
Уровень сложностиПростой
Время на прочтение5 мин
Количество просмотров42K
Немного расскажу про установку Grafana на windows и настройку базовых метрик системы.
Пару слов о самой Grafana и для чего она нужна.
Grafana – это платформа для мониторинга, анализа данных и визуализации собранных данных с открытым исходным кодом. По сути она используется для визуального представления собранных метрик для более комфортного слежения за состоянием системы.
В данной статье буду использовать:
-
Grafana
-
Prometheus
-
Windows_exporter
-
Blackbox_exporter
Для начала скачаем актуальный дистрибутив самой Grafana и установим его (Для скачивания, может потребоваться VPN).
Переходим по ссылке: https://grafana.com/grafana/download и выбираем необходимую версию для скачивания.

Затем скачаем и установим Prometheus.
Prometheus по сути является сборщиком метрик. Установив на один пк, который будет выступать в качестве сервера для Grafana, достаточно будет только запускать сбор метрик с других машин (вносить соответствующий блок в файл конфигурации Prometheus), а Prometheus в свою очередь подготовит метрики уже для самой Grafana.
Prometheus: https://prometheus.io/download
Для установки потребуется NSSM — это сервисный помощник, который помогает установить служебные вспомогательные программы.
Ссылка NSSM: https://www.nssm.cc/download
Приступим к установке Prometheus.
Переходим в CMD и вводим следующие команды (запускаем CMD от админа):
-
Переходим в директорию с пакетом NSSM:
cd C:\GrafanaSetup\nssm-2.24\win64 -
Выполняем установку сервиса Prometheus:
nssm.exe install prometheus C:\GrafanaSetup\prometheus-2.43.0.windows-amd64\prometheus.exe

На данном этапе служба Prometheus должны быть установлена, Далее установим службы для сбора метрик.
Установим Windows_exporter – сборщик метрик, который как раз собирает статистику с системы и составляет своего рода «логи».
Ссылка для скачивания Windows exporter: https://github.com/prometheus-community/windows_exporter/releases
Выбираем подходящую нам версию и устанавливаем

После установки, так же проверяем в службах, что установка прошла успешно и служба запущена (название службы по умолчанию windows_exporter).
Теперь можно проверить сбор метрик по ссылке к порту службы: http://localhost:9182/metrics

На данном этапе можем установить Blackbock exporter — используется для мониторинга статуса доступности URL-ов. Переходим по ссылка и скачиваем нужную нам версию Blackbox: https://prometheus.io/download/ и устанавливаем.

Теперь приступим к настройке установленных сервисов.
Начинаем с Grafana:
Переходим в папку C:\Program Files\GrafanaLabs\grafana\conf и открываем файл defaults.ini при помощи текстового редактора и меняем значение в блоке smtp в поле enabled на true и сохраняем изменения. Запускаем службу Grafana, если она уже запущена, просто делаем перезапуск для вступления изменений в силу.

Перейдя по ссылке: http://localhost:3000 увидим активный интерфейс Grafana. Для входа по умолчанию используется комбинация admin / admin, затем попопросит Вас изменить пароль и направит на домашнюю страницу управления Grafana.
Далее приступаем к настройке Prometheus:Нам необходимо внести изменения в конфигурацию, включив метрики в конфиг. Для этого переходим в каталог prometheus») и открываем файл prometheus.yml и вносим следующие изменения:
Добавляем блок для подключения windows_exporter:
- job_name: "Любое комфортное имя"
static_configs:
#IP-адрес и порт, где собираются метрики window_exporter\
- targets: ["localhost:9182”]При добавлении нескольких машин, можно добавить блок lables, который изменит отображаемый IP-адрес на свое описание:
static_configs:
- targets: ["localhost:9182"]
labels:
instance: Server-1
- targets: ["192.168.0.254:9182"]
labels:
instance: Server-2Сразу добавим блок для blackbox_exporter:
- job_name: 'blackbox'
metrics_path: /probe
params:
module: [http_2xx] # Look for a HTTP 200 response.
static_configs:
- targets:
-https://youtube.com
-https://google.com
relabel_configs:
- source_labels: [__address__]
target_label: __param_target
- source_labels: [__param_target]
target_label: instance
- target_label: __address__
replacement: localhost:9115 # The blackbox exporter's real hostname:portВ блоке targets перечисляем необходимые URL-адреса.
Только обратите внимание, для того, что бы блок корректно заработал и не было ошибок при запуске службы, необходимо строго соблюдать табуляцию строк.
Добавив необходимые блоки можем запускать prometheus.
Затем убедитесь, что все службы запущены:
-
Grafana
-
Prometheus
-
Windows_ exporter
-
Blackbox_exporter
и теперь проверяем статус сервисов по ссылке: http://localhost:9090/targets

