
Введение
В цифровом мире уникальная идентификация объектов играет ключевую роль. Будь то пользователь в системе, файл, запись в базе данных или веб-ресурс — всем им требуется надёжный механизм уникального обозначения. Одним из самых эффективных решений является GUID (Globally Unique Identifier), также известный как UUID (Universally Unique Identifier).
GUID представляет собой 128-битное число, которое записывается в виде строки из 32 шестнадцатеричных символов, разделённых дефисами. Например: 550e8400-e29b-41d4-a716-446655440000 . Этот идентификатор может быть сгенерирован случайным или детерминированным способом, что делает вероятность его дублирования ничтожно малой даже в глобальных распределённых системах.
Сегодня GUID используется повсеместно: в базах данных, операционных системах, разработке ПО, облачных сервисах и даже в игровой индустрии. Например, в Windows GUID применяется в реестре и Active Directory, в базах данных он играет роль уникального первичного ключа, а в API и веб-приложениях помогает идентифицировать запросы и пользователей без риска повторений.
Почему нужен GUID?
Главное предназначение GUID — это обеспечение глобально уникальных идентификаторов без необходимости централизованного учёта. Это делает GUID незаменимым в следующих сценариях:
- Работа с базами данных. GUID часто применяется в качестве первичных ключей в таблицах, особенно в распределённых системах.
- Разработка ПО. В COM-объектах, реестре Windows, конфигурационных файлах и программных интерфейсах GUID помогает организовывать работу программ.
- Сетевые и облачные сервисы. В микросервисной архитектуре GUID обеспечивает уникальность данных без необходимости синхронизации между узлами.
- Игровая индустрия. В многопользовательских играх уникальные идентификаторы объектов позволяют синхронизировать их состояние между игроками.
Как GUID гарантирует уникальность?
Одной из главных причин популярности GUID является его практически нулевая вероятность дублирования. Благодаря 128-битному размеру (что даёт 2128 возможных значений) и различным методам генерации (включая временные метки, MAC-адреса и случайные числа), вероятность совпадения двух идентификаторов крайне мала. Даже если миллиарды устройств будут генерировать GUID каждую секунду в течение миллионов лет, вероятность коллизии останется минимальной.
Далее разберём историю появления GUID, изучим его структуру, узнаем о разных методах генерации и рассмотрим практическое применение уникальных идентификаторов в разработке и администрировании. Будет интересно!
Концепция глобально уникальных идентификаторов возникла в 1980-х годах, когда началось активное развитие распределённых вычислительных систем. В таких средах традиционные последовательные идентификаторы, использующие автоинкремент, стали проблематичными, поскольку требовали централизованного учёта. Разработчикам требовался механизм, который позволял бы генерировать уникальные идентификаторы независимо друг от друга.
Первые шаги: появление уникальных идентификаторов
Одним из первых решений, обеспечивающих уникальность, стало использование временных меток и аппаратных характеристик устройства. Однако со временем стало ясно, что этих параметров недостаточно: если идентификаторы генерируются в один момент времени на разных машинах, вероятность коллизии остаётся.
Разработка GUID в Microsoft
В 1991 году корпорация Microsoft внедрила GUID (Globally Unique Identifier) как часть технологии COM (Component Object Model). Эта технология позволяла программным компонентам взаимодействовать друг с другом без необходимости отслеживать идентификаторы вручную. GUID стал базовым идентификатором для объектов Windows, реестра и различных библиотек.
Применение GUID в Windows вскоре распространилось на Active Directory, DCOM (Distributed COM) и многие другие технологии, где требовались уникальные идентификаторы. Например, каждый установленный в Windows драйвер получает свой GUID, который регистрируется в системном реестре:
HKEY_CLASSES_ROOT\CLSID\{550e8400-e29b-41d4-a716-446655440000}Стандартизация UUID
Параллельно с Microsoft над решением проблемы работала организация IETF (Internet Engineering Task Force). В 1997 году был опубликован документ RFC 4122, который формализовал стандарт UUID (Universally Unique Identifier). По своей сути UUID идентичен GUID, но термин UUID получил более широкое распространение за пределами экосистемы Microsoft.
RFC 4122 описывает несколько версий UUID, включая:
- UUID версии 1 — основан на временных метках и MAC-адресах.
- UUID версии 3 и 5 — создаются на основе хеш-функций.
- UUID версии 4 — полностью случайные значения, наиболее популярный вариант.
Реальные случаи коллизий и усовершенствования UUID
Хотя вероятность коллизии GUID крайне мала, зафиксированы редкие случаи её возникновения. Например, в 2008 году исследователи обнаружили, что при неправильной генерации UUID версии 1 в некоторых реализациях Java возможны дубликаты из-за сбоя при генерации временных меток.
Со временем появлялись новые усовершенствованные версии UUID:
- UUID версии 6 — улучшенная версия 1 с удобной сортировкой.
- UUID версии 7 — использует случайные данные, но учитывает временные метки.
- UUID версии 8 — зарезервирован для пользовательских алгоритмов генерации.
Современное использование GUID и UUID
Сегодня GUID и UUID широко используются в базах данных, операционных системах, облачных сервисах и API. Например:
- Windows использует GUID для идентификации компонентов системы.
- SQL Server, PostgreSQL, MongoDB используют UUID в качестве уникальных первичных ключей.
- REST API применяют UUID для идентификации ресурсов.
- Игровые движки (Unity, Unreal Engine) используют GUID для синхронизации игровых объектов.
Таким образом, идея глобально уникальных идентификаторов, появившаяся как решение проблемы распределённых систем, превратилась в ключевой инструмент идентификации в современных технологиях.
Формат и структура GUID
GUID состоит из 128 бит (16 байт) и обычно представляется в виде 32 шестнадцатеричных символов, разделённых дефисами. Стандартный формат записи:
xxxxxxxx-xxxx-Mxxx-Nxxx-xxxxxxxxxxxxГде:
- xxxxxxxx-xxxx — случайные или временные данные.
- M — версия GUID (определяет алгоритм генерации, например, 1, 4 или 5).
- N — вариативность (определяет определённые технические параметры, такие как совместимость с разными стандартами).
- xxxxxxxxxxxx — оставшиеся случайные или псевдослучайные данные.
Пример реального GUID:
550e8400-e29b-41d4-a716-446655440000В зависимости от метода генерации структура GUID может включать дополнительные параметры, например:
- Версия 1 (time-based) — включает метку времени и MAC-адрес устройства.
- Версия 3 и 5 (namespace-based) — использует хеш-функции MD5 или SHA-1 для получения идентификатора.
- Версия 4 (random-based) — полностью случайное значение.
В следующих разделах мы рассмотрим подробнее каждый из типов GUID и их применение.
Виды GUID и методы генерации
GUID может генерироваться различными способами, в зависимости от требований к уникальности, скорости работы и уровня детерминированности. Существует несколько стандартных версий UUID, определённых в RFC 4122, каждая из которых предназначена для разных сценариев.
Версия 1 (Time-based)
GUID версии 1 основан на временной метке и MAC-адресе устройства, на котором он был сгенерирован. Такой идентификатор можно разобрать, чтобы определить, когда и на каком компьютере он был создан.
Формат включает:
- Микросекундную метку времени (с 15 октября 1582 года);
- MAC-адрес сетевого интерфейса;
- Случайный или инкрементальный счётчик.
Хотя это гарантирует уникальность, такой метод имеет недостаток: он может раскрывать информацию о системе, что делает его менее безопасным.
Версия 2 (DCE Security)
Редко используемый вариант, основанный на версии 1, но дополнительно включающий идентификатор пользователя или группы (UID, GID). Применяется в системах DCE (Distributed Computing Environment).
Версия 3 и 5 (Namespace-based, MD5/SHA-1)
Эти версии используют хеш-функции (MD5 для версии 3 и SHA-1 для версии 5) для генерации идентификатора на основе определённого пространства имён (например, имени домена, URL или другого текстового значения). Это позволяет получить одинаковые UUID для одинаковых входных данных.
Версия 4 (Random-based)
Наиболее популярный вариант, основанный полностью на случайных данных. Использует криптографически стойкий генератор случайных чисел, что делает вероятность коллизии практически нулевой.
Версии 6, 7, 8
Эти версии являются относительно новыми и разрабатываются для улучшенной сортируемости и гибкости:
- Версия 6 — модифицированная time-based версия, которая облегчает сортировку.
- Версия 7 — основана на временных метках, но использует случайные компоненты.
