
- Home
- /
- Windows-1251
- /
- Windows-1251 in C#
Welcome to our comprehensive guide on «Windows-1251 in C#,» where we delve into the intricacies of this character encoding system commonly used for Cyrillic scripts. Whether you’re a seasoned developer looking to handle text processing in Russian or a newcomer exploring the world of encoding, this page will equip you with the knowledge and tools you need. From understanding the basics of Windows-1251 to practical implementation techniques in your C# applications, you’ll discover how to seamlessly manage character encoding, avoid common pitfalls, and ensure your applications communicate effectively across languages. Join us as we unlock the potential of Windows-1251 and enhance your programming skills!
What is Windows-1251?
Windows-1251 is a character encoding system used primarily for encoding Cyrillic scripts. It was developed by Microsoft for use in their operating systems and applications, particularly to support languages such as Russian, Bulgarian, Ukrainian, and Serbian. Windows-1251 is an 8-bit single-byte character encoding that allows for the representation of 256 different characters, including standard Latin characters, various punctuation marks, and a range of Cyrillic characters. This encoding is significant for applications that need to handle text in languages that use the Cyrillic alphabet, ensuring accurate representation and manipulation of text data.
Top Use Cases for Windows-1251
Windows-1251 is widely used in a variety of applications and scenarios, particularly in Eastern Europe and Central Asia. Some of its top use cases include:
- Text Processing: Applications that require manipulation of text data in Cyrillic languages, such as word processors and text editors.
- Data Storage: Databases and file systems that store records in Cyrillic languages often use Windows-1251 for encoding text fields.
- Legacy Systems: Many older software systems and applications were built using Windows-1251, making it essential for maintaining compatibility with these systems.
- Web Development: Although UTF-8 is now the preferred encoding for web content, some websites still use Windows-1251 to support legacy content or specific user bases.
Encoding text in C# using Windows-1251 is straightforward. The .NET Framework provides built-in support for various character encodings, including Windows-1251. Here’s a simple example of how to encode a string:
using System;
using System.Text;
class Program
{
static void Main()
{
string originalText = "Привет, мир!"; // Hello, world! in Russian
Encoding windows1251 = Encoding.GetEncoding("windows-1251");
// Encode the string to a byte array
byte[] encodedBytes = windows1251.GetBytes(originalText);
Console.WriteLine("Encoded Bytes: " + BitConverter.ToString(encodedBytes));
}
}
In this example, we retrieve the Windows-1251 encoding using Encoding.GetEncoding and then convert a string into a byte array representing the encoded text.
How to Decode in C# Using Windows-1251
Decoding bytes back into a string using Windows-1251 is equally simple. You can use the same Encoding class to decode a byte array. Here’s an example:
using System;
using System.Text;
class Program
{
static void Main()
{
byte[] encodedBytes = new byte[] { 0xCF, 0xE5, 0xE2, 0xB8, 0xE2, 0x2C, 0x20, 0xEC, 0xE8, 0xF0, 0x21 }; // Encoded bytes
Encoding windows1251 = Encoding.GetEncoding("windows-1251");
// Decode the byte array back to a string
string decodedText = windows1251.GetString(encodedBytes);
Console.WriteLine("Decoded Text: " + decodedText);
}
}
In this code snippet, we decode a byte array that represents a Windows-1251 encoded string back into a human-readable format.
Pros and Cons of Windows-1251
Pros
- Simplicity: Being an 8-bit encoding, Windows-1251 is easy to implement and use in applications.
- Legacy Support: Many existing systems and applications still rely on Windows-1251, making it important for compatibility.
- Efficiency: For Cyrillic characters, Windows-1251 is more space-efficient than UTF-16, which uses more bytes per character.
Cons
- Limited Character Set: Windows-1251 only supports a limited range of characters compared to Unicode, potentially leading to data loss when dealing with international text.
- Obsolescence: With the increasing adoption of UTF-8, Windows-1251 is becoming less common, which may lead to challenges in modern applications.
- Potential for Confusion: Different encodings can lead to confusion when exchanging data between systems, especially if the encoding is not specified or recognized.
Tools and Libraries for Windows-1251
When working with Windows-1251, several tools and libraries can help facilitate encoding and decoding processes:
- .NET Framework: Provides built-in support for Windows-1251 through the
System.Text.Encodingclass. - Iconv: A widely-used conversion tool that can convert between different character encodings, including Windows-1251.
- Notepad++: A text editor that supports viewing and converting files in various encodings, including Windows-1251
Кодировка Windows 1251 является одной из самых распространенных кодировок для работы с русским языком. Она используется во многих файловых форматах, таких как TXT, CSV и HTML, и может понадобиться при выполнении скриптов и обработке данных в Powershell.
Для того чтобы использовать кодировку Windows 1251 в Powershell, необходимо установить соответствующую настройку. Это можно сделать с помощью команды [Console]::OutputEncoding = [System.Text.Encoding]::GetEncoding(«windows-1251»). После этого Powershell будет использовать кодировку Windows 1251 для вывода текста в консоли.
Если вы хотите работать с файлами в кодировке Windows 1251, можно использовать команду Get-Content с параметром -Encoding windows-1251. Например, Get-Content -Encoding windows-1251 file.txt. Это позволит правильно интерпретировать содержимое файла с кодировкой Windows 1251.
Важно отметить, что при работе с кодировкой Windows 1251 в Powershell необходимо убедиться, что используемый шрифт в консоли поддерживает данную кодировку. В противном случае символы могут быть отображены некорректно.
Теперь вы знаете, как использовать кодировку Windows 1251 в Powershell. Это полезное умение, которое может пригодиться при работе с русскоязычными данными и файлами в Windows среде.
Что такое кодировка Windows 1251?
В кодировке Windows 1251 каждому символу кириллицы сопоставляется определенный числовой код, который состоит из одного байта. Это означает, что кодировка Windows 1251 может представлять до 256 различных символов, включая все буквы кириллицы, пунктуацию, цифры и другие специальные символы. Кодировка Windows 1251 была широко использована во многих устаревших системах, но все еще может быть полезной при работе с некоторыми старыми файлами и текстами, которые сохранены в этом формате.
При работе с кодировкой Windows 1251 в Powershell необходимо учитывать, что символы в этой кодировке могут быть отображены неправильно, если текущая консоль не поддерживает эту кодировку. Для правильного отображения символов в кодировке Windows 1251 можно использовать команду `chcp 1251`, чтобы установить кодировку консоли на Windows 1251. Также возможно использование функций для конвертации строк из кодировки Windows 1251 в другие кодировки и наоборот.
Подготовка
Перед использованием кодировки Windows 1251 в PowerShell необходимо выполнить несколько шагов подготовки:
| Шаг | Описание |
| 1 | Открыть PowerShell |
| 2 | Установить нужную кодировку с помощью команды $OutputEncoding = [System.Text.Encoding]::GetEncoding(1251) |
| 3 | Выполнить нужные действия с текстом в кодировке Windows 1251 |
После выполнения этих шагов вы сможете работать с текстом, используя кодировку Windows 1251 в PowerShell.
Установка PowerShell
1. Установка через Windows Update
Наиболее простым способом установки PowerShell является его установка из магазина приложений Windows или через Windows Update. Вам просто нужно проверить наличие доступных обновлений через «Параметры» -> «Обновление и Страницы безопасности» -> «Windows Update». Если доступна новая версия PowerShell, она будет автоматически загружена и установлена.
2. Установка через Microsoft Store
Вы также можете установить PowerShell через Microsoft Store. Просто откройте Microsoft Store на вашем устройстве и выполните поиск PowerShell. Затем нажмите на кнопку «Получить» или «Установить», чтобы начать установку.
3. Установка с помощью инсталляционного пакета
Если вы предпочитаете больше контроля над процессом установки, вы можете загрузить и установить PowerShell с помощью официального инсталляционного пакета от Microsoft. Перейдите на официальный сайт PowerShell (https://github.com/PowerShell/PowerShell/releases) и найдите последнюю версию PowerShell для вашей операционной системы. Загрузите инсталляционный пакет и запустите его для установки.
Благодаря разным вариантам установки, вы можете выбрать наиболее подходящий способ получения PowerShell на своем устройстве. После установки вы сможете начать использовать и изучать эту мощную среду командной строки и сценариев для администрирования Windows.
Использование
Чтобы использовать кодировку Windows 1251 в Powershell, необходимо выполнить следующие шаги:
- Открыть Powershell.
- Импортировать модуль «PCodePage» с помощью команды:
Import-Module -Name PCodePage. - Установить кодировку Windows 1251 с помощью команды:
Set-CodePage -CodePage 1251. - Теперь вы можете использовать кодировку Windows 1251 для чтения и записи файлов, вывода текста в консоль и выполнения других операций с текстом.
Ниже приведен пример использования кодировки Windows 1251 для чтения файла:
$fileContent = Get-Content -Path "C:\path\to\file.txt" -Encoding Windows1251В этом примере функция Get-Content используется для чтения содержимого файла «file.txt» с использованием кодировки Windows 1251.
После выполнения этих шагов вы будете работать с текстом, используя кодировку Windows 1251 в Powershell.
Выбор кодировки в Powershell
Для выбора кодировки в Powershell можно использовать команду $OutputEncoding. Эта переменная определяет кодировку, которая будет использоваться при выводе текста в консоль.
Для использования кодировки Windows 1251, нужно установить переменную $OutputEncoding в значение [System.Text.Encoding]::GetEncoding(1251). Ниже приведен пример кода:
$OutputEncoding = [System.Text.Encoding]::GetEncoding(1251)
Теперь все текстовые данные, выводимые в консоль, будут использовать кодировку Windows 1251. Это может быть полезно, например, при работе с файлами, которые используют эту кодировку.
Однако, стоит отметить, что изменение переменной $OutputEncoding не изменит кодировку самого Powershell. Если требуется использование определенной кодировки при чтении или записи файлов, то следует использовать соответствующие методы в классе System.IO.File.
Важно помнить, что правильное отображение текста в консоли зависит не только от выбранной кодировки, но и от консольного шрифта. Поэтому, если возникают проблемы с отображением символов после изменения кодировки, стоит проверить и настроить шрифт консоли.
Вывод кодировки в Powershell можно получить с помощью команды $OutputEncoding.EncodingName. Например, для проверки текущей кодировки можно использовать следующий код:
$OutputEncoding.EncodingName
В результате выполнения этого кода, будет выведено имя текущей кодировки, которая должна соответствовать выбранной.
Таким образом, правильное использование кодировки в Powershell позволяет работать с текстом на выбранном языке и обрабатывать файлы в соответствующей кодировке.
Чтение и запись файлов с кодировкой Windows 1251
Кодировка Windows 1251 (также известная как CP1251 или Cyrillic) широко используется для представления текста на русском языке в операционных системах Windows. В Powershell можно легко работать с файлами, использующими эту кодировку.
Для чтения файла с кодировкой Windows 1251 в Powershell можно использовать следующую команду:
Get-Content -Path "путь_к_файлу" -Encoding UTF8
Здесь «путь_к_файлу» — это путь к файлу, который вы хотите прочитать. Флаг «-Encoding UTF8» указывает Powershell, что файл содержит текст, закодированный в UTF-8. При этом Powershell автоматически конвертирует содержимое файла в Unicode и представляет его в соответствующем формате.
Аналогично, для записи текста в файл с кодировкой Windows 1251 в Powershell можно использовать команду:
Set-Content -Path "путь_к_файлу" -Encoding UTF8
Здесь «путь_к_файлу» — это путь к файлу, в который вы хотите записать текст. Флаг «-Encoding UTF8» указывает Powershell, что текст нужно закодировать в формате UTF-8 перед записью в файл. Если сам файл не существует, он будет автоматически создан.
Таким образом, с помощью этих команд вы можете легко работать с файлами, использующими кодировку Windows 1251, в Powershell. Вы можете читать текст из таких файлов и записывать в них новый текст, сохраняя при этом правильную кодировку.
Преобразование кодировки в Powershell
Кодировка текста играет важную роль при работе с текстовыми данными в Powershell. В некоторых случаях может потребоваться изменить кодировку текста для его корректной обработки.
За изменение кодировки в Powershell отвечает команда Set-Content. Она позволяет записать текст в файл с определенной кодировкой. Чтобы изменить кодировку файла, необходимо создать новый файл и скопировать содержимое с изменением кодировки.
Например, для преобразования текста в кодировку Windows 1251 можно использовать следующий код:
$filePath = "C:\path\to\file.txt"$newFilePath = "C:\path\toewfile.txt"$encoding = [System.Text.Encoding]::GetEncoding(1251)$text = Get-Content $filePath$text | Out-File -FilePath $newFilePath -Encoding $encodingВ данном примере файл с исходным текстом находится по пути «C:\path\to\file.txt». Создается новый файл по пути «C:\path\to
ewfile.txt» с кодировкой Windows 1251. Полученное содержимое записывается в новый файл.
Помимо команды Set-Content, существуют и другие методы для преобразования кодировки текста в Powershell, включая использование функций из сторонних модулей. Однако, приведенный выше код является одним из наиболее распространенных и простых способов изменения кодировки текста.
Примеры
Вот несколько примеров использования кодировки Windows 1251 в Powershell:
- Создание файла в кодировке Windows 1251:
powershell$content = @"Some text in Windows 1251 encoding.русский текст."@$content | Out-File -Encoding Default -FilePath "C:\path\to\file.txt" - Чтение файла в кодировке Windows 1251:
powershell$content = Get-Content -Encoding Default -FilePath "C:\path\to\file.txt"Write-Output $content - Преобразование строки в кодировку Windows 1251:
powershell$string = "Some text in Windows 1251 encoding."$encodedString = [System.Text.Encoding]::GetEncoding(1251).GetString([System.Text.Encoding]::Default.GetBytes($string))Write-Output $encodedString
Это лишь некоторые примеры использования кодировки Windows 1251 в Powershell. Кодировка может быть полезна при работе с файлами, содержащими текст на русском языке или других языках, поддерживаемых Windows 1251.
Пример чтения файла с кодировкой Windows 1251
Для того чтобы прочитать файл с кодировкой Windows 1251 в Powershell, мы можем использовать следующий код:
$filepath = "C:\путь_к_файлу\файл.txt"$filecontent = Get-Content -Path $filepath -Encoding Default
В данном примере, мы сначала задаем путь к файлу в переменной $filepath, затем с помощью командлета Get-Content мы читаем содержимое файла и сохраняем его в переменную $filecontent. Параметр -Encoding указывает, что файл имеет кодировку по умолчанию, которая в Windows обычно является кодировкой Windows 1251.
После выполнения данного кода, содержимое файла будет доступно для дальнейшей обработки в переменной $filecontent. Мы можем, например, вывести его на экран с помощью команды:
Write-Output $filecontent
Таким образом, в Powershell мы можем легко прочитать файл с кодировкой Windows 1251 и выполнять необходимые действия с его содержимым.
12820080ЂCyrillic capital letter Dje
12920181ЃCyrillic capital letter Gje
13020282‚Single low-9 quotation mark
13120383ѓCyrillic small letter gje
13220484„Double low-9 quotation mark
13320585…Horizontal ellipsis
13420686†Dagger
13520787‡Double dagger
13621088€Euro sign
13721189‰Per mille sign
1382128AЉCyrillic capital letter Lje
1392138B‹Single left-pointing angle quotation
1402148CЊCyrillic capital letter Nje
1412158DЌCyrillic capital letter Kje
1422168EЋCyrillic capital letter Tshe
1432178FЏCyrillic capital letter Dzhe
14422090ђCyrillic small letter dje
14522191‘Left single quotation mark
14622292’Right single quotation mark
14722393“Left double quotation mark
14822494”Right double quotation mark
14922595•Bullet
15022696–En dash
15122797—Em dash
15223098Unused
15323199™Trade mark sign
1542329AљCyrillic small letter lje
1552339B›Single right-pointing angle quotation mark
1562349CњCyrillic small letter nje
1572359DќCyrillic small letter Kje
1582369EћCyrillic small letter Tshe
1592379FџCyrillic small letter Dzhe
160240A0Non-breaking space
161241A1ЎCyrillic capital letter short U
162242A2ўCyrillic small letter short u
163243A3ЈCyrillic capital letter Je
164244A4¤Currency sign
165245A5ҐCyrillic capital letter Ghe with upturn
166246A6¦Pipe, broken vertical bar
167247A7§Section sign
168250A8ЁCyrillic capital letter Io
169251A9©Copyright sign
170252AAЄCyrillic capital letter Ukrainian Ie
171253AB«Left double angle quotes
172254AC¬Negation
173255ADSoft hyphen
174256AE®Registered trade mark sign
175257AFЇCyrillic capital letter Yi
176260B0°Degree sign
177261B1±Plus-or-minus sign
178262B2ІCyrillic capital letter Byelorussian-Ukrainian I
179263B3іCyrillic small letter Byelorussian-Ukrainian i
180264B4ґCyrillic small letter ghe with upturn
181265B5µMicro sign
182266B6¶Pilcrow sign — paragraph sign
183267B7·Middle dot — Georgian comma
184270B8ёCyrillic small letter io
185271B9№Numero Sign
186272BAєCyrillic small letter Ukrainian ie
187273BB»Right double angle quotes
188274BCјCyrillic small letter je
189275BDЅCyrillic capital letter Dze
190276BEѕCyrillic small letter dze
191277BFїCyrillic small letter yi
192300C0АCyrillic capital letter A
193301C1БCyrillic capital letter Be
194302C2ВCyrillic capital letter Ve
195303C3ГCyrillic capital letter Ghe
196304C4ДCyrillic capital letter De
197305C5ЕCyrillic capital letter Ie
198306C6ЖCyrillic capital letter Zhe
199307C7ЗCyrillic capital letter Ze
200310C8ИCyrillic capital letter I
201311C9ЙCyrillic capital letter Short I
202312CAКCyrillic capital letter Ka
203313CBЛCyrillic capital letter El
204314CCМCyrillic capital letter Em
205315CDНCyrillic capital letter En
206316CEОCyrillic capital letter O
207317CFПCyrillic capital letter Pe
208320D0РCyrillic capital letter Er
209321D1СCyrillic capital letter Es
210322D2ТCyrillic capital letter Te
211323D3УCyrillic capital letter U
212324D4ФCyrillic capital letter Ef
213325D5ХCyrillic capital letter Ha
214326D6ЦCyrillic capital letter Tse
215327D7ЧCyrillic capital letter Che
216330D8ШCyrillic capital letter Sha
217331D9ЩCyrillic capital letter Shcha
218332DAЪCyrillic capital letter Hard Sign
219333DBЫCyrillic capital letter Yeru
220334DCЬCyrillic capital letter Soft Sign
221335DDЭCyrillic capital letter E
222336DEЮCyrillic capital letter Yu
223337DFЯCyrillic capital letter Ya
224340E0аCyrillic Small Letter A
225341E1бCyrillic small letter be
226342E2вCyrillic small letter ve
227343E3гCyrillic small letter ghe
228344E4дCyrillic small letter de
229345E5еCyrillic small letter ie
230346E6жCyrillic small letter zhe
231347E7зCyrillic small letter ze
232350E8иCyrillic small letter i
233351E9йCyrillic small letter short i
234352EAкCyrillic small letter ka
235353EBлCyrillic small letter el
236354ECмCyrillic small letter em
237355EDнCyrillic small letter en
238356EEоCyrillic small letter o
239357EFпCyrillic small letter pe
240360F0рCyrillic small letter er
241361F1сCyrillic small letter es
242362F2тCyrillic small letter te
243363F3уCyrillic small letter u
244364F4фCyrillic small letter ef
245365F5хCyrillic small letter ha
246366F6цCyrillic small letter tse
247367F7чCyrillic small letter che
248370F8шCyrillic small letter sha
249371F9щCyrillic small letter shcha
250372FAъCyrillic small letter hard sign
251373FBыCyrillic small letter yeru
252374FCьCyrillic small letter soft sign
253375FDэCyrillic small letter e
254376FEюCyrillic small letter yu
255377FFяCyrillic small letter ya
Содержание
- Как изменить кодировку текстового файла на UTF-8 или Windows 1251
- Блокнот Windows
- Notepad++
- Akelpad
- Txt кодировка
- Подробно о кодировке txt файлов
- Неправильная кодировка файла txt пример:
- Какая кодировка в txt файле
- Поменять кодировку txt файла
- Поисковые запросы : «кодировка txt файла»
- хорошая кодировка txt файла
- Сообщение системы комментирования :
- Выбор кодировки текста при открытии и сохранении файлов
- В этой статье
- Общие сведения о кодировке текста
- Различные кодировки для разных алфавитов
- Юникод: единая кодировка для разных алфавитов
- Выбор кодировки при открытии файла
- Выбор кодировки при сохранении файла
- Выбор кодировки
- Поиск кодировок, доступных в Word
- Как сменить кодировку в Блокноте по умолчанию с ANSI на другую
- Очень кратко:
- Немного лирики о том, почему всё так, а не иначе:
- Что делать, чтобы сменить кодировку в Блокноте по умолчанию с ANSI на другую:
- Кодировка в bat файлах
Как изменить кодировку текстового файла на UTF-8 или Windows 1251
Кодировка текста – это схема нумерации символов, в которой каждому символу, цифре или знаку присвоено соответствующее число. Кодировку используют для сохранения и обработки текста на компьютере. Каждый раз при сохранении текста в файл он сохраняется с использованием определенной схемы кодирования, и при открытии этого файла необходимо использовать такую же схему, иначе восстановить исходный текст не получится. Самыми популярными кодировками для кириллицы сейчас являются UTF-8, Windows-1251 (CP1251, ANSI).
Для того чтобы программа смогла правильно открыть текстовый файл, иногда приходится вручную менять кодировку, перекодируя текст из одной схемы в другую. Например, не редко возникают проблемы с открытием файлов CSV, XML, SQL, TXT, PHP.
В этой небольшой статье мы расскажем о том, как изменить кодировку текстового файла на UTF-8, Windows-1251 или любую другую.
Если вы используете операционную систему Windows 10 или Windows 11, то вы можете изменить кодировку текста с помощью стандартной программы Блокнот. Для этого нужно открыть текстовый файл с помощью Блокнота и воспользоваться меню « Файл – Сохранить как ».

