
Время на прочтение11 мин
Количество просмотров280K
Данная статья будет полезной тем, кто только начал знакомиться с микросервисной архитектурой и с сервисом Apache Kafka. Материал не претендует на подробный туториал, но поможет быстро начать работу с данной технологией. Я расскажу о том, как установить и настроить Kafka на Windows 10. Также мы создадим проект, используя Intellij IDEA и Spring Boot.
Зачем?
Трудности в понимании тех или иных инструментов часто связаны с тем, что разработчик никогда не сталкивался с ситуациями, в которых эти инструменты могут понадобиться. С Kafka всё обстоит точно также. Опишем ситуацию, в которой данная технология будет полезной. Если у вас монолитная архитектура приложения, то разумеется, никакая Kafka вам не нужна. Всё меняется с переходом на микросервисы. По сути, каждый микросервис – это отдельная программа, выполняющая ту или иную функцию, и которая может быть запущена независимо от других микросервисов. Микросервисы можно сравнить с сотрудниками в офисе, которые сидят за отдельными столами и независимо от коллег решают свою задачу. Работа такого распределённого коллектива немыслима без централизованной координации. Сотрудники должны иметь возможность обмениваться сообщениями и результатами своей работы между собой. Именно эту проблему и призвана решить Apache Kafka для микросервисов.
Apache Kafka является брокером сообщений. С его помощью микросервисы могут взаимодействовать друг с другом, посылая и получая важную информацию. Возникает вопрос, почему не использовать для этих целей обычный POST – reqest, в теле которого можно передать нужные данные и таким же образом получить ответ? У такого подхода есть ряд очевидных минусов. Например, продюсер (сервис, отправляющий сообщение) может отправить данные только в виде response’а в ответ на запрос консьюмера (сервиса, получающего данные). Допустим, консьюмер отправляет POST – запрос, и продюсер отвечает на него. В это время консьюмер по каким-то причинам не может принять полученный ответ. Что будет с данными? Они будут потеряны. Консьюмеру снова придётся отправлять запрос и надеяться, что данные, которые он хотел получить, за это время не изменились, и продюсер всё ещё готов принять request.
Apache Kafka решает эту и многие другие проблемы, возникающие при обмене сообщениями между микросервисами. Не лишним будет напомнить, что бесперебойный и удобный обмен данными – одна из ключевых проблем, которую необходимо решить для обеспечения устойчивой работы микросервисной архитектуры.
Установка и настройка ZooKeeper и Apache Kafka на Windows 10
Первое, что надо знать для начала работы — это то, что Apache Kafka работает поверх сервиса ZooKeeper. ZooKeeper — это распределенный сервис конфигурирования и синхронизации, и это всё, что нам нужно знать о нём в данном контексте. Мы должны скачать, настроить и запустить его перед тем, как начать работу с Kafka. Прежде чем начать работу с ZooKeeper, убедитесь, что у вас установлен и настроен JRE.
Скачать свежею версию ZooKeeper можно с официального сайта.
Извлекаем из скаченного архива ZooKeeper`а файлы в какую-нибудь папку на диске.
В папке zookeeper с номером версии, находим папку conf и в ней файл “zoo_sample.cfg”.

Копируем его и меняем название копии на “zoo.cfg”. Открываем файл-копию и находим в нём строчку dataDir=/tmp/zookeeper. Прописываем в данной строчке полный путь к нашей папке zookeeper-х.х.х. У меня это выглядит так: dataDir=C:\\ZooKeeper\\zookeeper-3.6.0
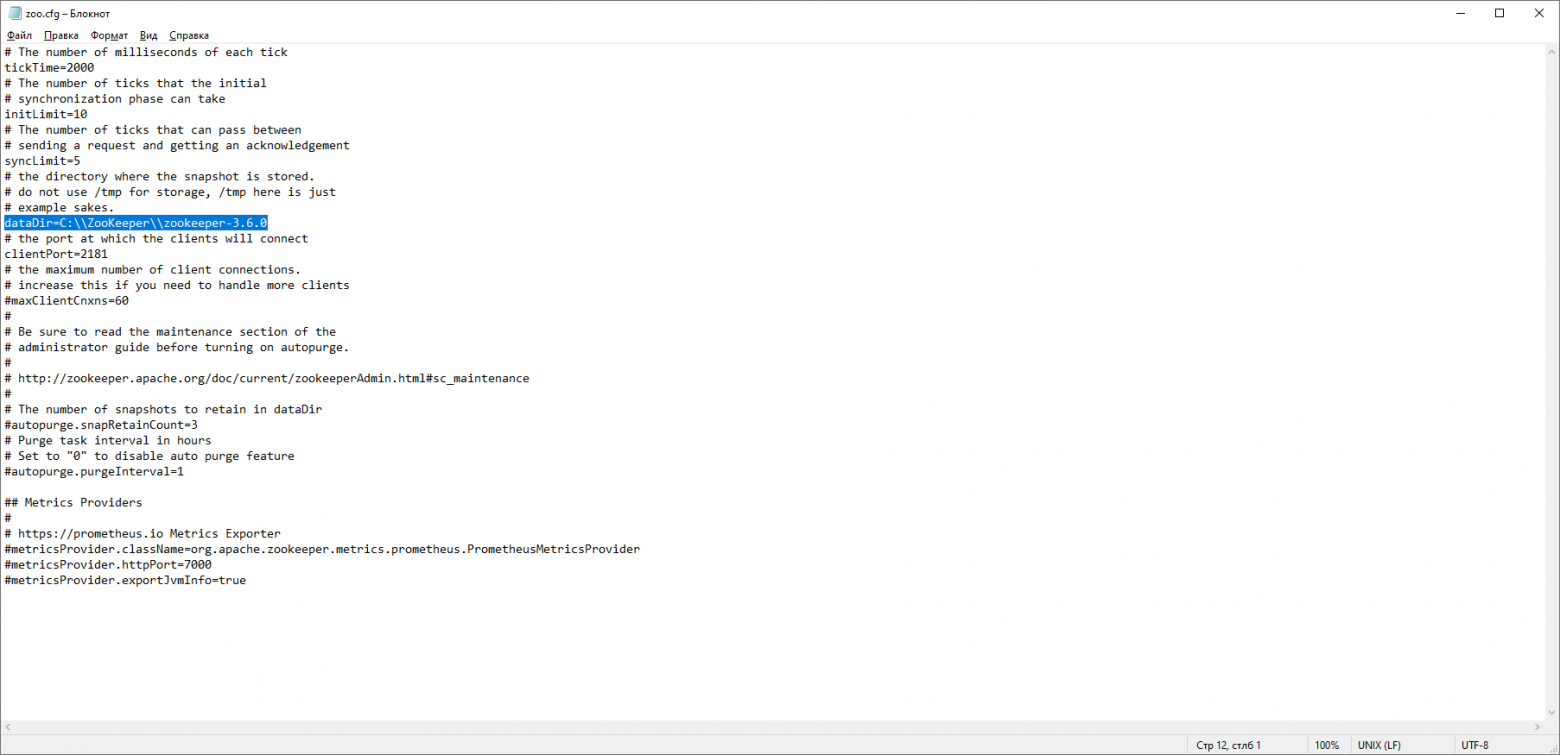
Теперь добавим системную переменную среды: ZOOKEEPER_HOME = C:\ ZooKeeper \zookeeper-3.4.9 и в конце системной переменной Path добавим запись: ;%ZOOKEEPER_HOME%\bin;
Запускаем командную строку и пишем команду:
zkserverЕсли всё сделано правильно, вы увидите примерно следующее.

Это означает, что ZooKeeper стартанул нормально. Переходим непосредственно к установке и настройке сервера Apache Kafka. Скачиваем свежую версию с официального сайта и извлекаем содержимое архива: kafka.apache.org/downloads
В папке с Kafka находим папку config, в ней находим файл server.properties и открываем его.
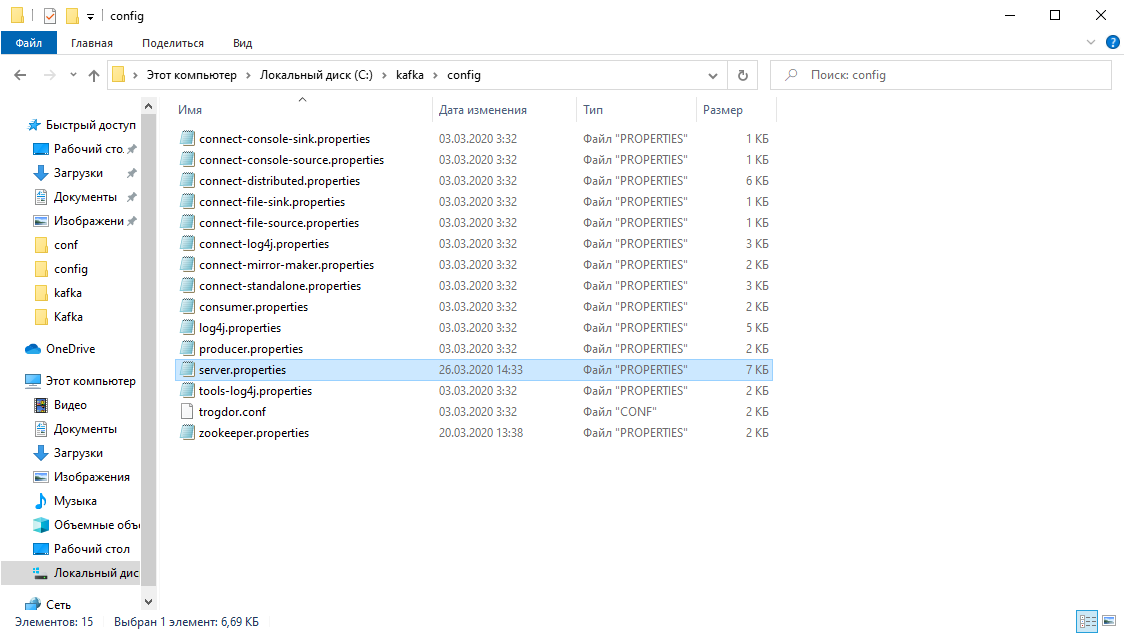
Находим строку log.dirs= /tmp/kafka-logs и указываем в ней путь, куда Kafka будет сохранять логи: log.dirs=c:/kafka/kafka-logs.
В этой же папке редактируем файл zookeeper.properties. Строчку dataDir=/tmp/zookeeper меняем на dataDir=c:/kafka/zookeeper-data, не забывая при этом, после имени диска указывать путь к своей папке с Kafka. Если вы всё сделали правильно, можно запускать ZooKeeper и Kafka.

Для кого-то может оказаться неприятной неожиданностью, что никакого GUI для управления Kafka нет. Возможно, это потому, что сервис рассчитан на суровых нёрдов, работающих исключительно с консолью. Так или иначе, для запуска кафки нам потребуется командная строка.