- Версия 8 — зарезервирована для пользовательских алгоритмов генерации.
Вероятность коллизий
Одним из главных преимуществ GUID является исключительно малая вероятность повторений. Поскольку GUID занимает 128 бит, общее число возможных значений составляет:
2^128 ≈ 3,4 × 10^38Для сравнения, если бы каждый человек на Земле генерировал по миллиарду UUID каждую секунду в течение миллиардов лет, вероятность совпадения всё равно была бы крайне низкой.
Коллизии в разных версиях UUID
- Версия 1 (time-based) теоретически исключает коллизии, так как использует MAC-адрес и временную метку.
- Версии 3 и 5 (namespace-based) также не допускают коллизий, так как одинаковые входные данные всегда дают одинаковый результат.
- Версия 4 (random-based) имеет вероятность коллизии, но она настолько мала, что её можно игнорировать.
Реальные случаи возникновения коллизий
На практике ошибки в генерации GUID случаются редко, но возможны из-за:
- Использования некачественных генераторов случайных чисел;
- Ручного копирования GUID вместо их генерации;
- Ошибок в алгоритмах, особенно в старых библиотеках.
В следующих разделах мы разберём, как применяются GUID в реальных системах и какие у них есть недостатки.
Применение GUID
GUID применяется в самых разных сферах, от операционных систем до облачных сервисов и баз данных. Его основное преимущество — возможность уникальной идентификации объектов без необходимости централизованного учёта.
Использование GUID в базах данных
В реляционных базах данных GUID нередко используется в качестве первичного ключа. Это удобно в распределённых системах, где разные серверы создают записи независимо друг от друга. Например, в Microsoft SQL Server можно создать GUID с помощью:
Другие СУБД, такие как PostgreSQL, используют:
SELECT gen_random_uuid();Но у GUID в базах данных есть недостатки: они занимают больше места (16 байт против 4-8 байт у автоинкрементного ID), а также снижают производительность индексов.
GUID в Windows
GUID широко используется в Windows, особенно в реестре, где он идентифицирует программные компоненты и настройки. Например, каждая программа, зарегистрированная в системе, имеет уникальный идентификатор, который можно найти в реестре:
HKEY_CLASSES_ROOT\CLSID\{550e8400-e29b-41d4-a716-446655440000}Также GUID применяется в Active Directory, где он назначается пользователям, группам и объектам безопасности.
Использование в вебе и API
Во многих REST API GUID используется как идентификатор ресурса. Это позволяет избежать коллизий и упрощает работу с распределёнными сервисами. Например:
https://api.example.com/users/550e8400-e29b-41d4-a716-446655440000Таким образом, серверы могут генерировать идентификаторы независимо друг от друга, а клиентам не нужно беспокоиться о совпадениях.
Игровая индустрия
Во многих игровых движках (например, Unity и Unreal Engine) GUID используется для идентификации игровых объектов, текстур и сцен. Это особенно важно в многопользовательских играх, где необходимо синхронизировать уникальные объекты между разными клиентами.
Проблемы и недостатки GUID
Несмотря на свои преимущества, GUID не всегда является лучшим выбором. В некоторых ситуациях он может привести к проблемам с производительностью и удобством использования.
Повышенное потребление памяти
GUID занимает 16 байт, тогда как традиционные автоинкрементные числовые идентификаторы (например, INT в SQL) занимают всего 4 байта. В больших базах данных это может значительно увеличить общий объём данных и замедлить работу индексов.
Фрагментация индексов в базах данных
Поскольку случайно сгенерированные GUID распределяются по всему диапазону значений, вставка новых записей происходит в произвольных местах индекса. Это приводит к его фрагментации, снижая скорость поиска.
В SQL Server существует альтернатива — NEWSEQUENTIALID(), которая генерирует GUID, упорядоченные по времени, что уменьшает фрагментацию:
CREATE TABLE Users (
ID UNIQUEIDENTIFIER DEFAULT NEWSEQUENTIALID() PRIMARY KEY,
Name NVARCHAR(100)
);GUID трудно запоминать и использовать вручную
Людям проще работать с короткими числовыми идентификаторами, чем с длинными строками вида 550e8400-e29b-41d4-a716-446655440000 . В пользовательских интерфейсах GUID редко отображаются напрямую, так как они неудобны для копирования и ввода.
Необходимость в кодировке для URL
GUID содержит дефисы, из-за чего его иногда приходится кодировать в URL или использовать другие представления (например, Base64), чтобы сделать его компактнее.
Безопасность и утечки информации
GUID версии 1 содержит MAC-адрес устройства, на котором он был создан. Это может представлять угрозу конфиденциальности, так как злоумышленник может определить, на каком компьютере был сгенерирован идентификатор.
Поэтому для большинства приложений рекомендуется использовать GUID версии 4, который основан на случайных числах и не содержит потенциально раскрывающей информации.
Лучшие практики использования GUID
Несмотря на удобство GUID, его неправильное применение может привести к проблемам с производительностью, удобством работы и безопасностью. Рассмотрим основные рекомендации по эффективному использованию GUID в различных системах.
Используйте правильную версию GUID
Выбор версии GUID зависит от задачи:
- Версия 1 (time-based) подходит, если важно отслеживать время создания объекта, но может раскрывать MAC-адрес.
- Версия 4 (random-based) — лучший выбор для большинства случаев, так как не содержит лишней информации и генерируется случайным образом.
- Версия 5 (SHA-1 namespace-based) полезна, если нужен детерминированный GUID на основе входных данных (например, URL или имени пользователя).
Будьте осторожны при использовании GUID в базах данных
GUID не всегда удобен в реляционных базах данных, поскольку:
- Он занимает больше места, чем обычные числовые идентификаторы (16 байт против 4-8 байт у
INTилиBIGINT). - Случайно распределённые значения приводят к фрагментации индексов и снижению производительности.
Чтобы избежать проблем, можно использовать NEWSEQUENTIALID() (SQL Server) или другие методы, обеспечивающие упорядоченную генерацию идентификаторов.
Не используйте GUID для коротких URL
Стандартный GUID слишком длинный для удобного использования в URL. Вместо этого можно применять:
- Хеш-идентификаторы (например, Base64-кодирование GUID).
- ULID (Universally Unique Lexicographically Sortable Identifier).
- Snowflake ID (Twitter) — числовые идентификаторы, включающие временные метки.
Защищайте GUID от утечек
Если используется GUID версии 1, он может содержать MAC-адрес устройства, что может представлять угрозу конфиденциальности. Если важно избежать утечек, лучше выбрать GUID версии 4 или использовать анонимизированные идентификаторы.
Оптимизируйте хранение GUID
В некоторых базах данных можно хранить GUID в бинарном формате ( BINARY(16) ) вместо текстового ( VARCHAR(36) ), что экономит место и ускоряет поиск.
Альтернативы GUID
Хотя GUID является универсальным инструментом для уникальной идентификации, в некоторых случаях существуют более подходящие альтернативы.
ULID (Universally Unique Lexicographically Sortable Identifier)
ULID — это улучшенный вариант UUID, который:
- Сортируется по времени (первые 48 бит — временная метка).
- Использует алфавит [0-9A-Z] для компактного представления.
- Является читаемым и удобным для использования в URL.
Пример ULID: 01GZMECHXV4ZP3J2FB4QCT2JVQ .
KSUID (K-Sortable Unique ID)
Разработан для Go-приложений и похож на ULID, но использует другой формат представления. Применяется для создания масштабируемых идентификаторов в распределённых системах.
Snowflake ID (Twitter)
Twitter разработал Snowflake ID как уникальный числовой идентификатор, содержащий:
- Метки времени.
- Идентификатор сервера.
- Счётчик уникальности.
Он занимает меньше места, чем GUID, и удобен для индексации в базах данных.
Автоинкрементные ID
В локальных базах данных использование автоинкрементных идентификаторов ( INT AUTO_INCREMENT ) остаётся лучшим решением, если не требуется глобальная уникальность.
Выбор альтернативы зависит от конкретного сценария.
Часто задаваемые вопросы
Можно ли создать два одинаковых GUID?
Теоретически вероятность совпадения GUID крайне мала, особенно если используется версия 4, основанная на случайных числах. Однако при ошибках генерации или некорректной реализации алгоритма коллизии возможны.
Какой GUID лучше использовать в базе данных?
