

Привет! Хочу рассказать простым языком о механике возникновения steal внутри виртуальных машин и о некоторых неочевидных артефактах, которые нам удалось выяснить при его исследовании, в которое мне пришлось погрузиться как техдиру облачной платформы Mail.ru Cloud Solutions. Платформа работает на KVM.
CPU steal time — это время, в течение которого виртуальная машина не получает ресурсы процессора для своего выполнения. Это время считается только в гостевых операционных системах в средах виртуализации. Причины, куда деваются эти самые выделенные ресурсы, как и в жизни, весьма туманны. Но мы решили разобраться, даже поставили целый ряд экспериментов. Не то чтобы мы теперь всё знаем о steal, но кое-что интересное сейчас расскажем.
1. Что такое steal
Итак, steal — это метрика, указывающая на нехватку процессорного времени для процессов внутри виртуальной машины. Как описано в патче ядра KVM, steal — это время, в течение которого гипервизор выполняет другие процессы на хостовой ОС, хотя он поставил процесс виртуальной машины в очередь на выполнение. То есть, steal считается как разница между временем, когда процесс готов выполниться, и временем, когда процессу выделены процессорное время.
Метрику steal ядро виртуальной машины получает от гипервизора. При этом гипервизор не уточняет, какие именно другие процессы он выполняет, просто «пока занят, тебе времени уделить не могу». На KVM поддержка подсчёта steal добавлена в патчах. Ключевых моментов здесь два:
- Виртуальная машина узнаёт о steal от гипервизора. То есть, с точки зрения потерь, для процессов на самой виртуалке это непрямое измерение, которое может быть подвержено различным искажениям.
- Гипервизор не делится с виртуалкой информацией о том, чем другим он занят — главное, что он не уделяет время ей. Из-за этого сама виртуалка не может выявить искажения в показателе steal, которые можно было бы оценить по характеру конкурирующих процессов.
2. Что влияет на steal
2.1. Вычисление steal
По сути, steal считается примерно так же, как и обычное время утилизации процессора. Информации о том, как считается утилизация, не много. Наверное, потому что большинство считает этот вопрос очевидным. Но здесь тоже бывают подводные камни. Для ознакомления с этим процессом можно прочитать статью Brendann Gregg: вы узнаете о куче нюансов при расчете утилизации и о ситуациях, когда этот подсчёт будет ошибочным по следующим причинам:
- Перегрев процессора, при котором пропускаются такты.
- Включение/выключение турбобуста, в результате которого изменяется тактовая частота процессора.
- Изменение продолжительности кванта времени, происходящее при использовании технологий энергосбережения процессора, например SpeedStep.
- Проблема подсчёта среднего: оценка утилизации в течение одной минуты на уровне 80 % может спрятать кратковременный бурст в 100 %.
- Циклическая блокировка (spin lock) приводит к тому, что процессор утилизирован, но пользовательский процесс не видит продвижения по своему выполнению. В результате расчётная утилизация процессора процессом будет стопроцентной, хотя физически процессорное время процесс потреблять не будет.
Статьи, описывающей подобный подсчёт для steal, я не нашел (если знаете — поделитесь в комментариях). Но, судя по исходникам, механизм расчёта такой же, как и для утилизации. Просто в ядре добавляется еще один счётчик, непосредственно для процесса KVM (процесса виртуальной машины), который считает длительность пребывания процесса KVM в состоянии ожидания процессорного времени. Счётчик берет информацию о процессоре из его спецификации и смотрит, все ли его тики утилизированы процессом виртуалки. Если все, то считаем, что процессор занимался только процессом виртуальной машины. В ином случае мы информируем, что процессор занимался чем-то ещё, появился steal.
Процесс подсчёта steal подвержен тем же самым проблемам, что и обычный подсчёт утилизации. Не сказать, что такие проблемы появляются часто, но выглядят обескураживающе.
2.2. Типы виртуализации на KVM
Вообще говоря, есть три типа виртуализации, и все они поддерживаются KVM. От типа виртуализации может зависеть механизм возникновения steal.
Трансляция. В этом случае работа операционной системы виртуальной машины с физическими устройствами гипервизора происходит примерно так:
- Гостевая операционная система посылает своему гостевому устройству команду.