В открывшемся окне нужно указать новое название для файла, выбрать подходящую кодировку и нажать на кнопку « Сохранить ».

К сожалению, для подобных задач программа Блокнот часто не подходит. С ее помощью нельзя открывать документы большого размера, и она не поддерживает многие кодировки. Например, с помощью Блокнота нельзя открыть текстовые файлы в DOS 866.
Notepad++
Notepad++ (скачать) является одним из наиболее продвинутых текстовых редакторов. Он обладает подсветкой синтаксиса языков программирования, позволяет выполнять поиск и замену по регулярным выражениям, отслеживать изменения в файлах, записывать и воспроизводить макросы, считать хеш-сумы и многое другое. Одной из основных функций Notepad++ является поддержка большого количества кодировок текста и возможность изменения кодировки текстового файла в UTF-8 или Windows 1251.
Для того чтобы изменить кодировку текста с помощью Notepad++ файл нужно открыть в данной программе. Если программа не смогла правильно определить схему кодирования текста, то это можно сделать вручную. Для этого нужно открыть меню « Кодировки – Кириллица » и выбрать нужный вариант.

После открытия текста можно изменить его кодировку. Для этого нужно открыть меню « Кодировки » и выбрать один из вариантов преобразования. Notepad++ позволяет изменить текущую кодировку текста на ANSI (Windows-1251), UTF-8, UTF-8 BOM, UTF-8 BE BOM, UTF-8 LE BOM.

После преобразования файл нужно сохранить с помощью меню « Файл – Сохранить » или комбинации клавиш Ctrl-S.
Akelpad
Akelpad (скачать) – достаточно старая программа для работы с текстовыми файлами, которая все еще актуальна и может быть полезной. Фактически Akelpad является более продвинутой версией стандартной программы Блокнот из Windows. С его помощью можно открывать текстовые файлы большого размера, которые не открываются в Блокноте, выполнять поиск и замену с использованием регулярных выражений и менять кодировку текста.
Для того чтобы изменить кодировку текста с помощью Akelpad файл нужно открыть в данной программе. Если после открытия файла текст не читается, то нужно воспользоваться меню « Файл – Открыть ».

В открывшемся окне нужно выделить текстовый файл, снять отметку « Автовыбор » и выбрать подходящую кодировку из списка. При этом в нижней части окна можно видеть, как будет отображаться текст.

Для того чтобы изменить текущую кодировку текста нужно воспользоваться меню « Файл – Сохранить как » и сохранить документ с указанием новой схемы кодирования.

В отличие от Notepad++, текстовый редактор Akelpad позволяет сохранить файл в практически любой кодировке. В частности, доступны Windows 1251, DOS 886, UTF-8 и многие другие.
Источник
Txt кодировка
Я очень часто использую txt файлы и периодически получается так, что кодировка txt файла не та. Которая требуется!
Но как я определил, что кодировка неправильная!? Тут мы собрались написать новую статью и там, для иллюстрации работы придется использовать txt файла и фот что он выводит, если применить javascript include
Подробно о кодировке txt файлов
Неправильная кодировка файла txt пример:
Хотел показать результат неправильной кодировки, которая периодически встречается при работе с txt файлами.
Какая кодировка в txt файле
Самое простое, как определить кодировку txt файла открыть файл в блокноте(простой текстовый блокнот! Либо в любой другой программе), который есть в любой операционной системе. Давайте сразу узнаем и изменим кодировку файла txt

Какая кодировка в txt файле
Поменять кодировку txt файла

Поменять кодировку txt файла
Поисковые запросы : «кодировка txt файла»
Интересный поисковый запрос:
хорошая кодировка txt файла
В смысле хорошая!? Ты чЁ на рынке!?
— Покажите мне вон ту хорошую кодировку. Не. это плохая кодировка, протухла совсем. вон ту рядом. У вас кодировка свежая!? Только свежая может быть хорошей кодировкой!
Сообщение системы комментирования :
Форма пока доступна только админу. скоро все заработает. надеюсь.
Источник
Выбор кодировки текста при открытии и сохранении файлов
Как правило, при совместной работе с текстовыми файлами нет необходимости вникать в технические аспекты хранения текста. Однако если необходимо поделиться файлом с человеком, который работает с текстами на других языках, скачать текстовый файл из Интернета или открыть его на компьютере с другой операционной системой, может потребоваться задать кодировку при его открытии или сохранении.
Когда вы открываете текстовый файл в Microsoft Word или другой программе (например, на компьютере, язык операционной системы на котором отличается от того, на котором написан текст в файле), кодировка помогает программе определить, в каком виде нужно вывести текст на экран, чтобы его можно было прочитать.
В этой статье
Общие сведения о кодировке текста
То, что отображается на экране как текст, фактически хранится в текстовом файле в виде числового значения. Компьютер преобразует числические значения в видимые символы. Для этого используется кодикон.
Кодировка — это схема нумерации, согласно которой каждому текстовому символу в наборе соответствует определенное числовое значение. Кодировка может содержать буквы, цифры и другие символы. В различных языках часто используются разные наборы символов, поэтому многие из существующих кодировок предназначены для отображения наборов символов соответствующих языков.
Различные кодировки для разных алфавитов
Сведения о кодировке, сохраняемые с текстовым файлом, используются компьютером для вывода текста на экран. Например, в кодировке «Кириллица (Windows)» знаку «Й» соответствует числовое значение 201. Когда вы открываете файл, содержащий этот знак, на компьютере, на котором используется кодировка «Кириллица (Windows)», компьютер считывает число 201 и выводит на экран знак «Й».
Однако если тот же файл открыть на компьютере, на котором по умолчанию используется другая кодировка, на экран будет выведен знак, соответствующий числу 201 в этой кодировке. Например, если на компьютере используется кодировка «Западноевропейская (Windows)», знак «Й» из исходного текстового файла на основе кириллицы будет отображен как «É», поскольку именно этому знаку соответствует число 201 в данной кодировке.
Юникод: единая кодировка для разных алфавитов
Чтобы избежать проблем с кодированием и декодированием текстовых файлов, можно сохранять их в Юникоде. В состав этой кодировки входит большинство знаков из всех языков, которые обычно используются на современных компьютерах.
Так как Word работает на базе Юникода, все файлы в нем автоматически сохраняются в этой кодировке. Файлы в Юникоде можно открывать на любом компьютере с операционной системой на английском языке независимо от языка текста. Кроме того, на таком компьютере можно сохранять в Юникоде файлы, содержащие знаки, которых нет в западноевропейских алфавитах (например, греческие, кириллические, арабские или японские).
Выбор кодировки при открытии файла
Если в открытом файле текст искажен или выводится в виде вопросительных знаков либо квадратиков, возможно, Word неправильно определил кодировку. Вы можете указать кодировку, которую следует использовать для отображения (декодирования) текста.
Откройте вкладку Файл.
Нажмите кнопку Параметры.
Нажмите кнопку Дополнительно.
Перейдите к разделу Общие и установите флажок Подтверждать преобразование формата файла при открытии.
Примечание: Если установлен этот флажок, Word отображает диалоговое окно Преобразование файла при каждом открытии файла в формате, отличном от формата Word (то есть файла, который не имеет расширения DOC, DOT, DOCX, DOCM, DOTX или DOTM). Если вы часто работаете с такими файлами, но вам обычно не требуется выбирать кодировку, не забудьте отключить этот параметр, чтобы это диалоговое окно не выводилось.
Закройте, а затем снова откройте файл.
В диалоговом окне Преобразование файла выберите пункт Кодированный текст.
В диалоговом окне Преобразование файла установите переключатель Другая и выберите нужную кодировку из списка.
В области Образец можно просмотреть текст и проверить, правильно ли он отображается в выбранной кодировке.
Если почти весь текст выглядит одинаково (например, в виде квадратов или точек), возможно, на компьютере не установлен нужный шрифт. В таком случае можно установить дополнительные шрифты.
Чтобы установить дополнительные шрифты, сделайте следующее:
Нажмите кнопку Пуск и выберите пункт Панель управления.
Выполните одно из указанных ниже действий.
На панели управления выберите раздел Удаление программы.
В списке программ щелкните Microsoft Office или Microsoft Word, если он был установлен отдельно от пакета Microsoft Office, и нажмите кнопку Изменить.
На панели управления выберите раздел Удаление программы.
В списке программ щелкните Microsoft Office или Microsoft Word, если он был установлен отдельно от пакета Microsoft Office, и нажмите кнопку Изменить.
На панели управления щелкните элемент Установка и удаление программ.
В списке Установленные программы щелкните Microsoft Office или Microsoft Word, если он был установлен отдельно от пакета Microsoft Office, и нажмите кнопку Изменить.
В группе Изменение установки Microsoft Office нажмите кнопку Добавить или удалить компоненты и затем нажмите кнопку Продолжить.
В разделе Параметры установки разверните элемент Общие средства Office, а затем — Многоязыковая поддержка.
Выберите нужный шрифт, щелкните стрелку рядом с ним и выберите пункт Запускать с моего компьютера.
Совет: При открытии текстового файла в той или иной кодировке в Word используются шрифты, определенные в диалоговом окне Параметры веб-документа. (Чтобы вызвать диалоговое окно Параметры веб-документа, нажмите кнопку Microsoft Office, затем щелкните Параметры Word и выберите категорию Дополнительно. В разделе Общие нажмите кнопку Параметры веб-документа.) С помощью параметров на вкладке Шрифты диалогового окна Параметры веб-документа можно настроить шрифт для каждой кодировки.
Выбор кодировки при сохранении файла
Если не выбрать кодировку при сохранении файла, будет использоваться Юникод. Как правило, рекомендуется применять Юникод, так как он поддерживает большинство символов большинства языков.
Если документ планируется открывать в программе, которая не поддерживает Юникод, вы можете выбрать нужную кодировку. Например, в операционной системе на английском языке можно создать документ на китайском (традиционное письмо) с использованием Юникода. Однако если такой документ будет открываться в программе, которая поддерживает китайский язык, но не поддерживает Юникод, файл можно сохранить в кодировке «Китайская традиционная (Big5)». В результате текст будет отображаться правильно при открытии документа в программе, поддерживающей китайский язык (традиционное письмо).
Примечание: Так как Юникод — это наиболее полный стандарт, при сохранении текста в других кодировках некоторые знаки могут не отображаться. Предположим, например, что документ в Юникоде содержит текст на иврите и языке с кириллицей. Если сохранить файл в кодировке «Кириллица (Windows)», текст на иврите не отобразится, а если сохранить его в кодировке «Иврит (Windows)», то не будет отображаться кириллический текст.
Если выбрать стандарт кодировки, который не поддерживает некоторые символы в файле, Word пометит их красным. Вы можете просмотреть текст в выбранной кодировке перед сохранением файла.
При сохранении файла в виде кодированного текста из него удаляется текст, для которого выбран шрифт Symbol, а также коды полей.
Выбор кодировки
Откройте вкладку Файл.
Выберите пункт Сохранить как.
Чтобы сохранить файл в другой папке, найдите и откройте ее.
В поле Имя файла введите имя нового файла.
В поле Тип файла выберите Обычный текст.
Нажмите кнопку Сохранить.
Если появится диалоговое окно Microsoft Office Word — проверка совместимости, нажмите кнопку Продолжить.
В диалоговом окне Преобразование файла выберите подходящую кодировку.
Чтобы использовать стандартную кодировку, выберите параметр Windows (по умолчанию).
Чтобы использовать кодировку MS-DOS, выберите параметр MS-DOS.
Чтобы задать другую кодировку, установите переключатель Другая и выберите нужный пункт в списке. В области Образец можно просмотреть текст и проверить, правильно ли он отображается в выбранной кодировке.
Примечание: Чтобы увеличить область отображения документа, можно изменить размер диалогового окна Преобразование файла.
Если появилось сообщение «Текст, выделенный красным, невозможно правильно сохранить в выбранной кодировке», можно выбрать другую кодировку или установить флажок Разрешить подстановку знаков.
Если разрешена подстановка знаков, знаки, которые невозможно отобразить, будут заменены ближайшими эквивалентными символами в выбранной кодировке. Например, многоточие заменяется тремя точками, а угловые кавычки — прямыми.
Если в выбранной кодировке нет эквивалентных знаков для символов, выделенных красным цветом, они будут сохранены как внеконтекстные (например, в виде вопросительных знаков).
Если документ будет открываться в программе, в которой текст не переносится с одной строки на другую, вы можете включить в нем жесткие разрывы строк. Для этого установите флажок Вставлять разрывы строк и укажите нужное обозначение разрыва (возврат каретки (CR), перевод строки (LF) или оба значения) в поле Завершать строки.
Поиск кодировок, доступных в Word
Word распознает несколько кодировок и поддерживает кодировки, которые входят в состав системного программного обеспечения.
Ниже приведен список письменностей и связанных с ними кодировок (кодовых страниц).
Юникод (UCS-2 с прямым и обратным порядком байтов, UTF-8, UTF-7)
Стандартный шрифт для стиля «Обычный» локализованной версии Word
Windows 1256, ASMO 708
Китайская (упрощенное письмо)
GB2312, GBK, EUC-CN, ISO-2022-CN, HZ
Китайская (традиционное письмо)
BIG5, EUC-TW, ISO-2022-TW
Windows 1251, KOI8-R, KOI8-RU, ISO8859-5, DOS 866
Английская, западноевропейская и другие, основанные на латинице
Источник
Как сменить кодировку в Блокноте по умолчанию с ANSI на другую

Рано или поздно любой пользователь Windows сталкивается с проблемой кодировки текста. «Кракозяблики» настигают всех, кто более-менее часто пользуется компьютером. Особенно остро эта задача стоит перед теми, кто не просто пользуется компьютером, а создаёт какой-то осмысленный контекст, например у себя на сайте. Сайт может находиться на удалённом сервере, где кодировка может отличаться от той, которую предлагает Windows по умолчанию.
Очень кратко:
Немного лирики о том, почему всё так, а не иначе:
Но и для пользователей, остающихся обычными «пользователями ПК» проблема с кодировками кириллистических символов иногда встаёт довольно остро. «Кракозяблики» — наследие предыдущей эпохи, когда каждый программист писал собственную таблицу кодировок. Например, скачал и хочешь почитать интересную книжку, а тут такое >=O
И так продолжалось до тех пор, пока не начали вводиться стандарты. Но и стандартов на текущее время уже немало. Например, есть кодировка Unicode, есть UTF-8, есть UTF-16 и так далее.
Я так и не нашёл, как сменить кодировку по умолчанию при открытии Блокнота и создания нового документа уже из открытой сессии Блокнота.
Зато нашёл, как сменить кодировку по умолчанию, когда текстовый документ сначала создаётся (из контекстного меню) и только потому открывается Блокнотом. Тогда кодировка файла будет та, которая будет прописана по умолчанию. Об этом и пойдёт ниже речь.
Итак, для того, чтобы поменять кодировку создаваемых текстовых документов по умолчанию, нам понадобиться внести изменения в Реестр Windows.
Ну и хватит лирики. К делу!

