
Список из 256 символов и их коды в ASCII.
1
Управляющие символы
| DEC | OCT | HEX | BIN | Символ | Escape послед. | HTML код | Описание |
|---|---|---|---|---|---|---|---|
| 0 | 000 | 0x00 | 00000000 | NUL | \0 | � | Нулевой байт |
| 1 | 001 | 0x01 | 00000001 | SOH |  | Начало заголовка | |
| 2 | 002 | 0x02 | 00000010 | STX |  | Начало текста | |
| 3 | 003 | 0x03 | 00000011 | ETX |  | Конец «текста» | |
| 4 | 004 | 0x04 | 00000100 | EOT |  | конец передачи | |
| 5 | 005 | 0x05 | 00000101 | ENQ |  | «Прошу подтверждения!» | |
| 6 | 006 | 0x06 | 00000110 | ACK |  | «Подтверждаю!» | |
| 7 | 007 | 0x07 | 00000111 | BEL | \a |  | Звуковой сигнал – звонок |
| 8 | 010 | 0x08 | 00001000 | BS | \b |  | Возврат на один символ (BACKSPACE) |
| 9 | 011 | 0x09 | 00001001 | TAB | \t | 	 | Табуляция |
| 10 | 012 | 0x0A | 00001010 | LF | \n | 
 | Перевод строки |
| 11 | 013 | 0x0B | 00001011 | VT | \v |  | Вертикальная табуляция |
| 12 | 014 | 0x0C | 00001100 | FF | \f |  | Прогон страницы, новая страница |
| 13 | 015 | 0x0D | 00001101 | CR | \r | 
 | Возврат каретки |
| 14 | 016 | 0x0E | 00001110 | SO |  | Переключиться на другую ленту (кодировку) | |
| 15 | 017 | 0x0F | 00001111 | SI |  | Переключиться на исходную ленту (кодировку) | |
| 16 | 020 | 0x10 | 00010000 | DLE |  | Экранирование канала данных | |
| 17 | 021 | 0x11 | 00010001 | DC1 |  | 1-й символ управления устройством | |
| 18 | 022 | 0x12 | 00010010 | DC2 |  | 2-й символ управления устройством | |
| 19 | 023 | 0x13 | 00010011 | DC3 |  | 3-й символ управления устройством | |
| 20 | 024 | 0x14 | 00010100 | DC4 |  | 4-й символ управления устройством | |
| 21 | 025 | 0x15 | 00010101 | NAK |  | «Не подтверждаю!» | |
| 22 | 026 | 0x16 | 00010110 | SYN |  | Символ для синхронизации | |
| 23 | 027 | 0x17 | 00010111 | ETB |  | Конец текстового блока | |
| 24 | 030 | 0x18 | 00011000 | CAN |  | Отмена | |
| 25 | 031 | 0x19 | 00011001 | EM |  | Конец носителя | |
| 26 | 032 | 0x1A | 00011010 | SUB |  | Подставить | |
| 27 | 033 | 0x1B | 00011011 | ESC | \e |  | Escape (Расширение) |
| 28 | 034 | 0x1C | 00011100 | FS |  | Разделитель файлов | |
| 29 | 035 | 0x1D | 00011101 | GS |  | Разделитель групп | |
| 30 | 036 | 0x1E | 00011110 | RS |  | Разделитель записей | |
| 31 | 037 | 0x1F | 00011111 | US |  | Разделитель юнитов | |
| 127 | 177 | 0x7F | 01111111 | Delete |  | Символ для удаления (на перфолентах) |
2
Печатные символы
| DEC | OCT | HEX | BIN | Символ | HTML код | Мнемоника |
|---|---|---|---|---|---|---|
| 32 | 040 | 0x20 | 00100000 | Пробел |   | |
| 33 | 041 | 0x21 | 00100001 | ! | ! | |
| 34 | 042 | 0x22 | 00100010 | « | " | " |
| 35 | 043 | 0x23 | 00100011 | # | # | |
| 36 | 044 | 0x24 | 00100100 | $ | $ | |
| 37 | 045 | 0x25 | 00100101 | % | % | |
| 38 | 046 | 0x26 | 00100110 | & | & | & |
| 39 | 047 | 0x27 | 00100111 | ‘ | ' | ' |
| 40 | 050 | 0x28 | 00101000 | ( | ( | |
| 41 | 051 | 0x29 | 00101001 | ) | ) | |
| 42 | 052 | 0x2A | 00101010 | * | * | |
| 43 | 053 | 0x2B | 00101011 | + | + | |
| 44 | 054 | 0x2C | 00101100 | , | , | |
| 45 | 055 | 0x2D | 00101101 | — | - | |
| 46 | 056 | 0x2E | 00101110 | . | . | |
| 47 | 057 | 0x2F | 00101111 | / | / | |
| 48 | 060 | 0x30 | 00110000 | 0 | 0 | |
| 49 | 061 | 0x31 | 00110001 | 1 | 1 | |
| 50 | 062 | 0x32 | 00110010 | 2 | 2 | |
| 51 | 063 | 0x33 | 00110011 | 3 | 3 | |
| 52 | 064 | 0x34 | 00110100 | 4 | 4 | |
| 53 | 065 | 0x35 | 00110101 | 5 | 5 | |
| 54 | 066 | 0x36 | 00110110 | 6 | 6 | |
| 55 | 067 | 0x37 | 00110111 | 7 | 7 | |
| 56 | 070 | 0x38 | 00111000 | 8 | 8 | |
| 57 | 071 | 0x39 | 00111001 | 9 | 9 | |
| 58 | 072 | 0x3A | 00111010 | : | : | |
| 59 | 073 | 0x3B | 00111011 | ; | ; | |
| 60 | 074 | 0x3C | 00111100 | < | < | < |
| 61 | 075 | 0x3D | 00111101 | = | = | |
| 62 | 076 | 0x3E | 00111110 | > | > | > |
| 63 | 077 | 0x3F | 00111111 | ? | ? | |
| 64 | 100 | 0x40 | 01000000 | @ | @ | |
| 65 | 101 | 0x41 | 01000001 | A | A | |
| 66 | 102 | 0x42 | 01000010 | B | B | |
| 67 | 103 | 0x43 | 01000011 | C | C | |
| 68 | 104 | 0x44 | 01000100 | D | D | |
| 69 | 105 | 0x45 | 01000101 | E | E | |
| 70 | 106 | 0x46 | 01000110 | F | F | |
| 71 | 107 | 0x47 | 01000111 | G | G | |
| 72 | 110 | 0x48 | 01001000 | H | H | |
| 73 | 111 | 0x49 | 01001001 | I | I | |
| 74 | 112 | 0x4A | 01001010 | J | J | |
| 75 | 113 | 0x4B | 01001011 | K | K | |
| 76 | 114 | 0x4C | 01001100 | L | L | |
| 77 | 115 | 0x4D | 01001101 | M | M | |
| 78 | 116 | 0x4E | 01001110 | N | N | |
| 79 | 117 | 0x4F | 01001111 | O | O | |
