
Материал из РУВИКИ — свободной энциклопедии
| Windows-1251 | |
|---|---|
| Описывается по ссылке |
iana.org/assignments/cha… msdn.microsoft.com/en-us… microsoft.com/typography… unicode.org/Public/MAPPI… unicode.org/Public/MAPPI… ibm.com/docs/en/db2/11.5… |
Windows-1251 — набор символов и кодировка, являющаяся стандартной 8-битной кодировкой для русских версий Microsoft Windows до 10-й версии. В прошлом пользовалась довольно большой популярностью. Была создана на базе кодировок, использовавшихся в ранних «самопальных» русификаторах Windows в 1990—1991 гг. совместно представителями «Параграфа», «Диалога» и российского отделения Microsoft. Первоначальный вариант кодировки сильно отличался от представленного ниже в таблице (в частности, там было значительное число «белых пятен»). Но, однако был вариативным и представленным в 6 формах применения.
В современных приложениях отдаётся предпочтение Юникоду (UTF-8). На 1 апреля 2019 лишь на 1 % всех веб-страниц используется Windows-1251.[1]
Windows-1251 выгодно отличается от других 8‑битных кириллических кодировок (таких как CP866, KOI8-R и ISO 8859-5) наличием практически всех символов, использующихся в русской типографике для обычного текста (отсутствует только значок ударения); она также содержит все символы для других славянских языков: украинского, белорусского, сербского, македонского и болгарского.
Windows-1251 имеет два недостатка:
- строчная буква «я» имеет код 0xFF (255 в десятичной системе). Она является «виновницей» ряда неожиданных проблем в программах без поддержки чистого 8-го бита, а также (гораздо более частый случай) использующих этот код как служебный (в CP437 он обозначает «неразрывный пробел», в Windows-1252 — ÿ, оба варианта практически не используются; число же
-1, в дополнительном коде длиной 8 бит представляющееся числом255, часто используется в программировании как специальное значение). Тот же недостаток имеет и KOI8-R, но в ней 0xFF есть заглавный твёрдый знак, который применяется редко (только при написании одними лишь заглавными буквами). - отсутствуют символы псевдографики, имеющиеся в CP866 и KOI8 (хотя для самих Windows, для которых она предназначена, в них не было нужды, это делало несовместимость двух использовавшихся в них кодировок заметнее).
Также как недостаток может рассматриваться отдельное расположение буквы «ё», тогда как остальные символы расположены строго в алфавитном порядке. Это усложняет программы лексикографического упорядочения.
Синонимы: CP1251; ANSI (только в русскоязычной ОС Windows).
Первая половина таблицы кодировки (коды от 0x00 до 0x7F) полностью соответствует кодировке ASCII. Числа под буквами обозначают шестнадцатеричный код подходящего символа в Юникоде.
Кодировка Windows-1251[править | править код]
| .0 | .1 | .2 | .3 | .4 | .5 | .6 | .7 | .8 | .9 | .A | .B | .C | .D | .E | .F | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 8. |
Ђ 402 |
Ѓ 403 |
‚ 201A |
ѓ 453 |
„ 201E |
… 2026 |
† 2020 |
‡ 2021 |
€ 20AC |
‰ 2030 |
Љ 409 |
‹ 2039 |
Њ 40A |
Ќ 40C |
Ћ 40B |
Џ 40F |
| 9. |
ђ 452 |
‘ 2018 |
’ 2019 |
“ 201C |
” 201D |
• 2022 |
– 2013 |
— 2014 |
™ 2122 |
љ 459 |
› 203A |
њ 45A |
ќ 45C |
ћ 45B |
џ 45F |
|
| A. |
A0 |
Ў 40E |
ў 45E |
Ј 408 |
¤ A4 |
Ґ 490 |
¦ A6 |
§ A7 |
Ё 401 |
© A9 |
Є 404 |
« AB |
¬ AC |
AD |
® AE |
Ї 407 |
| B. |
° B0 |
± B1 |
І 406 |
і 456 |
ґ 491 |
µ B5 |
¶ B6 |
· B7 |
ё 451 |
№ 2116 |
є 454 |
» BB |
ј 458 |
Ѕ 405 |
ѕ 455 |
ї 457 |
| C. |
А 410 |
Б 411 |
В 412 |
Г 413 |
Д 414 |
Е 415 |
Ж 416 |
З 417 |
И 418 |
Й 419 |
К 41A |
Л 41B |
М 41C |
Н 41D |
О 41E |
П 41F |
| D. |
Р 420 |
С 421 |
Т 422 |
У 423 |
Ф 424 |
Х 425 |
Ц 426 |
Ч 427 |
Ш 428 |
Щ 429 |
Ъ 42A |
Ы 42B |
Ь 42C |
Э 42D |
Ю 42E |
Я 42F |
| E. |
а 430 |
б 431 |
в 432 |
г 433 |
д 434 |
е 435 |
ж 436 |
з 437 |
и 438 |
й 439 |
к 43A |
л 43B |
м 43C |
н 43D |
о 43E |
п 43F |
| F. |
р 440 |
с 441 |
т 442 |
у 443 |
ф 444 |
х 445 |
ц 446 |
ч 447 |
ш 448 |
щ 449 |
ъ 44A |
ы 44B |
ь 44C |
э 44D |
ю 44E |
я 44F |
-
Таблица основного кода ASCII
-
Таблица расширенного кода ASCII
Другие варианты[править | править код]
(Показаны только отличающиеся строки, поскольку всё остальное совпадает)
Официальная кодировка Amiga-1251 (Amiga Inc., 2004 г.)[править | править код]
| .0 | .1 | .2 | .3 | .4 | .5 | .6 | .7 | .8 | .9 | .A | .B | .C | .D | .E | .F | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| A. |
A0 |
¡ A1 |
¢ A2 |
£ A3 |
€ 20AC |
¥ A5 |
¦ A6 |
§ A7 |
Ё 401 |
© A9 |
№ 2116 |
« AB |
¬ AC |
AD |
® AE |
¯ AF |
| B. |
° B0 |
± B1 |
² B2 |
³ B3 |
´ B4 |
µ B5 |
¶ B6 |
· B7 |
ё 451 |
¹ B9 |
º BA |
» BB |
¼ BC |
½ BD |
¾ BE |
¿ BF |
Официальная кодировка KZ-1048 (казахский стандарт)[править | править код]
Данная кодировка утверждена стандартом СТ РК 1048—2002 и зарегистрирована в IANA как KZ-1048 [1].
