
Доброго времени суток
Мне нужно перекодировать этот файл
в Windows-1251
Пытался это сделать с помощью встроенный функции sublime но получал ошибку
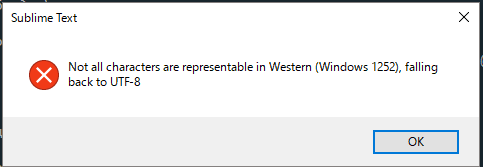
После нашел код на python для перекодировки
# -*- coding: utf-8 -*-
# UTF8 to cp1251 and ShiftJIS recoder
# by Chtobi and Nazon, 2016
import codecs
import argparse
from os import path
JAPANESE_CODEPAGE = 'shift_jis'
UTF_CODEPAGE = 'utf-8'
RUS_CODEPAGE = 'cp1251'
def nonrus_handler(e):
if e.object[e.start:e.end] == '~': # UTF-8: 0xEFBD9E -> SHIFT-JIS: 0x8160
japstr_byte = b'\x81\x60'
elif e.object[e.start:e.end] == '-': # UTF-8: 0xEFBC8D -> SHIFT-JIS: 0x817C
japstr_byte = b'\x81\x7c'
else:
japstr_byte = (e.object[e.start:e.end]).encode(JAPANESE_CODEPAGE)
return japstr_byte, e.end
if __name__ == '__main__':
arg_parser = argparse.ArgumentParser(prog="Recode to cp1251 and ShiftJIS",
description="Program to encode UTF8 text file to "
"cp1251 for all cyrillic symbols and ShiftJIS for others. "
"Output file will be inputfilename.s",
usage="recode_to_cp1251_shiftjis.py file_name")
arg_parser.add_argument('file_name', nargs=1, type=argparse.FileType(mode='r', bufsize=-1),
help="Input text file name. Only files coded in UTF8 are allowed.\n")
codecs.register_error('nonrus_handler', nonrus_handler)
input_name = arg_parser.parse_args().file_name[0].name
output_name = path.splitext(input_name)[0] + ".s"
with open(input_name, 'rt', encoding = UTF_CODEPAGE) as input_file:
with open(output_name, 'wb') as output_file:
if input_name.find(u'\xa0') >= 0:
input_name = input_name.replace(u'\xa0', u' ')
elif input_name.find(u'\ufeff') >= 0:
input_name = input_name.replace(u'\ufeff', u'')
for line in input_file:
for char1 in line:
bytes_out = bytes(line, UTF_CODEPAGE)
output_file.write(char1.encode(RUS_CODEPAGE, "nonrus_handler"))
print("Done.")Он перекодировал файл правда все русские символы превратились в непонятно что
Âðåìÿ òÿíåòñÿ áåñêîíå÷íî äîëãî.@
` Íî â ðåàëüíîì ìèðå íå ðàçäàëîñü è òûñÿ÷íîãî òèêàíüÿ ÷àñîâ.@
` Àðêâåéä ïîäíèìàåò ãîëîâó, è ñìîòðèò íà ìåíÿ òàê, ñëîâíî âèäèò ñîí.\
` – Øèêè, òû âñ¸ íå óõîäèë äîìîé.@ È ÿ ïðèøëà ñþäà, ïîòîìó ÷òî íå ìîãëà îñòàâèòü òåáÿ îäíîãî...@ Õîòü ÿ è ñîáèðàëàñü âîçâðàùàòüñÿ ê ñåáå.@
` Îíà íåìíîãî çàïèíàåòñÿ, íî ãîâîðèò â ñâîåé îáû÷íîé æèçíåðàäîñòíîé ìàíåðå.\
` – Êîíå÷íî ÿ íå óõîäèë.@ Ðàçâå ÿ íå ãîâîðèë ÷òî áóäó äåðæàòü ñâî¸ îáåùàíèå?@ ß âñ¸ åù¸ íèêàê íå ïîìîã òåáå ñåãîäíÿ.@
` – Õâàòèò óæå...@ Òåáå áîëüøå íå íóæíî ýòîãî äåëàòü.@
` – Õâàòèò?.. ×åãî õâàòèò, Àðêâåéä?!..\
` – Ðàçâå íå ÿñíî?@ Ïðîñòî òû ÷åëîâåê, Øèêè, à ÿ âàìïèð.@
` Ó ìåíÿ íå áûëî ïðàâà ïðîñèòü òåáÿ î ïîìîùè.@ ß íå ïîíèìàëà ýòîãî ðàíüøå, è ÿ áû ðàçðóøèëà òåáÿ, åñëè áû çàøëà íåìíîãî äàëüøå.@
` Ïîýòîìó...@
` «...äîñòàòî÷íî», øåï÷åò îíà.\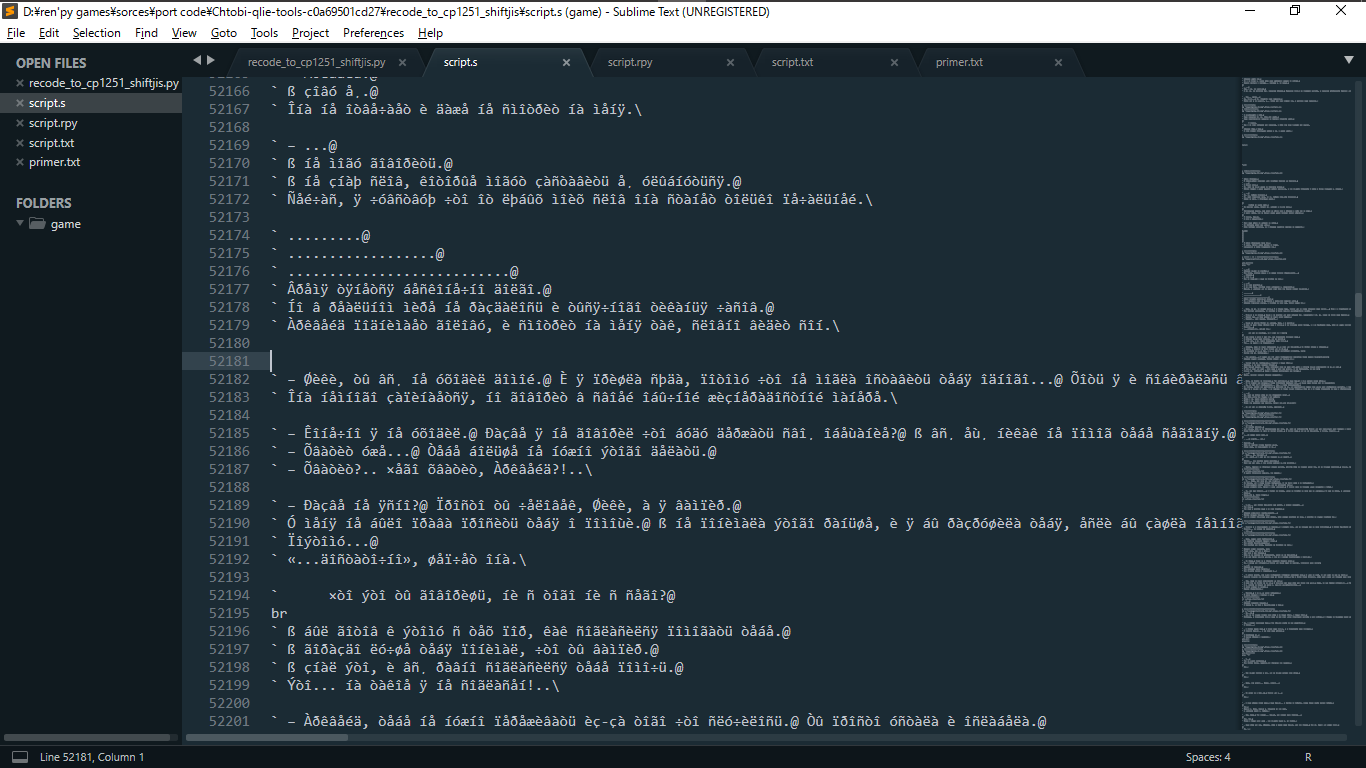
Есть ли способ вернуть русским смволам их изнчалный вид ? или же есть метод который не будить шакалить символы ?
