
Where Does PostgreSQL Store the Database? 🗄️
So, you just installed PostgreSQL on your computer or server, and now you’re wondering where it actually stores the database files. 🤔 Don’t worry, you’re not alone! Many PostgreSQL beginners often find themselves asking the same question. In this blog post, we’ll explore the answer to this common question and provide easy solutions to any related issues you may encounter. Let’s dive in! 💦
Understanding PostgreSQL’s Data Directory 📂
PostgreSQL stores its database files in a specific directory called the data directory. This directory is typically created during the installation process and is where PostgreSQL keeps all the data necessary for running a database.
The location of the data directory can vary depending on your operating system and the installation method you used. Here are some common default locations:
-
Linux:
/var/lib/postgresql/[version]/main -
macOS:
/usr/local/var/postgres -
Windows:
C:\Program Files\PostgreSQL\[version]\data
Keep in mind that these are the default locations, and you might have chosen a different location during the installation. If you’re unsure about where your data directory is located, don’t worry! There’s an easy way to find out.
Finding Your PostgreSQL Data Directory 🕵️♀️
To determine the location of your PostgreSQL data directory, you can use the pg_config command-line tool. Open your terminal or command prompt and run the following command:
pg_config --datadirThis command will display the absolute path to the data directory on your system. Once you have the location, you’ll know where PostgreSQL stores your precious database files. 🎉
Common Issues and Easy Solutions 💡
Issue #1: Running out of disk space 📉
One common issue that PostgreSQL users may face is running out of disk space. As your database grows and accumulates data over time, it can consume a significant amount of disk space.
To address this issue, you have a few options:
-
Monitor database size: Regularly check the size of your database using PostgreSQL’s built-in functions, such as
pg_size_pretty(), to keep track of its growth. -
Archiving and purging: Implement data archiving and purging strategies to remove unnecessary data and free up disk space.
-
Add more disk space: If you have the flexibility to do so, consider adding more disk space to accommodate your growing database.
Issue #2: Moving the data directory 🚚
Sometimes, you may need to move the PostgreSQL data directory to a different location. Perhaps your current disk is running out of space, or you need to migrate your database to a different server.
Here’s a high-level overview of the steps involved in moving the data directory:
-
Stop PostgreSQL: First, you’ll need to stop the PostgreSQL service to ensure that the database is not actively writing to the data directory.
-
Copy the data directory: Copy the contents of the current data directory to the new location. This can be done using the
rsynccommand on Unix-based systems orrobocopyon Windows. -
Update configuration: Modify the PostgreSQL configuration file (
postgresql.conf) to reflect the new data directory location. -
Start PostgreSQL: Finally, start the PostgreSQL service and verify that everything is working correctly in the new data directory.
It’s important to note that manually moving the data directory can be a complex process, so make sure to follow detailed guides and backup your data before proceeding.
Your Engaging Call-to-Action 📣
Now that you know where PostgreSQL stores its database files and have learned some common issues and easy solutions, it’s time to put your knowledge into action! 🚀
If you’re facing any specific issues or have any questions related to PostgreSQL, feel free to reach out to our helpful community or leave a comment below! Let’s share our knowledge and help each other overcome any PostgreSQL challenges we encounter. 💪
Remember, curiosity and learning never stop, especially in the vast world of tech. Stay tuned for more engaging blog posts, share this post with others who might find it helpful, and let’s keep exploring PostgreSQL together! 🌟
Уровень сложностиСредний
Время на прочтение10 мин
Количество просмотров22K
Дисклеймер
На скорость написания этого текста повлияли такие непреодолимые обстоятельства как: лето, шашлычное настроение, солнце и лень обилие работы. Возможно, за несколько месяцев эту информацию в разных вариациях уже публиковали, но я честно не видел.
Основная часть
В этом тексте хочется подробнее рассмотреть хранение данных в PostgreSQL на физическом уровне.
Для начала определимся с общеизвестными вещами. Данные хранятся в таблицах, таблицы находятся в схемах, схемы, в свою очередь, в базах данных. Под данными я тут подразумеваю одну или несколько строк. В качестве примера будем рассматривать эталон критики, по моему личному мнению, цитаты Линуса Торвальдса

Я загрузил все данные в базу данных и теперь планирую найти физическое местоположение этого шедевра и параллельно понять, что да как лежит в этом вашем PostgreSQL.
Скрытый текст
CREATE TABLE public.test_table (
id int4 NULL,
author varchar NULL,
phrase varchar NULL
);
INSERT INTO test_table
VALUES
(1
, 'Linus Torvalds'
, 'The thing that has always disturbed
me about O_DIRECT is that the whote interface is just stupid,
and was probabty designed by а deranged monkey on some serious mind—controlling substances'),
(2
, 'Linus Torvalds'
, 'Sadly, database реор1е don''t seem to have аnу understanding of good taste,
and various 0S реорlе end uр usually just saying “Yes, Мr Oracle“,
I''ll open up any orifice I have for уоur pleasure'); -- наши записи
INSERT INTO test_table
SELECT ROW_NUMBER () OVER()+2
, gen_random_uuid()
FROM pg_catalog.generate_series(0,1500) --немного синтетикиНачнем с общего обзора базы данных и постепенно перейдем к уровню отдельных строк.
