
Время на прочтение18 мин
Количество просмотров2.2K
В моей первой статье на сайте об автоматизации оборудования Juniper в качестве подопытного выступал коммутатор, который стоит под столом, и до которого имеется полный прямой доступ по сети. Однако, такая ситуация скорее исключение. Безопасности работы сетевого оборудования в наше время, когда практически все аспекты жизни завязаны на «всемирную паутину» и различные онлайн-сервисы, уделяется повышенное внимание. И один из подходов к повышению безопасности — использование доступа к оборудованию только с выделенных устройств, которые называют jump host или bastion. В дальнейшем я буду писать «сервер» подразумевая jump host. Сценарий работы в этом случае обычно выглядит так: пользователь подключается к серверу по SSH, а уже с него выходит по SSH, telnet либо другому протоколу на оборудование. Ну и на самом оборудовании установлены списки доступа, запрещающие подключение откуда-либо, кроме отдельных разрешенных адресов. Схема простая и рабочая. И в большинстве случаев не создает каких-то особых неудобств в работе. Но, в случае с автоматизацией, тут есть о чем подумать. Теперь мы должны сделать непростой выбор: либо наши скрипты должны запускаться прямо на этом сервере, с которого прямой доступ до оборудования имеется, либо наша программа должна учесть наличие промежуточного устройства и научиться с ним работать.
У первого подхода, кроме преимущества простоты, есть и определенные подводные камни:
-
Наличие на сервере необходимых библиотек/версии Python. На сервере может оказаться какая-то экзотическая система либо очень стабильная, но древняя версия, для которой не так то просто поставить Python вообще, не говоря уже про последние версии, где много приятных возможностей языка. Кроме того, этот сервер, как правило, огражден от Интернета, и установка туда нужных пакетов может стать отдельной задачей.
-
Доступность с сервера внешних сервисов. Например, наш скрипт обошел кучу оборудования, что-то там сделал, и мы хотим по окончанию отработки отправить письмо с результатом. Но не факт, что почтовый сервер будет доступен с этого сервера, скорее всего никакой связи между ними нет. Тоже касается и возможностей хранения информации, использую базу данных
-
Удобство отладки. На своей машине у нас в этом вопросе полный доступ, а на удаленном сервере, в большинстве случаев, все приходится проверять через print/логирование. Поэтому в этой статье я бы хотел рассмотреть возможные решения в рамках второго подхода, когда мы с нашей машины работаем с оборудованием через сервер.
Метод №1. Встроенные возможности SSH
Проблема необходимости работы через промежуточный сервер не нова. Так что неудивительно, что в самом протоколе SSH заложен подобный сценарий. Действительно,
мы можем написать в файле .ssh/config примерно следующее
host jumphost
HostName 192.168.0.100
IdentitiesOnly yes
IdentityFile ~/.ssh/rsa
User jh_user
host * !jumphost
User dev_user
ProxyJump jumphost
Тут мы определяем сервер jumphost, вход на который будет осуществляться по ключу из файла ~/.ssh/rsa под пользователем jh_user. А далее указываем, что на все остальные устройства мы будем ходить через этот сервер. И все. Теперь достаточно в консоли написать ssh <router_ip> и мы попадаем на нужное нам устройство. В скриптах, возможно, придется подсказать, что нужно использовать конфигурацию из файла. Например, если мы используем netmiko, нужно при создании соединения указать параметр ssg_config_file
dev = {
'device_type': 'huawei',
'ip': IP,
'username': USER_NAME,
'password': USER_PWD,
'ssh_config_file': '~/.ssh/config'
'port': 22,
}
connect = netmiko.ConnectHandler(**dev)
Казалось бы, решение найдено и статью можно заканчивать. Но у данного метода есть пара проблемных моментов:
-
Встроенный механизм использования jump host предполагает, что авторизация на нем производиться по ключу пользователя. А если такая авторизация не поддерживается, механизм не заработает.
-
Есть еще оборудование, которое не поддерживает SSH и управляется по telnet. В этом случае этот метод тоже не подойдет.
На самом деле, первую проблему иногда можно обойти
Если вы используете Linux, то можно воспользоваться утилитой sshpass, которая перехватывает вывод команды ssh, ожидает запрос на ввод пароля и вводит его. Для примера, если мы запишем наш пароль в файл jh_pass, то можем изменить файл .ssh/config следующим образом
Host * !jumphost
ProxyCommand sshpass -f ~/jh_pass ssh -W %h:%p -q jh_user@jh_ip
В случае Windows можно использовать WSL
Метод №2. Netmiko и redispatch
Я уже упоминал замечательную библиотеку netmiko, которая заметно упрощает работу с сетевым оборудованием. Не обошли в ней стороной и возможность работы через промежуточное устройство.
Первый способ, можно сказать «в лоб», состоит из следующих простых шагов:
-
Подключаемся с помощью библиотеки к нашему серверу.
-
Выполняем на нем команду для подключения к нужному устройству, например ssh user@host
-
Работаем уже с нашим устройством. Фактически мы просто повторяем те действия, которые выполняли бы работая с устройством без всякого скрипта через терминал. Давайте попробуем реализовать эти шаги при помощи python.
Подключение к серверу
Код подключения стандартный для библиотеки, тип устройства указываем как linux (в том случае, если на нашем сервере стоит Linux, если это какое-то специализированное устройство тип может быть другим). Подключимся и распечатаем вывод команды uname -a. Сразу хочу оговориться, что тут и далее, в целях сокращения, код будет содержать минимум каких либо проверок и обработок исключений. В боевом коде это, несомненно, это нужно будет учесть.
import netmiko
def connect_to_jh():
dev = {
'device_type': 'linux',
'ip': JH_IP,
'username': JH_NAME,
'password': JH_PWD,
'port': 22,
}
net_connect = netmiko.ConnectHandler(**dev)
return net_connect
def main():
connect = connect_to_jh()
if connect:
print(connect.send_command('uname -a'))
if __name__ == "__main__":
main()
На выходе получим что-то вроде этого:
Linux JH-U1 5.15.10-1.el7.x86_64 #1 SMP Sat Dec 18 18:25:19 MSK 2021 x86_64 x86_64 x86_64 GNU/Linux
а значит первый шаг мы прошли успешно.
Подключение к маршрутизатору
На втором шаге сформируем команду подключения с нашего сервера до целевого устройства, например маршрутизатора, и отправим ее на сервер. Тут нас ждет первая проблема. Если ранее, когда мы подключались средствами библиотеки netmiko, она сама заботилась о нахождении приглашения на ввод пароля, то теперь нам придется делать это самим. Поэтому, вместо вызова функции send_commnad, которая ожидает получения стандартного приглашения для завершения работы, нам надо воспользоваться функцией send_command_expect, в которой мы явно укажем, что мы ждем в качестве отклика. Вот код функции для подключения:
def connect_to_device(connect, ip):
cmd = f'ssh -o "StrictHostKeyChecking=no" {USER_NAME}@{ip}'
connect.send_command_expect(cmd, expect_string="assword:")
connect.send_command_timing(USER_PWD)
def main():
connect = connect_to_jh()
connect_to_device(connect, DEV_IP)
print(connect.send_command('show version'))
В функцию мы передаем объект типа BaseConnection из библиотеки netmiko и ip адрес устройства для подключения. Внутри функции формируем из имени пользователя и ip полноценную команду на подключение по ssh, после чего вызываем connect.send_command_expect(cmd, expect_string="assword:"), которая отправляет команду на сервер и считывает вывод, ожидая, пока не появится приглашение на ввод пароля. Отдельно хочу обратить внимание на опцию -o "StrictHostKeyChecking=no" при формировании команды. Добавить ее при вызове ssh надо, чтобы ключ от устройства автоматически сохранился в файле .ssh/known_hosts. Если этого не сделать, а устройства не будет в этом файле, ssh будет запрашивать разрешения сохранить ключ и до приглашения на ввод пароля дело не дойдет, что нам создаст дополнительные трудности. Можно, конечно, обработать вывод и при запросе отправить yes, но зачем усложнять программу?
Работа с устройством
Сразу перейдем к шагу 3 и попробуем с помощью нашей программы подключиться через промежуточный сервер к какому-нибудь маршрутизатору juniper и посмотреть на вывод команды show version (вызов этой команды я уже добавил в скрипт выше).
На выходе получим что-то вроде этого (вывод я сократил для наглядности)
Hostname: ************-AR1
Model: mx480
Junos: 16.1R7.7
JUNOS OS Kernel 32-bit [20180601.93ff995_builder_stable_10]
JUNOS OS libs [20180601.93ff995_builder_stable_10]
JUNOS OS runtime [20180601.93ff995_builder_stable_10]
JUNOS OS time zone information [20180601.93ff995_builder_stable_10]
JUNOS py extensions [20180612.033802_builder_junos_161_r7]
JUNOS py base [20180612.033802_builder_junos_161_r7]
JUNOS OS crypto [20180601.93ff995_builder_stable_10]
JUNOS network stack and utilities [20180612.033802_builder_junos_161_r7]
JUNOS libs [20180612.033802_builder_junos_161_r7]
JUNOS runtime [20180612.033802_builder_junos_161_r7]
...
Как видим, программа успешно вывела результат работы команды. Однако, расслабляться нам пока рано. В последнее время Ростелеком все больше использует оборудование отечественных производителей. Подключимся к коммутатору одного из них — Eltex и попробуем вывести конфигурацию коммутатора выполнив show running-config. Результат нас разочарует
netmiko.exceptions.ReadTimeout:
Pattern not detected: 'TEST\\-SW10\\#' in output..
В чем проблема? Чтобы понять, что произошло, добавим в наш скрипт логирование обмена данными по SSH.
import logging
logging.basicConfig(filename='netmiko.log', level=logging.DEBUG)
logger = logging.getLogger("netmiko")
После повторного запуска скрипта в файле netmiko.log мы увидим следующие строки (вывод сокращен)
DEBUG:netmiko:write_channel: b'show running-config\n'
DEBUG:netmiko:read_channel:
DEBUG:netmiko:read_channel:
DEBUG:netmiko:read_channel:
DEBUG:netmiko:read_channel:
DEBUG:netmiko:read_channel:
DEBUG:netmiko:read_channel:
DEBUG:netmiko:read_channel: s
DEBUG:netmiko:read_channel:
DEBUG:netmiko:read_channel:
DEBUG:netmiko:read_channel: how running-config
no spanning-tree
!
