
В Windows Server 2012 появилась новая функция Data Deduplication (Дедупликация данных). Что же такое дедубликация? Дедупликация данных в общем случае – это процедура поиска и удаления дублирующих данных на носителе информации без ущерба для целостности информации. Цель дудупликации – хранить информацию в небольших блоках (32-128 Кб), выявлять одинаковые (дублирующие блоки) и сохранять только одну копию для каждого блока, а блоки-дубликаты заменять ссылками на единственную копию.
Ранее для организации дедупликации приходилось использовать сторонние продукты (существуют как аппаратные решение по дедупликации на уровне дисковых массивов, так и программные на уровне файлов). Стоимость подобных решений была достаточно высока, ведь они в первую очередь ориентированы на богатых корпоративных заказчиков. Теперь эта функция абсолютно бесплатно доступна всем пользователям a Windows Server 2012.
Есть небольшой хак, позволяющий включить дедупликацию и в клиентских ОС (Windows 8 и Windows 8.1).
В Windows Server 2012 функция дедупликация реализована в виде двух компонентов:
- Драйвера–фильтра, который контролирует функции ввода/вывода
- Службы дедупликации – контролирует три операции («Сборка мусора», «Оптимизация» и «Очистка»).
Указанные компоненты отвечают за поиск совпадающих данных, организации их хранения в единственном числе и корректное предоставление к ним доступа.
Ранее дедупликация в продуктах Microsoft встречалась в почтовом сервер Exchange 200/2003/2007 – в компоненте Single Instance Storage (на сервере в ящике одного из адресатов хранится только один экземпляр сообщения, а остальные адресаты получают просто ссылку на него).
Дедупликация данных в Windows Server 2012 выполняется в фоновом режиме и по-умолчанию запускается каждый час. Процесс запускается при низкой нагрузке на сервер и не снижает общую производительность сервера. Также по-умолчанию дедупликации подвергаются файлы, к которым не было доступа более 30 дней. Кроме того, процедура не осуществляется для следующих типов файлов:: aac, aif, aiff, asf, asx, au, avi, flac, jpeg, m3u, mid, midi, mov, mp1, mp2, mp3, mp4, mpa, mpe, mpeg, mpeg2, mpeg3, mpg, ogg, qt, qtw, ram, rm, rmi, rmvb, snd, swf, vob, wav, wax, wma, wmv, wvx, accdb, accde, accdr, accdt, docm, docx, dotm, dotx, pptm, potm, potx, ppam, ppsx, pptx, sldx, sldm, thmx, xlsx, xlsm, xltx, xltm, xlsb, xlam, xll, ace, arc, arj, bhx, b2, cab, gz, gzip, hpk, hqx, jar, lha, lzh, lzx, pak, pit, rar, sea, sit, sqz, tgz, uu, uue, z, zip, zoo.
Функционал управления дедупликацей доступен из графического интерфейса и через PowerShell. Рассмотрим оба варианта.
Windows Server 2012 Data Deduplication GUI
Чтобы включить дедупликацию данных нужно установить компонент Data Deduplicaion роли File and Storage Services. Сделать это можно из консоли Server Manahger.

После окончания установки компонента откройте консоль Server manager -> File and Storage Servcies -> Volumes –> и щелкните правой кнопкой по разделу, для которого хотите включить дедупликацию и выберите Configure Data Deduplication.

В следующем окне поставьте галочку на пункт “Enable data deduplication”. Здесь же можно указать каталоги, которые не нужно дедуплицировать и настройки планировщика дедупликации.
Текущий уровень дедупликации будет отображаться в столбце Deduplication Rate (обновится через несколько часов).

Для анализа использования дискового пространства и возможной экономии от включения дедупликаций для данного тома, разработана утилита DDPEVAL.exe. Оценить, сколько же дискового пространства получится сэкономить после включении Data deduplication, можно с помощью следующей команды (учтите, для больших томов она может создать существенную нагрузку на CPU)
c:\windows\system32\ddpeval.exe e:\
В моем случае экономия составила бы порядка 57%.

Дедупликация с Powershell
Процессом дедупликации можно управлять и из Powershell. Для этого нужно установить функцию Data-Deduplicationс помощью команд:
Import-Module ServerManager
Add-WindowsFeature -name FS-Data-Deduplication
Import-Module Deduplication
После того, как функция дедупликации включена, ее нужно сконфигурировать. Чтобы включить дедуплликацию для диска D:, выполним команду:
Enable-DedupVolume D:

По-умолчаию дедупликации подвергаются файлы, к которым не было доступа (Last Access)более 30 дней. Это значение можно изменить, например, на 2 дня, для этого выполните команду:
Set-DedupVolume D: -MinimumFileAgeDays 2
Обычно процесс дедупликации запускается планировщиком Windows, но его можно запустить и вручную:
Start-DedupJob D: –Type Optimization
Текущую статистику можно посмотреть с помощью команды:
Get-DedupStatus

Со списком текущих заданий можно познакомится с помощью команды:
Get-DedupJob
Все результаты работы для тома можно отобразить командой PoSH:
Get-DedupMetadata -Volume D:
И, наконец, полностью отменить дедупликацию для тома можно командой:
Start-DedupJob -Volume D: -Type Unoptimization
На скриншоте ниже видно, что после включения дедупликации на диске E: (для теста я сложил на него 4 одинаковых ISO с Windows 8), размер занятого места на диске уменьшился с 12 Гб до 3Гб.

