
На этом уроке мы с вами
вспомним, что такое иерархическая структура и из каких элементов она состоит.
Также рассмотрим несколько примеров иерархической базы данных.
Начнём мы с вами с
рассмотрения иерархической структуры базы данных.
Иерархическая структура
– это многоуровневая форма организации объектов со строгой соотнесённостью
объектов нижнего уровня определённому объекту верхнего уровня. Т. е. можно
сказать, что иерархическая структура напоминает собой пирамиду, в которой
объекты более низкого уровня подчиняются объектам более высокого уровня.
Из этого можно сделать
вывод, что в иерархической структуре существуют отношения между её объектами
(элементами).
Ещё иерархическую
структуру называют древовидной. К примерам можно отнести содержание
учебника.
А сейчас рассмотрим
иерархическую структуру более подробно на примере.
Давайте построим
иерархическую структуру школы.
Во главе всегда находится
директор школы. Далее будут идти завуч старших классов, завуч младших классов,
заведующий хозяйственной деятельностью. После завучей идут учителя, которые,
соответственно, делятся на преподавателей младших и старших классов. Не будем
расписывать всех учителей, а возьмём по три учителя каждых классов. Заведующему
по хозяйственной деятельности будет подчиняться весь технический персонал. Его
мы расписывать не будем. Далее у каждого учителя есть свой класс, в котором он
является классным руководителем, а в каждом классе – ученики. В свою очередь,
учителя старших классов ведут уроки и в других классах. Давайте отобразим
несколько таких классов в нашей структуре. Если же всю эту структуру
расписывать более подробно, то нам понадобится очень много места, так как
объектов в этой системе очень большое количество.
Итак, во главе любой
иерархической структуры всегда находится один элемент (объект). В нашем случае
– это директор школы. Он является корнем вершины и находится на верхнем
(первом) уровне.
Далее идёт второй
уровень, на котором находятся заместители.
На третьем уровне
находятся учителя и технический персонал, на четвёртом – классы и на пятом –
ученики.
Как говорилось ранее,
между всеми объектами существуют связи. Каждый объект более высокого уровня
может включать в себя несколько объектов более низкого уровня. Давайте снова
обратимся к нашему примеру. Так, завуч старшей школы включает в себя всех
учителей, которые ведут уроки в старших классах. А заведующий хозяйственной
деятельностью управляет всем техническим персоналом школы. Такие объекты
находятся в отношении предка (объект более высокого уровня) к потомку
(объект более низкого уровня). То есть завуч старшей школы и заведующий
хозяйственной деятельностью являются предками, а учителя и технический персонал
– потомками.
Также мы можем видеть,
что у объекта-предка может быть несколько потомков. Но в то же время у
объекта-потомка может быть только один предок. Объекты, которые находятся на
одном уровне и у которых один общий предок, называются близнецами.
Рассмотрим ещё один
пример. Построить иерархическую структуру, исходя из следующего условия: на кафедре
иностранных языков работают три преподавателя. Иванова Инна Сергеевна преподаёт
английский язык, Кулибина Анна Васильевна преподаёт немецкий язык, а Рудков
Игорь Сергеевич преподаёт французский язык.
Корневой вершиной в этой
структуре будет являться кафедра. Изобразим её в виде круга. Она включает в
себя трёх преподавателей. Также изобразим их схематично, а от кафедры к каждому
преподавателю проведём стрелки.
Далее у каждого
преподавателя есть свои предметы, которые он ведёт. Также изобразим их
схематично и проведём стрелки.
Таким образом мы получили
графическое отображение иерархической структуры кафедры.
Корневой вершиной
является кафедра.
Учителя являются потомками
по отношению к кафедре и предками по отношению к предметам, которые они
преподают. Также они между собой являются близнецами, так как находятся на
одном уровне структуры и имеют одного предка – кафедру.
У нас получилось
несколько определений.
Корень
– это единственный объект, который стоит на вершине иерархической системы и
является её первым уровнем.
Предок
– это объект, который стоит более близко к корню системы и у него может быть
несколько потомков.
Потомок
– это объект, который стоит на более низком уровне по отношению к предку и у
него может быть только один предок.
Близнецы –
это объекты, которые имеют одного предка и находятся на одном уровне.
А сейчас рассмотрим ещё
несколько примеров.
Начнём с иерархической
базы данных папки Windows.
Иерархической базой
данных является каталог папок Windows. Перед вами
рисунок системного диска. Для того, чтобы увидеть древовидную структуру в
проводнике в Windows 7, необходимо выбрать кнопку
«Упорядочить», далее из появившегося списка – «Представления», а затем «Область
переходов». Это в том случае, если данная область не отображается.
А вот, например, в Windows 10 необходимо в проводнике, во вкладке «Вид»,
выбрать «Область навигации» и из списка снова «Область навигации».
На рисунке представлен
проводник операционной системы Windows 10.
Итак, корневой является
папка «Этот компьютер».
Далее, на втором уровне
на представленном рисунке находится локальный диск С, который включает в себя
несколько папок третьего уровня.
В нашем случае выбрана
папка «Program Files». Она
в себя включает несколько папок-потомков.
Исходя из этого можно
сказать, что корнем является – «Этот компьютер». Далее и предком, и потомком
является локальный диск С. Папка «Program Files» также является и потомком (по отношению к локальному
диску С), и предком (по отношению к остальным папкам, которые она в себя
включает). Файл «Rar.txt» является потомком папки «WinRAR».
В свою очередь, мы можем видеть, что у файла «Rar.txt» нет своих потомков. Также,
например, файлы «Rar.txt» и «Rar.exe» являются близнецами, так как
находятся на одном уровне и у них один общий предок – папка «WinRAR».
Ещё одним примером
иерархической базы данных является файловая система Linux.
Мы ранее её
рассматривали. В ней существует одна корневая папка, все остальные папки являются
потомками. В корневой папке содержатся все системные файлы. А вот, например,
каталоги логических томов и запоминающих устройств содержатся в составе других
каталогов. Директории томов жёсткого диска содержатся в папке «mnt».
Другие запоминающие устройства находятся в папке «media».
В свою очередь, папки «mnt» и «media»
содержатся в одном системном корневом каталоге. Таким образом, папки «mnt»
и «media» являются и потомками (по отношению к
основному корневому каталогу), и предками (по отношению к каталогам логических
томов и запоминающих устройств). Помимо этого, эти две папки являются
близнецами, так как они находятся на одном уровне и имеют одного предка.
А сейчас давайте
рассмотрим такую иерархическую базу данных, как «Системный реестр Windows».
В этой иерархической базе
данных хранится вся информация, которая нужна для нормального функционирования
компьютерной системы. То есть в этой базе данных содержится информация о
настройках компьютера, установленных драйверах, настройках графического
интерфейса, сведения о программах, которые установлены на компьютере, и многое
другое.
Вся эта информация
автоматически обновляется при установке нового оборудования, удалении или
установке программ и так далее.
Давайте рассмотрим
рисунок.
Корневым объектом
является сам компьютер. Папка «Adobe»
является потомком по отношению к папке «SOFTWARE» и предком для всех
остальных папок, которые она в себя включает. Папки «7-Zip» и «Adobe» являются близнецами, так как они
находятся на одном уровне и у них один предок – папка «SOFTWARE». Файл «UserID»
является потомком папки «IAC».
В свою очередь, мы можем видеть, что у файла «UserID» нет своих потомков.
В операционной же системе
Linux
как такового реестра нет. Вместо этого в ней существует папка «etc».
А сейчас мы с вами
рассмотрим иерархическую базу данных «Доменная система имён». Эта система
получила название DNS.
DNS – это распределённая
база данных, которая поддерживает иерархическую систему имён для идентификации
узлов сети Интернет.
Эта служба предназначена
для автоматического поиска IP-адреса
по известному символьному имени узла. То есть в этой базе данных содержится
информация о всех компьютерах, подключённых к сети Интернет.
Корневой вершиной в этой
системе является табличная база данных, которая содержит перечень доменов
верхнего уровня.
Сам же корень управляется
центром Internet Network Information Center. Домены
верхнего уровня назначаются для каждой страны, а также на организационной
основе. Для обозначения стран используются трёхбуквенные и двухбуквенные
аббревиатуры.
Так, например, для
русскоязычных сайтов доменом верхнего уровня является «.ru»,
для Казахстана – «.kz» и т. д. Для различных типов организаций
также есть свои аббревиатуры.
На втором уровне
находятся также табличные базы данных, но они уже в себя включают перечень
доменов второго уровня для каждого домена первого уровня.
На третьем уровне
содержатся табличные базы данных и таблицы. Табличные базы данных содержат
перечень доменов третьего уровня для каждого домена второго уровня. Таблицы, в
свою очередь, содержат IP-адреса
компьютеров, которые находятся в домене второго уровня.
А теперь представьте,
какой большой будет база данных, которая должна включать в себя информацию о
всех компьютерах, подключенных к Интернету. Как вы
думаете, много ли места она будет занимать?
Такая база данных огромна
по своим размерам и соответственно она не будет умещаться в памяти одного
компьютера, а если бы и можно было загрузить такую базу данных в один
компьютер, то работа в Интернете была бы очень медленной. Представьте себе
количество запросов, которые поступают от пользователей всего мира в течение,
например, 1 минуты. Их количество огромно. А теперь представьте, что все эти
запросы должен принять и обработать один компьютер. Это просто невозможно, так
как приведёт не только к медленной работе компьютера, но также и к зависанию,
если не к поломке. Таким образом, размещение базы данных доменной системы имён
на одном компьютере неэффективно. Но решение этой проблемы было найдено. Вся
база данных была разделена на части и размещена на различных DNS-серверах, которые связаны между
собой. Такая иерархическая база данных является распределённой базой данных.
А сейчас давайте
рассмотрим, как происходит поиск информации в такой огромной иерархической
распределённой базе данных.
Например, вам нужно зайти
на свою почту в Яндексе. Для этого вы вводите в адресную строку запрос.
Ваш запрос сначала
отправляется на DNS-сервер вашего провайдера, с которого он переадресуется
на DNS -сервер верхнего уровня базы данных.