Что делать, чтобы сменить кодировку в Блокноте по умолчанию с ANSI на другую:

Если в файле-образце набрать какой-то текст, то он будет во всех новых файлах, создаваемых с помощью контекстного меню.
Источник
Кодировка в bat файлах
В этой статье я хочу поговорить о кодировке русского текста в bat файлах. Имеются различные способы правильного отображения кирилицы в bat файлах. Некоторые из достаточно запутанные и сложные. Так как я сторонник простоты и эфффективности, то в этой статье я разберу два самых простых способа, которых вам будет достаточно в самых различных ситуациях.
Создадим какой-нибудь bat файл, так называемый батник. Будет он называться test.bat. Ранее с помощью обычного блокнота, в нём были набраны строки:
При запуске его как bat файла, выводятся две строки. Одна на латинице, другая на кирилице.
Итак, что мы видим, строка на латинице выводится без изменений, строка на кирилице в виде каких-то скрякозябров. Это то, что случается в случае не правильной кодировки. Теперь давайте разберёмся, почему так получилось, и как это поправить.
Первое, документ test.bat обработал и вывел интерпритатор командной строки(cmd). Cmd кодирует програмный код в своей кодировке. Это, так называемая, DOS кодировка. Как подробнее узнать, какая это кодировка?
Откройте test.bat в любом текстовом редакторе(я воспользуюсь Notepad++). Наберите команду chcp.
Это команда покажет, в какой кодировке выполняет cmd bat файл. Сохраните документ и запустите его.
Итак, мы видим строку: Текущая кодовая страница: 866. Это говорит о том, что cmd кодирует bat файл в кодировке 866. Теперь выясним, в какой кодировке закодирован наш bat файл. Для этого можно открыть его в том текстовом редакторе, который показывает кодировку документа. Я воспользуюсь для этого редактором Notepad++. Открыв в нём test.bat в нижней правой части мы видим кодировку Windows-1251.
Теперь мы видим несоответствие в кодировках. Что нужно сделать? Нужно перекодировать документ test.bat в ту кодировку, в которую кодирует документ интерпритатор командной строки. Как это сделать? Открыв документ test.bat в текстовом редакторе Notepad++, в верхнем горизонтальном меню выберите: Кодировки > Кодировки > Кирилица > ОЕМ866.
Теперь в Notepad++ там, где была кодировка Windows-1251, стала ОЕМ866. Не забывайте сохранять документ после различных манипуляций с ним. Теперь можно опять запустить уже перекодированный файл test.bat.
Мы видим, что и кирилица и латиница стали корректно отображаться после работы команды вывода echo в test.bat.
Что если у вас на компьютере нет редактора Notepad++, и вы принципиально не хотите его устанавливать. Или текст вы не набирали сами, а где-то скачали его, и он в DOS кодировке.
К примеру, вы хотит скачать в текстовый файл справочник команд CMD. Создайте в папке С файл Help.txt. Запустите на выполнение bat файл со следующим кодом.
Вот текст записанный в файл Help.txt.
Теперь добавьте в bat файл следующую строку: «chcp 1251 >nul». Она аннулирует действующую кодировку 1251, которая мешает нам читать кирилицу.
И запустите его на выполнение.
Мы разобрали два простых способа, как в bat файлах настроить кодировку для правильного отображения русского текста. Надеюсь моя статья была вам полезна.
Источник
Windows-1251 — набор символов и кодировка, являющаяся стандартной 8-битной кодировкой для всех русских версий Microsoft Windows. Данная кодировка пользуется довольно большой популярностью в восточно-европейских странах. Windows-1251 выгодно отличается от других 8-битных кириллических кодировок (таких как CP866, KOI8-R и ISO 8859-5) наличием практически всех символов, использующихся в традиционной русской типографике для обычного текста (отсутствует только знак ударения). Кириллические символы идут в алфавитном порядке.
Windows-1251 также содержит все символы для близких к русскому языку языков: белорусского, украинского, сербского, македонского и болгарского.
На практике этого оказалось достаточно, чтобы кодировка Windows-1251 закрепилась в интернете вплоть до распространения UTF-8.
Таблица кодов символов Windows-1251
| Dec | Hex | Символ | Dec | Hex | Символ | |
|---|---|---|---|---|---|---|
| 000 | 00 | NOP | 128 | 80 | Ђ | |
| 001 | 01 | SOH | 129 | 81 | Ѓ | |
| 002 | 02 | STX | 130 | 82 | ‚ | |
| 003 | 03 | ETX | 131 | 83 | ѓ | |
| 004 | 04 | EOT | 132 | 84 | „ | |
| 005 | 05 | ENQ | 133 | 85 | … | |
| 006 | 06 | ACK | 134 | 86 | † | |
| 007 | 07 | BEL | 135 | 87 | ‡ | |
| 008 | 08 | BS | 136 | 88 | € | |
| 009 | 09 | TAB | 137 | 89 | ‰ | |
| 010 | 0A | LF | 138 | 8A | Љ | |
| 011 | 0B | VT | 139 | 8B | ‹ | |
| 012 | 0C | FF | 140 | 8C | Њ | |
| 013 | 0D | CR | 141 | 8D | Ќ | |
| 014 | 0E | SO | 142 | 8E | Ћ | |
| 015 | 0F | SI | 143 | 8F | Џ | |
| 016 | 10 | DLE | 144 | 90 | ђ | |
| 017 | 11 | DC1 | 145 | 91 | ‘ | |
| 018 | 12 | DC2 | 146 | 92 | ’ | |
| 019 | 13 | DC3 | 147 | 93 | “ | |
| 020 | 14 | DC4 | 148 | 94 | ” | |
| 021 | 15 | NAK | 149 | 95 | • | |
| 022 | 16 | SYN | 150 | 96 | – | |
| 023 | 17 | ETB | 151 | 97 | — | |
| 024 | 18 | CAN | 152 | 98 | ||
| 025 | 19 | EM | 153 | 99 | ™ | |
| 026 | 1A | SUB | 154 | 9A | љ | |
| 027 | 1B | ESC | 155 | 9B | › | |
| 028 | 1C | FS | 156 | 9C | њ | |
| 029 | 1D | GS | 157 | 9D | ќ | |
| 030 | 1E | RS | 158 | 9E | ћ | |
| 031 | 1F | US | 159 | 9F | џ | |
| 032 | 20 | SP | 160 | A0 | ||
| 033 | 21 | ! | 161 | A1 | Ў | |
| 034 | 22 | « | 162 | A2 | ў | |
| 035 | 23 | # | 163 | A3 | Ћ | |
| 036 | 24 | $ | 164 | A4 | ¤ | |
| 037 | 25 | % | 165 | A5 | Ґ | |
| 038 | 26 | & | 166 | A6 | ¦ | |
| 039 | 27 | ‘ | 167 | A7 | § | |
| 040 | 28 | ( | 168 | A8 | Ё | |
| 041 | 29 | ) | 169 | A9 | © | |
| 042 | 2A | * | 170 | AA | Є | |
| 043 | 2B | + | 171 | AB | « | |
| 044 | 2C | , | 172 | AC | ¬ | |
| 045 | 2D | — | 173 | AD | | |
| 046 | 2E | . | 174 | AE | ® | |
| 047 | 2F | / | 175 | AF | Ї | |
| 048 | 30 | 0 | 176 | B0 | ° | |
| 049 | 31 | 1 | 177 | B1 | ± | |
| 050 | 32 | 2 | 178 | B2 | І | |
| 051 | 33 | 3 | 179 | B3 | і | |
| 052 | 34 | 4 | 180 | B4 | ґ | |
| 053 | 35 | 5 | 181 | B5 | µ | |
| 054 | 36 | 6 | 182 | B6 | ¶ | |
| 055 | 37 | 7 | 183 | B7 | · | |
| 056 | 38 | 8 | 184 | B8 | ё | |
| 057 | 39 | 9 | 185 | B9 | № | |
| 058 | 3A | : | 186 | BA | є | |
| 059 | 3B | ; | 187 | BB | » | |
| 060 | 3C | < | 188 | BC | ј | |
| 061 | 3D | = | 189 | BD | Ѕ | |
| 062 | 3E | > | 190 | BE | ѕ | |
| 063 | 3F | ? | 191 | BF | ї | |
| 064 | 40 | @ | 192 | C0 | А | |
| 065 | 41 | A | 193 | C1 | Б | |
| 066 | 42 | B | 194 | C2 | В | |
| 067 | 43 | C | 195 | C3 | Г | |
| 068 | 44 | D | 196 | C4 | Д | |
| 069 | 45 | E | 197 | C5 | Е | |
| 070 | 46 | F | 198 | C6 | Ж | |
| 071 | 47 | G | 199 | C7 | З | |
| 072 | 48 | H | 200 | C8 | И | |
| 073 | 49 | I | 201 | C9 | Й | |
| 074 | 4A | J | 202 | CA | К | |
| 075 | 4B | K | 203 | CB | Л | |
| 076 | 4C | L | 204 | CC | М | |
| 077 | 4D | M | 205 | CD | Н | |
| 078 | 4E | N | 206 | CE | О | |
| 079 | 4F | O | 207 | CF | П | |
| 080 | 50 | P | 208 | D0 | Р | |
| 081 | 51 | Q | 209 | D1 | С | |
| 082 | 52 | R | 210 | D2 | Т | |
| 083 | 53 | S | 211 | D3 | У | |
| 084 | 54 | T | 212 | D4 | Ф | |
| 085 | 55 | U | 213 | D5 | Х | |
| 086 | 56 | V | 214 | D6 | Ц | |
| 087 | 57 | W | 215 | D7 | Ч | |
| 088 | 58 | X | 216 | D8 | Ш | |
| 089 | 59 | Y | 217 | D9 | Щ | |
| 090 | 5A | Z | 218 | DA | Ъ | |
| 091 | 5B | [ | 219 | DB | Ы | |
| 092 | 5C | 220 | DC | Ь | ||
| 093 | 5D | ] | 221 | DD | Э | |
| 094 | 5E | ^ | 222 | DE | Ю | |
| 095 | 5F | _ | 223 | DF | Я | |
| 096 | 60 | ` | 224 | E0 | а | |
| 097 | 61 | a | 225 | E1 | б | |
| 098 | 62 | b | 226 | E2 | в | |
| 099 | 63 | c | 227 | E3 | г | |
| 100 | 64 | d | 228 | E4 | д | |
| 101 | 65 | e | 229 | E5 | е | |
| 102 | 66 | f | 230 | E6 | ж | |
| 103 | 67 | g | 231 | E7 | з | |
| 104 | 68 | h | 232 | E8 | и | |
| 105 | 69 | i | 233 | E9 | й | |
| 106 | 6A | j | 234 | EA | к | |
| 107 | 6B | k | 235 | EB | л | |
| 108 | 6C | l | 236 | EC | м | |
| 109 | 6D | m | 237 | ED | н | |
| 110 | 6E | n | 238 | EE | о | |
| 111 | 6F | o | 239 | EF | п | |
| 112 | 70 | p | 240 | F0 | р | |
| 113 | 71 | q | 241 | F1 | с | |
| 114 | 72 | r | 242 | F2 | т | |
| 115 | 73 | s | 243 | F3 | у | |
| 116 | 74 | t | 244 | F4 | ф | |
| 117 | 75 | u | 245 | F5 | х | |
| 118 | 76 | v | 246 | F6 | ц | |
| 119 | 77 | w | 247 | F7 | ч | |
| 120 | 78 | x | 248 | F8 | ш | |
| 121 | 79 | y | 249 | F9 | щ | |
| 122 | 7A | z | 250 | FA | ъ | |
| 123 | 7B | { | 251 | FB | ы | |
| 124 | 7C | | | 252 | FC | ь | |
| 125 | 7D | } | 253 | FD | э | |
| 126 | 7E | ~ | 254 | FE | ю | |
| 127 | 7F | DEL | 255 | FF | я |
Описание специальных (управляющих) символов
Первоначально управляющие символы таблицы ASCII (диапазон 00-31, плюс 127) были разработаны для того, чтобы управлять устройствами аппаратных средств, таких как телетайп, ввод данных на перфоленту и др.
Управляющие символы (кроме горизонтальной табуляции, перевода строки и возврата каретки) не используются в HTML-документах.
Cпециальные (управляющие) символы
| Код | Описание |
|---|---|
| NUL, 00 | Null, пустой |
| SOH, 01 | Start Of Heading, начало заголовка |
| STX, 02 | Start of TeXt, начало текста |
| ETX, 03 | End of TeXt, конец текста |
| EOT, 04 | End of Transmission, конец передачи |
| ENQ, 05 | Enquire. Прошу подтверждения |
| ACK, 06 | Acknowledgement. Подтверждаю |
| BEL, 07 | Bell, звонок |
| BS, 08 | Backspace, возврат на один символ назад |
| TAB, 09 | Tab, горизонтальная табуляция |
| LF, 0A | Line Feed, перевод строки Сейчас в большинстве языков программирования обозначается как n |
| VT, 0B | Vertical Tab, вертикальная табуляция |
| FF, 0C | Form Feed, прогон страницы, новая страница |
| CR, 0D | Carriage Return, возврат каретки Сейчас в большинстве языков программирования обозначается как r |
| SO, 0E | Shift Out, изменить цвет красящей ленты в печатающем устройстве |
| SI, 0F | Shift In, вернуть цвет красящей ленты в печатающем устройстве обратно |
| DLE, 10 | Data Link Escape, переключение канала на передачу данных |
| DC1, 11 DC2, 12 DC3, 13 DC4, 14 |
Device Control, символы управления устройствами |
| NAK, 15 | Negative Acknowledgment, не подтверждаю |
| SYN, 16 | Synchronization. Символ синхронизации |
| ETB, 17 | End of Text Block, конец текстового блока |
| CAN, 18 | Cancel, отмена переданного ранее |
| EM, 19 | End of Medium, конец носителя данных |
| SUB, 1A | Substitute, подставить. Ставится на месте символа, значение которого было потеряно или испорчено при передаче |
| ESC, 1B | Escape Управляющая последовательность |
| FS, 1C | File Separator, разделитель файлов |
| GS, 1D | Group Separator, разделитель групп |
| RS, 1E | Record Separator, разделитель записей |
| US, 1F | Unit Separator, разделитель юнитов |
| DEL, 7F | Delete, стереть последний символ. |
Смотрите также:
URL коды символов ACSII
URL коды символов UTF-8 диапазон от U+0400 до U+04FF
HTML Кодирование URL
Таблица кодов символов кирилицы UTF-8
Кодировка текста – это схема нумерации символов, в которой каждому символу, цифре или знаку присвоено соответствующее число. Кодировку используют для сохранения и обработки текста на компьютере. Каждый раз при сохранении текста в файл он сохраняется с использованием определенной схемы кодирования, и при открытии этого файла необходимо использовать такую же схему, иначе восстановить исходный текст не получится. Самыми популярными кодировками для кириллицы сейчас являются UTF-8, Windows-1251 (CP1251, ANSI).
Для того чтобы программа смогла правильно открыть текстовый файл, иногда приходится вручную менять кодировку, перекодируя текст из одной схемы в другую. Например, не редко возникают проблемы с открытием файлов CSV, XML, SQL, TXT, PHP.
В этой небольшой статье мы расскажем о том, как изменить кодировку текстового файла на UTF-8, Windows-1251 или любую другую.
Блокнот Windows
Если вы используете операционную систему Windows 10 или Windows 11, то вы можете изменить кодировку текста с помощью стандартной программы Блокнот. Для этого нужно открыть текстовый файл с помощью Блокнота и воспользоваться меню «Файл – Сохранить как».
В открывшемся окне нужно указать новое название для файла, выбрать подходящую кодировку и нажать на кнопку «Сохранить».
К сожалению, для подобных задач программа Блокнот часто не подходит. С ее помощью нельзя открывать документы большого размера, и она не поддерживает многие кодировки. Например, с помощью Блокнота нельзя открыть текстовые файлы в DOS 866.
Notepad++
Notepad++ (скачать) является одним из наиболее продвинутых текстовых редакторов. Он обладает подсветкой синтаксиса языков программирования, позволяет выполнять поиск и замену по регулярным выражениям, отслеживать изменения в файлах, записывать и воспроизводить макросы, считать хеш-сумы и многое другое. Одной из основных функций Notepad++ является поддержка большого количества кодировок текста и возможность изменения кодировки текстового файла в UTF-8 или Windows 1251.
Для того чтобы изменить кодировку текста с помощью Notepad++ файл нужно открыть в данной программе. Если программа не смогла правильно определить схему кодирования текста, то это можно сделать вручную. Для этого нужно открыть меню «Кодировки – Кириллица» и выбрать нужный вариант.
После открытия текста можно изменить его кодировку. Для этого нужно открыть меню «Кодировки» и выбрать один из вариантов преобразования. Notepad++ позволяет изменить текущую кодировку текста на ANSI (Windows-1251), UTF-8, UTF-8 BOM, UTF-8 BE BOM, UTF-8 LE BOM.
После преобразования файл нужно сохранить с помощью меню «Файл – Сохранить» или комбинации клавиш Ctrl-S.
Akelpad
Akelpad (скачать) – достаточно старая программа для работы с текстовыми файлами, которая все еще актуальна и может быть полезной. Фактически Akelpad является более продвинутой версией стандартной программы Блокнот из Windows. С его помощью можно открывать текстовые файлы большого размера, которые не открываются в Блокноте, выполнять поиск и замену с использованием регулярных выражений и менять кодировку текста.
Для того чтобы изменить кодировку текста с помощью Akelpad файл нужно открыть в данной программе. Если после открытия файла текст не читается, то нужно воспользоваться меню «Файл – Открыть».
В открывшемся окне нужно выделить текстовый файл, снять отметку «Автовыбор» и выбрать подходящую кодировку из списка. При этом в нижней части окна можно видеть, как будет отображаться текст.
Для того чтобы изменить текущую кодировку текста нужно воспользоваться меню «Файл – Сохранить как» и сохранить документ с указанием новой схемы кодирования.
В отличие от Notepad++, текстовый редактор Akelpad позволяет сохранить файл в практически любой кодировке. В частности, доступны Windows 1251, DOS 886, UTF-8 и многие другие.
Посмотрите также:
- Чем открыть PDF файл в Windows 7 или Windows 10
- Как перевернуть страницу в Word
- Как копировать текст с помощью клавиатуры
- Как сделать рамку в Word
- Как сделать буклет в Word
Автор
Александр Степушин
Создатель сайта comp-security.net, автор более 2000 статей о ремонте компьютеров, работе с программами, настройке операционных систем.
Остались вопросы?
Задайте вопрос в комментариях под статьей или на странице
«Задать вопрос»
и вы обязательно получите ответ.
Здравствуйте, уважаемые читатели блога KtoNaNovenkogo.ru. Сегодня мы поговорим с вами про то, откуда берутся кракозябры на сайте и в программах, какие кодировки текста существуют и какие из них следует использовать. Подробно рассмотрим историю их развития, начиная от базовой ASCII, а также ее расширенных версий CP866, KOI8-R, Windows 1251 и заканчивая современными кодировками консорциума Юникод UTF 16 и 8.