Служба дедупликации хранит свою базу и дедуплицированные чанки в каталоге System Volume Information. Поэтому ни в коем случае не стоит вручную вмешиваться в его структуру.
Рекомендации по использованию технологии Data Deduplication в Windows Server 2012
Microsoft опубликовала следующие результаты исследования эффективности при дудупликации различных типов данных.
| Типы данных | Возможная экономия места |
| Общие данные | 50-60% |
| Документы | 30-50% |
| Библиотека приложений | 70-80% |
| Библиотека VHD(X) | 80-95% |
Основные особенности Data Deduplication в Windows Server 2012:
- Работает только на NTFS томах и не подерживает файловую систему ReFS
- Не поддерживается для загрузочных и системных томов
- Не работает со сжатыми и шифрованными файлами NTFS
- Поддерживает кеширование и BITS
- Не поддерживает файлы меньше 32KB
- Не настраивается через групповые политики
- Не поддерживает Cluster Shared Volumes
- Дедупликация – процесс не мгновенный и требует определённого времени
Рассмотрим само понятие дедупликации, инсталляцию компонентов и работу в Windows Server. Включение дедупликации на томе, использование Планировщика заданий, а также использование PowerShell для проверки статуса работы и управления.
Что такое дедупликация данных в Windows Server?
Файловый сервер предприятия – хороший пример, с помощью которого можно визуализировать, на сколько могут быть огромны объемы пользовательских данных. На файловом ресурсе можно найти множество копий одних и тех же файлов или близко схожих по внутренней структуре, т.е. в нескольких файлах будут дублироваться блоки данных. Одни и те же отчеты, письма, служебные документы пересылаются и сохраняются пользователями разных подразделений на одном и том же файловом сервере. А это, в свою очередь, приводит к появлению избыточных копий, которые влияют на эффективность хранения данных и последующего резервирования.
В традиционных средах хранения так и происходит. Дедупликация предоставляет средства для однократного сохранения данных и создания ссылок на фактическое расположение данных. Таким образом, среда хранения перестает хранить дублирующуюся информацию. Компания Microsoft также продолжает совершенствовать функции дедупликации. В Windows Server 2019 появилась возможность выполнять дедупликацию томов NTFS и ReFS. До Windows Server 2019 дедупликация ReFS была невозможна.
Как работает дедупликация данных Windows Server?
Для реализации дедупликации данных в Windows Server использует два принципа
- Процесс дедупликации с данными выполняется не моментально. Это означает, что процесс дедупликации не будет влиять на производительность в процессе записи файла. Когда данные записываются в хранилище, они не оптимизируются. После этого запускается процесс оптимизации дедупликации, чтобы гарантировать дедупликацию данных.
- Конечные пользователи не знают о процессе дедупликации — дедупликация в Windows Server полностью прозрачна. Пользователи не подозревают, что они могут работать с дедуплицированными данными.
Для успешной дедупликации данных в соответствии с принципами, перечисленными выше, Windows Server использует следующие шаги:
- Файловая система сканирует хранилище, чтобы найти файлы, соответствующие политике оптимизации дедупликации.
- Файлы дробятся на фрагменты.
- Идентифицируются уникальные фрагменты данных
- Фрагменты помещаются в хранилище фрагментов.
- Создаются ссылки на хранилище фрагментов, чтобы было перенаправление при чтении этих файлов на соответствующие фрагменты.
Использование дедупликации
Ниже описана примерная экономия места при использовании дедупликации.
- 80–95% для сред виртуализации VDI, ISO файлы.
- 70–80% для файлов программного обеспечения, файлов CAB и других файлов.
- 50–60% для общих файловых ресурсов, которые могут содержать огромное количество дублированных данных.
- 30–50% для стандартных пользовательских файлов, которые могут включать фотографии, музыку и видео.
Установка компонентов дедупликации в Windows Server
Процесс установки Data Deduplication прост. Дедупликация данных является частью роли файловых служб и служб хранения. Можно установить используя графический интерфейс Server Manager, используя Windows Admin Center или командлет PowerShell.

Включить Дедупликацию из PowerShell можно следующим командлетом:
Install-WindowsFeature -Name FS-Data-Deduplication


Третий способ установить Дедупликацию данных – через Windows Admin Center перейдя в меню Roles & Features и установить галку напротив Data Deduplication. Затем нажать Install. Windows Admin Center предварительно должен быть установлен!

Включение дедупликации данных на томе
После того, как была установлена Дедупликация данных, процесс включения на томе будет простым. Используя Server Manager (Диспетчер серверов) перейдите к File and Storage Services (Файловым службам и службам хранения) -> Volumes (Тома) -> Disks (Диски). Выберите нужный диск. Затем выберите том, который находится на диске, на котором нужно запустить процесс дедупликации.

Выберем Configure Data Deduplication
На этом этапе можно выбрать тип данных для дедупликации: файловый сервер, VDI или Backup Server, в Параметрах установить возраст файлов для дедупликации, возможность добавить файлы или папки для исключения.

Здесь же настраивается расписание

В конфигурации расписания можно добавить дополнительное задание на то время, когда сервер используется минимально, чтобы максимально использовать возможности дедупликации.
Выполнение запланированных задач дедупликации данных
После создания расписания, в Task Scheduler (Планировщик заданий) создается новая задача, работающая в фоновом режиме. По умолчанию процесс дедупликации стартует каждый час. Запустив Task Scheduler и перейдя по пути MicrosoftWindowsDeduplication можно запустить задачу BackgroundOptimization вручную.

Использование PowerShell для проверки работы и управления дедупликацией
В PowerShell имеются командлеты для мониторинга и управления дедупликацией
Get-DedupSchedule – покажет расписание заданий

Можно создать отдельное дополнительное задание по оптимизации дедупликации на томе E: с максимальным использованием ОЗУ 20%
Start-DedupJob -Volume "E:" -Type Optimization -Memory 20

Get-DedupStatus – отобразит состояние операций дедупликации и процент дедупликации

На данном этапе нет экономии места после включения дедупликации данных. В настройках расписания указано дедуплицировать файлы старше 2-х дней.
После запуска процесса мы начинаем видеть экономию места на томе.

Get-DedupMetadata — просмотр метаданных по дедупликации

Server Manager также отобразит измененную информацию.

Если нужно отключить использование дедупликации, нужно использовать два командлета:
Disable-DedupVolume -Volume <буква тома>
Start-DedupJob -type Unoptimization -Volume <буква тома>
Необходимо учесть, что обратный процесс уменьшит свободное пространство на томе и у вас должно быть достаточно для этого места.
Вывод
Дедупликация данных в Windows Server — отличный способ эффективно использовать место на устройствах хранения данных. С каждым выпуском Windows Server возможности дедупликации продолжают улучшаться. Дедупликация обеспечивает огромную экономию места, особенно для файловых серверов и сред виртуализации VDI. Для последних экономия места может достигать 80 и более %.
Использование дополнительных опций, таких как расписание, управление типами файлов и возможность использовать исключения позволяет гибко настраивать дедупликацию. PowerShell предоставляет несколько командлетов, которые позволяют взаимодействовать, управлять и контролировать дедупликацию данных в Windows Server.
Всем доброго времени суток!
Сегодня хотелось бы провести обзор такой интересной новой фичи в Windows Server 2012 как дедупликация данных (data deduplication). Фича крайне интересная, но все же сначала нужно разобраться насколько она нужна…

А нужна ли вообще деупликация?
С каждым годом (если не днем) объемы жестких дисков растут, а при этом носители сами еще и дешевеют.
Исходя из этой тенденции возникает вопрос: «А нужна ли вообще дедупликация данных?».
Однако, если мы с вами живем в нашей вселенной и на нашей планете, то практически все в этом мире имеет свойство подчиняться 3-му закону Ньютона. Может аналогия и не совсем прозрачная, но я подвожу к тому, что как бы не дешевели дисковые системы и сами диски, как бы не увеличивался объем самих носителей — требования с точки зрения бизнеса к доступному для хранения данных пространства постоянно растут и тем самым нивелируют увеличение объем и падение цен.
По прогнозам IDC примерно через год в суммарном объеме будет требоваться порядка 90 миллионов терабайт. Объем, скажем прямо, не маленький.