Сначала необходимо найти файлы данных, используемые кластером базы данных, обычно они хранятся в каталоге данных кластера, который по классике называют PGDATA /var/lib/pgsql/data на Linux,.
\Program Files\PostgreSQL\[version]\data на Windows)
В этом каталоге лежит куча подкаталогов и несколько файлов конфигурации, относящихся к кластеру (https://postgrespro.ru/docs/postgresql/15/storage-file-layout). Мы не будем разбирать все подкаталоги, ибо их довольно много, а остановимся на тех, которые помогут найти строку данных.

pg_tblspc
Прежде всего, все данные находятся на одном из физических носителей.
Табличные пространства определяют физическое расположение данных. Фактически табличное пространство — это каталог файловой системы. Например, табличные пространства можно использовать, чтобы разместить архивные данные на медленных носителях, а данные, с которыми идет активная работа, — на быстрых.
https://postgrespro.ru/education/books/internals — PostgreSQL16 Internals
всем советую
При инициализации кластера создается два пространства:
-
pg_default, который «лежит» в PGDATA/base и используется как дефолтное пространство, если не указать иное
-
pg_global, который «лежит» в PGDATA/global и хранит общие объекты системного каталога
В подкаталоге pg_tblspc лежат символьные ссылки на каталоги с пользовательскими табличными пространствами. Перейдя по ним, найдем каталоги типа PGDATA/base, в которых также лежат подкаталоги с oid баз данных. Если база данных имеет объекты, расположенные на разных физических носителях, то для каждого пространства создается отдельный подкаталог базы данных (с одинаковым oid), и в каждый из этих каталогов добавляются файлы объектов, лежащих в этом пространстве.
Скрытый текст
абличные SELECT * FROM pg_catalog.pg_tablespace;
")
base
Любая БД представляет собой каталог, который хранится в PGDATA/base (название чаще всего соответствует oid объекта). В каждом из этих каталогов хранятся файлы, которые предназначены для хранения и доступа к данным. Для каждого объекта БД есть один или несколько файлов. Например, для обычной таблицы без индексов существует три файла (четыре, если таблица UNLOGGED). Каждый из файлов соответствует одному из слоев.
Скрытый текст
SELECT relfilenode , oid, relname
FROM pg_class
WHERE relname = 'test_table';
Oid и relfilenode таблицы, которую мы создали вы 20508")
Остальные файлы — это другие таблицы, TOAST- файлы, индексы, сиквенсы, материализованные вьюхи
Основной слой
Файлы без постфиксов (в нашем примере /PostgreSQL/15.7/data/base/20508). Место, где собственно находятся данные. Максимальный размер файла 1 Гбайт(можно увеличить при сборке параметромwith-segsize), при его достижении создается следующий файл этого же слоя(сегмент). Порядковый номер добавляется в конец через точку (если таблица test_table разрастется более 1 Гб, то создастся новый файл 20508.1)
Карта свободного пространства (free space map)
Постфикс _fsm. Это слой отношения, состоящий из FSM страниц, который помогает быстро найти страницу из основного слоя для записи новой версии строки. Максимальный размер файла 1 Гбайт(можно увеличить при сборке параметромwith-segsize). Чтобы обеспечить быстрый поиск свободного пространства, карта хранится в виде дерева (вообще в виде множества деревьев, но сегодня не об этом).
Скрытый текст
The purpose of the free space map is to quickly locate a page with enough
free space to hold a tuple to be stored; or to determine that no such page
exists and the relation must be extended by one page. As of PostgreSQL 8.4
each relation has its own, extensible free space map stored in a separate
«fork» of its relation.Ссылка на Github
Чтобы заглянуть внутрь карты есть специальный модуль pg_freespacemap
--pg_freespace(rel regclass IN, blkno OUT bigint, avail OUT int2)
Выдаёт объём свободного пространства на каждой странице отношения
, согласно FSM. Возвращается набор кортежей (blkno bigint, avail int2)
, по одному кортежу для каждой страницы в отношении.
SELECT * FROM pg_freespace('test_table');
blkno|avail|
-----+-----+
0| 32|
1| 32|
2| 32|
3| 32|
4| 32|
5| 32|
6| 32|
7| 32|
8| 32|
9| 32|
10| 32|
11| 32|
12| 32|
13| 32|
14| 32|
15| 256|По FSM написана более конкретная и сложная статья. Если интересно, можете ознакомиться
Карта видимости (visibility map)
Постфикс _vm. Этот слой позволяет определить надо ли почистить или заморозить страничку. Также помогает с index only scan (когда транзакция пытается прочитать строку из такой страницы, можно не проверять ее видимость, а это позволяет использовать сканирование только индекса).Файлы этого слоя обычно довольно маленькие. На каждую страницу выделяется 2 бита (1бит — все версии строк актуальны, 2 бит — все версии строк заморожены). Ссылка на GitHub
Карта видимости не создается для индексов.
Страницы
Каждый файл логически поделен на блоки(страницы)- это минимальный объем данных, который считывается или записывается. Это сделано для оптимизации операций ввода-вывода. Размер страницы задается переменной BLKSZ, по дефолту это 8Кбайт, по максимуму 32Кбайт (можно настроить при сборке, но делается это никогда редко).