В целом мы настроили базовые метрики, осталось включить отображение метрик в Grafana.
Переходим на главную страницу grafana ( По умолчанию: http://localhost:3000 ).
Подключаем источник данных Prometheus:
На главной странице, переходим в меню Data sources
Выбираем наш Prometheus

И указываем наш URL. В нашем случае, всё находится на одной локальной машине и можем прописывать через формат: http://localhost:port/

И нажимаем кнопку: Save & test
Теперь необходимо настроить панели мониторинга для метрик windows exporter. Для настройки переходим на главную страницу и добавляем панель:

На момент написания статьи, нашёл два наиболее охватывающих Dashboard`а:
-
14510
-
14694
Можете использовать их или же настроить всё самостоятельно.
Для добавления Dashboard`а указываем в поле ID и нажимаем на кнопку Load.

Затем нас направляет на панель настроек, где мы указываем источник данных Prometheus и можем изменить имя самой панели. Затем жмём кнопку Import
И у нас уже готовая, настроенная панель мониторинга, которую уже можно добавлять необходимым функционалом. Не нужные графики можно удалить или расставить в нужном для себя порядке.

При добавлении новых пк для мониторинга, достаточно внести строки в конфигурационный файл Prometheus.yml и перезапустить службу Prometheus. Служба самостоятельно разберёт метрики и добавить новый пк к мониторингу на уже готовый dashboard, где уже не составит труда переключаться между пк.
Далее уже можно поиграть с конкретными метриками, и отображением конкретных служб с различных машин. К примеру: На главном экране нажимаем ADD > Visualization и попадаем в меню создания панели. В поле Metrics browser вносим выбранную метрику и указываем параметры, которые хотим получить (ну или отобразить). Сделаем на примере службы windows:
-
Name — имя службы
-
State — вид статуса, который относится к метрике windows_service_state
-
Instance — с какой конкретной машины брать метрику.
windows_service_state{name="нужная служба", state="running", instance="Server-1"}
и в правом верхнем углу выбираем нужный вид панели, в моем случае это Stat:

В параметрах панели в меню Value mappings и меняем цифровые значения метрик на удобные для восприятия слова, к примеру: Ok/Bad Up/Down.

Сохраняем и получаем такую панель :
Ну и настроим метрику для получения статусов HTTP:
Используем метрику: probe_http_status_code и настроим Value mapping:
probe_http_status_code{instance="https://youtube.com"}

И в итоге получаем такую панель:
Далее можно самостоятельно зайти в http://localhost:9090/targets выбрать нужные для своих задач метрики и настроить нужные под свои задачи.
Думаю, на этом можно закончить. Базовая настройка не так сложна, но когда ты сталкиваешься с этим в первый раз, могут возникнуть трудности, поэтому хотел поделиться пошаговой настройкой. Надеюсь, кому-то это поможет и сократить достаточно времени на поиске информации и первичной настройки.
Technology
4 Minutes
In last post, we created Dashboards for Linux nodes monitoring. Please note, Linux and Windows are not only things which can be monitored but would leave that part to figure you out in case if you have any use case.
Let’s talk about creating a Windows summary dashboard this time like below one. It’s for just one node but it would keep on scaling as more nodes added in Prometheus target config.

Let’s talk of Windows Summary Dashboard.