Кому-то эти сведения могут показаться излишними, но знали бы вы, сколько мне приходит вопросов именно касаемо вылезших кракозябров (не читаемого набора символов). Теперь у меня будет возможность отсылать всех к тексту этой статьи и самостоятельно отыскивать свои косяки. Ну что же, приготовьтесь впитывать информацию и постарайтесь следить за ходом повествования.
ASCII — базовая кодировка текста для латиницы
Развитие кодировок текстов происходило одновременно с формированием отрасли IT, и они за это время успели претерпеть достаточно много изменений. Исторически все начиналось с довольно-таки не благозвучной в русском произношении EBCDIC, которая позволяла кодировать буквы латинского алфавита, арабские цифры и знаки пунктуации с управляющими символами.
Но все же отправной точкой для развития современных кодировок текстов стоит считать знаменитую ASCII (American Standard Code for Information Interchange, которая по-русски обычно произносится как «аски»). Она описывает первые 128 символов из наиболее часто используемых англоязычными пользователями — латинские буквы, арабские цифры и знаки препинания.
Еще в эти 128 знаков, описанных в ASCII, попадали некоторые служебные символы навроде скобок, решеток, звездочек и т.п. Собственно, вы сами можете увидеть их:
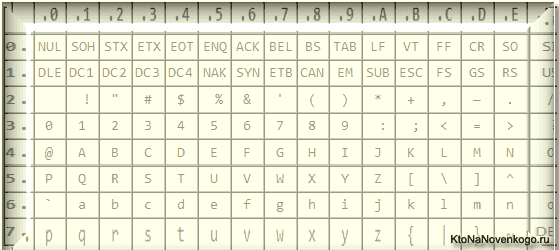
Именно эти 128 символов из первоначального вариант ASCII стали стандартом, и в любой другой кодировке вы их обязательно встретите и стоять они будут именно в таком порядке.
Но дело в том, что с помощью одного байта информации можно закодировать не 128, а целых 256 различных значений (двойка в степени восемь равняется 256), поэтому вслед за базовой версией Аски появился целый ряд расширенных кодировок ASCII, в которых можно было кроме 128 основных знаков закодировать еще и символы национальной кодировки (например, русской).
Тут, наверное, стоит еще немного сказать про системы счисления, которые используются при описании. Во-первых, как вы все знаете, компьютер работает только с числами в двоичной системе, а именно с нулями и единицами («булева алгебра», если кто проходил в институте или в школе). Один байт состоит из восьми бит, каждый из которых представляет из себя двойку в степени, начиная с нулевой, и до двойки в седьмой:
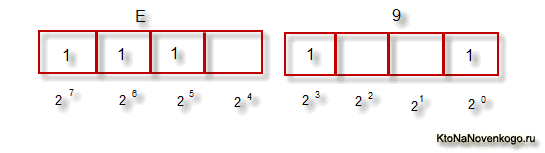
Не трудно понять, что всех возможных комбинаций нулей и единиц в такой конструкции может быть только 256. Переводить число из двоичной системы в десятичную довольно просто. Нужно просто сложить все степени двойки, над которыми стоят единички.
В нашем примере это получается 1 (2 в степени ноль) плюс 8 (два в степени 3), плюс 32 (двойка в пятой степени), плюс 64 (в шестой), плюс 128 (в седьмой). Итого получает 233 в десятичной системе счисления. Как видите, все очень просто.
Но если вы присмотритесь к таблице с символами ASCII, то увидите, что они представлены в шестнадцатеричной кодировке. Например, «звездочка» соответствует в Аски шестнадцатеричному числу 2A. Наверное, вам известно, что в шестнадцатеричной системе счисления используются кроме арабских цифр еще и латинские буквы от A (означает десять) до F (означает пятнадцать).
Ну так вот, для перевода двоичного числа в шестнадцатеричное прибегают к следующему простому и наглядному способу. Каждый байт информации разбивают на две части по четыре бита, как показано на приведенном выше скриншоте. Т.о. в каждой половинке байта двоичным кодом можно закодировать только шестнадцать значений (два в четвертой степени), что можно легко представить шестнадцатеричным числом.
Причем, в левой половине байта считать степени нужно будет опять начиная с нулевой, а не так, как показано на скриншоте. В результате, путем нехитрых вычислений, мы получим, что на скриншоте закодировано число E9. Надеюсь, что ход моих рассуждений и разгадка данного ребуса вам оказались понятны. Ну, а теперь продолжим, собственно, говорить про кодировки текста.
Расширенные версии Аски — кодировки CP866 и KOI8-R с псевдографикой
Итак, мы с вами начали говорить про ASCII, которая являлась как бы отправной точкой для развития всех современных кодировок (Windows 1251, юникод, UTF 8).
Изначально в нее было заложено только 128 знаков латинского алфавита, арабских цифр и еще чего-то там, но в расширенной версии появилась возможность использовать все 256 значений, которые можно закодировать в одном байте информации. Т.е. появилась возможность добавить в Аски символы букв своего языка.
Тут нужно будет еще раз отвлечься, чтобы пояснить — зачем вообще нужны кодировки текстов и почему это так важно. Символы на экране вашего компьютера формируются на основе двух вещей — наборов векторных форм (представлений) всевозможных знаков (они находятся в файлах со шрифтами, которые установлены на вашем компьютере) и кода, который позволяет выдернуть из этого набора векторных форм (файла шрифта) именно тот символ, который нужно будет вставить в нужное место.
Понятно, что за сами векторные формы отвечают шрифты, а вот за кодирование отвечает операционная система и используемые в ней программы. Т.е. любой текст на вашем компьютере будет представлять собой набор байтов, в каждом из которых закодирован один единственный символ этого самого текста.
Программа, отображающая этот текст на экране (текстовый редактор, браузер и т.п.), при разборе кода считывает кодировку очередного знака и ищет соответствующую ему векторную форму в нужном файле шрифта, который подключен для отображения данного текстового документа. Все просто и банально.
Значит, чтобы закодировать любой нужный нам символ (например, из национального алфавита), должно быть выполнено два условия — векторная форма этого знака должна быть в используемом шрифте и этот символ можно было бы закодировать в расширенных кодировках ASCII в один байт. Поэтому таких вариантов существует целая куча. Только лишь для кодирования символов русского языка существует несколько разновидностей расширенной Аски.
Например, изначально появилась CP866, в которой была возможность использовать символы русского алфавита и она являлась расширенной версией ASCII.
Т.е. ее верхняя часть полностью совпадала с базовой версией Аски (128 символов латиницы, цифр и еще всякой лабуды), которая представлена на приведенном чуть выше скриншоте, а вот уже нижняя часть таблицы с кодировкой CP866 имела указанный на скриншоте чуть ниже вид и позволяла закодировать еще 128 знаков (русские буквы и всякая там псевдографика):

Видите, в правом столбце цифры начинаются с 8, т.к. числа с 0 до 7 относятся к базовой части ASCII (см. первый скриншот). Т.о. русская буква «М» в CP866 будет иметь код 9С (она находится на пересечении соответствующих строки с 9 и столбца с цифрой С в шестнадцатеричной системе счисления), который можно записать в одном байте информации, и при наличии подходящего шрифта с русскими символами эта буква без проблем отобразится в тексте.
Откуда взялось такое количество псевдографики в CP866? Тут все дело в том, что эта кодировка для русского текста разрабатывалась еще в те мохнатые года, когда не было такого распространения графических операционных систем как сейчас. А в Досе, и подобных ей текстовых операционках, псевдографика позволяла хоть как-то разнообразить оформление текстов и поэтому ею изобилует CP866 и все другие ее ровесницы из разряда расширенных версий Аски.
CP866 распространяла компания IBM, но кроме этого для символов русского языка были разработаны еще ряд кодировок, например, к этому же типу (расширенных ASCII) можно отнести KOI8-R:

Принцип ее работы остался тот же самый, что и у описанной чуть ранее CP866 — каждый символ текста кодируется одним единственным байтом. На скриншоте показана вторая половина таблицы KOI8-R, т.к. первая половина полностью соответствует базовой Аски, которая показана на первом скриншоте в этой статье.
Среди особенностей кодировки KOI8-R можно отметить то, что русские буквы в ее таблице идут не в алфавитном порядке, как это, например, сделали в CP866.
Если посмотрите на самый первый скриншот (базовой части, которая входит во все расширенные кодировки), то заметите, что в KOI8-R русские буквы расположены в тех же ячейках таблицы, что и созвучные им буквы латинского алфавита из первой части таблицы. Это было сделано для удобства перехода с русских символов на латинские путем отбрасывания всего одного бита (два в седьмой степени или 128).
Windows 1251 — современная версия ASCII и почему вылезают кракозябры
Дальнейшее развитие кодировок текста было связано с тем, что набирали популярность графические операционные системы и необходимость использования псевдографики в них со временем пропала. В результате возникла целая группа, которая по своей сути по-прежнему являлись расширенными версиями Аски (один символ текста кодируется всего одним байтом информации), но уже без использования символов псевдографики.
Они относились к так называемым ANSI кодировкам, которые были разработаны американским институтом стандартизации. В просторечии еще использовалось название кириллица для варианта с поддержкой русского языка. Примером такой может служить Windows 1251.
Она выгодно отличалась от используемых ранее CP866 и KOI8-R тем, что место символов псевдографики в ней заняли недостающие символы русской типографики (окромя знака ударения), а также символы, используемые в близких к русскому славянских языках (украинскому, белорусскому и т.д.):
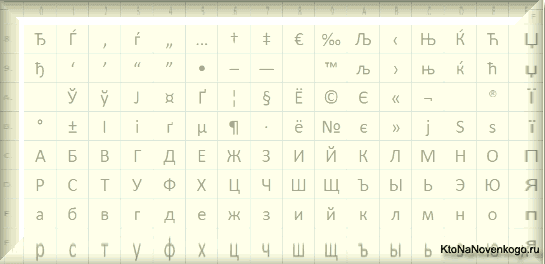
Из-за такого обилия кодировок русского языка, у производителей шрифтов и производителей программного обеспечения постоянно возникала головная боль, а у нас с вам, уважаемые читатели, зачастую вылезали те самые пресловутые кракозябры, когда происходила путаница с используемой в тексте версией.
Очень часто они вылезали при отправке и получении сообщений по электронной почте, что повлекло за собой создание очень сложных перекодировочных таблиц, которые, собственно, решить эту проблему в корне не смогли, и зачастую пользователи для переписки использовали транслит латинских букв, чтобы избежать пресловутых кракозябров при использовании русских кодировок подобных CP866, KOI8-R или Windows 1251.
По сути, кракозябры, вылазящие вместо русского текста, были результатом некорректного использования кодировки данного языка, которая не соответствовала той, в которой было закодировано текстовое сообщение изначально.
Допустим, если символы, закодированные с помощью CP866, попробовать отобразить, используя кодовую таблицу Windows 1251, то эти самые кракозябры (бессмысленный набор знаков) и вылезут, полностью заменив собой текст сообщения.
Аналогичная ситуация очень часто возникает при создании сайтов на WordPress и Joomla, форумов или блогов, когда текст с русскими символами по ошибке сохраняется не в той кодировке, которая используется на сайте по умолчанию, или же не в том текстовом редакторе, который добавляет в код отсебятину не видимую невооруженным глазом.
В конце концов такая ситуация с множеством кодировок и постоянно вылезающими кракозябрами многим надоела, появились предпосылки к созданию новой универсальной вариации, которая бы заменила собой все существующие и решила бы, наконец, на корню проблему с появлением не читаемых текстов. Кроме этого существовала проблема языков подобных китайскому, где символов языка было гораздо больше, чем 256.
Юникод (Unicode) — универсальные кодировки UTF 8, 16 и 32
Эти тысячи знаков языковой группы юго-восточной Азии никак невозможно было описать в одном байте информации, который выделялся для кодирования символов в расширенных версиях ASCII. В результате был создан консорциум под названием Юникод (Unicode — Unicode Consortium) при сотрудничестве многих лидеров IT индустрии (те, кто производит софт, кто кодирует железо, кто создает шрифты), которые были заинтересованы в появлении универсальной кодировки текста.
Первой вариацией, вышедшей под эгидой консорциума Юникод, была UTF 32. Цифра в названии кодировки означает количество бит, которое используется для кодирования одного символа. 32 бита составляют 4 байта информации, которые понадобятся для кодирования одного единственного знака в новой универсальной кодировке UTF.
В результате чего, один и тот же файл с текстом, закодированный в расширенной версии ASCII и в UTF-32, в последнем случае будет иметь размер (весить) в четыре раза больше. Это плохо, но зато теперь у нас появилась возможность закодировать с помощью ЮТФ число знаков, равное двум в тридцать второй степени (миллиарды символов, которые покроют любое реально необходимое значение с колоссальным запасом).
Но многим странам с языками европейской группы такое огромное количество знаков использовать в кодировке вовсе и не было необходимости, однако при задействовании UTF-32 они ни за что ни про что получали четырехкратное увеличение веса текстовых документов, а в результате и увеличение объема интернет трафика и объема хранимых данных. Это много, и такое расточительство себе никто не мог позволить.
В результате развития Юникода появилась UTF-16, которая получилась настолько удачной, что была принята по умолчанию как базовое пространство для всех символов, которые у нас используются. Она использует два байта для кодирования одного знака. Давайте посмотрим, как это дело выглядит.
В операционной системе Windows вы можете пройти по пути «Пуск» — «Программы» — «Стандартные» — «Служебные» — «Таблица символов». В результате откроется таблица с векторными формами всех установленных у вас в системе шрифтов. Если вы выберете в «Дополнительных параметрах» набор знаков Юникод, то сможете увидеть для каждого шрифта в отдельности весь ассортимент входящих в него символов.
Кстати, щелкнув по любому из них, вы сможете увидеть его двухбайтовый код в формате UTF-16, состоящий из четырех шестнадцатеричных цифр:
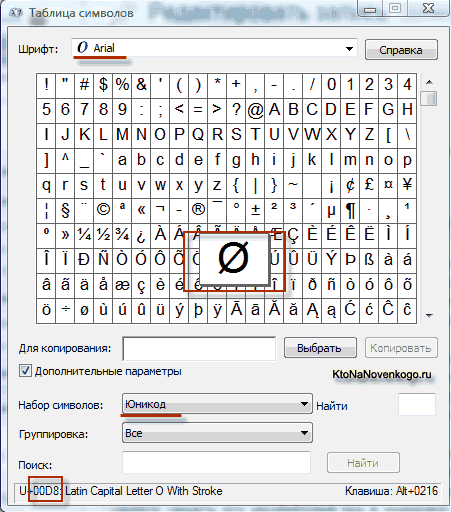
Сколько символов можно закодировать в UTF-16 с помощью 16 бит? 65 536 (два в степени шестнадцать), и именно это число было принято за базовое пространство в Юникоде. Помимо этого существуют способы закодировать с помощью нее и около двух миллионов знаков, но ограничились расширенным пространством в миллион символов текста.
Но даже эта удачная версия кодировки Юникода не принесла особого удовлетворения тем, кто писал, допустим, программы только на английском языке, ибо у них, после перехода от расширенной версии ASCII к UTF-16, вес документов увеличивался в два раза (один байт на один символ в Аски и два байта на тот же самый символ в ЮТФ-16).
Вот именно для удовлетворения всех и вся в консорциуме Unicode было решено придумать кодировку переменной длины. Ее назвали UTF-8. Несмотря на восьмерку в названии, она действительно имеет переменную длину, т.е. каждый символ текста может быть закодирован в последовательность длиной от одного до шести байт.
На практике же в UTF-8 используется только диапазон от одного до четырех байт, потому что за четырьмя байтами кода ничего уже даже теоретически не возможно представить. Все латинские знаки в ней кодируются в один байт, так же как и в старой доброй ASCII.
Что примечательно, в случае кодирования только латиницы, даже те программы, которые не понимают Юникод, все равно прочитают то, что закодировано в ЮТФ-8. Т.е. базовая часть Аски просто перешла в это детище консорциума Unicode.
Кириллические же знаки в UTF-8 кодируются в два байта, а, например, грузинские — в три байта. Консорциум Юникод после создания UTF 16 и 8 решил основную проблему — теперь у нас в шрифтах существует единое кодовое пространство. И теперь их производителям остается только исходя из своих сил и возможностей заполнять его векторными формами символов текста. Сейчас в наборы даже эмодзи смайлики добавляют.
В приведенной чуть выше «Таблице символов» видно, что разные шрифты поддерживают разное количество знаков. Некоторые насыщенные символами Юникода шрифты могут весить очень прилично. Но зато теперь они отличаются не тем, что они созданы для разных кодировок, а тем, что производитель шрифта заполнил или не заполнил единое кодовое пространство теми или иными векторными формами до конца.
Кракозябры вместо русских букв — как исправить
Давайте теперь посмотрим, как появляются вместо текста кракозябры или, другими словами, как выбирается правильная кодировка для русского текста. Собственно, она задается в той программе, в которой вы создаете или редактируете этот самый текст, или же код с использованием текстовых фрагментов.
Для редактирования и создания текстовых файлов лично я использую очень хороший, на мой взгляд, Html и PHP редактор Notepad++. Впрочем, он может подсвечивать синтаксис еще доброй сотни языков программирования и разметки, а также имеет возможность расширения с помощью плагинов. Читайте подробный обзор этой замечательной программы по приведенной ссылке.
В верхнем меню Notepad++ есть пункт «Кодировки», где у вас будет возможность преобразовать уже имеющийся вариант в тот, который используется на вашем сайте по умолчанию:
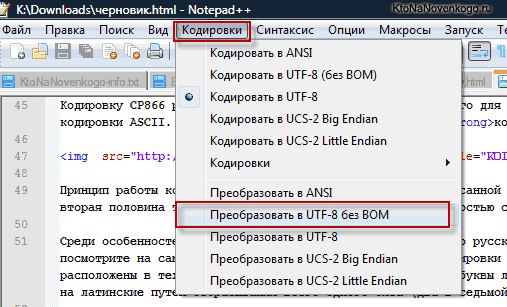
В случае сайта на Joomla 1.5 и выше, а также в случае блога на WordPress следует во избежании появления кракозябров выбирать вариант UTF 8 без BOM. А что такое приставка BOM?
Дело в том, что когда разрабатывали кодировку ЮТФ-16, зачем-то решили прикрутить к ней такую вещь, как возможность записывать код символа, как в прямой последовательности (например, 0A15), так и в обратной (150A). А для того, чтобы программы понимали, в какой именно последовательности читать коды, и был придуман BOM (Byte Order Mark или, другими словами, сигнатура), которая выражалась в добавлении трех дополнительных байтов в самое начало документов.
В кодировке UTF-8 никаких BOM предусмотрено в консорциуме Юникод не было и поэтому добавление сигнатуры (этих самых пресловутых дополнительных трех байтов в начало документа) некоторым программам просто-напросто мешает читать код. Поэтому мы всегда при сохранении файлов в ЮТФ должны выбирать вариант без BOM (без сигнатуры). Таким образом, вы заранее обезопасите себя от вылезания кракозябров.
Что примечательно, некоторые программы в Windows не умеют этого делать (не умеют сохранять текст в ЮТФ-8 без BOM), например, все тот же пресловутый Блокнот Windows. Он сохраняет документ в UTF-8, но все равно добавляет в его начало сигнатуру (три дополнительных байта). Причем эти байты будут всегда одни и те же — читать код в прямой последовательности. Но на серверах из-за этой мелочи может возникнуть проблема — вылезут кракозябры.
Поэтому ни в коем случае не пользуйтесь обычным блокнотом Windows для редактирования документов вашего сайта, если не хотите появления кракозябров. Лучшим и наиболее простым вариантом я считаю уже упомянутый редактор Notepad++, который практически не имеет недостатков и состоит из одних лишь достоинств.
В Notepad ++ при выборе кодировки у вас будет возможность преобразовать текст в кодировку UCS-2, которая по своей сути очень близка к стандарту Юникод. Также в Нотепаде можно будет закодировать текст в ANSI, т.е. применительно к русскому языку это будет уже описанная нами чуть выше Windows 1251. Откуда берется эта информация?
Она прописана в реестре вашей операционной системы Windows — какую кодировку выбирать в случае ANSI, какую выбирать в случае OEM (для русского языка это будет CP866). Если вы установите на своем компьютере другой язык по умолчанию, то и эти кодировки будут заменены на аналогичные из разряда ANSI или OEM для того самого языка.
После того, как вы в Notepad++ сохраните документ в нужной вам кодировке или же откроете документ с сайта для редактирования, то в правом нижнем углу редактора сможете увидеть ее название:
Чтобы избежать кракозябров, кроме описанных выше действий, будет полезным прописать в его шапке исходного кода всех страниц сайта информацию об этой самой кодировке, чтобы на сервере или локальном хосте не возникло путаницы.
Вообще, во всех языках гипертекстовой разметки кроме Html используется специальное объявление xml, в котором указывается кодировка текста.
<?xml version="1.0" encoding="windows-1251"?>
Прежде, чем начать разбирать код, браузер узнает, какая версия используется и как именно нужно интерпретировать коды символов этого языка. Но что примечательно, в случае, если вы сохраняете документ в принятом по умолчанию юникоде, то это объявление xml можно будет опустить (кодировка будет считаться UTF-8, если нет BOM или ЮТФ-16, если BOM есть).
В случае же документа языка Html для указания кодировки используется элемент Meta, который прописывается между открывающим и закрывающим тегом Head:
<head> ... <meta charset="utf-8"> ... </head>
Эта запись довольно сильно отличается от принятой в стандарте в Html 4.01, но полностью соответствует новому внедряемому потихоньку стандарту Html 5, и она будет стопроцентно правильно понята любыми используемыми на текущий момент браузерами.
По идее, элемент Meta с указание кодировки Html документа лучше будет ставить как можно выше в шапке документа, чтобы на момент встречи в тексте первого знака не из базовой ANSI (которые правильно прочитаются всегда и в любой вариации) браузер уже должен иметь информацию о том, как интерпретировать коды этих символов.
В начале 90-х, когда произошел развал СССР и границы России были открыты, к нам стали поступать программные продукты западного производства. Естественно, все они были англоязычными. В это же время начинает развиваться Интернет. Остро встала проблема русификации ресурсов и программ. Тогда и была придумана русская кодировка Windows 1251. Она позволяет корректно отображать буквы славянских алфавитов:
- русского;
- украинского;
- белорусского;
- сербского;
- болгарского;
- македонского.
Разработка велась русским представительством Microsoft совместно с компаниями «Диалог» и «Параграф». За основу были взяты самописные разработки, которые в 1990-91гг имели хождение среди немногочисленных идеологов ИТ в России.
На сегодняшний день разработан более универсальный способ кодировать символы — UTF-8 (Юникод). В нем представлено почти 90% всех программных и веб-ресурсов. Windows 1251 применяется в 1,6% случаев. (Информация по исследованиям Web Technology Surveys)

Кодировка сайта utf 8 или Windows 1251?
Чтобы ответить на этот вопрос, необходимо немного понять, что такое кодировка и чем они отличаются. Текстовая информация, как впрочем, и любая другая, в компьютере хранится в закодированном виде. Нам легче представить ее как числа. Каждый символ может занимать один или более байт. Windows 1251 является однобайтной кодировкой, а UTF-8 восьмибайтной. Это значит, что в Windows 1251 можно закодировать всего 256 символов.
Так как все сводится к двоичной системе исчисления, а байт – это 8 бит (0 и 1), то и максимальное число сочетаний составляет 28 = 256. Юникод позволяет представлять куда большее число символов, да и на каждый может быть выделен больший размер.
Отсюда и следуют преимущества Юникода:
- В шапке сайта следует указать кодировку, которая используется. Иначе вместо символов отобразятся «кракозяблы». А Юникод является стандартным для всех браузеров – они ловят его «на лету» как установленный по умолчанию.
- Символы сайта останутся одними и теми же, независимо от того, в какой стране загружается ресурс. Это зависит не от географического расположения серверов, а от языка программного обеспечения рабочих станций клиента. Житель Португалии, очевидно, использует клавиатуру и все ПО, включая операционную систему, на родном языке. В его компьютере, скорее всего вообще отсутствует Windows 1251. А если это так, то и сайты на русском языке корректно открываться не будут. Юникод, в свою очередь, «зашит» в любую ОС на любом языке.
- UTF-8 позволяет закодировать большее количество символов. На данный момент используется 6 байт из 8-ми, а русские символы кодируются двумя байтами.
Именно поэтому предпочтительней использовать универсальную кодировку, а не узкоспециализированную, которая применяется только в славянских странах.
Таблица кодировки Windows 1251
Для программистов и разработчиков сайтов бывает необходимо знать номера символов. Для этого используются специальные таблицы кодировки. Ниже представлена таблица для Windows 1251.