Сначала надо запустить ZooKeeper. В папке с кафкой находим папку bin/windows, в ней находим файл для запуска сервиса zookeeper-server-start.bat, кликаем по нему. Ничего не происходит? Так и должно быть. Открываем в этой папке консоль и пишем:
start zookeeper-server-start.batОпять не работает? Это норма. Всё потому что zookeeper-server-start.bat для своей работы требует параметры, прописанные в файле zookeeper.properties, который, как мы помним, лежит в папке config. Пишем в консоль:
start zookeeper-server-start.bat c:\kafka\config\zookeeper.properties Теперь всё должно стартануть нормально.

Ещё раз открываем консоль в этой папке (ZooKeeper не закрывать!) и запускаем kafka:
start kafka-server-start.bat c:\kafka\config\server.propertiesДля того, чтобы не писать каждый раз команды в командной строке, можно воспользоваться старым проверенным способом и создать батник со следующим содержимым:
start C:\kafka\bin\windows\zookeeper-server-start.bat C:\kafka\config\zookeeper.properties
timeout 10
start C:\kafka\bin\windows\kafka-server-start.bat C:\kafka\config\server.propertiesСтрока timeout 10 нужна для того, чтобы задать паузу между запуском zookeeper и kafka. Если вы всё сделали правильно, при клике на батник должны открыться две консоли с запущенным zookeeper и kafka.Теперь мы можем прямо из командной строки создать продюсера сообщений и консьюмера с нужными параметрами. Но, на практике это может понадобиться разве что для тестирования сервиса. Гораздо больше нас будет интересовать, как работать с kafka из IDEA.
Работа с kafka из IDEA
Мы напишем максимально простое приложение, которое одновременно будет и продюсером и консьюмером сообщения, а затем добавим в него полезные фичи. Создадим новый спринг-проект. Удобнее всего делать это с помощью спринг-инициалайзера. Добавляем зависимости org.springframework.kafka и spring-boot-starter-web


В итоге файл pom.xml должен выглядеть так:

Для того, чтобы отправлять сообщения, нам потребуется объект KafkaTemplate<K, V>. Как мы видим объект является типизированным. Первый параметр – это тип ключа, второй – самого сообщения. Пока оба параметра мы укажем как String. Объект будем создавать в классе-рестконтроллере. Объявим KafkaTemplate и попросим Spring инициализировать его, поставив аннотацию Autowired.
@Autowired
private KafkaTemplate<String, String> kafkaTemplate;В принципе, наш продюсер готов. Всё что осталось сделать – это вызвать у него метод send(). Имеется несколько перегруженных вариантов данного метода. Мы используем в нашем проекте вариант с 3 параметрами — send(String topic, K key, V data). Так как KafkaTemplate типизирован String-ом, то ключ и данные в методе send будут являться строкой. Первым параметром указывается топик, то есть тема, в которую будут отправляться сообщения, и на которую могут подписываться консьюмеры, чтобы их получать. Если топик, указанный в методе send не существует, он будет создан автоматически. Полный текст класса выглядит так.
@RestController
@RequestMapping("msg")
public class MsgController {
@Autowired
private KafkaTemplate<String, String> kafkaTemplate;
@PostMapping
public void sendOrder(String msgId, String msg){
kafkaTemplate.send("msg", msgId, msg);
}
}
Контроллер мапится на localhost:8080/msg, в теле запроса передаётся ключ и само сообщений.
Отправитель сообщений готов, теперь создадим слушателя. Spring так же позволяет cделать это без особых усилий. Достаточно создать метод и пометить его аннотацией @KafkaListener, в параметрах которой можно указать только топик, который будет слушаться. В нашем случае это выглядит так.
@KafkaListener(topics="msg")У самого метода, помеченного аннотацией, можно указать один принимаемый параметр, имеющий тип сообщения, передаваемого продюсером.
Класс, в котором будет создаваться консьюмер необходимо пометить аннотацией @EnableKafka.
@EnableKafka
@SpringBootApplication
public class SimpleKafkaExampleApplication {
@KafkaListener(topics="msg")
public void msgListener(String msg){
System.out.println(msg);
}
public static void main(String[] args) {
SpringApplication.run(SimpleKafkaExampleApplication.class, args);
}
}Так же в файле настроек application.property необходимо указать параметр консьюмера groupe-id. Если этого не сделать, приложение не запустится. Параметр имеет тип String и может быть любым.
spring.kafka.consumer.group-id=app.1Наш простейший кафка-проект готов. У нас есть отправитель и получатель сообщений. Осталось только запустить. Для начала запускаем ZooKeeper и Kafka с помощью батника, который мы написали ранее, затем запускаем наше приложение. Отправлять запрос удобнее всего с помощью Postman. В теле запроса не забываем указывать параметры msgId и msg.
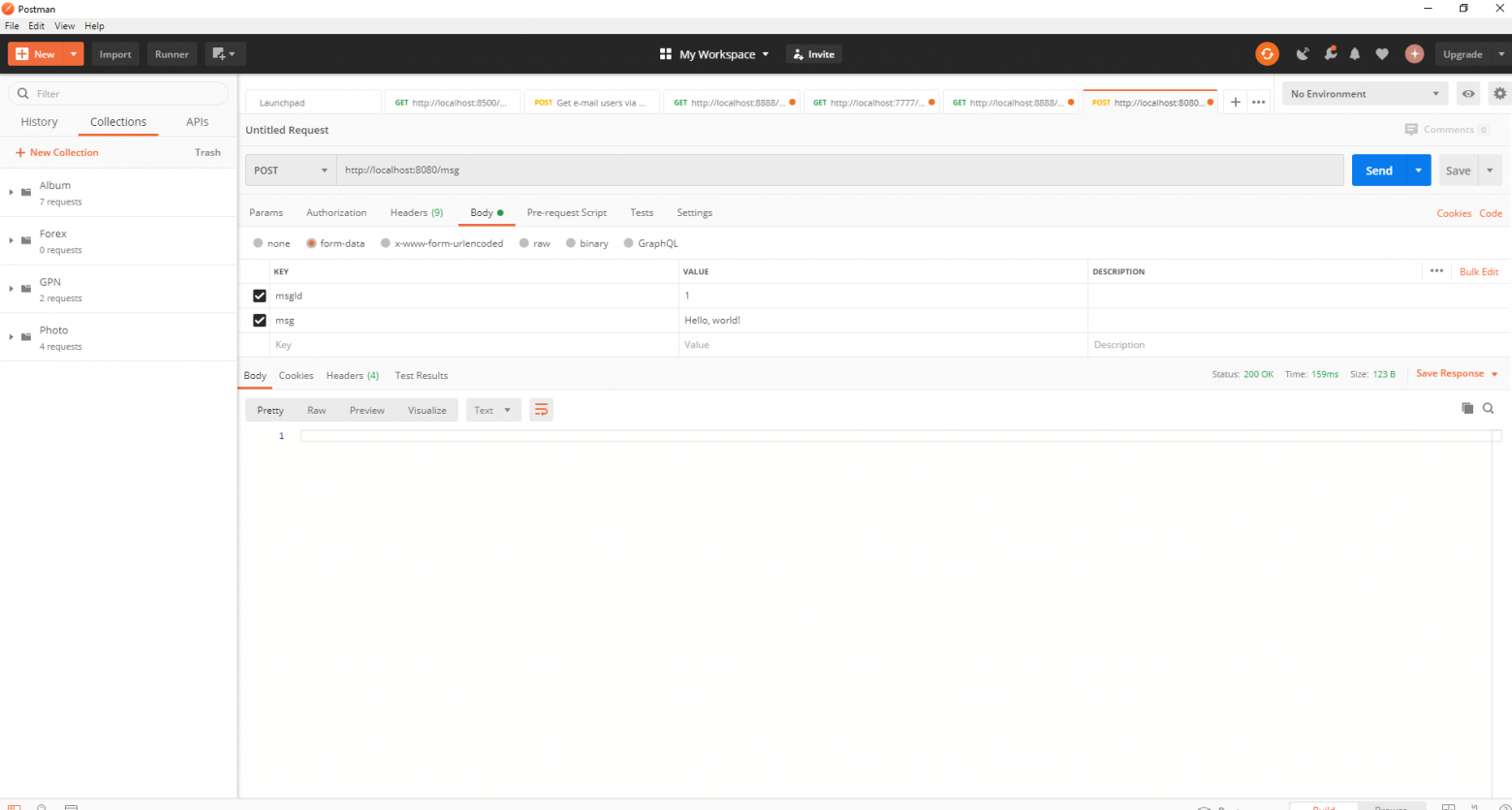
Если мы видим в IDEA такую картину, значит всё работает: продюсер отправил сообщение, консьюмер получил его и вывел в консоль.
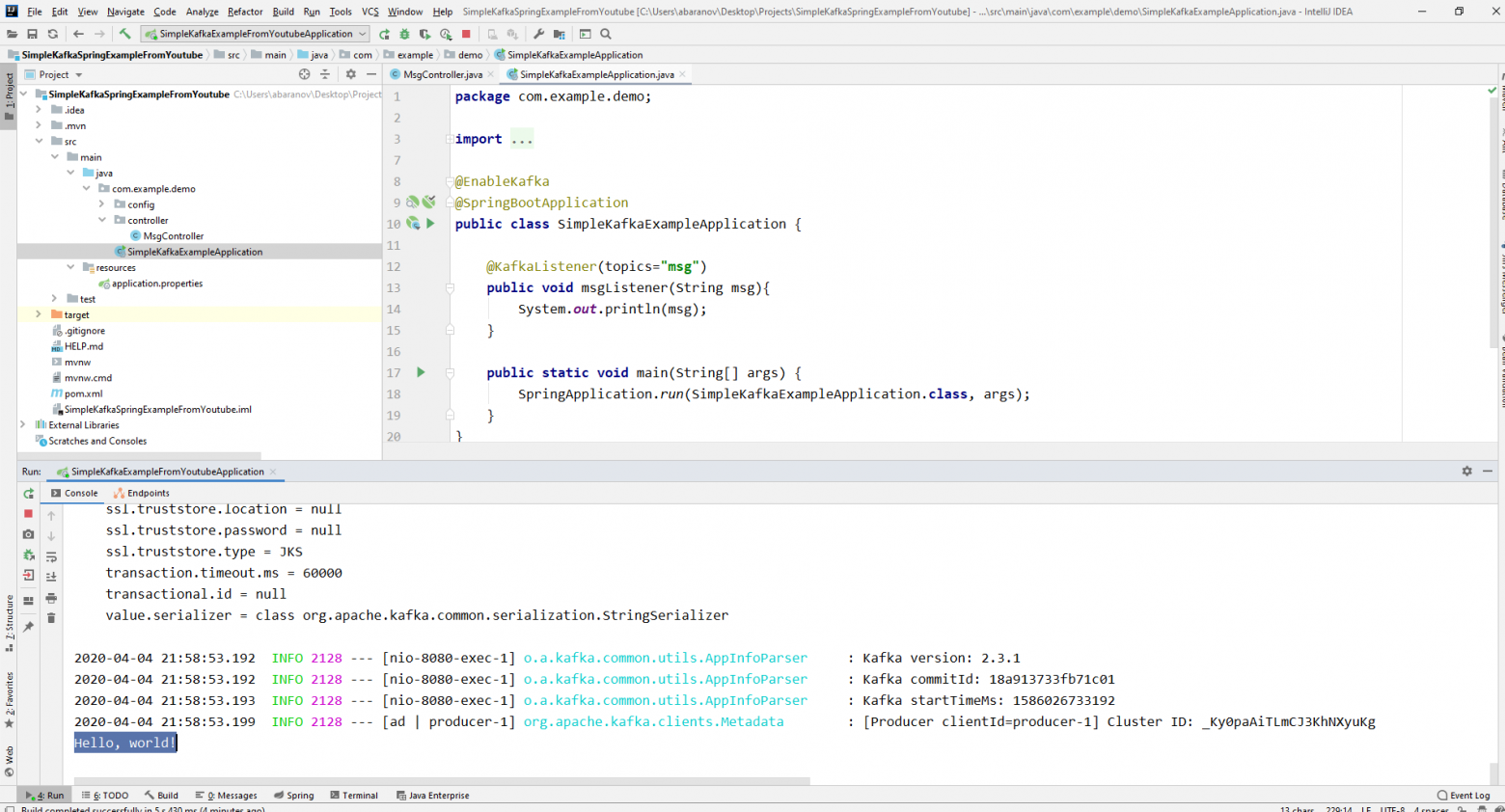
Усложняем проект
Реальные проекты с использованием Kafka конечно же сложнее, чем тот, который мы создали. Теперь, когда мы разобрались с базовыми функциями сервиса, рассмотрим, какие дополнительные возможности он предоставляет. Для начала усовершенствуем продюсера.