- Драйвер гостевого устройства принимает команду, формирует запрос для BIOS устройства и отправляет её в гипервизор.
- Процесс гипервизора производит трансляцию команды в команду для физического устройства, делая её, в том числе, более безопасной.
- Драйвер физического устройства принимает модифицированную команду и отправляет её уже в само физическое устройство.
- Результаты выполнения команд идут обратно по тому же пути.
Преимущество трансляции в том, что она позволяет эмулировать любое устройство и не требует специальной подготовки ядра операционной системы. Но за это приходится расплачиваться, прежде всего, быстродействием.
Аппаратная виртуализация. В этом случае устройство на аппаратном уровне понимает команды из операционной системы. Это самый быстрый и хороший способ. Но, к сожалению, он поддерживается далеко не всеми физическими устройствами, гипервизорами и гостевыми операционками. На текущий момент основные устройства, которые поддерживают аппаратную виртуализацию, — это процессоры.
Паравиртуализация (paravirtualization). Самый распространённый вариант виртуализации устройств на KVM и вообще самый распространенный режим виртуализации для гостевых операционных систем. Особенность его в том, что работа с некоторыми подсистемами гипервизора (например, с сетевым или дисковым стеком) или выделение страниц памяти происходит с использованием API гипервизора, без трансляции низкоуровневых команд. Недостаток этого способа виртуализации — необходимость модификации ядра гостевой операционной системы, чтобы оно могло взаимодействовать с гипервизором с помощью этого API. Но обычно это решается за счет установки специальных драйверов на гостевую операционную систему. В KVM это API называется virtio API.
При паравиртуализации, по сравнению с трансляцией, путь до физического устройства значительно сокращается за счёт отправки команд напрямую из виртуальной машины в процесс гипервизора на хосте. Это позволяет ускорить выполнение всех инструкций внутри виртуальной машины. В KVM за это отвечает virtio API, который работает только для определенных устройств, вроде сетевого или дискового адаптера. Именно поэтому внутрь виртуальных машин ставятся virtio-драйверы.
Обратная сторона такого ускорения — не все процессы, которые выполняются внутри виртуалки, остаются внутри неё. Это создаёт некоторые спецэффекты, которые могут привести к появлению на steal. Подробное изучение этого вопроса рекомендую начать с An API for virtual I/O: virtio.
2.3. «Справедливый» шедулинг
Виртуалка на гипервизоре является, фактически, обычным процессом, который подчиняется законам шедулинга (распределения ресурсов между процессами) в ядре Linux, поэтому рассмотрим его подробнее.
В Linux используется так называемый CFS, Completely Fair Scheduler, начиная с ядра 2.6.23 ставший диспетчером по умолчанию. Чтобы разобраться с этим алгоритмом, можно почитать Linux Kernel Architecture или исходники. Суть CFS заключается в распределении процессорного времени между процессами в зависимости от длительности их выполнения. Чем больше процессорного времени требует процесс, тем меньше этого времени он получает. Это гарантирует «честное» выполнение всех процессов — чтобы один процесс не занимал все процессоры постоянно, и остальные процессы тоже могли выполняться.
Иногда такая парадигма приводит к интересным артефактам. Давние пользователи Linux наверняка помнят замирание обычного текстового редактора на десктопе во время запуска ресурсоемких приложений типа компилятора. Так получалось, потому что нересурсоемкие задачи десктопных приложений конкурировали с задачами, активно потребляющими ресурсы, такими как компилятор. CFS считает, что это нечестно, поэтому периодически останавливает текстовый редактор и даёт процессору обработать задачи компилятора. Это поправили с помощью механизма sched_autogroup, но остались многие другие особенности распределения процессорного времени между задачами. Собственно, это рассказ не про то, как всё плохо в CFS, а попытка обратить внимание на то, что «честное» распределение процессорного времени — не самая тривиальная задача.
Ещё один важный момент в шедулере — preemption. Это нужно, чтобы выгнать зажравшийся процесс с процессора и дать поработать другим. Процесс изгнания называется context switching, переключение контекста процессора. При этом сохраняется весь контекст таски: состояние стека, регистры и прочее, после чего процесс отправляется ждать, а на его место встает другой. Это дорогая операция для ОС, и используется она редко, но по сути ничего плохого в ней нет. Частое переключение контекста может говорить о проблеме в ОС, но обычно оно идет непрерывно и ни на что особенно не указывает.