DEBUG:netmiko:Pattern found: (show\ running\-config) show running-config
DEBUG:netmiko:read_channel: vlan database
vlan 10,17,220
DEBUG:netmiko:read_channel:
exit
DEBUG:netmiko:read_channel:
!
port jumbo-frame
DEBUG:netmiko:read_channel: !
loopback-detection enable
DEBUG:netmiko:read_channel:
DEBUG:netmiko:read_channel: loopback-detection vlan-based
DEBUG:netmiko:read_channel: More: <space>, Quit: q or CTRL+Z, One line: <return>
DEBUG:netmiko:read_channel:
DEBUG:netmiko:read_channel:
DEBUG:netmiko:read_channel:
DEBUG:netmiko:read_channel:
DEBUG:netmiko:read_channel:
DEBUG:netmiko:read_channel:
DEBUG:netmiko:read_channel:
DEBUG:netmiko:read_channel:
DEBUG:netmiko:read_channel:
DEBUG:netmiko:read_channel:
DEBUG:netmiko:read_channel:
...
В самом начале лога мы видим, что команда отправлена и начинаем считывать приходящие данные. В ответ на команду наш коммутатор начинает отправлять конфигурация. В несколько вызовов read_channel мы считываем часть ответа, после чего новая информация перестает поступать — в конце куча вызовов read_channel, которые не возвращают новых данных. Этих вызовов гораздо больше (вывод сильно сокращен), до самого наступления таймаута. Из вывода проблема становится сразу видна. More: <space>, Quit: q or CTRL+Z, One line: <return> — вывод коммутатора производится в постраничном режиме и выведя первую порцию данных коммутатор ждет нашей реакции.
Все дело в том, что библиотека netmiko при подключении к устройству не только обрабатывает процесс авторизации пользователя, но и, в зависимости от переданного типа устройства, выполняет некоторую начальную подготовку, в том числе выполняет команду отключения постраничного вывода. Это мы знаем, что уже подключились к коммутатору Eltex, а вот программе об этом не сообщили. Как ей сказали при первом подключение, что это устройство типа linux, так программа с ним и работает. Мы отправили команду, коммутатор отдал часть вывода. И в конце добавил More: <space>, Quit: q or CTRL+Z, One line: <return> сигнализируя, что ждет от нас команды на продолжение либо на отмену. А для библиотеки же сигналом на окончание вывода является получение TEST\-SW10\#. Не дождавшись этого библиотека бросает исключение. В случае с MX480, к которому подключались ранее, нам повезло, что вывод поместился в одну страницу. Если бы информации было бы больше или мы попробовали бы произвести настройку через send_config_set, нас так же ждало бы разочарование. Что же делать? Именно для этого в библиотеке netmiko предусмотрен механизм redispatch. Суть этого механизма в том, что мы сообщаем netmiko тип нового устройства, а библиотека динамически меняет тип нашего подключения на соответствующий. Для этого имеется следующая функция:
def redispatch(
obj: "BaseConnection", device_type: str, session_prep: bool = True
) -> None
Как видно из объявления функции, которое я скопировал из кода библиотеки, она принимает на вход 3 параметра. Первый — это существующее подключение, тип которого мы хотим изменить. Второй — новый тип устройства. А третий параметр как раз и позволяет нам выполнить на текущем устройства начальные команды по подготовки сессии к работе (отключение различных «улучшайзеров», отключение постраничного ввода и др.). По умолчанию данная функциональность включена.
Библиотека Netmiko поддерживает работу с широкой номенклатурой оборудования. В том числе есть модуль для работы с оборудованием Eltex. Изменим нашу функцию и явно укажем, что новое устройство это eltex. Вот, что получается.
def main():
connect = connect_to_jh()
if connect:
connect_to_device(connect, DEV_IP)
netmiko.redispatch(connect, device_type='eltex')
print(connect.send_command('show running-config', read_timeout=60))
Запускаем скрипт — и конфигурация коммутатора успешно отображается у нас на экране.
Хочу отметить, что желательно обновить версию библиотеки до последней. Дело в том, что, при переходе на 4 версию, механизм redispatch для некоторых устройств (в том числе Juniper, Еltex) сломался. На что я наткнулся и был озадачен, что скрипт работает на ноутбуке, а на другой машине — нет. Вот ссылка на ошибку в библиотеке, которая была исправлена.
Нужного результата мы добились. Более того, теперь мы можем многократно прыгать с одного устройства на другое, каждый раз менять тип на нужный и все будет работать.
Из неочевидных минусов данного метода хочу заметить следующее. Фактически мы подключаемся к jump host под учетной записью пользователя, поднимается полноценная сессия. И обежав таким методом несколько тысяч устройств, а потом подключившись самостоятельно через терминал, можно обнаружить, что история команд пополнилось на несколько тысяч новых записей. Теи, кто привык стрелочками выбирать команды из списка последних — будет грустно 
Метод №3. Проброс портов
Фактически, все современные программы для работы по SSH, такие как SecureCRT, XShell и другие, поддерживают возможность работы через промежуточное устройство. И для этого они используют возможность протокола SSH по пробросу портов. В SSH мы можем создать канал между портом нашей локальной машины и определенным портом на удаленном устройстве через jump host. Сделать это можно, передав необходимые параметры клиенту SSH, но мы сделаем это с помощью кода. Для этого мы обратимся к библиотеке paramiko, которая реализует работу по протоколу SSH. Именно эту библиотеку использует «под капотом» и netmiko, и ncclient (который реализует протокол NETCONF) , когда мы работаем по SSH (netmiko может работать не только по SSH). Сначала напишем функцию, которая соединит локальный порт нашего компьютера с нужным нам портом удаленного устройства через jump host. Незамедлительно приступим:
def get_new_channel_via_jump_host(ip, local_port):
vm = paramiko.SSHClient() #создаем клиента
vm.set_missing_host_key_policy(paramiko.AutoAddPolicy())
vm.connect(JH_IP, username=JH_NAME, password=JH_PWD) #подключаемся к нашему jump_host
transport = vm.get_transport()
dest_addr = (ip, 22)
local_addr = ('127.0.0.1', local_port)
return transport.open_channel("direct-tcpip", dest_addr, local_addr) #создаем канал через jump host между local_port нашего компьютера и 22 портом целевого устройства
В коде постарался прокомментировать основные моменты, но, думаю, должно быть понятно, благо тут всего несколько строчек.
Бежим дальше. Канал между нами и целевым устройством создан и можем им воспользоваться для подключения. Как уже и говорил, netmiko хорошо дружит с paramiko, и создать подключение, используя уже созданный канал, достаточно просто. Новая функция подключения выглядит следующим образом:
def connect_to_device(ip, dev_type):
local_port = 40700
channel = get_new_channel_via_jump_host(ip, local_port)
dev_connect_params = {
'device_type': dev_type,
'ip': '127.0.0.1',
'username': USER_NAME,
'password': USER_PWD,
'sock': channel,
'conn_timeout': 30,
}
return netmiko.ConnectHandler(**dev_connect_params)
Тут тоже нет ничего сложного. Мы выбираем локальный порт на нашей машине (тут я его прописал жестко, в реальном коде выбор этого порта на ваш вкус) и пробрасываем канал. А потом создаем подключение стандартным для netmiko способом, только добавляем дополнительный параметр sock, в котором передаем ранее созданный канал.
Вот весь код нашего второго способа.
import netmiko
import paramiko
def get_new_channel_via_jump_host(ip, local_port):
vm = paramiko.SSHClient()
vm.set_missing_host_key_policy(paramiko.AutoAddPolicy())
vm.connect(JH_IP, username=JH_NAME, password=JH_PWD)
transport = vm.get_transport()
dest_addr = (ip, 22)
local_addr = ('127.0.0.1', local_port)
return transport.open_channel("direct-tcpip", dest_addr, local_addr)
def connect_to_device(ip, dev_type):
local_port = 40700
channel = get_new_channel_via_jump_host(ip, local_port)
dev_connect_params = {
'device_type': dev_type,
'ip': '127.0.0.1',
'username': USER_NAME,
'password': USER_PWD,
'sock': channel,
'conn_timeout': 30,
'global_delay_factor': 5,
}
return netmiko.ConnectHandler(**dev_connect_params)
def main():
connect = connect_to_device(DEV_IP, 'huawei')
if connect:
print(connect.send_command('display version'))
if __name__ == "__main__":
main()
Поскольку я подключался к живому устройству я добавил в число параметров 'global_delay_factor': 5, чтобы нагруженная коробка успела вывести prompt за отведенный таймаут.
Попробуем с помощью этого кода подключиться к маршрутизатору Huawei и вывести результат команды display version . На выходе получим что-то вроде этого:
Huawei Versatile Routing Platform Software
VRP (R) software, Version 5.160 (CX600 V600R008C10SPC300)
Copyright (C) 2000-2014 Huawei Technologies Co., Ltd.
HUAWEI CX600-X8 uptime is 3103 days, 18 hours, 42 minutes
Patch version : V600R008SPH131
CX600-X8 version information:
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
BKP 1 version information:
PCB Version : CX61BKP08B REV C
MPU Slot Quantity : 0
SRU Slot Quantity : 2
SFU Slot Quantity : 1
LPU Slot Quantity : 8
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
MPU version information:
MPU(Master) 9 : uptime is 3103 days, 18 hours, 41 minutes
StartupTime 2015/12/17 02:28:53
SDRAM Memory Size : 3904M bytes
FLASH Memory Size : 32M bytes
NVRAM Memory Size : 4096K bytes
CFCARD Memory Size : 1954M bytes
...
Хочется отметить, что поскольку в параметре sock мы передаем уже готовый к работе сокет, то параметр ip смысла не имеет и не будет никак использоваться. Однако он обязательный и хоть что-то в нем передать надо.
Поскольку мы можем пробросить наш туннель до любого порта на удаленном устройстве, то данный подход мы можем использовать и для подключения по протоколу telnet. Для этого чуть поменяем функцию get_new_channel_via_jump_host, добавив параметр с номером удаленного порта, и напишем функцию для подключения по протоколу telnet, использую библиотеку telnetlib.
def get_new_channel_via_jump_host(ip, local_port, remote_port=22):
vm = paramiko.SSHClient()
vm.set_missing_host_key_policy(paramiko.AutoAddPolicy())
vm.connect(JH_IP, username=JH_NAME, password=JH_PWD)
transport = vm.get_transport()
dest_addr = (ip, remote_port)
local_addr = ('127.0.0.1', local_port)
return transport.open_channel("direct-tcpip", dest_addr, local_addr)
def login(tn):
login_prompt = [l.encode('utf-8') for l in
["login:", 'Username:', ]]
pass_prompt = [l.encode('utf-8') for l in ["Password:", 'password:', "PassWord:",]]
num, _, read_data = tn.expect(login_prompt, 5)
if read_data:
tn.write((USER_NAME + '\r\n').encode('utf-8'))
num, _, read_data = tn.expect(pass_prompt, 5)
if read_data:
tn.sock.sendall((USER_PWD + '\r\n').encode('utf-8'))
prompt = [b'>', b'#']
num, _, read_data = tn.expect(prompt, 10)
def connect_to_device_telnet(ip):
local_port = 40701
channel = get_new_channel_via_jump_host(ip, local_port, 23)
con = tn.Telnet()
con.sock = channel
login(con)
con.write(b'show version\n')
sleep(2)
ret = con.read_very_eager()
print(ret.decode('utf-8'))
Сразу хотел бы обратить внимание на создание подключения. Обычно при создании объекта Telnet в качестве параметра в него передается ip адрес устройства, получив который конструктор пытается открыть новый сокет. Но нам этого делать не надо, сокет у нас уже есть. Поэтому мы вызываем конструктор без параметра, а после присваиваем полю sock значение ранее созданного туннеля.