Если вы открывали метод send(), то могли заметить, что у всех его вариантов есть возвращаемое значение ListenableFuture<SendResult<K, V>>. Сейчас мы не будем подробно рассматривать возможности данного интерфейса. Здесь будет достаточно сказать, что он нужен для просмотра результата отправки сообщения.
@PostMapping
public void sendMsg(String msgId, String msg){
ListenableFuture<SendResult<String, String>> future = kafkaTemplate.send("msg", msgId, msg);
future.addCallback(System.out::println, System.err::println);
kafkaTemplate.flush();
}Метод addCallback() принимает два параметра – SuccessCallback и FailureCallback. Оба они являются функциональными интерфейсами. Из названия можно понять, что метод первого будет вызван в результате успешной отправки сообщения, второго – в результате ошибки.Теперь, если мы запустим проект, то увидим на консоли примерно следующее:
SendResult [producerRecord=ProducerRecord(topic=msg, partition=null, headers=RecordHeaders(headers = [], isReadOnly = true), key=1, value=Hello, world!, timestamp=null), recordMetadata=msg-0@6]Посмотрим ещё раз внимательно на нашего продюсера. Интересно, что будет если в качестве ключа будет не String, а, допустим, Long, а в качестве передаваемого сообщения и того хуже – какая-нибудь сложная DTO? Попробуем для начала изменить ключ на числовое значение…

Если мы укажем в продюсере в качестве ключа Long, то приложение нормально запуститься, но при попытке отправить сообщение будет выброшен ClassCastException и будет сообщено, что класс Long не может быть приведён к классу String.

Если мы попробуем вручную создать объект KafkaTemplate, то увидим, что в конструктор в качестве параметра передаётся объект интерфейса ProducerFactory<K, V>, например DefaultKafkaProducerFactory<>. Для того, чтобы создать DefaultKafkaProducerFactory, нам нужно в его конструктор передать Map, содержащий настройки продюсера. Весь код по конфигурации и созданию продюсера вынесем в отдельный класс. Для этого создадим пакет config и в нём класс KafkaProducerConfig.
@Configuration
public class KafkaProducerConfig {
private String kafkaServer="localhost:9092";
@Bean
public Map<String, Object> producerConfigs() {
Map<String, Object> props = new HashMap<>();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,
kafkaServer);
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
LongSerializer.class);
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
StringSerializer.class);
return props;
}
@Bean
public ProducerFactory<Long, String> producerFactory() {
return new DefaultKafkaProducerFactory<>(producerConfigs());
}
@Bean
public KafkaTemplate<Long, String> kafkaTemplate() {
return new KafkaTemplate<>(producerFactory());
}
}
В методе producerConfigs() создаём мапу с конфигурациями и в качестве сериализатора для ключа указываем LongSerializer.class. Запускаем, отправляем запрос из Postman и видим, что теперь всё работает, как надо: продюсер отправляет сообщение, а консьюмер принимает его.
Теперь изменим тип передаваемого значения. Что если у нас не стандартный класс из библиотеки Java, а какой-нибудь кастомный DTO. Допустим такой.
@Data
public class UserDto {
private Long age;
private String name;
private Address address;
}
@Data
@AllArgsConstructor
public class Address {
private String country;
private String city;
private String street;
private Long homeNumber;
private Long flatNumber;
}Для отправки DTO в качестве сообщения, нужно внести некоторые изменения в конфигурацию продюсера. В качестве сериализатора значения сообщения укажем JsonSerializer.class и не забудем везде изменить тип String на UserDto.
@Configuration
public class KafkaProducerConfig {
private String kafkaServer="localhost:9092";
@Bean
public Map<String, Object> producerConfigs() {
Map<String, Object> props = new HashMap<>();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,
kafkaServer);
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
LongSerializer.class);
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
JsonSerializer.class);
return props;
}
@Bean
public ProducerFactory<Long, UserDto> producerFactory() {
return new DefaultKafkaProducerFactory<>(producerConfigs());
}
@Bean
public KafkaTemplate<Long, UserDto> kafkaTemplate() {
return new KafkaTemplate<>(producerFactory());
}
}Отправим сообщение. В консоль будет выведена следующая строка:

Теперь займёмся усложнением консьюмера. До этого наш метод public void msgListener(String msg), помеченный аннотацией @KafkaListener(topics=«msg») в качестве параметра принимал String и выводил его на консоль. Как быть, если мы хотим получить другие параметры передаваемого сообщения, например, ключ или партицию? В этом случае тип передаваемого значения необходимо изменить.
@KafkaListener(topics="msg")
public void orderListener(ConsumerRecord<Long, UserDto> record){
System.out.println(record.partition());
System.out.println(record.key());
System.out.println(record.value());
}Из объекта ConsumerRecord мы можем получить все интересующие нас параметры.
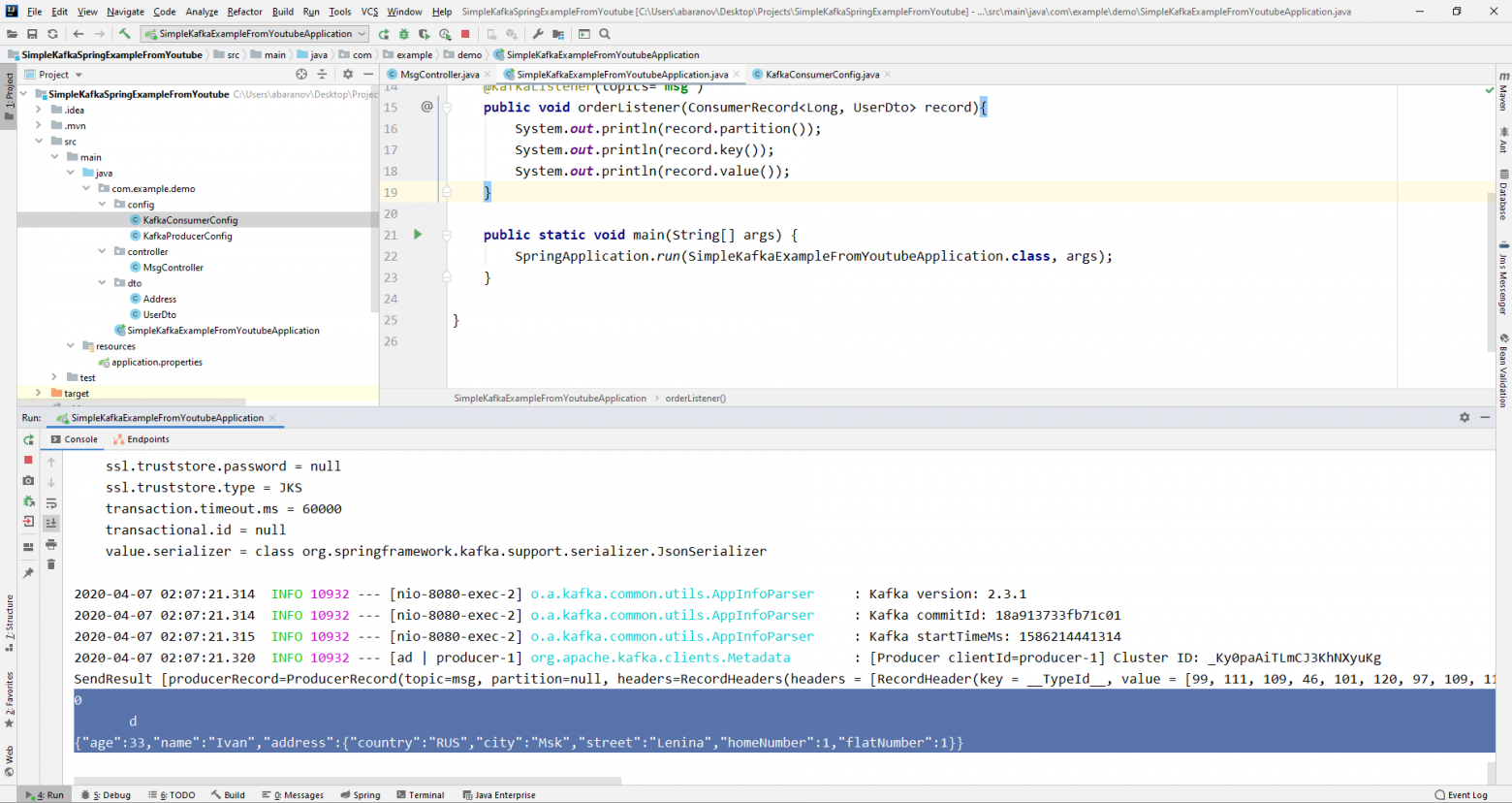
Мы видим, что вместо ключа на консоль выводятся какие-то кракозябры. Это потому, что для десериализации ключа по умолчанию используется StringDeserializer, и если мы хотим, чтобы ключ в целочисленном формате корректно отображался, мы должны изменить его на LongDeserializer. Для настройки консьюмера в пакете config создадим класс KafkaConsumerConfig.
