
В связи с тем, что довольно много людей обращается с просьбой помочь исправить проблему с кодировками MySQL, решил написать статью с описанием, как «лечить» наиболее часто встречающиеся случаи.
В статье описывается не то, как первоначально правильно настроить кодировки MySQL (об этом уже довольно много написано), а о случаях, когда есть довольно большие таблицы с неправильными кодировками и нужно всё исправить.
Самое плохое в неправильно настроенных кодировках — то, что зачастую проблему сложно обнаружить, и с первого взгляда может казаться, что сайт работает правильно, и никаких проблем нет.
Небольшое отступление. Sypex Viewer
В какой-то момент надоело отправлять людей в громоздкий phpMyAdmin, и была написана крошечная утилитка Sypex Viewer. Она представляет собой один PHP-файл, использует современные Web 2.0 технологии AJAX, JSON и другие. Основные задачи, которые ставилась при создании — минимальный вес, и максимальное удобство и скорость работы. В дальнейшем в примерах будут скриншоты из неё, но все те же действия можно сделать и в phpMyAdmin.
Данные в cp1251 таблицы в latin1
Наверное, самая популярная проблема. Когда данные в кодировке cp1251 (Windows-1251), а у таблиц указана кодировка по умолчанию latin1. Такие ситуации возникают в следующих случаях:
- при неграмотном обновлении с версии MySQL меньше 4.1 на более новые;
- очень часто возникает в «буржуйских» скриптах, которых вполне устраивает кодировка по умолчанию, и они «забывают», что неплохо бы указывать кодировку, как таблиц, так и соединения;
- также бывают случаи, когда переезжают с одного сервера (у которого установлена дефолтная кодировка cp1251, в частности, так сделано в Денвере) на другой (у которого стоит стандартная кодировка latin1).
В результате на сайте вроде как всё нормально, но если посмотреть в Sypex Viewer, то русские символы будут выглядеть как «кракозябры» (как их обычно называют пользователи).
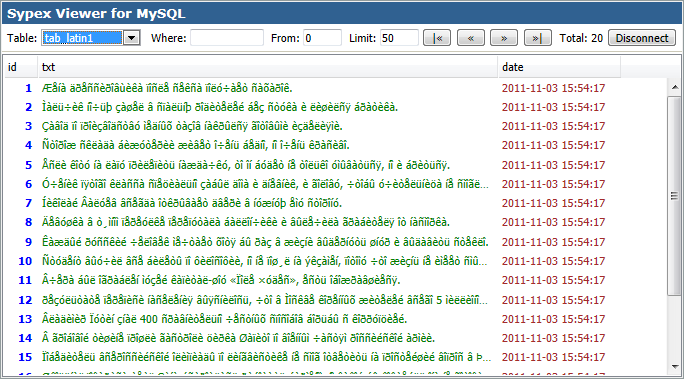
В статье я рассмотрю один из вариантов преобразование кодировок с помощью бесплатного php-скрипта Sypex Dumper, в качестве готового решения.
- На вкладке «Экспорт» выбираем нужные таблицы.
- Кодировка должна быть auto (остальные параметры неважны, можно комментарий добавить, например, «Дамп перед исправлением кодировки»).
- Нажимаем «Выполнить». Теперь у нас есть бэкап (его в любом случае желательно делать при любых преобразованиях базы данных).
- Переходим на вкладку «Импорт»
- Выбираем только что сделанный файл бэкапа.
- Выбираем кодировку cp1251 и помечаем опцию «Коррекция кодировки».
- Нажимаем «Выполнить».
- Вот и всё заходим в Sypex Viewer, чтобы убедиться, что русские символы выводятся корректно.

Данные и таблицы в utf8, но кодировка соединения latin1
Теперь рассмотрим более запущенный случай. Набирающая популярность в последнее время проблема, в связи с повальным увлечением UTF-8. Создатели софта стали переводить свои детища на UTF-8, но и тут не всё так гладко, как хотелось бы.