На этом сервере, в
таблице первого уровня, произойдёт поиск интересующего нас домена «ru»,
после чего запрос будет перенаправлен на DNS-сервер второго уровня, который
содержит перечень доменов второго уровня, зарегистрированных в домене «ru».
На втором уровне будет
происходить поиск среди доменов второго уровня. После того, как был найден
интересующий нас домен «yandex», произойдёт
перенаправление на DNS-сервер
третьего уровня, на котором находится перечень доменов третьего уровня,
зарегистрированных в домене «yandex».
В таблице третьего уровня
будет найден домен «mail», и запрос будет
переадресован на DNS-сервер
четвёртого уровня.
В таблице четвёртого
уровня будет найдена запись, которая соответствует доменному имени,
содержащемуся в запросе. После этого поиск в самой базе данных «Доменная
система имён» будет завершён и начнётся поиск компьютера в сети по его IP-адресу.
Пришла пора подвести
итоги урока.
Сегодня мы с вами узнали,
что такое иерархическая структура и построили такую структуру на примере. Более
подробно познакомились с элементами иерархической базы данных: корнем, предком,
потомком, близнецами.
Рассмотрели несколько
иерархических баз данных на примере Windows и Linux,
а также реестра Windows.
Узнали, как составлена и
работает иерархическая база данных «Доменная система имён».
Источник статьи
Автор24
— учеба по твоим правилам
Определение 1
База данных является совокупностью организованной определенным образом информации, которая позволяет упорядоченно сохранять данные о группах объектов, которые имеют одинаковый набор свойств. К базам данных можно отнести, к примеру, всевозможные справочники, энциклопедии, каталоги, картотеки и прочее.
Систематизированные данные издавна еще до появления первых вычислительных машин и устройств хранились в виде различных карточек. Переход к компьютеризированному хранению информации был охарактеризован для человека множеством преимуществ: оперативным доступом к неограниченному объему данных, возможностью логического контроля вводимой информации, контролем целостности базы данных, регулированием уровня доступа к данным для пользователей разных категорий. Но главным преимуществом явилось то, что использование компьютерного хранения информации дало возможность заменить механические процедуры извлечения отдельных сведений мощными методами обработки запросов человека и автоматическим составлением произвольных справок и отчетов. Появление компьютерных сетей позволило хранить данные не в одной машине, а в нескольких, таким образом появились так называемые распределенные базы данных. Вершиной объединения компьютерных данных можно считать Всемирную информационную сеть Интернет.
Типы баз данных
В базах данных информация хранится, как было отмечено выше, в упорядоченном виде. В связи с этим существуют различные типы баз данных: иерархические, сетевые и табличные.
Иерархические базы данных графически представляются в виде дерева, состоящего из объектов различных уровней. На самом верхнем уровне находится один объект, на втором — объекты второго уровня и т. д.
Объекты связаны между собой, причем каждый из них может включать в себя объекты более низкого уровня. Примером иерархической базы данных является каталог папок в операционной системе Windows.
Замечание 1
Сетевую базу данных от иерархической отличает то, что в ней каждый элемент верхнего уровня может быть связан одновременно с любыми элементами следующего уровня.
«Табличные базы данных» 👇
Отметим, что связи между объектами в сетевых моделях не имеют никаких ограничений. Примером сетевой базы данных является Всемирная паутина глобальной сети Интернет. Миллионы документов связаны между собой при помощи гиперссылок в единую распределенную сетевую базу данных.
Табличная (реляционная) база данных представляет сбой перечень объектов одного типа, т.е. объектов с одинаковым набором свойств.
Табличные базы данных
База данных, хранящая данные о группе объектов с одинаковыми свойствами, представляется в виде двумерной таблицы, где каждая ее строка последовательно размещает значения свойств одного из объектов; а каждое значение свойства находится в своем столбце, названном по имени свойства.
Столбцы подобной таблицы называются полями, причем каждое поле имеет свое имя (имя соответствующего свойства) и тип данных, который представляет значения этого свойства.
Поле базы данных является столбцом таблицы, содержащим значения определенного свойства.
Определение 2
Строки таблицы – это записи об объекте, которые разбиты на поля столбцами таблицы, в результате каждая запись представлена набором значений, находящихся в полях.
Запись базы данных представляет собой строку таблицы, содержащую набор значений свойств, размещенных в полях базы данных.
Каждая таблица, как правило, содержит одно ключевое поле, содержимое которого является уникальным для каждой записи данной таблицы. С помощью ключевого поля однозначно идентифицируются записи в таблице.
Замечание 2
Таким образом, ключевое поле является полем, значения которого однозначно определяют записи в таблице.
Ключевое поле, как правило, имеет тип данных счетчик. Однако в некоторых случаях удобнее, чтобы ключевое поле таблицы имело другой тип (например, числовой — инвентарный номер или код объекта).
Тип поля
Тип поля определяется по типу данных, содержащихся в нем. В полях могут содержаться данные следующих типов:
- Счетчик, в нем содержится последовательность целых чисел, задаваемых автоматически при вводе записей. Пользователь данные числа не может изменить;
- Текстовый, в нем содержатся символы различных типов;
- Числовой, в нем содержатся числа различных типов;
- Дата/Время используется для содержания даты или времени;
- Картинка, используется для хранения изображения;
- Логический, имеет значения Истина (Да) или Ложь (Нет).
Для каждого типа характерен свой набор свойств. Наиболее важными из которых являются:
- размер поля используется для определения максимальной длины текстового или числового поля;
- формат поля используется для установления формата данных;
- обязательное поле используется для указания на то, что это поле обязательно нужно заполнить.
Пример табличной базы данных
Рассмотрим базу данных «Компьютер» (рис.3), которая представляет собой перечень объектов (компьютеры), каждый из которых имеет свое имя (название). В качестве характеристик (свойств) будут выступать тип процессора и объем оперативной памяти.
Столбцы этой таблицы представляют поля, каждое из которых имеет свое имя (название соответствующего свойства) и тип данных, которые отражают значения этого свойства. Тип полей Название и Тип процессора — текстовый, а тип поля Оперативная память — числовой. При этом каждое поле имеет определенный набор свойств (размер, формат и др.). Так, для поля Оперативная память задается формат данных «целое число».
Определение 3
Полем базы данных является столбец таблицы, который включает в себя значения определенного свойства.
Строки таблицы представляют записи об объекте, которые разбиты столбцами таблицы на поля. Запись базы данных представляет собой строку таблицы, содержащую набор значений различных свойств объекта.
Замечание 3
Каждая таблица должна иметь хотя бы 1 ключевое поле, содержимое которого является уникальным для любой записи в данной таблице. Значениями ключевого поля однозначно определяются записи в таблице.
Что такое база данных
База данных — это структурированный набор сведений о каких-либо объектах. Обычно базы данных управляются специальным ПО или системами управления базами данных (СУБД).
Простейшие типы баз данных
К таким базам данных относятся БД, где хранятся данные с простой структурой: список разрешенных IP-адресов для доступа к сети, настройки окружения проекта, список подписчиков на рассылку компании и прочее. Они все еще широко распространены.
Текстовые файлы
Информация об объектах собирается в простых по структуре файлах различных форматов – txt, csv и др. Для разделения полей применяются пробелы, табуляция, запятые, точка с запятой и двоеточие.
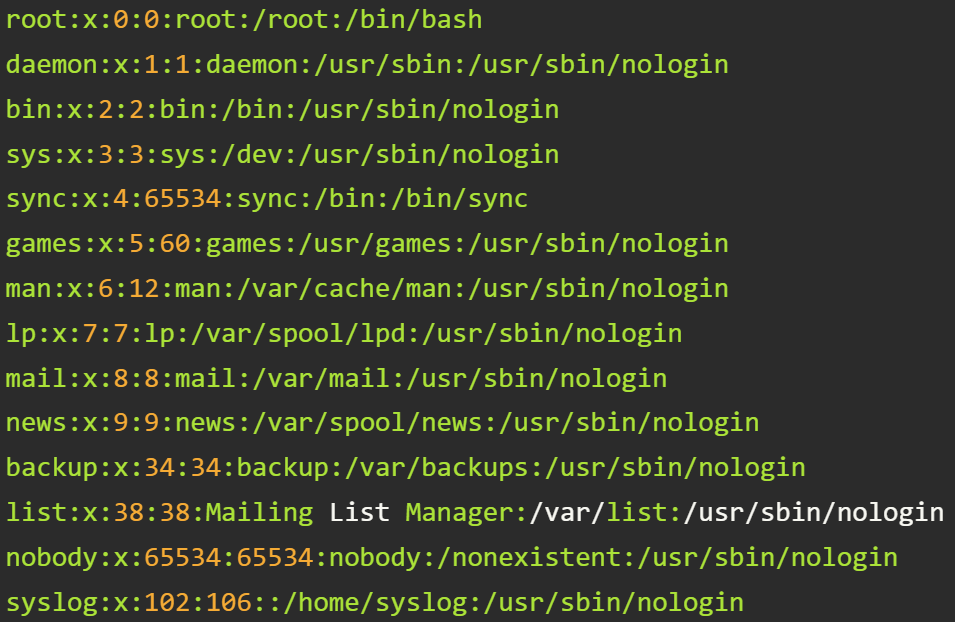
Примеры: etc/passwd и etc/fstab в Unix-подобных системах, csv-файлы, ini-файлы и др.
Особенности:
- Просто использовать. Для работы с файлами достаточно примитивного текстового редактора.
- Удобно работать с конфигурационными данными приложений (учетные данные, настройки подключения к удаленным серверам и устройствам, порты и пр.).
Ограничения:
- Сложно установить связи между компонентами данных.
- Не для всех типов информации.
Иерархические базы данных
В отличие от текстовых файлов здесь между хранимыми объектами устанавливаются связи. Объекты делятся на родителей (основные классы или категории объектов) и потомков (экземпляры этих классов или категорий). При этом у каждого потомка может быть не более одного родителя.