| 80 | 120 | 0x50 | 01010000 | P | P | |
| 81 | 121 | 0x51 | 01010001 | Q | Q | |
| 82 | 122 | 0x52 | 01010010 | R | R | |
| 83 | 123 | 0x53 | 01010011 | S | S | |
| 84 | 124 | 0x54 | 01010100 | T | T | |
| 85 | 125 | 0x55 | 01010101 | U | U | |
| 86 | 126 | 0x56 | 01010110 | V | V | |
| 87 | 127 | 0x57 | 01010111 | W | W | |
| 88 | 130 | 0x58 | 01011000 | X | X | |
| 89 | 131 | 0x59 | 01011001 | Y | Y | |
| 90 | 132 | 0x5A | 01011010 | Z | Z | |
| 91 | 133 | 0x5B | 01011011 | [ | [ | |
| 92 | 134 | 0x5C | 01011100 | \ | \ | |
| 93 | 135 | 0x5D | 01011101 | ] | ] | |
| 94 | 136 | 0x5E | 01011110 | ^ | ^ | |
| 95 | 137 | 0x5F | 01011111 | _ | _ | |
| 96 | 140 | 0x60 | 01100000 | ` | ` | |
| 97 | 141 | 0x61 | 01100001 | a | a | |
| 98 | 142 | 0x62 | 01100010 | b | b | |
| 99 | 143 | 0x63 | 01100011 | c | c | |
| 100 | 144 | 0x64 | 01100100 | d | d | |
| 101 | 145 | 0x65 | 01100101 | e | e | |
| 102 | 146 | 0x66 | 01100110 | f | f | |
| 103 | 147 | 0x67 | 01100111 | g | g | |
| 104 | 150 | 0x68 | 01101000 | h | h | |
| 105 | 151 | 0x69 | 01101001 | i | i | |
| 106 | 152 | 0x6A | 01101010 | j | j | |
| 107 | 153 | 0x6B | 01101011 | k | k | |
| 108 | 154 | 0x6C | 01101100 | l | l | |
| 109 | 155 | 0x6D | 01101101 | m | m | |
| 110 | 156 | 0x6E | 01101110 | n | n | |
| 111 | 157 | 0x6F | 01101111 | o | o | |
| 112 | 160 | 0x70 | 01110000 | p | p | |
| 113 | 161 | 0x71 | 01110001 | q | q | |
| 114 | 162 | 0x72 | 01110010 | r | r | |
| 115 | 163 | 0x73 | 01110011 | s | s | |
| 116 | 164 | 0x74 | 01110100 | t | t | |
| 117 | 165 | 0x75 | 01110101 | u | u | |
| 118 | 166 | 0x76 | 01110110 | v | v | |
| 119 | 167 | 0x77 | 01110111 | w | w | |
| 120 | 170 | 0x78 | 01111000 | x | x | |
| 121 | 171 | 0x79 | 01111001 | y | y | |
| 122 | 172 | 0x7A | 01111010 | z | z | |
| 123 | 173 | 0x7B | 01111011 | { | { | |
| 124 | 174 | 0x7C | 01111100 | | | | | |
| 125 | 175 | 0x7D | 01111101 | } | } | |
| 126 | 176 | 0x7E | 01111110 | ~ | ~ |
3
Расширенные символы ASCII Win-1251 кириллица
| DEC | OCT | HEX | BIN | Символ | HTML код | Мнемоника |
|---|---|---|---|---|---|---|
| 128 | 200 | 0x80 | 10000000 | Ђ | € | |
| 129 | 201 | 0x81 | 10000001 | Ѓ |  | |
| 130 | 202 | 0x82 | 10000010 | ‚ | ‚ | ‚ |
| 131 | 203 | 0x83 | 10000011 | ѓ | ƒ | |
| 132 | 204 | 0x84 | 10000100 | „ | „ | „ |
| 133 | 205 | 0x85 | 10000101 | … | … | … |
| 134 | 206 | 0x86 | 10000110 | † | † | † |
| 135 | 207 | 0x87 | 10000111 | ‡ | ‡ | ‡ |
| 136 | 210 | 0x88 | 10001000 | € | ˆ | € |
| 137 | 211 | 0x89 | 10001001 | ‰ | ‰ | ‰ |
| 138 | 212 | 0x8A | 10001010 | Љ | Š | |
| 139 | 213 | 0x8B | 10001011 | ‹ | ‹ | ‹ |
| 140 | 214 | 0x8C | 10001100 | Њ | Œ | |
| 141 | 215 | 0x8D | 10001101 | Ќ |  | |
| 142 | 216 | 0x8E | 10001110 | Ћ | Ž | |
| 143 | 217 | 0x8F | 10001111 | Џ |  | |
| 144 | 220 | 0x90 | 10010000 | Ђ |  | |
| 145 | 221 | 0x91 | 10010001 | ‘ | ‘ | ‘ |
| 146 | 222 | 0x92 | 10010010 | ’ | ’ | ’ |
| 147 | 223 | 0x93 | 10010011 | “ | “ | “ |
| 148 | 224 | 0x94 | 10010100 | ” | ” | ” |
| 149 | 225 | 0x95 | 10010101 | • | • | • |
| 150 | 226 | 0x96 | 10010110 | – | – | – |
| 151 | 227 | 0x97 | 10010111 | — | — | — |
| 152 | 230 | 0x98 | 10011000 | Начало строки | ˜ | |
| 153 | 231 | 0x99 | 10011001 | ™ | ™ | ™ |
| 154 | 232 | 0x9A | 10011010 | љ | š | |
| 155 | 233 | 0x9B | 10011011 | › | › | › |
| 156 | 234 | 0x9C | 10011100 | њ | œ | |
| 157 | 235 | 0x9D | 10011101 | ќ |  | |
| 158 | 236 | 0x9E | 10011110 | ћ | ž | |
| 159 | 237 | 0x9F | 10011111 | џ | Ÿ | |
| 160 | 240 | 0xA0 | 10100000 | Неразрывный пробел |   | |
| 161 | 241 | 0xA1 | 10100001 | Ў | ¡ | |
| 162 | 242 | 0xA2 | 10100010 | ў | ¢ | |
| 163 | 243 | 0xA3 | 10100011 | Ј | £ | |
| 164 | 244 | 0xA4 | 10100100 | ¤ | ¤ | ¤ |
| 165 | 245 | 0xA5 | 10100101 | Ґ | ¥ | |
| 166 | 246 | 0xA6 | 10100110 | ¦ | ¦ | ¦ |
| 167 | 247 | 0xA7 | 10100111 | § | § | § |
| 168 | 250 | 0xA8 | 10101000 | Ё | ¨ | |
| 169 | 251 | 0xA9 | 10101001 | © | © | © |
| 170 | 252 | 0xAA | 10101010 | Є | ª | |
| 171 | 253 | 0xAB | 10101011 | « | « | « |
| 172 | 254 | 0xAC | 10101100 | ¬ | ¬ | ¬ |
| 173 | 255 | 0xAD | 10101101 | Мягкий перенос | ­ | ­ |
| 174 | 256 | 0xAE | 10101110 | ® | ® | ® |
| 175 | 257 | 0xAF | 10101111 | Ї | ¯ | |
| 176 | 260 | 0xB0 | 10110000 | ° | ° | ° |
| 177 | 261 | 0xB1 | 10110001 | ± | ± | ± |
| 178 | 262 | 0xB2 | 10110010 | І | ² | |
| 179 | 263 | 0xB3 | 10110011 | і | ³ | |
| 180 | 264 | 0xB4 | 10110100 | ґ | ´ | |
| 181 | 265 | 0xB5 | 10110101 | µ | µ | µ |
| 182 | 266 | 0xB6 | 10110110 | ¶ | ¶ | ¶ |