Что делать, если слетела кодировка командной строки?
Иногда Вы можете столкнуться с ситуацией, когда в командной строке вместо русских отображаются непонятные символы. Это означает, что возникла проблема кодировки командной строки Windows 7. Почему 7-ка? Потому что, начиная с 8-й версии, используется UTF-8, а в семерке еще Windows 1251.
Единовременно помочь решить проблему может команда chcp 866. Текущий сеанс будет работать корректно. А вот чтобы исправить ошибку кардинально, понадобится реестр.
- Нажмите Win+R и наберите команду regedit. Это позволит попасть в редактор реестра.

- Перейдите по ветке HKEY_CURRENT_USERConsole и посмотрите, чему равно значение для CodePage. Скорее всего, вы увидите что-то, отличное от 866 (правильный вариант).

- Исправьте на 866 в положении «Десятичная».
- Закройте и откройте вновь командную строку. Ситуация должна исправиться.


Отличного Вам дня!
Продолжение. См. № 7/2009
Выполняя лабораторную работу (см. №
7/2009), учащиеся получили кодовую таблицу для Windows
—
CP-1251. Следующие этапы практикума — познакомиться
с существованием множества кодовых таблиц,
самостоятельно получить другие кодовые таблицы
с символами кириллицы и, наконец, написать
программу перекодировки текста (все
программирование в этом варианте курса
информатики — на Лого).
Учебные материалы и задания для
учащихся
Таблицы кодировки
Наверное, вам приходилось
сталкиваться с ситуацией, когда текст на экране
компьютера выглядит, как нарочно зашифрованный.
Например, так:

Происходят такие неприятности в
результате существования не одной-единственной,
а нескольких таблиц кодировки. Почему так
получилось?
Американский стандартный код для
обмена информацией (ASCII) первоначально был
разработан для передачи текстов по телеграфу,
причем в то время он был 7-битовым, то есть для
кодирования символов английского языка,
служебных и управляющих символов использовались
только 128 семибитовых комбинаций. При этом первые
32 кода служили для кодирования управляющих
сигналов (начало текста, конец строки, перевод
каретки, звонок, конец текста и т.д.). При
разработке первых компьютеров фирмы IBM этот код
был использован для представления символов в
компьютере. На кодирование каждого символа был
отведен байт, а поскольку в исходном коде ASCII было
всего 128 символов, для их кодирования хватило
половины восьмибайтовых кодов.
Оставшуюся вторую половину кодов
стали использовать для представления символов
псевдографики, математических знаков и
некоторых символов из языков, отличных от
английского (греческих букв, немецких умляутов,
французских диакритических знаков и т.п.).
Когда стали приспосабливать
компьютеры для других стран и языков, фирма IBM
ввела в употребление несколько кодовых таблиц,
ориентированных на конкретные страны. Так, для
скандинавских стран была предложена таблица CP-865
(Nordic), для арабских стран — таблица CP-864 (Arabic), для
Израиля — таблица CP-862 (Israel) и так далее. В этих
таблицах часть кодов из второй половины кодовой
таблицы использовалась для представления
символов национальных алфавитов.
С русским языком ситуация развивалась
особым образом. Появилось несколько разных
таблиц с символами кириллицы: KOI8-R, CP-866, CP-1251
(именно ее вы получили в лабораторной работе),
ISO-8551-5…
Одна из причин в том, что таблица
кодировки связана с операционной системой
(операционная система управляет компьютером и
осуществляет операции ввода-вывода информации).
Программы для работы с текстами —
текстовые редакторы, браузеры — “умеют”
перекодировать текст в соответствии с указанной
таблицей кодировки.
Кодировка на web-странице
Грамотно сделанный HTML-документ
обязательно должен содержать специальный тег с
указанием использованной в нем таблицы
кодировки. Если вы попали в Интернете на
“нечитаемую” страницу, то скорее всего в HTML-коде
нет тега с кодировкой. Но браузер поможет вам
прочесть страницу. Для этого в браузерах есть
специальное меню.
Например, в браузере Internet Explorer зайдите
в пункт меню View/Encoding (Вид/Кодировка). Вы
увидите меню, в котором можно выбрать таблицу
кодировки. Попробуйте изменить кодировку этой
страницы.
Но даже наличие множества различных
национальных таблиц кодировки не может решить
всех проблем с кодированием текстов. Для таких
языков, как китайский или японский, вообще 256
символов недостаточно. Кроме того, всегда
существует проблема вывода или сохранения в
одном файле одновременно текстов на разных
языках (например, при цитировании).
Поэтому была разработана
универсальная кодовая таблица UNICODE, содержащая
символы, применяемые в языках всех народов мира,
а также различные служебные и вспомогательные
символы (знаки препинания, математические и
технические символы, стрелки, диакритические
знаки и т.д.).
Очевидно, что одного байта
недостаточно для кодирования такого большого
количества символов в одной таблице. Поэтому в
UNICODE используются 16-битовые (двухбайтовые) коды. К
настоящему времени задействовано около 49 000
кодов, время от времени в таблицу добавляются
новые знаки. Например, в сентябре 1998 г. в таблицу
был внесен символ валюты EURO.
Сейчас в компьютерном мире
сосуществуют однобайтовые и двухбайтовые
таблицы кодировки, но постепенно будет полностью
осуществлен переход на UNICODE.
Задание
1. Подберите с помощью браузера
кодировку для следующих страниц.
Примечание для читателя
“Информатики”: учитель создает для этого
задания две-три web-страницы с текстом в разных
кодировках и тэг <meta> с указанием кодовой
страницы удаляет.
Запишите, какие таблицы кодировки
использованы в этих документах.
2. Вы обратили внимание на то, что при
любых изменениях кодировки английские слова
прекрасно читаются? Объясните, почему так
получается.
3. Рассчитайте, сколько всего различных
текстовых символов можно закодировать двоичным
кодом при двухбайтовой системе кодирования.
Получение разных кодовых таблиц
Выполняя лабораторную работу, вы
получили шестнадцатеричную кодовую таблицу CP-1251.
Ведь именно с этой таблицей работает
русифицированная операционная среда Windows.
Для получения таблицы вы написали
программу на Лого. А таблицу поместили и оформили
в документе MS Word. Если эту таблицу поместить на
web-страницу (то есть в документ HTML), то можно с
помощью браузера получить и другие таблицы
кодировки.
1. Получение web-страницы с таблицей
кодировки
Помните, какие тэги нужны для создания
таблицы на web-странице? Вот пример HTML-кода для
таблицы, состоящей из четырех ячеек (двух
столбцов и двух строк):
<TABLE>
<TR> (начало первой строки)
<TD> содержимое ячейки 1 </TD>
<TD> содержимое ячейки 2 </TD>
</TR>(конец первой строки)
<TR> (начало второй строки)
<TD> содержимое ячейки 3 </TD>
<TD> содержимое ячейки 4 </TD>
</TR>(конец второй строки)
</TABLE>
Откройте вашу программу получения
таблицы кодировки. Внесите в программу
изменения: в текстовое окно должны попасть
теперь еще и тэги для строк и ячеек. Не забудьте
добавить тэги структуры HTML-документа.
В результате в текстовом окне должен
появиться HTML-код web-страницы, содержащей кодовую
таблицу.
Сохраните текст в файле. Не забудьте про
расширение имени файла!
Просмотрите получившуюся страницу в
браузере. Если с таблицей все в порядке, можно
начинать эксперименты.
Попробуйте менять кодировку страницы
— вид таблицы должен меняться. Таким образом
можно получить все кодовые таблицы, имеющиеся в
браузере (только однобайтовые, конечно!).
Сформулируйте, что именно меняется
в таблице при переходе от одной кодировки к
другой.
2. Добавление десятичного номера
Для вашей следующей работы (создания
программы-перекодировщика) нужно, чтобы в
таблице были еще и десятичные номера символов.
Например, так, как на этой картинке:

Усовершенствуйте вашу программу так,
чтобы на web-странице появились и номера. Сделайте
скриншоты кодовых таблиц с кириллицей: Windows-1251,
KOI8-R, CP-866, MacCyrillic. Сохраните скриншоты в отдельных
файлах в формате GIF.
Время на выполнение этой части
практикума — 3 урока.
Пример решения
Исходная программа:
это таблица
make «n 32
repeat 14 [строчка :n pr [] make «n :n + 16]
end
это строчка :n
repeat 16 [insert char :n insert char 32
make «n :n + 1]
end
Результат — 14 строк по 16 символов в
каждой.
Программа, создающая HTML-код (без
десятичных номеров):
это таблица_html
make «n 32
insert [<html> <body> <table>]
repeat 14 [insert [<tr>] строчка_html :n
insert [</tr>] pr[] make «n :n + 16]
insert [</table> </body> </html>]
end
это строчка_html :n
repeat 16
[insert [<td>] insert char :n insert char 32
insert [</td>] make «n :n + 1]
end
Результат — код web-страницы с кодовой
таблицей. В коде не содержится тэг с указанием
кодировки, поэтому на этой странице можно
увидеть любую однобайтовую таблицу кодировки.
Программа, выводящая HTML-код для
страницы, на которой кодовая таблица с
подписанными под каждым символом десятичными
номерами:
это таблица_html_1
make «n 32
insert [<html> <body> <table>]
repeat 14
[insert [<tr>] строчка_html :n insert
[</tr>] pr[]
insert [<tr>] номер :n pr []
make «n :n + 16]]
insert [</table> </body> </html>]
end
это строчка_html :n
repeat 16
[insert [<td>] insert char :n
insert char 32 insert [</td>] make «n :n + 1]
end
это номер :n
repeat 16
[insert [<td>] insert :n
insert char 32 insert [</td>]
make «n :n + 1]
end
В таблице оказывается вдвое больше
строк (28). Дополнительная вспомогательная
процедура номер создает под
каждым символом его десятичный код.
Выполняя предыдущее задание, учащиеся
самостоятельно получили несколько кодовых
таблиц с символами кириллицы. Конечная цель
практикума — создание программы
перекодирования текста, содержащего русские
буквы, из кодировки Windows-1251 в кодировку DOS-866 и
обратно.
Сначала нужно познакомиться со
средствами языка программирования для работы с
текстом и более подробно разобрать некоторые
особенности языка Лого, а также решить несколько
подготовительных задач.
Версия среды — ЛогоМиры 2.0. Время — 6
уроков.
|
Команды |
Команды |
||
|
CF |
на одну позицию |
SELECT |
включить режим |
|
CB |
на одну позицию |
UNSELECT |
снять выделение |
|
CU |
на одну строку |
COPY |
|
|
CD |
на одну строку |
CUT |
|
|
TOP |
в начало текста |
PASTE |
|
|
BOTTOM |
в конец текста |
DELETE |
Учебные материалы и задания для
учащихся
Как зашифровать текст
Редактируя какой-либо текст, вы
перемещаете курсор, выделяете фрагменты, затем
копируете или вырезаете их. При этом копия
фрагмента попадает в буфер обмена и потом может
быть использована для вставки. Все эти действия
можно запрограммировать, и для этого в среде
ЛогоМиры имеется целый набор команд и операций.
Например, инструкция REPEAT 10
[CF] переместит курсор на десять “шагов”
вправо. А выполнение инструкции SELECT
REPEAT 10 [CF] приведет к тому, что следующие десять
знаков текста будут выделены. Если выполнить
после этого команду CUT, то
выделенный фрагмент текста будет вырезан.
Все новые команды не имеют параметров.
Откройте новый файл ЛогоМиров и
создайте на листе текстовое окно. Сохраните файл
в вашем рабочем каталоге. Для дальнейшей работы
вам понадобится небольшой пробный текст — 3–4
абзаца. Наберите текст произвольного содержания
и сохраните его с помощью команды SAVETEXT
«имя_файла . Текстовый файл будет записан в
ваш рабочий каталог. Проверьте действие
приведенных выше инструкций, содержащих команды
для работы с текстом.
Кроме команд, вам понадобятся новые
операции. В языке Лого команда позволяет
выполнить какие-то действия. Операция (иногда
используется слово датчик) помогает что-либо
измерить или вычислить. Например, операция COLOR нужна для определения цвета
черепашки, а операция COLORUNDER —
для определения цвета поля, на котором черепашка
находится. Результат, возвращаемый операцией,
должен быть передан команде (или другой операции,
которая передаст его команде).
Разберем, например, инструкцию PRINT RANDOM 100.
PRINT — это команда, RANDOM
— операция. Инструкция выполняется справа
налево, как бы с конца. Вначале компьютер выберет
случайное целое число в диапазоне от 0 до 100. Затем
результат выполнения операции RANDOM
будет передан команде вывода PRINT
. В результате на экране появится случайное
число.
Еще один пример.
QUESTION [Ваше имя?]
MAKE «N ANSWER
INSERT :N INSERT [! Мне приятно с Вами
познакомиться!]
Команда QUESTION выводит
текст вопроса в специальное диалоговое окно,
которое закроется после того, как вы ответите на
этот вопрос. Затем команда присваивания MAKE помещает в переменную N на хранение ваш ответ,
возвращаемый операцией ANSWER.
Значение переменной N затем
используется в диалоге.
Операции, так же как и команды, могут
быть с параметрами и без них.
Выполняя лабораторную работу
“Кодирование текста”, вы использовали операции
для работы с символами CHAR и ASCII .
Кроме них, вам понадобятся еще две новые
операции:
Эти операции не имеют параметров.
Результат операции EOT? —
логическая величина, то есть ИСТИНА или ЛОЖЬ.
Логические величины используются в качестве
условий в командах ветвления.
Как можно использовать новые операции?
Предположим, нужно пересчитать все запятые в
тексте. Это можно сделать с помощью рекурсивной
процедуры. Сначала текст надо вывести на экран.
Для этого можно воспользоваться командой LOADTEXT «имя (укажите имя файла, в
котором вы сохранили пробный текст). Выведем
текст, установим курсор в начало текста и
присвоим переменной K (счетчику
запятых) значение, равное нулю. А затем запустим
рекурсивную процедуру:
это подсчет
IF EOT? [STOP]
SELECT CF COPY
IF CLIPBOARD = «, [MAKE «K :K + 1]
подсчет
END
В первой строке процедуры — условие
остановки. Если дошли до конца текста, то работа
закончена.
Во второй строке — помещение
следующего знака в буфер обмена.
В третьей строке — анализ содержимого
буфера обмена (в нем содержится единственный
символ). Если этот символ — запятая, то к счетчику
прибавляется единица.
Обратите внимание: перед запятой стоит
специальный знак языка Лого — двойная кавычка
(без пробела). Так отмечаются отдельные символы и
последовательности символов — слова. Именно
поэтому двойной кавычкой предваряется имя
переменной в команде присваивания. (А двоеточием
— другим специальным знаком языка Лого —
предваряется значение переменной.)
В четвертой, последней строке —
рекурсивный вызов нашей процедуры. Все действия
будут повторяться снова и снова, пока курсор не
доберется до конца текста.
Проверьте все приведенные примеры
использования операций в вашем файле ЛогоМиров.
А затем решите несколько задач.
Задачи
1. Напишите процедуру, вставляющую
пробелы после каждого символа в тексте.
Напишите вторую процедуру для
приведения текста в первоначальное состояние
(она должна удалить только те пробелы, которые
были вставлены первой процедурой).
Для вызова этих и последующих процедур
создавайте на листе кнопки.
2. Напишите процедуру, удаляющую все
пробелы в тексте.
3. Если вы читали “Золотого теленка”,
то, наверное, помните, как Остап Бендер купил на
толкучке печатную машинку с “турэцким
акцэнтом” (у нее отсутствовала клавиша с буквой
“е”). Напишите процедуру, заменяющую во всем
тексте буквы “е” на “э”.
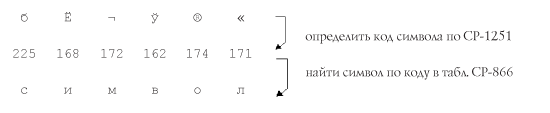
4. Действуя подобным образом, можно
зашифровать текст. Подготовьте для этого
инструмент: процедуру ЗАМЕНА с двумя параметрами
— какую букву искать и на какую ее заменять.
Зашифруйте ваш текст: замените все
“а” на “ы”, “с” — на “з”, “т” — на “д”.
А затем попробуйте расшифровать,
используя ту же процедуру.
Придумайте способ, позволяющий
зашифровывать и расшифровывать текст с помощью
процедуры ЗАМЕНА. Напишите две процедуры для
шифрования и дешифрования текста методом
подстановки.
5. Напишите процедуру для другого
способа шифрования текста: каждый символ текста
с кодом больше ста должен быть заменен на
предыдущий в таблице символов (то есть на символ,
имеющий код на единицу меньше).
Напишите процедуру для дешифрования
измененного таким образом текста.
Создание программы для перекодировки
текстов
Получив несколько кодовых таблиц, вы
установили, что в таблицах кодировок CP-1251 и CP-866
русские буквы стоят на разных местах. Это и
приводит порой к тому, что текст не удается
прочитать. Если русские буквы были закодированы
по одной таблице, а программа пытается
раскодировать текст по другой таблице, то на
экране можно увидеть “абракадабру”.
Как расшифровать такой текст? Пусть мы
открыли текстовый файл редактором Блокнот и
увидели следующее:
Редактор Блокнот — это программа,
работающая под управлением операционной системы
Windows. Значит, она использует кодовую таблицу CP-1251.
Определим десятичный код каждого знака по этой
таблице, а затем посмотрим в другую кодовую
таблицу — предположим, в CP-866. И выясним, какие
знаки соответствуют этим кодам (см. схему выше).
Слово расшифровано. (Коды указаны в
десятичной системе.)
Конечно, никто не делает такую
расшифровку вручную, эту работу можно
запрограммировать. А для этого полезно выяснить,
какая зависимость существует между кодами
русских букв в таблицах CP-1251 и CP-866. Рассмотрим это
на примере слова СИМВОЛ .
|
225 |
168 |
172 |
162 |
174 |
171 |
код по табл. CP-866 |
|
с |
и |
м |
в |
о |
л |
|
|
241 |
232 |
236 |
226 |
238 |
235 |
код по табл. CP-1251 |
Оказывается, для первой буквы
разность кодов равна 16, а для остальных — 64. То
есть программа должна заменять такие символы,
увеличив код на 64 (так, как в задаче 5 из
предыдущего параграфа).
Для наглядности удобно изобразить
расположение символов в кодовой таблице CP-1251 на
отрезке длиной 256 условных единиц (см. рисунок
ниже).
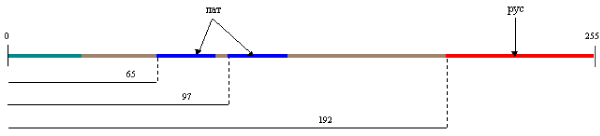
Задание
1. Откройте новый документ MS Word.
Создайте с помощью векторного графического
редактора, встроенного в MS Word, две схемы
расположения символов в кодовых таблицах CP-1251 и
CP-866.
Полезный совет: установите для
страницы альбомную ориентацию.
Выясните с помощью ваших схем величину
сдвига в кодах для русских букв. Создайте таблицу
и внесите в нее полученные данные.
После того как вы построили и сравнили
две диаграммы, у вас есть все необходимые данные
для того, чтобы написать программу
перекодировки.
В программе будет необходимо
анализировать код символа — находится ли код в
некотором интервале значений. В таких случаях в
команде условного ветвления нужно
сформулировать составное условие. Для этого в
языках программирования используют специальные
логические операции AND , OR, NOT (И, ИЛИ, НЕ).
Например, программе надо выполнить некоторые
действия, если значение переменной 100
< K < 200. То есть должны быть выполнены два
простых условия: K > 100 И K < 200 . По правилам языка Лого это
записывается так:
IF AND :K > 100 :K < 200 […]
Если же необходимо, наоборот, выделить
такую ситуацию, когда значение K
не попадает в этот интервал, то команду условного
ветвления можно записать так:
IF OR :K < 100 :K > 200 […]
То есть K < 100 ИЛИ K >200 *.
В обоих примерах с помощью логической
операции из двух простых условий сформировано
составное условие. В соответствии с правилами
языка Лого логические операции OR и AND записаны перед своими
операндами (простыми условиями).
Задание
1. Напишите программу для
перекодировки текста
CP-1251–CP-866 и программу для обратной перекодировки.
Проверьте программы на вашем пробном тексте.
Для проверки правильности работы
программы используйте файловый менеджер Far. В
режиме просмотра можно менять кодировку
клавишей F8.
Используйте панель инструментов среды
ЛогоМиры для того, чтобы сделать работу с
программой удобной. Например, реализуйте
управление с помощью кнопок; поместите на листе
инструкцию-“подсказку” по работе с программой.
Предусмотрите возможность сохранить
перекодированный текст в файле. Для этого вам
понадобятся команда QUESTION ,
операция ANSWER , команда SAVETEXT .
Примеры выполнения заданий
Задачи
Предварительно на листе проекта
ЛогоМиров должно быть создано текстовое окно,
файл должен быть сохранен и в этой же папке
записан текстовый файл пробный.txt.
это подготовка
ct loadtext «пробный top
end
это пробелы
подготовка удаление
end
это удаление
if eot? [stop]
select cf copy
if clipboard = char 32 [cb delete]
удаление
end
это турецкий_акцент
подготовка акцент
end
это акцент
if eot? [stop]
select cf copy
if clipboard = «е [cb delete insert «э]
акцент
end
это подстановка :a :b
if eot? [stop]
select cf copy
if clipboard = :a [cb delete insert :b]
if clipboard = :b [cb delete insert :a]
подстановка :a :b
end
это демо_1
подготовка
подстановка «а «е
wait 30 top
подстановка «а «е
end
Процедура демо_1
демонстрирует шифрование текста методом
подстановки. Через три секунды текст
расшифровывается.
это шифровка
if eot? [stop]
select cf copy make «n ascii clipboard
if :n > 100 [cb delete insert char :n — 1]
шифровка
end
это расшифровка
if eot? [stop]
select cf copy make «n ascii clipboard
if :n > 99 [cb delete insert char :n + 1]
расшифровка
end
это демо_2
подготовка
шифровка wait 30 top расшифровка
end
Процедура демо_2
демонстрирует шифрование текста способом,
указанным в последней задаче. Через три секунды
текст расшифровывается.
Линейные диаграммы
Вывод: если в тексте, закодированном по
CP-1251, попадаются буквы с кодом от 192 до 239, то от
кода необходимо отнять 64. Тогда мы перейдем в CP-866
(это русские буквы от А до п). Для букв с кодами от
240 до 255 (р – я) для перехода из CP-1251 в CP-866 разность
в коде — 16.
Программы перекодировки
это Win-DOS
if eot? [stop]
select cf copy make «n ascii clipboard
if and :n > 191 :n < 240
[cb delete insert char :n — 64]
if and :n > 239 :n < 256
[cb delete insert char :n — 16]
Win-DOS
end
это DOS-Win
if eot? [stop]
select cf copy make «n ascii clipboard
if and :n > 127 :n < 176
[cb delete insert char :n + 64]
if and :n > 223 :n < 240
[cb delete insert char :n + 16]
DOS-Win
end
это демо_3
подготовка
Win-DOS wait 30 top DOS-Win
end
Процедура демо_3
демонстрирует перевод текста из кодировки CP-1251 в
кодировку CP-866. Затем, через три секунды,
производится обратный перевод.
Методические комментарии к практикуму
Предложенный читателям
“Информатики” практикум — часть базового курса
для 7–9-х классов. Этот вариант курса информатики
построен на нескольких принципах. Во-первых,
различные “линии” курса — программирование,
технология обработки графики, текста, теория
(например, системы счисления) и т.д. — не
разнесены по годам обучения или, скажем, по
полугодиям. А, наоборот, перемежаются и
переплетаются. Во-вторых, новый учебный материал
появляется перед учащимися в тот момент, когда
возникает практическая необходимость. То есть в
контексте некоторого задания или мини-проекта.
Например, разговор о логических операторах
заходит первый раз, когда нужно написать
программу перекодировки. И без нового средства
никак не обойтись. Это не означает, конечно, что
потом не будет обобщения и рассказа и об
Аристотеле, и о Дж. Буле. Другими словами, общий
подход в обучении информатике в данном курсе —
не от общего к частному, а наоборот. Поэтому в
основе лежит цепочка задач, заданий,
мини-проектов и практикумов.
Задания практикума “Кодирование текста”
имеют комплексный характер. Учащиеся и
программируют, и переводят числа из одной
системы счисления в другую, работают с векторным
графическим редактором, подготавливают
иллюстрации для текстового документа (отчета),
форматируют таблицы, используют язык HTML,
работают с браузером и файловым менеджером.
Переходы от одного вида деятельности к другому
не мешают осваивать достаточно сложный раздел
курса. Наоборот, такое разнообразие помогает
поддерживать интерес к работе над заданиями и к
нашему предмету.