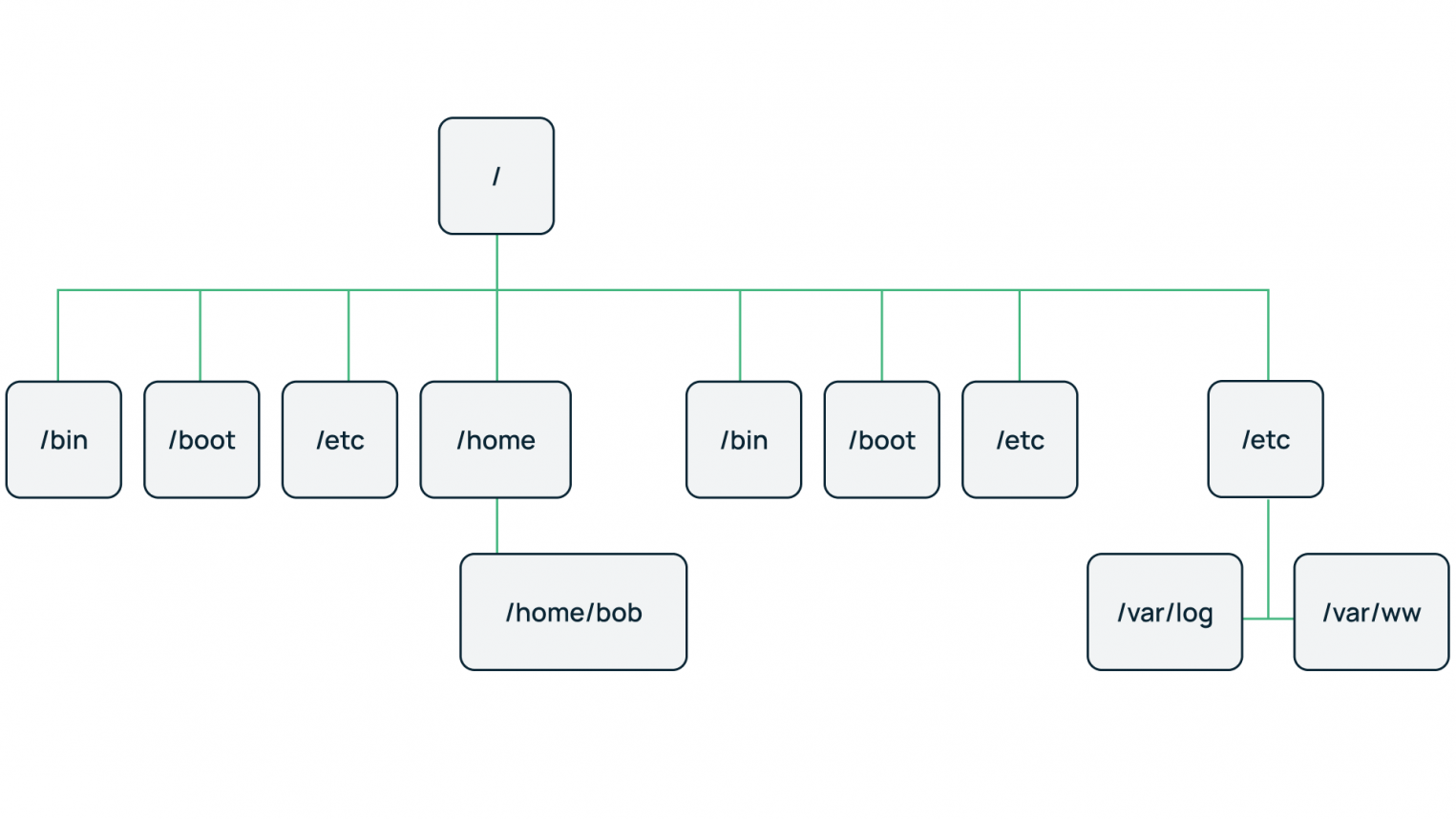
Графическим представлением такой базы данных является древовидная структура.
Примеры: Организация файловых систем; DNS и LDAP-соединения.
Особенности:
- Отношения между объектами реализованы в виде физических указателей. Например, в файловой системе путь к папке или файлу строится из имен корневых и вложенных каталогов;
- Моделирование отношений вложенности и подчиненности.
Ограничения: Технология иерархической организации не предполагает связи «многие-ко-многим», а значит, система хранения данных довольно ограничена.
Сетевые базы данных
Эта технология развивает иерархический подход за счет моделирования сложных отношений между объектами. Здесь потомки могут иметь более одного родителя, однако ограничения иерархического подхода сохраняются.
Пример: IDMS — специализированная СУБД для мейнфреймов.
Реляционные базы данных
Данный тип БД является старейшим: теоретические основы подхода заложены британским ученым Эдгаром Коддом в 1970 году. Здесь данные формируются в таблицы из строк и столбцов. В строках приводятся сведения об объектах (значения свойств), а в столбцах — сами свойства объектов (поля).
Нормализация
Сложные взаимоотношения объектов в реляционных БД моделируются с помощью внешних ключей – ссылок на другие таблицы. Это позволяет подходить к вопросу проектирования базы данных с позиций нормализации – минимизации избыточности при описании свойств объектов.
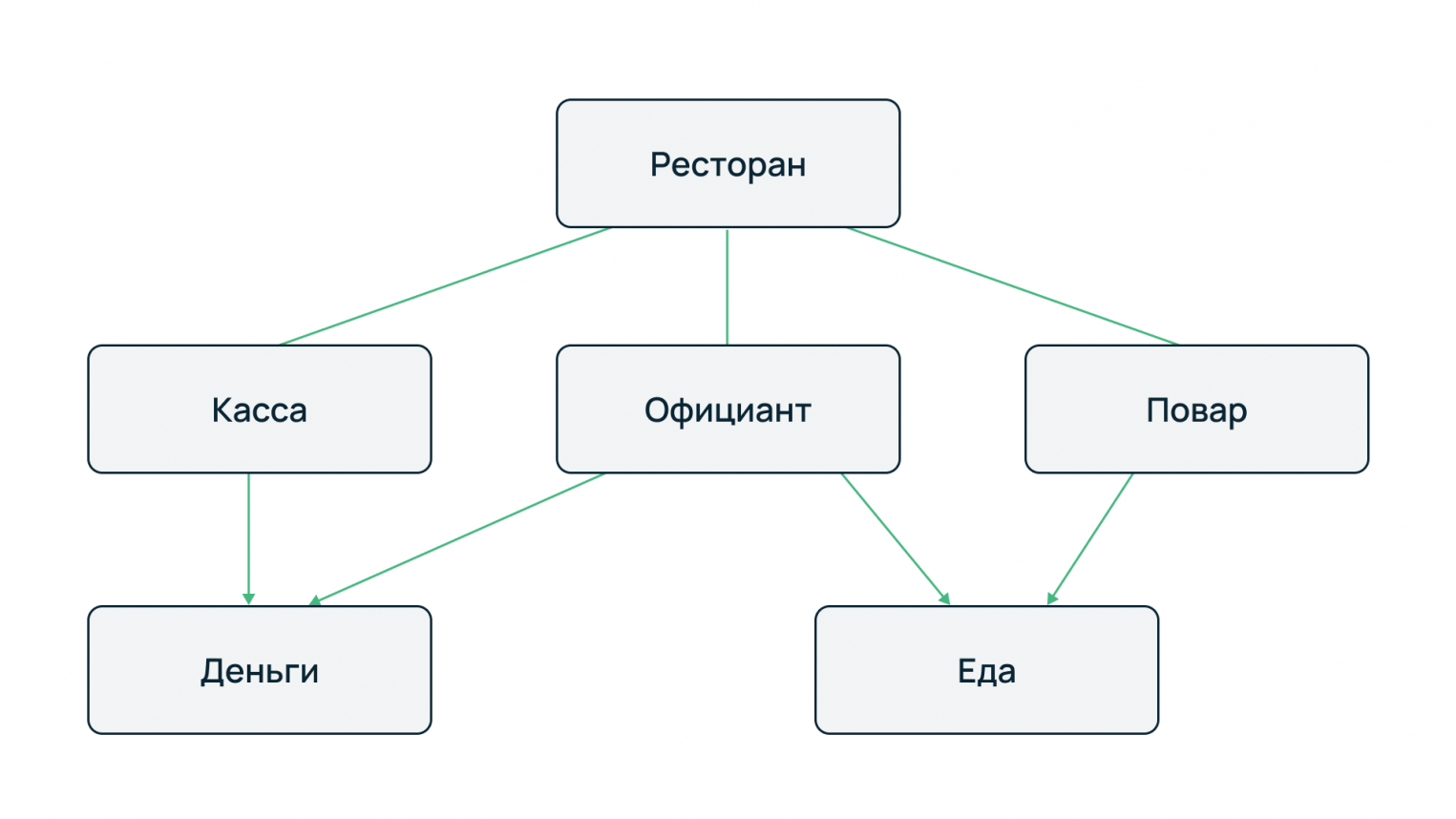
Например, если речь идет о меню ресторана, то у каждого блюда есть вес, цена, наименование, калорийность и категория, к которой оно относится — горячие закуски, холодные закуски, первые блюда, десерты, салаты и так далее. Связь между блюдами и категорией выполняется посредством ссылочного поля индекса категории в таблице блюд.
Такой подход позволяет:
- Минимизировать объем базы данных: не нужно каждому блюду прописывать название категории.
- Повысить целостность системы: в указанном примере все блюда привязаны к категориям меню. Добавление блюда без категории невозможно, равно как и указание в качестве ссылки индекса несуществующей категории.
- Упростить масштабирование: новые блюда могут быть добавлены в существующие категории. Также не исключается добавление новых категорий, привязка новых блюд к ним и перераспределение блюд по категориям.
- Повысить отказоустойчивость: за счет оптимальной организации схемы таблиц запросы на выборку и агрегацию будут работать с меньшим объемом данных, а значит, быстрее, чем без нормализации. При увеличении числа записей в таблицах со временем это позволит поддерживать положительный пользовательский опыт.