| 183 | 267 | 0xB7 | 10110111 | · | · | · |
| 184 | 270 | 0xB8 | 10111000 | ё | ¸ | |
| 185 | 271 | 0xB9 | 10111001 | № | ¹ | |
| 186 | 272 | 0xBA | 10111010 | є | º | |
| 187 | 273 | 0xBB | 10111011 | » | » | » |
| 188 | 274 | 0xBC | 10111100 | ј | ¼ | |
| 189 | 275 | 0xBD | 10111101 | Ѕ | ½ | |
| 190 | 276 | 0xBE | 10111110 | ѕ | ¾ | |
| 191 | 277 | 0xBF | 10111111 | ї | ¿ | |
| 192 | 300 | 0xC0 | 11000000 | А | À | |
| 193 | 301 | 0xC1 | 11000001 | Б | Á | |
| 194 | 302 | 0xC2 | 11000010 | В | Â | |
| 195 | 303 | 0xC3 | 11000011 | Г | Ã | |
| 196 | 304 | 0xC4 | 11000100 | Д | Ä | |
| 197 | 305 | 0xC5 | 11000101 | Е | Å | |
| 198 | 306 | 0xC6 | 11000110 | Ж | Æ | |
| 199 | 307 | 0xC7 | 11000111 | З | Ç | |
| 200 | 310 | 0xC8 | 11001000 | И | È | |
| 201 | 311 | 0xC9 | 11001001 | Й | É | |
| 202 | 312 | 0xCA | 11001010 | К | Ê | |
| 203 | 313 | 0xCB | 11001011 | Л | Ë | |
| 204 | 314 | 0xCC | 11001100 | М | Ì | |
| 205 | 315 | 0xCD | 11001101 | Н | Í | |
| 206 | 316 | 0xCE | 11001110 | О | Î | |
| 207 | 317 | 0xCF | 11001111 | П | Ï | |
| 208 | 320 | 0xD0 | 11010000 | Р | Ð | |
| 209 | 321 | 0xD1 | 11010001 | С | Ñ | |
| 210 | 322 | 0xD2 | 11010010 | Т | Ò | |
| 211 | 323 | 0xD3 | 11010011 | У | Ó | |
| 212 | 324 | 0xD4 | 11010100 | Ф | Ô | |
| 213 | 325 | 0xD5 | 11010101 | Х | Õ | |
| 214 | 326 | 0xD6 | 11010110 | Ц | Ö | |
| 215 | 327 | 0xD7 | 11010111 | Ч | × | |
| 216 | 330 | 0xD8 | 11011000 | Ш | Ø | |
| 217 | 331 | 0xD9 | 11011001 | Щ | Ù | |
| 218 | 332 | 0xDA | 11011010 | Ъ | Ú | |
| 219 | 333 | 0xDB | 11011011 | Ы | Û | |
| 220 | 334 | 0xDC | 11011100 | Ь | Ü | |
| 221 | 335 | 0xDD | 11011101 | Э | Ý | |
| 222 | 336 | 0xDE | 11011110 | Ю | Þ | |
| 223 | 337 | 0xDF | 11011111 | Я | ß | |
| 224 | 340 | 0xE0 | 11100000 | а | à | |
| 225 | 341 | 0xE1 | 11100001 | б | á | |
| 226 | 342 | 0xE2 | 11100010 | в | â | |
| 227 | 343 | 0xE3 | 11100011 | г | ã | |
| 228 | 344 | 0xE4 | 11100100 | д | ä | |
| 229 | 345 | 0xE5 | 11100101 | е | å | |
| 230 | 346 | 0xE6 | 11100110 | ж | æ | |
| 231 | 347 | 0xE7 | 11100111 | з | ç | |
| 232 | 350 | 0xE8 | 11101000 | и | è | |
| 233 | 351 | 0xE9 | 11101001 | й | é | |
| 234 | 352 | 0xEA | 11101010 | к | ê | |
| 235 | 353 | 0xEB | 11101011 | л | ë | |
| 236 | 354 | 0xEC | 11101100 | м | ì | |
| 237 | 355 | 0xED | 11101101 | н | í | |
| 238 | 356 | 0xEE | 11101110 | о | î | |
| 239 | 357 | 0xEF | 11101111 | п | ï | |
| 240 | 360 | 0xF0 | 11110000 | р | ð | |
| 241 | 361 | 0xF1 | 11110001 | с | ñ | |
| 242 | 362 | 0xF2 | 11110010 | т | ò | |
| 243 | 363 | 0xF3 | 11110011 | у | ó | |
| 244 | 364 | 0xF4 | 11110100 | ф | ô | |
| 245 | 365 | 0xF5 | 11110101 | х | õ | |
| 246 | 366 | 0xF6 | 11110110 | ц | ö | |
| 247 | 367 | 0xF7 | 11110111 | ч | ÷ | |
| 248 | 370 | 0xF8 | 11111000 | ш | ø | |
| 249 | 371 | 0xF9 | 11111001 | щ | ù | |
| 250 | 372 | 0xFA | 11111010 | ъ | ú | |
| 251 | 373 | 0xFB | 11111011 | ы | û | |
| 252 | 374 | 0xFC | 11111100 | ь | ü | |
| 253 | 375 | 0xFD | 11111101 | э | ý | |
| 254 | 376 | 0xFE | 11111110 | ю | þ | |
| 255 | 377 | 0xFF | 11111111 | я | ÿ |
A newline (frequently called line ending, end of line (EOL), next line (NEL) or line break) is a control character or sequence of control characters in character encoding specifications such as ASCII, EBCDIC, Unicode, etc. This character, or a sequence of characters, is used to signify the end of a line of text and the start of a new one.[1]
In the mid-1800s, long before the advent of teleprinters and teletype machines, Morse code operators or telegraphists invented and used Morse code prosigns to encode white space text formatting in formal written text messages. In particular, the Morse prosign BT (mnemonic break text), represented by the concatenation of literal textual Morse codes «B» and «T» characters, sent without the normal inter-character spacing, is used in Morse code to encode and indicate a new line or new section in a formal text message.
Later, in the age of modern teleprinters, standardized character set control codes were developed to aid in white space text formatting. ASCII was developed simultaneously by the International Organization for Standardization (ISO) and the American Standards Association (ASA), the latter being the predecessor organization to American National Standards Institute (ANSI). During the period of 1963 to 1968, the ISO draft standards supported the use of either CR+LF or LF alone as a newline, while the ASA drafts supported only CR+LF.