@Configuration
public class KafkaConsumerConfig {
@Value("${spring.kafka.bootstrap-servers}")
private String kafkaServer;
@Value("${spring.kafka.consumer.group-id}")
private String kafkaGroupId;
@Bean
public Map<String, Object> consumerConfigs() {
Map<String, Object> props = new HashMap<>();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, kafkaServer);
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, LongDeserializer.class);
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
props.put(ConsumerConfig.GROUP_ID_CONFIG, kafkaGroupId);
return props;
}
@Bean
public KafkaListenerContainerFactory<?> kafkaListenerContainerFactory() {
ConcurrentKafkaListenerContainerFactory<Long, UserDto> factory =
new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(consumerFactory());
return factory;
}
@Bean
public ConsumerFactory<Long, UserDto> consumerFactory() {
return new DefaultKafkaConsumerFactory<>(consumerConfigs());
}
}Класс KafkaConsumerConfig очень похож на KafkaProducerConfig, который мы создавали ранее. Здесь так же присутствует Map, содержащий необходимые конфигурации, например, такие как десериализатор для ключа и значения. Созданная мапа используется при создании ConsumerFactory<>, которая в свою очередь, нужна для создания KafkaListenerContainerFactory<?>. Важная деталь: метод возвращающий KafkaListenerContainerFactory<?> должен называться kafkaListenerContainerFactory(), иначе Spring не сможет найти нужного бина и проект не скомпилируется. Запускаем.
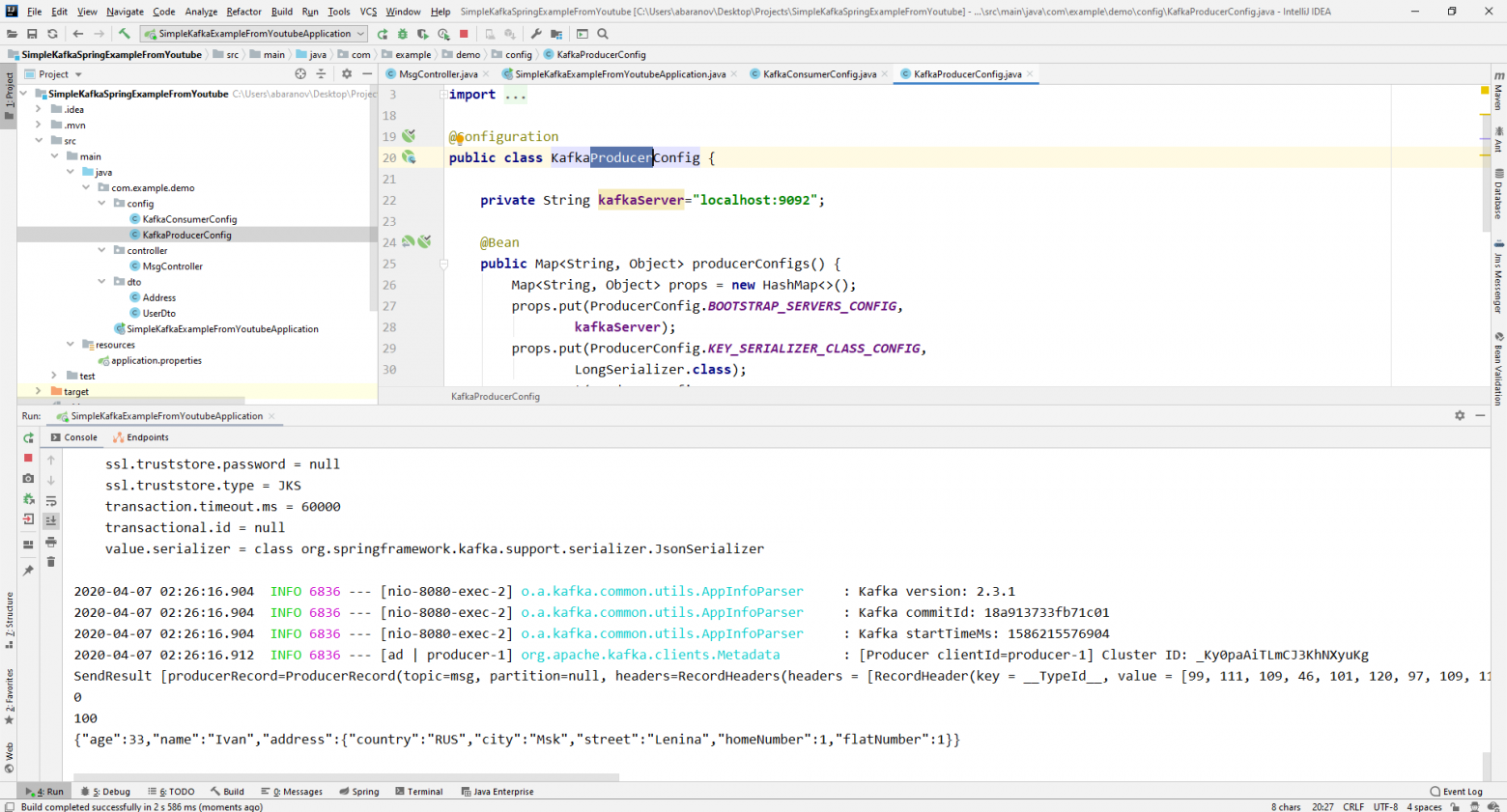
Видим, что теперь ключ отображается как надо, а это значит, что всё работает. Конечно, возможности Apache Kafka далеко выходят за пределы тех, что описаны в данной статье, однако, надеюсь, прочитав её, вы составите представление о данном сервисе и, самое главное, сможете начать работу с ним.
Мойте руки чаще, носите маски, не выходите без необходимости на улицу, и будьте здоровы.
Брокер сообщений — это программное обеспечение, которое служит промежуточным звеном для пересылки сообщений между различными приложениями. Он действует как определенный сервер, который получает сообщения от одного приложения (называемого продюсером) и маршрутизирует их к одному или нескольким другим приложениям (называемым консьюмером). Основная цель брокера сообщений — обеспечить устойчивую и надежную связь между различными системами, при этом не требуя, чтобы эти системы всегда были доступны и имели прямую связь друг с другом. Это позволяет приложениям работать асинхронно, обеспечивая отказоустойчивость и возможность работы в режиме реального времени. Брокер сообщений может принимать сообщения от множества источников и эффективно маршрутизировать их к нужному приемнику. Сообщения могут быть сгруппированы в топики или очереди в зависимости от требуемой бизнес-логики.
Существует множество различных брокеров сообщений, каждый из которых имеет свои собственные особенности и преимущества. В данной статье мы сфокусируемся на изучении Kafka.
Apache Kafka — это быстрый и масштабируемый брокер сообщений, способный обрабатывать миллионы сообщений в секунду. Брокер особенно ценится за свою отказоустойчивость и возможность длительного хранения данных. Проект изначально разрабатывался компанией LinkedIn, в настоящее время является самым популярным open-source решением в сфере брокеров сообщений и имеет лицензию Apache Software Foundation. Это решение широко используется для построения реальных пайплайнов данных и потоковых приложений. Перемещение и обработка потоков данных между системами или приложениями становится критической задачей. Именно здесь приходит на помощь Kafka, помогая пользователю обрабатывать потоки данных в реальном времени, с минимальной задержкой. В качестве распределенной системы, рассматриваемый брокер делится на множество серверов, которые могут хранить и обрабатывать потоки данных параллельно. Такое распределение позволяет Kafka обеспечивать обработку данных в реальном времени для множества различных источников, обеспечивая надежность и устойчивость к сбоям системы.
В этой статье мы будем изучать процесс установки и настройки Kafka, чтобы вы могли использовать все его преимущества для ваших проектов. Мы рассмотрим процесс для различных операционных систем, включая Windows, Ubuntu и MacOS, чтобы обеспечить максимально возможную гибкость для различных пользователей и потребностей.
cloud
Системные требования
Apache Kafka был разработан таким образом, чтобы максимально эффективно использовать возможности железа, на котором он работает. Однако, существуют некоторые общие рекомендации, которые полезно иметь в виду при настройке системы для работы с этим брокером:
-
Процессор (CPU): Kafka обычно не требует много процессорной мощности, так как большую часть операций он выполняет с помощью прямого доступа к диску (zero-copy). Однако количество ядер CPU может влиять на пропускную способность.
-
Оперативная память (RAM): Рекомендуется иметь как минимум 8GB оперативной памяти, но итоговый объем будет сильно зависеть от массива данных и количества параллельных операций.
-
Дисковое пространство: Kafka эффективно использует файловую систему и прямую запись на диск. Желательно использовать SSD с повышенной скоростью записи/чтения данных. Рекомендуется использовать отдельный диск, чтобы изолировать его работу от других процессов.
-
Сеть: Брокер активно использует сеть для передачи данных. Рекомендуется иметь стабильное подключение с высокой пропускной способностью.
-
Операционная система: Apache Kafka, как правило, работает на Unix-подобных системах, таких как Linux, однако это не ограничивает пользователя в выборе операционной системы.
-
Java: Поскольку инструмент написан на Java, вам потребуется среда выполнения Java (JDK), версии 8 или выше.
Несмотря на то, что Linux дает Kafka ключевое преимущество в виде производительности и масштабируемости, брокер хорошо работает как на Windows, так и на MacOS. Чуть позже мы разберем плюсы и минусы каждого решения, а сейчас приступим к установке.
Процесс установки Kafka достаточно прямолинейный, тем не менее он требует некоторой аккуратности. Вот пошаговая инструкция:
-
Скачивание и установка Java Development Kit (JDK): Apache Kafka работает на Java, поэтому первым делом нужно установить средства разработки, если они у вас были не установлены. Скачать JDK можно с официального сайта Oracle. После установки обязательно проверьте работоспособность, для этого достаточно ввести в командной строке (cmd) следующую команду:
java -version-
Скачивание Apache Kafka: Apache Kafka можно скачать с официального сайта проекта (нам нужны Binary downloads). Рекомендуется выбирать последнюю стабильную версию продукта (на момент написания статьи это 3.7.0, поэтому здесь будет показана установки именно этой версии. Однако, установка от версии к версии не сильно меняется, поэтому эту инструкцию можно применять и к другим версиям продукта)
-
Распаковка: После скачивания архива его следует распаковать и переместить в удобное для вас место. После распаковки дистрибутива, вы увидите различные папки, такие как:
-
bin: Эта папка содержит исполняемые файлы, которые используются для запуска и управления распределенной системой обмена сообщениями. В подпапке/windowsнаходятся специальные версии файлов, предназначенные для использования в OS Windows. -
config: Здесь собраны файлы конфигурации Kafka, в том числеzookeeper.propertiesиserver.properties, которые можно отредактировать для более точной настройки. -
libs: Это папка со всеми библиотеками, которые нужны для запуска и работоспособности. -
logs: Здесь содержатся журналы работы или другими словами логи. Они могут быть полезны при отладке проблем и нахождении зависимостей между компонентами. -
site-docs: Эта папка содержит документацию для версии Kafka, которую вы установили. Может быть полезна для начинающих специалистов. -
LICENSEиNOTICE: Эти файлы содержат лицензионное соглашение и правовые замечания.

