
Эти полезные инструменты возьмут рутинные задачи на себя и ускорят повседневные процессы.
1. Notion

За счёт модульности и огромного количества шаблонов Notion заслуженно пользуется популярностью как универсальный комбайн продуктивности, позволяющий вести заметки, календари, управление проектами и выполняющий ещё десятки других функций.
С внедрением Notion AI возможностей стало ещё больше — фирменный ИИ поможет экономить время и разгрузит вас от рутины. Всего в пару кликов можно делать саммари текстов или, наоборот, расширять их, а также переводить на другие языки, править ошибки и так далее. Само собой, функции обычного чат‑бота для общих запросов тоже присутствуют.
Notion AI предлагается по цене 10 долларов в месяц как дополнение к основой подписке. Бесплатно у вас есть до 20 запросов для одного рабочего пространства, после этого придётся создать новое или заплатить.
Скачать →
2. ClickUp

Удобный сервис для управления проектами и организации работы в команде, который за счёт интуитивного интерфейса и гибкой масштабируемости одинаково хорош как для личного таск‑менеджмента, так и для успешного взаимодействия в больших компаниях.
ИИ‑ассистент поможет ускорить рутинные процессы благодаря множеству команд с различными шаблонами на основе контекста. Можно писать тексты, назначив ClickUp AI определённую роль, например письма клиентам или руководителю. В один клик можно делать выжимки или расширять документы, переводить на разные языки, улучшать читаемость, проверять орфографию. Либо обращаться к ИИ с общими вопросами вместо поисковиков и ChatGPT.
В бесплатной версии ClickUp AI доступен с ограничением до 25 запросов на рабочее место, далее в каждый из платных тарифов включено от 50 до 100 промптов.
Скачать →
3. Canary Mail

Кросс‑платформенный почтовый клиент Canary Mail неоднократно получал награды за инновационный подход к обработке имейлов. Фишками приложения являются минималистичный и продуманный дизайн, а также удобная сортировка писем, очистка входящих в один клик, отчёты о прочтении и сквозное шифрование соединения.
Не так давно ко всему этому добавили функцию второго пилота, с помощью которой ИИ сможет вместо вас отвечать на сообщения и даже писать новые — нужно лишь указать тему, немного контекста и подходящий тон. Помимо этого Copilot может выполнять поиск в почте или оценить расписание на основе задач из входящих.
В бесплатную версию для личного пользования включён виртуальный помощник AI Lite с базовыми функциями. Для расширенных возможностей нужна будет подписка за 50 долларов в год.
Скачать →
4. Яндекс Браузер

Не нуждающийся в представлении популярный браузер, который значительно улучшился за последние годы. Разработчики продолжают внедрять всё новые и новые функции, в том числе на основе ИИ.
Так, «Яндекс Браузер» умеет на лету переводить видео с английского и других языков на русский, делать краткий пересказ роликов, экономя ваше время. То же касается и текстов — нейросеть подготовит выжимку, исправит ошибки и подскажет, как улучшить написанное. С помощью «Алисы» доступно генерирование изображений, а все QR‑коды на страницах автоматически будут превращены в обычные ссылки, чтобы вам не пришлось возиться со сканированием.
«Яндекс Браузер» полностью бесплатен на всех платформах, включая использование нейросетевых функций.
Скачать →
5. Miro

Виртуальная доска для карт мыслей и мозговых штурмов, которая поможет зафиксировать наброски и поделиться ими с коллегами либо продолжить уже совместную работу. Miro содержит уйму готовых шаблонов и все необходимые инструменты, чтобы визуализировать идеи и раскладывать по полочкам даже самые сложные проекты.
Благодаря ИИ, приложение Miro Assist позволяет автоматически генерировать карты мыслей на основе ключевых слов и фраз, экономя время и силы, а также создавать картинки прямо по описанию блоков. Кроме того, есть перевод, проверка и улучшение текста, а также саммари и изменение тона согласно указанной роли.
На данный момент ИИ‑функции доступны без дополнительной платы. Самим приложением также можно пользоваться бесплатно в базовой версии.
Скачать →
6. Krisp

Krisp является специализированным инструментом, использующим ИИ для облегчения жизни всех, кто в течение дня проводит много времени на созвонах и видеовстречах. Главная фишка — обработка сигнала с микрофона для автоматической очистки от посторонних шумов вроде гула кондиционера, бубнящих коллег, лающих собак или стройки за окном. Благодаря этому вы не будете привязаны к офису и можете участвовать в обсуждениях из любого места.
Помимо этого Krisp предлагает функцию изменения акцента на лету, а также расшифровку аудио со встреч и конспекты‑саммари, которые позволят освежить детали или поделиться ими с коллегами.
В бесплатном варианте доступно до 60 минут работы аудиофильтра и до двух заметок со встреч в день. Транскрибация аудио в текст при этом не ограничена.
Скачать →
7. TypingMind

Сторонний клиент для использования ChatGPT с расширенными возможностями для тех, кому не хватает стандартных. С TypingMind вы получите удобный интерфейс взаимодействия с чат‑ботом и большую библиотеку промптов с ИИ‑персонажами в различных ролях (преподаватель английского, учёный, математик), которые в узкоспециальных задачах дадут лучшие результаты.
Вы сможете загружать документы и взаимодействовать с ChatGPT на основе его контекста, использовать результаты поиска в интернете при обсуждении, а также синтезировать текст в речь.
TypingMind можно применять бесплатно в ограниченном виде. Для полноценной работы — с доступом ко всем функциям — необходимо купить лицензию стоимостью от 39 долларов (единоразовый платёж). Также нужна будет подписка ChatGPT Plus, поскольку лимиты на токены в API при активном пользовании закончатся довольно быстро.
Скачать →
8. Rewind

Интересное приложение, которое представляет собой что‑то вроде дополнительной памяти или персональной базы знаний, сохраняющей всё, что вы просматриваете или читаете на компьютере в течение дня. ИИ под капотом Rewind выполняет захват экрана, а затем индексирует полученную информацию и позволяет легко находить её, выполняя поиск по ключевым словам. Можно даже задавать вопросы и получать ответы на основе контекста. Все данные при этом сохраняются и обрабатываются локально: приложение никуда их не пересылает.
В бесплатной версии Rewind можно просматривать элементы на шкале времени и копировать их. Поиск по результатам доступен с ограничением на последние три записи, а ответы содержат только пару первых предложений. Для снятия лимитов необходима подписка за 19 долларов в месяц.
Скачать →
Найдите передовые приложения ИИ, разработанные для бесперебойной работы в Windows
Текст и письмо
Изображение
Видео
Код и ИТ
Голос
Бизнес
Маркетинг
AI детектор
Чатбот
Дизайн и искусство
Больше+
-

52.41%
LockedIn AI улучшает подготовку к собеседованиям с помощью AI-поддержки в реальном времени.
-
15.16%
Бесплатный мощный изменитель голоса для креативного самовыражения в режиме оффлайн и онлайн.
-
13.99%
Быстро и легко восстанавливайте поврежденные видео и файлы.
-
9.97%
Легко удаляйте фоны с изображений с помощью технологий ИИ.
-
11.11%
CoTester™ — это первый в мире AI-агент, специально разработанный для тестирования программного обеспечения.
-
34.47%
Пишите код из Figma в своем собственном стиле с Superflex.
-
58.84%
NoteX — это приложение для заметок, поддерживаемое ИИ, которое преобразует голосовые записи в организованные заметки.
-
Вызов функции, который упрощает использование веб-API.
-
23.79%
Визуализируйте и проектируйте пользовательские интерфейсы для веб, настольных и мобильных приложений с помощью разметки XAML.
-
15.92%
Инновационная платформа для всех ваших дизайнерских нужд, от веб- до мобильных приложений.
-
Создавайте интересные идеи и сценарии для видео на YouTube с помощью ИИ.
-
100.00%
Современные инструменты ИИ для редактирования и генерации изображений.
-
14.91%
AI-решения для повышения производительности, конфиденциальности и устойчивости.
-
Комплексный финансовый оценочный инструмент для владельцев бизнеса и профессионалов.
-
AI-соавтор, который генерирует инновационные научные работы с внутритекстовыми ссылками, рисунками и многим другим.
-
Моментальные ответы и объяснения ИИ на ваши вопросы по домашнему заданию.
-
100.00%
ChatGPT на японском: бесплатный, неограниченный доступ к AI-чат-боту на японском языке без регистрации.
-
68.78%
Advanced Voice предлагает профессиональные решения для распознавания речи для различных приложений.
-
94.15%
Samespace предлагает инструменты, управляемые ИИ, для повышения продуктивности команд, найма, сотрудничества и клиентского опыта.
-
Конструктор чат-ботов и онлайн-чат для веб-сайтов, WhatsApp, Facebook и Telegram.
-
Akiflow объединяет задачи и встречи в одной мощной платформе для повышения продуктивности.
-
13.53%
Легко удаляйте фоны изображений онлайн с помощью SharkFoto BGRemover.
-
100.00%
Медицинский писатель, использующий ИИ, для точной клинической документации.
-
30.19%
Arsturn предлагает инновационную онлайн-платформу для совместной работы и общения команд.
-
59.38%
Отслеживайте и организуйте все с помощью Memento Database, универсального кроссплатформенного приложения.
-
16.39%
Современные инструменты ИИ для аудиоанализа и приложений.
-
34.95%
Платформа на основе ИИ для автоматизации обслуживания клиентов и оптимизации рабочих процессов.
-
Универсальное цифровое портфолио для комплексной документации и организации.
-
33.13%
Инструмент аналитики данных без кода, который позволяет пользователям легко анализировать CSV-файлы любого размера.
-
Talespinner упрощает создание интерактивных историй с помощью комплекта инструментов на базе ИИ для писателей и дизайнеров.
-
100.00%
CLI-инструмент на базе ИИ для улучшения качества кода.
-
Легко управляйте своим магазином с Dimestore.
-
21.96%
SharkFoto ImageColorizer мгновенно превращает черно-белые изображения в цветные с помощью ИИ.
-
100.00%
Программное обеспечение для редактирования клинических фотографий на основе ИИ для стоматологических специалистов.
-
52.48%
Fellow.app — это помощник для встреч и инструмент для ведения заметок, работающий на основе искусственного интеллекта.
-
Создавайте и разворачивайте ИИ-приложения с помощью передовой автоматизации.
-
Maya AI преобразует рабочие процессы с помощью ИИ-решений, разработанных для продаж, обслуживания клиентов и образования.
-
Создавайте уникальные будильники с помощью настройки звука, управляемой ИИ, для освежающего опыта пробуждения.
-
100.00%
Универсальный инструмент для автоматизации задач и повышения продуктивности.
-
Интегрируйте помощников OpenAI в VS Code для более умного кодирования с использованием ИИ.
-
29.90%
APIPark — это open-source шлюз LLM, который обеспечивает эффективную и безопасную интеграцию моделей ИИ.
-
100.00%
Автоматизируйте управление вашими социальными медиа и увеличьте вовлеченность с PhantomFlow.
-
CAROOT — это платформа для оптимизации анализа первопричин в вашей организации.
-
Легко анализируйте данные Excel с помощью естественного языка.
-
72.27%
Note Companion – это плагин на основе ИИ, который автоматически организует и форматирует ваши заметки.
-
Трансформация медицинского сотрудничества с помощью единой платформы телемедицины.
-
100.00%
Легко конвертируйте, управляйте и взаимодействуйте с вашими PDF.
-
83.70%
Усовершенствованное программное обеспечение для управления проектами и командного взаимодействия с более чем 45 функциями.
-
35.77%
Billabex автоматизирует последующие действия по электронной почте, телефону, SMS и почте для своевременных платежей по счетам.
-
32.08%
Преобразуйте ваши заметки в динамичные, интерактивные ментальные карты с помощью ИИ.
-
38.56%
Omniverse — Универсальная платформа приложений для современных решений.
-
Безопасное облачное хранилище для шифрованного обмена данными и управления резервными копиями.
-
IT-решения нового поколения, которые меняют способы работы малых и средних предприятий.
-
100.00%
Запускайте модели ИИ локально на своем ПК с максимальной скоростью до 30 раз быстрее.
-
Создавайте потрясающие аниме-ролики без усилий с помощью передовых технологий ИИ.

Энтузиасты, что жаждали бы запустить на домашнем ПК большую языковую модель (large language model, LLM) современного уровня, сталкиваются с принципиальной проблемой: их машинам остро не хватает видеопамяти. Дело в том, что плотная многослойная нейронная сеть, к работе которой в конечном итоге сводится LLM, выдаёт некий результат в ходе взвешенного суммирования огромного количества — десятков и сотен миллиардов — операндов. Чтобы производить такие — сравнительно несложные, но чрезвычайно массированные — расчёты за разумное время, необходимо свести к минимуму задержки при передаче сигналов между вычислительными узлами и памятью, с которой те оперируют.

Безусловно, аргумент этот чисто количественный. Законы природы не запрещают применять для эмуляции нейронной сети исключительно центральный процессор с его 4, 8 или 16 ядрами и оперативную память DRAM. Но поскольку вычисления непосредственно в памяти в рамках классической x86-архитектуры не реализуются, потери времени при переносе небольших (обработанных считаными единицами, максимум первыми десятками ядер) пакетов данных между ЦП и ОЗУ оказываются попросту несуразными. И это проблема любых подобных вычислений: к примеру, Stable Diffusion — нейросетевая модель с открытым исходным кодом для создания изображений по текстовым описаниям — при запуске на ПК без дискретного графического адаптера генерирует простейшие картинки за многие десятки минут, тогда как на компьютере даже с не самой современной видеокартой — за пару-тройку минут максимум, а с какой-нибудь NVIDIA RTX 4080 — и вовсе за секунды.
LLM ещё более требовательны как к доступному числу физических вычислителей, способных автономно и параллельно производить взвешенные суммирования (для чего почти идеально подходят ядра CUDA), так и к объёму напрямую связанной с ними памяти (при использовании дискретного графического адаптера) — видеопамяти. Для запуска и эксплуатации больших языковых моделей активно применяются специализированные видеокарты — с гигантскими объёмами VRAM в десятки гигабайт на каждой, объединённые сверхскоростными мостами (NVLink, если речь идёт о продуктах NVIDIA) в кластеры из 4 или 8 единиц.

