
Большинство браузеров сейчас имеют графический интерфейс – страницы представлены в ярком виде, с изображениями, анимацией и рекламными объявлениями. Но есть отличный аналог им – консольные браузеры, в которых отображается только текст, без единого графического элемента. Сегодня я рассмотрю самые лучшие консольные браузеры для Linux, Windows и macOS, рассмотрю их основные преимущества, способы установки и правила пользования.
Lynx
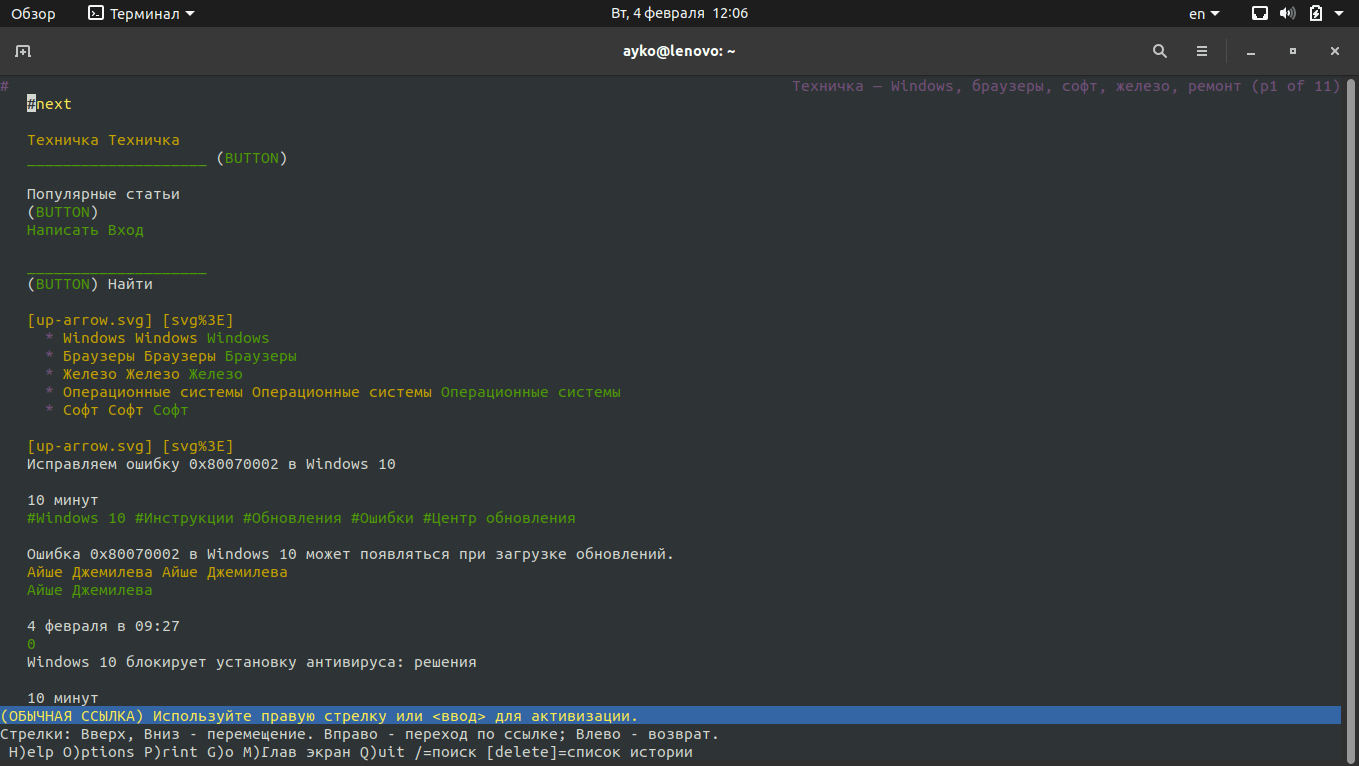
Мне нравится, что ссылки и простой текст в браузере Lynx выделены разными цветами
Это один из самых первых и наиболее известных текстовых браузеров, который был выпущен в далеком 1992 году. Работает практически на всех операционных системах, основанных на Unix. Оптимизирован для слабовидящих. Используется чаще всего для проверки достоверности информации на сайте при ее проверке ботами.
Официальный сайт – lynx.browser.org. Распространяется бесплатно, с открытым исходным кодом.
Как пользоваться Lynx
Для открытия браузера в ОС Linux необходимо ввести команду lynx или lynx <URL-адрес>. Для перемещения по элементам используется курсор и кнопки вверх-вниз. Перейти по активной гиперссылке (подсвечивается зеленым) можно нажатием на кнопку «вправо» на клавиатуре, а кнопка «влево» вернет на предыдущую страницу. Вот некоторые клавиши и их комбинации, запускающие актуальные команды.
- / — поиск по странице.
- Del – история просмотров.
- Ctrl + R — повторная загрузка текущей страницы.
- H – открытие окна помощи для пользователя.
- – переход к параметрам браузера.
- P — печать текущей страницы.
- L — открытие списка всех URL-адресов в текущем документе.
- M — переход на главный экран.
- = — подробная информация о текущем сайте, в том числе тип сервера, дата последнего изменения, кодировка и размер.
- Q – выход из приложения.
Поддерживаемые платформы
- GNU, Linux.
- Minix.
- HP-UX.
- Sun Solaris.
- IBM AIX.
- OS/2.
- macOS.
Преимущества
- Поддержка популярных протоколов, таких как HTTP, FTP, WAIS, Gopher и так далее.
- Есть SSL-шифрование.
- Выбор ссылки по номеру.
- Возможность быстрой загрузки страниц на слабых компьютерах и при низкой пропускной способности сети.
- Работа с удаленным доступом.
Недостатки
- Не поддерживает фреймы и JavaScript.
- Таблицы отображаются в виде столбика.
- Отсутствует поддержка Adobe Flash.
- Могут быть проблемы с конфиденциальностью.
Как установить
- Linux – ввести команду sudo apt install lynx в командной строке «Терминал».
- Windows – скачать с официального сайта.