-
Базовая настройка каталога данных и логирования: По умолчанию, файлы логов и каталог данных сохраняется в папке
/tmp, что может привести к проблемам производительности, безопасности и управления данными. Рекомендуется поменять стандартные пути на свои -
Перейдите в
config/server.propertiesи откройте файл в любом текстовом редакторе (на скриншоте VSCode). -
Найдите поле
log.dirs(можно воспользоваться поиском, для этого нажмите сочетание клавиш Ctrl+F)
-
Поменяйте стандартный путь
/tmp/kafka-logsна постоянный путь. Напримерc:/kafka/kafka-logs. После чего сохраните файл и закройте его. -
Аналогичные действия нужно сделать и для каталога данных. Для этого перейдите в
config/zookeeper.propertiesи откройте файл в любом текстовом редакторе. -
В параметре
dataDirтакже нужно поменять стандартный путь на свой. Пример постоянного пути есть ниже на скриншоте.
На этом базовая настройка закончена. Этого хватит чтобы запустить сервер Zookeeper и Kafka и проверить работоспособность системы.
-
Запуск сервера Zookeeper и Kafka: Для запуска нужно перейти в папку с распакованным архивом и открыть командную строку. Для запуска Zookeeper используйте следующую команду:
.\bin\windows\zookeeper-server-start.bat .\config\zookeeper.properties. Обратите внимание, наш Zookeeper запущен на 2181 порту. Это стандартный порт для этой службы.
Если у вас появляется ошибка «The input line is too long. The syntax of the command is incorrect», переместите папку с Kafka в каталог, ближе к корню диска. Во время запуска zookeeper-server-start.bat вызывает CLASSPATH несколько раз, что приводит к переполнению переменной. Среда cmd.exe поддерживает не более 8191 символов.
Откройте новое окно терминала для запуска Kafka-server и используйте следующую команду:
.\bin\windows\kafka-server-start.bat .\config\server.properties-
Проверка работоспособности: Для проверки работоспособности попробуем создать тему с помощью следующей команды:
.\bin\windows\kafka-topics.bat --create --bootstrap-server localhost:9092 --partitions 1 --replication-factor 1 --topic TestTopicОбратите внимание, что порт 2181 совпадает с открытым портом для Zookeeper.
Для наглядности создадим еще одну тему под названием NewTopic. Теперь проверим, какие темы у нас существуют, следующей командой:
.\bin\windows\kafka-topics.bat --list --bootstrap-server localhost:9092В новой командной строке мы можем повзаимодействовать с темой, а именно создать несколько сообщений и прочитать их после. Для этого в новом окне введите следующую команду:
.\bin\windows\kafka-console-producer.bat --broker-list localhost:9092 --topic TestTopicПосле старта команды можно передавать любые сообщения:
Для того чтобы начать получать сообщения, в новом окне консоли введите следующую команду:
.\bin\windows\kafka-console-consumer.bat --bootstrap-server localhost:9092 --topic TestTopic --from-beginningКак видно на скриншоте, мы получили сообщения по теме TestTopic.
Это простой функционал, который помогает понять и разобраться в инструментах Kafka. Однако у вас может что-то пойти не так, походу установки и тестов. Вот некоторые типовые ошибки, которые могут возникнуть:
-
Проблемы с JDK: Убедитесь что у вас установлен JDK, а не JRE. Также обратите внимание на версию, она должна быть 8 или выше.
-
Проверка переменных окружения: После установки Java убедитесь, что переменная
JAVA_HOMEправильно установлена и что путь к каталогуbinприсутствует в системном пути. -
Проблемы с firewall и антивирусом: Иногда сторонние антивирусные программы или firewall могут блокировать Kafka. Если вы столкнулись с проблемами подключения, попробуйте на время отключить их.
-
Порты: По умолчанию Zookeeper слушает на порту 2181, а Kafka на 9092. Убедитесь, что эти порты свободны или переназначьте стандартные порты для этих служб.
-
Запуск Zookeeper перед Kafka: Перед тем как запускать Kafka, убедитесь, что Zookeeper уже работает. Если нет, то запустите Zookeeper.
-
Неправильное завершение Kafka: Если Kafka завершается неправильно, то возможно некоторые данные еще остались во временной папке. Если вы начинаете сталкиваться с трудностями при запуске, попробуйте очистить временные файлы.
Установка и настройка Kafka на Ubuntu
На самом деле, шаги не будут сильно отличаться, в зависимости от дистрибутива Linux, который вы выбрали (в нашем случае это Ubuntu). Отличия будут касаться установочных менеджеров и незначительных особенностей каждой операционной системы. Шаги будут похожи на установку для Windows, поэтому вы можете обращаться к этому разделу тоже, даже если у вас операционная система Linux.
vds
-
Скачивание и установка Java Development Kit (JDK): Как уже упоминалось, Apache Kafka работает на Java, поэтому первым делом нужно установить JDK. Однако перед этим, рекомендуем обновить список пакетов и версии этих пакетов командой:
sudo apt update
sudo apt upgradeВ Linux-системах установку можно сделать довольно просто через терминал, для этого достаточно ввести следующие команды:
sudo apt install default-jre
sudo apt install default-jdk-
Скачивание и разархивирование: Apache Kafka можно скачать с официального сайта проекта. Рекомендуется выбирать последнюю стабильную версию продукта. Для скачивания можно воспользоваться утилитой
wgetиз консоли:
wget https://downloads.apache.org/kafka/3.7.0/kafka_2.13-3.7.0.tgzДля распаковки воспользуйтесь следующей командой:
tar xzf kafka_2.13-3.7.0.tgzОбратите внимание, что на момент прочтения статьи, версия продукта может быть другой, соответственно команды, а конкретно цифры в ссылке, будут выглядеть по-другому. По итогу вышеописанных действий у вас должна появиться папка с продуктом рядом с архивом. Перейдите в появившуюся папку командой:
cd kafka_2.13-3.7.0-
Проверка работоспособности: Остальные пункты похожи на то, что мы делали для Windows, поэтому рекомендуем прочитать инструкцию начиная с 3 пункта. Для запуска Zookeeper нужно написать следующую команду:
bin/zookeeper-server-start.sh config/zookeeper.propertiesЗатем в новом окне терминала запустите Kafka:
bin/kafka-server-start.sh config/server.propertiesЭто основная установка и настройка. Для продакшн-среды есть возможность настройки различных параметров, таких как многочисленные бэкапы, конфигурация сети, разделение данных и так далее, но это более трудоемкий и сложный процесс.
Также стоит упомянуть про некоторые возможные трудности, с которыми можно столкнуться в процессе установки Kafka на Linux:
-
Разрешение прав доступа: При работе с Linux иногда возникают проблемы с правами доступа к определенным файлам или каталогам. Чтобы обойти это, можно использовать sudo перед командами, которые будут вызывать проблемы. Однако будьте осторожны с этим, потому что sudo дает полный админский доступ, что может повлечь за собой последствия с нарушением безопасности.
-
Ошибки памяти Java: Если у вас возникают проблемы с памятью Java при работе с Kafka, вы можете попробовать увеличить максимальное количество памяти, выделенной для JVM с помощью флага -Xmx. Для этого нужно будет добавить флаг в файл конфигурации, который находится в
bin/kafka-server-start.sh. Однако учтите, что важно оставить достаточно памяти для работы других процессов в системе. Увеличение максимального объема памяти JVM может привести к замедлению работы системы, если JVM начнет использовать все доступные ресурсы. -
Управление версиями: При работе с Linux иногда возникают проблемы с версиями. Всегда проверяйте версию Kafka и все связанные инструменты, такие как Zookeeper, для обеспечения совместимости.
-
Правильная остановка Kafka и Zookeeper: Для остановки Kafka и Zookeeper в Linux вы можете использовать команды
kafka-server-stop.sh
zookeeper-server-stop.shРекомендуется всегда останавливать эти службы правильно, чтобы избежать потери данных.
-
Проблемы с логированием: Инструмент генерирует огромное количество логов, удостоверьтесь, что у вас есть достаточно свободного места на диске и активирована ротация логов.
-
Порты и пределы файлов: Убедитесь, что у вас есть разрешение на открытие необходимого количества файлов или сокетов. Linux имеет системные ограничения, которые можно изменить при необходимости.
Установка и настройка Kafka на MacOS
Вот пошаговый процесс установки и настройки Kafka на системе MacOS:
-
Установка Homebrew: Homebrew — менеджер пакетов, который упрощает установку программного обеспечения на операционной системе MacOS. Homebrew не требует прав администратора для установки ПО, что делает его удобным для использования и уменьшает риски связанные с безопасностью. Если у вас еще нет Homebrew, вы можете установить его, используя следующую команду в терминале:
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"В нашем случае, Homebrew понадобится для установки Kafka и его зависимостей.
-
Обновление Homebrew: В случае если у вас уже был установлен Homebrew, его не помешало бы обновить до новейшей версии командой.
brew update-
Установка Java Development Kit (JDK): Для установки JDK можно воспользоваться Homebrew, который мы только что установили. Для этого в консоли введите следующую команду:
brew install openjdk-
Установка Kafka: Установите Kafka следующей командой:
brew install kafka-
Запуск Kafka и Zookeeper: Сначала запустите Zookeeper, а затем Kafka. Замените
usr/local/binна путь к исполняемым файлам Kafka и Zookeeper, если они у вас в другом месте:
zookeeper-server-start /usr/local/etc/kafka/zookeeper.properties
kafka-server-start /usr/local/etc/kafka/server.propertiesТакже стоит отметить, что для простоты демонстрации мы запустили Zookeeper и Kafka в режиме standalone на локальной машине. Для создания полноценной распределенной сети на нескольких машинах, вам потребуется изменить файлы конфигурации соответствующим образом. Среди ключевых параметров для изменения:
-
Разделы — сущности, которые позволяют распараллелить обработку данных. Количество разделов определяет, сколько потоков одновременно сможет обрабатывать данные в рамках топика.
-
Реплики — копии существующих разделов, для обеспечения отказоустойчивости. Количество реплик определяет, сколько копий каждого раздела будет храниться в кластере.
-
Информация о брокере — полный список всех серверов, которые будут участвовать в кластере.
Как и для других операционных систем, мы отметим типичные проблемы при установке Kafka на MacOS:
-
JDK нужной версии: Проверьте, установлен ли JDK версии 8 или выше. Если JDK не установлен, то вы можете столкнуться с ошибкой при попытке запуска.
-
Переменные среды: Kafka может не работать, если переменные среды установлены неправильно или не установлены вовсе. Например, вы должны установить переменную среды
KAFKA_HOMEна путь к директории. Иногда для корректной работы могут потребоваться и другие переменные среды, напримерJAVA_HOME. -
Путь к файлам и разрешения: Kafka может не найти нужные файлы или не сможет запуститься, если у него нет разрешения на чтение и запись в определенные директории. Вам может потребоваться изменить разрешения или переместить некоторые файлы.
-
Проблемы с Homebrew: Убедитесь, что Homebrew установлен корректно и обновлен до последней версии. Иногда установка через Homebrew может привести к конфликту версия или проблемам с зависимостями.
-
Проблемы с зависимостями: Система требует наличия Zookeeper чтобы функционировать. Первым делом запускайте Zookeeper, а потом уже Kafka.