В базах данных GUID лучше использовать с осторожностью. Версия 4 даёт высокую уникальность, но приводит к фрагментации индексов. В SQL Server можно применять NEWSEQUENTIALID(), чтобы уменьшить фрагментацию.
Чем отличается GUID от UUID?
GUID (Globally Unique Identifier) — термин, чаще используемый Microsoft, а UUID (Universally Unique Identifier) — международный стандарт. По сути, это одно и то же, различия лишь в названии.
Какой размер занимает GUID в памяти?
GUID занимает 128 бит (16 байт). В текстовом формате он требует 36 символов, но в бинарном виде его можно хранить компактнее, например, в BINARY(16) в базе данных.
Почему GUID нельзя использовать в коротких URL?
GUID слишком длинный (36 символов), что делает URL менее удобными. Вместо него можно использовать ULID, Snowflake ID или закодированный в Base64 GUID.
GUID можно декодировать, чтобы получить исходные данные?
GUID версии 1 содержит метку времени и MAC-адрес устройства, но другие версии, такие как 4 (random-based), не поддаются обратному декодированию.
Что делать, если в системе много одинаковых GUID?
Проверьте алгоритм генерации. Возможные причины: использование одного источника случайных чисел, ошибки кэширования или преднамеренное дублирование значений.
Какой GUID выбрать для API?
GUID версии 4 (random-based) — лучший вариант для API, так как он безопасен, не раскрывает MAC-адрес и не зависит от временной метки.
Можно ли создать GUID вручную?
Да, но это не рекомендуется. GUID должен генерироваться автоматически, чтобы исключить риск дублирования и ошибок при его создании.
Как проверить GUID на корректность?
Можно использовать регулярное выражение для проверки формата, например: ^[0-9a-f]{8}-[0-9a-f]{4}-[0-9a-f]{4}-[0-9a-f]{4}-[0-9a-f]{12}$ . Также существуют онлайн-валидаторы.
Где можно создать GUID онлайн?
Для удобного и быстрого создания уникальных идентификаторов вы можете воспользоваться нашим онлайн-сервисом генерации GUID. Этот инструмент обеспечивает генерацию GUID по стандартам v1, v3, v4, v5, v7. Гарантируется их уникальность и соответствие общепринятым форматам.
В мире разработки программного обеспечения каждое создание имеет свое уникальное свойство. Это как отпечаток пальца – одинаковых не бывает. Ведь каждая система, будь то операционная или программная, имеет свой собственный, неповторимый штрих-код, который позволяет ей выделяться среди остальных. В этом сокровищнице особое место занимает GUID: уникальный идентификатор глобального объекта.
Неожиданно, но главным героем нашей истории будет не мифический планетарный мир Меркурия, а более прозаическая система связи в программировании. Хотя, можно назвать его электронным Меркурием магического мира разработчиков. Мы узнаем, что такое GUID, как происходит его создание и зачем это нужно.
Возможно, вы заметили, что в программах, особенно на популярных языках, GUID активно используется при создании идентификаторов в объектах. Однако, если вы только начинаете путешествие в разнообразие программирования и никогда не слышали о GUID ранее, не стоит паниковать. Мы возьмем вас за руку и проведем через весь процесс разбора этого загадочного обозначения, чтобы вы поняли, как и зачем должны быть созданы эти уникальные идентификаторы. Готовы узнать, что скрыто за кодовыми строками и цифрами? Вперед, и переступайте порог мира GUID!
Определение и смысл термина
В данном разделе мы рассмотрим термин, связанный с программированием и соответствующей сферой деятельности. Основное внимание будет уделено понятию, важности и применению данного термина в контексте современных технологий.
Рассмотрим на примере языка программирования FreeBASIC. Упомянутый язык используется для разработки приложений, операционных систем и других программных решений. Одним из ключевых элементов в создании структурированных программ с использованием FreeBASIC является термин «меркурий».
Система меркурия, определенная в рамках языка программирования FreeBASIC, представляет собой набор специальных функций и методов, которые позволяют разработчикам работать с определенными типами данных и структурами в программном коде. Меркурий предоставляет возможность эффективно взаимодействовать с такими объектами, как списки, массивы и файлы.
Одним из главных преимуществ меркурия является его гибкость и удобство в использовании. Благодаря этому разработчики получают возможность настраивать и оптимизировать код в соответствии с конкретными потребностями проекта. Меркурий также обеспечивает высокую эффективность работы программы и облегчает ее тестирование и отладку.
Резюмируя, можно сказать, что понимание и грамотное применение системы меркурия в языке программирования FreeBASIC является важным аспектом для разработчиков. Определение и смысл этого термина позволяют создавать эффективные и надежные программные решения, справляться с различными задачами и повышать качество программирования в целом.
История и происхождение понятия
Когда мы взглядываем в историю, мы можем увидеть, что в конце 1970-х и начале 1980-х годов в области программирования стала возникать необходимость в создании уникального идентификатора, который бы мог быть использован для идентификации объектов в системе. В те времена ведущие языки программирования, такие как FreeBASIC, не предоставляли специальных функций для генерации таких идентификаторов.
Ситуация изменилась с появлением системы GUID (Globally Unique Identifier) или глобального уникального идентификатора. Суть этой системы заключается в создании идентификаторов, которые быть уникальными на глобальном уровне. Сегодня GUID широко применяется в разных областях программирования, а не только в языке FreeBASIC.
Структура GUID представляет собой последовательность из нескольких блоков, каждый из которых состоит из чисел и букв. Эти блоки разделены дефисами или другими знаками препинания. Благодаря такой структуре каждый GUID уникален и может быть использован в качестве идентификатора объекта или данных.
Интересно отметить, что происхождение понятия GUID связано с задачей создания уникальных идентификаторов на уровне всего мира. Применение GUID позволяет с легкостью создавать идентификаторы, которые нетрудно взять в использование и использовать в разных системах и приложениях.
В итоге стоит сказать, что понятие GUID является неотъемлемой частью современного программирования. Его история берет начало в конце 1970-х, а сегодня оно широко распространено и применяется в разнообразных сферах.
Роль и значение уникального идентификатора Guid в современном мире
В современной системе информационных технологий, где пространство данных и информационных объектов неуклонно расширяется во все стороны, необходимо иметь надежный способ их идентификации и отслеживания. Представьте, что возьмете в руки каплю ртути и пытаетесь пронаблюдать ее движение в масштабах всей Меркурийской системы. Без точной системы идентификации и структурирования информации это может оказаться практически невозможным.
И здесь на сцену выходит Guid, уникальный глобальный идентификатор, который становится важной составляющей в построении информационных систем и повседневной жизни в целом. Guid представляет собой 128-битное число, которое генерируется с использованием определенного алгоритма и содержит информацию о времени, уникальном идентификаторе компьютера и других параметрах. В отличие от других идентификаторов, Guid гарантирует, что каждое его значение является уникальным, что делает его незаменимым инструментом для идентификации информации в различных системах и приложениях.
Структура Guid состоит из пяти групп чисел, разделенных дефисами. Каждая группа состоит из определенного количества шестнадцатеричных символов. Группы чисел в Guid имеют свою специфическую семантику, что позволяет использовать этот идентификатор для решения различных задач: от простой идентификации объектов в базах данных до генерации уникальных идентификаторов для пользователей и документов.
| Группа чисел | Семантика |
|---|---|
| 1-8 | Дата и время |
| 9-12 | Уникальный идентификатор компьютера |
| 13-14 | Зарезервированные значения |
| 15 | Версия Guid |
| 16-21 | Случайные числа |
Роль и значение Guid в современном мире невозможно переоценить. Он используется в различных областях, начиная от баз данных и систем учета до разработки программного обеспечения и создания уникальных идентификаторов для пользователей, приложений и документов. Guid стал надежным инструментом, обеспечивающим уникальность и структурирование информации в глобальном масштабе, упрощающим процессы идентификации и управления данными.
Принципы работы и структура идентификатора уникального объекта
Прежде чем изучать принципы работы и структуру Guid, полезно взглянуть на аналогию с ежедневной жизнью. Представим, что каждому объекту окружающего мира присваивается уникальная метка, позволяющая легко идентифицировать этот объект среди других. Например, допустим у нас есть метка «меркурий», которая может быть присвоена одной из планет солнечной системы. Таким образом, по этой метке мы сможем легко различить и идентифицировать планету Меркурий.
Аналогично, в информационных системах используется Guid для идентификации ресурсов. Он представляет собой последовательность символов, имеющую определенную структуру. Структура Guid состоит из шестнадцатеричных значений, разделенных дефисами. Например, такой Guid может выглядеть следующим образом: 3f2504e0-4f89-11d3-9a0c-0305e82c3301.