* Более строго следовало записать K ≤ 100 ИЛИ K ≥ 200.
Не каждый человек обладает большими познаниями в компьютерной технике.
Что такое windows-1251 кодировка и какую роль играет в работе компьютера предстоит узнать.
Что это такое?
Кодировка 1251 представляет собой совокупность символов, которая составляет восьми-битную систему Windows для русифицированных устройств.
Стоит отметить, что довольное широкое применение она нашла на территории Европы.
Считается одной из самых выгодных кодировок, поскольку в ней присутствует все необходимые символы, которые используются в российской типографии. Все кириллические символы имею алфавитную последовательность.
Немного из истории
С наступлением 90-х годов, после распада СССР, границы России стали открыты.
Поэтому на территорию страны стало постепенно проникать оборудование из европейских стран.
Изначально все они были запрограммированы на английском языке.
В этот же промежуток времени начинает активно распространяться интернет.
В результате стало необходимо как можно быстрее русифицировать все оборудование и программное обеспечение. В связи с данной необходимостью появилась кодировка 1251. С ее помощью на компьютерах корректно отображаются славянские буквы алфавита.
А значит стало возможным использовать компьютеры со следующими языками:
- Русский
- Белорусский
- Украинский
- Сербский
- Болгарский
- Македонский.
Совместно с двумя российскими компаниями «Параграф» и «Диалог», представительства компании Microsoft начали активно заниматься разработкой данной кодировки.
В качестве основы были использованы обыкновенные самостоятельно написанные разработки.
Однако технический прогресс не стоит на месте, поэтому в последнее время широкое применение нашел Юникод UTF-8.
В него заложено порядком 90% web-ресурсов. Что касается 1251, то она используется менее, чем в 2%.
UTF-8 против 1251
Вся информация, которая хранится на компьютере, имеет кодированный вид.
Можно предположить, что символ имеет вес порядком 1 байт. 1251 – это разновидность кодировки однобайтовой, а UTF-8 – восьмибайтная.
Отсюда можно сделать вывод, что первый вариант способен к программированию 256 знаков.
Что касается второго варианта, то он представляет большее количество. Кроме того, для этого выделяют большой размер.
Можно сделать вывод, что оба варианта имеют следующие отличия:
- В верхней части необходимо указывать кодировку, которая необходима для использования. В противном случае, вместо обыкновенных символов появляются нечитаемые иероглифы. Используя UTF-8 (которая считается более универсальной кодировкой), все переводы и расшифровки осуществляются в автоматическом режиме
- Вне зависимости от того, на территории какой страны будет загружаться страница, символика останется без изменения. Важно отметить, что местоположение в данном случае не играет абсолютно никакой роли. Главное обращать внимание на языковые серверы, используемые пользователем. Каждый человек обращается к программному обеспечению на родном языке. Для жителей Европы, 1251 будет недоступна в силу использования латиницы. Соответственно можно сделать вывод о том, что русскоязычные сайты не будут открывать в корректном формате. Что касается юникода, то он присутствует в любой ОС
- Второй вид имеет возможность кодировки большего количества символов. На сегодняшний день стоит отметить 6 и 8 байт. Что касается кириллицы, то для ее кодировки достаточно двух байт.
В связи с выше перечисленными отличиями можно сделать вывод о том, что универсальная кодировка более актуальна для использования, чем 1251, поскольку она подойдет только для славянской группы языков.
Для профессиональных программистов и технических специалистов, знание кодировки 1251 является обязательным условием для осуществления полноценной работы.
Чтобы символы можно было запомнить быстро и просто, чаще всего используют следующую таблицу:
Инструкция по восстановлению кодировки
Ситуация, когда в командной строке присутствуют непонятные символы, вопросительные знаки или иероглифы довольна распространенная.
Однако исправить положение возможно самостоятельно, не прибегая к помощи специалистов.
Сразу стоит отметить, что это первый признак того, что в седьмом Windows слетела кодировка 1251.
С восьмой версии активно используют UTF-8.
Для того, чтобы решить задачу максимально быстро, возможно использование команды CHCP 866, но это только временная мера и в полной мере проблему она не решит.
Как правило, реестр используется для основательного решения проблемы:
- Чтобы вызвать командную строку, нажимаем сочетание клавиш Win и R. Пишем regedit, при помощи которого открывается специальный реестр
- Как показано на рисунке, находим соответствующую папку HKEY_CURRENT_USER далее выбираем Console. Далее смотрим какой код задан для страниц (Code Page). В том случае, если там стоит число не 866, что скорее всего так и будет, значит проблема была определена верно
- Исправляем в строке на десятичное значение
- Чтобы править, произошли ли изменения, достаточно открыть и снова вызвать командную строчку.
Почему до сих пор используется 1251
Существует несколько причин, почему 1251 продолжает пользоваться большой популярностью среди разработчиков онлайн ресурсов:
- Многие программисты php используют стандартную кодировку, поскольку OC Windows ее поддерживает в режиме по умолчанию. И хотя в последнее время разработчики стали активно внедрять UTF-8, все же 1251 пока не сдает свои активные позиции
- Если брать для примера старую версию MySQL до четвертой, то стоит отметить, что при включении даже тестового режима, вылезало множество ошибок в UTF-8. Только после выпуска 4.1 многие «глюки» были исправлены. Существует категория программистов, которая вовсе остается верна 1251, а их последователи рьяно берут с них пример и даже не собираются использовать нечто другое
- Поскольку один символ в системе 1251 весит меньше (один байт), то вполне логично, что возникает некая экономия в отличие от последнего варианта.
По сравнению с данной кодировкой, UTF-8 считается более оптимальным вариантом, поскольку она может распознать большее количество символов.
Существуют и другие аргументы, активно выступающие «ЗА» использование данной системы:
- Возможно включение любых знаков из набора Юникода. Кроме того, вполне логично, что здесь поддерживается 100 000 символов против 256. Здесь можно найти от стандартных смайликов до апострофа абсолютно все. Их использование возможно в любом документе. Кроме того, их можно прочитать даже в редакторе, что исключает вероятность появления нечитабельных знаков
- Ранее существовало мнение о том, что современный utf занимает больше места. В итоге оказалось, что символы также весят всего лишь байт. Значит, стоит сделать вывод о том, что увеличение веса странички не происходит и ее использование такое же легкое. Однако, если используется только русский алфавит, то в таком случае размер будет увеличен вдвое, поскольку изначально кириллица не включена в систему
- Система считается одной из самых универсальных, которые уже смогли достать. В таком случае можно создавать сайты для любого населения мира. Можно уже не думать о том, какая кодировка используется, поскольку Юникод является универсальной вещью
- UTF – это оптимальный вариант работы с php страницами.
Важно отметить, что изначально многие разработчики стали использовать 1251.
И хотя сейчас тенденции поменялись, последователей именно этой кодировки осталось, а значит она продолжает пользоваться большой популярностью среди пользователей.
Кто-то считает, что универсальная utf – это неплохое решение, которое устанавливается для современных ресурсов, но 1251 – это проверенный алгоритм для стран, использующих кириллицу.
Стоит отметить, что в большинстве случаев используют автоматические переключение. Так, например, если понадобится прочитать информацию на иностранном языке или на русском, достаточно просто переключить кодировку на актуальный формат.
Вероятно, что в будущем 1251 станет еще меньше востребованной, а на смену придут новые проверенные системы. Однако сегодня многие все же используют именно ее.
Также важно принять на заметку, что для работы с utf знание английского языка является обязательным условием.
Источник
Кодировка windows 1251 была создана в начале 90 годов для русификации программных продуктов, выпускаемых корпорацией Microsoft:

Кодировка является 8-битной и включает в себя символы славянской группы языков, в которую входят русский, белорусский, украинский, болгарский, македонский, сербский – это дает преимущество перед остальными кириллическими кодировками (ISO 8859-5, KOI8-R, CP866). Однако у 1251-кодировки имеются и весомые недостатки:
- Кодировка windows 1251 в html
- Кодировка windows 1251 в PHP
- Кодировка windows 1251 в htaccess
- 0xFF (25510) – это код, который зарезервирован для символа «я». В программах, которые не поддерживают чистый 8-ой бит, часто возникают непредсказуемые проблемы;
- Нет псевдографики, которая присутствует в KOI8, CP866.
Ниже приведены символы из Code Page 1251 или сокращенно СР1251 (числа под символами являются кодом в шестнадцатеричной системе такого же символа в Юникоде):

Нередко у web-разработчиков и блогеров, обладающих различной квалификацией возникает проблема с кодировкой страниц: вместо подготовленного текста появляются неизвестные, нечитаемые символы. Чтобы разобраться с данной проблемой, необходимо понимать суть термина «кодировка страницы».
Текст в памяти компьютера хранится в виде определенного количества байт, а не в том виде, в котором он отображается в текстовом редакторе. Каждый байт является кодом, который соответствует одному символу. Для того чтобы текст на странице отображался как следует, нужно сообщить браузеру, какую таблицу кодов для расшифровки и отображения он должен использовать.
Таблица кодировок не является универсальной, то есть, для расшифровки текста необходимо использовать ту, которая соответствует кодировке символов:

Для того чтобы html-документ корректно отобразился в браузере, необходимо указать используемую кодировку. Делается это следующим образом:
— между тегом <head> и закрывающим его </head> нужно прописать <meta http-equiv=»Content-Type» content=»text/html; charset=windows-1251″> — исходя из этой строки, браузер будет использовать символы русского алфавита для отображения текста на странице.
Ни для кого не является тайной, что генерация страниц проходит путем выборки и использования какой-то части информации, которая хранится в базе данных. При написании сайта на PHP, чаще всего это mysql:

Нередко при смене хостинга возникает проблема: различные кодировки информации в базе данных и в шаблонах страниц. Из-за этого одна сгенерированная страница может одновременно содержать несколько кодировок. Если информация на сайте представлена в кодировке виндовс 1251, то и чтение из базы данных должно осуществляться с помощью таблицы, в которой представлена win 1251 кодировка.
Для согласования расшифровки необходимо выполнить функцию mysql_query(«SET NAMES cp1251») – это означает, что преобразование из машинного кода будет осуществляться согласно таблице cp1251.
При создании сайта, предварительно настроив кодировки в шаблонах и базах данных, все равно может всплыть проблема некорректного отображения информации в браузере.
Для того чтобы для веб-ресурса была задана кодировка виндовс-1251, необходимо найти (или создать) файл .htaccess. Это файл, который хранит в себе дополнительные настройки и описания конфигураций web-сервера.
В нем для установки кодировки следует прописать следующие строки:
- DefaultLanguage ru;
- AddDefaultCharset windows-1251;
- php_value default_charset «cp1251».
Таким образом, для корректного отображения текста должны совпадать его кодировка и таблица кодов, с помощью которой браузер будет расшифровывать символы. Для текстов, написанных на славянских языках, необходима win 1251 кодировка. Важно помнить, что элементы страниц и баз данных должны быть описаны с помощью одной таблицы кодов.
Что такое кодировка:
Кодировка это процесс преобразования данных или сигналов из формы, удобной для восприятия, в форму, удобную для хранения, обработки и передачи.
Данные в микроконтроллере хранятся, обрабатываются и передаются в виде логических единиц и нулей, то есть в двоичной системе счисления. Числа можно перевести из любой системы счисления в двоичную и обратно, а символы (буквы) перевести в двоичную систему нельзя. Символы не переводятся а кодируются в числа, в соответствии с используемой таблицей символов. Таблица символов это таблица в которой каждому символу соответствует число, например, символу ‘J’ соответствует число 74. Значит в памяти Arduino символ ‘J’ будет храниться как число 0b01001010 = 0x4A = 74.
Исторически сложилось так, что было создано множество таблиц символов. Виной тому и множество алфавитов различных языков, и разные взгляды на очерёдность следования символов в таблице, и стремление разработчиков уместить все символы в 1 байт, и наоборот создать универсальные кодировки ценой увеличения занимаемого места и т.д. Но в большинстве таблиц, первые 127 символов совпадают и являются знаками, числами и символами латиницы.
Ваш компьютер не является исключением, текст на нём так же хранится в виде чисел, а значит он кодируется. При этом разные файлы могут использовать разную кодировку (использовать разные таблицы символов). Значит и скетчи хранящиеся на Вашем компьютере так же используют определённую кодировку. А именно от кодировки скетча зависит как будут записаны русские символы в микроконтроллер, ведь компилятор не кодирует текст, а читает и сохраняет его числовое (кодированное) представление.
Наиболее распространёнными кодировками с поддержкой Русского языка (с использованием символов Кириллицы) являются: UTF-8, Windows-1251, CP-866, KOI-8R, ISO-8859-5. Стоит отметить что все эти кодировки представляют один символ одним однобайтным числом, кроме кодировки UTF-8 в которой один символ Кириллицы кодируется двухбайтным числом, а значит в кодировке UTF-8 строка русского текста занимает в два раза больше памяти.
Какую кодировку использует Arduino IDE:
Точно сказать какую кодировку использует Arduino IDE нельзя, так как разные её версии использовали разную кодировку. На момент написания данной статьи последняя версия Arduino IDE 1.8.5 сохраняет скетчи в кодировке UTF-8 и монитор последовательного порта этой версии использует кодировку UTF-8. Но не сохранённые скетчи используют кодировку предыдущих версий — Windows-1251.
Попробуйте в Arduino IDE 1.8.5 создать новый скетч (меню: «Файл>Новый») и напишите в нём следующий код:
void setup(){ //
Serial.begin(9600); // Инициируем работу шины UART на скорости 9600 бит/сек.
Serial.println("Привет"); // Отправляем текст в монитор последовательного порта.
} //
void loop(){ //
} //
Загрузите скетч в Arduino (меню: «Скетч>Загрузка»). Arduino IDE предложит Вам сохранить скетч перед загрузкой, откажитесь нажав на кнопку «Отмена», начнётся загрузка скетча в Arduino. Дождитесь завершения загрузки и откройте монитор последовательного порта (меню: «Инструменты>монитор порта»). В мониторе порта вы увидите текст «⸮⸮⸮⸮⸮⸮». Дело в том, что скетч был загружен в Arduino в кодировке Windows-1251, а монитор последовательного порта использует кодировку UTF-8.
Теперь загрузите тот же скетч в Arduino (меню: «Скетч>Загрузка»), но согласитесь с сохранением скетча, а после его загрузки откройте монитор последовательного порта (меню: «Инструменты>монитор порта»). В мониторе порта вы увидите текст «Привет». Дело в том, что теперь скетч был загружен в кодировке UTF-8 и в той же кодировке работает монитор порта. Кодировки совпали и текст стал читаемым.
Если вместо строки «Привет» Вы напишете «Privet», то в обоих случаях строка корректно отобразится в мониторе порта, так как числовое представление символов латиницы совпадает в большинстве кодировок.
Запись и вывод текста в Arduino IDE на русском языке:
Как видно из предыдущего примера, кодировка выводимого текста на русском языке должна совпадать с кодировкой устройства для которого этот текст предназначен. Но многие устройства (дисплеи, модули gsm, bluetooth и т.д.) используют кодировку отличную от UTF-8 и тогда возникает вопрос, как в скетче записать текст на русском языке?
Для записи одного символа достаточно указать его код из таблицы символов (в примере указан код в 10-тичной системе счисления):
char i = 74; // Определяем символ с кодом 74 (это код символа 'J').
void setup(){ //
Serial.begin(9600); // Инициируем работу шины UART на скорости 9600 бит/сек.
Serial.println(i); // Отправляем символ в монитор последовательного порта.
} //
void loop(){ //
} //
В мониторе последовательного порта отобразится символ ‘J’.
Для записи любого символа в строке нужно указать его код из таблицы символов в 8-ричной системе счисления, которому должен предшествовать обратный слеш «\». Данное правило действует для любых строк в Arduino IDE.
char i[]="\110\145\154\154\157"; // Определяем строку из 5 кодов символов "Hello". Символ конца строки добавляется автоматически.
void setup(){ //
Serial.begin(9600); // Инициируем работу шины UART на скорости 9600 бит/сек.
Serial.println(i); // Отправляем строку в монитор последовательного порта.
} //
void loop(){ //
} //
Не смотря на то что запись строки «i» кажется громоздкой, она занимает всего 6 байт (5 символов + автоматически добавленный символ конца строки). В мониторе последовательного порта отобразится строка «Hello».
Для записи символов и строк на русском языке действуют те же правила:
char i[] = "\320\237\321\200\320\270\320\262\320\265\321\202"; // текст "Привет" в кодировке UTF-8. char j[] = "\317\360\350\342\345\362"; // текст "Привет" в кодировке Windows-1251. char k[] = "\217\340\250\242\245\342"; // текст "Привет" в кодировке CP-866. char l[] = "\360\322\311\327\305\324"; // текст "Привет" в кодировке KOI-8R. char m[] = "\277\340\330\322\325\342"; // текст "Привет" в кодировке ISO-8859-5. char n[] = "Привет"; // текст "Привет" в кодировке файла скетча.
В данном примере строки «j», «k», «l» и «m» занимают по 7 байт (6 символов + автоматически добавленный символ конца строки), а строка «i» занимает 13 байт (6 символов по 2 байта каждый + автоматически добавленный символ конца строки). Строка «n» может занимать либо 7, либо 13 байт, это зависит от кодировки используемой Arduino IDE.
Если в тексте с символами Кириллицы присутствуют числа, знаки или символы латиницы, то символы Кириллицы пишутся кодами, а символы знаков, цифр и латиницы можно писать символами, так как они будут корректно отображаться для практически любой кодировки.
char m[] = "\277\340\330\322\325\342 - Hello"; // текст "Привет - Hello" в кодировке ISO-8859-5.
Таблица символов:
В таблице каждому символу сопоставлен его код в десятичной, шестнадцатеричной и восьмеричной системах счисления. Для указания символа в строке, используется его код записанный в восьмеричной системе счисления (указан в таблице серым цветом и начинается обратным слешем).
| Симв: | UTF-8 | Win-1251 | CP-866 | KOI-8R | ISO-8859-5 | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| пробел | 32 | 0x20 | \40 | 32 | 0x20 | \40 | 32 | 0x20 | \40 | 32 | 0x20 | \40 | 32 | 0x20 | \40 |
| ! | 33 | 0x21 | \41 | 33 | 0x21 | \41 | 33 | 0x21 | \41 | 33 | 0x21 | \41 | 33 | 0x21 | \41 |
| « | 34 | 0x22 | \42 | 34 | 0x22 | \42 | 34 | 0x22 | \42 | 34 | 0x22 | \42 | 34 | 0x22 | \42 |
| # | 35 | 0x23 | \43 | 35 | 0x23 | \43 | 35 | 0x23 | \43 | 35 | 0x23 | \43 | 35 | 0x23 | \43 |
| $ | 36 | 0x24 | \44 | 36 | 0x24 | \44 | 36 | 0x24 | \44 | 36 | 0x24 | \44 | 36 | 0x24 | \44 |
| % | 37 | 0x25 | \45 | 37 | 0x25 | \45 | 37 | 0x25 | \45 | 37 | 0x25 | \45 | 37 | 0x25 | \45 |
| & | 38 | 0x26 | \46 | 38 | 0x26 | \46 | 38 | 0x26 | \46 | 38 | 0x26 | \46 | 38 | 0x26 | \46 |
| ‘ | 39 | 0x27 | \47 | 39 | 0x27 | \47 | 39 | 0x27 | \47 | 39 | 0x27 | \47 | 39 | 0x27 | \74 |
| ( | 40 | 0x28 | \50 | 40 | 0x28 | \50 | 40 | 0x28 | \50 | 40 | 0x28 | \50 | 40 | 0x28 | \50 |
| ) | 41 | 0x29 | \51 | 41 | 0x29 | \51 | 41 | 0x29 | \51 | 41 | 0x29 | \51 | 41 | 0x29 | \51 |
| * | 42 | 0x2A | \52 | 42 | 0x2A | \52 | 42 | 0x2A | \52 | 42 | 0x2A | \52 | 42 | 0x2A | \52 |
| + | 43 | 0x2B | \53 | 43 | 0x2B | \53 | 43 | 0x2B | \53 | 43 | 0x2B | \53 | 43 | 0x2B | \53 |
| , | 44 | 0x2C | \54 | 44 | 0x2C | \54 | 44 | 0x2C | \54 | 44 | 0x2C | \54 | 44 | 0x2C | \54 |
| — | 45 | 0x2D | \55 | 45 | 0x2D | \55 | 45 | 0x2D | \55 | 45 | 0x2D | \55 | 45 | 0x2D | \55 |
| . | 46 | 0x2E | \56 | 46 | 0x2E | \56 | 46 | 0x2E | \56 | 46 | 0x2E | \56 | 46 | 0x2E | \56 |
| / | 47 | 0x2F | \57 | 47 | 0x2F | \57 | 47 | 0x2F | \57 | 47 | 0x2F | \57 | 47 | 0x2F | \57 |
| UTF-8 | Win-1251 | CP-866 | KOI-8R | ISO-8859-5 | |||||||||||
| 0 | 48 | 0x30 | \60 | 48 | 0x30 | \60 | 48 | 0x30 | \60 | 48 | 0x30 | \60 | 48 | 0x30 | \60 |
| 1 | 49 | 0x31 | \61 | 49 | 0x31 | \61 | 49 | 0x31 | \61 | 49 | 0x31 | \61 | 49 | 0x31 | \61 |
| 2 | 50 | 0x32 | \62 | 50 | 0x32 | \62 | 50 | 0x32 | \62 | 50 | 0x32 | \62 | 50 | 0x32 | \62 |
| 3 | 51 | 0x33 | \63 | 51 | 0x33 | \63 | 51 | 0x33 | \63 | 51 | 0x33 | \63 | 51 | 0x33 | \63 |
| 4 | 52 | 0x34 | \64 | 52 | 0x34 | \64 | 52 | 0x34 | \64 | 52 | 0x34 | \64 | 52 | 0x34 | \64 |
| 5 | 53 | 0x35 | \65 | 53 | 0x35 | \65 | 53 | 0x35 | \65 | 53 | 0x35 | \65 | 53 | 0x35 | \65 |
| 6 | 54 | 0x36 | \66 | 54 | 0x36 | \66 | 54 | 0x36 | \66 | 54 | 0x36 | \66 | 54 | 0x36 | \66 |
| 7 | 55 | 0x37 | \67 | 55 | 0x37 | \67 | 55 | 0x37 | \67 | 55 | 0x37 | \67 | 55 | 0x37 | \74 |
| 8 | 56 | 0x38 | \70 | 56 | 0x38 | \70 | 56 | 0x38 | \70 | 56 | 0x38 | \70 | 56 | 0x38 | \70 |
| 9 | 57 | 0x39 | \71 | 57 | 0x39 | \71 | 57 | 0x39 | \71 | 57 | 0x39 | \71 | 57 | 0x39 | \71 |
| : | 58 | 0x3A | \72 | 58 | 0x3A | \72 | 58 | 0x3A | \72 | 58 | 0x3A | \72 | 58 | 0x3A | \72 |
| ; | 59 | 0x3B | \73 | 59 | 0x3B | \73 | 59 | 0x3B | \73 | 59 | 0x3B | \73 | 59 | 0x3B | \73 |
| < | 60 | 0x3C | \74 | 60 | 0x3C | \74 | 60 | 0x3C | \74 | 60 | 0x3C | \74 | 60 | 0x3C | \74 |
| = | 61 | 0x3D | \75 | 61 | 0x3D | \75 | 61 | 0x3D | \75 | 61 | 0x3D | \75 | 61 | 0x3D | \75 |
| > | 62 | 0x3E | \76 | 62 | 0x3E | \76 | 62 | 0x3E | \76 | 62 | 0x3E | \76 | 62 | 0x3E | \76 |
| ? | 63 | 0x3F | \77 | 63 | 0x3F | \77 | 63 | 0x3F | \77 | 63 | 0x3F | \77 | 63 | 0x3F | \77 |
| UTF-8 | Win-1251 | CP-866 | KOI-8R | ISO-8859-5 | |||||||||||
| @ | 64 | 0x40 | \100 | 64 | 0x40 | \100 | 64 | 0x40 | \100 | 64 | 0x40 | \100 | 64 | 0x40 | \100 |
| A | 65 | 0x41 | \101 | 65 | 0x41 | \101 | 65 | 0x41 | \101 | 65 | 0x41 | \101 | 65 | 0x41 | \101 |
| B | 66 | 0x42 | \102 | 66 | 0x42 | \102 | 66 | 0x42 | \102 | 66 | 0x42 | \102 | 66 | 0x42 | \102 |
| C | 67 | 0x43 | \103 | 67 | 0x43 | \103 | 67 | 0x43 | \103 | 67 | 0x43 | \103 | 67 | 0x43 | \103 |
| D | 68 | 0x44 | \104 | 68 | 0x44 | \104 | 68 | 0x44 | \104 | 68 | 0x44 | \104 | 68 | 0x44 | \104 |
| E | 69 | 0x45 | \105 | 69 | 0x45 | \105 | 69 | 0x45 | \105 | 69 | 0x45 | \105 | 69 | 0x45 | \105 |
| F | 70 | 0x46 | \106 | 70 | 0x46 | \106 | 70 | 0x46 | \106 | 70 | 0x46 | \106 | 70 | 0x46 | \106 |
| G | 71 | 0x47 | \107 | 71 | 0x47 | \107 | 71 | 0x47 | \107 | 71 | 0x47 | \107 | 71 | 0x47 | \114 |
| H | 72 | 0x48 | \110 | 72 | 0x48 | \110 | 72 | 0x48 | \110 | 72 | 0x48 | \110 | 72 | 0x48 | \110 |
| I | 73 | 0x49 | \111 | 73 | 0x49 | \111 | 73 | 0x49 | \111 | 73 | 0x49 | \111 | 73 | 0x49 | \111 |
| J | 74 | 0x4A | \112 | 74 | 0x4A | \112 | 74 | 0x4A | \112 | 74 | 0x4A | \112 | 74 | 0x4A | \112 |
| K | 75 | 0x4B | \113 | 75 | 0x4B | \113 | 75 | 0x4B | \113 | 75 | 0x4B | \113 | 75 | 0x4B | \113 |
| L | 76 | 0x4C | \114 | 76 | 0x4C | \114 | 76 | 0x4C | \114 | 76 | 0x4C | \114 | 76 | 0x4C | \114 |
| M | 77 | 0x4D | \115 | 77 | 0x4D | \115 | 77 | 0x4D | \115 | 77 | 0x4D | \115 | 77 | 0x4D | \115 |
| N | 78 | 0x4E | \116 | 78 | 0x4E | \116 | 78 | 0x4E | \116 | 78 | 0x4E | \116 | 78 | 0x4E | \116 |
| O | 79 | 0x4F | \117 | 79 | 0x4F | \117 | 79 | 0x4F | \117 | 79 | 0x4F | \117 | 79 | 0x4F | \117 |
| UTF-8 | Win-1251 | CP-866 | KOI-8R | ISO-8859-5 | |||||||||||
| P | 80 | 0x50 | \120 | 80 | 0x50 | \120 | 80 | 0x50 | \120 | 80 | 0x50 | \120 | 80 | 0x50 | \120 |
| Q | 81 | 0x51 | \121 | 81 | 0x51 | \121 | 81 | 0x51 | \121 | 81 | 0x51 | \121 | 81 | 0x51 | \121 |
| R | 82 | 0x52 | \122 | 82 | 0x52 | \122 | 82 | 0x52 | \122 | 82 | 0x52 | \122 | 82 | 0x52 | \122 |
| S | 83 | 0x53 | \123 | 83 | 0x53 | \123 | 83 | 0x53 | \123 | 83 | 0x53 | \123 | 83 | 0x53 | \123 |
| T | 84 | 0x54 | \124 | 84 | 0x54 | \124 | 84 | 0x54 | \124 | 84 | 0x54 | \124 | 84 | 0x54 | \124 |
| U | 85 | 0x55 | \125 | 85 | 0x55 | \125 | 85 | 0x55 | \125 | 85 | 0x55 | \125 | 85 | 0x55 | \125 |