Каждое отношение(таблица, индекс…) хранится как массив таких страниц. Они наполняют файл пока тот не достигнет максимального размера(SEGSIZE), после чего создается новый сегмент, и цикл продолжается.
Независимо от того, к какому слою принадлежат файлы, они используются сервером, примерно, одинаково. Страницы сначала помещаются в буферный кеш (где их могут читать и изменять процессы), а затем при необходимости вытесняются обратно на диск.
Внутри страницы
Страница также поделена на части. Ссылочка на код с более подробным описанием
Заголовок
Сначала идет заголовок, который занимает 24 байта, и хранит общую информацию.
-
Первые 2 блока: последняя запись в WAL, связанная с этой страницей(8 байт) и контрольная сумма страниц (2 байта)
-
Далее 2 байта флагов:
-
PD_HAS_FREE_LINES 0x0001. Если этот флаг установлен, это означает, что на странице может быть свободное место, которое можно использовать для хранения новых кортежей без необходимости деления страницы. -
PD_PAGE_FULL 0x0002.Устанавливается, когда страница полностью заполнена данными. -
PD_ALL_VISIBLE 0x0004.Устанавливается, когда все записи на странице видимы для всех транзакций. -
PD_VALID_FLAG_BITS 0x0007.Маска, определяющая допустимые значения для битового поля.
-
-
Далее идут 3 блока по 2 байта, указывающие на смещение:
-
pd_lower. Смещение до начала свободного пространства -
pd_upper.Смещение до конца свободного пространства -
pd_special.Смещение до начала специального пространства (до конца страницы)
-
-
Далее информация о размере страницы и номере версии компоновки (2 байта)
-
И в конце находится самый старый неочищенный идентификатор xmax на странице или ноль при отсутствии такового (необходимо для оптимизации VACUUM)
SELECT *
FROM page_header(get_raw_page('test_table',0));
lsn |checksum|flags|lower|upper|special|pagesize|version|prune_xid|
-----------+--------+-----+-----+-----+-------+--------+-------+---------+
40/CED9E4C8| -905| 4| 432| 480| 8192| 8192| 4|0 |Указатели
После заголовка следует массив указателей на версии строк (line pointers). Каждый указатель занимает 4 байта и содержит:
-
lp_off. Смещение строки относительно начала страницы -
lp_flags. Набор флагов состояния указателя-
LP_UNUSED |0 |/* unused (should always have lp_len=0)*/ -
LP_NORMAL |1 |/* used (should always have lp_len>0) */ -
LP_REDIRECT|2 |/* HOT redirect (should have lp_len=0) */ -
LP_DEAD |3 |/* dead, may or may not have storage */
-
-
lp_len. Длина строки
Ссылочка на исходный код, для дальнейшего погружения
SELECT lp, lp_off, lp_flags, lp_len
FROM heap_page_items(get_raw_page('test_table',0)) sub
lp |lp_off|lp_flags|lp_len|
---+------+--------+------+
1| 7944| 1| 241|--тут есть фраза
2| 7680| 1| 261|--тут есть фраза
3| 7608| 1| 65|--тут только имя
.
102| 480| 1| 65|
Оффсет уменьшается так как записи добавляются с конца к началуВерсии строк
После указателей до фактических данных (версий строк) идет блок свободного пространства. Собственно, тут ничего особо интересного, никакой фрагментации, единый блок пустого места. Наличие свободного места, как раз, и отмечается в карте свободного пространства.
В конец свободного пространства размещаются версии строк, а в начало указатели.
Скрытый текст
Слотированная страница
*
* +--------------------+---------------------------------------+
* | Заголовок страницы | Указатель1 Указатель2 Указатель3... |
* +--------------------+---------------------------------------+
* | ... УказательN | |
* +------------------------------------------------------------+
* | ^ Смещение до начала свободного пространства|
* | |
* | v Смещение до конца свободного пространства |
* +------------------------------------------------------------+
* | | кортежN ... |
* +------------------------------------------------------------+
* | ... кортеж3 кортеж2 кортеж1 | "Специальная область" |
* +--------------------+---------------------------------------+
* ^ pd_special
*Страница считается заполненной, когда между указателями начала и конца свободного пространства ничего нельзя добавить.
Далее, собственно, идет самое интересное — версии строк (tuples,rows,кортежи).
В случае таблиц мы говорим не просто о строках, а о версиях строк (row versions, tuples), поскольку многоверсионность предполагает существование нескольких версий одной и той же строки. На индексы многоверсионность не распространяется; вместо этого индексы ссылаются на все возможные табличные версии строк, среди которых по правилам видимости выбираются подходящие.
Версия строки состоит из заголовка и непосредственно данных. Заголовок записи (tuple_header) достаточно тяжелый (минимум 23 байта), он содержит служебную информацию о записи.
