
Преамбула: волею судьбы из мира академической науки (медицины) я попала в мир информационных технологий, где мне приходится использовать свои знания о методологии построения эксперимента и стратегиях анализа экспериментальных данных, однако, применять новый для меня стек технологий. В процессе освоения этих технологий я сталкиваюсь с рядом трудностей, которые пока, к счастью, удается преодолевать. Возможно, этот пост будет полезен тем, кто также только начинает работу с проектами Apache.
Итак, к сути. Вдохновившись статьей Юрия Емельянова о возможностях Apache Airflow в области автоматизации аналитических процедур, мне захотелось начать использовать предлагаемый набор библиотек в своей работе. Тем, кто еще совсем не знаком с Apache Airflow, может быть интересна небольшая обзорная статья на сайте Национальной библиотеки им. Н. Э. Баумана.
Поскольку обычные инструкции для запуска Airflow, судя по всему, не применяются в среде Windows, а использовать для решения данной задачи докер в моем случае было бы избыточно, я начала поиск других решений. К счастью для меня, я оказалась не первой на этом пути, поэтому мне удалось найти замечательную видео-инструкцию по установке Apache Airflow в Windows 10 без использования докера. Но, как это часто и бывает, при выполнении рекомендуемых шагов, возникают трудности, и, полагаю, не только у меня. Поэтому я хотела бы рассказать о своем опыте установки Apache Airflow, возможно кому-то это сэкономит немного времени.
Пройдемся по шагам инструкции (спойлер — 5-го шага все шло прекрасно):
1. Установка подсистемы Windows для Linux для последующей установки дистрибутивов Linux
Это меньшая из проблем, как говорится:
Панель управления → Программы → Программы и компоненты → Включение и отключение компонентов Windows → Подсистема Windows для Linux
2. Установка дистрибутива Linux по выбору
Я воспользовалась приложением Ubuntu.
3. Установка и апдейт pip
sudo apt-get install software-properties-common
sudo apt-add-repository universe
sudo apt-get update
sudo apt-get install python-pip4. Установка Apache Airflow
export SLUGIFY_USES_TEXT_UNIDECODE=yes
pip install apache-airflow5. Инициализация базы данных
И вот именно здесь начались мои маленькие трудности. Инструкция предписывает ввести команду airflow initdb и перейти к следующему шагу. Однако я неизменно получала ответ airflow: command not found. Логично предположить, что возникли трудности на этапе установки Apache Airflow и просто нет нужных файлов. Удостоверившись, что все там где и должно быть, я решила попробовать указать полный путь до файла airflow (выглядеть должно так: Полный/путь/до/файла/airflow initdb). Но чуда не произошло и ответ был тем же airflow: command not found. Я попробовала использовать относительный путь к файлу (./.local/bin/airflow initdb), что привело к появлению новой ошибки ModuleNotFoundError: No module named json', которую можно преодолеть, обновив библиотеку werkzeug (в моем случае до версии 0.15.4):
pip install werkzeug==0.15.4Подробнее о werkzeug можно почитать здесь.
После этой нехитрой манипуляции команда ./.local/bin/airflow initdb была выполнена успешно.
6. Запуск сервера Airflow
На этом сложности с обращением к airflow еще не завершились. Запуск команды ./.local/bin/airflow webserver -p 8080 привел к ошибке No such file or directory. Вероятно, опытный пользователь Ubuntu сразу бы попробовал преодолеть такие трудности с обращением к файлу, применив команду export PATH=$PATH:~/.local/bin/ (то есть, добавив к существующему пути поиска исполняемых файлов, определяемому переменной PATH каталог /.local/bin/), но этот пост предназначен для тех, кто преимущественно работает с Windows и, возможно, не считает такое решение очевидным.
После описанной выше манипуляции команда ./.local/bin/airflow webserver -p 8080 была успешно выполнена.
7. URL: localhost:8080/
Если все прошло удачно на предыдущих этапах, то вы готовы покорять аналитические вершины.
Надеюсь, описанный выше опыт установки Apache Airflow на Windows 10 будет полезен начинающим пользователям и ускорит их вхождение во вселенную современных инструментов аналитики.
В следующий раз хотелось бы продолжить тему и рассказать об опыте использования Apache Airflow в сфере анализа поведения пользователей мобильных приложений.
Что такое WSL, Docker и как запустить веб-сервер Apache AirFlow в контейнере на локальной машине в Ubuntu поверх Windows вместо любимого Google Colab. Пошаговое руководство для начинающих дата-инженеров.
Краткий ликбез по WSL и Docker для любителей Windows
Обычно я всегда запускала веб-сервер Apache AirFlow в интерактивной среде Google Colab, которая по своей сути представляет собой виртуальную машину с Unix-подобной ОС. А, чтобы получить доступ к localhost, использовала утилиту тунелирования ngrok. С одной стороны, это было удобно, поскольку каждая Colab-среда работает изолировано: можно было не связываться с виртуальными Python-средами, чтобы избежать «ада зависимостей», когда одна библиотека конфликтует с другой, достаточно просто закрыть ненужную Colab-среду. Однако, запускать приложения AirFlow в режиме standalone удобнее всего на собственной локальной машине, чтобы избежать задержек и других недостатков Colab, о которых я писала здесь. Поэтому решила запускать веб-серверы в своей собственной среде, независимо от внешних сервисов.
Избежать конфликта зависимостей, свойственных AirFlow, при запуске его на локальной машине с операционной системой Windows, можно 2-мя способами:
- использовать виртуальные среды Python;
- сделать контейнер, упаковав в него приложение со всеми зависимостями.
Далее рассмотрим именно 2-ой способ. Чтобы запустить контейнер на операционной системе Windows, надо установить WSL — подсистему Windows для Linux, которая позволяет запускать среду Linux на Windows без отдельной виртуальной машины. С WSL можно запускать Linux в оболочке Bash с выбранным дистрибутивом, чтобы работать с CLI-интерфейсом и приложениями Linux. В отличие от полноценной виртуальной машины, WSL требует меньше ресурсов (ЦП, памяти и хранилища), а также может обращаться к файлам Windows в Linux. Обеспечить изоляцию приложений, чтобы избежать конфликтов с зависимостями, свойственных Python-разработке, можно с помощью контейнеризации, что также хорошо поддерживается в WSL.
Сегодня наиболее популярным инструментом контейнеризации является Docker – он позволяет упаковать приложение со всем его окружением и зависимостями в контейнер, который можно запустить на любой Linux-подобной системе. Эта платформа дает возможность отделить приложения от инфраструктуры, перезапуская их по мере необходимости. Изоляцию обеспечивает запуск каждого контейнера в отдельном процессе. Docker-образ можно развернуть несколько раз, получив независимые контейнеры с работающими приложениями. Docker-контейнер — это запущенный и изолированный образ с возможностью временного сохранения данных, которые записываются в его верхний слой и при удалении контейнера удаляются.
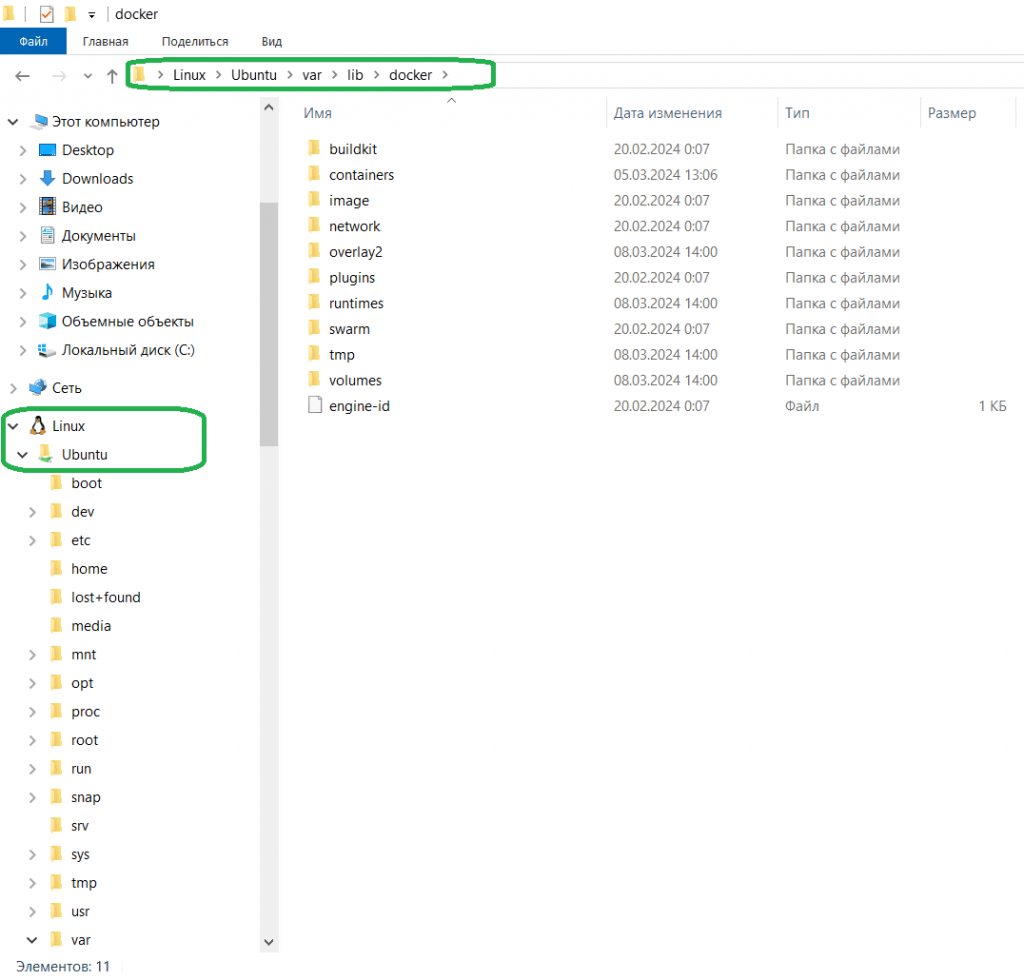
Создание и запуск docker-контейнера Apache AirFlow
После установки WSL и Docker на свой ноутбук с ОС Windows я загрузила готовый базовый docker-образ загрузить Apache Airflow версии 2.8.1 для python3.11:
docker pull apache/airflow:slim-2.8.1-python3.11
Чтобы запускать работающий контейнер с AirFlow одной строкой, т.е. уже с инициализированной базой данных метаданных и пользователем веб-интерфейса, пришлось немного модифицировать этот образ, внеся следующие изменения в Dockerfile — текстовый файл с последовательно расположенными инструкциями для создания образа. Каждому образу присваивается свой Dockerfile, куда надо записать команды для установки пакетов. Поскольку я работаю с Телеграм и PostgreSQL, а также Elasticsearch, в dockerfile включила инструкции установки этих библиотек, а также добавила команды инициализации базы данных метаданных и создания локального пользователя:
FROM apache/airflow:slim-2.8.1-python3.11 RUN airflow db init RUN airflow users create --username anna --password admin --firstname Anna --lastname Vi --role Admin --email admin@example.com RUN pip install elasticsearch7==7.10.1 RUN pip install apache-airflow-providers-telegram RUN pip install psycopg2-binary RUN pip install apache-airflow-providers-postgres ENTRYPOINT ["airflow", "standalone"]
Для запуска AirFlow в режиме standalone, т.е. на локальной машине, это надо указать в параметрах входной точки ENTRYPOINT в файле Dockerfile. Затем для создания своего образа надо выполнить команду build в той папке, где находится этот Dockerfile:
docker build -t my-airflow-image .
Для работы с контейнерами Docker предоставляет всего несколько команд: docker run, stop и restart. Однако, они имеют множество полезных опций. Например, команда run позволяет запускать контейнер в фоновом режиме, монтировать директории и пр. Чтобы запустить docker-контейнер на основе созданного образа с названием my-airflow-image, надо выполнить команду docker run. Поскольку порт 8080, используемый по умолчанию для запуска веб-приложений, у меня занят другим приложением, я решила развернуть AirFlow на другом порту, 8081. Также при запуске контейнера AirFlow надо указать директорию для хранения Python-файлов с задачами и DAG. Для этого создала папку workspace/airflow/my_dags на диске С и примонтировала ее внутрь контейнера в директорию /opt/airflow/dags/, чтобы управлять DAG-файлами AirFlow извне контейнера. Для запуска docker-контейнера my-airflow на основе образа my-airflow-image с приложениями AirFlow в фоновом режиме надо добавить флаг –d к команде run:
docker run -d -p 8081:8080 -v /mnt/c/workspace/airflow/my_dags/:/opt/airflow/dags/ --name my-airflow my-airflow-image
Эта команда запускает контейнер в фоновом режиме с Apache AirFlow и пробрасывает порты, чтобы иметь доступ к веб-интерфейсу ETL-планировщика через порт 8081 локальной машины, а также читать и выполнять DAG-файлы, расположенные в директории workspace/airflow/my_dags на диске С.
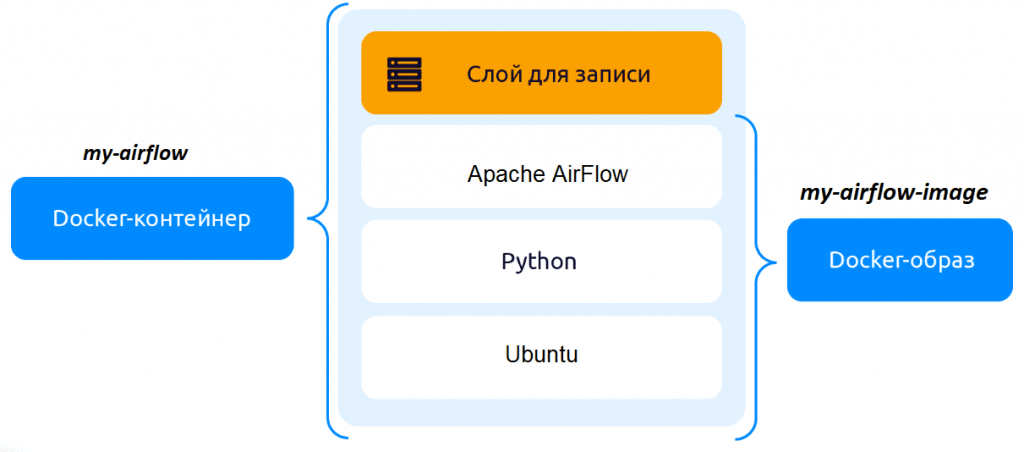
Все последующие запуски docker-контейнера my-airflow выполняются в несколько шагов:
- Открыть командную строку;
- Запустить WSL;
- Стартовать работу контейнера с помощью команды
docker start my-airflow
- Запустить командную оболочку bash в уже запущенном контейнере в интерактивном режиме:
docker exec -it my-airflow bash
- Наконец, запустить Apache AirFlow в режиме standalone:
airflow standalone
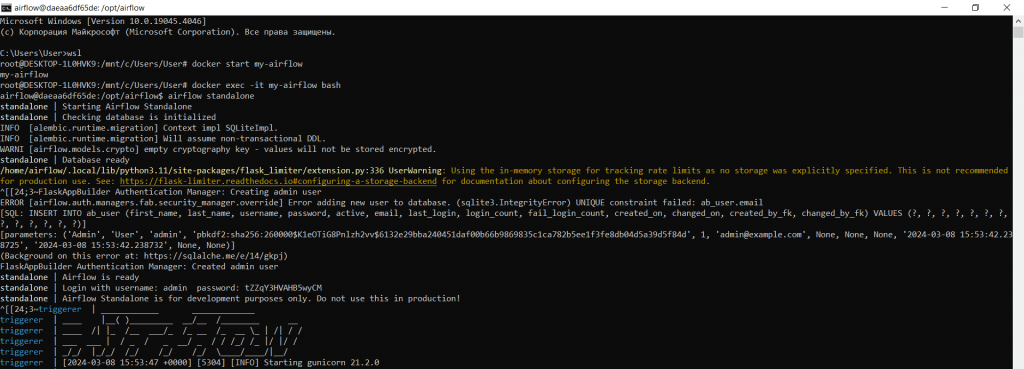
Для разработки DAG-файлов и файлов задач можно использовать редактор VSCode, который, хоть и не является полноценной IDE, намного удобнее обычного блокнота.
