
Привет.
Первым пробным камнем в сфере High Performance Computing корпорации Microsoft была разработка Windows Compute Cluster Server (Windows Server 2003). Прошло какое-то время, которое показало, что Microsoft может буквально без всякой предварительной подготовки войти на рынок кластерных систем и занять на нем какое-то место.
Однако функциональности WCCS было мало, мало также и тех, кто интересовался этим, и в Microsoft сделали ОС для кластерных систем на базе последней своей разработки – Server 2008. Так появился HPC (High Performance Computing) Server 2008.
Немного теории о кластерных технологиях. Выжимка, необходимая для понимания сути различий между кластерами в стандартном нынешнем их понимании и суперкомпьютерном:
“Кластер — это разновидность параллельной или распределённой системы, которая:
1. состоит из нескольких связанных между собой компьютеров;
2. используется как единый, унифицированный компьютерный ресурс».
“
Необходимо добавить, что суперкомпьютерный кластер предназначен для вычислений, а не для NLB или failover.
Немного теории о Windows HPC Server 2008
Минимальные требования для Windows HPC Server 2008, как рекомендуют Microsoft, следующие:
Processor (x64-based):
Minimum: 1.4 GHz
Recommended: 2 GHz or faster
RAM:
Minimum: 512 MB
Recommended: 2 GB or more
Available disk space:
Minimum: 50 GB
Recommended: 80 GB or more
Network adapters: >1 в большинстве случаев. Количество сетевых адаптеров зависит от топологии сети, которую вы выберите на этапе установки HPC Pack.
Различия между Windows Server 2008 и HPC Server 2008
HPC Server = Windows Server Standard, за исключением:
– HPC Server поставляется только в 64-битной версии;
– На HPC Server необходимо установить HPC Pack, пакет, содержащий в себе утилиты для обеспечения работы кластера: Cluster Manager, HPC Runtime etc.
(HPC Server)-related products
1) HPC Server – содержит в себе ОС + HPC Pack;
2) HPC Server OS – содержит в себе ОС;
3) HPC Pack – пакет, содержащий в себе утилиты для обеспечения работы кластера. Необходимо, чтобы HPC Pack был установлен на всех узлах, включая управляющий и клиентские компьютеры, с которых планируется использовать кластер;
4) HPC SDK – хидеры и библиотеки для HPC-разработки, распространяется свободно. Необходим для компиляции программ с MS-MPI.
Ограничения HPC Server 2008
– отключены IIS, Sharepoint, Exchange, MSSQL (за счёт особенностей лицензирования данных продуктов под HPC),
– основные ограничения накладываются на софт, который так или иначе использует вышеперечисленные сервисы. Так, если вы захотите запустить сервисы IIS, MSSQL или Exchange, вы получите ошибку. Например, TS Gateway и FTP не заработают в связи с зависимостью от IIS.
Однако, если необходим доступ к полной функциональности Windows Server Standard/Enterprise, можно приобрести лицензию и доставить HPC Pack.
C чего начать?
Первым делом необходимо определиться с компьютером, который будет иметь роль управляющего узла. Из своего опыта: если у вас гомогенная аппаратная среда, берите любой из узлов. Если же нет – исходите из того, что еще будет установлено на данном сервере (в идеале он должен быть управляющим и только им).
Забрать дистрибутив можно по ссылке. Установка HPC Server 2008 ничем не отличается от установки Windows Server 2008.
Следующим шагом определяем, как мы будем формировать наш кластер. Существует три метода добавления узлов в кластер:
– bare metal, в этом случае всё необходимое, включая ОС, устанавливается на узел в момент добавления в кластер;
– настроенные узлы с установленной вручную ОС;
– узлы из XML-файла. В XML-файле содержатся записи об узлах, при этом неважно, как планируется их вводить в кластер – bare metal или preconfigured.
Мы будем использовать настроенные узлы.
Развертывание кластера
Будем придерживаться следующего плана:
1) Планирование инфраструктуры;
2) Настройка «железа»;
3) Настройка управляющего узла;
4) Настройка узлов-вычислителей;
5) Ввод узлов в кластер;
Планирование инфраструктуры
Первая задача – необходимо поднять домен для нашего кластера. Воспользуемся dcpromo со всеми настройками по умолчанию. Без Active Directory кластер работать не будет – HPC-утилиты используют доменные credentials для аутентификации и всё довольно органично завязано друг на друге. После этого устанавливаем и настраиваем DHCP-сервер. В данном посте DHCP мы использовать не будем, но он пригодится для дальнейших изысканий.
Конфигурация: 192.168.0.1 для домен-контроллера, 192.168.0.2 и 3 для узлов.
Настройка железа
В случае наличия лишнего NIC на управляющем узле пользуемся следующим сценарием:
1) Подключаем один NIC к Enterprise Network. Второй NIC, нужный для Private Network, пока не трогаем;
2) Открываем Network and Sharing Center;
3) Переименовываем подключенный NIC в Enterprise;
4) Переименовываем второй NIC в Private;
В случае отсутствия лишнего NIC нам необходимо создать loopback-заглушку для «обмана» HPC Pack.
1) Открываем Device Manager;
2) Нажимаем Add legacy hardware;
3) Next. Нажимаем Install the hardware that i manually select from a list;
4) Выбираем Network adapters. Next;
5) Выбираем Microsoft, в правом окошке выбираем Microsoft Loopback Adapter;
6) Выполняем шаги 3-4 из первой последовательности действий.
Настройка управляющего узла
1) Монтируем HPC Pack Express ISO и запускаем установщик. На управляющем узле необходимо выбрать вариант установки HPC Pack 2008 R2 Express.
<img src=»http://habrastorage.org/storage1/ce6b58df/c2bf6da1/db1df576/d809120f.png»/>
2) Выбираем Create a new HPC cluster by creating a Head Node.
<img src=»http://habrastorage.org/storage1/ced2c74f/922754a2/12adea89/fbbe2b2d.png»/>
3) Next.
4) Install.
В зависимости от ресурсов установка может занимать до 10 минут и более. В процессе кроме собственного instance SQL Server будут установлены роли DHCP, WDS, File Services и Network Policy and Access Services.
HPC Manager предлагает удобно структурированный To-Do список действий для настройки кластера.
<img src=»http://habrastorage.org/storage1/af97d21a/76611e9f/368e11bf/80067b73.png»/>
1) Configure your network.
<img src=»http://habrastorage.org/storage1/561b344f/3c64bd95/c93b64e5/37198846.png»/>
<i>На этом этапе необходим краткий ликбез.
Enterprise network – публичная сеть организации, в которой происходит основная работа пользователей
Private network – выделенная внутренняя сеть, по которой между узлами ходят пакеты (management, deployment, application traffic), связанные с кластерными коммуникациями.
Application network – выделенная сеть с высокой пропускной способностью и низкими задержками. Обычно используется для Message Passing Interface-коммуникаций между узлами. Ключевые слова для поиска: InfiniBand, Infinihost, ConnectX, NetworkDirect.
HPC Pack предлагает нам пять сетевых топологий, отличающихся методом соединения узлов между собой и соединения узлов и Enterprise-сети:
Topology 1: Compute Nodes Isolated on a Private Network
На мой взгляд, самая адекватно отвечающая всем требованиям безопасности и эффективности топологии. Именно её мы и будем использовать и именно для неё мы подключали/создавали второй NIC. В данной топологии только управляющий узел «смотрит» в Enterprise-сеть, узлы изолированы в Private-сеть.
Topology 2: All Nodes on Enterprise and Private Networks
Все узлы, включая управляющий, имеют второй NIC, который «смотрит» в Enterprise. Не вижу причин использовать данную топологию в Production.
Topology 3: Compute Nodes Isolated on Private and Application Networks
Узлы изолированы в приватной и application-сети. В таком случае необходимо иметь три NIC на управляющем узле, один из которых должен (но не обязан) быть от Mellanox и иже с ними.
Topology 4: All Nodes on Enterprise, Private, and Application Networks
Все узлы доступны во всех сетях.
Topology 5: All Nodes on an Enterprise Network
Все узлы находятся в Enterprise.
Мой опыт сообщает, что публиковать узлы в Enterprise есть только одна причина – если у нас есть что-то типа менеджера Matlab, который в случае своей работы должен иметь connectivity со всеми узлами.