The sequence CR+LF was commonly used on many early computer systems that had adopted Teletype machines—typically a Teletype Model 33 ASR—as a console device, because this sequence was required to position those printers at the start of a new line. The separation of newline into two functions concealed the fact that the print head could not return from the far right to the beginning of the next line in time to print the next character. Any character printed after a CR would often print as a smudge in the middle of the page while the print head was still moving the carriage back to the first position. «The solution was to make the newline two characters: CR to move the carriage to column one, and LF to move the paper up.»[2] In fact, it was often necessary to send extra padding characters—extraneous CRs or NULs—which are ignored but give the print head time to move to the left margin. Many early video displays also required multiple character times to scroll the display.
On such systems, applications had to talk directly to the Teletype machine and follow its conventions since the concept of device drivers hiding such hardware details from the application was not yet well developed. Therefore, text was routinely composed to satisfy the needs of Teletype machines. Most minicomputer systems from DEC used this convention. CP/M also used it in order to print on the same terminals that minicomputers used. From there MS-DOS (1981) adopted CP/M’s CR+LF in order to be compatible, and this convention was inherited by Microsoft’s later Windows operating system.
The Multics operating system began development in 1964 and used LF alone as its newline. Multics used a device driver to translate this character to whatever sequence a printer needed (including extra padding characters), and the single byte was more convenient for programming. What seems like a more obvious choice – CR – was not used, as CR provided the useful function of overprinting one line with another to create boldface, underscore and strikethrough effects. Perhaps more importantly, the use of LF alone as a line terminator had already been incorporated into drafts of the eventual ISO/IEC 646 standard. Unix followed the Multics practice, and later Unix-like systems followed Unix. This created conflicts between Windows and Unix-like operating systems, whereby files composed on one operating system could not be properly formatted or interpreted by another operating system (for example a UNIX shell script written in a Windows text editor like Notepad[3][4]).
The concepts of carriage return (CR) and line feed (LF) are closely associated and can be considered either separately or together. In the physical media of typewriters and printers, two axes of motion, «down» and «across», are needed to create a new line on the page. Although the design of a machine (typewriter or printer) must consider them separately, the abstract logic of software can combine them together as one event. This is why a newline in character encoding can be defined as CR and LF combined into one (commonly called CR+LF or CRLF).
Some character sets provide a separate newline character code. EBCDIC, for example, provides an NL character code in addition to the CR and LF codes. Unicode, in addition to providing the ASCII CR and LF control codes, also provides a «next line» (NEL) control code, as well as control codes for «line separator» and «paragraph separator» markers. Unicode also contains printable characters for visually representing line feed ␊, carriage return ␍, and other C0 control codes (as well as a generic newline, ) in the Control Pictures block.
- EBCDIC systems—mainly IBM mainframe systems, including z/OS (OS/390) and IBM i (OS/400)—use NL (New Line, 0x15)[8] as the character combining the functions of line feed and carriage return. The equivalent Unicode character (
0x85) is called NEL (Next Line). EBCDIC also has control characters called CR and LF, but the numerical value of LF (0x25) differs from the one used by ASCII (0x0A). Additionally, some EBCDIC variants also use NL but assign a different numeric code to the character. However, those operating systems use a record-based file system, which stores text files as one record per line. In most file formats, no line terminators are actually stored. - Operating systems for the CDC 6000 series defined a newline as two or more zero-valued six-bit characters at the end of a 60-bit word. Some configurations also defined a zero-valued character as a colon character, with the result that multiple colons could be interpreted as a newline depending on position.
- RSX-11 and OpenVMS also use a record-based file system, which stores text files as one record per line. In most file formats, no line terminators are actually stored, but the Record Management Services facility can transparently add a terminator to each line when it is retrieved by an application. The records themselves can contain the same line terminator characters, which can either be considered a feature or a nuisance depending on the application. RMS not only stores records, but also stores metadata about the record separators in different bits for the file to complicate matters even more (since files can have fixed length records, records that are prefixed by a count or records that are terminated by a specific character). The bits are not generic, so while they can specify that CRLF or LF or even CR is the line terminator, they can not substitute some other code.
- Fixed line length was used by some early mainframe operating systems. In such a system, an implicit end-of-line was assumed every 72 or 80 characters, for example. No newline character was stored. If a file was imported from the outside world, lines shorter than the line length had to be padded with spaces, while lines longer than the line length had to be truncated. This mimicked the use of punched cards, on which each line was stored on a separate card, usually with 80 columns on each card, often with sequence numbers in columns 73–80. Many of these systems added a carriage control character to the start of the next record; this could indicate whether the next record was a continuation of the line started by the previous record, or a new line, or should overprint the previous line (similar to a CR). Often this was a normal printing character such as
#that thus could not be used as the first character in a line. Some early line printers interpreted these characters directly in the records sent to them.
Communication protocols
[edit]
Many communications protocols have some sort of new line convention. In particular, protocols published by the Internet Engineering Task Force (IETF) typically use the ASCII CRLF sequence.
In some older protocols, the new line may be followed by a checksum or parity character.
«Paragraph separator» redirects here. For the symbol also known as a «paragraph sign», see Pilcrow.
The Unicode standard defines a number of characters that conforming applications should recognize as line terminators:[9]
| LF: | Line Feed, U+000A |
| VT: | Vertical Tab, U+000B |
| FF: | Form Feed, U+000C |
| CR: | Carriage Return, U+000D |
| CR+LF: | CR (U+000D) followed by LF (U+000A) |
| NEL: | Next Line, U+0085 |
| LS: | Line Separator, U+2028 |
| PS: | Paragraph Separator, U+2029 |
While it may seem overly complicated compared to an approach such as converting all line terminators to a single character (e.g. LF), because Unicode is designed to preserve all information when converting a text file from any existing encoding to Unicode and back (round-trip integrity), Unicode needs to make the same distinctions between line breaks made by other encodings. For instance EBCDIC has NL, CR, and LF characters, so all three have to also exist in Unicode.
Most newline characters and sequences are in ASCII’s C0 controls (i.e. have Unicode code points up to 0x1F). The three newline characters outside of this range—NEL, LS and PS—are often not recognized as newlines by software. For example:
- JSON recognizes CR and LF as whitespace, but not any other newline characters.[10] C0 controls cannot appear unescaped within strings, but any other line break characters can.[11]
- ECMAScript only recognizes CR, LF, LS and PS as line terminators.[12] Historically, unescaped line terminators were not permitted in string literals,[13] but this was changed in ES2019 to allow unescaped LS and PS in strings[12] for compatibility with JSON.[14]
- YAML 1.1 recognized all three as line breaks; YAML 1.2 no longer recognizes them as line breaks in order to be compatible with JSON.[15]
- Windows Notepad, the default text editor of Microsoft Windows, does not treat any of NEL, LS, or PS as line breaks.
- gedit, the default text editor of the GNOME desktop environment, treats LS and PS as line breaks, but not NEL.