Впрочем, быстро поправить py-файл можно и просто открыв его в Notepad++. Завтра я продолжу работу с этим контейнером Apache AirFlow и расскажу, как проверить доступность сайта с помощью веб-хуков.
Узнайте больше про Apache AirFlow и его использование в задачах реальной дата-инженерии на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Data Pipeline на Apache AirFlow и Apache Hadoop
Источники
- https://www.freecodecamp.org/news/install-apache-airflow-on-windows-without-docker/
- https://cloud.yandex.ru/ru/blog/posts/2022/03/docker-containers
- https://1cloud.ru/blog/docker_start
Contents
- 1 Что такое Apache Airflow?
- 1.1 Краткое описание функционала и предназначения
- 1.2 Плюсы Apache Airflow
- 1.3 Минусы Apache Airflow
- 1.4 Примеры за и против из книги Apache Airflow и конвейеры обработки данных
- 1.4.1 Причины выбрать Airflow
- 1.4.2 Причины не выбирать Airflow
- 1.5 Конкуренты Apache Airflow
- 1.5.1 Luigi
- 1.5.2 Apache NiFi
- 1.5.3 Dagster
- 1.5.4 Kedro
- 1.5.5 Apache Oozie
- 1.5.6 Таблица с характеристиками конкурентов (не всех вышеперечисленных)
- 2 Архитектура Apache Airflow
- 2.1 Обзор интерфейса Apache Airflow
- 2.1.1 Краткий обзор меню Apache Airflow
- 2.2 Обзор основных сущностей Apache Airflow
- 2.2.1 Перечень операторов
- 2.2.1.1 Описание основных параметров PythonOperator
- 2.2.2 DAG (Directed Acyclic Graph)
- 2.2.3 Что такое subdag в airflow? Основные подходы к использованию
- 2.2.4 Tasks и Task Instances (Экземпляр задачи)
- 2.2.1 Перечень операторов
- 2.3 Обзор компонентов Apache Airflow
- 2.3.1 Основные компоненты Airflow
- 2.3.2
- 2.3.3 Executors (Исполнители)
- 2.3.4 Обзор процесса обработки Airflow DAGs
- 2.3.5 Типы переменных в Airflow
- 2.3.5.1 Лучшие практики хранения информации в переменных Airflow
- 2.3.5.2 Существует несколько способов создания переменных Airflow:
- 2.3.5.3 Какие ограничения существуют для XCom в Airflow?
- 2.3.6 Как реализуется последовательность выполнения задач и ассинхронное выполнения задач в airflow?
- 2.1 Обзор интерфейса Apache Airflow
- 3 Установка и настройка Apache Airflow
- 3.1 Установка Apache Airflow с помощью Docker-Compose на Ubuntu 20.04
- 3.1.1 Минимальные требования для установки Apache Airflow следующие:
- 3.2 Настройка Apache Airflow
- 3.2.1 Основные параметры Airflow.cfg
- 3.1 Установка Apache Airflow с помощью Docker-Compose на Ubuntu 20.04
- 4 FAQ: Вопросы и ответы
- 4.1 Как переиспользовать функции Python между разными DAG? Как переиспользовать код в нескольких DAG?
- 4.2 Что такое модуль в Airflow? Как создать и подключить свой модуль в Airflow?
- 4.3 Как импортировать модули в Airflow, если Airflow развернут в контейнерах Docker?
- 4.4 Какие сложности часто возникают при работе в Airflow?
- 4.5 Как выполнить 2 задачи из одного DAG в разных контейнерах Docker?
- 4.6 Пример DAG отправки сообщения в Slack
- 4.7 Пример DAG с отправкой отчета Excel из Pandas Dataframe в канал Slack
- 4.8 Как указать в dag асинхронно или последовательно выполнять задачи? Пример асинхронного и последовательного dag
- 4.9 Отправка красивого письма с вложенным файлом excel через dag airflow
- 4.10 Как продать идею внедрения airflow руководству?
- 4.11 Как создать цепочку задач для выполнения etl в Apache PySpark
- 4.12 Как создать несколько задач и дождаться их выполнения в Apache Airflow
- 4.13 В чем разница между Apache NiFi vs Airflow?
- 4.14 Data Pipelines (пайплайны) внутри DAG. Пайплайн airflow
- 5 Подборка видео по тематике Airflow
- 5.1 Видео на русском
- 5.1.1 Что такое Apache Airflow («Школы Больших Данных» г. Москва)
- 5.1.2 Начало работы с apache Airflow — часть 1 («Школы Больших Данных» г. Москва)
- 5.1.3 ETL на airflow — часть 2 («Школы Больших Данных» г. Москва)
- 5.1.4 5 Оркестраторы и работа с Airflow (Канал Intellik)
- 5.1.5 ВВЕДЕНИЕ В AIRFLOW / ПОНЯТИЕ DAG’а / НАСТРОЙКА DAG’а В AIRFLOW (Канал DataLearn)
- 5.1.6 Airflow и MLFlow автоматизаций пайплайнов Machine Learning / MLOps (Канал miracl6)
- 5.2 Видео на английском
- 5.2.1 The Newcomer’s Guide to Airflow’s Architecture (Канал Apache Airflow)
- 5.2.2 How to write your first DAG in Apache Airflow — Airflow tutorials
- 5.2.3 Build your first pipeline DAG | Apache airflow for beginners
- 5.1 Видео на русском
Apache Airflow — это платформа управления рабочими процессами обработки данных с открытым исходным кодом (фактически это инструмент для построения конвейеров обработки данных, либо оркестратор, который позволяет запускать процессы в сторонней системе). Он был запущен в Airbnb в октябре 2014 года (автор Maxime Beauchemin), как решение для управления все более сложными workflow компании. Создание Airflow позволило Airbnb программно создавать и планировать свои рабочие процессы и отслеживать их через встроенный пользовательский интерфейс Airflow. С самого начала исходный код проекта был открыт, в марте 2016 года он стал проектом Apache Incubator, а в январе 2019 года — проектом верхнего уровня Apache Software Foundation.
Airflow написан на Python, а рабочие процессы создаются с помощью скриптов Python. Apache Airflow спроектирован по принципу «конфигурация как код». В то время как существуют другие платформы рабочих процессов «конфигурация как код», использующие языки разметки, такие как XML, использование Python позволяет разработчикам импортировать библиотеки и классы.
Краткое описание функционала и предназначения
Apache Airflow — это планировщик задач, используемый для планирования, создания и отслеживания процессов. Он выходит за рамки управления надежным оркестратором данных.
Airflow — это фреймворк для оркестровки.
Что именно он может сделать?
- Запуск заданий ETL/ELT (например python скриптов)
- Обучение моделей машинного обучения
- Работа Airflow как Track system
- Создание рабочих процессов через DAGs
- Управление расписанием задач, в том числе во внешних системах (например, запуск задач в QMC QlikView/Qlik Sense)
- Настройка зависимостей событий/задач/рабочих процессов
- Управление программным рабочим процессом
- Airflow можно использовать для создания отчетов
- Резервное копирование и другие задачи DevOps
Однако важно помнить, что Apache Airflow не обрабатывает потоковые рабочие процессы в реальном времени.
В версии Airflow 2.0+ были сделаны улучшения:
- Горизонтальная масштабируемость. Если нагрузка задач на один планировщик увеличивается, пользователь теперь может запускать дополнительные «реплики» планировщика, чтобы увеличить пропускную способность своего развертывания воздушного потока.
- Уменьшена задержка выполнения задачи. В Airflow 2.0 даже один планировщик позволяет планировать задачи с гораздо большей скоростью при том же уровне загрузки ЦП и памяти.
- В Airflow 2.0 представлен новый комплексный REST API, который заложил прочную основу для нового пользовательского интерфейса и командной строки Airflow в будущем.
Плюсы Apache Airflow
- Открытый исходный код. AirFlow активно поддерживается сообществом и имеет хорошо описанную документацию.
- На основе Python. Python считается относительно простым языком для освоения и общепризнанным стандартом для специалистов в области Big Data и Data Science.
- Когда ETL-процессы определены как код, они становятся более удобными для разработки, тестирования и сопровождения. Также устраняется необходимость использовать JSON- или XML-конфигурационные файлы для описания пайплайнов.
- Богатый инструментарий и дружественный UI. Работа с AirFlow возможна при помощи CLI, REST API и веб-интерфейса, построенного на основе Python-фреймворка Flask.
- Интеграция со множеством источников данных и сервисов. AirFlow поддерживает множество баз данных и Big Data-хранилищ: MySQL, PostgreSQL, MongoDB, Redis, Apache Hive, Apache Spark, Apache Hadoop, объектное хранилище S3 и другие.
- Кастомизация. Есть возможность настройки собственных операторов.
- Масштабируемость. Допускается неограниченное число DAG за счет модульной архитектуры и очереди сообщений. Worker могут масштабироваться при использовании Celery или Kubernetes.
- Мониторинг и алертинг. Поддерживается интеграция с Statsd и FluentD — для сбора и отправки метрик и логов. Также доступен Airflow-exporter для интеграции с Prometheus.
- Возможность настройки ролевого доступа. По умолчанию AirFlow предоставляет 5 ролей с различными уровнями доступа: Admin, Public, Viewer, Op, User. Также допускается создание собственных ролей с доступом к ограниченному числу DAG.
- Дополнительно возможна интеграция с Active Directory и гибкая настройка доступов с помощью RBAC (Role-Based Access Control).
- Поддержка тестирования. Можно добавить базовые Unit-тесты, которые будут проверять как пайплайны в целом, так и конкретные задачи в них.
Минусы Apache Airflow
- При проектировании задач важно соблюдать идемпотентность: задачи должны быть написаны так, чтобы независимо от количества их запусков, для одних и тех же входных параметров возвращался одинаковый результат.
- Необходимо разобраться в механизмах обработки execution_date. Важно понимать, что корректировки кода задач будут отражаться на всех их запусках за предыдущее время. Это исключает воспроизводимость результатов, но, с другой стороны, позволяет получить результаты работы новых алгоритмов за прошлые периоды.
- Нет возможности спроектировать DAG в графическом виде, как это, например, доступно в Apache NiFi. Многие видят в этом, напротив, плюс, так как ревью кода проводится легче, чем ревью схем.
- Высокая кривая обучения: Поскольку у Apache Airflow крутая кривая обучения, пользователям, особенно новичкам, может быть сложно адаптироваться к среде и выполнять такие задачи, как написание тестовых примеров для конвейеров данных, обрабатывающих необработанные данные.
- Документация по Airflow сносная, но не очень хорошая, и трудно понять, каковы лучшие практики, когда вы начинаете, потому что существует так много разных способов сделать что-то, и большинство примеров, которые вы найдете, слишком упрощены.
- Проблемы с переименованием: каждый раз, когда вы изменяете интервалы расписания, Apache Airflow просит вас переименовать ваши DAG, чтобы гарантировать, что ваши предыдущие экземпляры задач соответствуют новому периоду времени.
- Удаляет метаданные: поскольку в конвейерах данных Apache Airflow отсутствует система контроля версий, если вы удаляете задание из своего кода DAG, а затем повторно развертываете его, все метаданные, связанные с транзакцией, автоматически удаляются.
Примеры за и против из книги Apache Airflow и конвейеры обработки данных
Причины выбрать Airflow
В этом разделе будут описаны ключевые функции, которые делают Airflow идеальным вариантом для реализации конвейеров пакетной обработки данных.
- возможность реализовывать конвейеры с использованием кода на языке Python позволяет создавать сколь угодно сложные конвейеры, используя все, что только можно придумать в Python;
- язык Python, на котором написан Airflow, позволяет легко расширять и добавлять интеграции со многими различными системами. Сообщество Airflow уже разработало богатую коллекцию расширений, которые дают возможность Airflow интегрироваться в множество различных типов баз данных, облачных сервисов и т.д.;
- обширная семантика планирования позволяет запускать конвейеры через равные промежутки времени и создавать эффективные конвейеры, использующие инкрементную обработку, чтобы избежать дорогостоящего пересчета существующих результатов;
- такие функции, как backfilling (обратное заполнение), дают возможность с легкостью (повторно) обрабатывать исторические данные, позволяя повторно вычислять любые производные наборы данных после внесения изменений в код;
- многофункциональный веб-интерфейс Airflow обеспечивает удобный просмотр результатов работы конвейера и отладки любых сбоев, которые могут произойти.
Дополнительное преимущество Airflow состоит в том, что это фреймворк с открытым исходным кодом. Это гарантирует, что вы можете использовать Airflow для своей работы без какой-либо привязки к поставщику. У некоторых компаний также есть управляемые решения (если вам нужна техническая поддержка), что дает больше гибкости относительно того, как вы запускаете и управляете своей установкой Airflow.
Причины не выбирать Airflow
Хотя у Airflow имеется множество мощных функций, в определенных случаях это, возможно, не то, что вам нужно. Вот некоторые примеры, когда Airflow – не самый подходящий вариант:
- обработка потоковых конвейеров, поскольку Airflow в первую очередь предназначен для выполнения повторяющихся или задач по пакетной обработке данных, а не потоковых рабочих нагрузок;
- реализация высокодинамичных конвейеров, в которых задачи добавляются или удаляются между каждым запуском конвейера. Хотя Airflow может реализовать такое динамическое поведение, веб-интерфейс будет показывать только те задачи, которые все еще определены в самой последней версии DAG. Таким образом, Airflow отдает предпочтение конвейерам, структура которых не меняется каждый раз при запуске;
- команды с небольшим опытом программирования (Python) или вообще не имеющие его, поскольку реализация DAG в Python может быть сложной задачей для тех, у кого малый опыт работы с Python. В таких командах использование диспетчера рабочих процессов с графическим интерфейсом (например, Azure Data Factory) или определение статического рабочего процесса, возможно, имеет больше смысла;
- точно так же код Python в DAG может быстро стать сложным в более масштабных кейсах. Таким образом, внедрение и поддержка DAG в Airflow требуют должной строгости, чтобы поддерживать возможность сопровождения в долгосрочной перспективе.