Можно привести следующие рекомендации:
– не позволяйте APIPA адресам внедриться в конфигурацию вашего Enterprise адаптера на управляющем узле – в обязательном порядке должен быть динамический/статический IP-адрес;
– если вы выбрали топологию, в которой имеет место быть приватная сеть и собираетесь развертывать узлы из состояния bare metal, то убедитесь, что в сети нет PXE-серверов;
– отключите все DHCP-сервера в приватной и application сетях за исключением сервиса на управляющем узле
– если так получилось, что в вашем домене развернута политика IPSec Enforcement, вы можете столкнуться с определенными проблемами во время развертывания. Рекомендации приводятся разные, но самой адекватной считаю сделать управляющий узел IPsec boundary-сервером, чтобы узлы могли соединяться с ним во время загрузки PXE.
2) Как Enterprise Network Adapter выбираем тот NIC, который мы переименовывали в «Enterprise»;
3) Как Private Network Adapter Selection выбираем оставшийся NIC;
4) В Private Network Configuration ничего не меняем, next;
5) В настройке Firewall Setup можем поменять конфигурацию Firewall, но я бы порекомендовал оставить все настройки на этой вкладке по умолчанию;
6) Configure.
Если после непродолжительной настройки в отчете нет ненужных покраснений, переходим к следующему пункту в To-Do.
7) Provide installation credentials. В данной настройке вам необходимо указать учетные данные аккаунта, имеющего права на ввод машин в домен. Естественно, строка должна быть вида DOMAIN\User. Данная настройка также необходима для развертывания узлов из состояния Bare Metal.
 В следующем пункте To-Do, Configure the naming of new nodes, с помощью нехитрого синтаксиса указываем политику наименования узлов кластера. Поменяем %1000% на %1%. Необходимо помнить, что данная настройка имеет место только для развертываний узлов из состояния Bare Metal.
В следующем пункте To-Do, Configure the naming of new nodes, с помощью нехитрого синтаксиса указываем политику наименования узлов кластера. Поменяем %1000% на %1%. Необходимо помнить, что данная настройка имеет место только для развертываний узлов из состояния Bare Metal.
9) Create a node template;
10) На вкладке Node Template Type из четырех вариантов выбираем первый, Compute node template, то есть шаблон узла, который будет использоваться для узлов-вычислителей;
11) Оставим имя шаблона по умолчанию;
12) На вкладке Select Deployment Type выберем Without operating system. Поскольку мы используем в данном посте уже сконфигурированные узлы, нам нет нужды создавать шаблон с ОС внутри;
13) Указываем, необходимо ли включать в шаблон какие-либо апдейты.
Итак, с управляющим узлом мы пока закончили.
Настройка узлов-вычислителей и ввод узлов в кластер
1) Включаем узел в домен; именуем его согласно нашим конвенциям, например, winnode1;
2) Логинимся на узел под доменным аккаунтом и монтируем ISO Microsoft HPC Pack 2008 R2 Express;
3) В Select Installation Edition выбираем HPC Pack 2008 R2 Express. В Enterprise-версии есть дополнительные функции;
4) Все остальные настройки те же самые, за исключением Join an existing HPC Cluster by creating a new compute node. В Join Cluster в выпадающем меню должно быть имя управляющего узла.
Вот и всё. Давайте переключимся в HPC Manager на управляющем узле и увидим, что во вкладке Nodes Management появился наш узел.
Узел имеет Node State указанным в Unknown и Node Health как Unapproved.
Чтобы решить эту проблему, выделим узел и нажмем Assign node template, выбрав наш шаблон, который мы создали ранее. Для наблюдения за процессом так называемого provisioning выберем узел и нажмем Provisioning Log.
После окончания узел должен стать Offline и его Node Health OK. Выделим его и нажмем Bring Online. По поводу данного состояния – в случае Online узел может принимать участие в вычислениях, в Offline – нет. Можно использовать в вычислениях и управляющий узел, но не рекомендую.
Время на прочтение6 мин
Количество просмотров69K
Давным-давно, в далекой-далекой галактике…, стояла передо мной задача организовать подключение нового филиала к центральному офису. В филиале доступно было два сервера, и я думал, как было бы неплохо организовать из двух серверов отказоустойчивый кластер hyper-v. Однако времена были давние, еще до выхода 2012 сервера. Для организации кластера требуется внешнее хранилище и сделать отказоустойчивость из двух серверов было в принципе невозможно.
Однако недавно я наткнулся на статью Romain Serre в которой эта проблема как раз решалась с помощью Windows Server 2016 и новой функции которая присутствует в нем — Storage Spaces Direct (S2D). Картинку я как раз позаимствовал из этой статьи, поскольку она показалась очень уместной.
Технология Storage Spaces Direct уже неоднократно рассматривалась на Хабре. Но как-то прошла мимо меня, и я не думал, что можно её применять в «народном хозяйстве». Однако это именно та технология, которая позволяет собрать кластер из двух нод, создав при этом единое общее хранилище между серверами. Некий единый рейд из дисков, которые находятся на разных серверах. Причем выход одного из дисков или целого сервера не должны привести к потере данных.

Звучит заманчиво и мне было интересно узнать, как это работает. Однако двух серверов для тестов у меня нет, поэтому я решил сделать кластер в виртуальной среде. Благо и вложенная виртуализация в hyper-v недавно появилась.
Для своих экспериментов я создал 3 виртуальные машины. На первой виртуальной машине я установил Server 2016 с GUI, на котором я поднял контроллер AD и установил средства удаленного администрирования сервера RSAT. На виртуальные машины для нод кластера я установил Server 2016 в режиме ядра. В этом месяце загадочный Project Honolulu, превратился в релиз Windows Admin Center и мне также было интересно посмотреть насколько удобно будет администрировать сервера в режиме ядра. Четвертная виртуальная машина должна будет работать внутри кластера hyper-v на втором уровне виртуализации.
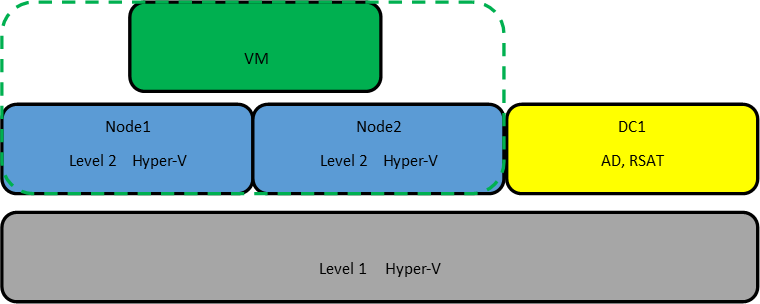
Для работы кластера и службы Storage Spaces Direct необходим Windows Server Datacenter 2016. Отдельно стоит обратить внимание на аппаратные требования для Storage Spaces Direct. Сетевые адаптеры между узлами кластера должны быть >10ГБ с поддержкой удаленного прямого доступа к памяти (RDMA). Количество дисков для объединения в пул – минимум 4 (без учета дисков под операционную систему). Поддерживаются NVMe, SATA, SAS. Работа с дисками через RAID контроллеры не поддерживается. Более подробно о требованиях docs.microsoft.com
Если вы, как и я, никогда не работали со вложенной виртуализацией hyper-v, то в ней есть несколько нюансов. Во-первых, по умолчанию на новых виртуальных машинах она отключена. Если вы захотите в виртуальной машине включить роль hyper-v, то получите ошибку, о том, что оборудование не поддерживает данную роль. Во-вторых, у вложенной виртуальной машины (на втором уровне виртуализации) не будет доступа к сети. Для организации доступа необходимо либо настраивать nat, либо включать спуфинг для сетевого адаптера. Третий нюанс, для создания нод кластера, нельзя использовать динамическую память. Подробнее по ссылке.
Поэтому я создал две виртуальные машины – node1, node2 и сразу отключил динамическую память. Затем необходимо включить поддержку вложенной виртуализации:
Set-VMProcessor -VMName node1,node2 -ExposeVirtualizationExtensions $trueВключаем поддержку спуфинга на сетевых адаптерах ВМ:
Get-VMNetworkAdapter -VMName node1,node2 | Set-VMNetworkAdapter -MacAddressSpoofing On
HDD10 и HDD 20 я использовал как системные разделы на нодах. Остальные диски я добавил для общего хранилища и не размечал их.
Сетевой интерфейс Net1 у меня настроен на работу с внешней сетью и подключению к контроллеру домена. Интерфейс Net2 настроен на работу внутренней сети, только между нодами кластера.