- macOS – скачать Homebrew и ввести команду brew install lynx
w3m
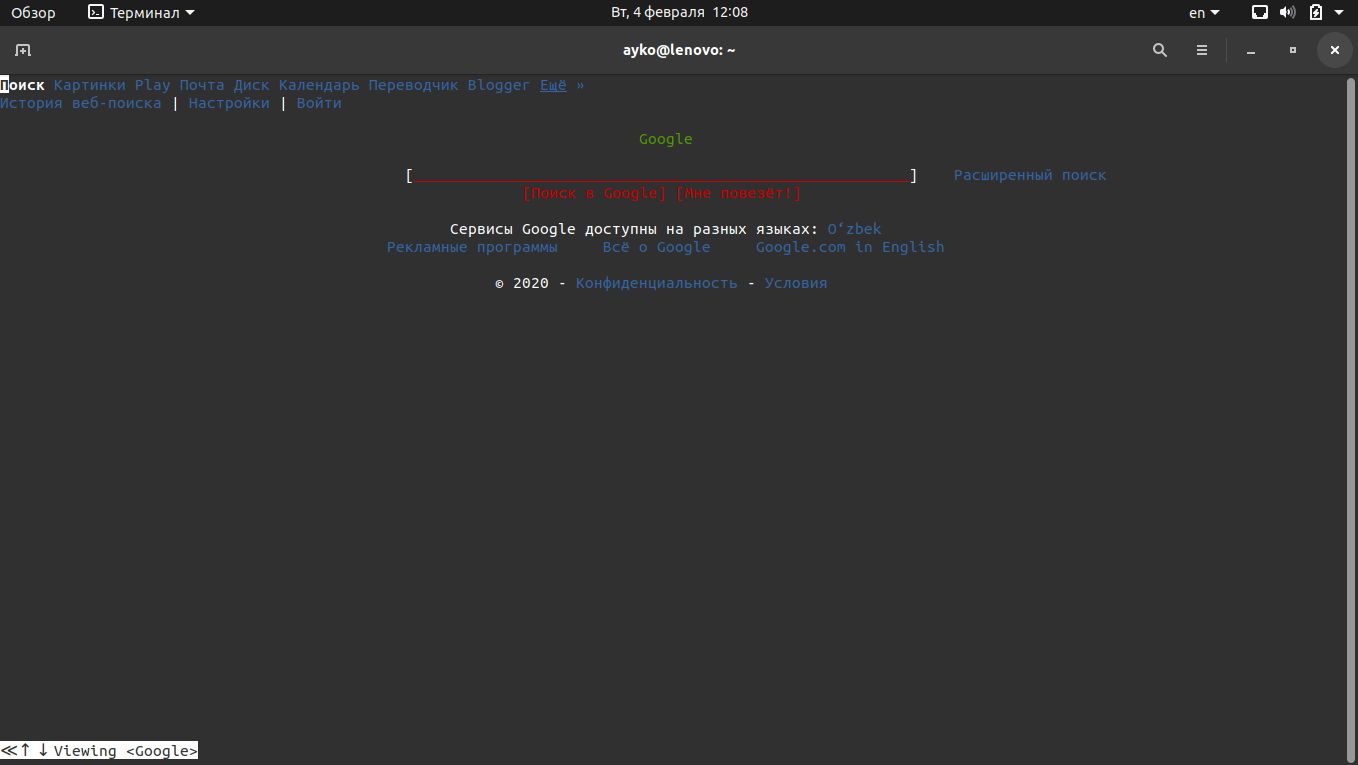
Стартовая страница Google в браузере w3m выглядит примерно вот так. Отмечу, что поисковая строка расположена посередине – приятная мелочь все же
Браузер w3m специально создавался для быстрого просмотра HTML страниц. В некоторых местах он похож на Lynx, но отличия все же есть, к примеру, в навигации по странице. Внешне w3m мне больше нравится, если сравнивать его с предыдущим консольным браузером. Для просмотра изображений в браузере необходимо открыть его в режиме фреймбуфера, и графический сервер запускать не придется.
Официальный сайт – w3m.sourceforge.net
Как пользоваться w3m
Для открытия браузера необходимо в командной строке «Терминал» ввести запрос w3m и адрес ссылки.
- Tab – переход между гиперссылками.
- Клавиши вверх-вниз, влево-вправо – перемещение между элементами.
- Shift + B – возврат на предыдущую страницу.
- Shift + U – загрузка другого URL адреса.
- Shift + H – просмотр всех клавиатурных комбинаций.
- Shift + T – открытие новой вкладки.
- Shift + [ и Shift + ] – переключение между вкладками.
Поддерживаемые платформы
Браузер w3m поддерживает Unix-подобные системы и все дистрибутивы Linux. Установщик для Windows доступен на сайте sourceforge.net. Есть еще поддержка в macOS — для инсталляции необходимо установить тот же Homebrew и ввести команду brew install w3m в командной строке «Терминал».
Преимущества
- Поддержка изображений, таблиц и куки (опционально).
- Отображение документа, переданного через поток stdin.
- Поддержка мыши через консоли xterm или gpm.
- Работа в интерфейсе Emacs.
Недостатки
- Отсутствие поддержки JavaScript.
- Последняя версия была выпущена в 2011 году.
Как установить
Linux – ввести в командной строке «Терминал» команду sudo apt install w3m
Windows – скачать браузер с сайта w3m.sourceforge.net
macOS – установить репозиторий Homebrew и скачать браузер, введя в командной строке запрос brew install w3m
Links
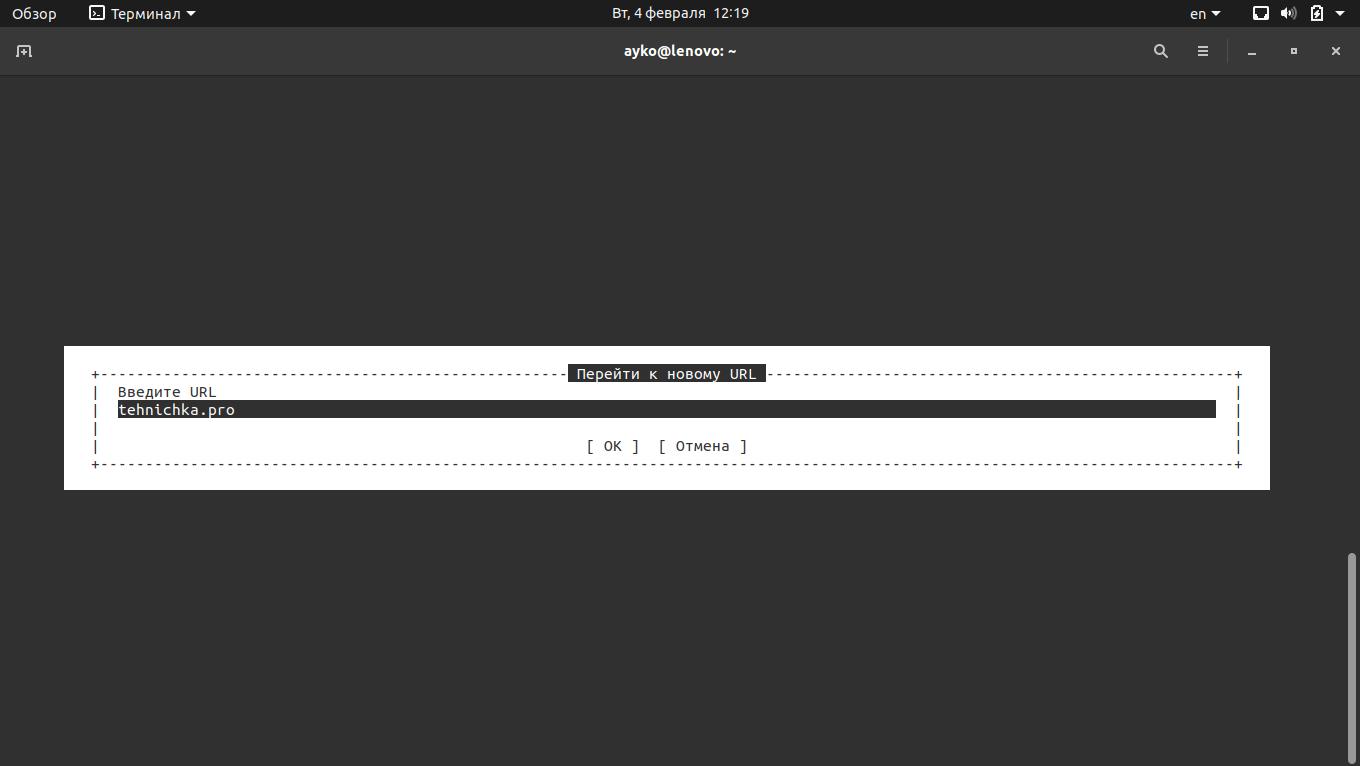
Вот так надо набирать URL-адрес в консольном браузере Links
Links в плане интерфейса более или менее похож на традиционные графические браузеры – в нем предусмотрено меню управления, да и адрес ссылки в нем ввести куда проще, чем в предыдущих аналогах. Кроме того, можно переходить по ссылкам и листать страницы с помощью мыши. В общем, именно с него началась «эра консольных браузеров, с которыми удобно работать», так как на его основе создавались Links2, ELinks и многие другие.