-
Порты: Kafka и Zookeeper используют определенные порты (9092 и 2181 соответственно) по умолчанию. Если эти порты используются другими приложениями, инструмент не сможет запуститься.
-
Конфигурация: Ошибки в файлах конфигурации Kafka или неправильно заданные параметры могут привести к проблемам при попытке запуска.
Зачастую установка Kafka идет довольно гладко, если использовать Homebrew. Вероятность столкнуться с проблемой в MacOS мала.
Установка и настройка Kafka в Docker
Docker — это платформа, предназначенная для разработки, доставки и запуска приложений в контейнерах. Контейнеры позволяют упаковать приложение со всем его окружением и зависимостями в один пакет, который можно легко распространять и устанавливать на любой системе. Установка Kafka в Docker — это хороший способ быстро и без особых трудностей начать работать с системой. Вот несколько простых шагов, для установки:
-
Первым делом, нужен сам Docker. Скачайте Kafka с официального сайта проекта способом, соответствующим вашей ОС.
-
Запустите экземпляр, с помощью этой команды:
docker run -p 9092:9092 apache/kafka:3.7.0Обратите внимание, что ваша версия Kafka может отличаться от той, что в примере.
Вы можете проверить работоспособность инструмента аналогично разделу установки на Linux.
Общие рекомендации по выбору ОС
Как мы выяснили, возможность установить Kafka есть во всех основных операционных системах, а также в Docker. В зависимости от конкретной ситуации и потребностей, каждая из них имеет свои преимущества и недостатки. Если у вас стоит выбор, на какой ОС развернуть Kafka, ниже будут рассмотрены плюсы и минусы каждой системы.
Windows
-
Плюсы:
-
Простота использования: Windows по-прежнему остается одной из самых популярных операционных систем с большим количеством документации и комьюнити.
-
Интеграция: Очень хорошо интегрируется с другими продуктами и сервисами Microsoft.
-
Минусы:
-
Windows не всегда является наилучшим выбором для развертывания серверных приложений, скорее всего вам придется столкнуться с некоторыми проблемами совместимости и производительности.
-
Наличие Powershell и WSL (Windows Subsystem for Linux) может упростить работу, однако эти системы не всегда могут быть оптимальными для работы с Linux-приложениями.
-
Kafka и Zookeeper обычно тестируются и используются на Unix-подобных системах, что может привести к большему количеству багов и проблем.
macOS
-
Плюсы:
-
Простая установка с минимальными трудностями.
-
Удобные инструменты для установки и управления продуктами.
-
Система на базе Unix, что облегчает работу с большинством инструментов.
-
Минусы:
-
Ресурсоемкая система: Если ваш Mac не обладает достаточными ресурсами, это может замедлить работу.
-
Возможные проблемы совместимости между версиями macOS и Kafka, что может привести к фатальным ошибкам.
Linux
-
Плюсы:
-
Из-за того, что Linux — это система с открытым исходным кодом и поддерживается большим сообществом, почти всегда есть способы решения той или иной проблемы.
-
Linux занимает меньше системных ресурсов, что делает его более эффективным в работе с Kafka.
-
Операционные системы на базе Linux часто являются предпочтительными для серверных приложений.
-
Минусы:
-
Требует больше технических навыков для настройки и управления, по сравнению с Windows и macOS.
-
Возможные сложности при установке и настройке GUI.
Docker
-
Плюсы:
-
Портативность: Docker-контейнеры можно запускать на любой операционной системе. Это может облегчить развертывание брокера в различных окружениях.
-
Изоляция: Docker обеспечивает изоляцию между приложениями, что означает, что работа Kafka не будет влиять на другие приложения.
-
Воспроизводимость: Используя Docker, можно создать конфигурацию, которую легко воспроизвести. Это облегчает процесс обновления и развертывания.
-
Интеграция с другими инструментами: Docker хорошо взаимодействует с популярными решениями, что упрощает управление и масштабирование контейнеров Kafka.
-
-
Минусы:
-
Сложность: Docker добавляет дополнительный слой сложности в установку брокера.
-
Управление данными: Брокер хранит все сообщения на диске. Его конфигурация и управление могут быть сложными, учитывая контейеризованную среду.
-
Производительность: Как и любая другая система, работающая в контейнере, производительность брокера может быть ограничена ресурсами контейнера. Это может потребовать более тонкой настройки Docker.
-
Управление: Управление и мониторинг брокера в контейнере может быть сложным, особенно в больших системах. Возможно потребуются инструменты автоматизации, такие как Kubernetes и Prometheus.
-
В целом, Linux является наиболее распространенным выбором для работы с Apache Kafka, особенно для серверов и рабочих станций. Однако, выбор операционной системы будет напрямую зависеть от ваших предпочтений и требований.
Запуск Kafka в облаке
Мы рассмотрели процесс установки Kafka на разные операционные системы, однако этот процесс может затянуться в связи с некоторыми ошибками. Если вы хотите избежать заморочек с установкой и настройкой, обратите внимание на наше решение.
Timeweb Cloud предлагает гибкое и масштабируемое облачное решение для запуска экземпляра Kafka за пару минут. Вам не нужно устанавливать и настраивать ПО, достаточно выбрать регион и конфигурацию.
Решение Timeweb Cloud обеспечит стабильность и быстродействие вашему проекту на Kafka, благодаря профессиональной поддержке и высокопроизводительной инфраструктуре. Все это позволяет полностью сосредоточиться на разработке и масштабировании вашего проекта, не беспокоясь о технической стороне процесса.
Попробуйте Timeweb Cloud уже сегодня и откройте для себя преимущества работы с надежным и высокопроизводительным облачных хостингом.
Заключение
Apache Kafka — это серьезный, надежный и масштабируемый брокер сообщений, который обеспечивает высокую пропускную способность, устойчивость к отказам и низкую временную задержку. Вот несколько причин, почему стоит выбирать Kafka в качестве среды обмена сообщениями:
-
Высокая пропускная способность: Apache Kafka способен обрабатывать миллионы сообщений в секунду, что делает его отличным выбором для приложений, которые обрабатывают огромные объемы данных в реальном времени.
-
Устойчивость к отказам: Kafka обеспечивает восстановление от сбоев и обеспечивает высокую доступность данных благодаря своим механизмам репликации.
-
Масштабируемость: Kafka легко масштабируется, добавляя больше узлов в кластер без прерывания сервиса.
-
Долгосрочное хранение данных: В отличие от большинства других брокеров сообщений, Kafka поддерживает долгосрочное хранение данных. Можно настроить период удержания данных в Kafka, и они будут сохраняться до истечении этого времени.
-
Распределенная система: Kafka по сути является распределенной системой, это означает, что сообщения могут быть потребляемы в любом порядке и по многим каналам.
-
Интеграция с большим количеством систем: Kafka может быть легко интегрирована с различными системами, такими как Hadoop, Spark, Storm, Flink и многими другими.
-
Быстрая обработка: Apache Kafka обеспечивает низкую задержку, что делает его отличным выбором для приложений, которым требуется быстрая обработка данных в реальном времени.
-
Топология «публикация-подписка»: Kafka позволяет источникам данных отправлять сообщения в топики, а приложениям-получателя — подписывать на интересующие их топики.
Все эти преимущества делают Kafka одним из наиболее популярных и надежных брокеров сообщений на рынке. Однако, как всегда, выбор инструмента должен основываться на требованиях проекта и предпочтениям команды.
Last Updated :
28 Jun, 2022
Apache Kafka is an open-source application used for real-time streams for data in huge amount. Apache Kafka is a publish-subscribe messaging system. A messaging system lets you send messages between processes, applications, and servers. Broadly Speaking, Apache Kafka is software where topics can be defined and further processed.
Downloading and Installation
Apache Kafka can be downloaded from its official site kafka.apache.org
For the installation process, follow the steps given below:
Step 1: Go to the Downloads folder and select the downloaded Binary file.
Step 2: Extract the file and move the extracted folder to the directory where you wish to keep the files.
Step 3: Copy the path of the Kafka folder. Now go to config inside kafka folder and open zookeeper.properties file. Copy the path against the field dataDir and add /zookeeper-data to the path.
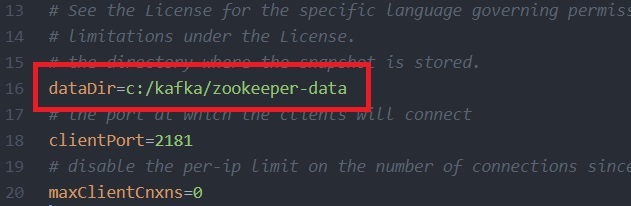
For example if the path is c:/kafka
Step 4: Now in the same folder config open server.properties and scroll down to log.dirs and paste the path. To the path add /kafka-logs
Step 5: This completes the configuration of zookeeper and kafka server. Now open command prompt and change the directory to the kafka folder. First start zookeeper using the command given below:
.\bin\windows\zookeeper-server-start.bat .\config\zookeeper.properties
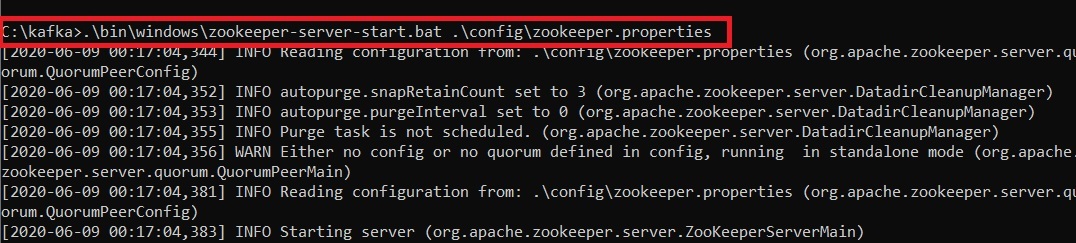
Step 6: Now open another command prompt and change the directory to the kafka folder. Run kafka server using the command:
.\bin\windows\kafka-server-start.bat .\config\server.properties

Now kafka is running and ready to stream data.
Запустить Apache Kafka и ZooKeeper на Windows 10 проще, чем кажется! Перед вами подробная инструкция без Docker и облаков: установка, настройка, создание тестового топика и обработка первых сообщений.

Apache Kafka — это распределённая система для стриминга данных, разработанная специально для обработки больших объёмов сообщений в реальном времени. Эта платформа используется повсеместно — от логирования и мониторинга до построения полноценных event-driven систем и микросервисной архитектуры. Она позволяет передавать сообщения между продюсерами (отправителями) и консьюмерами (получателями) через надёжную очередь, называемую топиком.
Однако Kafka не работает в одиночку. До версии 2.8 для управления кластером и хранения метаданных ей необходим компонент под названием ZooKeeper. ZooKeeper выполняет функции координатора: отслеживает состояние брокеров Kafka (серверов, обрабатывающих и хранящих сообщения), управляет выборами контроллера и помогает поддерживать целостность данных. Начиная с версии 2.8 Kafka поддерживает режим без ZooKeeper (KRaft mode). Однако в этом гайде используется классическая схема с ZooKeeper.
