle | ||
| 23 | 027 | 17 | 00010111 | ␗ |  | End of Transmission Block | ||
| 24 | 030 | 18 | 00011000 | ␘ |  | Cancel | ||
| 25 | 031 | 19 | 00011001 | ␙ |  | End of medium | ||
| 26 | 032 | 1A | 00011010 | ␚ |  | Substitute | ||
| 27 | 033 | 1B | 00011011 | ␛ |  | Escape | ||
| 28 | 034 | 1C | 00011100 | ␜ |  | File Separator | ||
| 29 | 035 | 1D | 00011101 | ␝ |  | Group Separator | ||
| 30 | 036 | 1E | 00011110 | ␞ |  | Record Separator | ||
| 31 | 037 | 1F | 00011111 | ␟ |  | Unit Separator |
ASCII printable characters (character code 32-127)
Codes 32-127 are common for all the different variations of the ASCII table, they are called printable characters, represent letters, digits, punctuation marks, and a few miscellaneous symbols. You will find almost every character on your keyboard. Character 127 represents the command DEL.
| DEC | OCT | HEX | BIN | Symbol | HTML Number | HTML Name | Description | |
|---|---|---|---|---|---|---|---|---|
| 32 | 040 | 20 | 00100000 | ␠ |   | Space | ||
| 33 | 041 | 21 | 00100001 | ! | ! | ! | Exclamation mark | |
| 34 | 042 | 22 | 00100010 | « | " | " | Double quotes (or speech marks) | |
| 35 | 043 | 23 | 00100011 | # | # | # | Number sign | |
| 36 | 044 | 24 | 00100100 | $ | $ | $ | Dollar | |
| 37 | 045 | 25 | 00100101 | % | % | % | Per cent sign | |
| 38 | 046 | 26 | 00100110 | & | & | & | Ampersand | |
| 39 | 047 | 27 | 00100111 | ‘ | ' | ' | Single quote | |
| 40 | 050 | 28 | 00101000 | ( | ( | &lparen; | Open parenthesis (or open bracket) | |
| 41 | 051 | 29 | 00101001 | ) | ) | &rparen; | Close parenthesis (or close bracket) | |
| 42 | 052 | 2A | 00101010 | * | * | * | Asterisk | |
| 43 | 053 | 2B | 00101011 | + | + | + | Plus | |
| 44 | 054 | 2C | 00101100 | , | , | , | Comma | |
| 45 | 055 | 2D | 00101101 | — | - | Hyphen-minus | ||
| 46 | 056 | 2E | 00101110 | . | . | . | Period, dot or full stop | |
| 47 | 057 | 2F | 00101111 | / | / | / | Slash or divide | |
| 48 | 060 | 30 | 00110000 | 0 | 0 | Zero | ||
| 49 | 061 | 31 | 00110001 | 1 | 1 | One | ||
| 50 | 062 | 32 | 00110010 | 2 | 2 | Two | ||
| 51 | 063 | 33 | 00110011 | 3 | 3 | Three | ||
| 52 | 064 | 34 | 00110100 | 4 | 4 | Four | ||
| 53 | 065 | 35 | 00110101 | 5 | 5 | Five | ||
| 54 | 066 | 36 | 00110110 | 6 | 6 | Six | ||
| 55 | 067 | 37 | 00110111 | 7 | 7 | Seven | ||
| 56 | 070 | 38 | 00111000 | 8 | 8 | Eight | ||
| 57 | 071 | 39 | 00111001 | 9 | 9 | Nine | ||
| 58 | 072 | 3A | 00111010 | : | : | : | Colon | |
| 59 | 073 | 3B | 00111011 | ; | ; | ; | Semicolon | |
| 60 | 074 | 3C | 00111100 | < | < | < | Less than (or open angled bracket) | |
| 61 | 075 | 3D | 00111101 | = | = | = | Equals | |
| 62 | 076 | 3E | 00111110 | > | > | > | Greater than (or close angled bracket) | |