Кроме того, Airflow – это в первую очередь платформа для управления рабочими процессами и конвейерами, и (в настоящее время) она не включает в себя более обширные функции, такие как data lineages, управление версиями данных и т.д. Если вам потребуются эти функции, то вам, вероятно, придется рассмотреть возможность объединения Airflow с другими специализированными инструментами, которые предоставляют эти функции.
Конкуренты Apache Airflow
Luigi
Luigi — это пакет Python, который выполняет длительную пакетную обработку. Это означает, что он управляет автоматическим выполнением процессов обработки данных для нескольких объектов в пакете. Задание обработки данных можно определить как серию зависимых задач в Luigi. Луиджи выясняет, какие задачи ему нужно выполнить, чтобы завершить задачу. Он обеспечивает основу для создания конвейеров обработки данных и управления ими в целом. Он был создан Spotify , чтобы помочь им управлять группами заданий, требующих извлечения и обработки данных из ряда источников.
Apache NiFi
Apache NiFi — это бесплатное приложение с открытым исходным кодом , которое автоматизирует передачу данных между системами. Приложение поставляется с пользовательским веб-интерфейсом для управления масштабируемыми ориентированными графами маршрутизации данных, преобразования и логики посредничества системы. Это сложная и надежная система обработки и распространения данных. Для редактирования данных во время выполнения он предоставляет очень гибкий и адаптируемый метод потока данных.
Dagster
Dagster — это машинное обучение , аналитика и оркестратор данных ETL . Поскольку он выполняет основную функцию планирования, эффективного упорядочивания и мониторинга вычислений, Dagster можно использовать в качестве альтернативы или замены для Airflow (и других классических механизмов рабочего процесса). Однако он выходит за рамки обычного определения оркестратора, заново изобретая весь сквозной процесс разработки и развертывания приложений для работы с данными.
Kedro
Kedro — это платформа Python с открытым исходным кодом для написания повторяемого, управляемого и модульного кода Data Science. Модульность, разделение задач и управление версиями относятся к числу идей, заимствованных из лучших практик разработки программного обеспечения и применяемых к алгоритмам машинного обучения.
Apache Oozie
Одним из сервисов/приложений планировщика рабочих процессов, работающих в кластере Hadoop, является Apache Oozie . Он используется для обработки задач Hadoop, таких как Hive, Sqoop, SQL, MapReduce и операций HDFS, таких как distcp. Это система, которая управляет рабочим процессом работ, которые зависят друг от друга. Здесь пользователи могут создавать направленные ациклические графы процессов, которые могут выполняться в Hadoop параллельно или последовательно.
Apache Oozie также вполне адаптируется . Задания можно просто запускать, останавливать, приостанавливать и перезапускать. Повторный запуск сбойных процессов с Oozie очень прост. Можно даже полностью обойти отказавший узел.
Таблица с характеристиками конкурентов (не всех вышеперечисленных)

Архитектура Apache Airflow
Обзор интерфейса Apache Airflow
Airflow поставляется с пользовательским интерфейсом, который позволяет вам видеть, что делают DAG и их задачи, запускать задачи DAG, просматривать журналы и выполнять некоторую ограниченную отладку и решение проблем с вашими DAG.
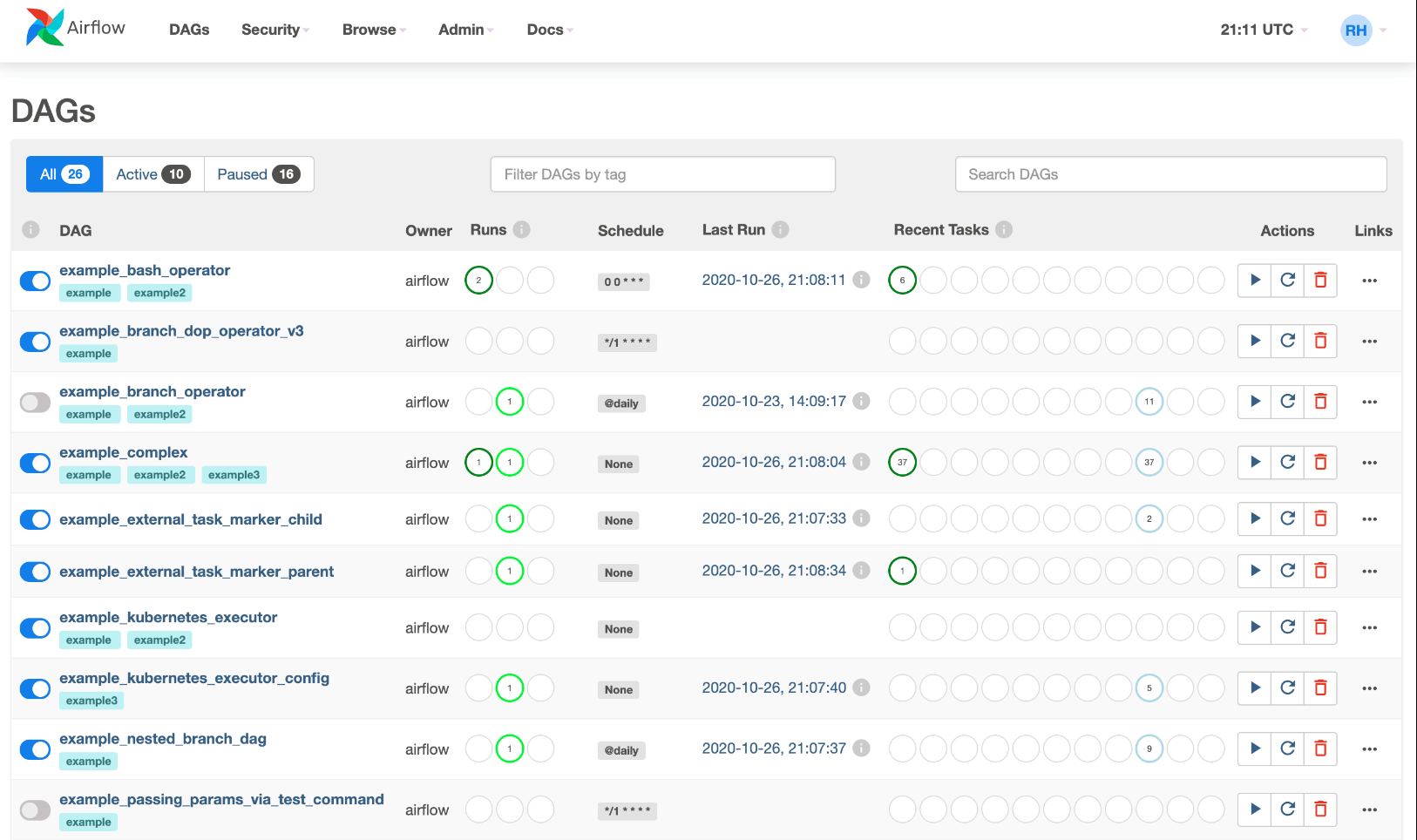
Краткий обзор меню Apache Airflow
Меню Apache Airflow версии 2.5 содержит следующие пункты:
- DAGs — Это пункт меню, который открывает страницу управления DAGs (Directed Acyclic Graphs) или графов, которые представляют собой структуру циклических зависимостей между задачами.
- Admin — Этот пункт меню содержит инструменты для управления пользовательскими учетными записями, настройками соединений, конфигурацией и мониторингом системы.
- Variables — Этот пункт меню позволяет задавать переменные, используемые в DAG-ах или задачах.
- Connections — Этот пункт меню обеспечивает доступ к настройкам соединений с внешними системами, такими как базы данных, хранилища данных и т. д.
- Plugins — Этот пункт меню предоставляет доступ к различным плагинам, которые могут использоваться в DAG-ах.
- Code — Этот пункт меню открывает страницу, на которой можно просмотреть и редактировать Python-код, используемый в DAG-ах или задачах.
- Docs — Этот пункт меню содержит документацию по Apache Airflow и различным инструментам, которые используются в системе.
- About — Этот пункт меню предоставляет информацию о версии Apache Airflow и разработчиках системы.
Эти пункты меню представляют собой основные инструменты для управления и настройки Apache Airflow версии 2, которые помогают пользователям создавать, отслеживать и управлять рабочими процессами и задачами.
Обзор основных сущностей Apache Airflow
- Процессы обработки данных, или пайплайны, в Airflow описываются при помощи DAG (Directed Acyclic Graph). DAG — это сущность, объединяющая ваши задачи в цепочку задач, в которой явно видны зависимости между узлами.
- В качестве узлов DAG выступают задачи (Task) — операции, применяемые к данным.
- За реализацию задач отвечают операторы (Operator) — это шаблоны для выполнения задач.
- Особую группу операторов составляют сенсоры (Sensor), позволяющие создавать триггер на событие.
- Существует возможность добавления пользовательского оператора через расширение базового класса BaseOperator.
- Hooks (Хуки) — это внешние интерфейсы для работы с различными сервисами: базы данных, внешние API ресурсы, распределенные хранилища типа S3, redis, memcached и т.д. Hooks являются строительными блоками операторов и берут на себя всю логику по взаимодействию с хранилищем конфигов и доступов.
- XCom (кросс-коммуникация) обеспечивает способ обмена сообщениями или данными между различными задачами (или между операторами). Xcom по своей сути представляет собой таблицу, в которой хранятся пары ключ-значение, а также отслеживаются, какая пара была предоставлена какой задачей и dag.
Перечень операторов
В Apache Airflow есть множество операторов, которые позволяют запускать различные задачи. Ниже приведены некоторые из них:
| Оператор | Назначение оператора (что делает Airflow Operator)? |
| Python Operator | Исполнение Python-кода |
| BranchPythonOperator | Выполняет функцию Python и в зависимости от результата переходит к определенной ветке |
| BashOperator | Запуск Bash-скриптов |
| SimpleHttpOperator | Отправка HTTP-запросов |
| MySqlOperator | Отправка SQL-запросов к базе данных MySQL |
| PostgresOperator | Отправка SQL-запросов к базе данных PostgreSQL |
| S3FileTransformOperator | Загрузка данных из S3 во временную директорию в локальной файловой системе, преобразование согласно указанному сценарию и сохранение результатов обработки в S3 |
| DockerOperator | Запуск Docker-контейнера под выполнение задачи |
| KubernetesPodOperator | Создание отдельного Pod под выполнение задачи. Используется совместно с K8s |
| SqlSensor | Проверка выполнения SQL-запроса |
| SlackAPIOperator | Отправка сообщений в Slack |
| EmailOperator | Отправка электронных писем |
| DummyOperator | «Пустой» оператор, который можно использовать для группировки задач (ничего не делает) |
| SubDagOperator | запускает поддаг |
| TriggerDagRunOperator | запускает другой DAG |
| SQLOperator | выполняет SQL-запрос в базе данных |
| TimeDeltaSensor | ждет определенный промежуток времени, прежде чем продолжить выполнение DAG |
| ExternalTaskSensor | ждет, пока другой DAG не завершится, прежде чем продолжить выполнение текущего DAG |
| FileSensor | ждет, пока файл не появится в определенном месте, прежде чем продолжить выполнение DAG |
| HttpSensor | ждет, пока HTTP-запрос не вернет определенный статус код, прежде чем продолжить выполнение DAG |
Описание основных параметров PythonOperator
task_id: уникальный идентификатор задачи в DAGpython_callable: функция Python, которая будет вызываться при выполнении задачиop_args: список аргументов, передаваемых в функциюpython_callableop_kwargs: словарь именованных аргументов, передаваемых в функциюpython_callableprovide_context: если установлено в True, то в функциюpython_callableбудут передаваться контекстные переменные Airflow (например, дата выполнения задачи)dag: объект DAG, к которому принадлежит задача
DAG (Directed Acyclic Graph)
DAG (Направленный ациклический граф) — это основная концепция Airflow, объединяющая задачи вместе, организованная через настроенные зависимости и отношения, которые определяют как должна отработать цепочка задач (или data pipeline). Задачи, входящие в состав DAG, в Apache Airflow называются операторами(Operator).
Классическая схема DAG:
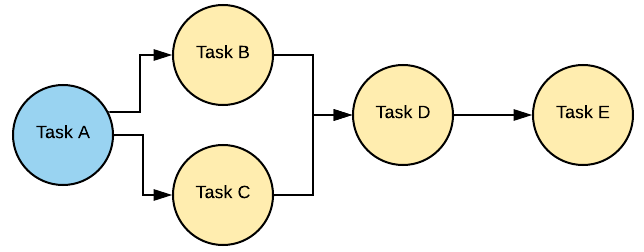
Пример DAG показан на диаграмме
Что такое subdag в airflow? Основные подходы к использованию
SubDAG в Apache Airflow — это специальный тип DAG, который может быть включен в другой DAG в качестве поддага. Он позволяет создавать более сложные DAG, разбивая их на более мелкие и управляемые единицы.
Основные подходы к использованию SubDAG в Apache Airflow:
- Разбиение больших задач на более мелкие: SubDAG позволяет разбить сложную задачу на более мелкие и управляемые единицы, что упрощает управление и отслеживание выполнения задач.
- Повторное использование кода: SubDAG можно использовать несколько раз в разных DAG, что позволяет повторно использовать код и сокращает время разработки.
- Улучшение читаемости и понимания DAG: SubDAG позволяет разбить большой DAG на более мелкие и понятные единицы, что улучшает читаемость и понимание кода.
- Управление зависимостями: SubDAG может быть использован для управления зависимостями между задачами в DAG, что позволяет легче контролировать порядок выполнения задач.
- Управление ресурсами: SubDAG может быть использован для управления ресурсами, такими как CPU и память, что позволяет более эффективно использовать ресурсы и ускорить выполнение задач.
Tasks и Task Instances (Экземпляр задачи)
Любой экземпляр оператора называется задачей. Каждая задача представлена как узел в DAG.
Экземпляр задачи — это запуск задачи. В то время как мы определяем задачи в DAG, запуск DAG создается при выполнении DAG, он содержит идентификатор dag и дату выполнения DAG для идентификации каждого уникального запуска. Каждый запуск DAG состоит из нескольких задач, и каждый запуск этих задач называется экземпляром задачи.