Один из способов создания Guid – это использование алгоритма, который генерирует его на основе определенных факторов, таких как текущее время, MAC-адрес сетевого адаптера и другие параметры. Такой алгоритм обеспечивает уникальность создаваемых идентификаторов. Примером такого алгоритма может быть алгоритм, используемый в языке программирования FreeBASIC.
Использование Guid обеспечивает уникальность идентификации ресурсов, что в свою очередь позволяет удобно и безопасно работать с ними в разных системах и приложениях. Понимание принципов работы и структуры Guid является важным аспектом при разработке и поддержке информационных систем.
| Преимущества использования Guid: |
| 1. Глобальная уникальность – нет вероятности возникновения дублирующих идентификаторов; |
| 2. Легкость использования и интеграции с различными системами; |
| 3. Защита от подделки или случайного совпадения идентификаторов. |
Примеры использования и структура Guid в разных областях
В данном разделе мы рассмотрим несколько примеров использования и структуру уникального идентификатора Guid в различных областях.
1. Системы управления базами данных: Многие современные системы управления базами данных используют Guid для генерации уникальных идентификаторов для записей в таблицах. Это позволяет избежать конфликтов и идентифицировать каждую запись без возможности дублирования.
2. Веб-разработка: Guid можно использовать в веб-разработке для генерации уникальных идентификаторов для элементов пользовательского интерфейса, таких как формы или кнопки. Это может быть полезно, например, для создания уникальных идентификаторов для элементов на странице или для обработки данных через AJAX-запросы.
3. Криптография и безопасность: Guid также используется в криптографии и системах безопасности для генерации случайных и уникальных значений, например для создания секретных ключей или токенов авторизации. Поскольку Guid обладает высокой степенью уникальности, он является надежным выбором для таких целей.
4. Информационные системы: В некоторых информационных системах Guid используется для идентификации и отслеживания объектов и записей. Например, в системе учета и отслеживания товаров в розничных магазинах, Guid может быть присвоен каждому товару в целях идентификации и контроля за его движением.
5. Медицинская область: В медицинской области Guid может использоваться для идентификации и отслеживания пациентов, медицинской истории, медицинского оборудования и других объектов и данных. Это позволяет эффективно вести учет и обеспечить безопасность личной информации пациентов.
Преимущества и недостатки использования уникальных идентификаторов (ГУИД) в системе
В информационных системах и программном обеспечении часто возникает необходимость в создании уникальных идентификаторов для различных объектов: пользователей, файлов, записей и прочего. Возьмем во внимание использование структур данных, включая, но не ограничиваясь, языком программирования FreeBASIC, для обсуждения преимуществ и недостатков использования глобально уникальных идентификаторов (ГУИД).
| Преимущества | Недостатки |
|---|---|
|
|
В целом, ГУИДы предоставляют надежный механизм для создания уникальных идентификаторов в системе, обладая глобальной уникальностью и простотой интеграции с различными базами данных и информационными системами. Однако, использование ГУИДов может быть оправдано только в случаях, когда глобальная уникальность имеет критическое значение и недостатки в производительности и чтимости кода не являются проблемой.
| Acronym | UUID |
|---|---|
| Organisation | Open Software Foundation (OSF), ISO/IEC, Internet Engineering Task Force (IETF) |
| No. of digits | 32 |
| Example | f81d4fae-7dec-11d0-a765-00a0c91e6bf6 |
| Website | RFC 9562 (obsoleted RFC 4122) |
A Universally Unique Identifier (UUID) is a 128-bit label used to uniquely identify objects in computer systems. The term Globally Unique Identifier (GUID) is also used, mostly in Microsoft systems.[1][2]
When generated according to the standard methods, UUIDs are, for practical purposes, unique. Their uniqueness does not depend on a central registration authority or coordination between the parties generating them, unlike most other numbering schemes. While the probability that a UUID will be duplicated is not zero, it is generally considered close enough to zero to be negligible.[3][4]
Thus, anyone can create a UUID and use it to identify something with near certainty that the identifier does not duplicate one that has already been, or will be, created to identify something else. Information labeled with UUIDs by independent parties can therefore be later combined into a single database or transmitted on the same channel, with a negligible probability of duplication.
Adoption of UUIDs is widespread, with many computing platforms providing support for generating them and for parsing their textual representation.
In the 1980s, Apollo Computer originally used UUIDs in the Network Computing System (NCS). Later, the Open Software Foundation (OSF) used UUIDs for their Distributed Computing Environment (DCE). The design of the DCE UUIDs was partly based on the NCS UUIDs,[5] whose design was in turn inspired by the (64-bit) unique identifiers defined and used pervasively in Domain/OS, an operating system designed by Apollo Computer.[6] Later,[when?] the Microsoft Windows platforms adopted the DCE design as «Globally Unique IDentifiers» (GUIDs).
RFC 4122 registered a URN namespace for UUIDs and recapitulated the earlier specifications, with the same technical content.[2] When in July 2005 RFC 4122 was published as a proposed IETF standard, the ITU had also standardized UUIDs, based on the previous standards and early versions of RFC 4122. On May 7, 2024, RFC 9562[1] was published, introducing 3 new «versions» and clarifying some ambiguities.
UUIDs are standardized by the Open Software Foundation (OSF) as part of the Distributed Computing Environment (DCE).[7][8]
UUIDs are documented as part of ISO/IEC 11578:1996 «Information technology – Open Systems Interconnection – Remote Procedure Call (RPC)» and more recently in ITU-T Rec. X.667 | ISO/IEC 9834-8:2014.[9]
The Internet Engineering Task Force (IETF) published the Standards-Track RFC 9562[1] from the «Revise Universally Unique Identifier Definitions Working Group»[10] as revision for RFC 4122.[2] RFC 4122 is technically equivalent to ITU-T Rec. X.667 | ISO/IEC 9834-8, but is now obsolete.
A UUID is 128 bits in size, in which 2 to 4 bits are used to indicate the format’s variant. The most common variant in use, OSF DCE, additionally defines 4 bits for its version.
The use of the remaining bits is governed by the variant/version selected.
The variant field indicates the format of the UUID (and in case of the legacy UUID also the address family used for the node field). The following variants are defined:
- The Apollo NCS variant (indicated by the one-bit pattern 0xxx2) is for backwards compatibility with the now-obsolete Apollo Network Computing System 1.5 UUID format developed around 1988. Though different in detail, the similarity with modern UUIDv1 is evident. The variant bits in the current UUID specification coincide with the high bits of the address family octet in NCS UUIDs. Though the address family could hold values in the range 0..255, only the values 0..13 were ever defined. Accordingly, the bit pattern
0xxxavoids conflicts with historical NCS UUIDs, should any still exist in databases.[11] This variant defines «families» as subtype. - The OSF DCE variant (10xx2) are referred to as RFC 4122/DCE 1.1 UUIDs, or «Leach–Salz» UUIDs, after the authors of the original Internet Draft. This variant defines «versions» as subtype.
- The Microsoft COM/DCOM variant (110x2) is characterized in the RFC as «reserved, Microsoft Corporation backward compatibility» and was used for early GUIDs on the Microsoft Windows platform.
- The Reserved variant space is not currently used by any specification.
Versions of the OSF DCE variant
[edit]
The OSF DCE variant defines eight «versions» in the standard, and each version may be more appropriate than the others in specific use cases. The version is indicated by the value of the higher nibble (higher 4 bits, or higher hexadecimal digit) of the 7th byte of the UUID. In hex, this is the character after the second dash. For example, the UUID 9c5b94b1-35ad-49bb-b118-8e8fc24abf80 is version 4, because of the digit after the second dash is 4 in ...-49bb-....