Unicode includes some glyphs intended for presenting a user-visible character to the reader of the document, and are thus not recognized themselves as a newline:
- U+23CE ⏎ RETURN SYMBOL
- U+240A ␊ SYMBOL FOR LINE FEED
- U+240D ␍ SYMBOL FOR CARRIAGE RETURN
- U+2424  SYMBOL FOR NEWLINE
In programming languages
[edit]
To facilitate creating portable programs, programming languages provide some abstractions to deal with the different types of newline sequences used in different environments.
The C language provides the escape sequences \n (newline) and \r (carriage return). However, these are not required to be equivalent to the ASCII LF and CR control characters. The C standard only guarantees two traits:
- Each of these escape sequences maps to a unique implementation-defined number that can be stored in one char value.
- When writing to a file, device node, or socket/fifo in text mode,
\nis transparently translated to the native newline sequence used by the system, which may be longer than one character. When reading in text mode, the native newline sequence is translated back to\n. In binary mode, no translation is performed, and the internal representation produced by\nis output directly.
On Unix operating system platforms, where C originated, the native newline sequence is ASCII LF (0x0A), so \n was simply defined to be that value. With the internal and external representation being identical, the translation performed in text mode is a no-op, and Unix has no notion of text mode or binary mode. This has caused many programmers who developed their software on Unix systems simply to ignore the distinction completely, resulting in code that is not portable to different platforms.
The C standard library function fgets() is best avoided in binary mode because any file not written with the Unix newline convention will be misread. Also, in text mode, any file not written with the system’s native newline sequence (such as a file created on a Unix system, then copied to a Windows system) will be misread as well.
Another common problem is the use of \n when communicating using an Internet protocol that mandates the use of ASCII CR+LF for ending lines. Writing \n to a text mode stream works correctly on Windows systems, but produces only LF on Unix, and something completely different on more exotic systems. Using \r\n in binary mode is slightly better.
Many languages, such as C++, Perl,[16] and Haskell provide the same interpretation of \n as C. C++ has an alternative input/output (I/O) model where the manipulator std::endl can be used to output a newline (and flushes the stream buffer).
Java, PHP,[17] and Python[18] provide the \r\n sequence (for ASCII CR+LF). In contrast to C, these are guaranteed to represent the values U+000D and U+000A, respectively.
The Java Class Library input/output (I/O) methods do not transparently translate these into platform-dependent newline sequences on input or output. Instead, they provide functions for writing a full line that automatically add the native newline sequence, and functions for reading lines that accept any of CR, LF, or CR+LF as a line terminator (see BufferedReader.readLine()). The System.lineSeparator() method can be used to retrieve the underlying line separator.
Example:
String eol = System.lineSeparator(); String lineColor = "Color: Red" + eol;
Python permits «Universal Newline Support» when opening a file for reading, when importing modules, and when executing a file.[19]
Some languages have created special variables, constants, and subroutines to facilitate newlines during program execution. In some languages such as PHP and Perl, double quotes are required to perform escape substitution for all escape sequences, including \n and \r. In PHP, to avoid portability problems, newline sequences should be issued using the PHP_EOL constant.[20]
Example in C#:
string eol = Environment.NewLine; string lineColor = "Color: Red" + eol; string eol2 = "\n"; string lineColor2 = "Color: Blue" + eol2;
Issues with different newline formats
[edit]
The different newline conventions cause text files that have been transferred between systems of different types to be displayed incorrectly.
Text in files created with programs which are common on Unix-like or classic Mac OS, appear as a single long line on most programs common to MS-DOS and Microsoft Windows because these do not display a single line feed or a single carriage return as a line break.
Conversely, when viewing a file originating from a Windows computer on a Unix-like system, the extra CR may be displayed as a second line break, as ^M, or as <cr> at the end of each line.
Furthermore, programs other than text editors may not accept a file, e.g. some configuration file, encoded using the foreign newline convention, as a valid file.
The problem can be hard to spot because some programs handle the foreign newlines properly while others do not. For example, a compiler may fail with obscure syntax errors even though the source file looks correct when displayed on the console or in an editor. Modern text editors generally recognize all flavours of CR+LF newlines and allow users to convert between the different standards. Web browsers are usually also capable of displaying text files and websites which use different types of newlines.
Even if a program supports different newline conventions, these features are often not sufficiently labeled, described, or documented. Typically a menu or combo-box enumerating different newline conventions will be displayed to users without an indication if the selection will re-interpret, temporarily convert, or permanently convert the newlines. Some programs will implicitly convert on open, copy, paste, or save—often inconsistently.
Most textual Internet protocols (including HTTP, SMTP, FTP, IRC, and many others) mandate the use of ASCII CR+LF (\r\n, 0x0D 0x0A) on the protocol level, but recommend that tolerant applications recognize lone LF (\n, 0x0A) as well. Despite the dictated standard, many applications erroneously use the C newline escape sequence \n (LF) instead of the correct combination of carriage return escape and newline escape sequences \r\n (CR+LF) (see section Newline in programming languages above). This accidental use of the wrong escape sequences leads to problems when trying to communicate with systems adhering to the stricter interpretation of the standards instead of the suggested tolerant interpretation. One such intolerant system is the qmail mail transfer agent that actively refuses to accept messages from systems that send bare LF instead of the required CR+LF.[21]
The standard Internet Message Format[22] for email states: «CR and LF MUST only occur together as CRLF; they MUST NOT appear independently in the body». Differences between SMTP implementations in how they treat bare LF and/or bare CR characters have led to SMTP spoofing attacks referred to as «SMTP smuggling».[23]
The File Transfer Protocol can automatically convert newlines in files being transferred between systems with different newline representations when the transfer is done in «ASCII mode». However, transferring binary files in this mode usually has disastrous results: any occurrence of the newline byte sequence—which does not have line terminator semantics in this context, but is just part of a normal sequence of bytes—will be translated to whatever newline representation the other system uses, effectively corrupting the file. FTP clients often employ some heuristics (for example, inspection of filename extensions) to automatically select either binary or ASCII mode, but in the end it is up to users to make sure their files are transferred in the correct mode. If there is any doubt as to the correct mode, binary mode should be used, as then no files will be altered by FTP, though they may display incorrectly.[24]
Conversion between newline formats
[edit]
Text editors are often used for converting a text file between different newline formats; most modern editors can read and write files using at least the different ASCII CR/LF conventions.