Same way, we did for Linux Summary Dashboard, go to settings via cog wheel and then go to variables then create a new variable named job. Type can be constant or custom and value would be the one, which you defined as job name in prometheus.yml

Now in dashboard create rows as you want to arrange panels and then proceed to add panels. I would list down all the queries in order.
count(up{job="$job"})-sum(up{job="$job"}) # Number of nodes offline
sum(up{job="$job"}) # Number of nodes online
up{job="$job"} # Tabular status of nodes up/down
(last_over_time(windows_cs_hostname{job="$job"}[$__rate_interval]) == 1) * on(job, instance) group_left(product,version) windows_os_info{} * on(job, instance) group_left(timezone) windows_os_timezone{} # System information
(windows_os_info{job="$job"}* on(instance) group_right(product) windows_system_system_up_time)*1000 # Last Boot Time
windows_os_processes{job="$job"} # Number of processes
windows_logical_disk_free_bytes{job="$job",volume=~".*:"}/1073741824<(windows_logical_disk_size_bytes{job="$job",volume=~".*:"}/1073741824)*0.2 # Node volumes with less than 20% Disk Space left
100-100* windows_os_physical_memory_free_bytes{job="$job"}/windows_cs_physical_memory_bytes{job="$job"} # Memory utilization in %
max by (job,instance, volume) (windows_logical_disk_free_bytes{job="$job",volume=~".*:"}/windows_logical_disk_size_bytes{job="$job",volume=~".*:"})*100<20 # Disk utilization
(max by (job, instance)(windows_logical_disk_size_bytes{job="$job",volume=~".*:"}))/1073741824 # Disk utilization query 1
(max by (job, instance)(windows_logical_disk_free_bytes{job="$job",volume=~".*:"}))/1073741824 # Disk utilization query 2
One more thing, to add hyper-link for individual nodes in tables, you need to add data links in individual panels with below code
http://[grafana-server-ip]:3000/d/[9_digit_code]/windows-metrices-detailed-base?orgId=1&var-host=${__data.fields.instance}&var-job=${__data.fields.job}
You would need to copy the URL from the second dashboard created in the same folder (Widows nodes) till orgId=1 to make sure that you get it right. We doing this so that when someone clicks on any individual row related to particular then it would pick the job variable value and instance value and then open the page specific to that node only. How? We would cover the same next in detailed dashboard.
Go to settings of new dashboard and define two variables, first job, exactly like we did in last dashboard and then another one named host (can chose instance as well but you would need to replace $host from queries which I would give next).

The query in above is the below one
label_values(up{job="$job"}, instance)
Once the two variables are set, I would list down the queries for creating a dashboard like below one:

The service one is a little different since it usages a plugin which would need to be installed but I would list the query anyways first then would let you know how to install the plugin.
Now here goes the queries in order
time()-windows_system_system_up_time{job="$job",instance="$host"} # Uptime
windows_cs_physical_memory_bytes{job="$job",instance="$host"}/1073741824 # Physical memory
100-(avg(irate(windows_cpu_time_total{job="$job",instance="$host",mode="idle"}[2m])))*100 # CPU load
windows_thermalzone_temperature_celsius{job="$job",instance="$host"} # Temperature
100-(windows_os_physical_memory_free_bytes{job="$job",instance="$host"}/windows_cs_physical_memory_bytes{job="$job",instance="$host"})*100 # Memory utilization
(max by (job,instance) (windows_logical_disk_free_bytes{job="$job",instance="$host"}))/1073741824 # Disk usages
sum(increase(windows_net_bytes_received_total{job="$job",instance="$host"}[24h])) # Data received in last 24 hrs
sum(increase(windows_net_bytes_received_total{job="$job",instance="$host"}[24h])) # Data sent in last 24 hrs
((last_over_time(windows_cs_hostname{job="$job",instance="$host"}[$__rate_interval]) == 1) * on(job, instance) group_left(product,version) windows_os_info{} * on(job, instance) group_left(timezone) windows_os_timezone{} * on(job, instance) group_left() windows_system_system_up_time{}) *1000 # System Information
((max_over_time(windows_service_state{job="$job", instance="$host",name=~"w32time|wuauserv|bits|dosvc|mpssvc|windefend|termservice"}[$__interval]) == 1) * on(job, instance, name) group_left(display_name) windows_service_info{job="$job", instance="$host"}) * 0 # Service Status for select services for which names are listed
sum by (mode)(irate(windows_cpu_time_total{job="$job",instance="$host"}[5m])) # CPU usages
windows_cs_physical_memory_bytes{job="$job",instance="$host"} # Memory usages query 1
windows_os_physical_memory_free_bytes{job="$job",instance="$host"} # Memory usages query 2
windows_os_virtual_memory_bytes{job="$job",instance="$host"} # Memory usages query 3
windows_os_virtual_memory_free_bytes{job="$job",instance="$host"} # Memory usages 4
irate(windows_net_bytes_sent_total{job="$job",instance="$host",nic!~'isatap.*|vpn.*'}[5m])*8 # Network usages query 1
irate(windows_net_bytes_received_total{job="$job",instance="$host",nic!~'isatap.*|vpn.*'}[5m])*8 # Network usages query 2
windows_logical_disk_free_bytes{job="$job",instance="$host",volume=~".*:"} # Disk usages<p>irate(windows_logical_disk_read_bytes_total{job="$job",instance="$host",volume=~".*:"}[5m]) # Disk activity
windows_os_processes{job="$job",instance="$host"} # Number of processes
windows_process_handles{job="$job",instance="$host"} # Process table
sum(windows_service_state{job="$job",instance="$host"}) by (state) # Service Status