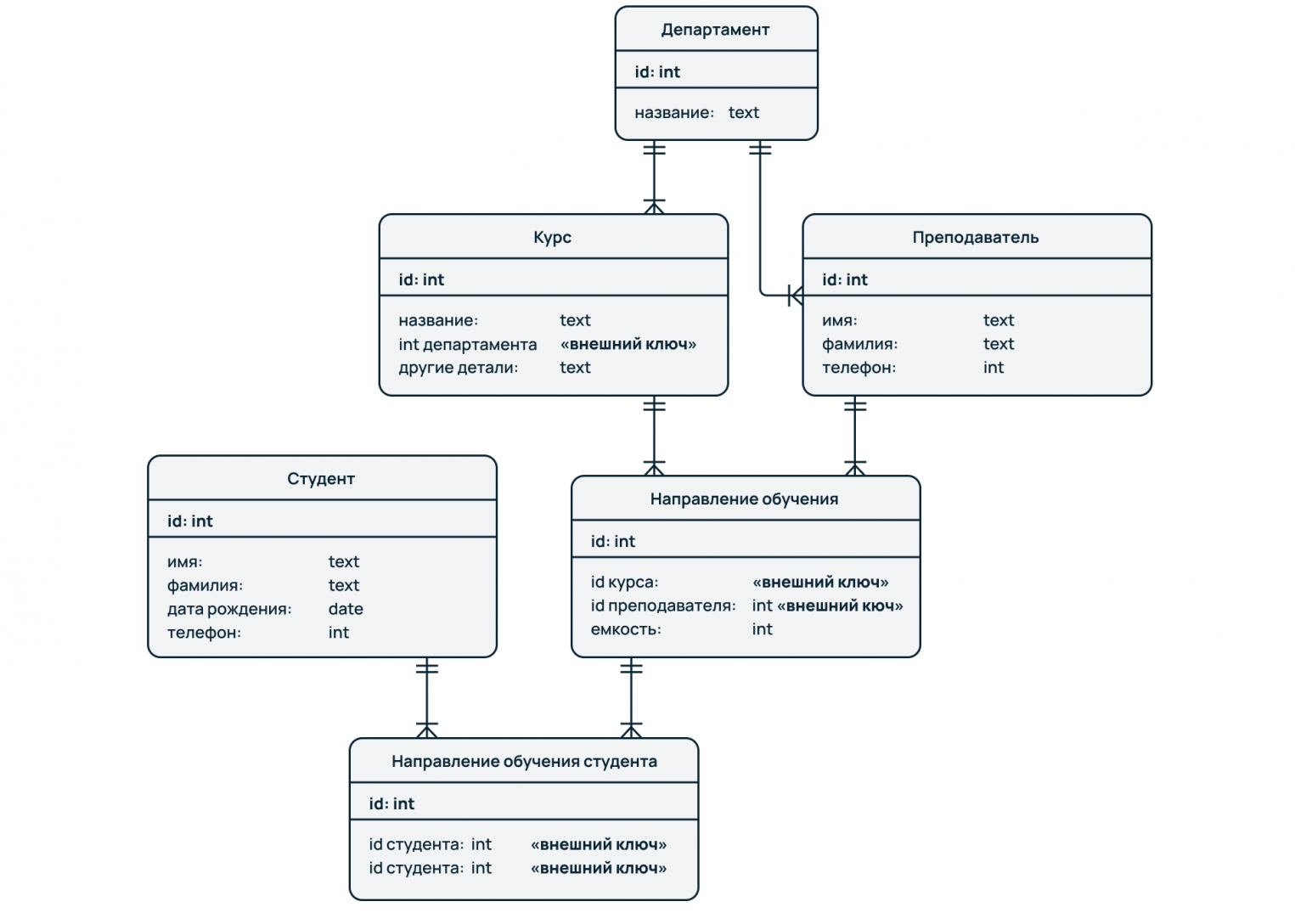
Наглядный пример моделирования сложных взаимоотношений в реляционных БД приведен на рисунке выше. Здесь мы видим модель базы данных учебного заведения, где есть следующие объекты: ученик, курс, преподаватель, отдел, направление обучения.
Связь преподавателя с отделом организована через секцию и курс (внешние ключи id курса и id преподавателя в таблице Секция, а также Отдел в таблице Курс). Связь ученика с направлением обучения реализована через таблицу Направление обучения студента (внешние ключи id студента и id направления обучения).
Таким образом, чтобы посчитать, например, количество студентов на курсе и детализировать статистику по преподавателям, необходимо написать запрос с присоединением учеников к направлению, курсу и преподавателям, сделав соответствующую группировку по преподавателям.
Язык запросов SQL
Запросы в реляционных базах данных формируют с помощью структурированного языка SQL. Его предложения позволяют:
- делать выборки,
- проводить агрегации и группировки,
- изменять и удалять данные,
- модифицировать структуру БД (создавать таблицы, поля),
- управлять доступом пользователей к тем или иным операциям и пр.
Денормализация
Помимо нормализации, в реляционных БД существует и обратный процесс — денормализация. Он направлен на перенос наиболее часто используемых полей из внешних таблиц во внутренние. Рассмотрим это на примере мессенджера.
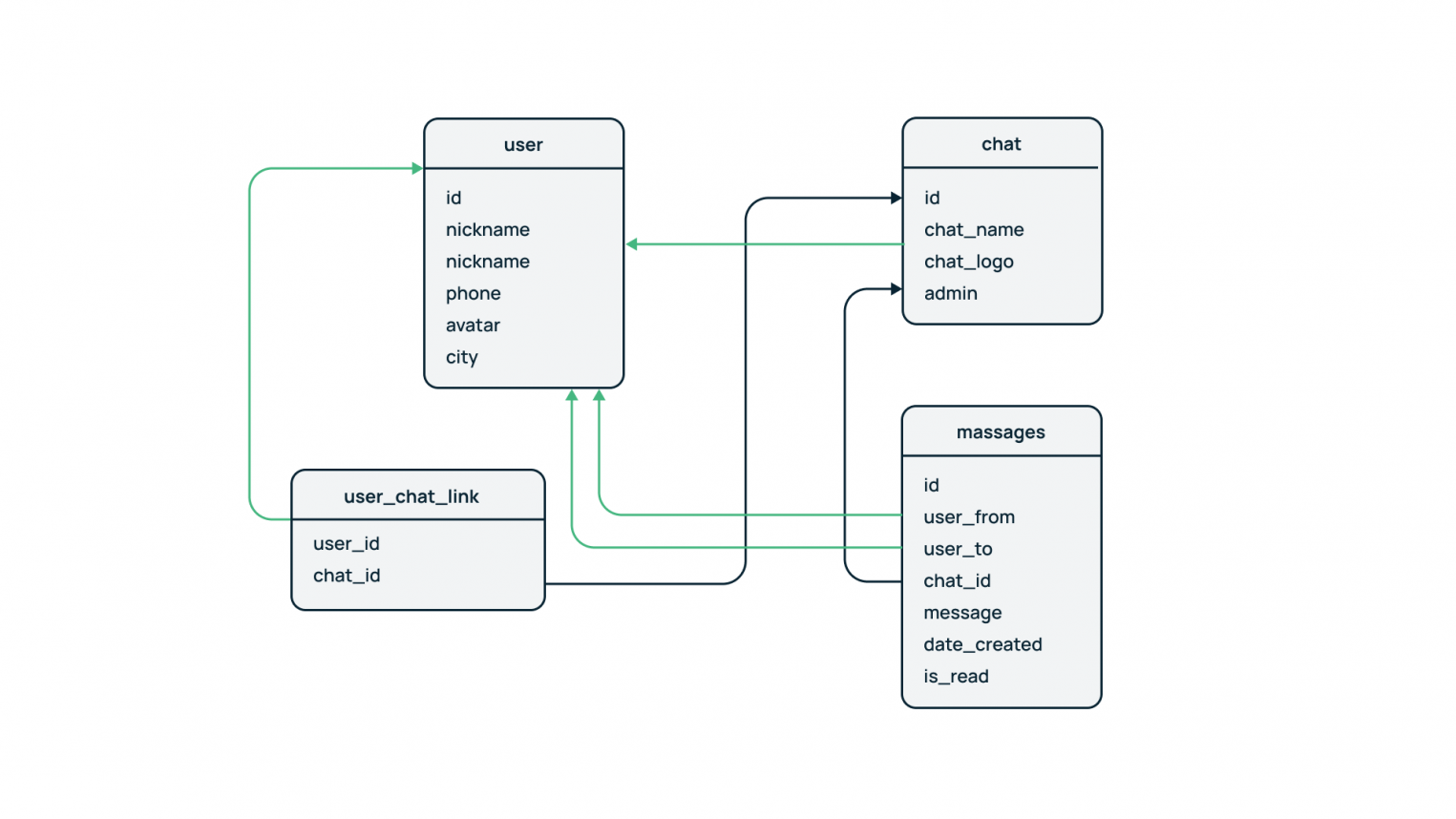
Пользователь (user) оставляет сообщения (messages) в чатах (chat). Структура данных такова, что сообщения связаны с пользователем и чатом через внешние ключи (user_from и user_to, а также chat_id в таблице сообщений; user_id и chat_id в таблице user_chat_link). Поскольку схема нормализована, то различные запросы на выборку, подсчет и агрегацию статистики по чатам, пользователям и сообщениям необходимо выполнять с помощью присоединения внешних таблиц.
На относительно небольших объемах данных эти запросы будут отрабатывать быстро, а с увеличением размера базы – замедляться. Причина кроется в механизме присоединения. Он основан на построчном сравнении двух и более таблиц по условию соединения — например, равенство chat_id в messages и id в chat. А это дает нагрузку на сервер базы данных, которая с ростом ее размера только увеличивается. Для оптимизации такого рода запросов и существует механизм денормализации.