Для сокращения изложения, я опущу действия необходимые для того, чтобы добавить ноды к домену и настройку сетевых интерфейсов. С помощью консольной утилиты sconfig это не составит большого труда. Уточню только, что установил Windows Admin Center с помощью скрипта:
msiexec /i "C:\WindowsAdminCenter1804.msi" /qn /L*v log.txt SME_PORT=6515 SSL_CERTIFICATE_OPTION=generateПо сети из расшаренной папки установка Admin Center не прошла. Поэтому пришлось включать службу File Server Role и копировать инсталлятор на каждый сервер, как в мс собственно и рекомендуют.
Когда подготовительная часть готова и перед тем, как приступать к созданию кластера, рекомендую обновить ноды, поскольку без апрельских обновлений Windows Admin Center не сможет управлять кластером.
Приступим к созданию кластера. Напомню, что все необходимые консоли у меня установлены на контролере домена. Поэтому я подключаюсь к домену и запускаю Powershell ISE под администратором. Затем устанавливаю на ноды необходимые роли для построения кластера с помощью скрипта:
$Servers = "node1","node2"
$ServerRoles = "Data-Center-Bridging","Failover-Clustering","Hyper-V","RSAT-Clustering-PowerShell","Hyper-V-PowerShell","FS-FileServer"
foreach ($server in $servers){
Install-WindowsFeature –Computername $server –Name $ServerRoles} И перегружаю сервера после установки.
Запускаем тест для проверки готовности нод:
Test-Cluster –Node "node1","node2" –Include "Storage Spaces Direct", "Inventory", "Network", "System ConfigurationОтчёт в фомате html сформировался в папке C:\Users\Administrator\AppData\Local\Temp. Путь к отчету утилита пишет, только если есть ошибки.
Ну и наконец создаем кластер с именем hpvcl и общим IP адресом 192.168.1.100
New-Cluster –Name hpvcl –Node "node1","node2" –NoStorage -StaticAddress 192.168.1.100 После чего получаем ошибку, что в нашем кластере нет общего хранилища для отказоустойчивости. Запустим Failover cluster manager и проверим что у нас получилось.

Включаем (S2D)
Enable-ClusterStorageSpacesDirect –CimSession hpvcl И получаем оповещение, что не найдены диски для кэша. Поскольку тестовая среда у меня на SSD, а не на HDD, не будем переживать по этому поводу.
Затем подключаемся к одной из нод с помощью консоли powershell и создаем новый том. Нужно обратить внимание, что из 4 дисков по 40GB, для создания зеркального тома доступно порядка 74GB.
New-Volume -FriendlyName "Volume1" -FileSystem CSVFS_ReFS -StoragePoolFriendlyName S2D* -Size 74GB -ResiliencySettingName Mirror 
На каждой из нод, у нас появился общий том C:\ClusterStorage\Volume1.
Кластер с общим диском готов. Теперь создадим виртуальную машину VM на одной из нод и разместим её на общее хранилище.
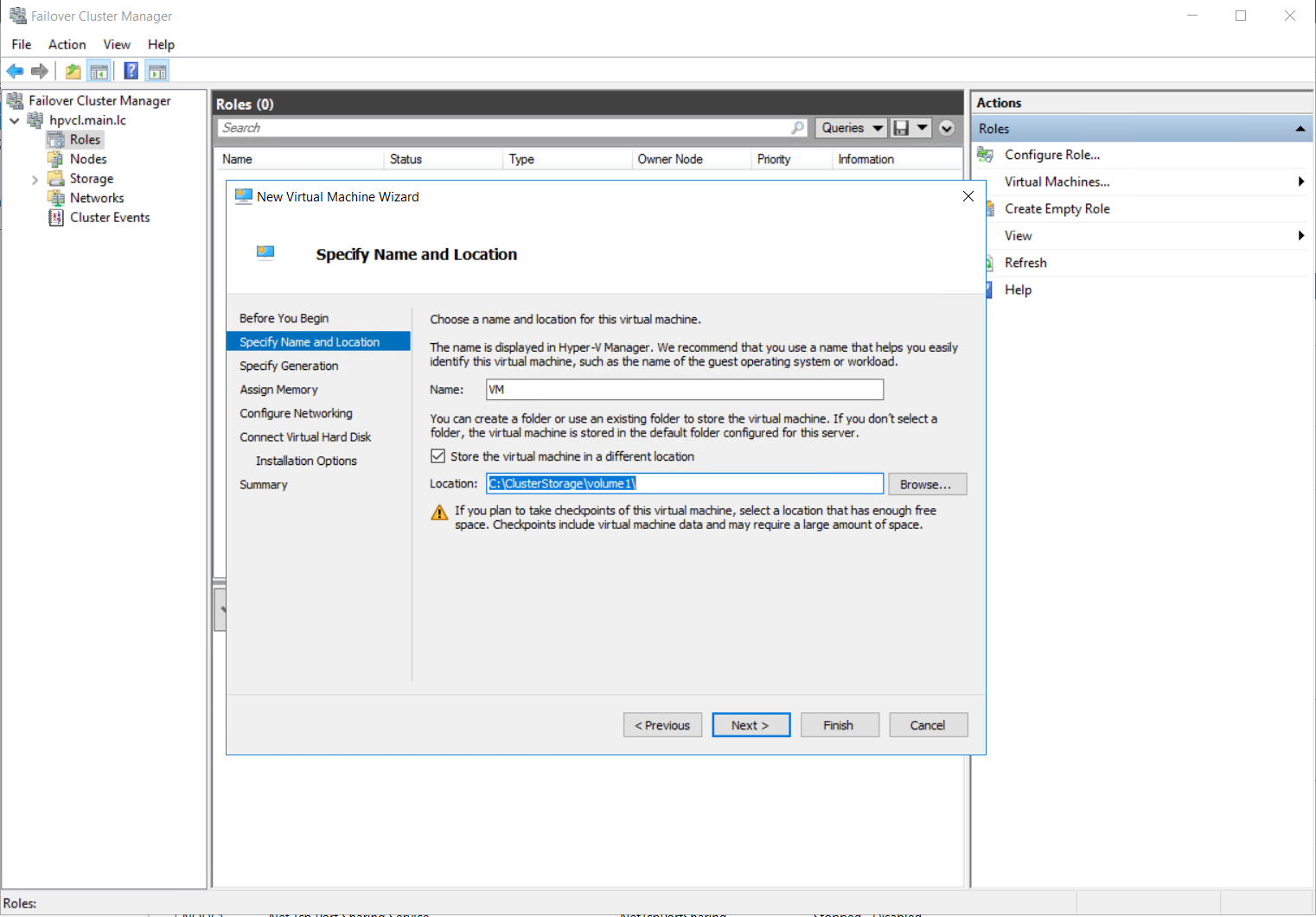
Для настроек сети виртуальной машины, необходимо будет подключиться консолью hyper-v manager и создать виртуальную сеть с внешним доступом на каждой из нод с одинаковым именем. Затем мне пришлось перезапустить службу кластера на одной из нод, чтобы избавиться от ошибки с сетевым интерфейсом в консоли failover cluster manager.