Пара A100, соединённых мостами NVLink (источник: NVIDIA)
Число рабочих параметров для LLM GPT-3.5, что легла в основу первого общедоступного ChatGPT, — 175 млрд. Если каждый из этих параметров кодировать 16-разрядным числом («представление с плавающей запятой половинной точности»; тип данных float16, т. е. по 2 байта на число), то только для одновременного размещения всех их в памяти — в видеопамяти, подчеркнём! — той потребуется более 320 Гбайт. Вот, собственно, и главная причина, по которой запустить ChatGPT на домашнем ПК невозможно в принципе. Да, известен целый ряд разрабатываемых энтузиастами менее требовательных к аппаратной части LLM-проектов, наиболее перспективным среди которых можно считать Alpaca — в вариантах модели с 7, 13 и 30 млрд входных параметров. Однако качество генерируемого ею текста откровенно расстроит завсегдатаев чатов с ChatGPT (и тем более GPT-4): настолько оно не соответствует успевшим уже сформироваться у них высоким стандартам, заданным свежайшими продуктами OpenAI.
Казалось бы, если выдавать адекватно воспринимаемый человеком текст для большой языковой модели настолько сложно — точнее, требует таких существенных аппаратных ресурсов, — то что уж говорить о создании изображений! Однако не тут-то было: упомянутая чуть выше Stable Diffusion в наиболее актуальных своих версиях нуждается в ГП NVIDIA как с минимум 4 Гбайт видеопамяти — либо AMD с 8 Гбайт и более. Так что даже далеко не самый современный игровой ПК вполне способен стать вместилищем для бота-художника, готового создавать практически любые изображения по вашему запросу — стоит лишь приложить немного усилий. Собственно, тому, что и как именно делать для установки, запуска и (самой базовой) тонкой настройки Stable Diffusion, и посвящён настоящий киберпрактикум.
⇡#Предварительные замечания
Бесспорно, лучше прочих из сравнительно широко доступных видеокарт для машинного преобразования текста в картинки подойдут новейшие NVIDIA RTX 4080 и 4090, в первую очередь по причине внушительного объёма их VRAM — 16 и 24 Гбайт соответственно. Объём ОЗУ компьютера и производительность его ЦП принципиального значения не имеют, но лучше всё-таки ориентироваться на 8 Гбайт DRAM как минимум и хотя бы на четырёхъядерный процессор — такое «железо» позволит быстрее производить служебные вычисления, необходимые для подготовки к собственно генерации изображений.
Однако «лучшее» вовсе не значит «единственно возможное». Все процедуры, описанные ниже, были проделаны и все изображения сгенерированы на не самом, мягко говоря, свежем игровом ПК, повидавшем многие виды: с ЦП Intel Core i7-2600K (это не опечатка: именно 2600, а не 12600), с 16 Гбайт ОЗУ и дискретным адаптером на основе ГП NVIDIA GeForce GTX 1070 (8 Гбайт VRAM). На системном SSD была развёрнута актуальная версия Windows 10; для её идейной наследницы Windows 11 все рекомендации и указания почти наверняка можно будет использовать без изменений.
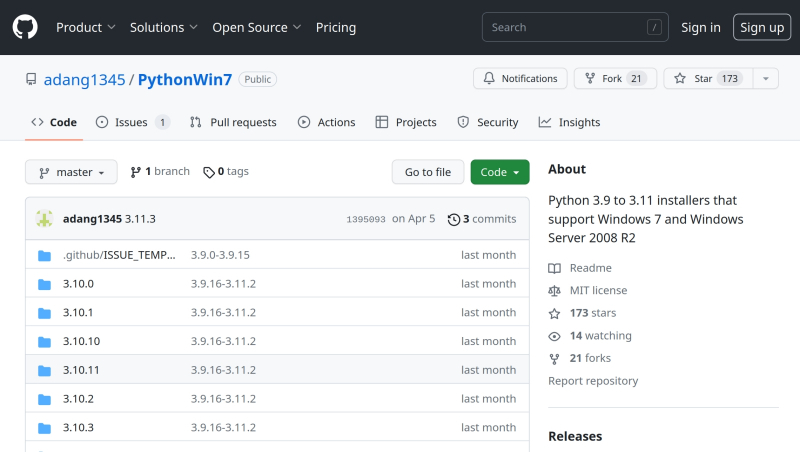
Рабочие сборки Python для Windows 7 доступны, к примеру, на GitHub (источник: скриншот сайта github.com)
С Windows 7 ситуация сложнее (поскольку нужная версия языка Python для неё официально не поддерживается), а для пользователей ОС с ядром Linux путь к финальной настройке генеративной модели для преобразования текста в картинки окажется даже короче — ибо в большинстве популярных дистрибутивов значительная часть необходимого ПО уже исходно предустановлена. Впрочем, в рамках настоящего киберпрактикума вопросы установки Stable Diffusion на других ОС затрагиваться не будут: sapienti sat. Свободного пространства на системном накопителе потребуется как минимум 20 Гбайт, однако с учётом того, что изображения по умолчанию сохраняются внутрь каталога установки, чем больше на диске места, тем лучше.
А как насчёт видеокарт AMD — годятся ли они для запуска Stable Diffusion? Практика показывает, что да, вполне, — однако придётся совершить несколько дополнительных шагов в ходе установки и настройки системы, да и в целом производительность при переводе текста в изображения тут будет ниже, чем у сопоставимых по классу графических адаптеров NVIDIA. Основная причина — в том, что сама система преобразования текстовых подсказок в картинку при написании опиралась на ряд проприетарных возможностей, реализованных в ядрах CUDA как на уровне «железа», так и в созданных для него ИИ-ориентированных программных библиотеках.
Учитывая, что на мировом рынке дискретной графики NVIDIA доминирует с долей 88% (данные JPR за III кв. 2022 г.), разработчиков трудно упрекнуть здесь в безосновательной избирательности. Впрочем, по слухам, сама Microsoft (ныне фактически владеющая половиной OpenAI, создательницы ChatGPT) сегодня активно сотрудничает с AMD по вопросу оптимизации графических продуктов последней — как раз для решения связанных с ИИ задач. Вполне вероятно поэтому, что следующее поколение дискретной графики AMD будет лучше подходить для преобразования текста в картинки (и в видео, кстати, но это уже и вовсе особая история).
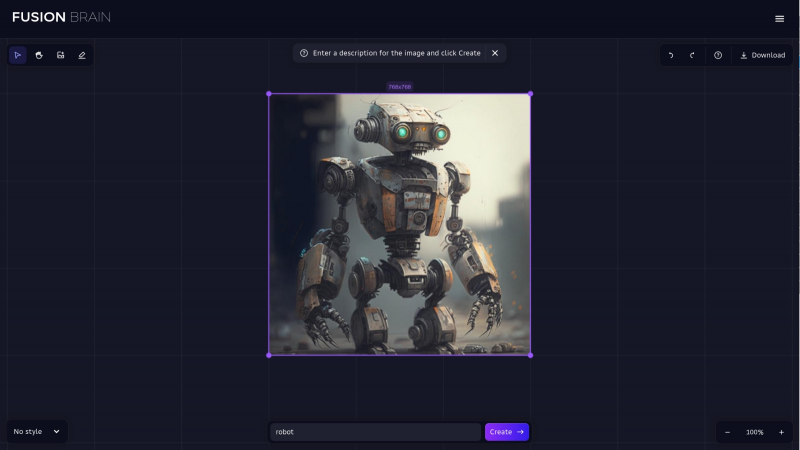
Так представляет себе робота доступная онлайн-модель Kandinsky 2.1 (источник: скриншот сайта fusionbrain.ai)
А можно ли генерировать изображения со Stable Diffusion вообще в отсутствие подходящего ПК под рукой? Да, разумеется! Онлайн совершенно бесплатно (а порой, хотя бы в ограниченных пределах, и анонимно, т. е. без требования непременной предварительной регистрации) доступен целый ряд действующих инсталляций: Stable Diffusion Playground, mage.space, Stable Diffusion Online, Dezgo и ещё множество, обнаружить которые через любой поисковик не составит труда (едва ли не единственная отечественная разработка среди них — модель Kandinsky 2.1). Понятно, что на пользователя, в особенности не имеющего возможности заплатить за визуализацию своих текстовых описаний, такие сайты накладывают немало ограничений: это и скудость выбора параметров генерации, и невозможность совершенствовать полученную базовую картинку, и кое-где даже принудительное наложение метки сайта (watermark) на готовое изображение. Кроме того, очереди на бесплатную генерацию на популярных сайтах могут быть довольно длинными. Но если очень-очень надо получить хоть какой-то визуальный образ на основе возникшего в голове сочетания слов, доступные онлайн модели — неплохое начало.
Другой вариант, тоже онлайновый, — задействовать Google Colab, бесплатную платформу, что позволяет каждому обладателю учётной записи Google разворачивать в облаке корпорации так называемые блокноты (Python notebooks) для исполнения кода, написанного на языке Python. Поскольку локальная инсталляция Stable Diffusion тоже, по сути, сводится к установке на ПК среды Python и ряда специализированных скриптов на этом языке, практически всё, что возможно проделать с этой моделью на вашем компьютере, доступно и после развёртывания её в Colab. Соответствующих инструкций в Сети имеется в избытке, однако следует помнить: только платным пользователям Colab (10 долл. США в месяц и более — причём оплата картой, да) доступно исполнение блокнота на физическом серверном ГП NVIDIA A100 с его великолепной ИИ-производительностью. В противном же случае скорость генерации изображений вряд ли будет намного выше, чем на видавшем виды локальном игровом ПК.
⇡#…Но Git установить обязан
В понимании рядового пользователя установка ПО на компьютер сводится к скачиванию и запуску инсталляционного файла — после чего в системе оказывается развёрнута вожделенная программа или целая платформа; как правило, уже в виде исполняемого бинарного файла (часто с рядом дополнительных файлов — служебных библиотек, конфигурационных и пр.). У программистов, особенно ориентированных на ПО с открытым исходным кодом, подход иной: если есть программа, написанная на некоем языке, и свободно доступная среда для исполнения кода на этом же языке, к чему городить огород с бинарниками? Проще запускать программы в этой же самой среде и горя не знать. Как раз такому принципу в целом и следует логика установки Stable Diffusion.
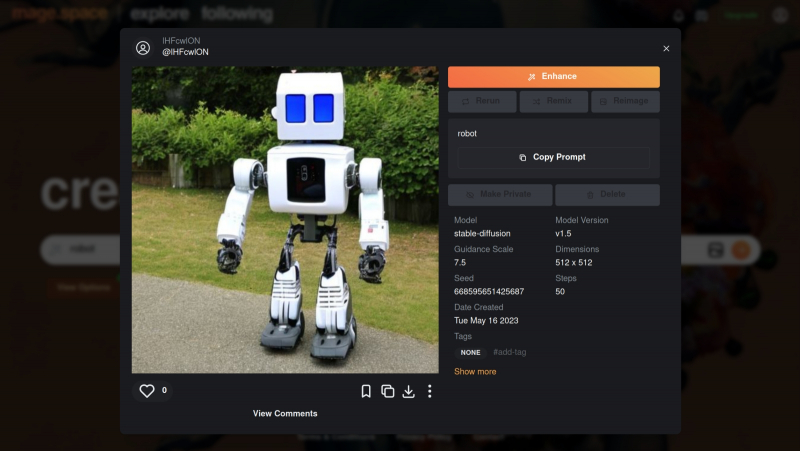
А такое изображение робота — предел возможностей для бесплатных и анонимных посетителей mage.space (источник: скриншот сайта mage.space)
Для начала на локальном ПК необходимо развернуть клиент Git. Git — это распределённая система контроля версий (version control system, VCS); платформа не безусловно необходимая, но до чрезвычайности полезная для множества независимых программистов, совместно и исключительно добровольно трудящихся над многочисленными проектами ПО с открытым кодом. Главное достоинство VCS — в том, что никакая информация из неё бесследно не исчезает (если не прикладывать к тому особых усилий), т. е. любое внесённое в код исправление не затирает прежнего состояния соответствующего фрагмента листинга программы. Более того, Git не отслеживает такие изменения и не ведёт им тщательный учёт по отдельности (в отличие от других популярных VCS, таких как Subversion, Bazaar, CVS и пр.), но после каждого коммита (отправки пользователем со своего локального ПК исправленной версии кода в облако Git) создаёт моментальную копию — снэпшот (snapshot) — всех файлов данного проекта.
Впрочем, красоту и практичность этого решения в полной мере оценят лишь программисты; рядовому же пользователю, просто желающему запустить Stable Diffusion на своём ПК, важно понимать, что загруженный через Git проект останется заведомо работоспособным именно в той версии, в которой его впервые установят. И что любые последующие изменения и дополнения — пока они не «втянуты» через тот же Git на локальный ПК — никак на работе уже инсталлированной системы не отразятся. В век подспудных фоновых автообновлений, частенько приводящих к внезапным кардинальным переменам в интерфейсах и функциональных возможностях привычных приложений, это дорогого стоит.
Источник: скриншот сайта git-scm.com
Итак, для загрузки Git для Windows следует воспользоваться репозиторием на сайте самой платформы.
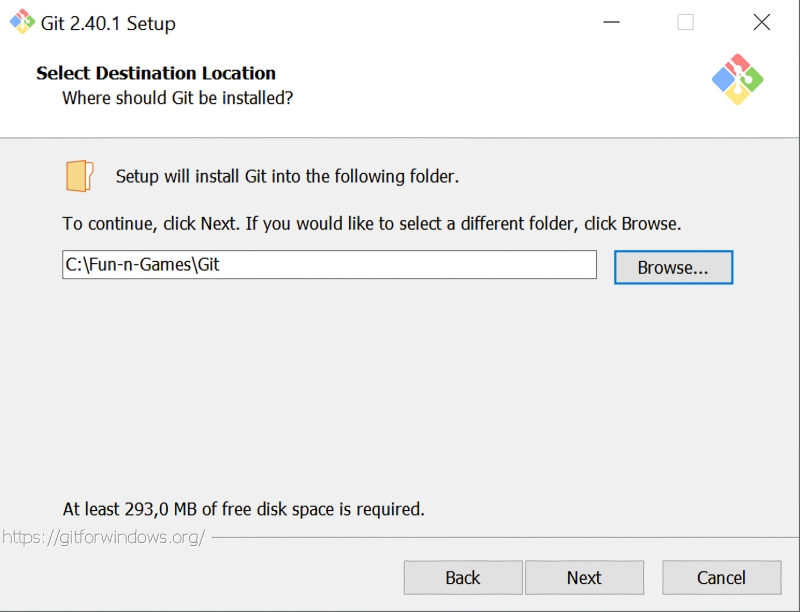
По завершении закачки инсталлятора надо его запустить — и пройти стандартную процедуру установки, раз за разом нажимая кнопку Next. Практически повсеместно достаточно будет лишь подтвердить параметры, предлагаемые инсталлятором по умолчанию. Возможно, для начала вам захочется поменять целевой каталог установки (самое первое окно)
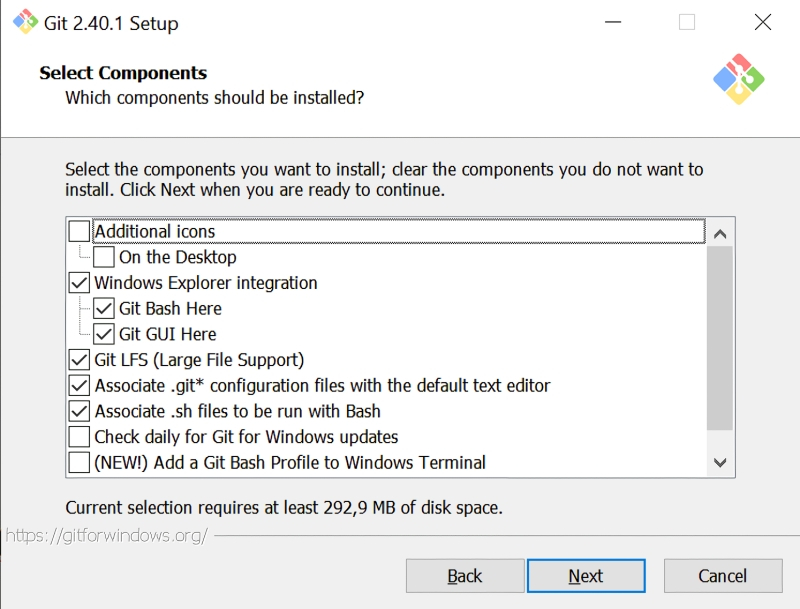
В окне «Select Components» необходимо будет удостовериться, что опция интеграции с «Проводником» Windows активна, равно как и две опции более низкого уровня — «Git Bash Here» и «Git GUI Here». Предпоследняя окажется крайне полезна как раз для удобной и быстрой загрузки с Git проекта, позволяющего запускать графический интерфейс для взаимодействия со Stable Diffusion.
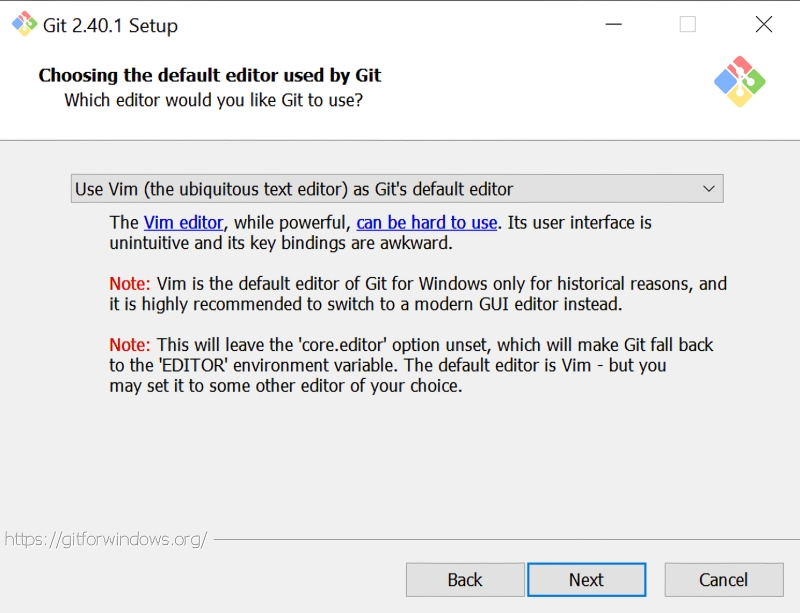
Программисты-олдфаги оценят изощрённый юмор разработчиков платформы: в окне «Choosing the default editor used by Git» по умолчанию выбран Vim — известный и заслуженный, но крайне противоречивый текстовый редактор; из мира не Linux даже, а стародавнего ещё UNIX (точнее, BSD). Не ввязываясь в дискуссию о плюсах и минусах различных редакторов эпохи исключительно текстовых компьютерных терминалов, отметим, что далёкому от этих материй пользователю (особенно пользователю Windows) имеет смысл выбрать в этом окне что-то менее остросюжетное, хотя бы банальный Notepad.
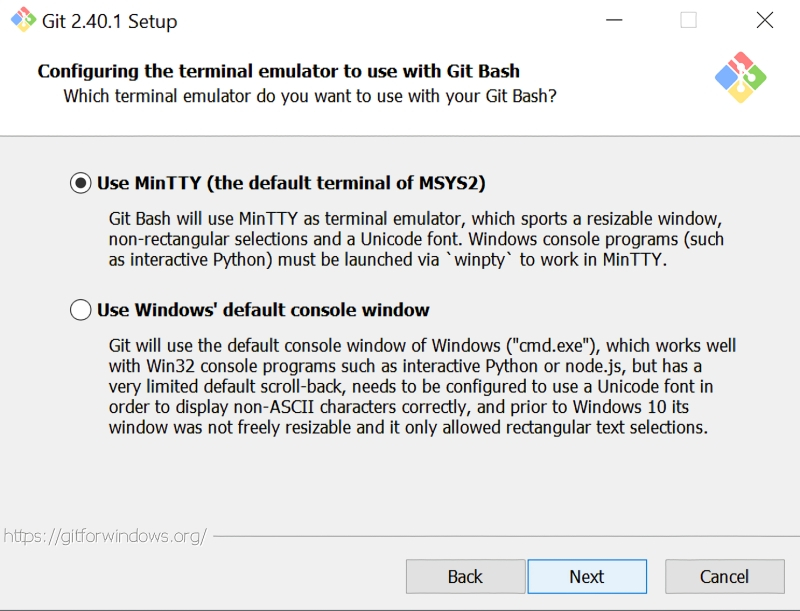
Ещё один момент: в окне «Configuring the terminal emulator to use with Git Bash» из предлагаемых опций лучше выбрать MiniTTY. Это не принципиальный вопрос, и консольное окно Windows по умолчанию тут вполне сгодится, — но из соображений лучшей совместимости (с Unicode-шрифтами прежде всего) MiniTTY всё-таки предпочтительнее.
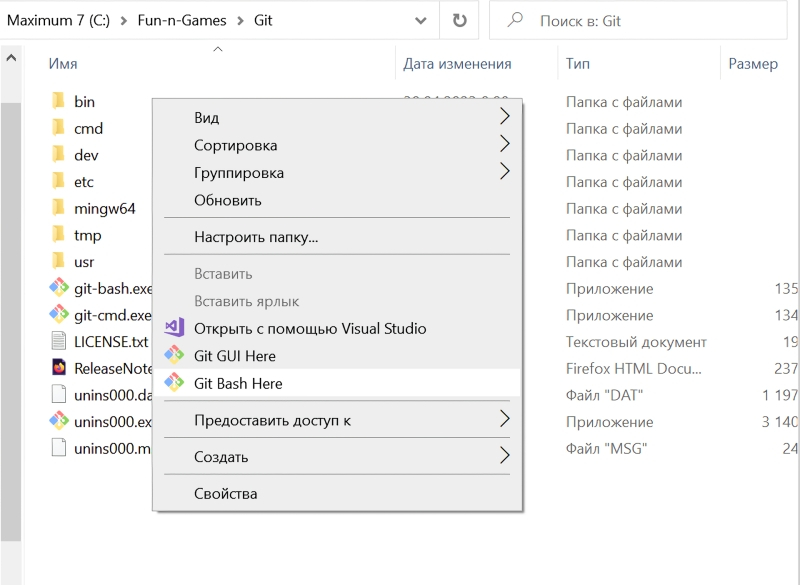
По завершении инсталляции в «Проводнике» Windows следует открыть папку, в которую Git был установлен, и, удерживая курсор мыши в пределах этого окна (не имеет значения, на каком именно файле), нажать на правую кнопку. Откроется меню, в котором — благодаря тому, что напротив опций «Git Bash Here» и «Git GUI Here» в ходе инсталляции были проставлены галочки, — появятся две новых соответствующих строчки. Нужно навести курсор на «Git Bash Here» и нажатием теперь уже левой кнопки мыши запустить тот самый терминал MiniTTY, о котором шла речь буквально только что.
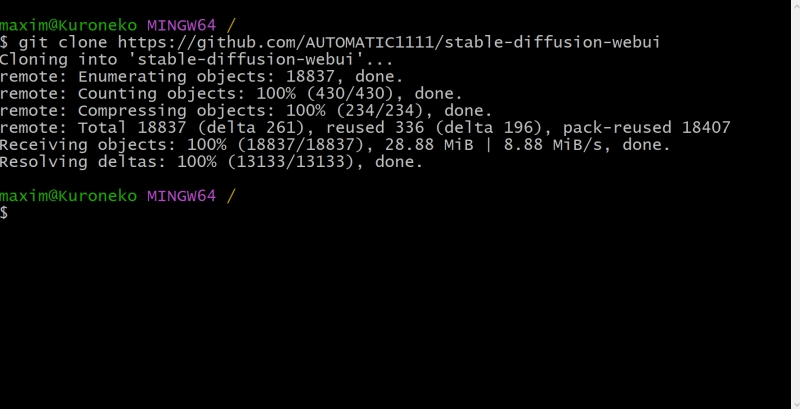
Именно из этого терминала пользователь и отдаёт команды Git — в частности, на закачку интересующих его проектов. «Закачка» в терминах этой платформы — «клонирование», т. е. создание локальной копии расположенного онлайн кода, поэтому требуемая команда выглядит следующим образом:
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui
AUTOMATIC1111 — это и есть название интересующего нас проекта веб-интерфейса для работы со Stable Diffusion. Это именно веб-интерфейс: доступ к нему производится через браузер; по умолчанию только с локального ПК, но при желании можно открыть его и для внешних пользователей — правда, вероятно, придётся повозиться с настройками брандмауэра на своём маршрутизаторе. Это, пожалуй, наиболее популярный на сегодня интерфейс для работы со Stable Diffusion: хотя имеются и другие подобные проекты, широта возможностей контроля над процессом генерации и множество доступных плагинов делают AUTOMATIC1111 отличным инструментом для экспериментирования.
⇡#Внимание: модель!
Интерфейс установлен, пользователь перед компьютером есть, — самое время загрузить собственно Stable Diffusion, т. е. модель на основе машинного обучения для преобразования текста в графический образ (text-to-image model), написанную на языке Python. К ней впервые предоставил свободный доступ 22 августа 2022 г. сам же её разработчик — компания Stability.ai, специализирующаяся на развитии генеративных ИИ с открытым кодом.
В основе Stable Diffusion лежит латентная диффузия: изначально в качестве базы для каждого нового изображения генерируется мешанина разноцветных точек на основе достаточно большого целого числа — «затравочного зерна» (seed), или попросту затравки, на основе которой работает псевдослучайный алгоритм такой генерации и которая в дальнейшем, совместно с текстом подсказки и другими параметрами, определяет конечный вид готового изображения.

Ряд последовательных наложений псевдослучайного шума на исходную картинку асимптотически трансформирует её в прямоугольник, залитый чистым гауссовским шумом (источник: University of California, Berkeley)
Не вдаваясь в детали, поясним, как происходит обучение таких моделей: на вход нейросети подаётся некое изображение и его достаточно полное текстовое описание. Затем система зашумляет исходную картинку, последовательно добавляя к ней разноцветные точки в псевдослучайном, но генерируемом по вполне детерминистическому алгоритму порядке (гауссовский шум) на основе набора токенов, связанных с описывающими картинку терминами, — и снова пропускает через нейросеть полученный результат. Несколько десятков итераций спустя изображение превращается — на взгляд человека — в совершенно бесструктурную мешанину разноцветных пикселей. Однако для самой системы в этом хаосе закодирована исходная картинка — просто скрытая под напластованиями множества шумовых слоёв, наложенных известным ей образом. Можно даже сказать, что в каком-то смысле исходная картинка заархивирована, — вот только для обратного процесса потребуется не линейный алгоритм разархивации, а та же самая нейронная сеть.