| 63 | 077 | 3F | 00111111 | ? | ? | ? | Question mark | |
| 64 | 100 | 40 | 01000000 | @ | @ | @ | At sign | |
| 65 | 101 | 41 | 01000001 | A | A | Uppercase A | ||
| 66 | 102 | 42 | 01000010 | B | B | Uppercase B | ||
| 67 | 103 | 43 | 01000011 | C | C | Uppercase C | ||
| 68 | 104 | 44 | 01000100 | D | D | Uppercase D | ||
| 69 | 105 | 45 | 01000101 | E | E | Uppercase E | ||
| 70 | 106 | 46 | 01000110 | F | F | Uppercase F | ||
| 71 | 107 | 47 | 01000111 | G | G | Uppercase G | ||
| 72 | 110 | 48 | 01001000 | H | H | Uppercase H | ||
| 73 | 111 | 49 | 01001001 | I | I | Uppercase I | ||
| 74 | 112 | 4A | 01001010 | J | J | Uppercase J | ||
| 75 | 113 | 4B | 01001011 | K | K | Uppercase K | ||
| 76 | 114 | 4C | 01001100 | L | L | Uppercase L | ||
| 77 | 115 | 4D | 01001101 | M | M | Uppercase M | ||
| 78 | 116 | 4E | 01001110 | N | N | Uppercase N | ||
| 79 | 117 | 4F | 01001111 | O | O | Uppercase O | ||
| 80 | 120 | 50 | 01010000 | P | P | Uppercase P | ||
| 81 | 121 | 51 | 01010001 | Q | Q | Uppercase Q | ||
| 82 | 122 | 52 | 01010010 | R | R | Uppercase R | ||
| 83 | 123 | 53 | 01010011 | S | S | Uppercase S | ||
| 84 | 124 | 54 | 01010100 | T | T | Uppercase T | ||
| 85 | 125 | 55 | 01010101 | U | U | Uppercase U | ||
| 86 | 126 | 56 | 01010110 | V | V | Uppercase V | ||
| 87 | 127 | 57 | 01010111 | W | W | Uppercase W | ||
| 88 | 130 | 58 | 01011000 | X | X | Uppercase X | ||
| 89 | 131 | 59 | 01011001 | Y | Y | Uppercase Y | ||
| 90 | 132 | 5A | 01011010 | Z | Z | Uppercase Z | ||
| 91 | 133 | 5B | 01011011 | [ | [ | [ | Opening bracket | |
| 92 | 134 | 5C | 01011100 | \ | \ | \ | Backslash | |
| 93 | 135 | 5D | 01011101 | ] | ] | ] | Closing bracket | |
| 94 | 136 | 5E | 01011110 | ^ | ^ | ^ | Caret — circumflex | |
| 95 | 137 | 5F | 01011111 | _ | _ | _ | Underscore | |
| 96 | 140 | 60 | 01100000 | ` | ` | ` | Grave accent | |
| 97 | 141 | 61 | 01100001 | a | a | Lowercase a | ||
| 98 | 142 | 62 | 01100010 | b | b | Lowercase b | ||
| 99 | 143 | 63 | 01100011 | c | c | Lowercase c | ||
| 100 | 144 | 64 | 01100100 | d | d | Lowercase d | ||
| 101 | 145 | 65 | 01100101 | e | e | Lowercase e | ||
| 102 | 146 | 66 | 01100110 | f | f | Lowercase f | ||
| 103 | 147 | 67 | 01100111 | g | g | Lowercase g | ||
| 104 | 150 | 68 | 01101000 | h | h | Lowercase h | ||
| 105 | 151 | 69 | 01101001 | i | i | Lowercase i | ||
| 106 | 152 | 6A | 01101010 | j | j | Lowercase j | ||
| 107 | 153 | 6B | 01101011 | k | k | Lowercase k | ||
| 108 | 154 | 6C | 01101100 | l | l | Lowercase l | ||
| 109 | 155 | 6D | 01101101 | m | m | Lowercase m | ||
| 110 | 156 | 6E | 01101110 | n | n | Lowercase n | ||
| 111 | 157 | 6F | 01101111 | o | o | Lowercase o | ||