| .0 | .1 | .2 | .3 | .4 | .5 | .6 | .7 | .8 | .9 | .A | .B | .C | .D | .E | .F | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 8. |
Ђ 402 |
Ѓ 403 |
‚ 201A |
ѓ 453 |
„ 201E |
… 2026 |
† 2020 |
‡ 2021 |
€ 20AC |
‰ 2030 |
Љ 409 |
‹ 2039 |
Њ 40A |
Қ 49A |
Һ 4BA |
Џ 40F |
| 9. |
ђ 452 |
‘ 2018 |
’ 2019 |
“ 201C |
” 201D |
• 2022 |
– 2013 |
— 2014 |
™ 2122 |
љ 459 |
› 203A |
њ 45A |
қ 49B |
һ 4BB |
џ 45F |
|
| A. |
A0 |
Ұ 4B0 |
ұ 4B1 |
Ә 4D8 |
¤ A4 |
Ө 4E8 |
¦ A6 |
§ A7 |
Ё 401 |
© A9 |
Ғ 492 |
« AB |
¬ AC |
AD |
® AE |
Ү 4AE |
| B. |
° B0 |
± B1 |
І 406 |
і 456 |
ө 4E9 |
µ B5 |
¶ B6 |
· B7 |
ё 451 |
№ 2116 |
ғ 493 |
» BB |
ә 4D9 |
Ң 4A2 |
ң 4A3 |
ү 4AF |
Кодировка Windows-1251 (чувашский вариант)[править | править код]
| .0 | .1 | .2 | .3 | .4 | .5 | .6 | .7 | .8 | .9 | .A | .B | .C | .D | .E | .F | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 8. |
Ђ 402 |
Ѓ 403 |
‚ 201A |
ѓ 453 |
„ 201E |
… 2026 |
† 2020 |
‡ 2021 |
€ 20AC |
‰ 2030 |
Љ 409 |
‹ 2039 |
Ӑ 4D0 |
Ӗ 4D6 |
Ҫ 4AA |
Ӳ 4F2 |
| 9. |
ђ 452 |
‘ 2018 |
’ 2019 |
“ 201C |
” 201D |
• 2022 |
– 2013 |
— 2014 |
™ 2122 |
љ 459 |
› 203A |
ӑ 4D1 |
ӗ 4D7 |
ҫ 4AB |
ӳ 4F3 |
Татарский вариант[править | править код]
Эта кодировка была официально принята в Татарстане в 1996 г.
| .0 | .1 | .2 | .3 | .4 | .5 | .6 | .7 | .8 | .9 | .A | .B | .C | .D | .E | .F | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 8. |
Ә 4D8 |
Ѓ 403 |
‚ 201A |
ѓ 453 |
„ 201E |
… 2026 |
† 2020 |
‡ 2021 |
€ 20AC |
‰ 2030 |
Ө 4E8 |
‹ 2039 |
Ү 4AE |
Җ 496 |
Ң 4A2 |
Һ 4BA |
| 9. |
ә 4D9 |
‘ 2018 |
’ 2019 |
“ 201C |
” 201D |
• 2022 |
– 2013 |
— 2014 |
™ 2122 |
ө 4E9 |
› 203A |
ү 4AF |
җ 497 |
ң 4A3 |
һ 4BB |
- ↑ Historical trends in the usage of character encodings, April 2019. Дата обращения: 11 февраля 2016. Архивировано 3 марта 2021 года.
- История создании кодировки в сообщении Игоря Семенюка в эхоконференции SU.LAN от 14 января 1996
Информация бывает разного вида: графическая, текстовая, знаковая. Для ее корректного отображения в компьютерах и другом оборудовании используются кодировки. Особую значимость они представляют для символьных и текстовых данных.
Сегодня предстоит выяснить, какие существуют кодировки символов, чем они отличаются, как и для чего используются. Эта информация будет полезна не только новым пользователям ПК, но и более опытным.
Кодирование – определение
Кодирование информации – это своеобразное преобразование информации из одной формы в другую. Такую, чтобы данные было удобно обрабатывать, хранить, а также передавать посредством некоторого кода.
Кодировка символов – процесс присвоения номеров графическим символам, в особенности элементам человеческого языка. Числовые значения, которые формируют кодировку, называются «кодовыми точками». В совокупности они представляют собой кодовое пространство или карту символов.
Для кодирования букв и алфавитов используются самые разные стандарты. Они могут отличаться в зависимости от языка или операционной системы. Наиболее популярные из них:
- ASCII («Аски»);
- ISO;
- KOI-8;
- CP866/CP1251;
- Unicode.
Далее все эти кодировки будут изучены более подробно. Наиболее распространенными из них выступают первый и последний пункты.
Первая группа кодировки – ASCII. Стандарт, который поддерживает английский алфавит (латиницу). Он включает в себя 128 уникальных символов, которые разделяются на:
- управляющие компоненты;
- печатные.

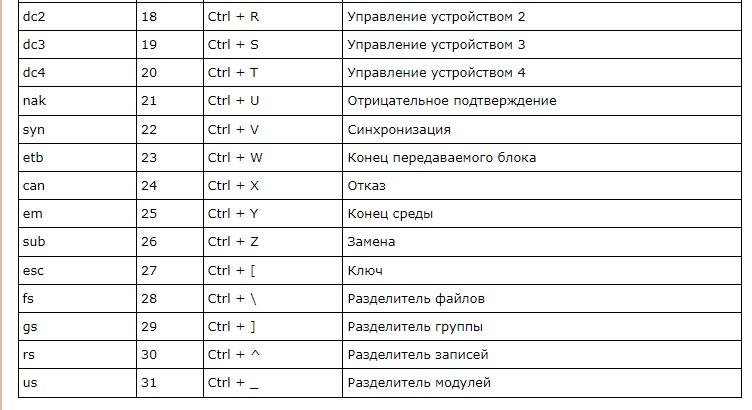
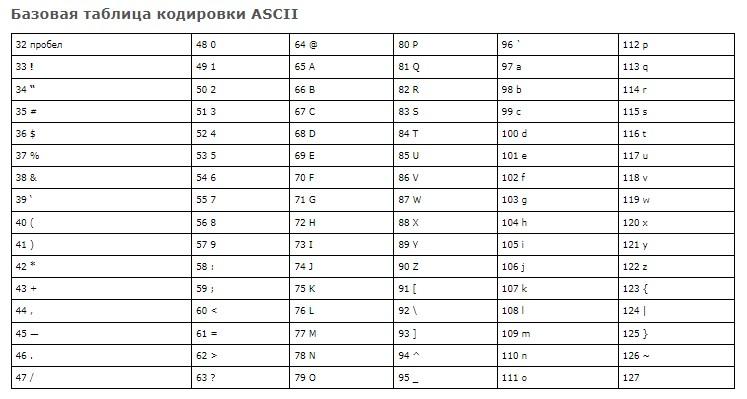
Соответствующий стандарт включает в себя:
- латинские буквы;
- арабские цифры;
- знаки препинания;
- служебные символы.