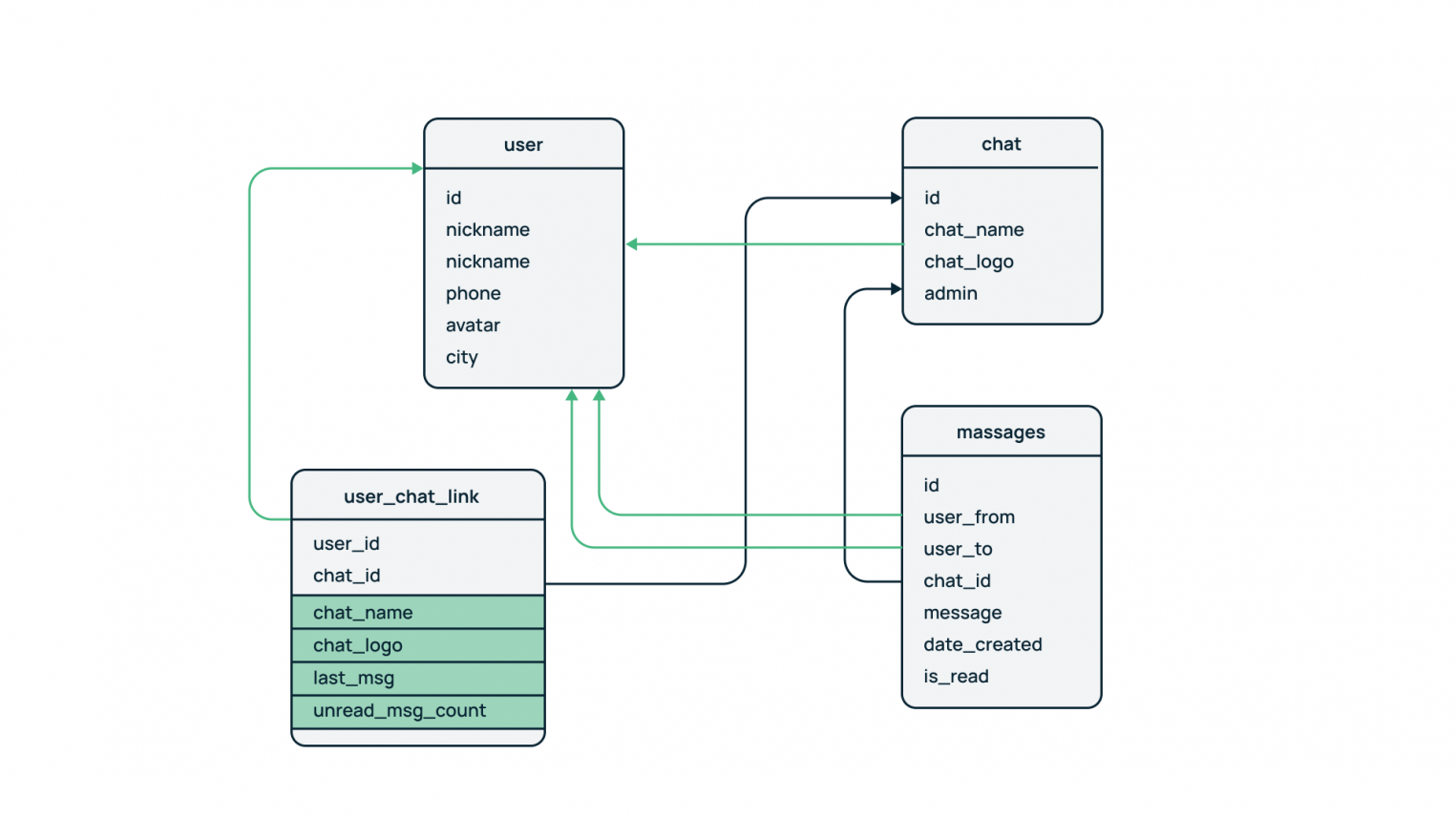
В таблицу связи пользователя и чата user_chat_link добавлены дублирующие поля имени чата (chat_name) и аватара (chat_logo). Также туда выводятся последнее сообщение (last_msg) и количество непрочитанных сообщений (unread_msg_count).
Теперь для получения указанных выше полей и проведения аналитики по ним можно использовать таблицу user_chat_link без необходимости соединения с таблицей сообщений. Тем не менее, такой подход имеет ограничения.
За счет дополнительных полей оптимизируются запросы на чтение и агрегацию данных, однако ценой этого является вынужденная избыточность и усложнение бизнес-логики приложения. В частности, усложняется написание запросов изменения данных (update и delete), а также модификации структуры базы (create).
Использование денормализации должно быть тщательно осмыслено. Нужно быть уверенным в том, что нормализованная структура, оптимизированные запросы и правильно настроенные индексы более не способны удовлетворять критерию быстродействия.
Преимущества реляционного подхода:
- определение сложных отношений между объектами,
- нормализация и денормализация данных,
- структурированный язык запросов,
- богатая история развития и широкое распространение (основной инструмент при разработке различных приложений и сервисов).
Недостатки подхода: жесткая структура сведений об объектах.
Примеры: MySQL, MariaDB, PostgreSQL, SQLite и др.
NoSQL и нереляционные базы данных
Все преимущества и недостатки реляционных БД основаны на жесткой структуризации и типизации сведений об объектах. С одной стороны, можно оптимизировать хранение и индексирование данных за счет нормализации или же денормализации. С другой — сложно организовать хранение и обработку плохо структурированных (например, объекты кэша) или вовсе не структурированных данных (например, данные из нескольких источников).
Для борьбы с этими ограничениями было разработано семейство нереляционных БД. Рассмотрим их подробнее.
Базы данных «Ключ-значение»
Это простейшая разновидность нереляционных БД. Данные хранятся в виде словаря, где указателем выступает ключ.
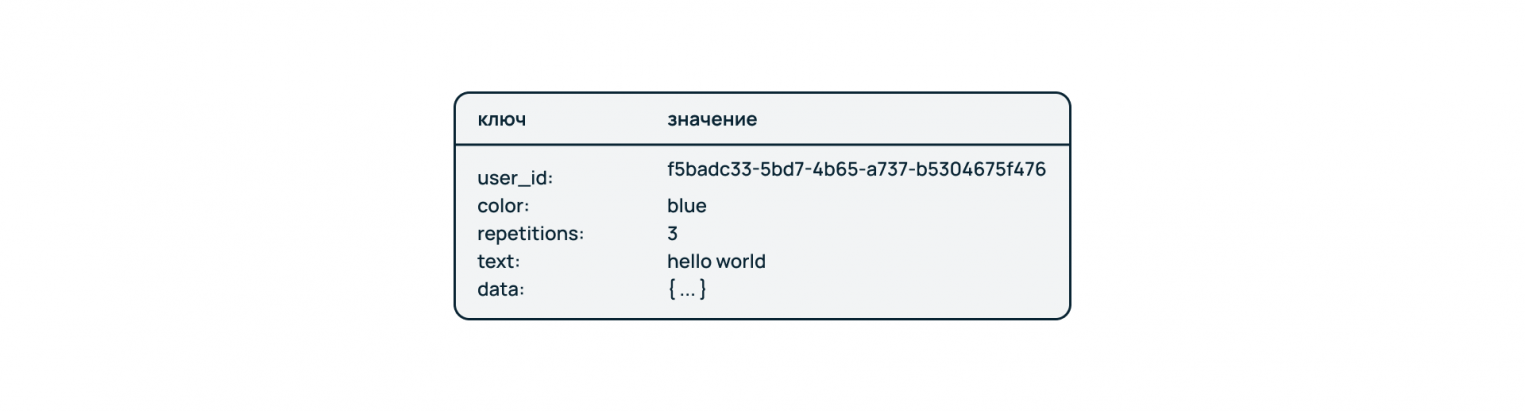
Особенности:
- Хранение и обработка разных по типу и содержанию данных: в одном хранилище под разными ключами могут находиться файлы, строки, текст, числа, JSON-объекты и другие типы данных.
- Высокая скорость доступа к данным за счет адресного хранения.
- Легкое масштабирование. Можно создать правила шардирования по определенным ключам – например, сессии пользователей разных сайтов хранятся в различных сегментах БД.
Ограничения: Поскольку подход не предполагает жесткой типизации и структуризации данных, то контроль их валидности, а также нейминг ключей отдаются на откуп разработчику.
Примеры: Amazon, DynamoDB, Redis, Riak, LevelDB, различные хранилища кэша – например, Memcached и пр.
Документоориентированные БД
В отличие от баз типа «Ключ-значение» данные здесь хранятся в структурированных форматах – XML, JSON, BSON. Тем не менее, сохраняется адресный доступ к данным по ключу. При этом содержимое документа может иметь различный набор свойств.
Например, каталог профилей пользователей: один в качестве предпочтений указал любимое блюдо, а другой – видеоигру. Поскольку эти сведения нельзя хранить в одном поле ввиду логической и структурной разобщенности, они записываются в отдельные свойства отдельных документов. При необходимости можно добавить в документы новые свойства, не нарушив при этом общей целостности данных.