Обратное преобразование из гауссовского шума с использованием токенов, описывающих нужное изображение, позволяет снова получить картинку за ряд итераций (источник: University of California, Berkeley)
Проведя много таких операций обучения — желательно десятки и даже сотни тысяч для каждого текстового термина, — нейросеть с обратным распространением ошибок формирует на входах своих перцептронов такие веса, что позволяют «разархивировать» картинки из шума по ключевым словам, проходя весь путь в обратном порядке. А именно: взяв прямоугольник, заполненный «белым шумом», и известный системе текстовый термин, слой за слоем удалять с картинки случайные пикселы в определённом порядке — и получать запрашиваемое изображение. Почти как ваятель удаляет лишние, на его взгляд, фрагменты мрамора с глыбы, открывая в итоге таившуюся там скульптуру. Аналогия эта вполне адекватна: как из двух идентичных каменных блоков можно изваять совершенно разные статуи, так и две затравочных картинки с «белым шумом», сгенерированным на основе одного и того же seed, в ответ на различные текстовые подсказки породят совершенно несхожие между собой изображения.
Источник: скриншот сайта huggingface.co
Сама модель Stable Diffusion версии 1.5 (сегодня есть уже и более поздние проекты самой Stability.ai, и аналоги за авторством других разработчиков, однако на данный момент именно эта пользуется наибольшей популярностью в кругах энтузиастов text2image-активности) доступна — опять-таки бесплатно, без SMS и регистрации — на репозитории онлайн-сообщества ИИ-кодеров Hugging Face.
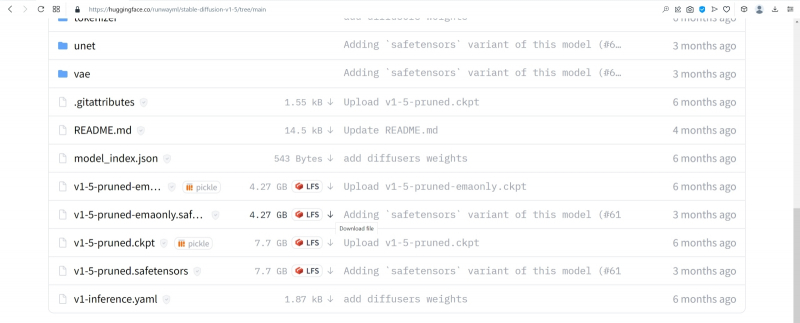
Источник: скриншот сайта huggingface.co
Чтобы загрузить эту модель, следует перейти на вкладку Files в веб-интерфейсе её странички на репозитории, чуть прокрутить вниз — и нажать на не самую приметную стрелочку с подчёркиванием, стоящую справа от букв «LFS» в строке, что начинается с «v-1-5-pruned-emaonly.safetensor». Как только при наведении на стрелочку всплывёт окошко с мелкой надписью «Download file» — можно нажимать и запасаться терпением: файл занимает несколько гигабайтов.
Почему среди прочих вариантов представления Stable Diffusion лучше выбирать именно этот? Первое соображение — размер: версия без «emaonly» тянет на 7,7 Гбайт, а выбранная нами — менее чем на 4,3 Гбайт. Для дальнейшей тренировки модели (натаскивания её на новых изображениях; тех, что не вошли в исходный пул обучения в 2,3 млрд аннотированных картинок) лучше подойдёт более полный и весомый вариант, но в ходе генерации по текстовым подсказкам разница между «pruned» и «pruned-emaonly» пренебрежимо мала. Но, может быть, более крупный файл модели позволит получать, исходя из той же самой текстовой подсказки, изображения лучшего качества? Не совсем так; но, чтобы обосновать этот тезис, придётся немного углубиться в технические детали.
Для начала сам термин pruned (англ. «обрезанный», «упрощённый») указывает на некоторую потерю информации в этой версии модели по сравнению с полной, полученной в Stability.ai после обработки тех самых 2,3 млрд изображений. По сути, итог обучения нейросети — это определённый набор весов на входах каждого перцептрона каждого из её слоёв. Некоторые из этих весов могут оказаться с высокой точностью равными нулю, а поскольку нейросеть высчитывает взвешенные суммы (произведение текущего значения аргумента и веса на данном входе данного перцептрона), умножение на почти ноль тоже даст в результате почти ноль. Иными словами, в pruned-версии все «почти нули» ниже некоторого порога величины заменены самыми обычными нулями, так что при формировании картинки по готовой модели разница между «урезанным» и полным вариантами практически неприметна.
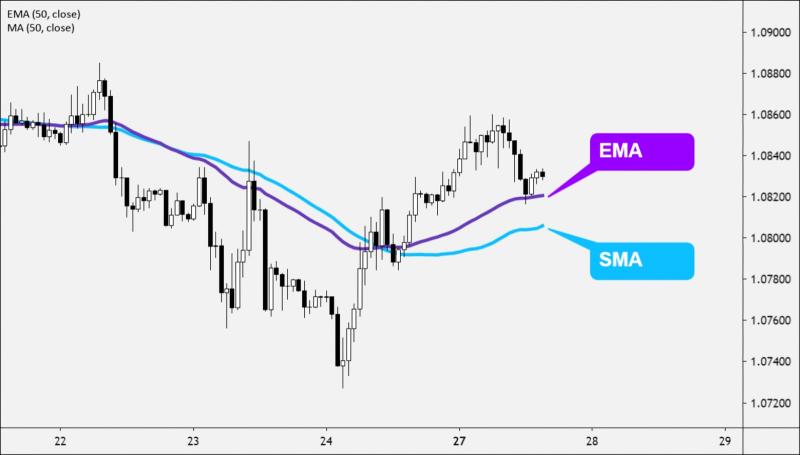
Наглядная демонстрация разницы между экспоненциально взвешенным скользящим средним (EMA) и простым, или арифметическим, скользящим средним (SMA) на примере динамики биржевых котировок за определённое время (источник: BabyPips)
Можно пойти и ещё дальше, применив к pruned-набору весов операцию вычисления экспоненциально взвешенного скользящего среднего (exponential moving average, EMA). Хорошо известная онлайн-трейдерам, эта операция представляет собой по сути свёртку: выявление главного тренда в динамике изменения некоего параметра за счёт сглаживания случайных флуктуаций в ряду наблюдений. Способов вычислять скользящее среднее известно немало; метод именно экспоненциального взвешивания привлекателен тем, что недавние наблюдения получают здесь больший вес по сравнению с более ранними. Иными словами, EMA позволяет усреднять длинные ряды наблюдений (для рассматриваемых моделей — весов на входах перцептронов) с упором на самые последние, ближние к стадии формирования финального результата.
Здесь подходит такой наглядный пример: студент за время обучения получает различные оценки (за сессионные экзамены и зачёты, за активность на коллоквиумах, лабораторные работы и т. п.), и в конце концов сдаёт госэкзамены. Так вот, итоги госэкзаменов можно рассматривать как финальные веса ИИ-модели на завершающем этапе её обучения. Однако на эти оценки может влиять огромное количество факторов: внезапное недомогание, чрезмерное волнение и пр. Поэтому о реальном прилежании студента и уровне накопленных им за период обучения знаний гораздо больше скажет EMA всех его прежних оценок вплоть до госэкзаменационных — с упором, конечно, на наиболее близкие к ним по времени. Потому что первая, к примеру, сессия была давно, и предметы, за которые на ней выставлялись оценки, для практической работы выпускника вуза, скорее всего, не будут иметь большого значения.
Интересующихся математическими подробностями отсылаем к оригинальной статье сотрудников OpenAI, впервые предложивших EMA-оптимизацию набора весов для моделей глубокого обучения. Здесь же важно, что для практических пользовательских приложений файлы моделей pruned-emaonly оптимальны по соотношению занимаемого дискового пространства (равно как и требуемого для закачки времени, кстати) и качества получаемого результата. Более того, они, по оценкам энтузиастов, креативнее исходных, с несвёрнутыми наборами весов, — причина этого станет яснее, когда мы дойдём до рассмотрения параметра Clip skip в настройках AUTOMATIC1111. Если браться за дообучение Stable Diffusion (за создание текстовых инверсий, LoRA и за прочее высокоуровневое шаманство, которое в рамках настоящего киберпрактикума мы рассматривать не станем) — тогда решительно необходимой окажется именно полная, pruned-модель.
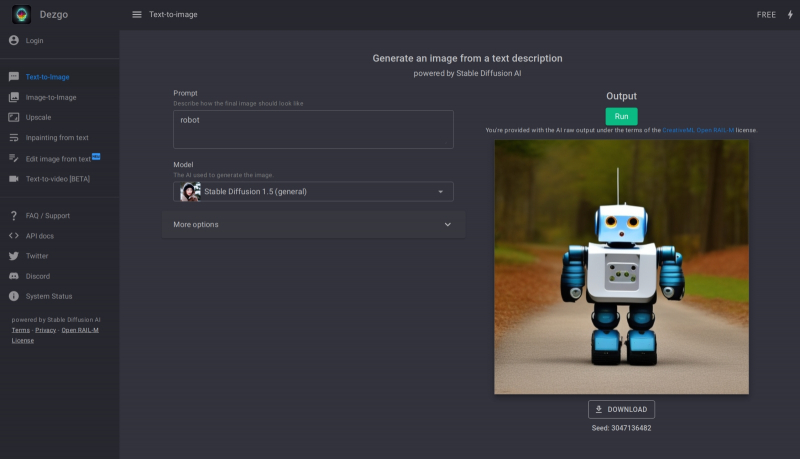
Если задействовать на различных сайтах одни и те же модели для генерации образов (Stable Diffusion 1.5 в данном случае), и результаты буду выходить схожими (источник: скриншот сайта dezgo.com)
Ещё один важный момент: рекомендуется всегда — особенно если интересная модель попадётся вам на, скажем так, не самых заслуживающих доверия сайтах — отдавать предпочтение версии с расширением .safetensors. Дело в том, что стандартный формат, в котором хранятся веса натренированной модели, pickle (расширения .ckpt, .pkl и пр.), небезопасен, поскольку допускает исполнение стороннего — потенциально вредоносного — кода. Это, по сути, машиночитаемый бинарный файл; набор инструкций, указывающих, с каким перцептроном в каком слое нейросети какие веса использовать при обработке входящего сигнала, — а не таблица с самими этими весами и соответствующими связями: та вышла бы чрезмерно громоздкой).
Как сообщает официальная документация, «модуль pickle имплементирует двоичные протоколы для сериализации и десериализации структуры объектов Python», т. е. устанавливает связи между различными объектами. В частности — позволяет при определённых условиях запускать сторонний код, написанный на Python, в том числе содержащий инструкции прямого исполнения — вроде eval или exec. Вот почему в среде энтузиастов машинного обучения в применении к моделям с открытым кодом всё большее распространение получает простейший формат сериализации .safetensors — безопасный, обеспечивающий ускоренную загрузку весов модели в память и более быстрое получение результата на системах с несколькими графическими процессорами.
⇡#Подползая к роботам
Загруженный файл модели v-1-5-pruned-emaonly.safetensors надо поместить в специально предназначенную для моделей папку внутри установочного каталога Stable Diffusion: /models/Stable-diffusion. Изначально она пуста, если не считать текстового файла нулевой длины с говорящим наименованием «Put Stable Diffusion checkpoints here» — «чекпойнтами» как раз и называют файлы с натренированными на определённым наборе картинок весами для данной нейросети.
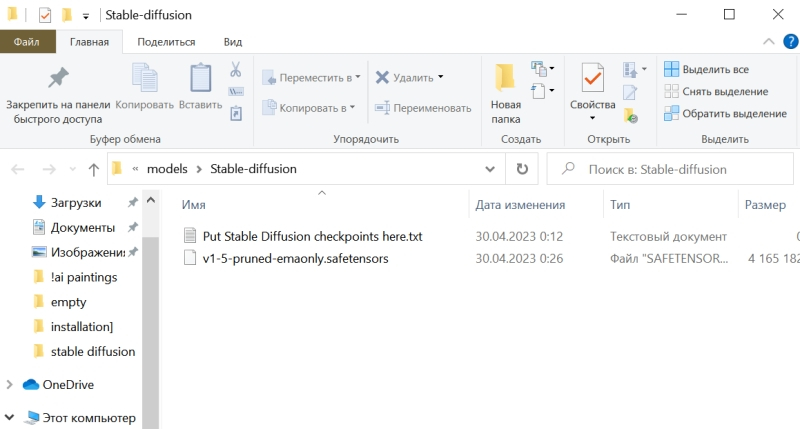
Для корректной работы системы по умолчанию требуется, чтобы базовый чекпойнт — тот, что будет сразу загружаться в память при запуске Stable Diffusion, — носил название «model», однако, помимо него, в этой папке может располагаться сколько угодно чекпойнтов. Поэтому следует либо переименовать «v-1-5-pruned-emaonly.safetensors» в «model.safetensors», либо сохранить прямо здесь же его копию с таким именем.
Источник: скриншот сайта python.org
Чекпойнт в формате файла сериализации для структуры объектов Python есть — а как же сам язык программирования Python? В Windows 10 его исходно, разумеется, нет, но он свободно доступен для загрузки с официального сайта. Главное — обращать пристальное внимание на выбираемую версию, а именно 3.10.6: следует загружать файл установщика для 64-битных систем — python-3.10.6-amd64.exe (проще всего найти «3.10.6» на странице через Ctrl+F). Дело в том, что разработка Stable Diffusion 1.5 (и, в меньшей степени, AUTOMATIC1111) велась именно на этой версии языка с поддержкой PyTorch — фреймворка, специально созданного для ускорения расчётов по части задач машинного обучения на современных графических адаптерах. И в целом следует помнить, что программы на Python не лучшим образом исполняются на любых иных (включая более свежие) его версиях, чем те, которыми пользовались их разработчики.
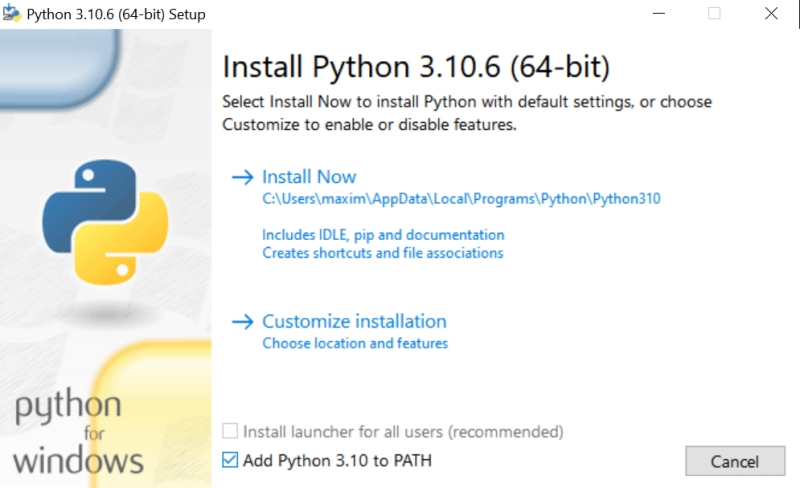
В ходе установки Python 3.10.6 на самом первом экране инсталляции потребуется поставить галочку напротив строки «Add Python 3.10 to PATH» — чтобы у Windows не возникало проблем с поиском соответствующих исполняемых файлов. Прочие опции в последующих окнах можно оставить нетронутыми.
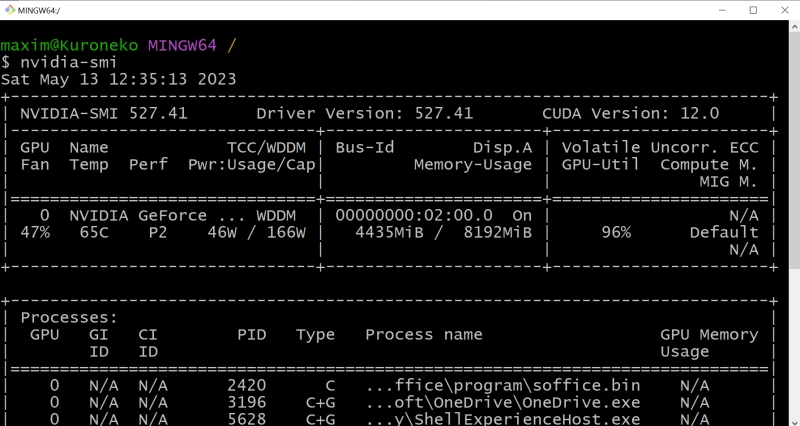
Да, и кстати: хорошо бы на всякий случай установить самые свежие из доступных драйверов для используемого графического адаптера, а заодно и CUDA Toolkit с сайта NVIDIA. Лишним не будет, поскольку обеспечиваемая этим пакетом поддержка инструкций xFormers позволяет Stable Diffusion и схожим text2image-моделям эффективнее использовать видеопамять. Чтобы узнать, имеется ли уже в системе CUDA Toolkit и какова текущая версия драйверов, следует выполнить из командной строки Windows команду
nvidia-smi
И если позиция «CUDA Version» в выдаче отсутствует либо номер этой версии меньше 11.7, имеет смысл скачать и проинсталлировать новую.
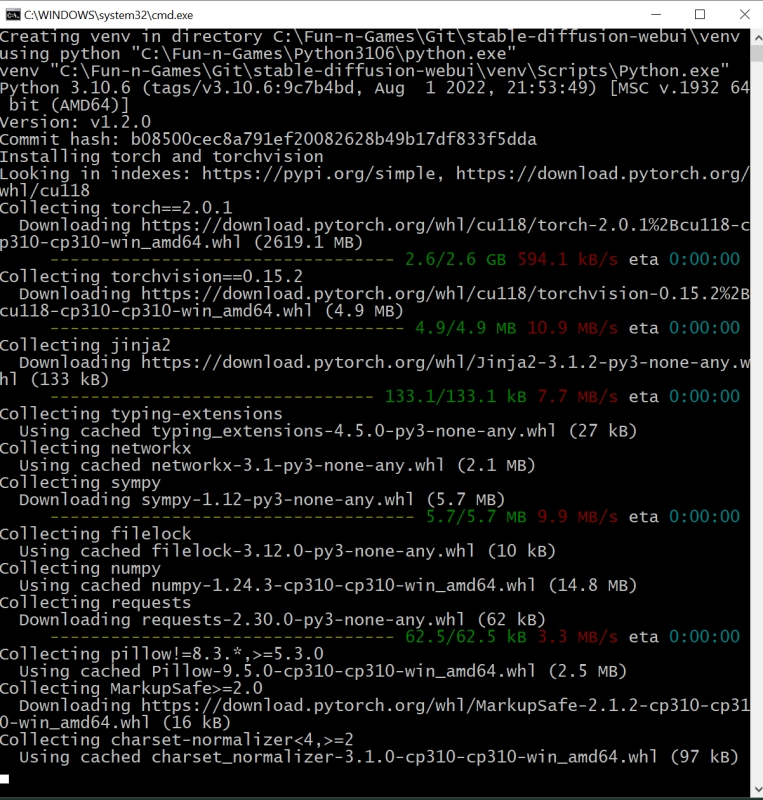
И вот, собственно, волнительный момент: первый запуск Stable Diffusion 1.5 с базовым чекпойнтом на вашем локальном ПК! Для этого теперь, когда всё необходимое ПО закачано и подготовлено, в «Проводнике», где открыт каталог stable-duffusion-webui, нужно дважды щёлкнуть левой кнопкой мыши по файлу webui-user.bat. Откроется окно терминала, в котором будут появляться служебные сообщения о производимых системой операциях. Сперва ей потребуется произвести ряд донастроек программного окружения, так что первый запуск может потребовать 5-10 минут, — но в дальнейшем всё будет происходить значительно быстрее.
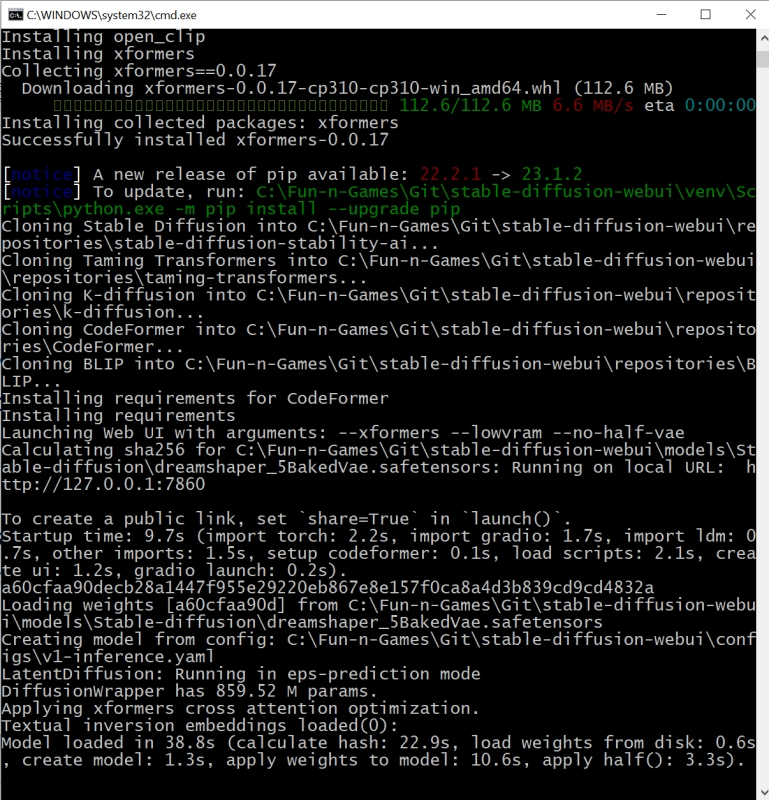
Обратите внимание, что в ходе установки система сообщает об обнаружении новой версии pip — и сразу же предлагает прямую ссылку для её установки. В принципе, это не обязательный момент, но pip — служебный пакет для управления зависимостями между пакетами (Python package manager), и как раз его — в отличие от рекомендованной версии самого Python — обновить лишним не будет.
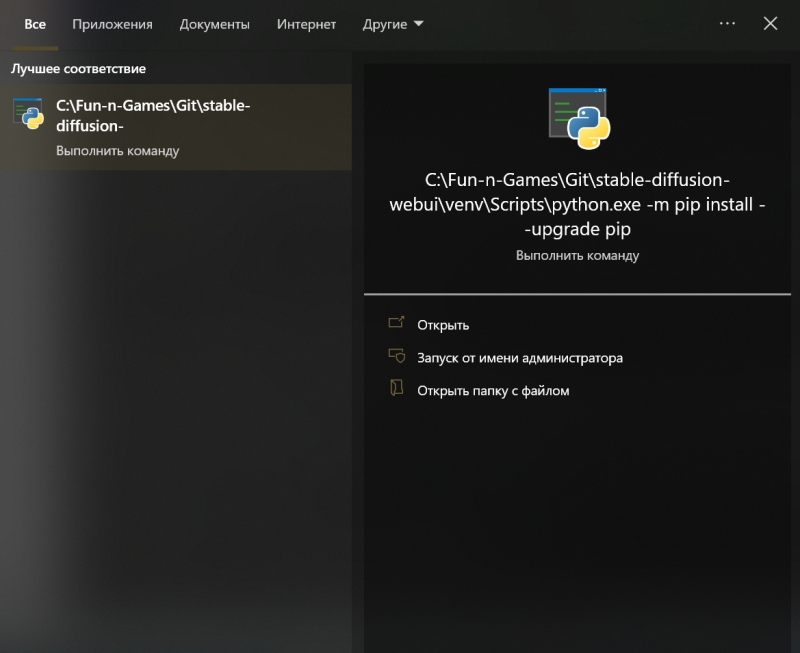
Скопировав прямо из терминального окна соответствующую команду (разумеется, точный путь до исполняемого файла будет зависеть от того, в какой каталог на данном ПК установлен Stable Diffusion), достаточно просто вставить её в системное поле поиска, что располагается слева на панели управления Windows 10/11, и нажать на «Enter».
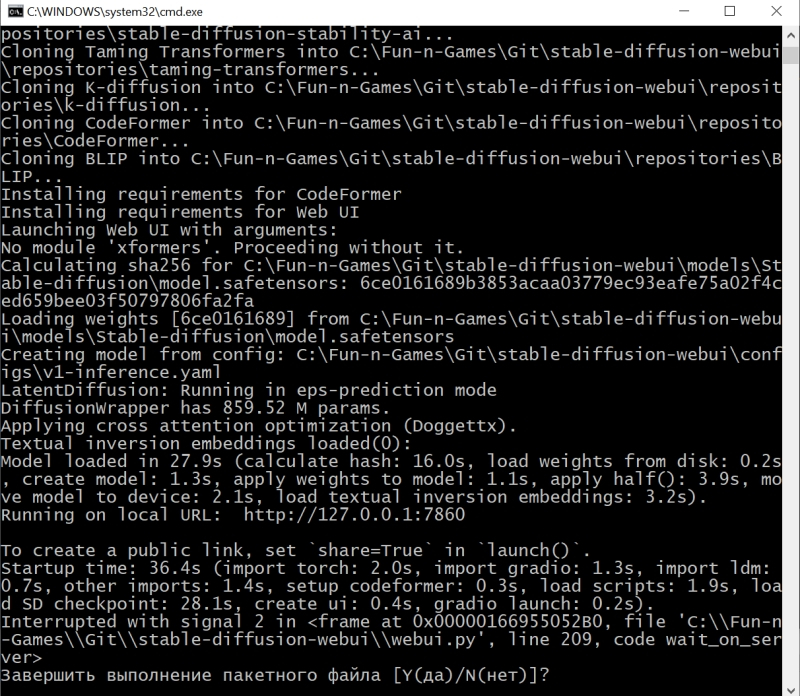
Итак, модель Stable Diffusion установлена и запущена. Можно уже приступать к рисованию? Почти: осталось лишь произвести тонкую настройку производительности, чтобы оптимизировать работу системы в дальнейшем. Остановим пока что работу пакета, нажав в активном терминале (открывшемся, напомним, после запуска файла webui-user.bat из «Проводника») клавиши «Ctrl» и «C» одновременно, а затем после появления подсказки введя «y» с подтверждающим «Enter». Окно терминала закроется после этого автоматически.
Обратимся снова к «Проводнику» и откроем уже знакомый файл с параметрами запуска webui-user.bat для редактирования: для этого нужно, подведя к нему курсор, нажать на правую кнопку мыши, а в появившемся меню выбрать опцию «Изменить».
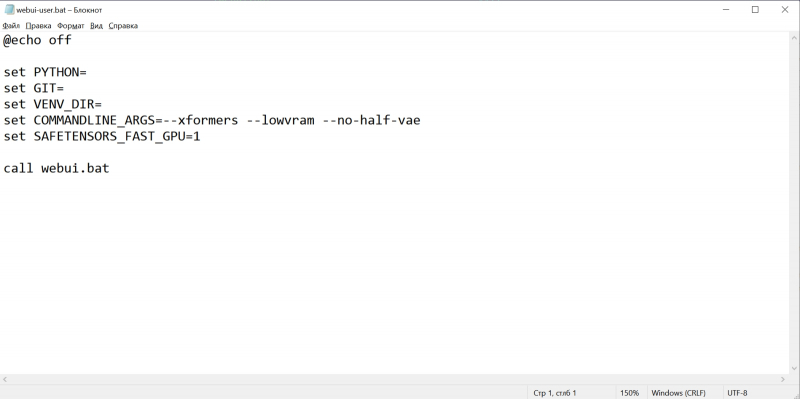
Вот так должен выглядеть webui-user.bat после редактирования. Здесь добавлены аргументы командной строки
—xformers —lowvram —no-half-vae
а также установлено значение переменной
SAFETENSORS_FAST_GPU=1
Кратко поясним, что здесь к чему. Xformers — точнее, xFormers, — это инструментарий для ускорения ИИ-вычислений, производимых с участием трансформеров, что применяются практически во всех современных диффузионных моделях — преобразователях текстовых подсказок в изображения, не исключая и Stable Diffusion. Навскидку на GTX 1070 указание аргумента —xformers при запуске системы ускоряет при прочих равных получение результата едва ли не вдвое. Правда, имеются основания утверждать, что xFormers добавляют изрядно стохастики в генеративный процесс, так что воспроизвести однажды полученную картинку с теми же стартовыми параметрами (затравка-seed, чекпойнт, CFG, подсказки и пр.) со стопроцентной точностью уже не удастся. В любом случае владельцам графических адаптеров менее чем с 12 Гбайт видеопамяти применять xFormers, скорее всего, придётся, поскольку этот инструментарий за счёт оптимизации вычислений ощутимо снижает объём используемой VRAM — и тем самым делает возможной дальнейшую ИИ-обработку полученных картинок внутри Stable Diffusion, включая до- и перерисовку, увеличение масштаба с наращиванием детализации и т. п.
Смысл —lowvram куда более очевиден: это указание системе на то, что видеопамяти в её распоряжении немного. В перечне доступных оптимизаций AUTOMATIC1111 указаны и этот параметр, и не так сильно сказывающийся на производительности (но зато и более требовательный к объёму памяти) —medvram. В отношении —lowvram приговор разработчиков лаконичен: «Devastating for performance». При использовании —medvram модель не загружается в видеопамять вся, а разбивается на три блока, каждый из которых подтягивается в VRAM последовательно, по мере необходимости, но целиком; —lowvram же дробит наиболее объёмистый из этих модулей на ещё более мелкие фрагменты, тем самым позволяя (теоретически; лично не проверялось) трансформировать текстовые подсказки в изображения даже на ГП с 2 Гбайт видеопамяти, — но ценой заметного увеличения времени работы.
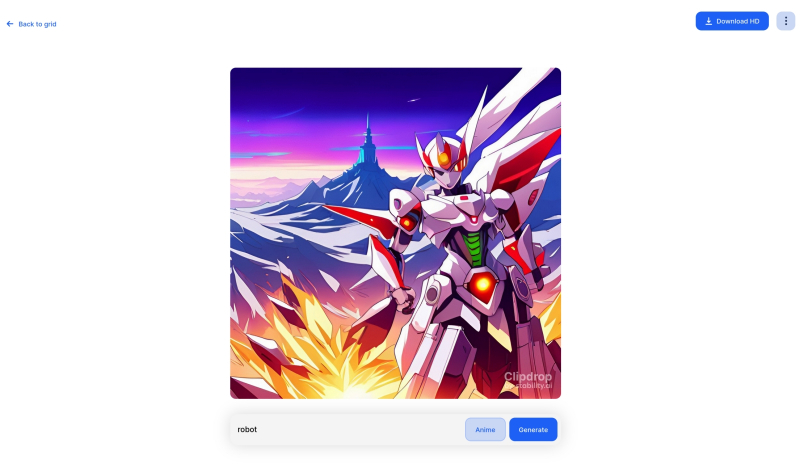
Чем хороша ИИ-генерация изображений на специализированных сайтах, так это отсутствием необходимости заботиться об установке и настройке системы (источник: скриншот сайта clipdrop.co)
Иными словами, с —lowvram система заработает практически на любом ПК, более или менее заслуживающем называться «игровым», почти гарантированно. Но едва первые изображения получены, есть смысл поменять в конфигурационном файле этот параметр на —medvram и, перезапустив Stable Diffusion, произвести генерацию заново; и если всё получится — оставить всё именно в таком виде. Например, для используемой в настоящем киберпрактикуме системы с GTX 1070 базовая генерация с параметром —lowvram занимает 28-35% от доступных 8 Гбайт видеопамяти, тогда как с —medvram — уже 68-75%, причём выигрыш во времени, что уходит на создание одной картинки, не превышает 25-30%. Счастливым же обладателям видеокарт с VRAM 12 Гбайт и более ни один из этой пары оптимизационных параметров не пригодится.
Параметр —no-half-vae — ещё одна оптимизация, дающая системе указание не использовать формат половинной точности (16 бит для 32-разрядных компьютеров) представления данных с плавающей запятой для работы VAE (вариационного автокодировщика; смысл его в том, чтобы снижать размерность пространства задаваемых модели параметров почти без потери информации о них). Строго говоря, такой формат в полной мере поддерживают лишь наиболее новые поколения ГП NVIDIA — Pascal, Volta, Ampere, — так что пользователям более ранних видеокарт имело бы смысл применять разом две оптимизации: и указанную нами —no-half-vae, и более глобальную —no-half (относится уже не к одному только VAE, а к базовому чекпойнту в целом). Однако, как показывает практика, в отсутствие —no-half даже на сравнительно старых ГП Stable Diffusion работает вполне уверенно, тогда как без —no-half-vae частенько выдаёт чёрные прямоугольники вместо сгенерированных картинок. Речь, подчеркнём ещё раз, идёт именно о GeForce GTX 2000-й серии и более ранних: для актуальных RTX 3000-го и 4000-го семейств в аргументах командной строки внутри .bat-файла не имеет смысла указывать параметры оптимизации — разве только —xformers.
Ещё одна дописанная нами в этот файл строка
SAFETENSORS_FAST_GPU=1
тоже направлена на ускорение работы системы. Здесь использована та особенность формата .safetensors, что представленные в нём веса модели оказывается возможно загрузить напрямую в видеопамять, минуя этап первоначальной подгрузки в основное ОЗУ.
Собственно, всё: сохранив изменения в webui-user.bat и закрыв его, снова запускаем этот файл двойным щелчком — и наблюдаем, как система (уже с оптимизированными параметрами) приходит в рабочее состояние. После появления надписи «Running on local URL» самое время открыть в браузере новую вкладку и набрать в ней адрес, по которому доступен веб-интерфейс AUTOMATIC1111, — http://127.0.0.1:7860.
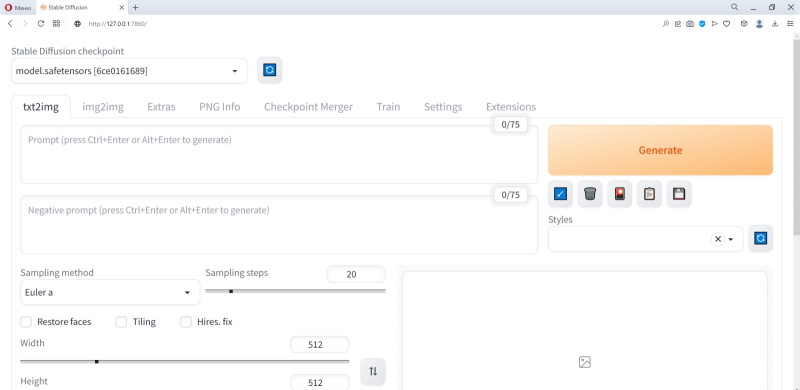
Вот примерно так он и выглядит изначально. Наконец-то пришла пора приниматься за творчество! Точнее, за побуждение ИИ к изобразительному действию путём выдачи ему текстовых подсказок.
⇡#Как художник художнику
Нет ничего проще: в основное поле для ввода (Prompt) впишем для начала одно-единственное слово «robot».
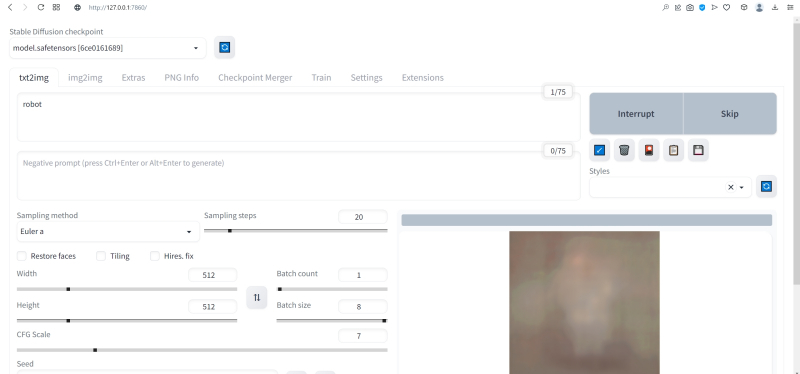
Оставим поле Negative prompt пустым, не будем трогать другие параметры, только ползунок Batch size (размер пакета) передвинем вправо до упора — чтобы получать сразу восемь картинок с различными затравками (seed) одновременно: так проще будет выбирать достойную дальнейшей обработки заготовку. Дальше следует нажать на огромную оранжевую кнопку Generate — и, если всё было сделано должным образом, через некоторое время Stable Diffusion визуализирует полученную подсказку.
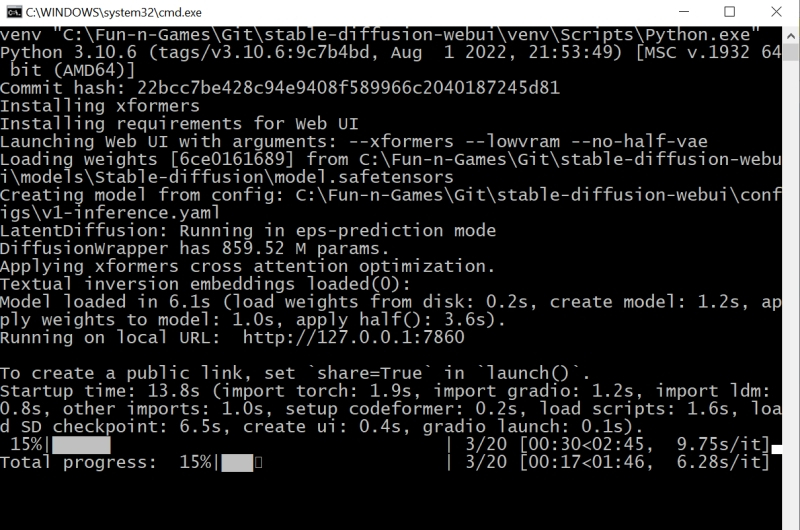
За ходом процесса можно наблюдать в терминальном окне, где запущена сама система, — там будет появляться детальная информация о времени, затраченном на загрузку рабочих параметров, и даваться оценка продолжительности работы.
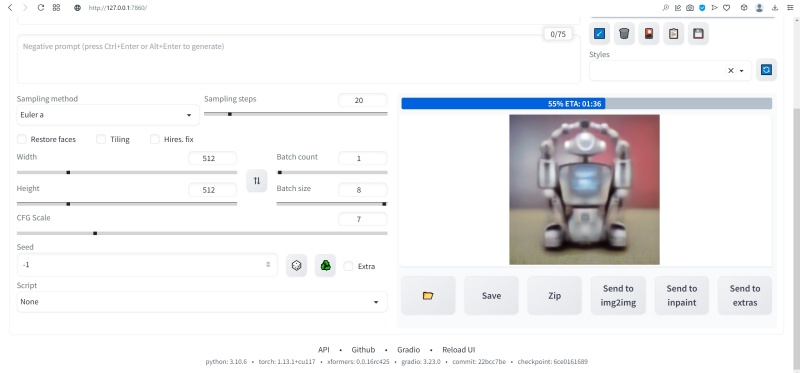
Ту же оценку можно видеть на фоне ползущей вправо синей полоски прогресса и в графическом веб-интерфейсе. Там же — для справки — система демонстрирует некоторые промежуточные результаты процесса диффузии: как из исходного «белого щума» постепенно проявляется ожидаемое изображение.
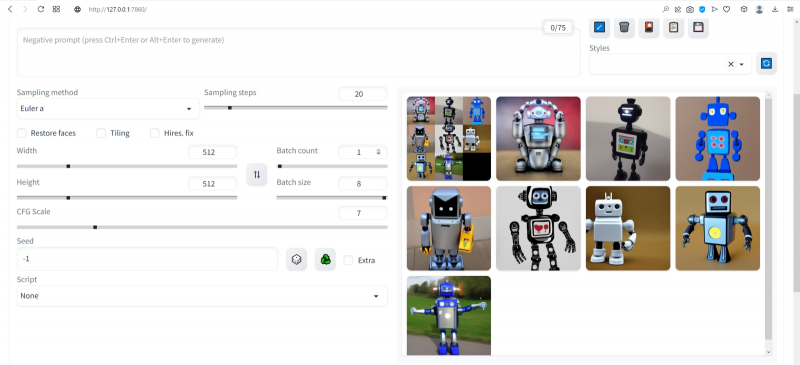
М-да. Результаты не то чтобы разочаровывают — скорее, не впечатляют. Роботы в этих фигурках вполне угадываются, но какие-то они… невыразительные, что ли. Нельзя ли как-нибудь повысить качество выдачи?
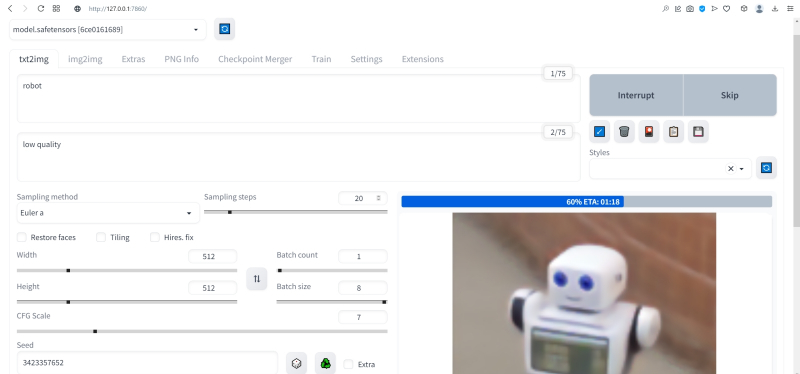
Можно и даже нужно: вся прелесть ИИ-преобразования текста в картинки заключается как раз не в самом рисовании роботом неких образов по заданной подсказке, а в том, насколько разнообразными и порой неожиданными могут быть плоды его трудов — в зависимости от приложенных оператором мыслительных усилий. Для начала задействуем поле Negative prompt, вписав туда то, чего не хочется видеть в итоговой картинке, а именно — low quality. Далее нажмём на зелёный треугольник из стрелочек, напоминающий условное обозначение вторичной переработки: это позволит зафиксировать случайно подобранную системой затравку (seed; в данном случае — 3423357652) для последующих генераций, что сделает оценку влияния вводимых нами параметров на итоговую картинку более наглядным.
Кстати, в домашнем каталоге Stable Diffusion есть теперь папка output, в которой хранятся результаты: сами картинки по отдельности (txt2img-images) и обзорные сборки пакетных генераций (txt2img-grids). Внутри этих папок изображения помещаются в помеченные текущей датой подкаталоги.
Как можно видеть, уже простейшая негативная подсказка сделала изображения более выразительными. Обратите внимание, как система именует их по умолчанию: сперва идёт сквозной номер генерации за текущую дату, далее через дефис — использованная для создания данной картинки затравка (seed). То есть здесь первому изображению в первом пакете (00000-3423357652) соответствует первое во втором (00008-3423357652) и т. д.