Первая ASCII с 7 битами была расширена до 8 битов (расширенная ASCII). В этом случае диапазон символов соответствует кодам от 0 до 255. Младшие биты (от 0 до 127) – это «классический» ASCII, старший отвечает за дополнительные 128 символов.
Стандарт ISO
ISO – это кодировка, которая представлена совокупностью 8-ми битных кодировок. В ней младшая половина – это ASCII, а старшая отвечает за символьное определение различных языков. Примеры ISO:
- 8859-0 – новые европейский стандарт;
- 8859-1 – Европа и Латинская Америка;
- 8859-5 – таблица кириллических символов;
- 8859-2 – Восточная Европа.
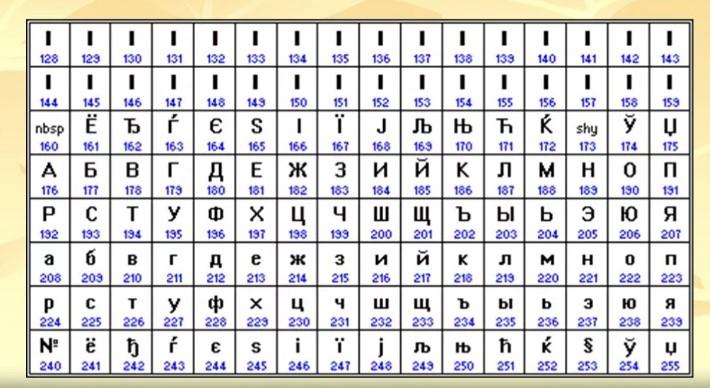
ISO 8859-5 – это одна из первых попыток введения кодировки для кириллицы. Данный стандарт до сих пор используется крупными компаниями, которые пишут программное обеспечение с поддержкой обработки кириллических символов. Их примеры: базы данных, решения OpenVMS.
CP866
Это – альтернативная кодировка от IBM. Здесь все специфические европейские элементы в верхней части таблицы были заменены на кириллицу. Псевдографические компоненты остались прежними. На общем виде программ такой подход никак не отражался.
CP866 до сих пор активно используется на практике. Он встречается в OS/2, а также в MS-DOS. На нем «шифруются» имена в файловых системах vfat и fat.
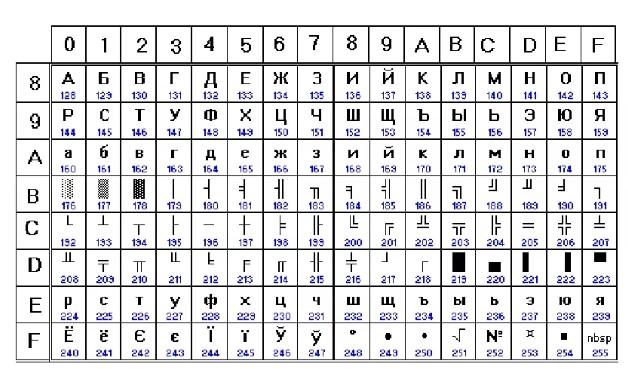
CP866 была создана в ВЦ АН СССР, для которого впервые были закуплены партии устройств IBM PC. Одним из авторов кодировки выступил некий Брябрин В.М., который написал собственную книгу «Программное обеспечение персональных ЭВМ».
Windows 1251
Windows 1251 – это «продукт», созданный компанией Microsoft. Его появление обусловлено популярностью развития графических операционных систем. Псевдографика для них стала ненужным элементом. Все это привело к появлению полноценной группы, которая по-прежнему считалась расширенной интерпретацией ASCII (где один символ теста будет закодирован всего одним байтом данных), но уже без символьной псевдографики.
Соответствующая группа относилась к так называемым ANSI-кодировкам. Они разрабатывались американским институтом стандартизации. Говоря простым языком, это кириллица для варианта с поддержкой русского алфавита. Наглядный пример – Windows 1251.

В нем нет псевдографики. Их место было отведено под недостающие:
- знаки русской типографии (за исключением ударения);
- славянские языки (украинский, белорусский и так далее).
В Windows 1251 нет совместимости с CP866. Если попытаться отобразить их между собой, на экране появится неточный текст сообщения, а бессмысленный знаковый набор (простыми словами – «кракозябры»).
Windows 1251 используется в семействе Windows. В основном встречается в операционных системах начала 90-х годов. Кириллица здесь отображается в алфавитном порядке.
KOI-8
Это достаточно старый стандарт. Он появился раньше CP866 и CP1251. Его разработчики разместили русскую кириллицу в верхней расширенной части ASCII так, чтобы позиции соответствовали их фонетическим аналогам в английском алфавите в нижней части таблицы. Это значит, что, если в тексте, написанном на KIO-8, убрать восьмой бит каждого элемента, на выходе получится читабельная информация, хоть и на английском.
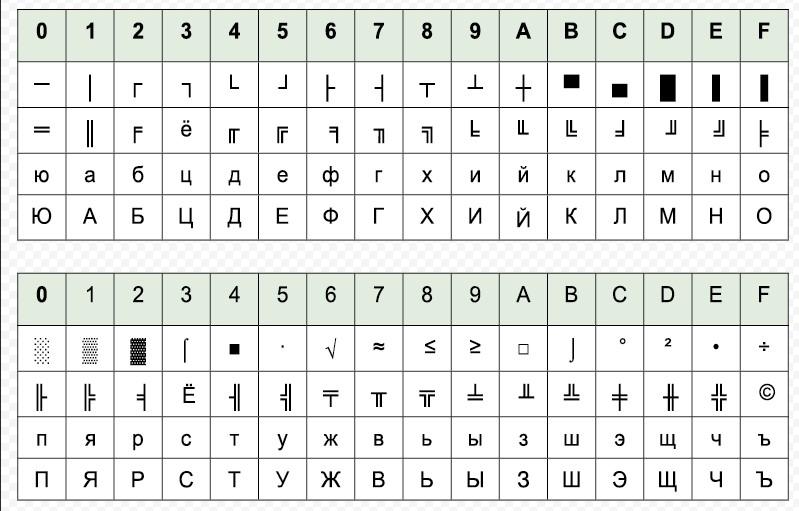
KOI-8 имеет несколько «диалектов». Он поддерживает:
- KOI8-R – для русского алфавита;
- KOI8-U – украинский.