-
t_xminПоле, которое наравне сxmaxиграет ключевую роль в обеспечении многоверсионной конкурентной работы (MVCC).xmin(minimum transaction ID) — это идентификатор транзакции, которая создала запись. -
t_xmax(maximum transaction ID) — это идентификатор транзакции, которая удалила или обновила запись. -
t_field.Поле разделенное между тремя виртуальными полямиCmin,Cmax,XvacWe store five «virtual» fields Xmin, Cmin, Xmax, Cmax, and Xvac in three physical fields. Xmin and Xmax are always really stored, but Cmin, Cmax and Xvac share a field. This works because we know that Cmin and Cmax are only interesting for the lifetime of the inserting and deleting transaction respectively. If a tuple is inserted and deleted in the same transaction, we store a «combo» command id that can be mapped to the real cmin and cmax, but only by use of local state within the originating backend. See combocid.c for more details. Meanwhile, Xvac is only set by old-style VACUUM FULL, which does not have any command sub-structure and so does not need either Cmin or Cmax.
ссылочка
-
t_ctid. Физическое расположение записи (номер блока, смещение) -
t_infomask. Различные флаги/* * information stored in t_infomask: */ #define HEAP_HASNULL 0x0001 /* Наличие NULL */ #define HEAP_HASVARWIDTH 0x0002 /* Наличие атрибутов переменной длины */ #define HEAP_HASEXTERNAL 0x0004 /* Хранится ли что-то в TOAST */ #define HEAP_HASOID_OLD 0x0008 /* Есть ли поле OID */ #define HEAP_XMAX_KEYSHR_LOCK 0x0010 /* Наличие key_share блокировки */ #define HEAP_COMBOCID 0x0020 /* t_cid является combo CID*/ #define HEAP_XMAX_EXCL_LOCK 0x0040 /* Эксклюзивная блокировка */ #define HEAP_XMAX_LOCK_ONLY 0x0080 /* Транзакция, установившая xmax, является единственным владельцем записи. */ /* xmax is a shared locker */ #define HEAP_XMAX_SHR_LOCK (HEAP_XMAX_EXCL_LOCK | HEAP_XMAX_KEYSHR_LOCK) #define HEAP_LOCK_MASK (HEAP_XMAX_SHR_LOCK | HEAP_XMAX_EXCL_LOCK | \ HEAP_XMAX_KEYSHR_LOCK) #define HEAP_XMIN_COMMITTED 0x0100 /* t_xmin committed */ #define HEAP_XMIN_INVALID 0x0200 /* t_xmin invalid/aborted */ #define HEAP_XMIN_FROZEN (HEAP_XMIN_COMMITTED|HEAP_XMIN_INVALID) #define HEAP_XMAX_COMMITTED 0x0400 /* t_xmax committed */ #define HEAP_XMAX_INVALID 0x0800 /* t_xmax invalid/aborted */ #define HEAP_XMAX_IS_MULTI 0x1000 /* t_xmax это MultiXactId */ #define HEAP_UPDATED 0x2000 /* Это обновленная версия строки*/ #define HEAP_MOVED_OFF 0x4000 /* Запись перемещена в другое место вакуумом*/ #define HEAP_MOVED_IN 0x8000 /* Запись перемещена из другого место вакуумом */ #define HEAP_MOVED (HEAP_MOVED_OFF | HEAP_MOVED_IN) #define HEAP_XACT_MASK 0xFFF0 /* Маска видимости */Еще одна ссылка на исходный код
-
t_infomask2Еще немного флагов/* * Информация сохраняемая в t_infomask2: */ #define HEAP_NATTS_MASK 0x07FF /* 11 бит для количества аттрибутов */ /* bits 0x1800 are available */ #define HEAP_KEYS_UPDATED 0x2000 /* строка была обновлена или удалена */ #define HEAP_HOT_UPDATED 0x4000 /* строка была HOT-updated */ #define HEAP_ONLY_TUPLE 0x8000 /* heap-only строка */ #define HEAP2_XACT_MASK 0xE000 /* биты видимости аттрибутов */Линк
-
t_hoff(tuple header offset).Поле, которое указывает на смещение, необходимое для доступа к первым данным кортежа. Иными словами, это своего рода «указатель» на начало полезной нагрузки данных внутри кортежа. -
t_bitsБитмап NULL значений. Может отсутствовать, если NULL нет.
SELECT
t_xmin,
t_xmax,
t_field3,
t_ctid,
t_infomask2,
t_infomask,
t_hoff,
t_bits
FROM
heap_page_items(get_raw_page('test_table',0)) sub
t_xmin|t_xmax|t_field3|t_ctid |t_infomask2|t_infomask|t_hoff|t_bits |
------+------+--------+-------+-----------+----------+------+--------+
110286|0 | 0|(0,1) | 3| 2306| 24| |
110286|0 | 0|(0,2) | 3| 2306| 24| |--нет NULL
113319|0 | 0|(0,3) | 3| 2307| 24|11000000|--третий атрибут NULL
113319|0 | 0|(0,4) | 3| 2307| 24|11000000|
113319|0 | 0|(0,5) | 3| 2307| 24|11000000|
113319|0 | 0|(0,6) | 3| 2307| 24|11000000|
.