Возникает проблема в основном в случае, когда у таблиц указана кодировка UTF-8, данные в UTF-8, но кодировка соединения установлена по умолчанию latin1 (типичный пример, vBulletin 4, хоть там и есть в конфигах настройка кодировки соединения, но она закомментирована по умолчанию).
В результате в MySQL присылаются данные в UTF-8, но поскольку указана кодировка соединения latin1, то MySQL пытается преобразовать данные из latin1 в UTF-8. В итоге русские символы выглядят так:
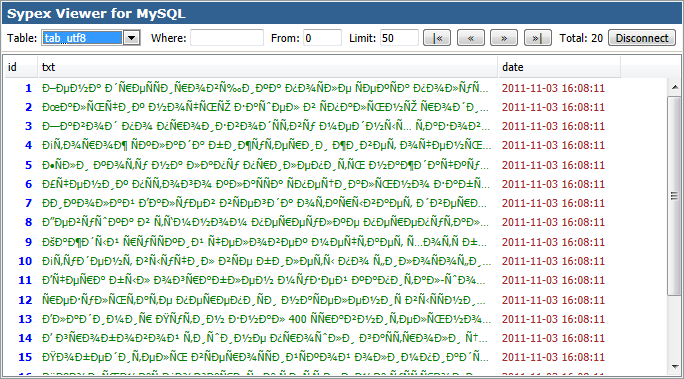
Ситуация более запущенная, но исправляется проблема почти также, как в первом случае, только в пункте 2 нужно выбрать кодировку latin1, а в пункте 6 нужно выбрать utf8 кодировку.
Изменение кодировки
Также часто встречающаяся проблема преобразования кодировки из cp1251 в UTF-8. До выполнения этого шага обязательно убедитесь, что русские символы у вас правильно показываются в Sypex Viewer или phpMyAdmin, если это не так, то предварительно исправьте кодировку.
Итак, опять заходим в Sypex Dumper.
- Во вкладке «Экспорт» выбираем нужные таблицы.
- Устанавливаем кодировку, в которую хотите преобразовать таблицы, в данном случае utf8.
- Нажимаем «Выполнить».
- После чего заходим в «Импорт» и выбираем нужный файл.
- Выставляем кодировку utf8 и опцию «Коррекция кодировки».
- Нажимаем «Выполнить».
- Вот и всё таблицы в UTF-8. Не забываем, что нужно еще установить кодировку соединения, сконвертировать ваши скрипты и шаблоны в UTF-8, выставить правильную кодировку в заголовках.
Кодировка соединения
Не забываем, что после исправлений кодировки, нужно убедиться, что ваши скрипты используют правильную кодировку соединения (в принципе, это будет сразу видно, они будут неправильно показывать русские символы без нужной кодировки соединения). У некоторых она выставляется в настройках, в некоторых придется добавить самостоятельно.
Для чего достаточно пройтись поиском по файлам, и найти где вызывается функция mysql_connect (или mysqli_connect). После этой строки нужно добавить строку которая укажет кодировку соединения.
mysql_query("SET NAMES 'cp1251'");Где вместо cp1251, указать нужную кодировку соединения.
Не забывайте перед преобразованиями кодировок делать бэкап, тут как с презервативами, лучше пусть он будет и не понадобится, чем когда понадобится — его не будет.
P.S. Спасибо Шортикам за веселый контент для примеров.
MySQL кодировки
Проблемы с кодировками MySQL могут возникать для версий 4.1 и выше, поскольку для них введена возможность задания разной кодировки для разных уровней иерархии базы данных (сервер, база данных, таблица, столбец) и отдельно для соединения сервера с клиентом. По умолчанию MySQL имеет кодировку latin1 на всех уровнях.
Кодировка, в которой хранятся данные на сервере MySQL, должна совпадать с кодировкой самих данных. Например, для русских символов используется кодировка cp1251. Если в таблице будут храниться записи русскими буквами, то и кодировка этой таблицы должна быть задана cp1251, иначе отображаться будут не русские символы, а знаки вопроса или другие знаки.