Пока на виртуальную машину устанавливается система, попробуем подключиться к Windows Admin Center. Добавляем в ней наш гиперконвергентный кластер и получаем грустный смайлик
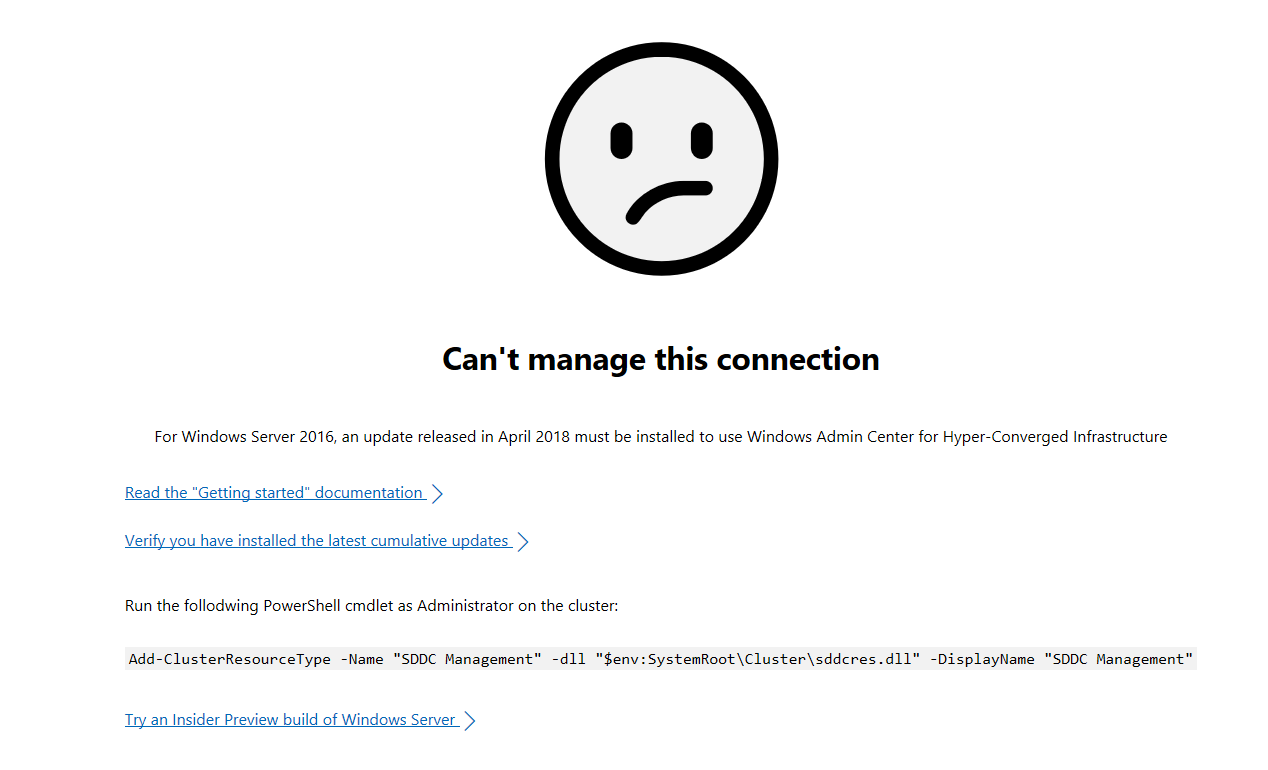
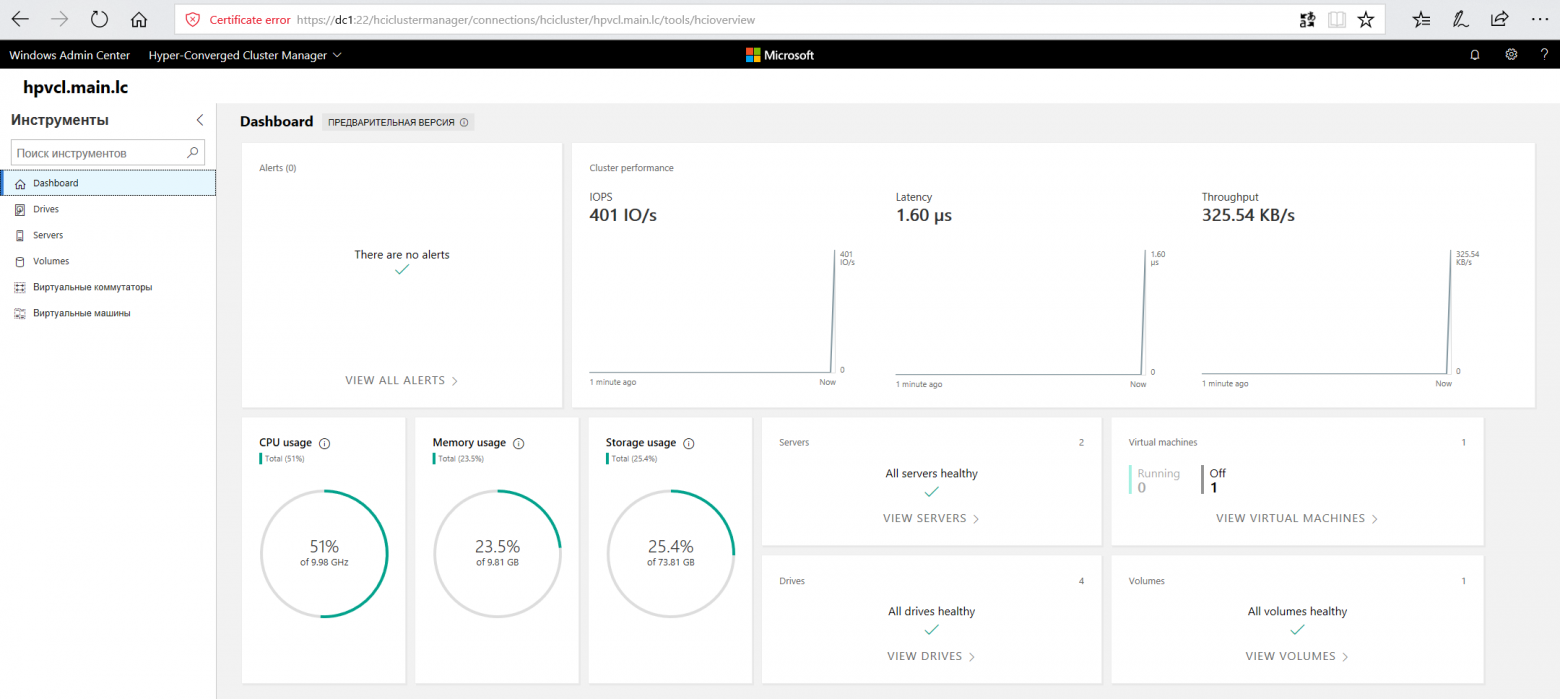
Подключимся к одной из нод и выполним скрипт:
Add-ClusterResourceType -Name "SDDC Management" -dll "$env:SystemRoot\Cluster\sddcres.dll" -DisplayName "SDDC Management"Проверяем Admin Center и на этот раз получаем красивые графики
После того, как установил ОС на виртуальную машину VM внутри кластера, первым делом я проверил Live migration, переместив её на вторую ноду. Во время миграции я пинговал машину, чтобы проверить насколько быстро происходит миграция. Связь у меня пропала только на 2 запроса, что можно считать весьма неплохим результатом.
И тут стоит добавить несколько ложек дёгтя в эту гиперконвергентную бочку мёда. В тестовой и виртуальной среде все работает неплохо, но как это будет работать на реальном железе вопрос интересный. Тут стоит вернуться к аппаратным требованиям. Сетевые адаптеры 10GB с RDMA стоят порядка 500$, что в сумме с лицензией на Windows Server Datacenter делает решение не таким уж и дешёвым. Безусловно это дешевле чем выделенное хранилище, но ограничение существенное.
Вторая и основная ложка дёгтя, это новость о том, что функцию (S2D) уберут из следующей сборки server 2016 . Надеюсь, сотрудники Microsoft, читающие Хабр, это прокомментируют.
В заключении хотел бы сказать несколько слов о своих впечатлениях. Знакомство с новыми технологиями это был для меня весьма интересный опыт. Назвать его полезным, пока не могу. Я не уверен, что смогу применить эти навыки на практике. Поэтому у меня вопросы к сообществу: готовы ли вы рассматривать переход на гиперконвергентные решения в будущем? как относитесь к размещению виртуальных контроллеров домена на самих нодах?
👉Вернуться к списку инструкций
Что такое суперкомпьютер?
Вычислительный кластер (суперкомпьютер) НИУ ВШЭ состоит из вычислительных узлов, объединенных высокоскоростной коммуникационной сетью. Каждый вычислительный узел имеет свою оперативную память и твердотельный накопитель, а также подключен к общему параллельному сетевому хранилищу. Чтобы независимые вычислительные узлы работали как единый компьютер, используется специальное параллельное программное обеспечение.
Как правило, работа с вычислительным кластером состоит из трех этапов:
- Пользователь подготавливает на своём компьютере исходные данные для имеющегося прикладного программного обеспечения суперкомпьютера или пишет собственную параллельную программу.
- Подключается к головному узлу кластера (логин-серверу) по SSH-протоколу (консолью), загружает исходные данные и ставит свою задачу в очередь на расчёт.
- Пользователь загружает результат с вычислительного кластера на свой персональный компьютер и изучает его локально.