Такой длинный рассказ нужен для объяснения одного факта: чем больше ресурсов процессора пытается потребить процесс в честном шедулере Linux, тем быстрее он будет остановлен, чтобы другие процессы тоже могли поработать. Правильно это или нет — сложный вопрос, который при разных нагрузках решается по-разному. В Windows до недавнего времени шедулер был ориентирован на приоритетную обработку десктопных приложений, из-за чего могли зависать фоновые процессы. В Sun Solaris было пять различных классов шедулеров. Когда запустили виртуализацию, добавили шестой, Fair share scheduler, потому что предыдущие пять работали с виртуализацией Solaris Zones неадекватно. Подробное изучение этого вопроса рекомендую начать с книг вроде Solaris Internals: Solaris 10 and OpenSolaris Kernel Architecture или Understanding the Linux Kernel.
2.4. Как мониторить steal?
Мониторить steal внутри виртуальной машины, как и любую другую процессорную метрику, просто: можно пользоваться любым средством съема метрик процессора. Главное, чтобы виртуалка была на Linux. Windows почему-то такую информацию своим пользователям не предоставляет. 
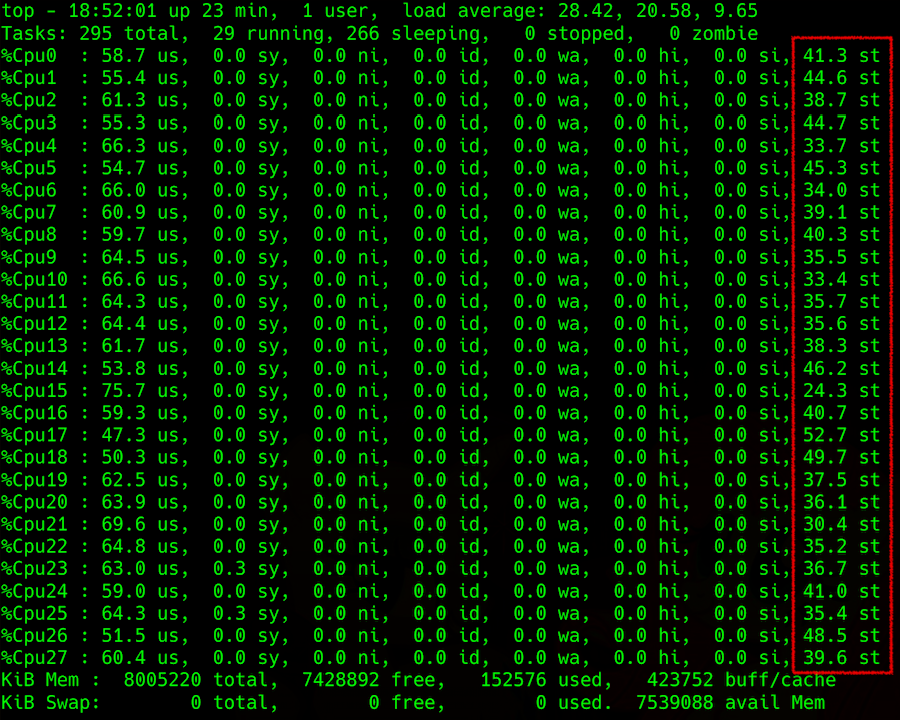
Вывод команды top: детализация нагрузки на процессор, в крайней правой колонке — steal
Сложность возникает при попытке получить эту информацию с гипервизора. Можно попробовать спрогнозировать steal на хостовой машине, например, по параметру Load Average (LA) — усредненного значения количества процессов, ожидающих в очереди на выполнение. Методика подсчёта этого параметра непростая, но в целом, если пронормированный по количеству потоков процессора LA больше 1, это говорит о том, что сервер с линуксом чем-то перегружен.
Чего же ждут все эти процессы? Очевидный ответ — процессора. Но ответ не совсем правильный, потому что иногда процессор свободен, а LA зашкаливает. Вспомните, как отваливается NFS и как при этом растёт LA. Примерно так же может быть и с диском, и с другими устройством ввода/вывода. Но на самом деле, процессы могут ожидать окончания любой блокировки, как физической, связанной с устройством ввода/вывода, так и логической, например мьютекса. Туда же относятся блокировки на уровне железа (того же ответа от диска), или логики (так называемых блокировочных примитивов, куда входит куча сущностей, mutex adaptive и spin, semaphores, condition variables, rw locks, ipc locks…).