Официальный сайт – links.twibright.com
Как пользоваться Links
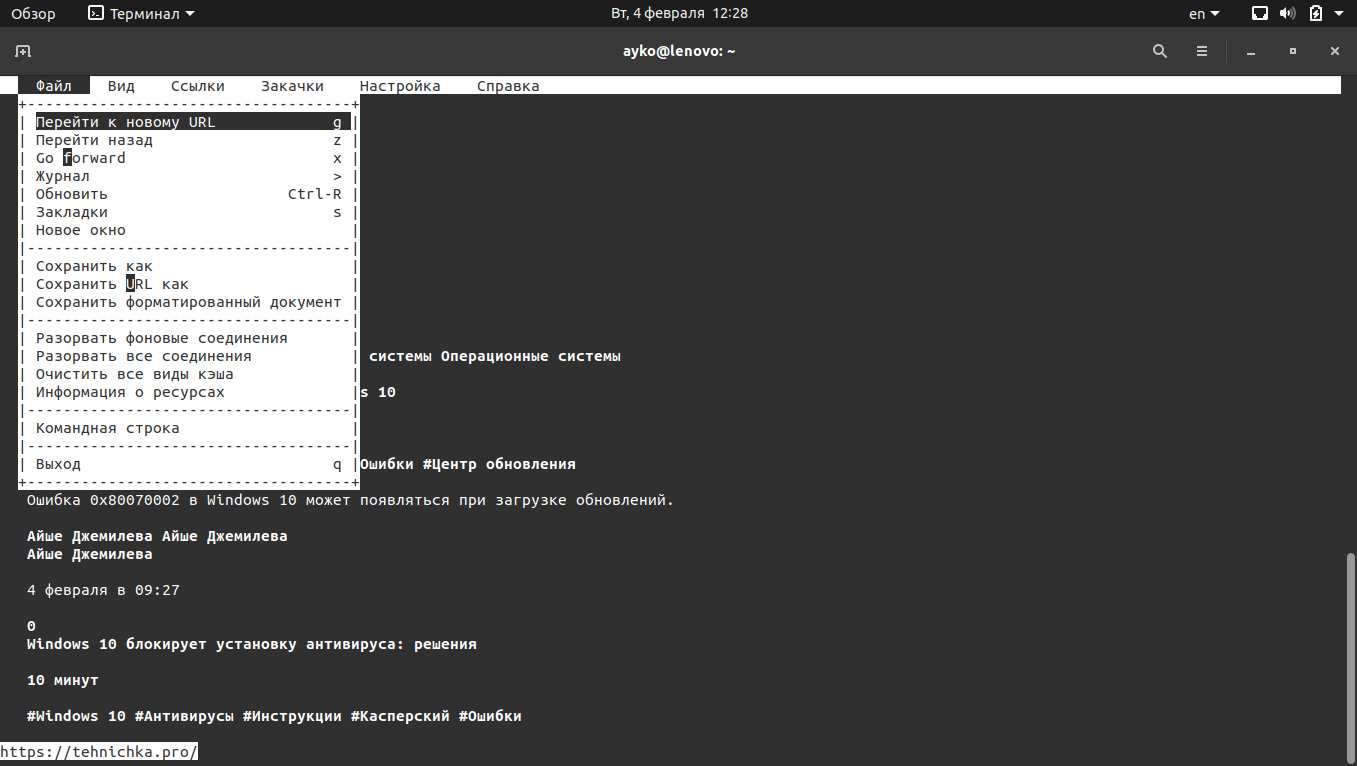
В меню напротив каждого пункта указана горячая клавиша, отвечающая за запуск этой функции
- Esc – выход к меню управления.
- G – ввод нового URL-адреса.
- Ctrl + R – обновление страницы.
- Q – выход из браузера.
- / — поиск по странице.
- Клавиши вверх-вниз – навигация по элементам.
- F1 – просмотр списка доступных горячих клавиш и связанных с ними операций.
Поддерживаемые платформы
- Linux, почти все дистрибутивы.
- Windows, причем как для 32, так и для 64-разрядных систем.
- OS/2.
- Прочие Unix-подобные системы.
- macOS.
Преимущества
- Постоянный выход обновлений.
- Есть возможность отображения графики.
- Использование шрифтов разного размера.
- Поддержка фреймов, вкладок, таблиц и JavaScript.
Недостатки
- Не выявила.
Как установить
Linux – ввести в «Терминале» запрос sudo apt install links
Windows – скачать установщик с официального сайта.
macOS – ввести в «Терминале» brew install links
Elinks
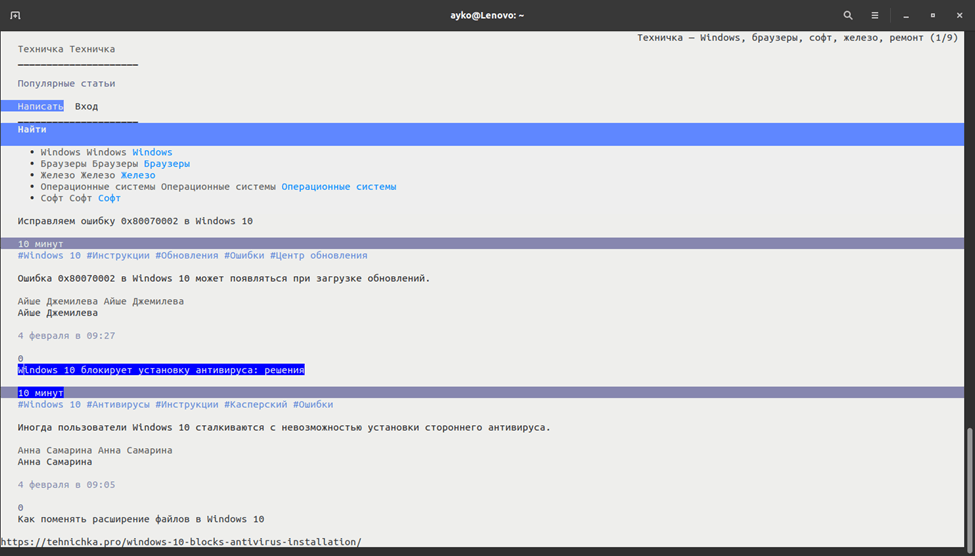
Из всех рассмотренных мной браузеров Elinks единственный, отображающий страницы на светлом фоне
Это, так сказать, усовершенствованная версия Links. Приставка E расшифровывается как экспериментальный. Интерфейс у него приятен и куда более продвинут, отдельные блоки на странице выделяются. К тому же, пользователь сможет провести полную кастомизацию и расширить функционал браузера с помощью скриптов Lua или Guile.
Официальный сайт — elinks.or.cz
Как пользоваться
Навигация в данном браузере осуществляется как клавишами вверх-вниз, так и с помощью компьютерной мыши. Можно не только прокручивать страницу, но также выбирать конкретные элементы и открывать ссылки. Есть еще некоторые важные горячие клавиши, которые пригодятся пользователю.
- Esc — вызов меню управления.
- T — открытие новой вкладки.
- G — ввод нового URL-адреса.
- Q — выход из браузера.
- / — поиск по странице.
- Ctrl + R — перезагрузка открытой страницы.
- D — переход ко списку закачанных файлов.
Поддерживаемые платформы
- Linux, почти все дистрибутивы.
- Unix-подобные системы.
- Windows.
- macOS.
Преимущества
- Поддержка таблиц и фреймов.
- Возможность отображения палитры в 16, 88 и 256 цветов.
- Работа с HTTP, HTTPS, FTP и proxy.