Зарание Спасибо за ответ
Уведомления
- Начало
- » Python для новичков
- » UTF-8 в 1251
#1 Авг. 23, 2012 14:36:18
UTF-8 в 1251
Есть utf=8 строка(“Абза́ц”) нужно преобразовать ее в 1251 кодировку. Как это сделать? Заранее благодарен.
Офлайн
- Пожаловаться
#4 Авг. 24, 2012 01:21:31
UTF-8 в 1251
в cp1251 нет буквы а с ударением
>>> bytes(range(256)).decode('cp1251', 'replace') '\x00\x01\x02\x03\x04\x05\x06\x07\x08\t\n\x0b\x0c\r\x0e\x0f\x10\x11\x12\x13\x14\x15\x16\x17\x18\x19\x1a\x1b\x1c\x1d\x1e\x1f !"#$%&\'()*+,-./0123456789:;<=>?@ABCDEFGHIJKLMNOPQRSTUVWXYZ[\\]^_`abcdefghijklmnopqrstuvwxyz{|}~\x7fЂЃ‚ѓ„…†‡€‰Љ‹ЊЌЋЏђ‘’“”•–—�™љ›њќћџ\xa0ЎўЈ¤Ґ¦§Ё©Є«¬\xad®Ї°±Ііґµ¶·ё№є»јЅѕїАБВГДЕЖЗИЙКЛМНОПРСТУФХЦЧШЩЪЫЬЭЮЯабвгдежзийклмнопрстуфхцчшщъыьэюя' >>>
Офлайн
- Пожаловаться
#5 Авг. 24, 2012 10:55:24
UTF-8 в 1251
py.user.next
в cp1251 нет буквы а с ударением>>> bytes(range(256)).decode('cp1251', 'replace') '\x00\x01\x02\x03\x04\x05\x06\x07\x08\t\n\x0b\x0c\r\x0e\x0f\x10\x11\x12\x13\x14\x15\x16\x17\x18\x19\x1a\x1b\x1c\x1d\x1e\x1f !"#$%&\'()*+,-./0123456789:;<=>?@ABCDEFGHIJKLMNOPQRSTUVWXYZ[\\]^_`abcdefghijklmnopqrstuvwxyz{|}~\x7fЂЃ‚ѓ„…†‡€‰Љ‹ЊЌЋЏђ‘’“”•–—�™љ›њќћџ\xa0ЎўЈ¤Ґ¦§Ё©Є«¬\xad®Ї°±Ііґµ¶·ё№є»јЅѕїАБВГДЕЖЗИЙКЛМНОПРСТУФХЦЧШЩЪЫЬЭЮЯабвгдежзийклмнопрстуфхцчшщъыьэюя' >>>
Угу, вот поэтому и хочу в нее перевести(или есть вариант по-лучше избавится от ударения?). А в гугле не смог найти ничего для 3 ветки(может плохо искал или чего-то не понимаю).
Офлайн
- Пожаловаться
#6 Авг. 24, 2012 13:24:03
UTF-8 в 1251
удаление ударения
для второго
>>> s = 'Абза́ц' >>> s '\xd0\x90\xd0\xb1\xd0\xb7\xd0\xb0\xcc\x81\xd1\x86' >>> s = s.replace('\xcc\x81', '') >>> s '\xd0\x90\xd0\xb1\xd0\xb7\xd0\xb0\xd1\x86' >>> print s Абзац >>>
для третьего
>>> s = 'Абза́ц' >>> s.encode('utf-8') b'\xd0\x90\xd0\xb1\xd0\xb7\xd0\xb0\xcc\x81\xd1\x86' >>> s = s.encode('utf-8').replace(b'\xcc\x81', b'').decode('utf-8') >>> s 'Абзац' >>> s.encode('utf-8') b'\xd0\x90\xd0\xb1\xd0\xb7\xd0\xb0\xd1\x86' >>>
в третьем можно str.translate() применить для такого результата
простой str.replace() тоже подойдёт, скорее всего
Отредактировано py.user.next (Авг. 24, 2012 13:32:27)
Офлайн
- Пожаловаться
#7 Авг. 24, 2012 13:32:35
UTF-8 в 1251
py.user.next
удаление ударениядля второго
>>> s = 'Абза́ц' >>> s '\xd0\x90\xd0\xb1\xd0\xb7\xd0\xb0\xcc\x81\xd1\x86' >>> s = s.replace('\xcc\x81', '') >>> s '\xd0\x90\xd0\xb1\xd0\xb7\xd0\xb0\xd1\x86' >>> print s Абзац >>>для третьего