Важно! Суперкомпьютер — это не сервер, а кластер. Сначала вы подключаетесь к головному узлу (логин-серверу), на котором нельзя запускать расчёты, с него можно только выполнять постановку задач в очередь. Непосредственное же выполнение расчётов происходит на мощных вычислительных узлах кластера, на которые ваши задачи распределит очередь задач.
Удаленный доступ к суперкомпьютеру
Удаленное подключение к суперкомпьютеру осуществляется через головной узел (логин-сервер) по протоколу SSH по адресу cluster.hpc.hse.ru, порт 2222.
В операционных системах Linux и Mac OS для подключения используется приложение ssh (см. инструкцию), для Microsoft Windows рекомендуется свободно распространяемая программа PuTTY (см. инструкцию).
Вход в систему начинается с системного приглашения login: В ответ на него следует ввести имя пользователя и нажать клавишу [ENTER]. Затем система запросит пароль пользователя. Введите пароль и нажмите клавишу [ENTER]. Обратите внимание, при вводе пароля символы на экране не печатаются, тем не менее, сам пароль вводится.
Для смены своего пароля после входа в систему необходимо воспользоваться командой passwd
Потребуется ввести свой текущий пароль, затем новый и подтверждение нового. Вводимые символы отображаться не будут.
Передача файлов на суперкомпьютер
Хранение файлов
В соответствии с правилами, пользователь самостоятельно обеспечивает резервное копирование своих данных. Хранение данных, которые уже не участвуют в вычислениях, на суперкомпьютере не допускается.
Пользовательские директории имеют вид /home/<имя_пользователя> и физически размещены на параллельном хранилище данных Lustre. Максимальный объем данных для пользователя обусловлен дисковой квотой, определяемой при регистрации (в дальнейшем квота может быть увеличена при необходимости). Для просмотра текущей квоты используйте команду checkquota. Кроме того, на каждом вычислительном узле доступен локальный каталог для временных файлов (/tmp), размещенный на SSD узла. После окончания работы программы временные файлы пользователя в /tmp узла удаляются автоматически.
Настройка окружения
Для управления версиями прикладных программных пакетов и библиотек на суперкомпьютере установлен программный пакет Lmod. Он позволяет гибко настраивать переменные окружения для использования тех или иных версий ПО и отслеживания их зависимостей (в том числе, при запуске в пакетном режиме с помощью sbatch). Также использование Lmod позволяет гибко управлять разными версиями приложения (например, можно быстро переключаться между различными версиям компиляторов и версиями библиотеки MPI).
Использование пакета Lmod
Основные команды работы с пакетом Lmod
- module avail – вывести список доступных модулей
- module list – вывести список загруженных модулей
- module load module1 – загрузить модуль module1 версии version
- module unload module1 – выгрузить модуль module1 версии version
- module swap module1 module2 – заменить загруженный модуль module1 на module2
- module purge – выгрузить все загруженные модули
- module whatis module1 – показать информацию о модуле module1
- module save [env_name] – сохранить текущий набор загруженных модулей под именем env_name. Если не указывать имя, то набор будет перезаписан набор по умолчанию
- module restore [env_name] – загрузить набор сохранённых модулей
- module describe [env_name] – показать состав набора сохранённых модулей
Примеры использования пакета Lmod
Просмотр загруженных модулей:
$ module list
Currently Loaded Modules:
1) autotools 2) prun/1.2 3) gnu7/7.3.0 4) openmpi3/3.1.3 5) ohpc
Просмотр доступных модулей:
$ module avail
— /opt/ohpc/pub/modulefiles —
CUDA/10.0 cnpy_lib/1.0 hpcx/hpcx-stack
Python/Anaconda_v10.2019 gnu7/7.3.0 (L) hpcx/hpcx (D)
EasyBuild/3.7.1 fltk/v1.3.5 hwloc/1.11.10
Где:
D: модуль, загружаемый по умолчанию;
L: модуль, загруженный в настоящий момент.
Пример: выгрузка всех модулей и загрузка модулей CUDA/10.2 и Python/Anaconda_v10.2019:
$ module purge
$ module load CUDA/10.2 Python/Anaconda_v10.2019
$ module list
Currently Loaded Modules:
1) CUDA/10.2 2) Python/Anaconda_v10.2019
Сохранение набора модулей по умолчанию:
$ module save
Saved current collection of modules to: «default»
Компиляция программ на суперкомпьютере
Для компиляции программ на вычислительном кластере НИУ ВШЭ установлены:
- Проприетарный пакет Intel Parallel Studio XE Cluster Edition for Linux.
- Набор бесплатных компиляторов GNU Compiler Collection.
Использование компилятора и библиотек Intel является предпочтительным, так как это обеспечивает существенное ускорение выполнения программ на центральных процессорах Intel суперкомпьютера.
Инструкция по компиляции программ на суперкомпьютере
Выбор компилятора осуществляется с помощью загрузки соответствующего модуля:
module load gnu8 openmpi3
или
module load INTEL/parallel_studio_xe_2020_ce
Для компиляции параллельных MPI-приложений с помощью компиляторов Intel Parallel Studio используйте команды mpiicc, mpiicpc, mpiifort:
- C: mpiicc [опции] -o program.out file1.c file2.c
- C++: mpiicpc [опции] -o program.out file1.cpp file2.cpp
- Fortran: mpiifort [опции] -o program.out file1.f90 file2.f90
Подробную информацию по использованию компиляторов Intel Parallel Studio можно получить на официальном сайте Intel.
Для компиляции параллельных MPI-приложений с помощью GNU Compiler Collection + OpenMPI используйте команды mpicc, mpixx, mpifort:
- C: mpicc [опции] -o program.out file1.c file2.c
- C++: mpicxx [опции] -o program.out file1.cpp file2.cpp
- Fortran: mpifort [опции] -o program.out file1.f90 file2.f90
Подробную информацию по использованию компиляторов GNU Compiler Collection и OpenMPI можно получить на официальном сайте.
При компиляции рекомендуется указывать особые флаги оптимизаций, позволяющие ускорить выполнение программы. Флаг оптимизации -O2 активирует векторизацию и базовую оптимизацию циклов. Данный флаг в большинстве случаев обеспечивает наилучшее быстродействие работы программы.
При использовании программ с большим количеством вычислений с плавающей точкой или обрабатывающих объёмные наборы данных рекомендуется использовать флаг -O3, активирующий более агрессивное преобразование циклов и условных выражений. Более подробную информацию по флагам оптимизации можно получить на сайте Intel Parallel Studio и GNU Compiler Collection.
При компиляции с использованием компиляторов Intel также рекомендуется указывать флаг -xHOST. Он позволяет компилятору использовать максимальный набор инструкций, доступных для процессоров на суперкомпьютере. Данный флаг ещё больше оптимизирует приложение, но снижает его переносимость на другие платформы (на всех узлах вычислительного кластера НИУ ВШЭ используется процессоры одного поколения с одинаковым набором инструкций).
Пример использования флагов оптимизации при компиляции MPI-программ:
mpiicpc -xHOST -O2 /opt/ohpc/pub/examples/mpi/hello.c -o ./program_name
mpicxx -O2 /opt/ohpc/pub/examples/mpi/hello.c -o ./program_name
Для компиляции обычных (не параллельных) программ с помощью Intel Parallel Studio используйте следующие команды:
- C: icc [опции] -o program.out file1.c file2.c
- C++: icpc [опции] -o program.out file1.cpp file2.cpp
- Fortran: ifort [опции] -o program.out file1.f90 file2.f90
Для компиляции обычных (не параллельных) программ с помощью GNU Compiler Collection используйте следующие команды:
- C: gcc [опции] -o program.out file1.c file2.c
- C++: g++ [опции] -o program.out file1.cpp file2.cpp
- Fortran: gfortran [опции] -o program.out file1.f90 file2.f90
Постановка задачи в очередь
Для запуска расчётов на суперкомпьютере пользователи обязаны использовать систему управления заданиями Slurm. Данная система (планировщик задач) управляет доступными ресурсами и размещает задачи на подходящих свободных вычислительных узлах. В соответствии с правилами, на головном узле запрещено выполнять задачи, требующие значимых вычислительных ресурсов.
Для постановки задачи в очередь рекомендуется использовать команду sbatch. Для её работы необходимо подготовить скрипт-файл с нужными ключами и командами:
#!/bin/bash
#SBATCH <ключ sbatch> <значение>
#SBATCH <ключ sbatch> <значение>
<пользовательские команды>
Другим способом запуска задачи в очереди является команда srun, выполняющая задачу интерактивно. Например: srun [опции] my_mpi_task
Подробная информация по запуску задач доступна в отдельной инструкции.