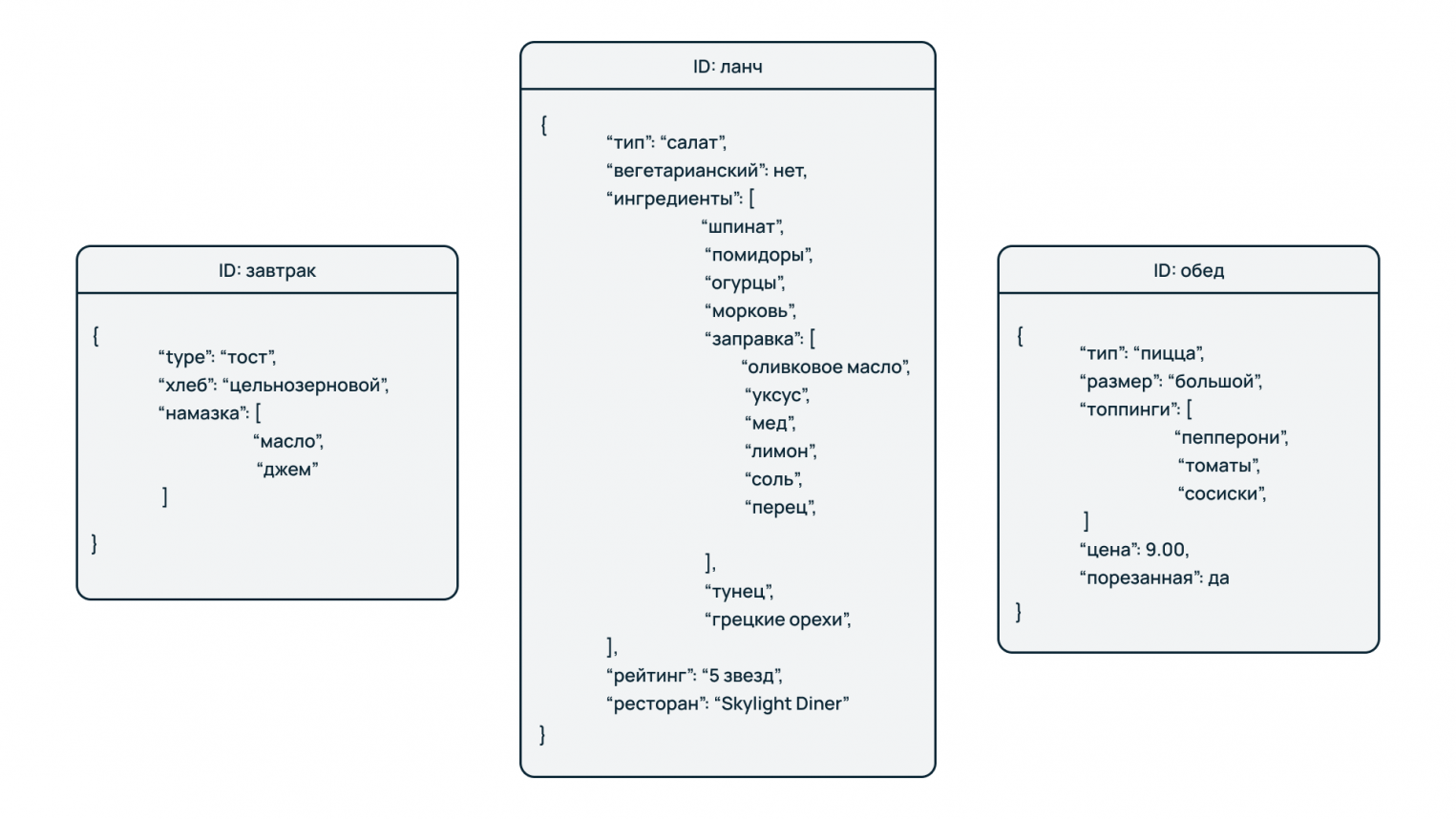
Особенности:
- хорошо подходят для быстрой разработки систем и сервисов, работающих с по-разному структурированными данными,
- легко масштабируются и меняют структуру при необходимости.
Примеры: MongoDB, RethinkDB, CouchDB, DocumentDB.
Графовые базы данных
Это семейство баз предназначено для моделирования сложных отношений с помощью теории графов, где связями выступают ребра графа, а сами объекты – это узлы или вершины.
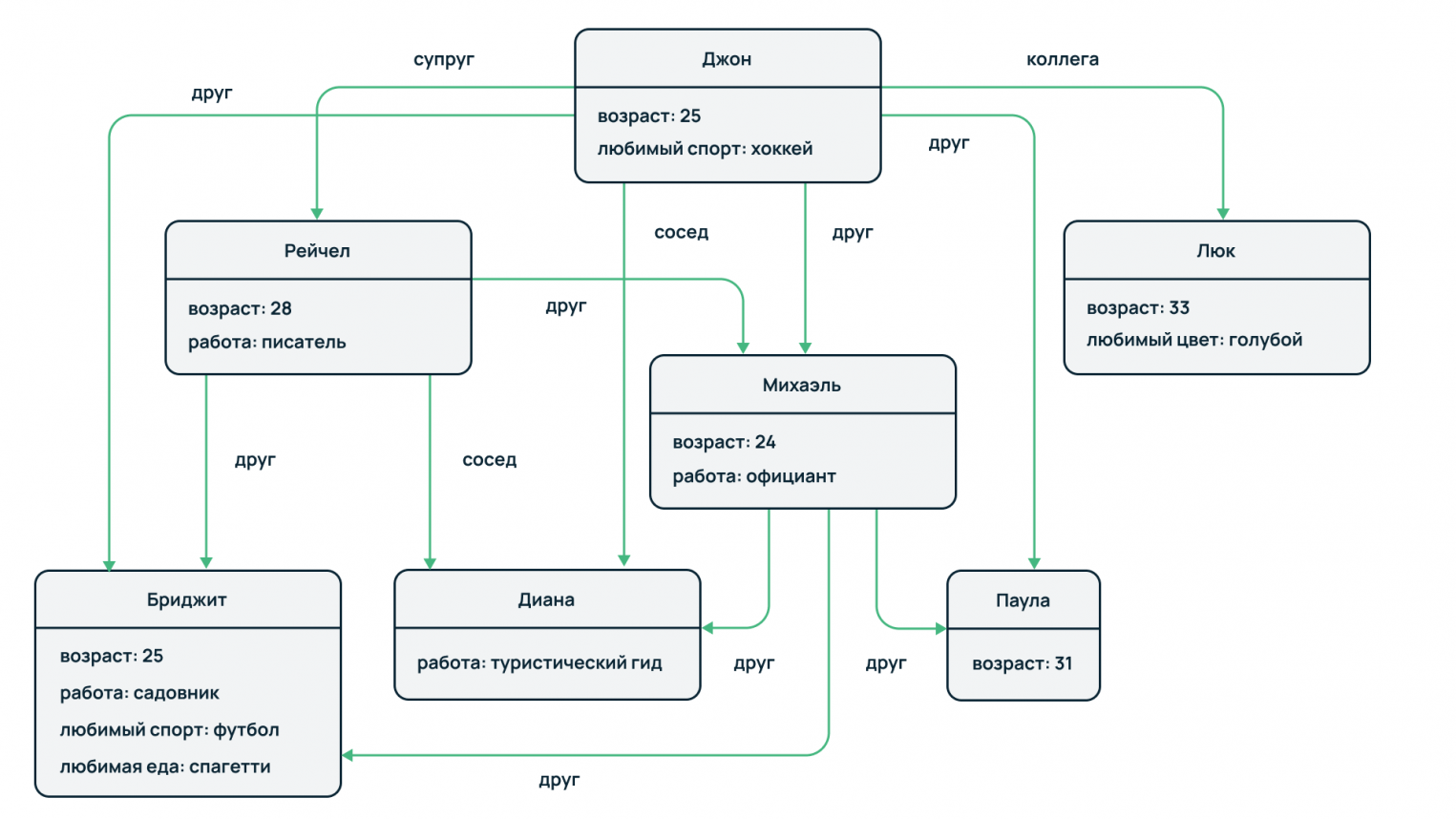
Такой подход может пригодиться при анализе профилей пользователей социальных сетей. Один пользователь подписан на обновления второго, другой пользователь подписан на определенное сообщество и так далее. Также технология может использоваться при анализе экономической активности контрагентов для выявления различных схем мошенничества. Например, можно отследить использование определенных счетов, карт или реквизитов контрагентов в различных операциях.
Особенности: высокая производительность, поскольку обход ребер и вершин значительно быстрее анализа множества внешних и внутренних таблиц и их соединения по условию отбора в реляционных БД.
Примеры: Neo4J, JanusGraph, Dgraph, OrientDB.
Колоночные базы данных
Как можно понять из названия, записи в таких базах хранятся не по строкам, а по столбцам (колонкам). Вместо таблиц здесь используются колоночные семейства. Они содержат ключи, указывающие на формат строки записи информации об объекте. Каждая строка имеет свой набор свойств, что позволяет хранить в рамках одного семейства разно структурированные данные.
Технология активно используется при построении аналитических систем и сервисов, работающих с большими объемами данных.
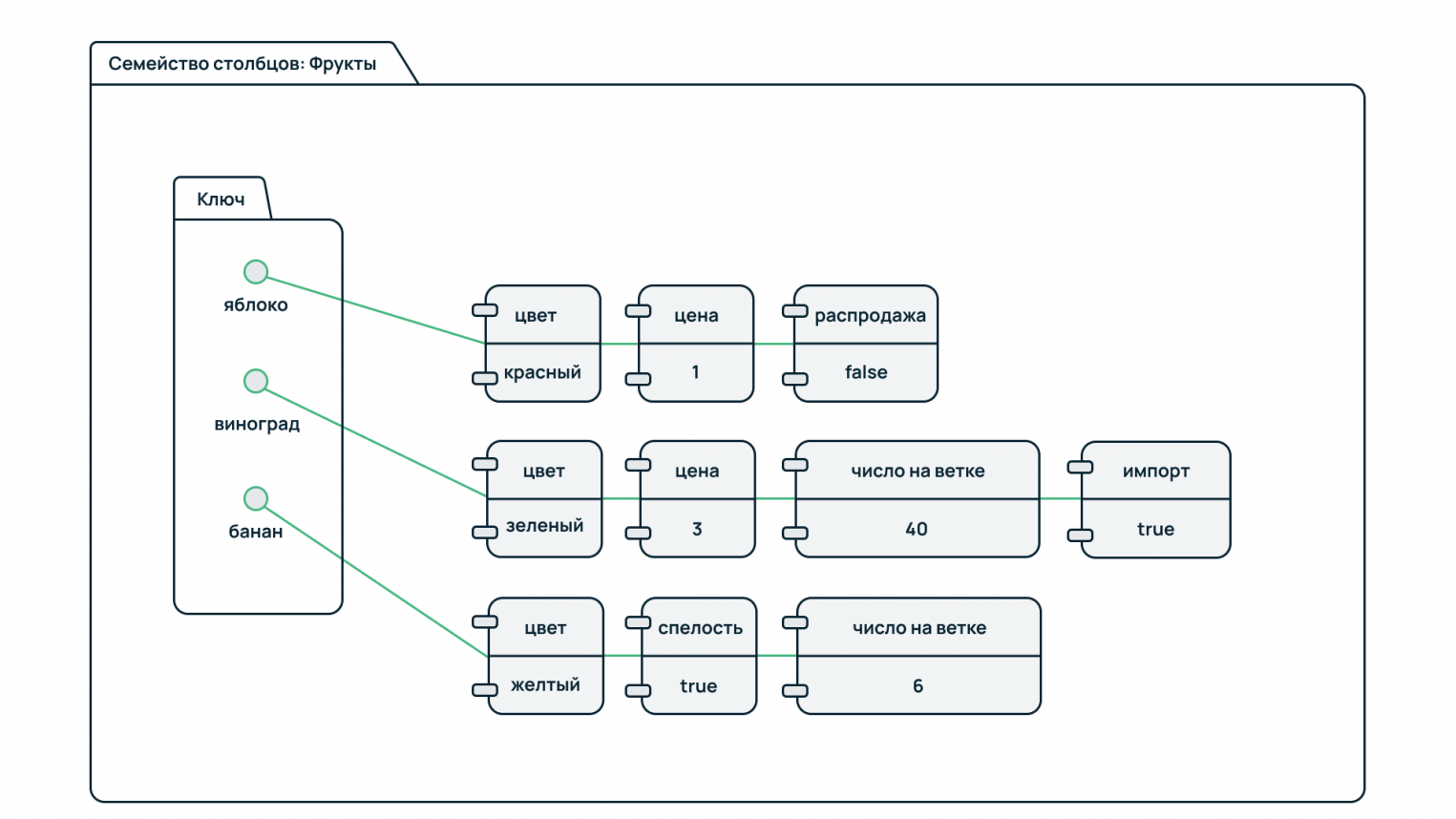
На рисунке приведен пример колоночного хранения информации о фруктах. Известно три типа фруктов: яблоки, виноград, бананы. Все они объединены в семейство фруктов.