И вот тут как раз вопрос о дедупликации данных очень сильно становится актуальным. Ведь данные, которые мы используем бывают и разных типов, и назначение у них могут быть разные — где-то это production-данные, где-то это архивы и резервные копии, а где-то это потоковые данные — я специально привел такие примеры, поскольку в первом случае эффект от использования дедупликации будет средним, в архивных данных — максимальным, а в случае с потоковыми данным — минимальным. Но все же экономить пространство мы с вами сможем, тем более что теперь дедупликация — это удел не только специализированных систем хранения данных, но и компонент, фича серверной ОС Windows Server 2012.
Типы дедупликации и их применение
Прежде чем перейти к обзору самого механизма дедупликации в Windows Server 2012, давайте разберемся какие типы дедупликации бывают. Предлагаю начать сверху-вниз, на мой взгляд так оно будет нагляднее.
1) Файловая дедупликация — как и любой механизм дедупликации, работа алгоритма сводится к поиску уникальных наборов данных и повторяющихся, где вторые типы наборов заменяются ссылками на первые наборы. Иными словами алгоритм пытается хранить только уникальные данные, заменяя повторяющиеся данные ссылками на уникальные. Как нетрудно догадаться из названия данного типа дедупликации — все подобные операции происходят на уровне файлов. Если вспомнить историю продуктов Microsoft — то данный подход уже неоднократно применялся ранее — в Microsoft Exchange Server и Microsoft System Center Data Protection Manager — и назывался этот механизм S.I.S. (Single Instance Storage). В продуктах линейки Exchange от него в свое время отказались из соображений производительности, а вот в Data Protection Manager этот механизм до сих пор успешно применяется и кажется будет продолжать это делать. Как нетрудно догадаться — файловый уровень самый высокий (если вспомнить устройство систем хранения данных в общем) — а потому и эффект будет самый минимальный по сравнению с другими типами дедупликации. Область применения — в основном применяется данный тип дедупликации к архивным данным.
2) Блочная дедупликация — данный механизм уже интереснее, поскольку работает он суб-файловом уровне — а именно на уровне блоков данных. Такой тип дедупликации, как правило характерен для промышленных систем хранения данных, а также именно этот тип дедупликации применяется в Windows Server 2012. Механизмы все те же, что и раньше — но на уровне блоков (кажется, я это уже говорил, да?). Здесь сфера применения дедупликации расширяется и теперь распространяется не только на архивные данные, но и на виртуализованные среды, что вполне логично — особенно для VDI-сценариев. Если учесть что VDI — это целая туча повторяющихся образов виртуальных машин, в которых все же есть отличия друг от друга (именно по этому файловая дедупликация тут бессильна) — то блочная дедупликация — наш выбор!
3) Битовая дедупликаия — самый низкий (глубокий) тип дедупликации данных — обладает самой высокой степенью эффективности, но при этом также является лидером по ресурсоемкости. Оно и понятно — проводить анализ данных на уникальность и плагиатичность — процесс нелегкий. Честно скажу — я лично не знаю систем хранения данных, которые оперируют на таком уровне дедупликации, но я точно знаю что есть системы дедупликации трафика, которые работают на битовом уровне, допустим тот же Citrix NetScaler. Смысл подобных систем и приложений заключается в экономии передаваемого трафика — это очень критично для сценариев с территориально-распределенными организациями, где есть множество разбросанных географически отделений предприятия, но отсутствуют или крайне дороги в эксплуатации широкие каналы передачи данных — тут решения в области битовой дедупликации найдут себя как нигде еще и раскроют свои таланты.
Очень интересным в этом плане выглядит доклад Microsoft на USENIX 2012, который состоялся в Бостоне в июне месяце. Был проведен достаточно масштабный анализ первичных данных с точки зрения применения к ним механизмов блочной дедупликации в WIndows Server 2012 — рекомендую ознакомиться с данным материалом.
Вопросы эффективности
Для того чтобы понять насколько эффективны технологии дедупликации в Windows Server 2012, сначала нужно определить на каком типе данных эту самую эффективность следует измерять. За эталоны были взяты типичные файловые шары, документы пользователей из папки «Мои документы», Хранилища дистрибутивов и библиотеки и хранилища виртуальных жестких дисков.
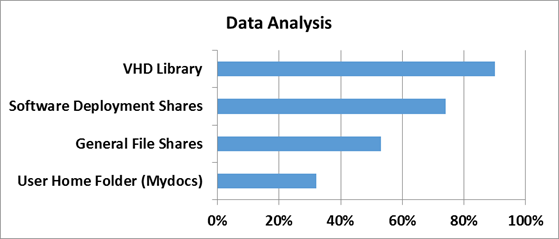
Насколько же эффективна дедупликация с точки зрения рабочих нагрузок проверили в Microsoft в отделе разработки ПО.
3 наиболее популярных сценария стали объектами исследования:
1) Сервера сборки билдов ПО — в MS каждый день собирается приличное количество билдов самых разных продуктов. Даже не значительно изменение в коде приводит к процессу сборки билда — и следовательно дублирующихся данных создается очень много
2) Шары с дистрибутивами продуктов на релиз — Как не сложно догадаться, все сборки и готовые версии ПО нужно где-то размещать — внутри Microsoft для этого есть специальные сервера, где все версии и языковые редакции всех продуктов размещаются — это тоже достаточно эффективный сценарий, где эффективность от дедупликации может достигать до 70%.
3) Групповые шары — это сочетание шар с документами и файлами разработчиков, а также их перемещаемые профили и перенаправленные папки, которые хранятся в едином центральном пространстве.

А теперь самое интересное — ниже приведен скриншот с томами в Windows Server 2012, на которых размещаются все эти данные.