| 112 | 160 | 70 | 01110000 | p | p | Lowercase p | ||
| 113 | 161 | 71 | 01110001 | q | q | Lowercase q | ||
| 114 | 162 | 72 | 01110010 | r | r | Lowercase r | ||
| 115 | 163 | 73 | 01110011 | s | s | Lowercase s | ||
| 116 | 164 | 74 | 01110100 | t | t | Lowercase t | ||
| 117 | 165 | 75 | 01110101 | u | u | Lowercase u | ||
| 118 | 166 | 76 | 01110110 | v | v | Lowercase v | ||
| 119 | 167 | 77 | 01110111 | w | w | Lowercase w | ||
| 120 | 170 | 78 | 01111000 | x | x | Lowercase x | ||
| 121 | 171 | 79 | 01111001 | y | y | Lowercase y | ||
| 122 | 172 | 7A | 01111010 | z | z | Lowercase z | ||
| 123 | 173 | 7B | 01111011 | { | { | { | Opening brace | |
| 124 | 174 | 7C | 01111100 | | | | | | | Vertical bar | |
| 125 | 175 | 7D | 01111101 | } | } | } | Closing brace | |
| 126 | 176 | 7E | 01111110 | ~ | ~ | ˜ | Equivalency sign — tilde | |
| 127 | 177 | 7F | 01111111 | ␡ |  | Delete |
The extended ASCII codes (character code 128-255)
Windows-1251 is a character encoding standard used to represent text in the Cyrillic script. It was introduced by Microsoft in the Windows operating system and is based on ISO 8859-5. Windows-1251 supports a range of characters and symbols used in the Cyrillic script, including Russian, Bulgarian, Serbian, and others.
Windows-1251 is widely used in the former Soviet Union countries and other countries that use the Cyrillic script. It is commonly used in word processing software, spreadsheets, and databases. However, it is important to note that Windows-1251 may not provide full support for all of the characters used in these languages and may cause issues when dealing with text in certain scripts.
| DEC | OCT | HEX | BIN | Symbol | HTML Number | HTML Name | Description | |
|---|---|---|---|---|---|---|---|---|
| 128 | 200 | 80 | 10000000 | Ђ | Ђ | Ђ | Cyrillic capital letter Dje | |
| 129 | 201 | 81 | 10000001 | Ѓ | Ѓ | Ѓ | Cyrillic capital letter Gje | |
| 130 | 202 | 82 | 10000010 | ‚ | ‚ | ‚ | Single low-9 quotation mark | |
| 131 | 203 | 83 | 10000011 | ѓ | ѓ | ѓ | Cyrillic small letter gje | |
| 132 | 204 | 84 | 10000100 | „ | „ | „ | Double low-9 quotation mark | |
| 133 | 205 | 85 | 10000101 | … | … | … | Horizontal ellipsis | |
| 134 | 206 | 86 | 10000110 | † | † | † | Dagger | |
| 135 | 207 | 87 | 10000111 | ‡ | ‡ | ‡ | Double dagger | |
| 136 | 210 | 88 | 10001000 | € | € | € | Euro sign | |
| 137 | 211 | 89 | 10001001 | ‰ | ‰ | ‰ | Per mille sign | |
| 138 | 212 | 8A | 10001010 | Љ | Љ | Љ | Cyrillic capital letter Lje | |
| 139 | 213 | 8B | 10001011 | ‹ | ‹ | ‹ | Single left-pointing angle quotation | |
| 140 | 214 | 8C | 10001100 | Њ | Њ | Њ | Cyrillic capital letter Nje | |
| 141 | 215 | 8D | 10001101 | Ќ | Ќ | Ќ | Cyrillic capital letter Kje | |