В коде я отдельно сделал функцию login для авторизации на устройстве. Код максимально упрощен, мы просто ожидаем приглашение на ввод имени пользователя, вводим, ждем запрос пароля, вводим пароль и отправляем команду show version. После чего ждем 2 секунды, чтобы хоть что-то пришло и выводим полученные данные в консоль. Вывод будет примерно таким:
show version
Cisco IOS Software, c7600s3223_rp Software (c7600s3223_rp-ADVIPSERVICES-M), Version 12.2(33)SRC2, RELEASE SOFTWARE (fc2)
Technical Support: http://www.cisco.com/techsupport
Copyright (c) 1986-2008 by Cisco Systems, Inc.
Compiled Thu 18-Sep-08 09:32 by prod_rel_team
ROM: System Bootstrap, Version 12.2(17r)SX3, RELEASE SOFTWARE (fc1)
TEST-AR1 uptime is 4 weeks, 7 hours, 9 minutes
Uptime for this control processor is 4 weeks, 7 hours, 11 minutes
System returned to ROM by power-on (SP by power-on)
System image file is "bootdisk:c7600s3223-advipservices-mz.122-33.SRC2.bin"
Last reload type: Normal Reload
cisco CISCO7604 (R7000) processor (revision 2.0) with 458752K/65536K bytes of memory.
Processor board ID FOX11170DK7
R7000 CPU at 300Mhz, Implementation 0x27, Rev 3.3, 256KB L2, 1024KB L3 Cache
Last reset from power-on
12 Virtual Ethernet interfaces
9 Gigabit Ethernet interfaces
1915K bytes of non-volatile configuration memory.
--More--
В выводе мы видим, что в начале ответа присутствует повторение команды, а в конце приглашение --More-- для вывода следующей страницы данных. В реальном боевом коде нам надо либо обрабатывать постраничный вывод, либо его отключать. Да и стратегия получения данных, когда отправляем команду, пару секунд ждем и считываем вывод, годиться только для тестовых целей, да и то, очень ограниченных. При «правильном» подходе, нам нужно находить приглашение консоли и уже на основании его обрабатывать вывод.
Но есть и хорошая новость. Для достаточно большого парка оборудования нам особо ничего изобретать не надо. В библиотеке netmiko для большинства типов оборудования есть не только классы, отвечающие за взаимодействие по протоколу SSH, но и их коллеги, работающие по протоколу telnet. Для этого при создании подключение нужно передать необходимое значение в параметре device_type. Как правило, к обычному значению просто добавляется _telnet, например cisco_ios_telnet или juniper_junos_telnet, после чего библиотека будет использовать внутри себя библиотеку telnetlib, в остальном практически не отличаясь от версии с SSH. Но одно, немного неприятное, отличие все же есть. Дело в том, что если при создании подключения по SSH библиотека обращает внимание на переданный ей параметр sock, то в случае с Telnet этот параметр не учитывается. И нам придется написать немного дополнительного кода.
def connect_to_device(ip, dev_type, auto_connect = True):
local_port = 40701
channel = get_new_channel_via_jump_host(ip, local_port, 23)
dev_connect_params = {
'device_type': dev_type,
'ip': '127.0.0.1',
'username': USER_NAME,
'password': USER_PWD,
'sock': channel,
'conn_timeout': 30,
'global_delay_factor': 5,
'auto_connect': auto_connect,
}
return netmiko.ConnectHandler(**dev_connect_params)
def main():
connect = connect_to_device(DEV_IP, 'cisco_ios_telnet', False)
if connect:
connect.remote_conn = tn.Telnet()
connect.remote_conn.sock = connect.sock
connect.channel = netmiko.channel.TelnetChannel(conn=connect.remote_conn,
encoding=connect.encoding)
connect.telnet_login()
connect._try_session_preparation()
print(connect.send_command('show version'))
Первое, что мы сделали в этом коде — добавили параметр auto_connect в функцию connect_to_device и передаем его в библиотеку netmiko при создании подключения. Название достаточно говорящее, получив в этом параметре False библиотека не пытается сразу создать подключение. А мы, создав нужный класс, сами выполним код по созданию подключения. Аналогично предыдущему примеру, создаем класс Telnet и передаем ему ранее созданный сокет. Дальше повторяем действия библиотеке при инициации подключения, вызываем telnet_login для входа и _try_session_preparation для выполнения подготовительных команд. Дальше работаем с подключением обычным образом.
А что с упомянутой в предыдущей статье библиотекой PyEZ для работы с оборудованием Juniper? Тут все не так красиво, как хотелось бы. Фактически, библиотека PyEZ внутри для подключения использует библиотеку ncclient, которая реализует протокол NETCONF. У нее, так же как и у netmiko имеется возможность передачи параметра sock, с уже созданным сокетом для работы, и способ подключения через эту библиотеку аналогичен. Однако, библиотека PyEZ этот параметр не принимает, не может его передать в нижележащую ncclient и изначально не готова к работе с пробросом портов. Костыльным решением в этом случае будет правка исходников PyEZ чтобы самостоятельно добавить новый параметр в конструктор и его передачу при создании подключение в ncclient. После внесения подобных правок все отлично работает. По этому поводу я создал заявку на изменение в PyEZ.
Заключение
В данной статье я постарался описать те решения по работе с jump host, которые использую сам. Разные методы обладают своими преимуществами и недостатками и могут использоваться исходя из условий текущей задачи. Например, если на jump host-е запрещен проброс портов, первый и третий методы работать не будут. Ни в коем случае не претендую на то, что данный список исчерпывающий. За любые дополнения и замечания буду благодарен — возможно, получится сделать работу более эффективной.
Введение
Python имеет множество возможностей для создания стандартных типов файлов Microsoft Officeએ, включая Excelએ, Wordએ и PowerPointએ. Однако в некоторых случаях может оказаться слишком сложно использовать чистый подход Python для решения проблемы. К счастью, для python есть пакет “Python for Windows Extensions” (Python для расширений Windows), известный как pywin32, который позволяет нам легко получить доступ к Component Object Model (COM), компонентной объектной модели Windows, и управлять приложениями Microsoft через python. В этой статье будут рассмотрены некоторые базовые сценарии использования этого типа автоматизации и рассказывается о том, как приступить к работе с некоторыми полезными скриптами.
С веб-сайта Microsoft о модели компонентных объектов (COM):
Платформенно-независимая распределенная объектно-ориентированная система для создания двоичных программных компонентов, которые могут взаимодействовать. COM является базовой технологией для технологий Microsoft OLE Automationએ (составные документы) и ActiveXએ (компоненты с доступом в Интернет). COM-объекты могут быть созданы с помощью множества языков программирования.
Эта технология позволяет нам управлять приложениями Windows из другой программы. Многие из читателей этого блога, вероятно, видели или использовали VBAએ для некоторой автоматизации задачи Excel. COM — это основополагающая технология, поддерживающая VBA.
pywin32
Пакет pywin32 существует уже очень давно. Фактически, книга, посвященная этой теме, была опубликована в 2000 году Марком Хаммондом и Энди Робинсоном. Несмотря на то, что с тех пор уже прошло много лет (что заставляет меня чувствовать себя действительно старым), лежащие в основе технологии и концепции работают и сегодня. Pywin32 — это, по сути, очень тонкая оболочка python, которая позволяет нам взаимодействовать с COM-объектами и автоматизировать приложения Windows с помощью python. Сила этого подхода заключается в том, что вы можете делать практически все, что может делать приложение Microsoft, через python. Обратной стороной является то, что вам придется запускать это в системе Windows с установленным Microsoft Office. Прежде чем мы рассмотрим несколько примеров, убедитесь, что в вашей системе установлен pywin32 с помощью pip или conda.
Еще одна рекомендация: держите под рукой ссылку на страницу Тима Голдена. На этом ресурсе есть еще много подробностей о том, как использовать python в Windows для автоматизации и других административных задач.
Начиная
Все наши приложения начинаются с одинакового импорта и процесса активации приложения. Вот очень короткий пример открытия Excel:
import win32com.client as win32
excel = win32.gencache.EnsureDispatch('Excel.Application')
excel.Visible = True
_ = input("Press ENTER to quit:")
excel.Application.Quit()
Как только вы запустите скрипт из командной строки, то должны увидеть, как открывается Excel. Когда вы нажмете ENTER, приложение закроется. Прежде чем мы действительно сделаем это приложение более полезным, необходимо изучить несколько ключевых концепций.
Первый шаг — импортировать клиента win32. Я использовал соглашение об импорте его как win32, чтобы сделать фактический код отправки немного короче.
Магия этого кода заключается в использовании EnsureDispatch для запуска Excel. В этом примере я использую gencache.EnsureDispatch для создания статического прокси. Я рекомендую прочитать эту статью, если вы хотите узнать больше о статических и динамических прокси. Мне посчастливилось использовать этот подход для примеров, включенных в эту статью, но буду честен — я не слишком много экспериментировал с различными подходами к диспетчеризации.
Теперь, когда объект excel запущен, нам нужно явно сделать его видимым, установив excel.Visible = TrueКод.
win32 довольно умен и закроет Excel после завершения работы программы. Это означает, что если мы просто оставим код работать самостоятельно, вы, вероятно, не увидите Excel. Я включаю фиктивную подсказку, чтобы Excel оставался видимым на экране, пока пользователь не нажмет ENTER.
Я включаю последнюю строку excel.Application.Quit(), как немного ремня и подтяжек. Строго говоря, win32 должен закрыть Excel, когда программа будет завершена, но я решил включить excel.Application.Quit(), чтобы показать, как принудительно закрыть приложение.
Это самый простой подход к использованию COM. Мы можем расширить это несколько более полезных способов. В оставшейся части этой статьи будут рассмотрены некоторые примеры, которые могут быть полезны для ваших нужд.