Я думаю слова здесь будут лишними — и все и так очень наглядно. Экономия в 6 Тб на носителях в 2 Тб — термоядерное хранилище? Не так опасно — но столь эффективно!
Характеристики дедупликации в Windows Server 2012
А теперь давайте рассмотрим основные характеристики дедупликации в Windows Server 2012.
1) Прозрачность и легкость в использовании — настроить дедупликацию крайне просто. Сначала в мастере ролей в Windows Server вы раскрывайте роль File and Storage Services, далее File and iSCSI Services — а у же там включаете опцию Data Deduplication.
После этого в Server Manager вы выбираете Fike and Storage Services, клик правой кнопкой мыши — и там вы выбираете пункт «Enable Volume Deduplication». Спешл линк для любителей PowerShell. Все крайне просто. С точки зрения конечного пользователя и приложений доступ и работа с данными осуществляются прозрачно и незаметно. Если говорить про дедупликацию с точки зрения фаловой системы — то поддерживается только NTFS. ReFS не поддается дедупликации, ровно как и тома защищенные с помощью EFS (Encrypted Fike System). Также под дедупликацию не попадают фалы объемом менее 32 KB и файлы с расширенными атрибутами (extended attributes). Дедупликация, однако, распространяется на динамические тома, тома зашифрованные с помощью BitLocker, но не распространяется на тома CSV, а также системные тома (что логично).
2) Оптимизация под основные данные — стоит сразу отметить, что дедупликация — это не онлайн-процесс. Дедупликации подвергаются файлы, которые достигают определенного уровня старости с точки зрения задаваемой политики. После достижения определенного срока хранения данные начинают проходить через процесс дедупликации — по умолчанию этот промежуток времени равен 5 дням, но никто не мешает вам изменить этот параметр — но будьте разумны в своих экспериментах!
3) Планирование процессов оптимизации — механизм который каждый час проверяет файлы на соответствия параметрам дедупликации и добавляет их в расписание.
4) Механизмы исключения объектов из области дедупликации — данный механизм позволяет исключит файлы из области дедупликации по их типу (JPG, MOV, AVI — как пример, это потоковые данны — то, что меньше всего поддается дедупликации — если вообще поддается). Можно также исключить сразу целые папки с файлами из области дедупликации (это для любителей немецких фильмов, у которых их тьма-тьмущая).
5) Мобильность — дедуплицированный том — это целостный объект — его можно переносить с одного сервера на другой (речь идет исключительно о Windows Server 2012). При этом вы без проблем получите доступ к вашим данным и сможете продолжить работу с ними. Все что для этого необходимо — это включенная опция Data Deduplication на целевом сервере.
6) Оптимизация ресурсоемкости — данные механизмы подразумевают оптимизацию алгоритмов для снижения нагрузки по операциям чтения/записи, таким образом если мы говорим про размер хеш-индекса блоков данных, то размер индекса на 1 блок данных составляет 6 байт. Таким образом применять дедупликацию можно даже к очень массивным наборам данных.
Также алгоритм всегда проверяет достаточно ли ресурсов памяти для проведения процесса дедупликации — если ответ отрицательный, то алгоритм отложит процесс до высвобождения необходимого объема ресурсов.
7) Интеграция с BranchCache — механизмы индексация для дедупликация являются общими также и для BranchCache — поэтому эффективность использования данных технологий в связке не вызывает сомнений!
Вопросы надежности дедуплицированных томов
Вопрос надежности крайне остро встает для дедуплицированных данных — представьте, что блок данных, от корого зависят по-крайней мере 1000 файлов безнадежно поврежден… Думаю, валидол-эз-э-сервис тогда точно пригодится, но не в нашем случае.
1) Резервное копирование — Windows Server 2012, как и System Center Data Protection Manager 2012 SP1 полностью поддерживают дедуплицированные тома, с точки зрения процессов резервного копирования. Также доступно специальное API, которое позволяет сторонним разработчикам использовать и поддерживать механизмы дедупликации, а также восстанавливать данные из дедуплицированных архивов.
2) Дополнительные копии для критичных данных — те данные, которые имеет самый частый параметр обращения продвергаются процессу создания дополнительных резервных блоков — это особенности алгоритма механизма. Также, в случае использования механизмов Storage Spaces, при нахождение сбойного блока, алгоритм автоматически заменяет его на целостный из пары в зеркале.
3) По умолчанию, 1 раз в неделю запускается процесс нахождения мусора и сбойных блоков, который исправляет данные приобретенные патологии. Есть также возможность вручную запустить данный процесс на более глубоком уровне. Если процесс по умолчанию исправляет ошибки, которые были зафиксированы в логе событий, то более глубокий процесс подразумевает сканирование всего тома целиком.
С чего начать и как померить
Перед тем как включать дедупликацию, всегда нормальному человеку в голову придет мысль о том насколько эффективен будет данный механизм конкретно в его случае. Для этого вы можете использовать Deduplication Data Evaluation Tool.
После установки дедупликации вы можете найти инструмент под названием DDPEval.exe, который находится в \Windows\System32\ — данная утиль может быть портирована на сменный носитель или другой том. Поддерживаются ОС Windows 7 и выше. Так что вы можете проанализировать ваши данный и понять стоимость овечье шкурки. (смайл).
На этом мой обзор завершен. Надеюсь вам было интересно. Если у вас возникнут вопросы — можете смело найти меня в соц.сетях — ВКонтакте, Facebook — по имени и фамилии — и я постараюсь вам помочь.
Для тех, кто хочет узнать про новые возможности в Windows Server 2012, а также System Center 2012 SP1 — я всех приглашаю посетить IT Camp — 26 ноября, накануне TechEd Russia 2012 состоится данное мероприятие — проводить его будем я, Георгий Гаджиев и Саймон Перриман, который специально прилетает к нам из США.
До встречи на IT Camp и на TechEd!
С уважением,
человек-огонь
Георгий А. Гаджиев
Microsoft Corporation
Возможность дедупликации данных впервые появилась еще в Windows Server 2012. В Windows Server 2016 представлена уже третья версия компонента дедупликации, значительно переработанная и улучшенная. В этой статье мы поговорим о новых функциях дедупликации, ее настройках и отличиях от предыдущих реализаций.
- Новые возможности дедупликации данных в Windows Server 2016
- Установка компонента дедупликации в Windows Server 2016
- Включение и настройка дедупликации
- Ручной запуск дедупликации
- Просмотр состояния дедупликации
- Как отключить дедупликацию
Содержание:
Новые возможности дедупликации данных в Windows Server 2016
-
- Многопоточность. Первое и самое важное изменение в дедупликации данных в Windows Server 2016 — введение многопоточности. Дедупликация в Windows Server 2012 R2 работала только в однопоточном режиме и не могла использовать более одного процессорного ядра для одного тома. Это сильно ограничивало производительность, и для обхода этого ограничения необходимо было разбивать диски на несколько томов меньшего размера. Максимальный размер тома не должен превышать 10 Тб.
Обновленный движок дудупликации в Windows Server 2016 выполнять задания дедупликации в многопоточном режиме, причем каждый том использует несколько вычислительных потоков и очередей ввода-вывода. Введение многопоточности и других изменений в компоненте сказалось на ограничениях на размер файлов и томов. Поскольку многопоточная дедупликация повышает производительность и устраняет необходимость разбиения диска на несколько томов в Windows Server 2016, вы можете использовать дедупликацию для тома до 64 ТБ. Также увеличен максимальный размер файла, теперь поддерживается дедупликация файлов до 1 Тб. - Поддержка виртуализированных приложений резервного копирования. В Windows Server 2012 был только один тип дедупликации, предназначенный в основном для обычных файловых серверов. Дедупликация непрерывно работающей ВМ не поддерживается, поскольку дедупликации не знает, как работать с открытыми файлами.
Дедупликация в Windows Server 2012 R2 начала использовать VSS, соответственно, стала поддерживаться дедупликация виртуальных машин. Для таких задач использовался отдельный тип дедупликации.В Windows Server 2016 добавлен еще третий тип дедупликации, предназначенный специально для виртуализированных серверов резервного копирования (например, DPM). - Поддержка Nano Server. Nano Server – эта технология позволяет развертывать операционную систему Windows Server 2016 с минимальным количеством установленных компонентов. Nano Server полностью поддерживает дедупликацию.
- Поддержка последовательного обновления кластера (Cluster OS Rolling Upgrade). Cluster OS Rolling Upgrade – это новая функция Windows Server 2016, которая может использоваться для обновления операционной системы на каждом узле кластера с Windows Server 2012 R2 до Windows Server 2016 без остановки кластера. Это возможно благодаря специальной смешанной работе кластера, когда узлы кластера одновременно могут работать под управлением Windows Server 2012 R2 и Windows Server 2016.Смешанный режим означает, что одни и те же данные могут быть расположены на узлах с разными версиями компонента дедупликации. Дедупликация в Windows Server 2016 поддерживает этот режим и обеспечивает доступ к дедуплицированным данным в процессе обновления кластера.
- Многопоточность. Первое и самое важное изменение в дедупликации данных в Windows Server 2016 — введение многопоточности. Дедупликация в Windows Server 2012 R2 работала только в однопоточном режиме и не могла использовать более одного процессорного ядра для одного тома. Это сильно ограничивало производительность, и для обхода этого ограничения необходимо было разбивать диски на несколько томов меньшего размера. Максимальный размер тома не должен превышать 10 Тб.
Установка компонента дедупликации в Windows Server 2016
Первое, что нужно сделать, чтобы включить дедупликацию — это установить соответствующую роль сервера. Запустите Server Role wizard и добавьте роль файлового сервера с компонентом «Data Deduplication».
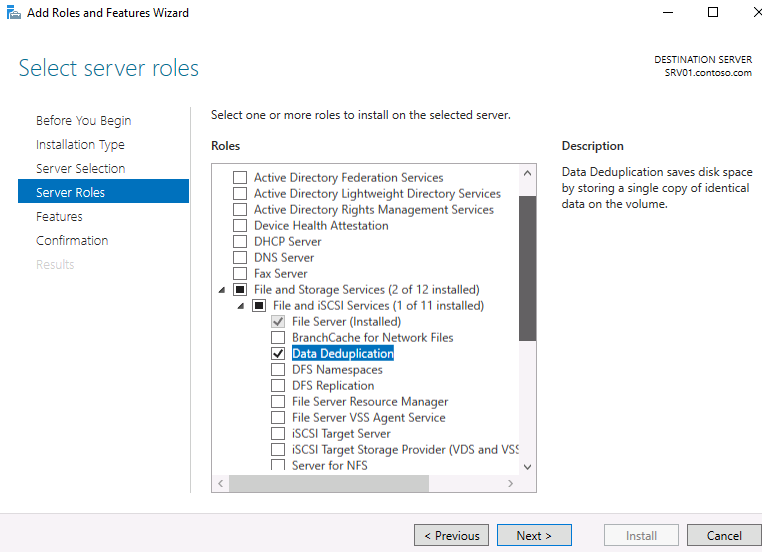
Или выполните следующую команду PowerShell:
Install-WindowsFeature -Name FS-Data-Deduplication -IncludeAllSubfeature -IncludeManagementTools