- Фоновая загрузка с уведомлением об ее окончании.
- Возможность работы с несколькими вкладками.
- Полная поддержка кодировки UTF-8.
- Экспериментальная поддержка протокола BitTorrent, соответственно, есть возможность закачки файлов через торрент-трекеры.
Недостатки
- В последний раз обновление выходило в 2012 году.
- Отключена поддержка libgnutls-openssl.
Как установить
Linux – ввести в командной строке запрос sudo apt install elinks
Windows – скачать архив с официального сайта и распаковать.
macOS – ввести команду brew install elinks
Edbrowse
Edbrowse – это не только консольный браузер, но и почтовый клиент, и даже редактор. Изначально он создан для пользователей со слабым зрением, но при этом стал востребован у всех остальных благодаря своим уникальным возможностям, которых больше нигде нет. Основан на языке программирования Perl, поэтому первое время поддерживался практически на всех операционных системах, поддерживающих его.
Официальный сайт – edbrowse.org
Поддерживаемые платформы
- Unix-подобные системы.
- Любые ОС, поддерживающие язык программирования Perl.
Преимущества
- Одновременное редактирование нескольких файлов.
- Рендеринг HTML.
- Отправка различных форм и электронной почты без вмешательства пользователя.
- Поддержка JavaScript, прокси и фреймов.
- Портативный формат.
- Наличие встроенного почтового клиента.
Недостатки
- Недостаточное количество официальной информации.
- Отсутствие обновленных источников для скачивания.
- Необходима самостоятельная сборка.
Links2
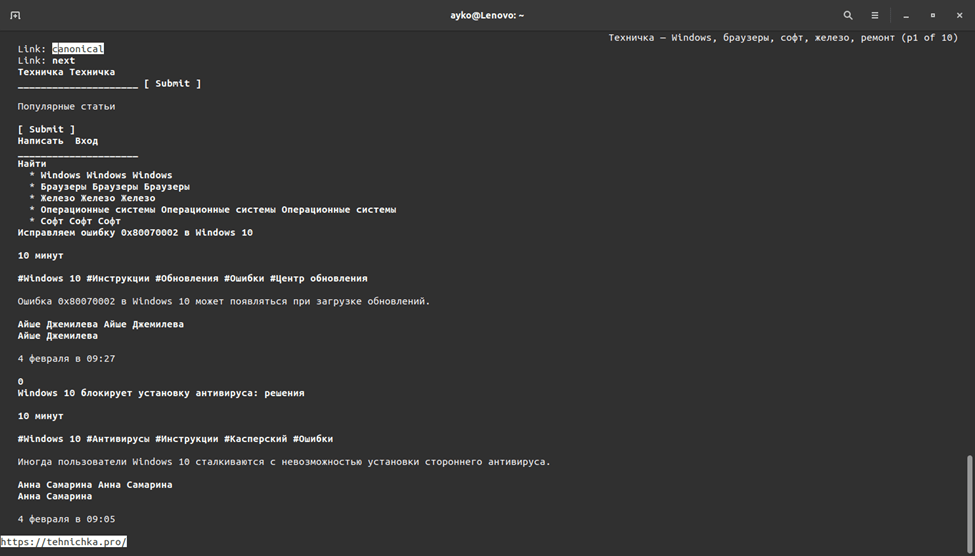
Интерфейс браузера Links2 в точности походит на предшественника – Links
Еще одно ответвление консольного браузера Links с более усовершенствованным функционалом. Только вот внешне он ничем не изменился — по умолчанию остался таким же черно-белым. Хотя когда-то говорилось, что цветной интерфейс с загрузкой графики все же поддерживается в Links2, да и JavaScript имеется. Для отображения картинок и прочих графических элементов необходимо запускать его из командной строки с ключом -g.
Официальная страница — links.twibright.com
Как пользоваться
- Клавиши вверх-вниз — навигация по странице.
- G — ввод и переход к новому URL-адресу.
- Z — возврат к предыдущей странице.
- Ctrl + R — обновление текущей страницы.
- S — открытие окна с закладками.
- Q — выход из браузера.
- D — скачивание по ссылке.
- F1 — просмотр доступных комбинаций горячих клавиш.
Поддерживаемые платформы
- Linux, почти все современные дистрибутивы.
- Windows.
- Unix-подобные системы.
Преимущества
- Отображение изображений в форматах PNG, JPEG, GIF, TIFF и XBM.
- Использование сглаженного шрифта.
- Масштабирование изображений.
- Изменение соотношения сторон картинок и возможность проведения гамма-коррекции.
- Поддержка работы через proxy.
- Возможность просмотра HTML-кода страницы.
- Ведение истории посещенных сайтов.
- Наличие встроенного менеджера закачек.
Как установить
Linux – ввести запрос sudo apt install links2
Windows – скачать установщик в виде архива с официального сайта.
Netrik
Еще один отличный текстовый браузер, разработка которого началась еще в 2001 году. Данный пример отличается именно хорошим пользовательским интерфейсом и уникальными функциями. В этой программе есть все, что необходимо для удобного базового просмотра страниц в сети Интернет – не больше, но и не меньше.
Официальный сайт – netrik.sourceforge.net
Поддерживаемые платформы
- Unix-подобные системы.
- ОС Windows.
- Linux.
Преимущества
- Одновременная работа с несколькими окнами или вкладками.
- Поддержка горизонтальной прокрутки (такого еще не было не в одном из вышеуказанных примеров).
- Ведение истории посещенных страниц.
- Поддержка JavaScript и CSS.
- Работа с юникодом UTF-8.
Недостатки
- Отсутствие поддержки фреймов.
- Имеет меньше функций, в сравнении с предыдущими браузерами.
Как установить
Linux – ввести в строке «Терминала» запрос sudo apt install netrik (у меня команда сработала, но браузер не запустился; вероятно, она уже не актуальна, и лучше качать установщик с сайта sourceforge.net).
Windows – скачать с сайта sourceforge.net/projects/netrik/
Заключение
Из всех вышеперечисленных браузеров отмечу именно Links, исходящие из него Links2 и ELinks, а также w3m. Больше всего мне пришелся по душе именно Links2 – он объединяет в себе практически все возможные и невозможные функции, да и просто работать с ним крайне удобно. Edbrowse не особо вдохновил, в особенности тем, что о нем практически нет информации. Но и исключать его не стоит, своим функционалом он заслуживает внимания. А Netrik хоть и произвел на меня впечатление, толком поработать я я на нем не смогла. Если у вас будут какие-то дополнения к этой статье, пишите в комментариях, делитесь своим мнением.
Загрузка …
Post Views: 3 589
Время на прочтение3 мин
Количество просмотров172K
Введение
Самое простое и в то же время полное определение текстового браузера — это приложение, которое отображает только текстовое содержимое web-сайтов. При работе с таким браузером вы не увидите так нами горячо любимых всплывающих баннеров. Во многих живущих ныне текстовых браузерах контент нагружающий трафик блокируется. Главный аспект применения текстовых браузеров, заключается в том, что их можно и нужно использовать в тех системах, где не предусмотрена графическая оболочка. В первую очередь, это, конечно, касается разнообразных UNIX-подобных операционных систем, но под MS Windows так же существуют аналоги. В этой статье хотелось бы описать некоторые текстовые браузеры и их возможности.
Lynx
Lynx — является одним из первых и наиболее известным из текстовых браузеров, на данный момент поставляется в комплекте практически с любой *nix системой. Не имеет поддержки таблиц, фреймов и Java Script. Распространяется по лицензии GNU GPL.
Часто данный браузер используется для проверки, увидит ли бот поисковой системы все изменения на сайте, которые были произведены. Поддерживает протоколы: HTTP, FTP, Gopher, WAIS, NNTP.