Добавим определённости в то, какими именно нам хочется видеть изображаемых роботов. В позитивные подсказки вместо просто «robot» напишем «fighting robot, shiny steel», а в негативные — один из стандартных нежелательных наборов контекстуальных терминов (undesired content prompt): «lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts,signature, watermark, username, blurry, artist name». Гораздо интереснее, не правда ли?

Общее правило в искусстве составления подсказок (promptsmithing, по аналогии со златокузнечным делом — goldsmithing) таково: всё, что точно должно присутствовать на картинке, прописывается в позитивные подсказки; всё, чего там ни при каких условиях не должно появляться, — в негативные; прочее отдаётся на откуп ИИ-художнику. При этом следует помнить, что чем ближе то или иное слово к началу подсказки, тем значительнее оно повлияет на итоговую картинку. Вообще, широта возможностей при составлении подсказок открывает огромный простор для экспериментаторства. В сообществе text2image-энтузиастов выработано уже немало схем (которые в любом случае следует подвергать конструктивному сомнению) их структурирования — например, такая:
Subject, Medium, Style, Artist, Website, Resolution, Additional details, Color, Lighting
(т. е. объект, среда, стиль, художник, веб-сайт, разрешение, дополнительные детали, цветовая палитра, освещение).
Попробуем обогатить нюансами нашу исходную подсказку, выстроив слова в ней следующим образом (перевод строки в интерфейсе AUTOMATIC1111 просто игнорируется обработчиком текста, что позволяет использовать его для пущей наглядности):
fighting robot,
digital painting,
hyperrealistic,
by Viktor Vasnetsov,
trending on ArtStation,
extremely high details, sharp focus, depth of field,
futuristic, stunningly beautiful, dystopian,
iridescent shiny steel,
cinematic lighting, dynamic lighting, sparks and flashes
Негативную подсказку оставим прежней. Не следует удивляться появлению ссылки на Васнецова: Stable Diffusion при обучении ознакомили с работами множества художников, так что их имена в подсказке оказывают влияние на общий стиль изображения — пусть даже сам этот реальный художник в своей практике сражающихся роботов не писал. Упоминание известного среди мастеров и поклонников цифровых художеств сайта ArtStation тоже не случайно: популярные на нём (trending) работы в целом имеют весьма определённую стилистику, и её система машинного обучения тоже вполне успешно ухватывает.
Ещё одна деталь: квадратные изображения Stable Diffusion 1.5 генерирует лучше всего (в том смысле, что генерация эта порождает минимум артефактов вроде искажённых пропорций человеческих тел или нарушений перспективы), поскольку обучалась на картинках с разрешением 256 × 256 и 512 × 512 пикселов. Однако AUTOMATIC1111 позволяет на страх и риск пользователя менять эти размеры, в том числе получая изображения альбомной или книжной ориентации, а не только квадратные. Базовая модель Stable Diffusion 1.5 не очень уверенно справляется с прямоугольниками (другие чекпойнты делают это лучше, плюс есть ещё целый ряд трюков, но об этом позже), но всё же в размере 512 × 768 пикселов должна выдавать более или менее приемлемый результат. Сдвинем поэтому ползунок «Height» на позицию 768 (или можно просто набрать это число вручную в соответствующем окошке) — и насладимся уже более впечатляющим результатом.
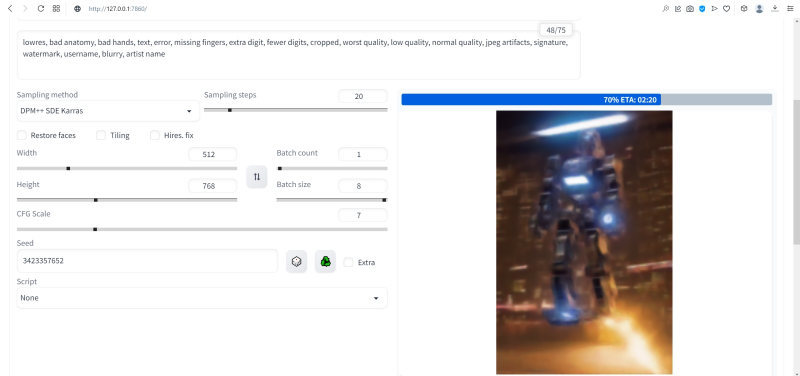
Продолжим изучать органы управления AUTOMATIC1111, обратив внимание на выпадающее меню Sampling method, где по умолчанию выбрано «Euler a». Как уже упоминалось, работа диффузионной генеративной модели заключается в поэтапном вычитании из исходного образа (квадрата или прямоугольника, заполненного «белым шумом») другого шума, уже упорядоченного (predicted noise), — специальным образом сгенерированного на основе текстовой подсказки. Непосредственно процесс снижения уровня шума (denoising) называется также сэмплингом (sampling), поскольку на каждом этапе последовательного снижения зашумлённости картинки получается новый её образчик (sample) — и, собственно, сколько именно шагов на этом пути будет пройдено, контролирует параметр Sampling steps. Для большинства чекпойнтов достаточно 20-30 шагов.

А вот то, каким именно образом модель решает, сколько шума и на каких именно участках надо оставить на картинке на каждом этапе, и определяется методом сэмплинга; говоря математическим языком — тем или иным методом градиентного спуска. Наиболее простой и быстрый (но и дающий менее выразительные с художественной точки зрения результаты) — это уже использованный нами Euler (см. схема Эйлера). Другие сэмплеры могут давать более интересные и/или более сложные результаты с бóльшим или меньшим учётом различных фрагментов подсказки — здесь нет ни единого рецепта, ни общего правила, что считать более предпочтительным. Однако, поменяв Euler на более «продвинутый», хотя и требующий большего времени на исполнение сэмплер DPM++ SDE Karras (Каррас — фамилия одного из авторов оригинальной статьи, где описан целый ряд таких методов), мы ровно с теми же самыми позитивной и негативной подсказками и с той же затравкой (seed) получим в целом более живописные изображения.

Продолжаем усложнять позитивную подсказку: уж слишком получающиеся роботы трансформерообразны, — добавим здравый элемент стимпанка:
fighting robot,
in ancient alien ruins,
digital painting,
hyperrealistic,
by Viktor Vasnetsov,
trending on ArtStation,
extremely high details, sharp focus, depth of field,
steampunk, stunningly beautiful, retrofuturistic,
iridescent shiny brass,
cinematic lighting, dynamic lighting, sparks and flashes
Разве не хорошо? Особенно вон те двое, что играют в чехарду (как раз здесь проявляется самотворчество цифрового художника: в заданной нами подсказке ничего ни про двух роботов, ни про их взаимное расположение не говорилось). Правда, становятся очевидными артефакты вертикальной композиции, прежде всего — отъединённые конечности. Чтобы бороться с этим, есть разные способы.

Попробуем для начала переставить стили (указание на художника и сайт) в конец, а заодно убрать «ретрофутуризм» как термин из подсказок — слишком уж невнятно определён, может сбивать модель с толку, — и добавим больше подразумеваемых им деталей: янтарно светящиеся лампы, бронзовые трубки, медные зубчатые колёса, хромированные цепи, циферблаты слоновой кости, вентили эбенового дерева:
fighting robot,
in ancient alien ruins,
digital painting,
hyperrealistic,
extremely high details, sharp focus, depth of field,
steampunk, stunningly beautiful,
iridescent shiny metal, amber neon tubes, brass pipes, copper gears, chrome chains, ivory dials, ebony valves,
cinematic lighting, dynamic lighting, sparks and flashes,
by Viktor Vasnetsov,
trending on ArtStation
Вот это поворот! Деталей стало явно больше.

А если вовсе отказаться от двух последних строк в поле позитивной подсказки? Пожалуй, это отсутствие заёмного стиля — само по себе стиль оригинальной Stable Diffusion 1.5 при работе с довольно развёрнутым текстовым вводом: несколько сумбурный, зато высокодетализированный.
⇡#Комбинируя комбинатора
Не раз уже мы называли используемый с AUTOMATIC1111 чекпойнт «v-1-5-pruned-emaonly.safetensors» (переименованный, напомним, в «model.safetensors») базовым. Значит, должны быть и какие-то не-базовые, производные? Так и есть: на основе изначальной модели Stable Diffusion 1.5 (только в версии pruned, без emaonly) энтузиасты производят дотренировку, прогоняя через систему — тем же путём, что пропутешествовали исходные миллиарды картинок, — ещё несколько сотен, или тысяч, или на сколько у них хватит терпения и вычислительных мощностей. Картинки эти, соответствующим образом подобранные и аннотированные, расширяют горизонты восприятия, если так можно выразиться, модели: она начинает значительно чаще выдавать изображения в стимпанковской стилистике без дополнительных подсказок, или лучше начинает рисовать фэнтезийных эльфов (базовый чекпойнт в ответ на подсказку «elf» c большой вероятностью изобразит помощника Санты в зелёном колпачке, а не горделивого обитателя зачарованных лесов), или ещё каким-то образом модифицирует результаты своей генерации.
Чего ради стоит возиться с чекпойнтами, мы покажем на примере одной из наиболее популярных сегодня доработок Stable Diffusion 1.5 под названием Deliberate v.2. Загрузить этот файл в формате .safetensors логичнее всего со страницы данного проекта на уже знакомом нам репозитории Hugging Face, после чего надо поместить дотренированную модель в ту же папку, где уже находится базовая, — model.safetensors. На сей раз переименовывать ничего не требуется.
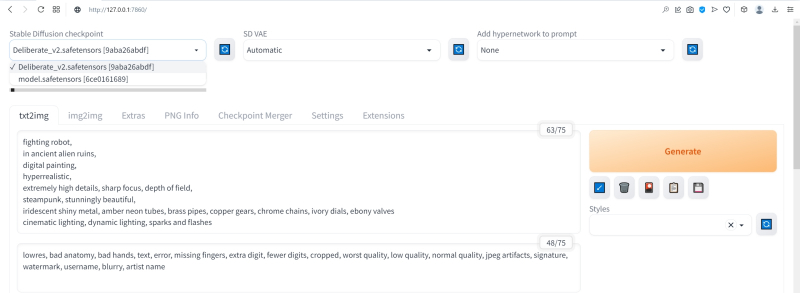
Перезапускать систему целиком (закрывать окно терминала и запустить webui-user.bat заново) не надо: достаточно нажать на синюю кнопку с белыми полукруглыми стрелочками у выпадающего меню Stable Diffusion checkpoint, затем открыть это меню, активировать появившуюся опцию Deliberate_v2.safetensors — и снова нажать на Generate.

Небо и земля! Фигуры роботов стали куда более статичными, но проработка и взаимосогласованность деталей определённо улучшились. В этом сила производных (от базовой модели) чекпойнтов: они позволяют с меньшими усилиями — со стороны конечного пользователя — получать более эстетически привлекательные изображения с теми же подсказками и затравками, чем ванильная Stable Diffusion 1.5.
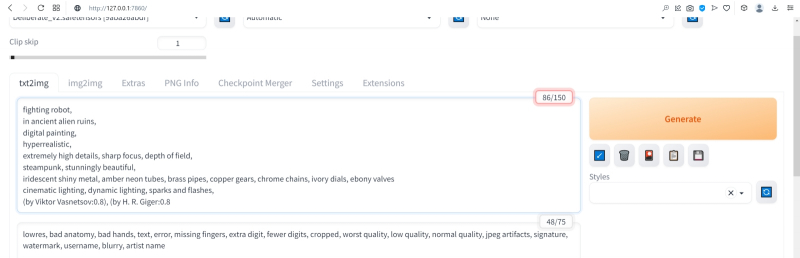
А теперь попробуем вернуть художников (сайт пока всё-таки упоминать не станем: понятие стиля для него в целом более размыто, чем для индивидуальных живописцев). Самой последней строкой в поле позитивных подсказок укажем:
(by Viktor Vasnetsov:0.7), (by H. R. Giger:0.9)
Кстати, если забыть закрыть одну из скобок, система предупредит о возможной ошибке: число параметров генерации (в правом верхнем углу соответствующего окошка; в данном примере — 86/150) окажется обведено тревожной красноватой рамочкой.

Имя Ханса «Рюди» Гигера известно немногим, однако стилистика его работ в жанре фантастического реализма знакома каждому, кто видел хотя бы пару кадров из культового фильма «Чужой», для которого именно этот художник разработал и образ ксеноморфа, и общий дизайн. Что же касается скобочек и цифр внутри, то это принятый в AUTOMATIC1111 способ изменения значимости (относительного веса) конкретной подсказки.
По умолчанию любая из них имеет условный вес 1; если просто заключить подсказку в круглые скобки, это будет соответствовать приданию ей веса 1,1 (т. е. она станет более значимой для генерации данного изображения, чем соседние), а если нужно установить какой-то иной вес, его указывают явно после двоеточия. Обычно стоит избегать весов менее 0,5 (по причине пренебрежимо малого влияния таких подсказок на итоговую картинку) и более 1,5 (результат может оказаться графически непредсказуемым), но в любом случае это ещё одна степень свободы опосредованного искусственным интеллектом творчества — которой энтузиасты охотно пользуются. Выставив для стилей обоих этих художников невысокие веса, мы избежим чрезмерного влияния их на итоговую картинку (роботизированный Чужой в сарафане уж точно не появится здесь), но живости и индивидуальности ей, безусловно, прибавим.
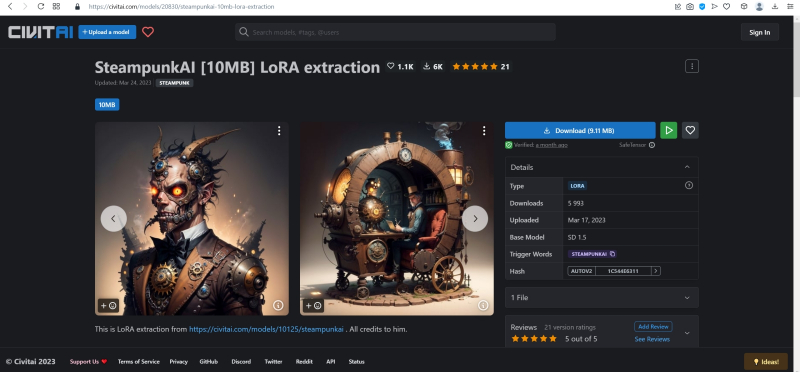
Источник: скриншот сайта civitai.com
Помимо полноценных дотренированных чекпойнтов, известны и другие методы обучения генеративной модели text2image определённой стилистике или рисованию новых объектов, не входивших в первичную тренировочную базу. Один из таких методов — LoRA (low-rank adaptation of large language models, низкоуровневая адаптация LLM), что подразумевает внедрение дополнительных обучаемых нейронных слоёв в уже готовые (натренированные в ходе создания базовой модели) блоки трансформеров. Как это реализуется математически — для нас в данном случае принципиального значения не имеет; важно понимать, как этим пользоваться.
Вот, к примеру, на сайте Civitai.com, открытом репозитории множества ресурсов для энтузиастов text2image-генераций, имеется LoRA под названием SteampunkAI. Она создана на основе чекпойнта, специально дообученного для рисования в соответствующем стиле, и может применяться с любым другим чекпойнтом, обеспечивая вполне узнаваемую и зрелищную стилистику. Чтобы скачать соответствующий файл в формате .safetensors, достаточно нажать на длинную синюю кнопку на правой стороне веб-страницы.
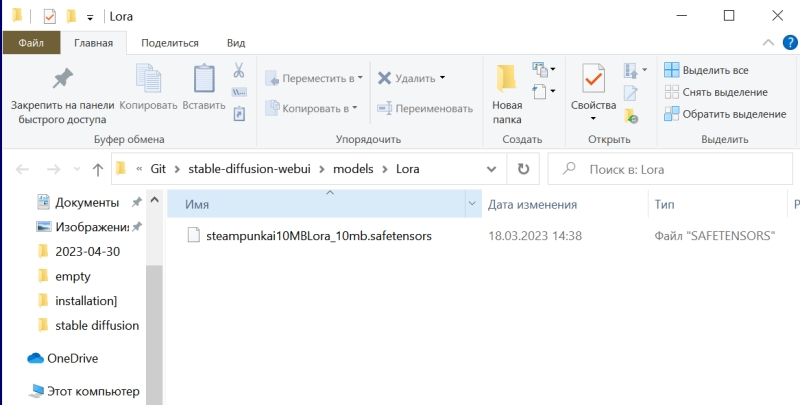
А поместить полученный файл, steampunkAI10MBLora_10mb (да, он занимает всего около 10 Мбайт — разительный контраст с чекпойнтом!) нужно будет в специально для того предназначенный каталог models\Lora.
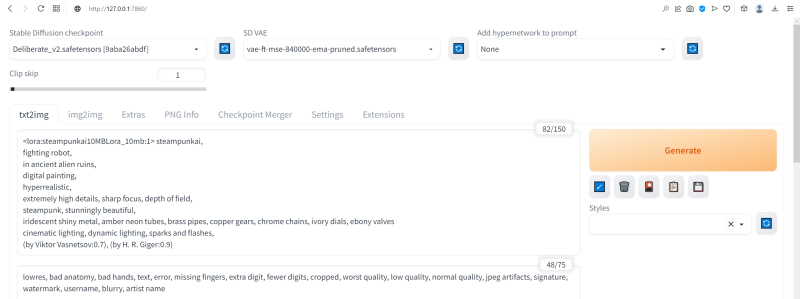
Для активации LoRA служит особая команда в треугольных скобках с указанием точного её наименования и условного веса (который в зависимости от желания оператора может быть и меньше, и больше единицы):
<lora:steampunkai10MBLora_10mb:1> steampunkai,
fighting robot,
in ancient alien ruins,
digital painting,
hyperrealistic,
extremely high details, sharp focus, depth of field,
steampunk, stunningly beautiful,
iridescent shiny metal, amber neon tubes, brass pipes, copper gears, chrome chains, ivory dials, ebony valves,
cinematic lighting, dynamic lighting, sparks and flashes,
(by Viktor Vasnetsov:0.7), (by H. R. Giger:0.9)
Негативная подсказка по-прежнему неизменна.