При создании баз данных сразу указывайте кодировку для хранения символов, поскольку в случае отсутствия явно заданной кодировки будет использовано значение по умолчанию (latin1). Например, создавайте базу данных командой:
create database `my-db` default charset cp1251;
Кодировка соединения сервера с клиентом устанавливает, в каком виде будут передаваться данные между ними. Например, если в скрипте на сайте используются русские символы, то при обращении сайта к базе данных MySQL должен правильно распознать эти символы, чтобы корректно выполнить скрипт. Если кодировка соединения использует значение по умолчанию latin1, то русские символы сервер баз данных не сможет правильно распознать, следовательно, скрипт выполнится с ошибкой.
Установите нужную вам кодировку соединения сразу после подключения к серверу MySQL запросом:
set names cp1251
Существует ряд клиентов, которые не могут установить нужную кодировку, имеют свою собственную. Для подобных случаев внесите в файл my.cnf в секцию [mysqld] строку:
set init_connect="set names cp1251" где cp1251 – это нужная вам кодировка.
В этом случае сервер выполнит команду «set names cp1251» сразу после соединения с клиентом и установит указанную в запросе кодировку.
Самые распространенные в России кодировки следующие:
utf8, cp866 (DOS), cp1251 (Windows), koi8r
Установка и использование на всех уровнях сервера баз данных одинаковой кодировки устраняет 90% проблем с кодировкой в MySQL.
Как русифицировать MySQL?
Внесите следующие изменения в файл my.cnf:
[client] default-character-set=cp1251 [mysqld] character-set-server=cp1251 collation-server=cp1251_general_ci init-connect = "set names cp1251"
Перезапустите MySQL сервер.
-
Доступные статьи
-
PHP
-
Локали и кодировки
Локали и кодировки
- Введение
-
Работа с локалями в PHP
- Windows
- UNIX (FreeBSD)
- Кодировки в MySQL
- Кодировка HTML-страниц
- Заключение
Введение
При разработке веб-приложений есть три важных момента, связанных с кодировками: информация в файлах-сценариях, информация в базе данных и браузер пользователя. Если выставить хотя бы одну кодировку неверно, то, в лучшем случае, данные отобразятся неверно, в худшем, безвозвратно потеряются. Чтобы этого не произошло, а приложение работало корректно при любых настройках сервера, нужно правильно выставить кодировки.
Работа с локалями в PHP
Работа с локалями в PHP выглядит одинаково и в UNIX, и в Windows, и в любой другой платформе. Для установки значений локали служит всего одна функция setlocale(). Чтобы выставить локаль, нужно передать функции первым аргументом категорию, на которую эта локаль распространяется, последующими список возможных локалей. Результатом будет название первой подходящей локали, которая и была установлена.
Пример - установка и использование локали
|
<?php // Установка локали echo setlocale(LC_ALL, 'ru_RU.CP1251', 'rus_RUS.CP1251', 'Russian_Russia.1251'); // Выведет ru_RU.CP1251 для FreeBSD // Выведет rus_RUS.CP1251 для линукса // Выведет Russian_Russia.1251 для Windows // ... // Вывод локализованных сообщений, например, даты echo '<br />', strftime('Число: %d, месяц: %B, день недели: %A'); ?> ru_RU.CP1251 Число: 10, месяц: октября, день недели: пятница или Russian_Russia.1251 Число: 10, месяц: Октябрь, день недели: пятница |
Локали в Windows
Для того, чтобы узнать, какие локали доступны в Windows, нужно зайти в панель управления, «Язык и региональные стандарты».
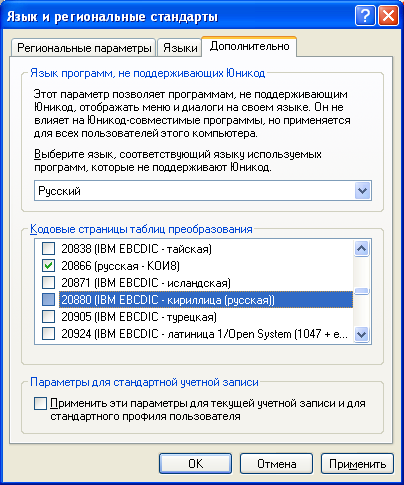
На вкладке «Дополнительно», в разделе «Кодовые страницы таблиц преобразования» показан список всех возможных локалей для Windows, которые можно использовать в PHP.