Поддерживаемые операционные системы и платформы:
— GNU/Linux, Minix
— *BSD
— HP-UX, Sun Solaris, IBM AIX,
— Windows и OS/2, а также DOS
— BeOS, ZetaOS
Ссылки для скачаивания:
— Windows — lynx
— *Nix — ищите в репозитариях, есть практически во все популярных дистрибутивах
Домашняя страница — lynx
Edbrowse
Edbrowse — практически полностью реализованный на Perl текстовый браузер. Главный разработчик браузера Karl Dahlke. На данный момент доступны версии для Windows и *nix. Имеется поддержка фреймов, java script, так же имеется встроенный почтовый клиент и поддержка proxy.
Домашняя страница — Edbrowse
W3M
w3m — еще один текстовый браузер. Основной целью создания данного текстового браузера, является создание инструмента для быстрого просмотра HTML-страниц. Похож на Lynx, но в отличие от него некоторые операции, такие как навигация по страницам, выполняются немного по другому. Так же в отличие от Lynx может отрисовывать таблицы и фреймы и отображать документ, переданный через поток stdin. В xterm- или gpm-консоли поддерживает мышь. Существует интерфейс к w3m для Emacs под названием emacs-w3m, обеспечивающий просмотр веб-страниц в Emacs.
Домашняя страница проекта — w3m
Links
Links — наиболее популярный текстовый браузер, базирующийся на текстовом браузере Lynx, но в отличие от своего родителя имеет следующие особенности: имеется поддержка фреймов, вкладок, таблиц и java script. Браузер распространяется под лицензией GNU GPL.

Домашняя страница — Links
Elinks
Elinks — текстовый браузер, базирующийся на браузере Links. Имеется поддержка таблиц, фреймов, цветовой палитры в 16, 88 или 256 цвета, HTTP, HTTPS, FTP и proxy аутентификацию, фоновые загрузки с оповещением об окончании загрузки, встроенная поддержка пользовательских протоколов: IRC, mailto, telnet, а также nntp и Gopher. Частично реализована поддержка каскадных стилевых таблиц CSS и ECMAScript, также присутствует поддержка вкладок (так называемых табов), и полная поддержка ввода/вывода UTF-8.
Домашняя страница — Elinks
Links2
Links2 — ближайший родственние Links. В отличие от Links в нем произведены графические улучшнеия, добавили поддержку java script. Так же имеется графический режим. По умолчанию Links2 работает в текстовом режиме, а чтобы был доступен графический, надо включить его поддержку на этапе конфигурирования перед компиляцией. Что до запуска Links2 в графическом режиме, то для этого нужно запустить браузер из терминала с ключом -g.

Домашняя страница — Links2
Netrik
Netrik — текстовый браузер, подобный w3m. Основной целью текстового браузера Netrik является использование vi-совместимых клавиш и макросов для просмотра интернет ресурсов. Работает с несколькими окнами, поддерживает JavaScript, CSS.
Домашняя страница — Netrik
А так же менее популярные, но тоже давольно широко используемые среди текстовых веб браузеров:
*W3mmee — вариант W3m с расширенной поддержкой кодировок;
*Debris — на 25% меньше lynx, но с поддержкой форм и таблиц;
*Zen web browser — Консольный web-браузер, отличающийся возможностью отображения с использованием Frame Buffer, т.е. умеет отображать картинки, без необходимости запуска X Window и предъявляя минимальные требования к размеру ОЗУ;
p.s. В этой статье описаны конечно же не все текстовые браузеры, здесь описаны те которыми я либо пользовался либо пытался пользоваться, а так же наиболее популярные из ныне существующих.
UDP. Добавил информацию об Links2. Cпасибо хаброюзеру ilembitov
Отдельная благодарность за исправления — 2sexy2lazy,pwd,bolk
You are here:Home » Command Line Web Browsing : Full Guide
Advertisement
Command Line Web Browsing is of fun, useful and actually fast and safe. We can use Lynx, Links like Free Software on UNIX / OS X, Linux or Windows to surf. For some special social networks, specially which are dependent on API based login or forces to accept cookies might require separate command line applications. We wrote about them before, we will go in to that part later. First let us understand, why we will use a command line browser instead of a normal web browser ? The answer is for increasing speed – we basically read the text and for more control of security and privacy. This security and privacy practically difficult to control with a visual web browser. Richard M. Stallman made the command line browsing quite popular – it is good that many new users are now getting interested about Command Line Web Browsing. Richard M. Stallman, usually wget the webpages and then open it locally. The tracking javascripts will fail to catch your information and send them. It is quite practical thought for browsing unknown websites. We will show different methods which any level of users can use.
Command Line Web Browsing : But Google Will Not Love
Any Advert related Internet brand’s work is to steal the users data, now with PRISM scandal, it is good that the common men are getting aware of Security and Privacy. Honestly, we can not say what data of you is getting stolen from this web page when you are viewing it on a typical graphical browser. Their need to steal data is for the sake of Adverts, which usually said as ‘interest based ads’. For making you interested, the data is stolen. You can read more on how data is stolen from Richard Stallman’s website :
If there was no intention of data theft; they could use old good text ads. Anyway, thats a separate topic. You can also read other special packages for specific social networks :
- Using Facebook From Command Line Interface
- Google Search from Command Line Interface
- Using Twitter From Command Line Interface
There is also WordPress Command Line Tool for blog owners.
Command Line Web Browsing : Tools of Trade
For full command line browser, there are three known options :
- Lynx
- Elinks
- Links
All can be installed with normal commands for UNIX or UNIX like OSes. You can setup Microsoft Windows PC (we do not recommend to use Windows OS ) like UNIX in this way. It depends on your Unix skill how you can avoid the default installation way for Windows – for Lynx like browser. It is possible to make packages and install them. For Apple OS X (again, there is question of data theft, but from command line if you can configure properly, the chance of data theft is lessened but never can be ruled out), you can use brew command in the way we wrote for another purpose. So, for Linux and UNIX / OS X, the commands to install Lynx and Links become easy :
Like for Debian based, REHL based or UNIX / OS X respectively :
and so on. The official websites are :
|
http://links.twibright.com/user_en.html |

Links can show graphics. By default, Links will not support graphics – you need to compile links for OS X :
|
./configure —enable—graphics |
This can be discussed separately. To open a webpage on Lynx, just type the url with lynx command :
|
lynx https://thecustomizewindows.com/ |
|
lynx http://stallman.org/ |
For our website, you have to accept cookies twice. But for Stallman’s website, you will not need to accept cookies. For our page, type Y and hit enter. The cookies are spying you – they are of Google’s products. Also try with N with our website – it will open, we kept it as opt in. But there are websites which will not allow you to continue.
Tagged With command line browser windows , windows web surfing command , command line web browser for windows , command for browsing on command , Command cmd link web , comman line web browser windows , cli website , cli browser on windows , browsing web with cmd windows , browsing web from the cli in windows
Abhishek Ghosh is a Businessman, Surgeon, Author and Blogger. You can keep touch with him on Twitter — @AbhishekCTRL.
Here’s what we’ve got for you which might like :
performing a search on this website can help you. Also, we have YouTube Videos.
Take The Conversation Further …
We’d love to know your thoughts on this article.
Meet the Author over on Twitter to join the conversation right now!
If you want to Advertise on our Article or want a Sponsored Article, you are invited to Contact us.
Contact Us
Skip to content
It is very hard to believe for the modern generations that there was a time when the web sites were mostly text based conglomeration of pages. Obviously, you did not need graphical user interface to visit these web sites. The web browsers as well as the operating systems had command line interface. You could fetch the web pages and view at the textual information they had – no images, no animations and no videos. One of the most popular web browsers in those times was the Lynx web browser. Lynx browser allowed you to browse around a web site comfortably and displayed the text based web pages in a command line interface.