Просмотр состояния очереди
Посмотреть текущее состояние очереди задач можно командой squeue.
Для просмотра состояния только своих задач используйте короткую команду mj.
Удаление задачи из очереди
Для удаления задачи из очереди используйте команду scancel [номер задачи].
Базовые команды ОС Linux
Список базовых команд в ОС Linux:
- pwd — вывести полный путь текущего каталога
- cd [путь] — сменить текущий каталог
- ls — показать содержимое каталога
- cp <источник> <получатель> — скопировать файл
- mv <источник> <получатель> — переместить файл
- rm <путь> — удалить файл
- cat <путь> — вывести содержимое файла в консоли
- mcedit [путь] — открыть текстовый редактор файлов
- exit — выйти из оболочки (или отключиться от суперкомпьютера)
Справку по любой команде в ОС Linux можно получить с помощью команды man <имя_команды> или <имя_команды> —help.
Для более подробного знакомства с ОС Linux Вы можете пройти бесплатные курсы, например:
- Stepik: Основы Linux
- Stepik: Введение в Linux
Предлагаем также краткие пособия по разработке параллельных программ с использованием MPI:
- Антонов А. С. Введение в параллельные вычисления (PDF, 696 Кб)
-
Антонов А. С. Параллельное программирование с использованием технологии MPI: Учебное пособие (PDF, 393 Кб)
Как пользоваться суперкомпьютером во время переоформления сотрудника?
Т.к. регистрация пользователей на суперкомпьютере производится через Единый личный кабинет НИУ ВШЭ, то при блокировке учетной записи отделом персонала, прекращается и доступ пользователя на суперкомпьютер. Если сотрудник при этом продолжает работать (идёт процесс переоформления договора или перевод в другое подразделение через увольнение), то руководитель работника может проставить дату повторного приёма в ЕЛК (сервис «Установка ДПП в подразделении»), либо обратиться в управление персонала по адресу personal@hse.ru с этой просьбой. В таком случае учетная запись разблокируется автоматически на следующий день после установки даты.
О профилактических работах
Плановые профилактические работы на суперкомпьютере проводятся ежемесячно в последний рабочий день месяца (пн-пт) с 9:30 до 18:00. На время профилактических работ очередь задач приостанавливается, a доступ для пользователей закрывается. Активные задачи снимаются. Задачи, поддерживающие перезапуск (см. пункт Перезапуск задач в инструкции по запуску), перезапускаются после окончания работ.
Плановая профилактика проводится для того, чтобы обеспечить пользователям стабильную работу кластера в течение целого месяца.
В случае проблем
Для решения возникающих вопросов по использованию вычислительного кластера НИУ ВШЭ обратитесь к специалистам отдела суперкомпьютерного моделирования, создав заявку на портале поддержки hpc.hse.ru/support, либо по электронной почте hpc@hse.ru. В заявке следует подробно описать возникшую проблему и шаги по её воспроизведению.
Присоединяйтесь к обсуждению
М
Гость
28 ПРОСТЫХ ЛАЙФХАКОВ, КОТОРЫЕ ИЗМЕНЯТ ВАШУ ЖИЗНЬ
13.05.2025
Есть действительно полезные советы. Но их очень мало..
М
Гость
Фильм — Видео
13.05.2025
крутой фильм
Данный фильм является только короткометражным фильмов повествующем о крупном блокбастере
с названием «двенадцатый дождь», так как на этом фильме режиссер только потренировался , фильм был снят 4 людми за один день
М
Гость
Чё в Блицухе #43 | Бабаху выводят из игры, но К…
13.05.2025
ее иза торта вывели, якобы стиль игры очень меняется после черепахи, потому и поставили аллигатора который по факту та же самая черепаха
М
Гость
Мое первое интро — Видео
13.05.2025
Это моё видео как вы его нашли
М
Гость
Угадай предмет по описанию челлендж — Видео
13.05.2025
Супер!
В статье показано, как можно использовать ресурсы CAFS для повышения уровня доступности и гибкости элементов существующей инфраструктуры. Технология CAFS обеспечивает более высокую доступность файловых ресурсов общего назначения, а также позволяет серверным приложениям, таким как SQL Server и Hyper-V, хранить свои данные на файловых ресурсах с высоким уровнем доступности, предоставляя новые возможности для хранения данных критически важных приложений
Постоянно доступные общие файловые ресурсы, Continuously Available File Shares (CAFS), – это новая технология, появившаяся в системе Windows Server 2012. На базовом уровне технология CAFS в системе Server 2012 расширяет возможности Windows по совместной работе с файлами с помощью кластерной технологии Server 2012. Механизмы CAFS используют преимущества новых функций протокола Server Message Block (SMB) 3.0, повышающих доступность общих ресурсов системы Windows Server, используемых для хранения документов и поддержки приложений. В число новых возможностей технологии SMB 3.0, позволяющих задействовать ресурсы CAFS, входят механизмы SMB Scale-Out, SMB Direct и SMB Multichannel.
Технология CAFS призвана решить проблемы, возникающие в ранних версиях файловых серверов высокой доступности, построенных на основе отказоустойчивых кластеров Windows Server. Предыдущие версии обеспечивали высокую доступность общих ресурсов, но были подвержены перерывам в работе и кратковременным потерям подключений в случаях отказа узла. Такие кратковременные сбои, как правило, допустимы в работе офисных приложений (например, Microsoft Office), часто выполняющих операции открытия и закрытия файлов, так как эти приложения могут повторно подключиться к ресурсу и сохранить изменения после отработки отказа. Однако подобные сбои недопустимы в работе таких приложений, как Hyper-V или SQL Server, которые держат файлы открытыми на протяжении длительного времени. В таких схемах сбой может привести к потере данных. До появления системы Server 2012 компания Microsoft не поддерживала установку серверов Hyper-V или SQL Server на общие ресурсы. Обеспечение поддержки приложений было одной из основных задач Microsoft при разработке технологии CAFS. Хотя вы можете использовать механизмы CAFS просто для предоставления клиентского доступа к общим ресурсам, реальной задачей данной технологии является поддержка серверных приложений. Технология CAFS дает возможность использовать преимущества недорогих механизмов хранения системы Windows Server применительно к критически важным приложениям. Технология CAFS обеспечивает непрерывный доступ к общим ресурсам, снижая время простоя практически до нуля.
Выберите решение
Существует два подхода к созданию ресурса CAFS.
- Файловый сервер общего назначения. Это очень похожая на поддержку файлового сервера с высокой доступностью в системе Windows Server 2008 R2, наиболее распространенная реализация технологии CAFS на файловом сервере, которая обеспечивает поддержку размещения общих ресурсов на отказоустойчивом кластере. Технология CAFS повышает доступность и производительность данной схемы, благодаря новому высокопроизводительному механизму клиентского доступа SMB 3.0.
- Масштабируемый файловый сервер. Реализация масштабируемого файлового сервера – это новая возможность технологии CAFS, предназначенная для обеспечения поддержки таких приложений как Hyper-V и SQL Server без простоя в работе. Данная реализация ограничена четырьмя серверами.
Обзор архитектуры CAFS приведен на рисунке.

|
| Рисунок. Архитектура CAFS |
Одной из ключевых технологий, сделавшей возможным использование ресурсов CAFS, является поддержка механизмов SMB Transparent Failover системой Server 2012. Механизмы SMB Transparent Failover позволяют службам файлового сервера выполнять аварийное переключение на резервный узел кластера, благодаря чему приложения, имеющие открытые файлы на файловом сервере, не заметят обрывов в подключениях. Технология CAFS обеспечивает нулевой простой в работе приложений как при плановом обслуживании, так и при незапланированных отказах.
Соответствие требованиям
Поскольку технология CAFS использует механизмы SMB 3.0 системы Server 2012, наличие операционной системы Server 2012 является обязательным требованием. Технология поддерживается в обеих редакциях, Server 2012 Standard и Server 2012 Datacenter. В редакциях Essentials или Foundation технология CAFS не поддерживается.