Кодовые страницы, которые отмечены в списке, из PHP могут быть использованы по их номеру.
В общем случае, использование выглядит по следующей схеме: Язык_Регион.Номер_кодовой_страницы
Для России это может выглядеть как Russian_Russia.1251 (cp1251) или Russian_Russia.20866 (KOI8-R).
Для Украины — Ukrainian_Ukraine.1251 (cp1251).
Вместо длинных названий можно использовать сокращённые russian, american, ukrainian и так далее. При этом кодовая страница выставится с учётом региональных настроек, для России и Украины — 1251, для Америки — 1252.
Единственная кодировка, с которой у меня возникли проблемы, как ни странно, оказалась UTF-8. При попытке выставить эту кодировку, выставляются все категории локалей, кроме основной. Вывод локализованных сообщений при этом идёт в cp1251.
Пример - установка локали UTF-8 на Windows
|
<? // Кодировка страницы windows-1251 header('Content-Type: text/html; charset=windows-1251'); echo '<pre>'; // Локаль устанавливаем UTF-8 echo setlocale(LC_ALL, 'Russian_Russia.65001'), PHP_EOL; // Но данные будут выводиться всё равно в cp1251 :((( echo strftime('%A'), PHP_EOL; ?> LC_COLLATE=Russian_Russia.65001;LC_CTYPE=Russian_Russia.1251; LC_MONETARY=Russian_Russia.65001;LC_NUMERIC=Russian_Russia.65001; LC_TIME=Russian_Russia.65001 пятница |
Пока это можно списать на внутренний механизм PHP работы со строками. С шестой версии PHP вся обработка строк должна будет вестись в UTF-8, но до тех пор надо просто знать об этом и делать поправку.
Ещё одной странностью при работе с локалями в PHP на Windows является неправильная работа с категориями локалей. Так, например, я выставляю локаль на функции времени KOI8-R, setlocale(LC_TIME, 'Russian_Russia.20866'), но почему-то выставляется cp1251 на все категории. Суть проблемы я так и не понял, возможно, это просто баг (проверялось на PHP 5.2.3), а возможно, что внутренний механизм Windows просто не позволяет этого делать. Хотя по мне, так это чистой воды баг.
В общем-то, на этом можно и закончить разговор о локалях на Windows. Главное, запомнить, что локали, которые портированы из UNIX, под WIndows работают только для «галочки». Шаг влево, шаг вправо и результат будет непредсказуемым. Безопасно можно использовать только cp1251 (windows-1251) и KOI8-R, и только для LC_ALL.
Код - установка локали на Windows
|
<?php // Устновка локалей для Windows // Кодировка Windows-1251 setlocale(LC_ALL, 'Russian_Russia.1251'); // Кодировка KOI8-R setlocale(LC_ALL, 'Russian_Russia.20866'); // Кодировка UTF-8 (использовать осторожно) setlocale(LC_ALL, 'Russian_Russia.65001'); ?> |
Локали в UNIX
Выше я описал работу с локалями в Windows, теперь можно заострить внимание на UNIX-like системах. Для простоты, я буду их называть UNIX, а подразумевать FreeBSD :). В контексте данной статьи это не особо важно.