Versions 1 and 6 (date-time and MAC address)
[edit]
Version 1 concatenates the 48-bit MAC address of the «node» (that is, the computer generating the UUID), with a 60-bit timestamp, being the number of 100-nanosecond intervals since midnight 15 October 1582 Coordinated Universal Time (UTC), the date on which the Gregorian calendar was first adopted by the bulk of Europe. RFC 4122 states that the time value rolls over around 3400 AD,[2]: 3 depending on the algorithm used, which implies that the 60-bit timestamp is a signed quantity. However some software, such as the libuuid library, treats the timestamp as unsigned, putting the rollover time in 5623 AD.[12] The rollover time as defined by ITU-T Rec. X.667 is 3603 AD.[13]: v
A 13-bit or 14-bit «uniquifying» clock sequence extends the timestamp in order to handle cases where the processor clock does not advance fast enough, or where there are multiple processors and UUID generators per node. When UUIDs are generated faster than the system clock could advance, the lower bits of the timestamp fields can be generated by incrementing it every time a UUID is being generated, to simulate a high-resolution timestamp. With each version 1 UUID corresponding to a single point in space (the node) and time (intervals and clock sequence), the chance of two properly generated version-1 UUIDs being unintentionally the same is practically nil. Since the time and clock sequence total 74 bits, 274 (1.8×1022, or 18 sextillion) version-1 UUIDs can be generated per node ID, at a maximal average rate of 163 billion per second per node ID.[2]
In contrast to other UUID versions, version-1 and -2 UUIDs based on MAC addresses from network cards rely for their uniqueness in part on an identifier issued by a central registration authority, namely the Organizationally Unique Identifier (OUI) part of the MAC address, which is issued by the IEEE to manufacturers of networking equipment.[14] The uniqueness of version-1 and version-2 UUIDs based on network-card MAC addresses also depends on network-card manufacturers properly assigning unique MAC addresses to their cards, which like other manufacturing processes is subject to error. Virtual machines receive a MAC address in a range that is configurable in the hypervisor.[15] Additionally some operating systems permit the end user to customise the MAC address, notably OpenWRT.[16]
Usage of the node’s network card MAC address for the node ID means that a version-1 UUID can be tracked back to the computer that created it. Documents can sometimes be traced to the computers where they were created or edited through UUIDs embedded into them by word processing software. This privacy hole was used when locating the creator of the Melissa virus.[17]
RFC 9562[1] does allow the MAC address in a version-1 (or 2) UUID to be replaced by a random 48-bit node ID, either because the node does not have a MAC address, or because it is not desirable to expose it. In that case, the RFC requires that the least significant bit of the first octet of the node ID should be set to 1.[2] This corresponds to the multicast bit in MAC addresses, and setting it serves to differentiate UUIDs where the node ID is randomly generated from UUIDs based on MAC addresses from network cards, which typically have unicast MAC addresses.[2]
Version 6 is the same as version 1 except all timestamp bits are ordered from most significant to least significant. This allows systems to sort UUIDs in order of creation simply by sorting them lexically, whereas this is not possible with version 1.
Version 2 (date-time and MAC address, DCE security version)
[edit]
RFC 9562[1] reserves version 2 for «DCE security» UUIDs; but it does not provide any details. For this reason, many UUID implementations omit version 2. However, the specification of version-2 UUIDs is provided by the DCE 1.1 Authentication and Security Services specification.[8]
Version-2 UUIDs are similar to version 1, except that the least significant 8 bits of the clock sequence are replaced by a «local domain» number, and the least significant 32 bits of the timestamp are replaced by an integer identifier meaningful within the specified local domain. On POSIX systems, local-domain numbers 0 and 1 are for user ids (UIDs) and group ids (GIDs) respectively, and other local-domain numbers are site-defined.[8] On non-POSIX systems, all local domain numbers are site-defined.
The ability to include a 40-bit domain/identifier in the UUID comes with a tradeoff. On the one hand, 40 bits allow about 1 trillion domain/identifier values per node ID. On the other hand, with the clock value truncated to the 28 most significant bits, compared to 60 bits in version 1, the clock in a version 2 UUID will «tick» only once every 429.49 seconds, a little more than 7 minutes, as opposed to every 100 nanoseconds for version 1. And with a clock sequence of only 6 bits, compared to 14 bits in version 1, only 64 unique UUIDs per node/domain/identifier can be generated per 7-minute clock tick, compared to 16,384 clock sequence values for version 1.[18]
Versions 3 and 5 (namespace name-based)
[edit]
Version-3 and version-5 UUIDs are generated by hashing a namespace identifier and name. Version 3 uses MD5 as the hashing algorithm, and version 5 uses SHA-1.[1]
The namespace identifier is itself a UUID. The specification provides UUIDs to represent the namespaces for URLs, fully qualified domain names, object identifiers, and X.500 distinguished names; but any desired UUID may be used as a namespace designator.
To determine the version-3 UUID corresponding to a given namespace and name, the UUID of the namespace is transformed to a string of bytes, concatenated with the input name, then hashed with MD5, yielding 128 bits. Then 6 or 7 bits are replaced by fixed values, the 4-bit version (e.g. 00112 for version 3), and the 2- or 3-bit UUID «variant» (e.g. 102 indicating an RFC 9562[1] UUIDs, or 1102 indicating a legacy Microsoft GUID). Since 6 or 7 bits are thus predetermined, only 121 or 122 bits contribute to the uniqueness of the UUID.
Version-5 UUIDs are similar, but SHA-1 is used instead of MD5. Since SHA-1 generates 160-bit digests, the digest is truncated to 128 bits before the version and variant bits are replaced.
Version-3 and version-5 UUIDs have the property that the same namespace and name will map to the same UUID. However, neither the namespace nor name can be determined from the UUID, even if one of them is specified, except by brute-force search. RFC 4122 recommends version 5 (SHA-1) over version 3 (MD5), and warns against use of UUIDs of either version as security credentials.[2]
A version 4 UUID is randomly generated. As in other UUIDs, 4 bits are used to indicate version 4, and 2 or 3 bits to indicate the variant (102 or 1102 for variants 1 and 2 respectively). Thus, for variant 1 (that is, most UUIDs) a random version 4 UUID will have 6 predetermined variant and version bits, leaving 122 bits for the randomly generated part, for a total of 2122, or 5.3×1036 (5.3 undecillion) possible version-4 variant-1 UUIDs. There are half as many possible version 4, variant 2 UUIDs (legacy GUIDs) because there is one less random bit available, 3 bits being consumed for the variant.
Per RFC 9562[1], the seventh octet’s most significant 4 bits indicate which version the UUID adheres to. This means that the first hexadecimal digit in the third group always starts with a 4 in UUIDv4s. Visually, this looks like this xxxxxxxx-xxxx-Mxxx-Nxxx-xxxxxxxxxxxx, where M is the UUID version field. The upper two or three bits of digit N encode the variant. Values are 8, 9, A or B for the 2 bit indication, values C or D for the 3 bit indication. For example, a random UUID version 4, variant 1 could be 8D8AC610-566D-4EF0-9C22-186B2A5ED793.[19]
Version 7 (timestamp and random)
[edit]
Version 7 UUIDs (UUIDv7) are designed for keys in high-load databases and distributed systems.
UUIDv7 begins with a 48 bit big-endian Unix Epoch timestamp with approximately millisecond granularity. The timestamp can be shifted by any time shift value. Directly after the timestamp follows the version nibble, that must have a value of 7. The variant bits have to be 10x. Remaining 74 bits are random seeded counter (optional, at least 12 bits but no longer than 42 bits) and random.
Two counter rollover handling methods can be used together:
- Zero seeded most significant, leftmost guard bit of the counter.
- Increment of the timestamp ahead of the actual time and reinitialize the counter when it overflows.
In DBMS UUIDv7 generator can be shared between threads (tied to a table or to a DBMS instance) or can be thread-local (with worse monotonicity, locality and performance).
Version 8 only has two requirements:
- The variant bits have to be
10, so the nibble containing the variant must be 8 (0b1000), 9 (0b1001), A (0b1010), or B (0b1011). - The version nibble has to be the value of 8.
Those requirements tell the system that it is a version 8 UUID. The remaining 122 bits are up to the vendor to customize. The difference with version 4 is that those 122 bits are random, but the 122 bits in UUID version 8 are not, because they follow vendor specific rules.