| 142 | 216 | 8E | 10001110 | Ћ | Ћ | Ћ | Cyrillic capital letter Tshe | |
| 143 | 217 | 8F | 10001111 | Џ | Џ | Џ | Cyrillic capital letter Dzhe | |
| 144 | 220 | 90 | 10010000 | ђ | ђ | ђ | Cyrillic small letter dje | |
| 145 | 221 | 91 | 10010001 | ‘ | ‘ | ‘ | Left single quotation mark | |
| 146 | 222 | 92 | 10010010 | ’ | ’ | ’ | Right single quotation mark | |
| 147 | 223 | 93 | 10010011 | “ | “ | “ | Left double quotation mark | |
| 148 | 224 | 94 | 10010100 | ” | ” | ” | Right double quotation mark | |
| 149 | 225 | 95 | 10010101 | • | • | • | Bullet | |
| 150 | 226 | 96 | 10010110 | – | – | – | En dash | |
| 151 | 227 | 97 | 10010111 | — | — | — | Em dash | |
| 152 | 230 | 98 | 10011000 | Unused | ||||
| 153 | 231 | 99 | 10011001 | ™ | ™ | ™ | Trade mark sign | |
| 154 | 232 | 9A | 10011010 | љ | љ | љ | Cyrillic small letter lje | |
| 155 | 233 | 9B | 10011011 | › | › | › | Single right-pointing angle quotation mark | |
| 156 | 234 | 9C | 10011100 | њ | њ | њ | Cyrillic small letter nje | |
| 157 | 235 | 9D | 10011101 | ќ | ќ | ќ | Cyrillic small letter Kje | |
| 158 | 236 | 9E | 10011110 | ћ | ћ | ћ | Cyrillic small letter Tshe | |
| 159 | 237 | 9F | 10011111 | џ | џ | џ | Cyrillic small letter Dzhe | |
| 160 | 240 | A0 | 10100000 |   | | Non-breaking space | ||
| 161 | 241 | A1 | 10100001 | Ў | Ў | Ў | Cyrillic capital letter short U | |
| 162 | 242 | A2 | 10100010 | ў | ў | ў | Cyrillic small letter short u | |
| 163 | 243 | A3 | 10100011 | Ј | Ј | Ј | Cyrillic capital letter Je | |
| 164 | 244 | A4 | 10100100 | ¤ | ¤ | ¤ | Currency sign | |
| 165 | 245 | A5 | 10100101 | Ґ | Ґ | Cyrillic capital letter Ghe with upturn | ||
| 166 | 246 | A6 | 10100110 | ¦ | ¦ | ¦ | Pipe, broken vertical bar | |
| 167 | 247 | A7 | 10100111 | § | § | § | Section sign | |
| 168 | 250 | A8 | 10101000 | Ё | Ё | Ё | Cyrillic capital letter Io | |
| 169 | 251 | A9 | 10101001 | © | © | © | Copyright sign | |
| 170 | 252 | AA | 10101010 | Є | Є | Є | Cyrillic capital letter Ukrainian Ie | |
| 171 | 253 | AB | 10101011 | « | « | « | Left double angle quotes | |
| 172 | 254 | AC | 10101100 | ¬ | ¬ | ¬ | Negation | |
| 173 | 255 | AD | 10101101 | | ­ | ­ | Soft hyphen | |
| 174 | 256 | AE | 10101110 | ® | ® | ® | Registered trade mark sign | |
| 175 | 257 | AF | 10101111 | Ї | Ї | Ї | Cyrillic capital letter Yi | |
| 176 | 260 | B0 | 10110000 | ° | ° | ° | Degree sign | |
| 177 | 261 | B1 | 10110001 | ± | ± | ± | Plus-or-minus sign | |
| 178 | 262 | B2 | 10110010 | І | І | І | Cyrillic capital letter Byelorussian-Ukrainian I | |
| 179 | 263 | B3 | 10110011 | і | і | і | Cyrillic small letter Byelorussian-Ukrainian i | |
| 180 | 264 | B4 | 10110100 | ґ | ґ | Cyrillic small letter ghe with upturn | ||