У каждого фрукта индивидуальный набор свойств. Для яблок это цвет, цена и наличие. У винограда это цвет, цена, число ягод в связке и происхождение (импортный или нет). У бананов же это цвет, цена, число в связке и зрелость.
Чтобы получить детальную сводку по одному типу фруктов, достаточно в запросе указать его идентификатор. При этом можно построить аналитический запрос по общим для всего семейства признакам – например, посчитать число фруктов с группировкой по цвету, вычислить среднюю цену на все фрукты в магазине и т.д.
Особенности:
- С группировкой свойств по колонкам при запросе индексируется меньший объем данных, что обеспечивает высокую скорость его выполнения.
- Широкие возможности масштабирования и модификации структуры — так, при добавлении новых колонок не придется их жестко формализовывать, как в случае с реляционными базами.
Примеры: Cassandra, HBase, ClickHouse.
Базы данных временных рядов
Данный тип БД можно использовать при необходимости отслеживания исторической динамики по ряду показателей. Здесь данные группируются по временным меткам. Базы временных рядом чаще ориентированы на запись, чем на построение сложных аналитических запросов.
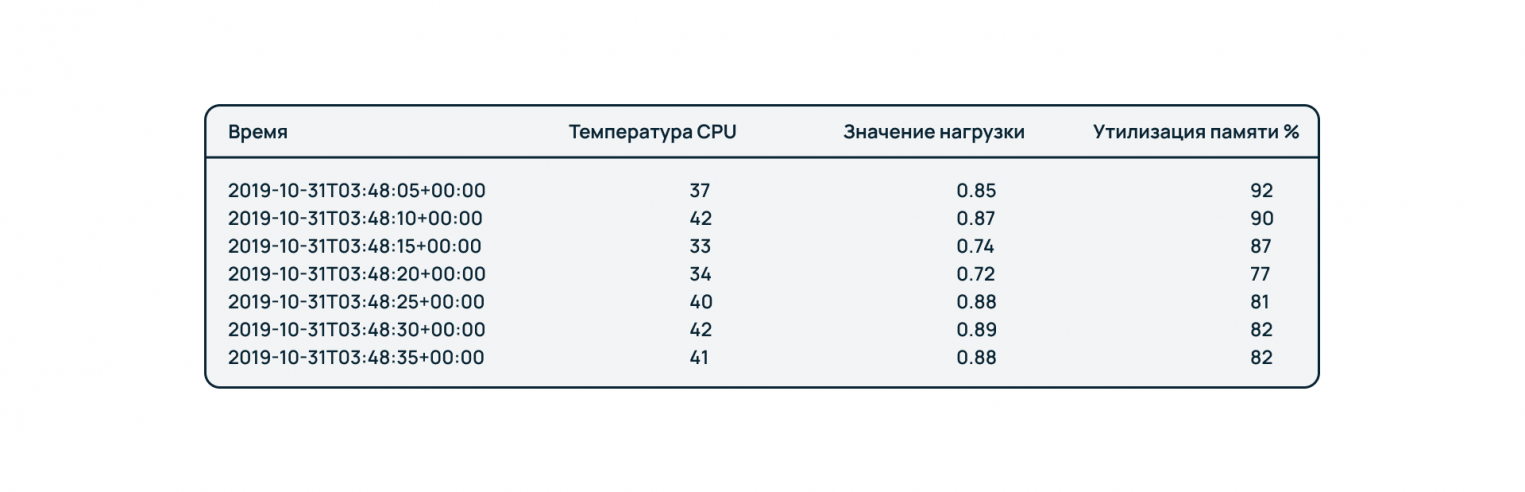
На рисунке выше приведен пример использования такой БД для отслеживания состояния ПК во времени по ряду показателей – температуре процессора, загрузке системы и потреблению оперативной памяти.
Особенности: Можно обрабатывать постоянный поток входных данных.
Ограничения: Производительность зависит от объема поступающей информации, количества отслеживаемых метрик, а также временного лага между записью новых данных и запросами на чтение
Примеры БД: OpenTSDB, Prometheus, InfluxDB, TimescaleDB
Комбинированные базы
Эта разновидность баз совмещает в себе SQL- и NoSQL-подходы к организации хранения и обработки данных. Этот класс баз включает в себя NewSQL и многомодельные решения. Рассмотрим их подробнее.
Базы данных NewSQL
Данный тип решений для хранения информации стремится обеспечить компромисс между масштабируемостью и согласованностью при сохранении реляционного подхода.
Термин предложил в 2011 году аналитик компании 451 Group Мэтью Аслет. Он отмечал высокую потребность в таких системах для сфер, работающих с критическими данными, — здравоохранение, FinTech и пр. Характерными признаками этих решений являются: использование алгоритмов обеспечения консенсуса (алгоритм Paxos, Raft и др.), шардирование и заточка под горизонтальное масштабирование.
Особенности:
- широкие возможности масштабирования,
- высокая производительность и доступность данных.
Ограничения: Высокие требования к аппаратным ресурсам разработчиков. Но если разрабатываемый продукт является высоконагруженной системой, то применение такой БД имеет смысл.
Примеры баз такого типа: MemSQL, VoltDB, Spanner и др.
Многомодельные базы
Такие БД сочетают в себе несколько подходов к организации данных одновременно. Это обеспечивает функциональное разнообразие при разработке систем с их использованием.
Особенности:
- возможность в одном запросе работать с данными, хранящимися в разных типах баз, не нарушая при этом согласованности;
- обширные возможности масштабирования за счет легкой интеграции новых моделей баз данных в существующую инфраструктуру проекта.
Пример решения данного типа: ArangoDB.
Базы данных в Selectel
В Selectel вы можете запустить готовые облачные базы данных — поддерживаем такие СУБД, как PostgreSQL (в том числе для 1С:Предприятие), MySQL, Redis, TimescaleDB.
Облачные базы данных позволяют исключить работу с инфраструктурой: поднять нужное количество нод можно за несколько минут в панели управления компании. Решение отказоустойчивое и легко масштабируется. На экстренный случай создаются резервные копии для отката состояния базы на срок до семи дней.
Большинство рутинных операций по системному администрированию (настройка, конфигурация, обслуживание и обеспечение безопасности) выполняются специалистами Selectel.
→ Как начать работу с облачными базами данных
Заключение
В данной статье мы рассмотрели 11 видов баз данных. Каждый имеет свои особенности и ограничения. Решение о выборе того или иного вида необходимо принимать с учетом:
- сложности хранимых данных и взаимосвязей между ними,
- производительности операций чтения/записи и модификации структуры БД на планируемом объеме данных,
- опыта команды разработки,
- стадии жизненного цикла разрабатываемого продукта (производите ли вы доработку действующего решения либо создаете что-то принципиально новое, каковы ваши текущие и перспективные ресурсные возможности).
Автор: Роман Андреев.
Презентация https://drive.google.com/file/d/0B1U__AnFwH_jcE5zR0ZWLXI5b1E/view?usp=sharing
1.5.1. Информационные системы и базы данных
Современный человек в своей практической деятельности всё чаще и чаще использует различные информационные системы, обеспечивающие хранение, поиск и выдачу информации по его запросам. Примерами информационных систем являются:
— справочная адресная служба большого города;
— транспортная информационная система, обеспечивающая не только возможность получения справочной информации о расписании поездов и самолётов, но и покупку железнодорожных и авиабилетов;
— информационно-поисковая система, содержащая информацию правового характера.
Центральной частью любой информационной системы является база данных.
База данных (БД) — совокупность данных, организованных по определённым правилам, отражающая состояние объектов и их отношений в некоторой предметной области (транспорт, медицина, образование, право и т. д.), предназначенная для хранения во внешней памяти компьютера и для постоянного применения.
Базу данных можно рассматривать как информационную модель предметной области.
Основными способами организации данных в базах данных являются иерархический, сетевой и реляционный.
В иерархической базе данных существует упорядоченность объектов по уровням. Между объектами существуют связи: каждый объект может быть связан с объектами более низкого уровня. Говорят, что такие объекты находятся в отношении предка к потомку. Иерархический способ организации данных реализован в системе папок операционной системы Windows. Верхний уровень занимает папка Рабочий стол. Папки второго уровня Мой компьютер, Корзина и Сетевое окружение являются её потомками. Папка Мой компьютер является предком для папок Диск А, Диск С и т. д. Поиск какого-либо объекта в такой базе данных может оказаться довольно трудоёмким из-за необходимости последовательно проходить несколько предшествующих иерархических уровней.