The «nil» UUID is the UUID 00000000-0000-0000-0000-000000000000; that is, all bits set to zero.[1]
The «max» UUID, sometimes also called the «omni» UUID, is the UUID FFFFFFFF-FFFF-FFFF-FFFF-FFFFFFFFFFFF; that is, all bits set to one.[1]
Binary representation
[edit]
Initially, Apollo Computer designed the UUID with the following wire format:[5][11]
The legacy wire format
| Name | Offset | Length | Description |
|---|---|---|---|
| time_high | 0x00 | 4 octets / 32 bits | The first 6 octets are the number of four-microsecond (μs) units of time that have passed since 1980-01-01 00:00 UTC. The time 248 × 4 μs after 1980 started was 2015-09-05 05:58:26.84262 UTC. Thus, the last time at which UUIDs could be generated in this original format was in 2015.[20] |
| time_low | 0x04 | 2 octets / 16 bits | |
| reserved | 0x06 | 2 octets / 16 bits | These octets are reserved for future use. |
| family | 0x08 | 1 octet / 8 bits | This octet is an address family. |
| node | 0x09 | 7 octets / 56 bits | These octets are a host ID in the form allowed by the specified address family. |
Later, the UUID was extended by combining the legacy family field with the new variant field. Because the family field only had used the values ranging from 0 to 13 in the past, it was decided that a UUID with the most significant bit set to 0 was a legacy UUID. This gives the following table for the family group:
Family / variant field
| MSB 0 | MSB 1 | MSB 2 | Legacy family field value range | In hex | Description |
|---|---|---|---|---|---|
| 0 | x | x | 0–127 (Only 0–13 are used) | 0x00–0x7f | The legacy Apollo NCS UUID |
| 1 | 0 | x | 128–191 | 0x80–0xbf | OSF DCE UUID |
| 1 | 1 | 0 | 192–223 | 0xc0–0xdf | Microsoft COM / DCOM UUID |
| 1 | 1 | 1 | 224–255 | 0xe0–0xff | Reserved for future definition |
The legacy Apollo NCS UUID has the format described in the previous table. The OSF DCE UUID variant is described in RFC 9562[1]. The Microsoft COM / DCOM UUID has its variant described in the Microsoft documentation.
When saving UUIDs to binary format, they are sequentially encoded in big-endian. For example, 00112233-4455-6677-8899-aabbccddeeff is encoded as the bytes 00 11 22 33 44 55 66 77 88 99 aa bb cc dd ee ff.[21][22]
An exception to this are Microsoft’s variant 2 UUIDs («GUID»): historically used in COM/OLE libraries, they use a little-endian format, but appear mixed-endian with the first three components of the UUID as little-endian and last two big-endian. Microsoft’s GUID structure defines the last eight bytes as an 8-byte array, which are serialized in ascending order, which makes the byte representation appear mixed-endian.[23] For example, 00112233-4455-6677-8899-aabbccddeeff is encoded as the bytes 33 22 11 00 55 44 77 66 88 99 aa bb cc dd ee ff.[24][25]
Textual representation
[edit]
In most cases, UUIDs are represented as hexadecimal values. The most used format is the 8-4-4-4-12 format, xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx, where every x represents 4 bits. Other well-known formats are the 8-4-4-4-12 format with braces, {xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx}, like in Microsoft’s systems, e.g. Windows, or xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx, where all hyphens are removed. In some cases, it is also possible to have xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx with the «0x» prefix or the «h» suffix to indicate hexadecimal values. The format with hyphens was introduced with the newer variant system. Before that, the legacy Apollo format used a slightly different format: 34dc23469000.0d.00.00.7c.5f.00.00.00. The first part is the time (time_high and time_low combined). The reserved field is skipped. The family field comes directly after the first dot, so in this case 0d (13 in decimal) for DDS (Data Distribution Service). The remaining parts, each separated with a dot, are the node bytes.
The lowercase form of the hexadecimal values is the generally preferred format. Specifically in some contexts such as those defined in ITU-T Rec. X.667, lowercase is required when the text is generated, but the uppercase version must also be accepted.
A UUID can be represented as a 128 bit integer. For example, the UUID 550e8400-e29b-41d4-a716-446655440000 can also be represented as 113059749145936325402354257176981405696. Note that it is possible to have both signed and unsigned values if the first bit of the UUID is set to 1.
A UUID can be represented as a 128 bit binary number. For example, the UUID 550e8400-e29b-41d4-a716-446655440000 can also be represented as 0101010100001110
RFC 9562[1] registers the «uuid» namespace. This makes it possible to make URNs out of UUIDs, like urn:uuid:550e8400-e29b-41d4-a716-446655440000. The normal 8-4-4-4-12 format is used for this. It is also possible to make a OID URN out of UUIDs, like urn:oid:2.25.113059749145936325402354257176981405696. In that case, the unsigned decimal format is used. The «uuid» URN is recommended over the «oid» URN.
Collision occurs when the same UUID is generated more than once and assigned to different referents. In the case of standard version-1 and version-2 UUIDs using unique MAC addresses from network cards, collisions are unlikely to occur, with an increased possibility only when an implementation varies from the standards, either inadvertently or intentionally.
In contrast to version-1 and version-2 UUIDs generated using MAC addresses, with version-1 and -2 UUIDs which use randomly generated node ids, hash-based version-3 and version-5 UUIDs, and random version-4 UUIDs, collisions can occur even without implementation problems, albeit with a probability so small that it can normally be ignored. This probability can be computed precisely based on analysis of the birthday problem.[26]
For example, the number of random version-4 UUIDs which need to be generated in order to have a 50% probability of at least one collision is 2.71 quintillion, computed as follows:[27]
This number would be equivalent to generating 1 billion UUIDs per second for about 86 years. A file containing this many UUIDs, at 16 bytes per UUID, would be about 43.4 exabytes (37.7 EiB).
The smallest number of version-4 UUIDs which must be generated for the probability of finding a collision to be p is approximated by the formula
Thus, the probability to find a duplicate within 103 trillion version-4 UUIDs is one in a billion.
Collisions have occurred when manufacturers assign a default UUID to a product, such as a motherboard, and then fail to over-write the default UUID later in the manufacturing process. For example, UUID 03000200-0400-0500-0006-000700080009 occurs on many different units of Gigabyte-branded motherboards.[citation needed]
Significant uses include ext2/ext3/ext4 filesystem userspace tools (e2fsprogs uses libuuid provided by util-linux), LVM, LUKS encrypted partitions, GNOME, KDE, and macOS,[28] most of which are derived from the original implementation by Theodore Ts’o.[12]
The «partition label» and the «partition UUID» are both stored in the superblock. They are both part of the file system rather than of the partition. For example, ext2–4 contain a UUID, while NTFS or FAT32 do not. The superblock is a part of the file system, thus fully contained within the partition, hence doing dd if=/dev/sda1 of=/dev/sdb1 leaves both sda1 and sdb1 with the same label and UUID.
The GUID Partition Table (GUID) is one example that utilised GUIDs to label partition types.
There are several flavors of GUIDs used in Microsoft’s Component Object Model (COM):
- IID – interface identifier; (The ones that are registered on a system are stored in the Windows Registry at
[HKEY_CLASSES_ROOT\Interface][29] ) - CLSID – class identifier; (Stored at
[HKEY_CLASSES_ROOT\CLSID]). In practice it is not entirely separate from the IID space, because remoting the interface can require a proxy/stub object which some toolsets used to create with a CLSID equal to the interface’s IID. - LIBID – type library identifier; (Stored at
[HKEY_CLASSES_ROOT\TypeLib][30]) - CATID – category identifier; (its presence on a class identifies it as belonging to certain class categories, listed at
[HKEY_CLASSES_ROOT\Component Categories][31])
UUIDs are commonly used as a unique key in database tables. The NEWID function in Microsoft SQL Server version 4 Transact-SQL returns standard random version-4 UUIDs, while the NEWSEQUENTIALID function returns 128-bit identifiers similar to UUIDs which are committed to ascend in sequence until the next system reboot.[32] The Oracle Database SYS_GUID function does not return a standard GUID, despite the name. Instead, it returns a 16-byte 128-bit RAW value based on a host identifier and a process or thread identifier, somewhat similar to a GUID.[33] PostgreSQL contains a UUID datatype[34] and can generate most versions of UUIDs through the use of functions from modules.[35][36] MySQL provides a UUID function, which generates standard version-1 UUIDs.[37]
The random nature of standard UUIDs of versions 3, 4, and 5, and the ordering of the fields within standard versions 1 and 2 may create problems with database locality or performance when UUIDs are used as primary keys. For example, in 2002 Jimmy Nilsson reported a significant improvement in performance with Microsoft SQL Server when the version-4 UUIDs being used as keys were modified to include a non-random suffix based on system time. This so-called «COMB» (combined time-GUID) approach made the UUIDs significantly more likely to be duplicated, as Nilsson acknowledged, but Nilsson only required uniqueness within the application.[38] By reordering and encoding version 1 and 2 UUIDs so that the timestamp comes first, insertion performance loss can be averted.[39]
COMB-like arrangements of UUID payloads were eventually standardized in RFC 9562[1] as UUIDv6 and UUIDv7.