Ещё одна особенность LA в том, что оно считается как среднее значение по операционной системе. К примеру, 100 процессов конкурируют за один файл, и тогда LA=50. Такое большое значение, казалось бы, говорит о том, что операционке плохо. Но для иного криво написанного кода это может быть нормальным состоянием, при том, что плохо только ему, а другие процессы в операционке не страдают.
Из-за этого усреднения (причём не меньше, чем за минуту), определение чего-то бы то ни было по показателю LA — не самое благодарное занятие, с весьма неопределёнными результатами в конкретных случаях. Если вы попытаетесь разобраться, то обнаружите, что в статьях на Википедии и прочих доступных ресурсах описаны только самые простые кейсы, без глубокого объяснения процесса. Всех интересующихся отправляю, опять же, сюда, к Brendann Gregg — далее по ссылкам. Кому лень на английском — перевод его популярной статьи про LA.
3. Спецэффекты
Теперь остановимся на основных кейсах появления steal, с которыми мы сталкивались. Расскажу, как они вытекают из всего вышесказанного и как соотносятся с показателями на гипервизоре.
Переутилизация. Самое простое и частое: гипервизор переутилизирован. Действительно, много запущенных виртуалок, большое потребление процессора внутри них, большая конкуренция, утилизация по LA больше 1 (в нормировке по процессорным тредам). Внутри всех виртуалок всё тормозит. Steal, передаваемый с гипервизора, также растёт, надо перераспределять нагрузку или кого-то выключать. В общем, всё логично и понятно.
Паравиртуализация против одиноких инстансов. На гипервизоре одна единственная виртуалка, она потребляет небольшую его часть, но даёт большую нагрузку по вводу/выводу, например по диску. И откуда-то в ней появляется небольшой steal, до 10 % (как показывают несколько проведённых экспериментов).
Случай интересный. Steal тут появляется как раз из-за блокировок на уровне паравиртуализированных драйверов. Внутри виртуалки создаётся прерывание, обрабатывается драйвером и уходит в гипервизор. Из-за обработки прерывания на гипервизоре для виртуалки это выглядит как отправленный запрос, она готова к исполнению и ждёт процессора, но процессорного времени ей не дают. Виртуалка думает, что это время украдено.
Это происходит в момент отправки буфера, он уходит в kernel space гипервизора, и мы начинаем его ждать. Хотя, с точки зрения виртуалки, он должен сразу вернуться. Следовательно, по алгоритму расчёта steal это время считается украденным. Скорее всего, в этой ситуации могут быть и другие механизмы (например, обработка ещё каких-нибудь sys calls), но они не должны сильно отличаться.
Шедулер против высоконагруженных виртуалок. Когда одна виртуалка страдает от steal больше других, это связано как раз с шедулером. Чем сильнее процесс нагружает процессор, тем скорее шедулер его выгонит, чтобы остальные тоже могли поработать. Если виртуалка потребляет немного, она почти не увидит steal: её процесс честно сидел и ждал, надо ему давать побольше времени. Если виртуалка производит максимальную нагрузку по всем своим ядрам, её чаще выгоняют с процессора и стараются не давать много времени.
Ещё хуже, когда процессы внутри виртуалки пытаются заполучить больше процессора, потому что не справляются с обработкой данных. Тогда операционная система на гипервизоре, за счёт честной оптимизации, будет давать всё меньше процессорного времени. Этот процесс происходит лавинообразно, и steal подскакивает до небес, хотя остальные виртуалки его могут почти не замечать. И чем больше ядер, тем хуже попавшей под раздачу машине. Короче говоря, больше всего страдают высоконагруженные виртуалки со множеством ядер.
Низкий LA, но есть steal. Если LA примерно 0,7 (то есть, гипервизор, кажется недозагружен), но внутри отдельных виртуалок наблюдается steal:
- Уже описанный выше вариант с паравиртуализацией. Виртуалка может получать метрики, указывающие на steal, хотя у гипервизора всё хорошо. По результатам наших экспериментов, такой вариант steal не превышает 10 % и не должен оказывать существенного влияния на производительность приложений внутри виртуалки.