Кроме того, для использования технологии CAFS необходимо наличие отказоустойчивого кластера Server 2012. Это означает, что у вас должен быть настроен кластер Server 2012 как минимум из двух узлов. Отказоустойчивые серверы Server 2012 поддерживают до 64 узлов. Вы можете найти пошаговые инструкции по настройке отказоустойчивого кластера в моей статье «Windows Server 2012: Building a Two-Node Failover Cluster» (опубликованной в Windows IT Pro/RE № за 2012 год).
Помимо собственно наличия кластера, на каждый его узел должна быть установлена роль файлового сервера. На кластерном файловом сервере должна быть настроена одна или несколько общих папок с активным новым параметром, отвечающим за постоянную доступность ресурса. Далее я подробно расскажу о создании и настройке постоянно доступных общих папок.
В отказоустойчивом кластере из двух узлов на кластерном хранилище должны быть настроены как минимум два различных тома LUN. На одном томе хранятся общие файлы. Этот том должен быть настроен в качестве общего тома кластера cluster shared volume (CSV). Другой том будет работать в качестве диска-свидетеля. В большинстве решений используется большее количество томов.
Также рекомендуется настроить сеть таким образом, чтобы между узлами было несколько путей. Благодаря такой топологии сеть перестает быть единственной точкой отказа. Использование объединения сетевых адаптеров и/или дублирующих маршрутизаторов позволяет повысить уровень отказоустойчивости вашей сети.
Наконец, для использования преимуществ нового механизма SMB Transparent Failover на компьютерах с клиентом SMB должны быть установлены операционные системы Windows 8 или Server 2012. Когда клиент SMB 3.0 подключается к ресурсу CAFS, он уведомляет службу-свидетеля кластера. Кластер назначает узел, который будет свидетелем для данного подключения. Узел-свидетель отвечает за переключение клиента на новый хост-сервер в случае остановки в работе службы, не вынуждая клиента дожидаться, пока пройдет время отклика протокола TCP.
Создание ресурсов CAFS общего назначения
Для настройки ресурса CAFS откройте мастер Failover Cluster Manager на любом из узлов кластера. Затем щелкните мышью на узле Roles в панели навигации. Как показано на экране 1, в окне Roles отображаются установленные роли.
|
|
| Экран 1. Мастер Failover Cluster Manager |
Кластер может поддерживать несколько ролей и обеспечивает высокий уровень доступности для каждой из них. На экране 1 мы видим настроенную виртуальную машину с высоким уровнем доступности. Для создания нового ресурса CAFS общего назначения щелкните мышью по ссылке Configure Role…, отмеченной в окне Actions. Будет запущен мастер High Availability Wizard, показанный на экране 2.
|
|
| Экран 2. Мастер High Availability Wizard |
Прокручивайте список ролей до тех пор, пока не увидите роль файлового сервера. Роль файлового сервера поддерживает ресурсы CAFS обоих типов: общего назначения и масштабируемых приложений. Выберите роль File Server и щелкните мышью на кнопке Next, чтобы перейти к экрану выбора типа ресурса CAFS, см. экран 3.
|
|
| Экран 3. Окно выбора типа ресурса CAFS |
Диалоговое окно File Server Type позволяет выбрать, какой сервер необходимо создать: файловый сервер общего назначения (File Server for general use) или масштабируемый файловый сервер для данных приложений (Scale-Out File Server for application data). Роль «общего назначения» может быть использована для настройки как общих папок на основе механизма Windows SMB, так и общих папок на основе NFS. Ресурсы CAFS общего назначения также поддерживают устранение дублирования данных, репликацию DFS и шифрование данных. Щелкните мышью на кнопке Next, чтобы продолжить создание ресурса CAFS общего назначения. На экране появится диалоговое окно Client Access Point, показанное на экране 4.
|
|
| Экран 4. Окно Client Access Point |
Для создания нового ресурса CAFS общего назначения необходимо указать имя сервера, которое клиенты будут использовать при обращении к ресурсу CAFS. Это имя будет зарегистрировано в DNS, и клиенты будут указывать его по аналогии с именем сервера. Кроме того, ресурсу CAFS общего назначения также необходим IP-адрес. На экране 4 я присвоил службе имя CAFS-Gen (для ресурса CFAS общего назначения) и статический IP-адрес 192.168.100.177. Щелкнув кнопку Next, вы сможете выбрать кластерное хранилище для ресурса CAFS.
Диалоговое окно Select Storage, показанное на экране 5, позволяет выбрать хранилище для ресурса CAFS общего назначения.
|
|
| Экран 5. Окно Select Storage |
Хранилище должно быть доступно для служб кластера. Другими словами, оно должно быть в списке узлов хранения кластера и должно быть отмечено как доступное хранилище. Вы не можете использовать предварительно назначенные общие тома кластера CSV для создания ресурса CAFS общего назначения. В данном примере я мог задействовать три различных диска, и выбрал Cluster Disk 5, потому что изначально готовил это хранилище под размещение ресурса CAFS (экран 5). Однако вы можете выбрать любой из доступных дисков кластера. Щелкнув мышью на кнопке Next, вы перейдете к экрану Confirmation. На нем можно подтвердить выбранные настройки или вернуться к диалоговым окнам мастера High Availability Wizard и внести изменения. Если все параметры вас устраивают, щелкните мышью на кнопке Next экрана Confirmation и перейдите к окну Configure High Availability, которое отображает прогресс настройки ресурса CAFS. По окончании настройки вы увидите экран Summary. Щелчок мышью на кнопке Finish экрана Summary закроет мастер High Availability Wizard и вернет вас в окно Failover Cluster Manager, показанное на экране 6.
|
|
| Экран 6. Создание постоянно доступной общей файловой папки |
Следующим шагом после создания роли CAFS будет создание постоянно доступной общей файловой папки, использующей данную роль. На экране 6 видно, что роль CAFS-Gen активно работает и использует роль файлового сервера. Для добавления новой постоянно доступной общей файловой папки выберите ссылку Add File Share в окне, которое вы видите в правой части экрана 6. Вы увидите диалоговое окно Task Progress, которое отображает процесс получения информации с сервера. Сразу по завершении на экране появится диалоговое окно New Share Wizard, которое вы видите на экране 7.
|
|
| Экран 7. Окно New Share Wizard |
Первым делом мастер New Share Wizard спросит, какой тип ресурса CAFS вы хотите создать. Вы можете выбрать ресурс CAFS одного из двух типов: SMB или NFS. Режим SMB Share—Quick активирует создание ресурса CAFS общего назначения. Режим SMB Share—Applications отвечает за создание высоконадежного общего ресурса приложений для таких систем как Hyper-V или SQL Server. Создание масштабируемых ресурсов CAFS для приложений я рассматриваю ниже. Для создания ресурса CAFS общего назначения выберите режим SMB Share—Quick и щелкните кнопку Next. Мастер New Share Wizard отобразит диалоговое окно Share Location, показанное на экране 8.
|
|
| Экран 8. Окно Share Location |
Имя роли CAFS отображается в поле Server Name. На экране 8 мы видим имя роли CAFS-Gen, которую я создал ранее, и ее состояние – online. Вы может выбрать размещение общего ресурса с помощью полей в нижней части экрана. В данном примере по умолчанию был выбран диск G (экран 8). Если вы хотите использовать другой диск, то можете ввести альтернативный путь в поле Type a custom path, расположенном внизу экрана. В этом примере я оставляю предложенный по умолчанию диск G и нажимаю кнопку Next для перехода к диалоговому окну Share Name, показанному на экране 9.
|
|
| Экран 9. Имя общего ресурса |
Диалоговое окно Share Name позволяет вам ввести имя общего файлового ресурса. Для простоты я использовал для ресурса CAFS то же имя, что и для службы, CAFS-Gen (экран 9), но это не обязательно. Вы можете дать общей папке любое корректное имя SMB. В центре экрана мы видим локальный и удаленный пути к ресурсу CAFS. Локальный путь в данном примере — G:\Shares\CAFS-Gen. Сетевые системы будут обращаться к общей папке по пути \\CAFS-gen\CAFS-Gen. Щелкнув мышью по кнопке Next, вы откроете диалоговое окно настройки общего ресурса Configure, показанное на экране 10.