- Birthday attack
- Object identifier (OID)
- Uniform Resource Identifier (URI)
- Snowflake ID
- ^ a b c d e f g h i j k l m Davis, K.; Peabody, B.; Leach, P. (2024). Universally Unique IDentifiers (UUIDs). Internet Engineering Task Force. doi:10.17487/RFC9562. RFC 9562. Retrieved 9 May 2024.
- ^ a b c d e f g h Leach, P.; Mealling, M.; Salz, R. (2005). A Universally Unique IDentifier (UUID) URN Namespace. Internet Engineering Task Force. doi:10.17487/RFC4122. RFC 4122. Retrieved 17 January 2017.
- ^ «Universally Unique Identifiers (UUID)». H2. Retrieved 21 March 2021.
- ^ ITU-T Recommendation X.667: Generation and registration of Universally Unique Identifiers (UUIDs) and their use as ASN.1 Object Identifier components. Standard. October 2012.
- ^ a b Zahn, Lisa; Dineen, Terence; Leach, Paul; Martin, Elizabeth; Mishkin, Nathaniel; Pato, Joseph; Wyant, Geoffrey (1990). Network Computing Architecture. Prentice Hall. p. 10. ISBN 978-0-13-611674-5.
- ^ Leach, P. J.; Levine, P.H.; Hamilton, J. A.; Stumpf, B.L. (18–20 August 1982). «UIDs as internal names in a distributed file system». Proceedings of the first ACM SIGACT-SIGOPS symposium on Principles of distributed computing — PODC ’82. pp. 34–41. doi:10.1145/800220.806679. ISBN 0-89791-081-8.
- ^ «DCE 1.1: Remote Procedure Call». The Open Group. 1997.
- ^ a b c «DCE 1.1: Authentication and Security Services». The Open Group. 1997.
- ^ «ITU-T Study Group 17 — Object Identifiers (OID) and Registration Authorities Recommendations». ITU.int. Retrieved 28 March 2023.
- ^ «Revise Universally Unique Identifier Definitions (uuidrev)». Retrieved 30 May 2023.
- ^ a b «uuid.c».
- ^ a b «ext2/e2fsprogs.git — Ext2/3/4 filesystem userspace utilities». Kernel.org. Retrieved 9 January 2017.
- ^ «Recommendation ITU-T X.667». www.itu.int. October 2012. Retrieved 19 December 2020.
- ^
«Registration Authority». IEEE Standards Association. Archived from the original on 4 April 2011. - ^ «MAC addresses for virtual machines».
- ^ «MAC Address Setup». OpenWRT. 15 September 2021.
- ^ Reiter, Luke (2 April 1999). «Tracking Melissa’s Alter Egos». ZDNet. Retrieved 16 January 2017.
- ^ Kuchling, A. M. «What’s New in Python 2.5». Python.org. Retrieved 23 January 2016.
- ^ «draft-ietf-uuidrev-rfc4122bis-14». University of Washington. 6 November 2023. Archived from the original on 17 April 2024.
- ^ But a bug in Domain/OS made only the first half of the timespace usable, so problems occurred on 1997-11-02.Jim Rees (1996). «Apollo Date Bug».
- ^ Steele, Nick. «Breaking Down UUIDs».
- ^ «UUID Versions Explained».
- ^ Chen, Raymond (28 September 2022). «Why does COM express GUIDs in a mix of big-endian and little-endian? Why can’t it just pick a side and stick with it?». The Old New Thing. Retrieved 31 October 2022.
- ^ Leach, Paul. «UUIDs and GUIDs».
- ^ «Guid.ToByteArray Method».
- ^ Jesus, Paulo; Baquero, Carlos; Almaeida, Paulo. «ID Generation in Mobile Environments» (PDF). Repositorium.Sdum.Uminho.pt.
- ^ Mathis, Frank H. (June 1991). «A Generalized Birthday Problem». SIAM Review. 33 (2): 265–270. CiteSeerX 10.1.1.5.5851. doi:10.1137/1033051. ISSN 0036-1445. JSTOR 2031144. OCLC 37699182.
- ^ gen_uuid.c in Apple’s Libc-391, corresponding to Mac OS X 10.4
- ^ «Interface Pointers and Interfaces». Windows Dev Center — Desktop app technologies. Microsoft. Retrieved 15 December 2015.
You reference an interface at run time with a globally unique interface identifier (IID). This IID, which is a specific instance of a globally unique identifier (GUID) supported by COM, allows a client to ask an object precisely whether it supports the semantics of the interface, without unnecessary overhead and without the confusion that could arise in a system from having multiple versions of the same interface with the same name.
- ^ «Registering a Type Library». Microsoft Developer Network. Microsoft. Retrieved 15 December 2015.
- ^ «Categorizing by Component Capabilities». Windows Dev Center — Desktop app technologies. Microsoft. Retrieved 15 December 2015.
A listing of the CATIDs and the human-readable names is stored in a well-known location in the registry.
- ^ «NEWSEQUENTIALID (Transact-SQL)». Microsoft Developer Network. Microsoft. 8 August 2015. Retrieved 14 January 2017.
- ^ «Oracle Database SQL Reference». Oracle.
- ^ «Section 8.12 UUID Type». PostgreSQL 9.4.10 Documentation. PostgreSQL Global Development Group. 13 February 2020.
- ^ «uuid-ossp». PostgreSQL: Documentation: 9.6. PostgreSQL Global Development Group. 12 August 2021.
- ^ «pgcrypto». PostgreSQL: Documentation: 9.6. PostgreSQL Global Development Group. 12 August 2021.
- ^ «Section 13.20 Miscellaneous Functions». MySQL 5.7 Reference Manual. Oracle Corporation.
- ^ Nilsson, Jimmy (8 March 2002). «The Cost of GUIDs as Primary Keys». InformIT. Retrieved 20 June 2012.
- ^ «Storing UUID Values in MySQL». Percona. 19 December 2014. Archived from the original on 29 November 2020. Retrieved 10 February 2021.
- Recommendation ITU-T X.667 (Free access)
- ISO/IEC 9834-8:2014 (Paid)
- Technical Note TN2166 — Secrets of the GPT — Apple Developer
- UUID Documentation — Apache Commons Id
- CLSID Key — Microsoft Docs
- Universal Unique Identifier — The Open Group Library
- UUID Decoder tool
- A Brief History of the UUID
- Understanding How UUIDs Are Generated
-
Home
-
News
- How to Find GUID in Windows 11? Follow This Guide
How to Find GUID in Windows 11? Follow This Guide
By Vega | Follow |
Last Updated
If you don’t know how to find GUID in Windows 11, this post is worth reading. It provides a full guide to find GUID in Windows 11. Explore the content with MiniTool Partition Wizard now.
What Is GUID in Windows 11
GUID stands for Globally Unique Identifier, which helps you identify something, such as your computer, hard drive, files, network, and more. Assigned to any interface at storage or installation time. That is, every application, piece of hardware, network, etc. you install has a GUID, or a unique set of numbers, that identifies the interface within the process.
For some reason, you may want to find GUID in Windows 11. Do you know how to find GUID in Windows 11? Don’t worry, you can read the following contents to know the steps.
Tips:
MiniTool Partition Wizard is a professional data recovery tool. It is designed for Windows 11/10/8/7 and can be used to recover various file types including documents, photos, videos, audio, music, emails, archives, and other files from all kinds of storage media. If you lose important data accidentally, you can try using it to recover them back.
MiniTool Partition Wizard DemoClick to Download100%Clean & Safe
To find GUID in Windows 11, you can use Registry Editor and Windows PowerShell to do that.
Way 1. Use Registry Editor
You can use Registry Editor to find GUID in Windows 11. The steps are as follows.
Step 1: Press the Win + R key to open the Run dialog box. Then type regedit in it and press Enter to open Registry Editor.