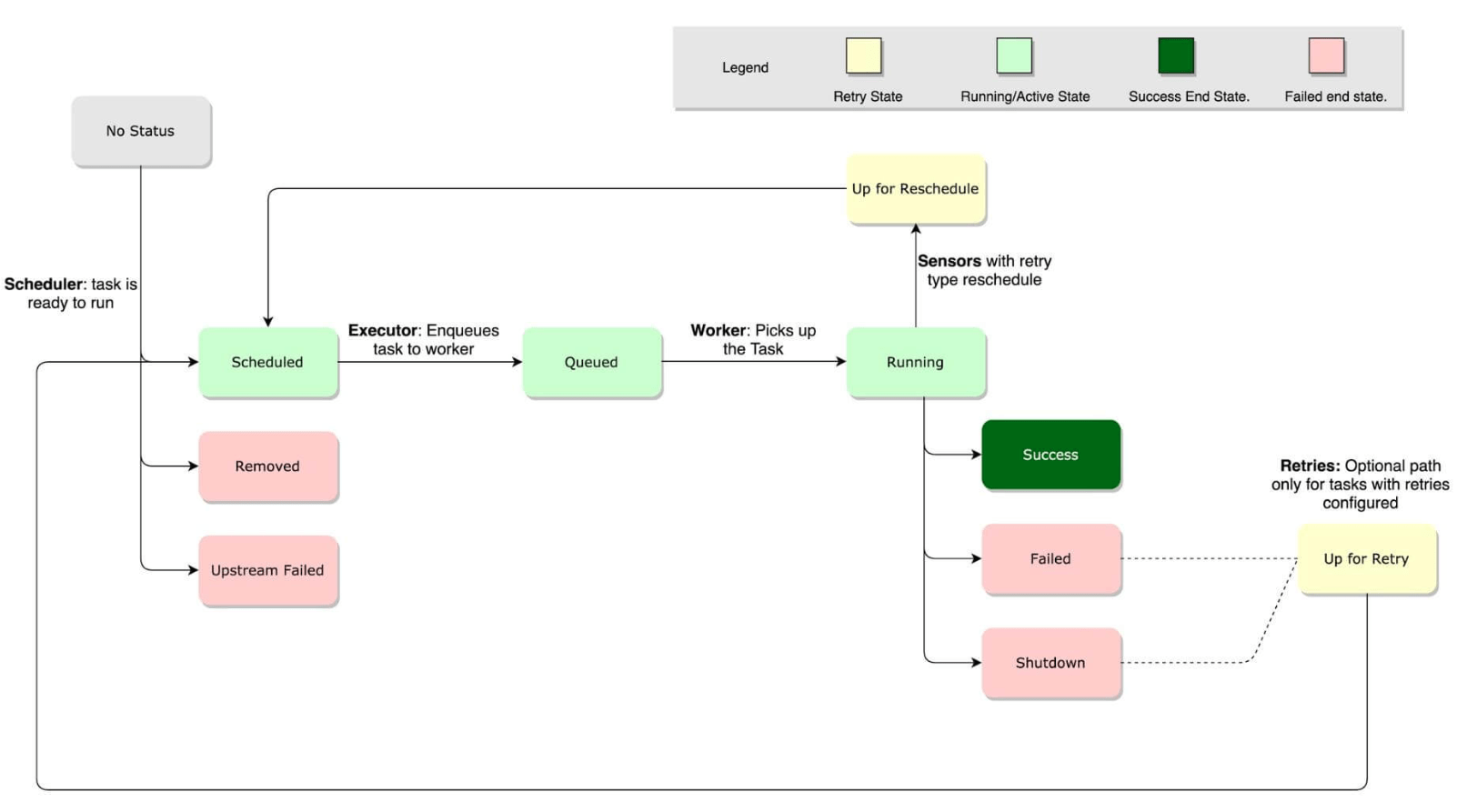
Экземпляр задачи проходит через несколько состояний при запуске. Обычно поток состоит из следующих этапов:
- No status (scheduler created empty task instance) — Нет статуса (планировщик создал пустой экземпляр задачи)
- Scheduled (scheduler determined task instance needs to run) — Запланировано (необходим запуск определенного планировщиком экземпляра задачи)
- Queued (scheduler sent the task to the queue – to be run) — В очереди (планировщик отправил задачу в очередь для выполнения)
- Running (worker picked up a task and is now executing it) — Выполняется (работник взял задачу и теперь выполняет ее)
- Success (task completed) — Успех (задача выполнена)
Жизненный цикл задачи:
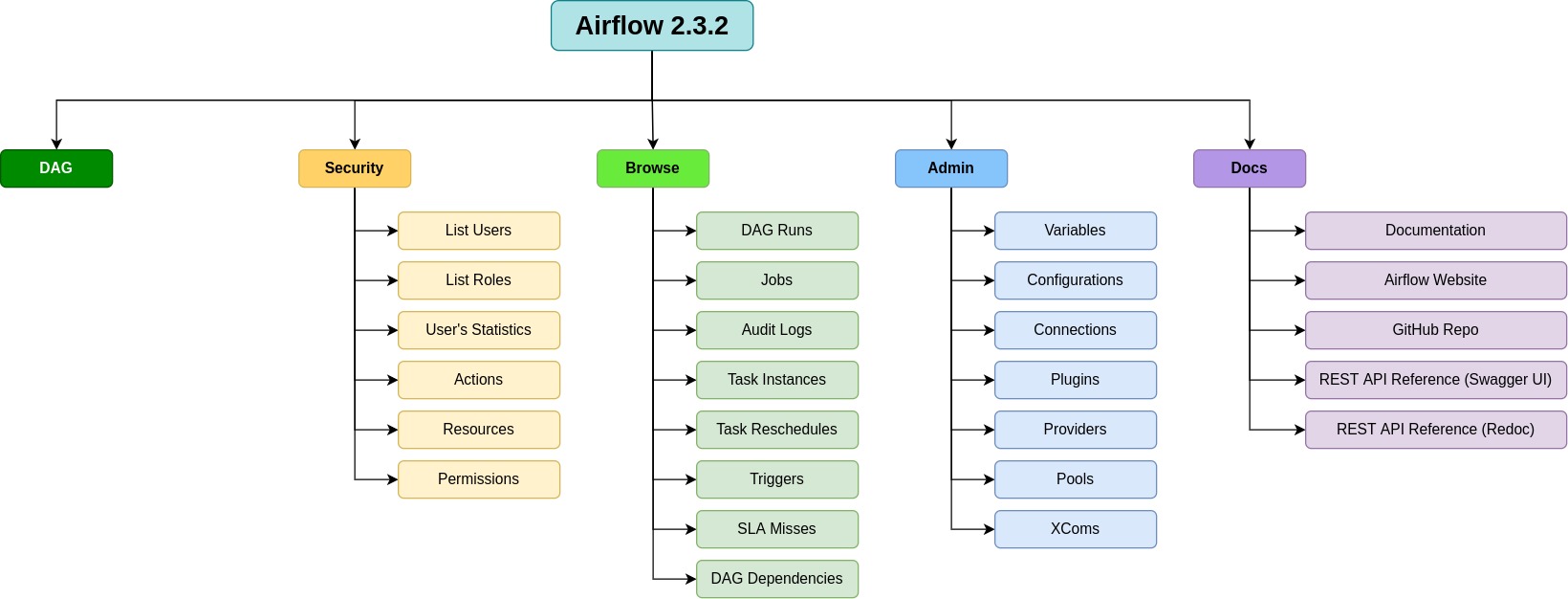
Обзор компонентов Apache Airflow
При работе с Airflow важно понимать основные компоненты его инфраструктуры. Даже если вы в основном взаимодействуете с Airflow как автор DAG, знание того, какие компоненты находятся «под капотом» и зачем они нужны, может быть полезно для разработки ваших DAG, отладки и успешного запуска в Airflow.
Обратите внимание, что в этой статье описаны компоненты и функции Airflow 2.0+. Некоторые из упомянутых здесь компонентов и функций недоступны в более ранних версиях Airflow.
Основные компоненты Airflow
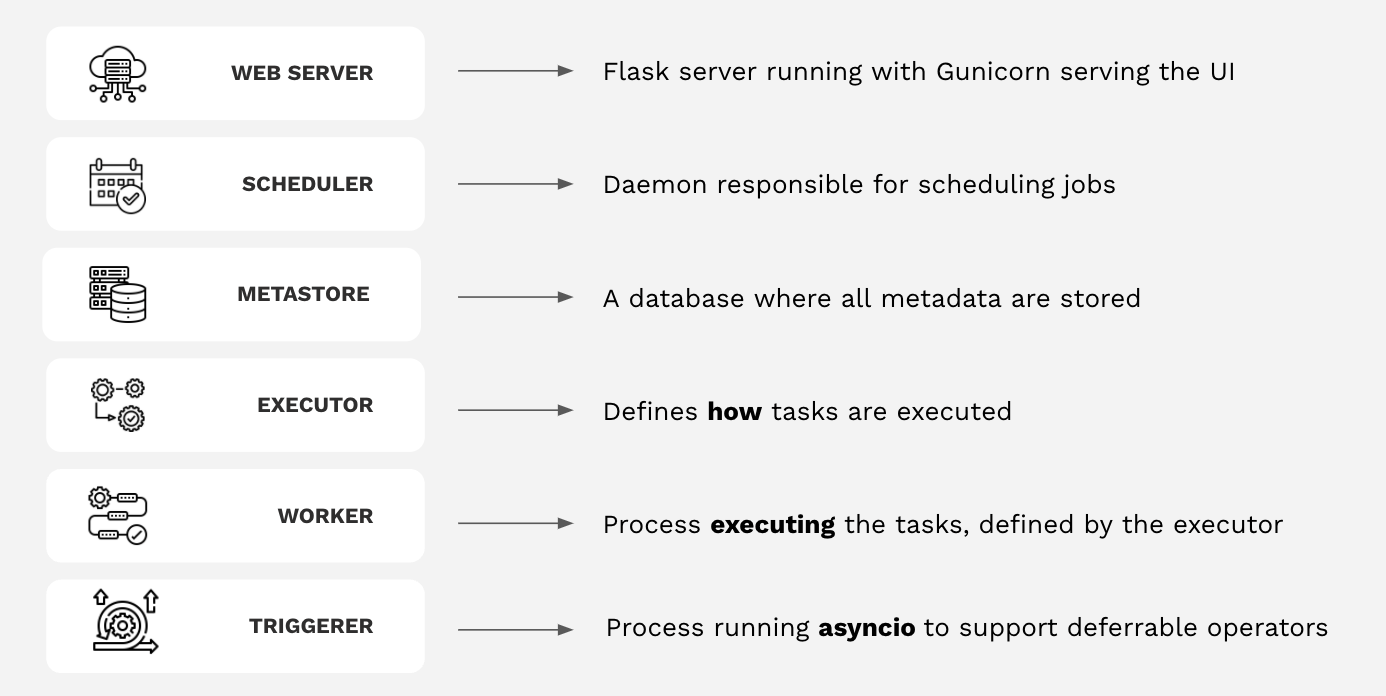
Apache Airflow имеет четыре основных компонента, которые работают постоянно:
- Webserver (Веб-сервер): сервер Flask, работающий с Gunicorn, который обслуживает пользовательский интерфейс Airflow.
- Scheduler (Планировщик): демон, отвечающий за планирование заданий. Это многопоточный процесс Python, который определяет, какие задачи нужно запускать, когда их нужно запускать и где они выполняются.
- Database(База данных): база данных, в которой хранятся все метаданные DAG и задач. Обычно это база данных Postgres, но также поддерживаются MySQL, MsSQL и SQLite.
- Executor: механизм запуска задач. Исполнитель запускается в планировщике всякий раз, когда Airflow работает.
- Папка с файлами DAG, прочитанная планировщиком и исполнителем (и любыми рабочими процессами, имеющимися у исполнителя)
В дополнение к этим основным компонентам есть несколько ситуационных компонентов, которые используются только для запуска задач или использования определенных функций:
- Worker(Рабочий): процесс, который выполняет задачи, определенные исполнителем. В зависимости от того, какого исполнителя вы выберете, у вас могут быть или не быть рабочие как часть вашей инфраструктуры Airflow.
- Trigger (Триггер): Отдельный процесс, поддерживающий отложенные операторы. Этот компонент является необязательным и должен запускаться отдельно. Он нужен только в том случае, если вы планируете использовать отложенные (или «асинхронные») операторы.
На следующей схеме указано, как все эти компоненты работают вместе:
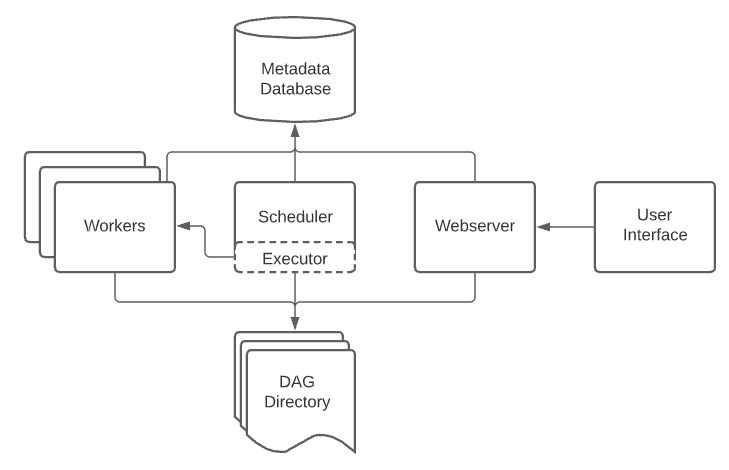

Схема работы Apache Airflow, изображенная на диаграмме, состоит из нескольких ключевых компонентов, каждый из которых играет важную роль в работе системы.
Вот описание работы Apache Airflow на основе этой схемы:
Data Engineer (Инженер по данным):
Инженер по данным отвечает за создание и написание DAGs (Directed Acyclic Graphs), которые описывают рабочие процессы. Эти DAGs сохраняются в специальной папке — DAG folder.
DAG folder (Папка DAG):
Папка, в которой хранятся все DAGs, написанные инженером по данным. Эти DAGs содержат информацию о последовательности задач, которые должны быть выполнены.
Scheduler (Планировщик):
Scheduler считывает DAGs из папки и отвечает за планирование выполнения задач в соответствии с определенными расписаниями.
Планировщик передает задачи на исполнение Executor и следит за тем, чтобы они выполнялись в правильной последовательности.
Executor (Исполнитель):
Executor получает задачи от планировщика и назначает их для выполнения различным Worker (Рабочим).
Он контролирует выполнение задач и отправляет результаты обратно в базу данных метаданных.
Worker (Рабочий):
Worker выполняет назначенные задачи, после чего результаты выполнения сохраняются в Metadata database (База данных метаданных).
Metadata database (База данных метаданных):
Эта база данных хранит результаты выполнения задач, информацию о запусках DAGs и другую метаинформацию, необходимую для работы всей системы.
Webserver (Веб-сервер):
Веб-сервер взаимодействует с базой данных метаданных, чтобы получать результаты выполнения задач и запусков DAGs.
Он также передает эти данные в Airflow UI для визуализации.
Airflow UI (Пользовательский интерфейс Airflow):
Интерфейс, через который инженеры по данным могут мониторить выполнение DAGs и результаты выполнения задач. Это основной способ взаимодействия пользователя с системой.
Таким образом, общая схема работы Apache Airflow выглядит следующим образом:
- Инженер по данным пишет DAGs и сохраняет их в папке DAG.
- Планировщик считывает эти DAGs и планирует выполнение задач.
- Исполнитель назначает задачи для выполнения рабочим.
- Рабочие выполняют задачи и сохраняют результаты в базе данных метаданных.
- Веб-сервер извлекает результаты из базы данных и отображает их через пользовательский интерфейс Airflow, где инженеры по данным могут их просматривать и анализировать.
Executors (Исполнители)
Пользователи Airflow могут выбрать один из нескольких доступных Executors или написать собственный. Каждый Executor имеет преимущества в определенных ситуациях:
- SequentialExecutor: последовательно выполняет задачи внутри процесса планировщика без параллелизма. Этот исполнитель редко используется на практике, но он используется по умолчанию в конфигурации Airflow.