В целом результат очень хорош, проработка деталей фантастическая, но какими-то эти роботы враз стали… статичными, что ли. И резко однотипными. Однако и с этой напастью ИИ-энтузиасты научились бороться, применяя такое сильнейшее шаманство, как clip skip. Сейчас поясним, что это значит.
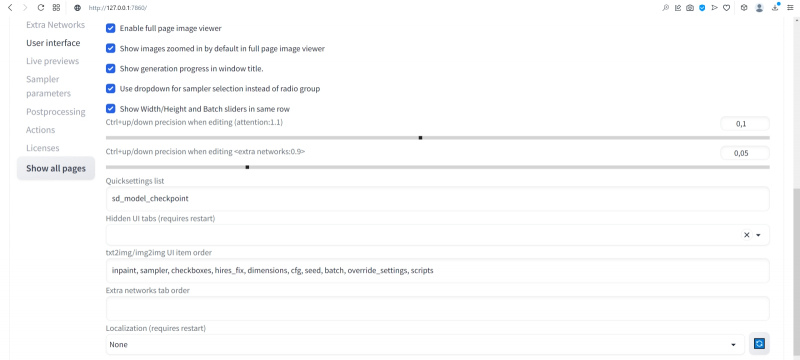
Но сперва слегка подкорректируем интерфейс AUTOMATIC1111. В настройках — Settings — веб-интерфейса надо открыть раздел User interface, и в нём — окошечко Quicksettings list. Это перечисление того, какие элементы управления будут вынесены на самый верх заглавной страницы интерфейса. Изначально там был единственный параметр, sd_model_checkpoint, — именно его наличие сделало доступным выпадающее меню, в котором мы поменяли model.safetensors на Deliberate_v2.safetensors.
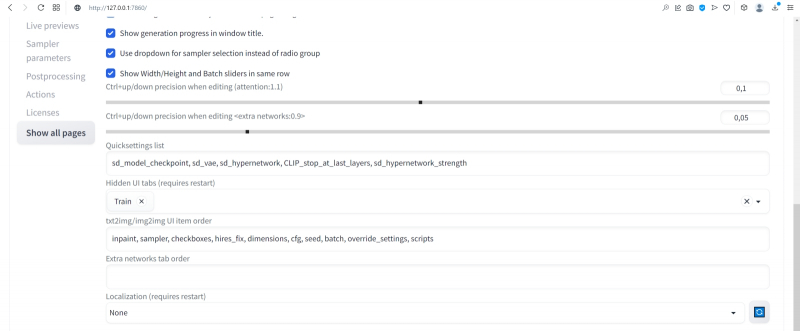
Добавим туда через запятую sd_vae, sd_hypernetwork, CLIP_stop_at_last_layers, sd_hypernetwork_strength (начиная с версии 1.2.0 AUTOMATIC1111 добавление это производится из выпадающего меню: достаточно начать набирать наименование желаемого параметра, и список предлагаемых опций будет автоматически сужаться).
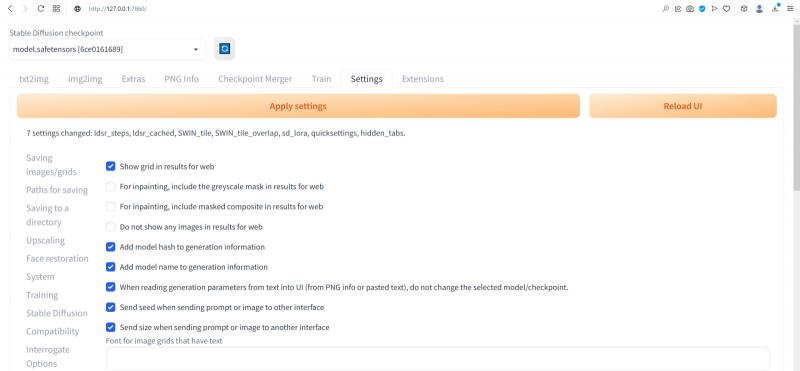
Прописав нужные параметры, вернёмся прокруткой в начало страницы и нажмём огромную оранжевую кнопку Apply settings, а затем — соседнюю с ней Reload UI.
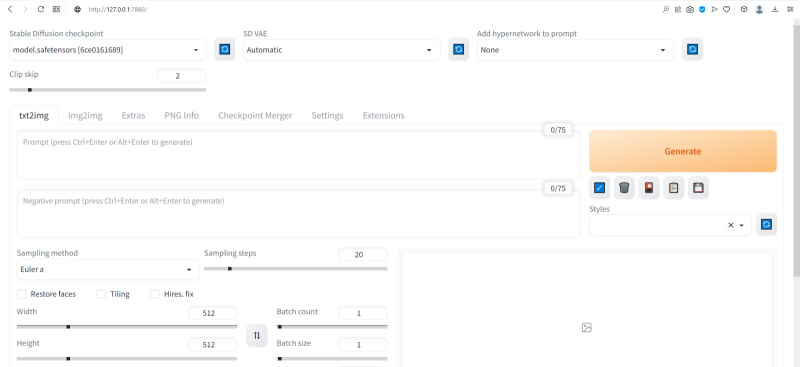
После возврата на заглавную страницу веб-интерфейса (вкладка txt2img) убеждаемся, что верхняя её часть теперь содержит два дополнительных выпадающих меню (SD-VAE, Add hypernetwork to prompt) и ползунок — собственно Clip skip. Вот его-то и следует передвинуть в позицию 2. Но с какой целью?
После запуска генерации картинки первым в работу вступает CLIP — построенный на трансформерах кодировщик текста в токены, которые используются в дальнейшем уже собственно диффузионной моделью, чтобы «убрать ненужный шум» с заготовки будущего изображения. Как и полагается такому кодировщику, он сам представляет собой многослойную нейросеть (для Stable Diffusion 1.5 — 12 слоёв), на каждом из которых, грубо говоря, производится дополнительная конкретизация подсказки. Скажем, невозможно изобразить «дом вообще», как концептуальную идею: модели необходимо определиться со стилистикой (будет ли это фото, реалистичный тщательный рисунок, стилизация из детской книжки, беглый набросок и т. п.), общими параметрами (этажность, форма крыши, наличие/отсутствие трубы), цветом, числом видимых окон и дверей и ещё множеством параметров. Хорошо, если подсказка детальная: «дом ведьмы» уже значительно сузит пространство выбора вариантов, но всё равно оставит значительный простор для (нет, не воображения, — у современных ИИ его всё ещё нет) псевдослучайного комбинирования вариантов, возникших на основе обучения модели. Ещё раз: это очень грубое описание, поскольку, как и всякая многослойная плотная нейросеть, работа CLIP принципиально не интерпретируема на внутреннем уровне и представляет собой по сути «чёрный ящик».
Так вот, на финальном шаге CLIP должна передать диффузионной модели достаточно подробные указания (в виде набора токенов), какая именно картинка должна скрываться в очередном заполненном «белым шумом» прямоугольнике. И чем лучше система натренирована на сравнительно узком наборе изображений — а как раз этим нередко страдают «авторские» чекпойнты, — тем более однотипные картинки она станет выдавать при различных затравках (seed). Что, собственно, хорошо иллюстрирует только что полученная нами галерея практически паспортных фотокарточек квазистимпанковских роботов. Да, каждая из них детально проработана, но именно все разом они явно демонстрируют некую перетренированность используемой диффузионной модели.
Скорее всего, это вина не чекпойнта Deliberate, а узкотематической LoRA, так что, поиграв с её значимостью (поменяв «:1» внутри треугольных скобок на «:0.7» для начала), можно было бы сгладить негативный эффект. Но мы поступим иначе, задав Clip skip = 2, т. е. заставив систему прерывать формирование структуры инструкций для диффузионной модели за шаг до исходно намеченного финала. Это словно бы несколько собьёт генератор токенов с толку — и во множестве случаев как раз предпоследний, а не финально вылизанный набор инструкций для ИИ-рисования и породит подлинно привлекательную на человеческий взгляд картинку. В качестве самостоятельного упражнения попробуйте и другие варианты Clip skip, вплоть до максимально возможного, — результат вас не на шутку удивит.
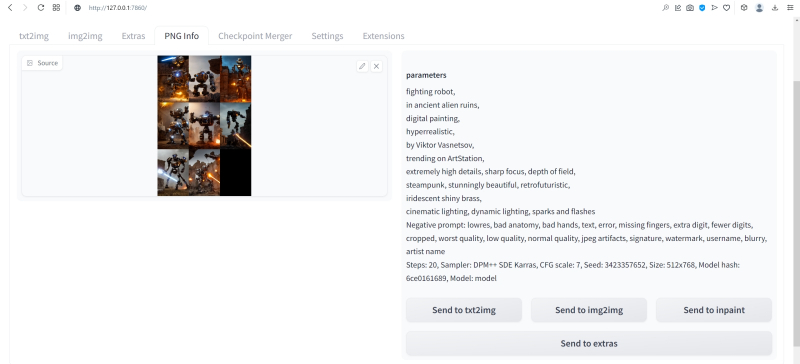
Практическое отступление: после перезагрузки интерфейса пропали все наши подсказки и настройки во вкладке txt2img. Можно, конечно, восстановить их вручную по предыдущим записям — но зачем, если AUTOMATIC1111 помещает все важнейшие данные прямо в генерируемые картинки; в поля текстовых комментариев, предусмотренные стандартами PNG и JPEG?
Обратите внимание на вкладку PNG Info в веб-интерфейсе: при переходе на неё появляется область для загрузки изображений. Поместим туда (просто перетащив мышкой) из окна «Проводника» Windows, в котором открыта папка txt2img-grids, последнюю из сгенерированных картинок в формате PNG — и справа появится вся информация, сохранённая в её метаданных. Теперь достаточно нажать на «Send to txt2img», чтобы все использованные для генерации данной картинки подсказки и параметры, вплоть до Seed, оказались на своих местах. Надо лишь только вернуть Batch size значение 8 — иначе будет сгенерирована не подборка, как всё время до сих пор, а только единичная картинка с исходной затравкой. В подборке же у каждой последующей картинки затравка (seed), напомним, отличается от предыдущей на единицу.

Итак, запускаем генерацию вновь с прежними параметрами (восстановленными через PNG Info), но с clip skip = 2. Ну вот, разительный контраст! Разнообразие явно увеличилось, а где-то даже и динамика появляется.
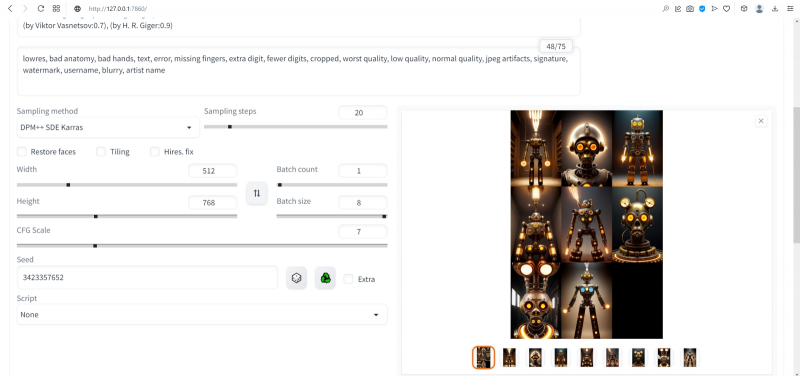
А что если перевести изображение из книжного формата в альбомный? Вертикальная композиция человекоподобной сущности всё-таки подразумевает некую портретность, соседствующую со статичностью, тогда как растянутая по ширине картинка может предоставить больше простора для динамики. Для простой перемены местами размерностей (чтобы вместо 512 × 768 пикселей стало 768 × 512) достаточно нажать на кнопку со стрелочками «вверх» и «вниз» рядом с ползунками Height и Width. Попробуем сгенерировать так.

Очень неплохо! Но простор для улучшения всё ещё есть.

Поиграем снова с порядком расположения подсказок:
<lora:steampunkai10MBLora_10mb:1> steampunkai,
fighting robot,
in ancient alien ruins,
iridescent shiny metal, amber neon tubes, brass pipes, copper gears, chrome chains, ivory dials, ebony valves,
steampunk, stunningly beautiful,
digital painting,
hyperrealistic,
extremely high details, sharp focus, depth of field,
cinematic lighting, dynamic lighting, sparks and flashes,
(by Viktor Vasnetsov:0.7), (by H. R. Giger:0.9)
Выходит вполне достойно.
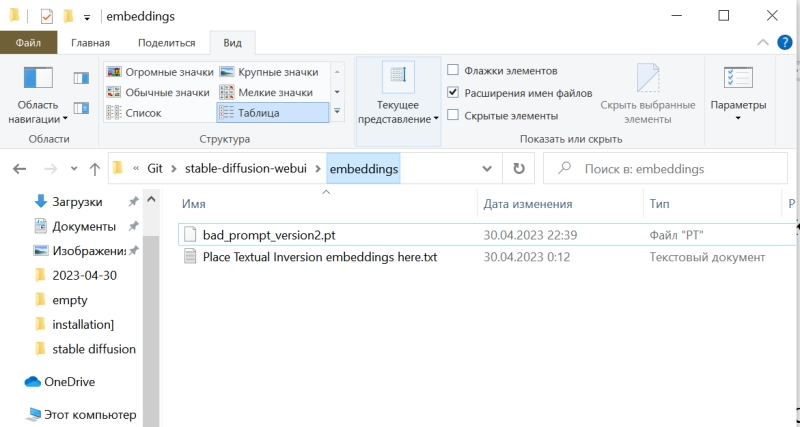
Следующий шаг — оптимизация негативной подсказки. Стандартный набор отрицаний, который мы применяли до сих пор, хорош своей относительной универсальностью, но всё же он не охватывает всего возможного круга недочётов, могущих возникнуть при преобразовании текста в изображение — особенно в ходе рисования роботов. Более универсальное решение даёт так называемая текстовая инверсия (textual inversion), ещё одна, наряду с LoRA, разновидность частной доработки генеративной модели. С уже знакомого сайта Huggingface скачаем ставшим привычным способом текстуальную инверсию Bad prompt, поместим её в файл в папку Git\stable-diffusion-webui\embeddings. Обратите внимание: не в \stable-diffusion-webui\models, где располагаются каталоги для самих моделей и LoRA, а на одном уровне с \models.
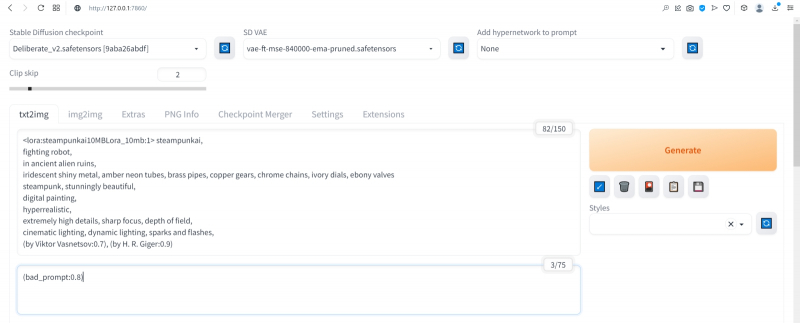
А в поле негативной подсказки вместо всего того, что там было, поместим теперь вызов текстовой инверсии с параметром значимости 0,8:
(bad_prompt:0.8)