- Неверно считается параметр LA. Точнее, в каждый конкретный момент он считается верно, но при усреднении за одну минуту получается заниженным. Например, если одна виртуалка на треть гипервизора потребляет все свои процессоры ровно полминуты, то LA за минуту на гипервизоре будет 0,15; четыре такие виртуалки, работающие одновременно, дадут 0,6. А то, что полминуты на каждой из них был дикий steal под 25 % по показателю LA, уже не вытащить.
- Опять же, из-за шедулера, решившего, что кто-то слишком много ест, и пусть этот кто-то подождёт. А я пока попереключаю контекст, пообрабатываю прерывания и займусь другими важными системными вещами. В итоге одни виртуалки не видят никаких проблем, а другие испытывают серьезную деградацию производительности.
4. Другие искажения
Есть ещё миллион причин для искажений честной отдачи процессорного времени на виртуалке. Например, сложности в расчёты вносят гипертрединг и NUMA. Они окончательно запутывают выбор ядра для исполнения процесса, потому что шедулер использует коэффициенты — веса, которые при переключении контекста делают подсчёт ещё сложнее.
Бывают искажения из-за технологий типа турбобуста или, наоборот, режима энергосбережения, которые при подсчёте утилизации могут искусственно повышать или понижать частоту или даже квант времени на сервере. Включение турбобуста уменьшает производительность одного процессорного треда из-за увеличения производительности другого. В этот момент информация об актуальной частоте процессора виртуальной машине не передаётся, и она считает, что её время кто-то тырит (например, она запрашивала 2 ГГц, а получила вдвое меньше).
В общем, причин искажений может быть много. В конкретной системе вы можете обнаружить что-то ещё. Начать лучше с книг, на которые я дал линки выше, и съема статистики с гипервизора утилитами типа perf, sysdig, systemtap, коих десятки.
5. Выводы
- Какое-то количество steal может возникать из-за паравиртуализации, и его можно считать нормальным. В интернете пишут, что эта величина может составлять 5-10 %. Зависит от приложений внутри виртуалки и от того, какую нагрузку она даёт на свои физические устройства. Тут важно обращать внимание на то, как себя чувствуют приложения внутри виртуалок.
- Соотношение нагрузки на гипервизоре и steal внутри виртуалки не всегда однозначно взаимосвязаны, обе оценки steal могут быть ошибочными в конкретных ситуациях при разных нагрузках.
- Шедулер плохо относится к процессам, которые много просят. Он старается давать меньше тем, кто просит больше. Большие виртуалки — зло.
- Небольшой steal может быть нормой и без паравиртуализации (с учётом нагрузки внутри виртуалки, особенностей нагрузки соседей, распределения нагрузки по тредам и прочих факторов).
- Если вы хотите выяснить steal в конкретной системе, приходится исследовать различные варианты, собирать метрики, тщательно их анализировать и продумывать, как равномерно распределять нагрузку. От любых кейсов возможны отклонения, которые надо подтверждать экспериментально или смотреть в дебагере ядра.
В нашем телеграм-канале — новости об этом и других сервисах на облачной платформе Mail.ru Cloud Solutions.
Что еще почитать:
1. Как CarPrice стал самой цифровой компанией российского авторынка.
2. Как благодаря Kubernetes и автоматизации мигрировать в облако за два часа.
3. Как Worki сократили время доступа к файлам клиентов и повысили надежность сервиса.
Steal time is the percentage of time a virtual CPU waits for a real CPU while the hypervisor is servicing another virtual processor. As such, it only happens in virtualized environments like AWS, GCP, Azure, vSphere, and Xen.
- What is steal time in top command?
- What is high CPU steal?
- What is CPU stolen?
- How is steal time calculated?
- What is CPU wait time?
- What is CPU guest nice time?
- How do I know if my CPU is stealing time?
- What is CPU ready time in vmware?
- What does stolen time mean?
- Does AWS oversubscribed CPU?
- What does it mean to steal in?
- What are the CPU metrics?
- What is steal in Iostat?
- What is proc stat?
- What is steal in Mpstat?
What is steal time in top command?
Steal time is the percentage of time the virtual machine process is waiting on the physical CPU for its CPU time. You can monitor processes and resource usage by running the “top” command on your Linux server. Among usage metrics, is steal time is labeled as ‘st’.