For example, the editor Vim can make a file compatible with the Windows Notepad text editor. Within vim
Editors can be unsuitable for converting larger files or bulk conversion of many files. For larger files (on Windows NT) the following command is often used:
D:\>TYPE unix_file | FIND /V "" > dos_file
Special purpose programs to convert files between different newline conventions include unix2dos and dos2unix, mac2unix and unix2mac, mac2dos and dos2mac, and flip.[25]
The tr command is available on virtually every Unix-like system and can be used to perform arbitrary replacement operations on single characters. A DOS/Windows text file can be converted to Unix format by simply removing all ASCII CR characters with
$ tr -d '\r' < inputfile > outputfile
or, if the text has only CR newlines, by converting all CR newlines to LF with
$ tr '\r' '\n' < inputfile > outputfile
The same tasks are sometimes performed with awk, sed, or in Perl if the platform has a Perl interpreter:
$ awk '{sub("$","\r\n"); printf("%s",$0);}' inputfile > outputfile # UNIX to DOS (adding CRs on Linux and BSD based OS that haven't GNU extensions) $ awk '{gsub("\r",""); print;}' inputfile > outputfile # DOS to UNIX (removing CRs on Linux and BSD based OS that haven't GNU extensions) $ sed -e 's/$/\r/' inputfile > outputfile # UNIX to DOS (adding CRs on Linux based OS that use GNU extensions) $ sed -e 's/\r$//' inputfile > outputfile # DOS to UNIX (removing CRs on Linux based OS that use GNU extensions) $ perl -pe 's/\r?\n|\r/\r\n/g' inputfile > outputfile # Convert to DOS $ perl -pe 's/\r?\n|\r/\n/g' inputfile > outputfile # Convert to UNIX $ perl -pe 's/\r?\n|\r/\r/g' inputfile > outputfile # Convert to old Mac
The file command can identify the type of line endings:
$ file myfile.txt myfile.txt: ASCII English text, with CRLF line terminators
The Unix egrep (extended grep) command can be used to print filenames of Unix or DOS files (assuming Unix and DOS-style files only, no classic Mac OS-style files):
$ egrep -L '\r\n' myfile.txt # show UNIX style file (LF terminated) $ egrep -l '\r\n' myfile.txt # show DOS style file (CRLF terminated)
Other tools permit the user to visualise the EOL characters:
$ od -a myfile.txt $ cat -e myfile.txt $ cat -v myfile.txt $ hexdump -c myfile.txt
Two ways to view newlines, both of which are self-consistent, are that newlines either separate lines or that they terminate lines. If a newline is considered a separator, there will be no newline after the last line of a file. Some programs have problems processing the last line of a file if it is not terminated by a newline. On the other hand, programs that expect newline to be used as a separator will interpret a final newline as starting a new (empty) line. Conversely, if a newline is considered a terminator, all text lines including the last are expected to be terminated by a newline. If the final character sequence in a text file is not a newline, the final line of the file may be considered to be an improper or incomplete text line, or the file may be considered to be improperly truncated.
In text intended primarily to be read by humans using software which implements the word wrap feature, a newline character typically only needs to be stored if a line break is required independent of whether the next word would fit on the same line, such as between paragraphs and in vertical lists. Therefore, in the logic of word processing and most text editors, newline is used as a paragraph break and is known as a «hard return», in contrast to «soft returns» which are dynamically created to implement word wrapping and are changeable with each display instance. In many applications a separate control character called «manual line break» exists for forcing line breaks inside a single paragraph. The glyph for the control character for a hard return is usually a pilcrow (¶), and for the manual line break is usually a carriage return arrow (↵).
Reverse and partial line feeds
[edit]
RI (U+008D REVERSE LINE FEED,[26] ISO/IEC 6429 8D, decimal 141) is used to move the printing position back one line (by reverse feeding the paper, or by moving a display cursor up one line) so that other characters may be printed over existing text. This may be done to make them bolder, or to add underlines, strike-throughs or other characters such as diacritics.
Similarly, PLD (U+008B PARTIAL LINE FORWARD, decimal 139) and PLU (U+008C PARTIAL LINE BACKWARD, decimal 140) can be used to advance or reverse the text printing position by some fraction of the vertical line spacing (typically, half). These can be used in combination for subscripts (by advancing and then reversing) and superscripts (by reversing and then advancing), and may also be useful for printing diacritics.
- End-of-file
- Enter key
- Page break
- ^ «What is a Newline?». www.computerhope.com. Retrieved 10 May 2021.
- ^ Qualline, Steve (2001). Vi Improved — Vim (PDF). Sams Publishing. p. 120. ISBN 9780735710016. Archived from the original (PDF) on 8 April 2022. Retrieved 4 January 2023.
- ^ Duckett, Chris. «Windows Notepad finally understands everyone else’s end of line characters». ZDNet. Archived from the original on 13 May 2018. Retrieved 4 January 2023.
[A]fter decades of frustration, and having to download a real text editor to change a single line in a config file from a Linux box, Microsoft has updated Notepad to be able to handle end of line characters used in Unix, Linux, and macOS environments.
- ^ Lopez, Michel (8 May 2018). «Introducing extended line endings support in Notepad». Windows Command Line. Archived from the original on 6 April 2019. Retrieved 4 January 2023.
As with any change to a long-established tool, there’s a chance that this new behavior may not work for your scenarios, or you may prefer to disable this new behavior and return to Notepad’s original behavior. To do this, you can change […registry keys…] to tweak how Notepad handles pasting of text, and which EOL character to use when Enter/Return is hit
- ^ Kahn-Greene, Will Guaraldi. «ASCII chart». bluesock.org.
- ^ Bray, Andrew C.; Dickens, Adrian C.; Holmes, Mark A. (1983). The Advanced User Guide for the BBC Microcomputer (PDF). Cambridge Microcomputer Centre. pp. 103, 104. ISBN 978-0946827008. Retrieved 30 January 2019.
- ^ «Character Output». RISC OS 3 Programmers’ Reference Manual. 3QD Developments Ltd. 3 November 2015. Retrieved 18 July 2018.
- ^ IBM System/360 Reference Data Card, Publication GX20-1703, IBM Data Processing Division, White Plains, NY
- ^ Heninger, Andy (20 September 2013). «UAX #14: Unicode Line Breaking Algorithm». The Unicode Consortium.
- ^ Bray, Tim (March 2014). «JSON Grammar». The JavaScript Object Notation (JSON) Data Interchange Format. sec. 2. doi:10.17487/RFC7159. RFC 7159.
- ^ Bray, Tim (March 2014). «Strings». The JavaScript Object Notation (JSON) Data Interchange Format. sec. 7. doi:10.17487/RFC7159. RFC 7159.
- ^ a b «ECMAScript 2019 Language Specification». ECMA International. June 2019. 11.3 Line Terminators.
- ^ «ECMAScript 2019 Language Specification». ECMA International. June 2018. 11.3 Line Terminators.
- ^ «Subsume JSON (a.k.a. JSON ⊂ ECMAScript)». GitHub. 22 May 2018.
- ^ «5.4. Line Break Characters». YAML Ain’t Markup Language revision 1.2.2. 1 October 2021.
- ^ «binmode». Perl documentation. Perl 5 Porters.
- ^ «PHP: Strings — Manual». PHP Manual. The PHP Group.
- ^ «2. Lexical analysis». The Python Language Reference. The Python Foundation.
- ^ «What’s new in Python 2.3». Python Software Foundation.
- ^ «PHP: Predefined Constants — Manual». PHP Manual. The PHP Group.
- ^ Bernstein, D. J. «Bare LFs in SMTP».
- ^ Resnick, Pete (April 2001). Internet Message Format. doi:10.17487/RFC2822. RFC 2822.