И вот это уже совершенно другое дело!
Но тем не менее всё это — лишь начало, самые первые этапы погружения в бездонную глубину мира диффузных моделей для преобразования текста в изображения. Возможностей для дальнейшего совершенствования картинок Stable Diffusion и AUTOMATIC1111 предлагают немало: это и перерисовка отдельных фрагментов полученной картинки, и укрупнение её до других форматов (скажем, из квадратной заготовки можно сделать прямоугольную — так, что вновь сгенерированные элементы будут дополнять уже имевшиеся бесшовно), и почти неограниченное увеличение в размерах, и создание многофигурных композиций по шаблону, и ещё многое, многое другое… И, что самое главное, для освоения всего этого великолепия достаточно лишь простенького игрового ПК, минимальных навыков в установке ПО и — вот это существенный момент — титанического усердия. Но у тех, кто осилил настоящий киберпрактикум до самого конца, оно, вне всякого сомнения, имеется.
Надеемся получить обратную связь от читателей, взявших на себя труд установить и запустить Stable Diffusion на локальном ПК или в Google Colab либо поднаторевших в работе с веб-сайтами для рисования картинок по текстовым подсказкам. В планах у нас дальнейшее углубление в тему — в частности, освоение расширения изображения (outpaint), перерисовки его отдельных фрагментов (inpaint), масштабирования (upscale), выявления текстовых подсказок из готовых картинок, не содержащих метаданных (interrogate), рисования по шаблонам (ControlNet) и ещё многое другое. Интересно было бы знать, с какими затруднениями и ограничениями на тропе ИИИИ (ИИзобразительного ИИскусства) вы успели уже столкнуться. Оставляйте ваши комментарии, попытаемся разобраться вместе!
Если Вы заметили ошибку — выделите ее мышью и нажмите CTRL+ENTER.
Chatbox AI — это приложение-клиент искусственного интеллекта и умный ассистент. Совместимо со многими передовыми ИИ-моделями и API. Доступно на Windows, MacOS, Android, iOS, веб и Linux.
Получить мобильное приложение
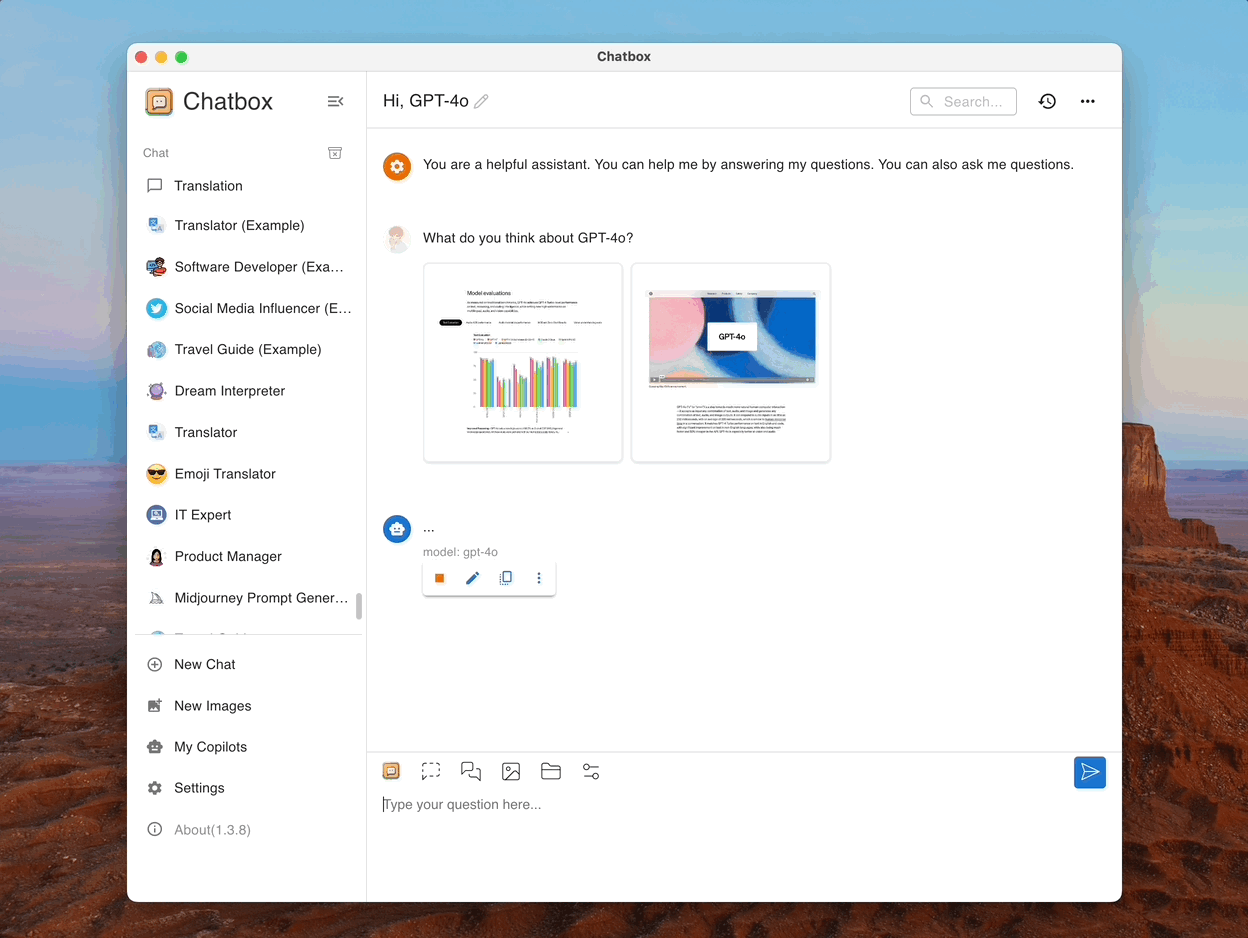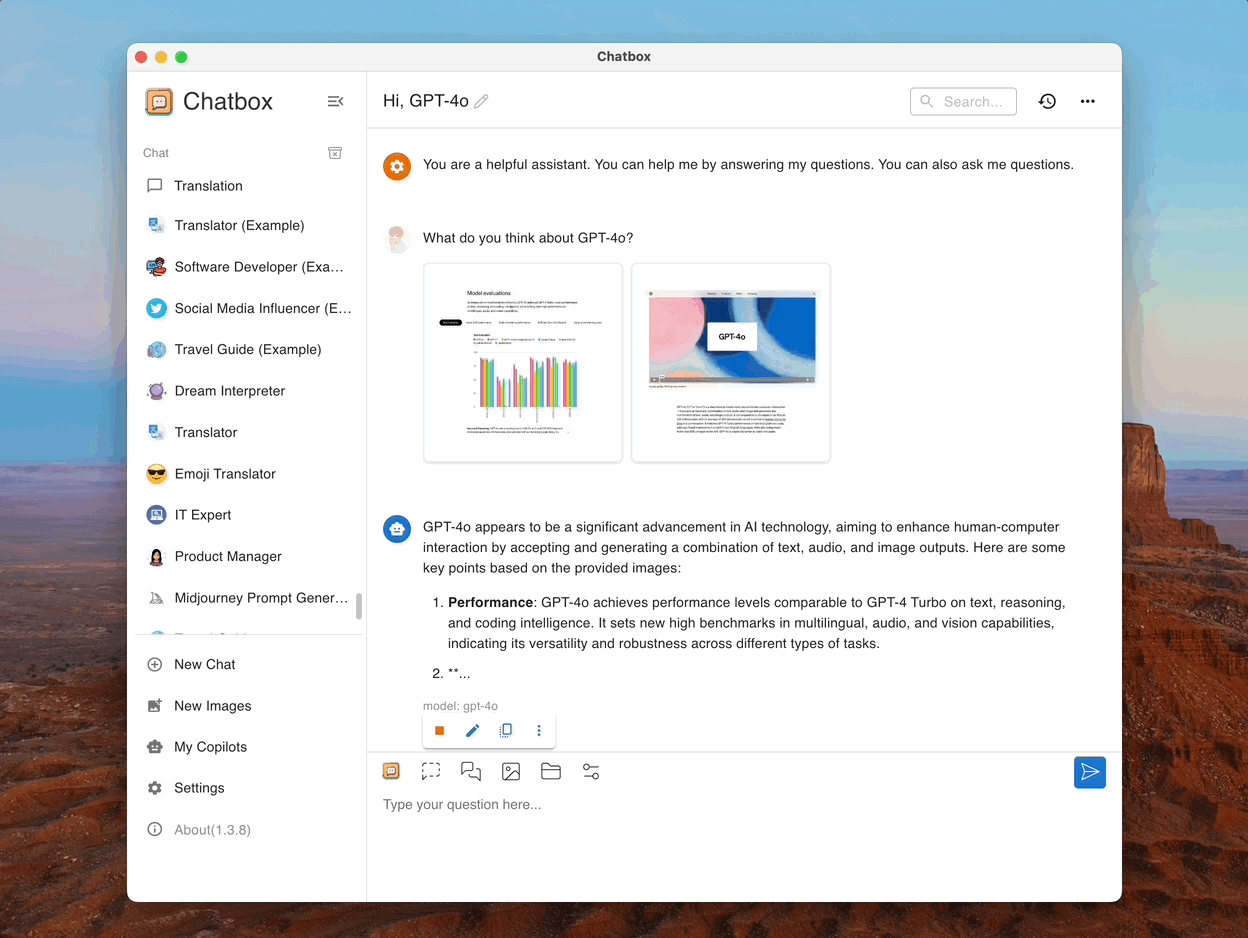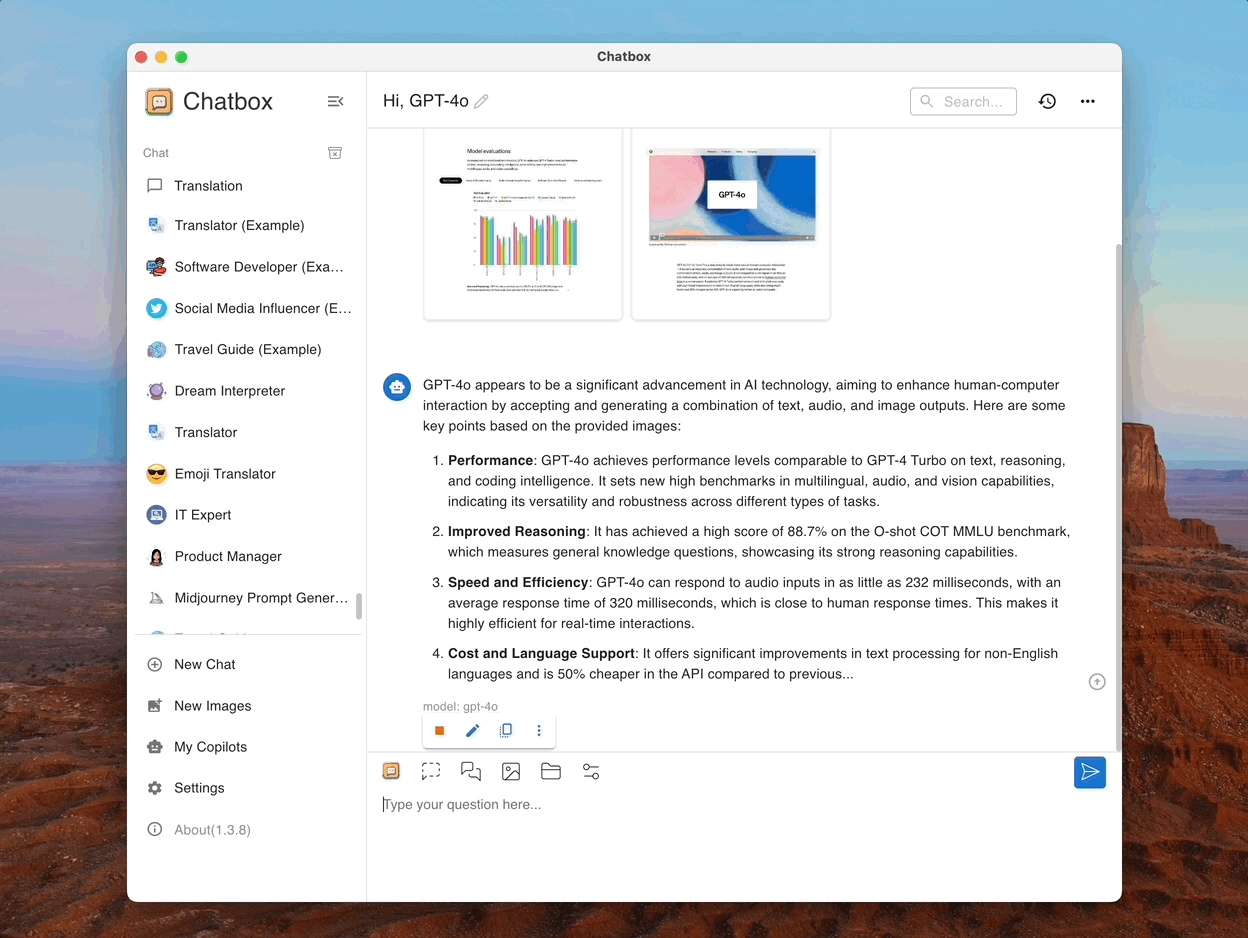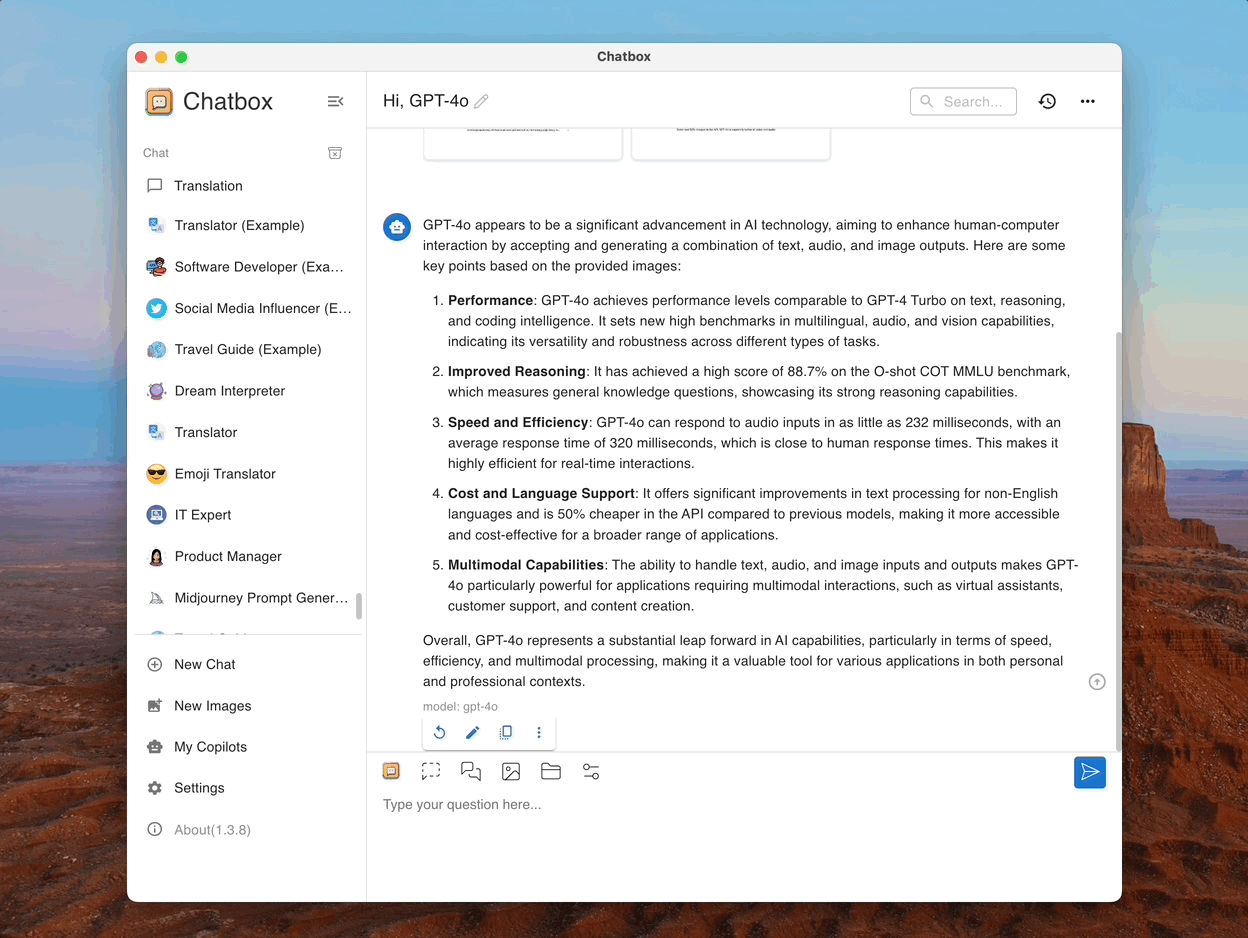
Чат с документами и изображениями
Независимо от того, являются ли это документами, изображениями или кодом, просто отправьте свои файлы в Chatbox. Он поймет содержание и предоставит интеллектуальные ответы, повышая вашу продуктивность и креативность в каждом взаимодействии.
•Также поддерживает сканированные и рукописные PDF-файлы.