If you want to have some of that nostalgic fun of accessing web sites using Lynx once again then you can install Lynx in your Windows machines. Some people have managed to keep the Lynx alive all these years and have been updating it to support the latest server protocols and commands. You can download and install the Lynx browser for Windows and launch it from its desktop shortcut.
If you want to change the startup page or the home page for the Lynx browser, then you have to open the Lynx installation folder, find the lynx.cfg file and edit the STARTFILE: line in this file. By default this entry points to the download webpage.

One thing you would notice that Lynx asks you permission for each and every cookie stored by websites – an old school practice of handling cookies that seems to have disappeared in the modern day web browsers. You can choose to accept or reject the cookies.
If you want to open a URL by typing it in the Lynx interface, then you have to press the G key and then type in the URL followed by the Enter key. Similarly, you can open the options by pressing the O key, print the current web page using the P key or close the browser window using the Q key.
The new age web sites are obviously not designed to work well with the Lynx’s text based interface, but Lynx still manages to do the job just like it used to in the early 90’s.
You can download the Lynx web browser for Windows from http://invisible-island.net/lynx/#installers.
We use cookies on our website to give you the most relevant experience by remembering your preferences and repeat visits. By clicking “Accept”, you consent to the use of ALL the cookies.
edbrowse, a line oriented editor browser.
Written and maintained by Karl Dahlke and others.
See our home page edbrowse.org for current releases and contact information.
See LICENSE for licensing agreements.
The history directory contains information on the history of edbrowse,
how it came to be and what it is trying to accomplish.
You might want to read that first, if you are unfamiliar with the project.
history/article.wikipedia is our wikipedia article, written in markup.
It was deleted by the wikipedia maintainers, for lack of sources.
If edbrowse is described in a book or mainstream magazine in the future,
perhaps this article can be reintroduced.
------------------------------------------------------------
Disclaimer: this software is provided as-is,
with no guarantee that it will perform as expected.
It might trash your precious files.
It might send bad data across the Internet,
causing you to buy a $37,000 elephant instead of
$37 worth of printer supplies.
It may delete all the rows in your mysql customer table.
Use this program at your own risk.
------------------------------------------------------------
Chrome and Firefox are graphical browsers.
Lynx and Links are screen browsers.
This is a command line browser, the only one of its kind.
The user's guide can be found as doc/usersguide.html in this package,
or online at http://edbrowse.org/usersguide.html.
The online guide corresponds to the latest stable release.
Of course this reasoning is a bit circular.
You need to use a browser to read the documentation,
which describes how to use the browser.
Well you can always do this:
cd doc ; lynx -dump usersguide.html >usersguide.txt
This produces the documentation in text form,
which you can read using your favorite editor.
Of course we hope edbrowse will eventually become your
favorite editor, whence you can browse the documentation directly.
The doc directory also includes a sample config file.
------------------------------------------------------------
OK, I'm going to assume you've read the documentation.
No need to repeat all that here.
You're here because you want to compile and/or package the program,
or modify the source in some way. Great!
There are more substantial, step by step instructions for building edbrowse from source,
on various platforms, in the edbrowse wiki.
If you run into trouble you may want to consult those; this is an overview.
Requirements:
pcre:
As you may know, edbrowse was originally a perl script.
As such, it was only natural to use perl regular expressions for
the search/substitute functions in the editor.
Once you've experienced the power of perl regexp, you'll never
go back to ed. So I use the perl-compatible regular expression
library, /lib/libpcre2-8
If you don't have this file, check your available packages.
the pcre and pcre-devel packages might be there, just not installed.
As of this writing, you need pcre2-8, which is generally available.
Note that buffers.c includes <pcre2.h>.
Some distributions put it in /usr/include/pcre2/pcre2.h,
so you'll have to adjust the source, the -I path, or make a link.
libcurl:
You need libcurl and libcurl-devel,
which are included in almost every Linux distro.
This is used for ftp, http, and https.
Check for /usr/include/curl/curl.h
Edbrowse requires version 7.29.0 or later. If you compiled with a version
prior to 7.29.0, the program will inform you that you need to upgrade.
If you have to compile curl from source, be sure to specify
--ENABLE-VERSION-SYMBOLS at the configure script.
It's rare, but curl, and hence edbrowse, cannot access certain websites,
giving the message
Cannot communicate securely with peer: no common encryption algorithm(s).
You can even see this from the command line.
curl https://weloveanimals.me
You'll either get the communication error or not.
This happens if openssl is too old,
or just doesn't support the ciphers that the website expects.
This is beyond edbrowse, and beyond curl; you have to upgrade openssl.
unixODBC:
Edbrowse provides database access through odbc.
Thus you need unixODBC and unixODBC-devel.
ODBC has been stable for quite some time.
unixODBC version 2.2.14 seems to satisfy edbrowse with odbc.
quickjs:
This is the javascript engine for edbrowse. It is not packaged,
in most distributions, so you will need to build it from source.
git clone https://github.com/bellard/quickjs
It is best to clone this tree in a directory adjacent to edbrowse.
That is, edbrowse and quickjs are in the same directory.
If you are unable to do this, set QUICKJS_INCLUDE and QUICKJS_LIB
to the quickjs directory tree before you build edbrowse.
cd quickjs
make
If you get a lot of atomic undefines:
make EXTRA_LIBS=-latomic
Even with this, some targets do not link properly on some platforms,
but I get the static library libquickjs.a, and qjs, which is all I need.
By default, edbrowse links to this library, and thus the
quickjs code is part of edbrowse, and a quickjs package,
or a dependency thereto, is not necessary.
If your distribution provides quickjs like a prebuilt package,
set QUICKJS_INCLUDE to the quickjs directory containing its
library header files, and QUICKJS_LIB to the directory containing
the libquickjs.a static library.
------------------------------------------------------------
Compiling edbrowse:
For a time, edbrowse could be built on windows, but this is no longer supported.
On all other systems, you should be able to use make.
cd src
make
The makefile supports the environment variables EBDEBUG=on,
(or yes or y or 1 or any nonempty string),
for symbolic debugging via gdb, and EBDEMIN=on for javascript deminimization.
Distributors should not set these flags.
You can test the executable by edbrowse src/jsrt
jsrt means javascript regression test.
You will get a number, the size of the file, just as you would from /bin/ed.
Then type b for browse.
You should get something like this; if you do then all is well.
relative
body loading
complete
688
30 seconds have passed!
lines 31 through 32 have been added
------------------------------------------------------------
Edbrowse creates a system wide temp directory if it is not already present.
This is /tmp/.edbrowse.
This directory contains a subdirectory per user, mod 700 for added security.
Thus one user cannot spy on the temp files, perhaps sensitive internet data,
of another user.
However, true multiuser security requires a root job at startup,
e.g. in /etc/rc.d/rc.local, to create the directory with the sticky bit.
mkdir /tmp/.edbrowse
chmod 1777 /tmp/.edbrowse
------------------------------------------------------------
The code in this project is indented via the script Lindent,
which is in the tools directory, and is taken from the Linux kernel source.
In other words, the indenting style is the same as the Linux kernel.
Except it isn't always.
I've drifted away from it on occasion.
If the statement under the if is just a break or continue or return,
I may well put it on the same line.
It's really not that important all in all, especially to blind developers.
If you take over this project, or send patches,
try to sort of follow our indenting style.
------------------------------------------------------------
Debug levels:
0: silent
1: show the sizes of files and web pages as they are read and written
2: show the url as you call up a web page,
and http redirection.