Итак, дистрибутивы UNIX поставляются в одном виде для всех, и работа рассчитана на многопользовательский режим, поэтому о правильной настройке локали должен заботиться сам пользователь, например:
zg# locale LANG= LC_CTYPE="ru_RU.KOI8-R" LC_COLLATE="ru_RU.KOI8-R" LC_TIME="ru_RU.KOI8-R" LC_NUMERIC="ru_RU.KOI8-R" LC_MONETARY="ru_RU.KOI8-R" LC_MESSAGES="ru_RU.KOI8-R" LC_ALL=ru_RU.KOI8-R zg#
Так может выглядеть работа системной команды locale, которая выводит текущие настройки локали для пользователя. А так, обычно, выглядят настройки локали для пользователя, под которым работает PHP:
passthru('locale'); ================ LANG= LC_CTYPE="C" LC_COLLATE="C" LC_TIME="C" LC_NUMERIC="C" LC_MONETARY="C" LC_MESSAGES="C" LC_ALL=
Функция ucwords() должна была сделать заглавными первые буквы всех слов. А перед этим strtolower() должна была предварительно все заглавные буквы сделать строчными. Но ничего не произошло. Так же не будет работать следующий код:
echo ucwords(strtolower('привет, МИР!')); ================ привет, МИР!
Хотя \w является множеством знаков, из которых может состоять слово (алфавит, цифры и _), регулярное выражение не срабатывает. Причина как раз в том, что, работая с cp1251, мы не сказали об этом php. Чтобы исправить положение, достаточно воспользоваться функцией setlocale() и указать правильную локаль, например, так:
setlocale(LC_ALL, 'ru_RU.CP1251');
Здесь первый аргумент — это категория, на которую будет распространяться локаль (константа LC_*), второй — название локали. Начиная с версии 4.3.0 можно указывать несколько имён локалей в виде массива или в качестве дополнительных аргументов. После вызова функция установит первую подходящую локаль и вернёт её имя:
echo setlocale(LC_ALL, 'cp1251', 'koi8-r', 'ru_RU.KOI8-R'); ================ ru_RU.KOI8-R
С помощью команды grep я отобрал локали, которые поддерживают русский язык. Любую из них можно использовать, однако следует понимать, что данные должны быть в кодировке, на которую рассчитана локаль. Если же это правило не будет соблюдено, то результат может оказаться весьма неожиданным:
echo setlocale(LC_ALL, 'ru_RU.KOI8-R'), PHP_EOL; echo ucwords(strtolower('привет, МИР!')); =============== ru_RU.KOI8-R пРИВЕТ, мИР!
Если учесть, что koi8-r достаточно популярная кодировка для UNIX-севреров, а windows-1251 для русскоязычных сайтов, то подобное «необычное» поведение не такая уж и редкость. Когда-то я и сам столкнулся с этой проблемой при портировании проекта на реальный хостинг.
После установки правильной локали все примеры, которые не работали выше, будут работать как нужно!
echo setlocale(LC_ALL, 'ru_RU.CP1251', 'rus_RUS.CP1251', 'Russian_Russia.1251'), PHP_EOL; echo ucwords(strtolower('привет, МИР!')), PHP_EOL; echo preg_match('/^\w+$/', 'привет') ? 'нашёл' : 'не работает', PHP_EOL; echo strftime('Сегодня: %A, %d %B, %Y года'); =============== ru_RU.CP1251 Привет, Мир! нашёл Сегодня: суббота, 12 июля, 2008 года
По-русски заговорит и функция strftime(), которая корректно работает с локалями, а также и всё остальное, что зависит от локали.
Кодировки в MySQL
Напомню, что возможность задавать кодировки появилась только в MySQL 4.1.11 и выше.
В отличие от php, проблемы с кодировками базы данных проявляют себя гораздо быстрее, чем проблемы с локалью. И связано это прежде всего с хранением и выборкой данных, поскольку от этого зависит информация на сайте. Я не буду подробно расписывать все тонкости, поскольку есть отдельная статья, остановлюсь на самых важных моментах.