Открыть файл в Excel
В своей повседневной работе я часто использую pandas для анализа и обработки данных, а затем вывожу результаты в Excel. Следующим шагом в этом процессе является открытие Excel и просмотр результатов. В этом примере мы можем автоматизировать процесс открытия файла, что может упростить его, чем попытки перейти в нужный каталог и открыть файл.
Вот полный пример:
import win32com.client as win32
import pandas as pd
from pathlib import Path
# Read in the remote data file
df = pd.read_csv("https://github.com/chris1610/pbpython/blob/master/data/sample-sales-tax.csv?raw=True")
# Define the full path for the output file
out_file = Path.cwd() / "tax_summary.xlsx"
# Do some summary calcs
# In the real world, this would likely be much more involved
df_summary = df.groupby('category')['ext price', 'Tax amount'].sum()
# Save the file as Excel
df_summary.to_excel(out_file)
# Open up Excel and make it visible
excel = win32.gencache.EnsureDispatch('Excel.Application')
excel.Visible = True
# Open up the file
excel.Workbooks.Open(out_file)
# Wait before closing it
_ = input("Press enter to close Excel")
excel.Application.Quit()
Вот результат в Excel:
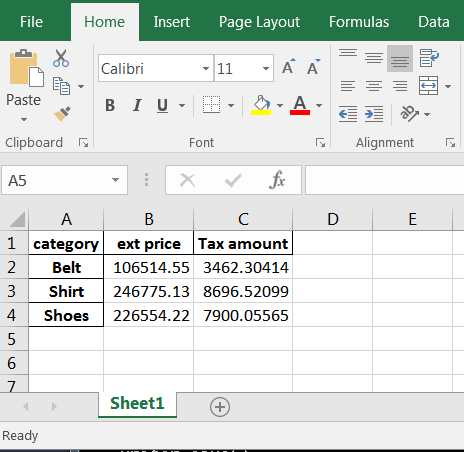
Этот простой пример расширяет предыдущий, показывая, как использовать объект Workbooks для открытия файла.
Прикрепите файл Excel к Outlook
Другой простой сценарий, в котором полезен COM, — это когда вы хотите прикрепить файл к электронному письму и отправить его в список рассылки. В этом примере показано, как выполнять некоторые манипуляции с данными, открывать электронную почту Outlook,прикрепите файл и оставьте его открытым для дополнительного текста перед отправкой.
Вот полный пример:
import win32com.client as win32
import pandas as pd
from pathlib import Path
from datetime import date
to_email = """
Lincoln, Abraham <>;
"""
cc_email = """
Franklin, Benjamin <>
"""
# Read in the remote data file
df = pd.read_csv("https://github.com/chris1610/pbpython/blob/master/data/sample-sales-tax.csv?raw=True")
# Define the full path for the output file
out_file = Path.cwd() / "tax_summary.xlsx"
# Do some summary calcs
# In the real world, this would likely be much more involved
df_summary = df.groupby('category')['ext price', 'Tax amount'].sum()
# Save the file as Excel
df_summary.to_excel(out_file)
# Open up an outlook email
outlook = win32.gencache.EnsureDispatch('Outlook.Application')
new_mail = outlook.CreateItem(0)
# Label the subject
new_mail.Subject = "{:%m/%d} Report Update".format(date.today())
# Add the to and cc list
new_mail.To = to_email
new_mail.CC = cc_email
# Attach the file
attachment1 = out_file
# The file needs to be a string not a path object
new_mail.Attachments.Add(Source=str(attachment1))
# Display the email
new_mail.Display(True)
Этот пример немного усложняется, но основные концепции те же. Нам нужно создать наш объект (в данном случае Outlook) и создать новое электронное письмо. Одним из сложных аспектов работы с COM является отсутствие согласованного API. Создание такого электронного письма не является интуитивным: new_mail = outlook.CreateItem (0) Обычно требуется немного поисков, чтобы выяснить точный API для конкретной проблемы. Google и stackoverflow — ваши друзья.
После создания объекта электронной почты вы можете добавить получателя и список CC, а также прикрепить файл. Когда все сказано и сделано, это выглядит так:
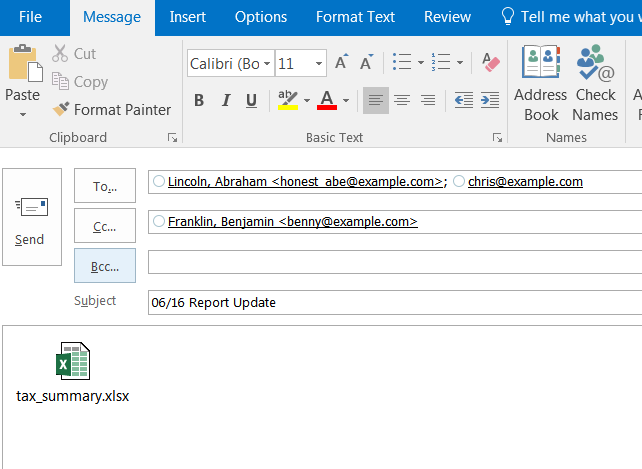
Электронное письмо открыто, и вы можете добавить дополнительную информацию и отправить ее. В этом примере я решил не закрывать Outlook и позволить python обрабатывать эти детали.
Последний пример является наиболее сложным, но иллюстрирует мощный подход к объединению анализа данных Python с пользовательским интерфейсом Excel.
С помощью pandas можно создать сложный Excel, но такой подход может быть очень трудоемким. Альтернативным подходом было бы создание сложного файла в Excel, затем выполните манипуляции с данными и скопируйте вкладку данных в окончательный вывод Excel.
Вот пример панели инструментов Excel, которую мы хотим создать:
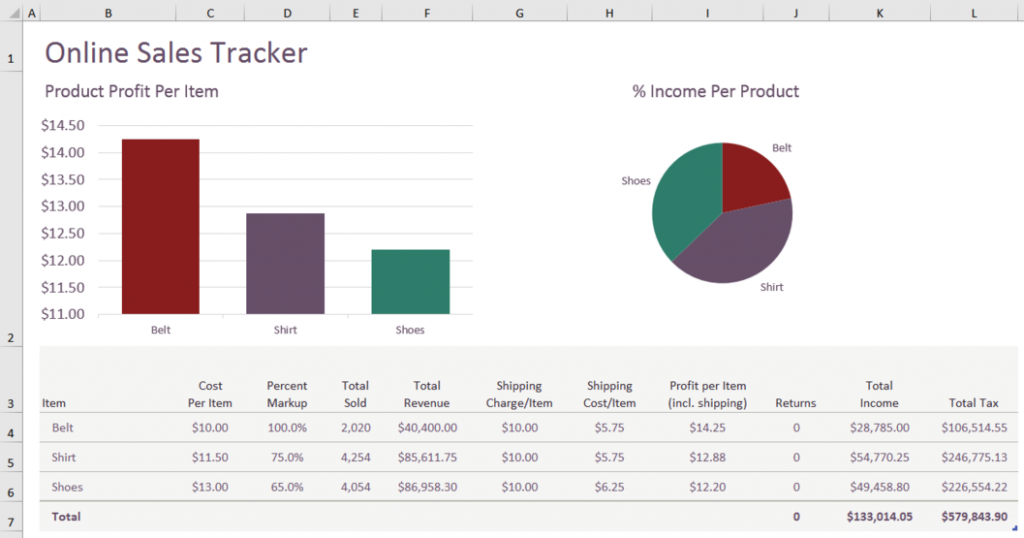
Да, я знаю, что круговые диаграммы ужасны, но я могу почти гарантировать, что кто-то попросит вас поместить их на панель инструментов в какой-то момент! Кроме того, в этом шаблоне была круговая диаграмма, и я решил оставить ее в окончательном виде вместо того, чтобы пытаться вычислить другую диаграмму. Было бы полезно сделать шаг назад и посмотреть на основной процесс, которому будет следовать код:
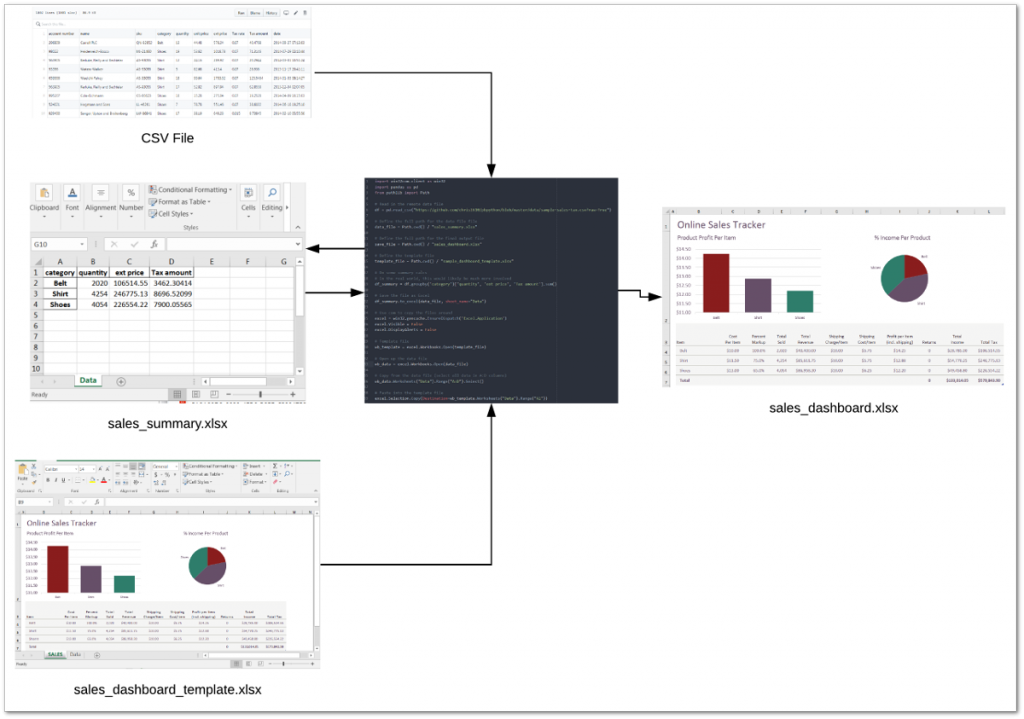
Приступим к работе с кодом.
import win32com.client as win32
import pandas as pd
from pathlib import Path
# Read in the remote data file
df = pd.read_csv("https://github.com/chris1610/pbpython/blob/master/data/sample-sales-tax.csv?raw=True")
# Define the full path for the data file file
data_file = Path.cwd() / "sales_summary.xlsx"
# Define the full path for the final output file
save_file = Path.cwd() / "sales_dashboard.xlsx"
# Define the template file
template_file = Path.cwd() / "sample_dashboard_template.xlsx"
В этом разделе мы выполнили импорт, прочитали данные и определили все три файла. Следует отметить, что этот процесс включает в себя этап суммирования данных с помощью pandas и сохранения данных в файле Excel. Затем мы повторно открываем этот файл и копируем данные в шаблон. Это немного запутано, но это лучший подход, который я мог придумать для этого сценария.