Магия кода: Генерация и предварительный просмотр
Код умнее, не сложнее. AI-powered coding assistant that turns ideas into reality — smarter and faster.
💡Генерация кода
👁️Предварительный просмотр
🎨Подсветка синтаксиса
🔍Проверка кода
🔄Переработка
📚Умные документы
🐞Помощник отладки
🚀Оптимизация
🔒Проверка безопасности
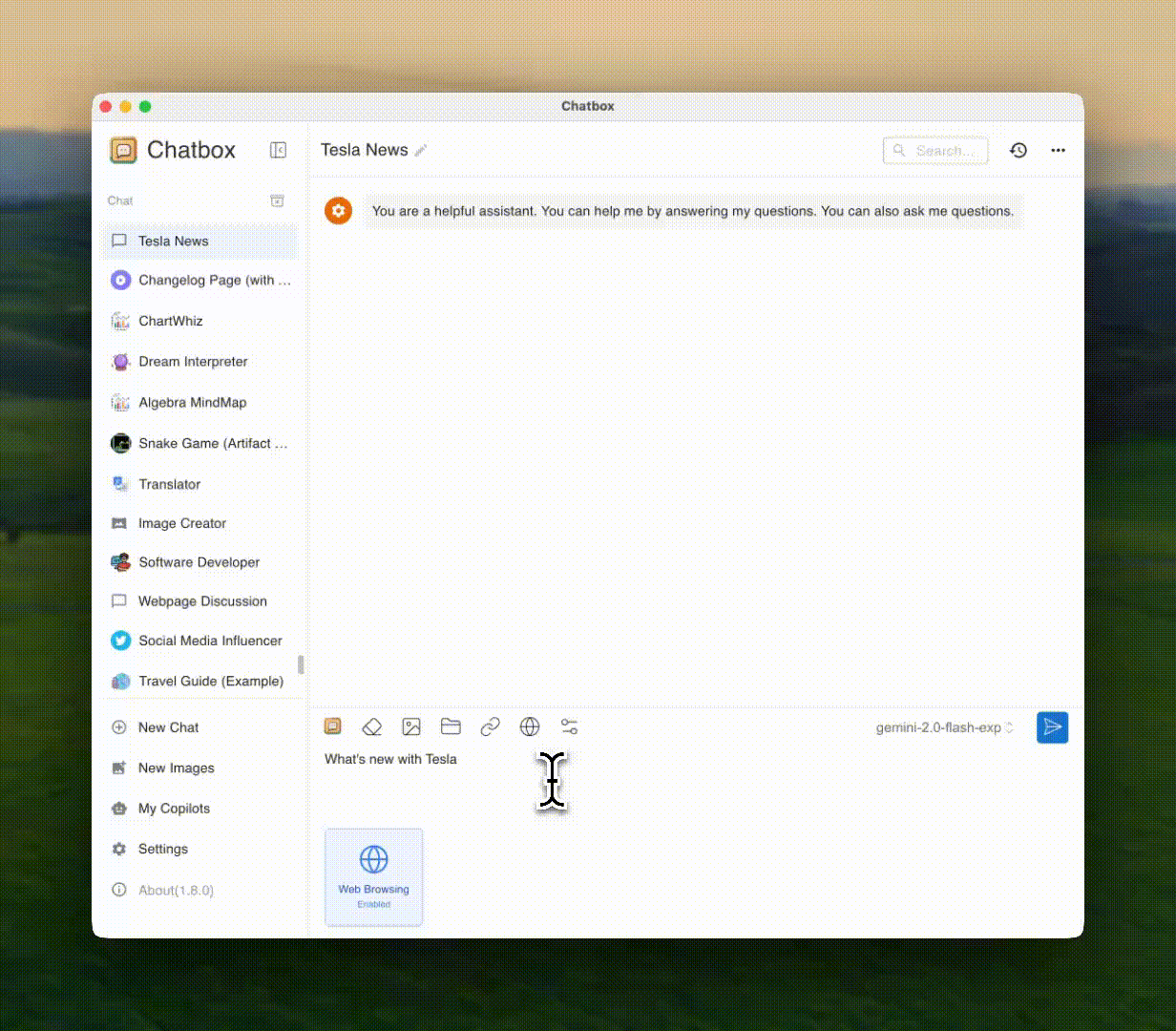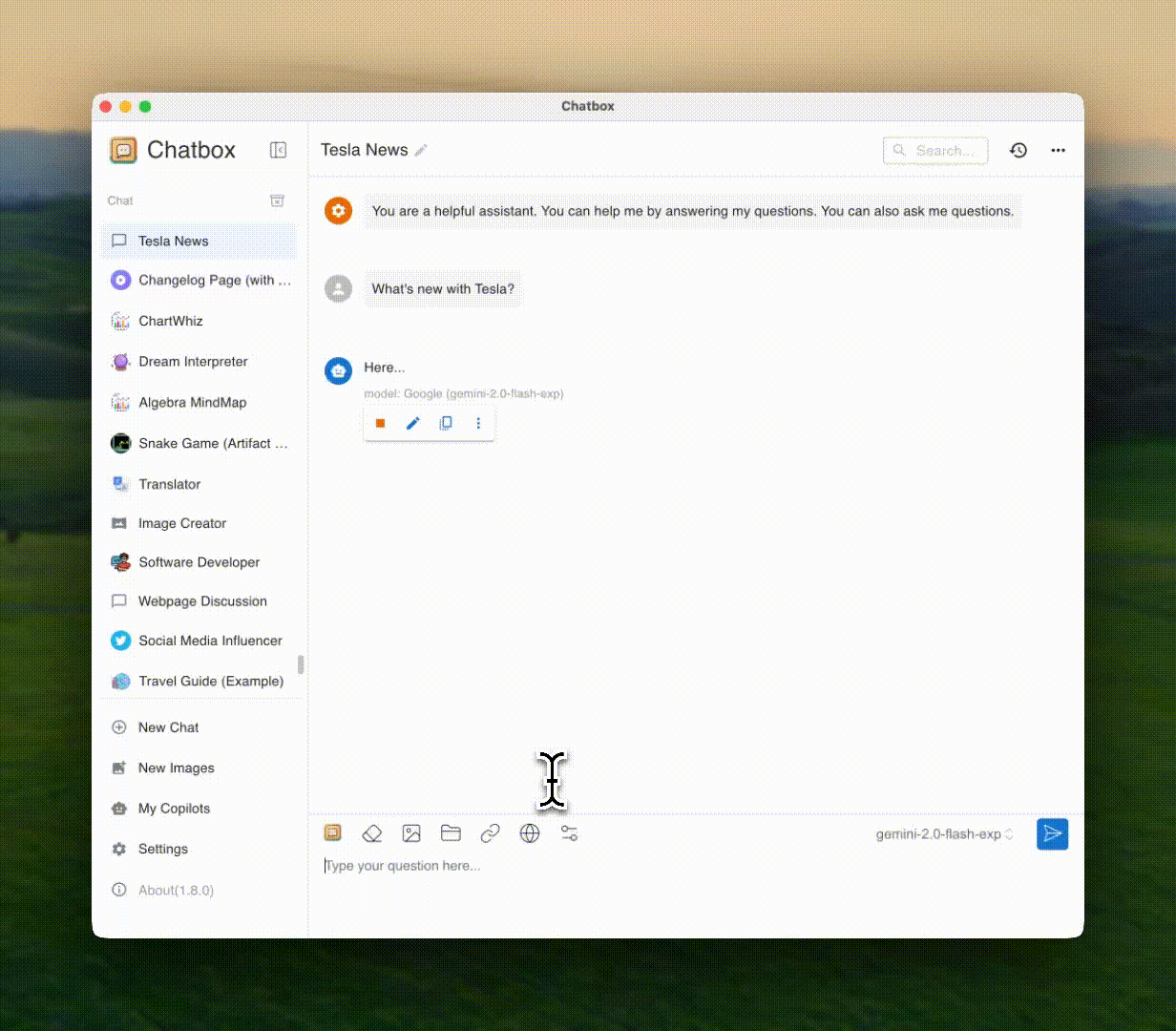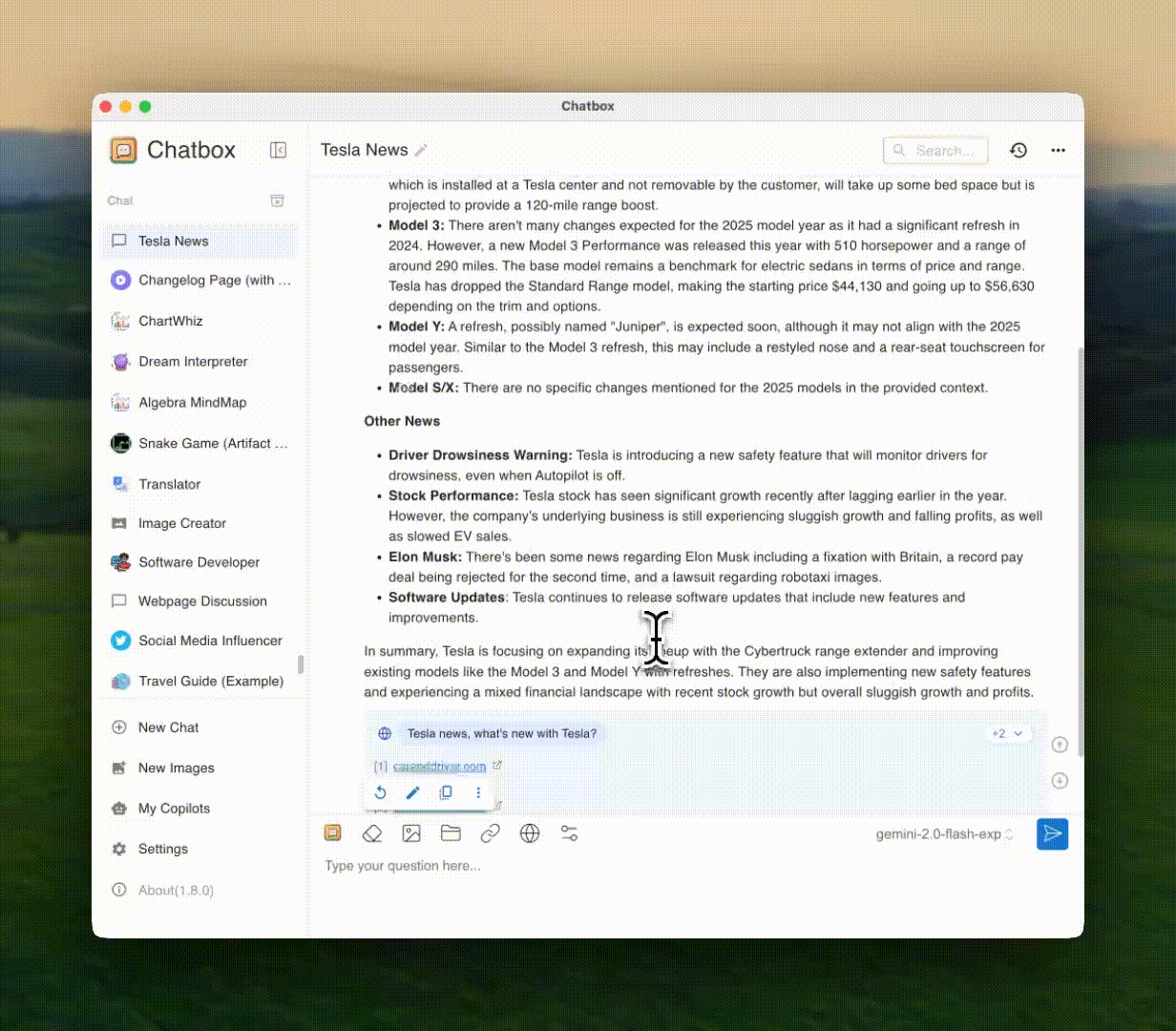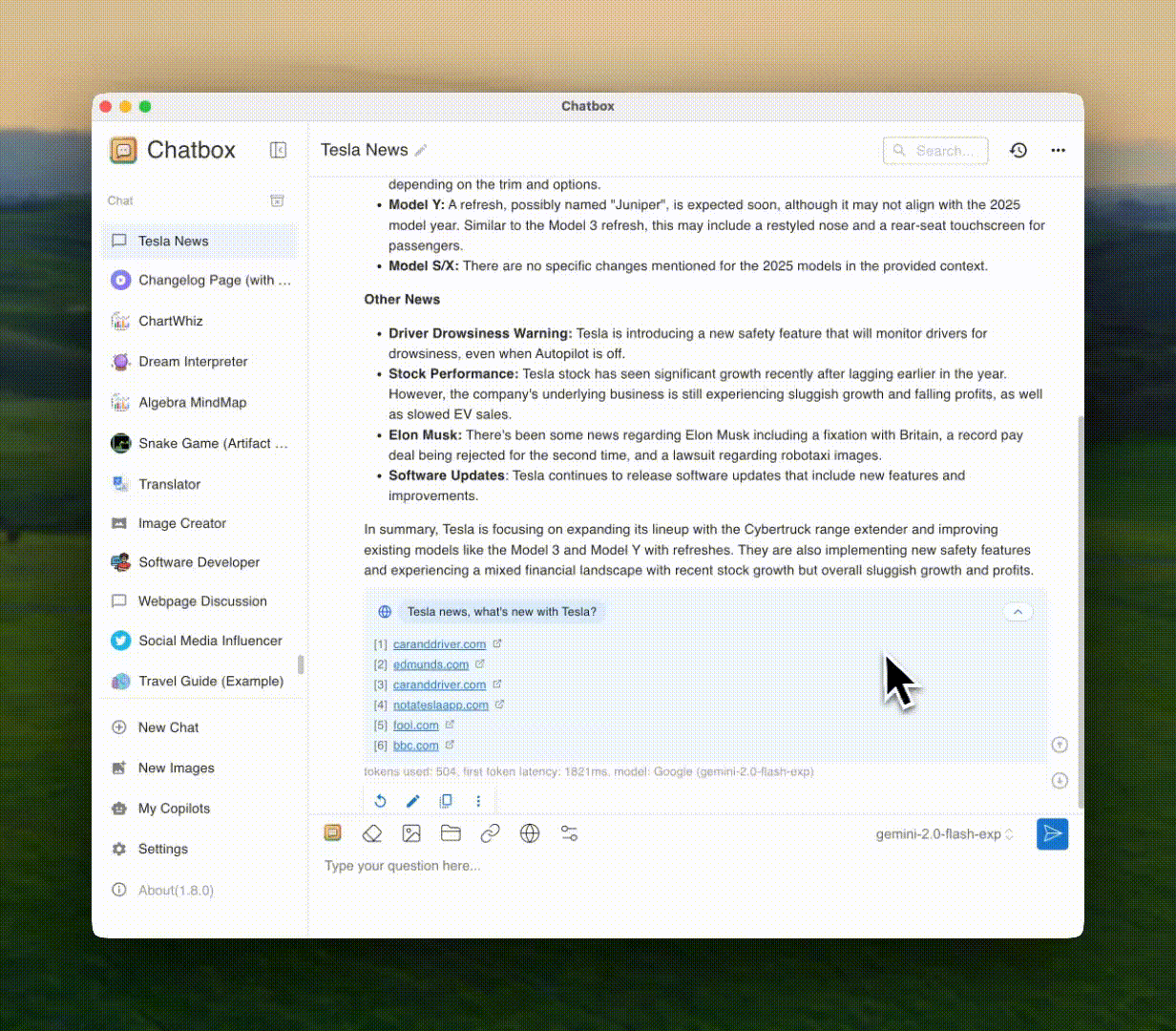
Реальное время Поиск в Интернете и перемещение по веб-страницам
Получите реальное время информации через AI-powered web search. Оставайтесь в курсе последних фактов, новостей и данных из всемирной паутины.
🌐Поиск в Интернете
📰Последние новости
📊Реальное время данных
🔗Анализ URL
📑Сводка содержимого
✓Проверка фактов
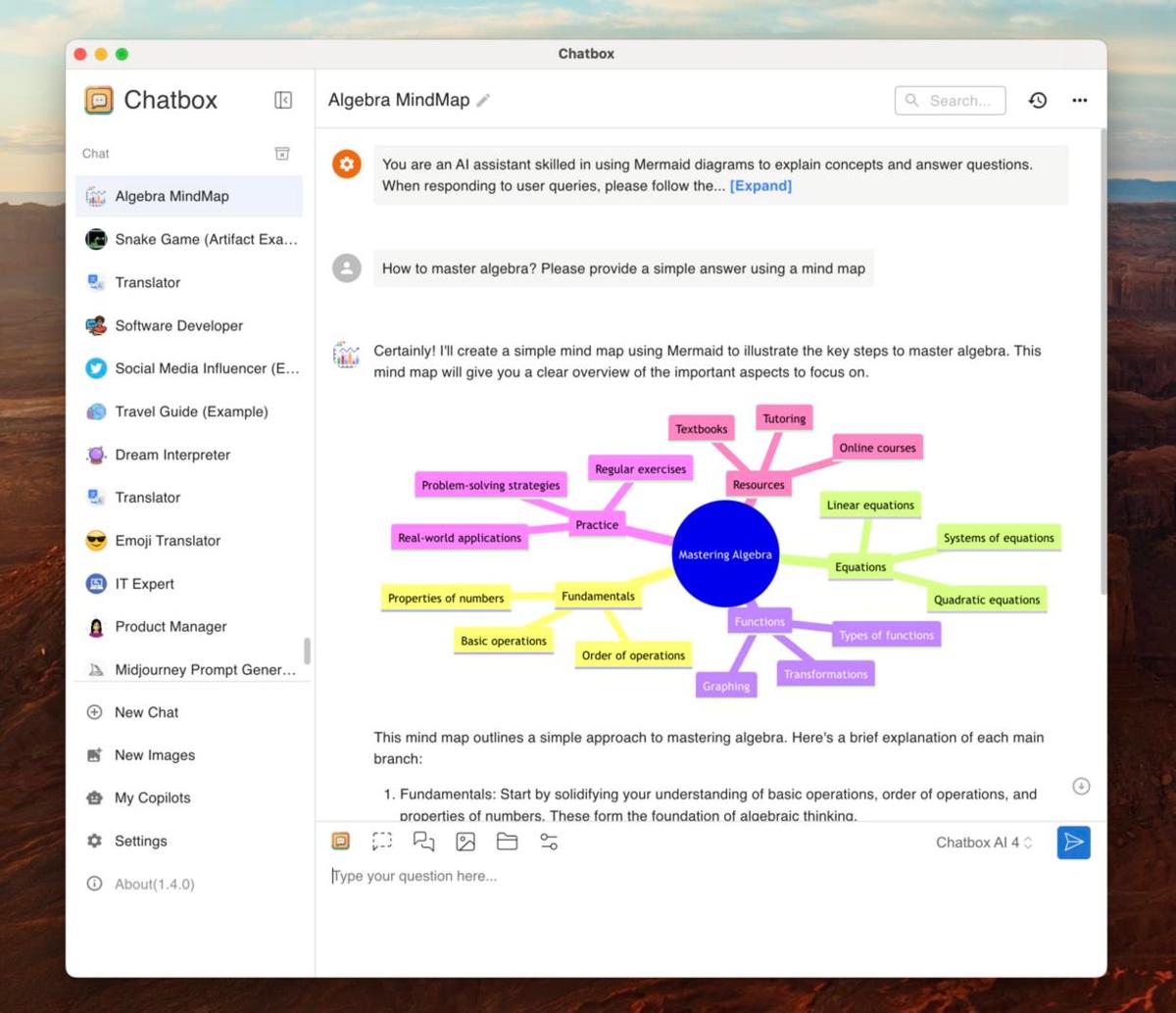
Визуализированные идеи с диаграммами, созданными ИИ
Визуальные исследования с использованием AI-генерируемых диаграмм, интегрированные в диалоги, эти визуализации ясно объясняют сложные концепции, тенденции и статистику. Улучшите свое понимание и принятие решений с помощью четких, настраиваемых визуальных вспомогательных средств – прямо когда вам это нужно.
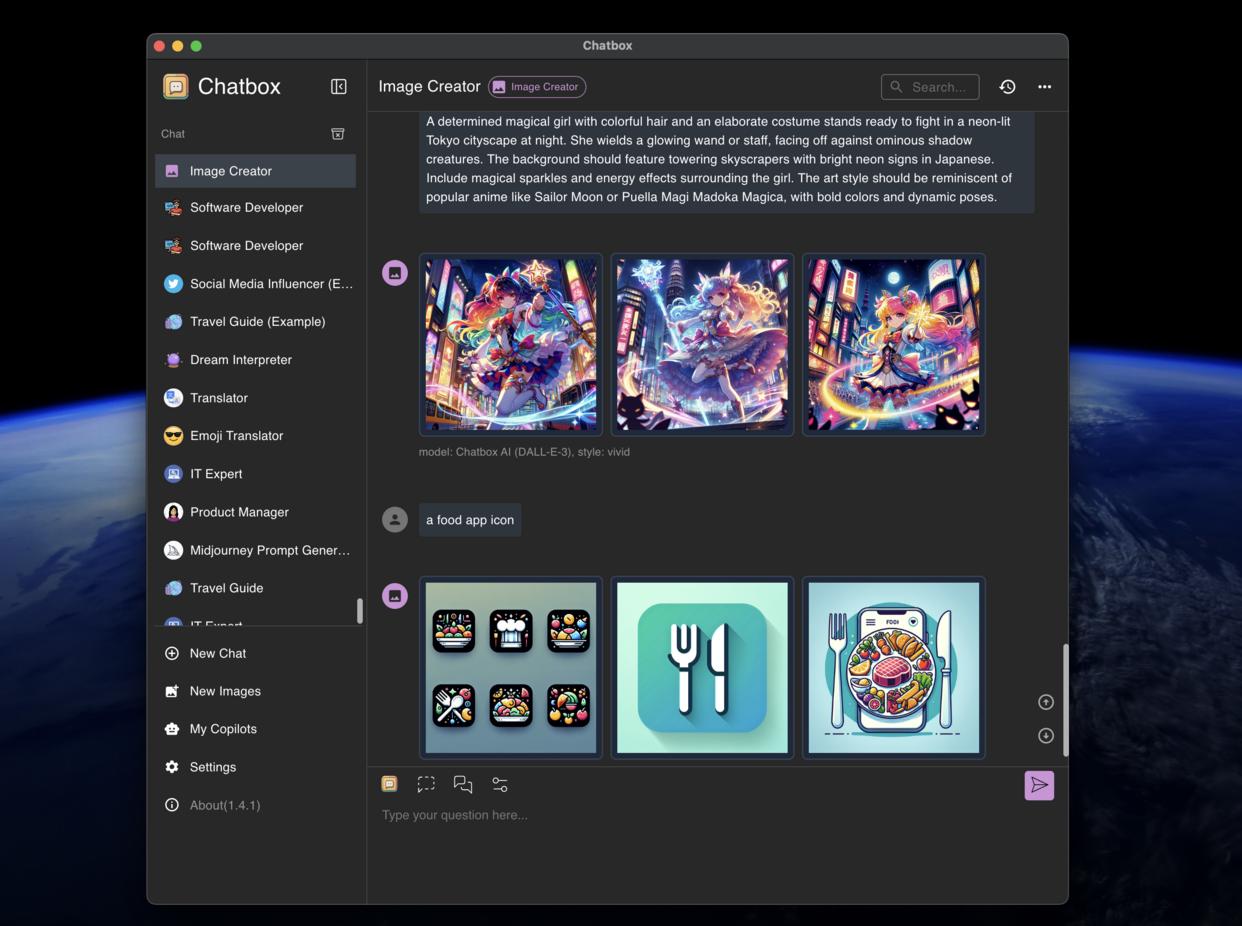
Создание изображений с помощью ИИ
Воплотите свои идеи в жизнь с помощью функции генерации изображений Chatbox. Просто опишите, что вы представляете, и наблюдайте, как наш ИИ превращает ваши слова в потрясающие визуальные образы.
Раскройте безграничную креативность
Легкое волшебство преобразования текста в изображение
Исследуйте бесконечные художественные стили
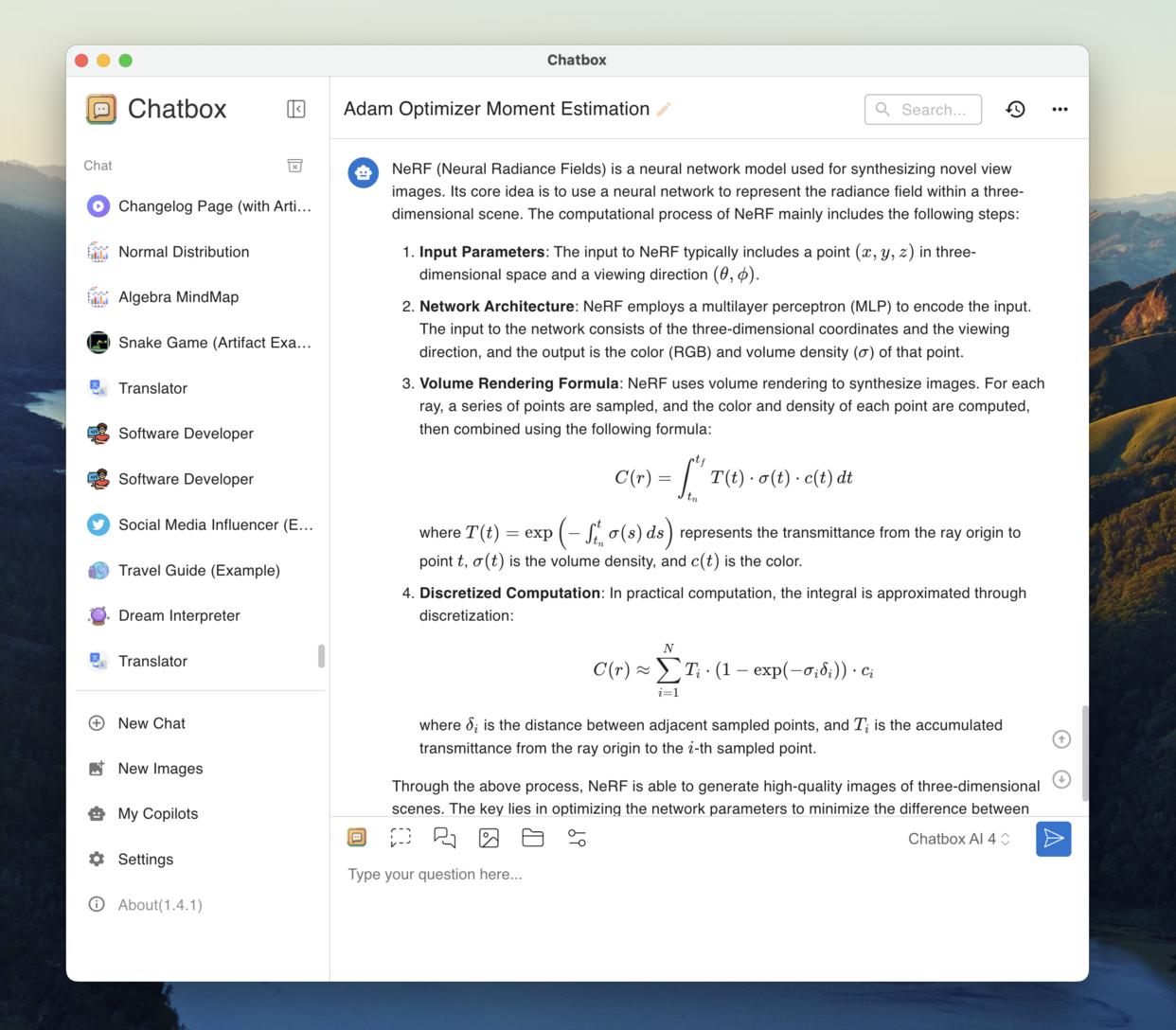
Рендеринг LaTeX и Markdown
Четко выражайте сложные идеи и формулы с помощью встроенной поддержки LaTeX и Markdown. Исследуйте, изучайте и расширяйте свои знания в различных академических областях.
📝Академическое письмо
∑Математические уравнения
🧬Академический дискурс
Локальное хранение
Все данные хранятся локально для обеспечения конфиденциальности и безопасности
Простое резервное копирование
Встроенные функции резервного копирования и экспорта данных
Поиск по истории сообщений
Быстрый поиск прошлых разговоров и сообщений
Конфиденциальность в основе:
Ваши данные хранятся локально
Chatbox хранит все ваши данные локально — от истории разговоров до личных настроек. Всё остаётся на вашем устройстве, обеспечивая вам полный контроль и спокойствие.
Узнайте, почему пользователи любят Chatbox