113319|0 | 0|(0,102)| 3| 2307| 24|11000000|Далее идут непосредственно данные, которые хранятся в шестнадцатеричной системе и выглядят угрожающе
SELECT tt.author, tt.phrase
FROM heap_page_items(get_raw_page('test_table',0)) sub
JOIN test_table tt
ON tt.ctid = sub.t_ctid; -- не надо так делать, ctid может не соответствовать
Заключение
Надеюсь, материал был интересен, и вы с пользой провели эти 15 минут. Закончить хочется словами с книги Postgres Internals, которые, как мне кажется, актуальны не только для Postgres:
«Обдумывайте, экспериментируйте, проверяйте все сведения самостоятельно.»
This section describes the storage format at the level of files and directories.
Traditionally, the configuration and data files used by a database cluster are stored together within the cluster’s data directory, commonly referred to as PGDATA (after the name of the environment variable that can be used to define it). A common location for PGDATA is /var/lib/pgsql/data. Multiple clusters, managed by different server instances, can exist on the same machine.
The PGDATA directory contains several subdirectories and control files, as shown in Table 65.1. In addition to these required items, the cluster configuration files postgresql.conf, pg_hba.conf, and pg_ident.conf are traditionally stored in PGDATA, although it is possible to place them elsewhere.
Table 65.1. Contents of PGDATA
| Item | Description |
|---|---|
PG_VERSION |
A file containing the major version number of PostgreSQL |
base |
Subdirectory containing per-database subdirectories |
current_logfiles |
File recording the log file(s) currently written to by the logging collector |
global |
Subdirectory containing cluster-wide tables, such as pg_database |
pg_commit_ts |
Subdirectory containing transaction commit timestamp data |
pg_dynshmem |
Subdirectory containing files used by the dynamic shared memory subsystem |
pg_logical |
Subdirectory containing status data for logical decoding |
pg_multixact |
Subdirectory containing multitransaction status data (used for shared row locks) |
pg_notify |
Subdirectory containing LISTEN/NOTIFY status data |
pg_replslot |
Subdirectory containing replication slot data |
pg_serial |
Subdirectory containing information about committed serializable transactions |
pg_snapshots |
Subdirectory containing exported snapshots |
pg_stat |
Subdirectory containing permanent files for the statistics subsystem |
pg_stat_tmp |
Subdirectory containing temporary files for the statistics subsystem |
pg_subtrans |
Subdirectory containing subtransaction status data |
pg_tblspc |
Subdirectory containing symbolic links to tablespaces |
pg_twophase |
Subdirectory containing state files for prepared transactions |
pg_wal |
Subdirectory containing WAL (Write Ahead Log) files |
pg_xact |
Subdirectory containing transaction commit status data |
postgresql.auto.conf |
A file used for storing configuration parameters that are set by ALTER SYSTEM |
postmaster.opts |
A file recording the command-line options the server was last started with |
postmaster.pid |
A lock file recording the current postmaster process ID (PID), cluster data directory path, postmaster start timestamp, port number, Unix-domain socket directory path (could be empty), first valid listen_address (IP address or *, or empty if not listening on TCP), and shared memory segment ID (this file is not present after server shutdown) |
For each database in the cluster there is a subdirectory within PGDATA/base, named after the database’s OID in pg_database. This subdirectory is the default location for the database’s files; in particular, its system catalogs are stored there.
Note that the following sections describe the behavior of the builtin heap table access method, and the builtin index access methods. Due to the extensible nature of PostgreSQL, other access methods might work differently.
Each table and index is stored in a separate file. For ordinary relations, these files are named after the table or index’s filenode number, which can be found in pg_class.relfilenode. But for temporary relations, the file name is of the form t, where BBB_FFFBBB is the process number of the backend which created the file, and FFF is the filenode number. In either case, in addition to the main file (a/k/a main fork), each table and index has a free space map (see Section 65.3), which stores information about free space available in the relation. The free space map is stored in a file named with the filenode number plus the suffix _fsm. Tables also have a visibility map, stored in a fork with the suffix _vm, to track which pages are known to have no dead tuples. The visibility map is described further in Section 65.4. Unlogged tables and indexes have a third fork, known as the initialization fork, which is stored in a fork with the suffix _init (see Section 65.5).
Caution
Note that while a table’s filenode often matches its OID, this is not necessarily the case; some operations, like TRUNCATE, REINDEX, CLUSTER and some forms of ALTER TABLE, can change the filenode while preserving the OID. Avoid assuming that filenode and table OID are the same. Also, for certain system catalogs including pg_class itself, pg_class.relfilenode contains zero. The actual filenode number of these catalogs is stored in a lower-level data structure, and can be obtained using the pg_relation_filenode() function.
When a table or index exceeds 1 GB, it is divided into gigabyte-sized segments. The first segment’s file name is the same as the filenode; subsequent segments are named filenode.1, filenode.2, etc. This arrangement avoids problems on platforms that have file size limitations. (Actually, 1 GB is just the default segment size. The segment size can be adjusted using the configuration option --with-segsize when building PostgreSQL.) In principle, free space map and visibility map forks could require multiple segments as well, though this is unlikely to happen in practice.
A table that has columns with potentially large entries will have an associated TOAST table, which is used for out-of-line storage of field values that are too large to keep in the table rows proper. pg_class.reltoastrelid links from a table to its TOAST table, if any. See Section 65.2 for more information.