В сетевой базе данных не накладывается никаких ограничений на связи между объектами: в ней могут быть объекты, имеющие более одного предка. Сетевой способ организации данных реализован во Всемирной паутине глобальной компьютерной сети Интернет.
Наибольшее распространение получили реляционные базы данных.
Пример сетевой БД
1.5.2. Реляционные базы данных
В реляционной базе данных (РБД) используется реляционная модель данных, основанная на представлении данных в виде таблиц. Реляционная БД может состоять из одной или нескольких взаимосвязанных прямоугольных таблиц.

Пример реляционной БД
Строка таблицы РБД называется записью, столбец — полем.
Запись содержит всю информацию об одном объекте, описываемом в базе данных: об одном товаре, продаваемом в магазине; об одной книге, имеющейся в библиотеке; об одном сотруднике, работающем на предприятии, и т. п.
Поле — это одна из характеристик (атрибутов, свойств) объекта: название товара, стоимость товара, количество имеющихся в наличии товаров; название книги, автор книги, год издания; фамилия, имя, отчество сотрудника, дата рождения, специальность и т. п. Значения полей в одном столбце относятся к одной характеристике объекта. Поле базы данных имеет имя, тип и длину.
Все имена полей таблицы должны быть разными.
Тип поля определяется типом данных, которые поле содержит.
Основные типы полей:
— числовой — для полей, содержащих числовую информацию;
— текстовый — для полей, содержащих всевозможные последовательности символов;
— логический — для полей, которые могут принимать всего два значения: ДА (ИСТИНА, TRUE, 1) и НЕТ (ЛОЖЬ, FALSE, 0);
— дата — для полей, содержащих календарные даты (в нашей стране принято писать день, а потом месяц и год).
Длина поля — это максимальное количество символов, которые могут содержаться в поле.
1. Иерархические и сетевые базы данных
Автор: Киршева Ирина Валериановна,
учитель информатики МБОУ
«Юнгинская СОШ м. С.М.Михайлова»
2. Что такое База данных?
База данных – это совокупность хранящихся
взаимосвязанных данных, организованных по
определенным правилам.
3. Как классифицируются БД По характеру хранимой информации?
Фактографические
(БД книжного фонда
библиотеки, кадровый состав учреждения).
Документальные (БД законодательных актов в
области уголовного права, БД современной рок
музыки…).
4.
Реляционные БД;
Нереляционные БД.
5. Что такое Ключевое поле?
Ключевое поле — это поле, значение которого
однозначно определяет запись в таблице.
Каждая таблица должна содержать, по крайней
мере, одно ключевое поле, содержимое которого
уникально для каждой записи в этой таблице.
Ключевое
поле
позволяет
однозначно
идентифицировать каждую запись в таблице.
6. Имеется база данных «Химические элементы»
Am
Db
Ge
Po
Год
открытия
1945
1970
1886
1898
5 Рутений
6 Галлий
Ru
Ga
1844
1875
7 Водород
8 Радий
H
Ra
1766
1998
Название Символ
1
2
3
4
Америций
Дубний
Германий
Полоний
Автор
Г. Сиборг
Г.Н.Флёров
К. Винклер
СклодовскаяКюри
К.Клаус
Ф. Лекон де
Буабодран
Кавендиш
СклодовскаяКюри
1.Определите ключевое поле таблицы
Место
открытия
США
СССР
Германия
Франция
Россия
Франция
Англия
Франция
7. Имеется база данных «Химические элементы»
Название Символ
Год
открытия
1945
1970
1886
1898
Автор
Место
открытия
США
СССР
Германия
Франция
Г. Сиборг
Г.Н.Флёров
К. Винклер
СклодовскаяКюри
5 Рутений
Ru
1844
К.Клаус
Россия
6 Галлий
Ga
1875
Ф. Лекон де
Франция
Буабодран
7 Водород
H
1766
Кавендиш
Англия
8 Радий
Ra
1998
Склодовская- Франция
Кюри
(Место
открытия = Франция
ИЛИотбора,
Место открытия
= Россия)
2. Сформулировать
условие
позволяющее
получить
И (Год > 1900
И Год <= 2000)
сведения
об элементах,
открытых учеными из Франции или
России в ХХ веке.
1
2
3
4
Америций
Дубний
Германий
Полоний
Am
Db
Ge
Po
8. Имеется база данных «Химические элементы»
Название Символ
Год
открытия
1945
1970
1886
1898
Автор
Место
открытия
США
СССР
Германия
Франция
Г. Сиборг
Г.Н.Флёров
К. Винклер
СклодовскаяКюри
5 Рутений
Ru
1844
К.Клаус
Россия
6 Галлий
Ga
1875
Ф. Лекон де
Франция
Буабодран
7 Водород
H
1766
Кавендиш
Англия
8 Радий
Ra
1998
Склодовская- Франция
Кюри
3. Запишите порядок строк
в таблице после сортировки по
7,5,6,3,4,8,1,2
возрастанию в поле Год открытия + Автор.
1
2
3
4
Америций
Дубний
Германий
Полоний
Am
Db
Ge
Po
9. Имеется база данных «Химические элементы»
Название Символ
Год
открытия
1945
1970
1886
1898
Автор
Г. Сиборг
Г.Н.Флёров
К. Винклер
СклодовскаяКюри
5 Рутений
Ru
1844
К.Клаус
6 Галлий
Ga
1875
Ф. Лекон де
Буабодран
7 Водород
H
1766
Кавендиш
8 Радий
Ra
1998
СклодовскаяКюри
4.Какие записи удовлетворяют условию
отбора
4,6,8
Место открытия = Франция И Год >1700.
1
2
3
4
Америций
Дубний
Германий
Полоний
Am
Db
Ge
Po
Место
открытия
США
СССР
Германия
Франция
Россия
Франция
Англия
Франция
10. Имеется база данных «Химические элементы»
Название Символ
Год
открытия
1945
1970
1886
1898
Автор
Место
открытия
США
СССР
Германия
Франция
Г. Сиборг
Г.Н.Флёров
К. Винклер
СклодовскаяКюри
5 Рутений
Ru
1844
К.Клаус
Россия
6 Галлий
Ga
1875
Ф. Лекон де
Франция
Буабодран
7 Водород
H
1766
Кавендиш
Англия
8 Радий
Ra
1998
Склодовская- Франция
Кюри
5. Произведите сортировку5,8,4,2,3,6,7,1
по полю Название по убыванию и
запишите порядок записей.
1
2
3
4
Америций
Дубний
Германий
Полоний
Am
Db
Ge
Po
11. Организация информации в БД
Иерархические
Сетевые,
Реляционные.
(в виде дерева),
12. Иерархические базы данных
графически могут быть
представлены как перевернутое дерево, состоящее из
объектов различных уровней.
Верхний уровень (корень дерева) занимает один
объект, второй — объекты второго уровня и так далее.
Такие объекты находятся в отношении предка (объект,
более близкий к корню) к потомку (объект более низкого
уровня).
Примером иерархической базы данных является
реестр Windows и каталог папок Windows.
Объект-предок может не иметь потомков или
иметь их несколько, тогда как объект-потомок
обязательно имеет только одного предка.
Объекты,
имеющие
общего
предка,
называются близнецами .
13. Иерархические БД
1. Папки Windows.
2. Системный реестр Windows.
3. Доменная система имен.
4. Генеалогическое древо семьи.
14. Сетевые базы данных
Сетевая база данных является обобщением
иерархической за счет допущения объектов,
имеющих более одного предка, т.е. на связи между
объектами в сетевых моделях не накладывается
никаких ограничений.
Примером сетевой базой данных фактически
является глобальная компьютерная сеть Интернет.
Гиперссылки связывают между собой сотни
миллионов документов в единую распределенную
сетевую базу данных.
15. Практическая работа 3.5 «Создание генеалогического древа семьи»
16. Домашнее задание
П.3.3, стр.120-124, П.3.4, стр.124-125
17. Интернет-ресурсы
Слайд 1. Иерархия http://ru.stockfresh.com/thumbs/4designersart/2939449_социальной-концепциякоманда-этап-компаниячеловека.jpghttp://ru.stockfresh.com/thumbs/4designersart/2939449_социальной-концепция-командаэтап-компания-человека.jpg
Дерево http://runo-teks.ru/husqayoy/6788
Сеть http://wercom.pl/cms/upload/63777-20150504.jpg
Слайд 2 Иерархия http://ru.stockfresh.com/thumbs/4designersart/2939449_социальной-концепциякоманда-этап-компаниячеловека.jpghttp://ru.stockfresh.com/thumbs/4designersart/2939449_социальной-концепция-командаэтап-компания-человека.jpg
Сеть http://wercom.pl/cms/upload/63777-20150504.jpg
Ноутбук http://52mayachok.68edu.ru/wp-content/uploads/2014/09/canstockphoto17043750.jpg
Слайд 3,4 компьютеры https://im0-tub-ru.yandex.net/i?id=d96134b0b628fcd9a272798c38f308acl&n=13
Слайд 5,6 Ключ http://www.freeiconspng.com/uploads/blue-key-icon-27.jpg
Слайд 7,9 https://oknahot.nethouse.ru/static/img/0000/0001/9900/19900221.4dlif63zem.W665.png
Слайд 8,10 https://codeseller.ru/wp-content/uploads/2016/05/sort.png
Слайд 11. Дерево http://runo-teks.ru/husqayoy/6788
Сеть http://wercom.pl/cms/upload/63777-20150504.jpg
Слайд 12,13 http://ru.stockfresh.com/thumbs/4designersart/2939449_социальной-концепция-командаэтап-компания-человека.jpghttp://ru.stockfresh.com/thumbs/4designersart/2939449_социальнойконцепция-команда-этап-компания-человека.jpg
Слайд 14 http://wercom.pl/cms/upload/63777-20150504.jpg
Слайд 15 Дерево http://runo-teks.ru/husqayoy/6788
Слайд 16 http://www.09web.ru/wp-content/uploads/2011/12/how_to_choose_website_designers1.jpg