>>> s = 'Абза́ц' >>> s.encode('utf-8') b'\xd0\x90\xd0\xb1\xd0\xb7\xd0\xb0\xcc\x81\xd1\x86' >>> s = s.encode('utf-8').replace(b'\xcc\x81', b'').decode('utf-8') >>> s 'Абзац' >>> s.encode('utf-8') b'\xd0\x90\xd0\xb1\xd0\xb7\xd0\xb0\xd1\x86' >>>
Спасибо, как оказалось, для 3 есть вариант по-проще:
>>> s = 'Абза́ц' >>> b=b'\xcc\x81' >>> s.replace(b.decode(),"") 'Абзац'
Офлайн
- Пожаловаться
#8 Авг. 24, 2012 13:36:43
UTF-8 в 1251
>>> s = 'Абза́ц' >>> s.encode('utf-8') b'\xd0\x90\xd0\xb1\xd0\xb7\xd0\xb0\xcc\x81\xd1\x86' >>> s = s.replace('а́', 'а') >>> s.encode('utf-8') b'\xd0\x90\xd0\xb1\xd0\xb7\xd0\xb0\xd1\x86' >>>
вот такой вариант имел в виду
Отредактировано py.user.next (Авг. 24, 2012 13:38:52)
Офлайн
- Пожаловаться
Вечно путаюсь в этих кодировках, поэтому решил сделать себе памятку. Покажу на примере.
Итак, кодировка исходного кода задается в первой-второй строке:
#-*-coding: UTF-8 -*-
Далее, допустим мы парсим какой-то сайт в windows-1251:
raw_data = urllib.urlopen(«bla bla bla»).read()
Мы получили данные, и сейчас они находятся в кодировке 1251, а исходник в utf-8, и нам нужно воспользоватся регулярками с кириллицей чтобы что-нибудь найти, выражение:
data = re.findall(r’Данные.*?<.*?>(.*?)<\/>’, raw_data)
выдаст нам пустой массив, потомому что данные в 1251 а регулярка в utf-8. В питоне есть несколько функций для перекодирования:
decode(‘WINDOWS-1251’) — декодирует строку из кодировки 1251 в ЮНИКОД(ЮНИКОД != UTF-8)
encode(‘UTF-8’) — кодирует строку из юникода в UTF-8.
Что касается Юникод vs UTF-8, то:
UNICODE: u’\u041c\u0430\u043c\u0430 \u043c\u044b\u043b\u0430 \u0440\u0430\u043c\u0443′
UTF-8: ‘\xd0\x9c\xd0\xb0\xd0\xbc\xd0\xb0 \xd0\xbc\xd1\x8b\xd0\xbb\xd0\xb0 \xd1\x80\xd0\xb0\xd0\xbc\xd1\x83’
нормальный вид: ‘Мама мыла раму’
Итак, чтобы у нас не было проблем с кодировками, нам достаточно сделать вот так:
raw_data = urllib.urlopen(«bla bla bla»).read().decode(‘WINDOWS-1251’).enco
de(‘UTF-8’)
И теперь наша запарсеная страница в той же кодировке что и исходник программы, и можно смело использовать кириллицу в регулярках, или в других ваших решениях. Конечно это не единственное решение, но в моем случае самое простое и удобное.
Столкнулся недавно с такой ситуацией, что пришлось открывать Windows файл в кодировке windows-1251, а там какие-то непонятные иероглифы. Так как я работаю в основном в Linux, то пришлось написать небольшую программу для конвертирования файлов в кодировку utf-8 и обратно.
Кому интересно создавать вот такие интерфейсы на Python, то представляю вашему вниманию исходный код этой программы.