В первом варианте также поддерживается Болгарская кириллица. С ее помощью были сформированы первые кириллизации для компьютеров. Сейчас в Болгарии активно используется Windows 1251.
КОИ8-R пользуется популярностью в интернете. Это фактический стандарт для русской кириллицы в Internet.
Unicode
Таблицы Unicode – консорциум, который выступает в качестве универсальной кодировки. Он появился из-за того, что языковые группы юго-восточной Азии невозможно уместить в одном байте информации, выделяемом для «шифрования» одного элемента в «Аски». Он имеет несколько вариантов представления:
- UTF-32;
- UTF-16;
- UTF-8.
Это – частичная реализация ISO. Сейчас в Юникоде распределены около 40 000 позиций из возможных 65 535 (это 2 байта на каждую букву). В 1998 году произошло последнее значительное изменение Unicode. Тогда была внедрена интерпретация знака «евро».
Отличительной чертой Юникода является то, что в нем позиции зарезервированы почти для всех существующих алфавитов, включая иероглифы, которыми пользовались в Древнем Египте. При помощи соответствующего вида «шифрования» допускается одновременная работа с русским и греческим, сочетая вставки на японском/китайском/азербайджанском, путем использования одного шрифта.
UTF-32
Первый вариант Unicode. Цифра в названии указывает на количество бит, используемое для кодирования одного элемента текста. 32 бита – это 4 байта данных. Столько потребуется при печати одного текстового компонента в UTF-32.
Это привело к тому, что исходный документ, переведенный из ASCII в Юникод стал весить в 4 раза больше. Такие изменения оказались неоправданными – большинству европейским стран огромное количество знаков не требовалось. Это привело к совершенствованию стандарта.
UTF-16
UTF-16 – более удобный вариант Unicode. По умолчанию именно такой вариант используется для всех элементов, используемых на компьютерах. Два байта требуются для «шифрования» одного символьного компонента.
При помощи 16 бит закодировать можно 65 536 элементов. Это – базовое пространство Unicode. Несмотря на свои преимущества, UTF-16 не принесло удовлетворения разработчикам. Особенно тем, кто писал исключительно на английском. Связано это с тем, что исходный документ у них увеличивался в 2 раза.
Чтобы посмотреть таблицы Unicode UTF-16 в Виндовс потребуется:
- Перейти в меню «Пуск».
- Зайти в «Программы»–«Стандартные»–«Служебные».
- Выбрать в появившемся меню «Таблица…».
- В дополнительных параметрах установить Unicode.
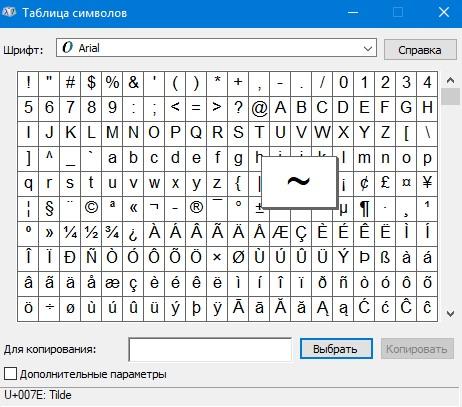
Выше – пример того, как будет выглядеть символьное отображение элемента текста и его код. Эта информация отображена в правом нижнем углу (U+007E).
UTF-8
Так называется Юникод с переменной длинной. Несмотря на восьмерку в своем названии, она все равно имеет неоднозначную длину. Каждый текстовый компонент может быть закодирован здесь в последовательность от 1 до 6 байт.
Практическое применение нашли первые 4 байта. Все, что расположено за их пределами, трудно представить. Латинские знаки в ней преобразовываются при помощи 1 байта.
Программы и приложения, которые не понимают Unicode, поддерживают отображение того, что закодировано через UTF-8. Связано это с тем, что соответствующий стандарт поддерживает базовую часть «Аски».
Кириллические компоненты в UTF-8 кодируются в 2 байта, грузинские и некоторые другие – в три.
Непонятный текст вместо русских букв – исправление
Самая распространенная ситуация при работе с текстовыми данными – это появление «кракозябр» вместо русского языка. Связано это с неправильным кодированием информации.
Чтобы редактировать текстовые документы, рекомендуется использовать Notepad++. Он позволяет программировать на различных языках разработки, а также поддерживает расширяемость через плагины.
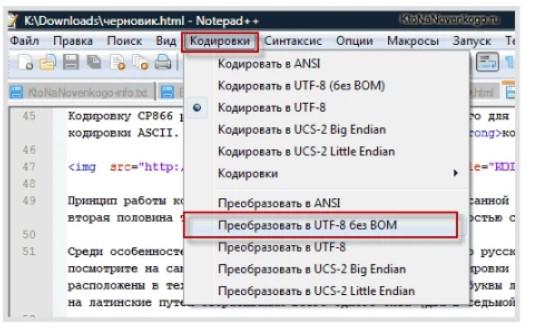
В Notepad++ имеется пункт «Кодирование». Там можно выбрать способ «шифрования» по умолчанию, а также воспользоваться преобразованием. Рекомендуется останавливаться на таблице UTF-8 без BOM. В этом случае в начало документа не вставляются три дополнительных байта.
Хотите освоить современную IT-специальность? Огромный выбор курсов по востребованным IT-направлениям есть в Otus!
Как работают кодировки текста. Откуда появляются «кракозябры». Принципы кодирования. Обобщение и детальный разбор
Время на прочтение10 мин
Количество просмотров143K
Данная статья имеет цель собрать воедино и разобрать принципы и механизм работы кодировок текста, подробно этот механизм разобрать и объяснить. Полезна она будет тем, кто только примерно представляет, что такое кодировки текста и как они работают, чем отличаются друг от друга, почему иногда появляются не читаемые символы, какой принцип кодирования имеют разные кодировки.
Чтобы получить детальное понимание этого вопроса придется прочитать и свести воедино не одну статью и потратить довольно значительное время на это. В данном материале же это все собрано воедино и по идее должно сэкономить время и разбор на мой взгляд получился довольно подробный.
О чем будет под катом: принцип работы одно байтовых кодировок (ASCII, Windows-1251 и т.д.), предпосылки появления Unicode, что такое Unicode, Unicode-кодировки UTF-8, UTF-16, их отличия, принципиальные особенности, совместимость и несовместимость разных кодировок, принципы кодирования символов, практический разбор кодирования и декодирования.