The contents of tables and indexes are discussed further in Section 65.6.
Tablespaces make the scenario more complicated. Each user-defined tablespace has a symbolic link inside the PGDATA/pg_tblspc directory, which points to the physical tablespace directory (i.e., the location specified in the tablespace’s CREATE TABLESPACE command). This symbolic link is named after the tablespace’s OID. Inside the physical tablespace directory there is a subdirectory with a name that depends on the PostgreSQL server version, such as PG_9.0_201008051. (The reason for using this subdirectory is so that successive versions of the database can use the same CREATE TABLESPACE location value without conflicts.) Within the version-specific subdirectory, there is a subdirectory for each database that has elements in the tablespace, named after the database’s OID. Tables and indexes are stored within that directory, using the filenode naming scheme. The pg_default tablespace is not accessed through pg_tblspc, but corresponds to PGDATA/base. Similarly, the pg_global tablespace is not accessed through pg_tblspc, but corresponds to PGDATA/global.
The pg_relation_filepath() function shows the entire path (relative to PGDATA) of any relation. It is often useful as a substitute for remembering many of the above rules. But keep in mind that this function just gives the name of the first segment of the main fork of the relation — you may need to append a segment number and/or _fsm, _vm, or _init to find all the files associated with the relation.
Temporary files (for operations such as sorting more data than can fit in memory) are created within PGDATA/base/pgsql_tmp, or within a pgsql_tmp subdirectory of a tablespace directory if a tablespace other than pg_default is specified for them. The name of a temporary file has the form pgsql_tmp, where PPP.NNNPPP is the PID of the owning backend and NNN distinguishes different temporary files of that backend.
PostgreSQL — это бесплатная объектно-реляционная СУБД с мощным функционалом, который позволяет конкурировать с платными базами данных, такими как Microsoft SQL, Oracle. PostgreSQL поддерживает пользовательские данные, функции, операции, домены и индексы. В данной статье мы рассмотрим установку и краткий обзор по управлению базой данных PostgreSQL. Мы установим СУБД PostgreSQL в Windows 10, создадим новую базу, добавим в неё таблицы и настроим доступа для пользователей. Также мы рассмотрим основы управления PostgreSQL с помощью SQL shell и визуальной системы управления PgAdmin. Надеюсь эта статья станет хорошей отправной точкой для обучения работы с PostgreSQL и использованию ее в разработке и тестовых проектах.