Включение и настройка дедупликации
После установки компонентов вам необходимо включить дедупликацию для определенного тома (или нескольких томов). Это можно сделать двумя способами: с помощью графического интерфейса или с помощью PowerShell.
Чтобы настроить компонент из GUI, откройте Server Manager, перейдите в File and storage services -> Volumes, выберите нужный том, щелкните правой кнопкой мыши и в меню выберите «Configure Data Deduplication».
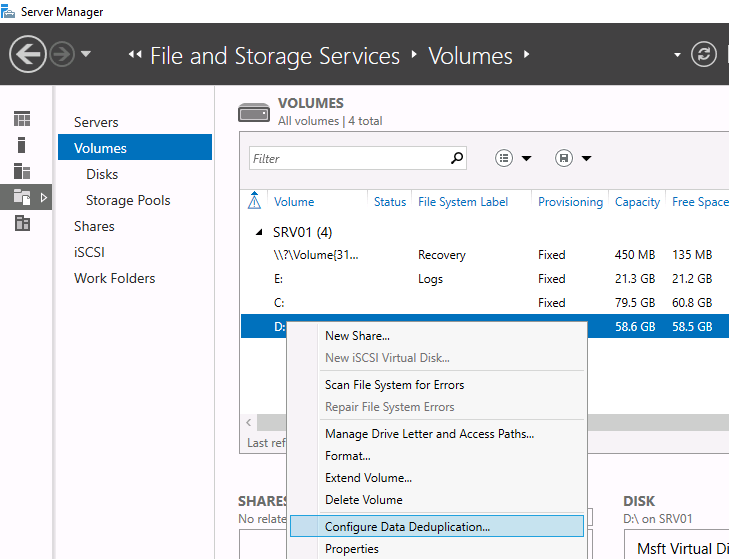
Затем выберите нужный тип дедупликации (например, General puprose file server) и нажмите «Применить». Кроме того, вы можете указать типы файлов, которые не должны подвергаться дедупликации, а также создать исключения для определенных каталогов (каталоги с мультимедиа файйлами, базами и т.д.).
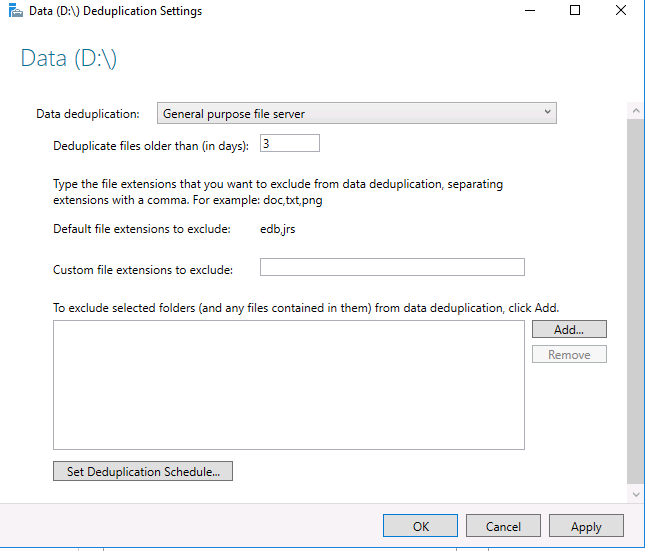
Затем вам необходимо настроить расписание, по которому будет работать задание дедупликации. Нажмите кнопку Set Deduplication Schedule.
По умолчанию включена фоновая оптимизация (background optimization), и вы можете настроить две дополнительные задачи принудительной оптимизации (throughput optimization). Здесь есть несколько настроек — вы можете выбрать дни недели, время начала и продолжительность работы.
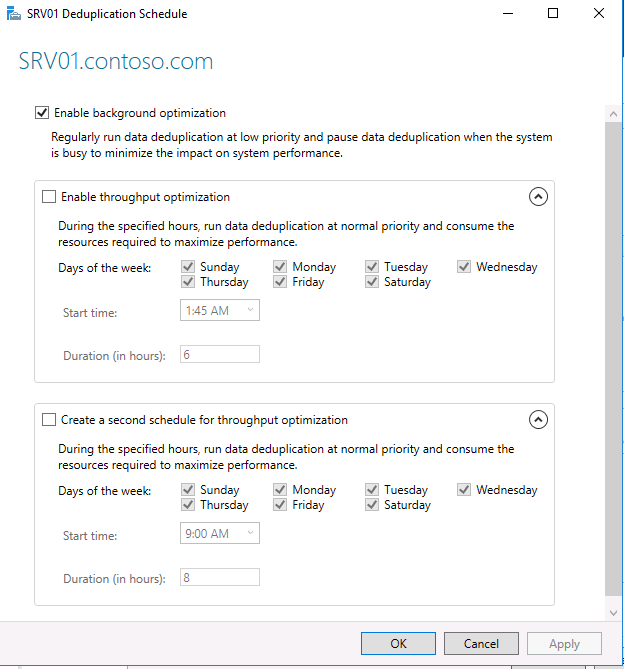
Еще больше возможностей для настройки дедупликации предоставляет PowerShell. Чтобы включить дедупликацию, используйте следующую команду:
Enable-DedupVolume -Name D: -UsageType HyperV
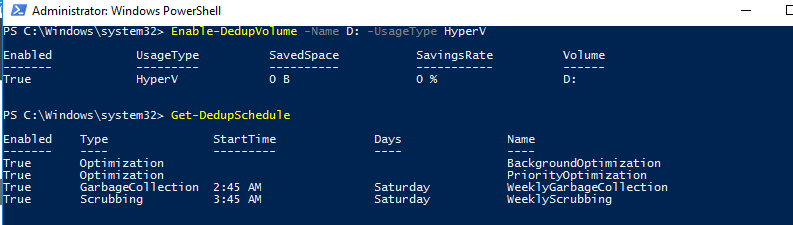
Список текущих заданий дедупликации:
Get-DedupSchedule
Как вы видите, в дополнении к фоновой задачи оптимизации есть задача приоритетной оптимизации (PriorityOptimization), а также задания по сбору мусора (GarbageCollection) и очистке (Scrubbing). Все эти задачи нельзя увидеть в графическом интерфейсе.
PowerShell позволяет вам точно настроить параметры заданий дедупликации. Например, создадим такую задачу оптимизации: задача должна запускаться в 9 утра с понедельника по пятницу и работать 11 часов, с нормальным приоритетом, используя не более 20% ОЗУ и 20% CPU:
New-DedupSchedule -Name ThroughputOptimization -Type Optimization -Days @(1,2,3,4,5) -DurationHours 11 -Start (Get-Date ″20/05/2017 9:00 PM″) -Memory 20 -Cores 20 -Priority Normal
Отключим приоритетную оптимизацию:
Set-DedupSchedule -Name PriorityOptimization -Enabled $false
Ручной запуск дедупликации
При необходимости вы можете запустить задание дедупликации вручную. Например, запустим полную оптимизацию тома D: с наивысшим приоритетом:
Start-DedupJob -Volume D: -Type Optimization -Memory 75 -Cores 100 -Priority High -Full