Вопрос с кодировками сейчас конечно уже потерял актуальность, но все же знать как они работают сейчас и как работали раньше и при этом не потратить много времени на это думаю лишним не будет.
Предпосылки Unicode
Начать думаю стоит с того времени когда компьютеризация еще не была так сильно развита и только набирала обороты. Тогда разработчики и стандартизаторы еще не думали, что компьютеры и интернет наберут такую огромную популярность и распространенность. Собственно тогда то и возникла потребность в кодировке текста. В каком то же виде нужно было хранить буквы в компьютере, а он (компьютер) только единицы и нули понимает. Так была разработана одно-байтовая кодировка ASCII (скорее всего она не первая кодировка, но она наиболее распространенная и показательная, по этому ее будем считать за эталонную). Что она из себя представляет? Каждый символ в этой кодировке закодирован 8-ю битами. Несложно посчитать что исходя из этого кодировка может содержать 256 символов (восемь бит, нулей или единиц 28=256).
Первые 7 бит (128 символов 27=128) в этой кодировке были отданы под символы латинского алфавита, управляющие символы (такие как переносы строк, табуляция и т.д.) и грамматические символы. Остальные отводились под национальные языки. То есть получилось что первые 128 символов всегда одинаковые, а если хочешь закодировать свой родной язык пожалуйста, используй оставшуюся емкость. Собственно так и появился огромный зоопарк национальных кодировок. И теперь сами можете представить, вот например я находясь в России беру и создаю текстовый документ, у меня по умолчанию он создается в кодировке Windows-1251 (русская кодировка использующаяся в ОС Windows) и отсылаю его кому то, например в США. Даже то что мой собеседник знает русский язык, ему не поможет, потому что открыв мой документ на своем компьютере (в редакторе с дефолтной кодировкой той же самой ASCII) он увидит не русские буквы, а кракозябры. Если быть точнее, то те места в документе которые я напишу на английском отобразятся без проблем, потому что первые 128 символов кодировок Windows-1251 и ASCII одинаковые, но вот там где я написал русский текст, если он в своем редакторе не укажет правильную кодировку будут в виде кракозябр.
Думаю проблема с национальными кодировками понятна. Собственно этих национальных кодировок стало очень много, а интернет стал очень широким, и в нем каждый хотел писать на своем языке и не хотел чтобы его язык выглядел как кракозябры. Было два выхода, указывать для каждой страницы кодировки, либо создать одну общую для всех символов в мире таблицу символов. Победил второй вариант, так создали Unicode таблицу символов.
Небольшой практикум ASCII
Возможно покажется элементарщиной, но раз уж решил объяснять все и подробно, то это надо.
Вот таблица символов ASCII:
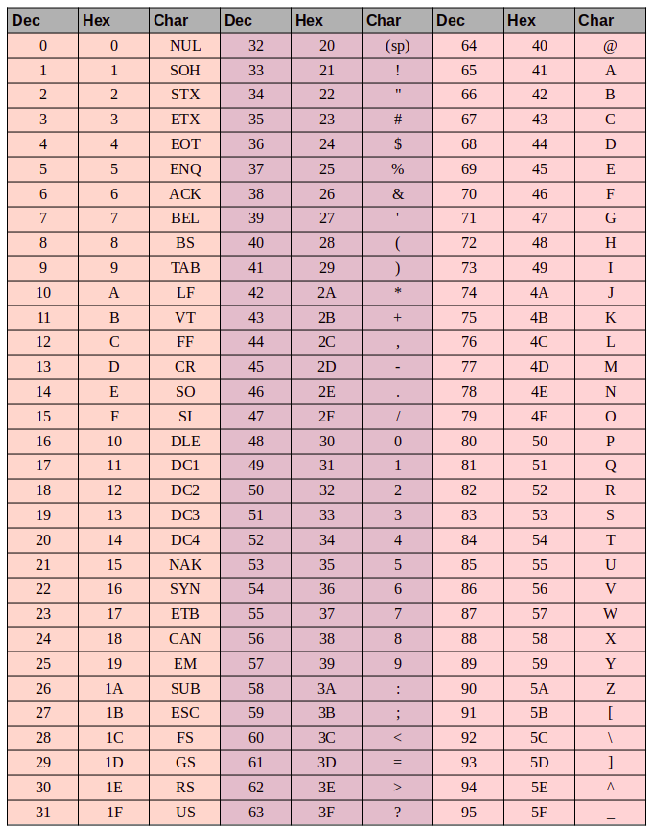
Тут имеем 3 колонки:
- номер символа в десятичном формате
- номер символа в шестнадцатиричном формате
- представление самого символа.
Итак, закодируем строку «ok» (англ.) в кодировке ASCII. Символ «o» (англ.) имеет позицию 111 в десятичном виде и 6F в шестнадцатиричном. Переведем это в двоичную систему — 01101111. Символ «k» (англ.) — позиция 107 в десятеричной и 6B в шестнадцатиричной, переводим в двоичную — 01101011. Итого строка «ok» закодированная в ASCII будет выглядеть так — 01101111 01101011. Процесс декодирования будет обратный. Берем по 8 бит, переводим их в 10-ичную кодировку, получаем номер символа, смотрим по таблице что это за символ.
Unicode
С предпосылками создания общей таблицы для всех в мире символов, разобрались. Теперь собственно, к самой таблице. Unicode — именно эта таблица и есть (это не кодировка, а именно таблица символов). Она состоит из 1 114 112 позиций. Большинство этих позиций пока не заполнены символами, так что вряд ли понадобится это пространство расширять.
Разделено это общее пространство на 17 блоков, по 65 536 символов в каждом. Каждый блок содержит свою группу символов. Нулевой блок — базовый, там собраны наиболее употребляемые символы всех современных алфавитов. Во втором блоке находятся символы вымерших языков. Есть два блока отведенные под частное использование. Большинство блоков пока не заполнены.
Итого емкость символов юникода составляет от 0 до 10FFFF (в шестнадцатиричном виде).
Записываются символы в шестнадцатиричном виде с приставкой «U+». Например первый базовый блок включает в себя символы от U+0000 до U+FFFF (от 0 до 65 535), а последний семнадцатый блок от U+100000 до U+10FFFF (от 1 048 576 до 1 114 111).