3: javascript execution and errors.
cookies, http codes, form data, and sql statements logged.
4: show the socket connections, and the http headers in and out.
side effects of running javascript.
Dynamic node linkage.
5: messages to and from javascript, url resolution.
Show mail headers when browsing a mail file.
6: show javascript to be executed
Show the entire email without sending it.
7: reformatted regular expressions, breakline chunks,
JSValues allocated and freed.
8: text lines freed, debug garbage collection
9: not used
Casual users should not go beyond db2.
Even developers rarely go beyond db4.
------------------------------------------------------------
Sourcefiles as follows.
src/main.c:
Read and parse the config file.
Entry point.
Command line options.
Invoke mail client if mail options are present.
If run as an editor/browser, treat arguments as files or URLs
and read them into buffers.
Read commands from stdin and invoke them via the command
interpreter in buffers.c.
Handle interrupt.
src/buffers.c:
Manage all the text buffers.
Interpret the standard ed commands, move, copy, delete, substitute, etc.
Run the 2 letter commands, such as qt to quit.
src/stringfile.c:
Helper functions to manage memory, strings, files, directories.
src/isup.c:
Internet support routines.
Split a url into its components.
Decide if it's a proxy url.
Resolve relative url into absolute url
based on the location of the current web page.
Send and receive cookies. Maintain the cookie jar.
Maintain a cache of http files.
Remember user and password for web pages that require authentication.
Only the basic method is implemented at this time.
Determine the mime type of a file or web page and the corresponding plugin,
if any. Launch the plugin automatically or on command.
A plugin can play the file, like music, or render the file, like pdf.
Run as an irc client.
src/format.c:
Arrange text into lines and paragraphs.
base64 encode and decode for email.
Convert utf8, iso8859-1, unicode 16, unicode 32, etc.
Process an html page for final display.
Manage emojis.
International print routines to display messages according to your locale.
src/http.c:
Send the http request, and read the data from the web server.
Handles https connections as well,
and 301/302 redirection.
gopher, ftp, sftp, download files, possibly in the background.
src/html-tags.c:
htmlScanner(), scan the html tags and build a tree of nodes.
prerender(), establish attributes and linkages among these nodes.
decorate(), decorate the tree with js objects corresponding to the html nodes,
if js is enabled.
src/html.c:
Turn js side effects, like document.write or innerHTML,
back into html tags if that makes sense.
Enter data into forms and watch for javascript side effects.
Submit/reset forms.
Render the tree of html nodes into a text buffer.
Rerender the tree after js has run, and report any changes to the user.
src/sendmail.c:
Send mail (smtp or smtps). Encode attachments.
src/fetchmail.c:
Fetch mail (pop3 or pop3s or imap). Decode attachments.
Browse mail files, separate mime components.
Delete emails, move emails to other imap folders, search on the imap server.
src/messages.h:
Symbolic constants for the warning/error messages of edbrowse.
lang/msg-*:
Edbrowse status and error messages in various languages.
Each is converted into a const array of messages in src/msg-strings.c,
thus src/msg-strings.c is not a source file.
lang/ebrc-*:
Default .ebrc config file that is written to your home directory
if you have no such file.
Different files for different languages.
Each is converted into a const string in src/ebrc.c,
thus src/ebrc.c is not a source file.
src/jseng-quick.c:
The javascript engine built around the quick js library.
Manage all the js objects corresponding to the web page in edbrowse.
All the js details are hidden in this file.
this is encapsulation, hiding the js library from the rest of edbrowse.
src/js_hello*
Various hello world files to exercise various javascript engines.
These are stand alone programs; build them by make hello.
src/startwindow.js:
Javascript that is run at the start of each session.
This creates certain classes and methods that client js will need.
It is converted into a const string in src/startwindow.c,
thus src/startwindow.c is not a source file.
As you write functions to support DOM,
your first preference is to write them in src/startwindow.js.
Failing this, write them in C, using the API presented by jseng-quick.c.
Failing this, and as a last resort, write them as native code within the js engine.
Obviously this last approach is not engine portable.
src/shared.js:
Functions or classes that can safely be shared amongst all edbrowse windows.
This saves time and memory.
src/demin.js:
Third party open source javascript routines that are used for debugging
and deminimization.
These are snapshots; you will need to update demin.js, i.e. grab a new
snapshot, as that software evolves.
Distributers don't have to worry about this one,
it isn't compiled in unless $EBDEMIN is set to on.
src/endwindow.js:
This is the close of shared.js, and it stands in if demin.js is not used.
src/jsrt:
This is the javascript regression test for edbrowse.
It exercises some of the javascript DOM interactions.
It also presents frames and hyperlinks and forms and input fields,
so you can play around.
src/acid3:
A snapshot of http://acid3.acidtests.org, with modifications,
so that some or all of the acid tests pass under edbrowse.
This is a work in progress.
My modifications are indicated by the comment //@`
src/dbops.c:
Database operations; insert update delete.
src/dbodbc.c:
Connect edbrowse to odbc.
src/dbinfx.ec:
Connect edbrowse directly to Informix.
Other connectors could be built, e.g. Oracle,
but it's probably easier just to go through odbc.
src/dbstubs.c:
Stubs for database functions, if you want to build edbrowse without database access.
------------------------------------------------------------
Error conventions.
Unix commands return 0 for ok and a negative number for a problem.
Some of my functions work this way, but most return
true for success and false for error.
The error message is left in a buffer, which you can see by typing h
in the /bin/ed style.
Sometimes the error is displayed no matter what,
like when you are reading or writing files.
error messages are created according to your locale, i.e. in your language,
if a translation is available.
Some error messages in the database world have not yet been internationalized.
Some are beyond my control, as they come from odbc or its native driver.
------------------------------------------------------------
Multiple Representations.
A web form asks for your name, and you type in Fred Flintstone.
This piece of data is part of your edbrowse buffer.
In this sense it is merely text.
You can make corrections with the substitute command, etc.
Yet it is also carried into the html tags in html.c,
so that it can be sent when you push the submit button.
This is a second copy of the data.
As if that weren't bad enough, I now need a third copy for javascript.
When js accesses form.fullname.value, it needs to find,
and in some cases change, the text that you entered.
These 3 representations are "separate but equal",
using a lot of software to keep them in sync.
Remember that an input field could be an entire text area,
i.e. the text in another editing session.
When you are in that session, composing your thoughts,
am I really going to take every textual change, every substitute,
every delete, every insert, every undo,
and map those changes over to the html tag that goes with this session,
and the js variable that goes with this session?
I don't think so.
When you submit the form, or run any javascript for any reason,
the text is carried into the html tag, under t->value, and into the js object,
to make sure everything is in sync before js runs.
This is accomplished by jSyncup() in html.c.
When js has run to completion, any changes it has made to the fields have
to be mapped back to the editor, where you can see them.
This is done by jSideEffects() in html.c.
In other words, any action that might in any way involve js
must begin with jSyncup() and end with jSideEffects().
Once this is done, the tree of tags is rerendered,
and the new buffer is compared with the old using a simple diff algorithm.
Edbrowse tells you if any lines have changed.
Line 357 has been updated.
Such updates are only printed every 20 seconds or so, since some visual websites change data, down in the lower left corner, a dozen times a second,
and we don't need to see a continuous stream of update messages.
However, if you submit something and that changes the screen, you want to know about that right away.
Implementing all of this was not trivial!
------------------------------------------------------------
Some text is invisible as per css{display:none},
and some text only comes to light if you hover over something.
Edbrowse does not display this text, but sometimes edbrowse gets it wrong,
so if the website seems sparse, like you're missing something important,
use the showall command to reveal all of this text,
even some sections that might not be relevant to your situation.