What is high CPU steal?
In a virtual environment, CPU cycles are shared across virtual machines on the server. If your VM displays a high %st in top (steal time), this means CPU cycles are being taken away from your VM to serve other purposes. You may be using more than your share of CPU resources or the physical server may be over-sold.
What is CPU stolen?
Stolen CPU represents the CPU cycles that are reclaimed by a virtual machine’s hypervisor because it reached maximum processing capacity performing other tasks. Specifically, it involves the re-allocation of processing resources to account for a lack somewhere else.
How is steal time calculated?
As described in the KVM kernel patch, steal is the time that a hypervisor spends running other processes in a host OS, while VM process is in a run queue. In other words, steal is calculated as the difference between the moment when a process is ready to run and the moment when CPU time is allocated to the process.
What is CPU wait time?
CPU wait is a somewhat broad and nuanced term for the amount of time that a task has to wait to access CPU resources. This term is popularly used in virtualized environments, where multiple virtual machines compete for processor resources.
What is CPU guest nice time?
On a CPU graph NICE time is time spent running processes with positive nice value (ie low priority). This means that it is consuming CPU, but will give up that CPU time for most other processes. Any USER CPU time for one of the processes listed in the above ps command will show up as NICE.
How do I know if my CPU is stealing time?
Steal time is the percentage of time a virtual CPU waits for a real CPU while the hypervisor is servicing another virtual processor. As such, it only happens in virtualized environments like AWS, GCP, Azure, vSphere, and Xen. To see the steal time in Linux, run top on the command line and look for %st.
What is CPU ready time in vmware?
CPU ready time is a vSphere metric that records the amount of time a VM is ready to use CPU but was unable to schedule physical CPU time because all the vSphere ESXi host CPU resources are busy. CPU ready time is dependent on the number of VMs on the host and their CPU loads.
What does stolen time mean?
To «steal» time in this way is to be able to assign, set aside, or reserve that time for a particular reason or activity. The presumption is that there other demands for this time.
Does AWS oversubscribed CPU?
An AWS Dedicated Host is oversubscribed 2 vCPU to 1 CPU, meaning each core is Hyper-Threaded.
What does it mean to steal in?
(Entry 1 of 2) intransitive verb. 1 : to take the property of another wrongfully and especially as a habitual or regular practice. 2 : to come or go secretly, unobtrusively, gradually, or unexpectedly.
What are the CPU metrics?
CPU Metrics
Percentage of CPU time spent on low priority processes. Percentage of time the CPU was busy processing kernel code. Percentage of time the CPU was busy processing non-kernel code. Percentage of CPU time spent waiting for an I/O request.
What is steal in Iostat?
In output of iostat there is a steal field, according to man page the field is used to: Show the percentage of time spent in involuntary wait by the virtual CPU or CPUs while the hypervisor was servicing another virtual processor.
What is proc stat?
DESCRIPTION procstat utility displays detailed information about the processes iden- tified by the pid arguments, or if the -a flag is used, all processes. It can also display information extracted from a process core file, if the core file is specified as the argument.
What is steal in Mpstat?
Answer. When running Aerospike in a virtualized platform, it is particularly important to monitor the %steal . This parameter shows the amount of time the physical CPU has “stolen” from the vCPU. … In this time, the physical CPU core is dealing with another vCPU request, from another virtual machine.
Effects
The impact of stolen CPU always manifests in slowness but can have more profound effects on your infrastructure. Here are some examples:
- Slower page load times
- Slower database query times
- Slower processing of reports
- Increased queue size of asynchronous tasks because of an inability to process them quickly
- Increased IaaS bill due to launching more servers to handle the same amount of load
There are two possible causes of steal time:
- The VM needs more CPU than the physical server can offer. AWS credits fall into this category
- The CPU on the physical server is oversubscribed.
Under no circumstances should you tolerate high steal time on a server. It means you’re getting worse performance than what you’re paying for. Moving and upgrading servers is quick and painless and solves the problem at its root.
Quick Fix
Manually terminate the virtual machine and launch a replacement.
Thorough Fix
If money is no object, then upgrading the VM is the easiest guaranteed solution.