Отлично теперь вместо зоопарка национальных кодировок, у нас есть всеобъемлющая таблица, в которой зашифрованы все символы которые нам могут пригодиться. Но тут тоже есть свои недостатки. Если раньше каждый символ был закодирован одним байтом, то теперь он может быть закодирован разным количеством байтов. Например для кодирования всех символов английского алфавита по прежнему достаточно одного байта например тот же символ «o» (англ.) имеет в юникоде номер U+006F, то есть тот же самый номер как и в ASCII — 6F в шестнадцатиричной и 111 в десятеричной. А вот для кодирования символа «U+103D5» (это древнеперсидская цифра сто) — 103D5 в шестнадцатиричной и 66 517 в десятеричной, тут нам потребуется уже три байта.
Решить эту проблему уже должны юникод-кодировки, такие как UTF-8 и UTF-16. Далее речь пойдет про них.
UTF-8
UTF-8 является юникод-кодировкой переменной длинны, с помощью которой можно представить любой символ юникода.
Давайте поподробнее про переменную длину, что это значит? Первым делом надо сказать, что структурной (атомарной) единицей этой кодировки является байт. То что кодировка переменной длинны, значит, что один символ может быть закодирован разным количеством структурных единиц кодировки, то есть разным количеством байтов. Так например латиница кодируется одним байтом, а кириллица двумя байтами.
Немного отступлю от темы, надо написать про совместимость ASCII и UTF
То что латинские символы и основные управляющие конструкции, такие как переносы строк, табуляции и т.д. закодированы одним байтом делает utf-кодировки совместимыми с кодировками ASCII. То есть фактически латиница и управляющие конструкции находятся на тех же самых местах как в ASCII, так и в UTF, и то что закодированы они и там и там одним байтом и обеспечивает эту совместимость.
Давайте возьмем символ «o»(англ.) из примера про ASCII выше. Помним что в таблице ASCII символов он находится на 111 позиции, в битовом виде это будет 01101111. В таблице юникода этот символ — U+006F что в битовом виде тоже будет 01101111. И теперь так, как UTF — это кодировка переменной длины, то в ней этот символ будет закодирован одним байтом. То есть представление данного символа в обеих кодировках будет одинаково. И так для всего диапазона символов от 0 до 128. То есть если ваш документ состоит из английского текста то вы не заметите разницы если откроете его и в кодировке UTF-8 и UTF-16 и ASCII (прим. в UTF-16 такие символы все равно будут закодированы двумя байтами, по этому вы не увидите разницы, если ваш редактор будет игнорировать нулевые байты), и так до момента пока вы не начнете работать с национальным алфавитом.
Сравним на практике как будет выглядеть фраза «Hello мир» в трех разных кодировках: Windows-1251 (русская кодировка), ISO-8859-1 (кодировка западно-европейских языков), UTF-8 (юникод-кодировка). Суть данного примера состоит в том что фраза написана на двух языках. Посмотрим как она будет выглядеть в разных кодировках.

В кодировке ISO-8859-1 нет таких символов «м», «и» и «р».
Теперь давайте поработаем с кодировками и разберемся как преобразовать строку из одной кодировки в другую и что будет если преобразование неправильное, или его нельзя осуществить из за разницы в кодировках.
Будем считать что изначально фраза была записана в кодировке Windows-1251. Исходя из таблицы выше запишем эту фразу в двоичном виде, в кодировке Windows-1251. Для этого нам потребуется всего только перевести из десятеричной или шестнадцатиричной системы (из таблицы выше) символы в двоичную.
01001000 01100101 01101100 01101100 01101111 00100000 11101100 11101000 11110000
Отлично, вот это и есть фраза «Hello мир» в кодировке Windows-1251.
Теперь представим что вы имеете файл с текстом, но не знаете в какой кодировке этот текст. Вы предполагаете что он в кодировке ISO-8859-1 и открываете его в своем редакторе в этой кодировке. Как сказано выше с частью символов все в порядке, они есть в этой кодировке, и даже находятся на тех же местах, но вот с символами из слова «мир» все сложнее. Этих символов в этой кодировке нет, а на их местах в кодировке ISO-8859-1 находятся совершенно другие символы. А конкретно «м» — позиция 236, «и» — 232. «р» — 240. И на этих позициях в кодировке ISO-8859-1 находятся следующие символы позиция 236 — символ «ì», 232 — «è», 240 — «ð»
Значит фраза «Hello мир» закодированная в Windows-1251 и открытая в кодировке ISO-8859-1 будет выглядеть так: «Hello ìèð». Вот и получается что эти две кодировки совместимы лишь частично, и корректно перекодировать строку из одной кодировке в другую не получится, потому что там просто напросто нет таких символов.
Тут и будут необходимы юникод-кодировки, а конкретно в данном случае рассмотрим UTF-8. То что символы в ней могут быть закодированы разным количеством байтов от 1 до 4 мы уже выяснили. Теперь стоит сказать что с помощью UTF могут быть закодированы не только 256 символов, как в двух предыдущих, а вобще все символы юникода
Работает она следующим образом. Первый бит каждого байта кодирующего символ отвечает не за сам символ, а за определение байта. То есть например если ведущий (первый) бит нулевой, то это значит что для кодирования символа используется всего один байт. Что и обеспечивает совместимость с ASCII. Если внимательно посмотрите на таблицу символов ASCII то увидите что первые 128 символов (английский алфавит, управляющие символы и знаки препинания) если их привести к двоичному виду, все начинаются с нулевого бита (будьте внимательны, если будете переводить символы в двоичную систему с помощью например онлайн конвертера, то первый нулевой ведущий бит может быть отброшен, что может сбить с толку).
01001000 — первый бит ноль, значит 1 байт кодирует 1 символ -> «H»
01100101 — первый бит ноль, значит 1 байт кодирует 1 символ -> «e»
Если первый бит не нулевой то символ кодируется несколькими байтами.
Для двухбайтовых символов первые три бита должны быть такие — 110
11010000 10111100 — в начале 110, значит 2 байта кодируют 1 символ. Второй байт в таком случае всегда начинается с 10. Итого отбрасываем управляющие биты (начальные, которые выделены красным и зеленым) и берем все оставшиеся (10000111100), переводим их в шестнадцатиричный вид (043С) -> U+043C в юникоде равно символ «м».
для трех-байтовых символов в первом байте ведущие биты — 1110
11101000 10000111 101010101 — суммируем все кроме управляющих битов и получаем что в 16-ричной равно 103В5, U+103D5 — древнеперситдская цифра сто (10000001111010101)
для четырех-байтовых символов в первом байте ведущие биты — 11110
11110100 10001111 10111111 10111111 — U+10FFFF это последний допустимый символ в таблице юникода (100001111111111111111)
Теперь, при желании, можем записать нашу фразу в кодировке UTF-8.