Содержание:
- Установка PostgreSQL 11 в Windows 10
- Доступ к PostgreSQL по сети, правила файерволла
- Утилиты управления PostgreSQL через командную строку
- PgAdmin: Визуальный редактор для PostgresSQL
- Query Tool: использование SQL запросов в PostgreSQL
Установка PostgreSQL 11 в Windows 10
Для установки PostgreSQL перейдите на сайт https://www.postgresql.org и скачайте последнюю версию дистрибутива для Windows, на сегодняшний день это версия PostgreSQL 11 (в 11 версии PostgreSQL поддерживаются только 64-х битные редакции Windows). После загрузки запустите инсталлятор.
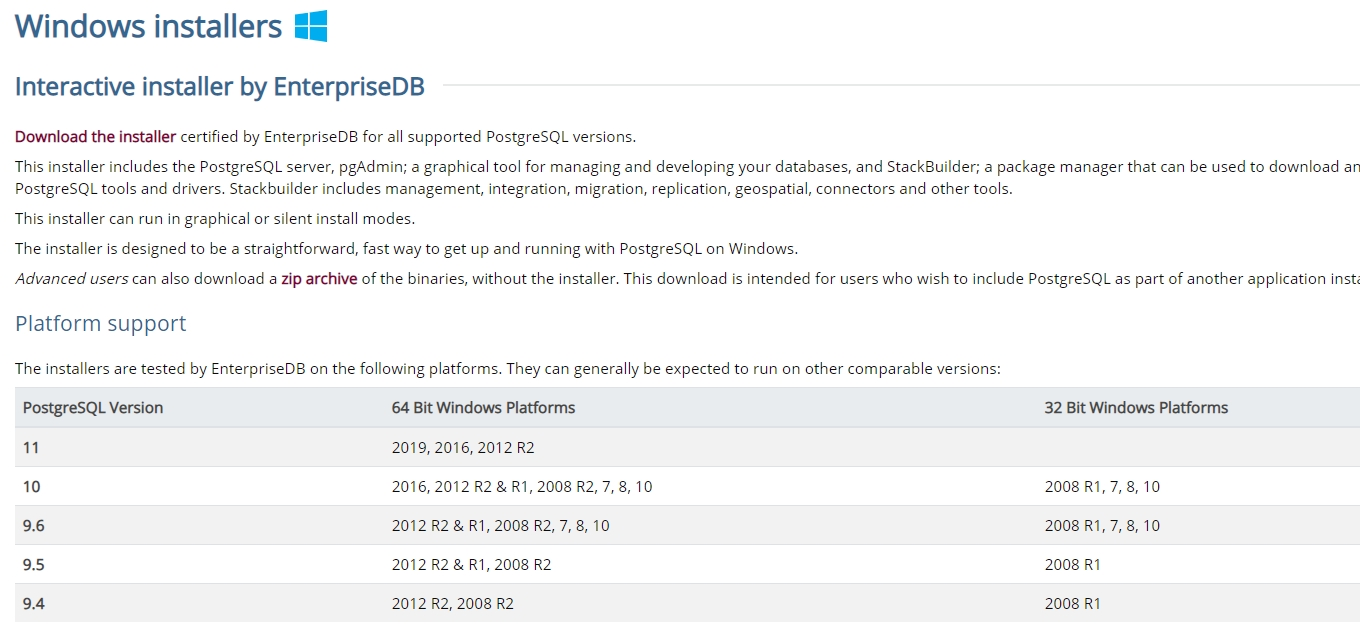
В процессе установки установите галочки на пунктах:
- PostgreSQL Server – сам сервер СУБД
- PgAdmin 4 – визуальный редактор SQL
- Stack Builder – дополнительные инструменты для разработки (возможно вам они понадобятся в будущем)
- Command Line Tools – инструменты командной строки
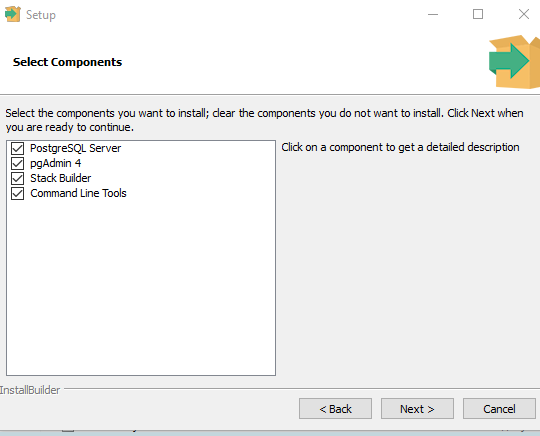
Установите пароль для пользователя postgres (он создается по умолчанию и имеет права суперпользователя).
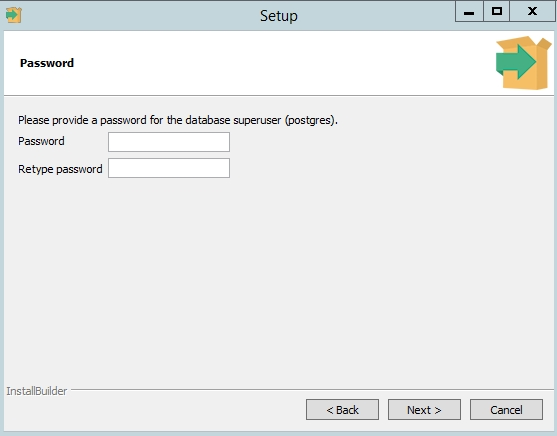
По умолчание СУБД слушает на порту 5432, который нужно будет добавить в исключения в правилах фаерволла.
Нажимаете Далее, Далее, на этом установка PostgreSQL завершена.
Доступ к PostgreSQL по сети, правила файерволла
Чтобы разрешить сетевой доступ к вашему экземпляру PostgreSQL с других компьютеров, вам нужно создать правила в файерволе. Вы можете создать правило через командную строку или PowerShell.
Запустите командную строку от имени администратора. Введите команду:
netsh advfirewall firewall add rule name="Postgre Port" dir=in action=allow protocol=TCP localport=5432
- Где rule name – имя правила
- Localport – разрешенный порт
Либо вы можете создать правило, разрешающее TCP/IP доступ к экземпляру PostgreSQL на порту 5432 с помощью PowerShell:
New-NetFirewallRule -Name 'POSTGRESQL-In-TCP' -DisplayName 'PostgreSQL (TCP-In)' -Direction Inbound -Enabled True -Protocol TCP -LocalPort 5432
После применения команды в брандмауэре Windows появится новое разрешающее правило для порта Postgres.
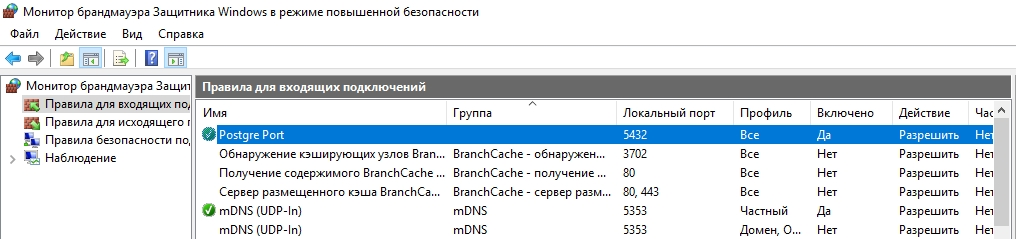
Совет. Для изменения порта в установленной PostgreSQL отредактируйте файл postgresql.conf по пути C:\Program Files\PostgreSQL\11\data.
Измените значение в пункте
port = 5432
. Перезапустите службу сервера postgresql-x64-11 после изменений. Можно перезапустить службу с помощью PowerShell:
Restart-Service -Name postgresql-x64-11

Более подробно о настройке параметров в конфигурационном файле postgresql.conf с помощью тюнеров смотрите в статье.