((last_over_time(windows_service_state{job="$job",instance="$host"}[$__rate_interval]) == 1) * on(job, instance, name) group_left(display_name,run_as) windows_service_info{job="$job",instance="$host"}) # Service Status Table
Again, this is in no way complete steps as you need to setup a few things about each type of panel, their placement, thresholds, value mapping, field organization, renaming etc as well but I would intentionally leave those over you for two reasons; mine is just primitive and there is a lot more available in dashboard gallery from Grafana and second reason, I trust you would be able to come up with even better-looking dashboards suitable for your environment.
Oh Wait! I forgot about the plugin? Didn’t I. So that would be as simple as running below
grafana-cli plugins install flant-statusmap-panel systemctl restart grafana-server systemctl status grafana-server –l
Want more plugins? Check out on https://grafana.com/grafana/plugins/
Let me know your feedback that how it’s going so far.
Published by Nitish Kumar
I love to write and raising voice, sharing thought and heated debate is a kind of passion for me. Jobwise I am just another Computer professional handling Infra and designing solutions for a big Indian Media house but I love to write, sketch, photography and a lot more.
View all posts by Nitish Kumar
Published
Мониторинг состояния сервисов в Prometheus/grafana
Dmitry BubnovЧасто хочется видеть состояние служб, запущенных в системе и получать своевременные уведомления о проблемах с ними. Попробуем реализовать это с помощью стека Prometheus/Grafana
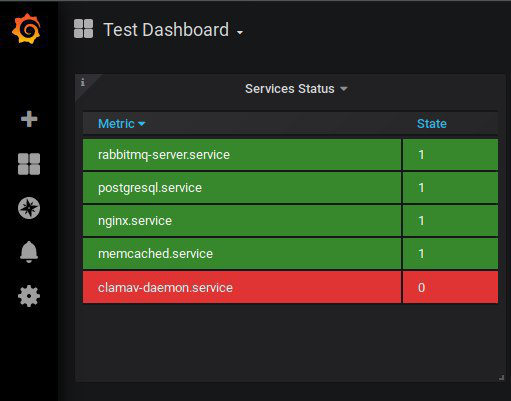
В статье рассмотрим:
- Сбор данных с node_exporter
- Изменение отображения метрик
- Выборка нужной информации из всех собранных данных
- Немного PromQL — язык запросов Prometheus
- Визуализация данных в Grafana
Я уже пытался писать о стеке prometheus/grafana. Надеюсь, этот пост станет достойным продолжением эпопеи про мониторинг.
Будем считать, что Prometheus/Grafana/Node-exporter уже работает. Если ещё не работает — воспользуйтесь моим плэйбуком.
Node exporter экспортирует состояние всех служб в параметре node_systemd_unit_state.
Выборка нужной информации из всех собранных данных
В качестве даных увидим что-то вроде node_systemd_unit_state{name=»nginx.service», instance=»10.0.0.1″, status=»active»}. Видеть всю эту строку в мониторинге не нужно и часто это только сбивает с толку. Нам ведь нужны только имя сервиса и его состояние.
За подписи данных отвечает параметр Legend под строкой запроса. Туда можно вписать что угодно и это будет отображаться в легенде. Воспользуемся переменной name, в которой указано имя нашего сервиса. Если сразу после изменения данные на графике не изменились — нажмите значок глаза над запросом — там, где стрелки и корзинка. Обратите внимание, что переменная должна быть в фигурных скобках: {{name}}