| V | 86 | 0x56 | \126 | 86 | 0x56 | \126 | 86 | 0x56 | \126 | 86 | 0x56 | \126 | 86 | 0x56 | \126 |
| W | 87 | 0x57 | \127 | 87 | 0x57 | \127 | 87 | 0x57 | \127 | 87 | 0x57 | \127 | 87 | 0x57 | \134 |
| X | 88 | 0x58 | \130 | 88 | 0x58 | \130 | 88 | 0x58 | \130 | 88 | 0x58 | \130 | 88 | 0x58 | \130 |
| Y | 89 | 0x59 | \131 | 89 | 0x59 | \131 | 89 | 0x59 | \131 | 89 | 0x59 | \131 | 89 | 0x59 | \131 |
| Z | 90 | 0x5A | \132 | 90 | 0x5A | \132 | 90 | 0x5A | \132 | 90 | 0x5A | \132 | 90 | 0x5A | \132 |
| [ | 91 | 0x5B | \133 | 91 | 0x5B | \133 | 91 | 0x5B | \133 | 91 | 0x5B | \133 | 91 | 0x5B | \133 |
| \ | 92 | 0x5C | \134 | 92 | 0x5C | \134 | 92 | 0x5C | \134 | 92 | 0x5C | \134 | 92 | 0x5C | \134 |
| ] | 93 | 0x5D | \135 | 93 | 0x5D | \135 | 93 | 0x5D | \135 | 93 | 0x5D | \135 | 93 | 0x5D | \135 |
| ^ | 94 | 0x5E | \136 | 94 | 0x5E | \136 | 94 | 0x5E | \136 | 94 | 0x5E | \136 | 94 | 0x5E | \136 |
| _ | 95 | 0x5F | \137 | 95 | 0x5F | \137 | 95 | 0x5F | \137 | 95 | 0x5F | \137 | 95 | 0x5F | \137 |
| UTF-8 | Win-1251 | CP-866 | KOI-8R | ISO-8859-5 | |||||||||||
| ` | 96 | 0x60 | \140 | 96 | 0x60 | \140 | 96 | 0x60 | \140 | 96 | 0x60 | \140 | 96 | 0x60 | \140 |
| a | 97 | 0x61 | \141 | 97 | 0x61 | \141 | 97 | 0x61 | \141 | 97 | 0x61 | \141 | 97 | 0x61 | \141 |
| b | 98 | 0x62 | \142 | 98 | 0x62 | \142 | 98 | 0x62 | \142 | 98 | 0x62 | \142 | 98 | 0x62 | \142 |
| c | 99 | 0x63 | \143 | 99 | 0x63 | \143 | 99 | 0x63 | \143 | 99 | 0x63 | \143 | 99 | 0x63 | \143 |
| d | 100 | 0x64 | \144 | 100 | 0x64 | \144 | 100 | 0x64 | \144 | 100 | 0x64 | \144 | 100 | 0x64 | \144 |
| e | 101 | 0x65 | \145 | 101 | 0x65 | \145 | 101 | 0x65 | \145 | 101 | 0x65 | \145 | 101 | 0x65 | \145 |
| f | 102 | 0x66 | \146 | 102 | 0x66 | \146 | 102 | 0x66 | \146 | 102 | 0x66 | \146 | 102 | 0x66 | \146 |
| g | 103 | 0x67 | \147 | 103 | 0x67 | \147 | 103 | 0x67 | \147 | 103 | 0x67 | \147 | 103 | 0x67 | \154 |
| h | 104 | 0x68 | \150 | 104 | 0x68 | \150 | 104 | 0x68 | \150 | 104 | 0x68 | \150 | 104 | 0x68 | \150 |
| i | 105 | 0x69 | \151 | 105 | 0x69 | \151 | 105 | 0x69 | \151 | 105 | 0x69 | \151 | 105 | 0x69 | \151 |
| j | 106 | 0x6A | \152 | 106 | 0x6A | \152 | 106 | 0x6A | \152 | 106 | 0x6A | \152 | 106 | 0x6A | \152 |
| k | 107 | 0x6B | \153 | 107 | 0x6B | \153 | 107 | 0x6B | \153 | 107 | 0x6B | \153 | 107 | 0x6B | \153 |
| l | 108 | 0x6C | \154 | 108 | 0x6C | \154 | 108 | 0x6C | \154 | 108 | 0x6C | \154 | 108 | 0x6C | \154 |
| m | 109 | 0x6D | \155 | 109 | 0x6D | \155 | 109 | 0x6D | \155 | 109 | 0x6D | \155 | 109 | 0x6D | \155 |
| n | 110 | 0x6E | \156 | 110 | 0x6E | \156 | 110 | 0x6E | \156 | 110 | 0x6E | \156 | 110 | 0x6E | \156 |
| o | 111 | 0x6F | \157 | 111 | 0x6F | \157 | 111 | 0x6F | \157 | 111 | 0x6F | \157 | 111 | 0x6F | \157 |
| UTF-8 | Win-1251 | CP-866 | KOI-8R | ISO-8859-5 | |||||||||||
| p | 112 | 0x70 | \160 | 112 | 0x70 | \160 | 112 | 0x70 | \160 | 112 | 0x70 | \160 | 112 | 0x70 | \160 |
| q | 113 | 0x71 | \161 | 113 | 0x71 | \161 | 113 | 0x71 | \161 | 113 | 0x71 | \161 | 113 | 0x71 | \161 |
| r | 114 | 0x72 | \162 | 114 | 0x72 | \162 | 114 | 0x72 | \162 | 114 | 0x72 | \162 | 114 | 0x72 | \162 |
| s | 115 | 0x73 | \163 | 115 | 0x73 | \163 | 115 | 0x73 | \163 | 115 | 0x73 | \163 | 115 | 0x73 | \163 |
| t | 116 | 0x74 | \164 | 116 | 0x74 | \164 | 116 | 0x74 | \164 | 116 | 0x74 | \164 | 116 | 0x74 | \164 |
| u | 117 | 0x75 | \165 | 117 | 0x75 | \165 | 117 | 0x75 | \165 | 117 | 0x75 | \165 | 117 | 0x75 | \165 |
| v | 118 | 0x76 | \166 | 118 | 0x76 | \166 | 118 | 0x76 | \166 | 118 | 0x76 | \166 | 118 | 0x76 | \166 |
| w | 119 | 0x77 | \167 | 119 | 0x77 | \167 | 119 | 0x77 | \167 | 119 | 0x77 | \167 | 119 | 0x77 | \174 |
| x | 120 | 0x78 | \170 | 120 | 0x78 | \170 | 120 | 0x78 | \170 | 120 | 0x78 | \170 | 120 | 0x78 | \170 |
| y | 121 | 0x79 | \171 | 121 | 0x79 | \171 | 121 | 0x79 | \171 | 121 | 0x79 | \171 | 121 | 0x79 | \171 |
| z | 122 | 0x7A | \172 | 122 | 0x7A | \172 | 122 | 0x7A | \172 | 122 | 0x7A | \172 | 122 | 0x7A | \172 |
| { | 123 | 0x7B | \173 | 123 | 0x7B | \173 | 123 | 0x7B | \173 | 123 | 0x7B | \173 | 123 | 0x7B | \173 |
| | | 124 | 0x7C | \174 | 124 | 0x7C | \174 | 124 | 0x7C | \174 | 124 | 0x7C | \174 | 124 | 0x7C | \174 |
| } | 125 | 0x7D | \175 | 125 | 0x7D | \175 | 125 | 0x7D | \175 | 125 | 0x7D | \175 | 125 | 0x7D | \175 |
| ~ | 126 | 0x7E | \176 | 126 | 0x7E | \176 | 126 | 0x7E | \176 | 126 | 0x7E | \176 | 126 | 0x7E | \176 |
| ⌂ | 127 | 0x7F | \177 | 127 | 0x7F | \177 | 127 | 0x7F | \177 | 127 | 0x7F | \177 | 127 | 0x7F | \177 |
| UTF-8 | Win-1251 | CP-866 | KOI-8R | ISO-8859-5 | |||||||||||
| А | 208, 144 | 0xD0, 0x90 | \320\220 | 192 | 0xC0 | \300 | 128 | 0x80 | \200 | 225 | 0xE1 | \341 | 176 | 0xB0 | \260 |
| Б | 208, 145 | 0xD0, 0x91 | \320\221 | 193 | 0xC1 | \301 | 129 | 0x81 | \201 | 226 | 0xE2 | \342 | 177 | 0xB1 | \261 |
| В | 208, 146 | 0xD0, 0x92 | \320\222 | 194 | 0xC2 | \302 | 130 | 0x82 | \202 | 247 | 0xF7 | \367 | 178 | 0xB2 | \262 |
| Г | 208, 147 | 0xD0, 0x93 | \320\223 | 195 | 0xC3 | \303 | 131 | 0x83 | \203 | 231 | 0xE7 | \347 | 179 | 0xB3 | \263 |
| Д | 208, 148 | 0xD0, 0x94 | \320\224 | 196 | 0xC4 | \304 | 132 | 0x84 | \204 | 228 | 0xE4 | \344 | 180 | 0xB4 | \264 |
| Е | 208, 149 | 0xD0, 0x95 | \320\225 | 197 | 0xC5 | \305 | 133 | 0x85 | \205 | 229 | 0xE5 | \345 | 181 | 0xB5 | \265 |
| Ж | 208, 150 | 0xD0, 0x96 | \320\226 | 198 | 0xC6 | \306 | 134 | 0x86 | \206 | 246 | 0xF6 | \366 | 182 | 0xB6 | \266 |
| З | 208, 151 | 0xD0, 0x97 | \320\227 | 199 | 0xC7 | \307 | 135 | 0x87 | \207 | 250 | 0xFA | \372 | 183 | 0xB7 | \267 |
| И | 208, 152 | 0xD0, 0x98 | \320\230 | 200 | 0xC8 | \310 | 136 | 0x88 | \210 | 233 | 0xE9 | \351 | 184 | 0xB8 | \270 |
| Й | 208, 153 | 0xD0, 0x99 | \320\231 | 201 | 0xC9 | \311 | 137 | 0x89 | \211 | 234 | 0xEA | \352 | 185 | 0xB9 | \271 |
| К | 208, 154 | 0xD0, 0x9A | \320\232 | 202 | 0xCA | \312 | 138 | 0x8A | \212 | 235 | 0xEB | \353 | 186 | 0xBA | \272 |
| Л | 208, 155 | 0xD0, 0x9B | \320\233 | 203 | 0xCB | \313 | 139 | 0x8B | \213 | 236 | 0xEC | \354 | 187 | 0xBB | \273 |
| М | 208, 156 | 0xD0, 0x9C | \320\234 | 204 | 0xCC | \314 | 140 | 0x8C | \214 | 237 | 0xED | \355 | 188 | 0xBC | \274 |
| Н | 208, 157 | 0xD0, 0x9D | \320\235 | 205 | 0xCD | \315 | 141 | 0x8D | \215 | 238 | 0xEE | \356 | 189 | 0xBD | \275 |
| О | 208, 158 | 0xD0, 0x9E | \320\236 | 206 | 0xCE | \316 | 142 | 0x8E | \216 | 239 | 0xEF | \357 | 190 | 0xBE | \276 |
| П | 208, 159 | 0xD0, 0x9F | \320\237 | 207 | 0xCF | \317 | 143 | 0x8F | \217 | 240 | 0xF0 | \360 | 191 | 0xBF | \277 |
| UTF-8 | Win-1251 | CP-866 | KOI-8R | ISO-8859-5 | |||||||||||
| Р | 208, 160 | 0xD0, 0xA0 | \320\240 | 208 | 0xD0 | \320 | 144 | 0x90 | \220 | 242 | 0xF2 | \362 | 192 | 0xC0 | \300 |
| С | 208, 161 | 0xD0, 0xA1 | \320\241 | 209 | 0xD1 | \321 | 145 | 0x91 | \221 | 243 | 0xF3 | \363 | 193 | 0xC1 | \301 |
| Т | 208, 162 | 0xD0, 0xA2 | \320\242 | 210 | 0xD2 | \322 | 146 | 0x92 | \222 | 244 | 0xF4 | \364 | 194 | 0xC2 | \302 |
| У | 208, 163 | 0xD0, 0xA3 | \320\243 | 211 | 0xD3 | \323 | 147 | 0x93 | \223 | 245 | 0xF5 | \365 | 195 | 0xC3 | \303 |
| Ф | 208, 164 | 0xD0, 0xA4 | \320\244 | 212 | 0xD4 | \324 | 148 | 0x94 | \224 | 230 | 0xE6 | \346 | 196 | 0xC4 | \304 |
| Х | 208, 165 | 0xD0, 0xA5 | \320\245 | 213 | 0xD5 | \325 | 149 | 0x95 | \225 | 232 | 0xE8 | \350 | 197 | 0xC5 | \305 |
| Ц | 208, 166 | 0xD0, 0xA6 | \320\246 | 214 | 0xD6 | \326 | 150 | 0x96 | \226 | 227 | 0xE3 | \343 | 198 | 0xC6 | \306 |
| Ч | 208, 167 | 0xD0, 0xA7 | \320\247 | 215 | 0xD7 | \327 | 151 | 0x97 | \227 | 254 | 0xFE | \376 | 199 | 0xC7 | \307 |
| Ш | 208, 168 | 0xD0, 0xA8 | \320\250 | 216 | 0xD8 | \330 | 152 | 0x98 | \230 | 251 | 0xFB | \373 | 200 | 0xC8 | \310 |
| Щ | 208, 169 | 0xD0, 0xA9 | \320\251 | 217 | 0xD9 | \331 | 153 | 0x99 | \231 | 253 | 0xFD | \375 | 201 | 0xC9 | \311 |
| Ъ | 208, 170 | 0xD0, 0xAA | \320\252 | 218 | 0xDA | \332 | 154 | 0x9A | \232 | 255 | 0xFF | \377 | 202 | 0xCA | \312 |
| Ы | 208, 171 | 0xD0, 0xAB | \320\253 | 219 | 0xDB | \333 | 155 | 0x9B | \233 | 249 | 0xF9 | \371 | 203 | 0xCB | \313 |
| Ь | 208, 172 | 0xD0, 0xAC | \320\254 | 220 | 0xDC | \334 | 156 | 0x9C | \234 | 248 | 0xF8 | \370 | 204 | 0xCC | \314 |
| Э | 208, 173 | 0xD0, 0xAD | \320\255 | 221 | 0xDD | \335 | 157 | 0x9D | \235 | 252 | 0xFC | \374 | 205 | 0xCD | \315 |
| Ю | 208, 174 | 0xD0, 0xAE | \320\256 | 222 | 0xDE | \336 | 158 | 0x9E | \236 | 224 | 0xE0 | \340 | 206 | 0xCE | \316 |
| Я | 208, 175 | 0xD0, 0xAF | \320\257 | 223 | 0xDF | \337 | 159 | 0x9F | \237 | 241 | 0xF1 | \361 | 207 | 0xCF | \317 |
| UTF-8 | Win-1251 | CP-866 | KOI-8R | ISO-8859-5 | |||||||||||
| а | 208, 176 | 0xD0, 0xB0 | \320\260 | 224 | 0xE0 | \340 | 160 | 0xA0 | \240 | 193 | 0xC1 | \301 | 208 | 0xD0 | \320 |
| б | 208, 177 | 0xD0, 0xB1 | \320\261 | 225 | 0xE1 | \341 | 161 | 0xA1 | \241 | 194 | 0xC2 | \302 | 209 | 0xD1 | \321 |
| в | 208, 178 | 0xD0, 0xB2 | \320\262 | 226 | 0xE2 | \342 | 162 | 0xA2 | \242 | 215 | 0xD7 | \327 | 210 | 0xD2 | \322 |
| г | 208, 179 | 0xD0, 0xB3 | \320\263 | 227 | 0xE3 | \343 | 163 | 0xA3 | \243 | 199 | 0xC7 | \307 | 211 | 0xD3 | \323 |
| д | 208, 180 | 0xD0, 0xB4 | \320\264 | 228 | 0xE4 | \344 | 164 | 0xA4 | \244 | 196 | 0xC4 | \304 | 212 | 0xD4 | \324 |
| е | 208, 181 | 0xD0, 0xB5 | \320\265 | 229 | 0xE5 | \345 | 165 | 0xA5 | \245 | 197 | 0xC5 | \305 | 213 | 0xD5 | \325 |
| ж | 208, 182 | 0xD0, 0xB6 | \320\266 | 230 | 0xE6 | \346 | 166 | 0xA6 | \246 | 214 | 0xD6 | \326 | 214 | 0xD6 | \326 |
| з | 208, 183 | 0xD0, 0xB7 | \320\267 | 231 | 0xE7 | \347 | 167 | 0xA7 | \247 | 218 | 0xDA | \332 | 215 | 0xD7 | \327 |
| и | 208, 184 | 0xD0, 0xB8 | \320\270 | 232 | 0xE8 | \350 | 168 | 0xA8 | \250 | 201 | 0xC9 | \311 | 216 | 0xD8 | \330 |
| й | 208, 185 | 0xD0, 0xB9 | \320\271 | 233 | 0xE9 | \351 | 169 | 0xA9 | \251 | 202 | 0xCA | \312 | 217 | 0xD9 | \331 |
| к | 208, 186 | 0xD0, 0xBA | \320\272 | 234 | 0xEA | \352 | 170 | 0xAA | \252 | 203 | 0xCB | \313 | 218 | 0xDA | \332 |
| л | 208, 187 | 0xD0, 0xBB | \320\273 | 235 | 0xEB | \353 | 171 | 0xAB | \253 | 204 | 0xCC | \314 | 219 | 0xDB | \333 |
| м | 208, 188 | 0xD0, 0xBC | \320\274 | 236 | 0xEC | \354 | 172 | 0xAC | \254 | 205 | 0xCD | \315 | 220 | 0xDC | \334 |
| н | 208, 189 | 0xD0, 0xBD | \320\275 | 237 | 0xED | \355 | 173 | 0xAD | \255 | 206 | 0xCE | \316 | 221 | 0xDD | \335 |
| о | 208, 190 | 0xD0, 0xBE | \320\276 | 238 | 0xEE | \356 | 174 | 0xAE | \256 | 207 | 0xCF | \317 | 222 | 0xDE | \336 |
| п | 208, 191 | 0xD0, 0xBF | \320\277 | 239 | 0xEF | \357 | 175 | 0xAF | \257 | 208 | 0xD0 | \320 | 223 | 0xDF | \337 |
| UTF-8 | Win-1251 | CP-866 | KOI-8R | ISO-8859-5 | |||||||||||
| р | 209, 128 | 0xD1, 0x80 | \321\200 | 240 | 0xF0 | \360 | 224 | 0xE0 | \340 | 210 | 0xD2 | \322 | 224 | 0xE0 | \340 |
| с | 209, 129 | 0xD1, 0x81 | \321\201 | 241 | 0xF1 | \361 | 225 | 0xE1 | \341 | 211 | 0xD3 | \323 | 225 | 0xE1 | \341 |
| т | 209, 130 | 0xD1, 0x82 | \321\202 | 242 | 0xF2 | \362 | 226 | 0xE2 | \342 | 212 | 0xD4 | \324 | 226 | 0xE2 | \342 |
| у | 209, 131 | 0xD1, 0x83 | \321\203 | 243 | 0xF3 | \363 | 227 | 0xE3 | \343 | 213 | 0xD5 | \325 | 227 | 0xE3 | \343 |
| ф | 209, 132 | 0xD1, 0x84 | \321\204 | 244 | 0xF4 | \364 | 228 | 0xE4 | \344 | 198 | 0xC6 | \306 | 228 | 0xE4 | \344 |
| х | 209, 133 | 0xD1, 0x85 | \321\205 | 245 | 0xF5 | \365 | 229 | 0xE5 | \345 | 200 | 0xC8 | \310 | 229 | 0xE5 | \345 |
| ц | 209, 134 | 0xD1, 0x86 | \321\206 | 246 | 0xF6 | \366 | 230 | 0xE6 | \346 | 195 | 0xC3 | \303 | 230 | 0xE6 | \346 |
| ч | 209, 135 | 0xD1, 0x87 | \321\207 | 247 | 0xF7 | \367 | 231 | 0xE7 | \347 | 222 | 0xDE | \336 | 231 | 0xE7 | \347 |
| ш | 209, 136 | 0xD1, 0x88 | \321\210 | 248 | 0xF8 | \370 | 232 | 0xE8 | \350 | 219 | 0xDB | \333 | 232 | 0xE8 | \350 |
| щ | 209, 137 | 0xD1, 0x89 | \321\211 | 249 | 0xF9 | \371 | 233 | 0xE9 | \351 | 221 | 0xDD | \335 | 233 | 0xE9 | \351 |
| ъ | 209, 138 | 0xD1, 0x8A | \321\212 | 250 | 0xFA | \372 | 234 | 0xEA | \352 | 223 | 0xDF | \337 | 234 | 0xEA | \352 |
| ы | 209, 139 | 0xD1, 0x8B | \321\213 | 251 | 0xFB | \373 | 235 | 0xEB | \353 | 217 | 0xD9 | \331 | 235 | 0xEB | \353 |
| ь | 209, 140 | 0xD1, 0x8C | \321\214 | 252 | 0xFC | \374 | 236 | 0xEC | \354 | 216 | 0xD8 | \330 | 236 | 0xEC | \354 |
| э | 209, 141 | 0xD1, 0x8D | \321\215 | 253 | 0xFD | \375 | 237 | 0xED | \355 | 220 | 0xDC | \334 | 237 | 0xED | \355 |
| ю | 209, 142 | 0xD1, 0x8E | \321\216 | 254 | 0xFE | \376 | 238 | 0xEE | \356 | 192 | 0xC0 | \300 | 238 | 0xEE | \356 |
| я | 209, 143 | 0xD1, 0x8F | \321\217 | 255 | 0xFF | \377 | 239 | 0xEF | \357 | 209 | 0xD1 | \321 | 239 | 0xEF | \357 |
| UTF-8 | Win-1251 | CP-866 | KOI-8R | ISO-8859-5 | |||||||||||
| Ё | 208, 129 | 0xD0, 0x81 | \320\201 | 168 | 0xA8 | \250 | 240 | 0xF0 | \360 | 179 | 0xB3 | \263 | 161 | 0xA1 | \241 |
| ё | 209, 145 | 0xD1, 0x91 | \321\221 | 184 | 0xB8 | \270 | 241 | 0xF1 | \361 | 163 | 0xA3 | \243 | 241 | 0xF1 | \361 |
В данной таблице символов указаны сразу 5 кодировок: «UTF-8», «Windows-1251», «CP-866», «KOI-8R» и «ISO-8859-5». Коды символов от 0 до 127 совпадают для всех кодировок. В кодировке «UTF-8» символы Кириллицы занимают 2 байта, следовательно, для них указано 2 числа.
Стоит отметить кодировку «KOI-8R» в которой (в отличии от остальных) на первый взгляд не просматривается закономерность следования кодов, но на самом деле закономерность есть и заключается она в том, что если сбросить старший бит, то код символа Кириллицы превратится в код сходного по произношению символа латиницы, и наоборот. Например символ «л» записывается кодом 0xCC, если сбросить старший бит то получится 0x4C, а это код символа «L». Значит, если в тексте из символов Кириллицы сбросить старшие биты кода каждого символа, то получится «читаемый» текст из символов латиницы, подобный транслиту.
Примечание:
К недостаткам записи строк кодами символов относится то, что строки в скетче становятся не удобочитаемыми. В качестве альтернативного варианта можно создать функцию преобразования кодировки строк перед их выводом, или хранить строки из символов Кириллицы в отдельном, подключаемом, файле, который будет сохранён в требуемой для вывода кодировке.