| 181 | 265 | B5 | 10110101 | µ | µ | µ | Micro sign | |
| 182 | 266 | B6 | 10110110 | ¶ | ¶ | ¶ | Pilcrow sign — paragraph sign | |
| 183 | 267 | B7 | 10110111 | · | · | · | Middle dot — Georgian comma | |
| 184 | 270 | B8 | 10111000 | ё | ё | ё | Cyrillic small letter io | |
| 185 | 271 | B9 | 10111001 | № | № | № | Numero Sign | |
| 186 | 272 | BA | 10111010 | є | є | є | Cyrillic small letter Ukrainian ie | |
| 187 | 273 | BB | 10111011 | » | » | » | Right double angle quotes | |
| 188 | 274 | BC | 10111100 | ј | ј | ј | Cyrillic small letter je | |
| 189 | 275 | BD | 10111101 | Ѕ | Ѕ | Ѕ | Cyrillic capital letter Dze | |
| 190 | 276 | BE | 10111110 | ѕ | ѕ | ѕ | Cyrillic small letter dze | |
| 191 | 277 | BF | 10111111 | ї | ї | ї | Cyrillic small letter yi | |
| 192 | 300 | C0 | 11000000 | А | А | А | Cyrillic capital letter A | |
| 193 | 301 | C1 | 11000001 | Б | Б | Б | Cyrillic capital letter Be | |
| 194 | 302 | C2 | 11000010 | В | В | В | Cyrillic capital letter Ve | |
| 195 | 303 | C3 | 11000011 | Г | Г | Г | Cyrillic capital letter Ghe | |
| 196 | 304 | C4 | 11000100 | Д | Д | Д | Cyrillic capital letter De | |
| 197 | 305 | C5 | 11000101 | Е | Е | Е | Cyrillic capital letter Ie | |
| 198 | 306 | C6 | 11000110 | Ж | Ж | Ж | Cyrillic capital letter Zhe | |
| 199 | 307 | C7 | 11000111 | З | З | З | Cyrillic capital letter Ze | |
| 200 | 310 | C8 | 11001000 | И | И | И | Cyrillic capital letter I | |
| 201 | 311 | C9 | 11001001 | Й | Й | Й | Cyrillic capital letter Short I | |
| 202 | 312 | CA | 11001010 | К | К | К | Cyrillic capital letter Ka | |
| 203 | 313 | CB | 11001011 | Л | Л | Л | Cyrillic capital letter El | |
| 204 | 314 | CC | 11001100 | М | М | М | Cyrillic capital letter Em | |
| 205 | 315 | CD | 11001101 | Н | Н | Н | Cyrillic capital letter En | |
| 206 | 316 | CE | 11001110 | О | О | О | Cyrillic capital letter O | |
| 207 | 317 | CF | 11001111 | П | П | П | Cyrillic capital letter Pe | |
| 208 | 320 | D0 | 11010000 | Р | Р | Р | Cyrillic capital letter Er | |
| 209 | 321 | D1 | 11010001 | С | С | С | Cyrillic capital letter Es | |
| 210 | 322 | D2 | 11010010 | Т | Т | Т | Cyrillic capital letter Te | |
| 211 | 323 | D3 | 11010011 | У | У | У | Cyrillic capital letter U | |
| 212 | 324 | D4 | 11010100 | Ф | Ф | Ф | Cyrillic capital letter Ef | |
| 213 | 325 | D5 | 11010101 | Х | Х | Х | Cyrillic capital letter Ha | |
| 214 | 326 | D6 | 11010110 | Ц | Ц | Ц | Cyrillic capital letter Tse | |
| 215 | 327 | D7 | 11010111 | Ч | Ч | Ч | Cyrillic capital letter Che | |
| 216 | 330 | D8 | 11011000 | Ш | Ш | Ш | Cyrillic capital letter Sha | |
| 217 | 331 | D9 | 11011001 | Щ | Щ | Щ | Cyrillic capital letter Shcha | |