Step 2: In the Registry Editor window, navigate to the following path:
HKEY_CLASSES_ROOT\Interface
Step 3: In the Interface key, you can find numerous sub-keys named like this:
{00000000-0000-0000-C000-000000000046}
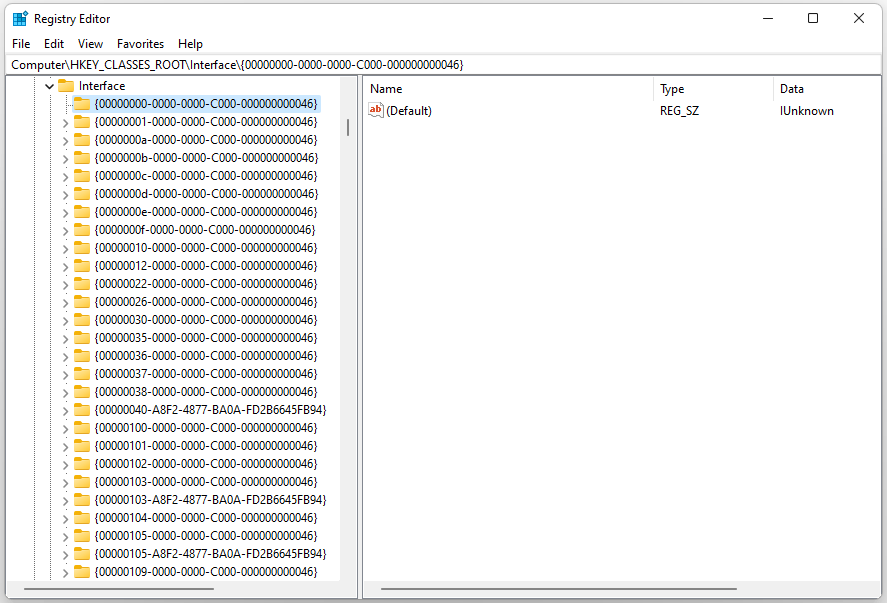
Unfortunately, there is no option to find the GUID of a specific or required interface. So, you need to open each subkey to check the name and find the GUID. However, you can use the Find option in the Edit menu. In this case, you need to enter the interface name and click on the Find Next button.
Since the Registry Editor method is quite time-consuming, you can use Windows PowerShell to find GUID faster. However, the only drawback is that you can only find the GUID of the installed application.
Way 2. Use Windows PowerShell
To find GUID in Windows 11 using Windows PowerShell, you can follow the steps below:
Step 1: Type powershell in the Windows Search bar, and then right-click on Windows PowerShell to select Run as administrator. Click the Yes button on the UAC prompt.
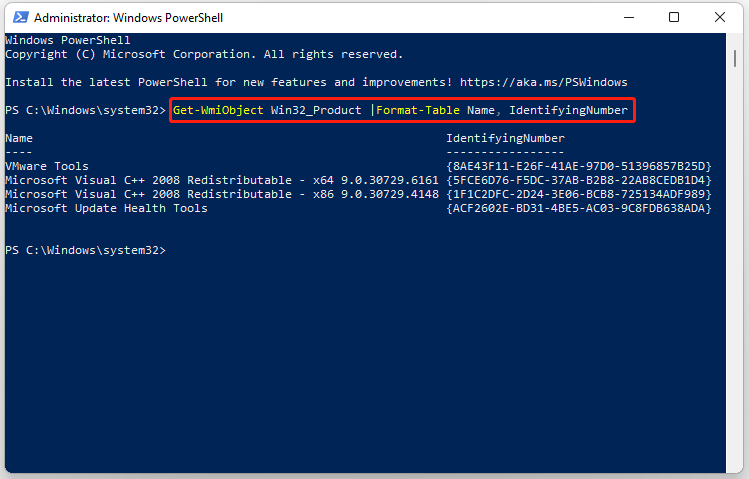
Step 2: In the PowerShell window, type the following command and press Enter:
Get-WmiObject Win32_Product |Format-Table Name, IdentifyingNumber
Step 3: Then all the applications and GUIDS will be visible on your screen.
Bottom Line
How to find GUID in Windows 11? This post has provided a full guide. If you have any other suggestions about it, leave them in the following comment zone.
MiniTool Partition Wizard is a powerful partition manager. It can migrate OS, clone disk, convert MBR to GPT, etc. If you have this need, download it to have a try.
MiniTool Partition Wizard FreeClick to Download100%Clean & Safe
About The Author
Position: Columnist
Vega joined MiniTool as an editor after graduation. She enjoys helping people with computer problems, including disk management, data recovery, and more. She is constantly expanding her knowledge in related fields. And she will continue to bring more easy-to-understand professional articles to help people solve various problems on the PC. In her daily life, Vega enjoys hanging out with friends, shopping online and listening to music. She is someone who knows how to enjoy life.
Материал из РУВИКИ — свободной энциклопедии
Для этого термина существует аббревиатура «GUID», которая имеет и другие значения, см. GUID.
GUID (Globally Unique Identifier) — статистически уникальный 128-битный идентификатор. Его главная особенность — уникальность, которая позволяет создавать расширяемые сервисы и приложения без опасения конфликтов, вызванных совпадением идентификаторов. Хотя уникальность каждого отдельного GUID не гарантируется, общее количество уникальных ключей настолько велико (2128 или 3,4028×1038), что вероятность того, что в мире будут независимо сгенерированы два совпадающих ключа, крайне мала.
«GUID» называют некоторые реализации стандарта, имеющего название Universally Unique Identifier (UUID).
В тексте GUID записывается в виде строки из тридцати двух шестнадцатеричных цифр, разбитой на группы дефисами и опционально окружённой фигурными скобками:
- {6F9619FF-8B86-D011-B42D-00CF4FC964FF}[1]
Структура идентификатора:
GUID STRUCT
Data1 dd
Data2 dw
Data3 dw
Data4 dw
Data5 dp
GUID ENDS
UUID-идентификаторы часто записывают в виде текстовой строки
{G4G3G2G1-G6G5-G8G7-G9G10-G11G12G13G14G15G16}, где Gx — значение соответствующего байта структуры в шестнадцатеричном представлении[1]:
Data1 = G4G3G2G1
Data2 = G6G5
Data3 = G8G7
Data4 = G9G10G11G12G13G14G15G16
Например, ‘22345200-abe8-4f60-90c8-0d43c5f6c0f6’ соответствует шестнадцатеричному 128-битному числу 0xF6C0F6C5430DC8904F60ABE822345200
Максимальное значение в GUID соответствует десятичному числу 340 282 366 920 938 463 463 374 607 431 768 211 455 (2128-1).
Microsoft применяет GUID в OLE, COM, DCOM и Windows Runtime — например, в качестве идентификаторов для классов (CLSID), интерфейсов (IID), параметризуемых интерфейсов (PIID), библиотек типов (LIBID). Использование GUID гарантирует, что две (возможно, несовместимые) версии одного компонента могут иметь одно и то же имя, но быть отличимыми по GUID.
Случайные GUID (UUIDv4)[править | править код]
Алгоритм, который Microsoft использовала для генерации GUID, был широко раскритикован. В частности, в качестве основы для генерации части цифр GUID использовался MAC-адрес сетевого адаптера, что означало, например, что по данному документу MS Word (также получающему при создании свой уникальный GUID) можно было определить компьютер, на котором он был создан. Позже Microsoft изменила алгоритм таким образом, чтобы он не включал в себя MAC-адрес.
Вычисляемые GUID (UUIDv5)[править | править код]
Проекция Windows Runtime, общая для всех нативных языков программирования, повторно использует механизмы COM. В Windows Runtime активно используются интерфейсы, параметризуемые типом аргумента, которым не было соответствия в COM. С точки зрения COM такие обобщённые интерфейсы не существуют, существуют только их специализации. Обобщённым интерфейсам вместо IID назначается параметрический PIID, а IID их специализаций вычисляется так, чтобы для одинаковых параметров производились одинаковые IID без какого-либо согласования. Программное вычисление IID специализаций требует знания алгоритма. Долгое время в Microsoft не публиковали алгоритм, и единственным способом для разработчиков трансляторов вычислить его был вызов WinAPI RoGetParameterizedTypeInstanceIID, доступный только на ОС Windows 8 и выше. В 2019м году алгоритм был опубликован.
Генерация GUID следует стандарту UUID версии 5 (SHA-1). UUID пространства имён: 11f47ad5-7b73-42c0-abae-878b1e16adee. Хешируемая строка строится из PIID обобщённого интерфейса и списка типовых параметров, закодированного согласно опубликованной грамматике.
Также GUID — основа Таблицы разделов GUID, замены MBR в EFI.
- ↑ 1 2 Последнее 8-байтное данное при записи часто разбивается на 2+6 (подробнее см. в английской версии статьи).
- Устройство и криптоанализ UUID-генератора в ОС Windows
- RFC: A Universally Unique IDentifier (UUID) URN Namespace
- The Windows Runtime (WinRT) Type System