- LocalExecutor: выполняет задачи локально внутри процесса планировщика, но поддерживает параллелизм и гиперпоточность. Этот исполнитель хорошо подходит для тестирования Airflow на локальном компьютере или на одном узле.
- CeleryExecutor: использует серверную часть Celery (например, Redis, RabbitMq или другую систему очередей сообщений) для координации задач между предварительно настроенными рабочими процессами. Этот исполнитель идеально подходит, если у вас есть большое количество более коротких задач или более постоянная загрузка задач.
- KubernetesExecutor: вызывает API Kubernetes для создания отдельного модуля для каждой выполняемой задачи, что позволяет пользователям передавать настраиваемые конфигурации для каждой из своих задач и эффективно использовать ресурсы. Этот исполнитель хорош в нескольких различных контекстах:
- У вас есть длительные задачи, которые вы не хотите прерывать развертыванием кода или обновлениями Airflow.
- Ваши задачи требуют очень специфических конфигураций ресурсов
- Ваши задачи выполняются нечасто, и вы не хотите нести расходы на рабочие ресурсы, когда они не выполняются.
Обратите внимание, что есть также несколько других исполнителей, которые мы здесь не рассматриваем, в том числе CeleryKubernetes Executor и Dask Executor. Они считаются более экспериментальными и не так широко распространены, как другие описанные здесь исполнители.
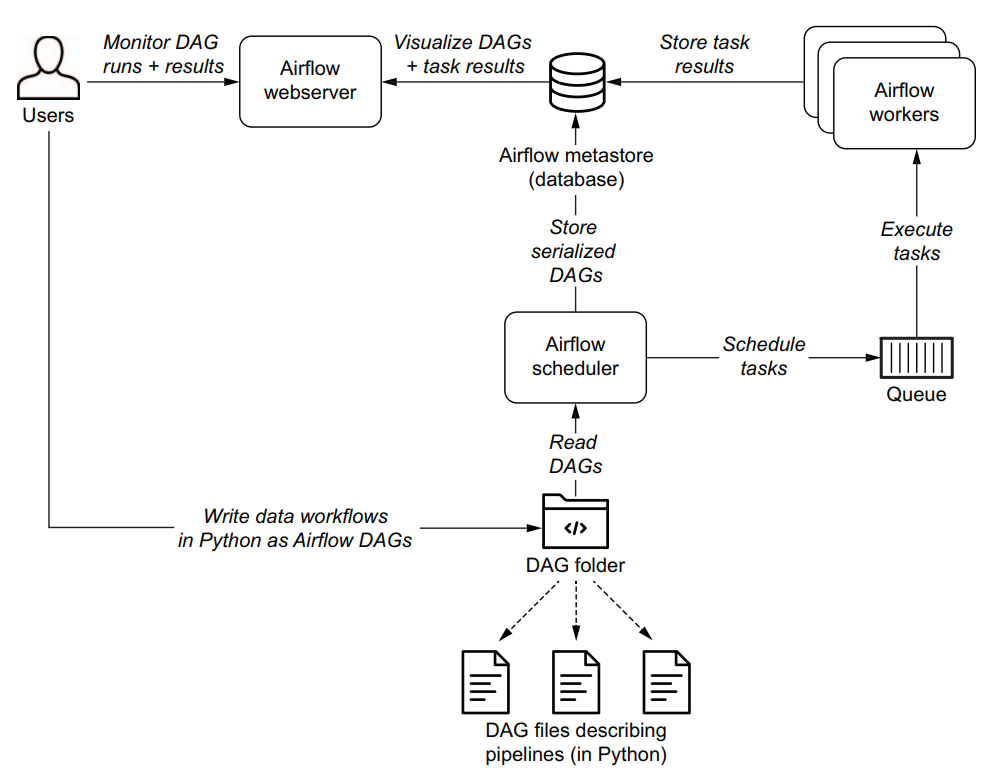
Обзор процесса обработки Airflow DAGs
Чтобы увидеть, как Airflow выполняет DAG, давайте кратко рассмотрим общий процесс, связанный с разработкой и запуском Airflow DAG. На высоком уровне Airflow состоит из трех основных компонентов:
- Airflow Scheduler — анализирует DAG, проверяет интервал их расписания и (если расписание DAG прошло) начинает планировать выполнение задач DAG, передавая их рабочим процессам Airflow.
- Airflow Workers — берут задачи, запланированные для выполнения, и выполняют их. Таким образом, workers несут ответственность за фактическое «выполнение работы».
- Airflow Webserver — визуализирует DAGs, проанализированные Scheduler, и предоставляет пользователям основной интерфейс для наблюдения за запусками DAGs и их результатами.
Сердцем Airflow, возможно, является планировщик, так как именно здесь происходит большая часть волшебства, которое определяет, когда и как выполняются ваши конвейеры.
Типы переменных в Airflow
Переменная Airflow — это пара ключ-значение, которую можно использовать для хранения информации в вашей среде Airflow. Они обычно используются для хранения информации на уровне экземпляра, которая редко меняется, включая секреты, такие как API key или путь к файлу конфигурации.
Существует два различных типа переменных Airflow:
- regular values (обычные значения) и
- JSON serialized values (сериализованные значения JSON).

Лучшие практики хранения информации в переменных Airflow
Переменные Airflow хранят пары ключ-значение или короткие объекты JSON, которые должны быть доступны во всем вашем экземпляре Airflow. Они являются концепцией конфигурации среды выполнения Airflow и определяются с помощью airflow.model.variable объекта.
При использовании переменных Airflow следует учитывать некоторые рекомендации:
- Переменные Airflow следует использовать для информации, которая зависит от времени выполнения, но не меняется слишком часто.
- Вам следует избегать использования переменных Airflow вне задач в коде DAG верхнего уровня, поскольку они будут создавать соединение с метахранилищем Airflow каждый раз при разборе DAG, что может привести к проблемам с производительностью.
- Если вы используете переменные Airflow в коде DAG верхнего уровня, используйте синтаксис шаблона Jinja, чтобы переменные Airflow отображались только при выполнении задачи.
- Переменные Airflow шифруются с помощью Fernet при записи в метахранилище Airflow. Чтобы скрыть переменные Airflow в пользовательском интерфейсе и журналах, включите подстроку, указывающую на конфиденциальное значение, в имя переменной Airflow.
Существует несколько способов создания переменных Airflow:
- Использование пользовательского интерфейса (Airflow UI)
- Использование интерфейса командной строки (Airflow CLI).
- Использование переменной среды (environment variable).
- Программно из задачи Airflow.
Какие ограничения существуют для XCom в Airflow?
XCom от Apache Airflow — это мощная функция, которая позволяет задачам взаимодействовать, отправляя и забирая сообщения. Однако важно понимать ограничения по размеру, связанные с XCom, чтобы обеспечить эффективное выполнение рабочего процесса.
Вот некоторые рекомендации и соображения:
- Используйте XCom экономно для небольших сообщений: XCom разработан для небольших фрагментов данных. Обработка больших объемов данных должна быть выгружена на внешние системы хранения, такие как S3 или HDFS.
- Избегайте конфиденциальных данных в XCom: Никогда не храните конфиденциальную информацию, такую как пароли или токены, в XCom. Используйте Airflow Connections для безопасного управления учетными данными.
- Пользовательские бэкэнды XCom: для особых случаев использования можно реализовать пользовательские бэкэнды XCom, создав подклассы BaseXCom и переопределив методы сериализации.
- TaskFlow API: в Airflow 2.0 TaskFlow API упрощает передачу данных между задачами с помощью неявных XComs, уменьшая необходимость в явных вызовах xcom_push и xcom_pull.
- Соображения по поводу базы данных: помните о нагрузке на базу данных, так как Airflow может быть требовательным к соединениям с базой данных, особенно с Postgres. Рекомендуется использовать решения для пула соединений, такие как PGBouncer.
- Мониторинг и регулировка: Динамичный характер воздушного потока требует постоянного мониторинга и регулировки конфигураций для поддержания оптимальной производительности.
- Безопасность и контроль доступа: обеспечьте принятие надлежащих мер безопасности, включая TLS, ограничение скорости, аутентификацию и авторизацию для защиты вашего экземпляра Airflow.
XComs следует использовать для передачи небольших объемов данных между задачами. Например, метаданные задач, даты, точность модели или результаты запроса с одним значением — все это идеальные данные для использования с XCom.
Как реализуется последовательность выполнения задач и ассинхронное выполнения задач в airflow?
Последовательность выполнения задач в Airflow определяется зависимостями между задачами в DAG (Directed Acyclic Graph). Каждая задача имеет список зависимостей, которые должны быть выполнены перед ее запуском. Airflow использует эту информацию для определения порядка выполнения задач в DAG.
Асинхронное выполнение задач в Airflow реализуется с помощью Celery Executor. Celery Executor позволяет выполнять задачи асинхронно на удаленных рабочих узлах. Это позволяет распараллеливать выполнение задач и ускорять обработку данных. Кроме того, Celery Executor поддерживает масштабирование, что позволяет обрабатывать большие объемы данных.
Установка и настройка Apache Airflow
Установка Apache Airflow с помощью Docker-Compose на Ubuntu 20.04
Подробная официальная документация по развертыванию Apache Airflow с помощью docker-compose: https://airflow.apache.org/docs/apache-airflow/stable/start/docker.html
Моя краткая инструкция с шагами, которые у меня заработали на Ubuntu 20.04:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
# Создаем директорию проекта airflow и переходим в нее mkdir airflow cd airflow # Проверка памяти, должно быть минимум 8Гб docker run —rm «debian:bullseye-slim» bash —c ‘numfmt —to iec $(echo $(($(getconf _PHYS_PAGES) * $(getconf PAGE_SIZE))))’ # Скачиваем последний docker-compose.yaml файл # Актуальную версию файла можно найти на странице https://airflow.apache.org/docs/apache-airflow/stable/start/docker.html curl —LfO ‘https://airflow.apache.org/docs/apache-airflow/2.3.2/docker-compose.yaml’ # Далее необходимо создать директории: # ./dags- вы можете разместить свои файлы DAG здесь. # ./logs- содержит журналы выполнения задач и планировщика. # ./plugins- здесь вы можете разместить свои собственные плагины. mkdir —p ./dags ./logs ./plugins # Создаем файл .env с параметром AIRFLOW_UUID echo —e «AIRFLOW_UID=$(id -u)» > .env # Инициализируем базу данных sudo docker—compose up airflow—init # Запуск Apache Airflow с помощью docker-compose sudo docker—compose up |
После установки нужно зайти по адресу http://localhost:8080/
Логин/Пароль по умолчанию: airflow/airflow
Используемый при развертывании выше файл docker-compose.yaml содержит несколько сервисов:
- airflow-scheduler — Планировщик отслеживает все задачи и DAG, а затем запускает экземпляры задач после завершения их зависимостей.
- airflow-webserver — Веб-сервер доступен по адресу http://localhost:8080.
- airflow-worker — Выполняет задачи, определенные планировщиком.
- airflow-init — Служба инициализации.
- postgres — База данных.
- redis — брокер, который пересылает сообщения от планировщика к воркеру.
Примерное потребление ресурсов контейнерами Airflow (без нагрузки):
Airflow довольно требователен к ресурсам.

Я бы указал 4 Gb Ram как минимум (в документации минимальная планка 4Gb RAM), но на мой взгляд на прод лучше сразу запросить 8 Гб RAM.
Процесс установки также описан в видео «Running Airflow 2.0 in 5 mins with Docker»:
Минимальные требования для установки Apache Airflow следующие:
- Операционная система Linux (CentOS 7 или Ubuntu 18.04)
- Python 3.6+ (рекомендуется использовать 3.7+)
- База данных PostgreSQL 9.6+ или MySQL 5.7
- Хранилище сообщений (message broker) Apache Celery
- Веб-сервер Nginx (рекомендуется)
- Рекомендуемый объем оперативной памяти: 256 МБ или больше.
Таким образом, одна из рекомендованных конфигураций сервера для установки Apache Airflow может быть следующей:
- Операционная система: CentOS 7 или Ubuntu 18.04
- Процессор: Intel Core i5 или эквивалентный
- Оперативная память: 4 ГБ или больше
- Хранилище сообщений (message broker): Apache Celery (должен быть установлен и настроен отдельно)
- База данных: PostgreSQL 9.6+ или MySQL 5.7
- Веб-сервер: Nginx (рекомендуется).
Однако, если вы планируете запускать большое число DAG-файлов, которые будут выполняться одновременно, то может потребоваться более мощное железо. Например, в таком случае вы можете рассматривать использование многопроцессорной системы с большим объемом оперативной памяти и быстрым хранилищем сообщений.
Настройка Apache Airflow
Обязательно проверьте в docker-compose.yaml какие директории привязаны к volume. В новой версии используются переменные и если они не сработают, то DAG, размещенный в соответствующей директории, не подтянется.
|
volumes: — ${AIRFLOW_PROJ_DIR:—.}/dags:/opt/airflow/dags — ${AIRFLOW_PROJ_DIR:—.}/logs:/opt/airflow/logs — ${AIRFLOW_PROJ_DIR:—.}/plugins:/opt/airflow/plugins |
Если не знаете как настроить переменные, то можно отредактировать docker-compose.yaml:
|
volumes: — ./dags:/opt/airflow/dags — ./logs:/opt/airflow/logs — ./plugins:/opt/airflow/plugins |
Основные параметры Airflow.cfg
Airflow.cfg — это конфигурационный файл Apache Airflow, который используется для определения параметров и настроек для организации рабочих процессов.
Основные параметры Airflow.cfg включают:
1. core:
- airflow_home: каталог домашней директории, в которой сохраняются все файлы, связанные с работой Airflow.
- dags_folder: определяет путь до папки, которая содержит DAG-файлы.
- executor: определяет тип исполнителя, который будет использоваться для запуска задач (SequentialExecutor, LocalExecutor, CeleryExecutor, DaskExecutor).
- load_examples: определяет, нужно ли загружать примеры DAG-файлов (True или False).
- pid_location: определяет местоположение файла PID для процесса управления.
2. webserver:
- web_server_host: адрес хоста, на котором запускается веб-сервер Airflow.
- web_server_port: номер порта, на котором будет доступен веб-сервер Airflow.
- web_server_worker_timeout: время тайм-аута (в секундах) для веб-сервера Airflow.
- secret_key: секретный ключ, используемый веб-сервером Airflow для защиты сессий пользователя.
3. scheduler:
- dag_dir_list_interval: интервал обновления списка файлов DAG (в секундах).
- max_threads: максимальное количество потоков, которые могут использоваться при запуске задач.
- statsd_on: включить или выключить источник метрик statsd.
4. email:
- email_backend: тип бэкэнда, используемого для отправки почты.
- email_from_name: имя отправителя электронной почты.
- email_from_address: адрес электронной почты отправителя.
5. logging:
- logging_config_class: класс конфигурации логирования.
- remote_logging: включить или выключить удаленное логирование.
- remote_log_conn_id: идентификатор соединения для удаленного логирования.
Эти параметры могут быть настроены в Airflow.cfg в соответствии с требованиями конкретного проекта или приложения.
FAQ: Вопросы и ответы
Как переиспользовать функции Python между разными DAG? Как переиспользовать код в нескольких DAG?