Otherwise, finding the cause is best done through trial and error. Terminate the VM and relaunching it will move it to another physical server. If steal time persists through multiple moves, then it’s time to upgrade the VM to have more CPU.
An automated solution where high steal time kicks off a relaunch can be effective but can also mask scaling issues.
Resources
- Understanding CPU Steal Time — when should you be worried? (Scout App)
- Is there a Windows equivalent of Unix ‘CPU steal time’? (Server Fault)
- AWS CPU Credits and Baseline Performance (AWS Documentation)
- Azure Monitoring CPU Steal time/Wait Time (Microsoft MSDN)
Map Your Next Move at VMware Explore
Join peers and leaders at the essential cloud event for IT professionals.
Learn More
Map Your Next Move at VMware Explore
Join peers and leaders at the essential cloud event for IT professionals.
Learn More
Community Search
Welcome to the Broadcom Community
Find Your Communities
Our communities are designed by division, as you can see below. Visit each division’s homepage for a list of product communities under each division. From there, click on the communities you’re interested in, choose «Join Community,» and select your notification settings. It’s that simple. Join as many as you’d like.
Register Here
Please note: Your first post to any of our communities will be placed in a moderation queue for review to help us prevent spammers from posting unwanted content. Our community managers closely monitor this moderation queue, and once your first post is approved, your posts will no longer go through moderation. Please do not submit the same post multiple times.
Check Out Our Events
Looking for product roadmap webcasts, technical sessions, user group meetings, conferences, and workshops? Check out our events calendars:
- Application Networking and Security
- Carbon Black — Symantec
- VeloCloud
- Carbon Black
- Tanzu
- VMware Cloud Foundation
- Enterprise Software Events
- Mainframe Software Events
- Symantec Enterprise Events
- VMware Events
Latest Discussions
-
Meet patel To clarify, whenever you see the issue of Black Screen on the VM, collect the support bundle and share it.
-
what do you mean reproduce the issue it’s not some kind of error i can share the video of the things that happen after booting and i added this things to the .vmx file:-mks.enableDX12Renderer = «FALSE» mks.enableGLRenderer = «TRUE» but still the same …
Recent Blogs
-
Auto Scaling of Kubernetes Workloads using Custom Application …
-
Posted in:
Bitnami
Model Context Protocol (MCP) has taken the world …
Upcoming Events
Engagement Leaderboard
17 февраля 2025 года, 00:41
Оказывается, на виртуальных серверах есть специальная метрика CPU steal time. Она показывает, сколько процессорного времени было «украдено» у вашего сервера другими виртуальными машинами на том же физическом сервере. Есть смысл проверить эту метрику, если вы сталкиваетесь с необъяснимыми подтормаживаниями. Их причина может быть не в вашей системе, а в соседях по серверу.
Я периодически сталкиваюсь с этой проблемой на моем хостинге. Она проявляется в том, что изредка база данных обрабатывает запросы в десятки раз медленнее, чем обычно. Отследить такую ситуацию без специальных инструментов почти невозможно, потому что просто ходя по сайту, вы либо не заметите, что на двадцатый раз страница открывалась дольше, либо не поймете причину. Я использую New relic, о чем уже писал.
Изучая статистику после долгого перерыва, опять заметил, что проблема вернулась. Рассмотрел график из нью-релика с использованным и «украденным» процессорным временем. На нем видно, что 9 декабря появился заметный CPU steal time. Кто-то из соседей по физическому серверу стал активно нагружать процессор.
Казалось бы, величина не сильно большая: steal time не превосходит полпроцента, в то время как собственное потребление виртуалки около 5%. Но надо помнить, что это средние значения. Мгновенные значения в отдельные моменты времени могут оказаться гораздо больше. Чтобы их оценить, нужно смотреть на графики перцентилей.