| 218 | 332 | DA | 11011010 | Ъ | Ъ | Ъ | Cyrillic capital letter Hard Sign | |
| 219 | 333 | DB | 11011011 | Ы | Ы | Ы | Cyrillic capital letter Yeru | |
| 220 | 334 | DC | 11011100 | Ь | Ь | Ь | Cyrillic capital letter Soft Sign | |
| 221 | 335 | DD | 11011101 | Э | Э | Э | Cyrillic capital letter E | |
| 222 | 336 | DE | 11011110 | Ю | Ю | Ю | Cyrillic capital letter Yu | |
| 223 | 337 | DF | 11011111 | Я | Я | Я | Cyrillic capital letter Ya | |
| 224 | 340 | E0 | 11100000 | а | а | а | Cyrillic Small Letter A | |
| 225 | 341 | E1 | 11100001 | б | б | б | Cyrillic small letter be | |
| 226 | 342 | E2 | 11100010 | в | в | в | Cyrillic small letter ve | |
| 227 | 343 | E3 | 11100011 | г | г | г | Cyrillic small letter ghe | |
| 228 | 344 | E4 | 11100100 | д | д | д | Cyrillic small letter de | |
| 229 | 345 | E5 | 11100101 | е | е | е | Cyrillic small letter ie | |
| 230 | 346 | E6 | 11100110 | ж | ж | ж | Cyrillic small letter zhe | |
| 231 | 347 | E7 | 11100111 | з | з | з | Cyrillic small letter ze | |
| 232 | 350 | E8 | 11101000 | и | и | и | Cyrillic small letter i | |
| 233 | 351 | E9 | 11101001 | й | й | й | Cyrillic small letter short i | |
| 234 | 352 | EA | 11101010 | к | к | к | Cyrillic small letter ka | |
| 235 | 353 | EB | 11101011 | л | л | л | Cyrillic small letter el | |
| 236 | 354 | EC | 11101100 | м | м | м | Cyrillic small letter em | |
| 237 | 355 | ED | 11101101 | н | н | н | Cyrillic small letter en | |
| 238 | 356 | EE | 11101110 | о | о | о | Cyrillic small letter o | |
| 239 | 357 | EF | 11101111 | п | п | п | Cyrillic small letter pe | |
| 240 | 360 | F0 | 11110000 | р | р | р | Cyrillic small letter er | |
| 241 | 361 | F1 | 11110001 | с | с | с | Cyrillic small letter es | |
| 242 | 362 | F2 | 11110010 | т | т | т | Cyrillic small letter te | |
| 243 | 363 | F3 | 11110011 | у | у | у | Cyrillic small letter u | |
| 244 | 364 | F4 | 11110100 | ф | ф | ф | Cyrillic small letter ef | |
| 245 | 365 | F5 | 11110101 | х | х | х | Cyrillic small letter ha | |
| 246 | 366 | F6 | 11110110 | ц | ц | ц | Cyrillic small letter tse | |
| 247 | 367 | F7 | 11110111 | ч | ч | ч | Cyrillic small letter che | |
| 248 | 370 | F8 | 11111000 | ш | ш | ш | Cyrillic small letter sha | |
| 249 | 371 | F9 | 11111001 | щ | щ | щ | Cyrillic small letter shcha | |
| 250 | 372 | FA | 11111010 | ъ | ъ | ъ | Cyrillic small letter hard sign | |
| 251 | 373 | FB | 11111011 | ы | ы | ы | Cyrillic small letter yeru | |
| 252 | 374 | FC | 11111100 | ь | ь | ь | Cyrillic small letter soft sign | |
| 253 | 375 | FD | 11111101 | э | э | э | Cyrillic small letter e | |
| 254 | 376 | FE | 11111110 | ю | ю | ю | Cyrillic small letter yu | |
| 255 | 377 | FF | 11111111 | я | я | я | Cyrillic small letter ya |