Далее выполняем анализ и сохраняем временный файл Excel:
# Do some summary calcs
# In the real world, this would likely be much more involved
df_summary = df.groupby('category')['quantity', 'ext price', 'Tax amount'].sum()
# Save the file as Excel
df_summary.to_excel(data_file, sheet_name="Data")
Теперь мы используем COM, чтобы объединить временный выходной файл с нашей вкладкой панели управления Excel и сохранить новую копию:
# Use com to copy the files around
excel = win32.gencache.EnsureDispatch('Excel.Application')
excel.Visible = False
excel.DisplayAlerts = False
# Template file
wb_template = excel.Workbooks.Open(template_file)
# Open up the data file
wb_data = excel.Workbooks.Open(data_file)
# Copy from the data file (select all data in A:D columns)
wb_data.Worksheets("Data").Range("A:D").Select()
# Paste into the template file
excel.Selection.Copy(Destination=wb_template.Worksheets("Data").Range("A1"))
# Must convert the path file object to a string for the save to work
wb_template.SaveAs(str(save_file))
Код открывает Excel и удостоверяется, что его не видно. Затем он открывает шаблон панели мониторинга и файлы данных. Он использует Range("A: D").Select() для выбора всех данных, а затем копирует их в файл шаблона.
Последний шаг — сохранить шаблон как новый файл. Этот подход может быть очень удобным ярлыком, когда у вас есть ситуация, когда вы хотите использовать python для обработки данных, но вам нужен сложный вывод Excel. Возможно, сейчас у вас нет явной потребности в этом, но если вы когда-нибудь создадите сложный отчет Excel, этот подход будет намного проще, чем пытаться вручную кодировать электронную таблицу с помощью python.
Заключение
Я предпочитаю стараться как можно больше придерживаться python для повседневного анализа данных. Однако важно знать, когда другие технологии могут упростить процесс или повысить эффективность результатов. Технология Microsoft COM является зрелой технологией, и ее можно эффективно использовать через Python для выполнения задач, которые в противном случае были бы слишком сложными. Надеюсь, эта статья дала вам несколько идей о том, как включить эту технику в свой рабочий процесс. Если у вас есть какие-либо задачи, для которых вы хотите использовать pywin32, сообщите нам об этом в комментариях.
По материалам Automating Windows Applications Using COM
Пройдите тест, узнайте какой профессии подходите
Изучите, как использовать Python для работы с планировщиком задач в операционной системе Windows с помощью библиотеки `schedule`.
Python является мощным инструментом для автоматизации и управления различными задачами на вашем компьютере. В этой статье мы рассмотрим, как использовать Python для работы с планировщиком задач на примере операционной системы Windows.
Освойте Python на курсе от Skypro. Вас ждут 400 часов обучения и практики (достаточно десяти часов в неделю), подготовка проектов для портфолио, индивидуальная проверка домашних заданий и помощь опытных наставников. Получится, даже если у вас нет опыта в IT.
Планировщик задач Windows
Планировщик задач Windows позволяет автоматически запускать программы или скрипты по расписанию. Это полезно для выполнения рутинных задач, таких как резервное копирование данных, обновление баз данных или отправка отчетов.
Библиотека schedule
Для работы с планировщиком задач в Python можно использовать стороннюю библиотеку schedule. Она предоставляет простой и удобный интерфейс для управления расписаниями.
Для установки библиотеки используйте команду:
pip install schedule
Создание задачи
Для создания задачи с использованием библиотеки schedule, выполните следующие шаги:
- Импортируйте библиотеку
schedule. - Определите функцию, которая будет выполняться по расписанию.
- Используйте метод
schedule.every()для задания интервала выполнения функции. - Используйте метод
schedule.run_pending()в цикле, чтобы проверять и выполнять запланированные задачи.
Ниже приведен пример скрипта, который выполняет функцию hello_world() каждые 10 секунд:
import schedule
import time
def hello_world():
print("Hello, World!")
schedule.every(10).seconds.do(hello_world)
while True:
schedule.run_pending()
time.sleep(1)
Расширенные возможности планирования
Библиотека schedule предоставляет различные методы для более гибкого планирования задач. Некоторые из них:
every(interval).secondsevery(interval).minutesevery(interval).hoursevery().day.at(time)every().monday.at(time)every().wednesday.at(time)every().friday.at(time)
Пример задачи, выполняющейся каждый день в 10:00:
import schedule
import time
def daily_task():
print("Running daily task")
schedule.every().day.at("10:00").do(daily_task)
while True:
schedule.run_pending()
time.sleep(1)
Изучайте Python на онлайн-курсе от Skypro «Python-разработчик». Программа рассчитана на новичков без опыта программирования и технического образования. Курс проходит в формате записанных коротких видеолекций. Будет много проверочных заданий и мастер-классов. В конце каждой недели — живая встреча с экспертами в разработке для ответов на вопросы и разбора домашек.
Заключение
Использование Python для работы с планировщиком задач позволяет легко и быстро автоматизировать рутинные процессы на вашем компьютере. Библиотека schedule предоставляет простой и удобный интерфейс для создания и управления задачами. Вам также могут быть интересны другие возможности этой библиотеки, такие как условное выполнение задач или планирование задач с использованием крон-выражений. Удачи в изучении Python! 🐍
Web scraping allows businesses to quickly obtain, analyze and interpret data from websites. It helps them better understand competition, market trends, customer behavior, and more. Web scraping can also help businesses identify potential opportunities in their industry and new areas of growth. Read more about Python Windows Automation.
A scripting language like Python can scale the process by gathering data across many different sources or websites. Involving well-defined Python libraries such as BeautifulSoup or Selenium improves data retrieval and automates tedious processes like logging into websites or navigating pagination. When you combine it with the scheduling functions provided by Windows Task Scheduler, you can create automated scripts that collect data regularly without needing much intervention. This Python and Windows automation combo is ideal for getting both small and mid-sized companies organized faster using less human effort.
This guide will cover the how-to’s you’ll need to plot your own web scraping operation via Python and Task Scheduler. Even beginners or less technical users can handle it, so smaller organizations won’t need extensive technical capabilities to get involved.
Why Python Is a Good Choice for Web Scraping

Python is excellent for web scraping due to its expansive libraries and platform independence. Libraries, especially “BeautifulSoup” (which specializes in data mining), make parsing information from websites easier and faster. Scrapers written in Python are portable, meaning they can run on almost any platform — Linux or Windows — without needing significant alterations.
The syntax is intuitive, so newcomers can learn the language quickly. Modern versions of Python are also more expressive than other languages, such as Perl or C++, so development time is drastically reduced. Complex tasks require minimal code compared to other programming languages. Its highly efficient code base makes it easy for developers of any level to create robust custom applications — such as automated web scrapers — without the overhead of more complex programming languages.
Python also offers other capabilities like URL requests, XPath selection, LXML parser, and more, so users have greater control when working with scraped data.
The Fundamentals of Web Scraping Using Python

There are a few protocols that govern how data is transferred online. Understanding how they work can help you decide which ones to specify for your web scraping needs. You’ll also want to understand the server’s underlying code so you can identify which parts of it you can safely neglect. You don’t need every bit of data, and you don’t want to waste time scraping irrelevant code, such as tags meant for design. And once you retrieve that data, you often need to parse it or make it readable by human users.
There are also certain website features to keep in mind when web scraping with Python. Some, like pagination (next page, previous page, etc.), will require additional automation. Otherwise, you’ll need to manually click “next page” instead of automating everything.
Requests protocols
When you need to access anything online, you’re performing a request. A request is sent from your computer (i.e., the client) to a web server (i.e., the website or app), typically to view content. The server responds with what’s technically known as a response, which includes the information you want.
Several different request protocols can be used for web scraping requests, each with benefits and drawbacks. The most commonly used protocols include:
- HTTP: HTTP is the least secure method of accessing web pages as it does not support encryption. However, it remains one of the simplest options.
- HTTP Secure (HTTPS): HTTPS is the more secure version that encrypts user data in transit. But it can be slower and more resource-intensive since the encryption and decryption process adds time to data transmission.
- File Transfer Protocol (FTP): FTP is faster and more reliable for transferring large files, as it bypasses encryption and decryption. However, it should only be used in cases where the user and server completely trust each other or there’s zero sensitive data transmitted. FTP is also better suited for applications that require simultaneous access to files, such as file sharing.
With a basic understanding of how these protocols transfer data between different points on the internet, users can build highly-efficient scraping techniques.
This leads to the next concept: the actual code structure of a source website.
HTML and CSS
Browsers use HTML to interpret a webpage’s content, while CSS (Cascading Style Sheets) format everything else, such as text sizes, colors, fonts, and more. HTML files provide organized code that can be read by humans and programs like Python and manipulated for certain activities or tasks.
After downloading pages with protocols using requests, you need to understand how computers view the retrieved data, so they’re processed properly by your Python programs. The content you need to scrape is often wrapped in HTML tags within downloaded pages. Some of these targets include the HTML elements below:
- Divs containing “IDs” & “classes”
- Anchors linking URLs inside elements called “hrefs” (often embedded inside list items “<li>”)
- Table data within rows ” <td>” and columns “<tr>”
- Paragraph tags denoted by “<p>”
- Images referenced through image source attribute (“<img src =>”)
All these are found deep within the HTML of web pages you scrape. Aside from familiarizing yourself with these tags, you would also do well to understand the selectors associated with CSS. Key selectors can help you better navigate HTML code at higher levels. More advanced websites (those designed with CSS3 and JavaScript, for instance) will require more nuanced scraping.
Once you understand where the content you’re after is located, you can plan how to parse them.
Parsing
Specific libraries, such as BeautifulSoup and LXML, simplify the readability of HTML documents by creating “parsers” that help decide which parts or paths within code need exploring.
BeautifulSoup is a popular library for parsing web sources written in Python, and it works well with standard and complex code. LXML is an alternative library that uses XPath and Xquery languages (XPath being the most common). Both these auxiliary programs speed up particularly intricate procedures by allowing you to process your scraped information more accurately. If you need to extract information from a large amount of code containing various nested elements, LXML’s XPath or Xquery languages can simplify the process of navigating through the code structure and quickly locating the desired data. For example, it allows you to create search criteria like “find all nodes which contain content with a specific keyword” or “locate all elements within an array.” This makes it easier to narrow down what needs processing without manually inspecting each element. Additionally, LXML libraries are optimized for speed and memory efficiency, making them ideal for performing large-scale searches in minimal time.