WorldofAI
«Chatbox revolutionizes the way you interact with artificial intelligence. This is an amazing application.«
«I have greatly enjoyed utilizing the Chatbox, as it has proven to be a valuable time and energy-saving tool in both my personal and professional endeavors. I first became acquainted with Chatbox through the Jike app and have been consistently using it since its initial version. I am tremendously grateful to Benn for developing this remarkable software.«
Corey Naas
«Chatbox has changed the way I use language models. Thank you so much!«

Aragorn
«Very epic software. Good job«
«This is great, thanks for sharing. I’m looking forward to adding the ability to talk to files and urls.«
Alberto Macias
«I’ve been using this tool for quite a while now (since version ~0.4 I believe) and it has become indispensable for me as a productivity multiplier, not just for writing software but for various things in life. Benn has been great at quickly folding in new LLMs and APIs as they become available and improving the performance of Chatbox. I love this tool!«
Huaer Mini
«HOOO! GOD! It is my necessity. I recommended it to many people.«
Zulfiqaar
«I’ve casually thought about making something like this, but was just making do with a combination of davinci playground. This is definitely useful! Thanks a lot«
Lightningstormz
«This is amazing work, I was building something similar but now dont have to waste resources. Thanks for the app keep pushing to make it better«
Richard M
«I have been using this app on daily basis . Very good app . The only complain is there is no auto spelling check and correction when I input the text . other than that , I really like it.«
Jack Song
«I have been using chatbox, I hope it will get better and better«
«When I use Chatbox, I feel happy. Thank you for creating this application.«
Al Mitchell
«Most useful tool I have used lately. Thank you!!«
Начать
Десктопные приложения
macOS
Linux
Мобильные приложения
Цены
Исследуйте наши сервисы и бесплатные приложения для повышения вашего пользовательского опыта
Сервис Chatbox AI
ЕжемесячноЕжегодно17% off
Chatbox AI Lite
Подходит для ежедневного обучения и офисных сценариев
$3.5$3.99/Месяц
- Чат с Стандартные модели
GPT-4o-mini, GPT-4.1-mini, GPT-4.1-nano, Claude 3.5 Haiku, Gemma 3 27B, Gemini 2.0 Flash, DeepSeek V3, DeepSeek R1
2,000,000 вычислительных баллов в месяц
С типичным сообщением (1,000 слов контекста, 200 слов вывода), вы можете сгенерировать примерно 4,000 ответов от GPT-3.5-Turbo. Фактическое использование может варьироваться, так как нет дополнительных ограничений на длину контекста или вывода.
1 балл приблизительно равен 1 выходному токену для GPT-3.5-Turbo. Использование других моделей приводит к разным ставкам расхода баллов. Разблокируйте полную длину контекста для каждой модели.
- Реальное время Поиск в Интернете и перемещение по веб-страницам
Получите реальное время информации через AI-powered web search. Оставайтесь в курсе последних фактов, новостей и данных из всемирной паутины.
- Создайте до 25 АИ-рисунков
- Чат с любыми изображениями
Отправьте изображения в ИИ. Извлекайте и обсуждайте содержимое, распознавайте элементы, собирайте информацию и взаимодействуйте более чем когда-либо.
- Поддерживается одновременное использование до 5 устройств
Начать
Chatbox AI ProРекомендуемые
Подходит для более профессионального обучения и офисных сценариев
$16.7$19.9/Месяц
- Чат с Продвинутые модели
GPT-4o, GPT-4.1, Claude 3.7 Sonnet, OpenAI o3, OpenAI o4 mini, Gemini 2.5 Pro
1,000,000 вычислительных баллов в месяц
С типичным сообщением (1,000 слов контекста, 200 слов вывода), вы можете сгенерировать примерно 2,000 ответов от GPT-4o. Фактическое использование может варьироваться, так как нет дополнительных ограничений на длину контекста или вывода.
1 балл приблизительно равен 1 выходному токену для GPT-4o. Использование других моделей приводит к разным ставкам расхода баллов. Разблокируйте полную длину контекста для каждой модели.
- Чат с Стандартные модели
GPT-4o-mini, GPT-4.1-mini, GPT-4.1-nano, Claude 3.5 Haiku, Gemma 3 27B, Gemini 2.0 Flash, DeepSeek V3, DeepSeek R1
2,000,000 вычислительных баллов в месяц
С типичным сообщением (1,000 слов контекста, 200 слов вывода), вы можете сгенерировать примерно 1,000 ответов от GPT-3.5-Turbo. Фактическое использование может варьироваться, так как нет дополнительных ограничений на длину контекста или вывода.
1 балл приблизительно равен 1 выходному токену для GPT-3.5-Turbo. Использование других моделей приводит к разным ставкам расхода баллов. Разблокируйте полную длину контекста для каждой модели.
- Реальное время Поиск в Интернете и перемещение по веб-страницам
Получите реальное время информации через AI-powered web search. Оставайтесь в курсе последних фактов, новостей и данных из всемирной паутины.
- Чат с любым документом
Отправьте PDF, DOC, XLS, TXT или файлы кода в ИИ. Вы можете задавать ИИ вопросы на основе документов.
- Создайте до 100 АИ-рисунков
- Чат с любыми изображениями
Отправьте изображения в ИИ. Извлекайте и обсуждайте содержимое, распознавайте элементы, собирайте информацию и взаимодействуйте более чем когда-либо.
- Поддерживается одновременное использование до 5 устройств
Начать
Chatbox AI Pro+
Для профессионального обучения и офисных сценариев высокой интенсивности
$33.3$39.9/Месяц
- Чат с Продвинутые модели
GPT-4o, GPT-4.1, Claude 3.7 Sonnet, OpenAI o3, OpenAI o4 mini, Gemini 2.5 Pro
2,000,000 вычислительных баллов в месяц
С типичным сообщением (1,000 слов контекста, 200 слов вывода), вы можете сгенерировать примерно 4,000 ответов от GPT-4o. Фактическое использование может варьироваться, так как нет дополнительных ограничений на длину контекста или вывода.
1 балл приблизительно равен 1 выходному токену для GPT-4o. Использование других моделей приводит к разным ставкам расхода баллов. Разблокируйте полную длину контекста для каждой модели.
- Чат с Стандартные модели
GPT-4o-mini, GPT-4.1-mini, GPT-4.1-nano, Claude 3.5 Haiku, Gemma 3 27B, Gemini 2.0 Flash, DeepSeek V3, DeepSeek R1
2,000,000 вычислительных баллов в месяц
С типичным сообщением (1,000 слов контекста, 200 слов вывода), вы можете сгенерировать примерно 2,000 ответов от GPT-3.5-Turbo. Фактическое использование может варьироваться, так как нет дополнительных ограничений на длину контекста или вывода.
1 балл приблизительно равен 1 выходному токену для GPT-3.5-Turbo. Использование других моделей приводит к разным ставкам расхода баллов. Разблокируйте полную длину контекста для каждой модели.
- Реальное время Поиск в Интернете и перемещение по веб-страницам
Получите реальное время информации через AI-powered web search. Оставайтесь в курсе последних фактов, новостей и данных из всемирной паутины.
- Чат с любым документом
Отправьте PDF, DOC, XLS, TXT или файлы кода в ИИ. Вы можете задавать ИИ вопросы на основе документов.
- Создайте до 200 АИ-рисунков
- Чат с любыми изображениями
Отправьте изображения в ИИ. Извлекайте и обсуждайте содержимое, распознавайте элементы, собирайте информацию и взаимодействуйте более чем когда-либо.
- Поддерживается одновременное использование до 5 устройств
Начать
Приложения Chatbox
Интерфейс чата AI для всех платформ
- Бесплатно используйте все функции приложений Chatbox
- Поддерживает все платформы: Windows/Mac/Linux/iOS/Android/Web
- Используйте свой API KEY для доступа к различным ИИ-услугам
Скачать
Часто задаваемые вопросы
Здесь представлены ответы на наиболее часто задаваемые вопросы.
Для получения дополнительной информации, пожалуйста, посетите Центр помощи.
Chatbox AI предлагает сервис, который более удобный, стабильный, быстрый и простой в использовании, чем при использовании собственного API-ключа. У вас есть возможность получать доступ к моделям ИИ с помощью Chatbox, используя ваш персональный API-ключ. Однако, использование собственного ключа влечет за собой необходимость управления сетевыми соединениями, поддержание аккаунта и решение различных технических задач. Кроме того, программное обеспечение Chatbox не может гарантировать надежность или качество услуг при использовании вашего собственного API-ключа.
С сервисами Chatbox AI вы можете забыть об этих заботах. Chatbox AI имеет официальное разрешение на использование этих моделей, предоставляя сервис ‘подключай и работай’, легкодоступный и высоконадежный онлайн-сервис. Вы платите только за фактические издержки бэкенда и взамен получаете преимущества повышения продуктивности, которые обеспечивает технология ИИ.
С помощью Chatbox AI вы можете создавать уникальные и оригинальные изображения способами, которые раньше были невозможны. Просто введите описание желаемой картинки, например, «мультяшный кот пьет кофе», и Chatbox AI воплотит ваше видение в жизнь.
Поскольку вы, теоретически, являетесь создателем изображения, у вас есть право утверждать авторские права и определять, как изображение будет использоваться. Однако очень важно, чтобы изображение не использовалось никаким образом, который нарушает местные законы или оскорбляет общественную нравственность.
Chatbox уделяет особое внимание конфиденциальности и безопасности ваших данных. При использовании приложения Chatbox все ваши сообщения чата и данные настроек хранятся локально на вашем устройстве. Без вашего разрешения Chatbox не будет загружать ваши данные на свои серверы.
При использовании сервиса модели Chatbox AI в приложении Chatbox (что является рекомендуемым подходом) сообщения, которые вы отправляете в ИИ, вместе с некоторым контекстом и любыми изображениями или файлами, которые вы загружаете, будут передаваться в сервис Chatbox AI для генерации ответов ИИ. Сервис Chatbox AI использует только данные, которые вы отправляете, для создания ответов ИИ, и ваши данные могут временно храниться на серверах Chatbox AI для ускорения ответов на последующие запросы. Chatbox AI не хранит ваши данные постоянно и не будет использовать их для других целей, включая, но не ограничиваясь, рекламой, обучением модели или любым другим коммерческим использованием.
Помимо использования сервиса модели Chatbox AI, при использовании сторонних API-сервисов для работы с другими моделями в приложении Chatbox мы не можем гарантировать конфиденциальность и безопасность ваших данных. Вам необходимо ознакомиться с политикой конфиденциальности и условиями обслуживания этих сторонних сервисов моделей, чтобы понять, как ваши данные могут быть использованы. Если вы придаете большое значение своей конфиденциальности и безопасности, рекомендуем выбрать сервис Chatbox AI.
Ваша история чата хранится локально, а информация о заказах надежно сохраняется на LemonSqueezy и в базе данных бэкенда Chatbox. Мы очень серьезно относимся к безопасности ваших данных и конфиденциальности — для подробностей, пожалуйста, проверьте нашу политику конфиденциальности.
Chatbox использует алгоритм оплаты на основе токенов, который соответствует базовой модели. Каждая сессия генерации оплачивается исходя из общего количества токенов в исторических сообщениях плюс вновь сгенерированные ответы.В среднем одно английское слово приблизительно эквивалентно 1.4 токена, а один китайский символ — около 3.5 токенов.
Вы можете просмотреть прошлые заказы, подписки и информацию о лицензиях, а также найти опции управления подписками здесь.
Если у вас есть любые другие вопросы, предложения или вы столкнулись с какими-либо ошибками или проблемами, пожалуйста, отправьте отзыв
Как установить DeepSeek как приложение на Windows 11 и Windows 10
Хотите использовать DeepSeek, передовую языковую модель, прямо на своем компьютере, не открывая браузер каждый раз? Это возможно! Вы можете установить веб-версию DeepSeek как приложение на Windows 11 и Windows 10. Это удобно, быстро и позволяет получить доступ к DeepSeek в один клик.
DeepSeek – это новая большая языковая модель (LLM), которая привлекает все больше внимания в AI-сообществе. Сообщается, что она превосходит Gemini от Google и ChatGPT от OpenAI во многих задачах, при этом все еще находится в разработке. DeepSeek выделяется своей эффективностью, специализацией, неограниченным доступом и открытым исходным кодом.
- LLM (Large Language Model) — Большая языковая модель, тип искусственного интеллекта, обученный на огромных объемах текстовых данных.
- PWA (Progressive Web App) — Прогрессивное веб-приложение, веб-сайт, который можно установить как приложение, предоставляющее расширенные функции, такие как офлайн-доступ и уведомления.
Установите DeepSeek как приложение: подробное руководство для Windows 11 и 10
В этом руководстве рассмотрим, как установить DeepSeek в качестве приложения на Windows 11 или Windows 10. Существуют два способа: через Microsoft Edge и Google Chrome. Обратите внимание, что браузер Firefox поддерживает PWA, но не позволяет устанавливать их как отдельные приложения.
Способ 1: Установка DeepSeek как приложения из Microsoft Edge
Шаг 1: Откройте Microsoft Edge.
Шаг 2: Перейдите на сайт DeepSeek и войдите в систему.
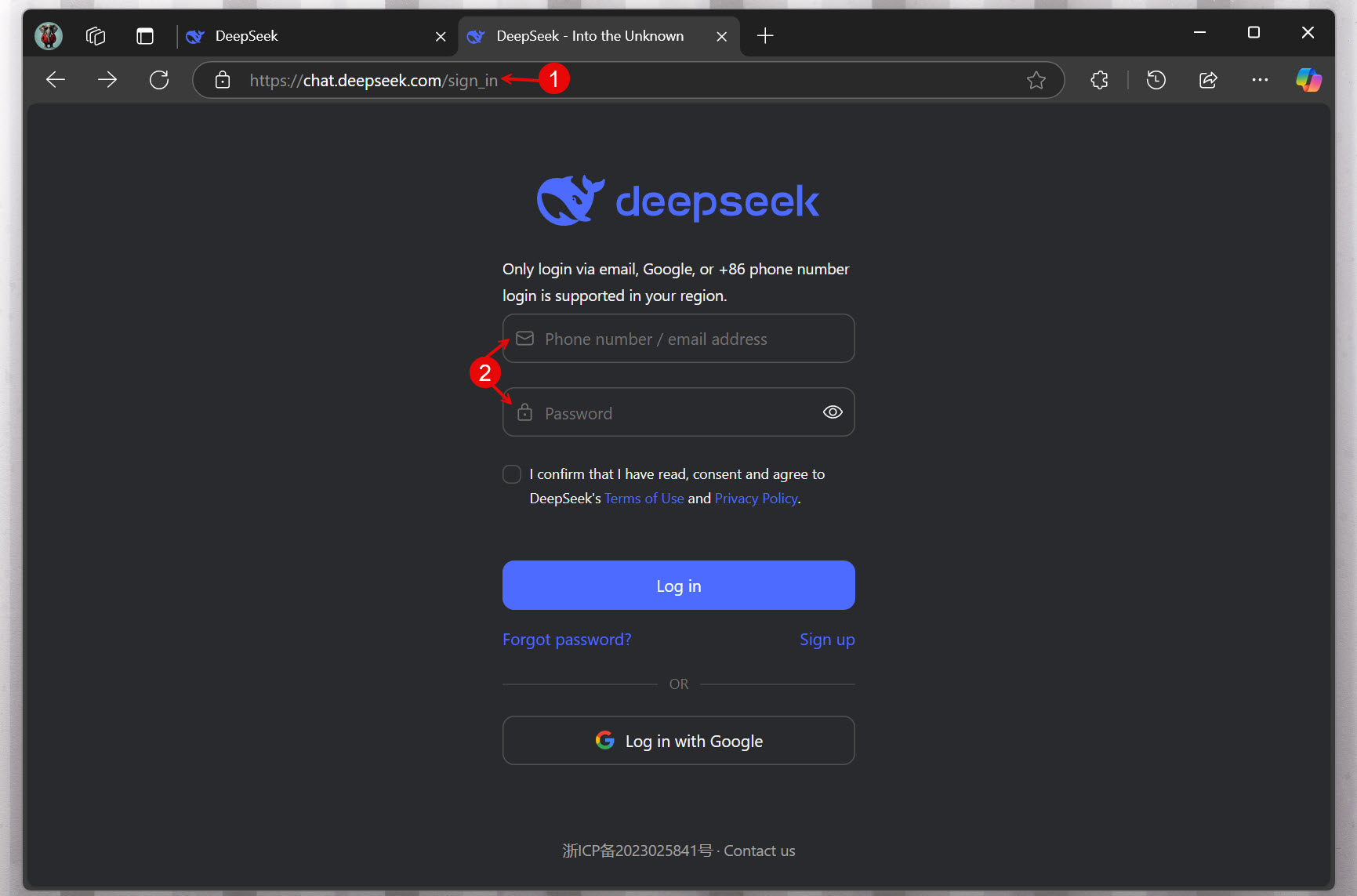
Шаг 3: Откройте меню «Настройки и прочее». Нажмите на кнопку с тремя точками в правом верхнем углу и выберите подменю «Приложения».
Шаг 4: Нажмите «Установить этот сайт как приложение».
Шаг 5: Подтвердите установку нажмите кнопку «Установить».
Шаг 6: Разрешите установку. При необходимости выберите дополнительные опции и нажмите «Разрешить».
После завершения этих шагов веб-версия DeepSeek будет установлена на вашем компьютере как отдельное приложение.
Совет: Вы можете закрепить установленное приложение DeepSeek в меню «Пуск» или на рабочем столе.
Удаление приложения DeepSeek из Microsoft Edge
Если вам больше не нужно приложение DeepSeek, его можно легко удалить.
Шаг 1: Откройте Microsoft Edge и в меню «Настройки и прочее» нажмите на кнопку с тремя точками в правом верхнем углу.
Шаг 2: Выберите подменю «Приложения».
Шаг 3: Нажмите «Просмотреть приложения».
Шаг 4: В окне «Приложения» кликните на три горизонтальные точки, чтобы открыть выпадающее меню и выберите «Управление приложениями».
Шаг 5: Перейдите в детали приложения. В разделе «Установленные приложения» нажмите кнопку «Подробные сведения» для приложения DeepSeek.
Шаг 6: Удалите приложение. Нажмите кнопку «Удалить».
Шаг 7: Подтвердите удаление. (Необязательно) Установите флажок «Удалить данные приложений из Microsoft Edge», чтобы удалить данные приложения.
Шаг 8: Подтвердите удаление. Нажмите кнопку «Удалить».
Альтернативный способ удаления: Вы можете удалить приложение DeepSeek «Параметры» → «Приложения» → «Установленные приложения». Найдите DeepSeek, кликните на три точки и нажмите «Удалить». Также можно кликнуть правой кнопкой мыши на значке приложения в меню «Пуск» и выбрать «Удалить».
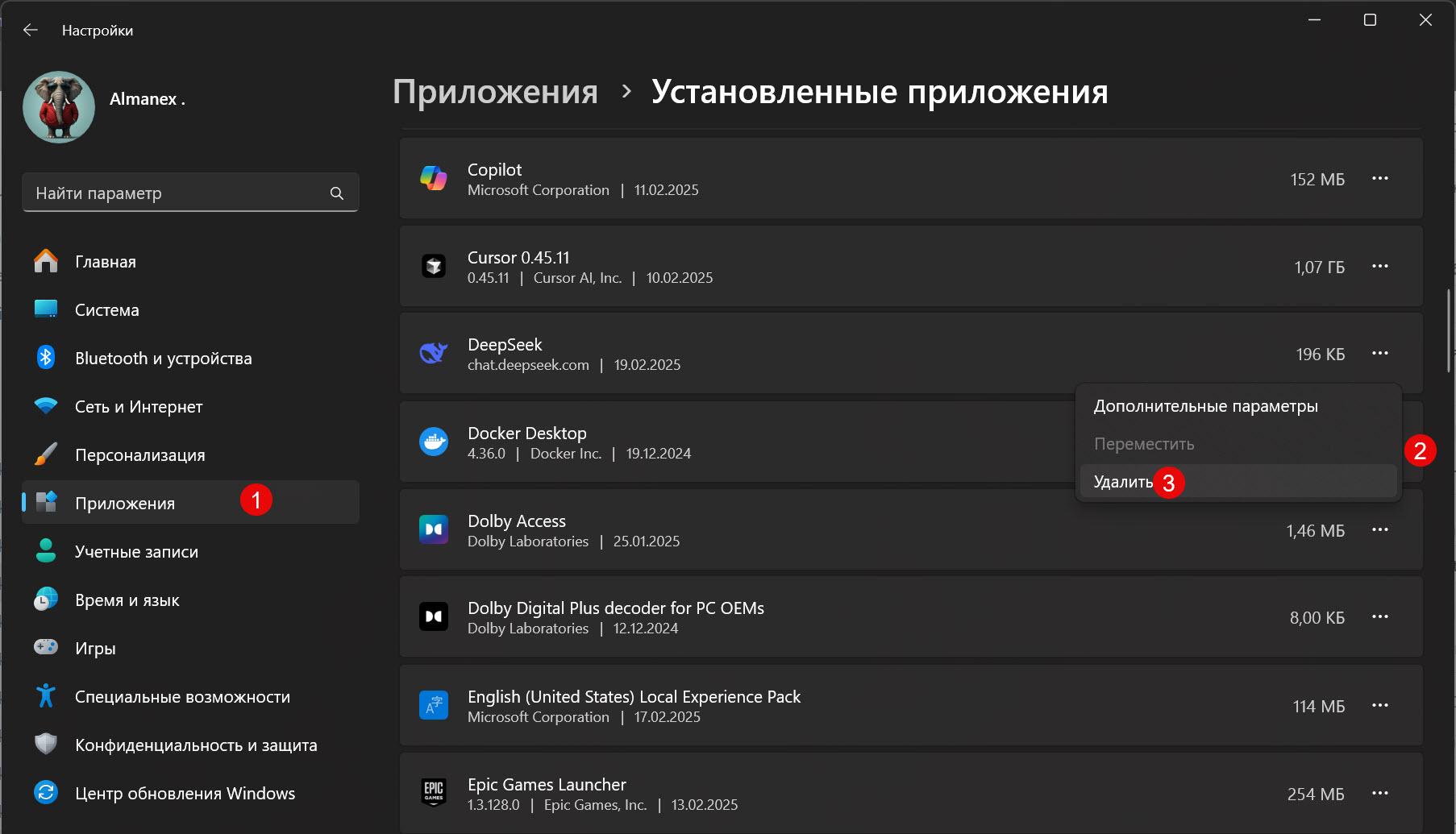
Способ 2: Установка DeepSeek как приложения из Google Chrome
Шаг 1: Откройте браузер Google Chrome.
Шаг 2: Перейдите на сайт DeepSeek.
Шаг 3: Откройте меню «Настройка и управление Google Chrome». Нажмите на кнопку с тремя точками в правом верхнем углу.
Шаг 4: Выберите «Транслировать, сохранить и поделиться» → «Установить страницу как приложение».
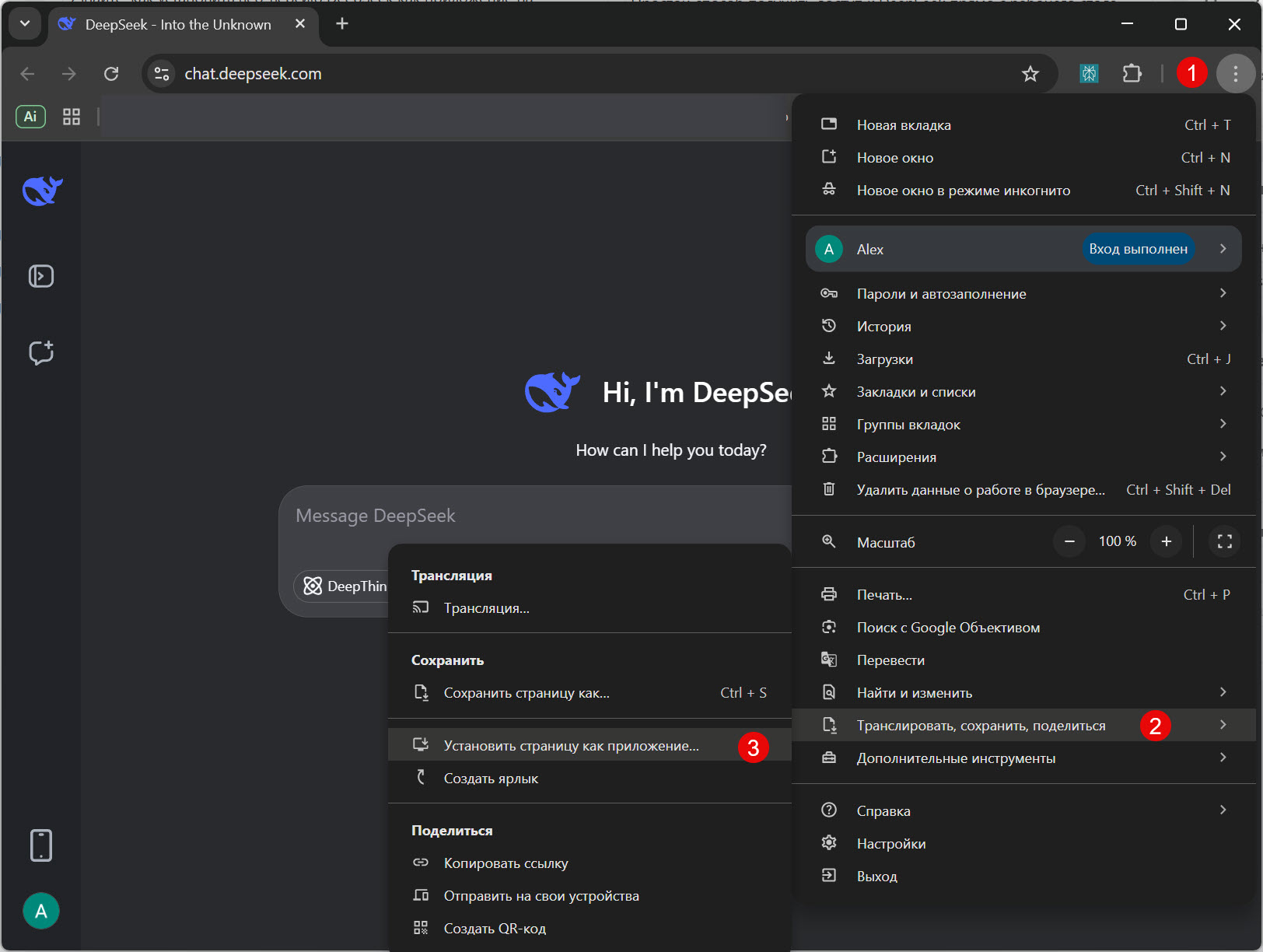
Шаг 5: Подтвердите имя приложения (необязательно).
Шаг 6: Установите приложение. Нажмите кнопку «Установить».
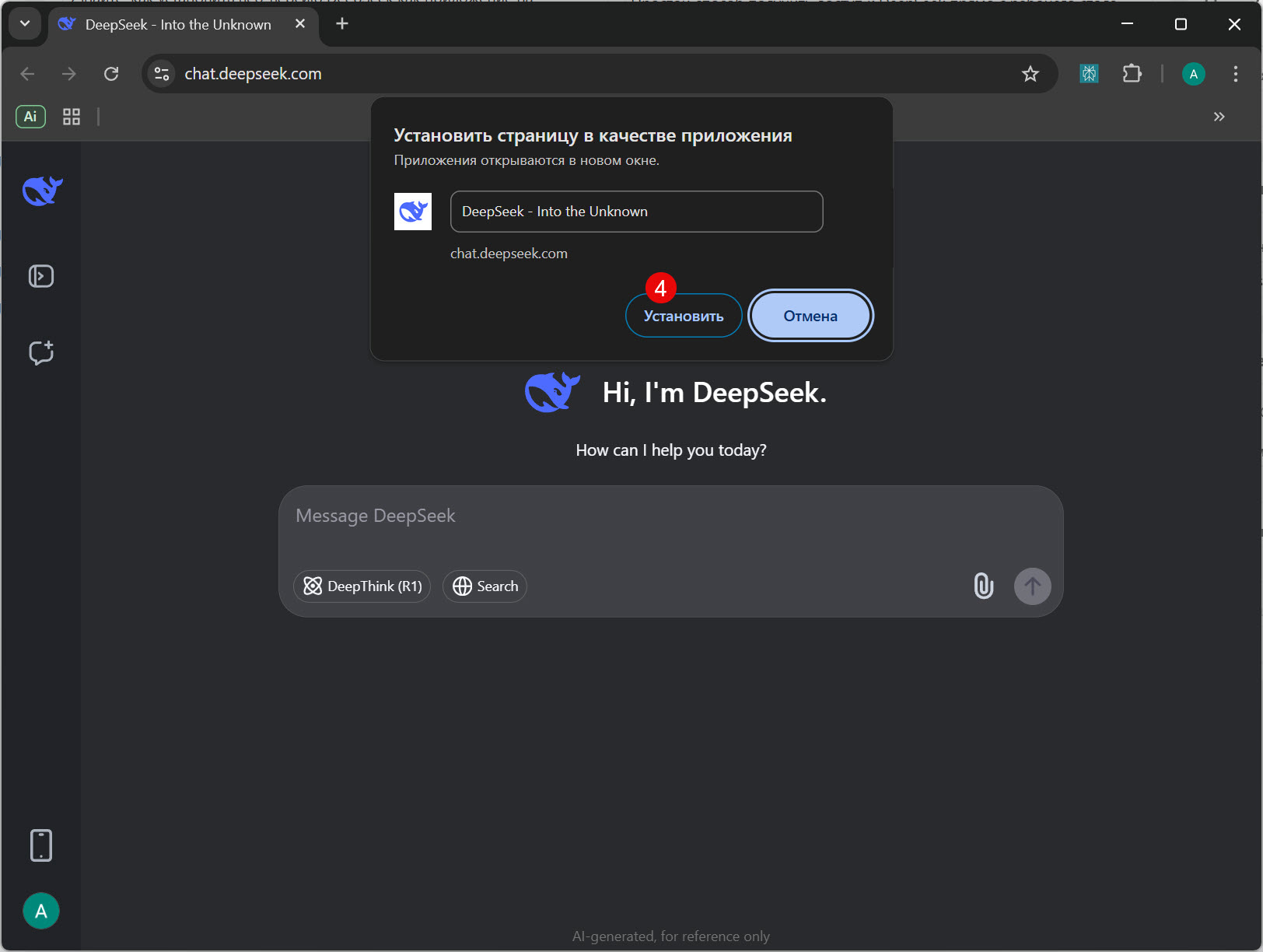
После выполнения этих шагов Google Chrome установит DeepSeek как веб-приложение на Windows 11 (или 10).
Удаление приложения DeepSeek из Google Chrome
Шаг 1: Откройте Google Chrome.
Шаг 2: Откройте страницу приложений: Введите в адресной строке chrome://apps и нажмите Enter.
Шаг 3: Кликните правой кнопкой мыши на значке DeepSeek и выберите «Удалить».
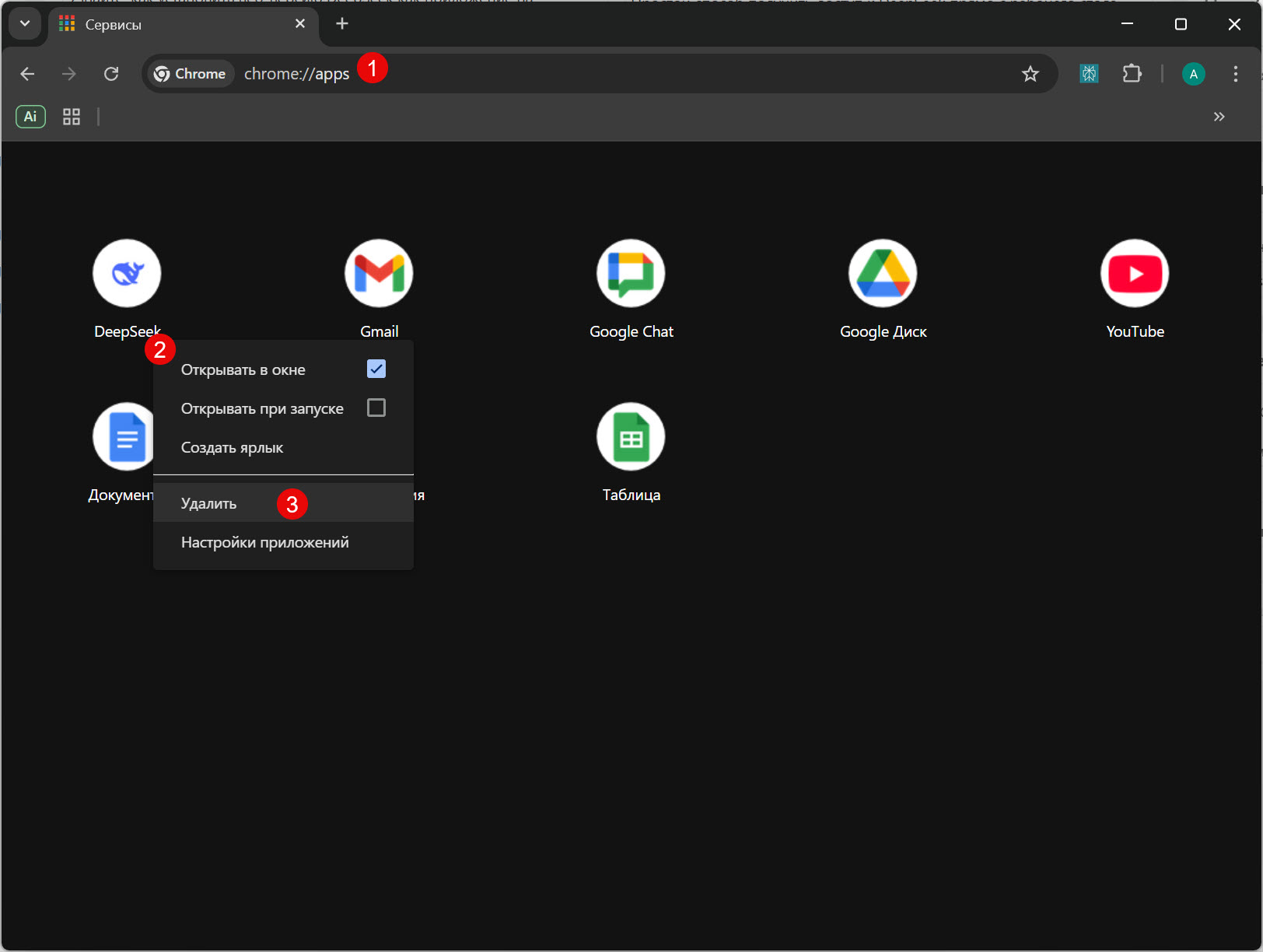
Альтернативный способ удаления: Вы можете удалить приложение DeepSeek используя «Параметры» → «Приложения» → «Установленные приложения». Найдите DeepSeek, выберите его и нажмите «Удалить». Также можно кликнуть правой кнопкой мыши на значке приложения в меню «Пуск» и выбрать «Удалить».
заключение
Установка DeepSeek как приложения в Windows 11 и Windows 10 – это простой и удобный способ быстрого доступа к этой мощной языковой модели. Вы можете выбрать способ установки через Microsoft Edge или Google Chrome, в зависимости от вашего предпочтения браузера. Теперь DeepSeek всегда под рукой, готовый помочь вам в решении различных задач!
Надеюсь, это руководство было полезным! Теперь вы можете наслаждаться DeepSeek как полноценным приложением на вашем компьютере.