Видеть состояние всех служб нужно не часто. Будем наблюдать только за важными нам сервисами. Для этого отфильтруем запрос по конкретным службам:
node_systemd_unit_state{name=~»(nginx.service|rabbitmq-server.service|memcached.service)»}
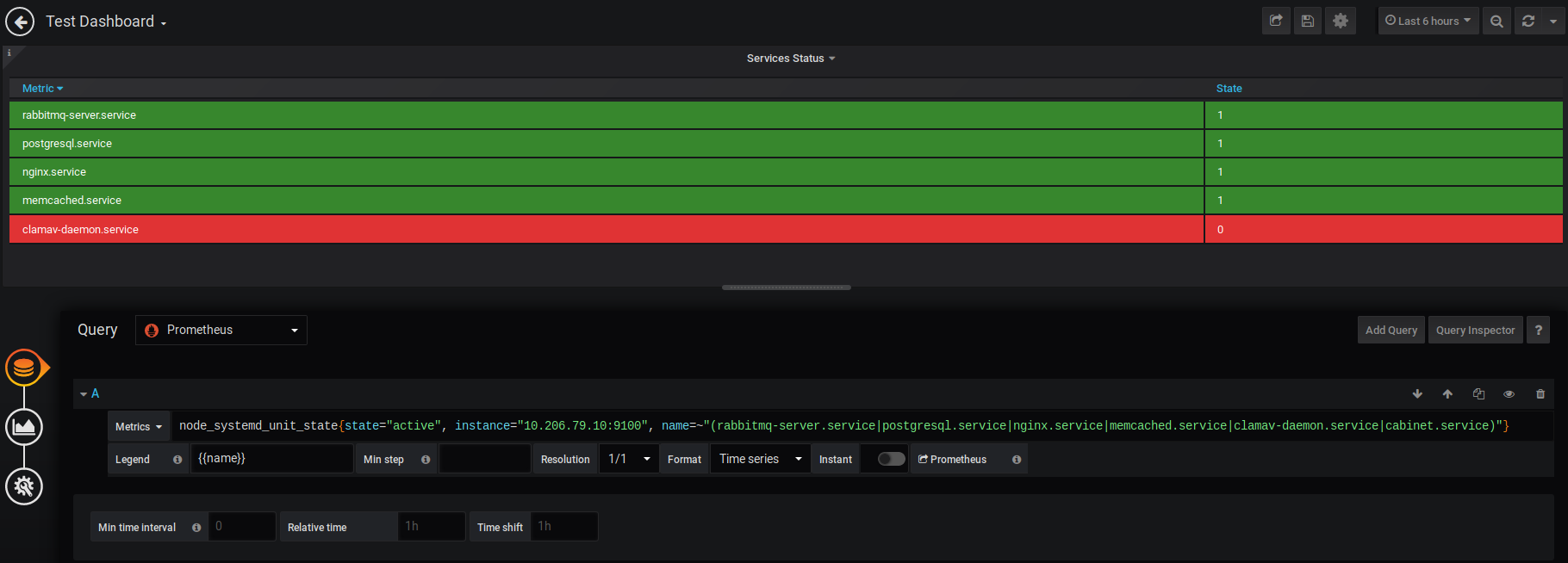
В параметре name указаны службы, за которыми будем наблюдать. Знак =~ означает выбор значений по регулярному выражению. Дальше в скобках перечислены службы, разделенные знаком | что означает ИЛИ. Теперь будем наблюдать только за нужными сервисами.
В параметрах есть ещё одно поле state — оно отвечает за состояние сервиса. нам интересны только активные, поэтому его значение active. Дополнительно можно указать хост, с которого будем отображать данные на этой панели.
Визуализация данных в Grafana
По умолчанию Grafana отображает наши данные в виде графика. В случае со службами это визуально неудобно. Поэтому будем показывать данные в виде таблицы.
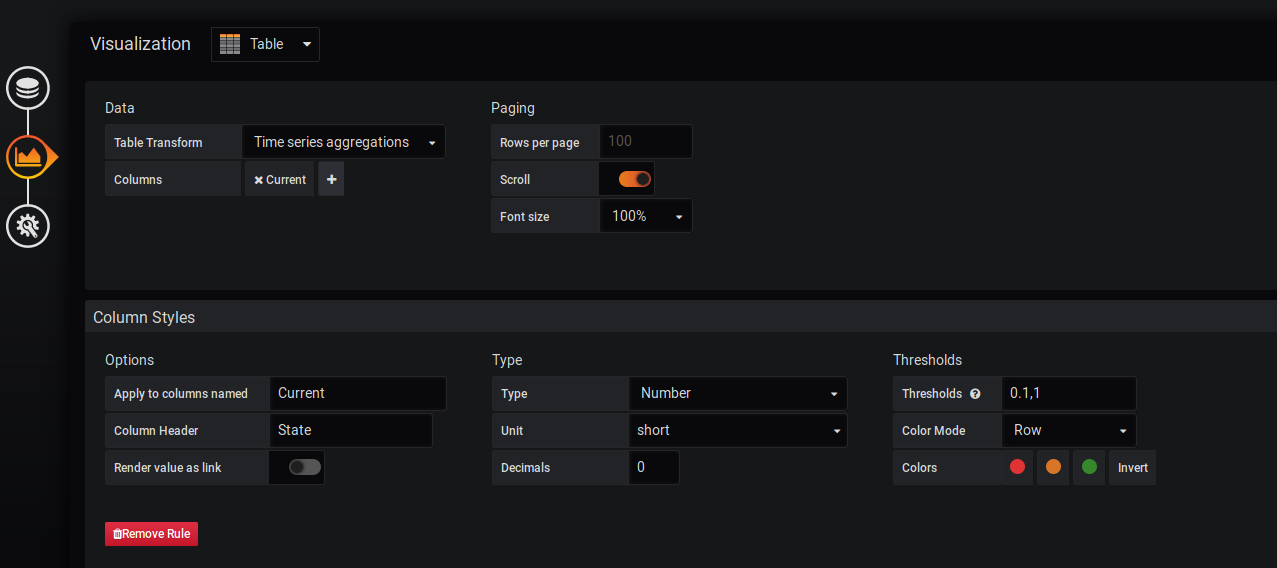
Для этого в раздел Visualization и выбираем таблицу. В Data указываем какие данные будем использовать для отображения. Нам нужно Time Series Aggregation — аггрегированные данные. В Columns выбираем Current — то есть последнее полученное значение. Мы ведь хотим знать актуальное состояние службы, а не средние данные за последний час. Сейчас уже можно видеть как преобразилось отображение данных.
Сейчас в таблице должно быть две колонки — Metric и Current, в которых описаны названия метрики и её значения. Current не очень понятно описывает колонку. Переименуем её.
В разделе Column Styles выбираем в Apply to columns named: Current, меняем Column Header на State. Ну теперь то точно понятно =)
И покрасим рабочие службы зеленым, а нерабочие красным. Для этого есть параметр Threshold, где выставляются критические и приемлемые значения метрик. В нашем случае 0 — не работает, 1 — работает. Поэтому всё, что выше 0 будем считать рабочим и красить зеленым, а все, что ниже 0,1 нерабочим. Пример можно увидеть на картинке.
Должно получиться что-то опхожее на первую картинку в этом посте. Об уведомлениях напишу в следующий раз. Здесь просто скажу, что Grafana сама умеет реагировать на изменения и слать алерты на почту, Telegram, Slack и в другие каналы. Но у grafana это реализовано не очень удобно, поэтому все цивилизованное человечество применяет AlertManager и различные плагины к нему.
Пост написан на коленке в час ночи. Ничего сложного в grafana нет, надеюсь этот пост доказал это вам. Ставьте систему мониторинга, экспериментируйте с отображением даных, изучайте PromQL. Всё это позволит вам создать мощную, удобную и красивую систему мониторинга!
Всем добра, да пребудет с нами АДСМ