- ^ Longin, Timo (18 December 2023). «SMTP Smuggling — Spoofing E-Mails Worldwide». SEC Consult.
- ^ Zeil, Steven (19 January 2015). «File Transfer». Old Dominion University. Archived from the original on 14 May 2016.
When in doubt, transfer in binary mode.
- ^ Sapp, Craig Stuart. «ASCII text converstion between UNIX, Macintosh, MS-DOS». Center for Computer Research in Music and Acoustics. Archived from the original on 9 February 2009.
- ^ «C1 Controls and Latin-1 Supplement» (PDF). unicode.org. Retrieved 13 February 2016.
- The Unicode reference; see paragraph 5.8 in Chapter 5 of the Unicode 4.0 standard (PDF)
- «The [NEL] Newline Character».
- The End of Line Puzzle
- Understanding Newlines at the Wayback Machine (archived 20 August 2006)
- «The End-of-Line Story»
-
При развитии компьютеров возникла необходимость стандартизации формата хранения и отображения текстовых файлов, чтобы с текстом, составленным в компьютере одного производителя, можно было работать на компьютере другого производителя без необходимости какого-либо преобразования. Для этого в 1963 году была разработана стандартная таблица ASCII, определяющая, как должны кодироваться буквы английского языка, цифры, некоторые другие символы (+%,@$…), а также ряд управляющих символов, не имеющих графического представления и служащих для управления выводом.
-
Первоначально таблица описывала 127 символов, позже была расширена до 255 символов (для хранения используются 8 бит). Коды символов из таблицы ASCII принято записывать в 16-ричном виде, например, латинская буква ‘A’ кодируется 10-тичным числом ’65’, которое в 16-ричном виде записывается как ‘0x41’.
-
Следует подчеркнуть, что в то время еще не существовало графических интерфейсов для взаимодействия с компьютером. Вместо этого в качестве интерактивных терминалов для взаимодействия оператора и ЭВМ использовались «телетайпы» (teletype), представляющие что-то вроде электромеханических печатающих машин, в которых вывод осуществлялся печатью на бумагу (или, в более поздних моделях, отображением на текстовый дисплей). И управляющие символы из состава таблицы ASCII отражают специфику управления такими устройствами. Например:
-
Символ с кодом ‘0x07’ (bell) ничего не печатает, вместо этого воспроизводится звуковой сигнал для привлечения внимания оператора.
-
Символ с кодом ‘0x08’ (backspace) означает ‘вернуть печатающую головку на одну позицию назад’. Это, в частности, позволяло печатать несколько символов поверх друг-друга и реализовывать жирный или подчёркнутый шрифт.
-
Символ с кодом ‘0x0A‘ (line feed) означает ‘перевести строку’, т.е. сдвинуть печатающую головку на 1 строку вниз.
-
Символ с кодом ‘0x0С’ (form feed) заставляет принтер завершить печать на используемом листе бумаги, промотать этот лист и дальнейшую печать продолжать на следующем листе.
-
Символ с кодом ‘0x0D‘ (carriage return) означает ‘возврат каретки’, т.е. возвращает курсор или головку в начало текущей строки (без перевода строки)
-
-
Однако полной стандартизации не получилось и так исторически сложилось, что в операционных системах разных семейств перевод строки в текстовом файле кодируется разными последовательностями управляющих символов ASCII:
-
Для семейств Unix / Linux / BSD / Solaris / … перевод строки кодируется одним символом с кодом ‘0x0A’. Видимо, подразумевается, что возврат на начало строки при этом происходит по умолчанию.
-
Для семейств DOS и Windows перевод строки кодируется двумя последовательными символами с 16-ричными кодами ‘0x0D’ и ‘0x0A’.
-
Для семейства Macintosh до версии 9.0 — одним символом с кодом ‘0x0D’.
-
Для семейства Macintosh после версии MacOS X — одним символом с кодом ‘0x0A’.
-
-
В результате текстовый файл, составленный в ОС семейства Windows и скопированный на интерфейсный сервер, может содержать лишние символы с кодом ‘0x0D’, которые в некоторых ситуациях приведут к ошибкам при его обработке.
-
Если такие символы присутствуют в скрипте для qsub, то попытка его запуска планировщиком завершится ошибкой следующего вида:
-bash: /var/spool/PBS/mom_priv/jobs/XXXXXX.vm-pbs.SC: /bin/bash^M: bad interpreter: No such file or directory
Дело в том, что вместо интерпретатора ‘/bin/bash’, указанного в самой первой строке скрипта, получился ‘/bin/bash^M’, а такого файла не существует (о чём и говорит фраза ‘No such file or directory’)
-
Управляющие символы внутри текстового файла можно увидеть, например, из Midnight Commanger, встав на файл курсором и затем:
-
или нажав F4 (редактирование файла). Если в тексте присутствуют символы с кодом ‘0x0D’, они будут отображаться в конце строки как ‘^M‘
-
или нажав F3 (просмотр файла), а затем F4 (отображение в 16-ричном виде).
-
-
Удалить все такие лишние символы ‘0x0D’ можно или вручную из mc, или выполнив на интерфейсном сервере утилиту ‘dos2unix‘, которой в качестве параметра сообщается имя файла, который необходимо преобразовать (будет модифицирован сам исходный файл, без создания нового файла или резервной копии):
dos2unix submit.sh
Существует и аналогичная утилита с именем ‘unix2dos’, осуществляющая преобразование в обратную сторону (добавляя ‘0x0D’ перед каждым ‘0x0A’).
-
Кроме того, многие программы для передачи файлов умеют сами преобразовывать передаваемые файлы, автоматически добавляя или удаляя символы перевода строки. Например, WinSCP так поступает по умолчанию, если передаваемый файл имеет определённые расширения (txt, html, …), но расширение ‘sh’ в их состав не входит. Нужно или каждый раз при пересылке текстового файла переключать режим передачи в Text, или зайти в настройки и добавить нужные расширения.
-
Либо, чтобы исключить необходимость перекодирования, создавать и редактировать текстовые файлы можно непосредственно на интерфейсном сервере.
Символ возврата каретки использовался в компьютерных терминалах, принтерах и системах обработки текста для перемещения курсора или печатающей головки в начало текущей строки.
В контексте компьютерных систем и текстовых файлов, символ Возврат каретки используется для обозначения конца строки. В разных операционных системах применяются разные комбинации символов для обозначения конца строки. В системах на базе UNIX и Linux используется символ
, а в операционных системах семейства Windows для обозначения конца строки используется комбинация символов
(Carriage Return) и
(Line Feed), представленная как «\r\n»
Как и остальные управляющие символы, этот символ не имеет визуального представления и не занимает места на экране или в печати. В разделе
Пиктограммы управляющих символов2400–243F
есть отдельный символ, представляющий графическое изображение символа возврата каретки в виде аббревиатуры CR (Carriage Return) —
␍
.
Escape-последовательность: \r.
Символ является одним из восьми управляющих символов, обязательного наличия которых требует стандарт POSIX:
\0
;\a
;\b
;\t
;\n
;\v
;\f
;\r
.