UTF-16
UTF-16 также является кодировкой переменной длинны. Главное ее отличие от UTF-8 состоит в том что структурной единицей в ней является не один а два байта. То есть в кодировке UTF-16 любой символ юникода может быть закодирован либо двумя, либо четырьмя байтами. Давайте для понятности в дальнейшем пару таких байтов я буду называть кодовой парой. Исходя из этого любой символ юникода в кодировке UTF-16 может быть закодирован либо одной кодовой парой, либо двумя.
Начнем с символов которые кодируются одной кодовой парой. Легко посчитать что таких символов может быть 65 535 (2в16), что полностью совпадает с базовым блоком юникода. Все символы находящиеся в этом блоке юникода в кодировке UTF-16 будут закодированы одной кодовой парой (двумя байтами), тут все просто.
символ «o» (латиница) — 00000000 01101111
символ «M» (кириллица) — 00000100 00011100
Теперь рассмотрим символы за пределами базового юникод диапазона. Для их кодирования потребуется уже две кодовые пары (4 байта). И механизм их кодирования немного сложнее, давайте по порядку.
Для начала введем понятия суррогатной пары. Суррогатная пара — это две кодовые пары используемые для кодирования одного символа (итого 4 байта). Для таких суррогатных пар в таблице юникода отведен специальный диапазон от D800 до DFFF. Это значит, что при преобразовании кодовой пары из байтового вида в шестнадцатиричный вы получаете число из этого диапазона, то перед вами не самостоятельный символ, а суррогатная пара.
Чтобы закодировать символ из диапазона 10000 — 10FFFF (то есть символ для которого нужно использовать более одной кодовой пары) нужно:
- из кода символа вычесть 10000(шестнадцатиричное) (это наименьшее число из диапазона 10000 — 10FFFF)
- в результате первого пункта будет получено число не больше FFFFF, занимающее до 20 бит
- ведущие 10 бит из полученного числа суммируются с D800 (начало диапазона суррогатных пар в юникоде)
- следующие 10 бит суммируются с DC00 (тоже число из диапазона суррогатных пар)
- после этого получатся 2 суррогатные пары по 16 бит, первые 6 бит в каждой такой паре отвечают за определение того что это суррогат,
- десятый бит в каждом суррогате отвечает за его порядок если это 1 то это первый суррогат, если 0, то второй
Разберем это на практике, думаю станет понятнее.
Для примера зашифруем символ, а потом расшифруем. Возьмем древнеперсидскую цифру сто (U+103D5):
- 103D5 — 10000 = 3D5
- 3D5 =
0000000000 1111010101(ведущие 10 бит получились нулевые приведем это к шестнадцатиричному числу, получим 0 (первые десять), 3D5 (вторые десять)) - 0 + D800 = D800 (
1101100000000000) первые 6 бит определяют что число из диапазона суррогатных пар десятый бит (справа) нулевой, значит это первый суррогат - 3D5 + DC00 = DFD5 (
1101111111010101) первые 6 бит определяют что число из диапазона суррогатных пар десятый бит (справа) единица, значит это второй суррогат - итого данный символ в UTF-16 —
1101100000000000 1101111111010101
Теперь наоборот раскодируем. Допустим что у нас есть вот такой код — 1101100000100010 1101111010001000:
- переведем в шестнадцатиричный вид = D822 DE88 (оба значения из диапазона суррогатных пар, значит перед нами суррогатная пара)
1101100000100010— десятый бит (справа) нулевой, значит первый суррогат1101111010001000— десятый бит (справа) единица, значит второй суррогат- отбрасываем по 6 бит отвечающих за определение суррогата, получим
0000100010 1010001000(8A88) - прибавляем 10000 (меньшее число суррогатного диапазона) 8A88 + 10000 = 18A88
- смотрим в таблице юникода символ U+18A88 = Tangut Component-649. Компоненты тангутского письма.
Спасибо тем кто смог дочитать до конца, надеюсь было полезно и не очень занудно.
Вот некоторые интересные ссылки по данной теме:
habr.com/ru/post/158895 — полезные общие сведения по кодировкам
habr.com/ru/post/312642 — про юникод
unicode-table.com/ru — сама таблица юникод символов
Ну и собственно куда же без нее
ru.wikipedia.org/wiki/%D0%AE%D0%BD%D0%B8%D0%BA%D0%BE%D0%B4 — юникод
ru.wikipedia.org/wiki/ASCII — ASCII
ru.wikipedia.org/wiki/UTF-8 — UTF-8
ru.wikipedia.org/wiki/UTF-16 — UTF-16
Отличие utf-8 и windows 1251. Рассмотрим, чем отличаются две кодировки «utf-8 и windows 1251» в теории и на практике. И как победить некоторые проблемы для кириллицы в utf-8!?
О кодировках utf-8 и windows 1251
Самое главное. что нас интересует, как и меня — в чем же отличие кодировок utf-8 и windows 1251. И отличается только кириллица!
Чем отличаются utf-8 и windows 1251
UTF-8 — это много-байтовая кодировка, а Windows- 1251 однобайтовая. И более того, отличие только в кириллице.
Количество байтов кириллицы в UTF-8 будет в 2 раза больше, чем 1). латиницы в UTF-8 и 2). латиницы + кириллицы в Windows- 1251 → пример
Главное отличие кодировок – это используемый набор символов. В UTF-8 гораздо больше количество символов возможно представить, чем в Windows- 1251. Кодировка Windows- 1251 однобайтовая, т.е. представить в ней можно только 255 символов. Для кириллицы, впрочем, этого вполне достаточно, именно поэтому однобайтовые кодировки до сих пор так массово применяются.
Что такое кодировка windows 1251
Windows-1251 – набор символов и кодировка, являющаяся стандартной 8-битной кодировкой для всех русских версий Microsoft Windows. Пользуется довольно большой популярностью. Windows-1251 выгодно отличается от других 8‑битных кириллических кодировок (таких как CP866, KOI8-R и ISO 8859-5) наличием практически всех символов, использующихся в русской типографике для обычного текста; она также содержит все символы для близких к русскому языку языков: украинского, белорусского, сербского и болгарского.
Что такое кодировка UTF-8
UTF-8 – в настоящее время распространённая кодировка, реализующая представление Юникода, совместимое с 8-битным кодированием текста. Нашла широкое применение в операционных системах и веб-пространстве. Текст, состоящий только из символов Юникода с номерами меньше 128, при записи в UTF-8 превращается в обычный текст ASCII. Остальные символы Юникода изображаются последовательностями длиной от 2 до 6 байт.