BeautifulSoup is great for extracting data from tags in HTML documents, while LXML might be better suited for complex XML files or nodes with elements inside them. It is important to choose the library or parser that best fits your project and maintain consistency when coding. This can help you optimize results when using Windows Task Scheduler because you can separate specific scraping tasks based on the source websites. If you’re scraping websites that require BeautifulSoup, for example, you can group them into one script and one Task Scheduler task and recurring schedule.
Automating website access and trigger activity
One last important factor you need to consider is automating interactions with websites.
Selenium is a Python library used to automate what would otherwise be manual interaction with a website’s graphical user interface (GUI) through a scripting language. It allows users to control browsers programmatically, i.e., make the computer automatically interact with website interfaces. That way, the computer won’t require human input to trigger certain actions when processing data from websites.
Selenium can be used in tandem with other libraries, such as BeautifulSoup or LXML, during the scraping process or simply on its own for automation purposes.
Python code can automate the entire process explained above using a variety of easily accessible features, libraries, and packages.
Using Windows Task Scheduler for Automated Data Retrieval

Windows Task Scheduler is a system-level program that allows users to launch programs or scripts at specific times, recurring dates, and intervals without manual intervention. It also has advanced features accessible in its dashboard, like adding triggers that initiate tasks for a specific event.
It can save time and effort by automating tedious scraping tasks such as visiting specific websites, filling out forms, reviewing data sources, and extracting content from website code. This makes it especially useful for small to mid-sized businesses that don’t have extensive technical experience or the time or staff to do it manually.
To set up a new run command and create triggers in the Windows dashboard, open the Start menu and select “Task Scheduler.” You will add a task by clicking on “Action” in the menu and selecting “Create Basic Task.” This will prompt you to name your task and provide details about when it should run, what type of program is involved (in this case, Python), and which script(s) to execute using arguments if needed. After entering this information, click “Next” to configure any necessary triggers before saving the changes.
Task Scheduler can also execute reactive algorithms when particular conditions are met. This means you don’t have to manually update the algorithm or code it again. It will react automatically when certain conditions, such as changes in an input file (like a web page), are detected. Windows Task Scheduler is designed to identify such changes and make corresponding adjustments according to preset parameters. For example, you could have a web scraping program written in Python that uses Pandas to collect data from a website. This same code can then be used to export the collected data as an Excel file. You could also set up Windows Task Scheduler to execute the same code daily without manual intervention or updates. This means that your program will look for changes in the website’s content each day and automatically update your saved output accordingly.
With these advanced features, you can quickly automate simpler but more frequent web scraping tasks across many machines. You’re saving substantial time and effort over the long term, increasing productivity rates. If your processes stay consistent, you also ensure data accuracy every time you scrape a web page.
If you need an alternative to Windows Task Scheduler, you can try freeware such as Z-Cron Scheduler.
Creating Simple Auto-scheduling Scripts With Python and Windows Task Scheduler

Indian software engineer working on his laptop
With the overview out of the way, it’s time to focus on how small to mid-sized businesses can leverage Windows Task Scheduler and Python scripts to automate their web scraping. By the end of this section, you’ll have a basic framework for setting up automated data retrieval tasks with your very own Python scheduler.
Setting up your Python script
Prep the Python code the Task Scheduler will be running:
- Install relevant packages such as BeautifulSoup4 and LXML (remember, for parsing content?) via PIP (a package manager). You’re going to need them later.
- Create a command line script in your preferred text editor (e.g., Notepad). Use #!/usr/bin/env Python as the first line of your program file — this tells the system what language you’re using — then write whatever automation code you want. Name it something descriptive and memorable, such as “webscraper_script.”
- Save it with the .py extension inside a scripts directory you can place in any folder (it doesn’t matter where, but exercise due diligence when managing directories).
- Open a CMD or Powershell window from the same location and run the command pip freeze > requirements2xshell. This will freeze all dependencies used by Python into a separate file called requirement2xshell, which you should also save inside the scripts directory next to the project’s files (.py files).
Now you have everything ready to set up your task scheduler job. Read our guide on Python web scraping for a more detailed breakdown of web scraping scripting with this programming language.
Creating tasks and triggers in the Task Scheduler Console
To set up an automated web scraping task with Python, first launch the Windows Task Scheduler application on your device. Then click “Create Task” and provide a relevant name and description of this operation. Select when you want the web scraping requests to run by defining the frequency in hours, days, or weeks. Configure any necessary logging settings for particular sessions from the drop-down panel by selecting supported options (optional).
Now head over to “Actions.” Choose the “Start a Program” option as an action type, then add a full path to the main “webscraper_script” (or whatever your automated Python script name is). Enter the parameter –b to indicate which libraries or modules the Python script should load when it runs. This is useful for ensuring that extra library functions and processes can run a web scraping task as intended. Finally, there’s an input area where you can list other module names you might need if you have the libraries installed.
To run our web scraper at the desired intervals, we need to set up tasks and triggers in the Windows Task Scheduler Console. In the Console, navigate to the “Triggers” tab. Here you can configure manual triggers that occur at specific intervals of time or data events. You can also run multiple instances in parallel should your business require larger-scale web scraping capabilities. Once all configurations have been properly set up and tested, save your changes and run the task.
There are other ways to set up Task Scheduler jobs. One such method is to create a separate batch file identifying every script required in the automated task. This approach lets you choose which Python environment you want to use, giving you more flexibility. However, the method above is more direct, as it only requires that your Python script is in the appropriate directory.
Adding more functionality to your automated Python scripts
Once an automated web scraping task has been set up with Windows Task Scheduler, the Python script can initiate a web request for targeted data. If you’re dealing with unstructured HTML or CSV files, libraries such as “BeautifulSoup” and “Pandas” could provide easy-to-use functions for formatting raw data into usable information.
Libraries like these can take almost any type of file, including XML, JSON, and PDFs (among others), and quickly obtain structured output files or APIs. There are also ready-made Python packages online that help streamline universal web scraping processes, so small businesses don’t have to build them from scratch. After all, these require significant time investments upfront.
Additionally, APIs such as those from Google provide the necessary tools to plot real-time data points like stock market prices in a matter of minutes. Consider adding these into your Python script, as well, if they’re relevant. Properly configured and coded API usage can filter topics based on keywords and make use of ready-made libraries, significantly reducing manual steps.
You can also include strategies for using a proxy server (e.g., rotating proxies) in your Python script. Or, if you use software like a VPN, you can add the appropriate steps to another Task Scheduler task.
A few common issues and workarounds
It might seem straightforward, but putting all of this together isn’t without its challenges. Here are some of the most common pitfalls you’re likely to encounter when web scraping and strategies for overcoming them.
Timing issues
Correct timing is one of the most challenging issues with automated scripting. Occasionally, scripts require more time than expected. To overcome this issue, create a script that doesn’t have to load fully to begin and allows different opening and closing times depending on variables or conditions within the code.
Incorrect data extraction
Incorrectly extracting data from websites is common and will significantly slow progress if not resolved quickly — especially when dealing with multiple pages over long periods. The best way to prevent incorrect extraction can be a bit technical:
- Double-check the code regularly.
- Set up throttling parameters that limit the amount of data taken from a website per cycle. These parameters prevent memory overload, which can slow down or strain a computer system. When setting up throttling parameters for web scraping, it’s important to consider how often visits will be made to the source website and if any specific rates need to be adhered to (if provided). Additionally, an efficient way of tracking extracted data sets needs to be implemented so that duplicate results are not generated on subsequent visits.
- Make sure XPath expressions are validated periodically within the source website’s Document Object Model structure. XPath expressions are instructions for the computer to find and extract data from websites. These instructions must remain valid when working with multiple pages over long periods, as webpages often change their content layout or formatting. To ensure this, we need to make sure XPath expressions are validated periodically within the source website’s DOM structure. This will maintain consistency in our extraction so that we get accurate results every time we visit a webpage.
You can Google these terms and your specific issues to find a lot of help from the substantial Python user community.
Data sanitization
Cleaning up scraped data can be very difficult but also necessary, depending on your application’s needs (for example, filtering out irrelevant listings). Fortunately, several Python tools, such as Pandas, are designed to sanitize large sets of information, and dedicated libraries like LXML make it easier to encode XML documents more cleanly.
If you find your automated code is returning results that are difficult to understand, you will have to dig deeper into the technical side of data sanitization. Fortunately, the Python community at large will again be very helpful, especially for common issues.
Sorting through coding issues while working on auto-scheduling scripts requires constant revisions, closely monitored output performance, and maintenance fixes for intermittent errors. It’s a very involved process. But by following these steps and correctly preparing scripts beforehand, small to medium-sized businesses should have no problem setting up effective automated web scraping projects on their own.
Utilizing Advanced Features in the Windows Task Scheduler Console

Windows Task Scheduler’s advanced features allow for more complex automation through triggers, including scheduled tasks, system events, logon events, and external programs. It provides an interface for adding additional information, such as username and password credentials, that a script or application may require. Additionally, it has options to configure repeat intervals and save task information in XML format for backup or transfer activities.
Advanced Windows Task Scheduler features have additional benefits for more complex or larger scraping projects. For one thing, it can help ensure secure data retrieval processes. The configuration options provide extra security to keep sensitive or confidential information from being exposed during network or web scraping operations.
Setting up automated tasks and triggers in Windows Task Scheduler requires a few simple steps.
- Open the application from the Start menu and create a new task. Fill in relevant information such as name, description, and security options — the usual.
- Select the Triggers tab to set when you want your trigger to execute (based on time or other events). Using scheduled triggers rather than running scripts immediately upon connection adds an extra level of security by delaying the execution window until specified conditions (such as correct login information) have been met.
- Configure conditions for execution by selecting the Conditions tab. This is important for resource management, as it ensures that tasks run when needed based on criteria such as battery life threshold or external program or user action. Doing this allows the system to save CPU cycles when running background processes, especially over increased activity and load periods. Additionally, event-based processing means that tasks will only execute after certain events have been triggered — like a window logon — rather than just predetermined intervals throughout the day. This provides further control and ensures the best use of valuable resources within your computer’s operating system environment.
- Go onto the Actions tab where scripts or applications are specified that need to be executed with each trigger activation (e.g., run program /Script/ Logoff). Utilizing XML backup files, for example, allows for easy transfer between multiple applications while keeping any authentication details encrypted in a format not viewable through conventional means like Resource Explorer tools. This prevents attackers from trying to obtain passwords and other related secrets stored in plain text files.
- Now verify the settings and press the OK button at the bottom. Note that this simplicity betrays how complex you can make your automated scripts. Explore the Task Scheduler Console to see your options.