Утилиты управления PostgreSQL через командную строку
Рассмотрим управление и основные операции, которые можно выполнять с PostgreSQL через командную строку с помощью нескольких утилит. Основные инструменты управления PostgreSQL находятся в папке bin, потому все команды будем выполнять из данного каталога.
- Запустите командную строку.
Совет. Перед запуском СУБД, смените кодировку для нормального отображения в русской Windows 10. В командной строке выполните:
chcp 1251 - Перейдите в каталог bin выполнив команду:
CD C:\Program Files\PostgreSQL\11\bin

Основные команды PostgreSQL:

PgAdmin: Визуальный редактор для PostgresSQL
Редактор PgAdmin служит для упрощения управления базой данных PostgresSQL в понятном визуальном режиме.
По умолчанию все созданные базы хранятся в каталоге base по пути C:\Program Files\PostgreSQL\11\data\base.
Для каждой БД существует подкаталог внутри PGDATA/base, названный по OID базы данных в pg_database. Этот подкаталог по умолчанию является местом хранения файлов базы данных; в частности, там хранятся её системные каталоги. Каждая таблица и индекс хранятся в отдельном файле.
Для резервного копирования и восстановления лучше использовать инструмент Backup в панели инструментов Tools. Для автоматизации бэкапа PostgreSQL из командной строки используйте утилиту pg_dump.exe.
Query Tool: использование SQL запросов в PostgreSQL
Для написания SQL запросов в удобном графическом редакторе используется встроенный в pgAdmin инструмент Query Tool. Например, вы хотите создать новую таблицу в базе данных через инструмент Query Tool.
- Выберите базу данных, в панели Tools откройте Query Tool
- Создадим таблицу сотрудников:
CREATE TABLE employee
(
Id SERIAL PRIMARY KEY,
FirstName CHARACTER VARYING(30),
LastName CHARACTER VARYING(30),
Email CHARACTER VARYING(30),
Age INTEGER
);
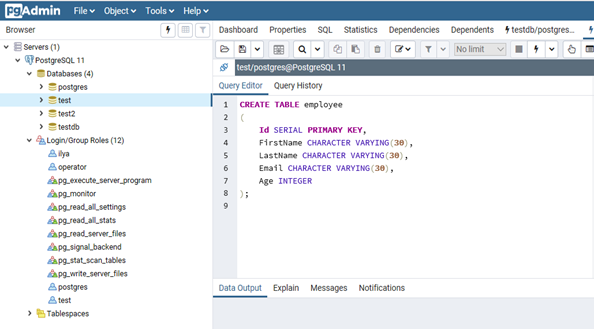
Id — номер сотрудника, которому присвоен ключ SERIAL. Данная строка будет хранить числовое значение 1, 2, 3 и т.д., которое для каждой новой строки будет автоматически увеличиваться на единицу. В следующих строках записаны имя, фамилия сотрудника и его электронный адрес, которые имеют тип CHARACTER VARYING(30), то есть представляют строку длиной не более 30 символов. В строке — Age записан возраст, имеет тип INTEGER, т.к. хранит числа.
После того, как написали код SQL запроса в Query Tool, нажмите клавишу F5 и в базе будет создана новая таблица employee.
Для заполнения полей в свойствах таблицы выберите таблицу employee в разделе Schemas -> Tables. Откройте меню Object инструмент View/Edit Data.
Здесь вы можете заполнить данные в таблице.
После заполнения данных выполним инструментом Query простой запрос на выборку:
select Age from employee;
Sometimes, you start working on a PostgreSQL instance but forget about the data directory, here we will discuss different methods to know the data directory location
The database parameter related to the data file directory is «data_directory»
Method 1: pg_settings
If you to know the value of any parameter in PostgreSQL, you can query the table pg_settings, now let’s see what the columns present in pg_settings using «\d pg_settings» command
postgres=# \d pg_settings;
View «pg_catalog.pg_settings»
Column | Type | Collation | Nullable | Default
——————+———+————+———-+———
name | text | | |
setting | text | | |
unit | text | | |
category | text | | |
short_desc | text | | |
extra_desc | text | | |
context | text | | |
vartype | text | | |
source | text | | |
min_val | text | | |
max_val | text | | |
enumvals | text[] | | |
boot_val | text | | |
reset_val | text | | |
sourcefile | text | | |
sourceline | integer | | |
pending_restart | boolean | | |
From these all columns, there are few important , i.e. name, setting, pending_restart, etc
to know data_directory location using pg_settings use below command
SELECT setting FROM pg_settings WHERE name = ‘data_directory’;
postgres=# SELECT setting FROM pg_settings WHERE name = ‘data_directory’;
setting
————————————-
C:/Program Files/PostgreSQL/10/data
(1 row)
Method 2 : using show command
most of parameters values can be retrieved using show command, one limitation is, you should know parameter name or else simply use pg_settings view with like operator
show data_directory command will give you location of data directory
postgres=# show «data_directory»;
data_directory
————————————-
C:/Program Files/PostgreSQL/10/data
(1 row)
Method 3 : configuration file
check the configuration file and find data_directory parameter value from it
Method 4 : using status of postgres services
using ps -ef|grep postgres on unix/linux system