- Home
- /
-
Windows-1251
- /
- Windows-1251 Encoding : Python
Welcome to our comprehensive guide on Windows-1251 encoding in Python! If you’re working with Cyrillic text or engaging with data from Eastern European languages, understanding Windows-1251 encoding is essential. In this article, we’ll explore what Windows-1251 encoding is, its importance in text processing, and how to effectively use it in Python. You’ll learn practical tips for encoding and decoding strings, handling data files, and troubleshooting common issues. Whether you’re a beginner or an experienced developer, this guide will equip you with the knowledge you need to manage text encoding seamlessly in your Python projects.
Introduction to Windows-1251
Windows-1251 is a character encoding system designed to support languages that use the Cyrillic alphabet, such as Russian, Bulgarian, and Serbian. Developed by Microsoft, it is widely used in various applications and systems. Windows-1251 is an 8-bit encoding scheme that can represent 256 different characters, including control characters, punctuation marks, and alphanumeric symbols. Understanding Windows-1251 encoding is essential for developers working with text data in these languages, especially when dealing with legacy systems or file formats that do not support Unicode.
Encoding text using Windows-1251 in Python is straightforward, thanks to the built-in encode() method. This method allows you to convert a string into bytes using the specified character encoding. Here’s how you can encode a string in Windows-1251:
# Sample string in Russian
text = "Привет, мир!" # "Hello, World!" in Russian
# Encoding the string using Windows-1251
encoded_text = text.encode('windows-1251')
# Displaying the encoded byte string
print(encoded_text) # Output: b'\xcf\xf0\xe8\xe2\xe5\xf2, \xec\xb8\xf0!'
In this example, the string «Привет, мир!» is encoded into a byte string using Windows-1251, which is suitable for storage or transmission in systems that require this encoding.
Decoding with Windows-1251 in Python
Decoding Windows-1251 encoded data back into a readable string format can also be accomplished using the decode() method in Python. This method converts bytes back into a string using the specified character encoding. Here’s an example:
# Sample byte string encoded in Windows-1251
encoded_text = b'\xcf\xf0\xe8\xe2\xe5\xf2, \xec\xb8\xf0!'
# Decoding the byte string back to a regular string
decoded_text = encoded_text.decode('windows-1251')
# Displaying the decoded string
print(decoded_text) # Output: Привет, мир!
This example demonstrates how to reverse the encoding process, allowing you to retrieve the original string from its byte representation.
Advantages and Disadvantages of Windows-1251
Advantages
- Simplicity: Windows-1251 is straightforward and easy to implement, especially for applications targeting Cyrillic languages.
- Legacy Support: Many older systems and applications still use Windows-1251, making it essential for compatibility with legacy data.
- Efficiency: Being an 8-bit encoding, it can be more efficient in terms of storage when dealing with Cyrillic text compared to multi-byte encodings like UTF-8.
Disadvantages
- Limited Character Set: Windows-1251 only supports Cyrillic characters, making it unsuitable for multilingual applications that require broader character support.
- Lack of Standardization: Unlike Unicode, which is a universal standard, Windows-1251 is proprietary and may not be recognized across all platforms.
- Potential Data Loss: When converting between Windows-1251 and other encodings, there is a risk of data loss or corruption for characters not supported by Windows-1251.
Key Applications of Windows-1251
Windows-1251 is primarily used in applications that need to display or process text in Cyrillic scripts. Key applications include:
- Text Editors: Many text editors support Windows-1251 for editing documents in Russian and other Cyrillic languages.
- Web Development: Websites targeting Russian-speaking audiences may use Windows-1251 encoding in their HTML pages and server responses.
- Databases: Legacy database systems often rely on Windows-1251 encoding for storing and retrieving text data in Cyrillic languages.
Popular Frameworks and Tools for Windows-1251
Several programming frameworks and tools support Windows-1251 encoding, making it easier for developers to work with Cyrillic text:
- Flask: A lightweight web framework for Python that allows you to specify character encoding in HTTP responses.
- Django: A high-level Python web framework that supports various character encodings, including Windows-1251, for internationalization.
- Pandas: A powerful data manipulation library in Python that can read and write CSV files encoded in Windows-1251.
By utilizing these frameworks and tools, developers can seamlessly integrate Windows-1251 encoding into their applications, ensuring proper handling of Cyrillic text.