Further Challenges Small Businesses May Face

Small businesses may run into some other web scraping challenges and should prepare for them.
Data types
One of the main challenges small and medium-sized businesses face when using automated web scraping services is determining which types of data to collect. Web scraping programs can acquire various types of data, ranging from emails and contact information to product descriptions and pricing. Depending on your specific needs, different combinations of data — and therefore different tools for web scraping — may be needed to get all the necessary pieces.
For example, some businesses may only need basic information such as names and emails, while others require an advanced combination that includes complex elements like images or detailed product specifications. Businesses need to understand which type(s) they will utilize to avoid overwhelming their customers’ experiences and wasting time trying to capture too much data at once.
Infrastructure
Small to mid-sized businesses often lack access to the same computing resources that larger organizations have, such as a cloud hosting provider, if their servers’ power or bandwidth falls short. Setting up and maintaining an autonomous setup will become more costly if they have to rent cloud services like Amazon EC2, Microsoft Azure, or DigitalOcean.
In general, there are a few infrastructure-related costs to keep an eye out for:
- Networking costs: If a small or mid-sized business doesn’t already have the necessary infrastructure for its web scraping projects, it will need to budget for network equipment such as routers or switches.
- Dedicated server installation costs: A dedicated server will be needed if businesses are looking into adding more capacity or resources that can handle larger amounts of traffic while ensuring all operations continue without interruption (including during peak times). Installation costs could include upfront hardware purchases, enterprise-level software support down the line, and other maintenance needs such as storage backups and cooling solutions.
- Security expenses: It is crucial that businesses consider security measures when web scraping. Data privacy regulations must also be taken into account when collecting personal information from websites which can cost extra depending on what type of protection services are required: firewalls, antiviruses, SSL encryption certificates, and one-time/annual fees at the hardware and software level.
- Website monitoring tools: Businesses may invest in website performance monitoring services or software that helps monitor, troubleshoot, and alert them to potential server issues. These options could include SaaS offerings or open-source solutions that require one-time setup fees or subscription costs based on usage levels. This can allow businesses to quickly identify any web scraping-related issues and potentially resolve them faster, reducing unplanned downtime.
Smaller businesses must carefully assess these costs against automation strategies before deciding to explore anything beyond web scraping with Python and Windows Task Scheduler for their business needs. More advanced scraping means more monetary and computational resources.
Technical and operational know-how
Smaller businesses are often restricted by their budget and may not have the technical expertise or capacity to manage large-scale web scraping projects on their own. Automating web scraping services requires the right operations to run effectively. These include ensuring reliable infrastructure, understanding how data can be reliably accessed from external sources, data security protocols, maintenance cycles for software updates/upgrades, and more.
Decisions must also be made concerning hiring new personnel and managing third-party service providers, such as proxy servers. Some things to consider include:
- The staffing needs for web scraping services, including roles such as data scientists, software engineers, etc.
- A hiring strategy that factors in both technical aptitude and business acumen experience or providing training and support materials where needed.
- Third-party service providers who can provide reliable infrastructure (proxy servers) along with continuous software updates and support on an ongoing basis.
Troubleshooting and testing issues
You must troubleshoot potential issues with the quality, amount, and speed of data updates. It can be challenging for a smaller organization to balance optimization with maintaining up-to-date databases. Your business must learn how to adjust settings such as frequency of execution to ensure it has up-to-date databases without sacrificing time or resources updating them too often. It also helps to ensure that only relevant and valuable data is collected from web scraping operations, saving time and energy when searching for information on their own.
You’ll also need effective error handling and notification methods so that users are quickly made aware of any errors encountered during automated operations. Add proactive approaches (like routine debugging or maintenance windows) in case something unexpected happens or results need adjusting periodically. Finally, bringing functional testing into play would allow you to measure whether expected functionality works as planned before changing anything.
Using Proxy Servers and Rayobyte’s Web Scraping API Providers

It’s important to ensure your company follows web scraping best practices by using proxy servers and/or web scraping providers. Both strategies can help protect your website’s content and other sites from which you may be attempting to obtain data.
Proxy servers and web scraper providers allow you to securely scrape web data from a variety of sources. Rayobyte’s Web Scraping APIs are automated programs that can crawl web pages, download files, extract content, and store it. Proxy servers act as middlemen between internet users and websites, providing secure access to an external service or website with less risk of being blocked by the target system.
For example, suppose you’re accessing a database that might be storing sensitive customer information on an internal server at your organization’s location. Proxy servers will provide security so that no one outside your network can gain access.
Robotic scraping allows business owners to quickly acquire large amounts of valuable data while protecting their intellectual property rights. Using a third-party provider for web data collection has several advantages. For one, scraping providers are designed to collect and organize data from any website quickly and efficiently. As most web scraping requires users to create custom bots or scripts, outsourcing it can often save time for businesses that lack technical expertise in coding or programming. They provide immediate access to a library of highly specialized bot templates.
Plus, using proxy servers from these same providers is convenient as they offer unlimited IPs globally, which helps ensure user anonymity while increasing the speed of data collection.
Types of proxy servers
Residential proxies are IP addresses established by normal internet service providers and provide users with real-time access that looks like a regular home user surfing the web. This makes them highly efficient for scraping large portions of data without getting blocked by websites since they blend in with all other web traffic.
Data center proxies use specialized servers located at corporate data centers across multiple countries instead of ISPs. Their main feature is increased speed and reliability compared to residential proxies, as well as scalability. Most major corporations own hundreds or thousands of servers worldwide in different locations and run different networks, so user requests don’t go through just one server host location (as they would if they used a residential proxy). Requests made with a data center proxy can go through multiple server host locations before being redirected, resulting in reduced latency and increased connection speeds.
ISP proxies are an intermediate solution that provides URL routing through residential proxy networks while masking as a single ISP provider. Proxies connected to an ISP are a combination of residential and data center proxies. These can be accessed through multiple network sources, allowing one to benefit from the convenience of data centers while harnessing the legitimization associated with using an ISP. This allows a limited degree of customization that can minimize problems associated with occasional latency issues.
A dependable proxy server is key for any successful data scraping operation. Rayobyte offers sophisticated features that can automate certain tasks, making it easier to manage resources and keep scrapers under the radar. Discover our proxies today and take your scraping to the next level.
Final Take

Automating web scraping with Python and Windows Task Scheduler provides many advantages to businesses that need up-to-date information. Aside from the obvious convenience of automated data collection, these programs can be fine-tuned to provide more accurate results than manual extraction. With efficient use of resources and minimal human intervention required, Python and Windows automation is an excellent solution for companies in search of cost-effective ways to manage large amounts of data on tight budgets and without taking too much time out of their busy schedules.
The information contained within this article, including information posted by official staff, guest-submitted material, message board postings, or other third-party material is presented solely for the purposes of education and furtherance of the knowledge of the reader. All trademarks used in this publication are hereby acknowledged as the property of their respective owners.
Вам надоело проводить бесчисленные часы, разбираясь с надоедливыми спам-письмами и повторяющимися задачами? Представьте себе мир, в котором вы можете расслабиться и наблюдать, как Python делает всю работу за вас. Что ж, приготовьтесь войти в царство автоматизации!
Попрощайтесь с рутинной работой и поздоровайтесь с безграничной продуктивностью. В этой статье мы приготовили для вас нечто особенное – крутые Python скрипты 2024 года, для автоматизации которые упростят вашу жизнь и сэкономят драгоценное время. С Python вы сможете без труда удалять спам, управлять резервным копированием, автоматизировать работу в социальных сетях как профессионал и многое другое.
В этой статье мы рассмотрим десять скриптов автоматизации на Python актуальные на 2024 год, которые помогут вам оптимизировать повседневные задачи и сэкономить драгоценное время. Давайте погрузимся в работу и узнаем, как Python и его библиотеки могут стать вашим главным союзником в автоматизации.
Вот несколько интересных примеров, демонстрирующих, как вы можете автоматизировать свои рутинные задачи с помощью этих скриптов автоматизации Python.
https://t.me/data_analysis_ml – в моем телеграм канале я публикую актуальные бесплатные курсы, гайды и уроки для разработчиков.
https://t.me/addlist/_FjtIq8qMhU0NTYy – Здесь я собрал папку для разработчиков, где вы найдете все необходимое для.
1. Оптимизатор изображений
Одним нажатием кнопки этот скрипт автоматизации на python позволяет вам без усилий улучшать и манипулировать вашими изображениями, как профессионал, без необходимости использования дорогостоящего программного обеспечения или сложных инструментов редактирования. Этот скрипт использует популярный модуль Pillow для манипуляции над изображениями. Он использует библиотеку Python Imaging Library (PIL) для обрезки, изменения размера, переворачивания, поворота, сжатия, размытия, повышения резкости, настройки яркости, контраста и добавления фильтров к изображению.
# Оптимизация изображений
из PIL import Image, ImageFilter, ImageOps, ImageEnhance
# Загрузка изображения
im = Image.open("Image1.jpg")
# Обрезать изображение
im = im.crop((34, 23, 100, 100))
# Изменить размер изображения
im = im.resize((50, 50))
# Переверните изображение по горизонтали
im = im.transpose(Image.FLIP_LEFT_RIGHT)
# Поверните изображение на 360 градусов
im = im.rotate(360)
# Сжать изображение
im.save("Image1.jpg", optimize=True, quality=90)
# Примените эффект размытия
im = im.filter(ImageFilter.BLUR)
# Применить эффект повышения резкости
im = im.filter(ImageFilter.SHARPEN)
# Настройте яркость
enhancer = ImageEnhance.Brightness(im)
im = enhancer.enhance(1.5)
# Настроить контрастность
enhancer = ImageEnhance.Contrast(im)
im = enhancer.enhance(1.5)
# Добавьте фильтры
im = ImageOps.grayscale(im)
im = ImageOps.invert(im)
im = ImageOps.posterize(im, 4)
# Сохраните оптимизированное изображение
im.save("Image1.jpg")2. Оптимизатор видео на Python
Оптимизаторы видео могут использоваться для сжатия видео для хранения или передачи, а также для улучшения качества видео. Этот скрипт использует модуль Moviepy для оптимизации видео путем обрезки, изменения скорости видно, добавления звука и применения визуальных эффектов (VFX).