Для переиспользования функций Python между разными DAG в Apache Airflow можно использовать модули Python. Модуль содержит функции и переменные, которые могут быть использованы в других модулях и DAG.
Для переиспользования кода в нескольких DAG можно создать отдельный файл с функциями и импортировать его в каждый DAG, где эти функции нужны. Это позволяет избежать дублирования кода и сократить время разработки.
Например, можно создать файл с названием utils.py, который содержит функции, используемые в нескольких DAG. Затем, в каждом DAG можно импортировать этот файл и вызывать нужные функции:
|
from datetime import datetime from airflow import DAG from utils import my_function default_args = { ‘owner’: ‘airflow’, ‘start_date’: datetime(2021, 1, 1), } dag = DAG(‘my_dag’, default_args=default_args) task = PythonOperator( task_id=‘my_task’, python_callable=my_function, dag=dag, ) |
В данном примере мы импортируем функцию my_function из файла utils.py и вызываем ее в задаче my_task в DAG my_dag. Таким образом, мы переиспользуем код и избегаем дублирования.
Что такое модуль в Airflow? Как создать и подключить свой модуль в Airflow?
Модуль в Apache Airflow — это файл с расширением .py, который содержит функции, классы и переменные, которые могут быть использованы в других модулях и DAG. Создание и подключение своего модуля в Airflow позволяет переиспользовать код и избежать дублирования.
Для создания модуля в Airflow нужно создать файл с расширением .py и определить в нем нужные функции, классы и переменные. Затем, этот файл можно импортировать в другие модули и DAG.
Например, мы можем создать файл utils.py со следующим содержимым:
|
def my_function(): print(‘Hello World!’) |
Затем, мы можем импортировать этот модуль в другой файл или DAG следующим образом:
|
from datetime import datetime from airflow import DAG from utils import my_function default_args = { ‘owner’: ‘airflow’, ‘start_date’: datetime(2021, 1, 1), } dag = DAG(‘my_dag’, default_args=default_args) task = PythonOperator( task_id=‘my_task’, python_callable=my_function, dag=dag, ) |
В данном примере мы импортируем функцию my_function из файла utils.py и вызываем ее в задаче my_task в DAG my_dag. Таким образом, мы переиспользуем код и избегаем дублирования.
Как импортировать модули в Airflow, если Airflow развернут в контейнерах Docker?
Если Airflow развернут в контейнерах Docker, то для импорта модулей нужно убедиться, что они находятся в правильном месте внутри контейнера. Обычно модули располагаются в папке dags, которая монтируется в контейнер с помощью Docker volume.
Например, если мы хотим импортировать модуль utils.py из папки dags, то нужно использовать следующий путь:
|
from dags.utils import my_function |
Важно также убедиться, что все зависимости и библиотеки, необходимые для работы модуля, установлены в контейнере. Это можно сделать с помощью Dockerfile и requirements.txt файла.
Пример Dockerfile для контейнера Airflow с установкой дополнительных библиотек:
|
FROM apache/airflow:2.1.2 USER root COPY requirements.txt . RUN pip install —no—cache—dir —r requirements.txt USER airflow |
В данном примере мы копируем файл requirements.txt в контейнер и устанавливаем все необходимые библиотеки перед переключением на пользователя airflow. Таким образом, мы гарантируем, что все зависимости будут установлены в контейнере и доступны для использования в модулях Airflow.
Какие сложности часто возникают при работе в Airflow?
При работе в Airflow могут возникать следующие сложности:
- Ошибки импорта модулей: если модули не находятся в правильном месте или не установлены все необходимые зависимости, то может возникнуть ошибка импорта.
- Неправильно настроенные подключения к базам данных: если подключения к базам данных не настроены правильно, то задачи, которые используют эти подключения, могут завершаться с ошибкой.
- Неправильно настроенные переменные окружения: если переменные окружения не настроены правильно, то задачи могут завершаться с ошибкой или не запускаться вовсе.
- Проблемы с расписанием выполнения задач: если расписание выполнения задач не настроено правильно, то задачи могут запускаться слишком часто или слишком редко, что может привести к нежелательным последствиям.
- Проблемы с масштабированием: если Airflow используется для обработки большого объема данных, то может возникнуть проблема с масштабированием. В этом случае необходимо настроить кластер Airflow для распределения задач на несколько узлов.
- Проблемы с безопасностью: при работе в Airflow необходимо обеспечить безопасность данных и защиту от несанкционированного доступа к системе. Для этого можно использовать различные инструменты, такие как SSL-шифрование, аутентификацию и авторизацию пользователей и т.д.
Как выполнить 2 задачи из одного DAG в разных контейнерах Docker?
Для выполнения двух задач из одного DAG в разных контейнерах Docker можно использовать операторы DockerOperator и BashOperator.
Пример кода DAG:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
from airflow import DAG from airflow.operators.bash_operator import BashOperator from airflow.operators.docker_operator import DockerOperator from datetime import datetime default_args = { ‘owner’: ‘airflow’, ‘depends_on_past’: False, ‘start_date’: datetime(2022, 1, 1), ’email_on_failure’: False, ’email_on_retry’: False, ‘retries’: 1 } dag = DAG(‘docker_dag’, default_args=default_args, schedule_interval=‘@daily’) # Оператор DockerOperator для запуска контейнера с задачей 1 task_1 = DockerOperator( task_id=‘task_1’, image=‘my_image:latest’, command=‘/bin/bash -c «python /app/task_1.py»‘, docker_url=‘tcp://localhost:2375’, network_mode=‘bridge’, dag=dag ) # Оператор BashOperator для запуска задачи 2 в отдельном контейнере task_2 = BashOperator( task_id=‘task_2’, bash_command=‘docker run my_image:latest python /app/task_2.py’, dag=dag ) # Задача 2 должна выполниться только после успешного выполнения задачи 1 task_1 >> task_2 |
В данном примере мы используем DockerOperator для запуска контейнера с задачей 1 и BashOperator для запуска задачи 2 в отдельном контейнере. Обратите внимание, что мы используем команду docker run для запуска задачи 2 в отдельном контейнере, а также указываем имя образа и путь к файлу с задачей.
Также мы указываем, что задача 2 должна выполниться только после успешного выполнения задачи 1, используя оператор >>. Это означает, что Airflow будет ждать успешного завершения задачи 1, прежде чем запустить задачу 2.
Пример DAG отправки сообщения в Slack
Для отправки сообщения в Slack через API можно использовать оператор PythonOperator и библиотеку Slack SDK.
Пример кода DAG:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
from airflow import DAG from airflow.operators.python_operator import PythonOperator from slack_sdk import WebClient from slack_sdk.errors import SlackApiError from datetime import datetime default_args = { ‘owner’: ‘airflow’, ‘depends_on_past’: False, ‘start_date’: datetime(2022, 1, 1), ’email_on_failure’: False, ’email_on_retry’: False, ‘retries’: 1 } dag = DAG(‘slack_dag’, default_args=default_args, schedule_interval=‘@daily’) # Функция для отправки сообщения в Slack def send_slack_message(): client = WebClient(token=‘your_slack_token’) try: response = client.chat_postMessage( channel=‘#general’, text=‘Hello, Airflow!’ ) print(response) except SlackApiError as e: print(«Error sending message: {}».format(e)) # Оператор PythonOperator для вызова функции отправки сообщения в Slack send_message_task = PythonOperator( task_id=‘send_message’, python_callable=send_slack_message, dag=dag ) |
В данном примере мы создаем функцию send_slack_message(), которая использует WebClient из библиотеки Slack SDK для отправки сообщения в канал #general. В функции мы указываем ваш токен доступа к Slack API.
Затем мы используем оператор PythonOperator для вызова функции send_slack_message() в DAG. Обратите внимание, что мы не используем оператор >>, так как задача отправки сообщения не зависит от выполнения других задач.
Данный DAG будет отправлять сообщение в Slack каждый день в соответствии с расписанием, указанным в параметре schedule_interval.
Пример DAG с отправкой отчета Excel из Pandas Dataframe в канал Slack
Для отправки отчета Excel из Pandas Dataframe в канал Slack через API можно использовать оператор PythonOperator и библиотеки Slack SDK и Pandas.
Пример кода DAG:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 |
from airflow import DAG from airflow.operators.python_operator import PythonOperator from slack_sdk import WebClient from slack_sdk.errors import SlackApiError import pandas as pd from datetime import datetime default_args = { ‘owner’: ‘airflow’, ‘depends_on_past’: False, ‘start_date’: datetime(2022, 1, 1), ’email_on_failure’: False, ’email_on_retry’: False, ‘retries’: 1 } dag = DAG(‘slack_excel_report’, default_args=default_args, schedule_interval=‘@daily’) # Функция для отправки сообщения с отчетом в Slack def send_excel_report(): client = WebClient(token=‘your_slack_token’) try: # Создаем датафрейм с данными для отчета data = {‘Name’: [‘John’, ‘Jane’, ‘Bob’], ‘Age’: [25, 30, 35]} df = pd.DataFrame(data) # Создаем Excel-файл из датафрейма excel_file = df.to_excel(‘report.xlsx’, index=False) # Отправляем сообщение в Slack с прикрепленным Excel-файлом response = client.files_upload( channels=‘#general’, file=‘report.xlsx’, title=‘Daily report’ ) print(response) except SlackApiError as e: print(«Error sending message: {}».format(e)) # Оператор PythonOperator для вызова функции отправки отчета в Slack send_report_task = PythonOperator( task_id=‘send_report’, python_callable=send_excel_report, dag=dag ) |
В данном примере мы создаем функцию send_excel_report(), которая использует WebClient из библиотеки Slack SDK и Pandas для создания Excel-файла из датафрейма и отправки его в канал #general. В функции мы указываем ваш токен доступа к Slack API.
Затем мы используем оператор PythonOperator для вызова функции send_excel_report() в DAG. Обратите внимание, что мы не используем оператор >>, так как задача отправки отчета не зависит от выполнения других задач.
Данный DAG будет отправлять отчет в Slack каждый день в соответствии с расписанием, указанным в параметре schedule_interval.
Как указать в dag асинхронно или последовательно выполнять задачи? Пример асинхронного и последовательного dag
В DAG можно указать порядок выполнения задач с помощью операторов PythonOperator и BashOperator, которые позволяют вызывать асинхронные или синхронные функции и скрипты.
Пример последовательного DAG:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
from airflow import DAG from airflow.operators.bash_operator import BashOperator from datetime import datetime default_args = { ‘owner’: ‘airflow’, ‘start_date’: datetime(2021, 1, 1), } dag = DAG(‘sequential_dag’, default_args=default_args) task1 = BashOperator( task_id=‘task1’, bash_command=‘echo «Task 1″‘, dag=dag, ) task2 = BashOperator( task_id=‘task2’, bash_command=‘echo «Task 2″‘, dag=dag, ) task3 = BashOperator( task_id=‘task3’, bash_command=‘echo «Task 3″‘, dag=dag, ) task1 >> task2 >> task3 |
В этом примере задачи task1, task2 и task3 будут выполнены последовательно, так как задача task2 зависит от выполнения задачи task1, а задача task3 зависит от выполнения задачи task2.
Пример асинхронного DAG:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
from airflow import DAG from airflow.operators.python_operator import PythonOperator from datetime import datetime import time default_args = { ‘owner’: ‘airflow’, ‘start_date’: datetime(2021, 1, 1), } dag = DAG(‘async_dag’, default_args=default_args) def my_function(): print(‘Starting my function’) time.sleep(5) print(‘Finishing my function’) task1 = PythonOperator( task_id=‘task1’, python_callable=my_function, dag=dag, ) task2 = PythonOperator( task_id=‘task2’, python_callable=my_function, dag=dag, ) task3 = PythonOperator( task_id=‘task3’, python_callable=my_function, dag=dag, ) task1 >> [task2, task3] |
В этом примере задачи task1, task2 и task3 будут выполнены асинхронно, так как задачи task2 и task3 не зависят от выполнения задачи task1.
Отправка красивого письма с вложенным файлом excel через dag airflow
Для отправки письма с вложенным файлом excel через DAG Airflow можно использовать оператор EmailOperator.
Пример DAG:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
from airflow import DAG from airflow.operators.email_operator import EmailOperator from datetime import datetime default_args = { ‘owner’: ‘airflow’, ‘start_date’: datetime(2021, 1, 1), } dag = DAG(’email_dag’, default_args=default_args) send_email = EmailOperator( task_id=‘send_email’, to=‘recipient@example.com’, subject=‘Airflow email with attachment’, html_content=‘<p>Dear recipient,</p><p>Please find attached the excel file.</p>’, files=[‘/path/to/file.xlsx’], dag=dag, ) |
В этом примере оператор EmailOperator отправляет письмо на адрес recipient@example.com с темой «Airflow email with attachment» и содержанием в формате HTML. Вложенный файл excel находится по пути /path/to/file.xlsx.
Как продать идею внедрения airflow руководству?
- Подготовьте анализ бизнес-процессов вашей компании и определите, где можно автоматизировать задачи с помощью DAG Airflow. Например, это может быть автоматическая отправка отчетов по электронной почте, запуск ETL-процессов для обработки данных или мониторинг работы приложений.
- Подготовьте презентацию, в которой покажите, как автоматизация задач с помощью DAG Airflow поможет увеличить эффективность работы и снизить затраты на ручное выполнение задач.
- Подготовьте демонстрационный проект, который покажет преимущества DAG Airflow. Например, это может быть DAG для автоматической отправки отчетов по электронной почте или DAG для мониторинга работы приложений.
- Подготовьте список преимуществ DAG Airflow, таких как возможность параллельного выполнения задач, удобный интерфейс для управления задачами и логирования выполнения задач.
- Объясните, какие затраты будут необходимы для внедрения DAG Airflow и какие выгоды они принесут в долгосрочной перспективе.
- Объясните, какую поддержку и обучение будут предоставлены сотрудникам, которые будут использовать DAG Airflow.
- Предложите план внедрения DAG Airflow, который будет учитывать потребности и возможности компании. Например, это может быть поэтапное внедрение DAG Airflow в различных бизнес-процессах компании.
- Подготовьте список возможных рисков и способов их уменьшения при внедрении DAG Airflow.
- Предложите план обновления и поддержки DAG Airflow после его внедрения.
- Проведите презентацию руководству компании и ответьте на все их вопросы. Дайте им время для обдумывания и принятия решения.