Formerly invisible text might look like this.
You are logged in as John Smith,
if you are not John Smith please <log out>.
This block might be invisible unless you are actually logged in.
And of course the button won't work, unless you are actually logged in.
All text is displayed if javascript is disabled via the js- command,
because css doesn't run without javascript.
------------------------------------------------------------
Use the help command for a quick list of all the edbrowse commands.
This is a copy of the quick reference guide in usersguide.html,
built into edbrowse.
------------------------------------------------------------
There is an in-built javascript dom debugger that you enter via the jdb command.
bye to exit.
Javascript expressions are evaluated, and the document objects are available.
document.head is the head of your document <head>,
document.body is the body <body>,
document.body.firstChild is the first node under <body>, and so on.
showscripts() shows all the javascripts, even those dynamically created.
Such debugging is beyond the scope of this README file.
Read the Debugging Javascript article in the edbrowse wiki.
------------------------------------------------------------
It is often asked why we don't use a headless browser,
instead of trying to reinvent and maintain all that js machinery.
Good question!
How would we marry these very different creatures?
Here is how it might play out.
e blah.example.com same as it works today.
http fetch through curl.
b (browse command)
launch the browser, or activate a tab in the browser if it is already launched.
I don't know if the headless interface allows for this.
I don't want a new browser process running for every page in edbrowse.
Hand the browser the url.
Yeah we already have the page and in theory we could pass it the html directly,
with a <base> tag, but it might be easier to just hand it the url and say go.
It is going to maintain cookies as it browses,
and there is sometimes a transient cookie that indicates session, the "session cookie",
so the cookie we got is no good, and the only way for the browser to get a proper cookie for its session is to fetch the url itself.
So we tolerate that small inefficiency.
When the browser is done browsing,
and already we're in trouble, how do we know?
Some pages change all the time, refreshing and so on,
so maybe we poll and watch for document.readyState or some such,
and when it indicates done, we call document.body.outerHTML.
That is the current html as rendered on the page, which could look nothing like the original page.
Pass that to our parser, then skip the decorate phase, we don't mess with js objects at all,
and don't run any scripts, no timers, and call render as we do today.
There is your page! And someone else did all that javascript dom work.
What actually shows on the screen? We have no idea!
Some items are hidden by css, and sometimes they pop to life depending on what you do on the page.
They are always there in html.
We would show them all the time.
Our page could be cluttered with everything it might have on it, and there isn't an easy way to fix that.
As mentioned before, pages change all the time.
Poll every 20 seconds and repeat the above.
New html, a new tree, new render, compare with the old, report if anything changed.
A lot of our software could be reused here.
alert, prompt, console.log, and perhaps other inbuilt methods.
These interact with the user on the screen.
What would they do headless?
Are there callback functions we can provide to manage these actions?
i=xyz
Set or change an input field.
How do we pass this over to the browser?
Use javascript, set the value of the input field to xyz.
But how do we designate the input field in the browser?
This is the correspondence problem.
If the input field has an id that's easy.
querySelector("#id").value = "xyz";
But if it doesn't?
We can't expect every checkbox and field to have an id.
We could perhaps count the input fields leading up to this one. If there are 17 then
QuerySelectorAll("input")[17].value = "xyz";
That will usually work but not guaranteed.
The page could have changed in some way since last we polled.
Let's say it still lines up.
This backdoor way doesn't call oninput or onchange etc,
we have to call those methods ourselves.
Or onclick() if it's a checkbox, you get the idea.
So what about the onchange or onclick code?
It could alert the user to a bad input, and I wrote about alerts and such above.
More likely it puts the error message in the page.
Or maybe not an error but maybe caused other things to change.
Like a selection choosing a submenu.
We need to rerender right after the action was taken, to see immediately what changed.
But what do we mean by immediately?
A millisecond? The changes might not have happened yet.
Then we'd have to wait another 20 seconds to see the changes.
Half a second? Still might not be enough time.
8 seconds? That's awkward. Most of the time there aren't any changes, except the field we just changed, so we want to render right away.
The browser is asynchronous from us, with no good way to coordinate, and that can cause headaches.
this is the coordination problem.
i* push the button.
The usual problems of designating the input field in the browser.
If we can find it, call the methods onclick, onsubmit, and finally submit.
If js finds a problem with the form, it will indicate this with an error message on the page.
Same as before, when do we rerender, what is the optimal time to let js act?
If it jumps to a new web page, as i* often does, how do we know?
The next rerender, whenever it is, will completely replace the page, but that's not what we want.
We want to push the current page on the stack and render the new one.
Perhaps the polling process looks at window.location and compares it to our filename and if it's different,
assume (and I kinda hate to assume) we have jumped to a new page.
Push the old one on the stack and render the new one.
But what do we do about raw html for the new page?
We don't have it.
We didn't fetch it.
We could try to fetch it but that might confuse things, because the browser has already fetched it, with its session cookie, that we don't have.
We might have to say no raw html available in this case.
g go to a hyperlink.
onclick code, watch the return, determines whether we jump or not.
The url itself may be javascript, it often is.
If the page changes, how do we know? Just like the above.
If it's a direct href=url I don't think there's a js backdoor.
We have to tell the browser to go to this page, this url, not in a new tab but pushing the old page onto the history.
Can we do that through headless?
g goes to an internal anchor. href=#blah
We could use our machinery to jump,
and push the prior location onto the stack for the & command.
Do we find that tag in the browser and call onfocus()?
Button says "go back to previous page".
Implemented through the js history object.
That's just a refocus to the previous page, it is an up command in the browser.
How do we know to do the same?
Do we compare window.location with all the locations on our stack, and go up if that is indicated, or push a new window if it's a new url?
For that matter, how do we do our own up down and ^ commands?
Use the history object in the browser for up and down, or window.close() for ^?
Page has a plugin.
For music and such we just do our own.
That works 95% of the time, but not always, not if a session cookie is required to fetch that audio, then it's a big oops!
That happens in audio captchas.
Does the browser use the same plugin, mp3 player or whatever, coming out the same speakers?
How do we know when it's done playing, or control it or pause it or stop it etc, it's not going through our plugin.
A rendering plugin like pdf is even more problematic.
Remember we don't have the raw data, and I don't know that we can always get the raw data,
and if the browser runs its plugin, it certainly has a way to render pdf,
that rendering is completely outside of anything we can get through the headless browser.
Frames on the page make everything complicated.
It looks seamless to the sighted user but it's not.
i=xyz within a frame has to work within the context of that frame.
And all the other commands.
We have to run all the javascript, on the browser, within that frame.
We do this in our world, we know the context,
just not sure how to convey that to the headless browser as we interact.
IntersectionObserver is a particularly vexing concept.
This is relatively new, but I think it will catch on.
A website can bring in resources: images, submenus, control panels, etc,
as the user scrolls down to see them. This is the pay-to-play philosophy,
and it makes perfect sense in the visual world.
But there is no scrolling in headless Chrome.
The top of the website is in the viewport, and those resources are fetched,
but none below. Perhaps just a framework.
The page that edbrowse presents could be lacking,
relative to what the user sees as he scrolls down or right or left.
IntersectionObserver is so visual, it is difficult to simulate in edbrowse
today, even more challenging when Chrome is rendering the page from afar.
This is the beginning of the thought process. 🐣
I don't know if it would come out better or worse than the path we are currently on.
And the only way to find out might be to do it. 😱
I love the idea of not maintaining all this js and dom client and interactions with the page and so on,
but I'm concerned about coordinating with the asynchronous browser,
and maintaining the text-based approach that makes edbrowse unique.