Первое, чему необходимо научиться, смотреть текущие настройки соединения с mysql:
mysql> show variables like 'char%'; +--------------------------+----------------------------------+ | Variable_name | Value | +--------------------------+----------------------------------+ | character_set_client | cp1251 | | character_set_connection | cp1251 | | character_set_database | cp1251 | | character_set_filesystem | binary | | character_set_results | cp1251 | | character_set_server | cp1251 | | character_set_system | utf8 | | character_sets_dir | /usr/local/share/mysql/charsets/ | +--------------------------+----------------------------------+ 8 rows in set (0.00 sec)
Критичными для пользователя являются character_set_client и character_set_results, которые отвечают за кодировку, в которой данные поступают в базу, и кодировку, в которой данные поступают из базы к пользователю. Если эти две кодировки отличаются от той, в которой работает клиент, в нашем случае php-скрипты, то неминуемо будут «странности», например, при сортировке выборки или внесении данных в базу.
Второе, что необходимо знать, как правильно сообщить mysql о кодировках. Самый простой и правильный способ, это использовать запрос set names:
mysql> set names 'cp1251'; Query OK, 0 rows affected (0.00 sec)
После этого три переменные character_set_client, character_set_connection и character_set_results примут значение cp1251. Это будет означать — клиент работает в кодировке windows-1251 (cp1251).
Помимо этого можно устанавливать непосредственно серверные переменные:
mysql> set character_set_client='UTF8'; Query OK, 0 rows affected (0.00 sec) mysql> show variables like 'char%'; +--------------------------+----------------------------------+ | Variable_name | Value | +--------------------------+----------------------------------+ | character_set_client | utf8 | | character_set_connection | cp1251 | .....
Теперь данные поступают и извлекаются в разных кодировках.
Список доступных кодировок можно просмотреть так:
mysql> show charset; +----------+-----------------------------+---------------------+--------+ | Charset | Description | Default collation | Maxlen | +----------+-----------------------------+---------------------+--------+ | dec8 | DEC West European | dec8_swedish_ci | 1 | | cp850 | DOS West European | cp850_general_ci | 1 | | hp8 | HP West European | hp8_english_ci | 1 | | koi8r | KOI8-R Relcom Russian | koi8r_general_ci | 1 | | latin1 | cp1252 West European | latin1_swedish_ci | 1 | | latin2 | ISO 8859-2 Central European | latin2_general_ci | 1 | | swe7 | 7bit Swedish | swe7_swedish_ci | 1 | | ascii | US ASCII | ascii_general_ci | 1 | | hebrew | ISO 8859-8 Hebrew | hebrew_general_ci | 1 | | koi8u | KOI8-U Ukrainian | koi8u_general_ci | 1 | | greek | ISO 8859-7 Greek | greek_general_ci | 1 | | cp1250 | Windows Central European | cp1250_general_ci | 1 | | latin5 | ISO 8859-9 Turkish | latin5_turkish_ci | 1 | | armscii8 | ARMSCII-8 Armenian | armscii8_general_ci | 1 | | utf8 | UTF-8 Unicode | utf8_general_ci | 3 | | cp866 | DOS Russian | cp866_general_ci | 1 | | keybcs2 | DOS Kamenicky Czech-Slovak | keybcs2_general_ci | 1 | | macce | Mac Central European | macce_general_ci | 1 | | macroman | Mac West European | macroman_general_ci | 1 | | cp852 | DOS Central European | cp852_general_ci | 1 | | latin7 | ISO 8859-13 Baltic | latin7_general_ci | 1 | | cp1251 | Windows Cyrillic | cp1251_general_ci | 1 | | cp1256 | Windows Arabic | cp1256_general_ci | 1 | | cp1257 | Windows Baltic | cp1257_general_ci | 1 | | binary | Binary pseudo charset | binary | 1 | | geostd8 | GEOSTD8 Georgian | geostd8_general_ci | 1 | +----------+-----------------------------+---------------------+--------+ 26 rows in set (0.00 sec)
И третье, что необходимо знать, — правила создания таблиц для хранения данных в нужной кодировке. К слову, данные можно хранить в любой кодировке, а работать с ними в кодировке клиента. Однако, важно понимать, что кодировки носят национальный характер и должны соответствовать вносимым данным. Иначе будут потери. Для русского языка есть три национальных кодировки koi8r, cp866, cp1251, которые могут конвертироваться друг в друга без потерь. Также можно использовать интернациональную кодировку UTF8.