# Оптимизатор видео
import moviepy.editor as pyedit
# Загрузить видео
video = pyedit.VideoFileClip("vid.mp4")
# Обрезать видео
vid1 = video.subclip(0, 10)
vid2 = video.subclip(20, 40)
final_vid = pyedit.concatenate_videoclips([vid1, vid2])
# Ускорение видео
final_vid = final_vid.speedx(2)
# Добавьте аудио к видео
aud = pyedit.AudioFileClip("bg.mp3")
final_vid = final_vid.set_audio(aud)
# Переверните видео
final_vid = final_vid.fx(pyedit.vfx.time_mirror)
# Объединить два видео
vid1 = pyedit.VideoFileClip("vid1.mp4")
vid2 = pyedit.VideoFileClip("vid2.mp4")
final_vid = pyedit.concatenate_videoclips([vid1, vid2])
# Добавьте VFX в видео
vid1 = final_vid.fx(pyedit.vfx.mirror_x)
vid2 = final_vid.fx(pyedit.vfx.invert_colors)
final_vid = pyedit.concatenate_videoclips([vid1, vid2])
# Добавьте изображения к видео
img1 = pyedit.ImageClip("img1.jpg")
img2 = pyedit.ImageClip("img2.jpg")
final_vid = pyedit.concatenate_videoclips([img1, img2])
# Сохраните финальное видео
final_vid.write_videofile("final.mp4")3. Планировщик отправки электронных писем
Email Scheduler – это мощный скрипт автоматизации на Python, который позволяет планировать и автоматически отправлять электронные письма в определенное время. С помощью этого скрипта вы можете попрощаться с ручной отправкой писем и начать общение с вашими контактами, с помощью бота на Python.
Этот скрипт позволяет планировать и отправлять электронные письма в определенное время автоматически. Он использует модули smtplib и schedule.
Видео на эту тему – https://www.youtube.com/watch?v=vKNGu8fVDGs&t=1s
import smtplib
import schedule
import time
def send_email():
sender_email = "your_email@gmail.com"
receiver_email = "recipient_email@gmail.com"
пароль = "ваш_пароль"
subject = "письмо"
body = "Это автоматическое письмо, отправленное с помощью Python."
message = f "Subject: {subject}\n\n{body}"
с smtplib.SMTP_SSL("smtp.gmail.com", 465) в качестве сервера:
server.login(sender_email, password)
server.sendmail(sender_email, receiver_email, message)
# Запланировать отправку письма ежедневно в 8 утра
schedule.every().day.at("08:00").do(send_email)
while True:
schedule.run_pending()
time.sleep(1)4. Автопостер в социальные сети на Python

Social Media Auto-Poster – это мощный Python-скрипт, который оптимизирует ваше присутствие в социальных сетях и делает управление несколькими платформами простым делом. С помощью этого скрипта вы можете планировать и автоматизировать публикацию контента на различных каналах социальных сетей, таких как Twitter, Facebook, LinkedIn и других. Этот скрипт использует библиотеку tweepy для автоматической публикации контента в Twitter через запланированные интервалы времени. Здесь мы используем библиотеку tweepy –https://docs.tweepy.org/en/stable/
# Автопостер для социальных сетей
import tweepy
import schedule
import time
def post_to_twitter():
api_key = "YOUR_API_KEY"
api_secret = "YOUR_API_SECRET"
access_token = "YOUR_ACCESS_TOKEN"
access_token_secret = "YOUR_ACCESS_TOKEN_SECRET"
auth = tweepy.OAuthHandler(api_key, api_secret)
auth.set_access_token(access_token, access_token_secret)
api = tweepy.API(auth)
tweet = "Это автоматический твит с использованием Python!"
api.update_status(tweet)
# Запланируйте публикацию твита на каждые 6 часов
schedule.every(6).hours.do(post_to_twitter)
while True:
schedule.run_pending()
time.sleep(1)5. Преобразование PDF в изображение
Преобразование PDF в изображение – распространенная задача в различных отраслях, от обработки документов до графического дизайна. Файлы PDF (Portable Document Format) широко используются для обмена документами с сохранением их форматирования на различных устройствах и платформах. Однако иногда вам может понадобиться извлечь отдельные страницы из PDF или преобразовать весь документ в формат изображения для дальнейшей обработки или отображения.
Этот скрипт использует модуль PyMuPDF для преобразования страниц PDF в изображения без особых усилий.
# PDF в изображения
import fitz
def pdf_to_images(pdf_file):
doc = fitz.open(pdf_file)
for page in doc:
pix = page.get_pixmap()
output = f "page{page.number}.png"
pix.writePNG(output)
pdf_to_images("test.pdf")6. Получить данные API
В современную цифровую эпоху мы полагаемся на различные веб-сервисы для получения ценной информации, но ручной сбор данных может отнимать много времени. Этот скрипт демонстрирует, как получить данные API с помощью модуля urllib3 для выполнения GET- и POST-запросов.
# Получение данных API
import urllib3
# Получение данных API с помощью GET-запроса
url = "https://api.gitфhub.com/users/psf/repos"
http = urllib3.PoolManager()
response = http.request('GET', url)
print("Код статуса:", response.status)
print("Данные ответа:", response.data)
# Публикация данных API с помощью POST-запроса
url = "https://httpbin.org/post"
http = urllib3.PoolManager()
response = http.request('POST', url, fields={'hello':'world'})
print("Код статуса:", response.status)7. Уровень заряда батареи на Python
Скрипт Battery Indicator Light – это удобная автоматизация на Python, которая позволяет не упустить момент, когда речь заходит о времени работы устройства от батареи. С помощью этого удобного инструмента вы можете установить определенный порог заряда батареи, и скрипт будет следить за его уровнем.
Этот скрипт использует модули plyer и psutil, чтобы уведомить пользователя о низком уровне заряда батареи.
# Уведомление о заряде батареи
from plyer import notification import psutil
from time import sleep
while True:
battery = psutil.sensors_battery()
life = battery.percent
if life < 50:
notification.notify(
title="Батарея разряжена",
message="Пожалуйста, подключитесь к источнику питания",
timeout=10
)
sleep(50)8. Веб-скрепинг Python
Веб-скрепинг – это мощная техника, используемая для извлечения данных с веб-сайтов. Она включает в себя автоматизацию процесса доступа к веб-страницам, извлечение необходимой информации и сохранение ее в структурированном формате для дальнейшего анализа или использования. Этот процесс неоценим для бизнеса, исследователей и энтузиастов, которые стремятся собирать и анализировать данные из различных источников в Интернете. Этот скрипт использует модули requests и BeautifulSoup для скрейпинга данных с веб-сайта и извлечения определенной информации.
#Скрипт для веб-скрапинга
import requests
from bs4 import BeautifulSoup
url = "https://example.com"
response = requests.get(url)
soup = BeautifulSoup(response.text, "html.parser")
# Извлечение определенных данных с сайта
data = soup.find("div", {"class": "content"}).get_text()
print(data)Советуем посмотреть: Асинхронный парсинг сайтов на Python
Продвинутые методы парсинга с помощью Python
9. Автоматизированное тестирование с помощью Pytest
Автоматизированное тестирование – важнейший аспект современной разработки программного обеспечения, позволяющий разработчикам проверять свой код, выявлять ошибки и обеспечивать надежность приложений. В Python один фреймворк для тестирования выделяется как мощное и удобное решение: Pytest. Этот скрипт демонстрирует, как выполнить автоматизированное тестирование с помощью фреймворка pytest для проверки Python-кода.
# Автоматизированное тестирование с помощью Pytest
import pytest
# Тестируемая функция
def add_numbers(x, y):
return x + y
# Тест функции
def test_addition():
assert add_numbers(1, 2) == 3
assert add_numbers(-1, 1) == 0
assert add_numbers(0, 0) == 0
assert add_numbers(10, 5) == 15
if __name__ == "__main__":
pytest.main()10. Резервное копирование и синхронизация файлов c Python
Скрипт File Backup and Sync – это мощный инструмент автоматизации на языке Python, призванный избавить вас от хлопот, связанных с управлением файлами и обеспечением их безопасности. Сохранение важных данных в безопасности и доступности является главным приоритетом в современный цифровой век, и этот скрипт предлагает простое, но эффективное решение. Этот скрипт автоматически создает резервные копии и синхронизирует файлы между двумя каталогами, гарантируя, что в обоих местах будет одинаковое содержимое.
# Сценарий резервного копирования и синхронизации файлов
импортировать os
import shutil
def backup_and_sync(source_folder, backup_folder):
for root, _, files in os.walk(source_folder):
for file in files:
source_path = os.path.join(root, file)
backup_path = os.path.join(backup_folder, root.replace(source_folder, ""), file)
# Создайте каталоги, если они не существуют в папке резервного копирования
os.makedirs(os.path.dirname(backup_path), exist_ok=True)
# Скопируйте файл в папку резервного копирования
shutil.copy2(source_path, backup_path)
# Удалите из папки резервного копирования файлы, которых нет в исходной папке
for root, _, files in os.walk(backup_folder):
for file in files:
backup_path = os.path.join(root, file)
source_path = os.path.join(source_folder, root.replace(backup_folder, ""), file)
if not os.path.exists(source_path):
os.remove(backup_path)
исходная_папка = "путь/к/источнику/папке"
backup_folder = "path/to/backup/folder"
backup_and_sync(source_folder, backup_folder)
Python скрипты 2024, какие проекты можно создать самостоятельно.
В 2024 году Python останется одним из самых популярных языков программирования, и его возможности будут по-прежнему широкими. Вот несколько интересных скриптов, которые вы можете создать на Python самостоятельно в 2024 году, если вы ищите практики:
1. Автоматизация задач: Python отлично подходит для автоматизации рутинных задач, таких как обработка файлов, сортировка данных, создание отчетов и т.д.
2. Веб-скрапинг: Python имеет мощные библиотеки для сбора данных с веб-сайтов. Вы можете написать скрипт, который будет извлекать информацию с различных сайтов, анализировать ее и сохранять в нужном формате.
3. Машинное обучение: Python является одним из основных языков для разработки алгоритмов машинного обучения. Вы можете создать скрипты для обучения моделей, классификации данных, анализа текста и многое другое.
4. Разработка игр: Python имеет библиотеки, такие как Pygame, которые позволяют создавать простые игры. Вы можете написать скрипт для создания своей собственной игры или модификации существующей.
5. Разработка приложений: Python используется для создания различных типов приложений, включая настольные и веб-приложения. Вы можете написать скрипт для создания простого приложения, которое решает определенную задачу.
6. Анализ данных: Python имеет много библиотек для анализа данных, таких как Pandas и NumPy. Вы можете написать скрипт для обработки и анализа больших объемов данных, построения графиков и визуализации результатов.
7. Разработка роботов: Python может быть использован для программирования роботов и устройств IoT (интернета вещей). Вы можете написать скрипт для управления роботом или устройством, собирать данные с датчиков и принимать решения на основе этих данных.
Это лишь некоторые примеры интересных скриптов, которые можно создать на Python в 2024 году. Возможности языка постоянно расширяются, поэтому в будущем появятся еще более увлекательные проекты и задачи.
Спасибо за прочтение!
Просмотры: 4 549