Как создать цепочку задач для выполнения etl в Apache PySpark
Для создания цепочки задач для выполнения ETL в Apache PySpark можно использовать библиотеку Apache Airflow. Вот пример создания такой цепочки:
1. Создайте DAG (Directed Acyclic Graph) — это граф, который определяет порядок выполнения задач.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
from airflow import DAG from datetime import datetime, timedelta default_args = { ‘owner’: ‘airflow’, ‘depends_on_past’: False, ‘start_date’: datetime(2022, 1, 1), ’email_on_failure’: False, ’email_on_retry’: False, ‘retries’: 1, ‘retry_delay’: timedelta(minutes=5), } dag = DAG( ‘etl_pipeline’, default_args=default_args, description=‘ETL pipeline with PySpark’, schedule_interval=timedelta(days=1), ) |
2. Определите задачи, которые нужно выполнить. В этом примере мы будем использовать две задачи: первая загружает данные из источника данных (например, базы данных), а вторая обрабатывает эти данные с помощью PySpark.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
from airflow.operators.python_operator import PythonOperator from pyspark.sql import SparkSession def load_data(): # код для загрузки данных из источника данных def process_data(): spark = SparkSession.builder.appName(‘ETL’).getOrCreate() # код для обработки данных с помощью PySpark load_data_task = PythonOperator( task_id=‘load_data’, python_callable=load_data, dag=dag, ) process_data_task = PythonOperator( task_id=‘process_data’, python_callable=process_data, dag=dag, ) |
3. Определите порядок выполнения задач. В этом примере мы будем выполнять задачи последовательно: сначала загрузка данных, затем обработка данных.
|
load_data_task >> process_data_task |
4. Запустите DAG в Apache Airflow. После запуска DAG задачи будут выполняться автоматически в заданном порядке.
|
airflow trigger_dag etl_pipeline |
Это простой пример создания цепочки задач для выполнения ETL в Apache PySpark с помощью Apache Airflow. В зависимости от требований проекта можно добавлять новые задачи и настраивать порядок их выполнения.
Как создать несколько задач и дождаться их выполнения в Apache Airflow
Для создания нескольких задач в Apache Airflow, вы можете создать несколько операторов (operators) в вашем DAG файле. Каждый оператор соответствует отдельной задаче.
Например, для создания трех задач — task1, task2 и task3, вам нужно определить три оператора:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
from airflow import DAG from airflow.operators.bash_operator import BashOperator from datetime import datetime dag = DAG(dag_id=‘my_dag’, start_date=datetime.now()) task1 = BashOperator( task_id=‘task1’, bash_command=‘echo «Hello from task1″‘, dag=dag, ) task2 = BashOperator( task_id=‘task2’, bash_command=‘echo «Hello from task2″‘, dag=dag, ) task3 = BashOperator( task_id=‘task3’, bash_command=‘echo «Hello from task3″‘, dag=dag, ) |
Затем вы можете установить правила зависимости между задачами, используя методы set_upstream и set_downstream.
|
task1.set_downstream(task2) task2.set_downstream(task3) |
В этом примере task1 будет зависеть от ничего, task2 будет зависеть от task1, и task3 будет зависеть от task2.
Чтобы дождаться выполнения всех задач, вы можете использовать метод wait_for_completion, который блокирует выполнение кода, пока все задачи не будут завершены:
|
from airflow.utils.trigger_rule import TriggerRule task3.set_downstream(wait_for_completion=True, trigger_rule=TriggerRule.ALL_DONE) |
Здесь задача task3 будет дожидаться, пока все предшествующие задачи завершатся, прежде чем выполниться.
В чем разница между Apache NiFi vs Airflow?
Ниже приведены некоторые из основных различий между Apache NiFi и Apache Airflow:
1. Назначение
Apache NiFi был разработан, чтобы обеспечить интеграцию данных и автоматизацию потоков данных, основанных на событиях. С другой стороны, Apache Airflow был разработан для управления процессами обработки данных в рамках конвейера обработки данных.
2. Функциональность
NiFi имеет встроенные функции обработки и интеграции данных, такие как маршрутизация, преобразование и фильтрация данных. Airflow же предоставляет возможность для создания и управления рабочими процессами, которые могут включать задачи и зависимости между ними.
3. Операционный процесс
NiFi обрабатывает потоки данных в реальном времени и может осуществлять масштабирование горизонтально. В то время как Airflow концентрируется на обработке задач на основе конвейера обработки данных и может использоваться для управления батч-процессами.
4. Язык программирования
NiFi использует язык программирования Java, в то время как Airflow использует Python.
5. Экосистема
NiFi имеет большую экосистему, включающую в себя множество плагинов и интеграций с различными технологиями. Airflow также имеет экосистему, но в несколько меньшем объеме.
В целом, NiFi и Airflow предоставляют различные функциональности и рассчитаны на разные типы задач. NiFi больше подходит для интеграции и обработки данных в режиме реального времени, а Airflow подходит для управления конвейерами обработки данных в контексте батч-процессов.
Data Pipelines (пайплайны) внутри DAG. Пайплайн airflow
DAG (Directed Acyclic Graph) — это графическая модель, которая позволяет определить зависимости между задачами и выполнить их в нужном порядке для достижения цели.
Pipeline — это конвейер, который позволяет передавать данные между различными этапами выполнения.
Пайплайны внутри DAG используются для определения шагов и логических зависимостей между этапами выполнения. Каждый пайплайн может быть представлен в виде отдельной задачи и выполняться в определенной последовательности.
Примером может служить DAG, в котором есть задачи: загрузка данных, предобработка данных, обучение модели и тестирование модели. Здесь можно использовать пайплайны для определения зависимостей между этими задачами. Например, задача предобработки данных может зависеть от задачи загрузки данных, а задача обучения модели может зависеть от задачи предобработки данных.
Таким образом, пайплайны внутри DAG помогают определить порядок выполнения задач и повышают эффективность и качество работы системы.
Подборка видео по тематике Airflow
Видео на русском
Что такое Apache Airflow («Школы Больших Данных» г. Москва)
Начало работы с apache Airflow — часть 1 («Школы Больших Данных» г. Москва)
ETL на airflow — часть 2 («Школы Больших Данных» г. Москва)
5 Оркестраторы и работа с Airflow (Канал Intellik)
ВВЕДЕНИЕ В AIRFLOW / ПОНЯТИЕ DAG’а / НАСТРОЙКА DAG’а В AIRFLOW (Канал DataLearn)
Airflow и MLFlow автоматизаций пайплайнов Machine Learning / MLOps (Канал miracl6)
Видео на английском
The Newcomer’s Guide to Airflow’s Architecture (Канал Apache Airflow)
How to write your first DAG in Apache Airflow — Airflow tutorials
Build your first pipeline DAG | Apache airflow for beginners
Также по теме Airflow:
- Apache Airflow и XCom
- TaskFlow API в Apache Airflow 2.0
Apache Airflow — это продвинутый workflow менеджер и незаменимый инструмент в арсенале современного дата инженера. Если смотреть открытые вакансии на позицию data engineer, то нередко встретишь опыт работы с Airflow как одно из требований к позиции.
Я разработал практический курс по Apache Airflow 2.0, он доступен на платформе StartDataJourney, создана она также мною. Приятного обучения — Apache Airflow 2.0: практический курс.
Airflow был разработан в 2014 году в компании Airbnb, автор Maxime Beauchemin. Позже инструмент был передан под опеку в организацию Apache, а в январе 2019 получил статус Top-Level проекта. В этой статье я расскажу про установку, настройку и запуск первого дата пайплайна средствами Apache Airflow. К слову, в 2017 году я уже писал про не менее классный и простой инструмент Luigi от компании Spotify. По своей сути эти два инструмента похожи — оба предназначены для запуска цепочек задач (дата пайплайнов), но есть у них и ряд различий о которых я говорил во время своего выступления на PyCON Russia 2019:
В этой статье я постараюсь рассказать о необходимом минимуме для работы с Airflow. Для начала давайте рассмотрим основные сущности инструмента.
DAG (Directed Acyclic Graph)
DAG — это ориентированный ациклический граф, т.е. граф у которого отсутствуют циклы, но могут быть параллельные пути, выходящие из одного и того же узла. Простыми словами DAG это сущность, объединяющая ваши задачи в единый data pipeline (или цепочку задач), где явно видны зависимости между узлами.
На картинке можно видеть классический DAG, где Task E является конечным в цепочке и зависит от всех задача слева от него.
Operator
Если вы знакомы с инструментом Luigi, то Operator в Airflow это аналог Task в Luigi. Оператор это звено в цепочке задач. Используя оператор разработчик описывает какую задачу необходимо выполнить. В Airflow есть ряд готовых операторов, например:
- PythonOperator — оператор для исполнения python кода
- BashOperator — оператор для запуска bash скриптов/команд
- PostgresOperator — оператор для вызова SQL запросов в PostgreSQL БД
- RedshiftToS3Transfer — оператор для запуска UNLOAD команды из Redshift в S3
- EmailOperator — оператор для отправки электронных писем
Полный список стандартных операторов можно найти в документации Apache Airflow.
DAG является объединяющей сущностью для набора операторов, т.е. если вернуться к картинке выше, то Task A, Task B и т.д. это отдельные операторы.
Важно! Операторы не могут принимать возвращаемые значения от выполнения предыдущих операторов в цепочке (как, например, цепочка из вызовов функций), т.к. могут исполняться в разном адресном пространстве и даже на разных физических машинах.
Sensor
Сенсор это разновидность Operator, его удобно использовать при реализации событийно ориентированных пайплайнов. Из стандартного набора есть, например:
- PythonSensor — ждём, когда функция вернёт
True - S3Sensor — проверяет наличие объекта по ключу в S3-бакете
- RedisPubSubSensor — проверяет наличие сообщения в pub-sub очереди
- RedisKeySensor — проверяет существует ли переданный ключ в Redis хранилище
Это лишь малая часть доступных для использования сенсоров. Чтобы создать свой сенсор, достаточно унаследоваться от BaseSensorOperator и переопределить метод poke.
Hook
Хуки это внешние интерфейсы для работы с различными сервисами: базы данных, внешние API ресурсы, распределенные хранилища типа S3, redis, memcached и т.д. Хуки являются строительными блоками операторов и берут на себя всю логику по взаимодействию с хранилищем конфигов и доступов (о нём ниже). Используя хуки можно забыть про головную боль с хранением секретной информации в коде (пароли к доступам, например).
Установка
Apache Airflow состоит из нескольких частей:
- Веб-приложение с панелью управления, написано на Flask
- Планировщик (Scheduler), в production среде чаще всего используется Celery
- Воркер, выполняющий работу. В production среде также чаще всего встречается конфигурация с Celery.
В качестве базы данных рекомендуется использовать PostgreSQL или MySQL. В этом посте речь пойдёт про установку и настройку Apache Airflow руками, я не буду использовать готовые образы Docker, чтобы наглядно показать как всё запускается изнутри.
Погнали! Создаём новое виртуальное окружение Python, и ставим в него Apache Airflow:
$ python3 -m venv .venv
$ source .venv/bin/activate
$ pip install apache-airflow
У Airflow много зависимостей в отличие от Luigi, поэтому на экране будет много текста. Вот, например, результат вывода pip freeze:
alembic==1.4.0
apache-airflow==1.10.9
apispec==1.3.3
argcomplete==1.11.1
attrs==19.3.0
Babel==2.8.0
cached-property==1.5.1
cattrs==0.9.0
certifi==2019.11.28
chardet==3.0.4
Click==7.0
colorama==0.4.3
colorlog==4.0.2
configparser==3.5.3
croniter==0.3.31
defusedxml==0.6.0
dill==0.3.1.1
docutils==0.16
Flask==1.1.1
Flask-Admin==1.5.4
Flask-AppBuilder==2.2.2
Flask-Babel==0.12.2
Flask-Caching==1.3.3
Flask-JWT-Extended==3.24.1
Flask-Login==0.4.1
Flask-OpenID==1.2.5
Flask-SQLAlchemy==2.4.1
flask-swagger==0.2.13
Flask-WTF==0.14.3
funcsigs==1.0.2
future==0.16.0
graphviz==0.13.2
gunicorn==19.10.0
idna==2.8
importlib-metadata==1.5.0
iso8601==0.1.12
itsdangerous==1.1.0
Jinja2==2.10.3
json-merge-patch==0.2
jsonschema==3.2.0
lazy-object-proxy==1.4.3
lockfile==0.12.2
Mako==1.1.1
Markdown==2.6.11
MarkupSafe==1.1.1
marshmallow==2.19.5
marshmallow-enum==1.5.1
marshmallow-sqlalchemy==0.22.2
numpy==1.18.1
pandas==0.25.3
pendulum==1.4.4
pkg-resources==0.0.0
prison==0.1.2
psutil==5.6.7
Pygments==2.5.2
PyJWT==1.7.1
pyrsistent==0.15.7
python-daemon==2.1.2
python-dateutil==2.8.1
python-editor==1.0.4
python3-openid==3.1.0
pytz==2019.3
pytzdata==2019.3
PyYAML==5.3
requests==2.22.0
setproctitle==1.1.10
six==1.14.0
SQLAlchemy==1.3.13
SQLAlchemy-JSONField==0.9.0
SQLAlchemy-Utils==0.36.1
tabulate==0.8.6
tenacity==4.12.0
termcolor==1.1.0
text-unidecode==1.2
thrift==0.13.0
typing==3.7.4.1
typing-extensions==3.7.4.1
tzlocal==1.5.1
unicodecsv==0.14.1
urllib3==1.25.8
Werkzeug==0.16.1
WTForms==2.2.1
zipp==2.2.0
zope.deprecation==4.4.0
После установки пакета apache-airflow, в виртуальном окружении будет доступна команда airflow. Запустите её без параметров, чтобы увидеть список доступных команд.
Apache Airflow свои настройки хранит в файле airflow.cfg, который по умолчанию будет создан в домашней директории юзера по пути ~/airflow/airflow.cfg. Путь можно изменить, присвоив переменной окружения новое значение:
$ export AIRFLOW_HOME=~/airflow/
Далее выполняем инициализацию для базы данных.
$ airflow initdb
Эта команда накатит все миграции, по умолчанию в качестве базы данных Airflow использует SQLite. Для демонстрационных возможностей это нормально, но в реальном бою лучше всё же переключиться на MySQL или PostgreSQL. Давайте делать всё по-взрослому. Я буду использовать Postgres, поэтому если он у вас до сих пор не стоит, то самое время установить PostgreSQL.
Создаю базу данных и пользователя к ней для Airflow:
postgres=# create database airflow_metadata;
CREATE DATABASE
postgres=# CREATE USER airflow WITH password 'airflow';
CREATE ROLE
postgres=# grant all privileges on database airflow_metadata to airflow;
GRANT
А теперь открываем airflow.cfg и правим значение параметра sql_alchemy_conn на postgresql+psycopg2://airflow:airflow@localhost/airflow_metadata и load_examples = False. Последний параметр отвечает за загрузку примеров с бесполезными DAGами, они нам не нужны.
В качестве python-драйвера для PostgreSQL я использую psycopg2, поэтому её необходимо поставить в окружение:
$ pip install psycopg2==2.8.4
Инициализируем новую базу данных:
$ airflow initdb
Airflow Executors
Хочу немножко отвлечься от запуска Airflow и рассказать про очень важную концепцию — Executors. Как понятно из названия, Executors отвечают за исполнение задач. В Airflow есть несколько видов исполнителей:
- SequentialExecutor
- LocalExecutor
- CeleryExecutor
- DaskExecutor
- KubernetesExecutor
В боевой среде чаще всего встречается CeleryExecutor, который, как можно догадаться, использует Celery. Но обо всём по порядку.
SequentialExecutor
Этот исполнитель установлен в качестве значения по умолчанию в airflow.cfg у параметра executor и представляет из себя простой вид воркера, который не умеет запускать параллельные задачи. Как можно догадаться, в конкретный момент времени выполняться может только одна единственная задача. Этот вид исполнителя используют в ознакомительных целях, для продуктивной среды он категорически не подходит.