Кодировку можно выставить на базу данных, таблицу и поле таблицы. Так, например, можно создать базу данных в кодировке koi8r:
CREATE DATABASE `test` DEFAULT CHARACTER SET koi8r;
Следует отметить, что кодировка базы данных влияет только на дефолтные значения кодировок при создании таблиц. Это значит, что неважно в какой кодировке была создана база, если кодировка таблицы была задана явно. Это же правило относится и к полям таблицы.
Следующим шагом я создам таблицу в cp1251 и одним полем в utf8:
CREATE TABLE `t` ( `id` VARCHAR( 60 ) NOT NULL , `data` TEXT CHARACTER SET utf8 NOT NULL , PRIMARY KEY ( `id` ) ) TYPE = MYISAM CHARACTER SET cp1251;
После того, как таблица создана с нужными параметрами кодировки, mysql автоматически начинает переводить данные при внесении и выборке.
mysql> select * from t; +--------+-------------+ | id | data | +--------+-------------+ | привет | привет мир! | +--------+-------------+ 1 row in set (0.00 sec)
Данные хранятся в разном виде, но поступают к пользователю именно так, как надо!
Подробнее с кодировками и проблемами их использования можно ознакомиться на http://dev.mysql.com/doc/refman/5.1/en/charset.html.
Кодировка HTML-страниц
Объявить кодировку html-страницы можно двумя способами: через заголовки и мета-тег в самой странице. Мета-тег используется только в статичных страницах.
<meta http-equiv="Content-Type" content="text/html; charset=windows-1251">
Я не буду его разбирать, это проблемы html. Во всех остальных случаях предпочтительней использовать HTTP-заголовок Content-Type.
PHP позволяет работать с HTTP-заголовками посредством функции header():
// Объявление типа содержимого и его кодировки header('Content-Type: text/html; charset=windows-1251');
Но браузер отобразит страницу корректно только в том случае, когда php-файлы сами были созданы в кодировке cp1251. Также нужно понимать, что заголовки должны быть отправлены до любого вывода на экран.
При необходимости перекодировать страницы «на лету», достаточно воспользоваться буферизацией и iconv:
Код - динамическая перекодировка
|
|
1 |
<?php iconv_set_encoding('internal_encoding', 'WINDOWS-1251'); // Исходная кодировка файлов iconv_set_encoding('output_encoding' , 'UTF-8'); // Конечная кодировка ob_start('ob_iconv_handler'); // буферизация header('Content-Type: text/html; charset=UTF8'); ?> Привет, мир! |
Надпись «Привет, мир!» будет выведена в юникоде, при этом браузер получит информацию о кодировке через заголовки и правильно отобразит страницу. Но важно понимать, что внутри скрипта и при соединении с базой данных надо использовать windows-1251 (cp1251), поскольку страница должна быть сформирована в одной кодировке.
Важно помнить, что функции iconv доступны не всегда, и проверка на доступность этих функций не будет лишней.
Заключение
Для безопасной разработки русскоязычных веб-проектов необходимо включать в файл с общими настройками следующие команды:
Код - файл общих настроек
|
|
1 |
<?php // Файл общих настроек ... // Вывод заголовка с данными о кодировке страницы header('Content-Type: text/html; charset=windows-1251'); // Настройка локали setlocale(LC_ALL, 'ru_RU.CP1251', 'rus_RUS.CP1251', 'Russian_Russia.1251', 'russian'); // Настройка подключения к базе данных mysql_query('SET names "cp1251"'); ?> |
Как ни странно, но эти три строчки кода значительно повышают портируемость веб-проектов.
Установка всего программного обеспечения как MySQL, так и прочих пакетов (PHP, Phpmyadmin) была произведена на самом начальном этапе, — если помните, делали мы это командой: apt-get install apache2 php5 php5-mysql mysql-server phpmyadmin — см. подробнее->>>.