В продакшене Kafka обычно разворачивают двумя способами. Первый — в облаке или в виде кластера на VPS или собственных Linux-серверах, управляют всей инфраструктурой при этом самостоятельно. И второй — бессерверный Kafka, управляемый сторонними поставщиками услуг. Но для обучения, тестирования и небольших задач вполне подойдёт и локальная установка на Windows. В этой статье мы разберём последний способ и пошагово пройдём через весь процесс: от подготовки системы до запуска Kafka и отправки первого сообщения.
Аренда VPS/VDS виртуального сервера от AdminVPS — это прозрачная и честная услуга с доступной ценой
Подготовка системы
Прежде чем приступать к установке, проверим, готова ли система. Обе платформы написаны на Java, поэтому для их работы требуется установленная Java Virtual Machine (JVM) и библиотеки. Также желательно иметь консольные утилиты, такие как curl, и текстовый редактор — например, Notepad++ или VS Code — для работы с конфигурационными файлами.
Установка Java
Kafka требует Java 8 или выше. Мы рекомендуем OpenJDK 17 или 21 как стабильные и совместимые версии.
Скачайте OpenJDK. Перейдите на официальный сайт Adoptium и скачайте Temurin 17 (это сборка OpenJDK). Выберите установочный .msi-файл для Windows 10.
Установите Java. Запустите установщик и следуйте инструкциям. Убедитесь, что вы отметили галочку «Set JAVA_HOME variable», если такая опция есть.
После установки Java убедитесь, что переменная окружения JAVA_HOME настроена, а в Path добавлен путь к её bin. Пример:
JAVA_HOME=C:\Program Files\Adoptium\jdk-17
Path=…;%JAVA_HOME%\binПроверьте установку. Откройте терминал PowerShell или CMD и выполните команду:
java -versionОжидаемый вывод:
openjdk version "17.0.x"Если команда не распознаётся, проверьте значение JAVA_HOME и Path.
Создание рабочих директорий
При раздельной установке выделите отдельные папки для ZooKeeper и Kafka. Продумайте структуру, в нашем примере оба каталога будут находиться в корне диска C. В этих директориях мы разместим и скачанные архивы, и конфигурационные файлы.
Папки нужно создавать как можно ближе к корню — чтобы избежать ошибок при запуске.
Установка 7-Zip
Продукты Apache распространяются в .tgz-архивах. Чтобы их распаковать, установите 7-Zip или любую другую win-утилиту, поддерживающую .tar.gz.
Теперь, когда подготовка завершена, приступим к установке и настройке ZooKeeper. Если вы устанавливаете обе платформы раздельно, то он потребуется первым, так как Kafka ставится поверх него.
ZooKeeper нужен для хранения метаданных, отслеживания брокеров и координации кластера. В этом разделе мы установим его и настроим базовую конфигурацию.
Скачайте ZooKeeper. Перейдите на официальный сайт ZooKeeper в раздел «Download» и скачайте последнюю стабильную версию (на момент написания статьи это 3.8.4) в архиве .tar.gz.
Переместите архив в C:\zookeeper\. Распакуйте его в 7-Zip или аналогичной программе. После распаковки ZooKeeper будет находиться в папке с номером версии:
C:\zookeeper\zookeeper-3.8.4\Следующий шаг — создание конфигурации. ZooKeeper может работать в двух режимах: Standalone и Replicated. Мы рассмотрим Standalone Mode. В этом режиме ZooKeeper использует конфигурационный файл zoo.cfg, который нужно создать вручную. Перейдите в директорию conf:
C:\zookeeper\zookeeper-3.8.4\conf\Там находится пример — файл zoo_sample.cfg. Скопируйте его и переименуйте копию в zoo.cfg, затем откройте для редактирования. В нём нужно указать путь к директории с данными. По умолчанию указано:
dataDir=/tmp/zookeeperПоменяем значение на актуальное:
tickTime=2000
dataDir=C:/zookeeper/zookeeper-3.8.4/data
clientPort=2181
maxClientCnxns=60Не забудьте создать соответствующий каталог.
После этого добавим переменную среды окружения:
ZOOKEEPER_HOME=C:\zookeeper\zookeeper-3.8.4И в конец системной переменной Path добавьте:
%ZOOKEEPER_HOME%\binОбратите внимание
В Windows не требуется ставить точку с запятой вручную, если редактировать переменные через GUI — система сама добавит разделитель. Указание «;%ZOOKEEPER_HOME%\bin;» допустимо только при редактировании переменной вручную через set.
Готово! Теперь переходим к запуску.
ZooKeeper запускается через скрипт zkServer.cmd. Откройте терминал PowerShell:
cd C:\zookeeper\zookeeper-3.8.4\bin
.\zkServer.cmdПо умолчанию ZooKeeper запускается на порту 2181. Этот порт можно изменить в конфигурационном файле zoo.cfg.
Установка Kafka и ZooKeeper одним пакетом
Kafka поставляется с базовой конфигурацией ZooKeeper и утилитами запуска, но не содержит полноценной самостоятельной сборки ZooKeeper. Для надёжной работы рекомендуется установить ZooKeeper отдельно. Скачайте архив с бинарными файлами с сайта проекта, у нас это kafka_2.13-4.0.0.tgz. Найдите его, и распакуйте с помощью архиватора, поддерживающего .tgz (например, 7-Zip). После распаковки у вас будет папка с номером версии в имени. Для удобства можно переименовать её, например, в Kafka.
Обратите внимание
Убедитесь, что версия Scala (2.13) совместима с установленной версией Kafka. Не всегда новые Kafka-сборки поддерживают все старые версии Scala.
Структура каталогов
Откройте проводник и перейдите в папку Kafka. Структура дерева каталогов
должна быть примерно такой:
C:\
└── kafka\
├── bin\
│ └── windows\
├── config\
└── ...Здесь:
- bin — исполняемые скрипты для управления кластером. В подкаталоге /windows расположены файлы, адаптированные для работы под ОС Windows.
- config — хранит конфигурационные файлы (например, zookeeper.properties, server.properties), позволяющие кастомизировать настройки брокера и ZooKeeper.
- libs — включает библиотеки зависимостей (JAR-файлы), необходимые для работы Kafka.
- logs — директория с журналами событий. Логи помогают анализировать работу системы, диагностировать ошибки и отслеживать взаимодействие компонентов.
- site-docs — официальная документация по текущей версии Kafka — полезный ресурс для изучения функционала.
- LICENSE и NOTICE — текстовые файлы с информацией о лицензионных условиях и юридическими уведомлениями.
Настройка ZooKeeper
Модуль ZooKeeper находится в папке bin\windows, его конфигурационный файл — по пути config\zookeeper.properties. Он уже содержит рабочие настройки по умолчанию, но для понимания стоит знать основные параметры:
dataDir=C:/kafka/zookeeper-data
clientPort=2181
maxClientCnxns=0Где:
- dataDir — путь, где ZooKeeper будет хранить свои данные. Его нужно изменить на win-совместимый. Windows не имеет каталога /tmp. Путь по умолчанию здесь — свидетельство того, что Kafka изначально создавался для Linux.
- clientPort — порт, на котором ZooKeeper принимает подключения. По умолчанию — 2181.
Изменим dataDir на Windows-путь.
Откройте в любом текстовом редакторе файл:
config\zookeeper.propertiesЗамените строку:
dataDir=/tmp/zookeeperна
dataDir=C:/kafka/zookeeper-dataСоздайте папку zookeeper-data внутри каталога Kafka, если она ещё не существует, затем дайте пользователю права на запись:
icacls "C:\kafka\zookeeper-data" /grant "*Users":(OI)(CI)FЗапуск ZooKeeper
В PowerShell или командной строке зайдите в корневую папку Kafka и выполните:
.\bin\windows\zookeeper-server-start.bat .\config\zookeeper.propertiesЕсли всё настроено верно, вы увидите лог со строкой:
INFO binding to port 0.0.0.0/0.0.0.0:2181Настройка и запуск Kafka
После запуска ZooKeeper можно переходить к Kafka.
Конфигурация Kafka
Конфиги Kafka находятся по пути:
config\server.propertiesОткройте этот файл для редактирования и найдите следующие параметры:
broker.id=0
log.dirs=C:/kafka/kafka-logs
zookeeper.connect=localhost:2181Внесём изменения для Windows. В строке log.dirs по умолчанию указан путь в стиле Linux (/tmp/kafka-logs), который не существует в Windows. Замените его, например, на:
log.dirs=C:/kafka/kafka-logsУбедитесь, что zookeeper.connect указывает на localhost и порт 2181 (если вы не меняли его ранее):
zookeeper.connect=localhost:2181Создайте папку kafka-logs в каталоге Kafka, чтобы избежать ошибок при запуске и предоставьте права на запись:
icacls "C:\kafka\kafka-logs" /grant "*Users":(OI)(CI)FЗапуск Kafka-сервера
Теперь, когда всё настроено, можно запускать Kafka. Откройте второе окно PowerShell или командной строки и войдите в каталог Kafka, например:
cd C:\kafkaЗатем запустите Kafka:
.\bin\windows\kafka-server-start.bat ".\config\server.properties"Если всё работает правильно, вы увидите в выводе сообщение, означающее, что Kafka успешно запущен и готов к работе:
INFO [KafkaServer id=0] started (kafka.server.KafkaServer)Проверка работы Kafka
После запуска Kafka можно проверить, как она работает, создав топик, отправив в него сообщение и считав его обратно. Для этого используем встроенные утилиты командной строки, входящие в состав Kafka.
Создание топика
Откройте ещё одно окно PowerShell (Kafka и ZooKeeper уже работают в своих окнах) и перейдите в папку Kafka:
cd C:\kafkaВыполните для создания нового топика:
.\bin\windows\kafka-topics.bat --create --topic test-topic --bootstrap-server localhost:9092 --partitions 1 --replication-factor 1Если всё прошло успешно, вы увидите сообщение:
Created topic test-topicПроверить список доступных топиков можно так:
.\bin\windows\kafka-topics.bat --list --bootstrap-server localhost:9092Отправка сообщения
Теперь отправим сообщение в созданный топик. Для этого используется Kafka Producer. Запустите в том же окне (третьем):
.\bin\windows\kafka-console-producer.bat --bootstrap-server localhost:9092 --topic test-topicПосле запуска вы не увидите приглашения командной строки — это нормально. Просто введите сообщение и нажмите Enter, чтобы отправить его в топик.
Если вы работаете с нестандартными типами данных (например, JSON или Avro), Kafka может потребовать указания сериализаторов. В этом случае при запуске Producer добавьте параметры:
--producer-property key.serializer=org.apache.kafka.common.serialization.StringSerializer ^
--producer-property value.serializer=org.apache.kafka.common.serialization.StringSerializerДля строковых сообщений эти параметры не обязательны — Kafka использует их по умолчанию.