LocalExecutor
Этот вид исполнителя даёт максимальные ощущения продуктивной среды в тестовом окружении (или окружении разработки). Он умеет выполнять задачи параллельно (например, исполнять несколько DAGов одновременно) путём порождения дочерних процессов, но всё же не совсем предназначен для продакшена ввиду ряда проблем:
- Ограничение при масштабировании (возможно эта проблема не будет актуальна для вас), исполнитель этого типа ограничен ресурсами машины на котором он запущен
- Отсутствие отказоустойчивости. Если машина с этим типом воркера падает, то задачи перестают исполнять до момента её возвращения в строй.
При небольшом количестве задач всё же можно использовать LocalExecutor, т.к. это проще, быстрее и не требует настройки дополнительных сервисов.
CeleryExecutor
Наиболее популярный вид исполнения задач. Под капотом использует всю магию таск-менеджера Celery, а соответственно тянет за собой все зависимости этого инструмента. Чтобы использовать CeleryExecutor необходимо дополнительно настроить брокер сообщений. Чаще всего используют либо Redis либо RabbitMQ. Преимущества этого вида в том, что его легко масштабировать — поднял новую машину с воркером, и он готов выполнять требуемую работу, а также в отказоустойчивости. В случае падения одного из воркеров его работа будет передана любому из живых.
DaskExecutor
Очень похож на CeleryExecutor, но только вместо Celery использует инструмент Dask, в частности dask-distributed.
KubernetesExecutor
Относительно новый вид исполнения задач на кластере Kubernetes. Задачи исполняются как новые pod инстансы. В связи с развитием контейнеров и их повсеместным использованием, данный вид исполнения может быть интересен широкому кругу людей. Но у него есть минус — если у вас нет Kubernetes кластера, то настроить его будет непростым упражнением.
Так к чему я начал разговор про Executors. В стандартной конфигурации Airflow предлагает нам использовать SequentialExecutor, но мы ведь стараемся подражать продуктивной среде, поэтому будем использовать LocalExecutor. В airflow.cfg поменяйте значение параметра executor на LocalExecutor.
Запускаем веб-приложение на 8080 порту:
$ airflow webserver -p 8080
Если всё настроено правильно, то переход по адресу localhost:8080 должен показать страницу как на скриншоте:
Поздравляю! Мы настроили и запустили Apache Airflow. На странице можно заметить сообщение:
The scheduler does not appear to be running. The DAGs list may not update, and new tasks will not be scheduled.
Сообщение указывает на то, что не запущен планировщик Airflow (scheduler). Он отвечает за DAG discovery (обнаружение новых DAG), а также за планирование их запуска. Запустить планировщик можно командой:
$ airflow scheduler
Для того, чтобы не переключаться между разными окнами терминалов, я люблю использовать менеджер терминалов tmux.
Итак, база настроена, веб-приложение и планировщик запущены. Нам остаётся только написать наш первый data pipeline и почувствовать себя в шкуре крутого дата инженера.
Строим data pipeline на Apache Airflow
В файле настроек airflow.cfg есть параметр dags_folder, он указывает на путь, где лежат файлы с DAGами. Это путь $AIRFLOW_HOME/dags. Именно туда мы положим наш код с задачами.
Какие задачи будет выполнять пайплайн? Я решил для демонстрации взять пример с датасетом Titanic о котором писал в статье про pandas. Суть в том, что сначала необходимо будет скачать датасет, следующим шагом будет этап создания сводной таблицы: сгруппируем пассажиров по полу и пассажирскому классу, чтобы узнать количество людей в каждом классе. Результатом будет новый csv-файл со сводной таблицей.
Вот так выглядит DAG:
А вот код всего DAGа, включая 2 оператора:
import os
import datetime as dt
import requests
import pandas as pd
from airflow.models import DAG
from airflow.operators.python_operator import PythonOperator
args = {
'owner': 'airflow',
'start_date': dt.datetime(2020, 2, 11),
'retries': 1,
'retry_delay': dt.timedelta(minutes=1),
'depends_on_past': False,
}
FILENAME = os.path.join(os.path.expanduser('~'), 'titanic.csv')
def download_titanic_dataset():
url = 'https://web.stanford.edu/class/archive/cs/cs109/cs109.1166/stuff/titanic.csv'
response = requests.get(url, stream=True)
response.raise_for_status()
with open(FILENAME, 'w', encoding='utf-8') as f:
for chunk in response.iter_lines():
f.write('{}\\n'.format(chunk.decode('utf-8')))
def pivot_dataset():
titanic_df = pd.read_csv(FILENAME)
pvt = titanic_df.pivot_table(
index=['Sex'], columns=['Pclass'], values='Name', aggfunc='count'
)
df = pvt.reset_index()
df.to_csv(os.path.join(os.path.expanduser('~'), 'titanic_pivot.csv'))
with DAG(dag_id='titanic_pivot', default_args=args, schedule_interval=None) as dag:
create_titanic_dataset = PythonOperator(
task_id='download_titanic_dataset',
python_callable=download_titanic_dataset,
dag=dag
)
pivot_titanic_dataset = PythonOperator(
task_id='pivot_dataset',
python_callable=pivot_dataset,
dag=dag
)
create_titanic_dataset >> pivot_titanic_dataset
В DAGе у нас используются 2 PythonOperator. Обратите внимание, что они принимают функцию, которую необходимы выполнить. В первом случае это download_titanic_dataset, которая скачивает датасет из сети, во втором случае это pivot_dataset, которая сохраняет сводную таблицу из исходного файла (сохраненного предыдущей функцией).
Стоит обратить внимание на объект DAG и то как описаны зависимости между двумя операторами. В Airflow допустимы конструкции >> и <<, а также методы .set_upstream и .set_downstream. Т.е. код:
create_titanic_dataset >> pivot_titanic_datasetМожно заменить на:
pivot_titanic_dataset.set_upstream(create_titanic_dataset)
# или
pivot_titanic_dataset << create_titanic_datasetЭто означает, что выполнение оператора pivot_titanic_dataset зависит от выполнения оператора create_titanic_dataset.
На уровне объекта DAG задаются настройки, например:
- Время начала выполнения пайплайна (
start_date) - Периодичность запуска (
schedule_interval) - Информация о владельце DAG (
owner) - Количество повторений в случае неудач (
retries) - Пауза между повторами (
retry_delay)
Параметров в разы больше. Более подробно как всегда можно прочитать в доках.
Итак, сохраняем в файл код и помещаем его по пути $AIRFLOW_HOME/dags. Для того, чтобы DAGи отображались в интерфейсе Airflow необходимо запустить планировщик:
$ airflow schedulerЕсли всё сделано верно, то в списке появится наш DAG:
Его можно активировать, переключив с Off на On и попробовать запустить (Trigger Dag).
Заключение
Эта статья лишь небольшое введение в Apache Airflow. Я не раскрыл и 20% того, что умеет инструмент, но и такой задачи себе не ставил. Лучшим способом изучить Apache Airflow является работа с ним. Пробуйте, экспериментируйте, чтобы понять подходит он под ваши задачи или нет.
Ссылка на репозиторий с примерами: https://github.com/adilkhash/apache-airflow-intro

By Aviator Ifeanyichukwu
Apache Airflow is a tool that helps you manage and schedule data pipelines. According to the documentation, it lets you «programmatically author, schedule, and monitor workflows.»
Airflow is a crucial tool for data engineers and scientists. In this article, I’ll show you how to install it on Windows without Docker.
Although it’s recommended to run Airflow with Docker, this method works for low-memory machines that are unable to run Docker.
Prerequisites:
This article assumes that you’re familiar with using the command line and can set up your development environment as directed.
Requirements:
You need Python 3.8 or higher, Windows 10 or higher, and the Windows Subsystem for Linux (WSL2) to follow this tutorial.
What is Windows Subsystem for Linux (WSL2)?
WSL2 allows you to run Linux commands and programs on a Windows operating system.
It provides a Linux-compatible environment that runs natively on Windows, enabling users to use Linux command-line tools and utilities on a Windows machine.
You can read more here to install WSL2 on your machine.
With Python and WSL2 installed and activated on your machine, launch the terminal by searching for Ubuntu from the start menu.
Step 1: Set Up the Virtual Environment
To work with Airflow on Windows, you need to set up a virtual environment. To do this, you’ll need to install the virtualenv package.
Note: Make sure you are at the root of the terminal by typing:
cd ~
pip install virtualenv
Create the virtual environment like this:
virtualenv airflow_env
And then activate the environment:
source airflow_env/bin/activate
Step 2: Set Up the Airflow Directory
Create a folder named airflow. Mine will be located at c/Users/[Username]. You can put yours wherever you prefer.
If you do not know how to navigate the terminal, you can follow the steps in the image below:
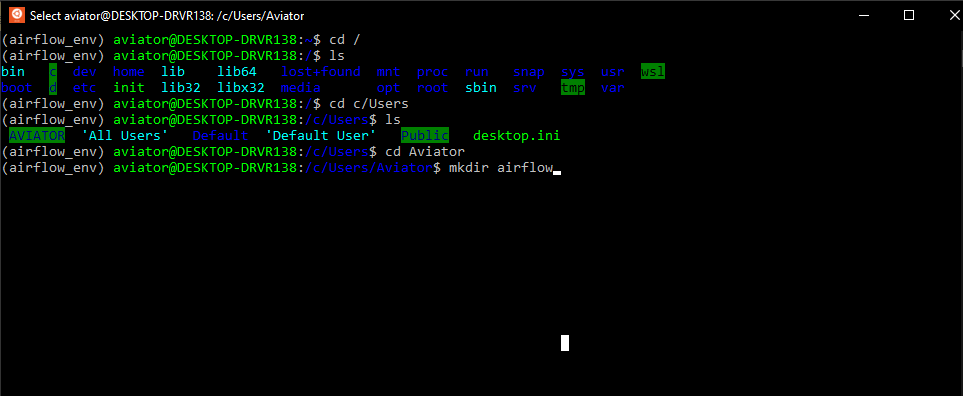
Create an Airflow directory from the terminal
Now that you have created this folder, you have to set it as an environment variable. Open a .bashrc script from the terminal with the command:
nano ~/.bashrc
Then write the following:
AIRFLOW_HOME=/c/Users/[YourUsername]/airflow
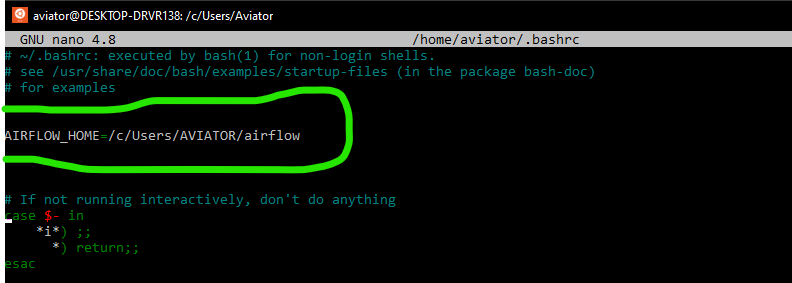
Setup Airflow directory path as an environment variable
Press ctrl s and ctrl x to exit the nano editor.
This part of the Airflow directory will be permanently saved as an environment variable. Anytime you open a new terminal, you can recover the value of the variable by typing:
cd $AIRFLOW_HOME
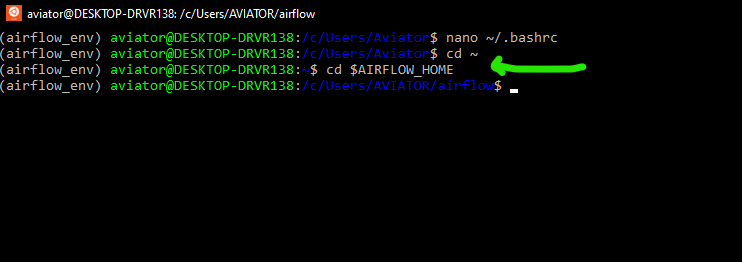
Navigate to Airflow directory using the environment variable
With the virtual environment still active and the current directory pointing to the created Airflow folder, install Apache Airflow:
pip install apache-airflow
Initialize the database:
airflow db init
Create a folder named dags inside the airflow folder. This will be used to store all Airflow scripts.
View files and folders generated by Airflow db init
Step 4: Create an Airflow User
When airflow is newly installed, you’ll need to create a user. This user will be used to login into the Airflow UI and perform some admin functions.
airflow users create --username admin –password admin –firstname admin –lastname admin –role Admin –email youremail@email.com
Check the created user:
airflow users list
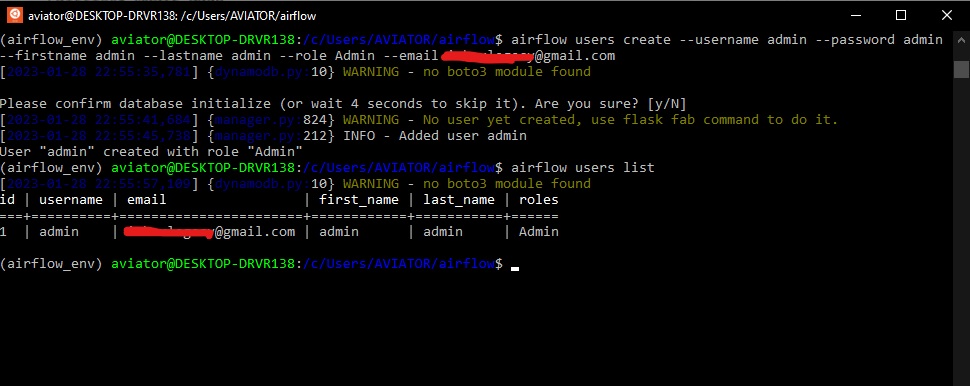
Create an Airflow user and list the created user
Step 5: Run the Webserver
Run the scheduler with this command:
airflow scheduler
Launch another terminal, activate the airflow virtual environment, cd to $AIRFLOW_HOME, and run the webserver:
airflow webserver
If the default port 8080 is in use, change the port by typing:
airflow webserver –port <port number>
Log in to the UI using the username created earlier with «airflow users create».
In the UI, you can view pre-created DAGs that come with Airflow by default.
How to Create the first DAG
A DAG is a Python script for organizing and managing tasks in a workflow.
To create a DAG, navigate into the dags folder created inside the $AIRFLOW_HOME directory. Create a file named «hello_world_dag.py». Use VS Code if it’s available.
Enter the code from the image below, and save it:
Example DAG script in VS Code editor
Go to the Airflow UI and search for hello_world_dag. If it does not show up, try refreshing your browser.
That’s it. This completes the installation of Apache Airflow on Windows.
Wrapping Up
This guide covered how to install Apache Airflow on a Windows machine without Docker and how to write a DAG script.
I do hope the steps outlined above helped you install airflow on your Windows machine without Docker.
In subsequent articles, you will learn about Apache Airflow concepts and components.
Follow me on Twitter or LinkedIn for more Analytics Engineering content.
Learn to code for free. freeCodeCamp’s open source curriculum has helped more than 40,000 people get jobs as developers. Get started