Символ в кодировке UTF-8 может кодироваться аж 6 байтами (пока используется только 4 и больше не планируется). Для русского языка, например, символ занимает 2 байта. Все символы, которые есть в таблице символов – поддерживаются этой кодировкой. К примеру, если вам нужен знак копирайта (©), то вам не нужно искать особый шрифт или же изображать символов в графическом формате.
Пример вывода текста в кодировках utf-8 латиницы
Когда и если вы прочитали теорию о разнице кодировок utf-8 и windows 1251 — это уже победа!
А если вы еще и поняли о чем идет речь, то вы вообще Эйнштейн! , то и смысла особого вам читать дальше нет.
А для всех остальных продолжим…
Чем отличается текст в кодировках utf-8 и windows 1251
Теория — это конечно классно и круто, но как обстоит дело на практике!
Как показать отличие двух кодировок!?
У нас на сайте основная кодировка utf-8, и мы не напрягаясь можем посмотреть, что творится с текстом в этой кодировке!
Нам понадобится какой-то текст на латинице:
И… нам нужно такое слово, чтобы имело одинаковое количество букв в слове, ну пусть это будет моё имя…
Пусть это будет слово — «Marat!»
Далее нам потребуется функция var_dump.
И выведем прямо здесь вот такую конструкцию :
var_dump(‘Marat’);
Результат:
string(5) «Marat»
Что мы здесь можем прочитать!?
Что это строка, и что в ней 5 элементов.
Пример вывода текста в кодировках utf-8 кириллицы
Теперь, проделаем тоже самое со строкой на кириллице:
У нас все таже кодировка utf-8.
Но теперь нам понадобится текст на кириллице:
Пусть это будет слово — «Марат!»
Опять var_dump.
И выведем прямо здесь вот такую конструкцию :
var_dump(‘Марат’);
Результат:
string(10) «Марат»
И что мы здесь видим!?
Что количество элементов в строке 10… Если вы читали теорию внимательно, то вот вам показатель того, что одна буква состоит из двух символов, а латиницы это не касается…!
Поэтому, и возникают проблемы с текстом в кодировке utf-8 кириллицы, множество функций тупо не работают.
Как пример…как-то я задолбался со strtolower в utf-8 для кириллицы, что решил написать собственную функцию strtolower, чтобы каждый раз не городить этажерку из нескольких функций…
Пример отличия в кодировках utf-8 и windows 1251
Если вы поленились прочитать два верхних пункта, то ещё раз выведем результаты вывода текста на латинице и на кириллице с одним количеством букв.
Результат вывода var_dump(‘Marat’);:
string(5) «Marat»
Результат var_dump(‘Марат’);:
string(10) «Марат»
Что делать, если функция для кириллицы на utf-8 не работают?
Поскольку я давно занимаюсь сайтами, то могу сказать, что на самом деле таких случаев не так много, когда нужна какая-то специальная функция для обработки кириллицы на utf-8.
Но если уж она возникала, то есть несколько вариантов решения!
Это функции с приставкой «mb_», естественно надо проверять, работает ли она у вас на хостинге.
Второй вариант, это написать собственную функцию, которая будет работать и для латиницы и кириллицы? как это я показал на функции strtolower
И третий вариант перекодировать строку из utf-8 в windows 1251
Рассмотрим, первый попавшийся на ум пример…
Пусть это будет функция str_split и её аналог mb_str_split
print_r (str_split(‘Марат’)); выдаст :
Array
(
[0] => �
[1] => �
[2] => �
[3] => �
[4] => �
[5] => �
[6] => �
[7] => �
[8] => �
[9] => �
)
print_r (mb_str_split(‘Марат’)); выдаст :

Как видим… полный отстой…
Мы далее разбирались с этим здесь.
Как перекодировать строку из utf-8 в windows 1251
Итак… есть третий вариант, борьбы с квадратиками(непонимание кодировки) — перекодировать строку из utf-8 в windows 1251:
iconv(«UTF-8», «windows-1251», $text)
После того, как вы выполнили все намеченные действия с текстом, возвращаем его в исходную кодировку :
iconv(«windows-1251», «UTF-8», $text)
Рассмотрим пример перекодировки текста из UTF-8 в windows-1251 и обратно
Мы использовали var_dump, и он посчитал не правильно, поскольку просто так, на страницу вывести данные с помощью var_dump нельзя, мы использовали вот такой костыль :
ob_start();
var_dump( ‘Марат’ );
echo ob_get_clean();
Теперь попробуем перекодировать строку прямо внутри :
ob_start();
var_dump(iconv(«UTF-8», «windows-1251», ‘Марат’)) ;
echo ob_get_clean() ;
Результат подсчета знаков верный, но видим что слово не было перекодировано обратно :
Исправим:
ob_start();
var_dump(iconv(«UTF-8», «windows-1251», ‘Марат’)) ;
echo iconv(«windows-1251», «UTF-8», ob_get_clean());
Результат :
Итак… вы видели процесс кодировки и перекодировки текста из utf-8 в windows 1251, а потом обратно!
Вы наверное подумали :
Что за дичь здесь происходит!? Это не дичь! Когда ты внутри, а не снаружи, то все кажется не простым, а очень простым.
И чем больше ты в теме, это просто, как есть, пить, дышать… просто не задумываешься…
Я не говорю, что всегда так, иногда бывает очень трудно какаю-то задачку решить…
Что лучше для кириллицы utf-8 или…
Интересный поисковый запрос — «Что лучше для кириллицы utf-8 или…«…
Дело в том, что я выбрал кодировку «utf-8» уже… 16 лет(число динамичное) назад… и… уже сейчас трудно вспомнить, почему именно её… но точно вам могу заявить, что когда-то пользовался «windows-1251″… и у неё были какие-то заморочки, в виде неадекватного вывода информации, что, я волей неволей перешел на «utf-8»
Какие минусы у utf-8?
Одна из самых главных проблем «utf-8» — это многобайтовость…
Да! Это несколько неудобно в самом начале, но для всякой функции, которая не хочет работать с кириллицей, существуют замены.
В процессе создания сайта у вас может возникнуть несколько проблем, которые вы решите и «тупо» забудете об этом…
Задумывался ли я о переходе с кодировки utf-8 на другую?
Смысл задумываться о переходе с кодировки utf-8 на другую, если всё работает так, как нужно!