На какую процедуру пришлось убить больше всего времени при настройке MySQL, так это настройка кодировки. При извлечении информации из базы средствами PHP русские слова отображаются как вопросительные знаки — ????????????????. Здесь существует проблема с кодировкой, так как загружаемая MySQL из репозитория Linux (Ubuntu 13.04) имеет кодировку UTF8 вперемешку с latin1, таким образом, любая из кодировок (cp1251 или utf8) при извлечении из MySQL будет отображаться коряво.
Если вам необходимо настроить кодировку cp1251, то первый способ, который легко отыскать в интернете и дающий решение данной проблемы – это просто в скрипт PHP, который у вас извлекает контент из базы, добавить вот такую строку:
mysql_query(«SET NAMES cp1251»);
Если не устраивает вариант, предусматривающий правку скритов, то необходимо править конфигурационный файл MySQL, в этой связи, прежде чем был найден ответ, была перепробована масса всяких вариантов, большинство из которых, вероятно, подходили для ранних версий Linux Ubuntu, но они не работают для UBUNTU 13.04.
default-character-set=cp1251 – не работает
Будем править конфигурационный файл my.cnf, который находится в каталоге /etc/mysql/my.cnf. Причем, если просто в my.cnf (путь — /etc/mysql/my.cnf ) [mysqld] заменить на такой вариант:
[mysqld]
default-character-set=cp1251
сохраняемся и перегружаемся:
service mysql restart
тогда при подключении к phpmyadmin мы получаем вот такую ошибку:
#2002 Невозможно подключиться к серверу MySQL
Взять за основу вышеописанный вариант и пробовать решить проблему по устранению возникающей ошибки, — скорее всего, такие действия не принесут положительного результата.
Рабочая конфигурация my.cnf MySQL
Выбираем другой алгоритм. Для начала входим в MySQL через phpmyadmin. На домашней странице в phpmyadmin видим заголовок «Основные настройки», в подразделе «Сопоставление кодировки соединения с MySQL» выбираем UTF8_UNICODE_ci.
Далее проверим конфигурацию MySQL. В phpmyadmin выберем вкладку SQL и пошлем туда запрос вида:
SHOW VARIABLES LIKE ‘char%’;
в ответ имеем:
| Variable_name | Value |
| character_set_client | utf8 |
| character_set_connection | utf8 |
| character_set_database | latin1 |
| character_set_filesystem | binary |
| character_set_results | utf8 |
| character_set_server | latin1 |
| character_set_system | utf8 |
| character_sets_dir | /usr/share/mysql/charsets/ |
Видим в приведенной конфигурации в двух местах значения latin1, которые необходимо исправить в зависимости от того, какая кодировка вам нужна. Допустим, мы будем заменять на cp1251, поэтому в конфигурационном файле my.cnf, который находится в каталоге /etc/mysql/my.cnf, ищем модуль [mysqld] и меняем его на:
[mysqld] skip-character-set-client-handshake character_set_client=cp1251
character_set_server=cp1251
Делаем рестарт MySQL (перезагрузку необходимо делать всегда после внесения каких-либо изменений): service mysql restart
В phpmyadmin снова посылаем SQL — запрос вида:
SHOW VARIABLES LIKE ‘char%’;
Получаем ответ, исходя из которого видим, что наша конфигурация MySQL поменялась:
| Variable_name | Value |
| character_set_client | utf8 |
| character_set_connection | utf8 |
| character_set_database | cp1251 |
| character_set_filesystem | binary |
| character_set_results | utf8 |
| character_set_server | cp1251 |
| character_set_system | utf8 |
| character_sets_dir | /usr/share/mysql/charsets/ |
У нас latin1 поменялись на cp1251, соответственно сразу после приведения конфигурации MySQL к указанному виду, из базы у нас извлекается все корректно, наконец-то видим русские слова. Вот пример нашего текста, извлекаемого из БД MySQL.
От кодировки БД MySQL теперь переходим к настройкам кодировки сообщений, которые у нас с сайта отправляются на электронную почту, см. PHP отправка на e-mail >>>