Символ «Возврат каретки» входит в подраздел «Управляющие символы C0» раздела «Основная латиница» и был утвержден как часть Юникода версии 1.1 в 1993 г.
Этот текст также доступен на следующих языках:
English;
перевод строки.
Время на прочтение3 мин
Количество просмотров61K
Notepad в windows 10 начал понимать юниксовый перевод строки, а не только формат Windows.
С проблемой «каши» вместо удобочитаемого текста десятилетиями сталкивались те, кто пытался открыть в среде Windows текстовые документы, подготовленные на других операционных системах. Теперь же всё в одночасье изменяется. И это изменение столь же мало, сколь и эпично по своим практическим результатам и идеологическим последствиям. Microsoft вновь пытается играть в кросс-интеграцию и поддержку открытых стандартов.
Долгие годы Windows Блокнот мог нормально отображать только те текстовые документы, которые содержали символы начала новой строки в формате Windows End of Line (EOL) — «возврат каретки» (CR) и «подача на строку» (LF). На деле это приводило к тому, что Notepad не смог правильно отобразить содержимое текстовых файлов, созданных в Unix, Linux и macOS, где в качестве признака конца строки использовался только символ LF.
Например, вот скриншот Notepad, пытающегося отобразить содержимое текстового файла Linux .bashrc, который содержит только символы Unix LF EOL:

А вот скриншот недавно обновленного «Блокнота», отображающего содержимое того же самого файла UNIX / Linux .bashrc, но с правильными переносами:
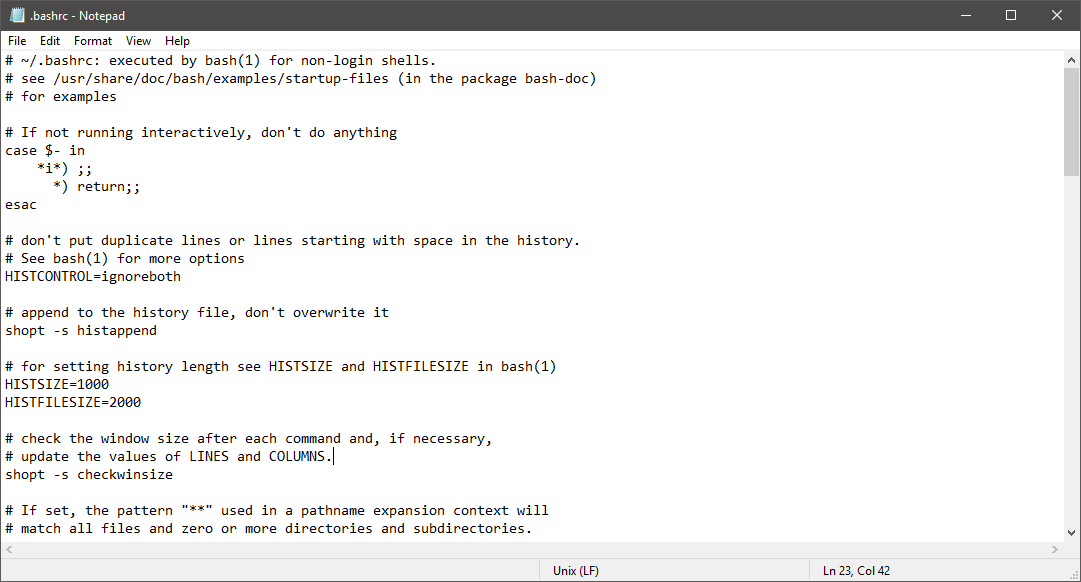
Обратите внимание, что строка состояния указывает обнаруженный формат EOL текущего открытого файла.
Так же для гибкого управления новой возможностью в разделе реестра [HKEY_CURRENT_USER\Software\Microsoft\Notepad] вводятся два дополнительных ключа:

По накалу страстей спор о способе начала новой строки в электронных документах сравним со спором о пробелах и табуляциях в исходных текстах программ. У этого противостояния «за строку» было много причин, как лежащих в области древних стандартов и традиций, так и берущих свои корни в особенностях конструкции печатных машин и телетайпов. Не меньшую роль сыграло и стремление одних программистов буквально выполнять (интерпретировать) команды и управляющие символы, а других — следовать здравому смыслу.
Что мы можем узнать о проблеме из Википедии
Исторически на механических пишущих машинках был рычаг, который возвращал каретку к левому краю страницы и прокручивал вал, подвигая бумагу вверх на строку. На телетайпах и более поздних алфавитно-цифровых печатающих устройствах (АЦПУ) вместо каретки была головка, в лазерных принтерах она перестала быть материальной, но в термине возврат каретки всё это продолжали называть кареткой, чтобы его не менять. На телетайпах возврат каретки и подачу строки разделили, откуда традиция представления перевода строки как CR+LF перешла и к текстовым файлам.
Системы, основанные на ASCII или совместимом наборе символов, используют или LF (перевод строки, 0x0A), или CR (возврат каретки, 0x0D) по отдельности, или последовательность CR+LF. Эти названия основаны на командах принтера: перевод строки означает, что одна строка на бумаге должна быть перенесена при печати, а возврат каретки означает, что каретка печатающего устройства должна вернуться к началу текущей строки.
- CR (ASCII 0x0D) использовался в 8-битовых машинах Commodore, машинах TRS-80, Apple II, системах Mac OS до версии 9 и OS-9;
- LF (ASCII 0x0A) используется в Multics, UNIX, UNIX-подобных операционных системах (GNU/Linux, AIX, Xenix, Mac OS X, FreeBSD), BeOS, Amiga UNIX, RISC OS и других;
- CR+LF (ASCII 0x0D 0x0A) используется в DEC RT-11 и большинстве других ранних не-UNIX- и не-IBM-систем, а также в CP/M, MP/M, MS-DOS, OS/2, Microsoft Windows, Symbian OS, протоколах Интернет.
По стандарту, любое совместимое с Юникодом приложение должно воспринимать как перевод строки каждый из нижеследующих символов:
- LF (U+000A): англ. line feed — подача строки <ПС>;
- CR (U+000D): англ. carriage return — возврат каретки <ВК>;
- NEL (U+0085): англ. next line — переход на следующую строку;
- LS (U+2028): англ. line separator — разделитель строк;
- PS (U+2029): англ. paragraph separator — разделитель абзацев.
Причем, последовательность CR+LF (U+000D U+000A) надлежит воспринимать как один перевод строки, а не два.
Но как известно, стандарты стандартами, а реализации у всех часто выходят разными. И масла в огонь подливает необходимость корректно отображать унаследованные документы, созданные до эпохи юникода. Отсутствие единого общепринятого представления перевода строки в разных операционных системах надолго осложнило обмен текстовыми данными между ними.
Юникод старается примирить эту разницу, уравнивая CR, LF и CR+LF, однако вступает в противоречие с наследуемым им ASCII при трактовке последовательности LF+CR, не предварённой CR: согласно ASCII это один перевод строки, а согласно Юникоду — два.
Если эта публикация вас вдохновила и вы хотите поддержать автора — не стесняйтесь нажать на кнопку