Отслеживать выполнение заданий дедупликации можно с помощью команды Get-DedupJob. Заметим, что одновременно может выполняться только одна такая задача, остальные при этом находятся в очереди и ждут ее завершения.
Просмотр состояния дедупликации
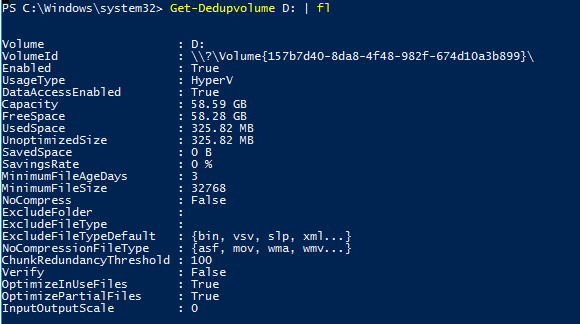
Состояние дедупликации данных для тома можно просмотреть, используя команду:
Get-DedupVolume -Volume D: | fl
Таким образом, вы можете видеть основные параметры тома — общий размер тома, использованный и сохраненный объем, уровень сжатия и т.д.
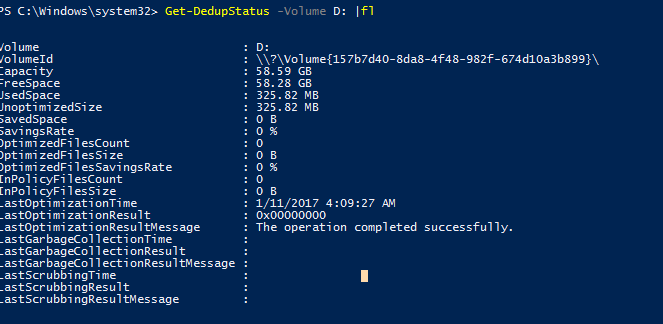
Чтобы проверить статус задания дедупликации, используйте команду:
Get-DedupStatus -Volume D: | fl
Как отключить дедупликацию
Вы можете отключить дедупликацию на диске из графического интерфейса или с помощью PowerShell. Например:
Disable-DedupVolume -Name D:

Отключение дедупликации для тома отменяет все запланированные задачи, а также предотвращает выполнение любых задач дедупликации, кроме операций на чтение (таких команд, как Get и unoptimization). Данные при этом остаются в неизменном состоянии, останавливается лишь дедупликация новых файлов.
Чтобы вернуть данные в исходное состояние, используйте процедуру обратной дедупликации. Например, выполните следующую команду для выполнения дедупликации данных на диске D с максимально возможной скоростью:
Start-DedupJob -Volume D: -Type Unoptimization -Memory 100 -Cores 100 -Priority High -Full

Обратите внимание, что для выполнения раздедупликации потребуется дополнительное пространство. Если свободного места на томе недостаточно, процедура не будет выполнена.
In starting to write on this topic I had intended to share a concise guide on my recommended methodology for handling disk images which contain Windows Server Data Deduplication, however as I delved a little deeper into research my inaugural post started to get a little unwieldy. I have split the original post into two parts, this first post serves as an introduction to Data Deduplication and speaks to how to identify whether a system or disk image has Data Deduplication enabled. If you already have a disk image and want to jump straight into how to extract the deduplicated data please head over to the second post in this series, Forensic Analysis of Volumes with Data Deduplication.
What is Data Deduplication
The Data Deduplication (‘Dedupe’) I am referring to in this post is specifically the Microsoft Server feature, while other similar technologies exist in other operating systems and for different filesystems these are not addressed here. Since Windows Server 2012 Microsoft has provided system administrators the option to enable Data Deduplication, which to paraphrase their description, is designed to assist in the reduction of costs associated with duplicated data. When enabled, «duplicate portions of the volume’s dataset are stored once and are (optionally) compressed for additional savings».
The Dedupe feature shouldn’t be confused with the Single-Instance Storage (‘SIS’) feature which was made available in Windows Storage Server 2008 R2 and could be found in Exchange Server previous to then; I may address SIS in a subsequent post.
There are a multitude of Microsoft and Third-Party resources which describe the functionality of Dedupe, a few good primers are available here (Server 2012), here (Server 2016) and here (Server 2012, 2016 and other deduplication technologies).
The key takeaways as they impact forensic analysis are as follows:
- Data Duplication cannot be enabled on the system or boot volumes and as such, in many investigations — particularly IR, the presence of Dedupe may not impact much of the analysis.
- By default Data Duplication will not impact certain filetypes and additional custom exclusions can be added/defined when the administrator enables the feature.
- It works below file level, deduplicating chunks of files rather than whole files and unique chunks are stored in the Chunk Store.
- Chunks stored in the Chunk Store can be compressed, again there is a default and customisable exclusion list. This will impact keyword searching and file examination in tools which are not Dedupe-aware (SPOILER ALERT: None of the major forensic tools are currently capable of processing Data Deduplication natively).
- Original file streams are replaced with a reparse points to the chunk store. Notably, these files are initially written to disk as per usual and then deduplicated on a scheduled basis with the original files being deleted, this introduces the possibility that the original files may be recoverable via traditional carving.
The Problem with Data Deduplication
While Dedupe has been available since Windows Server 2012, I was essentially unaware of it until mid-2017 when a colleague encountered it during a case which revolved around multiple Windows Server 2016 systems, many of which had the feature enabled. When conducting AV scans of the imaged physical disks a huge number of errors occurred relating to files being inaccessible. When these errors were explored it was identified that the files at each location were not in fact files, but reparse points.
The same issue arises when attempting to analyse a disk image which contains deduplicated data in forensic tools, carve data or keyword search. At the time of writing, and to the best of my knowledge, none of the major forensic suites recognise or handle Dedupe, likewise if one were to simply connect a drive to a computer system running a different operating system, or even the same operating system without the feature enabled the files would be unreadable.
My default position when capturing images of physical systems is to take a full physical disk image, and possibly a secondary logical image of the key volumes if the system is live and known to have Full Disk Encryption. Likewise, when acquiring virtual servers, it is often easier and more forensically sound to be provided with copies of full flat VMDKs or VHDs than to perform live imaging within the virtual environment. As such, it is easy to come away with images which contain deduplicated data without realising it, especially if you don’t explicitly check or ask the system owner at the time of acquisition.
How to check for Data Deduplication
If you approach a live system and you need to determine whether data deduplication is enabled on any of its volumes you can achieve this in a number of ways. The simplest way is to review the configuration within Server Manager.
In Server Manager, under File and Storage Services, and Volumes you can review the available volumes. Per the below screenshot any volume with active data deduplication will display a non-zero ‘Deduplication Rate’ and ‘Deduplication Saving’, as per the below screenshot:

If Data Deduplication is either not enabled or not installed then the same columns appear, however they will contain no values:

We can also check for the presence of dedupe via PowerShell. If we attempt to execute the PowerShell command ‘Get-DedupeStatus’ the output will tell us whether Dedupe is enabled on any volumes.
In the event that the Dedupe feature is not installed you will receive an error indicating that «the term ‘Get-DedupStatus’ is not recognised as the name of a cmdlet, function, script file, or operable program». This is because PowerShell cmdlets associated with optional features are only installed when those optional features are installed (in most cases). An example of the error you can expect is provided in the screenshot below:

If the data deduplication feature is installed, but not currently enabled on any volumes, you will return to the prompt without any further output (as below):

If it is installed and enabled you will receive output as below, this screenshot indicates that it is enabled on the E: volume:

Granted, relying upon the presence or absence of errors to confirm the system configuration is a little inelegant. If you wish to double check whether Data Deduplication feature is currently installed, this can be confirmed with:
Get-WindowsFeature -Name *Dedup*
This command will return all Windows Features for that OS containing «dedup» in their Name, such as ‘FS-Data-Deduplication’, and indicate their status. In the below screenshots the absence of an ‘X’ inside the square brackets and the ‘Install State’ of ‘Available’ confirm the feature is not currently installed and the presence of an ‘X’ and an ‘Install State’ of ‘Installed’… should be self-explanatory.
Get-WindowsFeature -Name Dedup output where Data Deduplication IS NOT enabled:
Get-WindowsFeature -Name Dedup output where Data Deduplication IS enabled
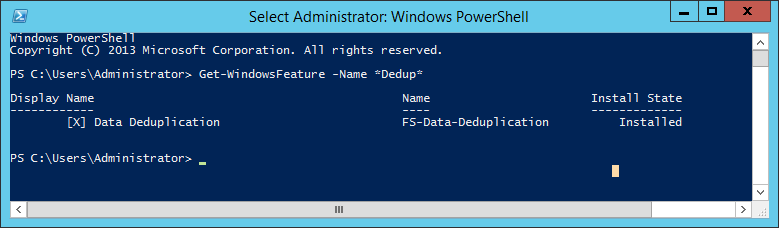
The same can be confirmed within the warmth and comfort of a GUI by reviewing the configuration in the ‘Add Roles and Features’ Wizard. From the Add Roles and Features Wizard, under Server Roles, File and Storage Services, File and iSCSI Services you will find the checkbox for Data Deduplication. If its Checked, it’s installed.
Checking a Disk Image for Data Deduplication
But what if you didn’t check in advance for data deduplication and you already have an image which you believe may contain deduplicated data. Fear not, a brief examination of the image will allow you to determine whether dedupe was enabled.
Most obviously, and the way many will stumble across the issue is through examining the data files contained on the drive. Unfortunately, it is easy to miss unless you actually review individual files.
Autopsy, EnCase, FTK, X-Ways and indeed Windows Explorer do little to warn you in advance that the data presented is not as it seems. Within Autopsy the default table view does little to indicate that the files are anything other than regular files. The filename, extension and metadata associated with the file are displayed as consistent with the true underlying file, and indeed the values at they appear in the MFT, but when a file is selected the Hex view would seem to indicate that the file at that location is zero filled:

A review of the ‘File Metadata’ tab does highlight that the deduplicated files have the SI Attribute ‘Reparse Point’ flag set, but it isn’t immediately obvious when taking a cursory review.
Things can become a little clearer depending on your processing options. If you enable the Extension Mismatch Detection processing option the files which have been deduplicated will be flagged as their content does not match their extension. Likewise, errors in processing compound files may serve as an additional warning.
EnCase is similar in that the files present as Zero-filled when viewed in hex view. Within Table Pane the tell-tale signs are the fact that EnCase does not specify a starting extent for the deduplicated files and notes them to be Symbolic Links (Sym Link) in the Description column. Additionally, depending on the processing options you enable, the reparse points will not have the Signature Analysis, File Type, MD5, SHA1 or Entropy columns populated while regular files will.

Similar behaviour is observed within FTK, FTK Imager and X-Ways. Notably, FTK Imager, due to its limited data displayed in the default view actually makes the files stand out somewhat more as it assigns the value of ‘Reparse Point’ within the Type column as opposed to ‘Regular File’.

X-Ways Forensics will highlight the reparse points in blue when the ‘Verify file types with signatures and algorithms’ processing option is enabled as it highlights the fact that the file signature does not match the extension.

It is also worth noting that when an image or a drive containing Deduplicted data is presented to a Windows OS which is not «Dedupe Aware», and browsed in Windows Explorer there is nothing to indicate that anything is amiss until one attempts to access the data. The below screenshot is of a VMDK containing Deduplicated data presented to Windows 10 using FTK Imager’s ‘Mount Image’ function.

Only once you try to access the files do you start to receive errors, the specific error will depend on the application associated with each filetype, some examples are provided below:

When performing a check of files in this manner in an attempt to identify whether data deduplication is in use the following things should be noted:
- Even when Data Deduplication is enabled files under a certain size will not be deduplicated, specifically files under 32kb.
- Certain filetypes can be excluded from deduplication, and file exclusions are configurable by the system administrator.
- It is possible for a volume to have a mix of deduplicated and duplicated data of the same filetype and size. The process of deduplicating files is referred to as ‘optimizing’ in Microsoft vernacular and by default files are only ‘optimized’ after they are a certain number of days old on disk. By default this is 3 days, but it is configurable.
- It is further possible for a volume to have a mix of deduplicated and duplicated data as a result of failed or incomplete unoptimization. Unoptimization is covered in more detail in the Unoptimization section below.
- Deduplication can be enabled on some volumes and not others, as such just because it is not employed on one volume doesn’t mean it isn’t used on another.
Evidently, while performing a spot check review of the data is certainly the quickest and dirtiest approach to identifying whether data deduplication is at play, it is hardly fool proof. In any event, we are forensicators and if we want to understand the configuration and settings of a Windows host there is nowhere we would rather be than knees deep in the registry.
A simple regshot before and after configuration changes is commonly the quickest way to test for and identify useful forensic artifacts. This was employed to compare the registry between a fresh OS install, just after installation of the data deduplication feature and subsequently after enabling data deduplication for one volume in both Server 2012 and 2016, in an effort to identify the which would speak to whether deduplication was installed and enabled.
The first point to note is that installation of the deduplication feature in Server 2012 resulted in the creation of 85525 registry keys, the addition of 322778 new values and the deletion of 2 values. Full disclosure: I have not reviewed all of these. With that said a cursory review identified a number of notable additions, specifically:
HKLM\SYSTEM\CurrentControlSet\Services\ddpsvc
HKLM\SYSTEM\CurrentControlSet\Services\ddpvssvc
HKLM\SYSTEM\CurrentControlSet\Services\Dedup
The presence of these Registry keys indicates that the ‘Data Deduplication’ feature has been installed. If the feature is subsequently uninstalled these keys are deleted. The fact that this feature has been installed doesn’t of course mean that it has been enabled on any volume however it is a key indication that caution is advisable.
When Data Deduplication has been enabled for a volume a registry key is created at:
HKLM\SYSTEM\CurrentControlSet\Services\ddpsvc\PerfTrace
This key is populated with subkeys related to the volumes for which Dedupe has been enabled e.g. when the E volume had it enabled a subkey is created at:
HKLM\SYSTEM\CurrentControlSet\Services\ddpsvc\PerfTrace\E__volume
While there are technical differences between the implementation of Data Deduplication between Server 2012 and Server 2016, the first obvious difference during analysis comes when examining the registry. When data deduplication is enabled in Server 2012 a single subkey is created for each volume, as per the screenshot below:

When the same change is enabled within Server 2016 we see two subkeys created for each volume which has Data Deduplication enabled, the same ‘[VOLUME_LETTER]__volume’ key and a further ____[volume_letter]___ key:

The presence of these Registry keys indicates that the Data Deduplication feature has been enabled for the volumes which are referenced in the key name. It should be noted however, that if Data Deduplication is then disabled and the volumes ‘Unoptimized’, the keys persist. Further analysis is required to identify a reliable artifact which can be examined to determine whether and where Dedupe is enabled.
Credit must go to the to the venerable Charlotte Hammond (@gh0stp0p) who took one look at this question and suggested “it might be worth looking at the file paths and location of the ChunkStore and other related directories”, and as per usual she was right.
When Data Deduplication is enabled for a volume, a ‘Dedup’ directory is created under the System Volume Information. This directory contains lots of useful information including the Chunk Store (evidence of which is enough to indicate that Data Decryption is enabled for the volume). When data deduplication is disabled for a volume the entire ‘Dedup’ directory and contents are deleted, per the below screenshot:
As such, if you find an active ‘Dedup’ directory within the SVI on any volume this is an indication that the Volume likely has Data Deduplication enabled. What’s more, the ‘Dedup’ folder contains a wealth of interesting information. It was beyond the scope of this research to delve into the full contents in depth, however a few notable observations and artefacts are detailed below.
The Dedup directory contains the chunk store itself, log data as well as notable configuration and state files such as [root]\System Volume Information\Dedup\Settings\dedupConfig.01.xml, a screenshot of which is provided below:

dedupConfig.01.xml appears to contain Data Deduplication configuration information specific to that volume. The properties appear to be fairly self-explanatory however I did not perform testing to confirm how the property values tie to configuration changes.
Further notable files were identified within ‘[root]\System Volume Information\Dedup\State’ specifically:
chunkStoreStatistics.xml
dedupStatistics.xml
optimizationState.xml
unoptimizationState.xml
chunkStoreStatistics.xml

chunkStoreStatistics.xml appears to contain information regarding , amongst other things, the chunk store size.
dedupStatistics.xml

dedupStatistics.xml in a dramatic turn of events appears to contain statistics relating to Dedup.
optimizationState.xml

unoptimizationState.xml

( Note:the volume examined had been optimised and unoptimized multiple times)
Unoptimization
Once a volume has been optimized (deduplicated) it can of course be unoptimized (why Microsoft didn’t settle on dededuplicated as a term of reference I will never understand). In simple terms, assuming there is adequate space on a volume the process of deduplication can be reversed and the reparse points will be replaced with full rehydrated files.
In a limited set of circumstances, it may be conceivable that unoptimizing a volume prior to acquisition may be a solution to afford access to the data, however in a live environment or business critical system this process will create a performance hit.
There are a myriad of reasons I would not advise doing this in the context of any investigation including but not limited to the loss of recoverable deleted data as additional freespace is overwritten and the fact that the methodology is not defensible when alternatives exist. This is covered in more detail within my follow up blog post here.
With that said, a volume can be Unoptimized with the following PowerShell command:
Start-DedupJob [volume] -Type Unoptimization
This command will unoptimize the data on the volume and then disable Data Deduplication for that volume
One issue with unoptimization is that it is possible that a volume may contain more deduplicated data than could be stored in a duplicated state. This will be especially likely in volumes with limited free space or a high level of duplication. During testing, I filled a volume with duplicated data, enabled Data Deduplication and then added more of the same data. I anticipated that when unoptimization was attempted it would error out either before starting or after it ran out of space.
Much to my surprise, the Unoptimization job completed, seemingly without error. When I then reviewed the drive in Windows Explorer I found it to be completely full:
Furthermore, the result of the Get-DedupStatus command indicated that a reduced number of files were now considered “InPolicy” and that they were still optimized:

When I then viewed the volume in EnCase I was able to confirm that some of the reparse points had now been replaced with rehydrated files and some still existed. All data was still accessible via Windows Explorer in the Host OS.
The key takeaway from this is that an unoptimize job can and will fail to complete if it runs out of space within the volume, however it does not necessarily alert the user to this fact. A review of the Get-DedupStatus output following an Unoptimize job will confirm whether Data Deduplication is still enabled.
Additionally, reviewing the Get-DedupStatus output for any volume you plan to Unoptimize prior to attempt it is advisable. If the SavedSpace exceeds the Free Space then the drive cannot be fully Unoptimized.
Other supported Operating Systems
While not a supported feature it should also be noted that users have identified methods to enable the Deduplicate Data feature within Desktop OSs, including Windows 8, 8.1 and 10. It’s probably unlikely you will stumble across any such system during your day to day investigations however it is worth being aware of.
Details of the methodology employed for are available at Teh Wei King’s blog for both Windows 8 and Windows 8.1. Some details regarding enabling this feature within Windows 10 is available here.
Forensic Acquisition of volume with Data Deduplication
Hopefully this post has provided some useful information regarding the Data Deduplication feature and provided resources for further reading where required. The second post in this series will deal with methods to extract deduplicated data, that post can be found here.
Commands used in testing
If you wish to validate any of the performed steps and statements, the following PowerShell commands were key in setting up my test environment:
Install-WindowsFeature -Name FS-Data-Deduplication
Installs the Data Deduplication Feature in Windows Server 2012/2016
Enable-DedupVolume -Volume e: -UsageType Default
Enables Data Deduplication for volume e: with default settings
Set-Dedupvolume E: -MinimumFileAgeDays 0
Reduces the Minimum File Age requirement to 0 days from default value of 3 (useful for testing)
Start-DedupJob E: -Type Optimization
Initiates a manual Optimization job rather than waiting for a scheduled job
Start-DedupJob E: -Type Unoptimization
Command to Unoptimize a volume
Hopefully the above is useful to anyone who finds themselves up against the same issue. If you get this far and it’s been helpful please let me know by leaving a comment or fire me a tweet. Comments, criticism and corrections all welcome too.