|
|
| Экран 10. Окно настройки общего ресурса |
Диалоговое окно настройки общего ресурса Configure позволяет контролировать процесс обработки ресурса сервером. Чтобы сделать файловый ресурс постоянно доступным, требуется установить флаг Enable continuous availability. Этот параметр активируется по умолчанию. Параметр Enable access-based enumeration управляет возможностью просмотра файлов и папок пользователями без привилегий. Этот параметр выключен по умолчанию. Параметр Allow caching of share разрешает доступ к ресурсу для пользователей, работающих автономно, посредством технологии BranchCache. И наконец, параметр Encrypt data access позволяет обезопасить удаленный доступ к файлам путем шифрования данных, передаваемых ресурсу и извлекаемых из него. Этот параметр по умолчанию отключен. Щелкнув мышью по кнопке Next, вы откроете диалоговое окно Permissions, показанное на экране 11.
|
|
| Экран 11. Назначение общему ресурсу разрешений |
По умолчанию ресурс CAFS создается с привилегиями Full Control, предоставленными группе Everyone. В большинстве решений вы, скорее всего, захотите изменить настройку прав доступа. В данном примере я соглашаюсь с правами доступа, заданными по умолчанию. Щелкнув мышью на кнопке Next, вы перейдете к диалоговому окну Confirmation, где сможете просмотреть сводку действий, выполненных на предыдущих экранах мастера New Share Wizard. Вы можете щелкнуть мышью по кнопке Previous, чтобы вернуться к этим экранам и изменить любые параметры. Нажатие мышью кнопки Create в диалоговом окне Confirmations приведет к созданию ресурса CAFS и настройке прав доступа для общей папки. После того, как ресурс CAFS будет создан, мы сможете обратиться к нему, как к любой общей файловой папке. На экране 12 показано, как подключиться к общему ресурсу, введя в проводнике Windows Explorer имена сервера и общей папки – \\cafs-gen\CAFS-Gen.
|
|
| Экран 12. Подключение к общему ресурсу |
Теперь вы можете наполнить общую папку документами и файлами других типов, использование которых станет более эффективным благодаря высокой доступности ресурсов CAFS.
Создание масштабируемых ресурсов CAFS
Основная задача ресурсов CAFS — обеспечить высокий уровень доступности приложений, хранящих данные в общих файловых папках. В прошлом компания Microsoft не предоставляла поддержку такого типа для приложений, подобных системе SQL Server, хранящих свои базы данных на общих файловых ресурсах. Ситуация изменилась с выпуском платформы Server 2012, поддерживающей технологию CAFS. Настройка масштабируемых ресурсов CAFS отличается от настройки ресурсов CAFS общего назначения. Однако для создания масштабируемого решения используется тот же мастер High Availability Wizard. Чтобы создать новый ресурс CAFS для поддержки масштабируемых приложений, выберите ссылку Configure Role… в окне Actions оснастки Failover Cluster Manager (см. экран 1). Далее в диалоговом окне Select Role выберите роль File Server (см. экран 2). Эти два шага такие же, как при создании ресурса CAFS общего назначения. Однако, как показано на экране 13, в диалоговом окне File Server Type необходимо выбрать режим Scale-Out File Server for application data.
|
|
| Экран 13. Выбор режима масштабирования ресурсов |
Механизм масштабируемого файлового сервера разработан для приложений, которые оставляют свои файлы открытыми на продолжительное время. Щелкнув мышью кнопку Next, вы перейдете к диалоговому окну Client Access Point, показанному на экране 14.
|
|
| Экран 14. Окно Client Access Point |
Диалоговое окно Client Access Point позволяет вам задать имя для роли CAFS. Я назвал масштабируемый ресурс CAFS именем CAFS-Apps (экран 14). Это серверное имя, которое клиентские приложения используют при обращении к общему ресурсу. Щелкнув мышью кнопку Next, вы перейдете на экран Confirmation, где можно подтвердить выбранные решения или вернуться назад к окнам High Availability Wizard и внести изменения. Если все верно, щелкните мышью на кнопке Next экрана Confirmation, чтобы перейти к диалоговому окну Configure High Availability, который отображает прогресс настройки ресурса CAFS. По завершении процесса настройки вы увидите экран Summary. Щелчок мышью на кнопке Finish на экране Summary приведет к закрытию мастера High Availability Wizard и вернет вас к оснастке Failover Cluster Manager.
Следующий шаг — добавление общей файловой папки к CAFS-серверу масштабируемых приложений. Чтобы создать новый файловый ресурс для роли CAFS, выберите ссылку Add File Share из окна Actions, по аналогии с созданием файловой папки общего назначения на экране 6. Щелкните мышью по ссылке Add File Share для масштабируемого ресурса CAFS, чтобы запустить мастер New Share Wizard, показанный на экране 15.
|
|
| Экран 15. Выбор профиля для общего ресурса |
Для создания масштабируемого ресурса CAFS из диалогового окна Select Profile выделите профиль SMB Share—Applications в списке File share profile, после чего щелкните мышью кнопку Next, чтобы перейти к диалоговому окну Share Location, показанному на экране 16.
|
|
| Экран 16. Выбор файлового сервера масштабируемых приложений |
В поле Server в верхней части диалогового окна отображаются два файловых сервера CAFS, созданных ранее. Для добавления ресурса CAFS к файловому серверу масштабируемых приложений выберите файловый сервер CAFS-APPS с описанием Scale-Out File Server в столбце Cluster Role. После этого выберите том CSV, на котором вы хотите создать общий ресурс CAFS. В этом примере доступно два созданных общих ресурса кластера. В качестве места размещения нового ресурса CAFS я выбрал том C:\ClusterStorage\Volume1. При желании вы можете вручную ввести путь и к другому тому CSV. После выбора тома CSV нажмите кнопку Next для перехода к экрану Share Name, показанному на экране 17.
|
|
| Экран 17. Указание имени для файлового ресурса |
Диалоговое окно Share Name позволяет назначить имя для файлового ресурса. Ресурсу CAFS для масштабируемых приложений я присвоил имя HyperV-CAFS (экран 17). В центре экрана мы видим локальный и удаленные пути к ресурсу CAFS. Локальный путь в данном примере — C:\ClusterStorage\Volume1\Shares\HyperV-CAFS. Удаленные обращения к общей папке будут выполняться с использованием сетевого имени \\cafs-apps\HyperV-CAFS. Щелкните мышью на кнопке Next, чтобы перейти к диалоговому окну Configure, см. экран 18.
|
|
| Экран 18. Диалоговое окно Configure |
При создании масштабируемого ресурса CAFS флаг Enable continuous availability устанавливается по умолчанию.
Параметры Enable access-based enumeration и Allow caching of share отключены, вы не можете выбрать их. Единственный дополнительный параметр, который вы можете выбрать — Encrypt data access. Я оставил без изменений настройки, предложенные по умолчанию (экран 18). Щелкните кнопку Next, чтобы перейти к диалоговому окну Specify permissions to control access, показанному на экране 19.
|
|
| Экран 19. Разрешения для масштабируемого ресурса CAFS |
Как и ресурс CAFS общего назначения, масштабируемый ресурс CAFS создается с привилегиями Full Control, предоставленными группе Everyone, — и эти права доступа вы, скорее всего, захотите изменить. Я согласился с привилегиями, предложенными по умолчанию, нажал кнопку Next, открывающую диалоговое окно Confirmation, в котором вы можете просмотреть сводку по действиям, выполненным в предыдущих диалоговых окнах мастера New Share Wizard. Вы можете щелкнуть мышью кнопку Previous, чтобы вернуться назад и изменить любой из параметров. Нажатие кнопки Create в окне Confirmations приведет к созданию масштабируемого ресурса CAFS и настройке заданных прав доступа. После того, как ресурс создан, к нему можно подключиться локально, используя путь C:\ClusterStorage\Volume1\Shares\HyperV-CAFS, или удаленно, используя путь \\cafs-apps\HyperV-CAFS. Новый ресурс CAFS теперь виден в точке подключения тома CSV (экран 20).
|
|
| Экран 20. Новый ресурс CAFS |
Теперь вы можете наполнить ресурс виртуальными машинами Hyper-V, данными SQL Server, а также файлами журналов и данными приложений других типов.
Повышение доступности файлов
В данной статье я показал, как можно использовать ресурсы CAFS для повышения уровня доступности и гибкости элементов существующей инфраструктуры. Технология CAFS обеспечивает более высокую доступность файловых ресурсов общего назначения, а также позволяет серверным приложениям, таким как SQL Server и Hyper-V, хранить свои данные на файловых ресурсах с высоким уровнем доступности, предоставляя новые возможности для хранения данных критически важных приложений.