Чтение сообщений из топика
Откройте ещё одно окно PowerShell (да, у вас теперь уже 4 окна) и запустите Kafka Consumer:
cd C:\kafka
.\bin\windows\kafka-console-consumer.bat --bootstrap-server localhost:9092 --topic test-topic --from-beginningЕсли обработка сообщений проходит успешно — и Producer, и Consumer работают корректно, — то вы должны увидеть отправленное сообщение.
Завершение работы Kafka и ZooKeeper
После тестирования или использования Kafka важно корректно завершить работу сервисов, чтобы избежать повреждения логов или потери информации.
Остановка Kafka
Найдите окно PowerShell, где запущен Kafka-сервер. Просто нажмите Ctrl+C — это отправит сигнал остановки, и Kafka завершит работу.
Пример вывода:
[KafkaServer id=0] shutting down
[KafkaServer id=0] shut down completedЕсли Kafka не реагирует на Ctrl+C, можно закрыть окно PowerShell, но это менее предпочтительный способ.
Остановка ZooKeeper
Перейдите в окно, где запущен ZooKeeper, и также нажмите Ctrl+C. Вы увидите строки, подтверждающие завершение:
Shutting down…
Closed socket...Очистка временных данных (по желанию)
Kafka и ZooKeeper хранят временные данные в папках:
- C:\kafka\kafka-logs — логи Kafka;
- C:\kafka\zookeeper-data — данные ZooKeeper (если вы указывали эту папку при запуске).
Их можно удалить перед следующим чистым запуском Kafka, если вы экспериментировали с настройками и нужно сбросить состояние. В PowerShell:
Remove-Item -Recurse -Force C:\kafka\kafka-logs
Remove-Item -Recurse -Force C:\kafka\zookeeper-dataБудьте осторожны: это удалит все сообщения, топики и внутреннее состояние кластера. Используйте эти команды, только если уверены в своих действиях.
Заключение

Мы рассмотрели, как установить и запустить ZooKeeper и Kafka на Windows 10. Несмотря на то что Kafka изначально разрабатывалась с прицелом на Linux, её вполне можно использовать и в среде Windows — особенно для целей разработки, обучения или тестирования.
В ходе статьи мы:
- установили Java и проверили её работоспособность;
- скачали и распаковали Kafka;
- запустили ZooKeeper и Kafka как отдельные процессы;
- создали и протестировали простой топик, отправив и получив сообщения;
- корректно завершили работу сервисов.
Читайте в блоге:
- Какие серверные SSD-накопители с интерфейсом NVMe лучше
- Как включить и настроить удалённый доступ к серверу
- Как выбрать виртуальный сервер для сложных задач: гайд по GPU-решениям
Learn to install Apache Kafka on Windows 10 and execute ‘start server‘ and ‘stop server‘ scripts related to Kafka and Zookeeper. We will also verify the Kafka installation by creating a topic, producing a few messages to it and then using a Kafka consumer to read the messages.
1. Prerequisites
- Minimum Java 8 is required to run the latest downloads from the Kafka site. Install Java if you have not already.
- Zookeeper (to store metadata about the Kafka cluster) is also mandatory. Kafka comes with an inbuilt Zookeeper to start with. But it is recommended to install Zookeeper separately in the production environment. Download it from its official site.
- Kafka can be run on any operating system. Linux is the recommended OS. With Windows, Kafka has some known bugs.
This tutorial is for beginners and does not use separate zookeeper instance – to keep things simple and focused towards Kafka only.
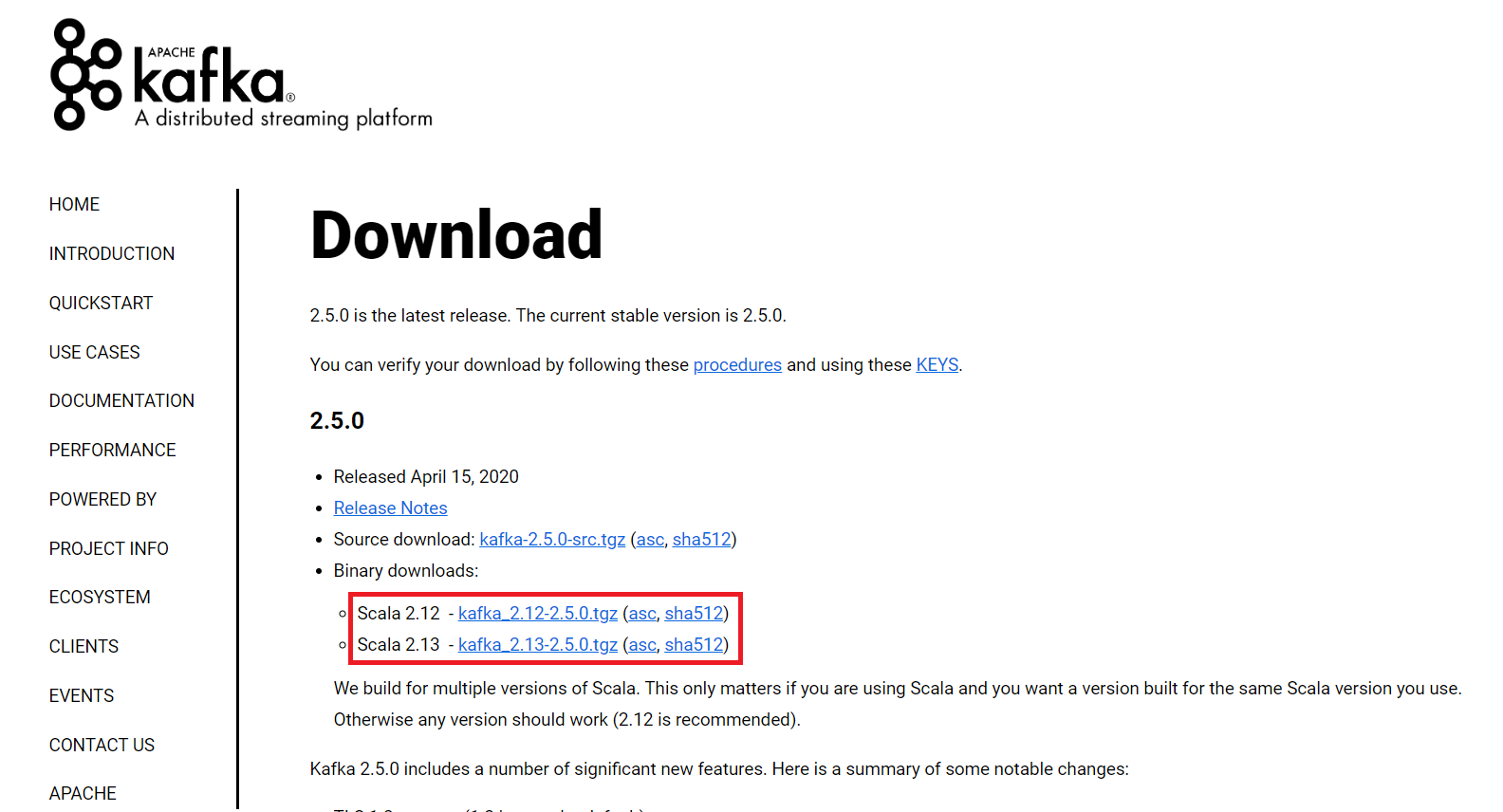
2. Download and Install Kafka
- Download Kafka from the official site. I download the latest version which is 2.5.0, and the file name is “kafka_2.12-2.5.0.tgz“.
- Copy the downloaded file to some folder and extract it using
tarcommand. - Copy the extracted folder to the desired location. I have put it on location “
E:\devsetup\bigdata\kafka2.5“.
tar -xzf kafka_2.12-2.5.0.tgzInstallation is pretty much complete, now.
3. Startup and Shutdown
To start Kafka, we first start Zookeeper and then Kafka. I am writing small batch files which navigate to the Kafka installation directory first and then execute the command in the new command prompt window.
3.1. Start Zookeeper
To start zookeeper, we need to run zookeeper-server-start.bat script and pass the zookeeper configuration file path.
cd E:\devsetup\bigdata\kafka2.5
start cmd /k bin\windows\zookeeper-server-start.bat config\zookeeper.properties3.2. Start Kafka
To start Kafka, we need to run kafka-server-start.bat script and pass broker configuration file path.
cd E:\devsetup\bigdata\kafka2.5
start cmd /k bin\windows\kafka-server-start.bat config\server.properties3.3. Shutdown Kafka
To stop Kafka, we need to run kafka-server-stop.bat script.
cd E:\devsetup\bigdata\kafka2.5
start cmd /k bin\windows\kafka-server-stop.bat3.4. Shutdown Zookeeper
To stop Zookeeper, we need to run zookeeper-server-stop.bat script.
cd E:\devsetup\bigdata\kafka2.5
start cmd /k bin\windows\zookeeper-server-stop.batDo not stop zookeeper and kafka using
CTRL+Ccommands. Always use above.batfiles or commands. Otherwise the data corruption may occur.
4. Verify Kafka Installation
First, start Zookeeper and Kafka using the above scripts.
Open a new command prompt, and create new Kafka topic.
bin\windows\kafka-topics.bat --create --bootstrap-server localhost:9092 --replication-factor 1 --partitions 1 --topic test
Created topic test.Now list all the topics to verify the created topic is present in this list. At this step, we have only one topic.
bin\windows\kafka-topics.bat --list --bootstrap-server localhost:9092
testNow list all the topics to verify the created topic is present in this list. At this step, we have only one topic.
bin\windows\kafka-topics.bat --list --bootstrap-server localhost:9092
testProduce some messages and submit to test topic. I added two messages i.e. “Hello” and “Kafka”.
bin\windows\kafka-console-producer.bat --bootstrap-server localhost:9092 --topic testConsume the messages and submit to test topic.
bin\windows\kafka-console-consumer.bat --bootstrap-server localhost:9092 --topic test --from-beginning
Hello
Kafka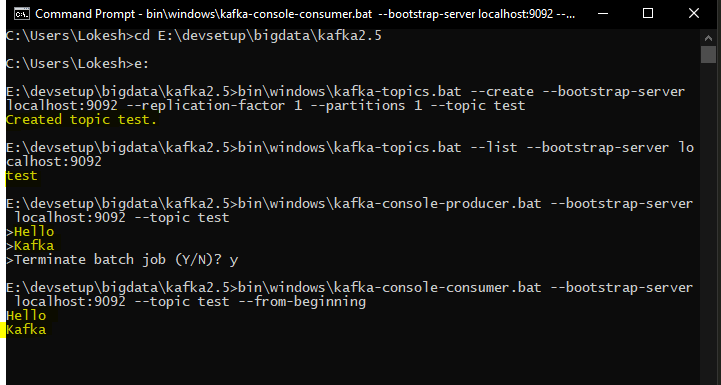
5. Conclusion
In this tutorial, we learned to install Kafka along with Zookeeper. We learned to start and stop both servers. Additionally, we verified the installation by creating a topic, posting some messages and then consuming using the console consumer script.
The important thing to note is that we should never stop the servers by killing processes or CTRL+C commands. Always use scripts to stop the servers.
Happy Learning !!
Sourcecode Download