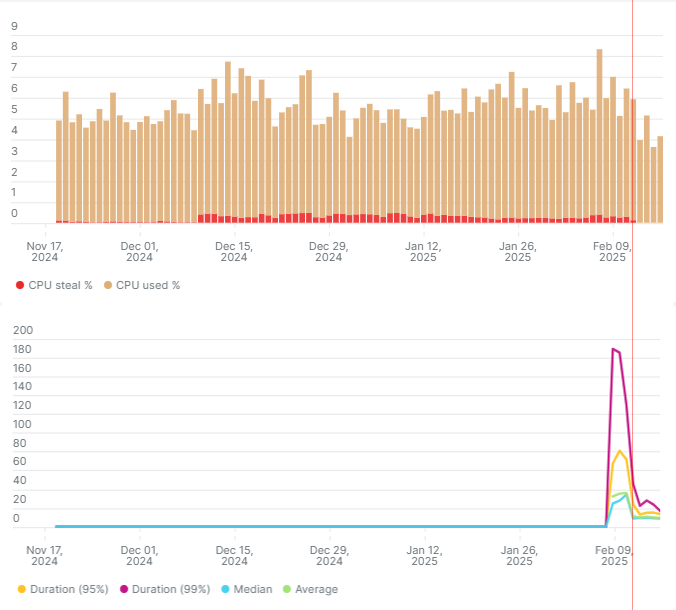
На втором графике я вывел 95-ю и 99-ю перцентили времени ответа сервера при генерации страниц блога. Перцентили вычисляются из детальной статистики, а ее нью-релик хранит только последние 8 дней, так что сейчас уже никак не узнаешь, что происходило в районе 9 декабря. Когда я обнаружил проблему, среднее и медианное время генерации были около 30 миллисекунд, а 99-я перцентиль — около 190 миллисекунд (это значит, что каждый сотый запрос выполнялся сервером дольше, чем 190 миллисекунд).
Что же делать с этой проблемой? Хостеру я писать не стал, скорее всего это бесполезно. Тариф предусматривает общий ресурс процессора, так что наверняка это штатное использование. В таких случаях я делаю временный «ресайз» виртуалки: перехожу на следующий тарифный план с дополнительным количеством памяти и дискового пространства, а потом возвращаюсь назад. С определенной долей вероятности на текущем гипервизоре не будет доступных ресурсов, и система переместит виртуалку на другой гипервизор. Если повезет, то и оборудование будет новее. При возврате к старому тарифному плану виртуалка скорее всего не будет никуда перемещаться.
Я сделал временный ресайз и виртуалка оказалась на другом гипервизоре. Этот момент я отметил на графике красной лииней. CPU steal time упал практически до нуля, перцентили приблизились к среднему и медиане. Среднее время генерации тоже снизилось с 30 до 10 миллисекунд, потому что на гипервизоре оказался более мощный процессор.
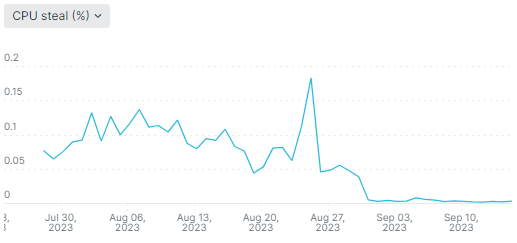
Влияние ресайза я обнаружил случайно в сентябре 2023 года, когда хотел проверить, поможет ли увеличение памяти победить непонятные подтормаживания. Эффект был, но не от увеличения объема оперативки, а от перемещения виртуалки на новый гипервизор. Это подтверждает упавший график steal time:
Однако проблема повторилась в декабре 2023 года в большем масштабе, когда steal time подскочил до 8% и дальше стал колебаться около 2%:
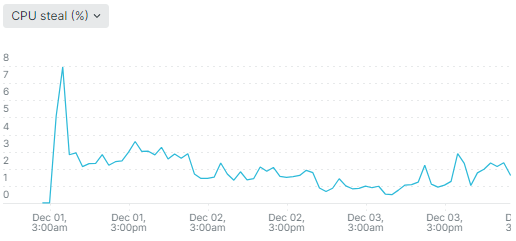
Пришлось опять делать ресайз. Мешающие соседи ушли, однако виртуалка оказалась на гипервизоре с более старым и слабым процессором. Получилось не так удачно, но я не стал дальше испытывать судьбу.
Я стараюсь не злоупотреблять временным ресайзом для переноса виртуалки на более новое железо. Мне кажется, этот прием из серой зоны. С одной стороны, я систему специально не взламываю, пароли не подбираю, уязвимости не ищу и не эксплуатирую, нажимаю только на доступные в интерфейсе кнопки. С другой стороны, цель моих действий — не увеличить ресурсы сервера, а избавиться от мешающих соседей. И хостер, если захочет, может ослеживать и наказывать таких умников.